1. Introduction
Adversarial attacks have revealed a significant lack of robustness in neural networks, as even slight perturbations to the input data can lead to incorrect predictions. These attacks exploit this vulnerability by making subtle changes to input data that are almost imperceptible to human observers but cause the model to fail [
1,
2]. This makes robustness essential for deep learning models, especially in high-reliability applications. Techniques such as adversarial training, gradient masking, and model ensembles have been proposed to mitigate these vulnerabilities [
3,
4,
5]. Adversarial training augments model training by incorporating adversarial examples during the training process, which helps the model learn to resist similar perturbations and improves its robustness against potential attacks [
6]. Gradient masking attempts to obscure the model’s gradients to prevent attackers from accurately computing perturbations, effectively reducing their ability to exploit model weaknesses [
7]. However, the effectiveness of these defenses has largely been demonstrated on image-based tasks, where pixel-level changes are common, leaving challenges when transferring these methods to other domains like natural language processing [
8].
Natural language processing (NLP) has reached a point where it outperforms humans in several specialized tasks, such as language translation, text classification, and question answering. For example, models like Bidirectional Encoder Representations from Transformers (BERT) and GPT-3 have achieved state-of-the-art performance in various benchmarks, sometimes surpassing human-level accuracy in tasks such as reading comprehension and sentiment analysis [
9,
10]. These advancements have made NLP an indispensable tool in numerous applications, from virtual assistants to content moderation. However, adversarial vulnerabilities that can confound these systems remain a significant challenge to their effectiveness in real-life applications. For instance, adversarial NLP can be used to evade detection systems [
11], such as bypassing spam filters, phishing detectors, or content moderation tools, allowing malicious actors to propagate harmful or misleading content undetected [
12]. It can also be exploited to manipulate sentiment analysis systems, altering the perception of products, brands, or individuals by artificially boosting or degrading reviews and feedback [
13,
14]. Additionally, adversarial attacks could be leveraged by competitors to undermine the performance of rival NLP systems, eroding user trust and gaining a competitive advantage in the marketplace [
15]. In sentiment analysis, adversarial attacks are particularly impactful due to the task’s sensitivity to tone and word choice. Sentiment analysis aims to gauge subjective opinions, and minor substitutions or tone shifts can drastically alter model predictions [
16]. For instance, substituting negative words with neutral or uncommon alternatives can change a model’s sentiment classification, exploiting the model’s reliance on high-impact words [
17]. Such manipulations could allow an adversary to unload a flood of negative or abusive comments about a target without the target or moderators being aware. It could be used to sow doubt about a previously effective sentiment analysis model’s usefulness or it can be used to manipulate systems that depend on sentiment for decision-making, such as stock market prediction algorithms [
18].
The motivation behind this work is to develop more robust sentiment analysis frameworks that can mitigate threats posed by adversarial text attacks, making NLP systems more resilient to manipulation. To achieve this, the work introduces two novel algorithms aimed at improving the accuracy of predictions under adversarial attacks while also distinguishing adversarial examples from benign text, an essential capability for practical applications. The two proposed models, the Lexicon-Based Random Substitute Model (LRSM) and the Word-Variant Voting Model (WVVM), are designed and evaluated for this purpose. The IMDB Sentiment Dataset and the Yelp Polarity Dataset are used as benchmarks, while adversarial examples are generated using three widely known attack methods: Probability Weighted Word Saliency (PWWS), TextFooler, and BERT-based Adversarial Examples (BAE). LRSM employs random word substitutions from a topic-specific lexicon to generate diverse variations of input sentences. It is evaluated for its ability to differentiate between benign and adversarial examples and is compared against two established defense mechanisms: Frequency-Guided Word Substitution (FGWS) and Synonym Random Substitute and Vote (RS&V).
Following the evaluation of LRSM, the WVVM model is introduced as an ensemble framework that combines LRSM, FGWS, and RS&V. This ensemble leverages a voting mechanism to integrate the outputs of the individual defenses, enhancing resilience against adversarial perturbations. The models are evaluated based on restored accuracy and F1 score. LRSM not only improves accuracy and F1 scores compared to existing defenses but also reduces computational overhead. WVVM further surpasses LRSM, demonstrating the effectiveness of ensemble learning in addressing the limitations of individual defense mechanisms for sentiment analysis. This work departs from existing defenses by eliminating the reliance on synonym dictionaries, instead using randomized substitutions from a dataset-specific lexicon to achieve both robustness and efficiency. It is among the first to demonstrate that such non-semantic, lexicon-guided substitutions can correct model misclassifications while resisting adversarial attacks. Furthermore, it introduces an adaptive ensemble framework that outperforms all individual methods across multiple adversarial scenarios and datasets. The study provides the following significant contributions:
Introduction of Novel Defense Models: Two new algorithms, Lexicon-Based Random Substitute Model (LRSM) and Word-Variant Voting Model (WVVM), specifically designed to defend sentiment analysis against adversarial text attacks.
Lexicon-Guided Random Substitution Approach: A novel substitution strategy (LRSM) using random substitutions from topic-specific lexicons, eliminating reliance on precomputed synonym dictionaries and improving computational efficiency.
Ensemble Framework Enhancement: WVVM demonstrates that integrating multiple defense mechanisms (LRSM, FGWS, RS&V) through ensemble learning significantly improves robustness compared to standalone methods.
Comprehensive Evaluation and Generalization: Thorough benchmarking across different adversarial attacks, sentiment datasets (IMDB and Yelp Polarity), and various sentiment classification architectures, establishing broad generalizability of the proposed models.
Problem Statement
Despite significant advancements in Natural Language Processing (NLP), existing research has primarily explored adversarial robustness in the context of continuous data domains, particularly images, where perturbations are applied at a pixel level [
2,
8]. In contrast, NLP models deal with discrete textual data, making them inherently susceptible to subtle, semantically impactful word-level modifications [
1,
14,
16]. This fundamental difference introduces unique challenges that have not yet been comprehensively addressed in the literature, especially within specialized NLP applications such as sentiment analysis [
14,
17].
Current defensive strategies, including adversarial training, gradient masking, and synonym-based substitutions, encounter notable limitations when applied to textual data. Adversarial training methods, though effective in image classification, struggle with the discrete and combinatorial nature of text, making representative adversarial examples difficult and computationally intensive to generate [
3,
5,
6]. Similarly, gradient masking techniques have proven less effective due to the inherent semantic complexity and discrete nature of language data [
4,
7]. Synonym-based substitution methods, meanwhile, rely heavily on precomputed semantic dictionaries, adding considerable computational overhead and failing to keep pace with evolving language usage and domain-specific vocabulary [
17].
For instance, subtle manipulations like substituting emotionally charged words in sentiment analysis (“enjoyable and inspiring” to “tolerable and acceptable”) can drastically alter model predictions, despite negligible semantic shifts from a human perspective [
1,
16]. Given the widespread deployment and reliance on sentiment analysis systems across fields like product reviews, brand reputation management, and financial forecasting, addressing these vulnerabilities is critical [
13,
18]. Consequently, there is a clear research gap regarding efficient and practical defensive frameworks specifically tailored for adversarial robustness in NLP, particularly sentiment analysis, that can overcome the limitations inherent in current synonym-dependent and computationally heavy defense strategies.
The remainder of the paper is structured as follows:
Section 2 provides a review of relevant literature.
Section 3 outlines the methodology, including the datasets and the architecture of the proposed algorithms.
Section 4 compares the performance of the defense mechanisms with the novel models and presents a detailed analysis of the results.
Section 5 revolves around a discussion of the results. Finally,
Section 6 concludes the study by summarizing the findings and proposing directions for future research.
2. Literature Review
In NLP, adversarial attacks involve modifying text at the character, word, or phrase level, making defenses more complex due to language’s semantic and syntactic nuances [
19,
20]. Unlike pixel-based image modifications, text perturbations may include synonym replacements, word reordering, minor rephrasing, and multi-level attacks that integrate character-level, word-level, and sentence-level swaps and alterations [
21,
22,
23]. Character-level attacks involve altering or swapping characters, while word-level attacks substitute words with similar or misleading alternatives [
24,
25]. However, word-level attacks often struggle with efficiency due to the high-dimensional search space involved [
26]. Sentence-level attacks may involve rephrasing or restructuring entire sentences [
27], and multi-level attacks combine these techniques to create more sophisticated perturbations [
28].
NLP attacks reveal limitations in adapting traditional adversarial defenses to NLP, where even slight changes can significantly alter the meaning of a text [
29]. Standard defenses, like adversarial training, perform inconsistently in NLP, as language’s complexity and context dependencies demand more adaptable solutions [
30]. Moreover, NLP models are often highly sensitive to minor word changes, a factor adversaries exploit to bypass detection [
31]. Adversarial perturbations in textual data present unique challenges compared to images, primarily due to the discrete nature of text [
32,
33]. The effectiveness of adversarial examples in text is often evaluated based on their naturalness (how fluent and human-like the altered text remains) and the efficiency with which these examples can be generated [
34]. Some researchers have managed to detect textual perturbations using relatively straightforward techniques, such as spell-checking and adversarial training [
35]. More advanced defenses such as synonym filtering or embedding-based transformations have been proposed, but their limited adaptability to various attack types often restricts their success [
36,
37]. Furthermore, increasingly sophisticated and harder-to-detect adversarial attacks have been proposed, which continue to threaten the robustness of NLP models [
38]. In response, various defense mechanisms have emerged in recent years to address this threat.
Adversarial defenses in NLP employ various strategies to mitigate attacks that exploit linguistic vulnerabilities. Adversarial training, a common defense against adversarial image attacks, has also been applied to NLP [
22,
39]. However, adversarial training in NLP exhibits limited effectiveness in enhancing model robustness due to concept drift, a phenomenon that arises during model retraining. Experimental findings reveal that the performance benefits of adversarial training diminish significantly over time, highlighting its transient impact on robustness [
40]. The synonym encoding method maps clusters of synonyms to unique encodings, effectively mitigating synonym substitution attacks without altering the model’s architecture or requiring additional data [
41]. The Dirichlet Neighborhood Ensemble (DNE) uses probabilistic modeling to generate diverse representations of input text, making attacks less effective but at the cost of computational efficiency [
42]. RS&V introduces random word substitutions and uses majority voting for classification, neutralizing perturbations but occasionally introducing noise [
43]. Defensive Input Sampling and Perturbation (DISP) creates perturbed input variations to identify consistent predictions, offering robustness against subtle changes but being less effective against semantic shifts [
44]. FGWS targets adversarial word choices by replacing rare words with frequent synonyms, leveraging lexical patterns to mitigate attacks but occasionally oversimplifying the input [
45].
Existing adversarial defense strategies in NLP, such as FGWS, RS&V, and DNE, depend on synonym-based substitution to neutralize adversarial perturbations [
41,
43,
45]. This reliance requires creating and querying extensive synonym dictionaries, introducing significant computational overhead, particularly for large-scale or real-time applications. However, it remains unclear whether synonym substitution should always be a prerequisite for effective adversarial defenses, as alternative strategies, such as random substitutions with unrelated words, have not been explored for their potential for adversarial defense. Furthermore, while ensemble approaches have demonstrated success in other areas, the potential of combining diverse substitution strategies—such as random substitution and frequency-based approaches—into a unified ensemble framework has yet to be systematically explored. This leaves open the question of whether such combinations could enhance robustness and accuracy against diverse adversarial attacks. These questions will be systematically explored in the subsequent sections of this paper.
3. Methodology
To evaluate the robustness of sentiment analysis models and the effectiveness of the proposed defenses, experiments were conducted on two benchmark datasets: Yelp Polarity [
46] and IMDB Reviews [
47]. A total of 4000 examples were randomly selected from each dataset such that 4000 examples were used for training and 4000 were used for the test set. The training set was used to find the optimal hyperparameters for the models, while the test set was used for evaluation. Each of these sets consisted of two subsets of data. The first subset of the datasets was used to generate benign unaltered examples to test whether the defense algorithms would correctly label them after their original sentiment or mistake them for adversary examples. For the second subset of the datasets, the examples were passed as input to three adversarial attack algorithms: PWWS [
48], TextFooler [
49], and BAE [
50]. These algorithms generated adversarial examples designed to manipulate the sentiment predictions of the trained models. The adversarial examples were then passed to LSTM, CNN, and BERT models to measure the impact of the attacks on their performance. Next, the combined dataset of adversarial and benign examples was exposed to three defense algorithms: RS&V (Synonym Random Substitution Voting), FGWS (Fixed Gradient Word Substitution), and LRSM. The defenses aimed to neutralize the adversarial perturbations while not falsely labeling benign examples as adversarial. The performance of each defense was evaluated using precision, recall and F1 score of the predictions, while restored accuracy (accuracy on adversarial examples) was also measured to assess how much of the adversarial damage was recovered.
After evaluating LRSM, an ensemble model, WVVM, was assembled from the three defense algorithms. The ensemble model was first trained on the training set, which also consisted of benign and adversarial examples, and then tested on the test set. Different ensemble layers, LR, Support Vector Classifier (SVC), and Random Forest (RF), were evaluated for their effectiveness. The best-performing ensemble configuration was determined by comparing the F1 score and accuracy of the ensemble model against the individual defenses. All attacks, defenses and evaluations were conducted on virtual machines using NVIDIA Tesla P4 GPUs. The TextAttack library was used for the NLP models and to conduct attacks [
51].
Figure 1 illustrates the process used to evaluate adversarial robustness in sentiment analysis models.
3.1. Data Collection
The study utilizes two primary datasets: the IMDB Sentiment Dataset [
46] and the Yelp Polarity Dataset [
47]. The IMDB Sentiment Dataset consists of 50,000 movie reviews, each categorized as either positive or negative. It is evenly split into two parts: 25,000 reviews for training and 25,000 for testing. The dataset is derived from the IMDB movie review corpus. The Yelp Polarity Dataset is composed of business reviews sourced from Yelp, labeled as either positive or negative based on their sentiment. The 4000 examples from each dataset were selected at random, with 2000 drawn from the positive sentiment examples and 2000 from the negative sentiment examples. A total of 2000 examples were used to tune hyperparameters while the other 2000 were used for testing, as demonstrated in
Table 1. The rest of the dataset was used to build the lexicon and synonym thesaurus.
3.2. NLP Model Selection
The study utilizes three different NLP models for sentiment analysis: LSTM, Word Convolutional Neural Network (Word CNN), and BERT Base Uncased. These models vary significantly in architecture and approach but share a common goal of understanding and predicting sentiment in textual data.
3.2.1. LSTM
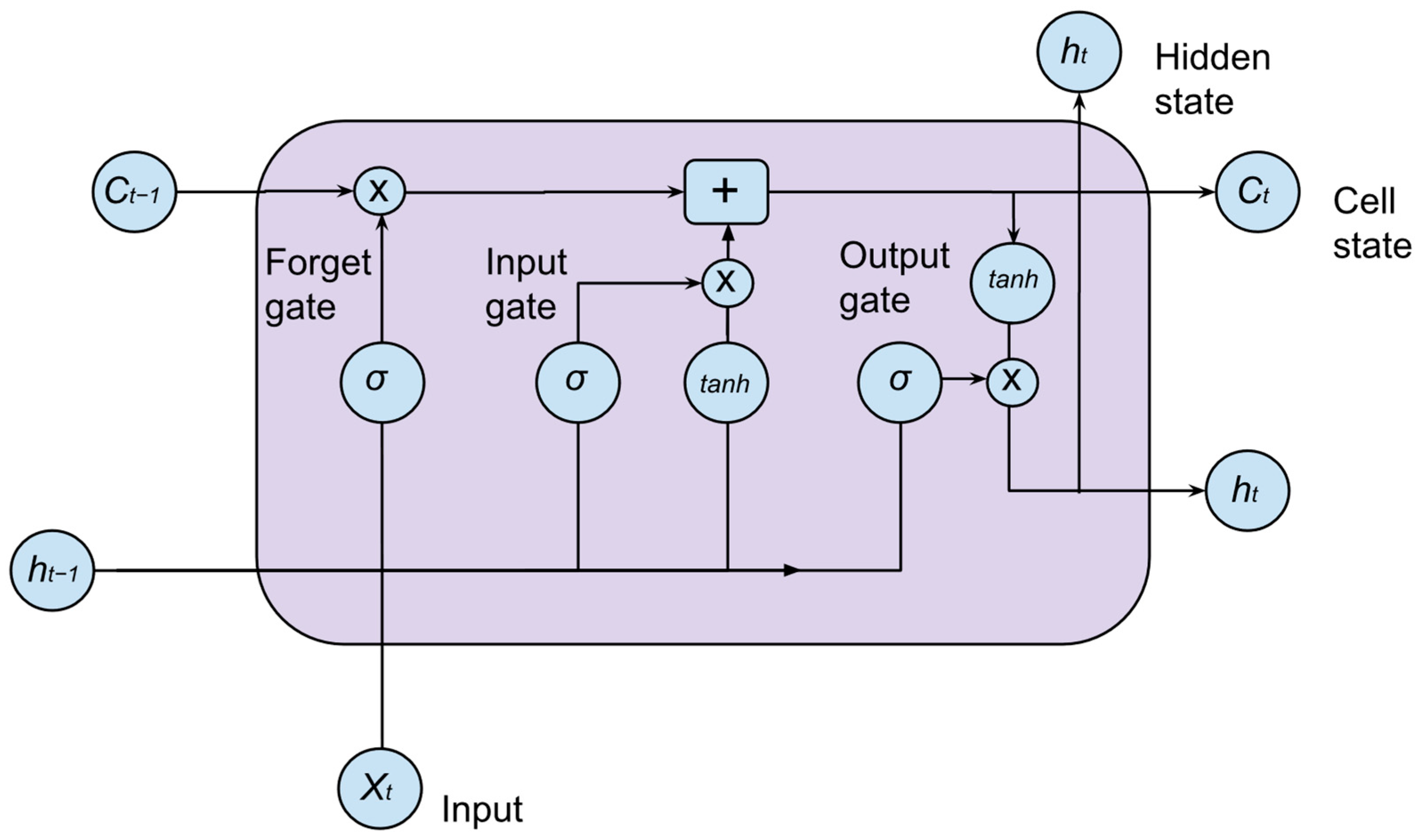
LSTM (Long Short-Term Memory) is an advanced recurrent neural network (RNN) architecture designed to address the vanishing gradient problem in traditional RNNs [
52]. It is particularly effective for sequence-based tasks such as sentiment analysis, speech recognition, and machine translation, enabling the model to capture long-range dependencies with high efficiency and accuracy. The exceptional performance of LSTM is attributed to its unique gating mechanism, which regulates information flow through memory cells, allowing the model to selectively retain or discard past information.
The core of LSTM lies in its three gating mechanisms—the input gate, forget gate, and output gate—which dynamically control how information is stored, updated, and passed through the network.
Figure 2 illustrates the architecture of an LSTM cell [
53]. The model processes input sequences through stacked LSTM layers, utilizing activation functions such as Sigmoid and Tanh, as well as dropout regularization, to mitigate overfitting. Loss computation is typically performed using categorical cross-entropy or mean squared error, depending on the application.
3.2.2. Word CNN
Word CNN is a convolutional neural network (CNN) designed for processing text data at the word level [
54]. Unlike LSTM, which processes sequences step by step, Word CNN applies convolutional filters to extract local dependencies in parallel, significantly improving training and inference speed. The model is particularly effective at capturing n-gram features, making it well-suited for tasks such as sentiment analysis, text classification, and spam detection, where local word interactions provide key insights.
The architecture of Word CNN consists of several convolutional layers that apply 1D filters over word embeddings, extracting local patterns and feature representations. The model typically employs multiple filter sizes (e.g., 3, 4, or 5 words in length) to capture different levels of semantic meaning. After convolution, max pooling layers help reduce dimensionality while retaining the most relevant features. The extracted features are then passed through fully connected layers before classification using Softmax or other activation functions. A key advantage of Word CNN over RNN-based models like LSTM is its ability to process input in parallel, leading to significantly lower computational costs while maintaining competitive accuracy. Additionally, regularization techniques such as dropout and batch normalization help prevent overfitting and improve generalization.
3.2.3. BERT
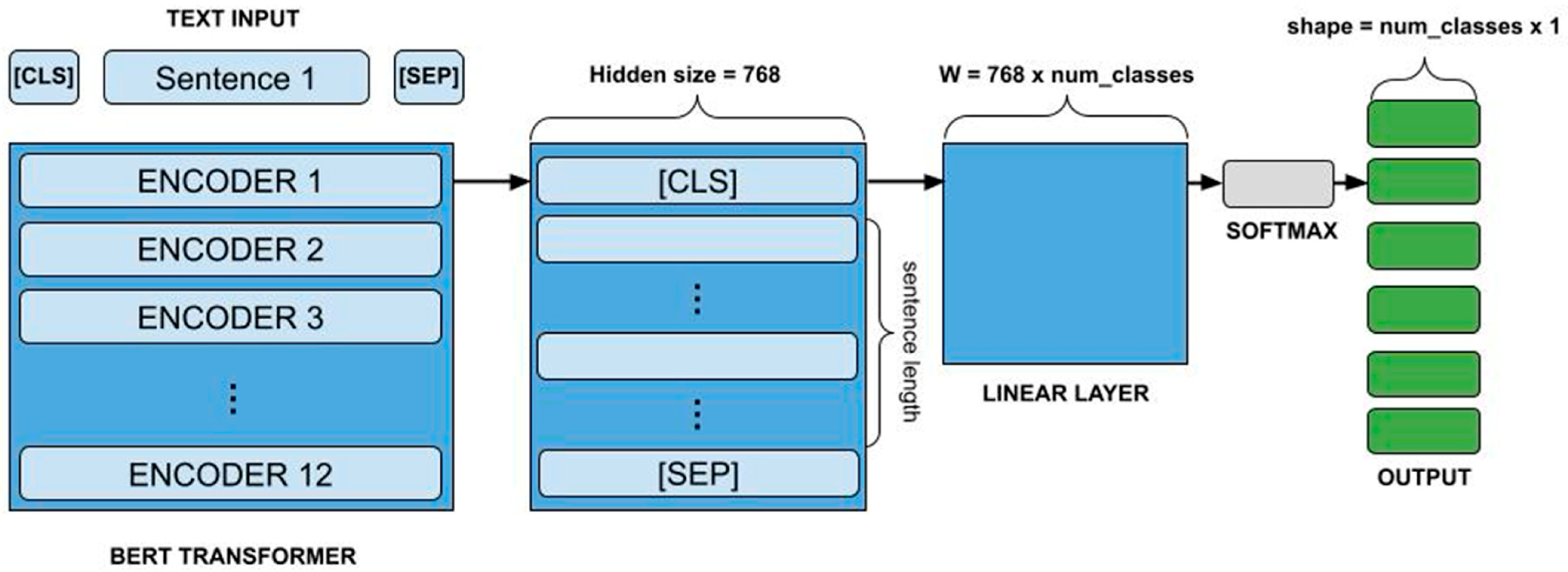
BERT is a transformer-based model that has achieved state-of-the-art results in various NLP tasks, including sentiment analysis [
9]. BERT utilizes a bidirectional attention mechanism, enabling it to grasp the meaning of a word by considering the context provided by the words on both its left and right sides. The Base Uncased version of BERT specifically refers to a smaller model (compared to larger variants) that ignores case sensitivity, which simplifies training while maintaining high performance.
Each model was further refined by being trained on the dataset corpora used in this study. Testing these models on the same datasets provides a robust comparison of how different architectures, with distinct methods of capturing context and dependencies, perform under adversarial conditions. The diversity in architecture [
55] also ensures that findings are not specific to a particular model type, thereby increasing the generalizability of the results.
Figure 3 illustrates the BERT architecture.
3.3. Adversarial Example Generation
Each of the sentiment analysis models (LSTM, Word CNN, and BERT Base Uncased) were subjected to adversarial attacks using PWWS, TextFooler, and BAE. Each dataset and model combination had its own attack iteration to ensure that the generated adversarial examples were tailored to exploit the specific weaknesses of that model. The three attacks were chosen since they implement word-level substitutions that attempt to maintain the meaning of the sentence, as character-level swaps can often be easily corrected with text correction tools. Word-level attacks that aim to preserve the original meaning pose a significant challenge, even to human reviewers, making them a critical area of focus for developing effective defenses.
3.3.1. PWWS
PWWS is a word-level adversarial attack that greedily targets the most salient words in a given text. It aims to maximize the impact of adversarial modifications while maintaining the fluency of the original text [
48]. It calculates a saliency score for each word and replaces those with the highest scores by considering synonyms that minimize classification confidence. This attack is particularly effective against sentiment analysis models due to its focus on modifying key words that are critical to sentiment polarity. The substitution process ensures the text remains as natural as possible, making it challenging for models to detect.
3.3.2. TextFooler
TextFooler, proposed by Jin et al. [
49], is another prominent word-level attack method that seeks to generate adversarial examples by replacing words with synonyms to mislead NLP models. It iteratively replaces the words that are most impactful to the model’s decision until the classification label changes. TextFooler is distinct for its balance between reducing the classification confidence and ensuring high semantic similarity with the original input. This makes TextFooler a strong benchmark adversarial attack for evaluating the robustness of NLP models, as it carefully crafts perturbations that deceive the model while preserving the intended meaning of the sentence.
3.3.3. BAE (BERT-Based Adversarial Examples)
BAE, developed by Garg et al. [
50], is an attack that utilizes the power of pre-trained language models, specifically BERT, to generate adversarial examples. BAE works by inserting or substituting words into the input sequence using contextual embeddings generated by BERT. This enables the attack to produce more contextually appropriate perturbations compared to other methods that rely solely on synonym substitutions. BAE’s use of BERT makes it particularly effective, as it leverages a language model trained on a vast corpus to generate high-quality adversarial examples that maintain naturalness and fluency.
3.4. Generating Defense Outputs
Once adversarial examples were generated for each model and dataset across the train and test sets, the process of evaluating the defense models began. The training set, comprising both benign and adversarial examples, was utilized for hyperparameter tuning to optimize the performance of each defense model. Grid search was employed to systematically explore the hyperparameter space and identify the best configuration for each model-dataset permutation. Following the tuning process, the defense models were exposed to the test set, containing unseen adversarial and benign examples, to obtain final evaluation results. This approach ensured that the models were both robust to adversarial perturbations and effective in maintaining accuracy on benign examples. A description of the algorithms used in the defense mechanisms is provided below.
3.4.1. FGWS
FGWS is a defense mechanism that mitigates adversarial attacks by leveraging word frequency to identify and replace key words that are likely to have been altered. FGWS operates by using a dictionary of word frequencies and a dictionary of semantically similar words. Words in the text below a certain threshold are replaced by synonyms that appear more frequently in the text. The intuition of FGWS is that attack algorithms will use less-orthodox semantically similar words to alter the polarity of a sentence. FGWS aims to minimize the impact of adversarial changes by swapping uncommon words with ones that have a higher probability to come from the topic lexicon. Compared to earlier defense strategies like adversarial training, FGWS directly targets the word-level weaknesses in a model without requiring retraining on adversarial examples, which makes it both effective and computationally efficient.
3.4.2. RS&V
RS&V works by generating multiple variations of the input text, where keywords are replaced by synonyms selected randomly from a predefined thesaurus. Each modified version of the input is then independently classified, and a voting mechanism is used to determine the final sentiment prediction. This approach leverages redundancy by ensuring that the influence of any single adversarial modification is minimized when averaged across multiple variations.
Compared to traditional defenses like adversarial training, RS&V does not require the model to be retrained on adversarial examples. Instead, it focuses on enhancing robustness through an ensemble-like approach, where multiple versions of the input are considered to reach a consensus. This voting mechanism is effective in preventing adversarial attacks partially because an effective attack would have to consider multiple variations of a sentence, which increases computational complexity. The random nature of the algorithm also obfuscates the gradients, which prevents confident adjustment of the gradients of the attack. RS&V requires a thesaurus of synonyms tuned to the keywords of the lexicon.
3.4.3. LRSM
LRSM operates by creating a lexicon, denoted as
L, from the dataset used to train the NLP models. This lexicon consists of words that are contextually appropriate and relevant to the task domain, making it a suitable source for word substitutions. Given an input sentence
, LRSM identifies all non-stop words, represented by the set
. Each word
in
is assigned to a random probability value
. LRSM then selects words with probabilities below a specified threshold
and substitutes each of these words with a randomly chosen word from the lexicon
L. This results in a modified sentence
. The overall procedure is outlined in Algorithm 1.
| Algorithm 1 Lexicon-Based Random Substitute Model (LRSM) |
| Require: Input sentence 5, lexicon L, threshold T, number of substitutions N, |
| | sentiment analysis model M |
| Ensure: Final predicted output |
| 1: | Identify all non-stopwords in S as W = {w1, w2, …, wn} |
| 2: | Initialize an empty set of modified sentences S’ = {} |
| 3: | for k = 1 to N do |
| 4: | Create a copy of S, denoted as Sk |
| 5: | for each word do |
| 6: | Assign a random probability [0,1] ▷ Reassign random |
| | probability for each sentence |
| 7: | if pi < T then |
| 8: | Replace in Sk with a randomly chosen word from the lexicon |
| | L |
| 9: | end if |
| 10: | end for |
| 11: | Add the modified sentence Sk to |
| 12: | end for |
| 13: | Pass each to the sentiment analysis model M to obtain predictions
|
| 14: | Compute the final predicted output: |
| | return |
This substitution process is repeated times, where is a parameter that defines the number of generated sentences. This produces a set of modified sentences, . Each of these modified sentences is passed to the sentiment analysis model to obtain a list of predictions, denoted as .
The final predicted output
is calculated by averaging the individual predictions:
By averaging the predictions across multiple modified versions of the input, LRSM effectively mitigates the impact of adversarial perturbations. This averaging approach ensures that the final prediction is less influenced by any single adversarial modification, thereby providing a more robust sentiment classification. The key strength of LRSM lies in its use of a completely randomized substitution strategy. This randomized substitution process introduces significant variability into the text, making it difficult for adversarial algorithms to craft effective perturbations as they would be diluted or neutralized by the unpredictable nature of LRSM’s substitutions. Moreover, randomness also prevents attackers from reverse-engineering a solution, as there is no fixed pattern or deterministic behavior in the substitutions. Each modified version of the input may differ substantially from the original and other generated versions, forcing attackers to contend with an expansive and dynamic search space.
Table 2 presents a sample of text modified by the three models mentioned above.
3.4.4. Assembling WVVM
WVVM is a two-layer framework designed to robustly evaluate the sentiment of adversarial text by integrating multiple defense algorithms and leveraging ensemble learning techniques. The system operates as follows:
The first layer of WVVM consists of three independently functioning adversarial text defense models: FGWS (Fixed Gradient Word Substitution), RS&V (Random Substitution Voting), and LRSM (Lexicon-Random Substitution Model). Let the input adversarial text be represented as S. This text is processed in parallel by the three models, each producing an independent sentiment evaluation. Equation (1) represents the sentiment predictions from these models.
where 0 denotes negative sentiment, 0.5 denotes neutral sentiment, and 1 denotes positive sentiment. These outputs collectively form a prediction vector as defined in Equation (2).
The prediction vector
v is passed to the second layer, which consists of a pre-trained ensemble classifier. The ensemble classifier takes
v as input and predicts the final sentiment, as shown in Equation (3).
In this work, three ensemble classifiers are evaluated:
3.4.5. Logistic Regression (LR)
LR predicts the probability of each sentiment class using the logistic function, as described in Equation (4).
where
is the weight vector and c denotes the sentiment class. LR is computationally efficient and well-suited for scenarios where the input features (i.e., the prediction vector) are linearly separable. It models the relationship between input features and output probabilities as a linear combination, making it interpretable and easy to implement. Additionally, its probabilistic output allows for flexibility in threshold selection, enabling better control over sensitivity to class imbalances or specific application requirements. Algorithm 2 details the steps involved in WVVM.
| Algorithm 2 Word-Variant Voting Model (WVVM) |
| Require: Input adversarial text S, |
| Ensure: Final sentiment prediction |
| 1: | Pass S through FGWS, SR&V, and LRSM to obtain individual predictions: |
| | , where |
| 2: | Pass the prediction vector v to the ensemble classifier: |
| | |
| 3: | Return |
3.4.6. SVC
SVC identifies a hyperplane that maximizes the margin between sentiment classes. SVC is particularly effective in scenarios where class boundaries are not strictly linear, as it can utilize kernel functions to map input features into higher-dimensional spaces. This capability allows SVC to handle complex decision boundaries while maintaining a focus on maximizing class separation. Additionally, SVC is less sensitive to outliers compared to simpler classifiers, as it emphasizes support vectors—key data points that define the decision boundary. Equation (5) describes its decision function.
where
w is the hyperplane normal vector and
b is the bias term.
3.4.7. Random Forest (RF)
RF is an ensemble of decision trees that outputs sentiment predictions for each tree. The final prediction is determined through majority voting across the trees, which provides robustness against overfitting and noisy data. RF’s ability to capture non-linear relationships and interactions between features makes it a powerful choice for handling diverse and complex input patterns. Furthermore, its inherent randomness—introduced during tree construction and feature selection—ensures that the model generalizes well to unseen data. During inference, each tree outputs a sentiment prediction y_i, and the final prediction is determined by majority voting, as shown in Equation (6).
where
T is the number of trees in the forest. WVVM’s strength lies in its layered design. The diversity of the first-layer defenses ensures that adversarial perturbations are counteracted from multiple angles, while the ensemble layer provides a unified, resilient prediction by averaging and refining the outputs. This structure makes WVVM particularly effective against complex adversarial attacks, as attackers face the challenge of bypassing multiple defenses simultaneously. Furthermore, the ensemble mechanism’s adaptability allows WVVM to dynamically select the best-performing layer configuration for a given task, ensuring optimal robustness across datasets and attack types. By integrating variability, aggregation, and adaptability, WVVM sets a high standard for defending against adversarial text attacks.
3.5. Performance Metrics
The evaluation metrics used include
Precision, Recall, F1 score, Adversarial Accuracy, and Restored Accuracy. Precision measures the proportion of correctly predicted positive instances, as shown in Equation (7).
Recall evaluates the proportion of correctly identified positive instances, as shown in Equation (8).
The F1 score balances precision and recall, as shown in Equation (9).
In Equation (10), adversarial accuracy measures performance on adversarial samples.
Restored accuracy evaluates classification accuracy after defense mechanisms are applied, as shown in Equation (11).
4. Results and Analysis
4.1. Performance Comparison Analysis of LRSM
Table 3 demonstrates the impact on accuracy when exposed to the adversarial attacks and the restored accuracy once the adversarial examples are passed to a defense algorithm.
Table 4 averages out performance metrics for the three defense models. Adversarial attacks substantially reduced the original accuracy of the NLP models across all datasets, attacks, and model permutations. For example, on the IMDb dataset using BERT under the PWWS attack, the original accuracy of 93.5% dropped to an adversarial accuracy of just 4.4%. Similarly, on the Yelp dataset using LSTM under the BAE attack, the original accuracy of 92.05% was reduced to 17.1%.
Among the defenses tested, LRSM consistently demonstrated robust performance in restoring accuracy across most dataset, attack, and NLP model permutations. For example, on the IMDb dataset using BERT under the PWWS attack, LRSM restored accuracy to 93%, compared to the original accuracy of 93.5%. In other cases, LRSM was particularly effective, even outperforming the original accuracy in restored accuracy. On the IMDB dataset using LSTM under the TextFooler attack, LRSM restored accuracy to 86%, exceeding the original accuracy of 83.4%, suggesting that the random substitutions in LRSM can not only neutralize adversarial perturbations but may also correct certain inherent misclassifications in the model. While FGWS and RS&V had better success in restoring accuracy in the Yelp Polarity dataset, LRSM had a higher average restored accuracy (83.7%) than either RS&V (75.7%) or FGWS (70.32%).
Precision and recall exhibited distinct challenges for the defenses.
Table 5 demonstrates the precision and recall for the three defenses across the different adversarial attacks, NLP models, and datasets. For RS&V and FGWS, recall was more challenging to maintain compared to precision, as models often struggled to correctly recover adversarially altered examples. Recall was 10 percentage points lower than precision for FGWS while RS&V was more balanced, with recall only being 3 percentage points lower. LRSM, in contrast, had higher precision than recall, indicating that it is more robust at identifying benign examples. Both average recall and average precision were higher for LRSM when compared to FGWS and RS&V (
Table 3). Looking at the Receiver Operating Characteristic (ROC) curves in
Figure 4, LRSM’s curve consistently lies above those of RS&V and FGWS, indicating it achieves a higher true-positive rate (TPR) for the same false-positive rate (FPR). This advantage appears across the three adversarial methods (BAE, PWWS, and TextFooler) and the different NLP models (BERT, CNN, and LSTM), although the margin varies. In some cases—particularly with BERT—FGWS tracks closer to LRSM, but overall, LRSM maintains a better balance of TPR and FPR.
Figure 5 shows the relationship between adversarial accuracy and perturbed accuracy across the different models and adversarial attack permutations. As adversarial accuracy drops, particularly when it is closer to 1, all models find it more difficult to relabel correctly the adversarial example.
Concerning LRSM hyperparameters, a grid search algorithm was used to find the optimal number of votes and thresholds. The number of votes, defined as the number of randomly substituted sentences generated for ensemble voting, showed that fewer than 5 votes was insufficient to generate the variability needed to neutralize adversarial perturbations, while increasing the number to 15 resulted in diminishing returns. The most effective configuration utilized 9 votes, which balanced the randomness introduced with sufficient consensus for robust predictions. The threshold parameter, determining the probability below which a word qualifies for substitution, was predominantly set at 0.33, indicating that substituting approximately one-third of the words achieved the best trade-off between disrupting adversarial modifications and maintaining semantic coherence.
4.2. Performance Comparison Analysis of WVVM
The ensemble-based WVVM variations surpassed all non-ensemble defenses in restored accuracy when results are averaged out.
Table 6 demonstrates different ensemble model iterations’ accuracy compared to the top performing individual model performance. Among the WVVM configurations, SVC achieved the highest restored accuracy, averaging 93.17%, outperforming the best-performing nonensemble model, LRSM, which achieved an average restored accuracy of 83.71%. In the majority of cases, WVVM was able to surpass the original accuracy of the NLP models. This significant improvement demonstrates the ability of WVVM to effectively leverage the outputs of individual defenses to counter adversarial perturbations, resulting in performance closer to and even better than the original accuracy. Logistic Regression and Random Forest also performed strongly, achieving restored accuracy of 91.66% and 90.77%, respectively.
Table 7 compares the precision, recall, and F1 scores of the evaluated models (BERT, Word-CNN, and LSTM) under three adversarial attack methods (BAE, PWWS, and TextFooler), alongside the best single-model. All ensemble-based defenses achieved higher F1 score than the best individual models. This finding shows that using information from all three models in an ensemble yields better results than only relying on the best-performing one. SVC WVVM was frequently the best-performing model, yielding the highest F1 score in 14 out of 18 scenarios. SVC’s superior performance over logistic regression and random forest suggests that margin-based classification is particularly effective at combining word substitution algorithm outputs for classification.
In terms of precision and recall, WVVM configurations demonstrated clear improvements over non-WVVM defenses, with notable differences in specific scenarios.
Table 6 shows the performance of different WVVM ensemble configurations’ performance against the best performing individual models. Logistic Regression achieved the highest average precision among the WVVM layers, at 81.74%, while SVC achieved the highest recall, at 93.17%. Non-ensemble LRSM, however, still had a higher average precision of 82.45%, but recall was lower by 10 percentage points (83.6%). The significant precision score improvement gave all WVVM models superior F1 scores compared to the individual models. Logistic Regression achieved the highest average F1-negative score of 86.26%, marginally surpassing SVC at 86.23% and Random Forest at 85.56%.
Table 8 lists the average precision, recall, restored accuracy, and F1 score of the three models. Recall is considerably improved by all ensemble models while precision faltered behind the best single model. This improvement is the main catalyst for the higher F1 score and indicates that the ensembles were better able to detect false negatives without significantly sacrificing false positive correction.
The hyperparameters of the best-performing WVVM configuration, Logistic Regression, reveal insights into how the base models—FGWS, RS&V, and LRSM—are utilized. The C = 0.01 parameter in Logistic Regression places a high penalty on overly complex decision boundaries, suggesting that sparsity in feature weighting was critical in combining the predictions of FGWS, RS&V, and LRSM. This aligns with RS&V’s random substitution strategy, which benefits from reduced complexity when aggregated, and LRSM’s high variability. The use of the L1 penalty ensured that Logistic Regression could adaptively balance the diverse input from the three defenses without introducing excessive bias from any single model.
Finally, the ensemble approach of WVVM provides additional advantages beyond simple voting. While RS&V and LRSM can be considered voting-based systems, WVVM introduces a second layer of learning, enabling it to adaptively weigh the outputs of each defense. This dynamic optimization allows WVVM to exploit complementary patterns across the three defenses. This adaptability to varied input makes WVVM not only a strong defense but also a framework capable of integrating new defenses as they emerge, ensuring its continued relevance in combating adversarial NLP attacks.
5. Discussion
5.1. Random Substitution Outperforms Saliency-Based
Originally, LRSM was designed to prioritize substituting words with higher saliency. Saliency, in this context, measures how much a word influences the polarity of a sentence when replaced with a benign word such as “the”. Saliency is crucial in in designing some word-swap algorithms [
56]. In PWWS, saliency is calculated as the probability-weighted change in the model’s output when a word is replaced, guiding the attack to target the words with the highest potential to alter the prediction. Based on this insight, initial LRSM attempts focused on identifying and altering high-saliency words and neutralizing adversarial examples. Other defenses such as TextFireWall were introduced that use the most salient words to identify adversarial examples [
57]. LRSM introduced a parameter, α, to control the substitution probability for high-saliency words. A higher α increased the likelihood of substituting high-saliency words, while at α = 0, all words had an equal chance of substitution.
Interestingly, as α approached zero, the F1 score of the model consistently improved. When α = 0, LRSM achieved its highest performance. This suggests that focusing exclusively on high-saliency words may not fully address the diversity of adversarial strategies. Instead, a uniform substitution approach creates a broader variability in substitutions, introducing unpredictability that disrupts adversarial attacks. This finding challenges the assumption that targeting high-saliency words alone is sufficient for effective adversarial defense, highlighting the value of uniform substitution in enhancing model robustness.
5.2. Synonym Closeness as a Parameter
LRSM demonstrates that synonym closeness can be treated as a hyperparameter in defense algorithms, with RS&V and LRSM at opposite extremes of the parameter. While, in the majority of attack and defense permutations, LRSM outperformed RS&V, there were a few cases where RS&V was the better-performing model. The LRSM lexicon pool from which a word is drawn can be thought of as a relaxation of the synonym pool from which RS&V draws synonyms. While RS&V might look for the n closest synonyms to a word for substitution, with n being a small number such as 3, 5, or 7, LRSM could be seen as also looking at the n most similar words to randomly select from, with n equal to the entire lexicon. This expansive search space allows LRSM to identify substitutions that RS&V would overlook, uncovering richer semantic variations and increasing resilience to sophisticated adversarial attacks. Furthermore, by treating the size of the lexicon as a tunable hyperparameter, LRSM introduces an additional layer of control, enabling researchers to fine-tune the balance between local substitutions (closer synonyms) and global substitutions (semantically similar words from the broader lexicon). Conceptually, RS&V can be seen as a specific instance of LRSM when the substitution range is limited to the closest synonyms. This positions LRSM as a general framework for adversarial text defense, accommodating a broader spectrum of substitution strategies.
5.3. Strengths
Among the individual defense models, LRSM achieved the highest average F1 score across all tested permutations, consistently outperforming FGWS and RS&V. While FGWS demonstrated effectiveness in certain cases, it struggled to maintain high F1 scores across diverse attack scenarios. Additionally, LRSM outperformed the other models in both precision and recall, indicating that it did not trade off one metric to improve the other. RS&V displayed strong results for select attack-model combinations but lacked consistency overall. A key advantage of LRSM is its minimal overhead: it does not require building or updating a thesaurus based on similarity, nor does it rely on enumerating keyword frequencies. This simplicity makes LRSM more adaptable to evolving training corpora, as new or changing vocabulary does not necessitate resource-intensive updates.
5.4. Limitations
Similar to RS&V, LRSM introduces an additional computational cost due to its voting procedure. To generate final predictions, multiple randomly substituted variants of each sentence must pass through the NLP model. This repeated inference process can be particularly burdensome when deployed with larger or more complex models, resulting in latency and scalability challenges. Another limitation of LRSM is its lack of interpretability. Since words are replaced with context-independent alternatives across multiple iterations, it becomes challenging to pinpoint which specific words caused a shift in sentiment polarity, making it difficult to identify why a sentence is labeled as adversarial. Additionally, LRSM does not consistently outperform all individual models across all permutations. An attacker aware of the defense and the NLP model could adapt their attack method to further degrade LRSM’s performance.
Although WVVM merges multiple defenses to achieve robust performance, its computational overhead can be substantial. The overall cost arises from several sources: generating frequency and similarity dictionaries for FGWS, producing multiple substituted variants for RS&V or LRSM, tuning hyperparameters for each individual defense, and then orchestrating the ensemble through an additional classification layer. These steps cumulatively increase both processing time and resource demands, posing challenges for large-scale or real-time deployments where minimal latency is critical. Another drawback is reduced interpretability. Because WVVM aggregates the outputs of multiple base defenses, tracing which defense mechanism or specific word substitution determines the final classification becomes more difficult. Furthermore, WVVM’s performance gains depend on the assumption that the base defenses are complementary. If multiple defenses share similar blind spots, particularly for complex or novel attack types, combining them may not substantially enhance overall resilience. Adversaries aware of WVVM’s underlying components could potentially exploit these shared weaknesses to degrade the ensemble’s effectiveness. Finally, the added complexity of a meta-classifier such as Logistic Regression or SVC requires additional hyperparameter tuning to balance the contributions of each defense, which may prolong deployment times and further increase resource consumption.
6. Conclusions
This paper introduced two novel defense mechanisms to address adversarial text attacks in sentiment analysis: the LRSM and WVVM. LRSM leverages randomized substitutions from a dataset’s lexicon to neutralize adversarial perturbations, achieving robust restored accuracy and, in some cases, exceeding original accuracy by correcting inherent model misclassifications. LRSM stood out from existing adversarial defense strategies like RS&V and FGWS by eliminating the need to create a dictionary of synonyms for substitution. The latter required precomputing a synonym dictionary by calculating the distance between all word embeddings and clustering them based on semantic closeness. This process is computationally intensive, and as new keywords are introduced, the dictionary must be updated, adding further overhead. In contrast, LRSM bypasses this requirement by directly substituting words with random alternatives drawn from the lexicon, without the need to predefine or query semantic relationships. Despite this simplified approach, LRSM not only reduces computational overhead but also demonstrates improved accuracy and F1 scores compared to RS&V and FGWS. LRSM achieved an average restored accuracy of 84% compared to 76% for RS&V and 70% for FGWS. LRSM achieved an F1 score of 83% compared to a score of 77% for RS&V and a score of 74% for FGWS. The results and smaller operational overhead highlight the potential of non-synonym-based substitution strategies to achieve both defense robustness and efficiency in adversarial defenses. Additionally, the discovery that LRSM’s uniform substitution outperformed saliency-based approaches highlights the value of randomness in neutralizing adversarial attacks, challenging assumptions about targeting high-saliency words alone.
WVVM builds on this foundation by integrating LRSM with FGWS and RS&V through an ensemble framework that adaptively combines their outputs using a classification layer. WVVM consistently outperformed standalone defenses across datasets, adversarial attacks, and NLP models, demonstrating superior restored accuracy and F1 scores while maintaining a balance between precision and recall. Notably, WVVM’s ability to adaptively weigh complementary patterns across the three defenses allowed it to address diverse adversarial strategies with enhanced robustness. Key findings include WVVM’s success in leveraging ensemble learning to overcome limitations observed in individual defenses. Logistic Regression emerged as the best-performing ensemble configuration, with its regularization parameters ensuring a balance in weighting the contributions of FGWS, RS&V, and LRSM. Logistic Regressions LRSM achieved an F1 score of 93.2% which was 10pp higher than the best performing individual model. SVC WVVM excelled at restored accuracy, achieving an accuracy of 93.2% which was 10pp higher than any single individual model.
While LRSM decreases computational complexity, WVVM’s complexity limits its applicability to large-scale or real-time scenarios. The need to generate multiple perturbed versions of input, process them through three defenses, and then aggregate their outputs introduces significant computational overhead. Hyperparameter optimization, such as tuning the number of votes or substitution thresholds, further adds to the resource demands.
Future work will focus on addressing these computational challenges. One direction involves reducing the number of perturbed sentences generated for voting, without compromising robustness. Techniques like lightweight substitution methods or efficient approximation algorithms could significantly reduce the processing overhead while maintaining the effectiveness of the ensemble. Exploring distributed or parallel processing for generating and evaluating substitutions could further enhance scalability. Narrowing the focus to these computational solutions will ensure that LRSM and WVVM remain practical, efficient, and effective defenses against the evolving landscape of adversarial NLP attacks. These advancements will be particularly useful for practitioners and researchers deploying sentiment analysis models in real-time and resource-constrained environments, where robustness against adversarial attacks must be balanced with computational efficiency.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}