1. Introduction
Social media platforms, such as X, Facebook, Instagram and YouTube, have transformed global communication, allowing for real-time connectivity between cultures. They foster vibrant online communities and shape public opinion [
1,
2]. However, their widespread use has amplified harmful content, particularly hate speech, which targets individuals or groups based on attributes such as race, religion, or gender [
3]. This phenomenon undermines online safety and social cohesion, necessitating robust detection mechanisms. In contrast, positive discourse, such as hope speech [
4,
5,
6] and social support, encourages constructive dialogue, underscoring the need for robust detection systems to mitigate harm and promote healthier online environments [
7]. Significant research has advanced hate speech detection [
8], primarily focusing on monolingual datasets in high-resource languages such as English, Spanish, and code-mixed Dravidian languages such as Tamil and Malayalam [
9]. Many studies have explored explainable datasets and regional linguistic nuances, achieving strong performance with transformer modifications [
10]. Multilingual efforts, such as the SemEval-2021 toxic spans detection task, have made further progress [
11].
However, hate speech detection using joint multilingual techniques such as Urdu, Spanish and English using large language models remains underdeveloped due to the lack of annotated datasets and the complexity of their linguistic structures. English, Spanish, and Urdu are widely spoken globally and present diverse linguistic challenges [
12]. English dominates social networks, Spanish is critical in regions like Latin America, and Urdu is prevalent in South Asia and diaspora communities, often in code-mixed forms [
13]. The lack of annotated datasets for Urdu limits effective natural language processing (NLP) solutions [
14]. To address this, we introduce a novel trilingual dataset of 10,193 tweets in English, Urdu, and Spanish annotated with high inter-annotator agreement and evaluate a unified multilingual pipeline using machine learning, transformer models, and large language models (LLMs).
Recent advancements in natural language processing (NLP), particularly the development of transformer-based and multilingual transformer models, have significantly improved cross-lingual understanding through transfer learning [
15,
16]. While translation-based methods facilitate the alignment of diverse linguistic data [
17], core NLP tasks such as clinical text classification [
18], sentiment analysis [
19], and Named Entity Recognition (NER) [
20] have also seen remarkable improvements. However, research on hate speech detection, toxic content classification, and entity extraction in the context of social media—especially using joint multilingual approaches across Urdu, English, and Spanish—remains largely underexplored. These three languages were deliberately chosen due to their global and digital significance: English is a dominant language on the internet and in NLP research, Spanish is one of the most widely spoken languages worldwide with a vast online presence, and Urdu represents a low-resource language with a growing digital content and a unique set of linguistic challenges. Together, they offer a diverse set of orthographic, morphological, and syntactic features that help evaluate the robustness and adaptability of multilingual NLP models. Low-resource languages such as Urdu continue to be underrepresented in this field, which hinders the development of inclusive and effective NLP solutions [
21].
To address this gap, we manually annotated three distinct datasets in English, Urdu, and Spanish, ensuring high-quality, language-specific hate speech annotations. Following rigorous preprocessing, we performed feature extraction using TF–IDF combined with classical machine learning models. In parallel, we employed pretrained word embeddings—FastText and GloVe—within BiLSTM and CNN architectures to capture contextual semantics. To further enhance performance, we incorporated advanced contextual embeddings using transformer-based models including BERT, RoBERTa, XLM-RoBERTa, and Google’s ELECTRA. Additionally, we employed the large language model OpenAI GPT-3.5-turbo to perform hate speech classification. Our comprehensive approach aims to develop a robust, real-time multilingual hate speech detection system tailored to the unique linguistic and cultural nuances of online discourse, thereby contributing to safer digital environments across diverse communities.
This study makes the following contributions:
- ✓
To the best of our knowledge, joint multilingual and translation-based techniques have not been previously explored on a combined Spanish, English, and Urdu dataset. Our work pioneers this approach, enabling more inclusive and effective hate speech detection across diverse languages.
- ✓
We developed a high-quality multilingual dataset comprising 10,193 annotated tweets in English, Urdu, and Spanish for hate speech detection. This dataset enhances cross-lingual research and supports the robust evaluation of multilingual hate speech models.
- ✓
We developed detailed pseudo-code for our multilingual hate speech detection content detection pipeline to support future research and enable better reproducibility.
- ✓
We conducted 41 experiments to evaluate and compare the performance of machine learning, deep learning, transfer learning, and large language models on our trilingual hate speech detection tasks, aiming to identify the most effective model for this challenge.
- ✓
Based on the results, our proposed GPT-3.5 Turbo model outperformed the transformer-based XLM-R model—achieving an up to 8% improvement in Urdu and an overall average gain of 4% across English, Spanish, and Urdu in hate speech detection.
3. Methodology and Design
3.1. Construction of Dataset
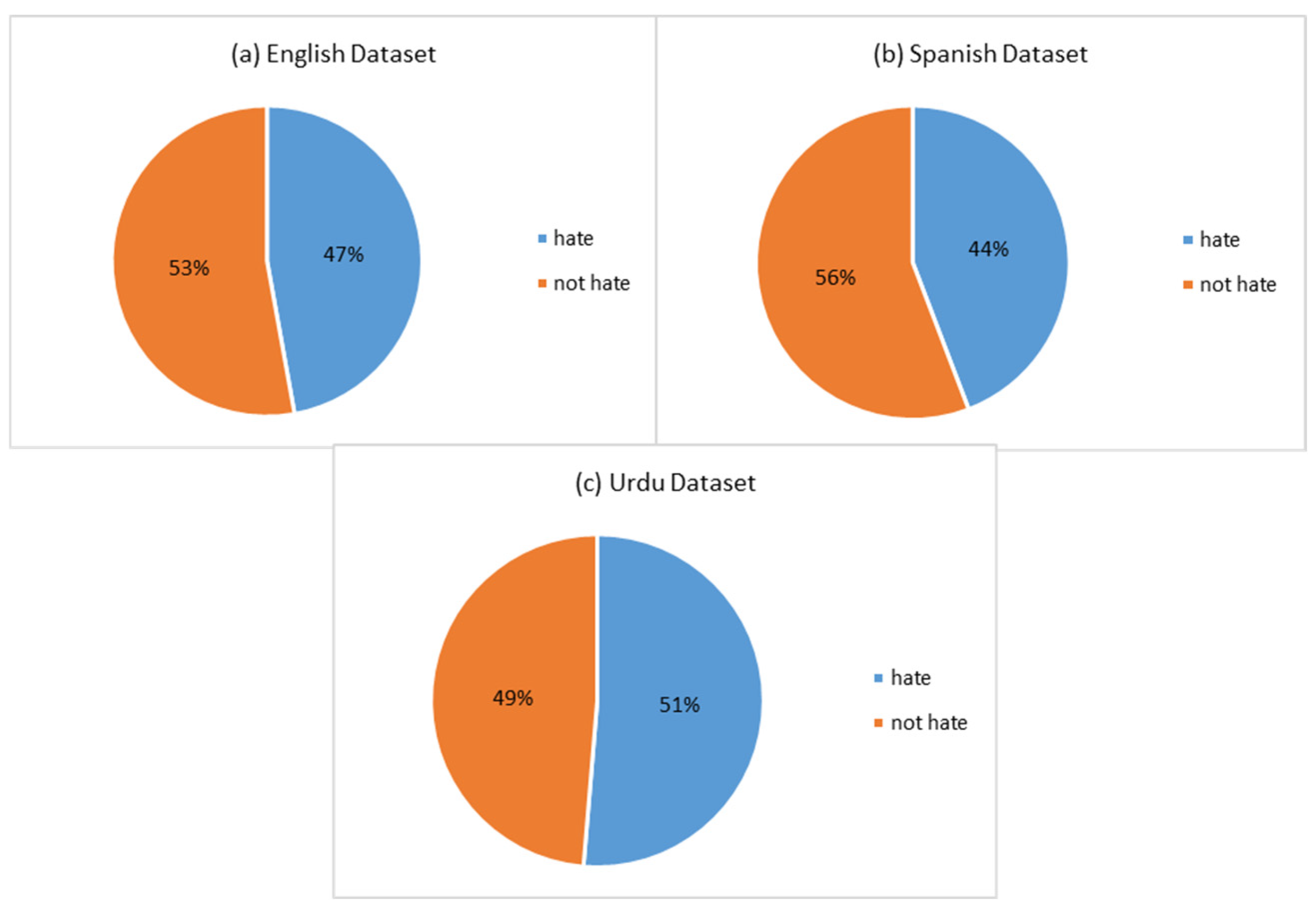
The dataset was curated using the Tweepy API to collect tweets from X (formerly Twitter) between January 2024 and February 2025, resulting in 10,193 tweets: 3834 English (1809 “Hateful,” 2025 “Not-Hateful”), 3197 Urdu (1642 “Hateful,” 1555 “Not-Hateful”), and 3162 Spanish (1398 “Hateful,” 1764 “Not-Hateful”), with a total of 4849 “Hateful” and 5344 “Not-Hateful” labels across the combined dataset.
We employed stratified sampling to ensure a balanced representation of hateful and non-hateful content across languages, maintaining proportional label distributions within each language subset. Keywords were selected to capture a broad emotional spectrum, including both hateful and non-hateful sentiments, to avoid bias toward negative content.
For English, terms included hate-related words such as “fuck,” “cunt,” and “shithead,” along with neutral terms like “support.” For Urdu, examples included offensive terms like “کتے” (dog) and “حرامی” (motherfucker), along with neutral or positive words like “امید” (hope). For Spanish, hateful expressions such as “hijo de puta” (son of a bitch) and “mierda” (shit) were used alongside neutral terms like “gracias” (thank you). Including neutral or positive terms like “gracias” and “support” helped capture non-hateful contexts such as gratitude or encouragement, ensuring the dataset reflects the diversity of real-world discourse. Additional terms like “war” and “sorrow” broadened the emotional range.
To evaluate the reliability of keyword-based sampling, we analyzed the annotation outcomes relative to the type of keywords used during data collection. Among tweets retrieved using hate-related keywords, approximately 43% were ultimately labeled as non-hateful, demonstrating that keyword presence alone is not a definitive indicator of hate speech and reflecting substantial noise introduced by keyword filtering. Conversely, 57% of these tweets were confirmed as hateful, indicating that keyword-based selection can still capture relevant content, albeit imperfectly. Interestingly, among tweets retrieved using neutral or positive keywords, approximately 12% were eventually annotated as hateful, often due to sarcastic expressions, coded language, or implicit hate not captured by overt keywords. These findings highlight both the strengths and limitations of keyword-based sampling. While it facilitates targeted data collection, it also introduces considerable noise and challenges for the annotation process, underscoring the critical role of comprehensive manual annotation to ensure dataset reliability. From an initial pool of 58,000 tweets, the final dataset was filtered and stored in three CSV files stratified by language. To clarify, the class distribution of 5344 “Not-Hateful” and 4849 “Hateful” across all languages reflects the total dataset counts, ensuring consistency with the reported 3834 English, 3197 Urdu, and 3162 Spanish tweets.
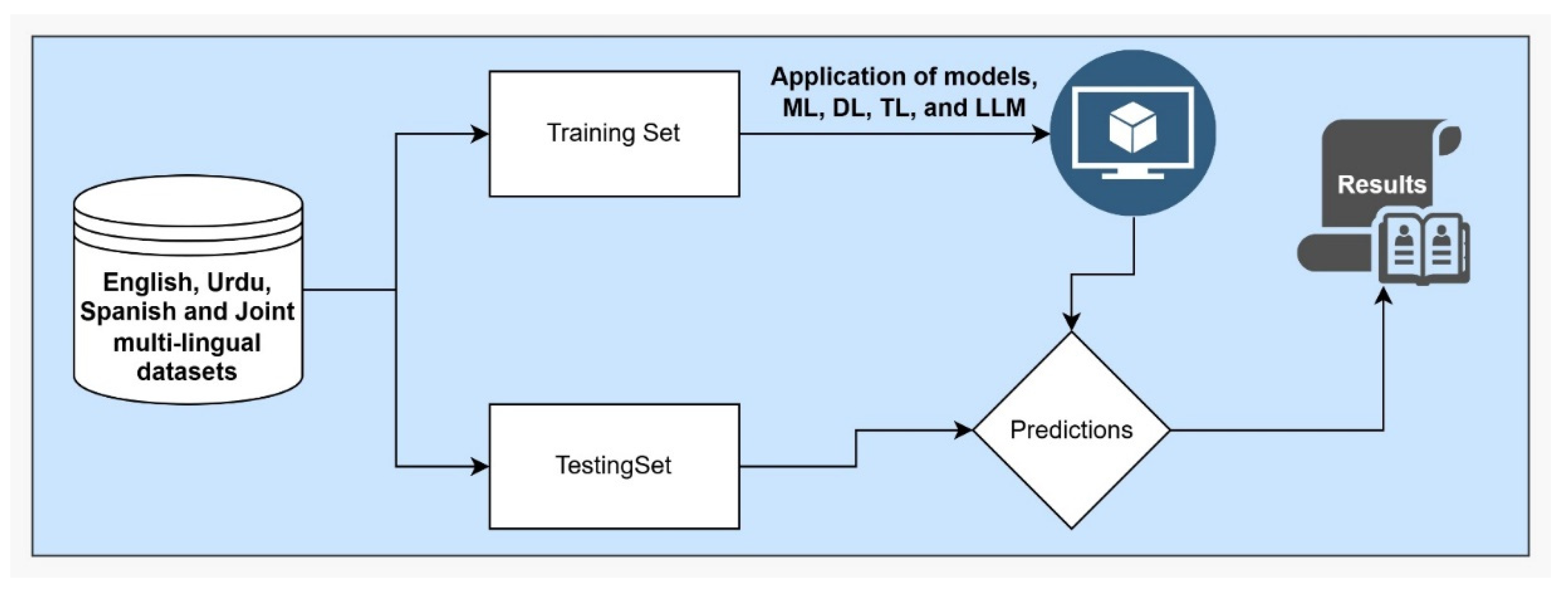
Figure 1 illustrates the methodology workflow and data collection process.
3.2. Annotation
Annotation involved binary classification (“Hateful” or “Not-Hateful”) by three native-speaking postgraduate Computer Science students per language, with distinct annotator groups for English, Urdu, and Spanish to ensure linguistic and cultural expertise.
The annotation team included one female and two male annotators for English (ages 24–28), two female and one male annotators for Urdu (ages 23–27), and one female and two male annotators for Spanish (ages 25–29), ensuring a diversity of perspectives to minimize annotation bias. Each annotator independently labeled the 10,193 tweets, and the final label for each instance was determined through majority voting (i.e., agreement by at least two annotators) within each language group.
The annotation process was guided by detailed, language-specific criteria designed to distinguish hateful content—such as the use of a hostile tone, derogatory slurs (e.g., “fuck”), and prejudice against minorities—from non-hateful content, which typically includes neutral or empathetic language without an intent to harm.
To ensure cross-lingual consistency, we developed a standardized annotation guideline, which was translated into English, Urdu, and Spanish, and conducted a joint training session for all annotators. During training, annotators collaboratively discussed cultural nuances to harmonize their understanding of hate speech across languages. For example, in Urdu, the word “کتا” (kutta-dog) is commonly used as a strong insult, whereas in Spanish, phrases like “hijo de puta” (son of a bitch) are considered highly offensive. Such discussions helped refine the annotation framework to accommodate linguistic and cultural variations across languages.
Additionally, a cross-language validation subset (510 tweets, 5% of the dataset) was translated into English as a pivot language by bilingual experts (e.g., Urdu–English and Spanish–English translators) and annotated by all groups. This process ensured that annotators, despite not speaking each other’s languages, could align their understanding through translated examples and shared guidelines. Periodic calibration meetings were held to resolve discrepancies, further ensuring consistency across languages.
Table 1 illustrates examples of hateful and non-hateful tweets.
3.3. Annotation Guidelines
To develop a high-quality and consistent multilingual hate speech detection dataset, we designed annotation guidelines for annotators working with English, Urdu, and Spanish social media posts. These guidelines were formulated based on previous literature, platform community standards, expert consultations, and with a focus on cultural sensitivity and linguistic diversity. Examples from the dataset are given in
Table 1.
3.3.1. Hate
- -
Identify whether the post targets a person or group based on characteristics such as race, religion, ethnicity, gender, sexual orientation, nationality, disability, or political beliefs. For example, in Urdu, posts targeting Pathans or Shias may reflect ethnic or sectarian bias common in Pakistan. In Latin American Spanish, xenophobic comments against Venezuelan or Bolivian migrants are prevalent.
- -
Read the sentence carefully and check for explicit hate using direct slurs, threats, or dehumanizing language. For instance, Urdu hate speech might include words implying certain ethnic groups are terrorists or criminals, while Spanish posts may use derogatory terms to demean migrants or minorities.
- -
Look closely at the language and detect implicit hate through sarcasm, coded language, stereotypes, or indirect suggestions of harm or inferiority. In Urdu, phrases limiting women’s roles to domestic spaces or controlling social behavior reflect deep-rooted patriarchy. In Latin American Spanish, homophobic slurs or stereotypes about laziness may be implied rather than directly stated.
- -
Pay attention to whether the post distinguishes between offensive but non-hateful language (e.g., profanity used casually or generally) and actual hate speech. Cultural context matters: certain slang or swear words in Urdu or Spanish may be used colloquially without hateful intent but could also be weaponized in hate speech.
- -
Read the sentence carefully and find context—evaluate tone, intention, and any references that might alter the meaning (e.g., satire, irony, or humor). Some posts may appear hateful but could be sarcastic or ironic. Understanding local humor or cultural references in Urdu or Spanish is crucial.
- -
Be alert to cultural and regional phrases or slang that may carry hateful meanings in local usage. For example, derogatory terms unique to Pakistani regional dialects or Latin American Spanish regionalisms should be recognized as potentially hateful.
- -
Consider if the post incites, encourages, or glorifies violence or discrimination. Posts calling for violence against ethnic groups such as Shias in Urdu or expulsions of migrants in Latin American contexts are clear examples.
- -
Avoid judging based solely on keywords—a word may be hateful in one context and neutral in another. The word “kutta” (dog) in Urdu is a common insult but context and target group must be considered.
- -
Evaluate whether the post contributes to hostility or social division against a group or individual. Posts that reinforce stereotypes or encourage exclusion, even subtly, contribute to social division.
- -
In case of doubt or ambiguity, flag the post for expert review or discuss it with the annotation team for consensus.
3.3.2. Not Hate
- -
Expresses opinions, disagreements, or criticism without targeting a group with hate or inciting violence.
- -
Uses sarcasm or humor without causing harm or marginalizing others.
- -
Contains offensive language or slang used casually or in non-targeted ways (e.g., swearing without targeting a group).
- -
Discusses social issues or controversial topics respectfully or neutrally.
- -
Makes personal experiences or general observations without demeaning others.
- -
Includes neutral, informative, or supportive content.
- -
Shows empathetic, constructive, or inclusive tone even when discussing sensitive topics.
- -
Debates or criticizes ideas or policies without attacking identity groups.
- -
Mentions protected characteristics (e.g., race and religion) in non-hostile, descriptive, or academic ways.
- -
Lacks harmful intent or effect and does not provoke hostility or fear.
3.4. Annotation Selection
In the present study, we prepared and used hate speech datasets in three languages, English, Spanish, and Urdu, with the aim of comprehensively examining multilingual hate speech detection models. The data sampling procedure was appropriately planned to include the linguistic and cultural situations where hate speech exists on online social sites.
To ensure the quality and reliability of the annotated data, we adopted a manual annotation approach carried out by domain-sensitive annotators who were experts in the respective languages. For the Urdu and English datasets, three members of the annotation team were involved: the first author, the second author, and another lab member proficient in Urdu. All three annotators are PhD students and native speakers of Urdu while also possessing a high level of academic proficiency in English, which is one of the national languages of Pakistan. This combination of linguistic expertise and academic background enabled them to identify nuanced linguistic features, cultural expressions, and contextual patterns of hate speech in both languages.
In the case of Spanish data, three PhD students of our lab participated in our data curation: they are all native speakers of Spanish. Their language affiliation and educational experience made sure that the Spanish data was annotated efficiently and sensitively and that both explicit and implicit indicators of hate speech in Spanish social media data could be identified.
In order to set up the annotation process as easily and consistent as possible, we had a separate Google Sheet per language-specific dataset. The different annotators received separate entries, and a set of annotation rules was provided that presented the definition of hate speech clearly and with more examples that helped minimize the degree of ambiguity and brought standardization in labeling. A majority voting method was applied to the three annotators in determining the final label applied to each instance. Where discrepancies and annotations could not be settled on and where no agreement was reached on any labels, we held a weekly session to agree on the issues and ensure the integrity and consistency of the final output on the dataset. In recognition of their time and effort, each annotator was compensated at a rate of $0.03 USD per annotated sample.
This multilingual, curated, and human-annotated dataset allowed us to train and test our machine learning, deep learning, transfer learning, and large language models in a robust, reliable, and ethically sound manner.
3.5. Inter-Annotator Agreement
In evaluating the consistency and reliability of the manual annotations among the annotators, we calculated the Inter-Annotator Agreement (IAA) score. The fact that every sample was separately annotated by three raters required the use of a statistic that would assess the agreement degree of a categorical data based on multiple raters; thus, we used Fleiss’ Kappa.
The score given by our analysis was 0.82 in Fleiss’ Kappa, and this shows that there was a strong agreement in annotations. Based on the general guidelines of interpreting Kappa values, a higher value than 0.80 implies substantial or near-perfect agreement, and the consistency and quality of our annotation are therefore confirmed.
Table 1 shows the interpretation of the Kappa values.
Additionally, we calculated Fleiss’ Kappa scores separately for each language to better understand potential variation in annotation difficulty: English achieved a Kappa of 0.82, Spanish scored 0.83, and Urdu had a slightly lower score of 0.80. This difference highlights that annotation in Urdu is more challenging, likely due to its script complexity
Table 2. shows interpretation of Cohen’s kappa values.
3.6. Corpus Characteristics
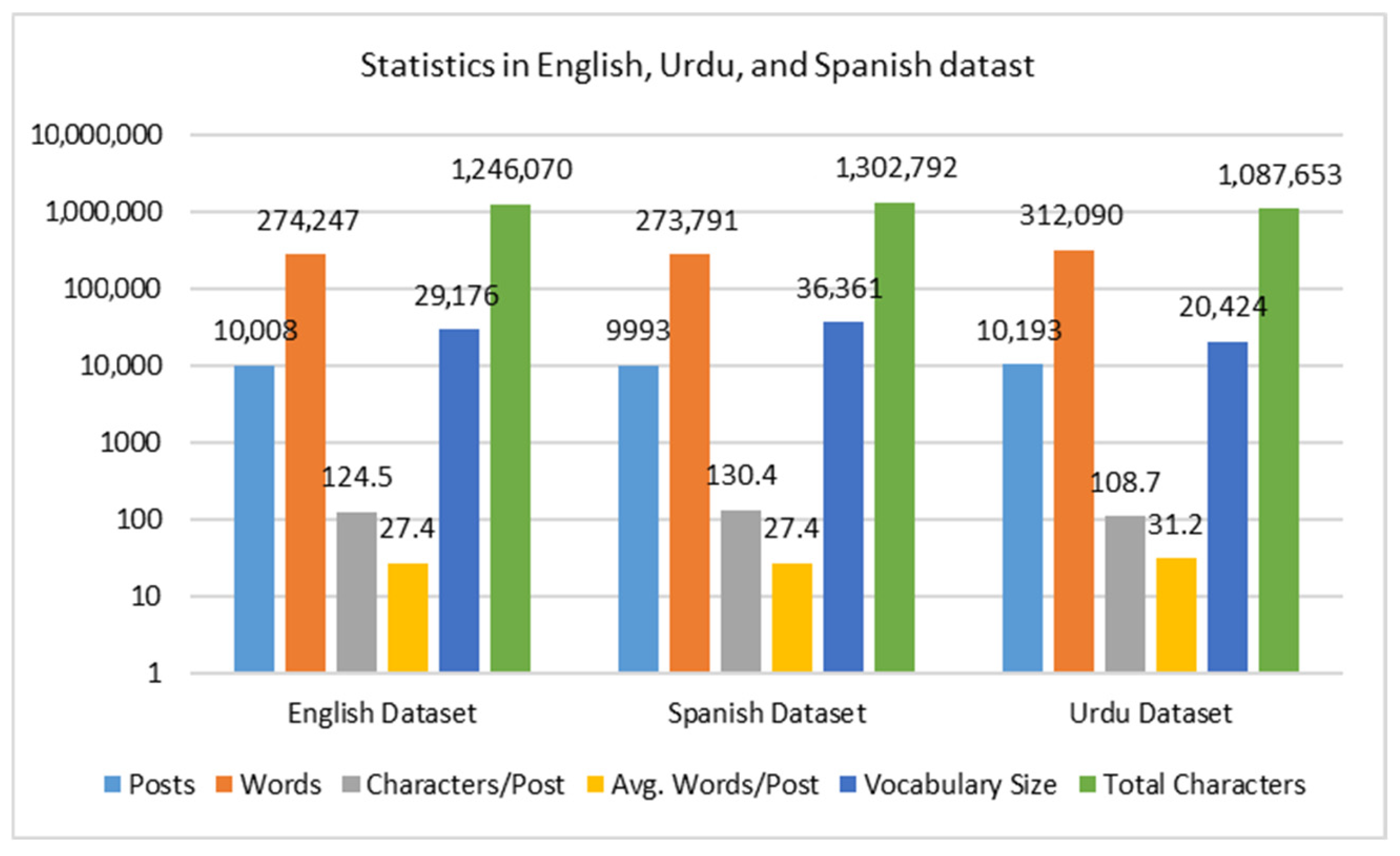
The dataset, comprising 10,193 tweets, showcases translation statistics across English, Spanish, and Urdu and Joint Multilingual language sets as shown in
Figure 2. English tweets lead with a total of 274,247 words and 1,246,070 characters, an average of 124.5 words per post, and a vocabulary of 29,176 words. Spanish tweets follow with 273,791 words, 1,246,070 characters, an average of 27.4 words per post, and a vocabulary of 20,424 words. Urdu tweets exhibit 312,090 words, 1,302,757 characters, an average of 31.2 words per post, and the largest vocabulary at 36,361 words. The chart highlights these metrics, with all languages sharing an equal post count of 10,193. Additionally, the Joint Multilingual dataset includes 10,193 posts, 281,865 words, an average of 28.1 words per post, a vocabulary of 41,660 words, and a total of 1,183,315 characters. While
Figure 3 shows the label distribution of our trilingual dataset and
Figure 4 shows a word cloud that provides a quick, visual summary of the most frequent words in the text.
3.7. Ethical Considerations
The research methodologies involved in this study only employed publicly available social media data in respect to user privacy and ethical considerations. We anonymized tweets by removing personal identifiers and prohibited contacting original posters. The dataset will only be shared with researchers adhering to stringent ethical protocols, ensuring privacy and responsible use.
3.8. Translation-Based Approach
The translation-based technique was designed to standardize Spanish, Urdu and English tweets by translating all content into a single target language. This unified format allows the dataset to be stored in a single CSV file, where the first column contains the tweet text and the second column holds the label. This structure simplifies both data processing and analysis. The translation pipeline consists of the following steps.
Pre-Translation Tokenization: Prior to translation, the text was segmented into smaller units such as words or phrases. This step enhanced translation accuracy by enabling the translation system to more effectively interpret the context and meaning of each segment.
- -
Handling Noisy Translations: After completing the translation, we conducted a thorough manual review of the entire process to identify and correct any potential errors. Special attention was given to idiomatic expressions and slang, which often do not translate directly, to ensure that the final content accurately preserved the original meaning and clarity.
- -
Post-Translation Alignment: To ensure consistency, we initially translated the Urdu text into English and compiled it into a single CSV file to form a unified corpus. For the second corpus, we translated the English content into Urdu, carefully aligning it with the original Urdu texts in the dataset. This approach ensured that both the translated and original texts were of comparable quality, making them suitable for reliable analysis.
- -
Text Length Standardization: To handle excessively long texts, truncation was applied to maintain a consistent input length, thereby making the data more suitable for processing by deep learning models.
This approach helped mitigate the impact of linguistic differences between Urdu, Spanish and English, ensuring that they did not hinder model performance. It also facilitated consistent text processing across the three languages.
Table 3 shows the step by step pseudo-code for multilingual hate speech classification using a GPT-3.5 Turbo model on the Spanish, Urdu and English corpus.
3.9. Preprocessing
Preprocessing is a critical step in natural language processing (NLP), as raw text data are often noisy, inconsistent, and filled with irrelevant elements that can compromise model performance. The goal of preprocessing is to clean and normalize the text, making it more suitable for analysis and downstream machine learning tasks.
Our workflow began by removing undesirable elements such as URLs, emojis, punctuation, numbers, user mentions, and hashtags. These elements are often stylistic or non-standardized and could introduce noise during model training. However, we acknowledge that hashtags—particularly in the context of hate speech—can carry important semantic and social signals (e.g., #BanMuslims and #KillAllX), often serving as markers of ideology, sentiment, or group identity. In this study, hashtags were removed to maintain consistency across multilingual text and reduce annotation complexity introduced by long or compound hashtags. Nevertheless, we recognize this as a limitation, and future work will explore retaining or extracting features from hashtags to enhance model sensitivity to contextually relevant hate speech cues.
Next, we normalize the text by converting all characters to lowercase, ensuring that words like “Love” and “love” were treated identically. We then eliminated stop words in English, Urdu, and Spanish—common words such as
is,
hai, or
de—that contribute little semantic value. Finally, stemming was applied to reduce words to their root forms (e.g.,
running to
run,
khushiyan to
khushi). These preprocessing steps helped transform messy and unstructured input into a cleaner, more uniform representation, allowing theNLP models to more effectively learn and better generalize.
Table 4 outlines the preprocessing steps used in this study.
3.10. Application of Models, Training, and Testing Phase
This section discusses how different models were applied in the process of training and testing in the hate speech detection task. In our work, all the major learning paradigms were included—machine learning (ML), deep learning (DL), transfer learning (TL), and large language models (LLMs)—to fully test the performance on different languages and data conditions as shown in
Figure 5.
In the machine learning method, four popular classifiers were used: random forest (RF), support vector machine (SVM), decision tree (DT), and eXtreme Gradient Boosting (XGBoost). The models were pre-trained on Text Frequency–Inverse Document Frequency (TF–IDF) feature extraction to transform the raw textual data into a numeric format to be trained upon. TF–IDF is useful because it identifies the worth of words in an individual document by the whole corpus.
We applied pretrained word embeddings to characterize the semantic framework of the supplied text within the framework of the deep-learning. Namely, FastText and GloVe embeddings were fed into the neural network architectures including convolutional neural networks (CNNs) and bidirectional long short-term memory (BiLSTM) networks. They can be used to learn complicated syntactic and semantic dependences in text and tend to be quite effective in sequence-based problems such as hate speech classification.
We also embedded contextual representations into the powerful transformer-based models (e.g., BERT, ELECTRA, RoBERTa, and XLM-RoBERTa) and used them in the transfer learning. These models are trained with huge corpora and could be used to fine-tune our hate speech datasets to make them suitable to downstream classification. With their contextual interpretation, they would be able to successfully absorb subtle interpretations and language-specific hints, particularly in multilingual and code-mixing contexts.
Lastly, we utilized the small language model (LLM) GPT-3.5 Turbo with the highest level of generative model capabilities that could execute classification with maximum contextual existence and generalization. The model uses its extensive knowledge base and ability to learn in context to admirably work on low-resource languages including the Urdu language. In our desire to have a strong and justifiable test, we incorporated a standardized 80–20 split across models and languages. Such a stable configuration made a difference in the comparative evaluation of the model behavior with the same data conditions, and they were then assessed with the help of the essential evaluation statistics (precision, recall, F1-score, and accuracy).
Table 5 shows the key parameters and optimal configurations used for fine-tuning the diverse set of models applied to the task of multilingual hate speech detection in English, Urdu, and Spanish tweets. We experimented with traditional machine learning models such as logistic regression, support vector machines (SVM), and random forest, each fine-tuned with their most effective hyperparameters—for example, the L2 penalty and the “liblinear” solver for logistic regression, a linear kernel and optimal regularization for SVM, and 100 estimators for random forest with Gini impurity. In the deep learning category, we optimized a convolutional neural network (CNN) using 128 filters, a kernel size of 3, ReLU activation, max pooling, and dropout for regularization. Similarly, the BiLSTM model was fine-tuned with 128 units, dropout, and recurrent dropout to enhance its ability to handle sequential data. Transformer-based models including BERT (uncased), mBERT, and XLM-R were fine-tuned using the pretrained bert-base-multilingual-cased checkpoint, with optimal settings such as a maximum sequence length of 128, learning rate of 2 × 10
−5, and 3 epochs, using the AdamW optimizer. Additionally, GPT-3.5 Turbo was fine-tuned on over a million tokens using a learning rate multiplier of 2, batch size of 15, and three training epochs. These carefully selected and optimized configurations helped maximize performance across all models, enabling the robust detection of hate speech across multiple languages.
4. Result and Analysis
This section presents a comprehensive evaluation of our proposed models for hate speech detection across three individual languages—Spanish translation, Urdu translation, and English translation—as well as a Joint Multilingual dataset combining all three. We explore the performance of a range of approaches, including classical machine learning (ML) algorithms, deep learning (DL) models, transfer learning (TL) techniques leveraging pre-trained multilingual transformers, and large language models (LLMs) via prompt-based and fine-tuning strategies.
The experiments were conducted with consistent training, validation, and test splits across all models to ensure a fair comparison. Evaluation metrics such as accuracy, precision, recall, F1-score, and macro-averaged results are reported for each setting.
4.1. Large Language Models
Table 6 shows the GPT-3.5 Turbo model performance in hate speech identification for the English translation, Spanish translation, Urdu translation, and a combination of all languages (Multilingual). According to four conventional measures, which are precision, recall, F1-score, and accuracy, the assessment was conducted. For all the datasets, GPT-3.5 Turbo showed a good and stable performance, highlighting its robustness and generalization within a multilingual set-up.
For the English dataset, GPT-3.5 Turbo achieved a high score of 0.87 across all evaluation metrics, indicating excellent precision and recall in correctly identifying hate speech in English social media discourse.
Similarly, on the Spanish dataset, the model maintained a strong performance with a consistent 0.85 score across all metrics, demonstrating its effectiveness in understanding and classifying hate speech in a non-English language. On the Urdu dataset, GPT-3.5 Turbo scored 0.81 for all metrics, which, while slightly lower than the scores for English and Spanish, still reflects a competent performance for a low-resource language. This result suggests that GPT-3.5 Turbo is capable of handling complex multilingual tasks, even when primarily trained on high-resource languages.
The most notable performance was observed for the Joint Multilingual dataset, where the model reached the highest scores—0.88 for precision, recall, F1-score, and accuracy. This indicates that GPT-3.5 Turbo not only adapts well to individual languages but also generalizes exceptionally when exposed to a diverse multilingual dataset. The Joint dataset results underscore the model’s strength in cross-lingual transfer learning and its ability to effectively manage linguistic variation in real-world multilingual social media scenarios.
4.2. Transformers Results
Table 7 presents a comparative evaluation of various transformer models for hate speech detection across four settings: English translation, Spanish translation, Urdu translation, and a Joint Multilingual dataset. The models evaluated include bert-base-uncased, electra-base-discriminator, roberta-base, and xlm-roberta-base, with performance measured using four metrics: precision, recall, F1-score, and accuracy.
In the English dataset, xlm-roberta-base was the best performing model, with precision, recall, F1-score and accuracy values of 0.84, beating roberta-base and also bert-base-uncased, which closely followed with scores of 0.84 and 0.83, respectively. This implies that even multilingual models such as XLM-R could perform well with monolingual English data.
In the Spanish context, xlm-roberta-base again achieved the highest and most balanced performance, with a uniform score of 0.81 across all metrics. Other models like bert-base-uncased and electra-base-discriminator performed slightly lower, ranging from 0.78 to 0.80, suggesting that XLM-R’s multilingual capabilities offer a consistent advantage for non-English languages.
For Urdu, performance generally declined across all models compared with English and Spanish, likely due to the complexity and lower resource availability for Urdu. However, xlm-roberta-base remained the top performer with a 0.74 score across all evaluation metrics, while other models such as roberta-base and electra-base-discriminator performed notably lower, with F1-scores of 0.68 and 0.69, respectively. This further emphasizes the strength of XLM-R in handling low-resource languages like Urdu.
Finally, for the Joint Multilingual dataset, which included a mix of English, Spanish, and Urdu, xlm-roberta-base again demonstrated superior performance with consistent 0.84 scores across all metrics. Notably, bert-base-uncased also performed well in this setting with a score of 0.84, indicating that with diverse multilingual training data, even models primarily pretrained on English can generalize effectively. However, electra-base-discriminator and roberta-base performed less well, with scores ranging between 0.76 and 0.78.
In summary, xlm-roberta-base consistently outperformed other transformer-based models across all languages and the Joint dataset, highlighting its robustness and generalization capability for hate speech detection across multilingual social media discourse.
4.3. Deep Learning Results
Table 8 summarizes the performance of various deep learning models, specifically CNN and BiLSTM models, across different languages (English translation, Spanish translation, and Urdu translation) and a Joint Multilingual setup using two types of word embeddings: FastText and GloVe. The evaluation metrics comprised precision, recall, F1-score, and accuracy.
For the English dataset, the BiLSTM models clearly outperformed the CNN regardless of the embedding type. Both FastText and GloVe with BiLSTM achieved the highest scores, with F1-score and accuracy values of 0.78, demonstrating that BiLSTM was better at capturing sequential information in the English data. The CNN models using both embeddings performed similarly but slightly lower, with an F1-score of 0.74.
In the Spanish dataset, the overall performance declined slightly. The best result was obtained using FastText + BiLSTM, which reached an F1-score of 0.75 and accuracy of 0.75. Other configurations, especially GloVe embeddings with the CNN or BiLSTM models, showed weaker performance, indicating that FastText may be more effective for Spanish texts, possibly due to its handling of sub-word information.
The Urdu dataset showed the lowest performance across all configurations. The best results were from FastText + BiLSTM, with an F1-score of 0.71. The GloVe-based models performed significantly worse, especially GloVe + BiLSTM, which achieved an F1-score of only 0.41. This suggests that GloVe embeddings may not represent Urdu well, possibly due to limited pretraining data in that language.
In the Joint Multilingual setup, which combined translated and original data from all languages, the BiLSTM models again outperformed the CNN. FastText + BiLSTM achieved the highest F1-score of 0.76 and accuracy of 0.76, showing that this combination is effective in capturing multilingual sequence patterns. GloVe-based models again trailed slightly behind, with a maximum F1-score of 0.68.
In summary, the results show that BiLSTM consistently outperformed the CNN across all languages and that FastText embeddings generally yielded better performance than GloVe, particularly for Spanish and Urdu. The Joint Multilingual setting enhanced performance, highlighting the advantage of training on diverse, translated datasets for deep learning-based hate speech detection.
4.4. Machine Learning Results
Table 9 shows the results of different classical machine learning models such as random forest (RF), support vector machine (SVM), decision tree (DT), and XGBoost (XGB) on hate speech detection datasets of English, Spanish, Urdu, and combined multilingual models. The reported metrics of the evaluation are precision, recall, F1-score, and accuracy.
For the English translation dataset, the SVM model achieved the best overall performance with an F1-score and accuracy of 0.82, outperforming the other models. Random forest and XGBoost also performed well, both achieving an F1-score of 0.80 or above. The Decision Tree lagged slightly behind with an F1-score of 0.76. In the Spanish dataset, all models showed a slightly lower performance compared with English, with SVM again leading with an F1-score of 0.78, indicating its relative robustness across languages.
For the Urdu translation dataset, performance declined slightly across all models, with the highest F1-score of 0.77 obtained by both SVM and random forest. This suggests that Urdu may pose greater linguistic challenges for traditional models, possibly due to script complexity or limited training data.
In the Joint Multilingual setting, where data from all languages were combined into a single training set, all models saw improved or stable performance. Notably, SVM again led with an F1-score and accuracy of 0.82, confirming its consistent effectiveness. Random forest and XGBoost also performed comparably well with F1-scores of 0.81 and 0.80, respectively.
Overall, the table highlights that SVM consistently outperformed the other traditional models across all individual and combined language datasets and that joint multilingual training improved model robustness and generalization.
4.5. Error Analysis
Table 10 presents the performance comparison of top-performing models from four learning paradigms—machine learning (ML), deep learning (DL), transfer learning (TL), and large language models (LLM)—across four linguistic settings: English translation, Spanish translation, Urdu translation, and a Joint Multilingual hate speech dataset. Each model was evaluated based on precision, recall, F1-score, and accuracy, allowing for a detailed assessment of hate speech detection capability across diverse approaches and languages.
All the model types yielded fairly good results in English. The best-performing GPT-3.5 Turbo (LLM) was rated 0.87 in all measures, a good measure of being able to define hate speech in English communication. This was closely followed by roberta-base (TL) 0.84, SVM (ML) 0.82, and BiLSTM (DL) 0.78 reaching the lowest performance rate. These findings clearly show that the classical ML and DL methods classified as English showed lower results compared with the LLM and TL models.
Following the same trend, GPT-3.5 Turbo was the best performer in the Spanish language, with the same overall score of 0.85 across the board. The bert-base-uncased (TL) model also ranked very well at 0.81, followed by SVM at 0.78. Despite its utility, the BiLSTM model fell behind with a score of 0.75, which implies deep learning with traditional embeddings (FastText) did not generalize to Spanish as well as the LLMs and pre-trained transformer-based models.
The Urdu dataset, representing a low-resource language, showed a relatively lower performance across all models. However, GPT-3.5 Turbo still outperformed the other methods, achieving 0.81 across all metrics. The xlm-roberta-base (TL) followed with 0.74, indicating its capability in multilingual and low-resource settings. The traditional SVM (ML) yielded 0.77, while BiLSTM (DL) showed the weakest performance with only 0.64, highlighting challenges in modeling Urdu with limited-feature-based or shallow architectures.
In the Joint Multilingual setting—which combined English, Spanish, and Urdu—GPT-3.5 Turbo achieved the highest results, with 0.88 across all evaluation metrics, showcasing its strength in handling mixed-language inputs and generalizing well across linguistic boundaries. The bert-base-uncased model also performed strongly with 0.84, while SVM and BiLSTM scored 0.82 and 0.76, respectively.
Across all languages and learning paradigms, GPT-3.5 Turbo (LLM) consistently outperformed the other models, highlighting the advantages of large-scale pretraining and context-rich language modeling. Transfer learning models, particularly roberta-base, bert-base-uncased, and xlm-roberta-base, also performed robustly across the languages, especially in English and Spanish.
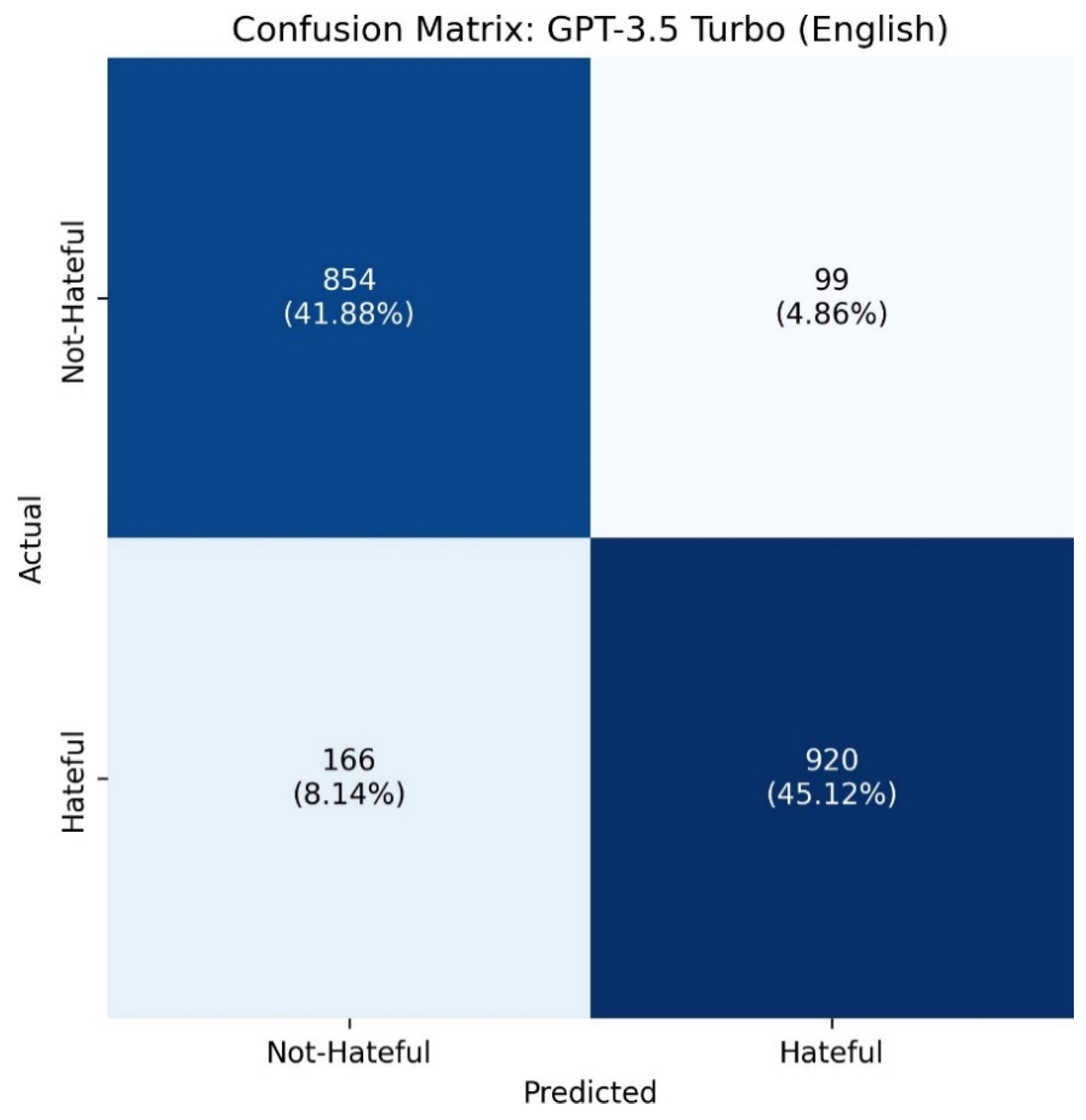
Table 11 presents the class-wise performance metrics of our proposed GPT-3.5 Turbo-based hate speech detection model evaluated under four distinct experimental settings: English, Spanish, Urdu, and a Joint Multilingual setup. In each setting, we report the precision, recall, and F1-score for the “Not-Hateful” and “Hateful” classes, as well as the overall accuracy, macro average, and weighted average values. Each language setting was constructed by translating the other two languages into the target language and merging them with the original data, thereby creating an enriched dataset for each experimental condition. In the English setting, the dataset included original English texts combined with Spanish and Urdu texts translated into English. The model achieved strong and balanced performance across both classes: a precision of 0.84 and recall of 0.90 for the “Not-Hateful” class and a precision of 0.90 and recall of 0.85 for the “Hateful” class, resulting in identical F1-scores of 0.87. The overall accuracy was also 0.87, indicating that the model effectively captured patterns of hate and non-hate speech in English when enhanced with cross-lingual data.
In the Spanish setting, the dataset consisted of original Spanish texts merged with Urdu and English data translated into Spanish. The performance remained strong but slightly lower than English, with F1-scores of 0.84 and 0.85 for the “Not-Hateful” and “Hateful” classes, respectively, and an overall accuracy of 0.85. This suggests that the model generalizes well to Spanish, though there may be some loss in nuance or fidelity during translation.
The Urdu setting, where both English and Spanish data were translated into Urdu and combined with original Urdu texts, showed a relatively lower performance. The model achieved F1-scores of 0.80 for “Not-Hateful” and 0.82 for “Hateful”, with an overall accuracy of 0.81. This moderate drop may be attributed to challenges in translating content into Urdu with semantic precision or limited syntactic regularities in the Urdu dataset that make learning harder for the model.
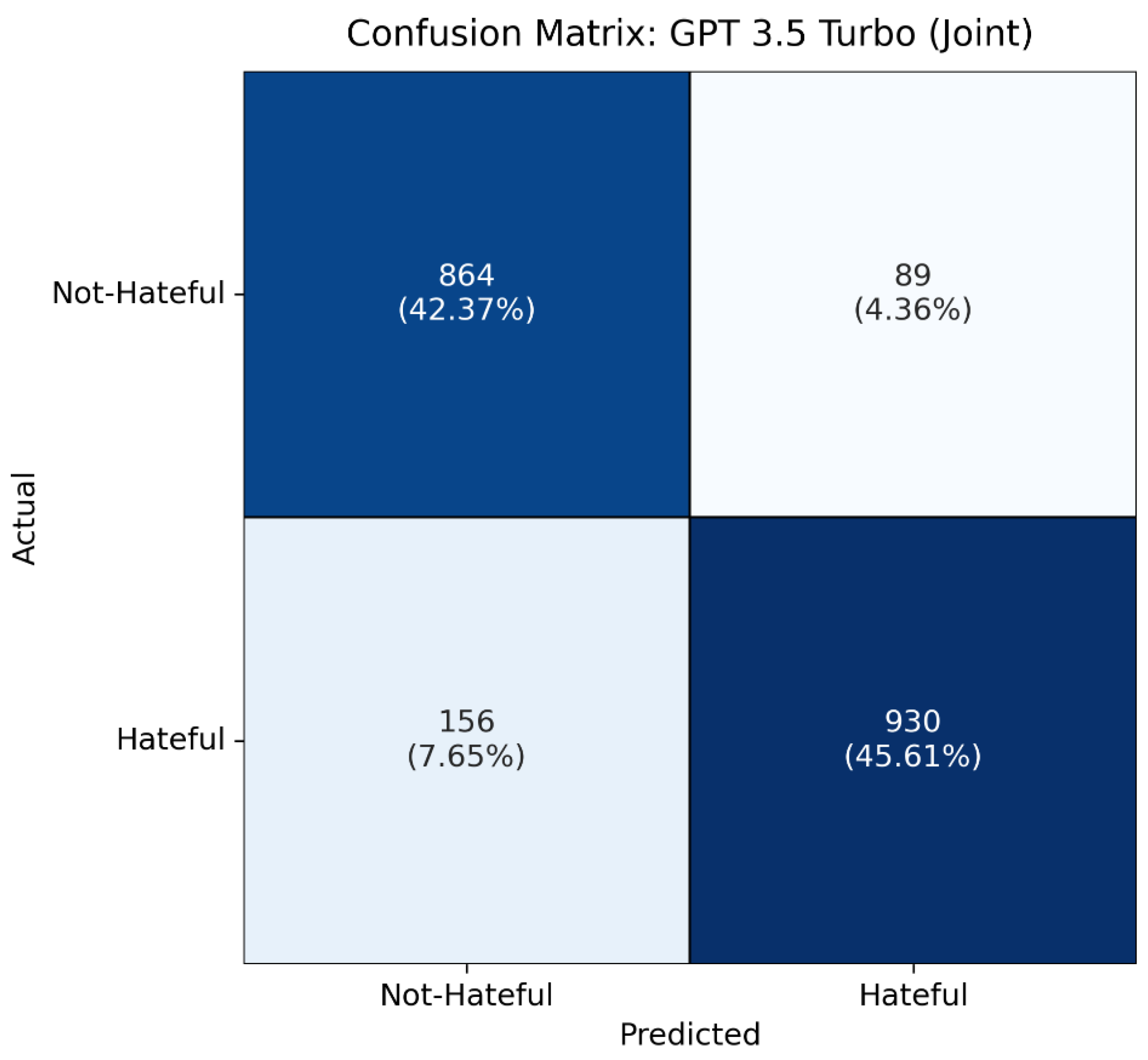
The best results were observed in the Joint Multilingual setup, in which all datasets—original and translated—were combined into a single multilingual training set. In this configuration, the model achieved precision, recall, and F1-scores of 0.88 for both classes and the highest accuracy of 0.88 overall. This demonstrates the effectiveness of training on a rich and diverse multilingual corpus, as it helps the model to generalize better across linguistic variations and context.
Figure 6,
Figure 7,
Figure 8 and
Figure 9 show confusion matrices to visually represent the performance of the classification model by showing the correct and incorrect predictions for each class, allowing us to evaluate the model’s accuracy, precision, recall, and overall classification behavior in more detail.
5. Limitations of Proposed Solution
Despite the promising results and advancements achieved in this study, several limitations remain. First, while our trilingual dataset addresses English, Spanish, and Urdu in its Nastaliq script form, it still represents only a fraction of the world’s languages, and the performance of the model on other low-resource or code-mixed languages remains untested. Each language presents unique linguistic challenges that impact hate speech detection. English, a high-resource language, benefits from established NLP tools but faces difficulties due to lexical ambiguity, sarcasm, and evolving slang. Spanish involves regional dialects, gendered grammar, and morphologically rich structures, with variations in hate expressions across communities and complications from code-mixing with English. Our focus on Nastaliq Urdu presents distinct challenges such as a complex morphology, script-specific tokenization issues, and culturally implicit hate speech embedded in idiomatic and religious references that are often subtle and difficult for annotators and models to capture accurately. Additionally, the syntactic difference—Urdu’s subject–object–verb order compared with the subject–verb–object structure of English and Spanish—adds to modeling complexity. Second, the translation-based approach, although effective for standardizing texts, may introduce semantic distortions or lose cultural and contextual nuances, especially in complex languages like Urdu with rich idiomatic expressions. Third, the reliance on annotated social media data limits the scope to public discourse on specific platforms, which might not generalize well to other online contexts or private communications. Fourth, the dataset size, while substantial for these languages, may still be insufficient for fully training extremely large models like GPT-3.5 Turbo without risking overfitting or bias towards dominant language patterns. Finally, the ethical considerations around annotation, although rigorously addressed, may still encounter challenges related to subjective interpretations of hate speech across diverse cultural backgrounds, potentially affecting annotation consistency.
6. Conclusions and Future Work
Social media platforms shape public discourse, amplifying both harmful and positive content. This study advances multilingual hate speech detection, with a focus on the understudied Urdu language. Our trilingual dataset (10,193 tweets) and translation-based pipeline, leveraging machine learning, deep learning, transformer models, and large language models (LLMs), achieved significant improvements over baseline SVM models. Notably, the framework yielded strong performance for English (GPT-3.5 Turbo: F1-score of 0.87), Spanish (GPT-3.5 Turbo: F1-score of 0.85), and the Joint Multilingual dataset (GPT-3.5 Turbo: F1-score of 0.88). Urdu performance (GPT-3.5 Turbo: F1-score of 0.81), while improved over baselines by 5.19%, highlights ongoing challenges in low-resource settings, particularly due to code-mixing and limited pre-training data. Issues such as cross-lingual generalization, model interpretability, and low-resource language performance remain critical and far from resolved. Future work should prioritize Urdu-specific embeddings, enhanced translation pipelines for slang and code-mixed texts, and semi-supervised learning to foster safer, more inclusive digital communication.
Building on this work, future research can expand in several directions. One priority is to extend the multilingual framework to include additional low-resource languages and dialects, especially those prevalent in underrepresented regions, to foster even more inclusive hate speech detection. Enhancing the translation pipeline with context-aware and culturally sensitive translation models could reduce semantic loss and improve detection accuracy. Moreover, integrating multimodal data—such as images, videos, and audio—from social media posts could provide a richer context for hate speech identification beyond text alone, and to further enhance the detection process, we plan to retain and analyze hashtags as potential features given their role in signaling hate-related content and online community affiliations. Additionally, future work may include a qualitative analysis of typical misclassifications and false positive/negative examples across languages, which could offer further insight into the nuanced linguistic challenges that persist despite quantitative evaluation.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}