
A Multi-Core Controller for an Embedded AI System Supporting Parallel Recognition


Abstract
:1. Introduction
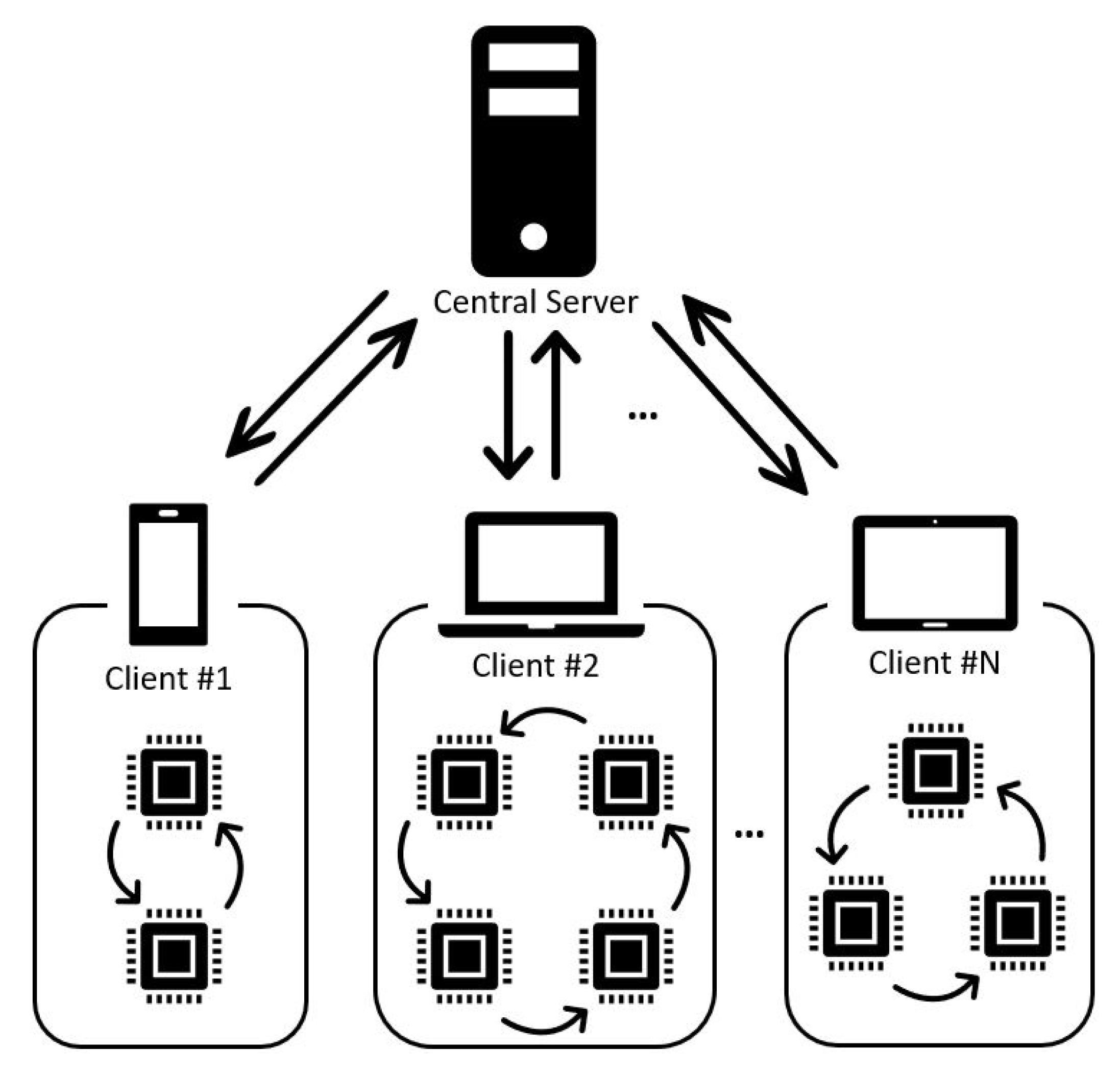
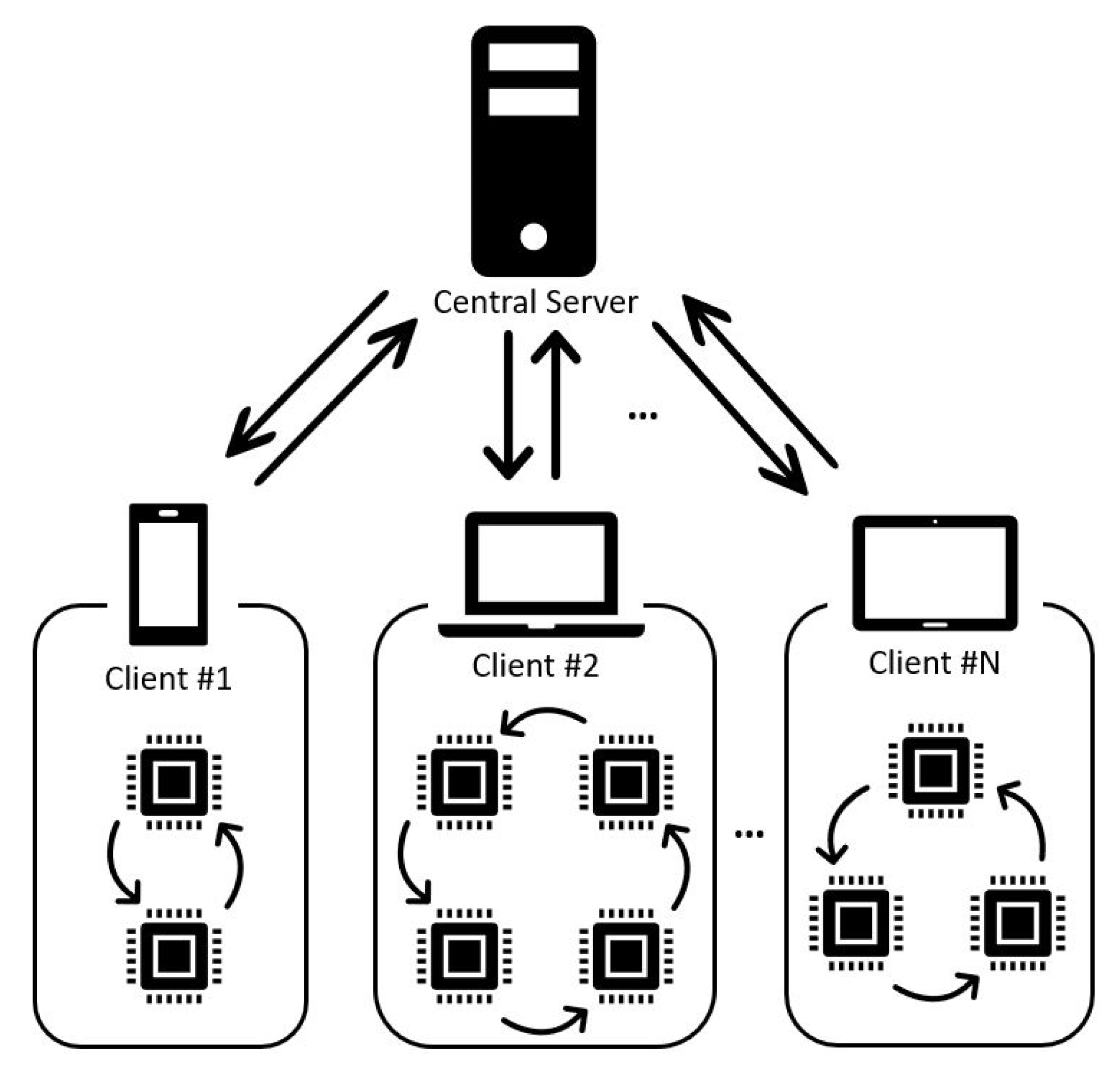
- Client selection: The server samples from a set of clients meeting eligibility requirements. For example, mobile phones might only check into the server if they are plugged in, on an unmetered Wi-Fi connection, and idle, in order to avoid impacting the user of the device.
- Broadcast: The selected clients download the current model weights and a training program from the server.
- Client computation: Each selected device locally computes an update to the model by executing the training program, which might, for example, run SGD on the local data (as in federated averaging).
- Aggregation: The server collects an aggregate of the device updates. For efficiency, stragglers might be dropped at this point once a sufficient number of devices have reported results. This stage is also the integration point for many other techniques that will be discussed later, possibly including: a secure aggregation for added privacy, lossy compression of aggregates for communication efficiency, and noise addition and update clipping for differential privacy.
- Model update: The server locally updates the shared model based on the aggregated update computed from the clients that participated in the current round.
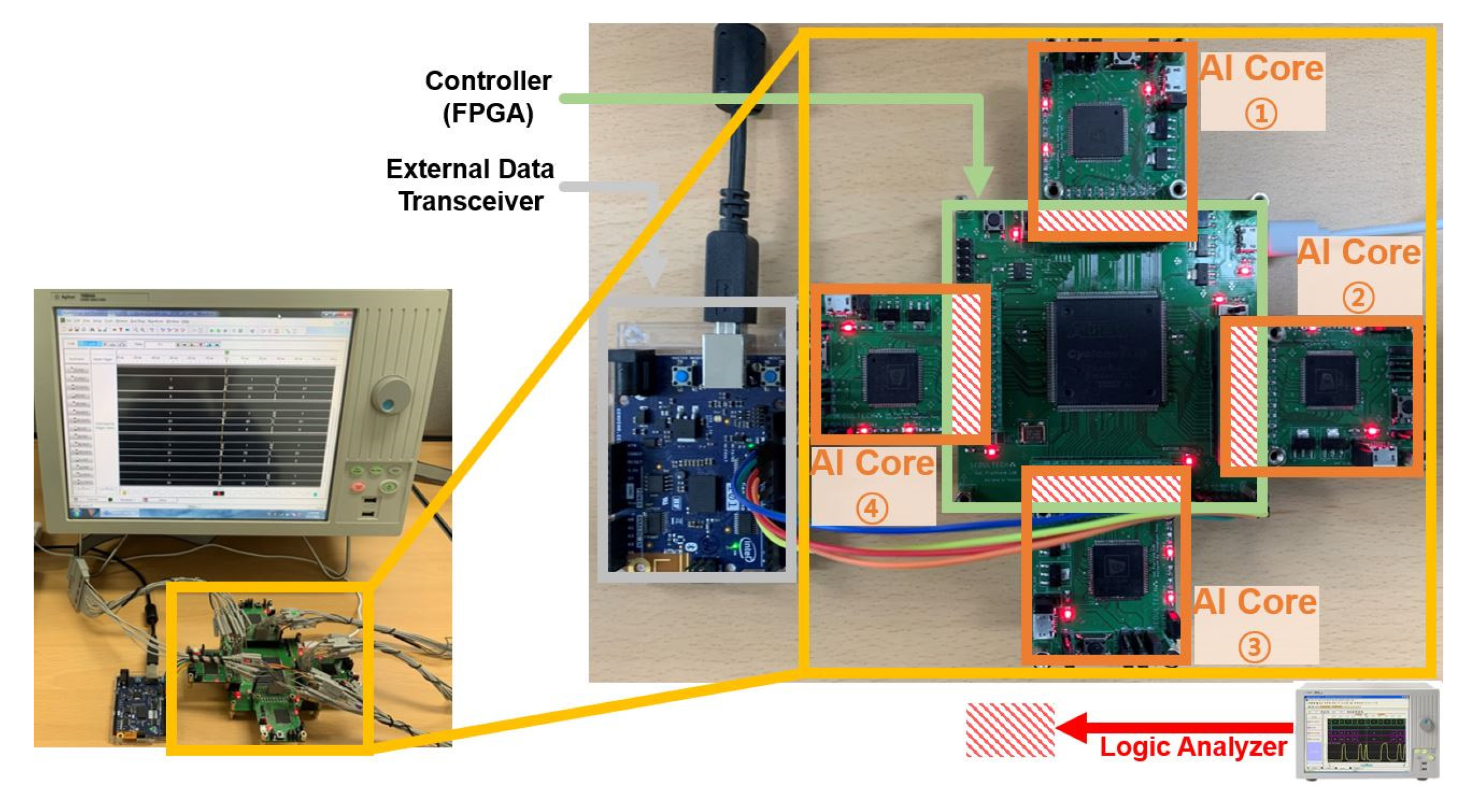
- Designing and verifying the controller for parallel processing of multiple AI cores.
- Constructing the protocol to transfer the training data and recognition data between the controller and the AI core.
- Performance analysis based on memory usage of the AI system with the k-NN algorithm.
2. Related Work
- Artificial Intelligence for Embedded Systems;
- Simulating and Performance Analysis for Hardware Implementation.
2.1. Artificial Intelligence for Embedded Systems
2.2. Simulating and Performance Analysis for Hardware Implementation
3. System Architecture
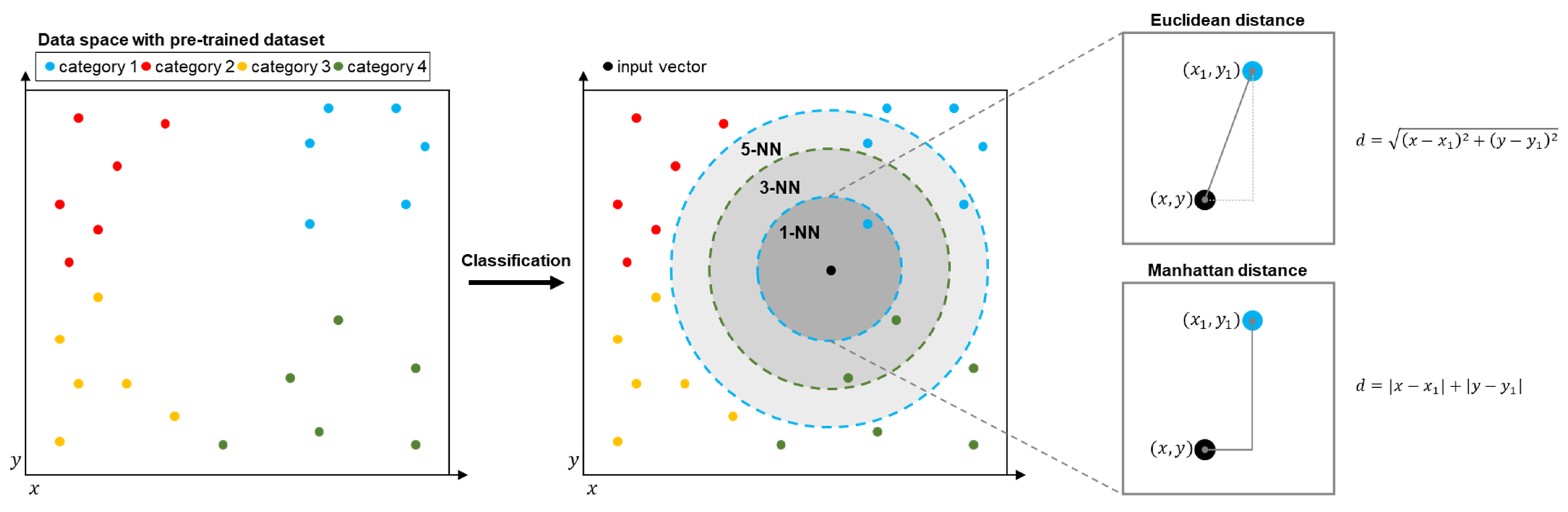
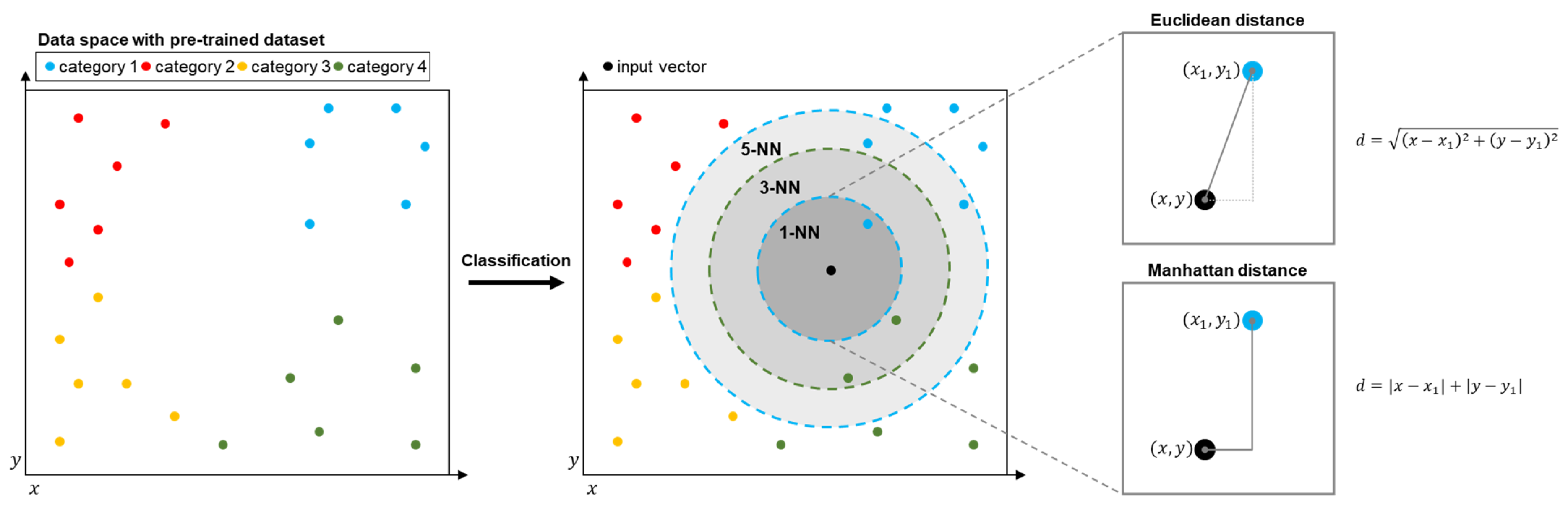
3.1. k-NN Algorithm
| Algorithm 1:k-NN classification algorithm pseudo-code |
 |
| Algorithm 2:1-NN classification algorithm pseudo-code |
 |
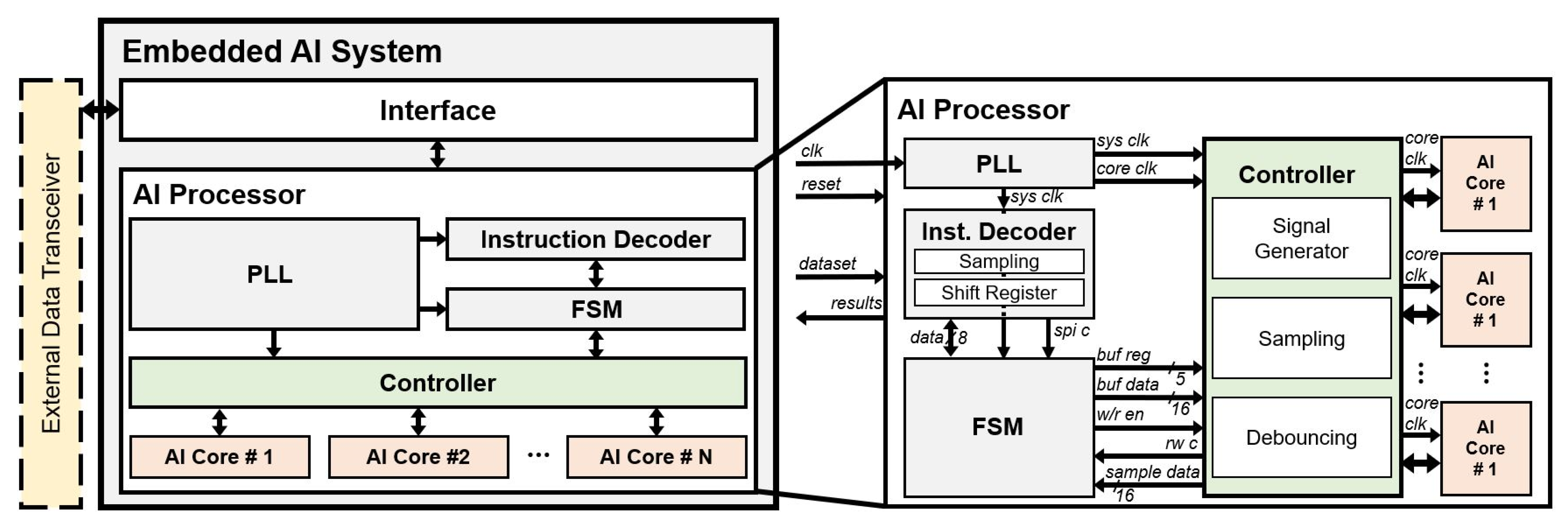
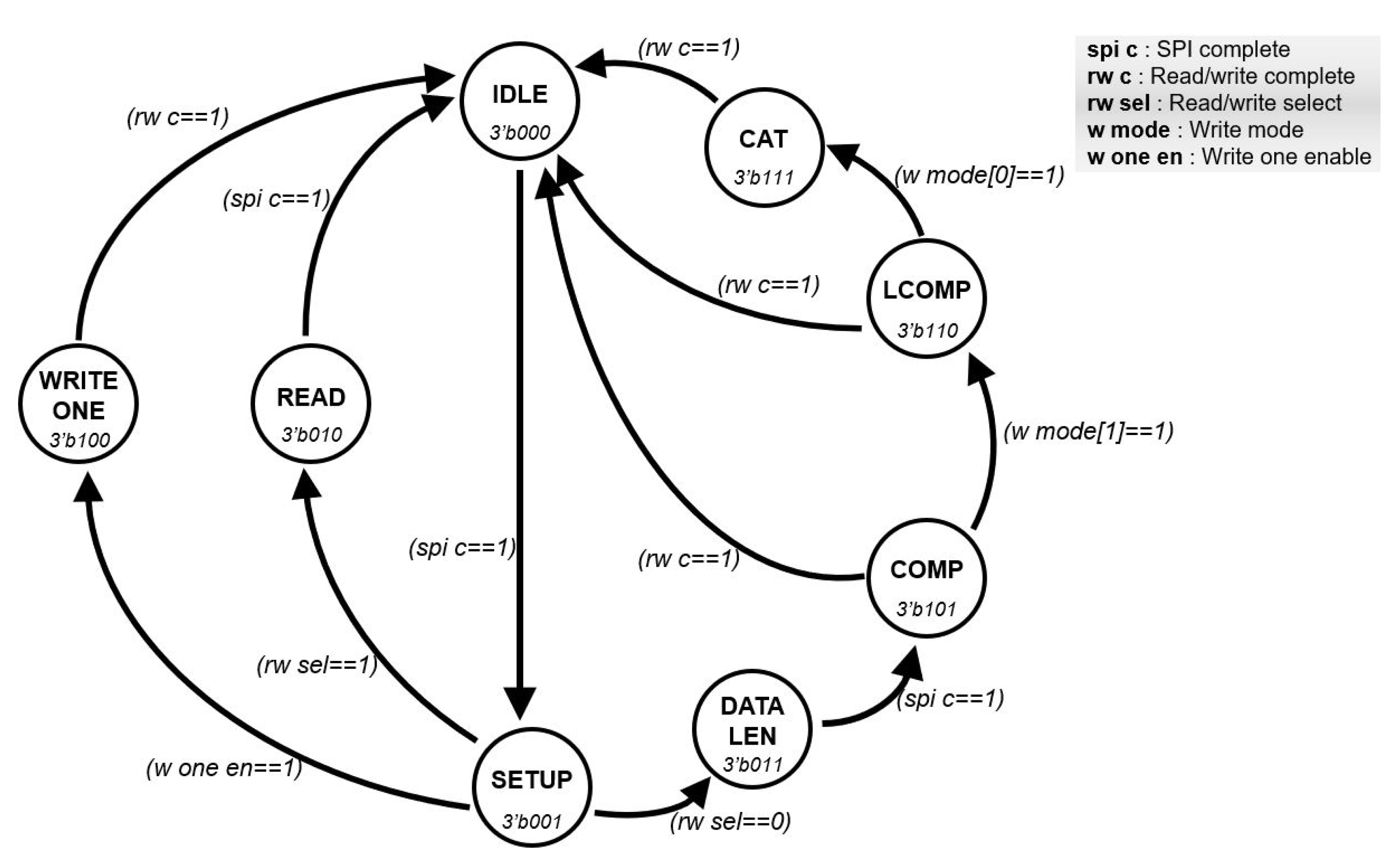
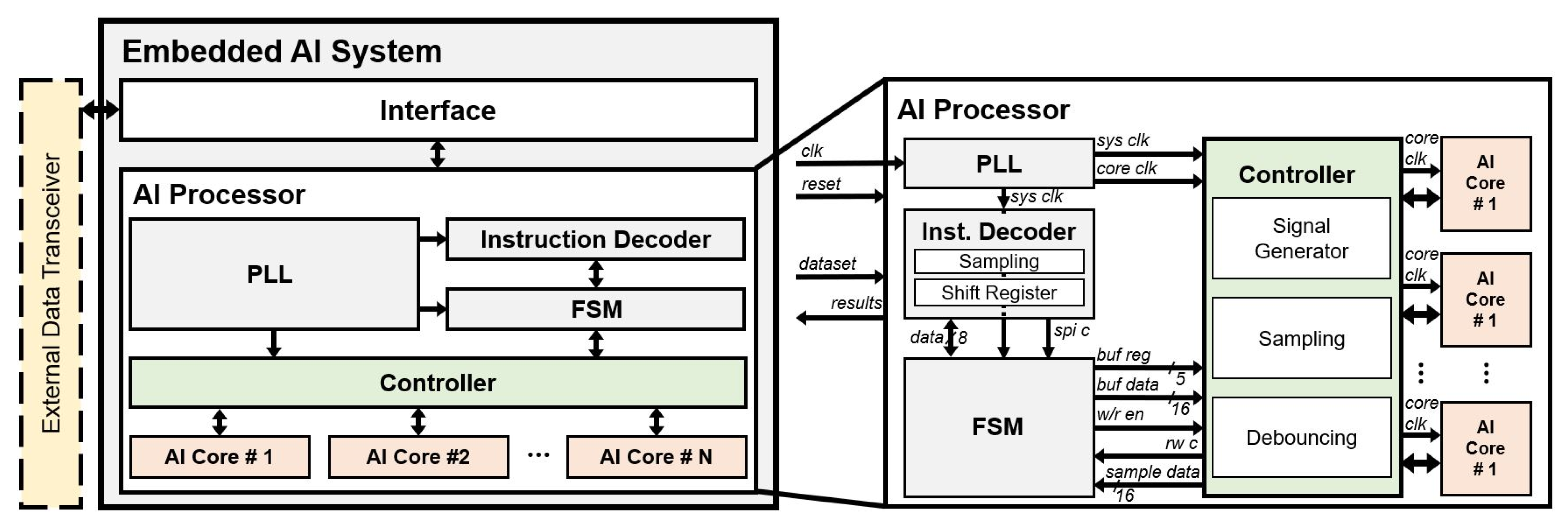
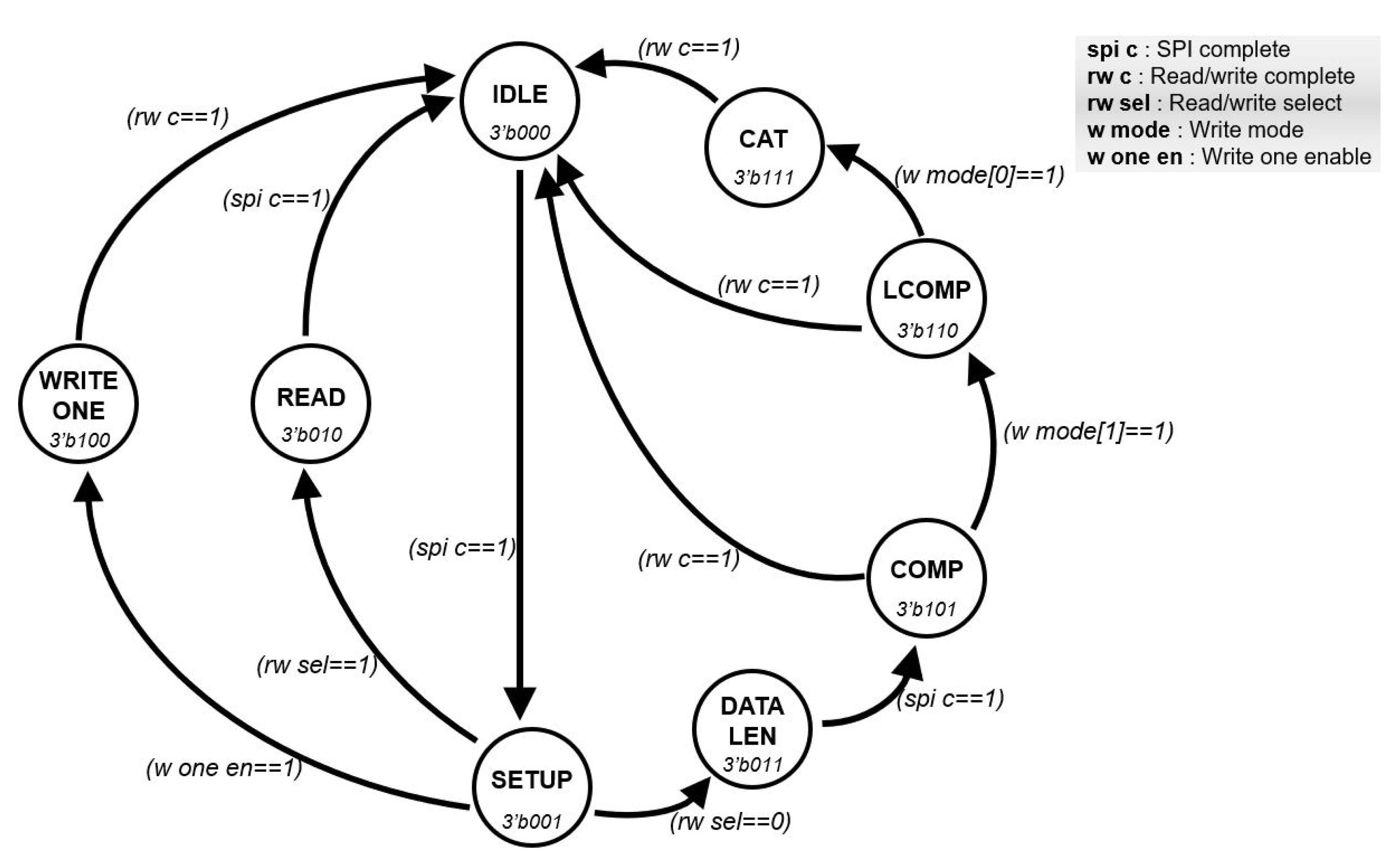
3.2. Microarchitecture
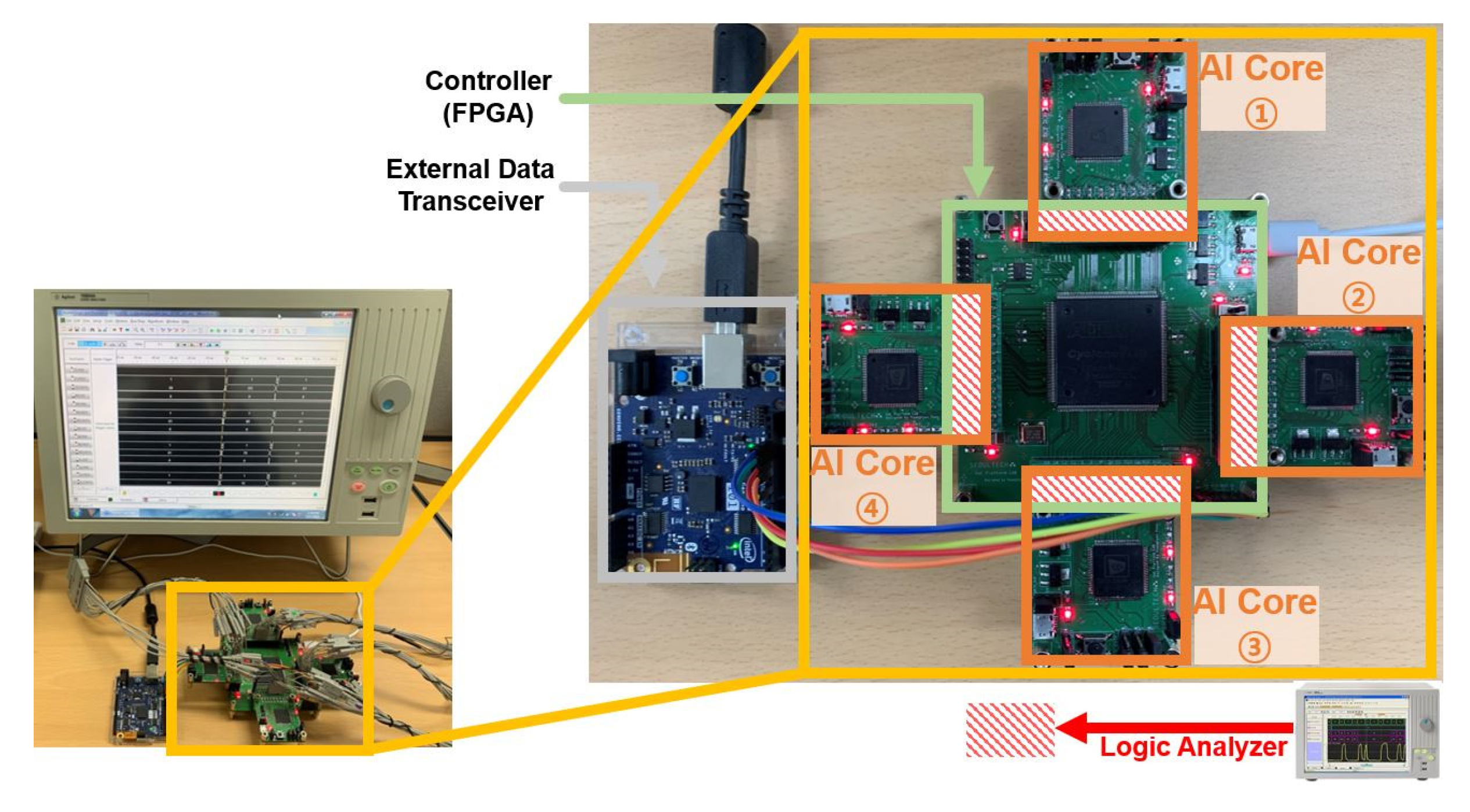
4. Implementation and Analysis
4.1. Implementation
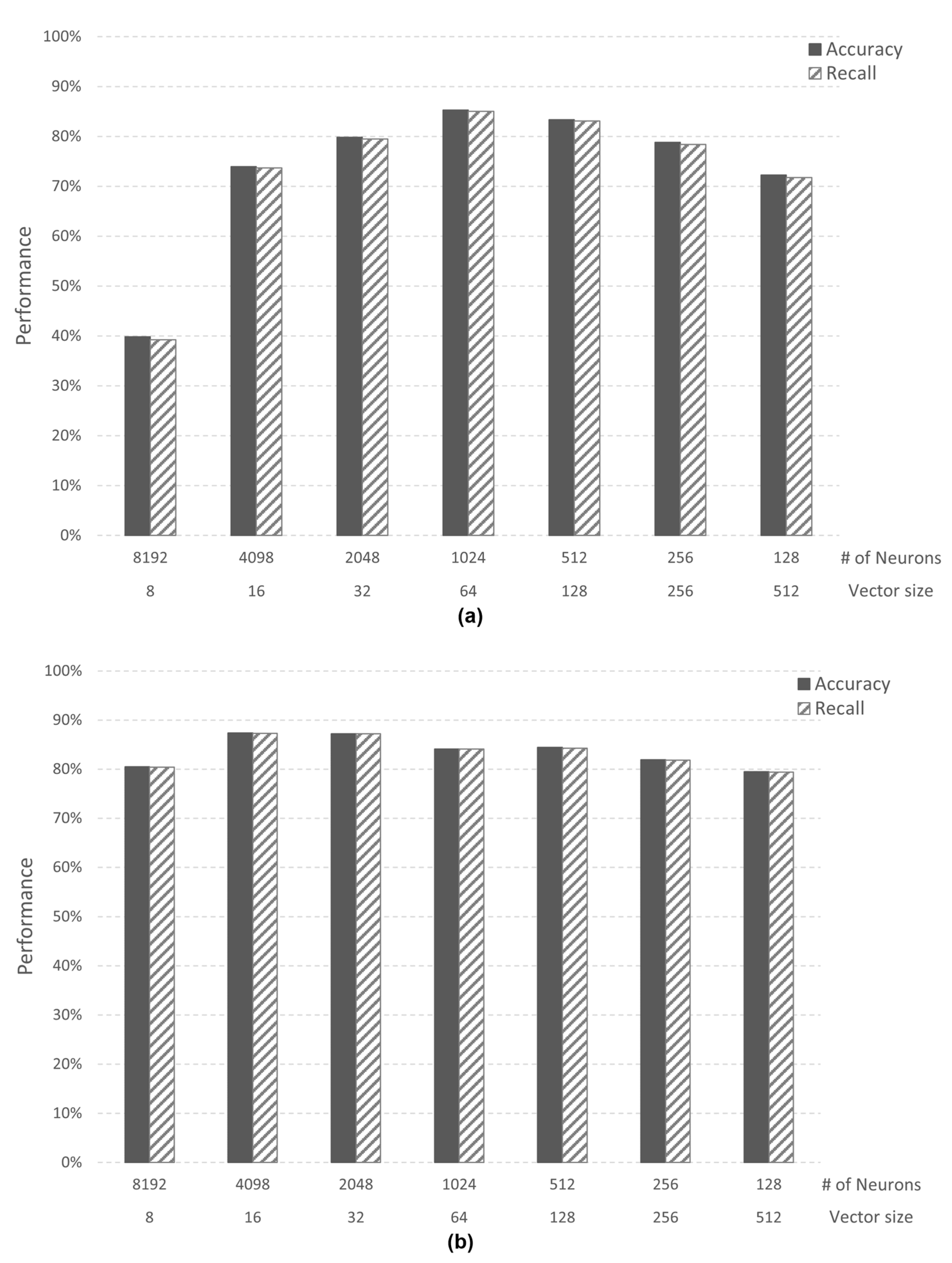
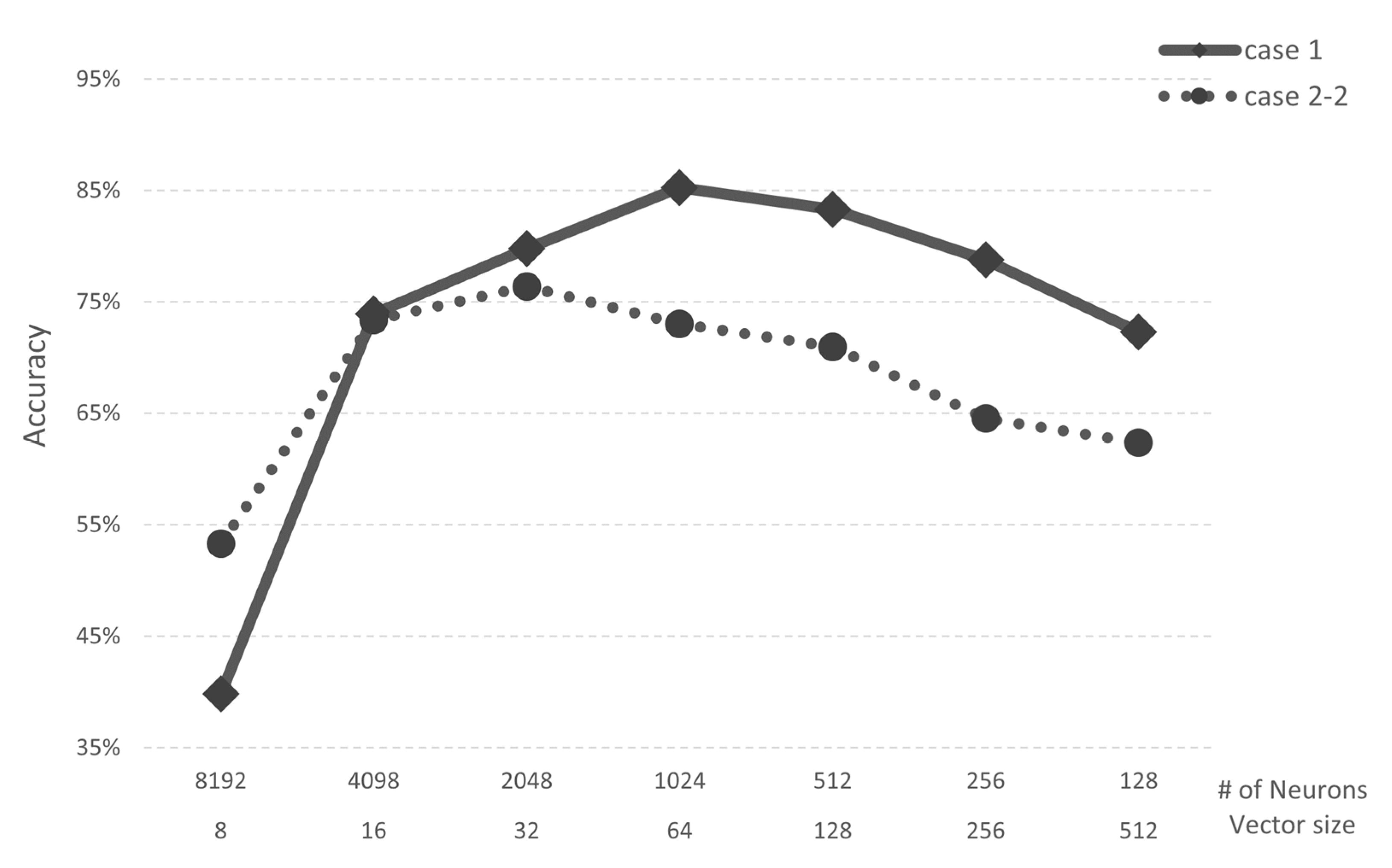
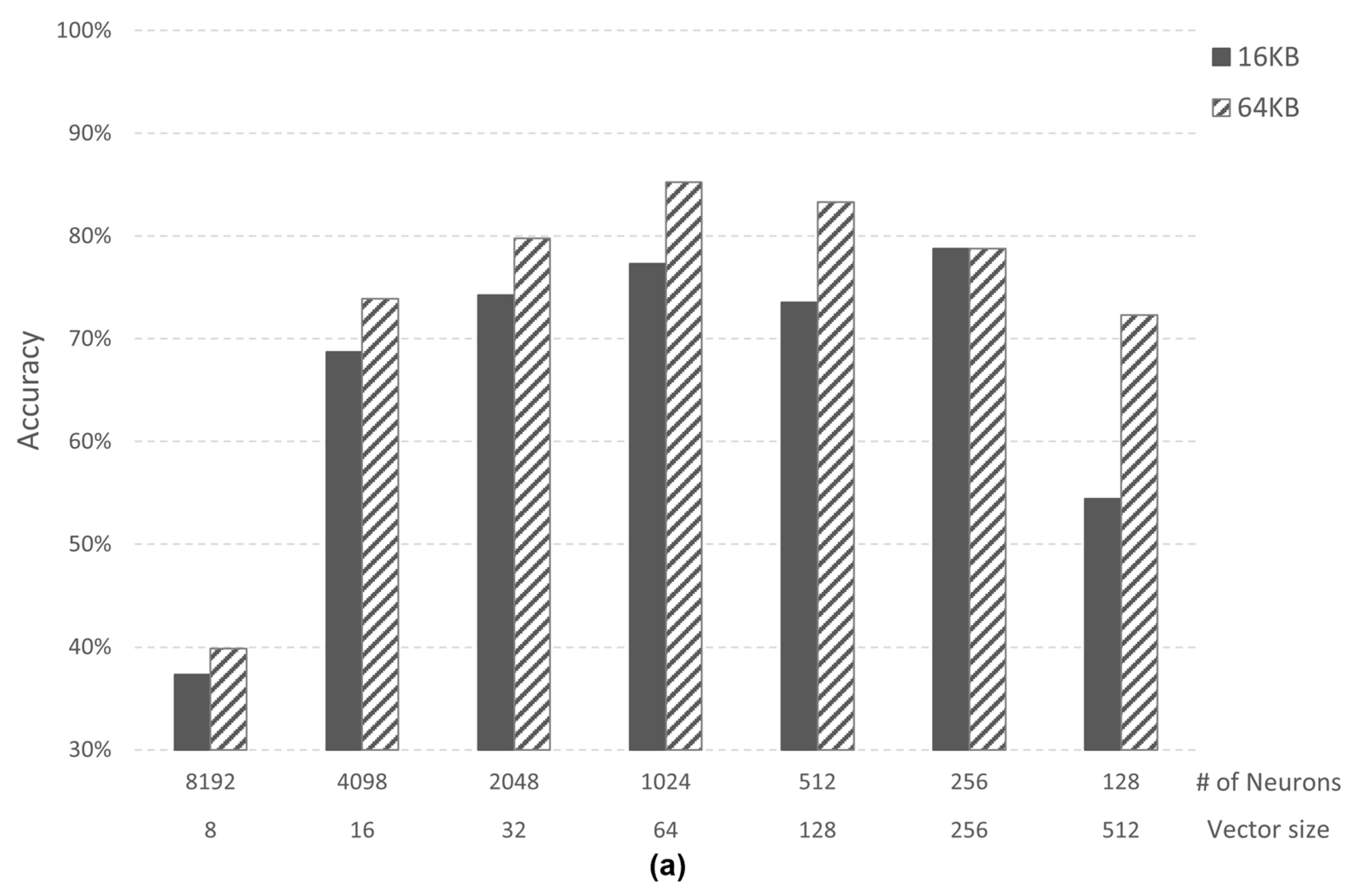
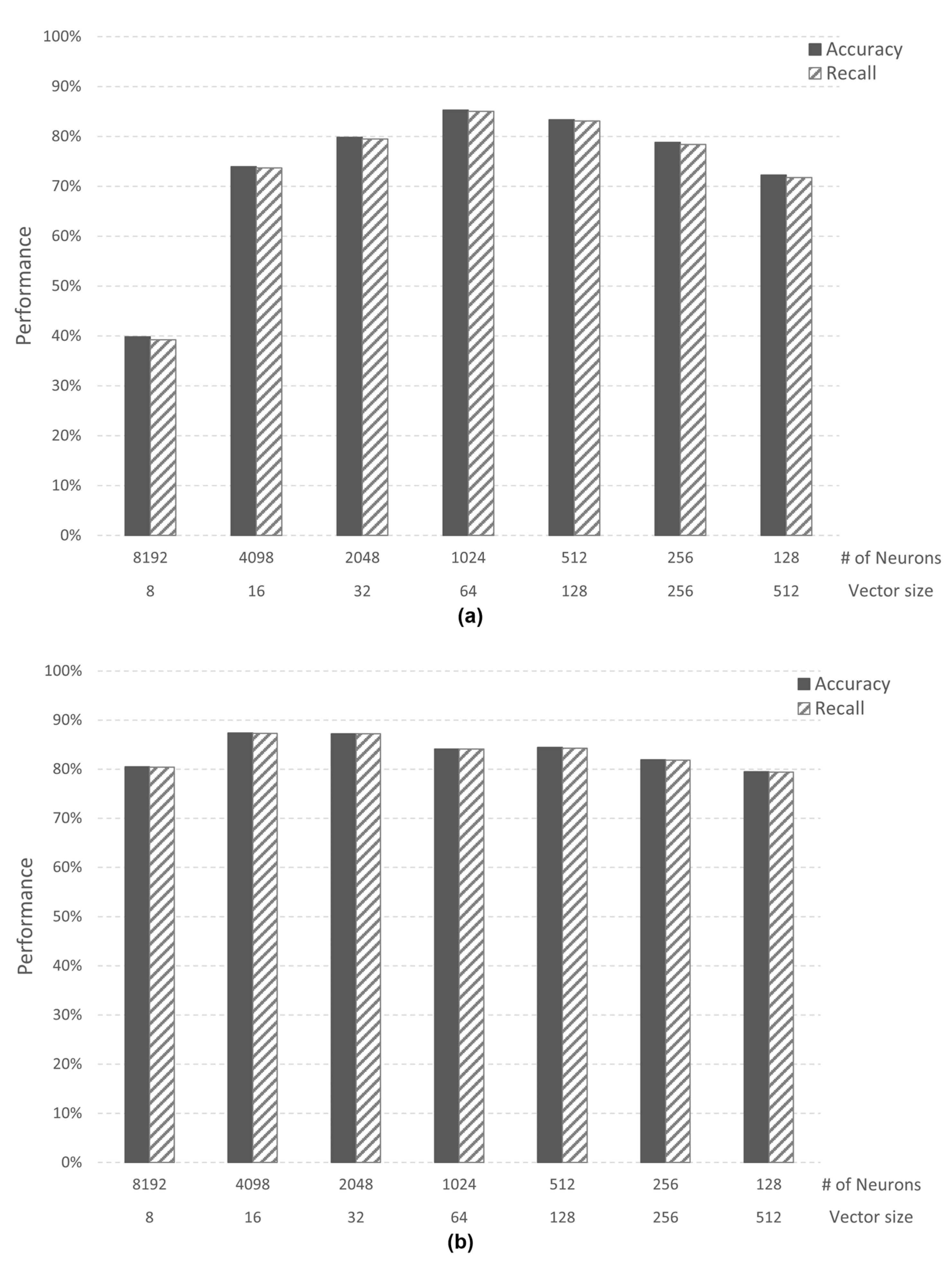
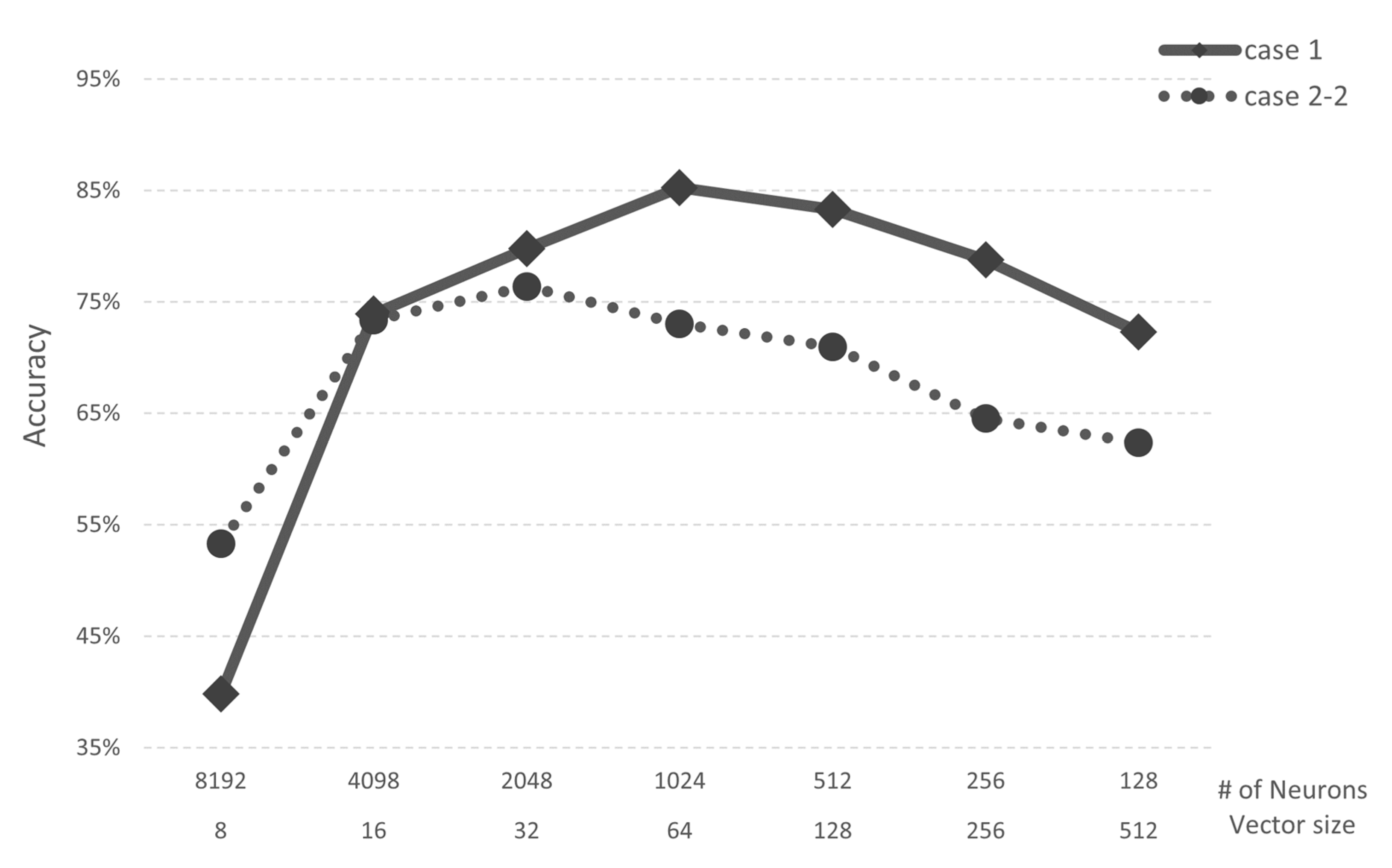
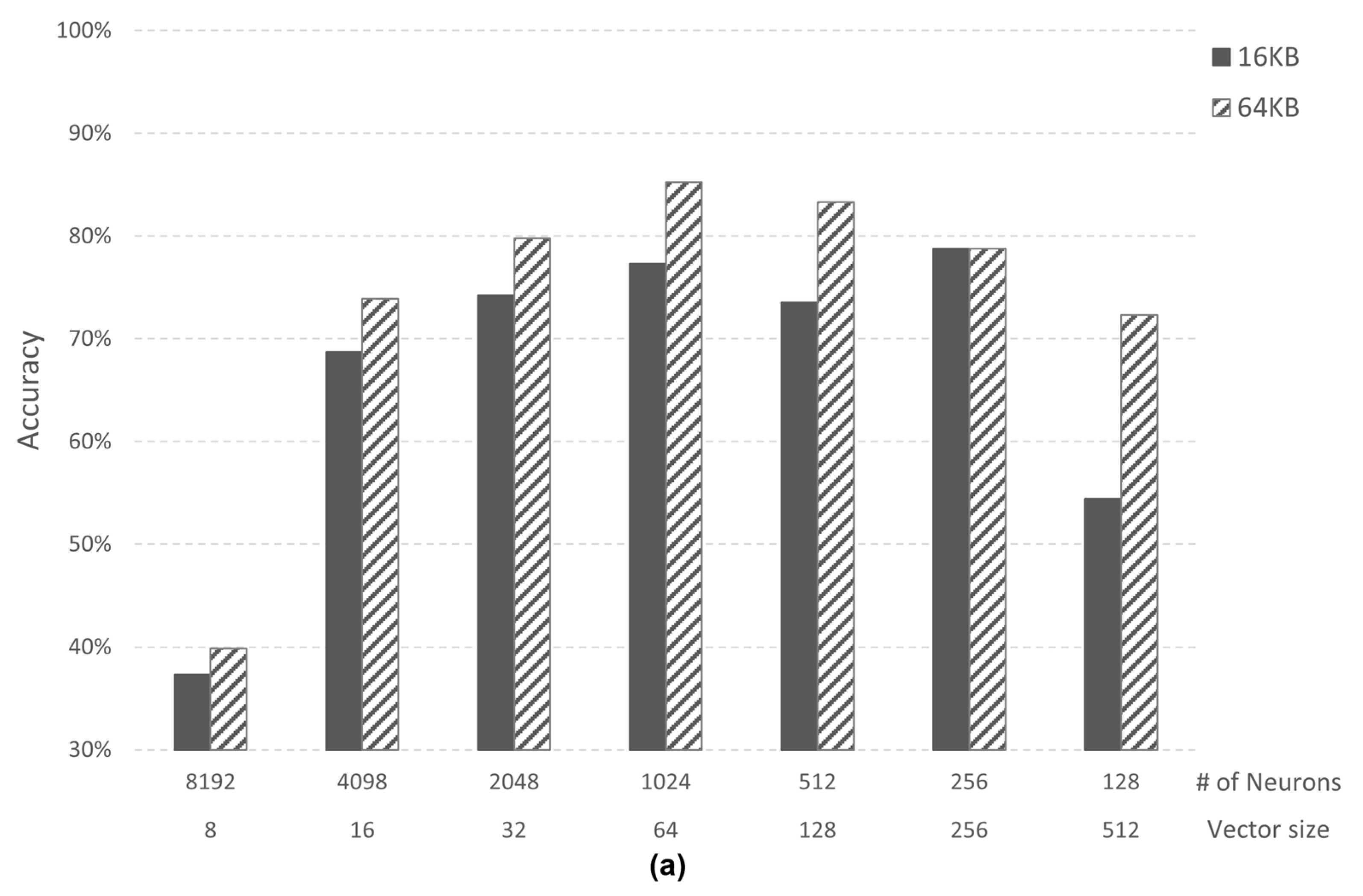
4.1.1. Case Study 1: Image Recognition
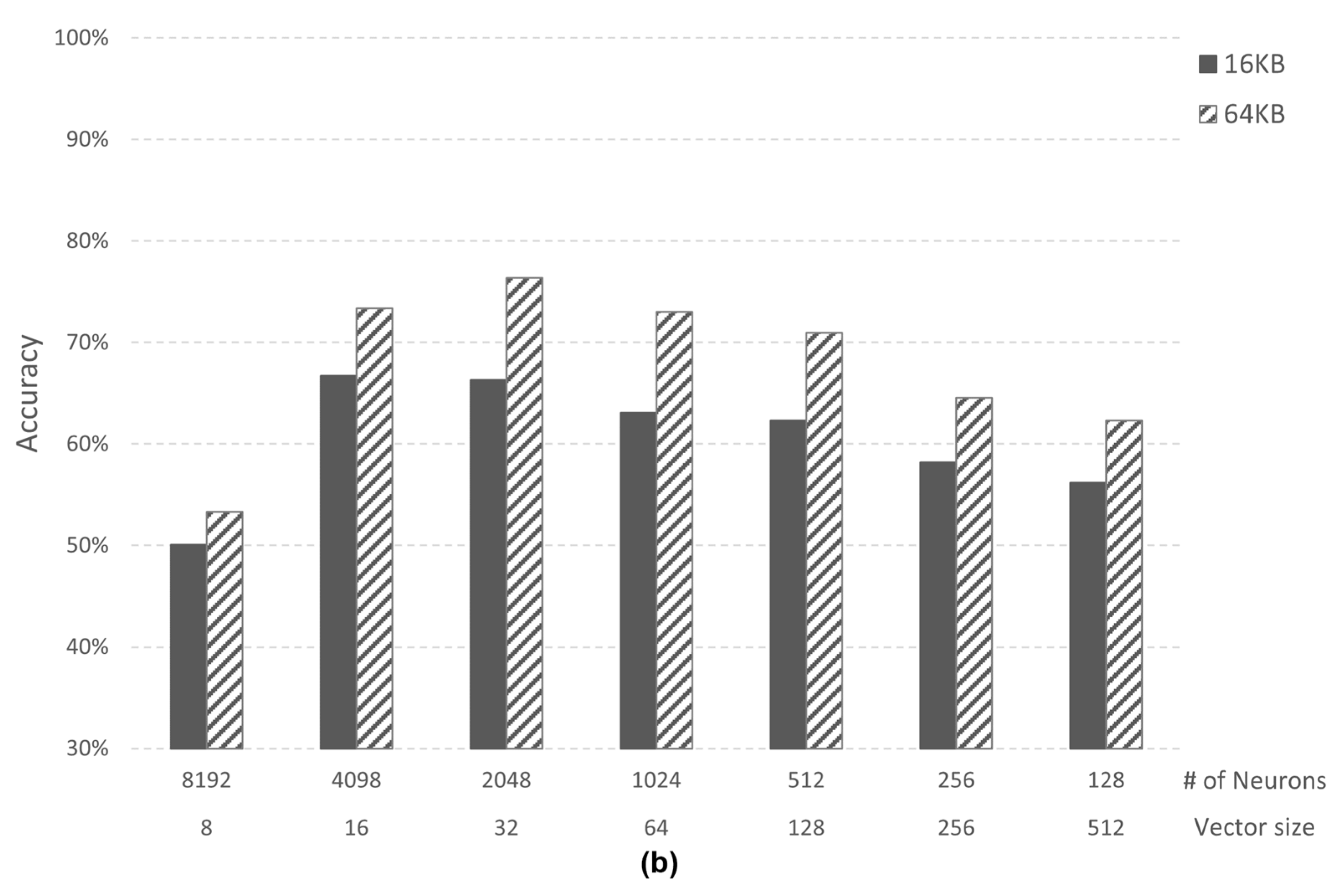
4.1.2. Case Study 2: Speech Recognition
- Google Brain’s 2 categories Speech Command;
- Google Brain’s 3 categories Speech Command;
- Two categories of Recorded Voice Data.
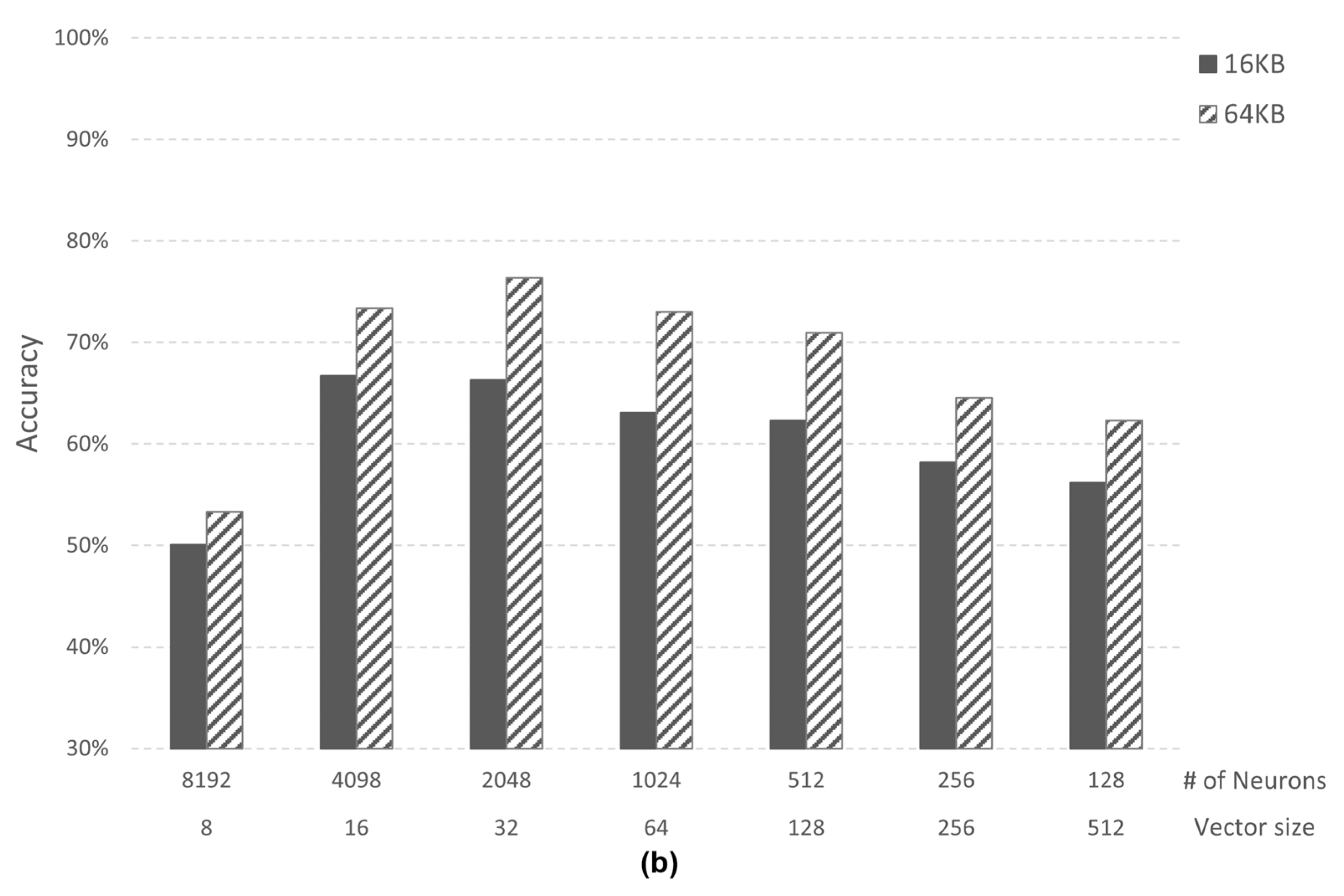
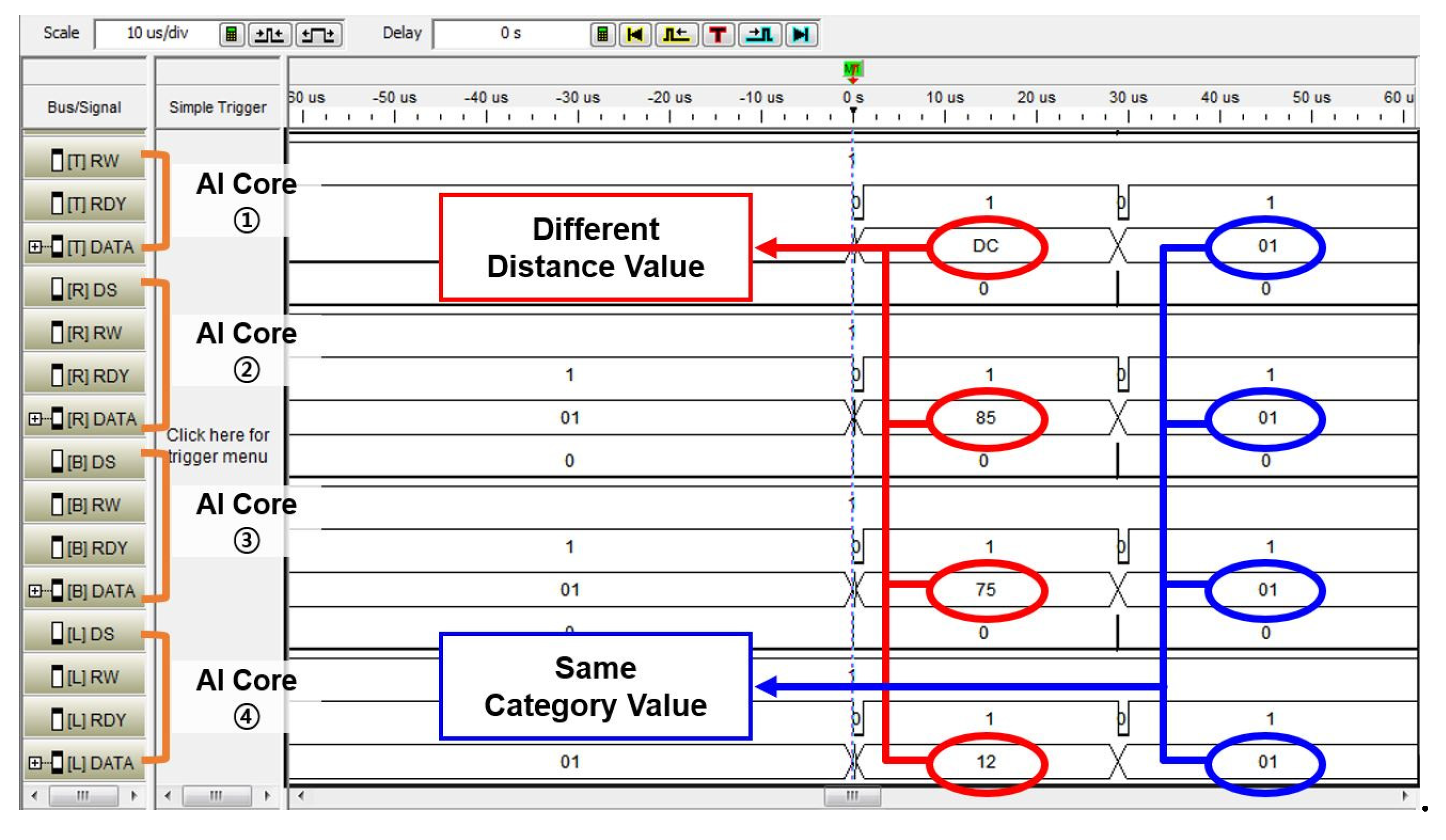
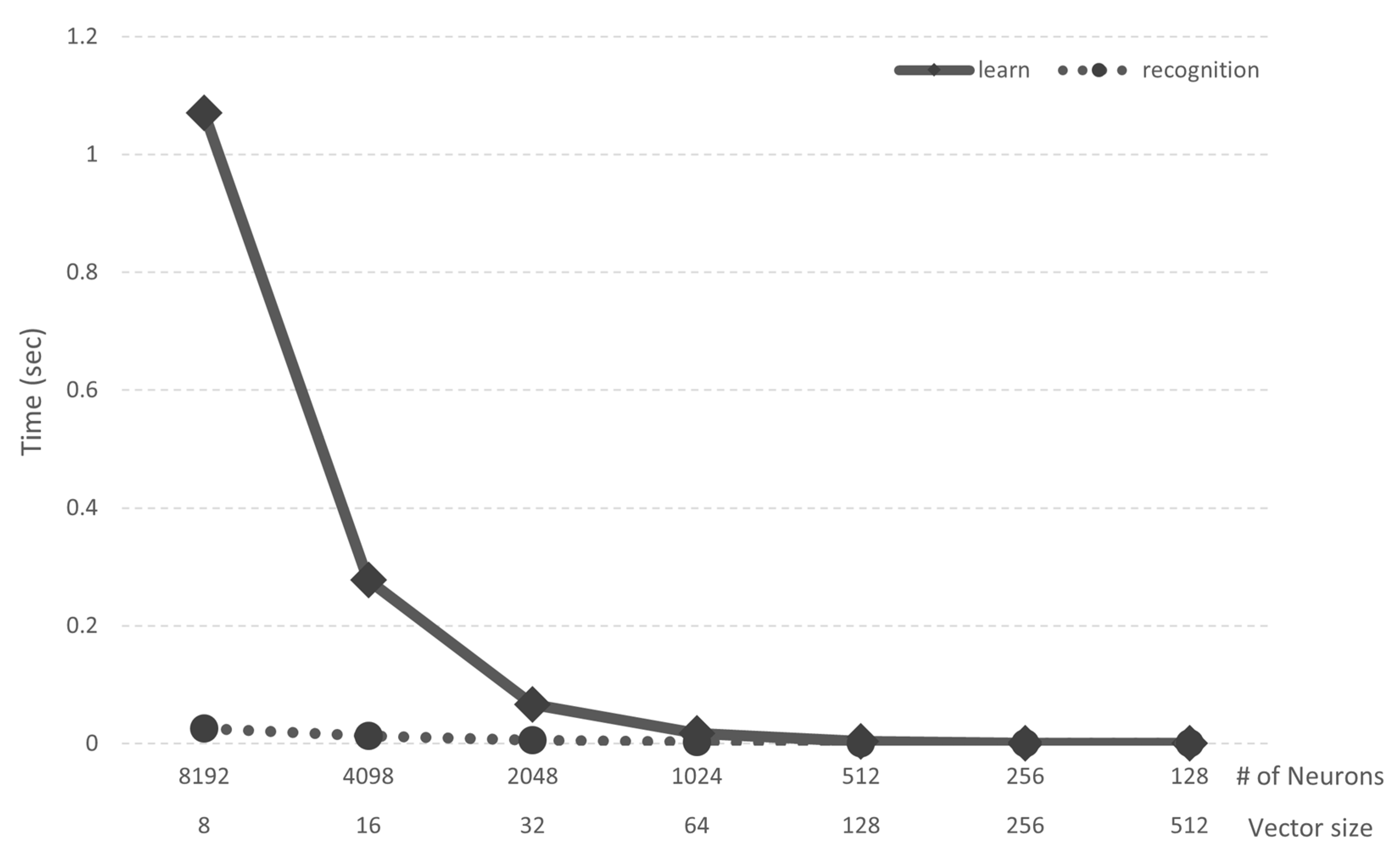
4.2. Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, C.; Wang, L.; Dang, J. Masking based Spectral Feature Enhancement for Robust Automatic Speech Recognition. In Proceedings of the IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 287–291. [Google Scholar]
- Jacob, S.; Menon, V.G.; Al-Turjman, F.; Vinoj, P.G.; Mostarda, L. Artificial Muscle Intelligence System with Deep Learning for Post-Stroke Assistance and Rehabilitation. IEEE Access 2019, 7, 133463–133473. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Kibria, M.G.; Nauyen, K.; Villardi, G.P.; Zhao, O.; Ishizu, K.; Kojima, F. Big Data Analytics, Machine Learning, and Artificial Intelligence in Next-Generation Wireless Networks. IEEE Access 2018, 6, 32328–32338. [Google Scholar] [CrossRef]
- Kuflik, T.; Kay, J.; Kummerfeld, B. Challenges and Solutions of Ubiquitous User Modeling. Ubiquitous Display Environments; Krüger, A., Kuflik, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 7–30. [Google Scholar]
- Yang, T. Trading computation for communication: Distributed stochastic dual coordinate ascent. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates: Red Hook, NY, USA; Volume 1. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards Federated Learning at Scale: System Design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. arXiv 2021, arXiv:1912.04977. [Google Scholar]
- Kim, H.; Park, J.; Bennis, M.; Kim, S. Blockchained On-Device Federated Learning. IEEE Commun. Lett. 2020, 24, 1279–1283. [Google Scholar] [CrossRef] [Green Version]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.H.; Hong, C.S. Federated Learning over Wireless Networks: Optimization Model Design and Analysis. In Proceedings of the IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1387–1395. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated Learning: Strategies for Improving Communication Efficiency; NIPS Workshop on Private Multi-Party Machine Learning; NIPS: Barcelona, Spain, 2016. [Google Scholar]
- Emam, K.E.; Dankar, F.K. Protecting privacy using k-anonymity. J. Am. Med. Inform. Assoc. 2008, 15, 627–637. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nergiz, M.E.; Clifton, C. δ-presence without complete world knowledge. IEEE Trans. Knowl. Data Eng. 2010, 22, 868–883. [Google Scholar] [CrossRef]
- Nikolaenko, V.; Weinsberg, U.; Ioannidis, S.; Joye, M.; Boneh, D.; Taft, N. Privacy-Preserving Ridge Regression on Hundreds of Millions of Records. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 334–348. [Google Scholar]
- Wan, J.; Wang, J.; Wang, Z.; Hua, Q. Artificial Intelligence for Cloud-Assisted Smart Factory. IEEE Access 2018, 6, 55419–55430. [Google Scholar] [CrossRef]
- Federated Learning: Collaborative Machine Learning without Centralized Training Data (Google AI Blog). Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 15 April 2021).
- Contreras, L.M.; Bernardos, C.J. Overview of Architectural Alternatives for the Integration of ETSI MEC Environments from Different Administrative Domains. Electronics 2020, 9, 1392. [Google Scholar] [CrossRef]
- Yoon, Y.H.; Jang, S.Y.; Choi, D.Y.; Lee, S.E. Flexible Embedded AI System with High-speed Neuromorphic Controller. In Proceedings of the International SoC Design Conference (ISOCC), Jeju, Korea, 6–9 October 2019; pp. 265–266. [Google Scholar]
- Yoon, Y.H.; Hwang, D.H.; Yang, J.H.; Lee, S.E. Intellino: Processor for Embedded Artificial Intelligence. Electronics 2020, 9, 1169. [Google Scholar] [CrossRef]
- Seng, K.P.; Lee, P.J.; Ang, L.M. Embedded Intelligence on FPGA: Survey, Applications and Challenges. Electronics 2021, 10, 895. [Google Scholar] [CrossRef]
- Fujii, T.; Toi, T.; Tanaka, T.; Togawa, K.; Kitaoka, T.; Nishino, K.; Nakamura, N.; Nakahara, H. New Generation Dynamically Reconfigurable Processor Technology for Accelerating Embedded AI Applications. In Proceedings of the IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 18–22 June 2018; pp. 41–42. [Google Scholar]
- Fang, F.; Shi, J.; Lu, S.; Zhang, M.; Ye, Z. An Efficient Computation Offloading Strategy with Mobile Edge Computing for IoT. Micromachines 2021, 12, 204. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Chen, W.M.; Lin, Y.; Cohn, J.; Gan, C.; Han, S. MCUNet: Tiny Deep Learning on IoT Devices. arXiv 2020, arXiv:2007.10319v2. [Google Scholar]
- Banbury, C.; Zhou, C.; Fedorov, I.; Navarro, R.M.; Thakker, U.; Gope, D.; Reddi, V.J.; Mattina, M.; Whatmough, P.N. MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers. arXiv 2021, arXiv:2010.11267v6. [Google Scholar]
- Burrello, A.; Garofalo, A.; Bruschi, N.; Tagliavini, G.; Rossi, D.; Conti, F. DORY: Automatic End-to-End Deployment of Real-World DNNs on Low-Cost IoT MCUs. IEEE Trans. Comput. 2021, 70, 1253–1268. [Google Scholar] [CrossRef]
- Cubero, L.; Peizerat, A.; Morche, D.; Sicard, G. Smart imagers modeling and optimization framework for embedded AI applications. In Proceedings of the 15th Conference on Ph.D Research in Microelectronics and Electronics (PRIME), Lausanne, Switzerland, 15–18 July 2019; pp. 245–248. [Google Scholar]
- Hwang, D.H.; Yoon, Y.H.; Han, C.Y.; Lee, S.E. Performance Analyzer for Embedded Artificial Intelligence Processor. J. Internet Comput. Serv. 2020, 21, 149–157. [Google Scholar]
- Bouchhima, A.; Yoo, S.; Jerraya, A. Fast and accurate timed execution of high level embedded software using HW/SW interface simulation model. In Proceedings of the Asia and South Pacific Design Automation Conference, Yokohama, Japan, 27–30 January 2004; pp. 469–474. [Google Scholar]
- General Vision Documents. Available online: https://www.general-vision.com/documentation/TM_CM1K_Hardware_Manual.pdf (accessed on 28 May 2021).
- The MNIST DATABASE of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 12 April 2021).
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Synthesis | ||
|---|---|---|---|
| Controller (Cyclone III: EP3C35Q240C8N) | Total logic elements 1 | 182 (<1%) | |
| Core dynamic power consumption | 1.62 mW | ||
| Core static power consumption | 81.03 mW | ||
| AI Core (CM1K 2) | Single chip | Idle mode | 15 mW |
| Active mode | ~275 mW | ||
| Multiple chip | - | ~500 mW | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, S.; Oh, H.W.; Yoon, Y.H.; Hwang, D.H.; Jeong, W.S.; Lee, S.E. A Multi-Core Controller for an Embedded AI System Supporting Parallel Recognition. Micromachines 2021, 12, 852. https://doi.org/10.3390/mi12080852
Jang S, Oh HW, Yoon YH, Hwang DH, Jeong WS, Lee SE. A Multi-Core Controller for an Embedded AI System Supporting Parallel Recognition. Micromachines. 2021; 12(8):852. https://doi.org/10.3390/mi12080852
Chicago/Turabian StyleJang, Suyeon, Hyun Woo Oh, Young Hyun Yoon, Dong Hyun Hwang, Won Sik Jeong, and Seung Eun Lee. 2021. "A Multi-Core Controller for an Embedded AI System Supporting Parallel Recognition" Micromachines 12, no. 8: 852. https://doi.org/10.3390/mi12080852
APA StyleJang, S., Oh, H. W., Yoon, Y. H., Hwang, D. H., Jeong, W. S., & Lee, S. E. (2021). A Multi-Core Controller for an Embedded AI System Supporting Parallel Recognition. Micromachines, 12(8), 852. https://doi.org/10.3390/mi12080852