Abstract
This paper introduces a new supervised classification method for hyperspectral images that combines spectral and spatial information. A support vector machine (SVM) classifier, integrated with a subspace projection method to address the problems of mixed pixels and noise, is first used to model the posterior distributions of the classes based on the spectral information. Then, the spatial information of the image pixels is modeled using an adaptive Markov random field (MRF) method. Finally, the maximum posterior probability classification is computed via the simulated annealing (SA) optimization algorithm. The combination of subspace-based SVMs and adaptive MRFs is the main contribution of this paper. The resulting methods, called SVMsub-eMRF and SVMsub-aMRF, were experimentally validated using two typical real hyperspectral data sets. The obtained results indicate that the proposed methods demonstrate superior performance compared with other classical hyperspectral image classification methods.
1. Introduction
In recent years, immense research efforts have been devoted to hyperspectral image classification. Given a set of observations (i.e., pixel vectors in a hyperspectral image), the goal of classification is to assign a unique label to each pixel vector such that it can be identified as belonging to a given class [1]. Classification techniques can be divided into unsupervised and supervised approaches, of which supervised classification methods are more widely used. However, the supervised classification of high-dimensional data sets, especially hyperspectral images, remains a challenging endeavor [2]. The Hughes phenomenon caused by the imbalance between the large number of spectral bands and the limited availability of training samples poses a major problem during this process. Additionally, the presence of noise and that of mixed pixels, affected by the spatial resolution, represent further hurdles hindering accurate hyperspectral image classification. To address these problems, machine learning models have been combined with several methods of feature dimension reduction that are able to produce accurate results, including support vector machines (SVMs) [3,4] and subspace projection methods [5,6].
Subspace projection methods have been shown to be a powerful tool in reducing the dimensionality of input data [7]. The fundamental idea of such a method is to project the original pixel vector to a lower-dimensional subspace that is spanned by a set of basis vectors. The details of subspace projection methods and the framework thereof are presented in Section 3.1. Recently, several approaches using subspace-based techniques have been exploited for hyperspectral image classification. In [8], an SVM nonlinear function called subspace-based SVM (SVMsub) was constructed by using the subspaces associated with each class for classification. In [9], a classifier that couples nearest-subspace classification with distance-weighted Tikhonov regularization was proposed for hyperspectral imagery. In [10], a subspace-based technique in a multinomial logistic regression (MLR) framework, called MLRsub, was developed to characterize mixed pixels in hyperspectral data. A general conclusion drawn from the aforementioned studies is that subspace projection methods are useful for reducing dimensionality by transforming the input data to the desired subspaces without loss of information. Additionally, such methods are suitable for the separation of classes that are spectrally similar because of spectral mixing and other reasons.
Another recent trend in attempts to improve classification accuracy is to combine spectral and spatial information [11,12,13]. On the one hand, Benediktsson et al. presented a series of studies of the integration of morphological features with segmentation techniques for the spectral-spatial classification of hyperspectral data [14,15]. The reported experiments proved that the proposed methods can yield promising results with high accuracy. On the other hand, the Markov random field (MRF) approach has also been proven to be an effective method of addressing spectral and spatial information. The basic principle of the MRF method is to integrate the spatial correlation information into the posterior probability distribution of the spectral features. Thus, this method can produce an accurate feature representation of pixels and their neighborhoods. Further details on the MRF method and its enhancement are presented in Section 2.2. In [16], a new supervised segmentation algorithm for remotely sensed hyperspectral image data was introduced that integrates a subspace-based MLR algorithm with a multilevel logistic Markov–Gibbs MRF prior; this algorithm is called MLRsub-MRF. To further improve the ability to characterize spatial information using the MRF approach, adaptive techniques have been applied to the spatial term to develop adaptive MRF methods. In [17], an edge-constrained MRF method (eMRF) was proposed for accurate land-cover classification over urban areas using hyperspectral imagery. In [18], an adaptive MRF approach that uses a relative homogeneity index (RHI) to characterize the spatial contribution was proposed for the classification of hyperspectral imagery; this method is called aMRF. Further details on these two methods are presented in Section 3.2 and Section 3.3.
As mentioned above, subspace projection methods can be used to efficiently improve the classification accuracy of algorithms such as those based on SVMs and MLR, which predominantly use information from the spectral domain [8,10]. Moreover, through the combination of MRF models and MLRsub, it has been proven that spatial correlation information is also useful for algorithms based on subspace projection [16]. A previous experimental comparison has shown that SVMsub outperforms MLRsub [8]. Therefore, we can integrate MRF models with SVMsub to achieve a higher classification accuracy than that offered by the MLRsub-MRF algorithm proposed in [16]. Furthermore, we improve our MRF modeling by using the adaptive strategy introduced in our previous works [17,18] to propose two novel algorithms called SVMsub-eMRF (SVMsub combined with the eMRF method proposed in [17]) and SVMsub-aMRF (SVMsub combined with the RHI-based aMRF method proposed in [18]). Compared with SVMsub and MLRsub-MRF, the main advantages and contributions of this work lie in the design and improvement of the classification algorithms through optimization in both the spectral and spatial domains. In the spectral domain, SVMsub can obtain results with higher accuracy than MLRsub, and eMRF and aMRF also demonstrate better performance than conventional MRF models.
Our method is implemented in two steps: (1) a learning step, in which the posterior probability distribution and pre-classification results are obtained using an SVM classifier integrated with a subspace projection method; and (2) a post-processing step, in which the class labels computed during the pre-classification process are revised via an adaptive MRF approach. The final result is optimized using the simulated annealing (SA) optimization algorithm [19]. The proposed method not only can cope with the Hughes phenomenon and the effect of mixed pixels but also is able to discriminatively address the relationships exhibited by pixels in homogeneous regions or on boundaries. We performed experiments to compare the performances of two adaptive MRF algorithms, the edge-constraint-based eMRF algorithm [17] and the RHI-based aMRF algorithm [18], and both of them achieved superior accuracies compared with other spectral-spatial hyperspectral image classifiers. In addition to these advantages, our approach also provides a fast computation speed by virtue of the subspace-based SVM analysis.
The remainder of this paper is organized as follows. Section 2 introduces the classical SVM model and MRF algorithm, along with some analysis of the problems encountered in their application to hyperspectral data sets. Section 3 presents the proposed classification method combining the subspace-based SVM approach and the adaptive MRF approach. Section 4 evaluates the performances of our methods compared with those of other hyperspectral image classifiers, using data sets collected by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) over the Indian Pines region in Indiana and by the Reflective Optics Spectrographic Imaging System (ROSIS) over the University of Pavia in Italy. Section 5 presents some concluding remarks.
2. Related Work
In this section, we introduce two basic components of our framework. The classical SVM model is introduced in Section 2.1, along with an analysis of its application to hyperspectral images. Section 2.2 presents the concept of MRFs and an introduction to the improvement achieved using this approach.
2.1. SVM Model
Consider a hyperspectral image data set , where is the total number of pixels, denotes the spectral vector associated with an image pixel , and is the number of spectral bands. Let and , where is the total number of classes. If and for , then pixel belongs to class .
The SVM classifier is a widely used supervised statistical learning classifier that is advantageous in the case of small training samples. The SVM model consists of finding the optimal hyperplane such that the distance between the hyperplane, which separates samples belonging to different classes, and the closest training sample to it is maximized [20,21]. The classic binary linear SVM classifier can be expressed as the following function:
For simplicity, it is sometimes necessary to set to ensure that the hyperplane passes through the origin of the coordinate system [22]. However, linear separability usually cannot be satisfied in the classification of real data, especially hyperspectral data. Thus, the soft margin concept and the kernel method have been introduced to cope with nonseparable scenarios [3]. The underlying idea of the kernel method is to map the data via a nonlinear transformation into a higher-dimensional feature space such that the nonseparable problem can be solved by replacing the original input data with the transformed data , i.e.,
where is the kernel function.
However, hyperspectral image data consist of hundreds of narrow, contiguous wavelength bands, and it has been demonstrated that the original spectral features exhibit high redundancy [23]. Specifically, there is a high correlation between adjacent bands, and the original dimensionality of the data contained in a hyperspectral image may be too high for classification purposes [24]. To address these difficulties, subspace projection has been shown to be a powerful technique that can cope with the high dimensionality of an input data set by transforming it to the desired subspaces without loss of information [16]. The details of this method are presented in Section 3.
2.2. MRF Model
The MRF model, which combines spectral and spatial information, is widely used in classification. It can provide an accurate feature representation of pixels and their neighborhoods. The basic principle of MRF is to integrate spatial correlation information into the posterior probability of the spectral features. Based on the maximum posterior probability principle [25], the classic MRF model can be expressed as follows:
where and are the mean vector and covariance matrix, respectively, of class and the neighborhood and class of pixel are represented by and , respectively. The constant parameter , called the weight coefficient, is used to control the influence of the spatial term.
According to Equation (3), the MRF model can be divided into two components: the spectral term and the spatial term. Thus, Equation (3) can be represented in the form
where is the spectral term and is the spatial term. Here,
where is the Kronecker delta function, defined as
Different MRF methods can be applied depending on the definition of in Equation (4); several examples are given below:
- (1)
- corresponds to the classic MRF method [26,27].
- (2)
- corresponds to spectral angle-MRF [28].
- (3)
- corresponds to Mahalanobis-MRF [29].
When a center pixel has the same class label as the rest of its neighborhood, this pixel has a high probability of being in a homogeneous region and has a strong consistency [30]. Thus, these spatial context relationships can be used to revise the class labels.
However, different ground objects exhibit large differences in distribution. For instance, the overcorrection phenomenon may be induced if pixels with complex boundary conditions are given the same weight coefficients as those in homogeneous regions. By contrast, full advantage of the spatial context features of homogeneous regions cannot be taken if the spatial term is given a lower weight. To address this problem, in the edge-constraint-based eMRF method and the RHI-based aMRF method [17,18], local spatial weights are defined for use in place of the global spatial weight to estimate the variability of spatial continuity. These two effective adaptive MRF methods are covered in greater detail in Section 3.2 and Section 3.3.
3. Proposed Method
In previous work, subspace projection and MRFs have proven to be two useful methods of enhancing classification accuracy based on the spectral and spatial domains separately. Therefore, MLRsub-MRF demonstrates promising performance in hyperspectral image classification. To achieve further accuracy improvement, we wish to optimize the features from the spectral and spatial domains simultaneously. To this end, this paper proposes two new algorithms that combine SVMsub with an adaptive MRF approach (eMRF or aMRF). This section introduces the proposed methods, which belong to a framework that is divided into three components. In the spectral domain, the subspace projection technique is combined with an SVM classifier, in the procedure that we call SVMsub, to reduce the dimensionality and thereby circumvent the problems of the Hughes phenomenon and mixed pixels. In the spatial domain, two adaptive MRF algorithms are considered to optimize the spectral term, characterize the spatial information and obtain stable results via SA. The general framework of the final methods, which we call SVMsub-eMRF and SVMsub-aMRF, is illustrated in Figure 1.

Figure 1.
General framework of the proposed methods.
3.1. SVMsub
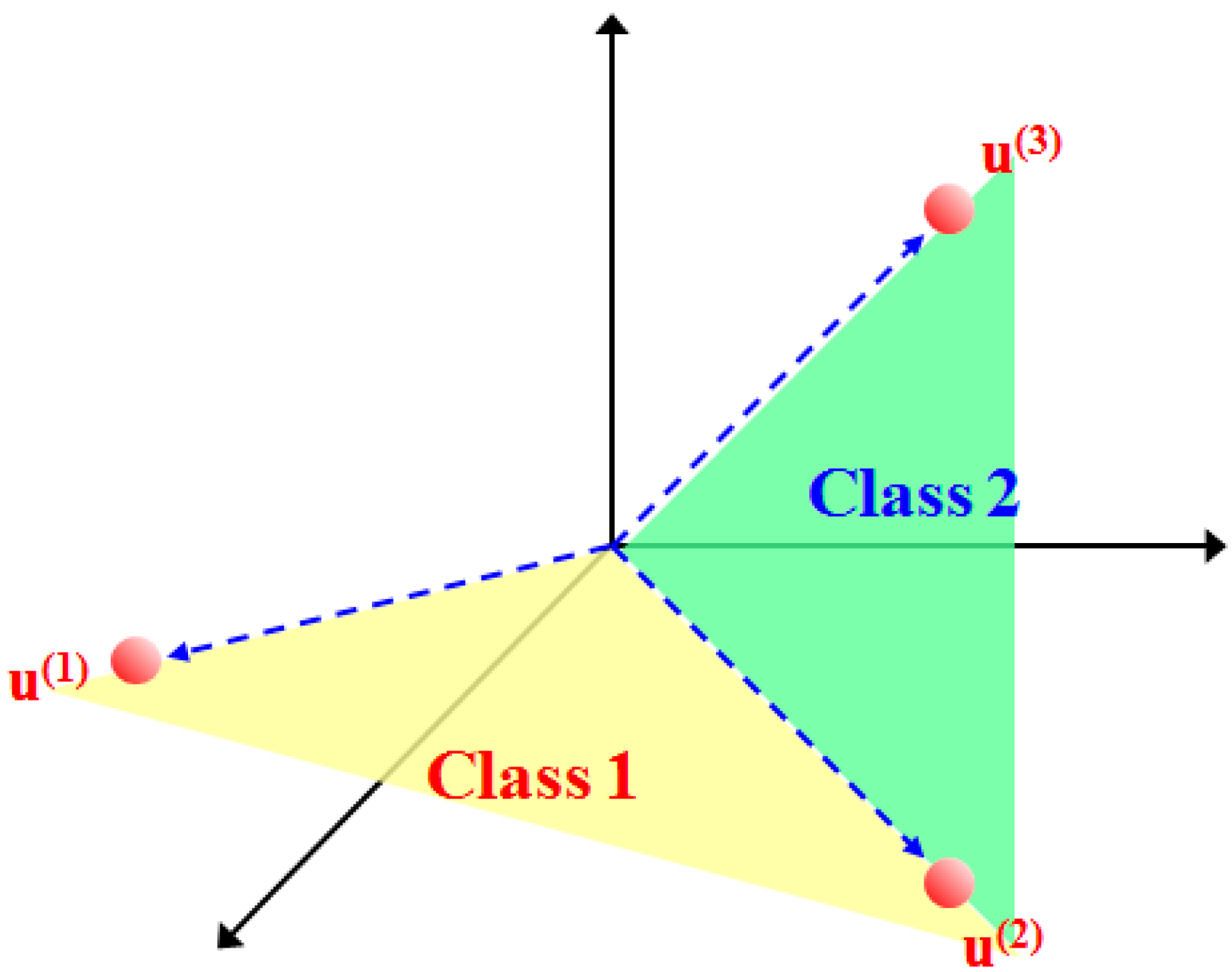
As shown in Figure 2, the basic assumption of the subspace projection method is that the samples of each class can be transformed to a lower-dimensional subspace spanned by a set of basis vectors [16]. In general, the SVMsub model is actually a novel form of an SVM nonlinear function. Under the linear mixture model assumption and the projection principle [31,32], the within-class autocorrelation matrix is first used to calculate the eigenvalues and the eigenvector matrix, which is used as the transformation matrix. Then, the class-dependent nonlinear function constructed from the transformation matrix and the original samples are defined to obtain the projected samples. Finally, these projected samples are used as the new training data for the SVM classifier to evaluate the results of the SVMsub model.
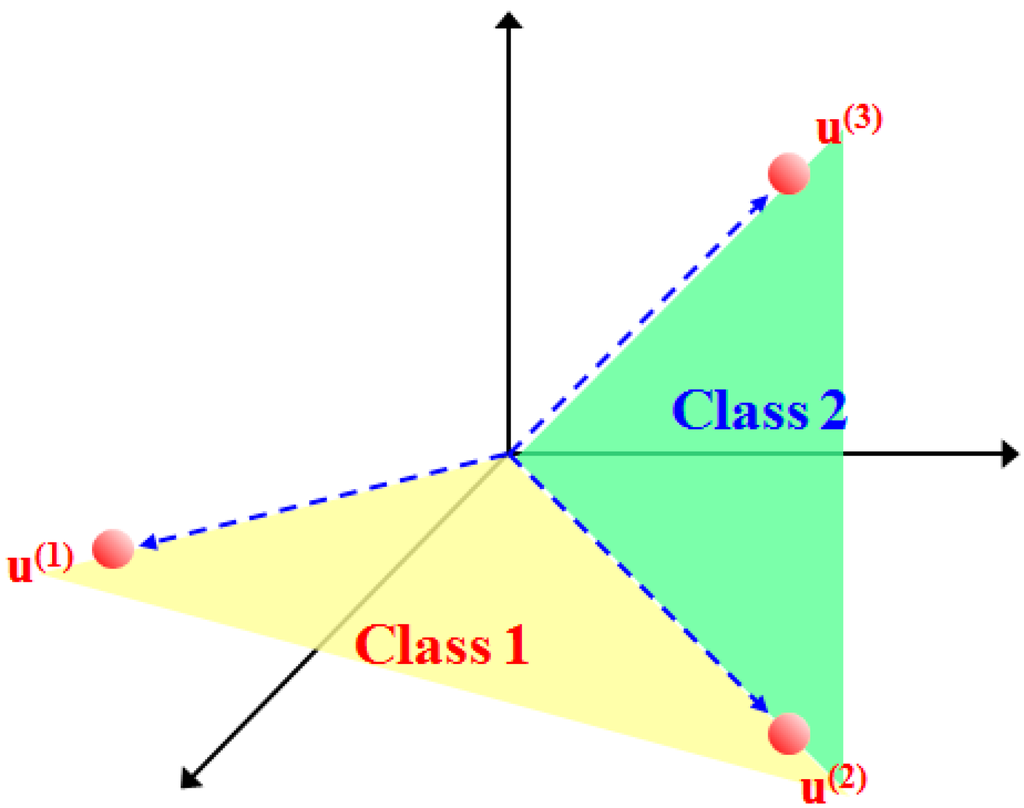
Figure 2.
Illustration of subspace projection under the linear mixture model assumption, where denote the spectral endmembers. The colored spaces are the class-dependent subspaces spanned by .
Under the linear mixture model assumption, for any pixel , we can write
where is the noise, is a set of -dimensional orthonormal basis vectors for the subspaces associated with the classes , and represents the coordinates of with respect to the basis . Let be the set of labeled samples, with size ; let denote the within-class autocorrelation matrix of class ; and let denote the training set of class , with samples. By computing the eigendecomposition of , we obtain
where is the eigenvector matrix and is the matrix of the eigenvalues in order of decreasing magnitude, i.e., . Following [8], we define to cover 99% of the original spectral information, i.e.,
where , and we take as an estimate of the class-independent -dimensional subspace. Thus, a nonlinear function defined as
is used to obtain the projected samples
Finally, these projected samples are used as new training data for the SVM classifier to evaluate the results of the SVMsub model.
where , with being the soft margin parameter. As shown in Equation (12), the projected samples that are used as the input data in our approach are approximately -dimensional, independent of the size of the training set. Thus, this constitutes a significant advantage of our method compared with certain conventional kernel methods, such as those based on Gaussian or polynomial radial basis functions (RBFs) [33,34]. The pseudocode for the subspace-based SVM algorithm, abbreviated as SVMsub, is shown in Algorithm 1.
| Algorithm 1 SVMsub |
| Input: The available training data , their class labels , and the test sample set with class labels represented by . |
| for to do |
| ( computes the subspace according to Equations (7)–(9) ) |
| end |
| for to do |
| ( computes the projected samples according to Equations (10) and (11) ) |
| end |
| for to do |
| ( computes the SVM results according to Equation (12) ) |
| end |
| Output: The class labels . |
3.2. SVMsub-eMRF
Based on the results of SVMsub and the improved version of Platt’s posterior probability [35,36], the posterior probability distribution of the classified pixels is given by
where and are the function parameters obtained by minimizing the cross-entropy error function. Thus, the classic MRF model based on SVMsub can be expressed as follows:
In this paper, we multiply by to construct the initial energy function [37] for the subsequent SA. Thus, a Maximum A Posteriori (MAP) problem is converted into an energy minimization problem, and the energy function of SVMsub-MRF can be written as follows:
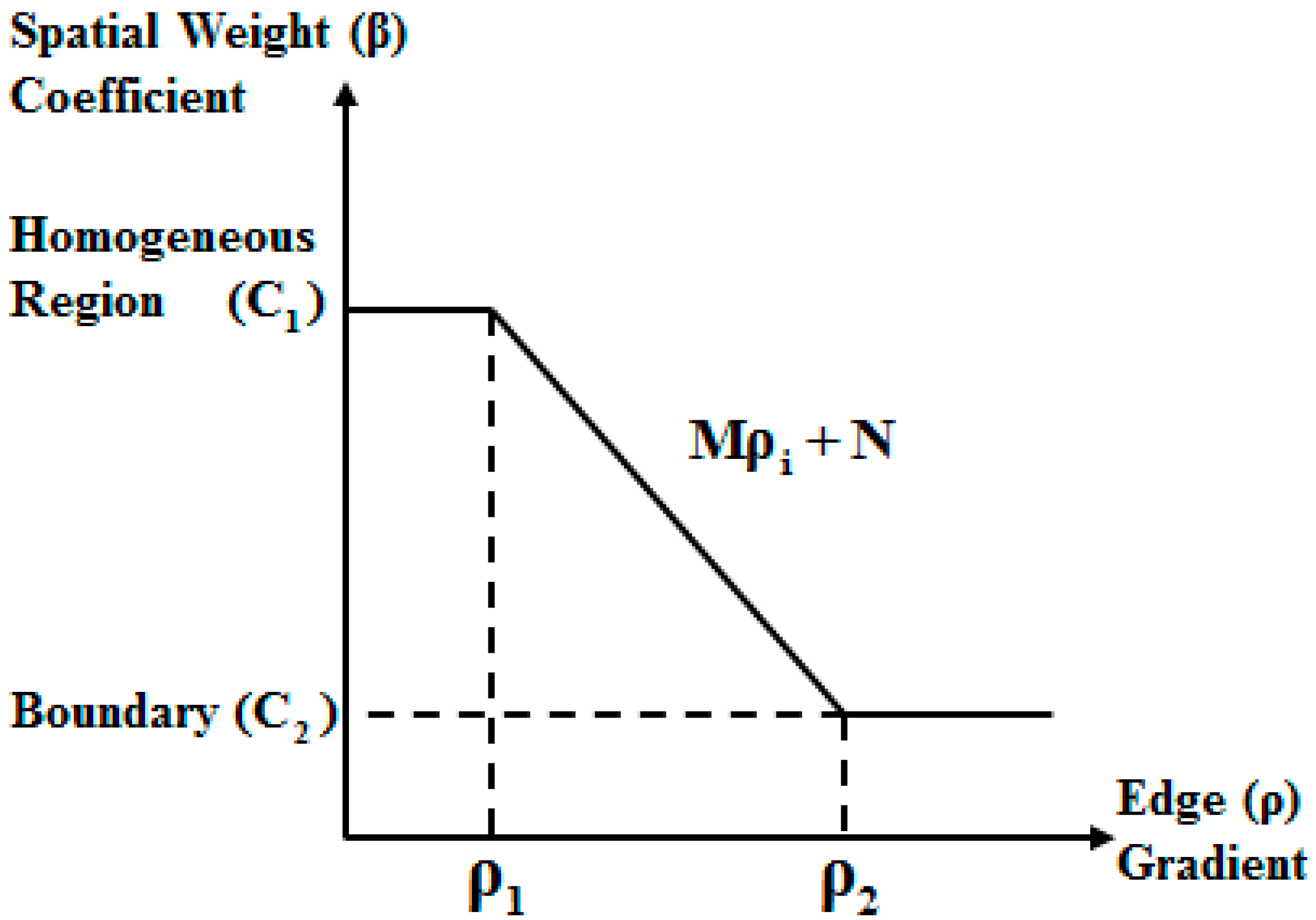
For the replacement of the global spatial weight coefficient with the local spatial weight coefficients , the eMRF algorithm first uses the minimum noise fraction (MNF) transform [38] to obtain the first principal component for edge detection using a detector such as the Canny detector or the Laplacian of Gaussian (LoG) detector [39]. Based on the edge detection results, the eMRF algorithm considers two thresholds, and , for identifying edges, where . As shown in Figure 3, when the gradient of pixel is higher than , it can be concluded that pixel is located on a boundary. By contrast, pixel is located in a homogeneous region when its gradient is lower than .
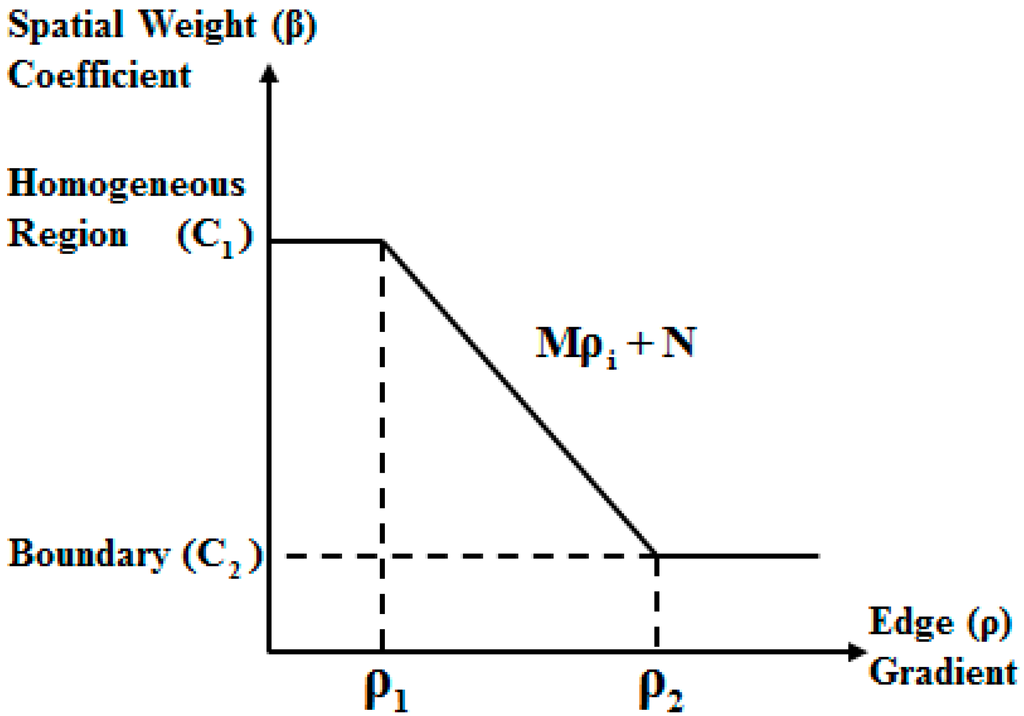
Figure 3.
Relationship between the weighting coefficient and the combined edge gradient.
According to the relationship between the spatial weight coefficient of a pixel and its spatial location, we have
where is the gradient of pixel and and () are the constants that define the best values of the spatial weight coefficient for a pixel in a homogeneous region and for a pixel on a boundary, respectively. Furthermore, and are function parameters that can be calculated based on the boundary thresholds:
After the normalization to obtain , the energy function of SVMsub-eMRF is finally given by
The pseudocode for the subspace-based SVM algorithm combined with the edge-constrained MRF algorithm, abbreviated as SVMsub-eMRF, is shown in Algorithm 2.
| Algorithm 2 SVMsub-eMRF |
| Input: The available training data , their class labels , and the test sample set with class labels represented by . |
| Step 1: Compute the results of SVMsub according to Algorithm 1; |
| Step 2: Obtain the first principal component using the MNF transform; |
| Step 3: Detect the edges using the Canny or LoG detector and the results of Step 2; |
| Step 4: Define the thresholds and to determine the using the results of Step 3 according to Equations (16) and (17); |
| Step 5: Determine the final class labels according to Equation (18); |
| Output: The class labels . |
3.3. SVMsub-aMRF
To obtain the local spatial weight coefficients , the RHI can also be used to estimate the local spatial variations. The aMRF model first uses the noise-adjusted principal components (NAPC) transform to obtain the first principal component to calculate the RHI:
where represents the class-decision variance of the neighborhood of pixel as determined by majority voting rules and is the local variance of pixel [40]. When is high, it can be concluded that pixel is located in a homogeneous region. By contrast, pixel is on a boundary when is low. Therefore, the local spatial weight coefficient can be defined as follows:
where is the spatial weight coefficient when ; usually, . For integration with the spectral term, it also necessary to normalize the spatial weight coefficients, i.e., , where is the number of pixels in the neighborhood. Thus, the SVMsub-aMRF model is finally given by
and the energy function is expressed as
The pseudocode for the subspace-based SVM algorithm combined with the RHI-based aMRF algorithm, abbreviated as SVMsub-aMRF, is shown in Algorithm 3.
| Algorithm 3 SVMsub-aMRF |
| Input: The available training data , their class labels , and the test sample set with class labels represented by . |
| Step 1: Compute the results of SVMsub according to Algorithm 1; |
| Step 2: Obtain the first principal component using the NAPC transform; |
| Step 3: Calculate the RHIs using the result of Step 1 and Step 2 according to Equation (19); |
| Step 4: Compute the using the results of Step 3 according to Equation (20); |
| Step 5: Determine the final class labels according to Equations (21) and (22); |
| Output: The class labels . |
4. Experiments
In this section, we evaluate the performance of the proposed SVMsub-eMRF and SVMsub-aMRF algorithms using two widely used hyperspectral data sets, one collected by AVIRIS over the Indian Pines region in Indiana and the other collected by ROSIS over the University of Pavia in Italy. The land-cover types in the Indian Pines region mainly consist of vegetation and crops. By contrast, the University of Pavia landscape is more urban, with several artificial geographical objects. For comparative purposes, we also consider several other supervised classifiers, such as MLRsub [10], MLRsub-MRF [16], SVM [3] and SVM-MRF [41], which are well-established techniques in the domain of spectral and spectral-spatial hyperspectral image classification. To ensure the fairness of the comparison of these methods, we use the overall accuracy (OA), the κ statistic, the individual accuracies and the computation time to evaluate the results of the different methods. Moreover, we set the same threshold parameters to control the loss of spectral information after the subspace projection of the data for MLRsub and SVMsub. Furthermore, we consider the same initial global spatial weight for the different MRF-based methods.
It should be noted that all spectral-spatial models considered in our experiments are optimized using the SA algorithm, which is a common method of minimizing the global energy of MRFs [42]. The Metropolis criterion and cooling schedule were used to control the behavior of the algorithm in obtaining the approximate global optimal solution. The pseudocode of the SA algorithm is presented in Algorithm 4.
| Algorithm 4 SA Optimization |
| Input: The available training data , their class labels , and a lowest temperature . |
| Step 1: Obtain the initial energy function according to the results of SVMsub-eMRF or SVMsub-aMRF; |
| Step 2: Randomly vary the classes and calculate a new energy function ; |
| Step 3: Compute the difference between the results of Step 1 and Step 2: ; |
| Step 4: If , replace the class labels with the current ones. Otherwise, leave them unchanged; |
| Step 5: Return to Step 2 until the predefined lowest temperature has been reached; |
| Step 6: Determine the final class labels ; |
| Output: The class labels . |
4.1. Experiments Using the AVIRIS Indian Pines Data Set
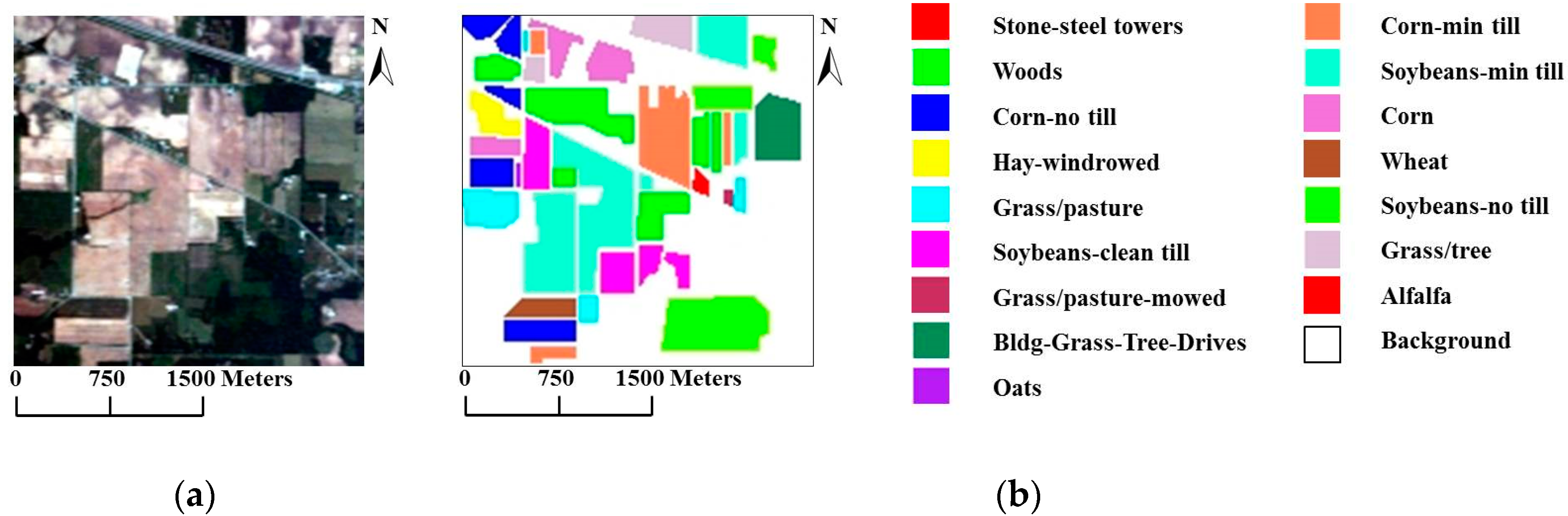
For our first experiment, we used the well-known AVIRIS Indian Pines data set, which was collected over northwestern Indiana in June of 1992, to compare the proposed models with other methods. The scene contains pixels, with 220 spectral bands in the spectral range from 0.4 to 2.5 and a nominal spectral resolution of 10 . The ground reference data contain a total of 10,366 samples belonging to 16 mutually exclusive classes. Figure 4a shows a true-color composite of the image, whereas Figure 4b shows the 16 ground reference object classes.
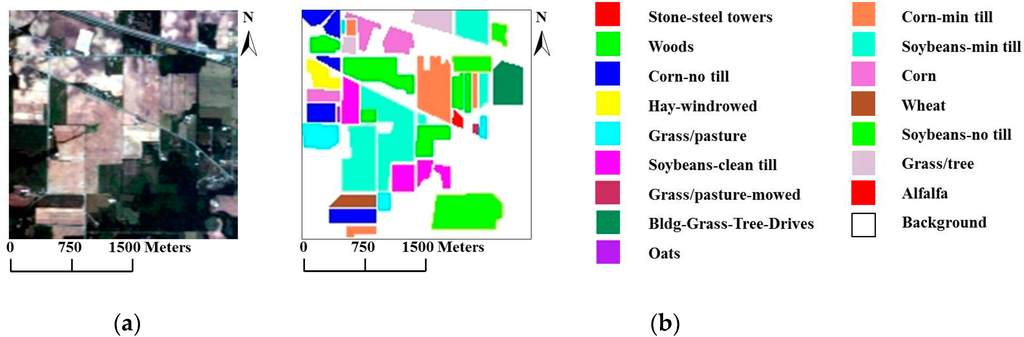
Figure 4.
(a) True-color composite of the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) Indian Pines scene; (b) Ground reference map containing 16 mutually exclusive land-cover classes.
In our first two tests, we used two versions of the Indian Pines data, one with all 220 spectral bands available and the other with only 200 channels after the removal of 20 bands due to noise and water absorption, to evaluate the performances of the compared methods under different noise conditions. Specifically, for these tests, 30 samples per class were randomly selected to obtain a total of 480 training samples, which is a very limited training sample size (approximately 2.3% of the total). Table 1 and Table 2 report the results for the two scenarios in terms of the OAs, κ statistic values and individual accuracies after twenty Monte Carlo runs. For this comparison, we defined to cover 99% of and set the initial global weight coefficient to 4.0.

Table 1.
Overall and average class accuracies and κ statistic values obtained for the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) Indian Pines data set using 220 spectral bands and a training sample size of 30 samples per class. The best results are highlighted in bold typeface.
Table 2.
Overall and average class accuracies and κ statistic values obtained for the AVIRIS Indian Pines data set using 200 spectral bands and a training sample size of 30 samples per class. The best results are highlighted in bold typeface.
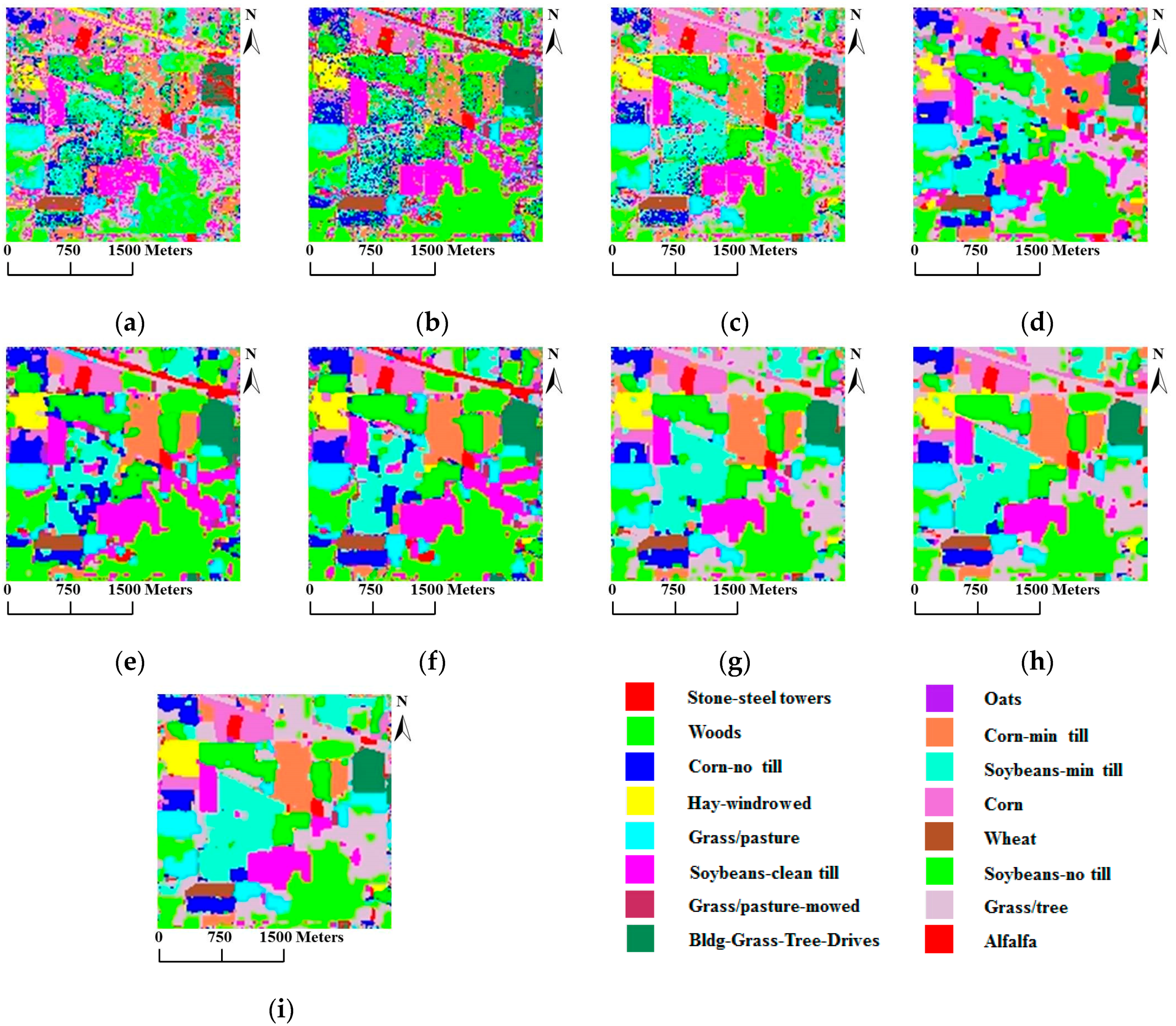
From these two tables, we can make the following observations: (1) SVMsub achieves the best results when only information from the spectral domain is used, thereby demonstrating the advantages of the subspace projection technique combined with the SVM classifier; (2) SVM-MRF yields higher accuracies than SVM, providing further evidence that the integration of spatial and spectral information via the MRF approach helps to improve the classification accuracy; (3) SVMsub-MRF achieves better results compared with SVMsub and SVM-MRF, which serves as further proof of the effectiveness of combining the subspace projection technique with the MRF approach. The same can be said of the results obtained by MLRsub-MRF and MLRsub; (4) SVMsub-aMRF yields the best accuracies compared with SVMsub-eMRF and SVMsub-MRF, thereby demonstrating that the adaptive technique is a powerful means of improving the classification accuracy; (5) SVMsub-aMRF achieves superior results compared with MLRsub-aMRF, thereby proving the effectiveness and robustness of the proposed method. In general, SVMsub-eMRF achieves excellent accuracies, with OAs of 90.57% and 87.16%. SVMsub-aMRF achieves the best accuracies in both scenarios, with OAs of 91.22% and 88.04%, respectively. Notably, the average individual accuracies of SVMsub-aMRF and SVMsub-eMRF are also generally superior to those of the other methods. Figure 5 shows the classification and segmentation maps produced by the methods listed in Table 1.
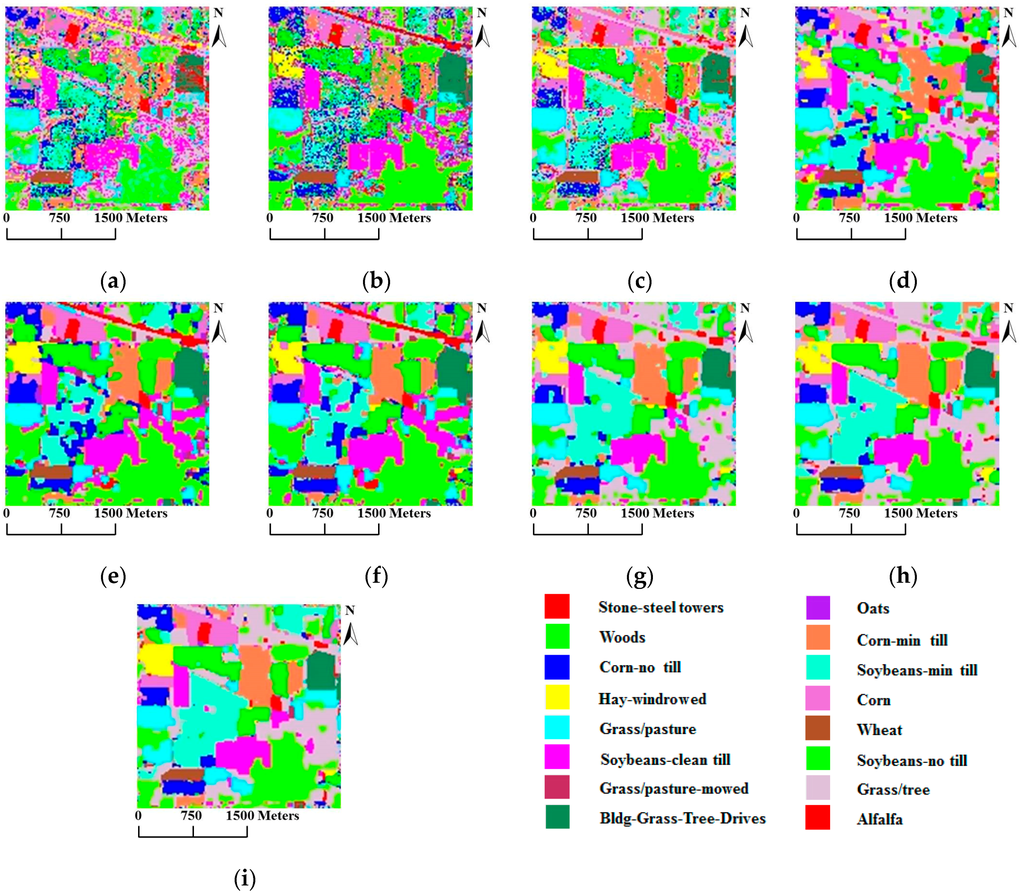
Figure 5.
Classification/segmentation maps produced by the various tested methods for the AVIRIS Indian Pines scene (overall accuracies are reported in parentheses). (a) SVM (58.47%); (b) MLRsub (67.62%); (c) SVMsub (77.78%); (d) SVM-MRF (75.72%); (e) MLRsub-MRF (84.20%); (f) MLRsub-aMRF (85.66%); (g) SVMsub-MRF (89.49%); (h) SVMsub-eMRF (90.57%); (i) SVMsub-aMRF (91.22%).
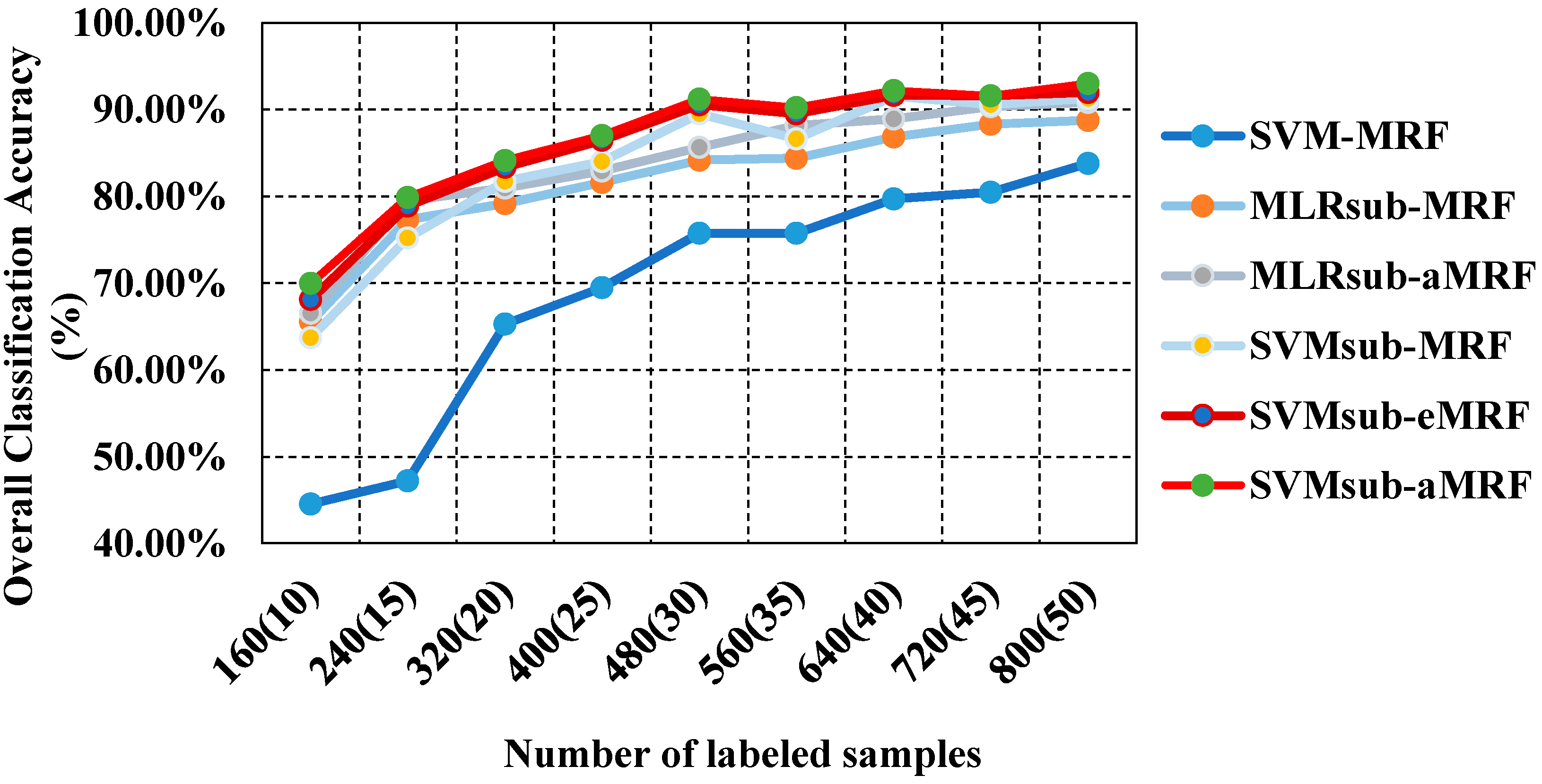
In our second test using the AVIRIS Indian Pines data set, we analyzed the performances of our methods compared with those of other spectral-spatial classifiers using different numbers of samples. To evaluate the sensitivity to the number of samples, we generated the training sets by randomly selecting 10, 15, 20, 25, 30, 35, 40, 45 and 50 labeled samples per class. Table 3 reports the obtained values of the OA, the κ statistic and the computational cost, including both training and testing times. This comparison yields similar conclusions to those drawn from the first two tests presented above: (1) SVMsub-MRF achieves better results than SVM-MRF (by approximately 10% in each group); (2) SVMsub-aMRF yields higher accuracies compared with SVMsub-eMRF and SVMsub-MRF. Additionally, MLRsub-aMRF performs better than MLRsub-MRF; (3) SVMsub-aMRF yields the best accuracies among all methods in each group; for example, this method achieves an OA of 93.03% and a value of 0.92 in the group corresponding to 900 labeled samples (approximately 50 samples per class). This experiment again proves that our proposed method is robust and reliable. In addition, it should be noted that the computational costs of the models integrated with a subspace projection method are generally less than those of the other methods, even when a large number of training samples are used. Figure 6 shows the OA results obtained by the various methods as a function of the number of labeled samples per class.
Table 3.
Overall classification accuracies (in percent) and κ statistic values obtained by the various tested methods for the AVIRIS Indian Pines scene using different numbers of training samples. The computational costs (in parentheses) are also presented. Both the total number of samples used and the (approximate) number of training samples per class (in parentheses) are shown.
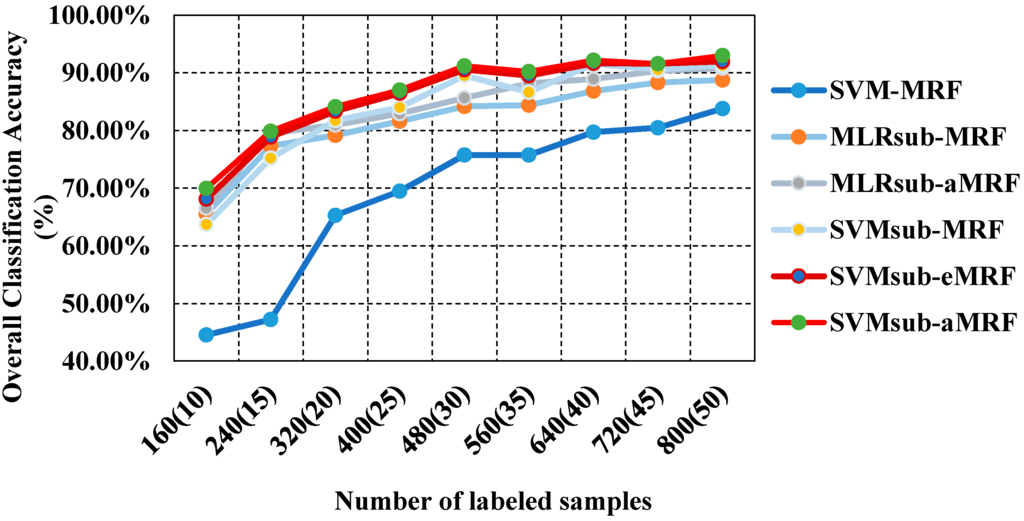
Figure 6.
Overall accuracy results as a function of the number of labeled samples for the Indian Pines data set.
4.2. Experiments Using the ROSIS University of Pavia Data Set
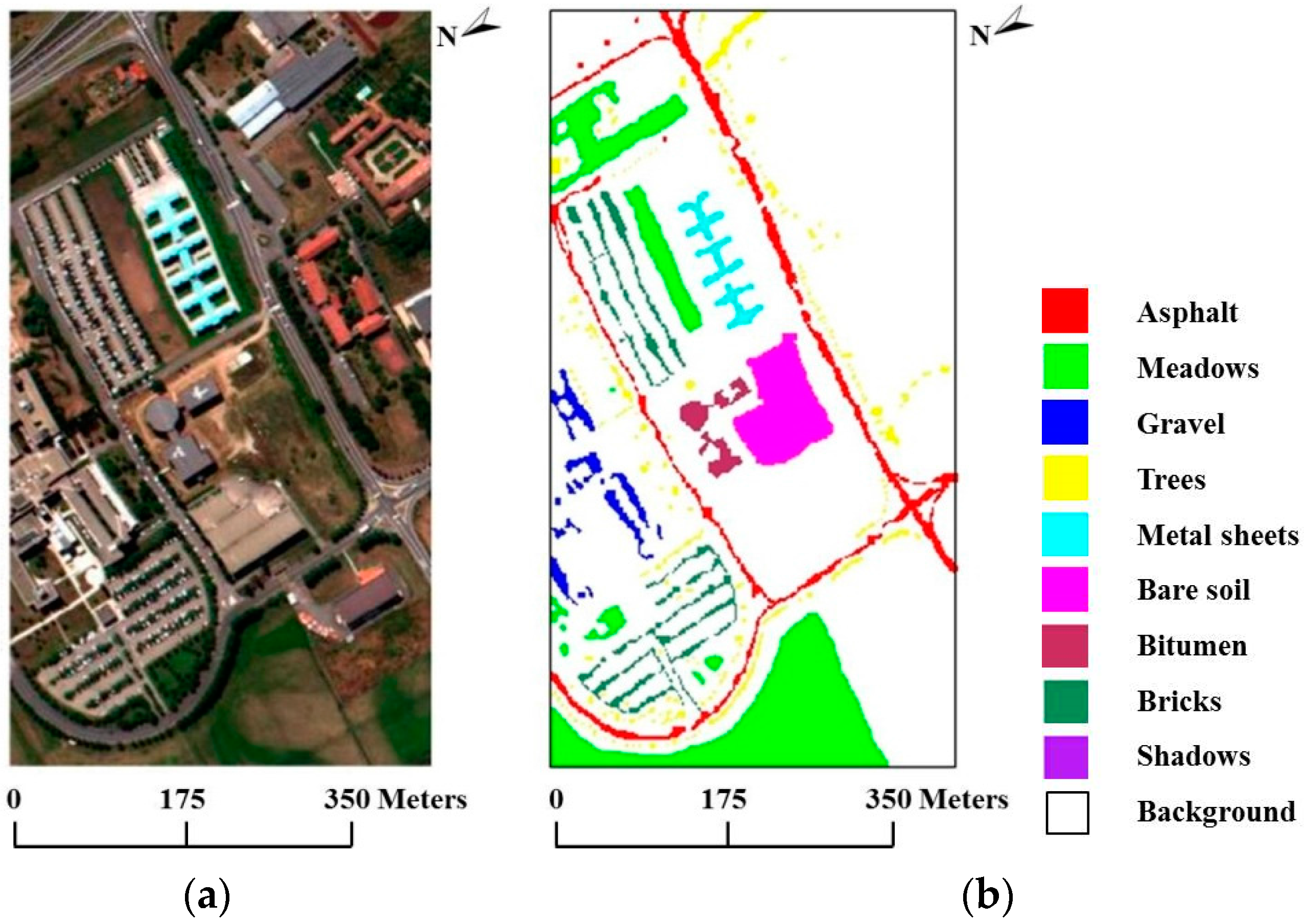
In our second experiment, we used the real hyperspectral data set collected in 2001 by ROSIS over the University of Pavia in Italy. The ROSIS optical sensor provides up to 115 bands with a spectral range coverage ranging from 0.43 µm to 0.86 µm. The size of the University of Pavia image is 610 × 340 pixels, with 103 spectral bands after the removal of 12 bands of noise and water absorption. The ground reference data contain a total of 3921 training samples and 42,776 test samples belonging to nine classes. Figure 7a shows a true-color composite of the image, whereas Figure 7b shows the nine ground reference classes corresponding to the detailed features in the image.
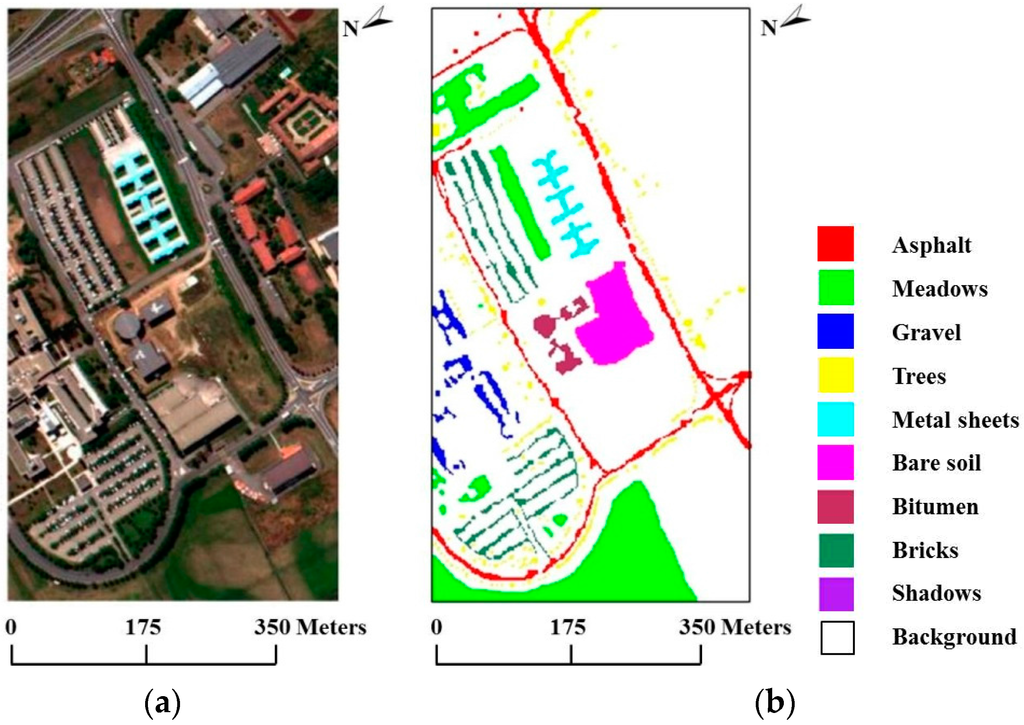
Figure 7.
(a) True-color composite of the Reflective Optics Spectrographic Imaging System (ROSIS) Pavia scene; (b) Ground reference map containing nine mutually exclusive land-cover classes.
In our first test using the University of Pavia data set, we used 20 training samples per class, for a total of 180 training samples, which is a relatively small number. Table 4 reports the OA, κ statistic and individual accuracy results after twenty Monte Carlo runs. For this comparison, we again defined to cover 99% of and set the global weight coefficient to 4.0. From the results, we obtain very similar conclusions to those obtained using the AVIRIS Indian Pines data set: (1) SVMsub achieves the best accuracy compared with SVM and MLRsub, with an OA of 71.38%; (2) SVMsub-eMRF provides a considerable improvement, with an OA of 79.84%, whereas SVMsub-aMRF yields the best accuracy in the spectral-spatial domain, with an OA of 81.94%. Likewise, the average individual accuracies of SVMsub-aMRF and SVMsub-eMRF are generally higher than those of the other approaches. Figure 8 shows the classification and segmentation maps produced by the aforementioned methods.
Table 4.
Overall, average, and individual class accuracies (in percent) and κ statistic values obtained for the Reflective Optics Spectrographic Imaging System (ROSIS) University of Pavia data set with a training sample size of 20 samples per class. The best results are highlighted in bold typeface.
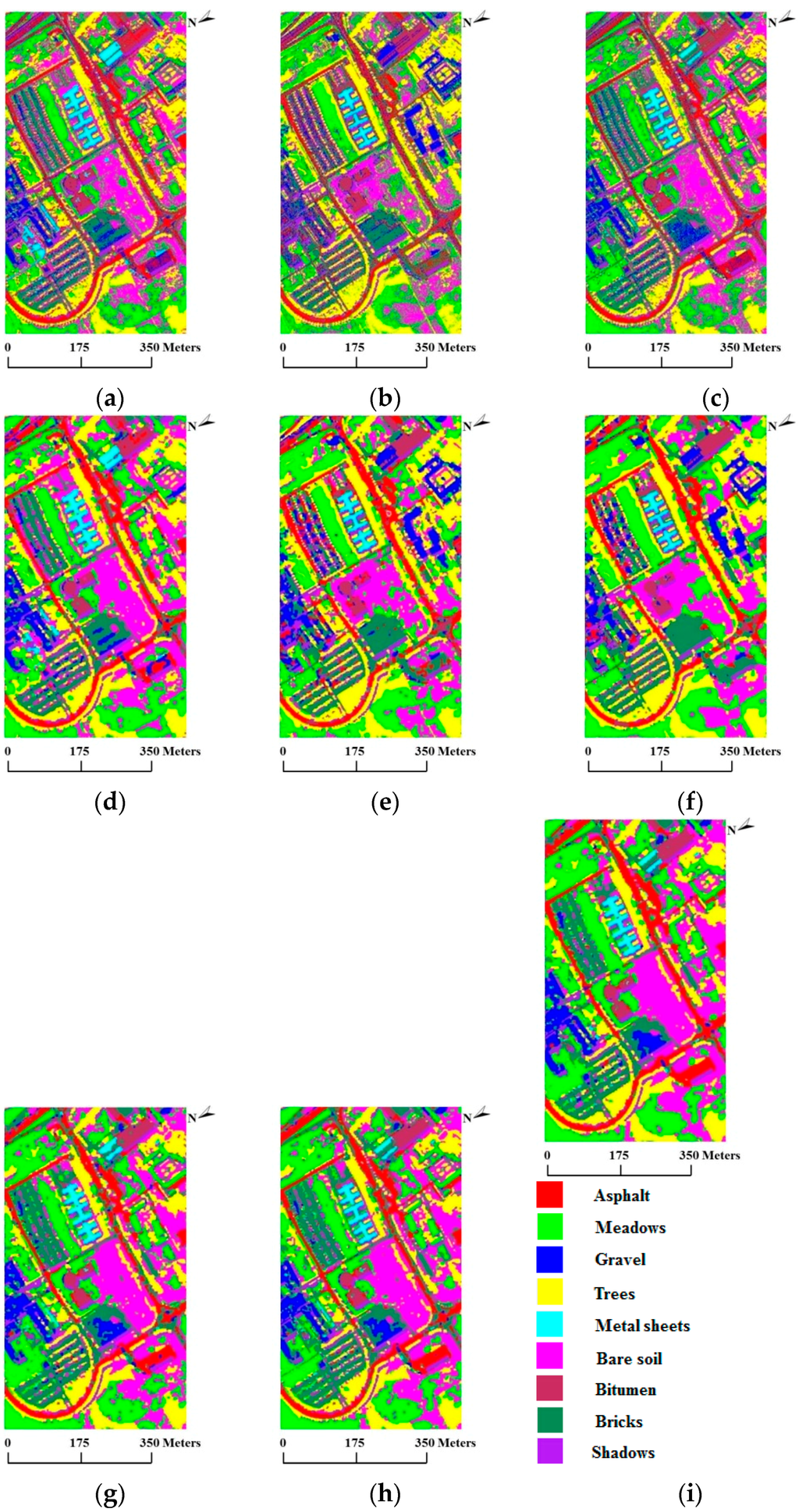
Figure 8.
Classification/segmentation maps produced by the various tested methods for the ROSIS University of Pavia scene (overall accuracies are reported in parentheses). (a) SVM (69.70%); (b) MLRsub (66.84%); (c) SVMsub (71.38%); (d) SVM-MRF (75.71%); (e) MLRsub-MRF (72.97%); (f) MLRsub-aMRF (73.67%); (g) SVMsub-MRF (79.20%); (h) SVMsub-eMRF (79.84%); (i) SVMsub-aMRF (81.94%).
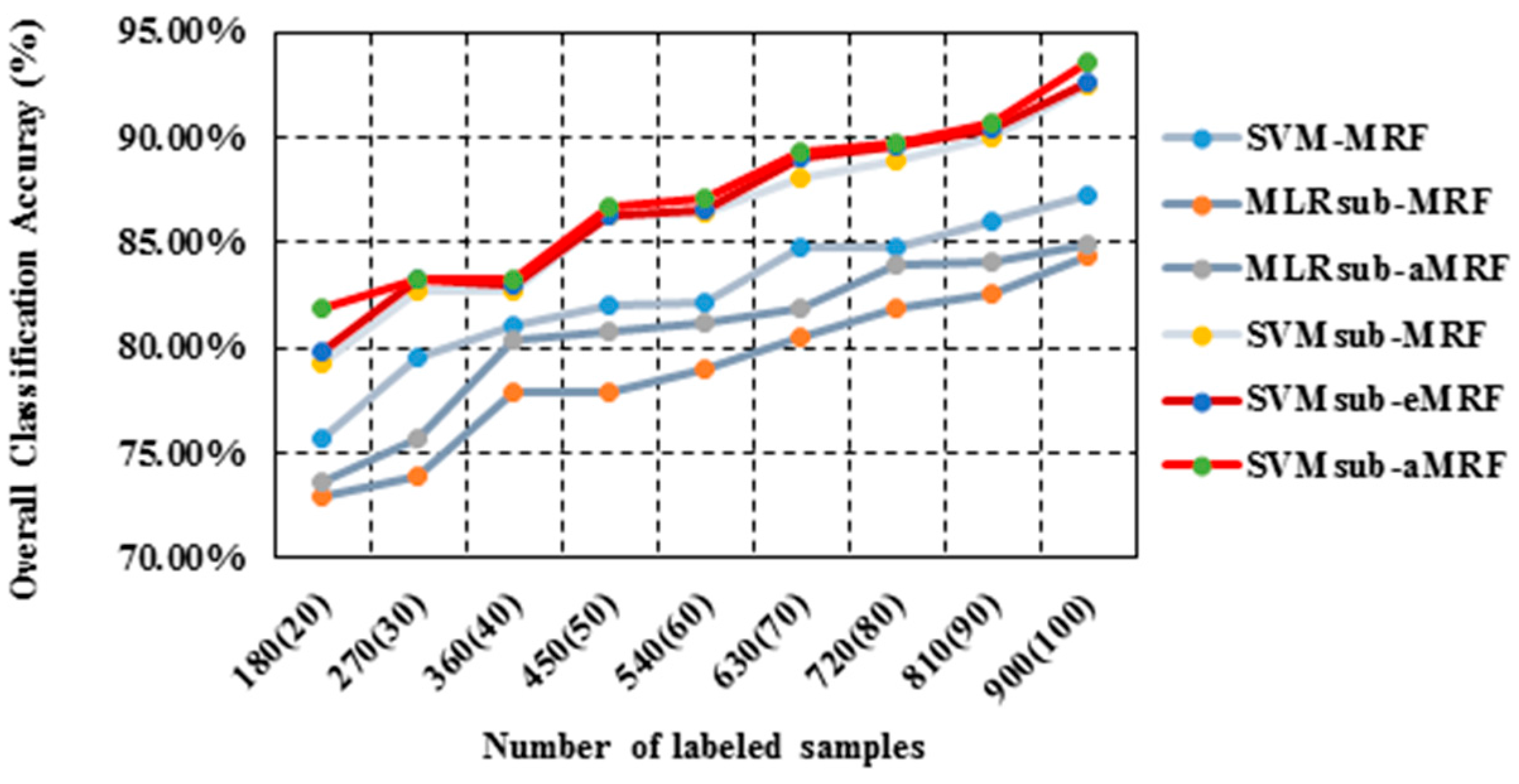
In our second test using the University of Pavia data set, we again analyzed the performances of the methods in the spectral-spatial domain using different numbers of training samples. We used approximately the same number of training samples per class (except for those classes that are very small) to generate a total of nine sets of training samples ranging in size from 180 to 900 samples. Table 5 reports the obtained values of the OA, the κ statistic and the computational cost. As shown in Table 5, SVMsub-aMRF yields the best accuracies compared with the other methods for each set. For instance, SVMsub-eMRF and SVMsub-aMRF achieve OAs of 92.61% and 93.50%, respectively, in the group corresponding to 900 labeled samples (approximately 35 samples per class). Figure 9 shows the OA results obtained by the various methods as a function of the number of labeled samples. Similar conclusions obtained in all cases for different types of images under different conditions further prove the effectiveness and robustness of our proposed method.
Table 5.
Overall classification accuracies (in percent) and κ statistic values obtained by the various tested methods for the ROSIS University of Pavia data set scene using different numbers of training samples. The computational costs (in parentheses) are also presented. Both the total number of samples used and the (approximate) number of training samples per class (in parentheses) are shown.
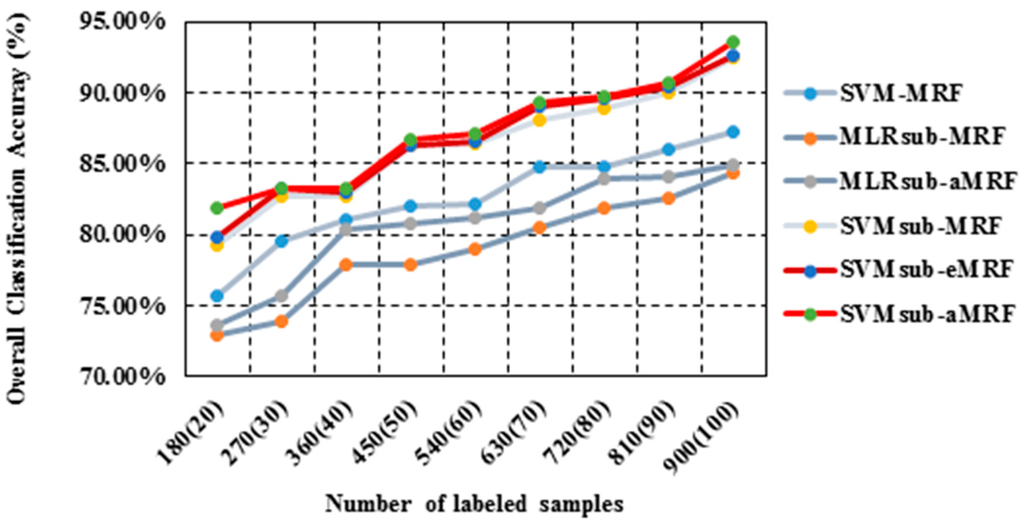
Figure 9.
Overall accuracy results as a function of the number of labeled samples per class for the University of Pavia data set.
As shown in Table 5, the proposed method is insensitive to the number of training samples used. In other words, its accuracy can be guaranteed even when only a limited number of training samples are used, and the computation time will not be too high even with a large training set. We note that the number of training samples used should be adjusted depending on the application. It is suggested that a relatively large training set can be adopted for improved accuracy because the resulting increase in computation time is minimal.
5. Conclusions
The classification of hyperspectral images faces various challenges related to the Hughes phenomenon, mixed pixels, noise and so on. Several techniques have been exploited to address these problems based on data from different domains. In the spectral domain, the subspace projection algorithm has proven to be an effective method of coping with the imbalance between the high dimensionality of the data and the limited number of training samples available. In the spatial domain, the MRF approach has been shown to be a powerful technique for integrating spatial correlation information into the posterior probability distribution of the spectral features. Thus, spectral-spatial models such as MLRsub-MRF, which combine the information from these two domains, can effectively improve the classification of hyperspectral images. To obtain classification results with higher accuracy than that of MLRsub-MRF, new frameworks should allow the further, simultaneous optimization of spectral and spatial features.
In this paper, we developed two new supervised spectral-spatial hyperspectral image classification approaches called SVMsub-eMRF and SVMsub-aMRF, which integrate the subspace-based SVM classification method with an adaptive MRF approach. By projecting the original data to a class-independent subspace representation, the proposed methods use adaptive MRFs to revise the MAP results of the SVM classifier based on the projected samples, including the optimization of the final segmentation results via the SA algorithm. Experiments on two real hyperspectral data sets demonstrated that the proposed methods not only can cope with the Hughes phenomenon and the effects of noise and mixed pixels but also are able to discriminatively address the relationships exhibited by pixels in homogeneous regions or on boundaries with a low computational cost. Moreover, the classification results of the proposed methods demonstrate considerable advantages compared with those of other models. In our future work, we will focus on the application of superpixels in the existing framework and test the proposed algorithms using additional hyperspectral images.
Acknowledgments
This research was supported by the National Natural Science Foundation of China under Grant No. 41325004 and 41571349 and by the Key Research Program of the Chinese Academy of Sciences under Grant No. KZZD-EW-TZ-18.
Author Contributions
Haoyang Yu was primarily responsible for mathematical modeling and experimental design. Lianru Gao contributed to the original idea for the proposed methods and to the experimental analysis. Jun Li improved the mathematical model and revised the paper. Shan Shan Li provided support regarding the application of adaptive Markov random fields. Bing Zhang completed the theoretical framework. Jón Atli Benediktsson provided important suggestions for improving the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SVM | Support Vector Machine |
| MRF | Markov Random Field |
| SA | Simulated Annealing |
| MLR | Multinomial Logistic Regression |
| SVMsub | Subspace-based SVM |
| MLRsub | Subspace-based MLR |
| RHI | Relative Homogeneity Index |
| MAP | Maximum A Posteriori |
| eMRF | Edge-constrained MRF |
| aMRF | RHI-based Adaptive MRF |
| NAPC | Noise-Adjusted Principal Components |
| RBF | Radial Basis Function |
| MNF | Minimum Noise Fraction |
| LoG | Laplacian of Gaussian |
| OA | Overall Accuracy |
References
- Landgrebe, D.A. Signal Theory Methods in Multispectral Remote Sensing; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Qian, Y.; Yao, F.; Jia, S. Band selection for hyperspectral imagery using affinity propagation. IET Comput. Vis. 2009, 3, 213–222. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Harsanyi, J.C.; Chang, C. Hyperspectral image classification and dimensionality reduction: An orthogonal subspace projection approach. IEEE Trans. Geosci. Remote Sens. 1994, 32, 779–785. [Google Scholar] [CrossRef]
- Larsen, R.; Arngren, M.; Hansen, P.W.; Nielsen, A.A. Kernel based subspace projection of near infrared hyperspectral images of maize kernels. Image Anal. 2009, 5575, 560–569. [Google Scholar]
- Chen, W.; Huang, J.; Zou, J.; Fang, B. Wavelet-face based subspace LDA method to solve small sample size problem in face recognition. Int. J. Wavelets Multiresolut. Inf. Process. 2009, 7, 199–214. [Google Scholar] [CrossRef]
- Gao, L.; Li, J.; Khodadadzadeh, M.; Plaza, A.; Zhang, B.; He, Z.; Yan, H. Subspace-based support vector machines for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 349–353. [Google Scholar]
- Li, W.; Tramel, E.W.; Prasad, S.; Fowler, J.E. Nearest regularized subspace for hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 477–489. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised hyperspectral image segmentation using multinomial logistic regression with active learning. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4085–4098. [Google Scholar] [CrossRef]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Jia, S.; Xie, Y.; Tang, G.; Zhu, J. Spatial-spectral-combined sparse representation-based classification for hyperspectral imagery. Soft Comput. 2014, 1–10. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Pesaresi, M.; Arnason, K. Classification and feature extraction for remote sensing images from urban areas based on morphological transformations. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1940–1949. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral-spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Ni, L.; Gao, L.; Li, S.; Li, J.; Zhang, B. Edge-constrained Markov random field classification by integrating hyperspectral image with LiDAR data over urban areas. J. Appl. Remote Sens. 2014, 8. [Google Scholar] [CrossRef]
- Zhang, B.; Li, S.; Jia, X.; Gao, L.; Peng, M. Adaptive Markov random field approach for classification of hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2011, 8, 973–977. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Xie, J.; Hone, K.; Xie, W.; Gao, X.; Shi, Y.; Liu, X. Extending twin support vector machine classifier for multi-category classification problems. Intell. Data Anal. 2013, 17, 649–664. [Google Scholar]
- Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Richards, J.A.; Jia, X. Remote Sensing Digital Image Analysis: An Introduction; Springer-Verlag: Berlin, Germany, 2006. [Google Scholar]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Zhang, Y.; Brady, M.; Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Trans. Med. Imaging 2001, 20, 45–57. [Google Scholar] [CrossRef] [PubMed]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.; Richards, J.A. Managing the spectral-spatial mix in context classification using Markov random fields. IEEE Geosci. Remote Sens. Lett. 2008, 5, 311–314. [Google Scholar] [CrossRef]
- Chang, C.I. Hyperspectral Imaging: Techniques for Spectral Detection and Classification; Springer Science and Business Media: New York, NY, USA, 2003. [Google Scholar]
- Zhong, Y.; Lin, X.; Zhang, L. A support vector conditional random fields classifier with a Mahalanobis distance boundary constraint for high spatial resolution remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1314–1330. [Google Scholar] [CrossRef]
- Jiménez, L.O.; Rivera-Medina, J.L.; Rodríguez-Díaz, E.; Arzuaga-Cruz, E.; Ramírez-Vélez, M. Integration of spatial and spectral information by means of unsupervised extraction and classification for homogenous objects applied to multispectral and hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 844–851. [Google Scholar] [CrossRef]
- Keshava, N.; Mustard, J.F. Spectral unmixing. IEEE Signal Process. Mag. 2002, 19, 44–57. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Scholkopf, B.; Sung, K.K.; Burges, C.J.C.; Girosi, F.; Niyogi, P.; Poggio, T.; Vapnik, V. Comparing support vector machines with Gaussian kernels to radial basis function classifiers. IEEE Trans. Signal Process. 1997, 45, 2758–2765. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Platt, J. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Lin, H.; Lin, C.; Weng, R.C. A note on Platt’s probabilistic outputs for support vector machines. Mach. Learn. 2007, 68, 267–276. [Google Scholar] [CrossRef]
- Gillespie, A.R. Spectral mixture analysis of multispectral thermal infrared images. Remote Sens. Environ. 1992, 42, 137–145. [Google Scholar] [CrossRef]
- Green, A.A.; Berman, M.; Switzer, P.; Craig, M.D. A transformation for ordering multispectral data in terms of image quality with implications for noise removal. IEEE Trans. Geosci. Remote Sens. 1988, 26, 65–74. [Google Scholar] [CrossRef]
- Maini, R.; Aggarwal, H. Study and comparison of various image edge detection techniques. Int. J. Image Process. 2009, 3, 1–11. [Google Scholar]
- Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J. Spectral-spatial classification of hyperspectral imagery based on partitional clustering techniques. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2973–2987. [Google Scholar] [CrossRef]
- Farag, A.A.; Mohamed, R.M.; El-Baz, A. A unified framework for map estimation in remote sensing image segmentation. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1617–1634. [Google Scholar] [CrossRef]
- Kirkpatrick, S. Optimization by simulated annealing: Quantitative studies. J. Stat. Phys. 1984, 34, 975–986. [Google Scholar] [CrossRef]

© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).