Highlights
What are the main findings?
- A novel language-guided resolution-continual learning framework (LaGu-RCL) is proposed to effectively mitigate catastrophic forgetting in multi-resolution remote sensing semantic segmentation.
- The combination of multi-resolution data augmentation and language-guided contrastive learning enables robust and consistent segmentation performance across all learned resolutions.
What are the implications of the main findings?
- The proposed method provides a practical solution for continual semantic segmentation under heterogeneous-resolution remote sensing scenarios with limited annotation availability.
- LaGu-RCL enhances model transferability and long-term usability, offering strong potential for large-scale, multi-source remote sensing applications.
Abstract
Remote sensing image semantic segmentation faces substantial challenges in training and transferring models across images with varying resolutions. This issue can be effectively mitigated by continuously learning knowledge derived from new resolutions; however, this learning process is severely plagued by catastrophic forgetting. To address this problem, this paper proposes a novel continual learning framework termed Language-Guided Resolution-Continual Learning (i.e., LaGu-RCL), which alleviates catastrophic forgetting through two complementary strategies. On the one hand, a multi-resolution image augmentation pipeline is introduced to synthesize higher- and lower-resolution variants for each training batch, allowing the model to learn from images of diverse resolutions at every training step. On the other hand, a language-guided learning strategy is proposed to aggregate features of the same resolution while separating those of different resolutions. This ensures that the knowledge acquired from previously learned resolutions is not disrupted by that from unseen resolutions, thereby mitigating catastrophic forgetting. To validate the effectiveness of the proposed approach, we construct MR-ExcavSeg, a multi-resolution dataset covering several counties in Chongqing, and conduct comparative experiments between LaGu-RCL and several state-of-the-art continual learning baselines. Experimental results demonstrate that LaGu-RCL achieves significantly superior segmentation performance and continual learning capability, verifying its advantages.
1. Introduction
Remote sensing image semantic segmentation, a critical task in remote sensing image interpretation, aims to achieve precise semantic classification of each pixel within images. It not only provides fundamental support for advanced remote sensing analysis tasks such as object detection [1], change detection [2,3,4,5], and land use classification [6], but also plays an irreplaceable role in a wide range of practical applications, including urban planning [6], land resource surveys [7], agricultural monitoring [8], environmental protection [9], and military reconnaissance [10,11].
In recent years, with the rapid advancement of aerospace remote sensing platforms and the remarkable improvement in the precision of imaging sensors, remote sensing images have become increasingly complex. Among the contributing factors, resolution diversification stands out as a prominent one. While the widespread adoption of multi-resolution remote sensing data has enriched the dimensions of remote sensing information expression, it has also imposed substantial challenges on model training and transfer [12,13,14]. Traditional single-resolution modeling approaches struggle to adapt to variations in semantic representation across different resolutions. Specifically, significant discrepancies exist in feature boundary clarity, texture details, and contextual structures between remote sensing images of varying resolutions, resulting in considerable degradation in model performance when applied to cross-resolution data [15,16]. Furthermore, manual annotation of high-resolution remote sensing images is prohibitively costly [17,18], whereas low-resolution data generally lacks fine-grained semantic information [19,20]. This creates an information gap during model transfer or ensemble learning.
In response to the practical demands and challenges posed by multi-resolution remote sensing data, resolution-continual learning has emerged. Its core concept lies in simulating the human cognitive process of “progressive learning from coarse to fine,” enabling models to gradually acquire richer semantic features of objects and spatial structural knowledge across training stages at different resolutions. Unlike traditional one-shot training models, resolution-continual learning methods first perform pre-training on low-resolution data before gradually introducing high-resolution images for fine-tuning or knowledge transfer. This approach reduces the computational burden during early training phases while enhancing the model’s ability to capture fine-grained features, achieving dual optimization of efficiency and accuracy. In remote sensing semantic segmentation tasks, resolution-continual learning holds significant application value and research merit. First, it mitigates issues of inconsistent and unevenly distributed annotations for multi-resolution data by progressively adapting to features across different scales, enhancing the model’s adaptability to multi-source images. Second, this strategy markedly improves the model’s transferability and generalization capabilities, offering distinct advantages in scenarios with scarce data or high annotation costs. Therefore, the objective of this paper is to ensure that when learning knowledge for new resolution data, the segmentation performance of existing resolution data does not suffer from catastrophic forgetting. As a result, the network can consistently achieve robust segmentation capabilities across all resolution levels it has ever encountered.
To achieve this objective, this paper considers four characteristics of multi-resolution data, as illustrated in Figure 1.
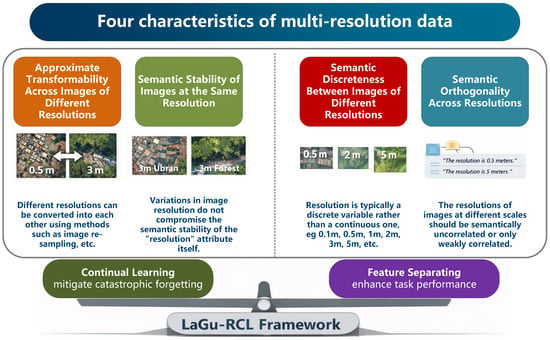
Figure 1.
Four characteristics of multi-resolution data and corresponding research framework for resolution-continual learning.
- (1)
- Approximate Transformability Across Images of Different. Images captured at different resolutions can be approximately transformed into each other through operations such as image resampling, super-resolution reconstruction, and blur modeling;
- (2)
- Semantic Stability of Images at the Same Resolution. Although remote sensing images at the same resolution may present significant differences in visual appearance due to scene content, sensor conditions, or imaging geometry, their semantics with respect to resolution remain stable. That is, when mapped into a resolution semantic space, images sharing the same resolution should exhibit consistent representations;
- (3)
- Semantic Discreteness Between Images of Different Resolutions. Resolution semantics are inherently discrete rather than continuous, as commonly used resolutions (e.g., 0.1 m, 0.5 m, 1 m, and 10 m) correspond to distinct and predefined levels. This discreteness is analogous to the token-based nature of language, making textual descriptions a natural and effective representation for resolution semantic variables;
- (4)
- Semantic Orthogonality Across Resolutions. The resolution semantics of images captured at different scales should be semantically uncorrelated or only weakly correlated.
Based on the first characteristic, we can use an image at one resolution to approximate images at various resolutions. This serves as a data augmentation method for different training stages, enabling each continual learning phase to learn from data at different resolutions. Leveraging the second characteristic, we can constrain the update range of model parameters by aligning the resolution-specific semantic features of images at the same resolution in their corresponding feature spaces. Therefore, we propose utilizing these two properties to facilitate the model’s continual learning across images of different resolutions. Concurrently, traditional continual learning methods often fuse features across resolutions, resulting in poor distinctiveness between resolution-specific features and consequently weak overall semantic segmentation performance. Therefore, leveraging the third and fourth characteristics, we can disentangle features from images of different resolutions to ensure high segmentation accuracy for each resolution.
Based on the above insights, this paper proposes LaGu-RCL, a semantic segmentation method for the continual learning of multi-resolution remote sensing image data. The core idea of LaGu-RCL is to utilize language descriptions at different resolutions to guide model parameter updates, which primarily consists of a multi-resolution remote sensing image augmentation method and a language-guided learning strategy. Specifically, the contributions of this paper can be summarized as follows:
- Multi-resolution remote sensing image data augmentation method: Leveraging the approximate transformability among different spatial resolutions of multi-resolution remote sensing imagery, this paper proposes a data augmentation method tailored for multi-resolution remote sensing images. In typical continual training settings, only data at a single resolution are available at each training stage. The proposed method can approximately generate images at multiple resolutions from the single-resolution data available in each stage, ensuring that the model is exposed to and can learn from diverse resolution data throughout the training process. Moreover, the generation of multi-resolution data serves as a prerequisite for supporting the subsequent continual learning strategy.
- Continual learning strategy for multi-resolution remote sensing images: Based on the resolution-wise semantic discreteness of multi-resolution remote sensing imagery and the inter-class orthogonality of resolution semantics, a dedicated continual learning strategy for multi-resolution remote sensing images is proposed. This strategy consists of two stages: an initial learning stage and an incremental learning stage. The core idea is to model different resolutions using language-based textual representations and map them into the RSHD space as semantic anchor points for each resolution. Guided by these anchors, resolution semantic features of images with the same resolution are pulled closer together, while those of different resolutions are pushed farther apart. In this way, the model achieves robust segmentation performance across all resolutions while effectively alleviating the problem of catastrophic forgetting in continual learning.
- Dataset construction and effectiveness validation: To validate the effectiveness and feasibility of the proposed methods and strategies, a new multi-resolution remote sensing image semantic segmentation dataset, termed MR-ExcavSeg, is constructed. The dataset contains remote sensing images with three spatial resolutions—2 m, 1 m, and 0.5 m—primarily covering regions in Chongqing, including Banan, Hechuan, and Wuxi districts. Experimental results on the MR-ExcavSeg dataset demonstrate that LaGu-RCL can effectively mitigate catastrophic forgetting in multi-resolution continual learning and achieve competitive segmentation performance at each resolution, outperforming current state-of-the-art continual learning methods.
2. Materials and Methods
This section primarily elaborates on the proposed multi-resolution continual learning method LaGu-RCL, which consists of two core components: a multi-resolution data augmentation method and a language-guided learning strategy.
2.1. Multi-Resolution Data Augmentation Method
This data augmentation method primarily leverages the property of approximate transformability between images of different resolutions, as illustrated in Figure 2a. It consists of two core components: High-Resolution Image Transformation (i.e., HRIT) and Low-Resolution Image Transformation (i.e., LRIT). A detailed description of these two components is provided below.
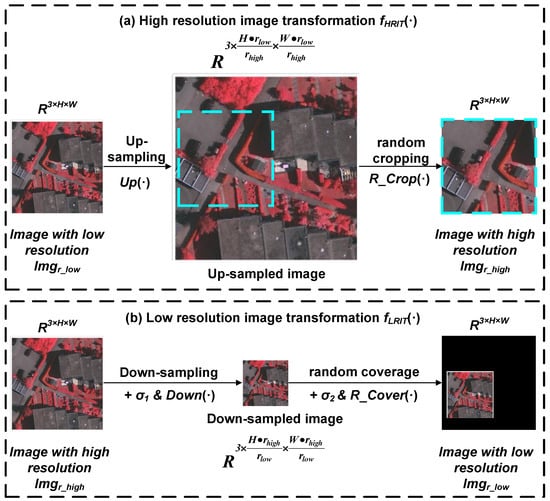
Figure 2.
Multi-resolution data augmentation method.
2.1.1. High-Resolution Image Transformation
The primary purpose of high-resolution image transformation (HRIT) is to convert the original low-resolution image into a high-resolution one, as shown in Figure 2a. Assuming the original low-resolution input image is with resolution , the high-resolution image obtained by applying is with resolution , where . The high-resolution image transformation can thus be formulated as:
where denotes the up-sampling function, and denotes the random cropping function. This process can be roughly described as follows: first, the up-sampling function is applied to process . The size of the up-sampled image is given by:
Subsequently, the up-sampled image is processed using the random cropping function to crop a region matching the original image size, yielding the final . It should be noted that the up-sampling function does not employ a fixed algorithm. Different up-sampling strategies may be adopted in practical applications. In this paper, bilinear interpolation is selected as the up-sampling strategy for this transformation process.
2.1.2. Low-Resolution Image Transformation
The primary purpose of low-resolution image transformation is to convert the original high-resolution image into a low-resolution one, as shown in Figure 2b. Assuming the original high-resolution image is with resolution , the low-resolution image obtained by applying is with resolution , where the numerical relationship between the resolutions also satisfies . The low-resolution image transformation can then be expressed as:
where denotes the down-sampling function, represents the random coverage function, and and denote Gaussian random errors. The process can be broadly described as follows: first, random error is added to , and subsequently, the down-sampling function is applied to perform down-sampling. The size of the down-sampled image is:
After downsampling the image, the random coverage function is applied. A random error is added to the downsampled image, which is then randomly overlaid onto a completely black background image (with all RGB pixel values set to 0), yielding the final result . It should be noted that the downsampling function is also not a fixed algorithm. Different strategies can be adopted for downsampling in practical applications. Here, bilinear interpolation is selected as the downsampling strategy for this transformation process. Additionally, the introduction of random errors and is intended to increase the degree of blurring in image information, thereby better reflecting the actual scenario where low-resolution images contain more noise than high-resolution ones.
During each model training iteration, the resolution of the original data within a batch input to the model remains consistent. Before applying this multi-resolution data augmentation method, this paper first sets the target resolution (randomly selected from the resolutions in the multi-resolution image language description library, detailed later) for each sample in a batch. After comparing this target resolution with the original resolution, the aforementioned different transformation methods are applied, respectively. This ensures that a single batch contains image data with varying resolutions.
2.2. Language Guided Learning Strategy
The schematic diagram of the language-guided learning strategy in LaGu-RCL is shown in Figure 3. This learning strategy primarily consists of two-stage approaches: the initial learning strategy and the continual learning strategy. This section will introduce them separately.
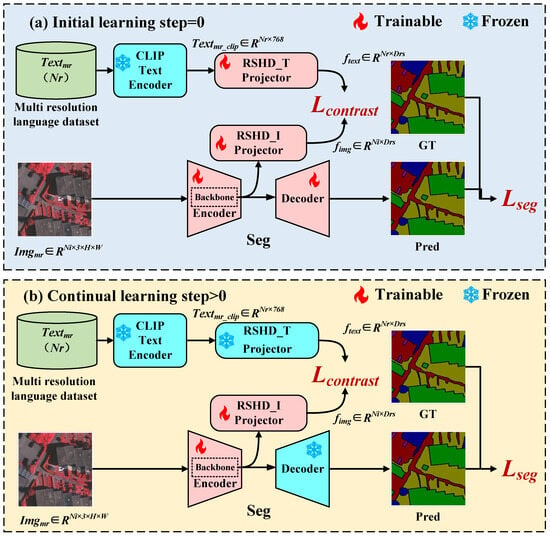
Figure 3.
Overall Pipeline of the Proposed LaGu-RCL Framework.
2.2.1. Initial Learning Strategy
The schematic diagram of the initial learning strategy is shown in Figure 3a. During the initial learning phase, for the text modality, this paper first employs a pre-trained CLIP [21] text encoder with frozen parameters to encode the text descriptions from the multi-resolution language dataset, yielding the corresponding language description text embeddings . Subsequently, the learnable Projector maps into the RSHD space, yielding feature vectors that represent the language descriptions of images at various resolutions within the RSHD space. In the image modality, the backbone network of the image semantic segmentation model Seg is employed to extract features from the multi-resolution images . These features undergo further processing through the Encoder of Seg before being decoded by the Decoder to generate the final segmentation mask. The segmentation performance of Seg is optimized using as the objective function, where adopts Focal Loss [22]. Additionally, the learnable Projector maps the features extracted by the Backbone of Seg into the RSHD space to obtain . This paper constructs the contrastive learning loss using and in the RSHD space, which brings the resolution semantic features of images at the same resolution closer together in their corresponding feature space while separating those of images at different resolutions. The initial training strategy consists of four key steps, i.e., construction of the multi-resolution language dataset, text embedding and RSHD space mapping, image feature extraction and RSHD space mapping, and optimization based on the contrastive learning loss .
Construction of the multi-resolution language dataset: When information of different resolutions serves as variables, their variable types fall under discrete variables. To represent the semantics of varying resolutions, this paper employs distinct language descriptions for different resolutions. After performing text embedding on these language descriptions, the vectorization of semantic distinctions across different resolutions is achieved. To represent as many resolutions as possible, this paper constructs a multi-resolution language dataset. This description dataset is organized as a key-value dictionary, where keys represent the resolution of remote sensing images and values correspond to text descriptions associated with that resolution (e.g., {0.5: “The resolution of this image is 0.5 m”}). Users can construct language description datasets with varying numbers of resolutions according to their specific task requirements.
Text embedding and RSHD space mapping: The multi-resolution language dataset represents the resolutions of various images using textual descriptions. However, these representations remain unvectorized and thus cannot participate in model computations. To vectorize the semantics of different resolutions, this paper performs text embedding on the multi-resolution language dataset. Specifically, before text embedding, input text must first be segmented into tokens using a tokenizer. These tokens are then encoded by a text encoder to produce text embeddings. This paper selects the CLIP text encoder as the text encoder for this task. CLIP [21], released by OpenAI in early 2021, stands as a landmark model in recent years within the multi-modal domain. Trained on 400 million image–text pairs crawled from the internet, CLIP demonstrates robust image–text understanding capabilities. Consequently, text embeddings encoded by the CLIP text encoder exhibit strong correlation with image features. Assuming the language descriptions in our built database are denoted as , the corresponding text embeddings obtained via the CLIP text encoder can be computed as follows:
where denotes the encoding process by the CLIP text encoder, and [EOS] indicates the embedding of the final End-of-Sequence (i.e., EOS) token. Features are extracted from the EOS token’s embedding because its position represents the “semantic summary” of the entire text sequence. The Transformer encoder used by CLIP employs a global attention mechanism, allowing each token to observe the entire sentence. Thus, the output vector at the EOS position serves as a global semantic aggregation representation, making it highly suitable as the final text representation. Since the parameters of the CLIP text encoder are not updated here, the resulting text embedding cannot be directly used for contrastive learning optimization. Simultaneously, following the approach in SimCLR, a learnable RSHD_T Projector maps into the RSHD space, yielding , where denotes the dimension of the RSHD space. The RSHD_T Projector adopts a simple MLP architecture.
Image feature extraction and RSHD space mapping: After mapping the text description to the RSHD space, the multi-resolution image must also be mapped to this space to compute the contrastive learning loss. Therefore, this paper first uses the image encoder of the segmentation network to extract features from the multi-resolution image , then employs the RSHD_I Projector to complete the mapping of to the RSHD space. Specifically, during the feature extraction stage, we employ DeepLab v3+ as the segmentation model within LaGu-RCL, utilising ResNet50 [23] as its backbone network. As illustrated in Figure 4, ResNet50’s five feature extraction layers first extract multi-scale features from . Subsequently, the projector transforms these multi-scale feature maps to a uniform channel count. However, the multi-scale feature maps retain differing dimensions, complicating their direct integration. To address this, this paper proposes a Masked Global Average Pooling (MGAPool) technique, capable of uniformly pooling multi-scale feature maps to a pixel size. The distinction between MGAPool and Global Average Pooling (GAPool) lies in their calculation methods: GAPool computes the mean across the entire feature map, whereas MGAPool calculates the mean based on the corresponding regions specified by the mask, which can be denoted as:
where denotes a specific channel of the input feature map, h and w represent the dimensions of this feature map, respectively. is a binary image. The choice of MGAPool primarily stems from the fact that in , low-resolution images generated through data augmentation from high-resolution images inevitably contain uncovered black background pixels, as shown in Figure 2b. Since these pixels contribute meaningless information to computations, MGAPool is employed to eliminate their influence. In this context, regions with a value of 1 in the mask represent areas where the black background image is masked, while regions with a value of 0 indicate areas where the black background image remains uncovered. After MGAPool uniformly pools the multi-scale feature maps to a pixel size, this paper concatenates them along the channel dimension. A convolution then maps these channels to , followed by a Reshape operation to obtain the final , where represents the number of images in a batch sample.
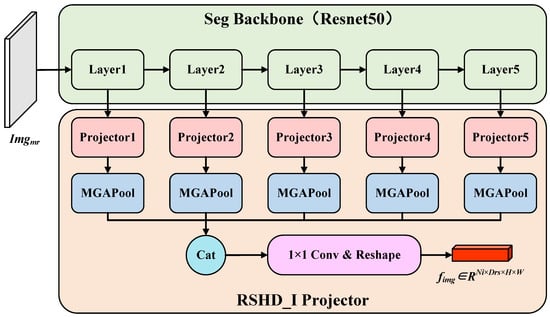
Figure 4.
Image feature extraction and RSHD space mapping.
Optimization based on contrastive learning loss : After mapping language descriptions and images to the space to obtain and , respectively, a contrast loss function can be constructed to optimize the network. This function brings the resolution-semantic features of images with the same resolution closer together in the corresponding feature space while separating the features of images with different resolutions. The overall contrast learning loss can be computed as follows:
where is text-to-text loss, is image-to-text loss, and is text–image loss. The image–text loss represents the distance between and . Since both feature distributions are unconditioned during the initial training phase, the Kullback–Leibler divergence () is typically employed to measure the distance between two unconditioned distributions. As shown in Figure 5, primarily consists of and , defined as:
where denotes the average loss between and at the same resolution. This loss serves to narrow the distance between paired positive samples during the optimization process, which can be calculated as:
where and denote the number of images and text descriptions within a batch, respectively. 1 is an indicator function, yielding a value of 1 when the condition is satisfied and 0 otherwise. and denote the resolutions of the i-th and j-th , respectively. Thus, in conjunction with the indicator function 1, this function takes the value 1 only when the resolutions of the i-th and j-th are equal, and 0 otherwise. and denote the probability vectors obtained by applying the Softmax function to and , respectively, thereby quantifying their probabilities in the RSHD space, which can be calculated as:
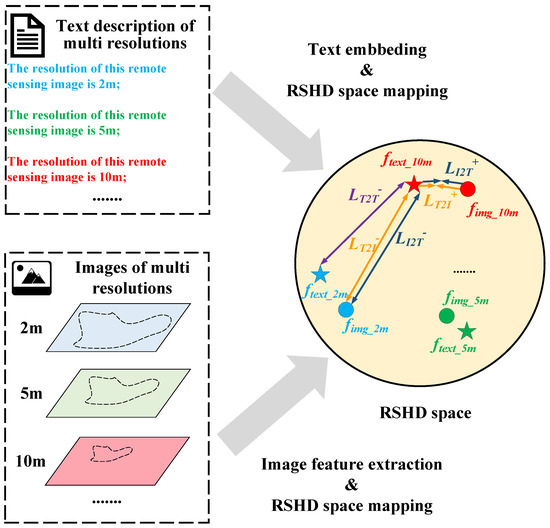
Figure 5.
Process of constructing the contrastive learning loss .
According to the formula for calculating KL divergence, the probability formula for is:
In this formula, the primary consideration for taking the negative sign when summing KL divergence is the negative correlation between and the distance between and . The purpose of applying exponential operations is to preserve the non-negative nature of the loss while ensuring robust gradient information. Consequently, the final probability calculation formula for is:
where the text–image loss represents the distance between and . Owing to the non-symmetric nature of the Kullback–Leibler divergence, the distance from to is unequal to that from to . To further strengthen the alignment constraint between and within the RSHD space, this paper additionally incorporates this loss. Similar to , comprises paired positive sample loss and unpaired negative sample loss . Following the preceding derivation process, the probability calculations for , , and can be obtained as:
The text-to-image loss represents the distance between to . Since there are no paired positive samples among the text descriptions, only accounts for unpaired negative samples as the loss . Therefore, can be calculated as:
2.2.2. Continual Learning Strategy
The schematic diagram of the incremental learning strategy is shown in Figure 3b. The learning strategy during this phase remains largely consistent with the initial learning strategy, with two key differences.
- (1)
- Freezing the RSHD_T Projector for Text Modalities
During the initial learning phase, this paper adopts multi-resolution images and a contrastive learning strategy to narrow the distance between the resolution semantic features of images with the same resolution in the corresponding feature space, and separate the features of images with different resolutions. The purpose of freezing the RSHD_T Projector in the continual learning phase is to keep , the vector of projected into the RSHD space via the RSHD_T Projector, fixed. Taking this as an anchor, it guides the alignment between (derived from the feature extraction of newly added resolution images by the Seg Backbone and their mapping to the RSCD space) and in the RSHD space. In this way, the image data at the new resolution is aligned with the previous spatial positions, thereby avoiding the loss of prior knowledge.
- (2)
- Freezing the segmentation network decoder
Following the parameter update constraints applied to the Backbone of the segmentation network via the aforementioned method, the extracted visual features become highly compatible with subsequent decoding by the decoder of the segmentation network. During the continual learning phase, should the decoder’s parameters participate in optimisation updates, the original visual features would struggle to adapt to subsequent decoding, similarly inducing catastrophic forgetting. Therefore, during the continual learning phase, this paper further freezes the decoder of the segmentation network to mitigate catastrophic forgetting.
3. Experimental Results
3.1. Dataset
To evaluate the performance of the proposed LaGu-RCL on multi-resolution continual learning semantic segmentation tasks, this paper specifically constructed a multi-resolution remote sensing excavated land segmentation dataset (MR-ExcavSeg).
The MR-ExcavSeg dataset information is shown in Table 1. The imagery primarily covers various counties and districts in Chongqing Municipality, such as Banan, Hechuan, and Wuxi. The dataset resolutions primarily include 0.5 m, 1.0 m, and 2.0 m. All images have been processed and stored, with each sample slice sized at pixels and cropped with a overlap rate. The final dataset comprises 20,320 images at 0.5 m resolution, 22,257 at 1.0 m, and 14,093 at 2.0 m, totaling 56,670 images. Figure 6 displays some typical images from the MR-ExcavSeg dataset, where pixels representing artificially excavated landforms were manually annotated and saved as binary mask images.

Table 1.
Basic information of our built MR-ExcavSeg dataset.

Figure 6.
Some typical images from the MR-ExcavSeg dataset.
The dataset used in this study is constructed under a specific application background of artificial excavation land extraction. As a result, only a single foreground semantic category, namely artificial excavation land, is annotated in the dataset, while all remaining regions are labeled as background. This setting allows us to focus on analyzing the impact of resolution variation on continual learning behavior without introducing additional interference from multi-class semantic complexity.
For each resolution level, the dataset is independently divided into training, validation, and testing sets with a ratio of 8:1:1, respectively. In addition, the total number of samples is strictly controlled to be the same across all three resolution datasets, such that each resolution contains an equal number of training, validation, and testing samples. This setting ensures a fair and stable evaluation of the proposed resolution-continual learning framework without introducing bias caused by data quantity imbalance.
3.2. Evaluation Metrics
To quantitatively evaluate the performance of our method, we employ 5 metrics commonly used in semantic segmentation tasks, including mean Intersection over Union (i.e., MIoU), Recall, Precision, Kappa coefficient, and Overall Accuracy (OA).
Metric MIoU represents the average of all IoU values. Prior to calculating MIoU, the Intersection over Union (i.e., IoU) for each class must first be computed. The formula for calculating IoU for a specific class is:
After calculating the IoU for each category, the mean value across all categories is taken to obtain the MIoU, which can be denoted as:
where N denotes the number of categories within the dataset, TP, FN, and FP represent the counts of true positives, false negatives, and false positives, respectively, within the confusion matrix.
Precision measures the proportion of true positives among samples predicted as positive, which can be calculated as:
Recall measures the proportion of all actual positive examples that are correctly predicted as positive, which can be computed as:
Overall accuracy is a commonly used metric for evaluating the performance of classification models. It reflects the model’s overall capability by calculating the proportion of correctly classified samples relative to the total sample size. A higher overall accuracy value typically indicates that the model achieves satisfactory classification results across all categories. Its can be obtained by:
where denotes the number of true negative cases in the confusion matrix.
The Kappa coefficient measures the consistency between a classification model’s predictions and true labels, proving particularly suitable for imbalanced datasets. It corrects for consistency arising from random guessing. For instance, in an extreme scenario where of a dataset comprises negative instances, simply predicting all samples as negative would yield accuracy. However, the Kappa value would remain low, indicating the model’s lack of practical value. Its can be computed as:
where denotes observed agreement, representing the proportion of instances where the model’s actual prediction is correct, which can be calculated as:
where denotes the expected agreement rate under random guessing conditions, calculated as follows:
3.3. Comparing with State-of-the-Art
This section quantitatively evaluates the performance of LaGu-RCL against state-of-the-art continual learning methods.
3.3.1. Experimental Setup
To train the LaGu-RCL, we set the number of training epochs to 100, with an initial learning rate of and a batch size of 32. After each training step, the model checkpoints achieving the highest MIoU on the validation set are selected as the set of parameters used for evaluation on the test set. For state-of-the-art continual learning methods, this study selected eight baselines, i.e., EWF [24], RCIL [25], UCD [26], MIB [27], ILT [28], PLOP [29], LAG [30], UCB [31] for performance comparison with LaGu-RCL. These methods are highly representative and can be broadly categorized into four types. Particularly, EWF [24], RCIL [25] are structure and parameter-based methods. These approaches aim to balance the stability-plasticity dilemma by either adjusting the network architecture or directly manipulating model parameters. MIB [27], ILT [28], and PLOP [29] are regularization and distillation-based methods. They primarily introduce knowledge distillation terms into the objective function to enforce consistency between the old and new models. UCD [26], LAG [30], and UCB [31] are feature learning and uncertainty-aware methods. These methods focus on enhancing the robustness of feature representations or leveraging uncertainty estimation to optimize the quality of supervision signals. The configurations for these eight baseline methods followed the experimental settings reported in their respective original papers that yielded the best performance. Regarding the data setup, the dataset used in this study is the MR-ExcavSeg dataset constructed by us. To mitigate the impact of class/data imbalance, the number of samples at each resolution used in the experiment was kept identical. In addition, since resolution progression typically follows a low-to-high trend, the learning order across resolutions was set to 2.0 m, 1.0 m, and 0.5 m; each step uses training data from a single, distinct resolution, and no resolution data is revisited once the model proceeds to the next step. After completing training at each resolution, all methods were evaluated on the test sets of all resolutions for semantic segmentation performance. The primary evaluation metric was MIoU, which is the most critical metric for semantic segmentation tasks. All algorithms and models in the experiment were implemented using PyTorch 3.8. The experiments were conducted on an NVIDIA RTX A6000 GPU (48 GB), with an Intel(R) Xeon(R) Gold 6248R CPU @ 3.00 GHz.
3.3.2. Experimental Results and Analysis
The semantic segmentation MIoU results of the eight baseline methods on the MR-ExcavSeg dataset across different learning stages and test-set resolutions are shown in Table 2. We can observe that, on MR-ExcavSeg, LaGu-RCL achieves higher semantic segmentation MIoU than all baseline methods at every training stage and across all resolutions. To compare the continual learning performance of each baseline more holistically, we further computed the mean MIoU over the three resolution-specific test sets at each stage for all methods, yielding the stage-wise average semantic segmentation MIoU reported in Table 3. The results show that LaGu-RCL outperforms all baselines in both the per-stage mean MIoU and the overall average MIoU across all stages. Specifically, in Step 1, LaGu-RCL exceeds the current state-of-the-art method by ; in Step 2 by ; and in Step 3 by . Overall, it improves the average performance across all stages by . For a more intuitive comparison, we plotted line charts of the mean MIoU for each method on the test sets at each resolution and for each learning stage. The resulting curves are shown in Figure 7. We can see that, whether considering the mean MIoU at each training stage or the overall mean MIoU across all stages, the curve of LaGu-RCL lies above those of the other baseline methods in most cases. As shown in Figure 7a,c,d, LaGu-RCL exhibits a consistently increasing trend in the MIoU curves for the mean value of overall resolution, mean value of 1.0 m resolution, and mean value of 0.5 m resolution, indicating its strong continual learning capability. Although LaGu-RCL shows a decreasing trend on the 2.0 m resolution data, as illustrated in Figure 7b, its decline is less steep than that of the other baselines, suggesting that LaGu-RCL mitigates catastrophic forgetting more effectively. In summary, based on the above three sets of experimental results, we compared LaGu-RCL with six state-of-the-art continual learning methods. Compared with other methods, LaGu-RCL not only delivers superior semantic segmentation performance across all resolutions but also more effectively alleviates catastrophic forgetting, thereby validating its stronger continual learning performance.
Table 2.
Semantic segmentation MIoU (%) of each baseline method on MR-ExcavSeg across learning stages and resolutions. The optimal results are marked in bold.
Table 3.
Mean semantic segmentation MIoU (%) across resolutions at each learning stage on MR-ExcavSeg. The optimal results are marked in bold.
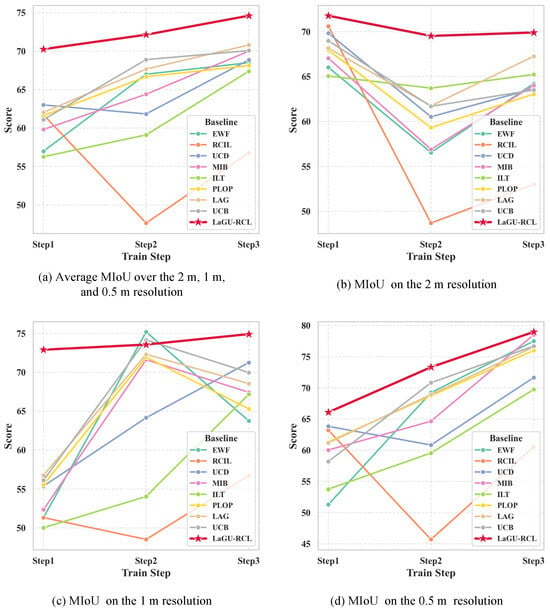
Figure 7.
Line plots of average MIoU across resolutions and learning stages on MR-ExcavSeg for each method.
3.4. Ablation Studies
3.4.1. Ablation Study Regarding Multi-Resolution Data Augmentation Method
The purpose of designing this ablation experiment is to validate and investigate the effectiveness of the multi-resolution data augmentation method. In this ablation study, the sole controlled variable in this ablation study is whether or not to use our developed data augmentation method. In addition to MIoU, we also compute the Precision, Recall, OA, and Kappa to provide a more comprehensive assessment of the impact of our augmentation method. Table 4 presents the experimental results of the LaGu-RCL with or without our proposed data augmentation method. It can be observed that, employing our developed data augmentation method, most of the metrics can be improved. To comprehensively evaluate the effectiveness of the multi-resolution remote sensing data augmentation method, we also calculate the average metrics of LaGu-RCL across three resolution test sets at each learning stage, both with and without our augmentation method, as illustrated in Table 5. It can be observed that, when introducing our method, LaGu-RCL exhibits significant performance improvements, both in the average metrics across all resolutions at each learning stage and in the overall average performance metrics. To more intuitively investigate and validate the effectiveness of this data augmentation method, we also plot line charts of the average metrics across the three resolution test sets at each learning stage, as shown in Figure 8. The experimental results show that the line charts obtained after applying the data augmentation method are generally positioned higher, as shown in Figure 8a,c–e. This indicates that our developed method not only preserves the continual learning capability of LaGu-RCL but also maintains its semantic segmentation performance at a high level across all resolutions.
Table 4.
Performance of LaGu-RCL with and without the developed multi-resolution data augmentation method. The optimal results are marked in bold.
Table 5.
Average value of different metrics of LaGu-RCL with and without the developed multi-resolution data augmentation method. The optimal results are marked in bold.
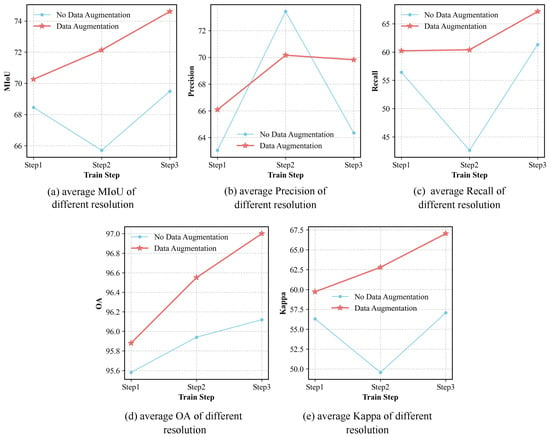
Figure 8.
Line charts of average semantic segmentation metrics in multi-resolution data augmentation method ablation experiment.
3.4.2. Ablation Study Regarding Language Description
This ablation study aims to investigate and validate the effectiveness of employing language description. In LaGu-RCL, multi-resolution language descriptions are usually used in combination with the subsequent contrastive loss . When multi-resolution language descriptions are excluded, the contrastive loss becomes inapplicable. Given that the Seg model in LaGu-RCL adopts Deeplab V3+, LaGu-RCL without language descriptions and contrastive loss is equivalent to the original Deeplab V3+ [32]. Therefore, both LaGu-RCL and DeeplabV 3+ were trained following the three-phase curriculum (i.e., 2.0 m → 1.0 m → 0.5 m); each step uses training data from a single, distinct resolution, and no resolution data is revisited once the model proceeds to the next step. During the training of each phase, the segmentation model in DeeplabV3+ performed the same operations as that in LaGu-RCL. Consistent with the previous settings, after the end of each training step, the model weights achieving the highest MIoU on the validation set of the current stage are selected to evaluate semantic segmentation performance across test sets of all resolutions. The evaluation metrics include MIoU, Precision, Recall, OA, and Kappa. In addition, this ablation experiment also serves as the ablation experiment on contrastive loss. Therefore, to explore and verify the effectiveness of the contrastive loss proposed in this paper, this experiment further employs t-SNE to visualize the features and mapped to the Remote Sensing Heterogeneous Description (RSHD) space for both Deeplab V3+ and LaGu-RCL, allowing for an observation of their distribution after dimensionality reduction.
The semantic segmentation metrics of LaGu-RCL with and without language descriptions on test sets of different resolutions at various learning stages on the MR-ExcavSeg dataset are shown in Table 6. Experimental results indicate that while DeepLab v3+ excels on the current stage’s resolution, it generalizes poorly to other resolutions, exhibiting severe catastrophic forgetting. Conversely, LaGu-RCL trades a marginal performance drop on the current resolution for significantly better generalization across other resolutions, thereby mitigating catastrophic forgetting. To verify the overall effectiveness, this experiment also calculated the average semantic segmentation metrics of LaGu-RCL with and without language descriptions on the three resolution test sets at each learning stage. The experimental results are shown in Table 7. We can see that LaGu-RCL achieves a remarkably significant performance improvement compared with DeepLab V3+, whether in terms of the average metrics of each resolution at each stage or the overall average performance metrics. To more intuitively verify the effectiveness of the language descriptions, this experiment also plotted the line chart of the average MIoU of LaGu-RCL with and without language descriptions on the three resolution test sets at each learning stage. The line chart of metrics for each learning stage obtained is shown in Figure 9. As illustrated in Figure 9a,c–e, LaGu-RCL consistently maintains higher performance levels. This indicates that language descriptions effectively bolster the continual learning capability of LaGu-RCL and sustain superior segmentation performance across all resolutions.
Table 6.
Performance of LaGu-RCL with and without language description. The optimal results are marked in bold.
Table 7.
Average value of different metric of LaGu-RCL with and without language descriptions. The optimal results are marked in bold.
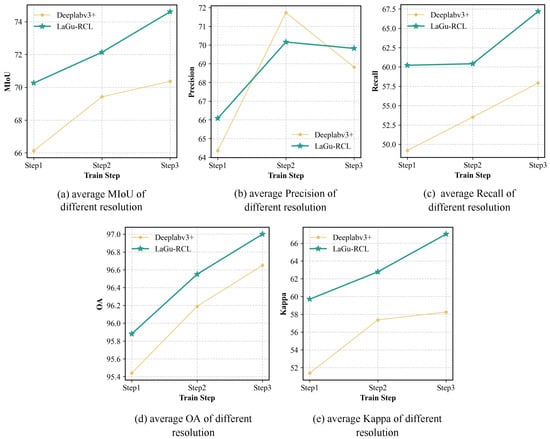
Figure 9.
Line charts of average semantic segmentation metrics in language description ablation experiment.
Since using language descriptions is bound to the contrastive loss constraint, to verify the effectiveness of the contrastive loss , the t-SNE dimensionality reduction visualization maps of and in the RSHD space with and without the contrastive loss are plotted, as shown in Figure 10. Results show that, without the contrastive loss, as shown in Figure 10a, the distributions of and of various resolutions in the RSHD space after t-SNE dimensionality reduction are disorganized. In contrast, with the contrastive loss constraint, as shown in Figure 10b, the distributions of and of various resolutions in the RSHD space after t-SNE dimensionality reduction are regular. Specifically, in Figure 10b, of the same resolution can cluster into one group. of different resolutions are also separated from each other in the RSHD space. Meanwhile, and of the same resolution are aligned. In this way, can guide to approach it, enabling of different resolutions to be separated from each other, which achieves the design purpose of the contrastive loss.
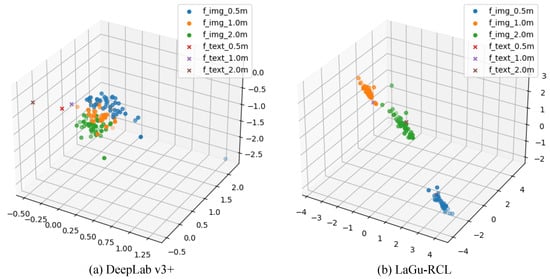
Figure 10.
3D T-SNE dimensionality reduction visualization map of and in RSHD space with and without contrastive loss.
3.4.3. Ablation Study on Continual Learning
The purpose of this ablation study is to evaluate the effectiveness of the proposed continual learning strategy. Compared with the initial learning stage, the continual learning stage mainly involves two distinct strategies. Accordingly, this ablation study aims to investigate the individual contributions of these two strategies. For the ablation on freezing the RSHD_T Projector, we train in Step 2 and Step 3 with the projector parameters either frozen or unfrozen. For the ablation on freezing the decoder of the segmentation model, we train the model with the decoder parameters either frozen or unfrozen. At the end of each training stage, we select the model checkpoint that achieves the minimum contrastive loss on the training set of the corresponding stage, and evaluate its semantic segmentation performance on the test sets of all resolutions. We adopt MIoU as the evaluation metric.
Ablation study regarding the RSHD_T Projector: The semantic segmentation performance of LaGu-RCL on the MR-ExcavSeg dataset, under settings where the RSHD_T Projector is either frozen or unfrozen, across different learning stages and test sets of various resolutions, is reported in Table 8. The experimental results show that, after unfreezing the RSHD_T Projector to allow its participation in training and parameter updates, the semantic segmentation performance (MIoU) decreases at each resolution in Step 2 and Step 3. To further verify this effect at an overall level, we also compute the average value of MIoU over the three test-set resolutions for each learning stage with the RSHD_T Projector frozen or unfrozen. The resulting stage-wise average MIoU values are reported in Table 9. The results indicate that, after unfreezing the RSHD_T Projector, both the average MIoU across all resolutions in Step 2 and Step 3 and the overall average MIoU decrease. To more intuitively illustrate the effect of freezing the RSHD_T Projector during continual learning, we plot the performance curves across learning stages, as shown in Figure 11. The results show that, compared with unfreezing the RSHD_T Projector, the performance curves obtained when its parameters are frozen consistently lie at higher values across different resolutions in each step. Moreover, except for 2 m resolution, the MIoU exhibits an upward trend, as shown in Figure 11a,c,d, indicating that freezing the RSHD_T Projector enables LaGu-RCL to achieve better continual learning performance. Although the curve at 2 m resolution shows a decreasing trend, as illustrated in Figure 11b, its decline is less steep than that observed when the RSHD_T Projector is unfrozen. This suggests that freezing the RSHD_T Projector can effectively mitigate catastrophic forgetting for LaGu-RCL.
Table 8.
Performance of LaGu-RCL with and without freezing the RSHD_T Projector. The optimal results are marked in bold.
Table 9.
Average value of MIoU of LaGu-RCL with and without freezing the RSHD_T Projector. The optimal results are marked in bold.
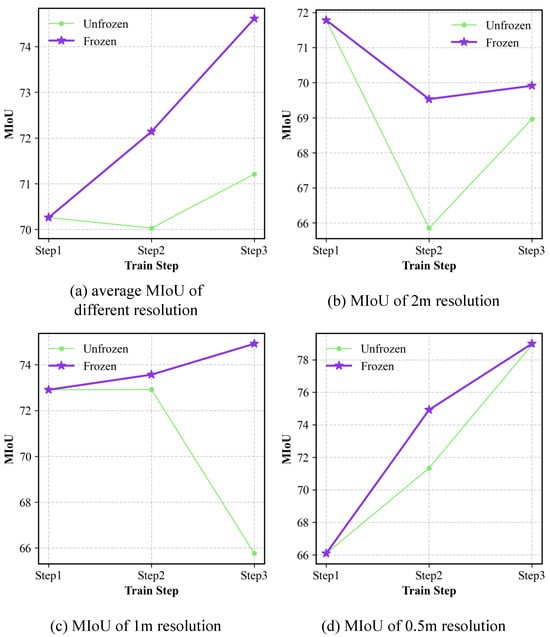
Figure 11.
Line charts of average MIoU in RSHD_T Projector ablation experiment.
Ablation study regarding the decoder: The MIoU of LaGu-RCL on the MR-ExcavSeg dataset, under settings where the segmentation (i.e., seg) decoder is either frozen or unfrozen, across different learning stages and test sets of various resolutions, is reported in Table 10. The results show that, after unfreezing the decoder to allow its participation in training and parameter updates, the model achieves relatively better performance on the resolution corresponding to the current step. However, the performance at the other resolutions is consistently worse. To verify the overall effect, we compute the average semantic segmentation performance of LaGu-RCL over the three test-set resolutions for each learning stage with the Seg Decoder frozen or unfrozen. The resulting stage-wise average MIoU values are reported in Table 11. The results indicate that, although unfreezing the decoder allows LaGu-RCL to learn the data at the current resolution more effectively, both the average MIoU across all resolutions in Step 2 and Step 3 and the overall average MIoU decrease compared with the setting where the decoder is frozen. To more intuitively illustrate the continual learning effect of freezing the Seg Decoder, we plot the performance curves across learning stages, as shown in Figure 12. The results show that, compared with freezing the decoder, the performance curves obtained when the decoder parameters are unfrozen are generally higher at the resolution corresponding to the current step, but lower at the other resolutions. Moreover, except for the 2 m resolution, the MIoU under the frozen-decoder setting exhibits an upward trend, as shown in Figure 12a,c,d, indicating that freezing the decoder likewise leads to better continual learning performance for LaGu-RCL. Similarly, as illustrated in Figure 12b, the decline in MIoU at 2 m resolution is less steep when the decoder is frozen than when it is unfrozen. In addition, as shown in Figure 12c, for the 1 m resolution, the MIoU in Step 3 drops substantially relative to Step 2 when the decoder is unfrozen, suggesting that freezing the decoder can also effectively alleviate catastrophic forgetting in LaGu-RCL.
Table 10.
Performance of LaGu-RCL with and without freezing the Seg Decoder. The optimal results are marked in bold.
Table 11.
Average value of MIoU of LaGu-RCL with and without freezing the Seg Decoder. The optimal results are marked in bold.
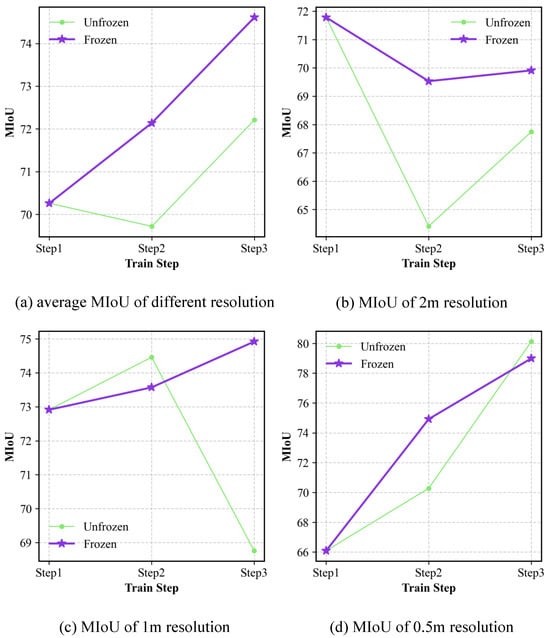
Figure 12.
Line charts of average MIoU in Seg Decoder ablation experiment.
Taken together, these results demonstrate that, during the continual learning stage, freezing both the RSHD_T Projector and the Decoder of LaGu-RCL can mitigate catastrophic forgetting to some extent and improve its continual learning capability, thereby validating the effectiveness of the continual learning strategy adopted in the proposed LaGu-RCL framework.
4. Conclusions
This paper focuses on the continual learning problem in multi-resolution remote sensing image semantic segmentation and proposes a language-guided resolution continual learning method, LaGu-RCL. First, to address the issue that each training stage typically involves only single-resolution data, this paper designs a multi-resolution remote sensing image data augmentation approach based on the approximate convertibility between images of different resolutions. This method enables the simulation and extension of multi-resolution images, allowing the model to learn from images of diverse resolutions at every training step. Second, leveraging the semantic discreteness and orthogonality of different resolutions, a language-guided continual learning strategy is developed. By mapping distinct resolutions to language-guided semantic anchor points, the model can learn intra-resolution aggregation and inter-resolution separation of feature distributions, thereby effectively mitigating catastrophic forgetting. Finally, a multi-resolution remote sensing image semantic segmentation dataset, MR-ExcavSeg, is constructed. Experiments conducted on this dataset demonstrate that the proposed method achieves excellent performance across all resolutions and significantly outperforms existing continual learning methods.
Author Contributions
Conceptualization, H.L. and P.L.; methodology, P.L., Z.M. and Z.H.; software, P.L. and Z.M.; validation, P.L. and Z.H.; formal analysis, H.L. and Z.H.; investigation, P.L. and H.L.; resources, H.L.; data curation, P.L. and Z.M.; writing—original draft preparation, P.L. and Z.M.; writing—review and editing, Z.H. and H.L.; visualization, Z.M. and H.L.; supervision, H.L.; project administration, P.L. and H.L.; funding acquisition, P.L. and H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Chongqing Scientific Research Institutions Performance Incentive Guidance Special Program under Grant no. CSTB2025JXJL-YFX0019 and the National Natural Science Foundation of China under Grant no. 424171419.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Yang, K.; Xia, G.S.; Liu, Z.; Du, B.; Yang, W.; Pelillo, M.; Zhang, L. Semantic change detection with asymmetric Siamese networks. arXiv 2020, arXiv:2010.05687. [Google Scholar]
- Tian, S.; Ma, A.; Zheng, Z.; Zhong, Y. Hi-UCD: A large-scale dataset for urban semantic change detection in remote sensing imagery. arXiv 2020, arXiv:2011.03247. [Google Scholar]
- Weixun, Z.; Jinglei, L.; Daifeng, P.; Haiyan, G.; Zhenfeng, S. MtSCCD: Land-use scene classification and change-detection dataset for deep learning. Natl. Remote Sens. Bull. 2024, 28, 321–333. [Google Scholar]
- Zhao, L.; Huang, Z.; Wang, Y.; Peng, C.; Gan, J.; Li, H.; Hu, C. SeFi-CD: A Semantic First Change Detection Paradigm That Can Detect Any Change You Want. Remote Sens. 2024, 16, 4109. [Google Scholar] [CrossRef]
- Jia, P.; Chen, C.; Zhang, D.; Sang, Y.; Zhang, L. Semantic segmentation of deep learning remote sensing images based on band combination principle: Application in urban planning and land use. Comput. Commun. 2024, 217, 97–106. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Wang, G.; Chen, J.; Mo, L.; Wu, P.; Yi, X. Lightweight land cover classification via semantic segmentation of remote sensing imagery and analysis of influencing factors. Front. Environ. Sci. 2024, 12, 1329517. [Google Scholar] [CrossRef]
- Boonpook, W.; Tan, Y.; Nardkulpat, A.; Torsri, K.; Torteeka, P.; Kamsing, P.; Sawangwit, U.; Pena, J.; Jainaen, M. Deep learning semantic segmentation for land use and land cover types using Landsat 8 imagery. ISPRS Int. J. Geo-Inf. 2023, 12, 14. [Google Scholar] [CrossRef]
- Feng, Q.; Chen, B.; Li, G.; Yao, X.; Gao, B.; Zhang, L. A review for sample datasets of remote sensing imagery. Natl. Remote Sens. Bull. 2022, 26, 589–605. [Google Scholar]
- Huang, L.; Jiang, B.; Lv, S.; Liu, Y.; Fu, Y. Deep-learning-based semantic segmentation of remote sensing images: A survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 8370–8396. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, C.; Li, R.; Duan, C.; Meng, X.; Atkinson, P.M. Scale-aware neural network for semantic segmentation of multi-resolution remote sensing images. Remote Sens. 2021, 13, 5015. [Google Scholar] [CrossRef]
- Zeng, J.; Gu, Y.; Qin, C.; Jia, X.; Deng, S.; Xu, J.; Tian, H. Unsupervised domain adaptation for remote sensing semantic segmentation with the 2D discrete wavelet transform. Sci. Rep. 2024, 14, 23552. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.; Lei, H. Semantic segmentation of remote sensing imagery based on multiscale deformable CNN and DenseCRF. Remote Sens. 2023, 15, 1229. [Google Scholar] [CrossRef]
- Wang, J.; Chen, T.; Zheng, L.; Tie, J.; Zhang, Y.; Chen, P.; Luo, Z.; Song, Q. A multi-scale remote sensing semantic segmentation model with boundary enhancement based on UNetFormer. Sci. Rep. 2025, 15, 14737. [Google Scholar] [CrossRef]
- Li, K.; Ji, H.; Li, Z.; Cui, Z.; Liu, C. AFNE-Net: Semantic Segmentation of Remote Sensing Images via Attention-Based Feature Fusion and Neighborhood Feature Enhancement. Remote Sens. 2025, 17, 2443. [Google Scholar] [CrossRef]
- Chan, S.; Zhou, W.; Lei, Y.; Li, C.; Hu, J.; Hong, F. Sparse point annotations for remote sensing image segmentation. Sci. Rep. 2025, 15, 27347. [Google Scholar] [CrossRef]
- Li, K.; Cao, X.; Liu, R.; Wang, S.; Jiang, Z.; Wang, Z.; Meng, D. Annotation-free open-vocabulary segmentation for remote-sensing images. arXiv 2025, arXiv:2508.18067. [Google Scholar]
- Pereira, M.B.; dos Santos, J.A. An end-to-end framework for low-resolution remote sensing semantic segmentation. In 2020 IEEE Latin American GRSS & ISPRS Remote Sensing Conference (LAGIRS); IEEE: Piscataway, NJ, USA, 2020; pp. 6–11. [Google Scholar]
- Wang, D.; Yan, Z.; Liu, P. Fine-Grained Interpretation of Remote Sensing Image: A Review. Remote Sens. 2025, 17, 3887. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 422, 318–327. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xiao, J.W.; Zhang, C.B.; Feng, J.; Liu, X.; van de Weijer, J.; Cheng, M.M. Endpoints weight fusion for class incremental semantic segmentation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7204–7213. [Google Scholar]
- Zhang, C.B.; Xiao, J.W.; Liu, X.; Chen, Y.C.; Cheng, M.M. Representation compensation networks for continual semantic segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7053–7064. [Google Scholar]
- Yang, G.; Fini, E.; Xu, D.; Rota, P.; Ding, M.; Nabi, M.; Alameda-Pineda, X.; Ricci, E. Uncertainty-aware contrastive distillation for incremental semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Cermelli, F.; Mancini, M.; Bulo, S.R.; Ricci, E.; Caputo, B. Modeling the background for incremental learning in semantic segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9233–9242. [Google Scholar]
- Michieli, U.; Zanuttigh, P. Incremental learning techniques for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Douillard, A.; Chen, Y.; Dapogny, A.; Cord, M. Plop: Learning without forgetting for continual semantic segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4040–4050. [Google Scholar]
- Yuan, B.; Zhao, D.; Shi, Z. Learning at a glance: Towards interpretable data-limited continual semantic segmentation via semantic-invariance modelling. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7909–7923. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Hu, Y.; Yang, F.; Liu, X. Enhancing Continual Semantic Segmentation via Uncertainty and Class Balance Re-weighting. IEEE Trans. Image Process. 2025, 34, 3689–3702. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.