Abstract
Adverse weather conditions, such as haze and raindrop, consistently degrade the quality of remote sensing images and affect subsequent vision-based applications. Recent years have witnessed advancements in convolutional neural networks (CNNs) and Transformers in the field of remote sensing image restoration. However, these methods either suffer from limited receptive fields or incur quadratic computational overhead, leading to an imbalance between performance and model efficiency. In this paper, we propose an effective vision state space model (called Weamba) for remote sensing image restoration by modeling long-range pixel dependencies with linear complexity. Specifically, we develop a local-enhanced state space module to better aggregate rich local and global information, both of which are complementary and beneficial for high-quality image reconstruction. Furthermore, we design a multi-router scanning strategy for spatially varying feature extraction, alleviating the issue of redundant information caused by repeated scanning directions in existing methods. Extensive experiments on multiple benchmarks show that the proposed Weamba performs favorably against state-of-the-art approaches.
1. Introduction
Adverse weather conditions significantly impact the quality and applicability of remote sensing (RS) images. These atmospheric disturbances reduce the clarity of the captured data, thereby hindering accurate analysis and interpretation. As RS technology becomes increasingly integral to various fields, including environmental monitoring, disaster management, and urban planning, removing these effects of such weather conditions (e.g., haze and rain) is crucial [,,].
In recent years, significant advances in image dehazing and deraining have been achieved [,], thanks to the rapid development of effective image priors and deep learning models. Early efforts frequently depended on hand-crafted priors to constrain the set of plausible solutions [,,]. However, these methods struggle to produce accurate results in more challenging RS images and involve laborious optimization processes. Afterwards, deep convolutional neural networks (CNNs) demonstrated remarkable progress in image restoration tasks, achieving superior performance compared to traditional prior-based approaches. However, the main operation in CNNs, convolution, prevents it from capturing the spatially variable properties of image content and exploring non-local information, which is crucial for high-quality image restoration [,,].
Different from the convolution operation, the self-attention mechanism [] in Transformers can facilitate non-local information by calculating the correlations between each token and other tokens. Although these methods outperform CNN-based approaches, they have quadratic complexity in relation to the token size. In such case, adapting the Transformer model for high-resolution settings poses a significant challenge, especially for large-scale RS images. Although several efficient strategies [,,,] have been proposed to reduce computational cost, these methods compromise their capacity to capture global information, impacting the quality of the reconstructed results. Thus, it is of great need to explore a new solution with better trade-off between model efficiency and performance.
The recent rise in popularity of state space models (SSMs) [] has provided a promising insight into this problem. The simplified-architecture SSM, specifically Mamba [], introduces a specific selective scan mechanism (S6) that can keep relevant information and model long-range dependencies, while maintaining linear computational complexity. This motivates us to leverage Mamba to explore non-local information for better image restoration. However, directly applying visual SSMs to restore weather-degraded RS images is insufficient. This is due to SSMs being primarily designed for global feature modeling, which lacks the flexibility to effectively capture local information. In fact, since non-uniform weather degradation and clear backgrounds are highly interlaced, both global and local representation learning are crucial for tackling the challenging RS task.
In this paper, we introduce Weamba, the first visual state space model designed for weather-degraded RS image restoration. Specifically, instead of directly employing SSMs for feature modeling, we develop a local-enhanced state space module to better help image restoration by collaboratively representing both local and global information. Furthermore, we find that existing Mamba-based methods [,] mostly enhance the model’s understanding of images by changing the scanning direction of image patches along a fixed-shaped path. This design may lead to redundant information during the scanning process, resulting in limited performance gains. To this end, we integrate multiple scanning paths of different shapes to form a new multi-router scanning mechanism that better captures useful non-local spatial information. Extensive experiments on multiple benchmarks demonstrate that the proposed Weamba model performs favorably compared to state-of-the-art CNN- and Transformer-based approaches see Figure 1.
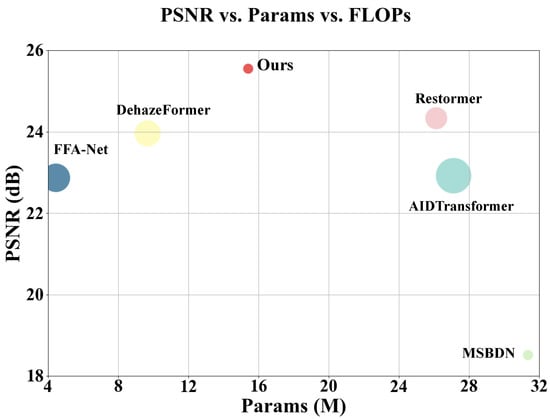
Figure 1.
Model complexity and average performance comparison between our proposed Weamba model and other methods on the SateHaze1k dataset. The sizes of the circles represent the number of parameters in each model. Our proposed approach demonstrates an improved trade-off between model complexity and reconstruction performance.
The main contributions of this paper are summarized as follows:
- We propose an effective local-enhanced visual state space model Weamba for RS image restoration under adverse weather conditions, which allows for exploring complementary components of local and global dependencies.
- We develop a simple yet effective multi-router scanning strategy for spatially varying feature extraction, allowing for comprehensive modeling of information flow through different pathways in high-resolution RS image data.
- We quantitatively and qualitatively evaluate the proposed method on haze removal and raindrop removal tasks. The results show that our method obtains a favorable trade-off between performance and model complexity.
In the next section, we provide an overview of relevant work in RS image restoration and the advancements in visual state space models. Section 3 introduces the main architecture of our model, detailing the composition and functions of its various modules. We also present the datasets chosen for our experiments and the implementation details, followed by comparison with state-of-the-art methods. In Section 4, we primarily discuss and analyze the ablation experiments of the model and the significance of the components within it. Additionally, we further assess the model’s complexity and its applications in downstream vision tasks. Finally, we outline the limitations of this paper and explore areas of focus for future work. Section 5 summarizes the conclusions of this study.
2. Related Work
In this section, we provide a brief overview of the related work on RS image restoration, as well as the research progress on state space models (SSMs).
2.1. RS Image Restoration
Since image restoration is a classic ill-posed problem, numerous approaches [,] have been proposed, including specific solutions for RS images. Early studies in image restoration are typically reliant on hand-crafted priors, such as those found in [,]. However, the employment of manually crafted priors might result in image distortion if the set conditions are not fulfilled. Recently, significant advancements have been achieved in this field using deep CNN-based approaches. For example, Li et al. [] proposed a coarse-to-fine two-stage network for haze removal of RS images. Afterwards, many methods further improved performance by designing various effective architectures and strategies, such as multi-scale network [] and multi-model fusion []. In addition, generative adversarial networks (GANs) have been widely applied in unsupervised hyperspectral reconstruction [,]. Although these methods outperform hand-crafted prior-based models, the spatial invariance and locality of the convolution operation restrict its capacity to capture global and spatially varying information in RS images.
Vision Transformers, with their capability to establish long-range dependencies and effectively model non-local information, have made significant strides in computer vision. Researchers have also extended them to the application of various RS vision tasks. For the field of RS image restoration, an efficient Transformer-based framework RSDformer [] was formulated for RS image dehazing, which can capture both global and local representations with detail-compensated transposed attention. Continuing this trend, Kulkarni et al. [] developed AIDtransformer, which utilizes space-aware deformable convolution-based multi-head self-attention to preserve image textures while removing haze disturbance. However, the self-attention mechanism in Transformers necessitates quadratic computational complexity [], which is not friendly for image restoration tasks involving high-resolution RS images. Instead of Transformer-based methods, we explore SSMs as the network backbone for efficient RS image restoration.
2.2. Visual State Space Models
Recent advancements in deep learning have witnessed the integration of Structured State Space Models (SSMs), a paradigm rooted in classical control theory, into its architecture, specifically for the transformation of state spaces. The S4 model [], or Structured State Space Sequence, along with its subsequent iteration, the S5 layer [], has garnered significant recognition for its capacity to scale linearly with respect to sequence length. This characteristic is particularly advantageous for modeling long-range dependencies inherent in sequential data. The S5 layer marks a noteworthy progression, introducing the concept of efficient parallel scanning, coupled with a multiple-input multiple-output (MIMO) configuration of the SSM. This innovation significantly enhances the operational efficiency and effectiveness of SSMs in processing complex data structures. Further augmenting the capabilities of the S4 model is the development of the gated state space layer, which integrates gating mechanisms that enable more nuanced control over information flow within the model, thereby facilitating improved learning dynamics.
Pushing the boundaries of this field, the Mamba framework [] emerges as a pioneering data-dependent SSM that has demonstrably outperformed traditional Transformers in various natural language processing tasks. This advancement underscores the evolving capabilities of SSMs in addressing complex linguistic challenges. Moreover, recent investigations have successfully applied SSMs across a spectrum of low-level vision tasks, yielding remarkable results in applications such as image dehazing [,,], image super-resolution [,,], and low-light image enhancement [,,,]. Despite these notable achievements, it is imperative to recognize that existing SSMs have not sufficiently prioritized the capture of local information—a critical component for ensuring high-quality reconstruction in remote sensing (RS) applications. Addressing this limitation could significantly enhance the fidelity and robustness of reconstruction processes, ultimately advancing the field of visual state space modeling.
3. Proposed Method
In this section, we first introduce the preliminary concepts of SSMs. Then, we outline the overall architecture of Weamba and delve into its main component.
3.1. Preliminaries
The SSM serves as a fundamental mathematical framework, drawing significant inspiration from continuous linear time-invariant (LTI) systems. These models transform one-dimensional functions or sequences into outputs through implicit latent states . This transformation is typically represented using first-order difference or differential equations:
where A, B, C, and D are matrices with learnable weights. The zero-order hold (ZOH) technique is frequently employed for discretizing the state equation, and is defined as follows:
However, the formulation described in (2) revolves around the LTI system, where parameters remain static regardless of input variations. To overcome this issue, Mamba [] introduces selective scanning (S6), aimed at achieving input-dependent weights. At the same time, the hidden state equation is set as a nonlinear function to model these relationships, thereby addressing the issue of inadaptability when handling nonlinear tasks. And visual tasks pose formidable challenges owing to the nonlinear nature of visual data, encompassing intricate spatial details like local textures and global structures. Inspired by this trend, we explore its effect on RS image restoration.
3.2. Overall Architecture
As depicted in Figure 2, the proposed Weamba is based on a hierarchical encoder–decoder framework. Given the input degraded image , we begin by applying a convolution layer to extract the shallow feature , where represents the spatial dimensions and C denotes the number of feature channels. Then, the shallow feature is fed into a 4-level symmetric encoder–decoder network. Each of the four levels in the encoder and decoder consists of local-enhanced state space modules (LSSMs), as described in Section 3.3. Similar to [,], we adopt bilinear interpolation and convolution for upsampling and downsampling. In addition, we add skip connections between the encoder and decoder at each level. Subsequently, the decoded features are passed through a convolution for the final output projection and reshaped to . Finally, the degraded image and the residual image are combined using residual connections to generate the final reconstructed result . The model is trained by minimizing the following loss function:
where represents the ground truth image and denotes the L1-norm.
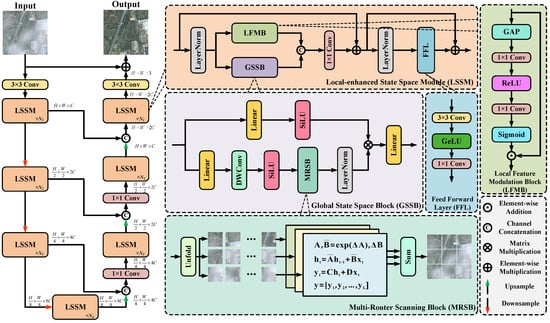
Figure 2.
The overall architecture of the proposed Weamba, which mainly contains a local−enhanced state space module (LSSM). The LSSM consists mainly of the Local Feature Modulation Block (LFMB) and the Global State Space Block (GSSB). We use the GSSB for global feature extraction, and in the parallel branch of the GSSB, we add the LFMB for extracting local features.
3.3. Local-Enhanced State Space Module (LSSM)
The LSSM consists of two key components: the Global State Space Block (GSSB) and Local Feature Modulation Block (LFMB). We design the main structure of the LSSM by drawing an analogy to the Transformer block []. The GSSB replaces the global feature processing module in the Transformer. To make the details more closely resemble real-world effects, we add the LFMB, which extracts local features, in a parallel branch to the GSSB. Together, these two components form the LSSM. Below is a detailed description of each module.
- Global State Space Block (GSSB). Inspired by the use of similar structures in the basic blocks of the Transformer and Mamba, we develop the GSSB to help image restoration. Specifically, the input features are processed sequentially through a linear layer, a depth-wise convolution, and a SiLU activation function, along with the multi-router scanning block (MRSB). Compared to the previous scanning mechanisms, our proposed MRSB can obtain strong feature representations, which will be detailed in the following. Next, layer normalization is applied to manage data across different batches. In addition, the nonlinear features are connected with a branch that bypasses the depth-wise convolution, enhancing the model’s capability to extract global features through differential learning. Finally, the processed features pass through another linear layer to produce the final GSSB output. The entire flow can be formulated as follows:
- Multi-Router Scanning Block (MRSB). Like ViT [], which divides images into patches and flattens them for input into the model, the SSM also handles flattened image patches as sequences. However, in contrast to ViT, which applies multi-head self-attention to these image patches, the SSM processes these patches sequentially. Thus, exploring effective methods for the sequential scanning of image patches is crucial. Recently, Vim [] and VMamba [] demonstrated that utilizing various scanning orders, including both row-wise and column-wise scans in different directions, can effectively enhance model performance.
However, in these methods, each scanning order covers only one type of 2D routing shape. For example, VMamba performs four-directional scanning only on R1 (as shown in Figure 3). In other words, repeating scans in different directions on the same-shaped scanning pathway may introduce information redundancy in feature extraction, thereby leading to limited performance gains. To this end, we propose a multi-router scanning block (MRSB) to perform continuous 2D scanning. The scanning mechanism of the MRSB consists of three distinct routing scan pathways designed to enhance perception of spatially varying distributions in high-resolution RS images. Specifically, the first scanning method scans image patches in a ‘Z’-shaped pattern. The second method performs a serpentine scan in an ‘S’-shaped pattern within the image patches to obtain sequence data. The third method scans image patches sequentially along the diagonal direction in a ‘W’-shaped pattern. The information from multi-routes is then fed into the Mamba, as described in Section 3.1, for global feature extraction. Finally, all image patch sequences are combined to integrate global modeling information. We will demonstrate its effectiveness in Section 4.
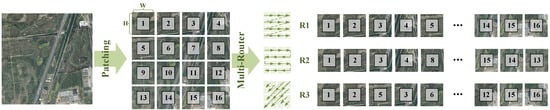
Figure 3.
Illustration of the proposed multi-router scanning block (MRSB). Compared to previous multi-directional scanning methods based on fixed routing, our method performs sequential scanning of image patches in ‘Z’-shaped, ‘S’-shaped, and ‘W’-shaped patterns. This combination enables the extraction of large spatial features from various perspectives in RS images.
- Local Feature Modulation Block (LFMB). The GSSB effectively captures the global information of images, but enhancing the extraction of local features is equally important. The LFMB enhances the model’s ability to focus on and extract local features by using dynamic feature weighting, thereby complementing the global information captured by the GSSB. Specifically, we begin by applying global average pooling to the features after layer normalization. These processed features are then subjected to a series of convolutional operations to extract high-level features. Finally, the sigmoid function is used on these deep features to generate channel weights. The LFMB dynamically adjusts the importance of each channel by performing element-wise multiplication with the normalized input features using these weights. The LFMB can be represented as follows:
In summary, the LFMB significantly enhances the model’s capability in tasks such as haze removal, ensuring intricate texture details are preserved in restored images.
3.4. Datasets and Implementation
- Datasets. To comprehensively evaluate the effectiveness of our approach under hazy and rainy conditions in RS images, we carry out extensive experiments using existing synthetic datasets, including SateHaze1k [], RS-Haze [], RICE [], UAV-Rain1k [], and a real-world dataset RRSD300 []. Specifically, the SateHaze1k dataset contains three different haze densities of RS images. Each subset of density includes 320 images for training and 45 images for testing. The RS-Haze dataset consists of 51,300 images for training, along with 2700 images for testing. The RICE dataset consists of 425 images used for training and 75 images used for testing. The UAV-Rain1k dataset consists of 800 synthetic raindrop images for training and 220 ones for testing. The RRSD300 dataset comprises 303 real RS hazy images. To maintain fairness in our comparisons, we follow the protocols of these benchmarks to evaluate our method.
- Implementation details. The initial feature layer comprises 32 channels, while the encoder/decoder utilizes vision Mamba modules with configurations of [2, 3, 3, 4] from level 1 to level 4, respectively. The Adam optimizer [] is employed during the training phase using its default parameters. To enhance the training dataset, data augmentation techniques, including flipping and rotation, are applied. The patch size is set to be pixels and the batch size is set to be 4. The initial learning rate is established at and is halved at designated milestones. The final learning rate is dynamically adjusted following the cosine annealing schedule []. All experiments are executed using the PyTorch framework on NVIDIA RTX 4090 GPUs. The source code will be available to the public.
3.5. Comparisons with the State of the Art
We test the model’s performance under different weather degradation conditions, selecting several typical weather scenarios, such as hazy and rainy days. We also choose representative synthetic remote sensing datasets for haze and rain. To make the results more convincing, we conduct experiments on a real-world dataset as well.
- Evaluations on datasets for image dehazing. We first conduct a comprehensive evaluation of our method against state-of-the-art ones on several benchmark datasets, including SateHaze1k [], RS-Haze [], and RICE []. Here, we compare our Weamba with one prior-based algorithm (DCP []), CNN-based methods (AOD-Net [], LD-Net [], GCANet [], GridDehazeNet [], FFA-Net [], FCTF-Net [], and M2SCN []), and recent Transformer-based approaches (Restormer [], Dehamer [], DehazeFormer [], AIDTransformer [], and RSDformer []). We retrain the deep learning-based methods to ensure fair comparisons if they have not been previously trained on these benchmarks. We employ PSNR and SSIM [] as evaluation metrics to measure the quality of the restored images. The quantitative results on different benchmark datasets are summarized in Table 1 and Table 2. These quantitative results clearly indicate that our proposed approach consistently outperforms all other dehazing techniques. Notably, our proposed Weamba achieves a significant improvement, surpassing RSDformer by 1.25 dB on average across the SateHaze1k dataset.
Figure 4 and Figure 5 vividly illustrate the comparative visual results of various methodologies applied to the SateHaze1k and RS-Haze benchmarks, highlighting their efficacy in tackling haze-related challenges in remote sensing images. Non-uniform haze is a prevalent phenomenon in remote sensing imagery, significantly complicating the process of image restoration. As depicted, the traditional DCP algorithm exhibits pronounced sensitivity to non-uniform haze conditions, leading to suboptimal performance and unsatisfactory restoration outcomes. In contrast, CNN-based approaches, while adept at local feature extraction, often fail to fully leverage global information, which results in images restored by methods such as those proposed by Liu et al. [] and Li et al. [] still displaying noticeable haze residuals.

Figure 4.
Visual comparison on the SateHaze1k dataset. Compared with the dehazed results in (b–i), our method recovers a clearer image. Zoom in for best view.

Figure 5.
Visual comparison on the RS-Haze dataset. Compared with the dehazed results in (b–i), our method recovers a clearer image. Zoom in for best view.
Although Transformer-based methods show promise in capturing global contextual information, they are not without their drawbacks; specifically, they can inadvertently compromise fine details in certain regions of the image, leading to a loss of texture fidelity. Our proposed method, however, strikes an effective balance between removing the spatially varying haze effects and preserving the intricate texture details inherent to the original remote sensing backgrounds. This capability not only underscores the robustness of our approach in addressing the complexities of non-uniform haze but also emphasizes its potential to enhance image clarity and detail retention. Consequently, the results produced by our method stand as a testament to its superior performance, delivering restored images that are markedly clearer and more detailed than those generated by existing techniques, thus advancing the state of the art in remote sensing dehazing applications.
- Evaluations on datasets for image deraining. We further assess our proposed method, Weamba using the recent UAV-Rain1k dataset []. Following the framework established by [], we compare Weamba against several notable algorithms, including DSC [], RCDNet [], SPDNet [], Restormer [], IDT [], and DRSformer []. The quantitative results for the various methods evaluated are comprehensively presented in Table 3. It is particularly noteworthy that our approach achieves the highest PSNR value among the compared algorithms, which serves to underscore its superior effectiveness in tackling the image deraining task. In addition to these numerical results, Figure 6 provides a detailed visual comparison of the restoration outcomes generated by each algorithm. It becomes increasingly clear that raindrops create varying levels of obstruction in remote sensing images, complicating the restoration process. Unlike other models that tend to leave behind differing degrees of rain artifacts, our method excels in not only effectively eliminating unexpected raindrops but also in successfully restoring the intricate texture details of the background, thereby bringing them into closer alignment with the ground truth. This dual capability enhances the overall quality of the restored images, demonstrating the robustness of our approach.

Figure 6.
Visual comparison on the UAV-Rain1k dataset. Compared with the derained results in (b–h), our method recovers a clearer image. Zoom in for best view.
- Evaluations on real-world datasets. To further validate the generalization performance of various approaches in real-world remote sensing scenarios, we conduct a thorough evaluation of our proposed method using the real-world RRSD300 dataset [], which is specifically designed for RS image dehazing tasks. It includes image data from multiple scenes, covering a variety of geographic regions and environmental conditions. In this context, Figure 7 presents a detailed comparative analysis of the visual results generated by several different algorithms, allowing for an insightful assessment of their effectiveness. It becomes increasingly evident that earlier methods [,,] often lead to noticeable color distortions when applied to real-world scenes, thereby compromising the overall visual fidelity and authenticity of the restored images.

Figure 7.
Visual comparison on the RRSD300 dataset. Compared with the dehazed results in (b–i), our method recovers a clearer image. Zoom in for best view.
In contrast, the results produced by advanced methods, such as those leveraging the superior capabilities of Transformers and Mamba in effectively modeling global information [,,], exhibit significant advantages in terms of clarity, detail, and overall image quality. However, our proposed method, Weamba, distinguishes itself by consistently generating noticeably clearer images. This marked improvement can be attributed to the enhanced modeling of local information facilitated by our innovative state space model, which allows for fine restoration of intricate image details and more accurate color representation. Consequently, Weamba not only addresses the shortcomings identified in the aforementioned approaches but also establishes a new baseline for performance in RS image dehazing.

Table 1.
Quantitative comparison on the SateHaze1k and RS-Haze datasets. Compared to previous CNN, Transformer-based, and Mamba-based methods, our method achieves the highest PSNR/SSIM results.
Table 1.
Quantitative comparison on the SateHaze1k and RS-Haze datasets. Compared to previous CNN, Transformer-based, and Mamba-based methods, our method achieves the highest PSNR/SSIM results.
| Benchmark Datasets | RS-Haze | SateHaze1k | SateHaze1k Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Thin Haze | Moderate Haze | Thick Haze | |||||||||
| Metrics | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Prior | DCP [] | 8.48 | 0.4801 | 13.45 | 0.6977 | 9.78 | 0.5739 | 10.90 | 0.5715 | 11.38 | 0.6144 |
| CNN | AOD-Net [] | 24.90 | 0.8300 | 18.74 | 0.8584 | 17.69 | 0.7969 | 13.42 | 0.6523 | 16.60 | 0.7692 |
| LD-Net [] | 25.84 | 0.8230 | 17.83 | 0.8568 | 19.80 | 0.8980 | 16.60 | 0.7649 | 18.08 | 0.8399 | |
| GCANet [] | 34.41 | 0.9490 | 22.27 | 0.9030 | 24.89 | 0.9327 | 20.51 | 0.8307 | 22.56 | 0.8888 | |
| GridDehazeNet [] | 34.19 | 0.9446 | 20.04 | 0.8651 | 20.96 | 0.8988 | 18.67 | 0.7944 | 19.89 | 0.8528 | |
| FFA-Net [] | 35.68 | 0.9446 | 22.30 | 0.9072 | 25.46 | 0.9372 | 20.84 | 0.8451 | 22.87 | 0.8965 | |
| MSBDN [] | 35.25 | 0.9357 | 18.02 | 0.7029 | 20.76 | 0.7613 | 16.78 | 0.5389 | 18.52 | 0.6677 | |
| FCTF-Net [] | 34.29 | 0.9321 | 20.06 | 0.8808 | 23.43 | 0.9265 | 18.68 | 0.8020 | 20.72 | 0.8698 | |
| M2SCN [] | 37.75 | 0.9497 | 25.21 | 0.9175 | 26.11 | 0.9416 | 21.33 | 0.8289 | 24.22 | 0.8960 | |
| Transformer | Restormer [] | 36.72 | 0.9514 | 24.97 | 0.9248 | 26.77 | 0.9452 | 21.28 | 0.8362 | 24.34 | 0.9021 |
| Dehamer [] | 36.74 | 0.9459 | 20.94 | 0.8717 | 22.89 | 0.8708 | 19.80 | 0.8086 | 21.21 | 0.8504 | |
| DehazeFormer [] | 39.62 | 0.9595 | 23.92 | 0.9121 | 25.94 | 0.9445 | 22.03 | 0.8373 | 23.96 | 0.8980 | |
| AIDTransformer [] | - | - | 23.12 | 0.9052 | 25.08 | 0.9124 | 20.56 | 0.8325 | 22.92 | 0.8834 | |
| RSDformer [] | 37.07 | 0.9575 | 24.06 | 0.9177 | 25.97 | 0.9390 | 22.87 | 0.8646 | 24.30 | 0.9071 | |
| Mamba | MambaIR [] | 38.65 | 0.9569 | 24.67 | 0.9267 | 26.36 | 0.9443 | 22.68 | 0.8570 | 24.57 | 0.9093 |
| Weamba (Ours) | 39.86 | 0.9610 | 25.75 | 0.9284 | 27.50 | 0.9468 | 23.39 | 0.8702 | 25.55 | 0.9151 | |
Table 2.
Quantitative comparison on the RICE dataset. Compared to previous CNN- and Transformer-based methods, our method achieves the highest PSNR/SSIM results.
Table 2.
Quantitative comparison on the RICE dataset. Compared to previous CNN- and Transformer-based methods, our method achieves the highest PSNR/SSIM results.
| Methods | DCP [] | AODNet [] | FFA-Net [] | MSBDN [] | LD-Net [] | DehazeFormer [] | RSDformer [] | Ours |
|---|---|---|---|---|---|---|---|---|
| Category | Prior | CNN | CNN | CNN | CNN | Transformer | Transformer | Mamba |
| PSNR | 17.48 | 23.77 | 28.54 | 30.37 | 28.88 | 30.91 | 33.01 | 33.84 |
| SSIM | 0.7841 | 0.8731 | 0.0.9396 | 0.8584 | 0.9336 | 0.9350 | 0.9525 | 0.9582 |
Table 3.
Quantitative comparison on the UAV-Rain1k dataset. Compared to previous CNN- and Transformer-based methods, our approach achieves the highest PSNR results.
Table 3.
Quantitative comparison on the UAV-Rain1k dataset. Compared to previous CNN- and Transformer-based methods, our approach achieves the highest PSNR results.
| Methods | Input | DSC [] | RCDNet [] | SPDNet [] | Restormer [] | IDT [] | DRSformer [] | Ours |
|---|---|---|---|---|---|---|---|---|
| Category | - | Prior | CNN | CNN | Transformer | Transformer | Transformer | Mamba |
| PSNR | 16.80 | 16.68 | 22.48 | 24.78 | 24.78 | 22.47 | 24.93 | 25.25 |
| SSIM | 0.7196 | 0.7142 | 0.8753 | 0.9054 | 0.8594 | 0.9054 | 0.9155 | 0.9080 |
4. Analysis and Discussion
In this section, we first conduct a series of ablation studies aimed at analyzing the effectiveness of the various components of our model. Following the ablation analysis, we examine the computational complexity associated with different models, allowing us to understand the efficiency and resource requirements of our method in comparison to others. Finally, we engage in a comprehensive discussion regarding the practical applications of our method, as well as its limitations. This discussion highlight the contexts in which our approach excels, while also addressing potential challenges and areas for improvement, providing a well-rounded perspective on its capabilities and constraints.
4.1. Ablation Study
To validate the effectiveness of our proposed method, we analyze the effect of different components by performing ablation studies. To ensure fairness, we train our method and all alternative baselines under the same experimental settings.
- Effectiveness of the MRSB. The essence of our methodology lies in the principal design of the MRSB, which adeptly models global information. To elucidate the efficacy of the MRSB, we commence by contrasting it with the prevalent multi-directional scanning technique, as detailed in reference [] (refer to Figure 8). Table 4 presents the performance outcomes of models (a–c), which employ uni-directional, bi-directional, and four-directional scanning methods along a defined Z-shaped trajectory, respectively. Furthermore, we elucidate the results of employing diverse routing configurations within the MRSB, as depicted in models (d–f) of Table 4. It is noteworthy that, in the context of remote sensing (RS) image restoration, the performance enhancement achieved by model (c) with an increased number of scanning directions, as compared to model (b), is relatively modest. This may be attributed to the inherent issue of information redundancy associated with the multi-directional scanning paradigm. In stark contrast, our MRSB markedly augments performance by leveraging a variety of routing shapes, thereby demonstrating a superior capability to effectively exploit salient information for global feature modeling throughout the scanning procedure.
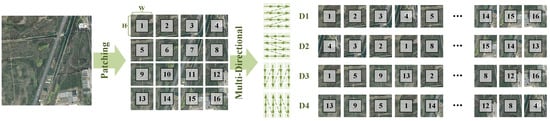
Figure 8.
Illustration of the multi-directional scanning method in MambaIR [].
Table 4.
Ablation study on different variants of our proposed approach on the UAV-Rain1k dataset. Here, similar to MambaIR [], we employ multi-directional scanning along a Z-shaped path to compare with our MRSB.
Figure 9 provides a visual comparison of the outcomes generated by different variants. The analysis reveals that the incorporation of the MRSB enables the model to more adeptly eliminate spatially varying degradation, showcasing its profound efficacy in enhancing the quality of RS image restoration. This underscores the pivotal role of the MRSB in optimizing the retrieval of critical features from the data, ultimately contributing to improved image clarity and fidelity. Based on both qualitative and quantitative results, it is evident that the performance of the multi-route design outperforms both the single-route and dual-route designs.

Figure 9.
Visual comparison of output results of Weamba in different variants. This suggests that each component we consider contributes to the final reconstruction quality.
- Effectiveness of the LFMB. We present the LFMB with the objective of empowering the model to adeptly capture complex global and local dependencies inherent in the data. To assess the impact of the LFMB, we conduct a performance comparison by omitting this critical component. In comparison to model (f) in Table 4, our proposed method (g) yields a notable Peak Signal-to-Noise Ratio (PSNR) enhancement of 0.12 dB on the UAV-Rain1k dataset. Furthermore, as illustrated in Figure 9, our approach demonstrates a superior ability to preserve fine textures in remote sensing (RS) images upon the integration of the LFMB. This improvement underscores the significance of the LFMB in enriching the model’s capability to maintain intricate details, thereby enhancing the overall fidelity and quality of the reconstructed images.
- Effectiveness of the number of LSSMs. The above experiments sufficiently demonstrate the effectiveness of the LSSM. To further validate the impact of the number of LSSMs on the final experimental results, we conduct additional ablation studies on the UAV-Rain1k dataset. As shown in the Table 5, we set up four groups of control experiments. As the model downsamples to gradually extract deeper image features, a larger number of LSSMs are needed for effective modeling. In the shallow layers of the image, the amount of useful information is relatively small, so an excessive number of LSSMs leads to information redundancy, which in turn limits the model’s performance. Therefore, we gradually adjust the number of LSSMs to achieve a balance between effectiveness and efficiency.
Table 5.
Ablation study of the number of LSSM modules on the UAV-Rain1k dataset.
- Discussions on a closely related method. The recent method referred to as MambaIR [] presents a straightforward baseline for image restoration using a state space model. Our method, however, differs from MambaIR in several significant ways. Firstly, we have devised an advanced multi-router scanning strategy, which stands in contrast to the multi-directional scanning technique employed by MambaIR. This scanning approach enables a more comprehensive and nuanced capture of spatial degradation present in high-resolution remote sensing (RS) images. By traversing the scene along multiple, strategically chosen routes, it significantly augments the hierarchical feature modeling within the state space framework, facilitating a deeper comprehension of spatial variations and intricacies inherent in the imagery. Secondly, we integrate local feature modulation, which serves to enhance the state space model by incorporating critical local information. This enhancement is crucial, as it allows us to synergistically leverage both global and local data. By adopting this dual focus, we achieve substantial improvements in the reconstruction quality of high-resolution RS images. The amalgamation of global and local features not only amplifies the model’s overall performance but also ensures the preservation of intricate details and contextual information, thereby achieving superior image fidelity and clarity. The results of our experiments substantiate the efficacy of our proposed strategy, demonstrating its potential to advance the field of image restoration within remote sensing applications.
4.2. Model Complexity
We analyze the model complexity associated with our proposed approach, Weamba, in comparison to other methods. This evaluation primarily centers on two critical metrics: the number of model parameters and the floating point operations (FLOPs). As illustrated in Table 6, Weamba exhibits a markedly lower FLOP value and fewer parameters than its counterparts. Considering the resource constraints commonly encountered by most real-world devices, these constraints necessitate solutions that not only deliver high performance but also operate within limited computational budgets. We further compare the proposed method with Transformer-based models in terms of inference speed. The results, as shown in Table 7, indicate that the proposed method achieves a faster inference speed. The results presented above underscore the considerable potential of our model for remote sensing (RS) applications. This combination of reduced complexity and robust performance positions Weamba as a viable option for deployment in resource-constrained environments, further enhancing its applicability in practical scenarios within the field of remote sensing.
Table 6.
Comparisons of model complexity against state-of-the-art methods using test images of pixels. All results are tested on an NVIDIA RTX 4090 GPU.
Table 7.
Comparison of inference speed between the proposed method and Transformer-based models on a image.
4.3. Application
With the progression of RS imaging technology, these methods are increasingly employed for evaluating forested regions, aiding conservation, management, and ecological research. To assess the impact of our image restoration process on subsequent vision-based RS applications, particularly object detection, we utilize established pre-trained object detection models like YOLOv5 to appraise our outcomes []. As depicted in Figure 10, our technique not only yields clearer images but also markedly improves the precision of target recognition, especially in pinpointing structures such as houses. For example, in contrast to SPDNet, which struggles to detect a house in the bottom left corner of the image, our method identifies it consistently and accurately. Following [], we calculate the mean Average Precision (mAP) for joint image deraining and object detection. Here, we set the IoU threshold to 0.5. From Table 8, our reconstruction results achieve the best quantitative performance. This demonstrates the strength of our approach and its potential to enhance the practicality and efficacy of real-world remote sensing applications. The capacity for dependable object detection in restored images is vital for a range of ecological and managerial tasks, thus reinforcing the significance of our method in the advancement of the remote sensing domain.

Figure 10.
Object recognition results for the degraded image and the restored images by different methods. Here, we crop a local region from a high-resolution RS image. Compared with other results in (b–g), our result achieves higher recognition accuracy.
Table 8.
Quantitative comparison of mAP for joint image deraining and object detection.
4.4. Limitations
In this work, we integrate an effective multi-router scanning strategy into SMMs for high-quality image restoration. However, these methods often rely on linear scanning curves, such as Zigzag, which may inherently limit their ability to fully capture complex spatial relationships and structural properties within images. Furthermore, though the multi-router scanning strategy can theoretically capture more spatial information, it may introduce more computational complexity in practical applications.In future work, we will explore fractal scanning curves as an advanced method for patch serialization, such as fractal-based or dynamic adaptive scanning, aiming to fully exploit the potential of SSMs in dynamically analyzing and understanding intricate image patterns. And we will further address the balance between computational complexity and the model’s processing capability.
5. Conclusions
In this paper, we have presented an effective vision state space model, denoted as Weamba, for remote sensing image restoration under adverse weather conditions. To more effectively combine the complementary benefits of rich local and global information for high-quality image reconstruction, we integrate a local-enhanced state space module into the network backbone. Furthermore, we show that our proposed multi-router scan mechanism is more effective at capturing spatially varying degradation representations compared to existing approaches that scan along multiple directions. Extensive experiments on haze removal and raindrop removal demonstrate that our Weamba outperforms state-of-the-art CNN and Transformer-based models in terms of accuracy and model complexity.
Author Contributions
S.W. wrote the main manuscript text, X.H. completed the experiments, and X.C. prepared all figures and tables. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The available online experimental datasets in this paper are https://github.com/MingTian99/RSDformer (accessed on 26 January 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rasti, B.; Chang, Y.; Dalsasso, E.; Denis, L.; Ghamisi, P. Image restoration for remote sensing: Overview and toolbox. IEEE Geosci. Remote Sens. Mag. 2021, 10, 201–230. [Google Scholar] [CrossRef]
- Mehta, A.; Sinha, H.; Mandal, M.; Narang, P. Domain-aware unsupervised hyperspectral reconstruction for aerial image dehazing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 413–422. [Google Scholar]
- Chang, W.; Chen, H.; He, X.; Chen, X.; Shen, L. UAV-Rain1k: A Benchmark for Raindrop Removal from UAV Aerial Imagery. arXiv 2024, arXiv:2402.05773. [Google Scholar]
- Chen, X.; Pan, J.; Dong, J.; Tang, J. Towards unified deep image deraining: A survey and a new benchmark. arXiv 2023, arXiv:2310.03535. [Google Scholar]
- Gui, J.; Cong, X.; Cao, Y.; Ren, W.; Zhang, J.; Zhang, J.; Cao, J.; Tao, D. A comprehensive survey and taxonomy on single image dehazing based on deep learning. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Long, J.; Shi, Z.; Tang, W.; Zhang, C. Single remote sensing image dehazing. IEEE Geosci. Remote Sens. Lett. 2013, 11, 59–63. [Google Scholar] [CrossRef]
- Luo, Y.; Xu, Y.; Ji, H. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3397–3405. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Chen, X.; Li, H.; Li, M.; Pan, J. Learning a sparse transformer network for effective image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5896–5905. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, H.; Chen, X.; Lu, J.; Li, Y. Rethinking Multi-Scale Representations in Deep Deraining Transformer. Proc. AAAI Conf. Artif. Intell. 2024, 38, 1046–1053. [Google Scholar] [CrossRef]
- Wu, X.; Chen, H.; Chen, X.; Xu, G. Multi-scale transformer with conditioned prompt for image deraining. Digit. Signal Process. 2025, 156, 104847. [Google Scholar] [CrossRef]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Zhou, H.; Wu, X.; Chen, H.; Chen, X.; He, X. RSDehamba: Lightweight Vision Mamba for Remote Sensing Satellite Image Dehazing. arXiv 2024, arXiv:2405.10030. [Google Scholar]
- Guo, H.; Li, J.; Dai, T.; Ouyang, Z.; Ren, X.; Xia, S.T. Mambair: A simple baseline for image restoration with state-space model. In Proceedings of the Computer Vision—ECCV 2024, Milan, Italy, 29 September–4 October 2024; European Conference on Computer Vision. Springer: Cham, Switzerland, 2025; pp. 222–241. [Google Scholar]
- Liu, M.; Tang, L.; Fan, L.; Zhong, S.; Luo, H.; Peng, J. Towards Blind-Adaptive Remote Sensing Image Restoration. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4705212. [Google Scholar] [CrossRef]
- Li, Y.; Chen, X. A coarse-to-fine two-stage attentive network for haze removal of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1751–1755. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Dai, L.; Kong, C. Hybrid high-resolution learning for single remote sensing satellite image dehazing. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Li, S.; Zhou, Y.; Xiang, W. M2scn: Multi-model self-correcting network for satellite remote sensing single-image dehazing. IEEE Geosci. Remote Sens. Lett. 2022, 20, 1–5. [Google Scholar] [CrossRef]
- Huang, B.; Zhi, L.; Yang, C.; Sun, F.; Song, Y. Single satellite optical imagery dehazing using SAR image prior based on conditional generative adversarial networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1806–1813. [Google Scholar]
- Song, T.; Fan, S.; Li, P.; Jin, J.; Jin, G.; Fan, L. Learning an effective transformer for remote sensing satellite image dehazing. IEEE Geosci. Remote Sens. Lett. 2023, 20, 8002305. [Google Scholar] [CrossRef]
- Kulkarni, A.; Murala, S. Aerial image dehazing with attentive deformable transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6305–6314. [Google Scholar]
- Smith, J.T.; Warrington, A.; Linderman, S.W. Simplified state space layers for sequence modeling. arXiv 2022, arXiv:2208.04933. [Google Scholar]
- Ju, M.; Xie, S.; Li, F. Improving skip connection in u-net through fusion perspective with mamba for image dehazing. IEEE Trans. Consum. Electron. 2024, 70, 7505–7514. [Google Scholar] [CrossRef]
- Zheng, Z.; Wu, C. U-shaped vision mamba for single image dehazing. arXiv 2024, arXiv:2402.04139. [Google Scholar]
- Lei, X.; ZHang, W.; Cao, W. DVMSR: Distillated Vision Mamba for Efficient Super-Resolution. arXiv 2024, arXiv:2405.03008. [Google Scholar]
- Xiao, Y.; Yuan, Q.; Jiang, K.; Chen, Y.; Zhang, Q.; Lin, C.W. Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution. arXiv 2024, arXiv:2405.04964. [Google Scholar] [CrossRef]
- Bai, J.; Yin, Y.; He, Q. Retinexmamba: Retinex-based Mamba for Low-light Image Enhancement. arXiv 2024, arXiv:2405.03349. [Google Scholar]
- Li, G.; Zhang, K.; Wang, T.; Li, M.; Zhao, B.; Li, X. Semi-LLIE: Semi-supervised Contrastive Learning with Mamba-based Low-light Image Enhancement. arXiv 2024, arXiv:2409.16604. [Google Scholar]
- Weng, J.; Yan, Z.; Tai, Y.; Qian, J.; Yang, J.; Li, J. MambaLLIE: Implicit Retinex-Aware Low Light Enhancement with Global-then-Local State Space. arXiv 2024, arXiv:2405.16105. [Google Scholar]
- Zou, W.; Gao, H.; Yang, W.; Liu, T. Wave-Mamba: Wavelet State Space Model for Ultra-High-Definition Low-Light Image Enhancement. arXiv 2024, arXiv:2408.01276. [Google Scholar]
- Wu, X.; Lu, J.; Wu, J.; Li, Y. Multi-Scale Dilated Convolution Transformer for Single Image Deraining. In Proceedings of the 2023 IEEE 25th International Workshop on Multimedia Signal Processing (MMSP), Poitiers, France, 27–29 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. Vmamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar]
- Wen, Y.; Gao, T.; Zhang, J.; Li, Z.; Chen, T. Encoder-free multi-axis physics-aware fusion network for remote sensing image dehazing. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4705915. [Google Scholar] [CrossRef]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Volume 5, p. 6. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Ullah, H.; Muhammad, K.; Irfan, M.; Anwar, S.; Sajjad, M.; Imran, A.S.; de Albuquerque, V.H.C. Light-DehazeNet: A novel lightweight CNN architecture for single image dehazing. IEEE Trans. Image Process. 2021, 30, 8968–8982. [Google Scholar] [CrossRef]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1375–1383. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Guo, C.L.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3d position embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Xie, Q.; Zhao, Q.; Meng, D. A model-driven deep neural network for single image rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3103–3112. [Google Scholar]
- Yi, Q.; Li, J.; Dai, Q.; Fang, F.; Zhang, G.; Zeng, T. Structure-preserving deraining with residue channel prior guidance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4238–4247. [Google Scholar]
- Xiao, J.; Fu, X.; Liu, A.; Wu, F.; Zha, Z.J. Image de-raining transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12978–12995. [Google Scholar] [CrossRef] [PubMed]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).