Abstract
In recent years, convolutional neural network (CNN)-based and transformer-based approaches have made strides in improving the performance of hyperspectral image (HSI) classification tasks. However, misclassifications are unavoidable in the aforementioned methods, with a considerable number of these issues stemming from the overlapping embedding spaces among different classes. This overlap results in samples being allocated to adjacent categories, thus leading to inaccurate classifications. To mitigate these misclassification issues, we propose a novel discrete vector representation (DVR) strategy for enhancing the performance of HSI classifiers. DVR establishes a discrete vector quantification mechanism to capture and store distinct category representations in the codebook between the encoder and classification head. Specifically, DVR comprises three components: the Adaptive Module (AM), Discrete Vector Constraints Module (DVCM), and auxiliary classifier (AC). The AM aligns features derived from the backbone to the embedding space of the codebook. The DVCM employs category representations from the codebook to constrain encoded features for a rational feature distribution of distinct categories. To further enhance accuracy, the AC correlates discrete vectors with category information obtained from labels by penalizing these vectors and propagating gradients to the encoder. It is worth noting that DVR can be seamlessly integrated into HSI classifiers with diverse architectures to enhance their performance. Numerous experiments on four HSI benchmarks demonstrate that our DVR scheme improves the classifiers’ performance in terms of both quantitative metrics and visual quality of classification maps. We believe DVR can be applied to more models in the future to enhance their performance and provide inspiration for tasks such as sea ice detection and algal bloom prediction in the marine domain.
1. Introduction
Hyperspectral image (HSI) is an advanced remote sensing technology that captures the electromagnetic radiation over a broad spectrum of wavelengths emitted from the Earth’s surface. This technology provides comprehensive surface information to facilitate various applications, such as precision agriculture, geological exploration, and marine environmental monitoring [1,2,3]. With the advancement of remote sensing technology, HSI classification has increasingly become a crucial research topic [4]. Nevertheless, accurate HSI classification [5,6] remains a challenging task due to its high dimensionality and intricate spectral–spatial relationships.
Traditional HSI classification methods [7,8,9] usually rely on manual feature extraction techniques or shallow classifiers, but they struggle to capture intricate spectral–spatial patterns present in the data. In order to address this limitation, deep learning-based techniques have gained popularity in the field of HSI classification [10,11,12]. Among these techniques, convolutional neural networks [13,14,15,16] (CNNs) have emerged as powerful tools for obtaining hierarchical representations of HSIs, leading to improved classification outcomes. Nevertheless, CNNs have inherent constraints [17] in both modeling long-range dependencies and capturing complex spectral–spatial relationships within hyperspectral data. These limitations are well addressed by the vision transformers (ViTs) [18,19,20,21,22] that leverage self-attention mechanisms to handle global dependencies and interactions. However, these above methods focus on enhancing classification performance through the redesign of model networks but overlook the fundamental cause of misclassification.
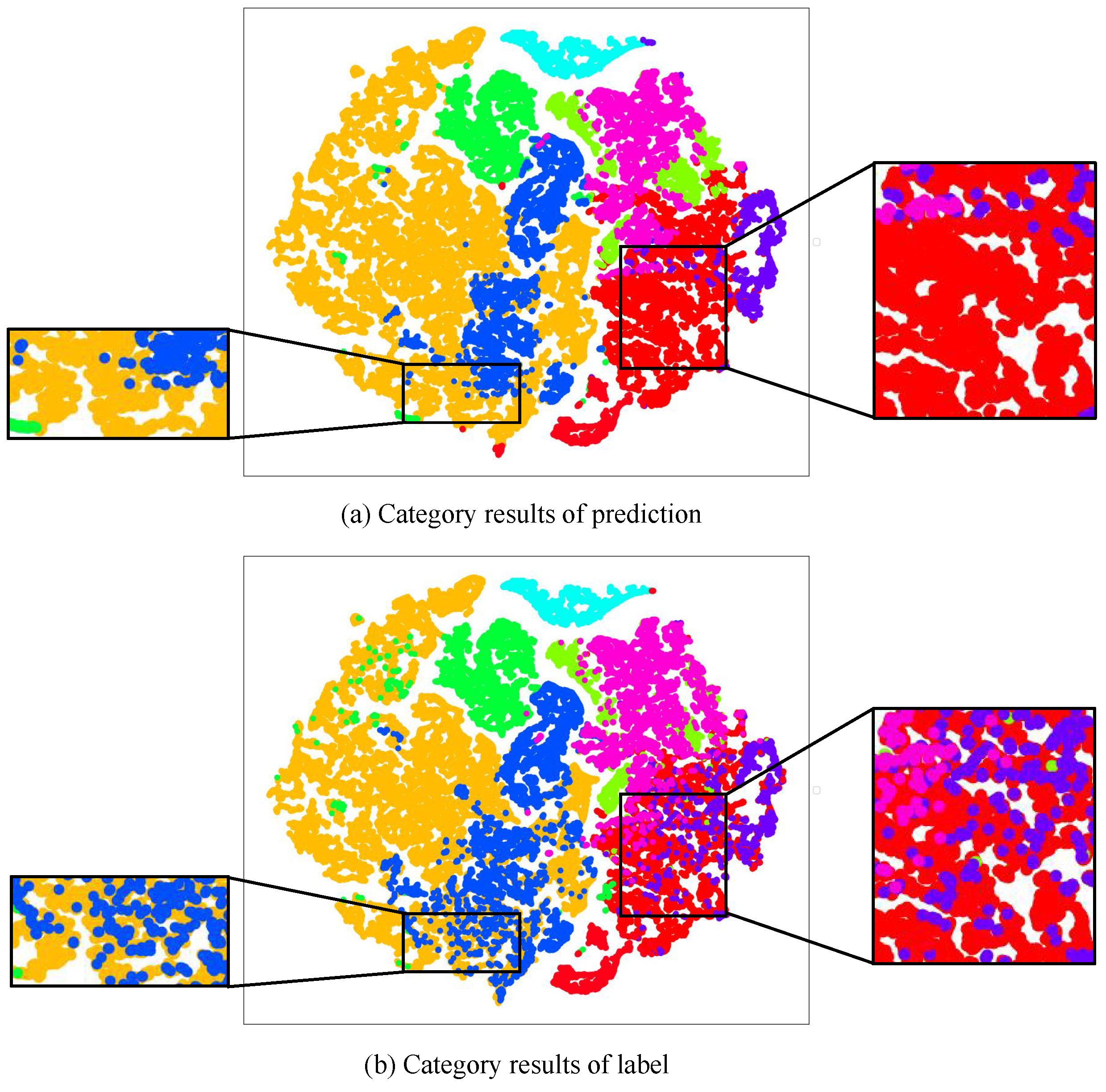
We aim to enhance HSI classification performance from a new perspective by analyzing the root causes of misclassification issues, identifying strategies to mitigate these errors, and reducing misclassifications. Specifically, deep learning classifiers typically comprise an encoder and a classification head. The encoder is responsible for capturing category representations, and these representations are subsequently used by the classification head for the accurate classification [23]. This demonstrates that encoded features play a decisive role in the accuracy of classification. Therefore, to analyze the causes of misclassification issues, we visualize the encoded features from a representative hyperspectral classification model SpectralFormer [18], using t-Distributed Stochastic Neighbor Embedding [24] (t-SNE, an effective approach for visualizing the distribution of high-dimensional data via dimension reduction). The t-SNE plot, as depicted in Figure 1, is based on the Pavia University (PU) dataset, with the model trained on 1% of the dataset and the t-SNE visualization generated using 98% of the dataset for testing. Due to overlapping distributions of distinct embedding features, SpectralFormer incorrectly categorizes instances labeled as blue (Figure 1b) to the yellow category (Figure 1a), resulting in heightened misclassification between categories. Likewise, SpectralFormer erroneously classifies the areas with true labels of blue and pink (Figure 1b), inaccurately grouping them into the red category (Figure 1a), as shown by the magnified portions. This occurrence significantly contributes to classification inaccuracies. Existing approaches do not take into account the encoded features, and solely supervise model training based on the classification outcomes. The absence of constraints on the encoded features frequently leads to inadequate clustering and overlaps between embedding spaces of different categories, as illustrated in Figure 2a. The presence of overlapping and disorganized embedding spaces poses a challenge for classifiers in discerning features belonging to different categories.
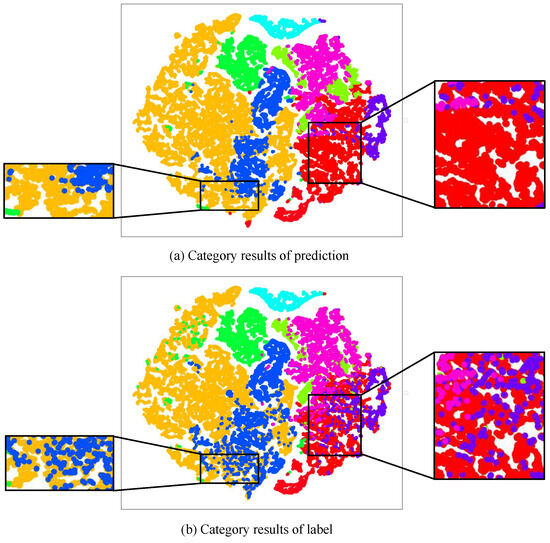
Figure 1.
Misclassification due to encoded features overlap. (a) Category results of prediction. (b) Category results of label. The t-SNE visualization of encoded features from SpectralFormer [18] on the Pavia University dataset clearly demonstrates that SpectralFormer incorrectly categorizes instances (labeled as blue) as belonging to the yellow category, while also misclassifying instances (labeled as blue and pink) as belonging to the red category. The overlap of encoded features significantly contributes to classification inaccuracies.
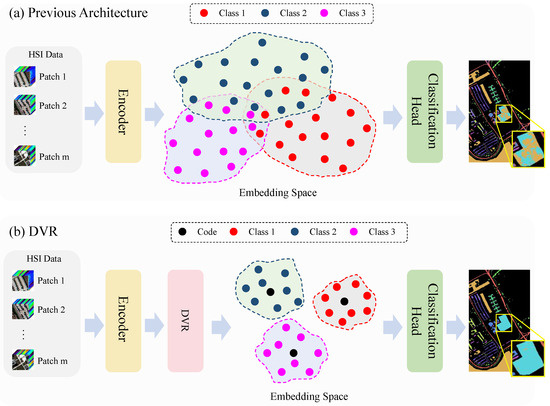
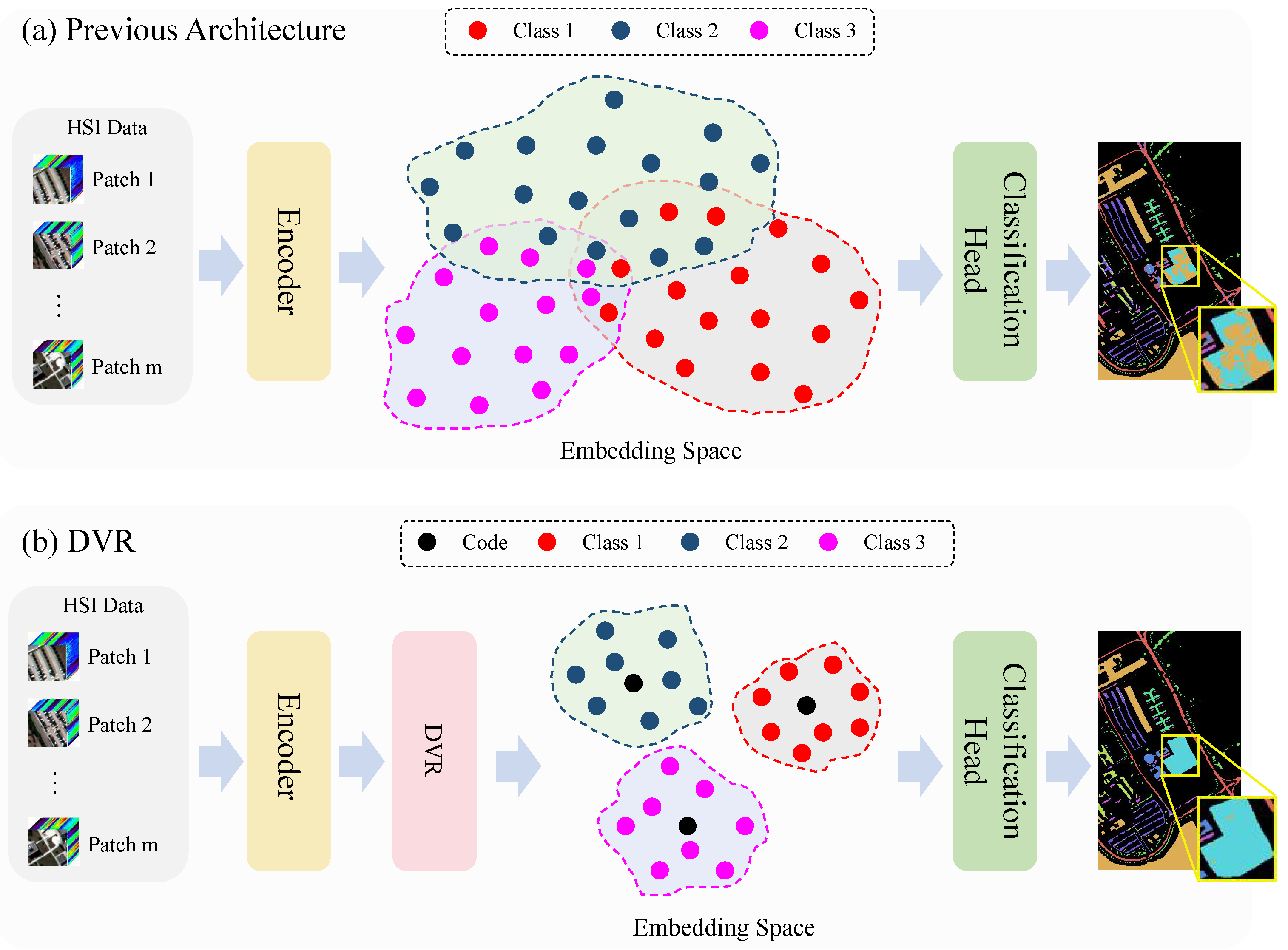
Figure 2.
Comparison between previous architecture and our DVR strategy. (a) Previous architecture. Previous architecture typically comprises an encoder and a classification head, however, it faces difficulties due to the disorderly distribution of encoded features, resulting in a decline in classification accuracy. (b) DVR. Our DVR approach integrates the discrete vector representation into the embedding space of encoded feature, aiming to optimize the distribution of encoded features by making features of the same category more compactly clustered and reduce the likelihood of misclassification by the classifier.
To address the above limitations, we investigate the discrete vector representation (DVR) strategy in order to optimize the distribution of class representation, thus boosting the performance of current HSI classification models. Discrete vectors have the ability to effectively represent essential features in low-dimensional space while preserving global structures of objects [25] and remaining stable when subjected to minor perturbations [26]. In contrast to designing a new network, as illustrated in Figure 2b, our methodology enforces discrete vector constraints on category representation from the encoder, with the goal of achieving a more rational embedding space. This strategy can be plug-and-play and easily integrated into existing HSI image classifiers to improve their classification accuracy. Specifically, DVR comprises three components: the Discrete Vector Constraints Module (DVCM), Adaptive Module (AM), and auxiliary classifier (AC). Initially, we establish a codebook in the DVCM to discretely represent the embedding space and store representative class features in a discrete vector manner. During the training phase, the AM aligns the features extracted by the encoder with the semantic space defined by the codebook. Simultaneously, the DVCM utilizes the vectors from the codebook to regulate the features extracted from the encoder, ensuring that features from the same class are clustered more closely together to prevent a confusing feature distribution. Subsequently, discrete vectors are chosen from the codebook by considering their resemblance to encoded features, and incorporated into the AC to enhance the accuracy of predictions. By implementing the aforementioned procedure, our DVR method efficiently optimizes the distribution of category representations, resulting in a notable improvement in the overall classification performance. The contributions of our work can be summarized as follows:
- We propose a novel discrete vector representation (DVR) strategy. Distinguished from previous approaches of optimizing network structures, DVR offers a fresh perspective on optimizing the distribution of category features to mitigate the misclassification problem. Moreover, it can be effortlessly incorporated into various existing HSI classification methods, thus improving their classification accuracy.
- We develop the AM, DVCM, and AC to form a complete DVR strategy. The AM aligns the encoded features with the semantic space of the codebook. The DVCM is able to capture essential and stable feature representations in its codebook. The AC enhances classification performance by utilizing representative code information from the codebook. These three components are integrated to improve the discriminability of feature categories and reduce misclassifications.
- Our comprehensive evaluations demonstrate that the proposed DVR approach with feature distribution optimization can enhance the performance of HSI classifiers. Through extensive experiments and visual analyses conducted on different HSI benchmarks, our DVR approach consistently surpasses other state-of-the-art backbone networks in terms of both classification accuracy and model stability, while requiring merely a minimal increase in parameters.
The remainder of this paper is organized as follows. In Section 2, we review related work on HSI classification methods and schemes for enhancing model performance. Section 3 presents the proposed methodology, which includes the details of our DVR framework and its training process. In Section 4, we describe experimental results of our approach in comparison to baseline methods. Section 5 discusses the limitations of DVR as well as potential directions for future improvements and applications. Finally, Section 6 concludes the article.
2. Related Work
In this section, we overview existing HSI classification approaches, encompassing convolutional neural networks, vision transformers, and schemes for enhancing model performance.
2.1. Convolutional Neural Networks for HSI Classification
With the advancement of deep learning, convolutional neural networks (CNNs) have emerged as powerful tools for HSI classification [13,27,28,29,30,31,32,33,34]. These CNN-based methods have demonstrated impressive achievements by leveraging convolutional layers to extract discriminative features from HSI data. Initially, two-dimensional (2-D) CNNs [27,28] employed convolutional and pooling layers to capture spatial dependencies within HSIs. A pioneering 2-D CNN architecture [27] was proposed for automated high-level feature extraction in HSI classification. Mei et al. [28] concentrated on memory-efficient 2-D CNNs to accelerate the forward step of the network. Then, Song et al. [29] introduced a fusion-based model to aggregate multi-layer features and leverage complementary HSI information. Moreover, Zhao et al. [30] introduced a dual-tunnel CNN to enforce the spatial consistency within deeper network layers. To account for the three-dimensional (3-D) nature of HSIs, many researchers explored 3-D CNNs [13,31,32,33,34] to incorporate spectral and spatial signatures simultaneously. Chen et al. [31] and He et al. [32] proposed an end-to-end multiscale 3-D deep CNN architecture to capture both multiscale spatial and spectral characteristics. To emphasize the importance of spectral–spatial integration, Zhong et al. [33] introduced a spectral–spatial residual network, while Hamida et al. [13] devised a joint spectral–spatial information processing approach. In addition, Mei et al. [34] proposed an unsupervised spatial–spectral feature learning strategy, enabling 3-D convolutional autoencoder networks to extract meaningful features without pixel-wise annotations. Although CNN-based methods show proficiency in extracting distinctive features using 2-D or 3-D structures to enhance feature representation, they generally demand substantial computational resources and fail to capture long-range dependencies of HSI data.
2.2. Vision Transformers for HSI Classification
The limitations have prompted researchers to explore alternative architectures. Recently, ViTs [19] have gained significant attentions for modeling global dependencies in long-range positions and bands of HSI pixels. These transformers [18,20,21,35], equipped with multi-head self-attention mechanisms, show great promise for HSI classification tasks. Hong et al. [18] proposed a backbone network based on the transformer architecture and utilized attention mechanisms to capture subtle spectral differences. Xue et al. [35] introduced a local transformer to incorporate a partial partition restore module for global context dependencies. Sun et al. [20] designed a Spectral–Spatial Feature Tokenization Transformer (SSFTT) to capture spectral–spatial features and high-level semantic features. Additionally, Mei et al. [21] proposed a Group-Aware Hierarchical Transformer (GAHT) for HSI classification, and enhanced the model’s ability to capture local relationships within HSI spectral channels while maintaining a global understanding of spatial–spectral context. Despite the proficiency of ViTs in modeling global dependencies, they usually lack distribution control over the embedding space, thus leading to the cross-aggregation of features.
2.3. Schemes for Enhancing Model Performance
To enhance the model performance, common techniques such as data augmentation and regularization are employed, and vector quantized-variational autoencoder (VQ-VAE) [25] methods leverage discrete representations to enhance the performance. Data augmentation involves transforming or expanding training data to increase the number and diversity of data samples, reducing the model’s reliance on specific data and enhancing its generalization capability. Various techniques, including random rotation, translation, scaling, and noise addition, are employed for data augmentation. Several carefully designed data augmentations were designed by [36,37]. Moreover, regularization techniques constrain the model’s complexity to prevent overfitting to the training data [38,39]. Common regularization methods include adding L1 or L2 norm penalties on loss functions to limit the magnitude of weights. Furthermore, VQ-VAE introduces a codebook learned through a vector-quantized autoencoder model, using an encoder–decoder architecture to transform images into discrete latent codes for enhancing model robustness. Mao et al. [26] demonstrated the use of discrete representations to strengthen model robustness by preserving the overall structure of an image while disregarding minor local details. Hu et al. [40] designed a discrete codebook for encoded feature representation, which helps combats semantic noise with reduced transmission overhead. These researchers demonstrated that discrete representation is an efficient scheme to achieve satisfactory performance. Data augmentation and regularization techniques have been commonly used in existing hyperspectral classification models to enhance model performance from the perspective of data or the model network. However, the current research in HSI classification mainly focuses on the design of new models [41], neglecting the improvement of model performance. Our proposed strategy aims to incorporate discrete representation schemes from the perspective of optimizing the feature space to boost model performance, thereby addressing the existing research gap in techniques.
3. Methods
3.1. Overall Architecture
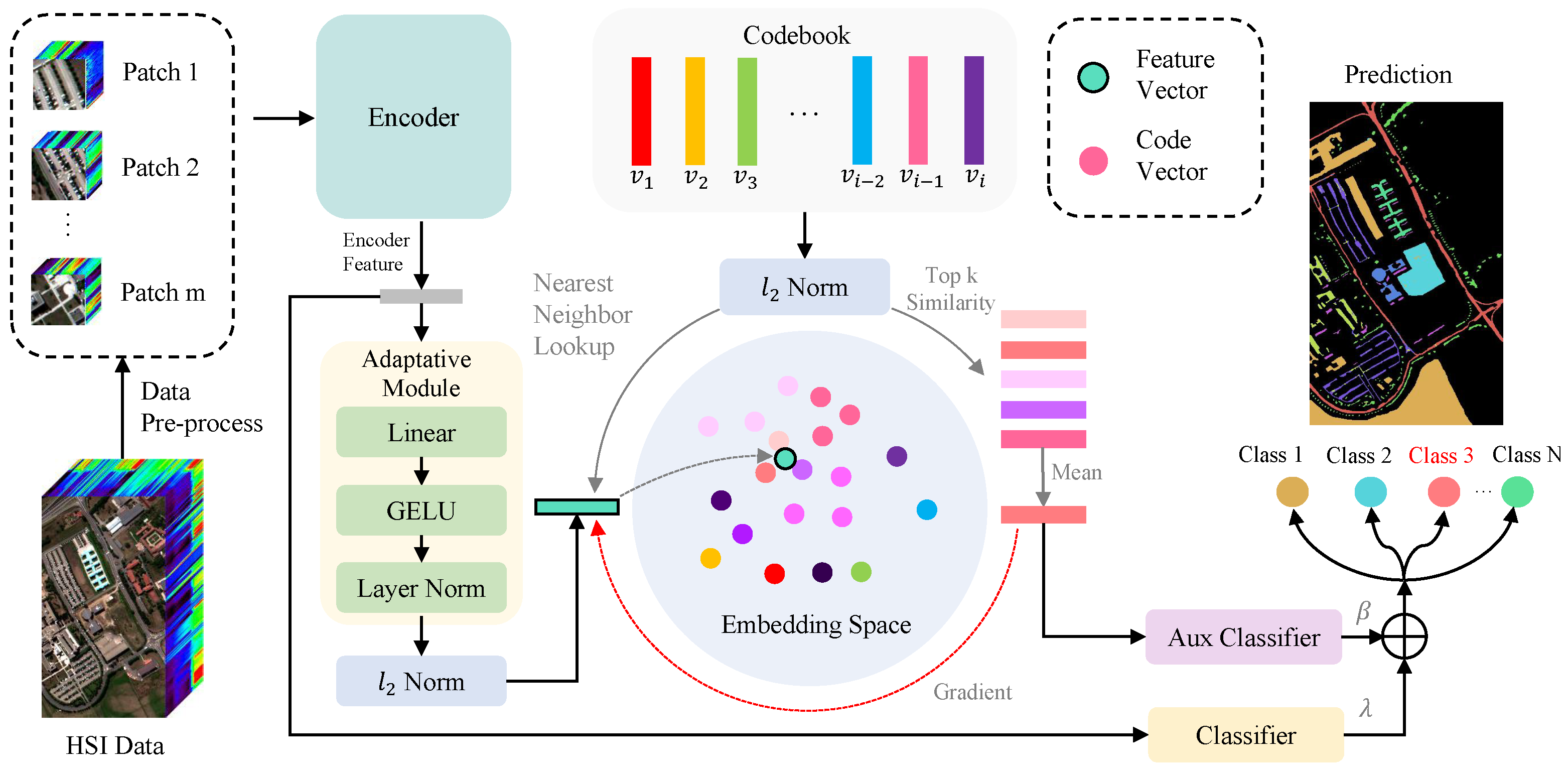
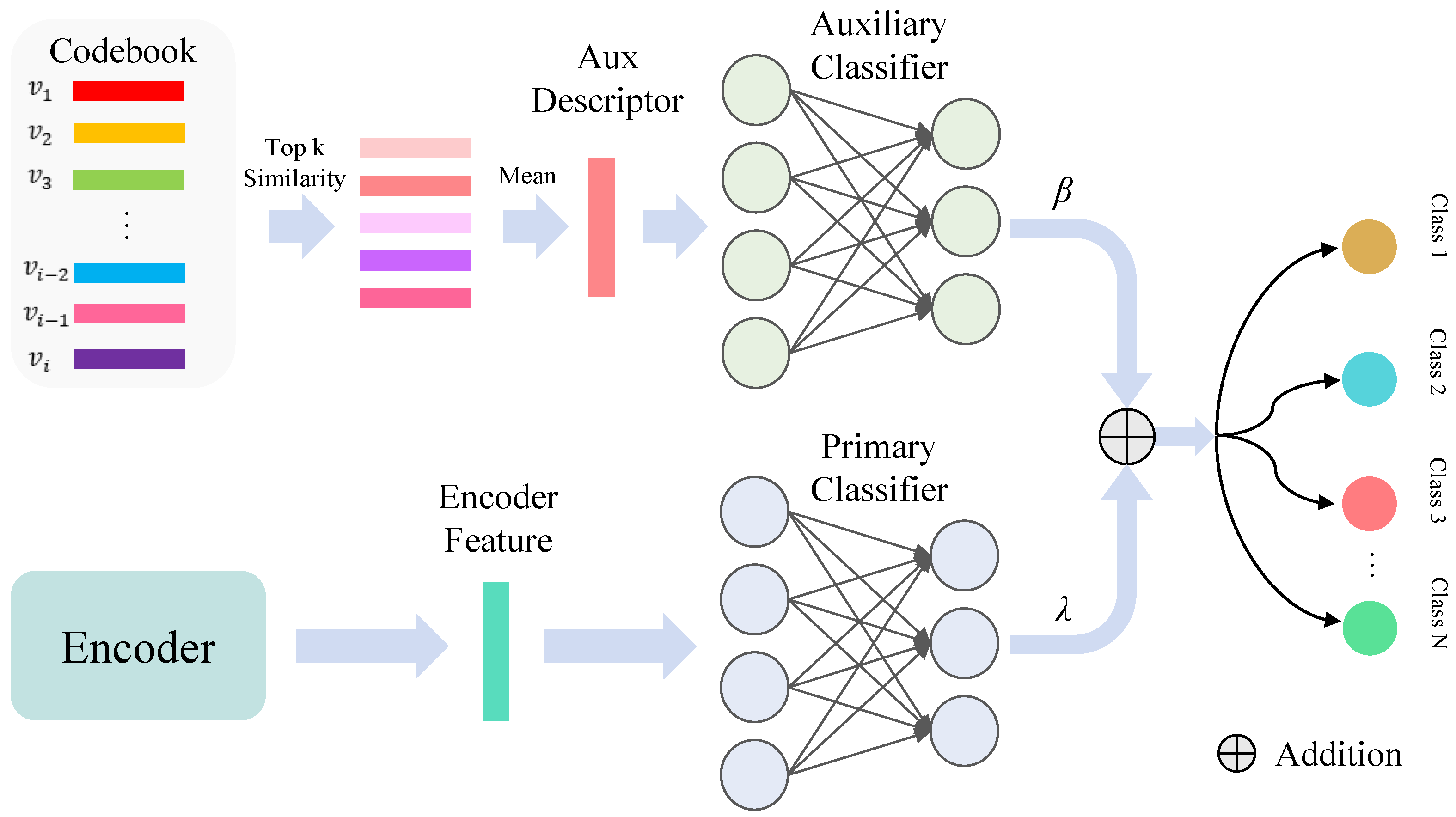
The architecture overview of the proposed approach is shown in Figure 3. Based on the encoder and classifier, our DVR incorporates the Adaptive Module (AM), DVCM, and auxiliary classifier (AC) into the existing classification model by optimizing the feature distribution to improve its classification performance. Specifically, given the original HSI data (C denotes the spectral bands and is the spatial resolution), we divide it into N patches in the preprocessing stage. Firstly, we established a codebook to discretize the embedding space and facilitate the extraction and storage of category representation vectors using our designed DVCM. Subsequently, the encoder processed the inputted patch data to obtain class representation, and the AM fine-tuned the encoded feature to align with the embedding space of the codebook. The top k nearest codes to the encoded feature were chosen and averaged to generate the auxiliary class descriptor. This descriptor was then fed into an AC to assist in the prediction. By leveraging the DVCM and AC during the gradual training process, encoded features of the same class are clustered closely together, while maintaining a clear separation between features of different classes. This distinctive attribute allowed the existing HSI classification model to capture more robust and representative class features, leading to significant performance improvements. The DVR and its training process are elaborated below. Table 1 details the definition of notations used in the proposed DVR.
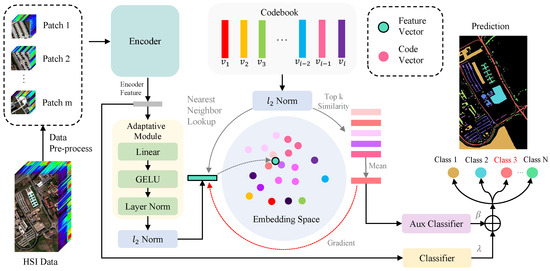
Figure 3.
The proposed DVR framework for HSI classification. Firstly, the encoder in the model extracts spatial–spectral features from each patch, and these features are then adjusted by the Adaptive Module to align with the embedding space defined by the codebook. This codebook comprises multiple discrete vectors that represent different classes, which are refined through the DVCM (between AM and AC) during training iterations. Subsequently, the framework calculates the auxiliary (Aux) class descriptor by averaging the top k nearest vectors from the codebook. The descriptor is employed by the Aux classifier to predict the class of each input patch. Ultimately, this prediction combines with the output of primary classifier to generate a classified image as final output.

Table 1.
Definition of notations used in DVR.
3.2. Discrete Vector Representation Strategy
Following the structure illustrated in Figure 3, we employed the encoder to transform a patch into a feature vector , where P and D denote the patch size and the dimension of the encoded feature.
Adaptive Module (AM): The AM is composed of a layer normalization step, a Gaussian error Linear Unit (GeLU) activation function and a linear layer. Layer normalization is a widely used normalization technique in deep learning models that standardizes and rescales the outputs of each neuron. This helps in reducing internal covariate shift, improving training stability and convergence speed, and enhancing the generalization capabilities of the model. The GeLU activation function imitates the behavior of stochastic neurons by multiplying the input x with the value from the cumulative distribution function of the standard normal distribution. This simulation enables the network to adjust to various input distributions, thereby improving its robustness. Additionally, the GeLU activation function provides excellent adaptability and flexibility to accommodate the diversity of codes within the codebook, which is defined as
where represents the standard Gaussian cumulative distribution function, and .
The AM is capable of aligning the extracted features from the encoder with the semantic framework defined by the codebook, as well as adjusting the feature dimensions to match the codebook dimension. The feature vector e is processed through an Adaptive Module to produce h.
Discrete Vector Constraint Module (DVCM): The DVCM introduces a codebook that leverages discrete vector quantification for capturing category representation. After aligning the embedding features with a created codebook, the codebook of the DVCM is able to represent the embedding space in a discrete format and retain representative features of classes as discrete vectors. Specifically, after h has been -normalized, the vector quantizer looks up the top k nearest neighbor codes in the codebook. These selected codes are then averaged to determine the quantized code for the patch feature. Let () represent the codes in the codebook, where K and denote the number and dimension of discrete vector, respectively. For each patch feature h, its quantized code is determined by
where the normalization is employed for the codebook lookup and presents the index of top k nearest vectors in the codebook. Furthermore, Topkmin refers to the selection of the k smallest-distance items from a set based on specified criteria. Due to the non-differentiable nature of the quantization process in Equation (2), the gradient is directly copied from the input of the auxiliary classifier to the encoder output, as depicted in Figure 3. Intuitively, the quantizer identifies the nearest code for each encoder output, and the gradient of the codebook embedding indicates the useful direction for optimizing the encoder. To ensure the codebook captures representative features, the codebook embeddings are updated using an exponential moving average (EMA) [25], which offers enhanced stability for training discrete vectors. The typical formula for updating with momentum is expressed by
where represents the decay factor, with a value typically close to 1, that determines the weight of the previous code value in the updated calculation. The training objective for updating the codebook vectors is formulated as
where the symbol denotes the stop-gradient operator, which is an identity in the forward pass and yielding zero gradients in the backward pass.
Additionally, the utilization of clustering techniques (K-means) divides the feature vector space into several regions, where each region’s centroid is represented by a vector in the codebook. These vectors effectively encapsulate the entire feature space and extract crucial information. The classification process consists of mapping feature vectors to the nearest codebook vector, thereby converting continuous data into discrete codified forms. These discrete representations not only optimize the feature distribution, but also boost the efficiency of the representation, ultimately enhancing the performance of classification algorithms.
Auxiliary Classifier (AC): After generating the codebook, we utilize the discrete vectors to improve the classification procedure. This enhancement entails combining the classification outcomes of codebook features with the features extracted by the encoder models. This collaborative strategy enhances the discriminative capability of the feature set, thus improving classification performance in HSI tasks.
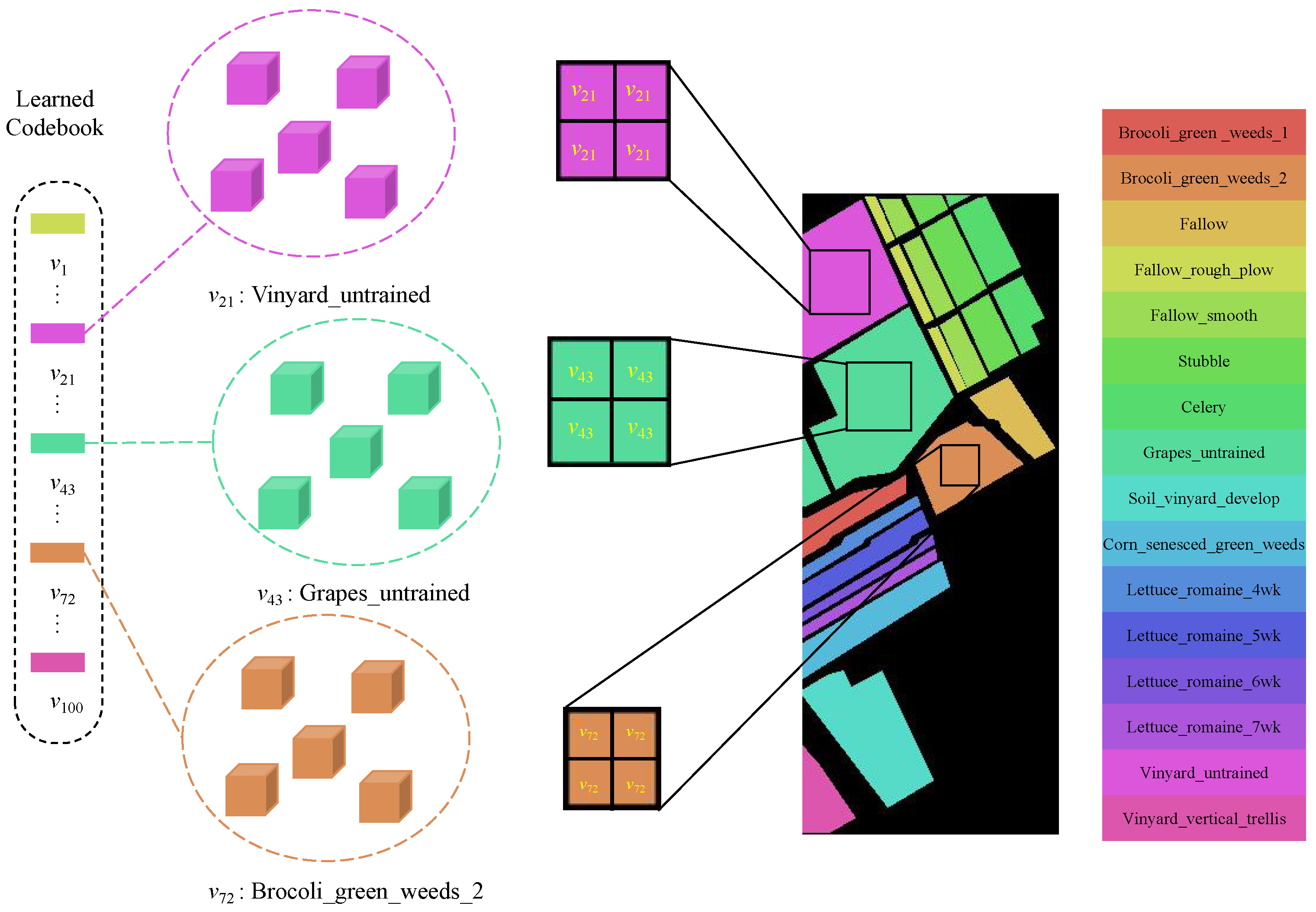
To clearly describe the role of a codebook in assisting with classification, we visualized the meanings of the encodings present in the codebook, as illustrated in Figure 4. The different codes in the codebook represent feature information for different categories, for instance, in the Salinas (SA) dataset, code 21 represents the category “Vinyard_untrained”. By utilizing representative code information from the codebook, samples can be classified more accurately. During the validation phase, we enhanced the primary classification procedure by incorporating outcomes obtained from the codebook features. As illustrated in Figure 5, we selected the top five closest codes within the embedding space and averaged them to generate our auxiliary class descriptor. By merging predictions from both the primary and codebook-based classifications, we harnessed the complementary information within the codebook features to enhance classification performance. This dual classification strategy improved the model’s capacity to accurately classify diverse and intricate data instances. The output o of the classification results following the combination of scores is as follows:
where p denotes the output of the primary classifier (PC) using the encoded features, and a represents the output from the AC using the codebook features. We carefully tuned parameters and to balance the contributions of primary and auxiliary classifiers, where and .
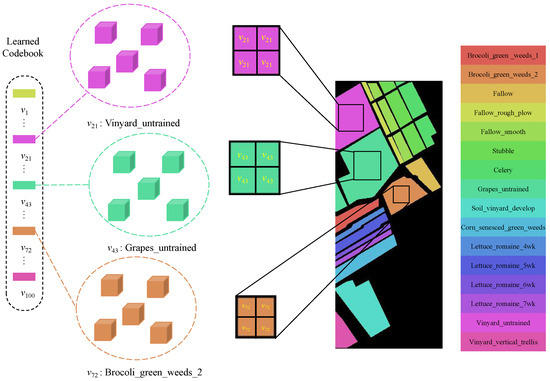
Figure 4.
Codebook visualization. The different codes in the codebook represent the feature information for various categories. For instance, in the SA dataset, code 21 corresponds to the category “Vinyard untrained”.
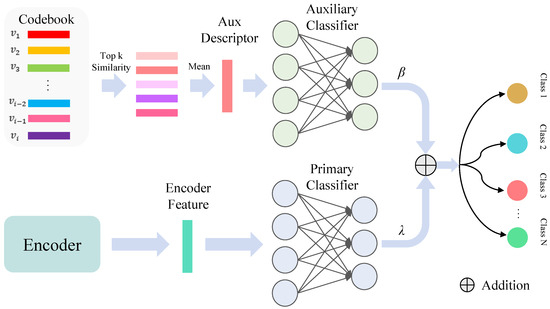
Figure 5.
Dual classification strategy. We select the top five closest codes within the embedding space and average them to generate our auxiliary class descriptor. By merging predictions from both the primary and codebook-based classifications, we leverage the complementary information within the codebook features to improve classification performance.
Building upon the integration of codebook features with encoder models, our approach introduces a novel loss function tailored to optimize the collaborative utilization of both feature sets. This loss function crucially underpins the dual-classification strategy, and guarantees that each element of the feature representation contributes optimally to the ultimate classification accuracy. Our loss function consists of three components:
where t represent the ground truth. In addition, we adopted the Cross-Entropy (CE) loss function [42] to calculate the classification loss:
where Equation (8) denotes the ground truth, and denotes the model’s output probability for the i th patch belonging to the class c. Furthermore, C represents the total number of classes.
We summarize the pseudocode for the DVR inference process in Algorithm 1.
| Algorithm 1: Inference of DVR |
 |
3.3. Train Strategy
We adopted a two-stage training strategy. Initially, we trained the model without the inclusion of codebook features. This initial phase allowed the model to learn basic patterns within the data. After a certain number of epochs, we incorporated the codebook features. The codebook was initialized with a number of samples equivalent to its capacity. These samples were batch-processed through the encoder to extract their features, which were then collectively used to initialize the codebook in the quantizer. This initialization step was crucial as it enhanced the utilization of the codebook, and improved the efficiency of the training process. Furthermore, introducing these features at a later stage enabled us to leverage their discriminative capabilities. This two-stage training strategy ensured that the model first learns simple features and then progressively refines its understanding by incorporating more representative discrete vector features.
4. Experiment Results
In this section, we evaluate the effectiveness of our DVR by employing four standard HSI datasets including Salinas (SA), Pavia University (PU), HyRANK-Loukia (HR-L), and WHU-Hi-HanChuan (HC) [43], which are extensively utilized for classification tasks. Then, we present the implementation details and evaluation metrics. Next, we conduct both qualitative and quantitative analyses compared to the state-of-the-art (SOTA) results. Last, we perform ablation experiments to gauge the impact of different modules and hyper-parameters on classification accuracy.
4.1. Data Description
We allocated varying proportions of labeled samples across different datasets. Specifically, for the SA and PU datasets, we randomly selected 1% of the labeled samples for training, 1% for validation, and 98% for testing. For the HR-L dataset, we designated 3% of the labeled samples for training, 3% for validation, and 94% for testing. As for the HC dataset, we used 0.2% of the samples for training, 0.2% for validation, and 99.6% for testing. The fixed number of training and testing samples can be found in Table 2.
Table 2.
The numbers of training, validation, and testing samples in the SA dataset, the PU dataset, the HR-L dataset, and the HC Dataset.
4.1.1. Salinas
The SA dataset was captured through the use of the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor over the Salinas Valley, California, USA. It is composed of 204 spectral bands after discarding the 20 water absorption bands, covering range from 400 nm to 2500 nm. The image size is 512 × 217 pixels with a ground sampling distance of 3.7 m. It includes 16 different land cover classes. (https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes#Salinas (accessed on 18 January 2025)).
4.1.2. Pavia University
The PU dataset was acquired utilizing the Reflective Optics System Imaging Spectrometer (ROSIS) sensor over the area of Pavia University and its surroundings in Italy. It comprises 103 spectral bands, spanning range from 430 nm to 860 nm. The image size is 610 × 340 pixels with a ground sampling distance of 1.3 m, encompassing nine different land cover categories (https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes#Pavia_University_scene (accessed on 18 January 2025)).
4.1.3. HyRANK-Loukia
The HR-L dataset was sourced by the Hyperion sensor on the Earth Observing-1 satellite. It encompasses a total of 176 spectral bands, spanning range from 400 nm to 2500 nm. The image size is 249 × 945 pixels with a ground sampling distance of 30m within this dataset, and there are 14 distinct land cover classes (https://zenodo.org/records/1222202 (accessed on 18 January 2025)).
4.1.4. WHU-Hi-HanChuan
The HC dataset was collected using the Headwall Nano-Hyperspec sensor mounted on a UAV. It contains 274 spectral bands ranging from 400 nm to 1000 nm, with a spatial resolution of 0.109 m. The imagery size is 1217 × 303 pixels, and the dataset includes seven crop species along with other land cover types such as buildings and water bodies (http://rsidea.whu.edu.cn/resource_WHUHi_sharing.htm (accessed on 18 January 2025)).
4.2. Experiment Setups
4.2.1. Implementation Details
In our experimental setup, we maintained the settings of the encoder models unchanged, while integrating our codebook to assist in the classification process. We implemented our approach using the PyTorch framework and trained it on an NVIDIA GeForce GTX 2080 Ti GPU with 11 GB of memory. The batch size and epoch count were configured at 64 and 300, respectively. To attain the best performance, as reported in [13,18,20,21], both the optimizer and scheduler were maintained at their default configurations. Additionally, data augmentation was employed to mitigate the issue of insufficient training samples in all approaches. For each batch of data in an iteration, one of the five augmentation techniques (vertical flip, horizontal flip, 90° rotation, 180° rotation, and 270° rotation) is randomly chosen with an equal probability.
4.2.2. Evaluation Metrics
To quantitatively evaluate the performance of HSI classification, we employ four metrics: overall accuracy (OA), average accuracy (AA), kappa coefficient (), and per-class accuracies. OA indicates the percentage of correctly predicted samples out of the total samples. AA represents the mean classification accuracy of each class. The coefficient measures the agreement between the ground truth and classification maps. To minimize experimental variability, we randomly split the labeled samples five times, and reported the mean values and standard deviations for these metrics. A lower standard deviation indicates a higher reliability and consistency.
4.2.3. Baseline Models
To demonstrate the effectiveness of the suggested DVR, a number of representative methods are selected for comparative experiments: the 3D-CNN [13], SpectralFormer (SF) [18], SSFTT [20], and GAHT [21]. The 3D-CNN employs a exclusively convolutional architecture, while the SpectralFormer is based on transformer architectures. The SSFTT and GAHT combine convolution and transformer elements in a hybrid architecture. The universality of DVR is better demonstrated through comparative experiments across various architectural types.
4.3. Comparative Experiments
4.3.1. Quantitative Assessment
Table 3, Table 4, Table 5 and Table 6 present the results for the OA, AA, kappa, and each class accuracy using various methods on the Salinas, Pavia University, and HyRANK-Loukia datasets, respectively. The optimal results are highlighted in bold. As the results illustrated, our method outperforms other SOTA methods across all four benchmark datasets. On the SA datasets, our DVR based on respective models achieved significantly higher OA compared with the 3D-CNN and SF, with a difference of 2.39% and 1.22%, respectively. It is obvious that our method also demonstrates lower standard deviations in both OA and specific accuracy for each class. On the PU datasets, our method incorporating DVR with the 3D-CNN achieved the highest improvement of 7.58% in OA. Meanwhile, the kappa value improved from 83.70% ± 1.77% to 94.06% ± 0.46%, indicating a substantial enhancement in model reliability and classification consistency. Similarly, our method based on the SSFTT and GAHT, respectively, showed performance enhancements. On the challenging HR-L dataset, DVR performed much better than the other methods. It is noted that the modified baseline model exhibited greater potential in classifying challenging datasets. This trend highlights the effectiveness of DVR in enhancing the reliability of the classification outcomes under constrained training scenarios.
Table 3.
Classification performance of various methods on the SA dataset using only 1% training samples.
Table 4.
Classification performance of various methods on the PU dataset using only 1% training samples.
Table 5.
Classification performance of various methods on the HR-L dataset using only 3% training samples.
Table 6.
Classification performance of various methods on the HC dataset using only 0.2% training samples.
4.3.2. Visual Evaluation
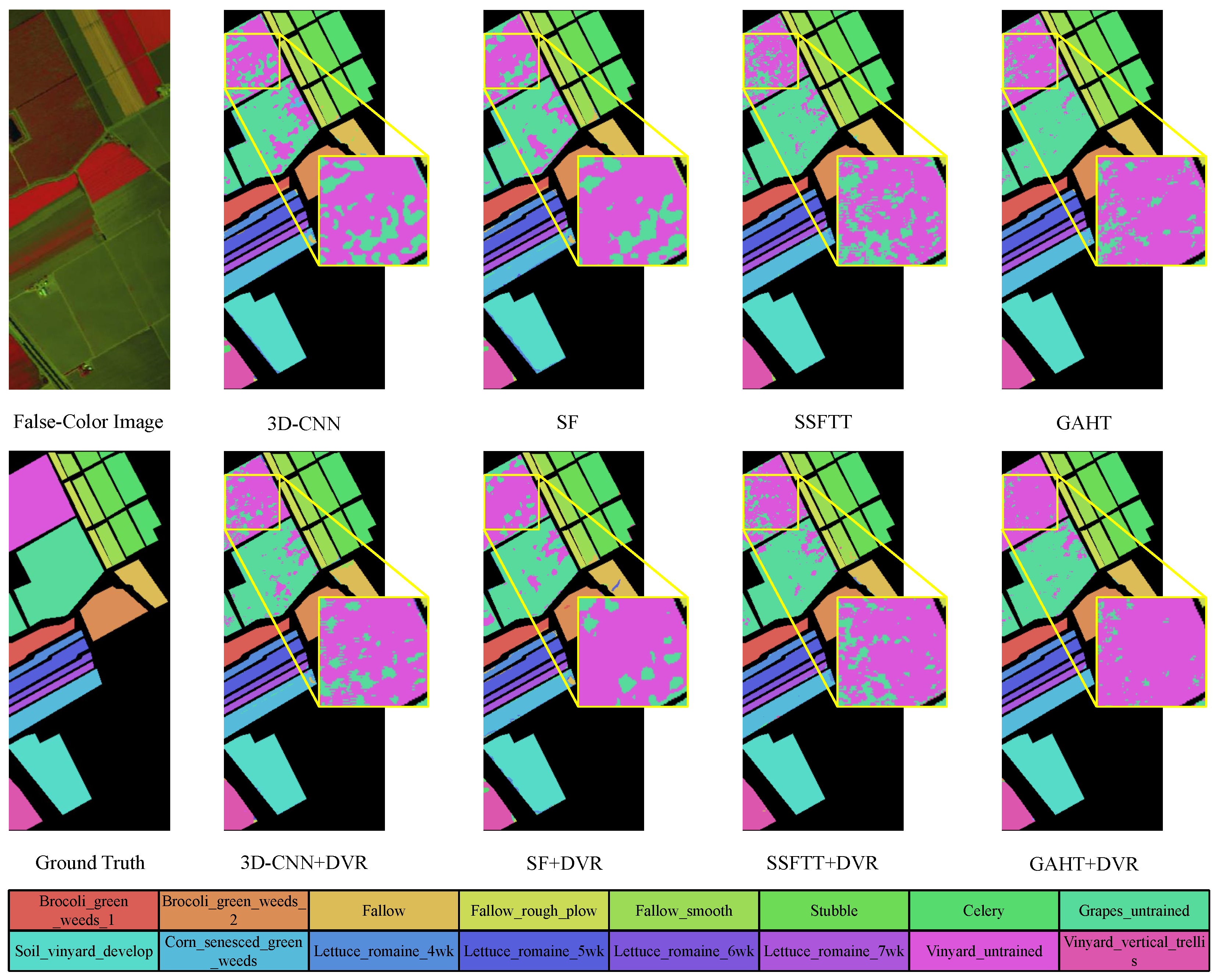
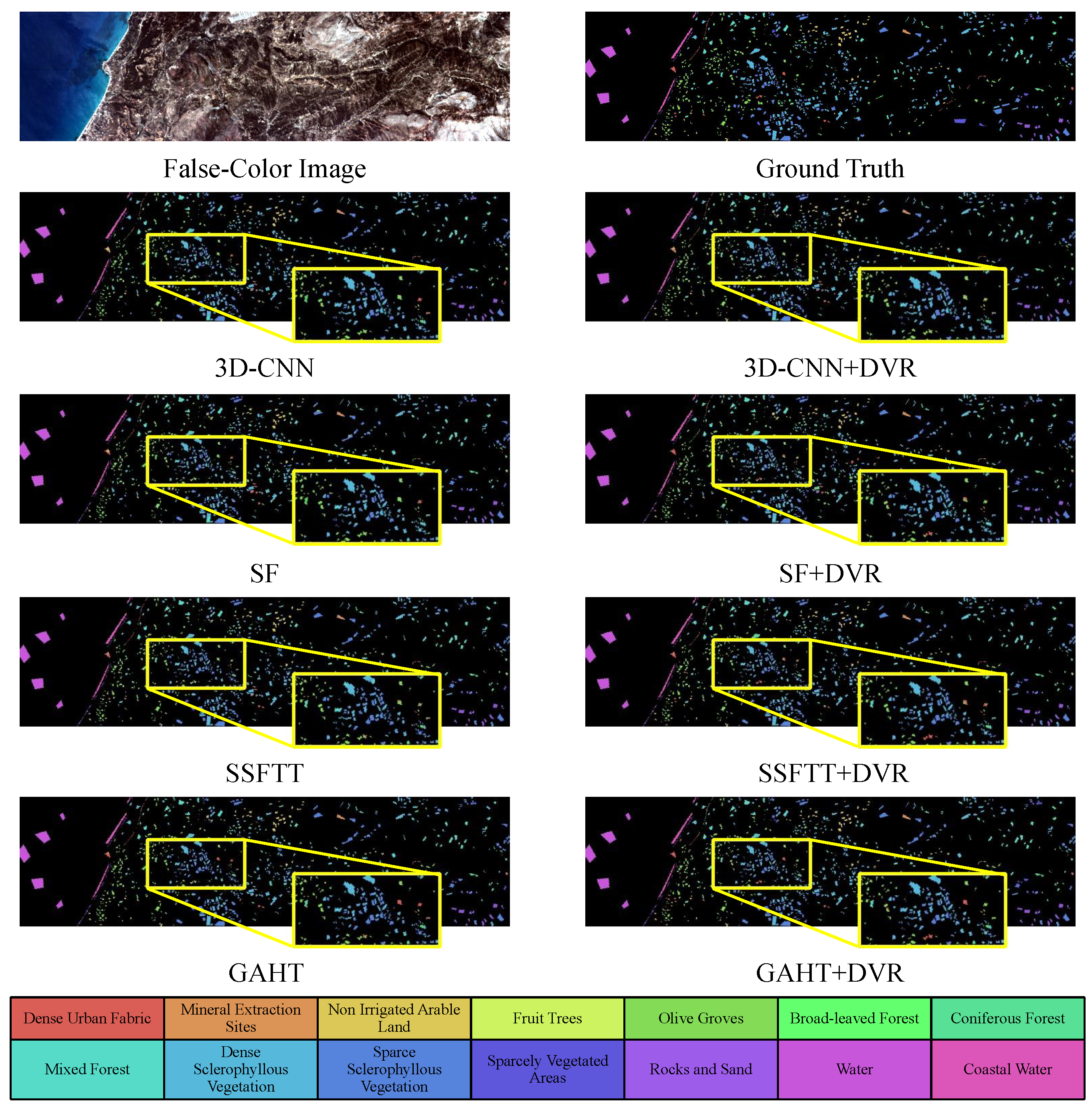
Figure 6, Figure 7, Figure 8 and Figure 9 display the classification maps obtained from various comparison methods on the Salinas, Pavia University, HyRANK-Loukia, and WHU-Hi-HanChuan datasets. We chose the results with the highest OA values from five trials to visualize the predicted samples using different methods for model comparison. Based on the visual comparisons, it is evident that the DVR strategy produces more accurate and less-noise classification maps, which more closely resembles the ground truth.
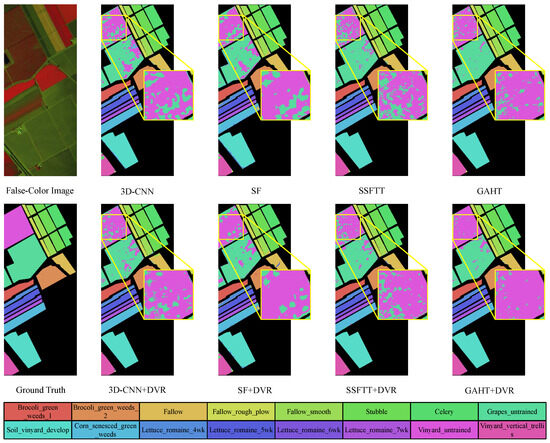
Figure 6.
Classification maps by different methods (3D-CNN [13], SF [18], SSFTT [20], GAHT [21]) on the SA dataset with 1% training samples.

Figure 7.
Classification maps by different methods (3D-CNN [13], SF [18], SSFTT [20], GAHT [21]) on the PU dataset with 1% training samples.
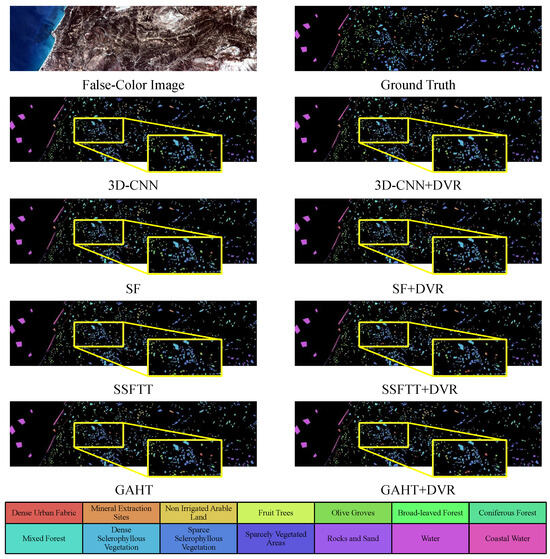
Figure 8.
Classification maps by different methods (3D-CNN [13], SF [18], SSFTT [20], GAHT [21]) on the HR-L dataset with 3% training samples.

Figure 9.
Classification maps by different methods (3D-CNN [13], SF [18], SSFTT [20], GAHT [21]) on the HC dataset with 0.2% training samples.
Furthermore, Figure 10 displays the t-SNE visualization [24] of hidden features from different methods on four distinct datasets. Compared to other methods, DVR demonstrates a more cohesive distribution, with less cross-aggregation and fewer instances of misclassifications among categories.
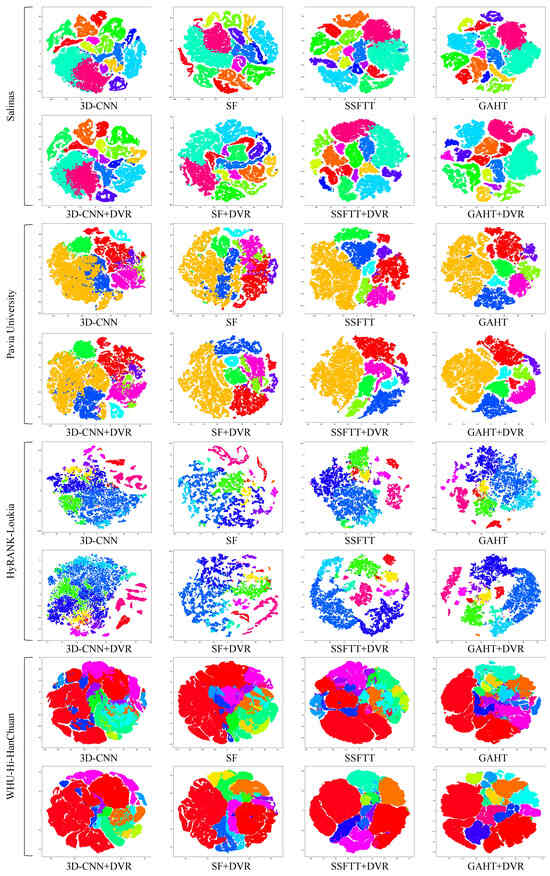
Figure 10.
The t-SNE visualization results of encoded features by different methods (3D-CNN [13], SF [18], SSFTT [20], GAHT [21]) on the four datasets. Compared to other methods, DVR demonstrates a more cohesive distribution, with less cross-aggregation and fewer instances of misclassifications among categories.
4.4. Ablation Study
In this subsection, we employ a representative HSI classification approach (SpectralFormer [18]) to conduct extensive ablation experiments, focusing on key components and parameters of DVR that impact classification performance. We investigate the significance of the DVCM and the AC; then, we examine the effects of codebook size, codebook dimension, and the top-k nearest vectors from the codebook. To assess the impact of individual hyper-parameters on classification performance, we employ a systematic grid search [44] approach and alter one hyper-parameter at a time while fixing the values of others. Table 7 provides a summary of the hyper-parameter configurations that yields the highest classification accuracy across the four datasets.
Table 7.
Hyper-parameter settings of four datasets.
4.4.1. Impact of DVCM
Table 8 displays the results from the ablation study of the DVCM on the PU dataset using the SpectralFormer backbone. The baseline model attains an OA of 88.80% ± 0.94%. By incorporating the AM and AC, our model improves the OA to 89.32% ± 0.85%. Taking into account these results, the inclusion of the DVCM enabled our model to achieve the highest OA of 90.90% ± 0.50%, underscoring the substantial performance enhancement facilitated by the codebook.
Table 8.
Analysis of the DVCM on the PU dataset.
4.4.2. Codebook Size
As shown in Table 9, the analysis results demonstrate the impact of codebook size on OA. In the case of the SA dataset, we increased the codebook size from 70 to 100, and the OA was improved from 91.99% to 92.19%. However, when the size further increased to 150, there was a slight decrease in OA to 91.93%. Similarly, for the HR-L dataset, an initial increase in OA from 74.02% to 74.26% was observed when the codebook size was enlarged from 70 to 100. Nevertheless, when the codebook size reached 150, the OA dropped to 73.90%. It is noted that beyond a certain threshold (100), larger codebooks result in inefficiencies or over-parameterization in the model. This suggests that a moderate enlargement in the codebook size can help in capturing more intricate data characteristics and slightly enhance model performance. For the PU dataset, a slight variation appeared in the trend, with the highest OA of 90.90% achieved using a codebook size of 70. As the codebook size increased from 70 to 100 and then to 150, the OA decreased to 90.63% and 90.38%, respectively. This trend highlights that a smaller codebook size (70) is more appropriate for the PU dataset as it aligns with its intrinsic characteristics featuring fewer categories.
Table 9.
Analysis of codebook size on the four datasets.
4.4.3. Codebook Dimension
We analyze the impact of the codebook dimension on the OA of the SpectralFormer model enhanced by our methodology on the PU dataset. Table 10 clearly demonstrates that varying the codebook dimension leads to subtle differences in model performance. Specifically, the codebook dimension was varied across five different sizes: 32, 64, 128, 256, and 512. The highest OA, at 90.90% ± 0.50%, was achieved with a codebook dimension of 64. This indicates an optimal setting at the size of 64, where the model was capable of effectively capturing essential features without excessive redundancy. As the dimension increased from 64 to 128, there was a slight decrease in OA to 90.59% ± 0.40%. This trend continued with further increments to 256 and 512, resulting in OA dropping slightly to 90.30% ± 0.60% and 90.58% ± 0.60%, respectively. These observations suggest that larger codebook dimensions do not confer better performance, as informative features become diluted within a larger embedding space. The consistent OA across all settings highlights the stability of the DVR model configuration. Our model maintains high performance regardless of substantial changes in the codebook dimension.
Table 10.
Analysis of codebook dimension on the PU dataset.
4.4.4. Top-k Selection
We investigate the impact of the Top-k parameter on the performance of our model, as detailed in Table 11. Here, Top-k denotes the k codes from the codebook that were closest to the encoder features. These codes were averaged before being fed into the AC. All experiments were carried out on the PU dataset with a consistent configuration where the codebook size was 70 and the codebook dimension was 64. With Top-k = 1, our model achieved an OA of 90.79% ± 0.58%, indicating a highly focused representation based on the most relevant code. Increasing to 5, the OA was slightly improved to 90.90% ± 0.50%, and it suggests that incorporating additional relevant codes can enhance model performance by providing a richer feature representation. However, expanding to 10 led to a slight decrease in OA to 90.75% ± 0.51%, indicating that including too many codes may dilute the feature representation, potentially introducing noise or less relevant information. These results demonstrate that the Top-k parameter has a nuanced impact on model accuracy, highlighting that a moderate number of codes offers a better balance between accuracy and feature representation.
Table 11.
Analysis of Top-k on the PU dataset.
4.4.5. Impact of AC
We evaluate the impact of AC on the OA of our model. We conducted experiments on the PU dataset using the SpectralFormer backbone with and without the AC, as shown in Table 12. The naive SpectralFormer achieved an OA of 88.80% ± 0.94%. When incorporating our modifications into the SpectralFormer without AC, we observed an improvement in OA to 90.66% ± 0.81%. Furthermore, the inclusion of the AC in the modified SpectralFormer led to a further enhancement in OA to 90.90% ± 0.50%. These results clearly demonstrate the positive contribution of the AC to both model accuracy and stability.
Table 12.
Analysis of the auxiliary classifier on the PU dataset.
4.5. Robustness Evaluation
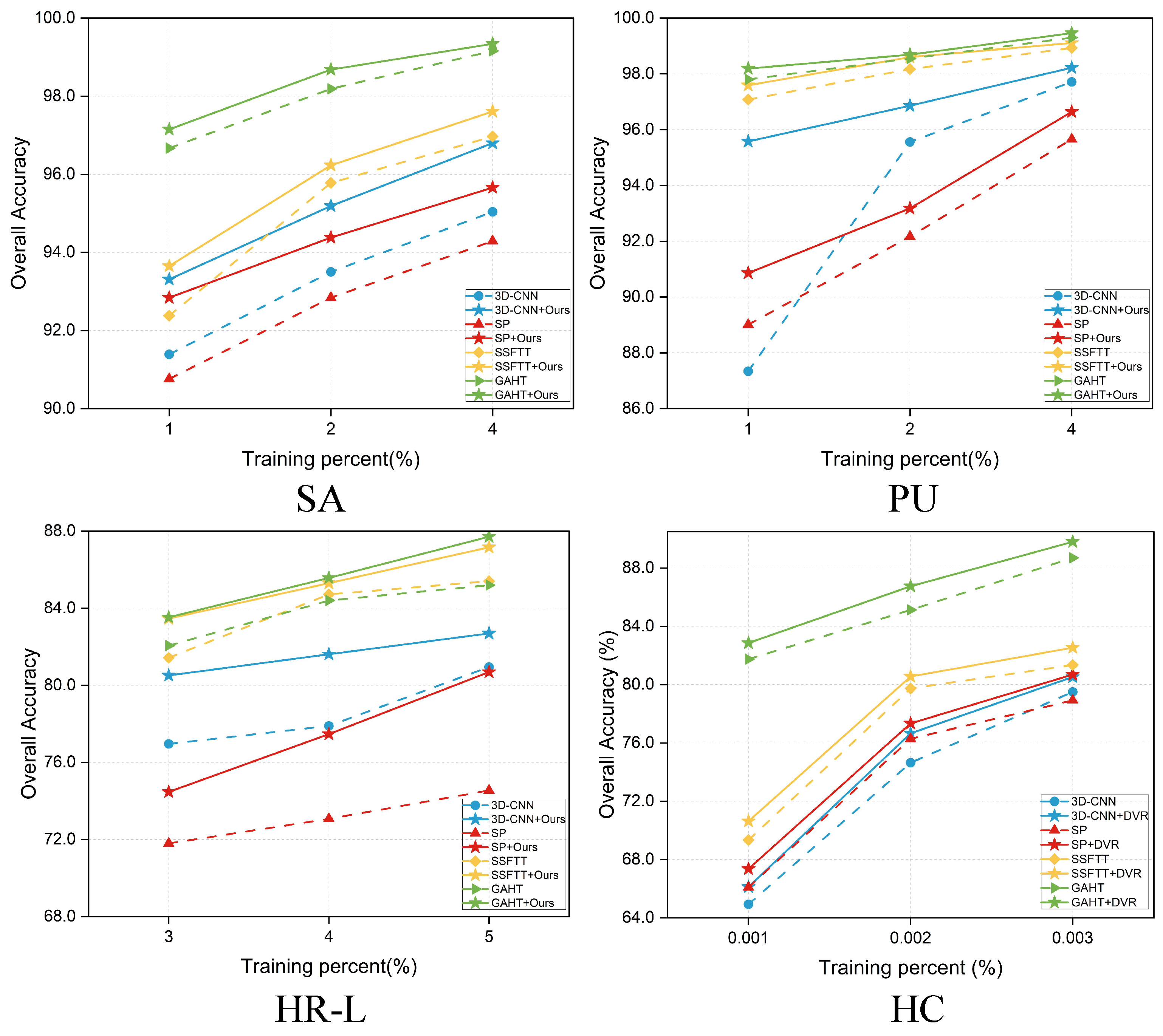
Figure 11 displays the results of OA achieved by different methods with different proportions of training samples. To assess the stability and robustness of our proposed method, we randomly selected 1%, 2%, and 4% of labeled samples for the SA and the PU datasets, and 3%, 4%, and 5% for the HR-L dataset. Our method consistently outperformed other methods in all scenarios, which highlights the robustness of our model. The OA of the 3D-CNN was obviously low when training data were limited. However, when our method was integrated, it significantly enhanced the performance of the 3D-CNN. Varying degrees of improvement were also observed in other methods. The most significant enhancement was pronounced in the HR-L dataset. As the volume of training data increased, our method maintained higher accuracy than the other baselines. As the OA approached 100%, the rate of improvement diminished, and the observed marginal effects could be logically explained.
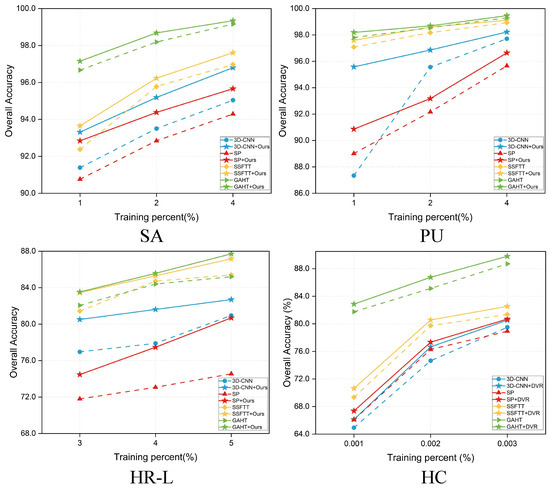
Figure 11.
OA of different models (3D-CNN [13], SF [18], SSFTT [20], GAHT [21]) with different percentages of training samples.
4.6. Computational Cost
This subsection evaluates the incremental computational cost of enhancing the SpectralFormer model with various components within our methodology. We analyzed the impact of integrating the AM, DVCM, and AC on the total number of parameters, trainable parameters, and FLOPs (floating point operations per second). In Table 13, the baseline configuration of SpectralFormer includes 352,405 parameters, all of which are trainable, with a computational workload of 16.235776 million FLOPs. To be specific, with adding AM, the parameters and computational cost experienced a slight increase by 1.18% and 0.025%, respectively. Furthermore, the introduction of the DVCM led to a total parameter increase of 6.31% and a 0.053% rise in FLOPs, while maintaining the trainable parameters constant. This highlights its role as a static feature extractor. Incorporating AC further raised both total and trainable parameters by 6.61% and 1.48%, respectively. The computational costs were minimally increased by 0.059%. It was emphasized that the increases in parameter count and computational load brought about by our proposed DVR were extremely negligible.
Table 13.
Analysis of computational cost.
5. Discussion
The proposed DVR method, while effective, has certain limitations. The performance shows slight sensitivity to codebook parameters, such as its size and dimension, which may require moderate tuning to achieve optimal results. An oversized codebook may increase computational costs, while an undersized one might fail to capture feature diversity effectively. Future work could focus on optimizing the codebook’s efficiency through advanced encoding algorithms, as well as leveraging automated hyper-parameter tuning methods to reduce the reliance on manual adjustments. Exploring dynamic codebook adjustment could further enhance the scalability and applicability of DVR. In future ocean applications, the visual or spectral differences between classes (e.g., in tasks such as sea ice detection or algal bloom prediction) can be very subtle, making it potentially difficult for existing models to distinguish between them effectively. DVR can leverage the codebook to regulate features, thereby enlarging the distance between features of different classes. This will enable more effective and accurate classification in such challenging scenarios.
6. Conclusions
To mitigate the common misclassification issues in current models for HSI classification, this article introduces an innovative DVR strategy that leverages discrete vectors from the codebook to regulate embedding features. This plug-and-play method enables models to attain a more robust aggregated distribution in the embedding space, thereby enhancing the overall performance of HSI classification. Experimental results conducted on four HSI benchmarks confirm the superiority of our proposed method on both the visual quality of classification maps and quantitative metrics compared to baseline models. Specifically, our DVR improves the OA of the 3D-CNN by 7.58% on the PU dataset and enhances the OA of SpectralFormer by more than 1% across all four datasets. Additionally, integrating DVR into SpectralFormer increases its trainable parameters by only 1.48% and computational cost by just 0.059%. In future work, we will extend the applications of our method to a wider range of models to further enhance performance and explore the potential of our approach in the marine domain, such as sea ice detection and algal bloom prediction.
Author Contributions
Conceptualization, J.L., H.W., X.Z. and J.W.; methodology, J.L., H.W., X.Z. and J.W.; software, H.W., X.Z. and J.W.; validation, J.L. and P.Z.; formal analysis, P.Z.; investigation, J.L. and H.W.; resources, P.Z.; data curation, T.Z.; writing—original draft preparation, J.L., H.W., X.Z. and J.W.; writing—review and editing, H.W., X.Z., T.Z. and P.Z.; visualization, H.W.; supervision, J.L. and P.Z.; project administration, J.L. and P.Z.; funding acquisition, J.L., P.Z. and T.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62171252, in part by the Fundamental Research Funds for the Central Universities under Grant 00007764, in part by the Natural Science Foundation of China under Grant 42201386, in part by the Interdisciplinary Research Project for Young Teachers of USTB (Fundamental Research Funds for the Central Universities: FRF-IDRY-22-018), and Fundamental Research Funds for the Central Universities of USTB: FRF-TP-24-060A.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Hu, C. Hyperspectral reflectance spectra of floating matters derived from Hyperspectral Imager for the Coastal Ocean (HICO) observations. Earth Syst. Sci. Data 2022, 14, 1183–1192. [Google Scholar] [CrossRef]
- Grøtte, M.E.; Birkeland, R.; Honoré-Livermore, E.; Bakken, S.; Garrett, J.L.; Prentice, E.F.; Sigernes, F.; Orlandić, M.; Gravdahl, J.T.; Johansen, T.A. Ocean color hyperspectral remote sensing with high resolution and low latency—The HYPSO-1 CubeSat mission. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Kumar, B.; Dikshit, O.; Gupta, A.; Singh, M.K. Feature extraction for hyperspectral image classification: A review. Int. J. Remote Sens. 2020, 41, 6248–6287. [Google Scholar] [CrossRef]
- Yang, X.; Cao, W.; Lu, Y.; Zhou, Y. QTN: Quaternion transformer network for hyperspectral image classification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7370–7384. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Pal, M.; Foody, G.M. Feature selection for classification of hyperspectral data by SVM. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2297–2307. [Google Scholar] [CrossRef]
- Fan, J.; Chen, T.; Lu, S. Superpixel guided deep-sparse-representation learning for hyperspectral image classification. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3163–3173. [Google Scholar] [CrossRef]
- Li, J.; Zhao, X.; Li, Y.; Du, Q.; Xi, B.; Hu, J. Classification of hyperspectral imagery using a new fully convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 292–296. [Google Scholar] [CrossRef]
- Hu, J.F.; Huang, T.Z.; Deng, L.J.; Jiang, T.X.; Vivone, G.; Chanussot, J. Hyperspectral image super-resolution via deep spatiospectral attention convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7251–7265. [Google Scholar] [CrossRef] [PubMed]
- Pu, C.; Huang, H.; Shi, X.; Wang, T. Semisupervised spatial-spectral feature extraction with attention mechanism for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef]
- Cao, X.; Xu, L.; Meng, D.; Zhao, Q.; Xu, Z. Integration of 3-dimensional discrete wavelet transform and Markov random field for hyperspectral image classification. Neurocomputing 2017, 226, 90–100. [Google Scholar] [CrossRef]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; He, N.; Fang, L.; Ghamisi, P. Multiscale densely-connected fusion networks for hyperspectral images classification. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 246–259. [Google Scholar] [CrossRef]
- Ran, R.; Deng, L.J.; Zhang, T.J.; Chang, J.; Wu, X.; Tian, Q. KNLConv: Kernel-space non-local convolution for hyperspectral image super-resolution. IEEE Trans. Multimed. 2024, 26, 8836–8848. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Mei, S.; Song, C.; Ma, M.; Xu, F. Hyperspectral image classification using group-aware hierarchical transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5539014. [Google Scholar] [CrossRef]
- Song, L.; Feng, Z.; Yang, S.; Zhang, X.; Jiao, L. Interactive Spectral-Spatial Transformer for Hyperspectral Image Classification. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 8589–8601. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Hang, R.; Zhang, B.; Chanussot, J. Deep encoder–decoder networks for classification of hyperspectral and LiDAR data. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Van Den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural discrete representation learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 6309–6318. [Google Scholar]
- Mao, C.; Jiang, L.; Dehghani, M.; Vondrick, C.; Sukthankar, R.; Essa, I. Discrete Representations Strengthen Vision Transformer Robustness. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 25–29 April 2022. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Mei, S.; Chen, X.; Zhang, Y.; Li, J.; Plaza, A. Accelerating convolutional neural network-based hyperspectral image classification by step activation quantization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral image classification with deep feature fusion network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Zhao, X.; Tao, R.; Li, W.; Li, H.C.; Du, Q.; Liao, W.; Philips, W. Joint classification of hyperspectral and LiDAR data using hierarchical random walk and deep CNN architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7355–7370. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Geng, Y.; Zhang, Z.; Li, X.; Du, Q. Unsupervised spatial–spectral feature learning by 3D convolutional autoencoder for hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6808–6820. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, Q.; Zhang, M. Local transformer with spatial partition restore for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4307–4325. [Google Scholar] [CrossRef]
- Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 8340–8349. [Google Scholar]
- Steiner, A.; Kolesnikov, A.; Zhai, X.; Wightman, R.; Uszkoreit, J.; Beyer, L. How to train your vit? data, augmentation, and regularization in vision transformers. arXiv 2021, arXiv:2106.10270. [Google Scholar]
- Wang, H.; Ge, S.; Lipton, Z.; Xing, E.P. Learning robust global representations by penalizing local predictive power. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 10506–10518. [Google Scholar]
- Huang, Z.; Wang, H.; Xing, E.P.; Huang, D. Self-challenging improves cross-domain generalization. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 124–140. [Google Scholar]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G.; Li, G.Y. Robust semantic communications with masked VQ-VAE enabled codebook. IEEE Trans. Wirel. Commun. 2023, 22, 8707–8722. [Google Scholar] [CrossRef]
- Xi, B.; Li, J.; Diao, Y.; Li, Y.; Li, Z.; Huang, Y.; Chanussot, J. Dgssc: A deep generative spectral-spatial classifier for imbalanced hyperspectral imagery. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1535–1548. [Google Scholar] [CrossRef]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Brito, J.A.; McNeill, F.E.; Webber, C.E.; Chettle, D.R. Grid search: An innovative method for the estimation of the rates of lead exchange between body compartments. J. Environ. Monit. 2005, 7, 241–247. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).