Mamba-STFM: A Mamba-Based Spatiotemporal Fusion Method for Remote Sensing Images

Abstract
1. Introduction
- (1)
- The VSS-FCAN block combines cross-scan global perception with channel attention mechanisms, significantly reducing computational and memory overhead at quadratic complexity. Additionally, it enhances model inference throughput through parallel scanning and kernel fusion techniques.
- (2)
- The spatial expert utilizes an enhanced 2D residual convolutional module and incorporates a channel attention mechanism, adaptively adjusting channel weights to optimize spatial feature representation, thereby achieving precise alignment and fusion of coarse and fine-resolution images.
- (3)
- The temporal expert introduces a 3D residual convolutional module for adjacent time steps, combining a temporal squeeze-and-excitation mechanism with selective state space model (SSM) techniques. This design efficiently captures short-range temporal dependencies while maintaining linear complexity in temporal sequence modeling, further improving the overall throughput of spatiotemporal fusion.
2. Methodology
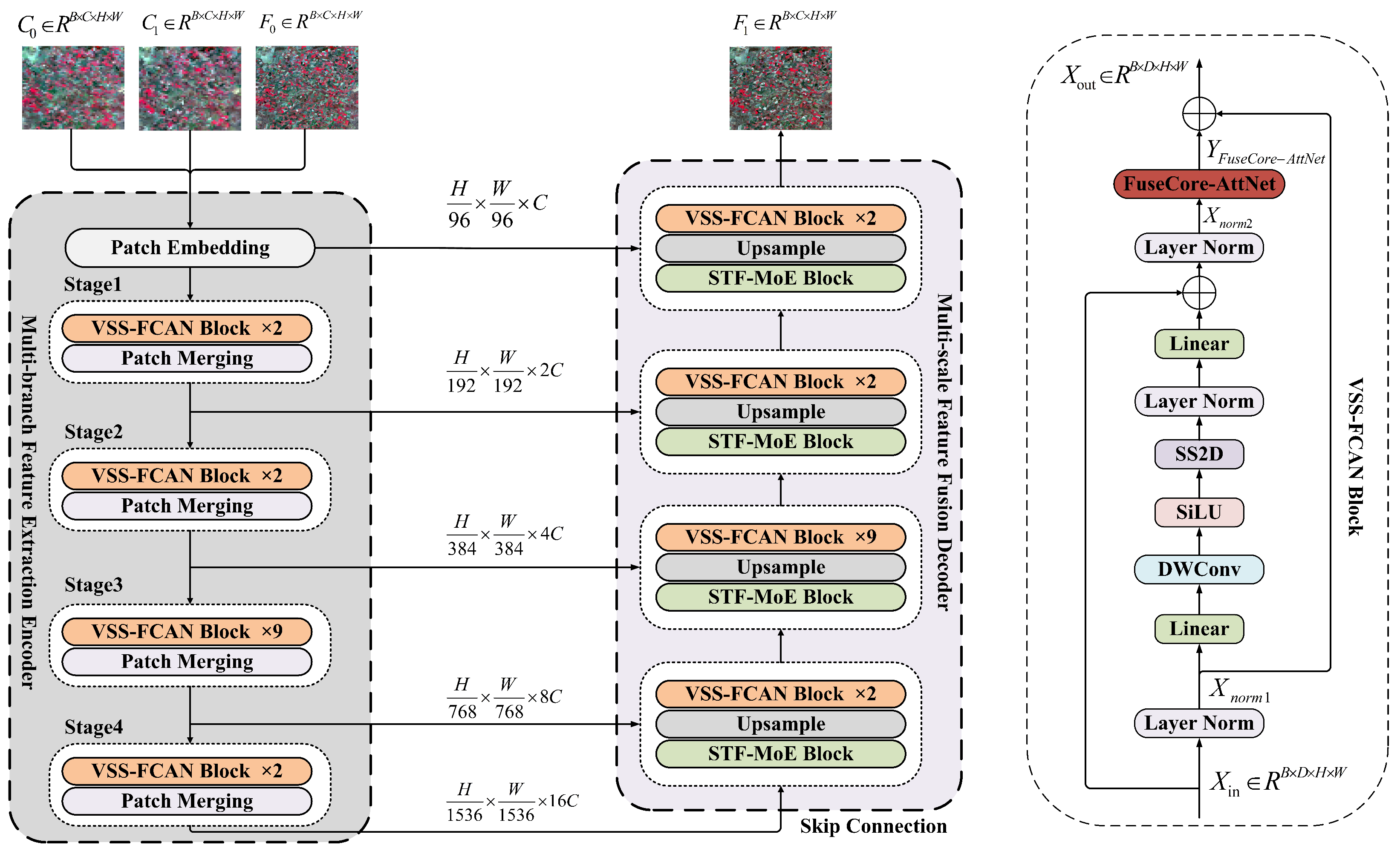
2.1. Overall Structure
2.2. Visual State Space-FuseCore-AttNet Block
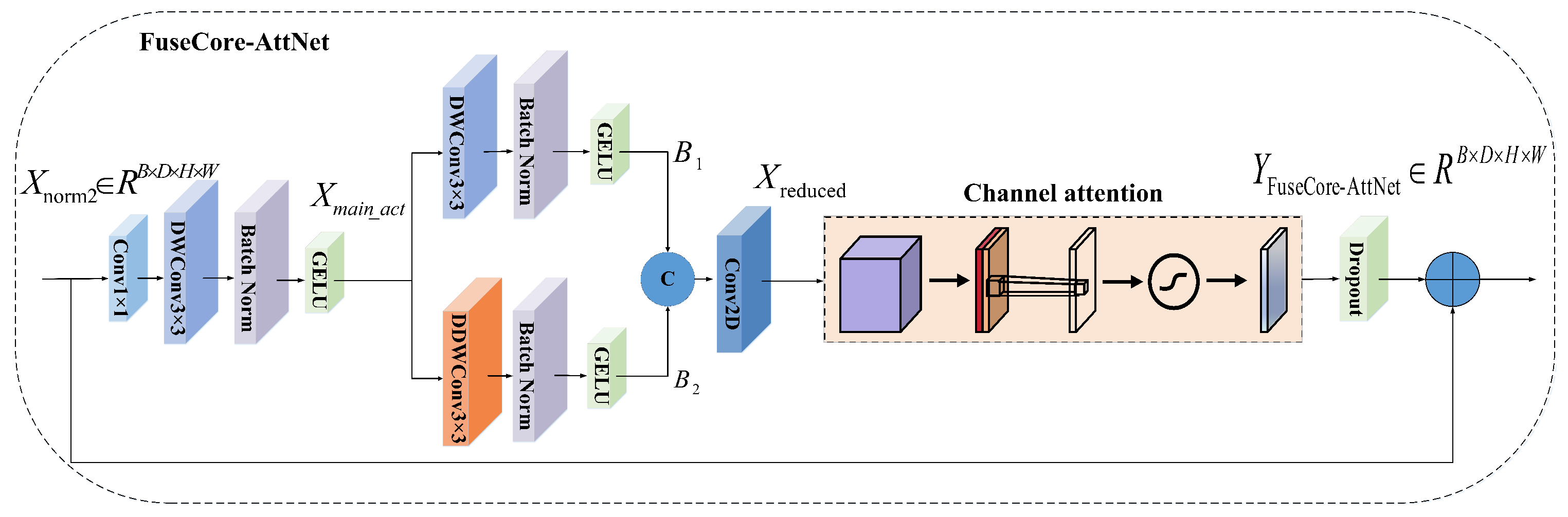
2.3. FuseCore-AttNet
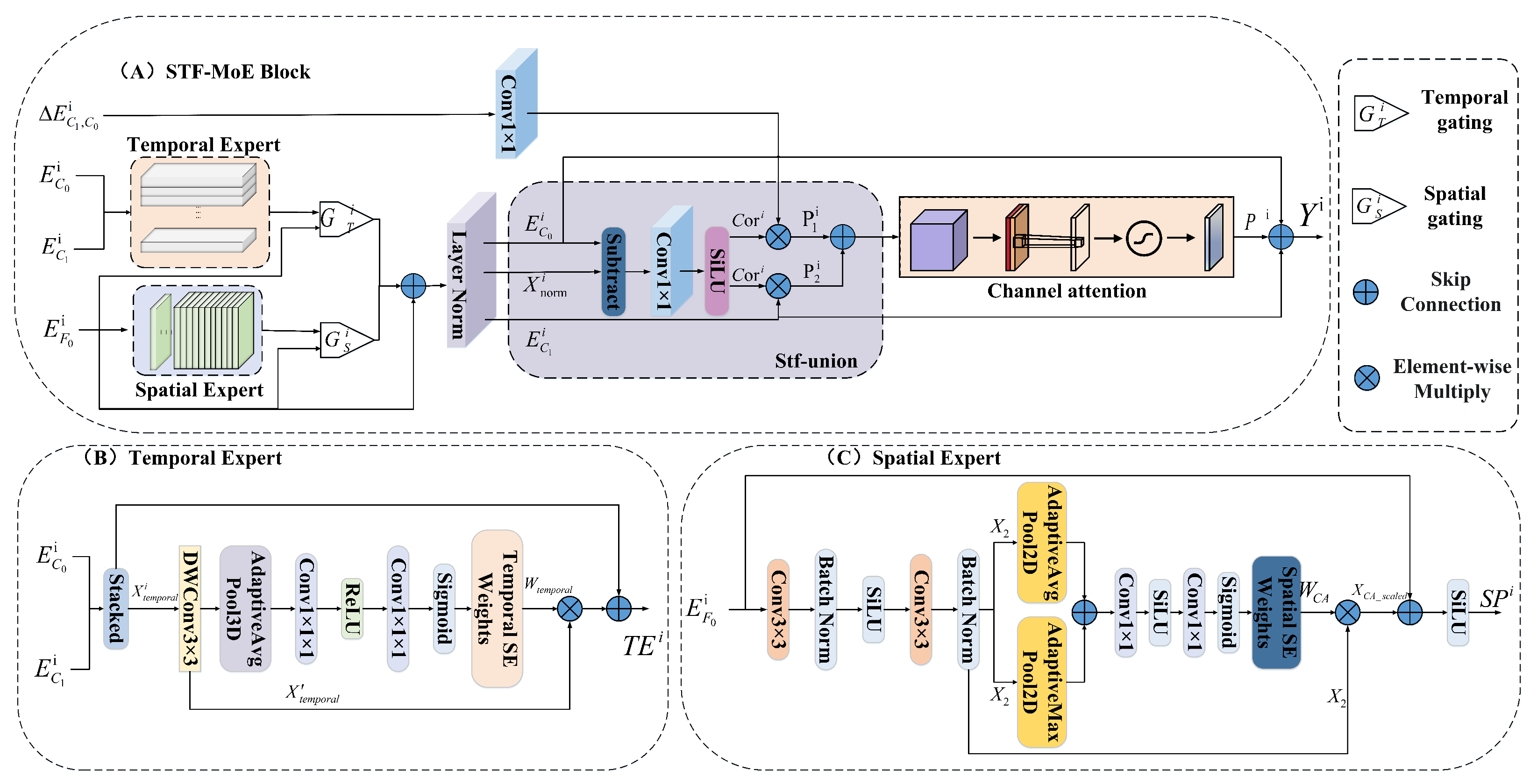
2.4. Spatiotemporal Mixture-of-Experts Fusion Block
2.5. Temporal Expert
2.6. Spatial Expert
2.7. Loss Function
3. Experiments
3.1. Study Area and Datasets
3.2. Experimental Details
3.3. Assessment of Metrics
4. Results
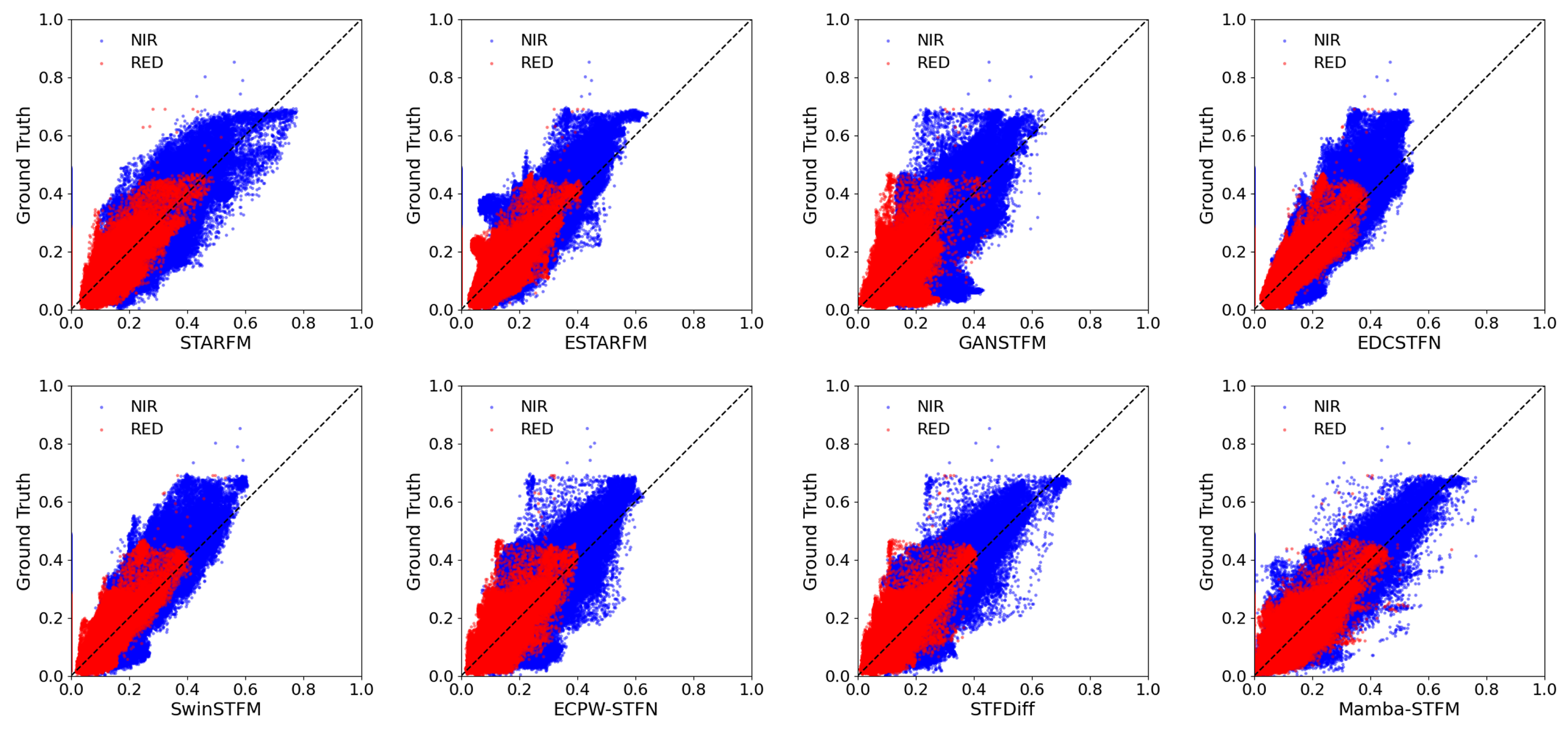
4.1. Comparison of Various Fusion Methods on the CIA Dataset
4.1.1. Quantitative Comparison
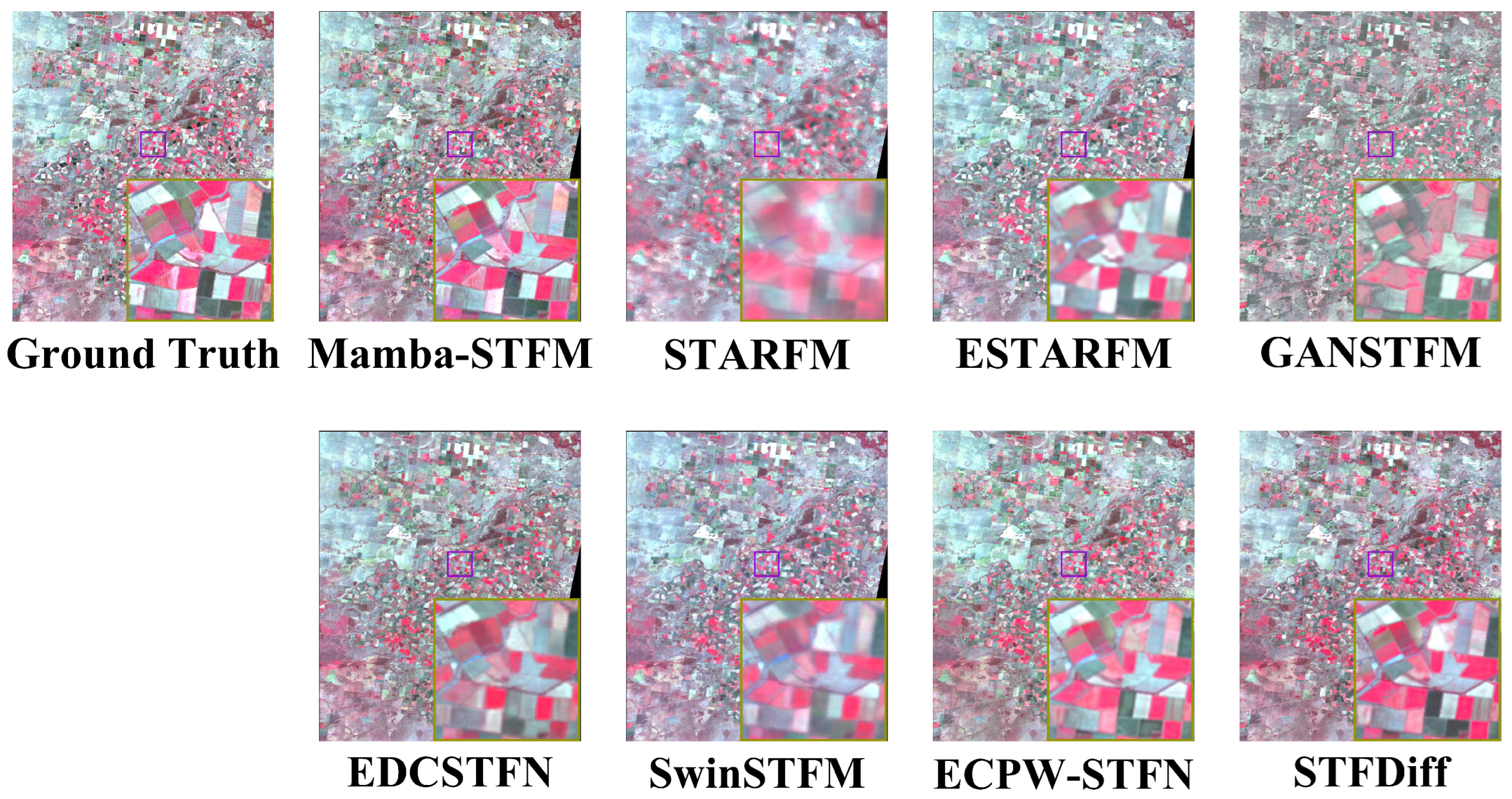
4.1.2. Detail Comparison
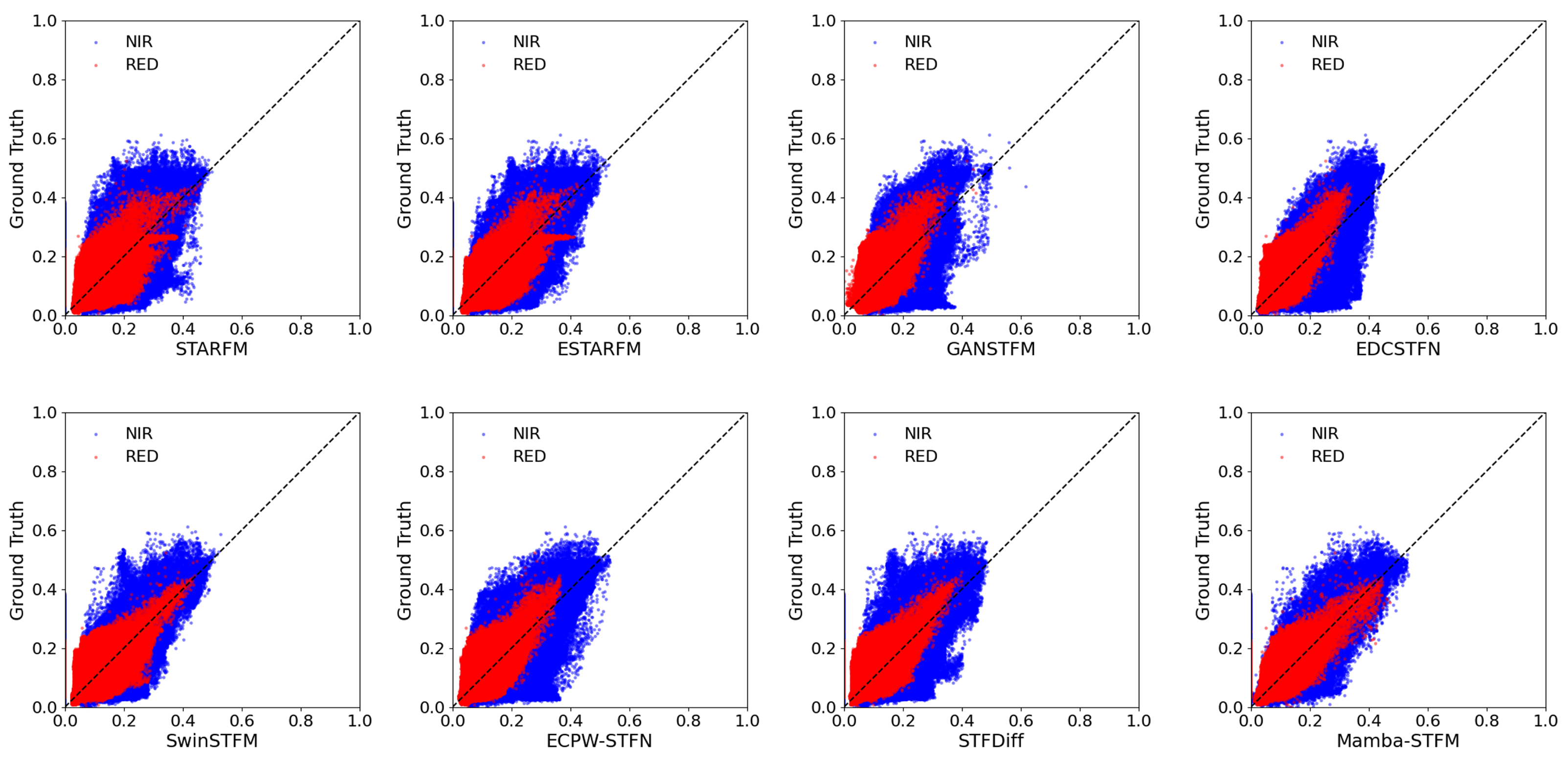
4.2. Comparison of Various Fusion Methods on the LGC Dataset
4.2.1. Quantitative Comparison
4.2.2. Detail Comparison
4.3. Comparison of the Efficiency of Various Spatiotemporal Fusion Methods
4.4. Ablation Study
4.5. Application Comparison
4.5.1. Comparison of Clustering Results in the CIA Study Area
4.5.2. Comparison of Clustering Results in the LGC Study Area
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Defourny, P.; Bontemps, S.; Bellemans, N.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Nicola, L.; Rabaute, T.; et al. Near real-time agriculture monitoring at national scale at parcel resolution: Performance assessment of the Sen2-Agri automated system in various cropping systems around the world. Remote Sens. Environ. 2019, 221, 551–568. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Du, Z.; Li, X.; Miao, J.; Huang, Y.; Shen, H.; Zhang, L. Concatenated deep-learning framework for multitask change detection of optical and SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 719–731. [Google Scholar] [CrossRef]
- Doña, C.; Chang, N.B.; Caselles, V.; Sánchez, J.M.; Camacho, A.; Delegido, J.; Vannah, B.W. Integrated satellite data fusion and mining for monitoring lake water quality status of the Albufera de Valencia in Spain. J. Environ. Manag. 2015, 151, 416–426. [Google Scholar] [CrossRef]
- Zhong, L.; Dzurisin, D.; Jung, H.; Zhang, J.; Zhang, Y. Radar image and data fusion for natural hazards characterisation. Int. J. Image Data Fusion 2010, 1, 217–242. [Google Scholar]
- Shao, Z.; Wu, W.; Li, D. Spatio-temporal-spectral observation model for urban remote sensing. Geo-Spat. Inf. Sci. 2021, 24, 372–386. [Google Scholar] [CrossRef]
- Xiao, J.; Aggarwal, A.K.; Duc, N.H.; Arya, A.; Rage, U.K.; Avtar, R. A review of remote sensing image spatiotemporal fusion: Challenges, applications and recent trends. Remote Sens. Appl. Soc. Environ. 2023, 32, 101005. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; He, L.; Chen, J.; Plaza, A. Spatio-temporal fusion for remote sensing data: An overview and new benchmark. Sci. China Inf. Sci. 2020, 63, 140301. [Google Scholar] [CrossRef]
- Shen, H.; Meng, X.; Zhang, L. An integrated framework for the spatio–temporal–spectral fusion of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7135–7148. [Google Scholar] [CrossRef]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef]
- Justice, C.O.; Vermote, E.; Townshend, J.R.; Defries, R.; Roy, D.P.; Hall, D.K.; Salomonson, V.V.; Privette, J.L.; Riggs, G.; Strahler, A.; et al. The Moderate Resolution Imaging Spectroradiometer (MODIS): Land remote sensing for global change research. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1228–1249. [Google Scholar] [CrossRef]
- Barnes, W.L.; Salomonson, V.V. MODIS: A global imaging spectroradiometer for the Earth Observing System. In Optical Technologies for Aerospace Sensing: A Critical Review; SPIE: St. Bellingham, WA, USA, 1992; Volume 10269, pp. 280–302. [Google Scholar]
- Zhu, X.; Cai, F.; Tian, J.; Williams, T.K.A. Spatiotemporal fusion of multisource remote sensing data: Literature survey, taxonomy, principles, applications, and future directions. Remote Sens. 2018, 10, 527. [Google Scholar] [CrossRef]
- Belgiu, M.; Stein, A. Spatiotemporal image fusion in remote sensing. Remote Sens. 2019, 11, 818. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Zhukov, B.; Oertel, D.; Lanzl, F.; Reinhackel, G. Unmixing-based multisensor multiresolution image fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1212–1226. [Google Scholar] [CrossRef]
- Lu, M.; Chen, J.; Tang, H.; Rao, Y.; Yang, P.; Wu, W. Land cover change detection by integrating object-based data blending model of Landsat and MODIS. Remote Sens. Environ. 2016, 184, 374–386. [Google Scholar] [CrossRef]
- Wang, Q.; Atkinson, P.M. Spatio-temporal fusion for daily Sentinel-2 images. Remote Sens. Environ. 2018, 204, 31–42. [Google Scholar] [CrossRef]
- Tan, Z.; Di, L.; Zhang, M.; Guo, L.; Gao, M. An enhanced deep convolutional model for spatiotemporal image fusion. Remote Sens. 2019, 11, 2898. [Google Scholar] [CrossRef]
- Liao, C.; Wang, J.; Pritchard, I.; Liu, J.; Shang, J. A spatio-temporal data fusion model for generating NDVI time series in heterogeneous regions. Remote Sens. 2017, 9, 1125. [Google Scholar] [CrossRef]
- Ghosh, R.; Gupta, P.K.; Tolpekin, V.; Srivastav, S. An enhanced spatiotemporal fusion method–Implications for coal fire monitoring using satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102056. [Google Scholar] [CrossRef]
- Dong, R.; Zhang, L.; Fu, H. RRSGAN: Reference-based super-resolution for remote sensing image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601117. [Google Scholar] [CrossRef]
- Wu, M.; Niu, Z.; Wang, C.; Wu, C.; Wang, L. Use of MODIS and Landsat time series data to generate high-resolution temporal synthetic Landsat data using a spatial and temporal reflectance fusion model. J. Appl. Remote Sens. 2012, 6, 063507. [Google Scholar]
- Lu, L.; Huang, Y.; Di, L.; Hang, D. A new spatial attraction model for improving subpixel land cover classification. Remote Sens. 2017, 9, 360. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Wang, S.; Wang, C.; Zhang, C.; Xue, J.; Wang, P.; Wang, X.; Wang, W.; Zhang, X.; Li, W.; Huang, G.; et al. A classification-based spatiotemporal adaptive fusion model for the evaluation of remotely sensed evapotranspiration in heterogeneous irrigated agricultural area. Remote Sens. Environ. 2022, 273, 112962. [Google Scholar] [CrossRef]
- Guo, D.; Shi, W.; Hao, M.; Zhu, X. FSDAF 2.0: Improving the performance of retrieving land cover changes and preserving spatial details. Remote Sens. Environ. 2020, 248, 111973. [Google Scholar] [CrossRef]
- Xue, J.; Leung, Y.; Fung, T. A Bayesian data fusion approach to spatio-temporal fusion of remotely sensed images. Remote Sens. 2017, 9, 1310. [Google Scholar] [CrossRef]
- Li, A.; Bo, Y.; Zhu, Y.; Guo, P.; Bi, J.; He, Y. Blending multi-resolution satellite sea surface temperature (SST) products using Bayesian maximum entropy method. Remote Sens. Environ. 2013, 135, 52–63. [Google Scholar] [CrossRef]
- Huang, B.; Song, H. Spatiotemporal reflectance fusion via sparse representation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3707–3716. [Google Scholar] [CrossRef]
- Song, H.; Huang, B. Spatiotemporal satellite image fusion through one-pair image learning. IEEE Trans. Geosci. Remote Sens. 2012, 51, 1883–1896. [Google Scholar] [CrossRef]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B. Spatiotemporal satellite image fusion using deep convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Tan, Z.; Yue, P.; Di, L.; Tang, J. Deriving high spatiotemporal remote sensing images using deep convolutional network. Remote Sens. 2018, 10, 1066. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Chanussot, J.; Hong, D.; Zhao, B. StfNet: A two-stream convolutional neural network for spatiotemporal image fusion. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6552–6564. [Google Scholar] [CrossRef]
- Cheng, F.; Fu, Z.; Tang, B.; Huang, L.; Huang, K.; Ji, X. Stf-egfa: A remote sensing spatiotemporal fusion network with edge-guided feature attention. Remote Sens. 2022, 14, 3057. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; He, L.; Chen, J.; Plaza, A. A new sensor bias-driven spatio-temporal fusion model based on convolutional neural networks. Sci. China Inf. Sci. 2020, 63, 140302. [Google Scholar] [CrossRef]
- Zhang, H.; Song, Y.; Han, C.; Zhang, L. Remote sensing image spatiotemporal fusion using a generative adversarial network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4273–4286. [Google Scholar] [CrossRef]
- Song, B.; Liu, P.; Li, J.; Wang, L.; Zhang, L.; He, G.; Chen, L.; Liu, J. MLFF-GAN: A multilevel feature fusion with GAN for spatiotemporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4410816. [Google Scholar] [CrossRef]
- Liu, H.; Yang, G.; Deng, F.; Qian, Y.; Fan, Y. MCBAM-GAN: The GAN spatiotemporal fusion model based on multiscale and CBAM for remote sensing images. Remote Sens. 2023, 15, 1583. [Google Scholar] [CrossRef]
- Chen, J.; Wang, L.; Feng, R.; Liu, P.; Han, W.; Chen, X. CycleGAN-STF: Spatiotemporal fusion via CycleGAN-based image generation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5851–5865. [Google Scholar] [CrossRef]
- Tan, Z.; Gao, M.; Li, X.; Jiang, L. A flexible reference-insensitive spatiotemporal fusion model for remote sensing images using conditional generative adversarial network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601413. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Li, W.; Cao, D.; Peng, Y.; Yang, C. MSNet: A multi-stream fusion network for remote sensing spatiotemporal fusion based on transformer and convolution. Remote Sens. 2021, 13, 3724. [Google Scholar] [CrossRef]
- Chen, G.; Jiao, P.; Hu, Q.; Xiao, L.; Ye, Z. SwinSTFM: Remote sensing spatiotemporal fusion using Swin transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410618. [Google Scholar] [CrossRef]
- Jiang, M.; Shao, H. A cnn-transformer combined remote sensing imagery spatiotemporal fusion model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 13995–14009. [Google Scholar] [CrossRef]
- Hu, M.; Wu, C.; Du, B. EMS-Net: Efficient multi-temporal self-attention for hyperspectral change detection. In Proceedings of the IGARSS 2023–2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 6664–6667. [Google Scholar]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled generative adversarial networks. arXiv 2016, arXiv:1611.02163. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. Vmamba: Visual state space model. In Proceedings of the Advances in Neural Information Processing Systems 37 (NIPS 2024), Vancouver, BC, Canada, 10–15 December 2024; pp. 103031–103063. [Google Scholar]
- Emelyanova, I.; McVicar, T.; Van Niel, T.; Li, L.; Van Dijk, A. Landsat and MODIS data for the Coleambally Irrigation Area; v3. Data Collection; CSIRO: Canberra, Australia, 2013. [Google Scholar] [CrossRef]
- Emelyanova, I.; McVicar, T.; Van Niel, T.; Li, L.; Van Dijk, A. Landsat and MODIS Data for the Lower Gwydir Catchment Study Site; v3. Data Collection; CSIRO: Canberra, Australia, 2013. [Google Scholar] [CrossRef]
- Zhang, X.; Li, S.; Tan, Z.; Li, X. Enhanced wavelet based spatiotemporal fusion networks using cross-paired remote sensing images. ISPRS J. Photogramm. Remote Sens. 2024, 211, 281–297. [Google Scholar] [CrossRef]
- Huang, H.; He, W.; Zhang, H.; Xia, Y.; Zhang, L. STFDiff: Remote sensing image spatiotemporal fusion with diffusion models. Inf. Fusion 2024, 111, 102505. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Formula | Symbol Explanation |
|---|---|---|
| RMSE | N: Total number of pixels : The i-th pixel in the reference image : The i-th pixel in the image to be evaluated | |
| SSIM | : Local mean of the two images : Local variance of the two images : Local covariance of the two images : Stability constants | |
| UIQI | Same symbols as SSIM: : Local mean : Local variance : Local covariance | |
| CC | N: Number of pixels : Pixel values in the two images , : Global mean of the images | |
| ERGAS | B: Number of bands : RMSE of the k-th band : Mean value of the reference image for the k-th band : Pixel size of low/high resolution images |
| Metrics | Band | STARFM | ESTARFM | GANSTFM | EDCSTFN | SwinSTFM | ECPW-STFN | STFDiff | Mamba-STFM |
|---|---|---|---|---|---|---|---|---|---|
| RMSE | 1 | 0.0174 | 0.0136 | 0.0139 | 0.0126 | 0.0112 | 0.0125 | 0.0093 | 0.0086 |
| 2 | 0.0236 | 0.0195 | 0.0202 | 0.0161 | 0.0148 | 0.0137 | 0.0128 | 0.0115 | |
| 3 | 0.0333 | 0.0306 | 0.0313 | 0.0255 | 0.0217 | 0.0152 | 0.0197 | 0.0169 | |
| 4 | 0.0538 | 0.0515 | 0.0547 | 0.0452 | 0.0299 | 0.0261 | 0.0263 | 0.0256 | |
| 5 | 0.0560 | 0.0537 | 0.0563 | 0.0484 | 0.0363 | 0.0349 | 0.0335 | 0.0311 | |
| 6 | 0.0544 | 0.0482 | 0.0552 | 0.0433 | 0.0306 | 0.0285 | 0.0288 | 0.0277 | |
| SSIM | 1 | 0.8756 | 0.9079 | 0.9037 | 0.9151 | 0.9387 | 0.9326 | 0.9424 | 0.9515 |
| 2 | 0.8674 | 0.8869 | 0.9093 | 0.9293 | 0.9254 | 0.9311 | 0.9385 | 0.9363 | |
| 3 | 0.8220 | 0.8538 | 0.8405 | 0.8634 | 0.8845 | 0.8904 | 0.8901 | 0.8976 | |
| 4 | 0.7516 | 0.7825 | 0.7350 | 0.8419 | 0.8216 | 0.8455 | 0.8468 | 0.8640 | |
| 5 | 0.7936 | 0.7847 | 0.7891 | 0.7853 | 0.7725 | 0.7893 | 0.7914 | 0.8092 | |
| 6 | 0.7717 | 0.7806 | 0.7822 | 0.7911 | 0.7917 | 0.7972 | 0.8116 | 0.8184 | |
| UIQI | 1 | 0.7227 | 0.7744 | 0.7983 | 0.8216 | 0.8362 | 0.8361 | 0.8355 | 0.8863 |
| 2 | 0.7157 | 0.7830 | 0.7371 | 0.8508 | 0.8656 | 0.8881 | 0.8816 | 0.9162 | |
| 3 | 0.8056 | 0.8231 | 0.8062 | 0.8619 | 0.8728 | 0.8908 | 0.9043 | 0.9206 | |
| 4 | 0.8228 | 0.8360 | 0.8419 | 0.9026 | 0.9168 | 0.9249 | 0.9222 | 0.9435 | |
| 5 | 0.8531 | 0.8586 | 0.8504 | 0.9212 | 0.9207 | 0.9311 | 0.9365 | 0.9430 | |
| 6 | 0.8604 | 0.8728 | 0.8849 | 0.9255 | 0.9215 | 0.9357 | 0.9331 | 0.9369 | |
| CC | 1 | 0.7305 | 0.7887 | 0.7636 | 0.8251 | 0.8463 | 0.8656 | 0.8739 | 0.8952 |
| 2 | 0.7554 | 0.7931 | 0.7760 | 0.8439 | 0.8723 | 0.9081 | 0.9058 | 0.9195 | |
| 3 | 0.7791 | 0.8296 | 0.8394 | 0.8510 | 0.8785 | 0.8907 | 0.9032 | 0.9226 | |
| 4 | 0.8336 | 0.8387 | 0.8532 | 0.9157 | 0.9188 | 0.9258 | 0.9217 | 0.9440 | |
| 5 | 0.8529 | 0.8595 | 0.8648 | 0.9215 | 0.9209 | 0.9344 | 0.9331 | 0.9471 | |
| 6 | 0.8514 | 0.8732 | 0.8917 | 0.9184 | 0.9215 | 0.9358 | 0.9386 | 0.9378 | |
| ERGAS | - | 1.7086 | 1.5995 | 1.6057 | 1.2590 | 1.0658 | 0.9633 | 0.9149 | 0.8615 |
| Metrics | Band | STARFM | ESTARFM | GANSTFM | EDCSTFN | SwinSTFM | ECPW-STFN | STFDiff | Mamba-STFM |
|---|---|---|---|---|---|---|---|---|---|
| RMSE | 1 | 0.0146 | 0.0139 | 0.0155 | 0.0134 | 0.0122 | 0.0117 | 0.0105 | 0.0098 |
| 2 | 0.0189 | 0.0185 | 0.0212 | 0.0196 | 0.0178 | 0.0145 | 0.0149 | 0.0127 | |
| 3 | 0.0269 | 0.0268 | 0.0264 | 0.0255 | 0.0229 | 0.0214 | 0.0197 | 0.0165 | |
| 4 | 0.0399 | 0.0395 | 0.0410 | 0.0381 | 0.0294 | 0.0288 | 0.0281 | 0.0234 | |
| 5 | 0.0541 | 0.0552 | 0.0538 | 0.0545 | 0.0435 | 0.0414 | 0.0427 | 0.0335 | |
| 6 | 0.0427 | 0.0424 | 0.0399 | 0.0406 | 0.0319 | 0.0299 | 0.0304 | 0.0257 | |
| SSIM | 1 | 0.9305 | 0.9381 | 0.9261 | 0.9327 | 0.9397 | 0.9472 | 0.9450 | 0.9494 |
| 2 | 0.8976 | 0.9024 | 0.9042 | 0.9187 | 0.9060 | 0.9114 | 0.9161 | 0.9246 | |
| 3 | 0.8577 | 0.8582 | 0.8718 | 0.8712 | 0.8736 | 0.8819 | 0.8812 | 0.8958 | |
| 4 | 0.7343 | 0.7672 | 0.7927 | 0.8129 | 0.8159 | 0.8142 | 0.8063 | 0.8395 | |
| 5 | 0.6114 | 0.6314 | 0.6353 | 0.6517 | 0.7039 | 0.7197 | 0.7260 | 0.7569 | |
| 6 | 0.6676 | 0.6792 | 0.6923 | 0.7160 | 0.7604 | 0.7646 | 0.7728 | 0.8026 | |
| UIQI | 1 | 0.6013 | 0.6792 | 0.6517 | 0.6983 | 0.7765 | 0.7855 | 0.7962 | 0.8775 |
| 2 | 0.6744 | 0.7153 | 0.6716 | 0.7579 | 0.7727 | 0.7750 | 0.7894 | 0.8826 | |
| 3 | 0.6948 | 0.7298 | 0.6970 | 0.7544 | 0.7693 | 0.7784 | 0.7751 | 0.8832 | |
| 4 | 0.7439 | 0.7801 | 0.7175 | 0.7973 | 0.8771 | 0.8913 | 0.8806 | 0.9244 | |
| 5 | 0.7422 | 0.8086 | 0.7652 | 0.8065 | 0.8683 | 0.8840 | 0.8752 | 0.9230 | |
| 6 | 0.7519 | 0.8060 | 0.7633 | 0.8073 | 0.8698 | 0.8699 | 0.8814 | 0.9148 | |
| CC | 1 | 0.6831 | 0.7018 | 0.6192 | 0.7236 | 0.7825 | 0.8144 | 0.8039 | 0.8845 |
| 2 | 0.7188 | 0.7511 | 0.6317 | 0.6964 | 0.7757 | 0.7829 | 0.7875 | 0.8873 | |
| 3 | 0.7062 | 0.7455 | 0.6510 | 0.6877 | 0.7719 | 0.7753 | 0.7803 | 0.8868 | |
| 4 | 0.7652 | 0.7942 | 0.7478 | 0.7973 | 0.8827 | 0.8966 | 0.9028 | 0.9266 | |
| 5 | 0.7913 | 0.8056 | 0.7892 | 0.8065 | 0.8715 | 0.8802 | 0.8896 | 0.9247 | |
| 6 | 0.8044 | 0.8032 | 0.7831 | 0.8073 | 0.8720 | 0.8911 | 0.8952 | 0.9174 | |
| ERGAS | - | 1.9042 | 1.8872 | 2.1317 | 1.9688 | 1.6179 | 1.4413 | 1.4260 | 1.2472 |
| Model | GANSTFM | EDCSTFN | SwinSTFM | ECPW-STFN | STFDiff | Mamba-STFM |
|---|---|---|---|---|---|---|
| FLOPs (G) | 37.7586 | 18.5838 | 28.1822 | 30.7110 | 4.5937 | 16.5276 |
| Parms (M) | 0.5771 | 0.2825 | 37.4656 | 0.4719 | 42.8226 | 47.1078 |
| Average inference time (ms) | 6.9053 | 2.5188 | 48.2391 | 120.3042 | 236.1877 | 44.8670 |
| Max memory usage (MB) | 187.4299 | 1983.3047 | 311.1792 | 605.1192 | 733.5072 | 288.7332 |
| CIA | 0.8315 | 0.8793 | 0.8931 | 0.9101 | 0.9127 | 0.9277 |
| LGC | 0.7037 | 0.7531 | 0.8261 | 0.8401 | 0.8432 | 0.9046 |
| Eliminate or Replace | SSIM ↓ | UIQI ↓ | CC ↓ | RMSE ↑ | ERGAS ↑ |
|---|---|---|---|---|---|
| ∖ | 0.8615 | 0.9009 | 0.9046 | 0.0203 | 1.2472 |
| FuseCore-AttNet | 0.8553 | 0.8974 | 0.8825 | 0.0238 | 1.2528 |
| Temporal Expert | 0.8472 | 0.8701 | 0.8683 | 0.0264 | 1.3575 |
| Spatial Expert | 0.8258 | 0.8562 | 0.8519 | 0.0315 | 1.4091 |
| All | 0.8211 | 0.8494 | 0.8447 | 0.0338 | 1.4216 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Zhang, X.; Quan, C.; Zhao, T.; Huo, W.; Huang, Y. Mamba-STFM: A Mamba-Based Spatiotemporal Fusion Method for Remote Sensing Images. Remote Sens. 2025, 17, 2135. https://doi.org/10.3390/rs17132135
Zhang Q, Zhang X, Quan C, Zhao T, Huo W, Huang Y. Mamba-STFM: A Mamba-Based Spatiotemporal Fusion Method for Remote Sensing Images. Remote Sensing. 2025; 17(13):2135. https://doi.org/10.3390/rs17132135
Chicago/Turabian StyleZhang, Qiyuan, Xiaodan Zhang, Chen Quan, Tong Zhao, Wei Huo, and Yuanchen Huang. 2025. "Mamba-STFM: A Mamba-Based Spatiotemporal Fusion Method for Remote Sensing Images" Remote Sensing 17, no. 13: 2135. https://doi.org/10.3390/rs17132135
APA StyleZhang, Q., Zhang, X., Quan, C., Zhao, T., Huo, W., & Huang, Y. (2025). Mamba-STFM: A Mamba-Based Spatiotemporal Fusion Method for Remote Sensing Images. Remote Sensing, 17(13), 2135. https://doi.org/10.3390/rs17132135