
Deep Learning Method for Wetland Segmentation in Unmanned Aerial Vehicle Multispectral Imagery




Abstract

1. Introduction
- (i)
- The study presents a novel deep learning approach for MS UAV imagery segmentation that integrates MS data and TIR features, significantly improving wetland segmentation accuracy and robustness.
- (ii)
- The validation, through an experimental comparison of loss functions, that the incorporation of TIR image features effectively addresses the issue of data imbalance, a common challenge that leads to reduced accuracy in segmentation tasks.
- (iii)
- The construction of a comprehensive dataset specifically designed for semantic segmentation of UAV MS remote sensing images. This dataset includes a diverse range of land cover types, providing a valuable resource for training and testing deep learning models.
2. Materials
3. Methods
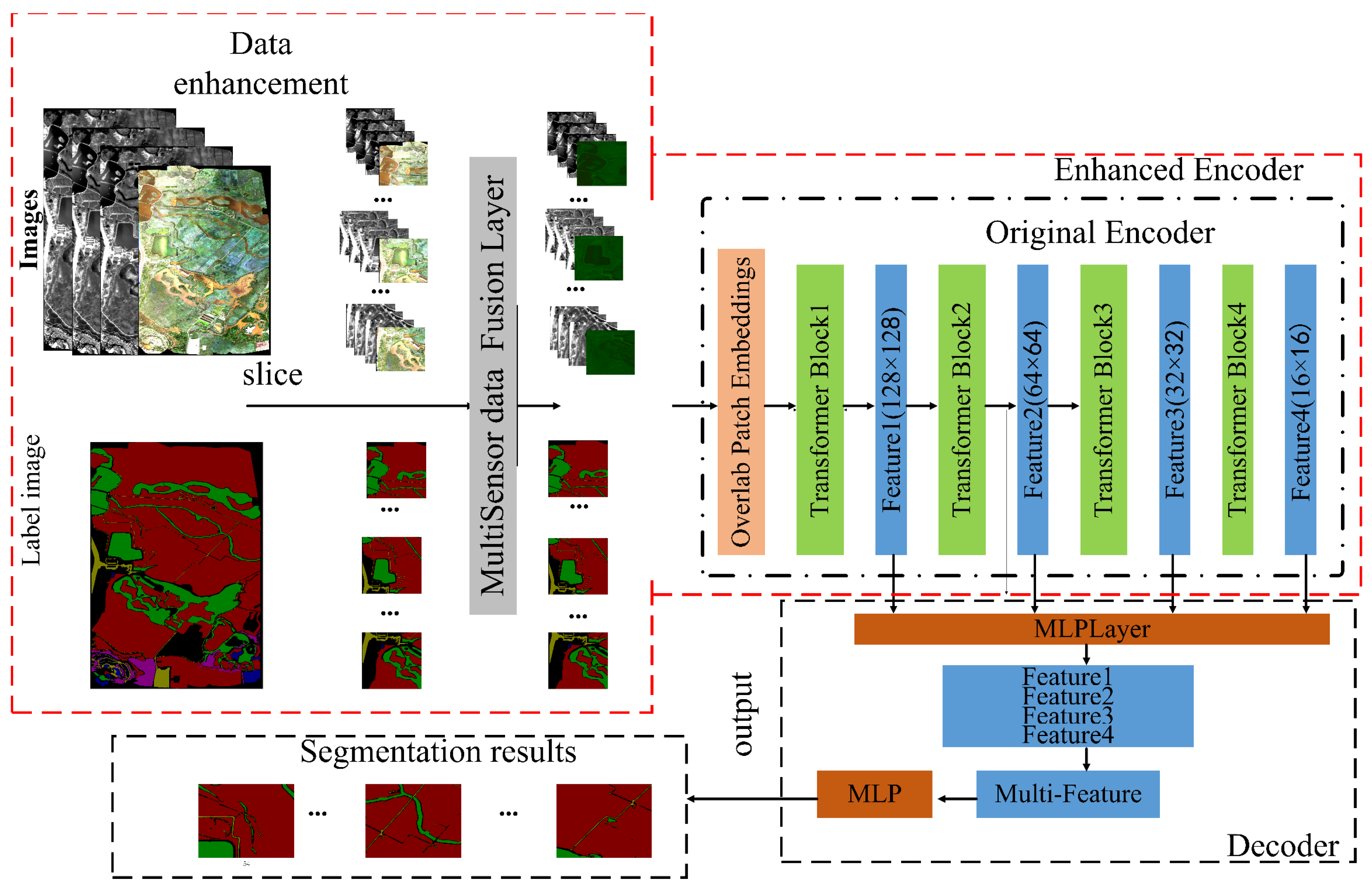
3.1. Technical Route
3.1.1. Data Preprocessing
- (i)
- Image Acquisition: DJ600 Pro is equipped with a TIR and MS camera to capture TIR and MS images.
- (ii)
- Image Stitching: Stitch together all the smaller images to obtain a larger image of the entire study area.
- (iii)
- Image Resampling: The MS and thermal infrared images are resized to a consistent dimension using bilinear interpolation. This method calculates new pixel values by averaging the four nearest pixel values, ensuring a smooth transition and balancing performance with image quality.
- (iv)
- Band Concatenation: The different spectral bands are combined to create a six-channel MS image.
- (v)
- Data Annotation and Slicing: We annotated large images from the entire study area and composed a semantic segmentation dataset comprising 1000 cropped images. The dataset was partitioned into 60% for training, 30% for validation, and 10% for testing.
- (vi)
- Training: We employ stand-alone synchronized training methods with the Adam optimizer in PyTorch, leveraging the combined strengths of AdaGrad and RMSProp. The initial learning rate is set to 1 × 10−4, with a batch size of 2000 (comprising 8 images per chip) and a learning rate decay of 0.7 every 30 epochs. Dropout is applied at a rate of 0.5, and L2 weight decay is set to 1 × 10−5. Image preprocessing follows the same protocol as Inception. Additionally, we utilize an exponential moving average with a decay rate of 0.9999. All convolutional layers incorporate batch normalization with an average decay of 0.9.
3.1.2. Segmentation Model
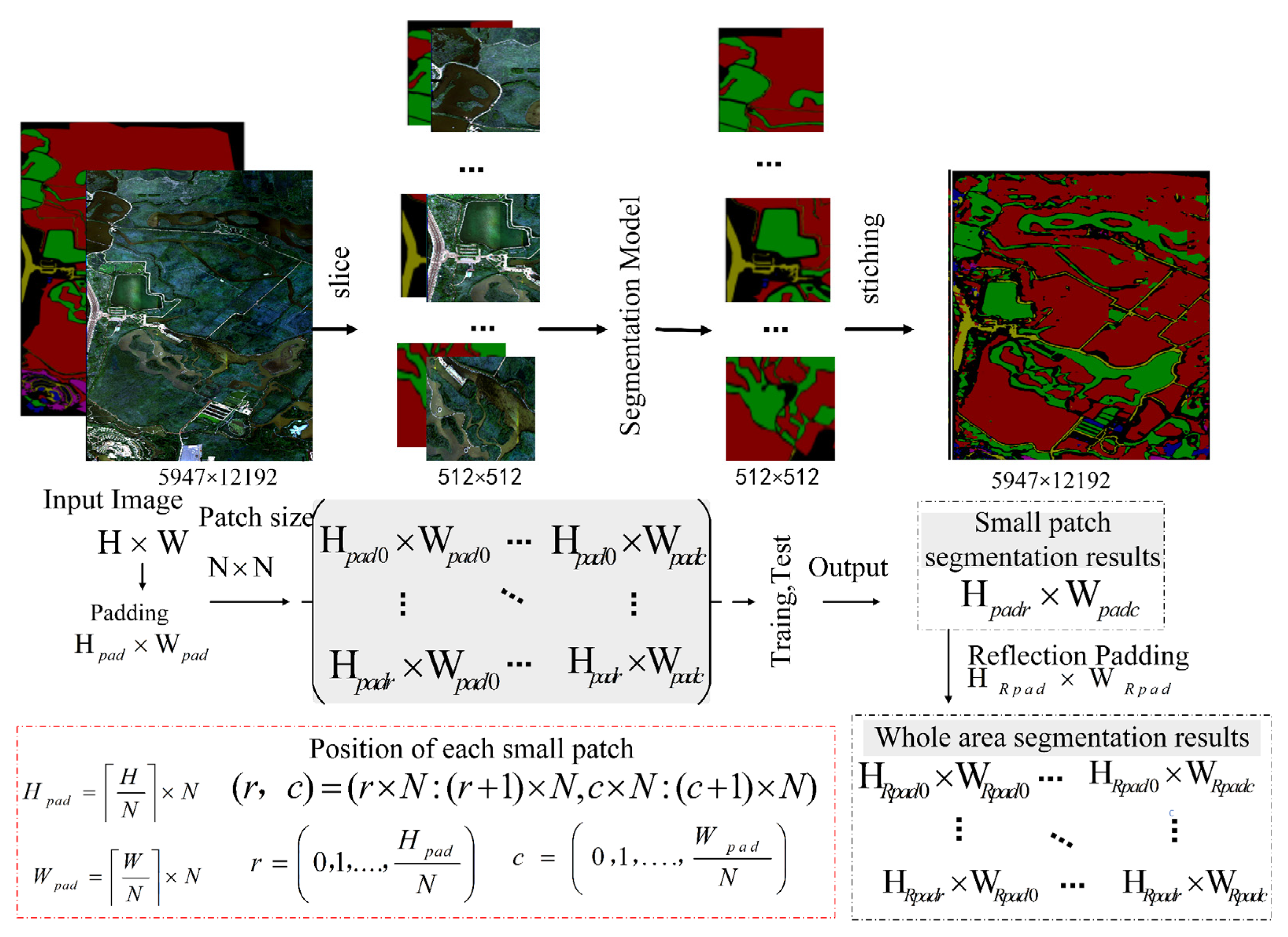
3.1.3. Data Post-Processing
3.2. Evaluation Indexes
3.3. Loss Function
3.3.1. Cross-Entropy Loss
3.3.2. Sigmoid Focal Loss
4. Results
4.1. Comparative Analysis of Single-Channel Segmentation Performance
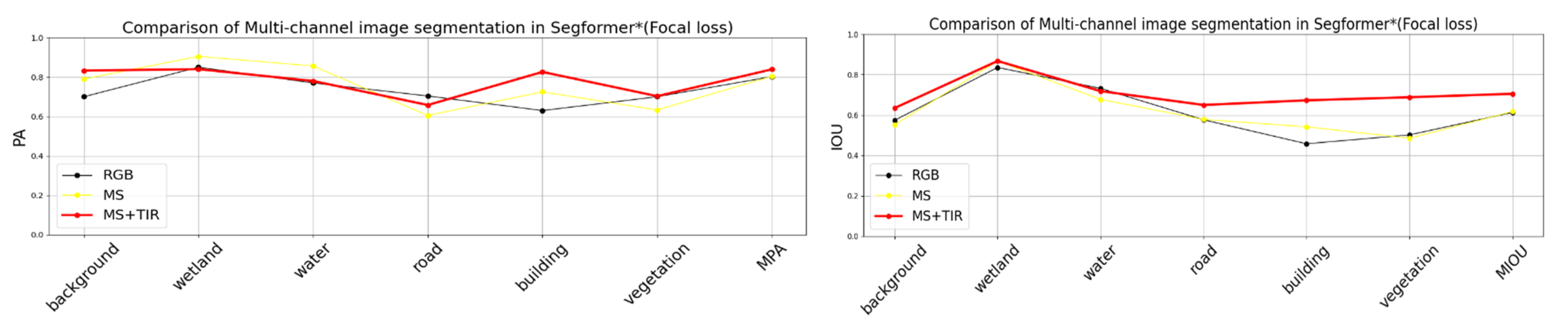
4.2. Comparative Analysis of Multichannel Segmentation
4.3. Limitations of the Proposed Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mishra, N.B. Wetlands: Remote Sensing. In Wetlands and Habitats, 2nd ed.; Wang, Y., Ed.; CRC Press: Boca Raton, FL, USA, 2020; pp. 201–212. ISBN 978-0-429-44550-7. [Google Scholar]
- Maltby, E.; Acreman, M.C. Ecosystem services of wetlands: Pathfinder for a new paradigm. Hydrol. Sci. J. 2011, 56, 1341–1359. [Google Scholar] [CrossRef]
- Cui, M.; Zhou, J.X.; Huang, B. Benefit evaluation of wetlands resource with different modes of protection and utilization in the Dongting Lake region. Procedia Environ. Sci. 2012, 13, 2–17. [Google Scholar] [CrossRef]
- Erwin, K.L. Wetlands and global climate change: The role of wetland restoration in a changing world. Wetl. Ecol. Manag. 2009, 17, 71–84. [Google Scholar] [CrossRef]
- Du, Y.; Bai, Y.; Wan, L. Wetland information extraction based on UAV multispectral and oblique images. Arab. J. Geosci. 2020, 13, 1241. [Google Scholar] [CrossRef]
- Guan, X.; Wang, D.; Wan, L.; Zhang, J. Extracting Wetland Type Information with a Deep Convolutional Neural Network. Comput. Intell. Neurosci. 2022, 2022, 5303872. [Google Scholar] [CrossRef]
- Lu, T.; Wan, L.; Qi, S.; Gao, M. Land Cover Classification of UAV Remote Sensing Based on Transformer–CNN Hybrid Architecture. Sensors 2023, 23, 5288. [Google Scholar] [CrossRef] [PubMed]
- Bhatnagar, S.; Gill, L.; Ghosh, B. Drone Image Segmentation Using Machine and Deep Learning for Mapping Raised Bog Vegetation Communities. Remote Sens. 2020, 12, 2602. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, J.; Liu, S.; Li, M.; Zhang, X.; Huang, Z.; Dong, W.; Ma, J.; Ai, L. A Land Surface Temperature Retrieval Method for UAV Broadband Thermal Imager Data. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7002805. [Google Scholar] [CrossRef]
- Deng, L.; Mao, Z.; Li, X.; Hu, Z.; Duan, F.; Yan, Y. UAV-based multispectral remote sensing for precision agriculture: A comparison between different cameras. ISPRS J. Photogramm. Remote Sens. 2018, 146, 124–136. [Google Scholar] [CrossRef]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Tong, L.; Wang, Y.; Cheng, L. Using unmanned aerial vehicle for remote sensing application. In Proceedings of the 2013 21st International Conference on Geoinformatics, Kaifeng, China, 20–22 June 2013; pp. 1–5. [Google Scholar]
- Matese, A.; Di Gennaro, S.F. Practical Applications of a Multisensor UAV Platform Based on Multispectral, Thermal and RGB High Resolution Images in Precision Viticulture. Agriculture 2018, 8, 116. [Google Scholar] [CrossRef]
- Khaliq, A.; Comba, L.; Biglia, A.; Ricauda Aimonino, D.; Chiaberge, M.; Gay, P. Comparison of Satellite and UAV-Based Multispectral Imagery for Vineyard Variability Assessment. Remote Sens. 2019, 11, 436. [Google Scholar] [CrossRef]
- Dash, J.P.; Watt, M.S.; Pearse, G.D.; Heaphy, M.; Dungey, H.S. Assessing very high resolution UAV imagery for monitoring forest health during a simulated disease outbreak. ISPRS J. Photogramm. Remote Sens. 2017, 131, 1–14. [Google Scholar] [CrossRef]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J. Hyperspectral Imaging: A Review on UAV-Based Sensors, Data Processing and Applications for Agriculture and Forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef]
- Wang, F.; Zheng, Y.; Lv, W.; Tang, J. Thermal infrared image semantic segmentation with Iightweight edge assisted context guided network. In Proceedings of the Third International Conference on Machine Learning and Computer Application (ICMLCA 2022), Shenyang, China, 16–18 December 2022; Zhou, F., Ba, S., Eds.; SPIE: Shenyang, China, 2023; p. 50. [Google Scholar]
- Weng, Q. Thermal infrared remote sensing for urban climate and environmental studies: Methods, applications, and trends. ISPRS J. Photogramm. Remote Sens. 2009, 64, 335–344. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolution Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Yu, H.; Yang, Z.; Tan, L.; Wang, Y.; Sun, W.; Sun, M.; Tang, Y. Methods and datasets on semantic segmentation: A review. Neurocomputing 2018, 304, 82–103. [Google Scholar] [CrossRef]
- Osco, L.P.; Marcato Junior, J.; Marques Ramos, A.P.; De Castro Jorge, L.A.; Fatholahi, S.N.; De Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Santosh, K.; Das, N.; Ghosh, S. Deep learning: A review. In Deep Learning Models for Medical Imaging; Elsevier: Amsterdam, The Netherlands, 2022; pp. 29–63. ISBN 978-0-12-823504-1. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net_: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3 2019. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Lombardi, A.; Nardo, E.D.; Ciaramella, A. Skip-SegFormer Efficient Semantic Segmentation for urban driving. In Proceedings of the Ital-IA 2023: 3rd National Conference on Artificial Intelligence, Organized by CINI, Pisa, Italy, 29–31 May 2023; pp. 54–59. [Google Scholar]
- Li, X.; Cheng, Y.; Fang, Y.; Liang, H.; Xu, S. 2DSegFormer: 2-D Transformer Model for Semantic Segmentation on Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4709413. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bai, H.; Mao, H.; Nair, D. Dynamically Pruning Segformer for Efficient Semantic Segmentation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3298–3302. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Knight, J.F.; Corcoran, J.M.; Rampi, L.P.; Pelletier, K.C. Theory and Applications of Object-Based Image Analysis and Emerging Methods in Wetland Mapping. In Remote Sensing of Wetlands; Tiner, R.W., Lang, M.W., Klemas, V.V., Eds.; CRC Press: Boca Raton, FL, USA, 2015; pp. 194–213. ISBN 978-0-429-18329-4. [Google Scholar]
- O’Neil, G.L.; Goodall, J.L.; Behl, M.; Saby, L. Deep learning Using Physically-Informed Input Data for Wetland Identification. Environ. Model. Softw. 2020, 126, 104665. [Google Scholar] [CrossRef]
- Lin, X.; Cheng, Y.; Chen, G.; Chen, W.; Chen, R.; Gao, D.; Zhang, Y.; Wu, Y. Semantic Segmentation of China’s Coastal Wetlands Based on Sentinel-2 and Segformer. Remote Sens. 2023, 15, 3714. [Google Scholar] [CrossRef]
- López-Tapia, S.; Ruiz, P.; Smith, M.; Matthews, J.; Zercher, B.; Sydorenko, L.; Varia, N.; Jin, Y.; Wang, M.; Dunn, J.B.; et al. Machine learning with high-resolution aerial imagery and data fusion to improve and automate the detection of wetlands. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102581. [Google Scholar] [CrossRef]
- Cheng, J.; Deng, C.; Su, Y.; An, Z.; Wang, Q. Methods and datasets on semantic segmentation for Unmanned Aerial Vehicle remote sensing images: A review. ISPRS J. Photogramm. Remote Sens. 2024, 211, 1–34. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, X.; Cai, J.; Yang, Q. MW-SAM:Mangrove wetland remote sensing image segmentation network based on segment anything model. IET Image Process. 2024, 18, 4503–4513. [Google Scholar] [CrossRef]
- Musungu, K.; Dube, T.; Smit, J.; Shoko, M. Using UAV multispectral photography to discriminate plant species in a seep wetland of the Fynbos Biome. Wetl. Ecol. Manag. 2024, 32, 207–227. [Google Scholar] [CrossRef]
- Fu, Y.; Zhang, X.; Wang, M. DSHNet: A Semantic Segmentation Model of Remote Sensing Images Based on Dual Stream Hybrid Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4164–4175. [Google Scholar] [CrossRef]
- Meng, L.; Zhou, J.; Liu, S.; Wang, Z.; Zhang, X.; Ding, L.; Shen, L.; Wang, S. A robust registration method for UAV thermal infrared and visible images taken by dual-cameras. ISPRS J. Photogramm. Remote Sens. 2022, 192, 189–214. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, J.; Ma, J.; Wang, Y.; Liu, S.; Ding, L.; Tang, W.; Pakezhamu, N.; Meng, L. Removing temperature drift and temporal variation in thermal infrared images of a UAV uncooled thermal infrared imager. ISPRS J. Photogramm. Remote Sens. 2023, 203, 392–411. [Google Scholar] [CrossRef]
- Nuradili, P.; Zhou, G.; Zhou, J.; Wang, Z.; Meng, Y.; Tang, W.; Melgani, F. Semantic segmentation for UAV low-light scenes based on deep learning and thermal infrared image features. Int. J. Remote Sens. 2024, 45, 4160–4177. [Google Scholar] [CrossRef]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Vina del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Data | PA(%) | MPA | |||||
|---|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | |||
| Segformer [37] | R | 73.22 | 82.12 | 42.63 | 53.98 | 74.07 | 37.20 | 72.68 |
| G | 73.34 | 86.33 | 68.48 | 58.74 | 60.43 | 56.14 | 79.30 | |
| B | 72.50 | 90.44 | 64.66 | 39.09 | 25.91 | 10.35 | 79.00 | |
| REG | 47.49 | 02.98 | 73.28 | 01.85 | 04.00 | 00.00 | 69.03 | |
| NIR | 25.65 | 01.96 | 89.04 | 01.13 | 04.00 | 21.31 | 74.84 | |
| TIR | 67.50 | 93.94 | 75.00 | 76.89 | 70.54 | 84.38 | 82.14 | |
| Segformer* | R | 66.78 | 83.13 | 40.24 | 46.13 | 32.70 | 58.98 | 71.52 |
| G | 74.21 | 88.99 | 80.17 | 63.79 | 75.93 | 46.32 | 82.74 | |
| B | 71.70 | 90.60 | 79.88 | 61.56 | 77.07 | 65.05 | 83.51 | |
| REG | 43.14 | 92.74 | 85.25 | 04.22 | 03.86 | 00.37 | 75.63 | |
| NIR | 71.76 | 95.21 | 92.93 | 37.69 | 40.69 | 40.73 | 80.60 | |
| TIR | 74.78 | 92.44 | 77.45 | 80.45 | 61.82 | 77.42 | 83.28 | |
| Method | Data | IOU(%) | MIOU | |||||
|---|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | |||
| Segformer | R | 48.97 | 68.66 | 32.73 | 48.35 | 52.43 | 32.62 | 47.29 |
| G | 52.40 | 77.26 | 54.70 | 46.89 | 50.86 | 40.97 | 53.83 | |
| B | 48.61 | 80.40 | 54.75 | 34.89 | 23.14 | 09.40 | 41.87 | |
| REG | 04.56 | 07.05 | 04.96 | 00.01 | 00.00 | 00.00 | 20.80 | |
| NIR | 21.52 | 01.79 | 58.58 | 01.13 | 04.00 | 14.50 | 28.96 | |
| TIR | 55.03 | 80.17 | 68.86 | 45.88 | 61.54 | 43.48 | 59.16 | |
| Segformer* | R | 51.55 | 68.68 | 28.17 | 40.64 | 25.07 | 25.90 | 40.00 |
| G | 58.73 | 80.28 | 62.50 | 55.70 | 48.96 | 40.05 | 57.70 | |
| B | 57.03 | 81.96 | 65.62 | 54.42 | 47.52 | 48.51 | 59.18 | |
| REG | 32.40 | 80.56 | 54.74 | 03.53 | 03.76 | 00.36 | 29.23 | |
| NIR | 58.14 | 87.48 | 80.14 | 32.68 | 35.88 | 38.45 | 55.46 | |
| TIR | 58.63 | 81.43 | 70.27 | 53.56 | 55.08 | 67.20 | 64.36 | |
| Method | PA(%) | MPA | |||||
|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | ||
| FCN [24] | 38.89 | 53.87 | 77.76 | 02.77 | 19.40 | 01.15 | 52.05 |
| MobilenetV3 [31] | 20.73 | 71.10 | 18.55 | 07.46 | 19.23 | 04.89 | 44.49 |
| DeepLabv3 [29] | 80.07 | 72.82 | 65.17 | 49.20 | 44.85 | 57.32 | 71.49 |
| Segformer [37] | 69.31 | 94.58 | 89.96 | 81.61 | 81.36 | 89.37 | 86.41 |
| Segformer* | 75.55 | 92.44 | 91.15 | 90.88 | 77.90 | 85.27 | 87.06 |
| Method | IOU(%) | MIOU | |||||
|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | ||
| FCN [24] | 29.70 | 41.62 | 33.45 | 02.62 | 18.34 | 01.14 | 21.15 |
| MobilenetV3 [32] | 15.19 | 46.36 | 15.01 | 01.84 | 05.53 | 02.42 | 14.39 |
| DeepLabv3 [29] | 44.94 | 67.17 | 56.10 | 26.96 | 41.56 | 43.38 | 46.68 |
| Segformer [33] | 59.44 | 85.98 | 77.30 | 74.06 | 65.83 | 83.00 | 74.27 |
| Segformer* | 63.51 | 85.88 | 78.22 | 76.20 | 64.68 | 83.08 | 75.26 |
| Method | Data | PA(%) | MPA(%) | |||||
|---|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | |||
| Segformer | RGB | 42.01 | 89.63 | 88.57 | 82.57 | 32.47 | 91.31 | 78.65 |
| MS | 76.40 | 86.85 | 81.95 | 57.14 | 78.25 | 54.68 | 82.26 | |
| MS + TIR | 83.32 | 91.48 | 79.25 | 55.43 | 81.55 | 73.76 | 86.50 | |
| Segformer* | RGB | 73.73 | 91.88 | 79.07 | 70.54 | 67.83 | 71.28 | 84.89 |
| MS | 71.79 | 91.54 | 86.56 | 66.05 | 71.25 | 62.33 | 85.04 | |
| MS+TIR | 85.29 | 91.84 | 77.32 | 69.58 | 86.26 | 78.03 | 87.39 | |
| Method | Data | IOU(%) | MIOU(%) | |||||
|---|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | |||
| Segformer | RGB | 37.03 | 83.82 | 66.76 | 49.13 | 26.34 | 21.89 | 47.50 |
| MS | 55.48 | 80.06 | 68.41 | 45.04 | 36.92 | 46.45 | 55.39 | |
| MS + TIR | 60.06 | 87.24 | 73.07 | 53.21 | 52.97 | 59.33 | 64.31 | |
| Segformer* | RGB | 57.40 | 83.55 | 73.20 | 57.64 | 45.77 | 50.17 | 61.29 |
| MS | 55.19 | 86.73 | 67.76 | 57.80 | 54.17 | 48.53 | 61.70 | |
| MS + TIR | 63.46 | 86.76 | 71.84 | 64.98 | 67.29 | 68.81 | 70.52 | |
| Method | PA(%) | MPA | |||||
|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | ||
| FCN [24] | 49.95 | 81.31 | 54.81 | 37.48 | 18.04 | 05.35 | 66.11 |
| MobilenetV3 [32] | 46.82 | 86.43 | 27.60 | 20.00 | 05.72 | 00.00 | 62.23 |
| DeepLabv3 [24] | 61.21 | 88.92 | 63.48 | 75.79 | 46.92 | 77.41 | 76.41 |
| Segformer [33] | 81.00 | 94.58 | 87.69 | 77.75 | 91.27 | 79.57 | 89.86 |
| Segformer* | 85.25 | 95.42 | 90.51 | 82.68 | 90.94 | 61.92 | 90.35 |
| Method | IOU(%) | MIOU | |||||
|---|---|---|---|---|---|---|---|
| Background | Wetland | Water | Road | Building | Vegetation | ||
| FCN [24] | 30.79 | 64.88 | 41.47 | 22.24 | 14.77 | 05.25 | 29.90 |
| MoilenetV3 [32] | 26.44 | 63.93 | 24.93 | 10.99 | 05.01 | 00.00 | 21.88 |
| DeepLabv3 [29] | 47.60 | 72.89 | 52.92 | 42.90 | 40.06 | 41.51 | 49.65 |
| Segformer [33] | 70.57 | 89.36 | 84.46 | 72.78 | 75.76 | 46.61 | 73.26 |
| Segformer* | 66.46 | 90.46 | 77.71 | 70.27 | 70.15 | 67.75 | 73.87 |
| Class | Background | Wetland | Water | Road | Building | Vegetation |
|---|---|---|---|---|---|---|
| Pixel number | 13,619,456 | 39,929,764 | 13,833,990 | 992,358 | 281,814 | 3,848,442 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nuradili, P.; Zhou, J.; Zhou, G.; Melgani, F. Deep Learning Method for Wetland Segmentation in Unmanned Aerial Vehicle Multispectral Imagery. Remote Sens. 2024, 16, 4777. https://doi.org/10.3390/rs16244777
Nuradili P, Zhou J, Zhou G, Melgani F. Deep Learning Method for Wetland Segmentation in Unmanned Aerial Vehicle Multispectral Imagery. Remote Sensing. 2024; 16(24):4777. https://doi.org/10.3390/rs16244777
Chicago/Turabian StyleNuradili, Pakezhamu, Ji Zhou, Guiyun Zhou, and Farid Melgani. 2024. "Deep Learning Method for Wetland Segmentation in Unmanned Aerial Vehicle Multispectral Imagery" Remote Sensing 16, no. 24: 4777. https://doi.org/10.3390/rs16244777
APA StyleNuradili, P., Zhou, J., Zhou, G., & Melgani, F. (2024). Deep Learning Method for Wetland Segmentation in Unmanned Aerial Vehicle Multispectral Imagery. Remote Sensing, 16(24), 4777. https://doi.org/10.3390/rs16244777