


From Data to Decision: Interpretable Machine Learning for Predicting Flood Susceptibility in Gdańsk, Poland


Abstract
1. Introduction
- To use machine learning models (SVM, RF, ANN) to effectively capture complex nonlinear interactions among hydrological, topographic, and built environment features.
- To introduce and assess the effectiveness of an EFFS method in optimising the selection of relevant flood conditioning factors.
- To incorporate explainable artificial intelligence to enhance the transparency and interpretability of the flood susceptibility models.
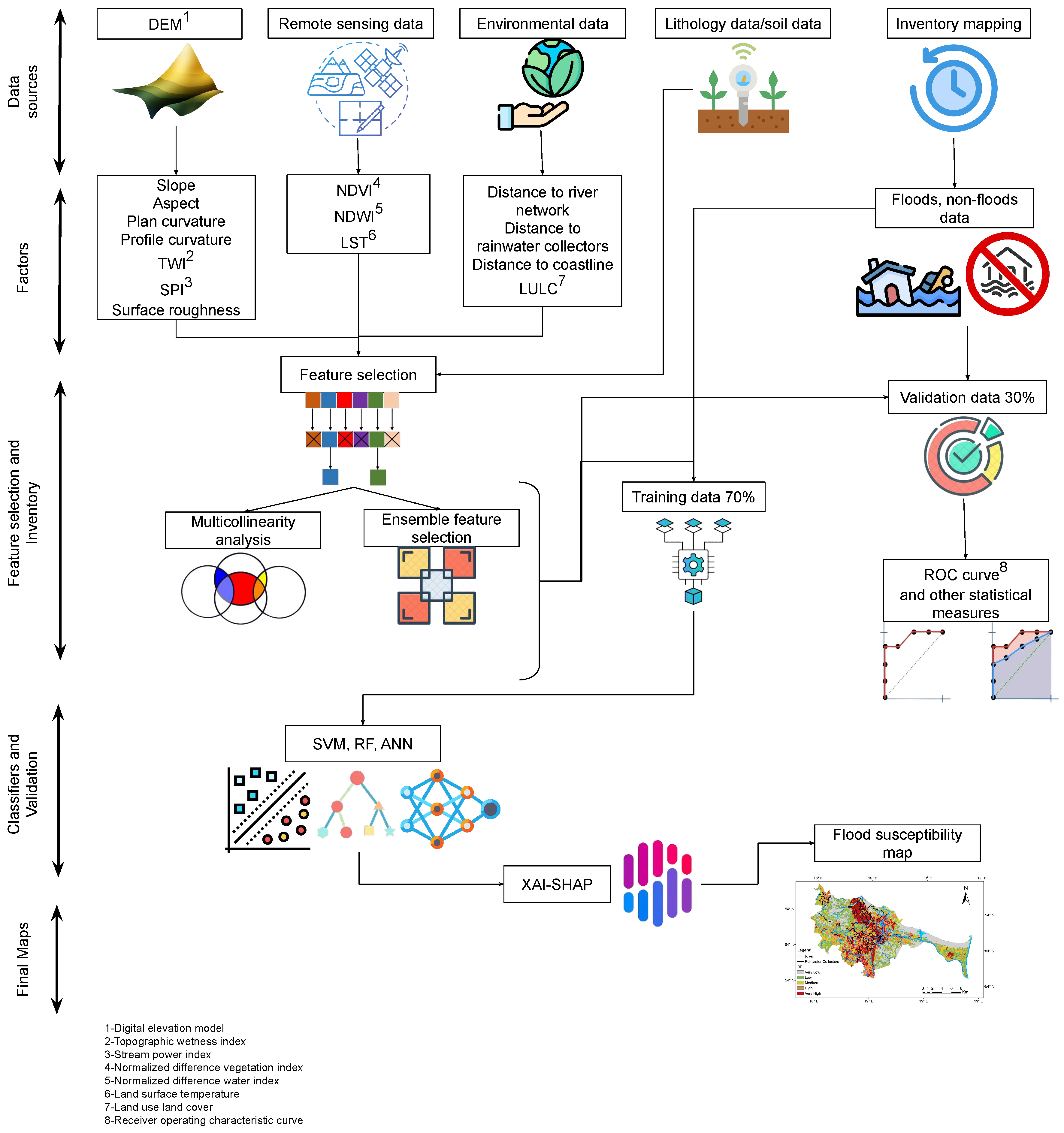
2. Datasets and Methodology
2.1. Local Conditions and Fire Brigade Interventions Dataset
- Intensive precipitation and runoff from the Moraine Hills, causing urban flash floods, as seen in July 2001 and 2016 [35].
- High discharge or ice jams in the main Vistula channel.
- Sea level rises in the Bay of Gdańsk, and severe storm surges.
2.2. Collection of Factors Dataset
2.3. Data Preprocessing
2.4. Multicollinearity Analysis of Flood Factors
2.5. The Ensemble-Based Filter Feature Selection (EFFS) Method
2.6. Models and Algorithms Used
2.7. Model Explainability
2.8. Performance Evaluation
3. Results
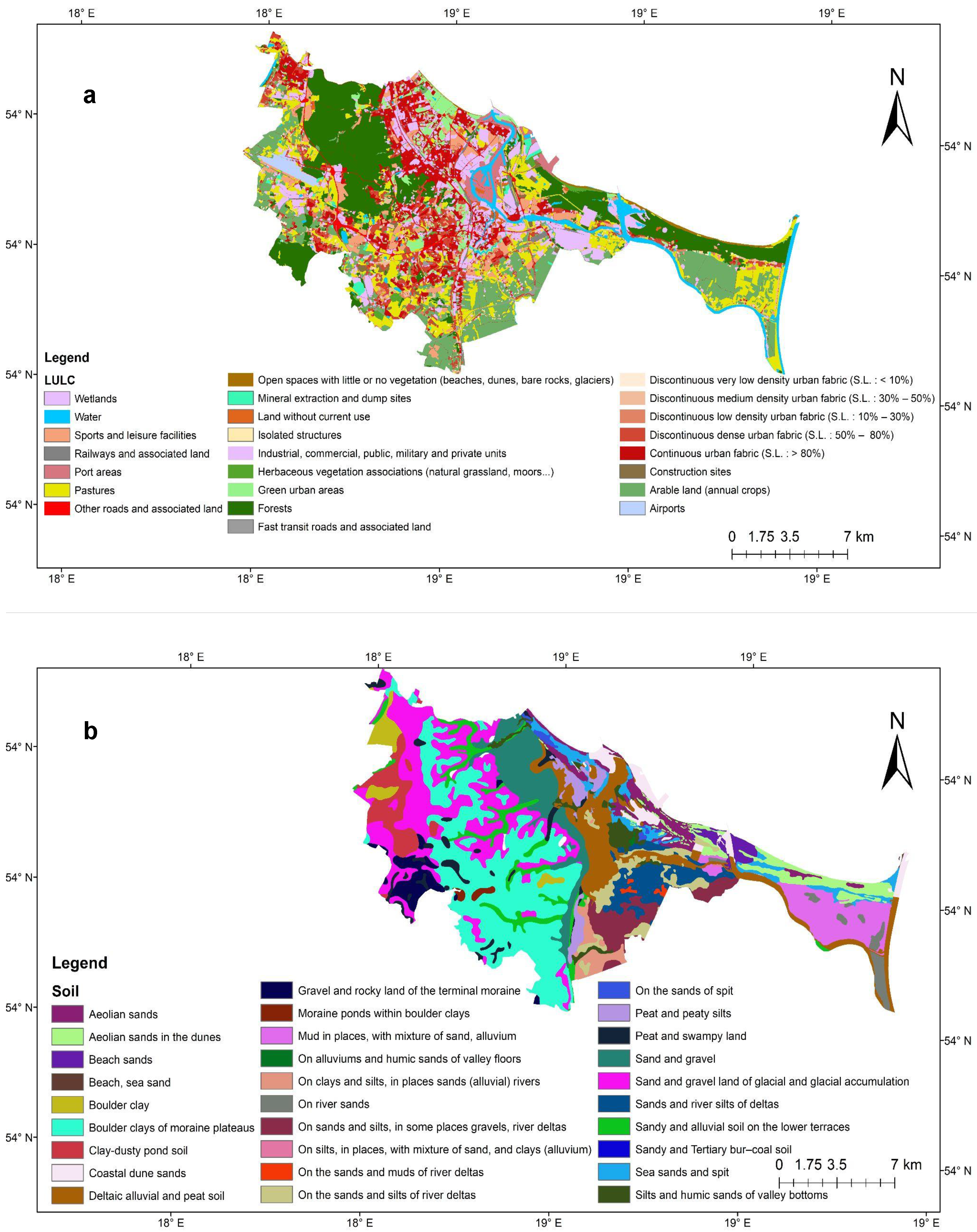
3.1. Flood Factor Maps
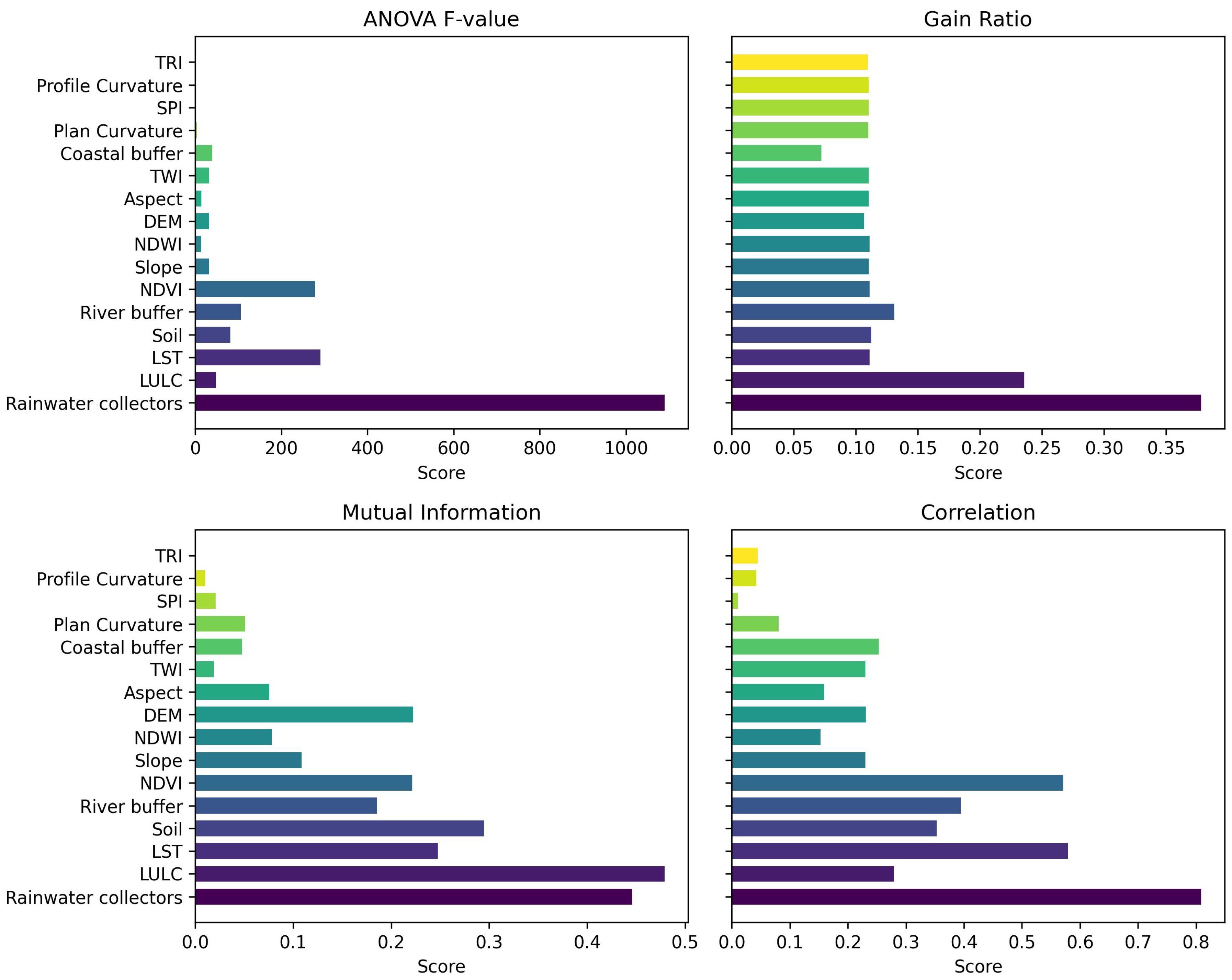
3.2. Multicollinearity of Factors
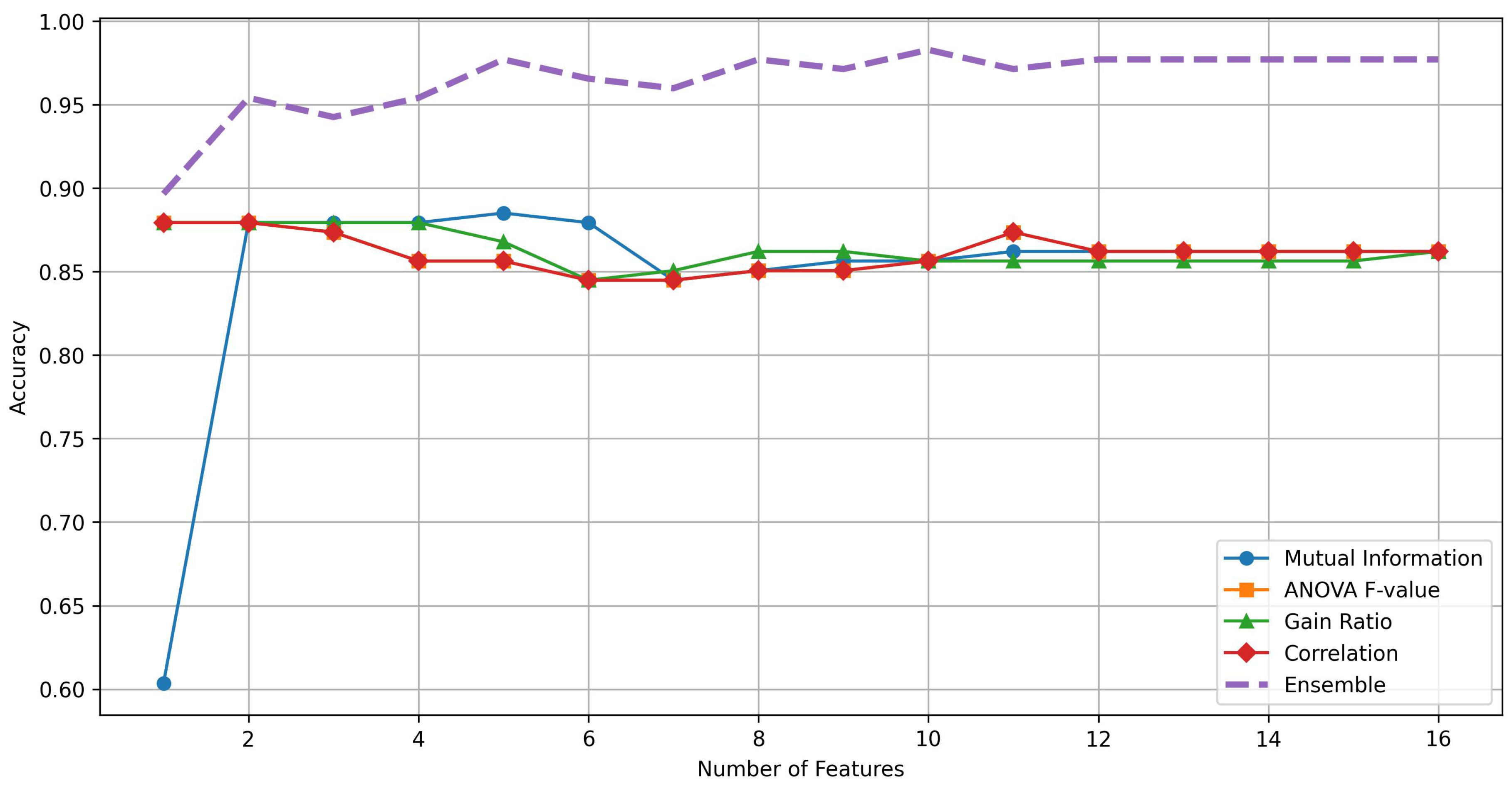
3.3. Ensemble Feature Selection
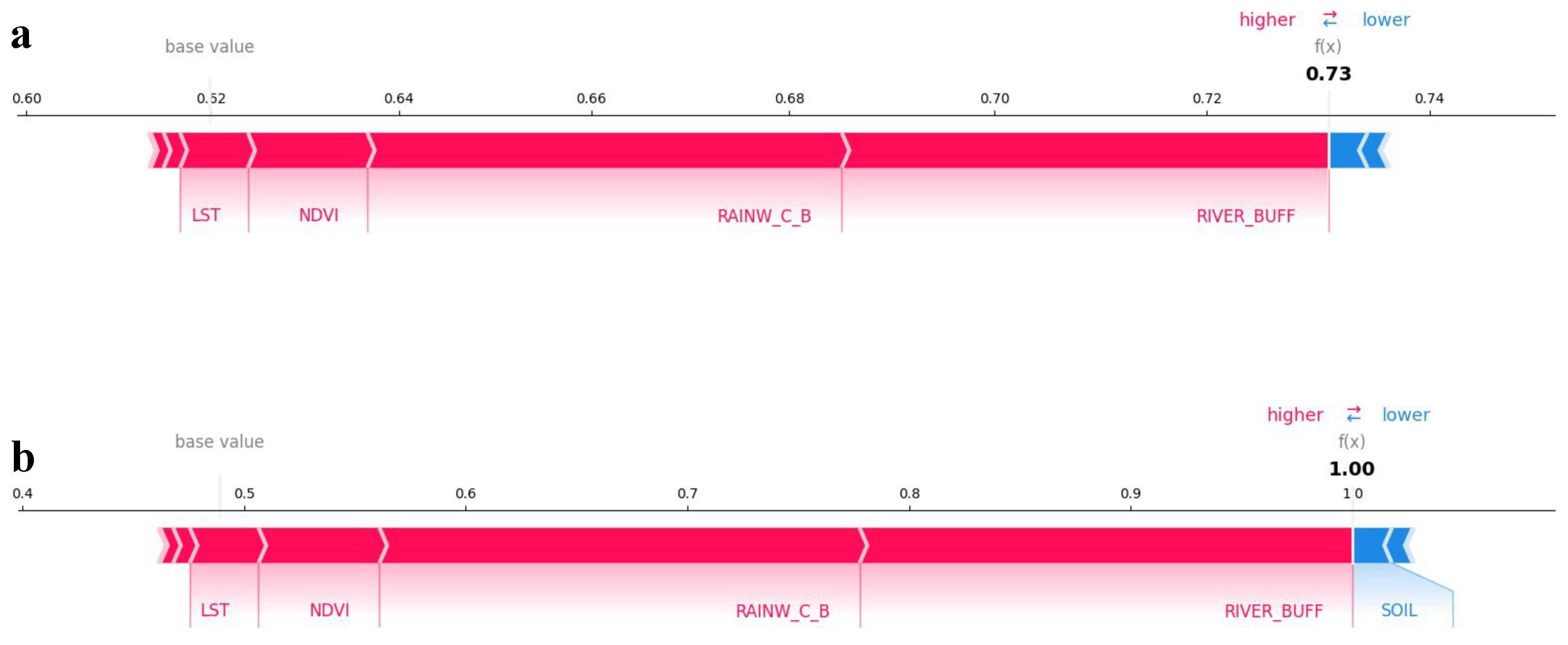
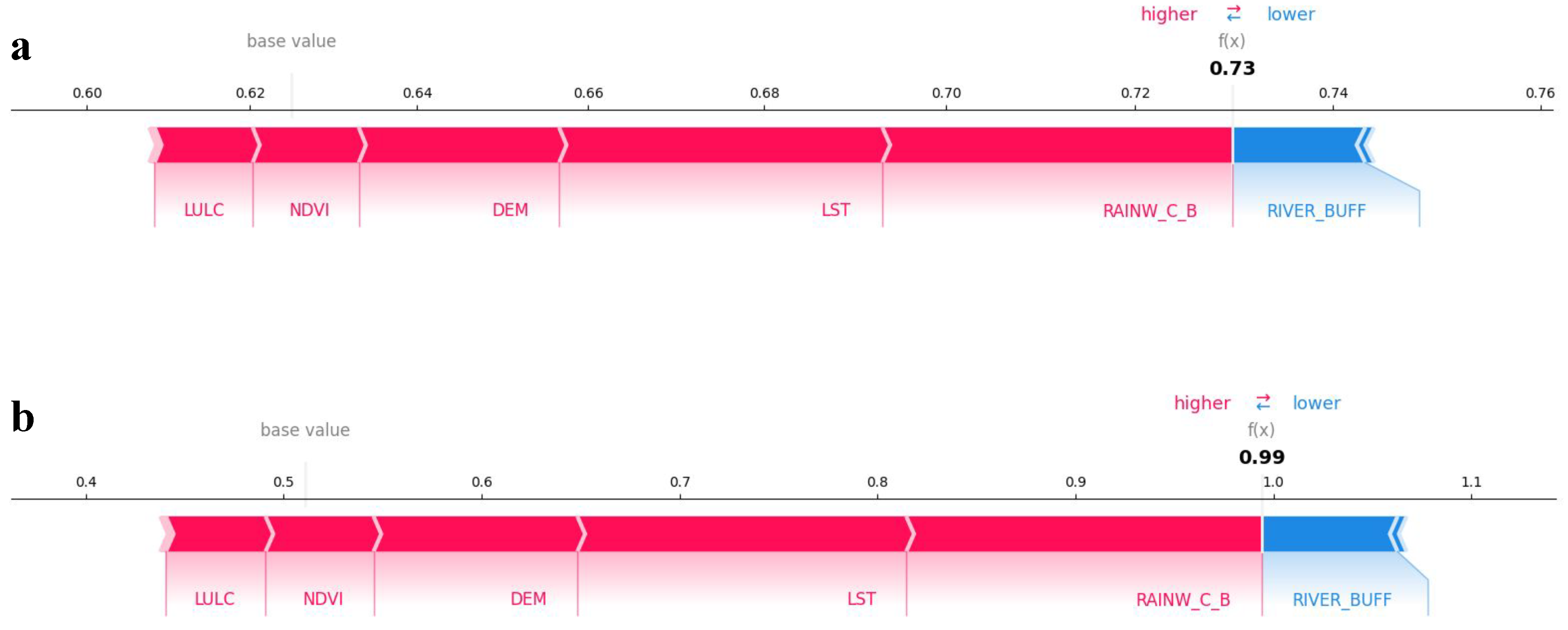
3.4. Explainability
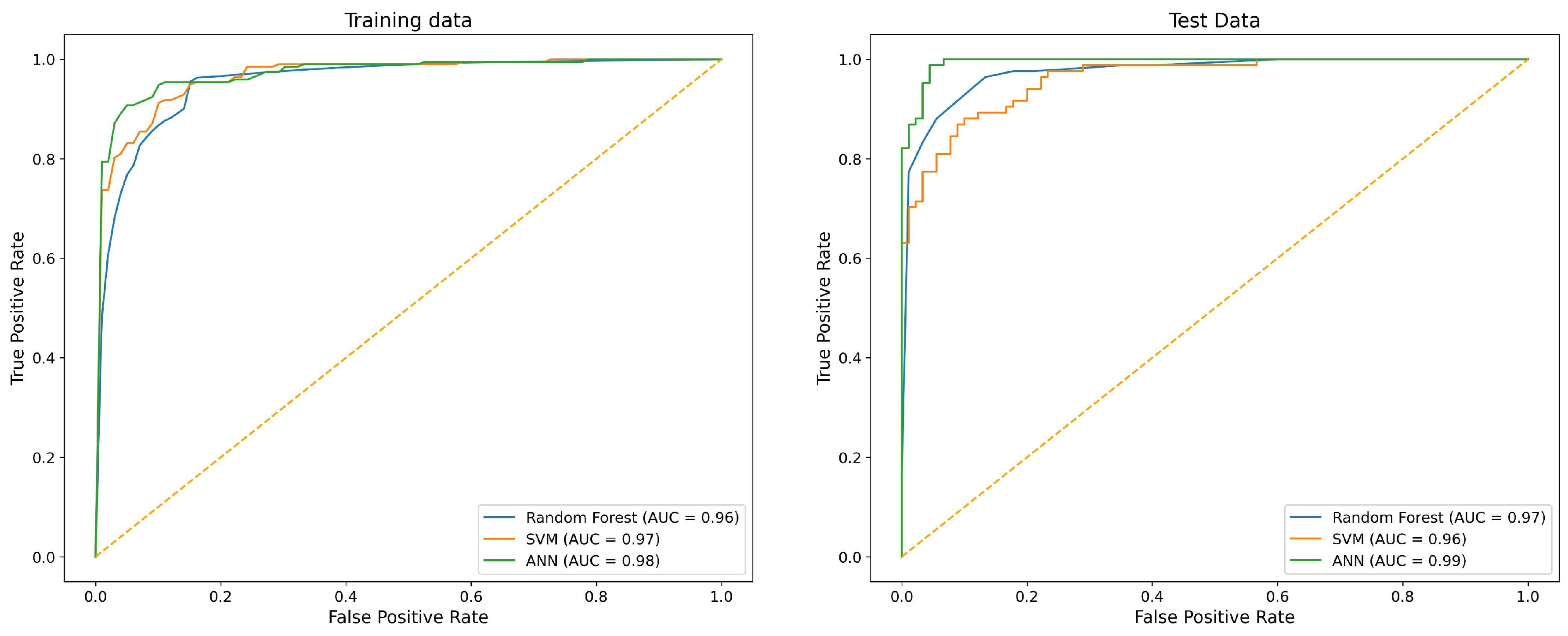
3.5. Performance of Flood Prediction
3.6. Flood Susceptibility Maps
- The plateau (Figure 11A) of Gdańsk moraine hills is less urbanised, with gentler slopes, leading to slower runoff. Increased urbanisation poses a threat by potentially raising peak flow during rainfall, surpassing the existing retention basins’ capacity. To address this, Gdańsk has implemented strict regulations [34], pausing some development plans, although enforcement varies by region. If urban expansion is managed or its impacts are mitigated, the need for urgent intervention on the plateau may be minimal [33].
- The moraine hills with slopes (Figure 11B) in southwest Gdańsk are increasingly urbanised and prone to flash floods due to their steep terrain, heavy rainfall, and urbanisation. Unlike low-lying areas, they are not vulnerable to storm surges because of their higher elevation. Urbanisation has stressed the water system, replacing natural ecosystems with an infrastructure that accelerates runoff and strains old sewage systems. The storm drainage network and impermeable surfaces direct water into waterways like the Radunia Canal, overwhelming their capacity and exacerbating flooding [35]. Retention basins are crucial in reducing peak flows in these hills [34]. Many basins have already been constructed, with more planned, mainly on the plateau. However, the rising land costs in this area diminish the cost-effectiveness of these measures [33]. Another measure is retaining up to 30 mm of rainwater in new developments [5].
- The rural zone, particularly the polder area southeast of the city (Figure 11C), is well-prepared for water-related challenges. Initially designed for agriculture with controlled water-level regulation, it has a sufficient buffering capacity to manage short, intense rainfalls without significant impact. Although flooding occurred in 2001 when Canal Radunia’s capacity was exceeded, overall, the polder’s drainage system effectively handles water flow. Rainfall–runoff in the polders poses no significant issues, making them a viable option for development compared to the moraine hills. However, enhancing the polder’s drainage and pumping systems would be necessary to accommodate the increased runoff from urbanised surfaces [33].
- Canal Radunia, an artificial channel dating back to the Middle Ages designed to drain the polder and supply water to Gdańsk, receives water from small natural streams in the moraine hills and has a maximum discharge capacity of 20 . During the 2001 flash flood, the canal was overwhelmed by a combined discharge of around 100 from streams, stormwater, and overland flow, resulting in breaches at five places and subsequent flooding east of the channel [4,33]. Gdańsk implemented a comprehensive three-stage rainwater management strategy involving on-site water management, municipal stormwater systems, retention reservoirs, and crisis response measures. Gdańsk has engaged residents in climate change adaptation measures through social platforms, citizens’ panels, and the Gdańsk Climate Change Forum, fostering knowledge-sharing about pluvial flood mitigation [5].
4. Limitations and Future Research Directions
5. Conclusions
- Ensemble feature selection identified critical factors influencing flood susceptibility in Gdańsk, including LULC, proximity to rainwater collectors, LST, river buffer zones, soil composition, and NDVI. These factors were consistently highlighted across multiple feature selection methods as pivotal in predicting flood-prone areas.
- The predictive performance of the SVM, RF, and ANN models was evaluated using AUC, with the ANN model demonstrating a superior performance (AUC 0.992) compared to RF (AUC 0.965) and SVM (AUC 0.905), underscoring the efficacy of machine learning approaches in accurately delineating flood susceptibility zones in Gdańsk.
- To tackle the issue of model interpretability, SHAP clarified the impact of specific features on model predictions. This approach improves transparency by providing insights into how particular factors (rainwater collectors, LST, NDVI, river buffer) contribute to flood susceptibility assessments and facilitating informed decision-making in flood mitigation strategies.
- Future research should focus on creating separate prediction models considering floods associated with sea level rises and climate change.
- Urban planners, policymakers, and disaster management authorities can prioritise interventions and distribute resources effectively using the practical insights from this study. Using machine learning techniques and geospatial data, stakeholders can anticipate flood hazards and improve community resilience.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Ionita, M.; Nagavciuc, V.; Guan, B. Rivers in the sky, flooding on the ground: The role of atmospheric rivers in inland flooding in central Europe. Hydrol. Earth Syst. Sci. 2020, 24, 5125–5147. [Google Scholar] [CrossRef]
- Mrozik, K.D. Problems of local flooding in functional urban areas in Poland. Water 2022, 14, 2453. [Google Scholar] [CrossRef]
- Konieczny, R.; Pińskwar, I.; Kundzewicz, Z. The September 2017 flood in Elblag (Poland) in perspective. Meteorol. Hydrol. Water Manag. Res. Oper. Appl. 2018, 6, 67–78. [Google Scholar] [CrossRef]
- Majewski, W. Urban flash flood in Gdańsk–2001. Case Study Meteorolology Hydrol. Water Manag. 2016, 4, 41–49. [Google Scholar] [CrossRef]
- Szydłowski, M.; Gulshad, K.; Mustafa, A.M.; Szpakowski, W. The impact of hydrological research, municipal authorities, and residents on rainwater management in Gdańsk (Poland) in the process of adapting the city to climate change. Acta Sci. Pol. Form. Circumiectus 2023, 22, 59–71. [Google Scholar] [CrossRef]
- Pińskwar, I.; Choryński, A.; Graczyk, D. Risk of Flash Floods in Urban and Rural Municipalities Triggered by Intense Precipitation in Wielkopolska of Poland. Int. J. Disaster Risk Sci. 2023, 14, 440–457. [Google Scholar] [CrossRef]
- Ahmadlou, M.; Karimi, M.; Alizadeh, S.; Shirzadi, A.; Parvinnejhad, D.; Shahabi, H.; Panahi, M. Flood susceptibility assessment using integration of adaptive network-based fuzzy inference system (ANFIS) and biogeography-based optimization (BBO) and BAT algorithms (BA). Geocarto Int. 2019, 34, 1252–1272. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Kaya, C.M.; Derin, L. Parameters and methods used in flood susceptibility mapping: A review. J. Water Clim. Chang. 2023, 14, 1935–1960. [Google Scholar] [CrossRef]
- Islam, A.R.M.T.; Talukdar, S.; Mahato, S.; Kundu, S.; Eibek, K.U.; Pham, Q.B.; Kuriqi, A.; Linh, N.T.T. Flood susceptibility modelling using advanced ensemble machine learning models. Geosci. Front. 2021, 12, 101075. [Google Scholar] [CrossRef]
- Yaseen, A.; Lu, J.; Chen, X. Flood susceptibility mapping in an arid region of Pakistan through ensemble machine learning model. Stoch. Environ. Res. Risk Assess. 2022, 36, 3041–3061. [Google Scholar] [CrossRef]
- Parvin, F.; Ali, S.A.; Calka, B.; Bielecka, E.; Linh, N.T.T.; Pham, Q.B. Urban flood vulnerability assessment in a densely urbanized city using multi-factor analysis and machine learning algorithms. Theor. Appl. Climatol. 2022, 149, 639–659. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility analysis and its verification using a novel ensemble support vector machine and frequency ratio method. Stoch. Environ. Res. Risk Assess. 2015, 29, 1149–1165. [Google Scholar] [CrossRef]
- Khosravi, K.; Nohani, E.; Maroufinia, E.; Pourghasemi, H.R. A GIS-based flood susceptibility assessment and its mapping in Iran: A comparison between frequency ratio and weights-of-evidence bivariate statistical models with multi-criteria decision-making technique. Nat. Hazards 2016, 83, 947–987. [Google Scholar] [CrossRef]
- Kolerski, T.; Kalinowska, D. Mathematical modeling of flood management system in the city of Gdańsk, Oruński stream case study. Acta Sci. Pol. Form. Circumiectus 2019, 18, 63–74. [Google Scholar] [CrossRef]
- Paprotny, D.; Vousdoukas, M.I.; Morales-Nápoles, O.; Jonkman, S.N.; Feyen, L. Pan-European hydrodynamic models and their ability to identify compound floods. Nat. Hazards 2020, 101, 933–957. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S.; Dikshit, A.; Kim, H. Spatial flood susceptibility mapping using an explainable artificial intelligence (XAI) model. Geosci. Front. 2023, 14, 101625. [Google Scholar] [CrossRef]
- Rahman, M.; Ningsheng, C.; Islam, M.M.; Dewan, A.; Iqbal, J.; Washakh, R.M.A.; Shufeng, T. Flood susceptibility assessment in Bangladesh using machine learning and multi-criteria decision analysis. Earth Syst. Environ. 2019, 3, 585–601. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef]
- Ngo, P.T.T.; Hoang, N.D.; Pradhan, B.; Nguyen, Q.K.; Tran, X.T.; Nguyen, Q.M.; Nguyen, V.N.; Samui, P.; Tien Bui, D. A novel hybrid swarm optimized multilayer neural network for spatial prediction of flash floods in tropical areas using sentinel-1 SAR imagery and geospatial data. Sensors 2018, 18, 3704. [Google Scholar] [CrossRef]
- Mahdizadeh Gharakhanlou, N.; Perez, L. Spatial prediction of current and future flood susceptibility: Examining the implications of changing climates on flood susceptibility using machine learning models. Entropy 2022, 24, 1630. [Google Scholar] [CrossRef] [PubMed]
- Tehrany, M.S.; Jones, S.; Shabani, F. Identifying the essential flood conditioning factors for flood prone area mapping using machine learning techniques. Catena 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Dikshit, A.; Pradhan, B. Interpretable and explainable AI (XAI) model for spatial drought prediction. Sci. Total Environ. 2021, 801, 149797. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Zhang, J.; Wang, J.; Geng, Y.; Wang, X. Robust human activity recognition using single accelerometer via wavelet energy spectrum features and ensemble feature selection. Syst. Sci. Control Eng. 2020, 8, 83–96. [Google Scholar] [CrossRef]
- Ab Hamid, T.M.T.; Sallehuddin, R.; Yunos, Z.M.; Ali, A. Ensemble based filter feature selection with harmonize particle swarm optimization and support vector machine for optimal cancer classification. Mach. Learn. Appl. 2021, 5, 100054. [Google Scholar] [CrossRef]
- Effrosynidis, D.; Arampatzis, A. An evaluation of feature selection methods for environmental data. Ecol. Inform. 2021, 61, 101224. [Google Scholar] [CrossRef]
- Osanaiye, O.; Cai, H.; Choo, K.K.R.; Dehghantanha, A.; Xu, Z.; Dlodlo, M. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 130. [Google Scholar] [CrossRef]
- García, M.V.; Aznarte, J.L. Shapley additive explanations for NO2 forecasting. Ecol. Inform. 2020, 56, 101039. [Google Scholar] [CrossRef]
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. USA 1953, 39, 1095–1100. [Google Scholar] [CrossRef]
- Aydin, H.E.; Iban, M.C. Predicting and analyzing flood susceptibility using boosting-based ensemble machine learning algorithms with SHapley Additive exPlanations. Nat. Hazards 2023, 116, 2957–2991. [Google Scholar] [CrossRef]
- Szpakowski, W.; Szydłowski, M. Probable rainfall in Gdańsk in view of climate change. Acta Sci. Pol. Form. Circumiectus 2018, 3, 175–183. [Google Scholar] [CrossRef]
- KuiperCompagnons. Urban Water Strategy for Gdańsk; Technical Report; KuiperCompagnons: Rotterdam, The Netherlands, 2015. [Google Scholar]
- Cieśliński, R.; Szydłowski, M.; Chlost, I.; Mikos-Studnicka, P. Hazards of a flooding event in the city of Gdansk and possible forms of preventing the phenomenon–case study. Urban Water J. 2024, 21, 1–17. [Google Scholar] [CrossRef]
- Walczykiewicz, T.; Skonieczna, M. Rainfall flooding in urban areas in the context of geomorphological aspects. Geosciences 2020, 10, 457. [Google Scholar] [CrossRef]
- IMGW-PIB. 2022. Available online: https://www.imgw.pl/ (accessed on 20 February 2024).
- Gdańskie Wody. 2024. Available online: http://www.gdmel.pl/ (accessed on 3 March 2024).
- Zhu, K.; Lai, C.; Wang, Z.; Zeng, Z.; Mao, Z.; Chen, X. A novel framework for feature simplification and selection in flood susceptibility assessment based on machine learning. J. Hydrol. Reg. Stud. 2024, 52, 101739. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R. Identification of critical flood prone areas in data-scarce and ungauged regions: A comparison of three data mining models. Water Resour. Manag. 2017, 31, 1473–1487. [Google Scholar] [CrossRef]
- Diakakis, M.; Deligiannakis, G.; Pallikarakis, A.; Skordoulis, M. Factors controlling the spatial distribution of flash flooding in the complex environment of a metropolitan urban area. The case of Athens 2013 flash flood event. Int. J. Disaster Risk Reduct. 2016, 18, 171–180. [Google Scholar] [CrossRef]
- Chakrabortty, R.; Pal, S.C.; Janizadeh, S.; Santosh, M.; Roy, P.; Chowdhuri, I.; Saha, A. Impact of climate change on future flood susceptibility: An evaluation based on deep learning algorithms and GCM model. Water Resour. Manag. 2021, 35, 4251–4274. [Google Scholar] [CrossRef]
- Geoportal.pl. Digital Elevation Model. 2021. Available online: https://geoportal.pl/ (accessed on 11 March 2024).
- Martınez-Casasnovas, J.; Ramos, M.; Poesen, J. Assessment of sidewall erosion in large gullies using multi-temporal DEMs and logistic regression analysis. Geomorphology 2004, 58, 305–321. [Google Scholar] [CrossRef]
- Riley, S.J.; DeGloria, S.D.; Elliot, R. Index that quantifies topographic heterogeneity. Intermt. J. Sci. 1999, 5, 23–27. [Google Scholar]
- Gdańskie Wody. 2024. Available online: https://www.gdansk.pl/zielony-gdansk/mapa-wody-gdanska,a,51862 (accessed on 3 March 2024).
- OpenStreetMap Contributors. Planet Dump. 2017. Available online: https://www.openstreetmap.org (accessed on 20 January 2023).
- SIPM-System Informacji Przestrzennej Administracji Morskiej. Coastline. 2021. Available online: https://sipam.gov.pl (accessed on 12 February 2024).
- Polish Geological Institute-National Research Institute. Soil and Geological Map of Gdańsk. 2021. Available online: https://geolog.pgi.gov.pl/ (accessed on 21 February 2024).
- Copernicus Land Monitoring Service, European Environment Agency. Urban Atlas LCLU 2018. 2021. Available online: https://doi.org/10.2909/fb4dffa1-6ceb-4cc0-8372-1ed354c285e6 (accessed on 3 February 2024).
- Gulshad, K.; Wang, Y.; Li, N.; Wang, J.; Yu, Q. Likelihood of Transformation to Green Infrastructure Using Ensemble Machine Learning Techniques in Jinan, China. Land 2022, 11, 317. [Google Scholar] [CrossRef]
- Habibi, A.; Delavar, M.; Sadeghian, M.; Nazari, B. Flood susceptibility mapping and assessment using regularized random forest and naïve bayes algorithms. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 10, 241–248. [Google Scholar] [CrossRef]
- Johnston, R.; Jones, K.; Manley, D. Confounding and collinearity in regression analysis: A cautionary tale and an alternative procedure, illustrated by studies of British voting behaviour. Qual. Quant. 2018, 52, 1957–1976. [Google Scholar] [CrossRef] [PubMed]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology/Un modèle à base physique de zone d’appel variable de l’hydrologie du bassin versant. Hydrol. Sci. J. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Solorio-Fernández, S.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. A new hybrid filter–wrapper feature selection method for clustering based on ranking. Neurocomputing 2016, 214, 866–880. [Google Scholar] [CrossRef]
- Kumar, M.; Rath, N.K.; Swain, A.; Rath, S.K. Feature selection and classification of microarray data using MapReduce based ANOVA and K-nearest neighbor. Procedia Comput. Sci. 2015, 54, 301–310. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, Y. Explainable heat-related mortality with random forest and SHapley Additive exPlanations (SHAP) models. Sustain. Cities Soc. 2022, 79, 103677. [Google Scholar] [CrossRef]
- Staudt, M.; Kordalski, Z.; Zmuda, J. Assessment of modelled sea level rise impacts in the Gdańsk region, Poland. Sea Level Chang. Affect. Spat. Dev. Balt. Sea Region. Geol. Surv. Finl. Spec. Pap. 2006, 41, 121–130. [Google Scholar]
- Habibi, A.; Delavar, M.R.; Nazari, B.; Pirasteh, S.; Sadeghian, M.S. A novel approach for flood hazard assessment using hybridized ensemble models and feature selection algorithms. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103443. [Google Scholar] [CrossRef]
- Firoozishahmirzadi, P.; Rahimi, S.; Seraji, Z.E. Application of Machine Learning Models for flood risk assessment and producing map to identify flood prone areas: Literature Review. Int. J. Data Envel. Anal. 2021, 9, 43–90. [Google Scholar]
- Chen, W.; Zhao, X.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Xue, W.; Wang, X.; Ahmad, B.B. Evaluating the usage of tree-based ensemble methods in groundwater spring potential mapping. J. Hydrol. 2020, 583, 124602. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M. Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flood Susceptibility Factors | Equations | Sources |
|---|---|---|
| Elevation | 1-m ALS DEM from Poland’s geoportal [42], ArcGIS 10.7 | |
| Slope | Derived from DEM | |
| Aspect | Derived from DEM | |
| Plan Curvature | Derived from DEM | |
| Profile Curvature | Derived from DEM | |
| Stream Power Index (SPI) | 1 | Derived from DEM [43] |
| Topographic Wetness Index (TWI) | 1 | Derived from DEM [43] |
| Surface Roughness | 2 | Derived from DEM, ArcGIS 10.7 [44] |
| Distance to Rainwater Collectors | Gdańskie Wody [45], scale 1:25,000 | |
| Distance to River Network | Open Street Map [46], updated using Gdańskie Wody | |
| Distance from Coastline | System Informacji Przestrzennej Administracji Morskiej (SIPM) [47] | |
| Soil | Polish Geological Institute—National Research Institute, spatial resolutions of 1:300,000 (2019–2021) and 1:50,000 [48] | |
| Land Use | Urban Atlas 2018 from Copernicus land monitoring service (CLMS) [49] | |
| Land Surface Temperature (LST) | 3 | Landsat 9 OLI/TIRS |
| NDVI (Normalized Difference Vegetation Index) | 4 | Landsat 9 OLI/TIRS |
| NDWI (Normalized Difference Water Index) | 5 | Landsat 9 OLI/TIRS |
| Algorithm | Parameters |
|---|---|
| SVM | Complexity parameter = 0.1; kernel = radial basis function; gamma = ‘auto’; probability = True |
| RF | n = 100, max_depth = 20; min_samples_split = 5 |
| ANN | model = Keras sequential model; hidden layers = 4; nodes for each layer = 100, 40, 30, 1; activation = ‘relu’, ‘sigmoid’; optimiser = Adam; loss = ‘binary_crossentropy’; learning rate = 0.0013, epochs = 50 |
| SHAP | Explainer = SVM: ‘KernelExplainer’; RF: ‘TreeExplainer’; ANN: ‘DeepExplainer’ |
| Variables | VIF | Variables | VIF |
|---|---|---|---|
| LST | 2.23 | Coastal buffer | 1.46 |
| Aspect | 1.03 | Soil | 1.98 |
| Slope | 3.36 | DEM | 1.86 |
| Plan curvature | 1.57 | NDWI | 1.92 |
| Profile curvature | 1.65 | SPI | 2.60 |
| NDVI | 2.04 | LULC | 1.20 |
| TRI | 1.25 | TWI | 2.40 |
| River buffer | 1.15 | Rainwater collectors | 1.42 |
| Filter Method | Selected Features |
|---|---|
| EFFS | Rainwater collectors, LULC, LST, soil, river buffer, NDVI, slope, NDWI, DEM, aspect |
| Methods | SVM | RF | ANN | |||||
|---|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | |||
| RMSE | 0.270 | 0.330 | 0.260 | 0.252 | 0.073 | 0.168 | ||
| MAE | 0.133 | 0.160 | 0.182 | 0.151 | 0.016 | 0.057 | ||
| Accuracy | 0.905 | 0.862 | 0.903 | 0.913 | 0.992 | 0.965 | ||
| AUC | 0.972 | 0.960 | 0.965 | 0.974 | 0.999 | 0.994 | ||
| Sensitivity | 0.907 | 0.892 | 0.855 | 0.964 | 0.989 | 0.988 | ||
| Specificity | 0.904 | 0.833 | 0.947 | 0.867 | 0.995 | 0.944 | ||
| Class | SVM (%) | RF (%) | ANN (%) |
|---|---|---|---|
| Very low | 17.686 | 6.151 | 9.709 |
| Low | 22.197 | 18.764 | 18.659 |
| Medium | 8.013 | 17.624 | 10.886 |
| High | 10.302 | 27.652 | 24.144 |
| Very High | 41.803 | 29.810 | 36.601 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gulshad, K.; Yaseen, A.; Szydłowski, M. From Data to Decision: Interpretable Machine Learning for Predicting Flood Susceptibility in Gdańsk, Poland. Remote Sens. 2024, 16, 3902. https://doi.org/10.3390/rs16203902
Gulshad K, Yaseen A, Szydłowski M. From Data to Decision: Interpretable Machine Learning for Predicting Flood Susceptibility in Gdańsk, Poland. Remote Sensing. 2024; 16(20):3902. https://doi.org/10.3390/rs16203902
Chicago/Turabian StyleGulshad, Khansa, Andaleeb Yaseen, and Michał Szydłowski. 2024. "From Data to Decision: Interpretable Machine Learning for Predicting Flood Susceptibility in Gdańsk, Poland" Remote Sensing 16, no. 20: 3902. https://doi.org/10.3390/rs16203902
APA StyleGulshad, K., Yaseen, A., & Szydłowski, M. (2024). From Data to Decision: Interpretable Machine Learning for Predicting Flood Susceptibility in Gdańsk, Poland. Remote Sensing, 16(20), 3902. https://doi.org/10.3390/rs16203902