
An Efficient Knowledge Distillation-Based Detection Method for Infrared Small Targets


Abstract
1. Introduction
- We designed a novel ISTD method based on the idea of knowledge distillation for infrared target detection. KDD not only improves the detection accuracy, but also achieves a lightweight network.
- KDD incorporates the ELA module and the GAB module. The small-target pixels account for a relatively small percentage of pixels. To enhance the localization ability, the ELA module was added to achieve precise localization of the region of interest without sacrificing the channel dimension. The GAB module was integrated to exploit grouping for multi-scale information capture and to make rational use of the contextual information.
2. Related Work
3. Methodology
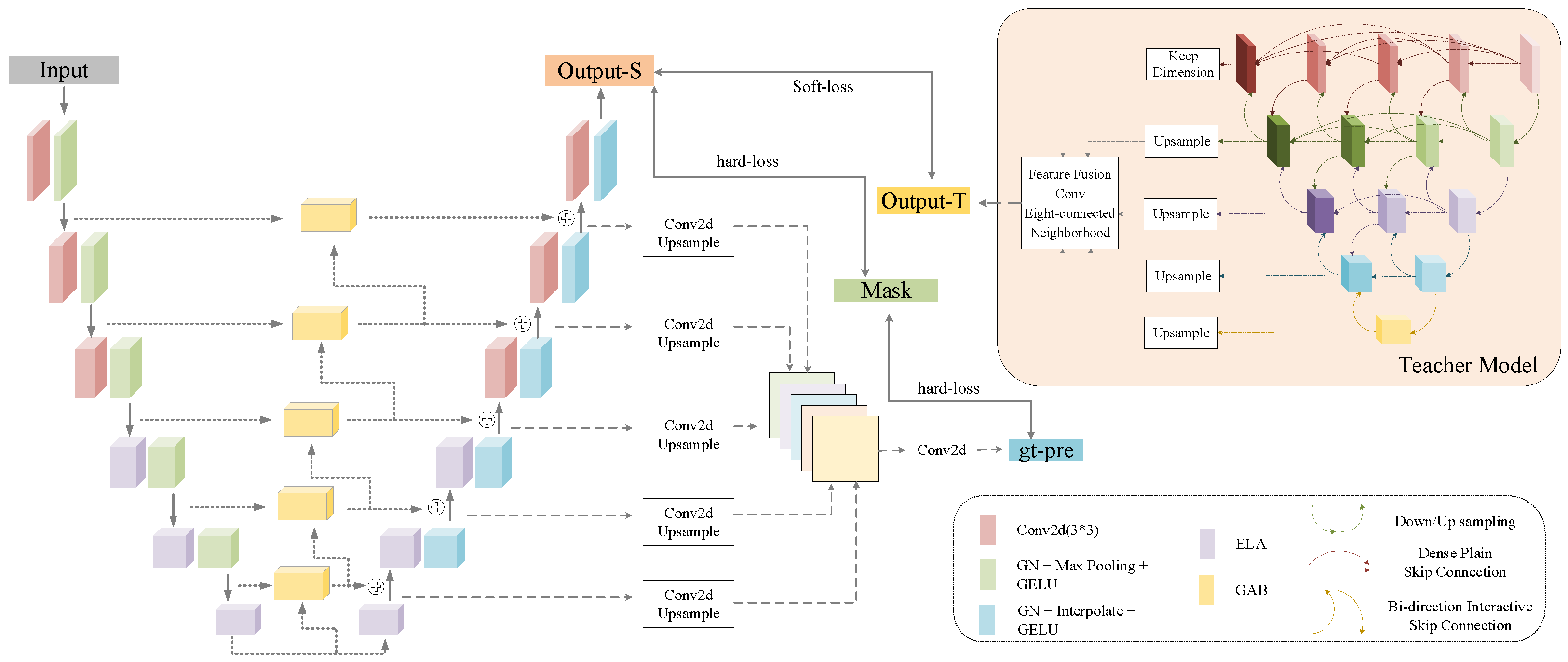
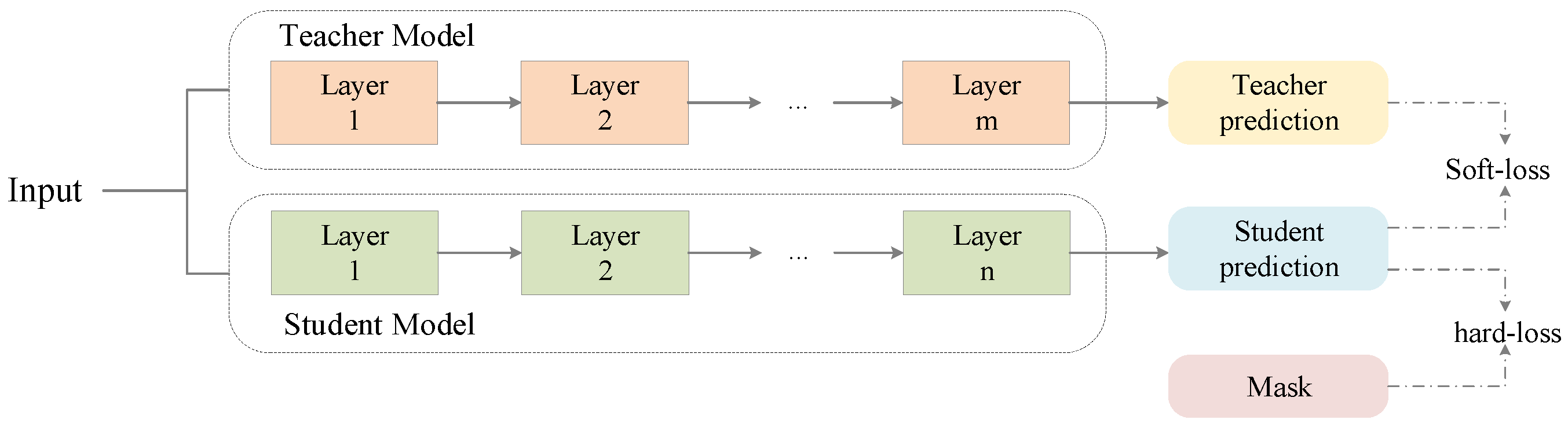
3.1. Overall Architecture
3.2. Network Details
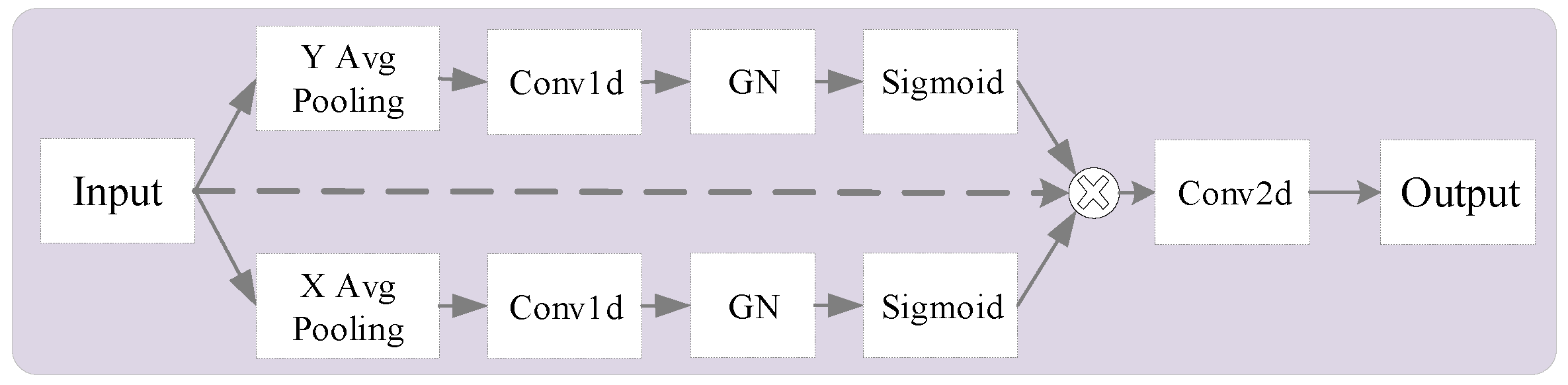
3.3. Efficient Local Attention
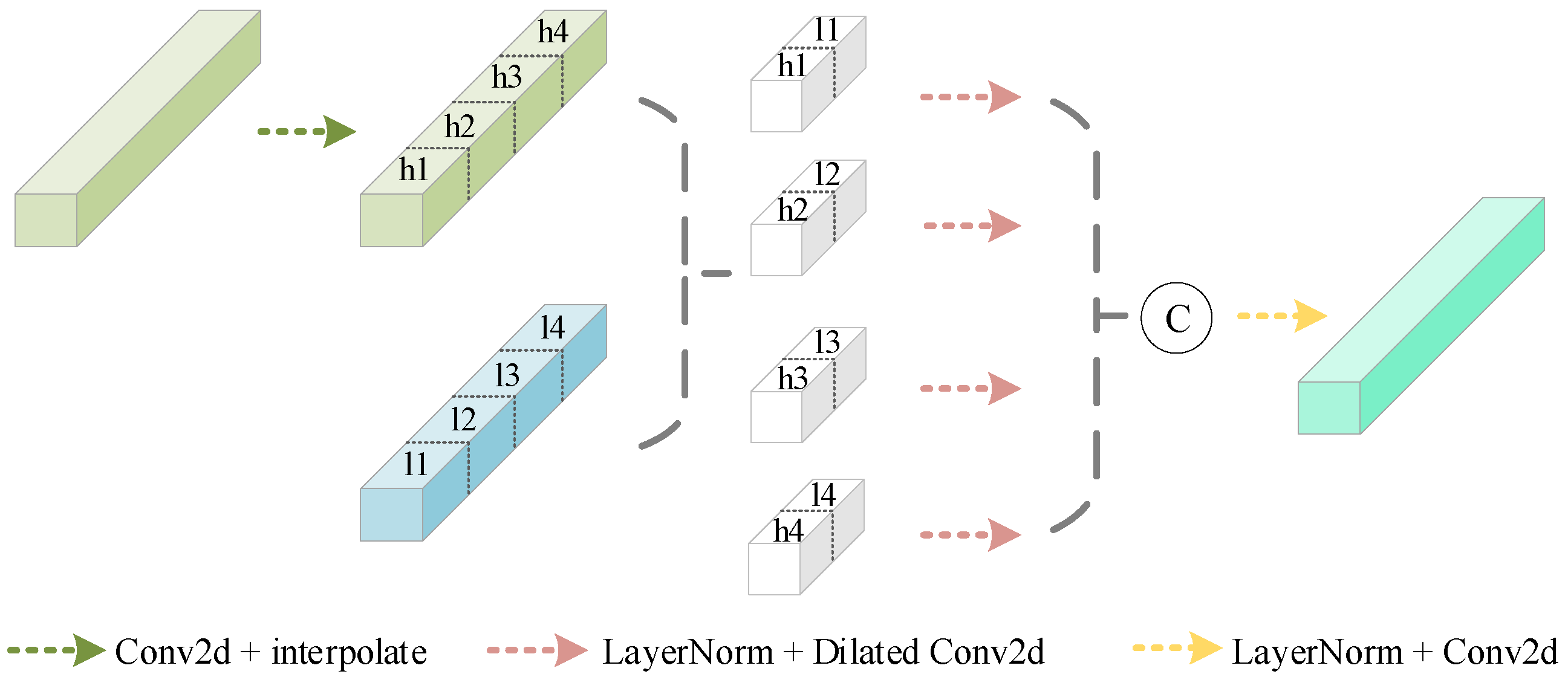
3.4. Group Aggregation Bridge
4. Experiments
4.1. Experimental Setup
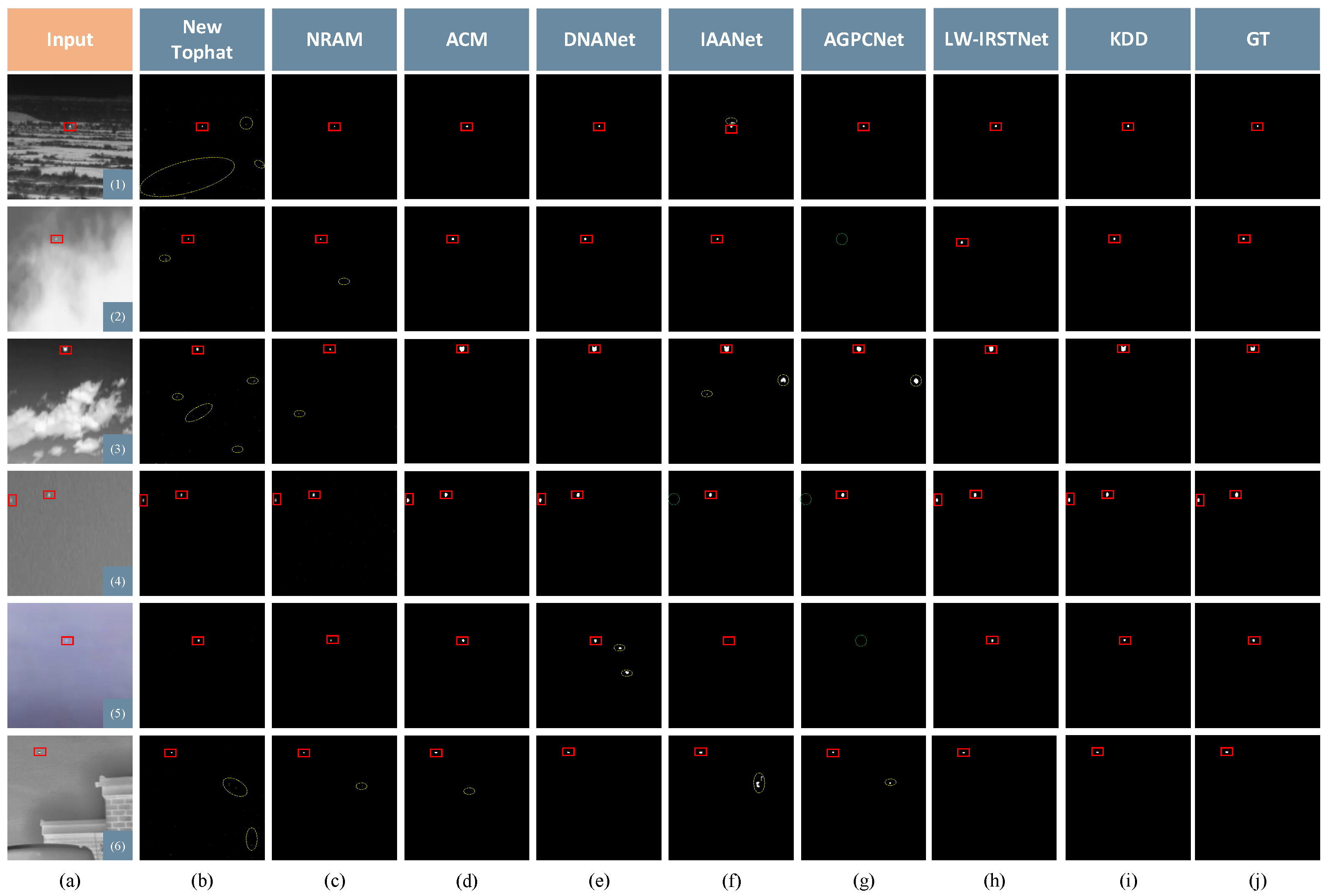
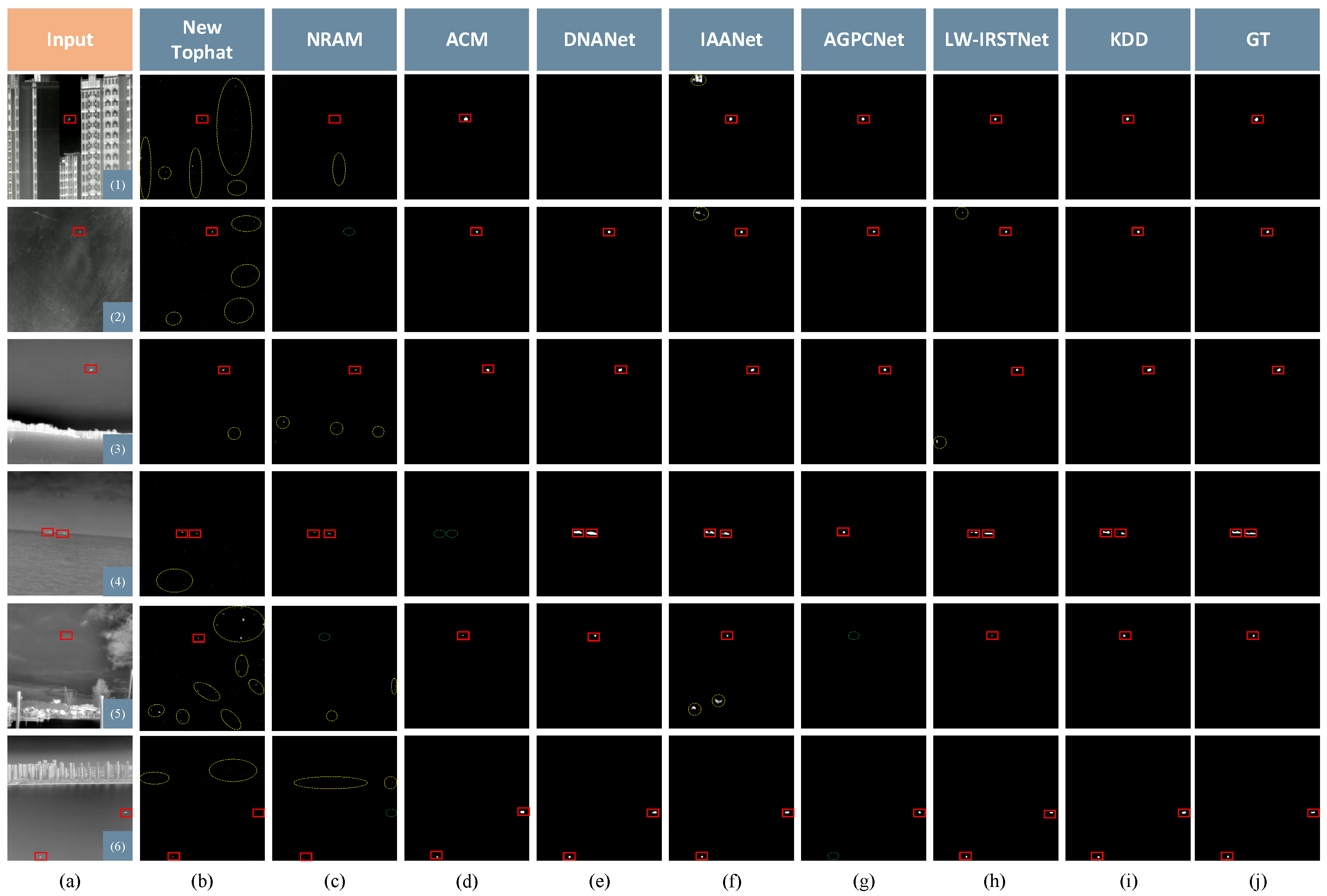
4.2. Basic Experiments
- (a)
- SIRST: From Table 1, it is evident that deep learning methods are superior to traditional methods. KDD scored the highest in , , and although DNANet had a high . The performance was average so it led to the value of the combined metric of the two to not be good. The results of the traditional methods included false alarms, which increased in connected areas between the detection results and the area of concatenation between detection results and targets, resulting in smaller values for . The of KDD reached 0.9601 on the STRST dataset.
- (b)
- IRSTD-1k: In the quantitative comparison, KDD had the best , which was 0.6359, and the ROC curve is shown in Figure 8b. Although DNANet performed the best on and , the difference with the results of KDD was very small and was not the best on several other metrics. In addition, due to the large impact of background and clutter in the images, as well as the small-target size, this dataset produced a lower metric than the SIRST dataset. Overall, KDD still obtained the best detection performance.
- (c)
- MSISTD: In quantitative evaluation, KDD had the highest value of and with 0.7571 and 0.6688, respectively. The ROC curve is shown in Figure 8c. DNANet also performed well on the MSISTD dataset and achieved the highest value on PRECISION. But the value of recall was lower than KDD, and the combined value of both F1 scores was not the best. IAANet achieved the highest value on AUC, and KDD was located at second.
4.3. Ablation Experiments
4.4. Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Yang, J.; Xu, Y.; Wang, R. Mitigate Target-level Insensitivity of Infrared Small Target Detection via Posterior Distribution Modeling. arXiv 2024, arXiv:2403.08380. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-Guided Pyramid Context Networks for Detecting Infrared Small Target Under Complex Background. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]
- Teutsch, M.; Krüger, W. Classification of small boats in infrared images for maritime surveillance. In Proceedings of the 2010 International WaterSide Security Conference, Carrara, Italy, 3–5 November 2010; pp. 1–7. [Google Scholar]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape Matters for Infrared Small Target Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–21 June 2022; pp. 867–876. [Google Scholar]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Bai, X.; Zhou, F. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Proceedings of the Signal and Data Processing of Small Targets 1999, Denver, CO, USA, 20–22 July 1999; Volume 3809, pp. 74–83. [Google Scholar]
- Zeng, M.; Li, J.; Peng, Z. The design of top-hat morphological filter and application to infrared target detection. Infrared Phys. Technol. 2006, 48, 67–76. [Google Scholar] [CrossRef]
- Azimi-Sadjadi, M.; Pan, H. Two-dimensional block diagonal LMS adaptive filtering. IEEE Trans. Signal Process. 1994, 42, 2420–2429. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.; Ma, Y.; Zhou, B.; Fan, F.; Liang, K.; Fang, Y. A robust infrared small target detection algorithm based on human visual system. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Zhu, H.; Liu, S.; Deng, L.; Li, Y.; Xiao, F. Infrared Small Target Detection via Low-Rank Tensor Completion With Top-Hat Regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1004–1016. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y. Reweighted Infrared Patch-Tensor Model With Both Nonlocal and Local Priors for Single-Frame Small Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Rank Approximation Minimization Joint l2,1 Norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Lin, Z.; Ganesh, A.; Wright, J.; Wu, L.; Chen, M.; Ma, Y. Fast Convex Optimization Algorithms for Exact Recovery of a Corrupted Low-Rank Matrix; Coordinated Science Laboratory Report No. UILU-ENG-09-2214, DC-246; Coordinated Science Laboratory: Urbana, IL, USA, 2009. [Google Scholar]
- Zhu, H.; Ni, H.; Liu, S.; Xu, G.; Deng, L. TNLRS: Target-Aware Non-Local Low-Rank Modeling With Saliency Filtering Regularization for Infrared Small Target Detection. IEEE Trans. Image Process. 2020, 29, 9546–9558. [Google Scholar] [CrossRef]
- Liu, M.; Du, H.-y.; Zhao, Y.-j.; Dong, L.-q.; Hui, M. Image Small Target Detection based on Deep Learning with SNR Controlled Sample Generation. In Current Trends in Computer Science and Mechanical Automation Vol. 1; Wang, S.X., Ed.; De Gruyter Open Poland: Warsaw, Poland, 2022; pp. 211–220. [Google Scholar]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Repulic of Korea, 27 October–2 November 2019; pp. 8508–8517. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense Nested Attention Network for Infrared Small Target Detection. IEEE Trans. Image Process. 2023, 32, 1745–1758. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Pang, S.; Hao, F. Generative Adversarial Differential Analysis for Infrared Small Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 6616–6626. [Google Scholar] [CrossRef]
- Wang, X.; Han, C.; Li, J.; Nie, T.; Li, M.; Wang, X.; Huang, L. Multiscale Feature Extraction U-Net for Infrared Dim- and Small-Target Detection. Remote Sens. 2024, 16, 643. [Google Scholar] [CrossRef]
- Kou, R.; Wang, C.; Peng, Z.; Zhao, Z.; Chen, Y.; Han, J.; Huang, F.; Yu, Y.; Fu, Q. Infrared small target segmentation networks: A survey. Pattern Recognit. 2023, 143, 109788. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian Detection Based on YOLO Network Model. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 1547–1551. [Google Scholar]
- Xia, Z.; Ma, K.; Cheng, S.; Blackburn, T.; Peng, Z.; Zhu, K.; Zhang, W.; Xiao, D.; Knowles, A.J.; Arcucci, R. Accurate identification and measurement of the precipitate area by two-stage deep neural networks in novel chromium-based alloys. Phys. Chem. Chem. Phys. 2023, 25, 15970–15987. [Google Scholar]
- Liu, S.; Liu, Z.; Li, Y.; Liu, W.; Ge, C.; Liu, L. Design Compact YOLO based Network for Small Target Detection on Infrared Image. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; pp. 4991–4996. [Google Scholar]
- Ciocarlan, A.; Le Hegarat-Mascle, S.; Lefebvre, S.; Woiselle, A.; Barbanson, C. A Contrario Paradigm for Yolo-Based Infrared Small Target Detection. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 5630–5634. [Google Scholar]
- Zhang, Z.W.; Liu, Z.G.; Martin, A.; Zhou, K. BSC: Belief Shift Clustering. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 1748–1760. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Xu, W.; Wan, Y. ELA: Efficient Local Attention for Deep Convolutional Neural Networks. arXiv 2024, arXiv:2403.01123. [Google Scholar]
- Ruan, J.; Xie, M.; Gao, J.; Liu, T.; Fu, Y. EGE-UNet: An Efficient Group Enhanced UNet for Skin Lesion Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2023, Vancouver, BC, Canada, 8–12 October 2023; pp. 481–490. [Google Scholar]
- Dong, X.; Chen, S.; Pan, S.J. Learning to prune deep neural networks via layer-wise optimal brain surgeon. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 4860–4874. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Ahn, S.; Hu, S.X.; Damianou, A.; Lawrence, N.D.; Dai, Z. Variational Information Distillation for Knowledge Transfer. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9155–9163. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2017, arXiv:1611.01578. [Google Scholar]
- Alizadeh Vahid, K.; Prabhu, A.; Farhadi, A.; Rastegari, M. Butterfly Transform: An Efficient FFT Based Neural Architecture Design. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12021–12030. [Google Scholar]
- Kim, Y.D.; Park, E.; Yoo, S.; Choi, T.; Yang, L.; Shin, D. Compression of Deep Convolutional Neural Networks for Fast and Low Power Mobile Applications. arXiv 2015, arXiv:1511.06530. [Google Scholar]
- Gusak, J.; Kholiavchenko, M.; Ponomarev, E.; Markeeva, L.; Blagoveschensky, P.; Cichocki, A.; Oseledets, I. Automated Multi-Stage Compression of Neural Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 2501–2508. [Google Scholar]
- Xu, X.; Li, M.; Tao, C.; Shen, T.; Cheng, R.; Li, J.; Xu, C.; Tao, D.; Zhou, T. A Survey on Knowledge Distillation of Large Language Models. arXiv 2024, arXiv:2402.13116. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4320–4328. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 13708–13717. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 949–958. [Google Scholar]
- Wang, A.; Li, W.; Huang, Z.; Wu, X.; Jie, F.; Tao, R. Prior-Guided Data Augmentation for Infrared Small Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 10027–10040. [Google Scholar] [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Kou, R.; Wang, C.; Yu, Y.; Peng, Z.; Yang, M.; Huang, F.; Fu, Q. LW-IRSTNet: Lightweight Infrared Small Target Segmentation Network and Application Deployment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SIRST | IRSTD-1k | MSISTD | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | IoU | AUC | Precision | Recall | F1 | IoU | AUC | Precision | Recall | F1 | IoU | AUC | |
| New Tophat | 0.5098 | 0.6968 | 0.5218 | 0.2260 | 0.8284 | 0.2265 | 0.6263 | 0.2702 | 0.0535 | 0.6635 | 0.2341 | 0.5237 | 0.2702 | 0.0483 | 0.5861 |
| NRAM | 0.8518 | 0.6142 | 0.6827 | 0.4831 | 0.7970 | 0.5199 | 0.3554 | 0.3587 | 0.1549 | 0.5867 | 0.5586 | 0.3270 | 0.3681 | 0.1040 | 0.5553 |
| ACM | 0.9095 | 0.6895 | 0.7677 | 0.4921 | 0.9367 | 0.6075 | 0.7589 | 0.6490 | 0.5821 | 0.8908 | 0.7808 | 0.5643 | 0.6274 | 0.5312 | 0.8671 |
| DNANet | 0.9506 | 0.6451 | 0.7549 | 0.5992 | 0.9424 | 0.8897 | 0.6370 | 0.7199 | 0.6172 | 0.9058 | 0.8630 | 0.7010 | 0.7522 | 0.6554 | 0.9159 |
| IAANet | 0.8541 | 0.6083 | 0.6774 | 0.5097 | 0.9459 | 0.6567 | 0.7815 | 0.6763 | 0.5038 | 0.9116 | 0.8137 | 0.6721 | 0.6992 | 0.5552 | 0.9500 |
| AGPCNet | 0.6943 | 0.4968 | 0.5396 | 0.4465 | 0.8531 | 0.4836 | 0.4983 | 0.4622 | 0.3910 | 0.8159 | 0.6961 | 0.4327 | 0.5042 | 0.3962 | 0.7836 |
| LW-IRSTNet | 0.9406 | 0.6217 | 0.7296 | 0.6109 | 0.9809 | 0.6685 | 0.6575 | 0.6241 | 0.5039 | 0.9388 | 0.8620 | 0.5063 | 0.6089 | 0.4931 | 0.8660 |
| KDD | 0.8641 | 0.7647 | 0.7949 | 0.6671 | 0.9601 | 0.7214 | 0.7691 | 0.7164 | 0.6359 | 0.9364 | 0.7616 | 0.7964 | 0.7571 | 0.6688 | 0.9261 |
| Dataset | ELA | GAB | Loss | Precision | Recall | F1 | IoU | AUC |
|---|---|---|---|---|---|---|---|---|
| SIRST | ✗ | ✓ | ✓ | 0.8391 | 0.7775 | 0.7849 | 0.6456 | 0.9501 |
| ✓ | ✗ | ✓ | 0.7957 | 0.8264 | 0.7883 | 0.6567 | 0.9721 | |
| ✓ | ✓ | ✗ | 0.8554 | 0.7361 | 0.7765 | 0.6620 | 0.9659 | |
| ✓ | ✓ | ✓ | 0.8641 | 0.7647 | 0.7949 | 0.6671 | 0.9601 | |
| IRSTD-1k | ✗ | ✓ | ✓ | 0.7135 | 0.7842 | 0.7001 | 0.5785 | 0.9042 |
| ✓ | ✗ | ✓ | 0.6216 | 0.8118 | 0.6673 | 0.5540 | 0.9158 | |
| ✓ | ✓ | ✗ | 0.7048 | 0.7659 | 0.7057 | 0.5966 | 0.9007 | |
| ✓ | ✓ | ✓ | 0.7214 | 0.7691 | 0.7164 | 0.6359 | 0.9364 |
| Params (M) | FLOPs (G) | FPS (Hz) | |
|---|---|---|---|
| New Tophat | – | – | 28 |
| NRAM | – | – | 0.6 |
| ACM | 0.39 | 0.22 | 22 |
| DNANet | 2.61 | 8.59 | 36 |
| IAANet | 14.05 | 408.90 | 16 |
| AGPCNet | 12.36 | 33.06 | 8 |
| LW-IRSTNet | 0.16 | 0.232 | 18 |
| KDD | 0.041 | 0.056 | 41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, W.; Dai, Q.; Hao, F. An Efficient Knowledge Distillation-Based Detection Method for Infrared Small Targets. Remote Sens. 2024, 16, 3173. https://doi.org/10.3390/rs16173173
Tang W, Dai Q, Hao F. An Efficient Knowledge Distillation-Based Detection Method for Infrared Small Targets. Remote Sensing. 2024; 16(17):3173. https://doi.org/10.3390/rs16173173
Chicago/Turabian StyleTang, Wenjuan, Qun Dai, and Fan Hao. 2024. "An Efficient Knowledge Distillation-Based Detection Method for Infrared Small Targets" Remote Sensing 16, no. 17: 3173. https://doi.org/10.3390/rs16173173
APA StyleTang, W., Dai, Q., & Hao, F. (2024). An Efficient Knowledge Distillation-Based Detection Method for Infrared Small Targets. Remote Sensing, 16(17), 3173. https://doi.org/10.3390/rs16173173