

Small Object Detection in Medium–Low-Resolution Remote Sensing Images Based on Degradation Reconstruction

Abstract
1. Introduction
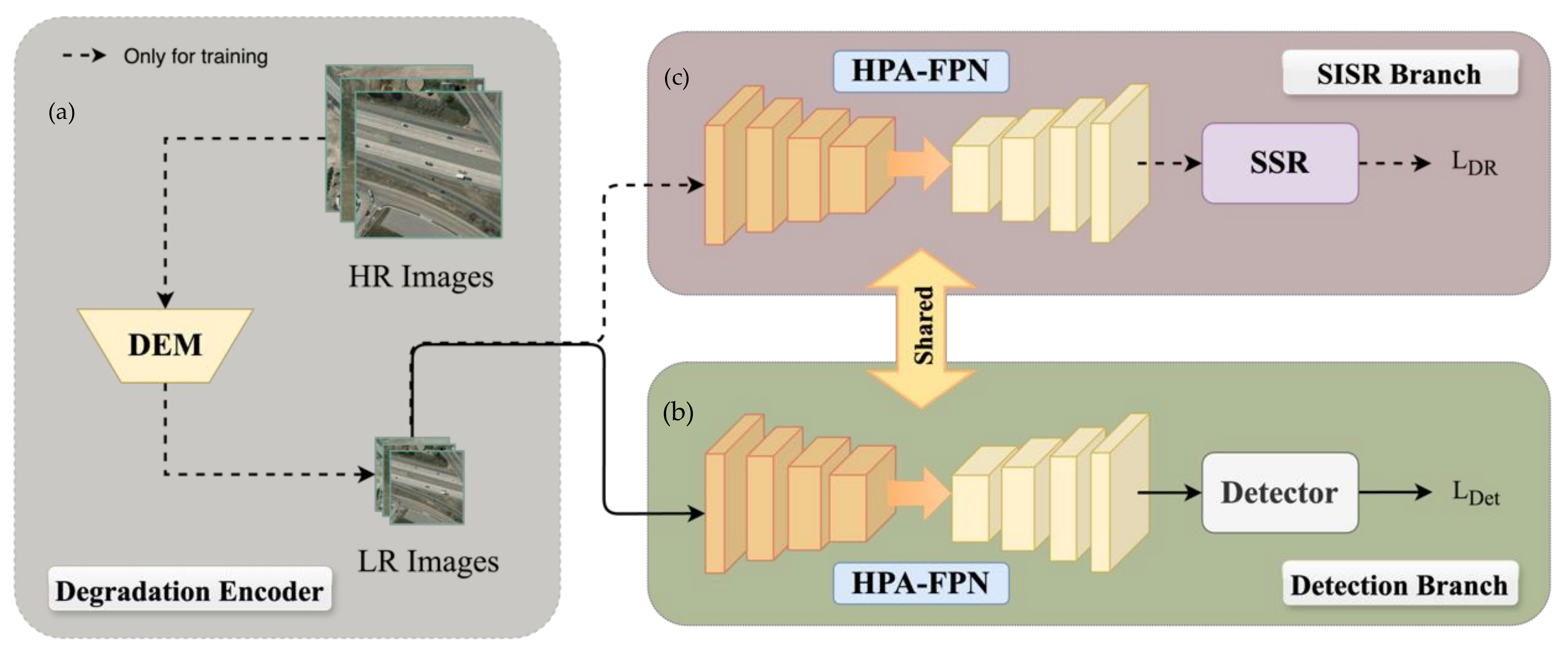
- We have designed a degradation reconstruction-assisted enhancement branch for learning M-LR remote sensing images with different degenerated degrees, and used it as a branch structure of the network to guide the model to capture feature expressions at different resolutions, so as to improve the feature learning ability of the network in M-LR images.
- To capture target details effectively and suppress the interference of redundant background information, we propose a feature fusion module based on hybrid parallel attention. This module can effectively use the feature information to help the network screen out the target against a complex background. It can make the network focus on the target features and improve the ability of feature extraction and model detection accuracy at the same time.
- We propose a method for small target detection within M-LR remote sensing images based on a degradation reconstruction-assisted detection network (DRADNet). We describe the results of extensive ablation experiments to demonstrate its effectiveness. In addition, we compare the results of several mainstream methods on public datasets. The results show that our method can improve the accuracy of detection significantly and has competitive performance.
2. Related Works
2.1. Image Super Resolution
2.2. Object Detection
2.3. Feature Fusion
3. Method
3.1. Overall Structure
3.2. Degradation Reconstruction-Assisted Enhancement Branch
3.2.1. Degradation Reconstruction-Assisted Enhancement Branch
3.2.2. Single-Image Super-Resolution Branch
3.3. Feature Fusion Module HPA-FPN
3.4. Loss Function
- (1)
- Degradation Reconstruction Loss
- (2)
- Target Detection Loss
- (3)
- Total Loss
4. Experiments
4.1. Dataset and Experimental Details
4.1.1. VEDAI Dataset
4.1.2. Airbus-Ships Dataset
4.1.3. Implementation Details
4.2. Ablation Study
4.3. Experimental Results and Discussions
4.3.1. Results on the VEDAI Dataset
4.3.2. Results on the Airbus-Ships Dataset
4.3.3. Visual Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Hird, J.N.; Montaghi, A.; McDermid, G.J.; Kariyeva, J.; Moorman, B.J.; Nielsen, S.E.; McIntosh, A.C. Use of unmanned aerial vehicles for monitoring recovery of forest vegetation on petroleum well sites. Remote Sens. 2017, 9, 413. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Z.; Wang, B.; Miao, L.; Zong, H. A novel CNN-based method for accurate ship detection in HR optical remote sensing images via rotated bounding box. IEEE Trans. Geosci. Remote Sens. 2020, 59, 686–699. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, G.; Zhu, P.; Zhang, T.; Li, C.; Jiao, L. GRS-Det: An anchor-free rotation ship detector based on Gaussian-mask in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3518–3531. [Google Scholar] [CrossRef]
- Xiong, G.; Wang, F.; Yu, W.X.; Truong, T.K. Spatial Singularity-Exponent-Domain Multiresolution Imaging-Based SAR Ship Target Detection Method. IEEE Trans. Geosci. Remote Sens. 2022, 60, 12. [Google Scholar] [CrossRef]
- Xiong, G.; Wang, F.; Zhu, L.Y.; Li, J.Y.; Yu, W.X. SAR Target Detection in Complex Scene Based on 2-D Singularity Power Spectrum Analysis. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9993–10003. [Google Scholar] [CrossRef]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small Object Detection Based on Deep Learning for Remote Sensing: A Comprehensive Review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Z.; Qi, G.; Hu, G.; Zhu, Z.; Huang, X. Remote Sensing Micro-Object Detection under Global and Local Attention Mechanism. Remote Sens. 2024, 16, 644. [Google Scholar] [CrossRef]
- Shi, T.; Gong, J.; Hu, J.; Zhi, X.; Zhu, G.; Yuan, B.; Sun, Y.; Zhang, W. Adaptive Feature Fusion with Attention-Guided Small Target Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 16. [Google Scholar] [CrossRef]
- Yu, L.; Hu, H.; Zhong, Z.; Wu, H.; Deng, Q. GLF-Net: A target detection method based on global and local multiscale feature fusion of remote sensing aircraft images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4021505. [Google Scholar] [CrossRef]
- Zhou, L.; Zheng, C.; Yan, H.; Zuo, X.; Liu, Y.; Qiao, B.; Yang, Y. RepDarkNet: A multi-branched detector for small-target detection in remote sensing images. ISPRS Int. J. Geo-Inf. 2022, 11, 158. [Google Scholar] [CrossRef]
- Courtrai, L.; Pham, M.-T.; Lefèvre, S. Small object detection in remote sensing images based on super-resolution with auxiliary generative adversarial networks. Remote Sens. 2020, 12, 3152. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Y.; Sun, Y. Salient target detection based on the combination of super-pixel and statistical saliency feature analysis for remote sensing images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2336–2340. [Google Scholar]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Hou, B.; Ren, Z.; Zhao, W.; Wu, Q.; Jiao, L. Object detection in high-resolution panchromatic images using deep models and spatial template matching. IEEE Trans. Geosci. Remote Sens. 2019, 58, 956–970. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.-S. RFLA: Gaussian receptive field based label assignment for tiny object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 526–543. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Lepcha, D.C.; Goyal, B.; Dogra, A.; Goyal, V. Image super-resolution: A comprehensive review, recent trends, challenges and applications. Inf. Fusion 2023, 91, 230–260. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Wang, X.; Yu, K.; Dong, C.; Loy, C.C. Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 606–615. [Google Scholar]
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K.; Van Gool, L.W. Weakly supervised photo enhancer for digital cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 691–700. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Wu, G.; Jiang, J.; Jiang, K.; Liu, X. Fully 1X1 Convolutional Network for Lightweight Image Super-Resolution. arXiv 2023, arXiv:2307.16140. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2223–2232. [Google Scholar]
- Ji, X.; Cao, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; IEEE Communications Society. Real-World Super-Resolution via Kernel Estimation and Noise Injection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020; pp. 1914–1923. [Google Scholar]
- Cui, Z.; Zhu, Y.; Gu, L.; Qi, G.-J.; Li, X.; Zhang, R.; Zhang, Z.; Harada, T. Exploring resolution and degradation clues as self-supervised signal for low quality object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 473–491. [Google Scholar]
- Bell-Kligler, S.; Shocher, A.; Irani, M. Blind super-resolution kernel estimation using an internal-gan. Adv. Neural Inf. Process. Syst. 2019, 32, 284–393. [Google Scholar]
- Fritsche, M.; Gu, S.; Timofte, R. Frequency separation for real-world super-resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3599–3608. [Google Scholar]
- Li, S.; Zhang, G.; Luo, Z.; Liu, J.; Zeng, Z.; Zhang, S. From general to specific: Online updating for blind super-resolution. Pattern Recognit. 2022, 127, 108613. [Google Scholar] [CrossRef]
- Wang, B.; Yang, F.; Yu, X.; Zhang, C.; Zhao, H. APISR: Anime Production Inspired Real-World Anime Super-Resolution. arXiv 2024, arXiv:2403.01598. [Google Scholar]
- Chen, S.; Han, Z.; Dai, E.; Jia, X.; Liu, Z.; Xing, L.; Zou, X.; Xu, C.; Liu, J.; Tian, Q. Unsupervised image super-resolution with an indirect supervised path. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 468–469. [Google Scholar]
- Zhang, K.; Liang, J.; Van Gool, L.; Timofte, R. Designing a practical degradation model for deep blind image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4791–4800. [Google Scholar]
- Zhang, W.; Shi, G.; Liu, Y.; Dong, C.; Wu, X.-M. A closer look at blind super-resolution: Degradation models, baselines, and performance upper bounds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 527–536. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Yang, G.; Li, B.; Ji, S.; Gao, F.; Xu, Q. Ship detection from optical satellite images based on sea surface analysis. IEEE Geosci. Remote Sens. Lett. 2013, 11, 641–645. [Google Scholar] [CrossRef]
- Song, M.; Qu, H.; Jin, G. Weak ShipTarget Detection of NoisyOptical Remote SensingImage on Sea Surface. Acta Opt. Sin. 2017, 37, 1011004-1–1011004-8. [Google Scholar] [CrossRef]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Zou, H.; He, S.; Cao, X.; Sun, L.; Wei, J.; Liu, S.; Liu, J. Rescaling-Assisted Super-Resolution for Medium-Low Resolution Remote Sensing Ship Detection. Remote Sens. 2022, 14, 2566. [Google Scholar] [CrossRef]
- Chen, J.; Chen, K.; Chen, H.; Zou, Z.; Shi, Z. A Degraded Reconstruction Enhancement-Based Method for Tiny Ship Detection in Remote Sensing Images with a New Large-Scale Dataset. IEEE Trans. Geosci. Remote Sens. 2022, 60, 14. [Google Scholar] [CrossRef]
- He, S.; Zou, H.; Wang, Y.; Li, R.; Cheng, F.; Cao, X.; Li, M. Enhancing Mid-Low-Resolution Ship Detection with High-Resolution Feature Distillation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Inversion, M.J.F. Airbus Ship Detection Challenge. Available online: https://kaggle.com/competitions/airbus-ship-detection (accessed on 31 July 2018).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vascon, N. Cascade R-CNN: High Qual. Object Detect. Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Targets in the Training Set | Targets in the Test Set | Total |
|---|---|---|---|
| Car | 1110 | 267 | 1377 |
| Truck | 242 | 65 | 307 |
| Pickup | 766 | 189 | 955 |
| Tractor | 154 | 36 | 190 |
| Camping Car | 326 | 71 | 397 |
| Boat | 139 | 32 | 171 |
| Van | 80 | 21 | 101 |
| Other Vehicle | 153 | 51 | 204 |
| Plane | 40 | 8 | 48 |
| 3010 | 740 | 3750 |
| Method | SISR Branch | HPA-FPN | mAP50 |
|---|---|---|---|
| Baseline | - | - | 64.4 |
| DRADNet | ✓ | - | 72.3 |
| - | ✓ | 69.8 | |
| ✓ | ✓ | 77.5 |
| Method | Car | Truck | Pickup | Tractor | Camping Car | Boat | Van | Other Vehicle | Plane | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [56] | 83.2 | 60.4 | 73.7 | 56.4 | 76.2 | 54.6 | 50.0 | 51.2 | 80.4 | 65.1 |
| Cascade R-CNN [57] | 81.6 | 65.4 | 75.1 | 67.7 | 77.3 | 42.8 | 60.2 | 47.0 | 92.8 | 67.8 |
| SuperYOLO [18] | 84.5 | 75.6 | 79.4 | 72.6 | 78.1 | 62.3 | 69.8 | 52.4 | 83.3 | 73.1 |
| RTMDet [59] | 64.9 | 68.1 | 77.5 | 74.5 | 76.0 | 52.2 | 65.4 | 37.0 | 88.4 | 67.1 |
| CenterNet [53] | 77.8 | 58.6 | 72.3 | 67.6 | 75.9 | 42.8 | 57.5 | 45.7 | 81.7 | 64.4 |
| FOCS [58] | 77.5 | 42.4 | 69.5 | 62.5 | 74.9 | 36.5 | 42.7 | 38.3 | 75.2 | 57.7 |
| RetinaNet [49] | 68.7 | 34.6 | 57.7 | 53.6 | 59.2 | 37.7 | 23.5 | 42.2 | 83.6 | 51.2 |
| NWD [16] | 81.8 | 70.2 | 74.5 | 69.2 | 77.2 | 43.1 | 61.3 | 46.7 | 90.6 | 68.3 |
| RFLA [17] | 83.1 | 68.2 | 78.4 | 72.1 | 74.9 | 63.4 | 67.6 | 50.7 | 85.6 | 71.6 |
| DRADNet | 89.0 | 76.0 | 80.2 | 82.8 | 82.0 | 73.7 | 71.9 | 51.1 | 90.3 | 77.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Sun, H.; Wang, S. Small Object Detection in Medium–Low-Resolution Remote Sensing Images Based on Degradation Reconstruction. Remote Sens. 2024, 16, 2645. https://doi.org/10.3390/rs16142645
Zhao Y, Sun H, Wang S. Small Object Detection in Medium–Low-Resolution Remote Sensing Images Based on Degradation Reconstruction. Remote Sensing. 2024; 16(14):2645. https://doi.org/10.3390/rs16142645
Chicago/Turabian StyleZhao, Yongxian, Haijiang Sun, and Shuai Wang. 2024. "Small Object Detection in Medium–Low-Resolution Remote Sensing Images Based on Degradation Reconstruction" Remote Sensing 16, no. 14: 2645. https://doi.org/10.3390/rs16142645
APA StyleZhao, Y., Sun, H., & Wang, S. (2024). Small Object Detection in Medium–Low-Resolution Remote Sensing Images Based on Degradation Reconstruction. Remote Sensing, 16(14), 2645. https://doi.org/10.3390/rs16142645