1. Introduction
Multiple target tracking (MTT) is an important research topic in the military field, and also a difficult problem at present [
1,
2,
3]. Multiple-input multiple-output (MIMO) [
4] radar is an extension of traditional phased array radar, and it is able to transmit signals in all directions and multi-beams at the same time. This operating mode is called simultaneous multi-beam mode [
5]. Technically speaking, in the simultaneous multi-beam mode, a single collocated MIMO radar can track multiple targets simultaneously by controlling different beams tracking different targets independently. In this case, the complex data association process of tracking can be avoided since the spatial diversity of multiple targets can be used to distinguish the echoes of different targets, and thus, the multi-target tracking problem can be divided into multiple single-target tracking problems.
In practical applications, we have to consider two limiting factors inherent to collocated MIMO radar [
6]. (1) The maximum number of beams that the system can generate is limited at each time. In theory, if the number of MIMO radar transmitters is
N, the system can only generate
M (
) orthogonal beams at most at each time. (2) The total transmitted power of simultaneous multiple beams is limited by the hardware. In real applications, it is necessary to limit the total transmitted power of multiple beams to ensure that the total transmission power of the system does not exceed the tolerance of the hardware. With the traditional transmitting mode, the number of beams is always set to a constant, and the transmitting power is uniformly allocated to the beams. Although it is easy to implement in engineering, the utilization efficiency of the resource is relatively low. In terms of the kinds of resources, the existing resource allocation methods can be roughly divided into two groups: one is based on the transmitting parameters, the other is based on the system composition structure. In this paper, the discussed problem of power and beam resource allocation belongs to the first one. The resource allocation based on the system composition structure mostly exists in multiple radar systems (MRS).
In [
7], the authors used the covariance matrix of the tracking filter as the evaluation of tracking performance, and established and solved an optimization cost function of transmitted power. The authors of [
8] proposed a cognitive MTT method based on prior information, and designed a cognitive target tracking framework. With this method, the radar transmit power parameters can be adaptively adjusted at each tracking time based on the information fed back by the tracker. In [
9], an MRS resource allocation method is proposed for MTT based on quality of service constrained (QoSC). This method cannot only illuminate multiple targets in groups, but also optimize the transmitted power of each radar. The authors of [
10,
11,
12,
13,
14] also studied the optimization-based resource allocation method with different resources limitation in different target–radar scenarios. Their similarity is to take the localization Cramér–Rao lower bound (CRLB) or the tracking Bayesian Cramér–Rao lower bound (BCRLB) [
13] as the performance evaluation in the cost function. However, the used CRLBs and BCRLBs are both derived with an assumption of constant velocity (CV) model or constant acceleration (CA) model, we thus conclude that these kinds of methods are model-based methods. These model-based methods can achieve excellent results on the premise that the target’s motion is conform to the model assumption. However, in the case of maneuvering targets (the targets undergoing non-uniform-linear motions with certain uncertainty and randomness), they would not work well because the inevitable model mismatch causes a lower resource utilization, a larger prediction error of the target state, and an unreliable BCRLB. To overcome this, in [
15], the resource problem was first formulated as a Markov decision process (MDP) and solved by a data-driven method, where recurrent neural network (RNN) [
16,
17] was used to learn a prediction model for BCRLB and target’s state, and deep-reinforcement-learning (DRL) [
18,
19] was adopted for solving the optimal power allocation solution. This method works under the condition that the number of generated beams is equal to the number of targets. However, in practice, radar system always have to face the challenge that the maximum beam number is far less than the number of targets. On this basis, the authors further propose a constrained-DRL-based MRS resource allocation method for meeting the given accuracy of single target tracking [
20]. It is noticed that, in [
15,
20], the output of RNN is characterized as a single Gaussian distribution. In this way, an accurate predictive information can be obtained as the target is maneuvering with low uncertainty. Based on above studies, in this paper, we will further discuss how to jointly schedule the power and beam resources of a radar system to enhance the overall performance of MTT in maneuvering target scenarios.
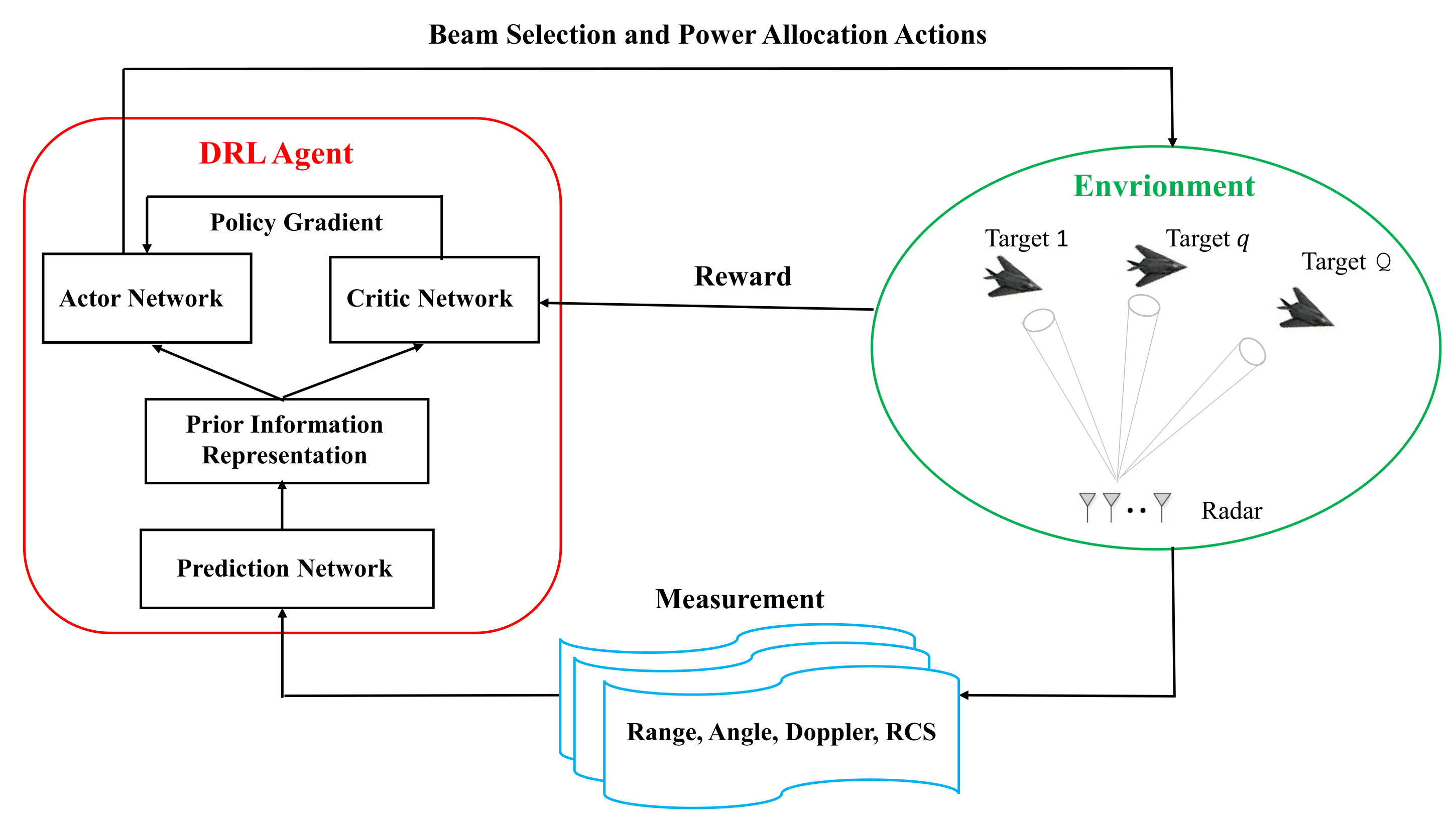
In this paper, a novel data-driven joint beam selection and power allocation (JBSPA) method is introduced. The main contributions of this paper can be summarized as follows:
- (1)
A JBSPA method for MTT is developed based on deep learning, which aims to maximize the performance of MTT by adjusting power and beam allocation within the limited resources at each illumination. Through mathematical optimization modeling and analysis, the problem of JBSPA is essentially a non-convex and nonlinear problem, and the conventional optimization method is thus not suitable. To address this problem, we characterize the original optimization cost function as a model-free MDP problem by designing and introducing a series of variable parameters of MDP, including state, action and reward. For a discrete MDP, a common way is dynamic programming (DP). However, our problem is a continuous controlling problem over the action and state space, and thus, DP-based methods are not available. Since the emerging DRL is a good model-free MDP [
21], it will be taken to solve MDP of JBSPA (DRL-JBSPA) in this paper.
- (2)
Considering the possible existence of a model-mismatch problem in maneuvering target tracking, the long short-term memory (LSTM) [
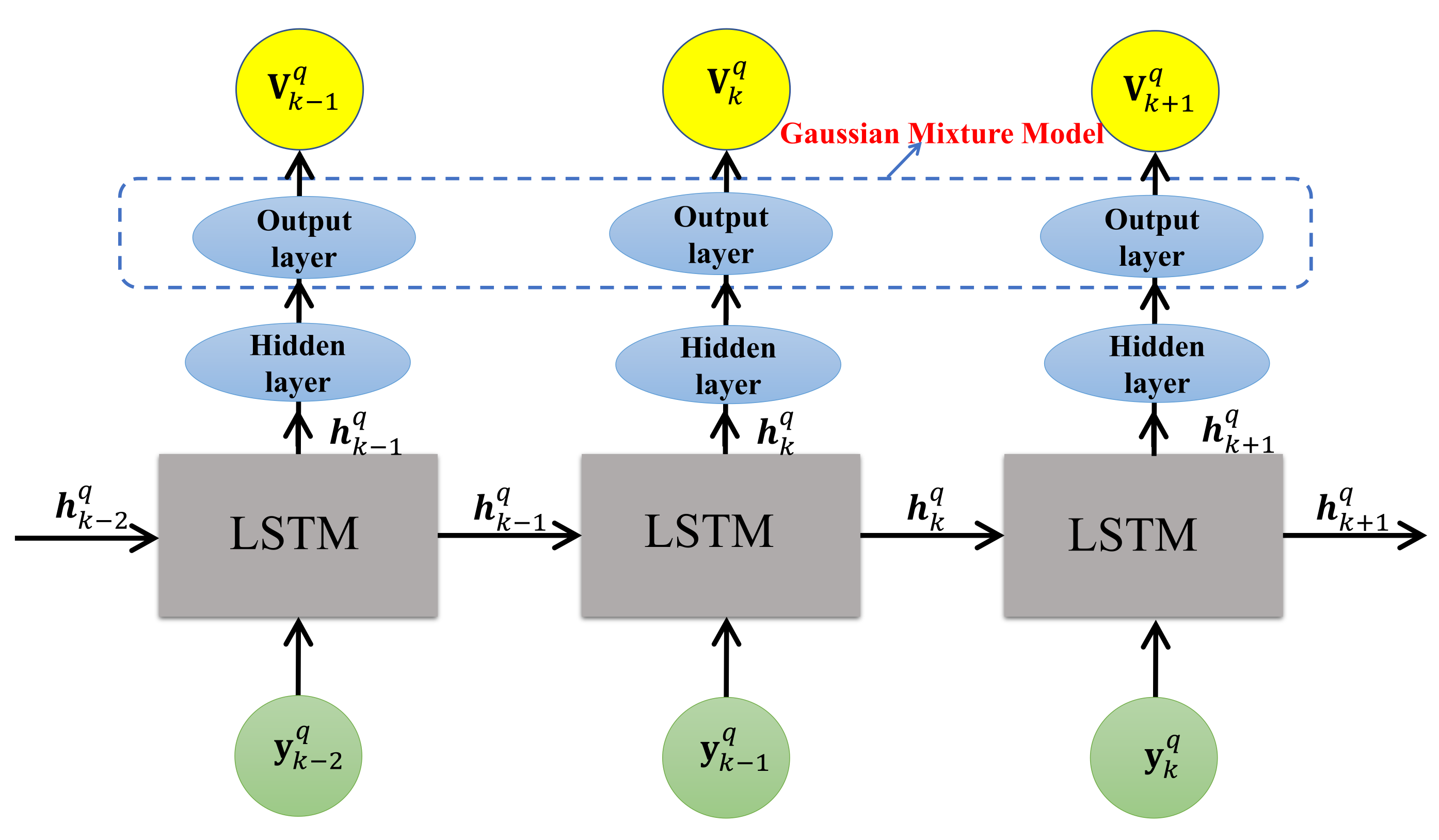
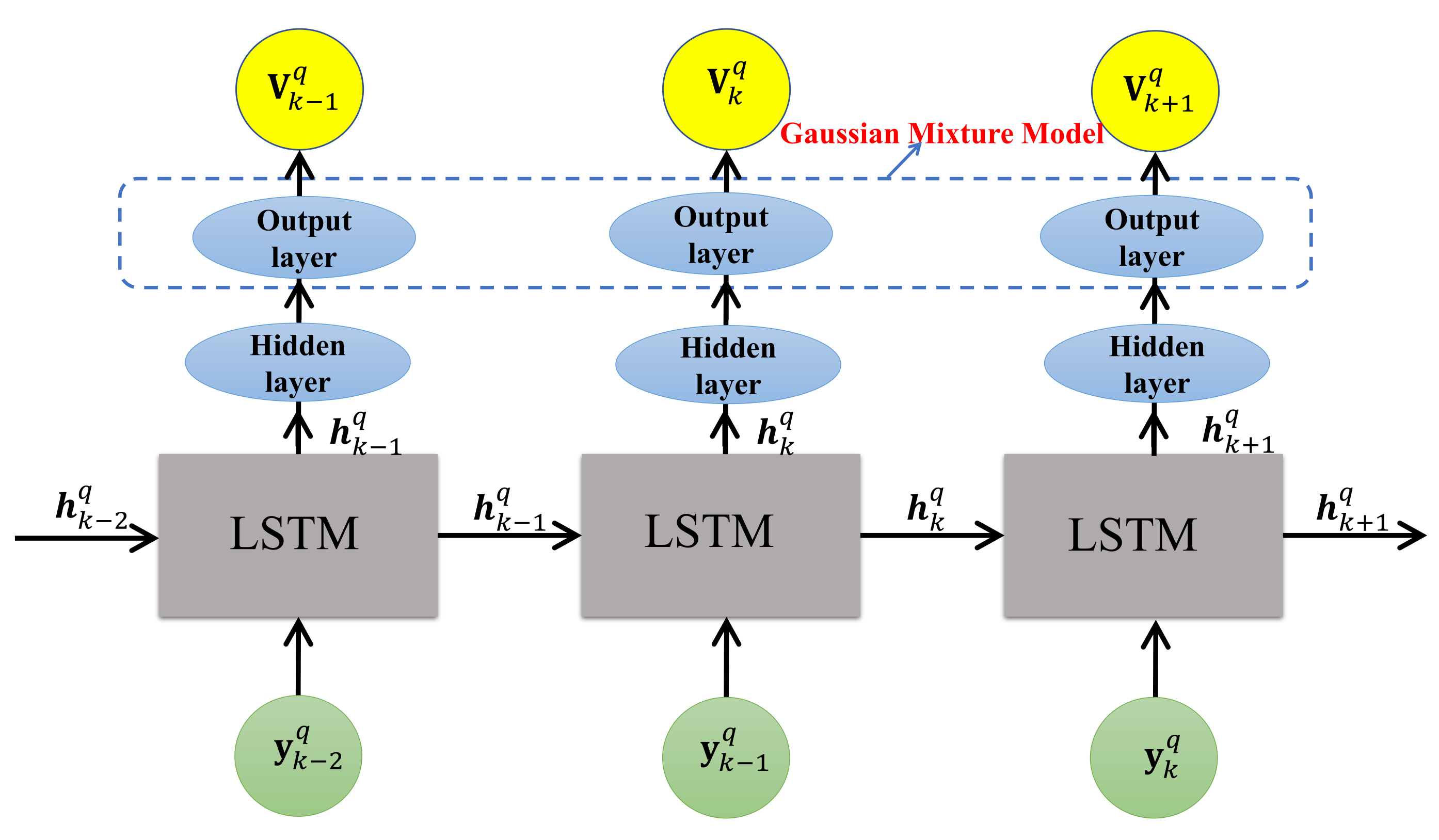
17] incorporating the Gaussian mixture model (GMM), say, LSTM-GMM, is used to derive prior information representation of targets for resource allocation. The biggest change exists in the output layer of LSTM; there, two different GMMs are utilized to describe the uncertainty of state transition of the maneuvering target and radar cross-section (RCS), respectively. In this way, at each tracking interval, the LSTM-GMM will not output a determined predicted extended target state, but multiple Gaussian distributions. Then, we select one of them randomly according to mixed coefficients, to obtain the predicted target state and RCS, and the Bayesian information matrix (BIM) of prior information at the next tracking time instant.
- (3)
Considering that the JBSPA is a continuous control problem over state and action spaces, in order to improve the computational efficiency, this work adopts a deterministic policy function in calculation of Q function, and deduces the deterministic policy gradient [
22,
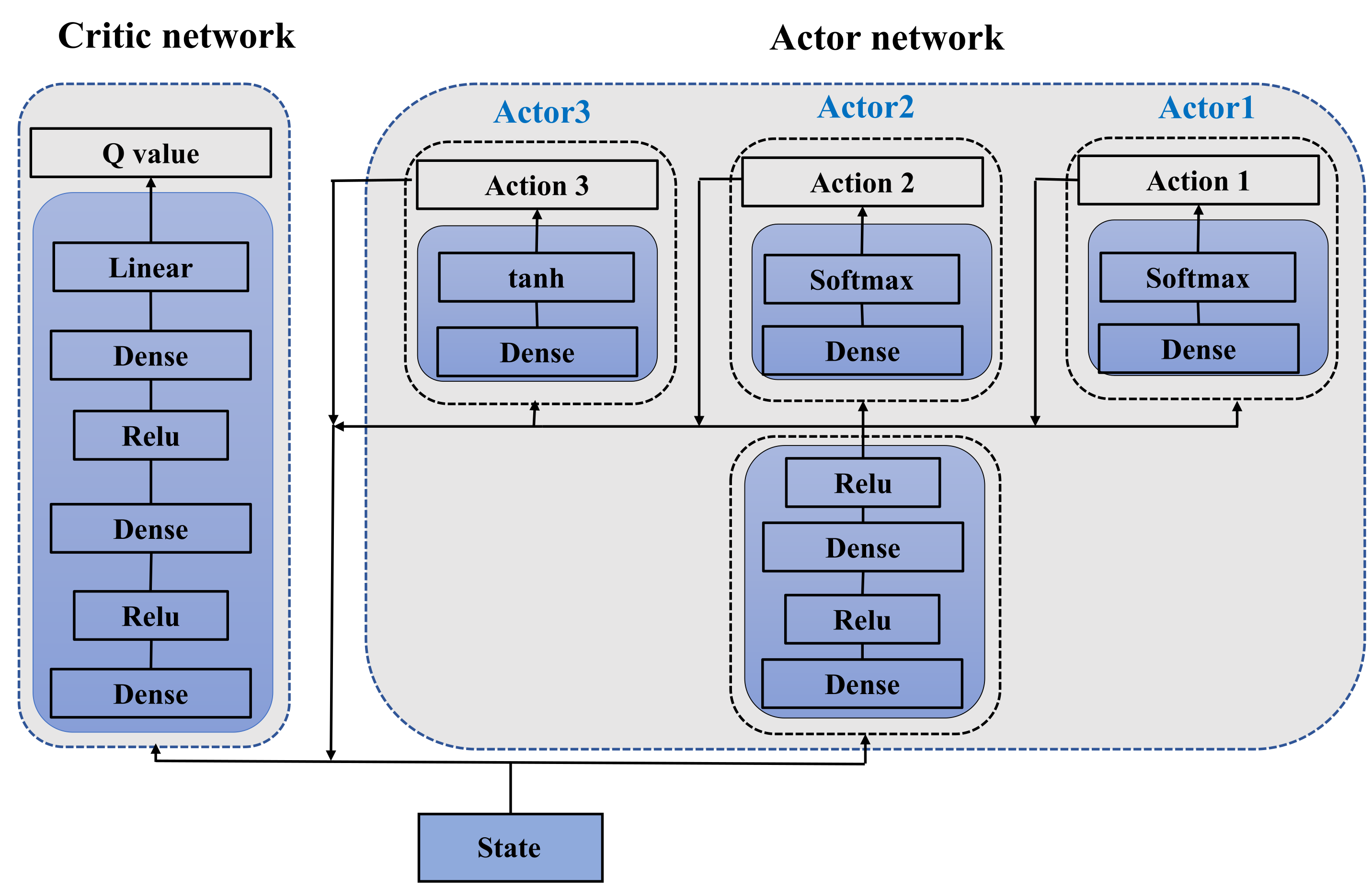
23] by deriving the Q function with respect to policy parameters. Then, we apply an actor network and a critic network to enhance the stability of the training. A modified actor network is designed to improve the applicability of the original actor-critic frame to JBSPA, where the output transmit parameters (i.e., the number of generated beams by the radar, the pointing of beams, and the power of each beam) are realized by taking three different output layers into the action network. Due to the usage of a trained network and avoiding optimization solving at each tracking time, the requirement of real time in resource allocation can be guaranteed in MTT.
The outline of the paper is as follows. In
Section 2, a brief review of DRL is introduced. In
Section 3, the resource allocation problem is described. In
Section 3, the resource allocation problem is abstracted into a mathematical cost function. In
Section 4, a deep-learning-based JBSPA method is detailed. In
Section 5, several numerical experiment results are provided to verify the effectiveness of the proposed method. Some problems and future works are discussed in
Section 6. In
Section 7, the conclusion of this paper is given.
2. Markov Decision Process and Reinforcement Learning
In this section, a brief introduction MDP and reinforcement learning (RL) is given. Being the fundamental model, MDP is often used to describe and solve the sequential decision-making problems involving uncertainties. In general, a model-free MDP is described as a tuple
, where
is the state set in the decision process,
is the action set,
r is the reward feedback by the environment after executing a certain action, and
is the discounted factor for measuring the current value of future return. The aim of MDP is to find the optimal policy that can maximize the cumulative discounted reward
, and the policy function
is expressed as follows:
which is the probability of taking action
with current state
.
Due to the randomness of the policy, the expectation operation is used to calculate the cumulative discounted reward function. When an action is given under a certain state, the cumulative discounted reward function becomes the state-action value function, i.e.,
which is also called
Q function. This function is generally used in DRL for seeking the optimal policy.
In reinforcement learning (RL), there is an agent that can interact with the environment by actions, accumulate interactive data, and learn optimal action policy. In general, the commonly used reinforcement learning methods are classed into two kinds: one is based on the value function and the other is based on the policy gradient (PG). In value-function-based RLs, such as Q-learning, the learning criteria are looking for the action that can maximize the Q function by exploring the whole action space, i.e.,
For the applications on continuous state and action space, value-function-based methods are not always available. Different from the circuitous way of Q-learning enumerating all action-value functions, policy-gradient-based methods find the optimal policy by directly calculating the update direction of policy parameters [
21]. Therefore, the PG is more suitable for MDP problems over continuous action and state space. The goal of PG is to find the policy
that can maximize the expectation of cumulative discounted reward, i.e.,
where
represents the trajectory obtained by interacting with the environment using policy
, and
denotes the cumulative discounted reward on
. The loss function of the policy is defined as the expectation of the cumulative return, which is given by
where
represents the occurrence probability of the trajectory
with the policy
. The policy gradient can be obtained by deriving (
5), as shown in the following:
Compared with value-function-based methods, the PG-based methods has two advantages, one is higher efficiency in the applications of continuous action and state space, the other is that randomization of the policy can be realized.
3. Problem Statement
There are a monostatic MIMO radar and Q independent point targets in the MTT scenario. The monostatic MIMO radar performs both the transmitting task and receiving task. Assume that the location of MIMO radar is , and the targets is initially located at . At k-th tracking time step, the q-th target’s state is given by , in which and denote the corresponding location and speed of q-th target, respectively. Besides that, the RCS components of targets can be also received by the radar at each time step, and that of the q-th target is denoted by , and are the RCS components of channel R and channel I, respectively. If we synthesize the target state component and the RCS component into a vector, an extended state vector can be obtained, i.e., .
3.1. Derivation of BCRLB Matrix on Transmitting Parameters
Before modeling JBSPA, we first deduce the mathematical relationship between the tracking BCRLB and the beam selection parameters and power parameters in this section. According to [
15], with the assumption that the beam number is the same as the target number, the expression of BIM is
and its inverse is BCRLB matrix, i.e.,
In (
7), the term
represents the covariance matrix of the predictive state error, and its inverse matrix is the Fisher information matrix (FIM) of prior information. The term
is the FIM of the data.
denotes the Jacobian matrix of the measurement
with respect to predictive target’s state
. The term
represents the covariance matrix of the measurement noise [
24,
25].
It is known that FIM of the prior information only depends on the motion model of the target, while the FIM of the data is directly proportional to the transmitted power of the radar. Assume that the transmitted power is
at time step
k. When
is zero, that is, there is no beam allocated to the
q-th target for illumination at time step
k, and the covariance matrix
of the measurement error is a zero matrix. In order to describe the beam allocation more clearly, a group of binary variables
is introduced here, where
where
indicates that the radar illuminates target
q at the
k-th tracking time instant, and
is the opposite. Then, substitute (
9) into (
7), and we obtain [
26,
27]
whose inverse matrix, BCRLB matrix, can be used as an evaluation function of transmitted power
and beam selection parameter
. The expression is as follows:
in which the original covariance matrix of the measurement error
is rewritten as a multiplication of
and
.
3.2. Problem Formulation of JBSPA
In JBSPA, since the target state
is unknown at the
-th time step, a predictive state
is taken to calculate the FIM of data. In addition, in order to ensure the requirement of real-time in MTT, we use one-sampling measurement to calculate the FIM of data instead of the expectation of FIM of data. The final BCRLB matrix is given by [
14]
where
denotes the Jacobian matrix of the measurement
with respect to predictive target’s state
.
is the approximation of the covariance matrix of measurement at the predictive state
. In theory, the diagonal elements of the derived BCRLB matrix represent the corresponding lower bounds of the estimation MSEs of the target states, and thus, the tracking BCRLB of the target is defined as the trace of the BCRLB matrix, i.e.,
where
represents trace operator. In order to enhance the MTT performance as much as possible, and ensure the tracking performance of each target, we take the worst-case tracking BCRLB among targets as an evaluation of the MTT performance to optimize the resource allocation result, which is expressed as
The problem of JBSPA is then described as follows: restricted by the predetermined maximum beam number
M and the power budget
, the power allocation and the beam selection are jointly optimized for the purpose of maximizing the cumulative discounted worst-case BCRLB of MTT. The cost function is written as
where constraints 1∼3 are the total power constraint, the beam number constraint and the single beam power constraint, respectively.
and
are the minimum and the maximum of the single beam transmitted power, respectively. Due to the existence of binary beam selection parameters, the cost function (
15) is a complex mixed-integer nonlinear optimization problem. As the discount factor is
, the cyclic minimizing method [
28] and projection gradient algorithm can be used to solve the problem [
14]. However, since this method needs to traverse all possible beam allocation solutions to find the optimal solution, the solving process is time-consuming. With this method, if there are a large number of targets to track, the real-time performance of MTT cannot be guaranteed. On the other hand, when the discount factor
is non-zero, to solve the problem requires accurate future multi-step predictions of target state and BCRLB which is, however, hardly realized in real applications, especially in the scenarios involving maneuvering targets because the potential model-mismatch problem would amplify the prediction error and reduce the reliability of BCRLB seriously along with the tracking time increasing.
To address above issues, we discuss the JBSPA from MDP perspective, and solve it with a data-driven method: DRL. Compared with the optimization-based method, this method is able to avoid the multi-step prediction problem and complex solving process, and ensure the real-time performance of resource allocation. Besides that, in order to make the method suitable for maneuvering target scenarios, RNN with LSTM-GMM unit is used to learn the state transition regularity of maneuvering targets, and then realize the information prediction of the maneuvering target.
5. Simulation Results
In practice, the radar system has to face the challenge that the target number is larger than the beam number. Therefore, the simulation experiments are carried out under the condition that the maximum number of beams is less than the target number. Specifically, simulation 1 is conducted to investigate the proposed method by comparing the optimization-based method with the discounted factor , simulation 2 is taken to discuss the effect of the discounted factor on the resource allocation results and the tracking performance.
The targets and the radar are depicted in the Cartesian coordinate system. Without loss of generality, the parameters of the radar system are set as follows: the radar system is assumed to be located at
, the signal effective bandwidth and effective time duration of the
qth beam are set as
MHz and
ms, respectively. The carrier frequency of each beam is set as 1 GHz, and thus, the carrier wavelength is
m. The time interval between successive frames is set as 2 s, and a sequence of 50 frames of data are utilized to support the simulation. The lower and upper bounds of the power of the
qth beam are set to
and
, respectively. The maximum number of beams is 5 and the target number is 8. For better illustration of the effectiveness of the proposed method, the initial positions and initial velocities of the targets are set the same, i.e.,
and
. The turning frequency of turn motion targets is set to 0.0035 Hz. The motion parameters of each target have been listed in
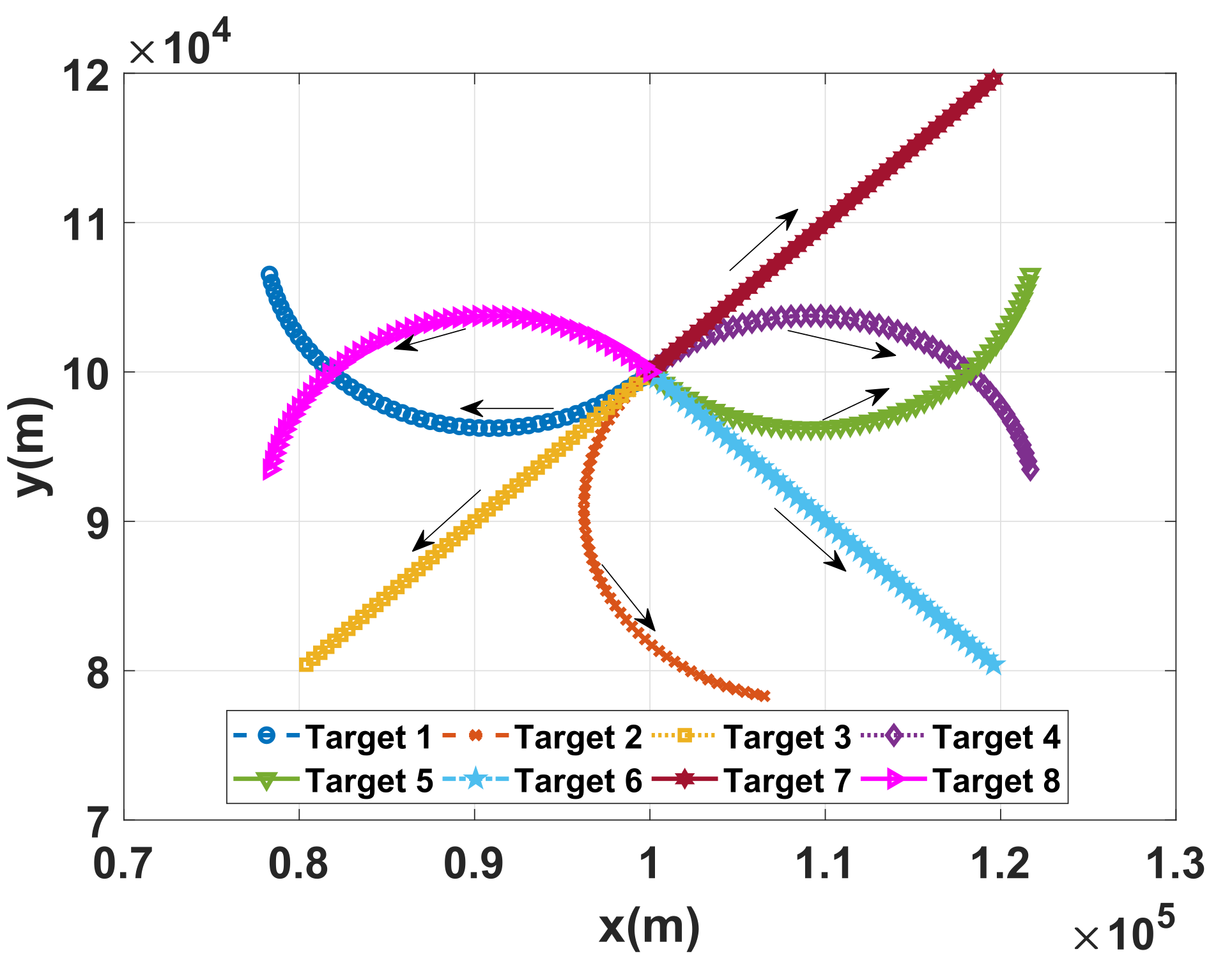
Table 1, where the symbol “*” indicates that a motion mode does not include this motion parameter. The real moving trajectories of the three targets are depicted in
Figure 4. As shown in
Figure 4, Target 1 and Target 4 are doing right-turn motion, Target 2, Target 5 and Target 8 are doing left-turn motion; Target 3, Target 6 and Target 7 are doing uniform linear motion.
The prediction network is first trained for deriving prior information representation, where the training examples are the measurements of the targets’ states with the trajectories of left-turn motion, right-turn motion, and uniform linear motion, and the corresponding labels are true targets’ states. The initial position and the speed of the targets are randomly generated within [50 km, 150 km] and [−300 m/s, 300 m/s] on x-axis and y-axis, respectively. The turning frequencies are randomly generated within [0.001 Hz, 0.008 Hz]. In the process of generating training examples, the noise power added in measurements is determined by the allocated transmit power that is randomly generated within the interval . We trained RNN over 200,000 epochs, and AC-JBSPA over 500,000 epochs (i.e., 500,000 transition samples) in an off-line manner.
Simulation 1: In this section, a series of simulation experiments are carried out to validate the effectiveness of the aforementioned methods, in which we adopt root mean square error (RMSE) to measure tracking performance, and it is given by
where
is the number of Monte Carlo trials,
denotes the 2-norm, and
is the estimate of the
qth target’s state at the
-th trial with Kalman filter [
30].
We first compare the proposed method with the allocation methods introduced in [
14] as the amplitude of target reflectivity is set to a constant 1. The optimization-based method is based on the optimization techniques, where the CV model is utilized for the prediction of target’s state and the calculation of the FIM of prior information. Since the optimization-based method only focuses on the performance of the current time instant, the discounted factor is set to
for a fair comparison. It is worth noting that the tracking RMSE of all the targets are set the same at the initial time, and in the figures about tracking performance, all of the RMSE curves start after the first resource allocation.
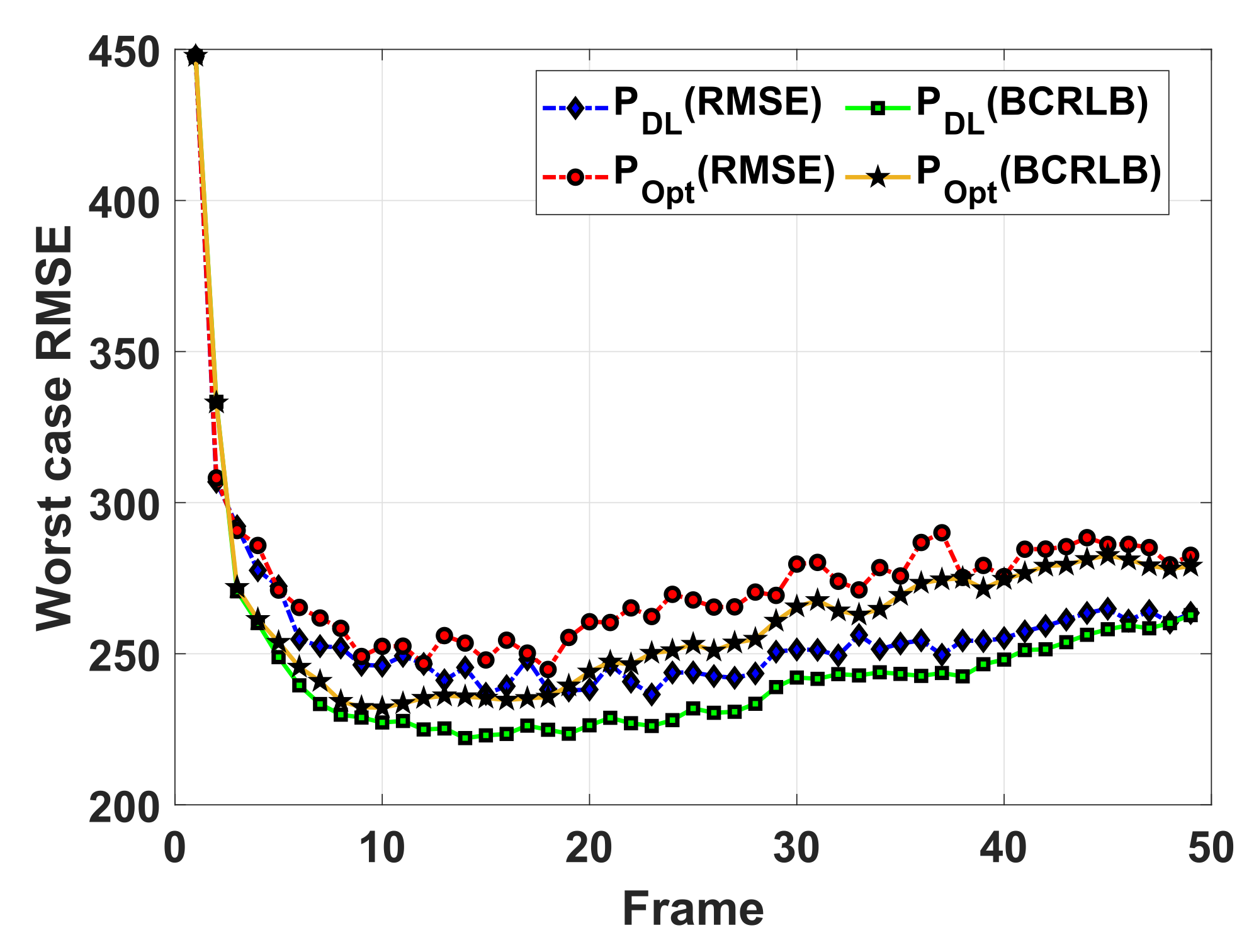
The comparison is shown in
Figure 5, in which the curves labeled “
” and “
” represent the tracking RMSEs averaged over 50 trails achieved with the optimization-based power allocation method, and proposed power allocation method, respectively. The curves labeled “
” and “
” are the corresponding tracking BCRLBs. It can be seen that the tracking of the worst RMSEs are approaching the corresponding worst BCRLBs along with the number of measurements increasing. From the about 20th frame, the performance of the proposed method is about 10% higher than that of the optimization-based method with the CV model.
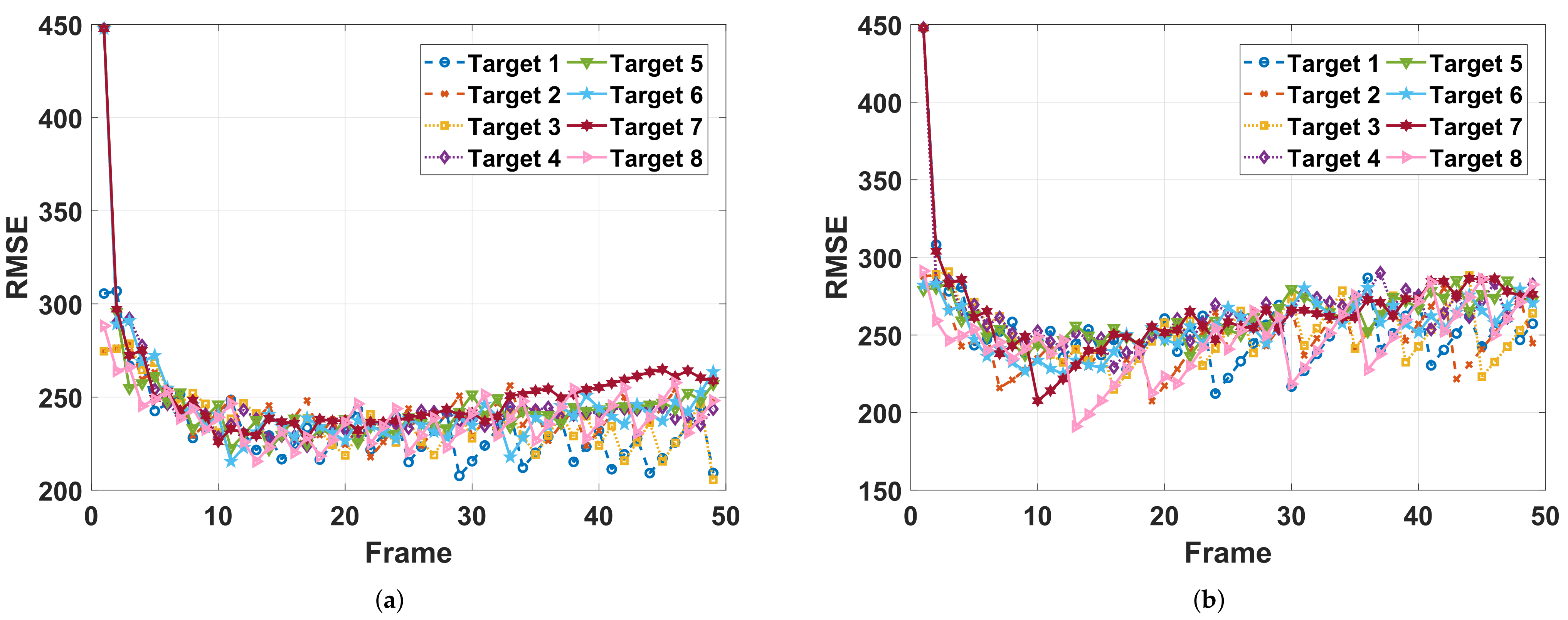
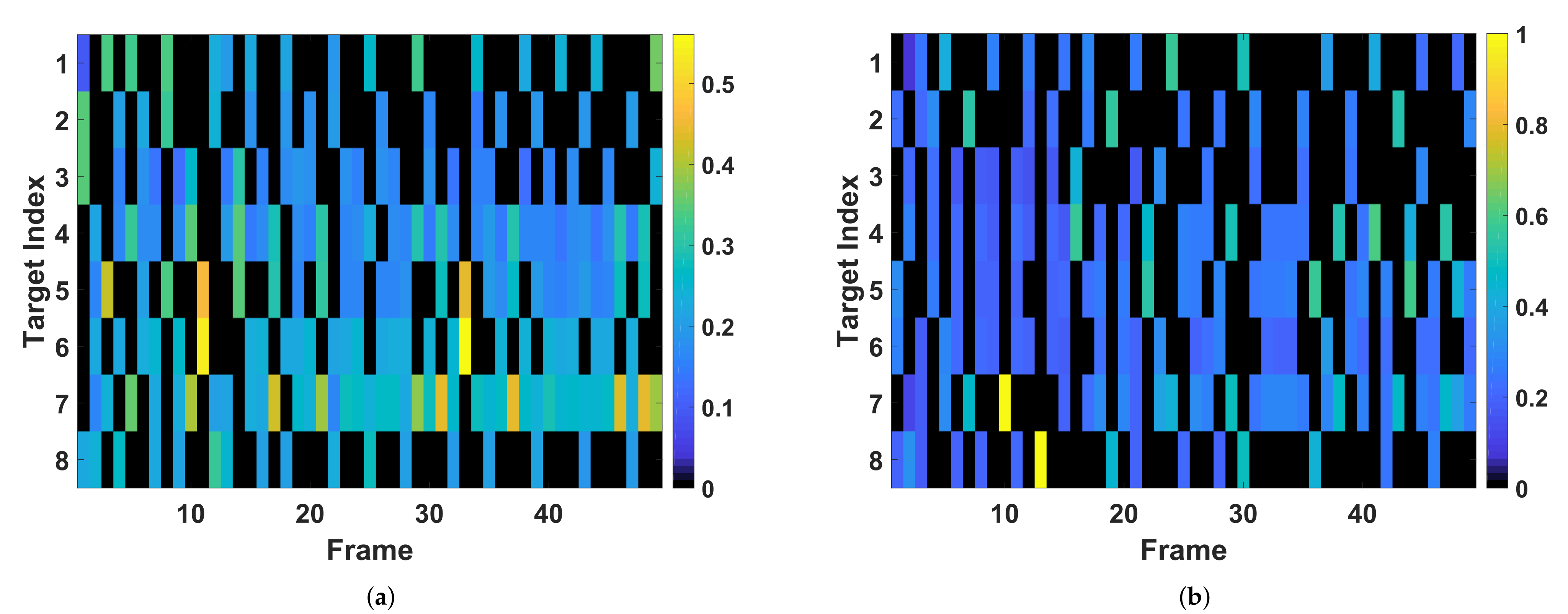
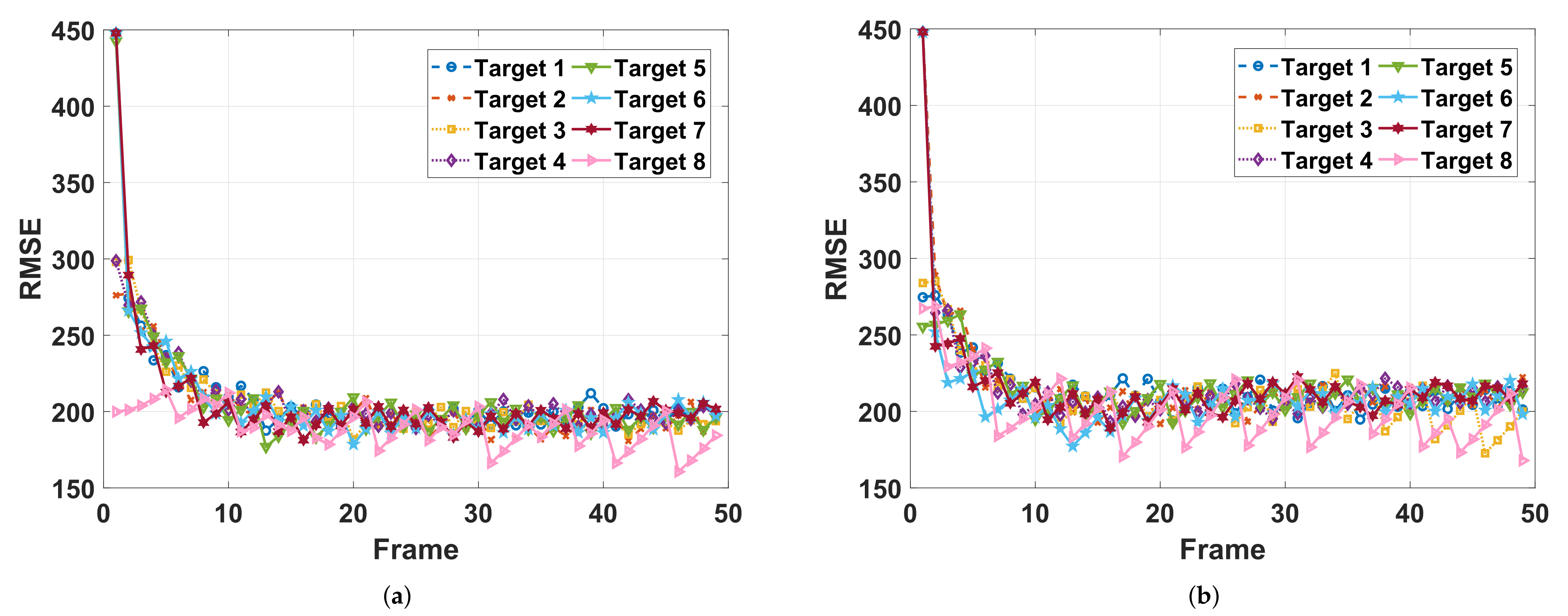
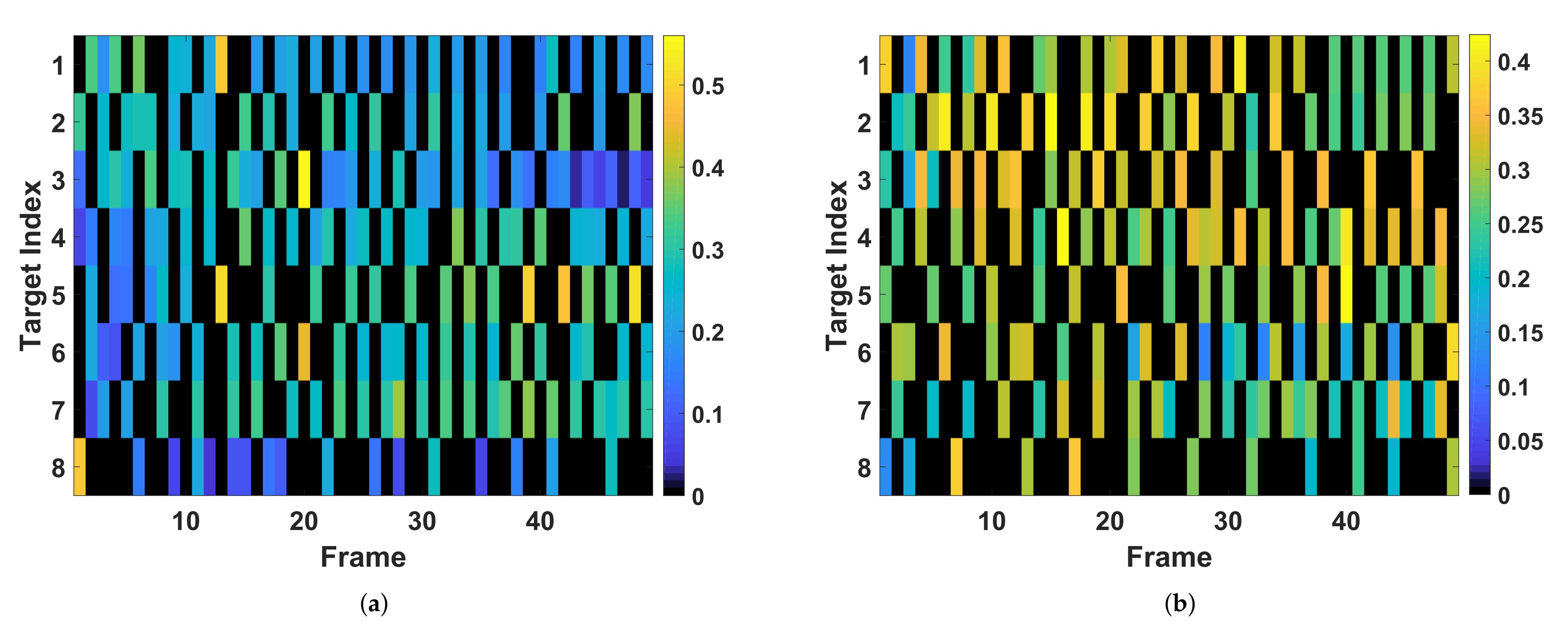
The estimation RMSEs and the corresponding power allocation results are presented in
Figure 6 and
Figure 7, respectively. In
Figure 6a, the power allocation solution given by the proposed method makes the tracking RMSEs of different targets closer than that of the optimization-based method, which implies the resource utilization efficiency of the power allocation solution based on the learned policy (shown in
Figure 7a) is higher than that of the optimization-based method with the CV model (shown in
Figure 7b). In other words, there is room for the solution given by optimization-based method to continue to be optimized.
In
Figure 7a,b, it can be seen that more power and beam resource tend to be allocated to targets that are moving away from radar, i.e., target 4, target 5, target 6, and target 7, for achieving a larger gain of tracking performance. Actually, the resource allocation is not only determined by targets’ radial distances but also by radius speeds, especially when the targets are close enough. As shown in
Figure 7a, comparing the allocation results of these targets that are approaching the radar, e.g., Target 1, Target 2, Target 3, and Target 8, we discover that more power tends to be allocated to the beam pointing to the closer Target 1 because Target 1’s larger radial speeds may cause a larger BCRLB. When using the CV model for prediction, the beam selection and the power allocation are mainly determined by comparing the radius distances of different targets. For example, for the resource allocation solution of Target 1, Target 2, Target 3 shown in
Figure 7b, more power and beam resources tend to be allocated to the farther targets, Target 1 and Target 2, from about frame 20. Therefore, we believe the proposed method can provide more accuracy prior information of targets, which benefits the utilization effectiveness of resource allocation.
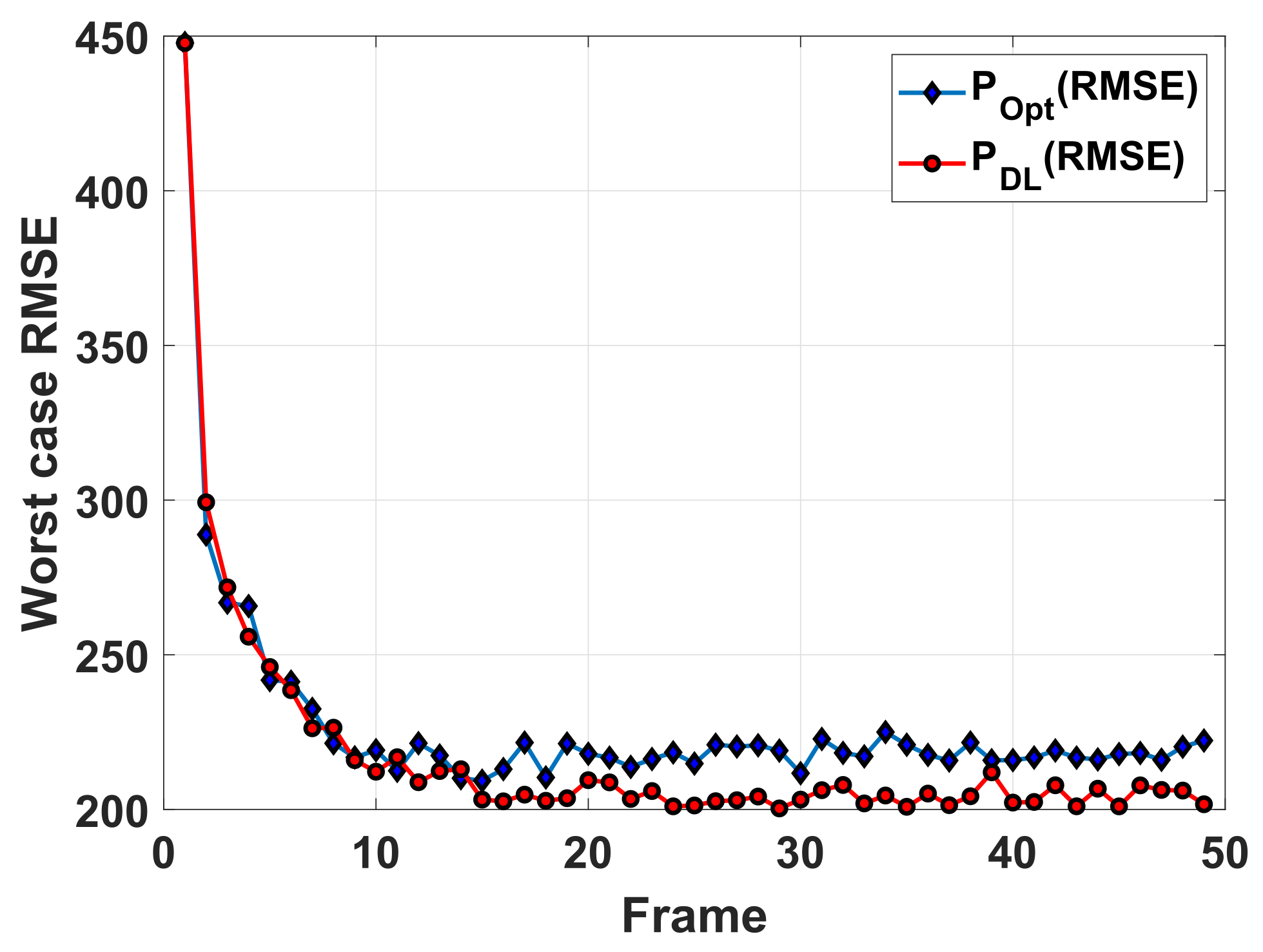
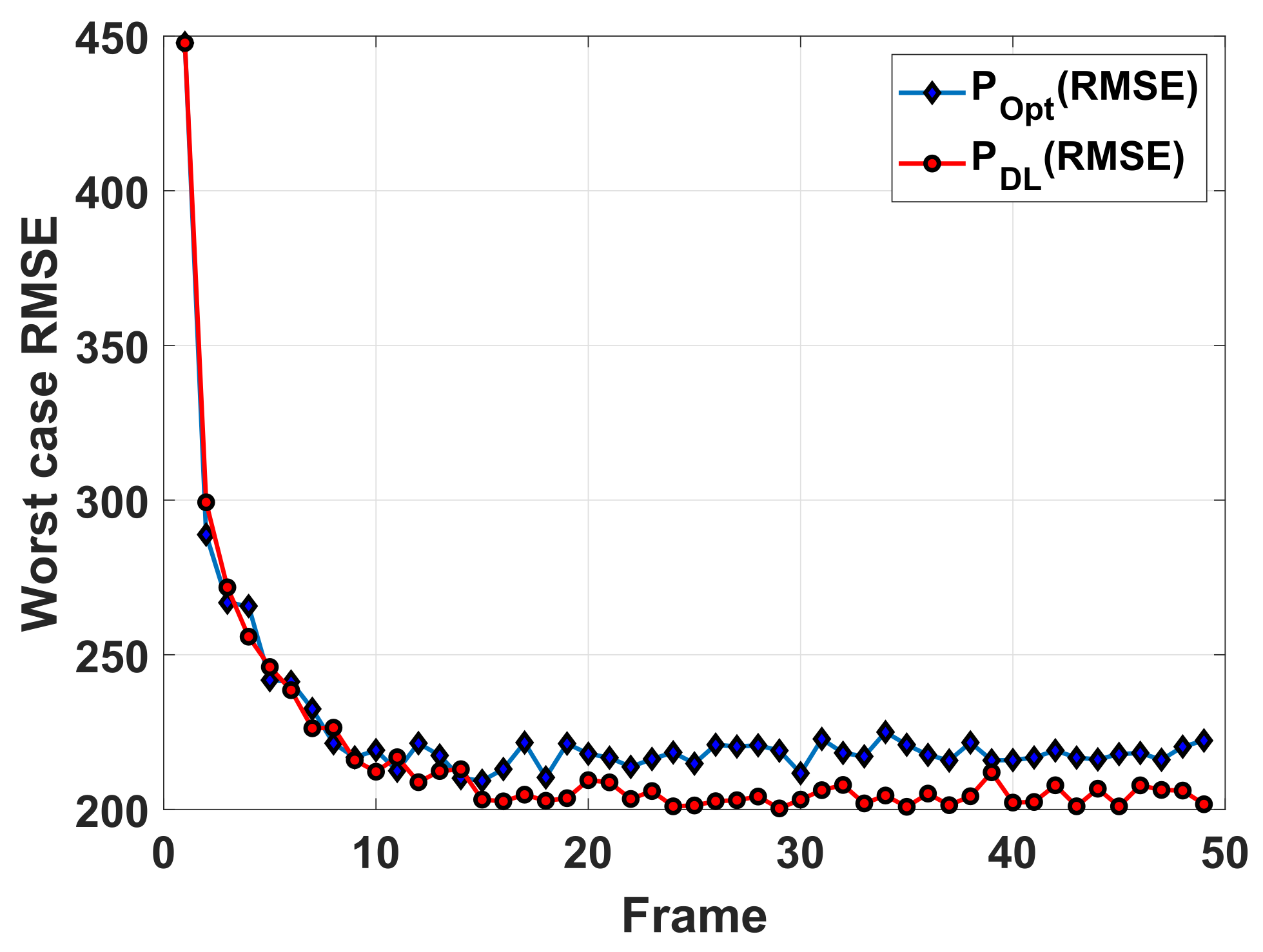
To better illustrate the effectiveness of the RNN-based prediction network, an additional simulation experiment is conducted, where the optimization-based method is used to solve cost function (5) based on the prior information representation derived from the prediction network. In
Figure 8, the curve labeled “
” represents the worst case tracking RMSE of the RNN-optimization-based method. It can be seen that this curve almost coincides with that of the proposed data-driven method and is also higher than that of the optimization-based method. This shows that the cost function (5) can be optimally solved with the method in [
14] once a one-step predictive state is accurate enough. According to the comparison shown in
Figure 8, it is known that, as
, the tracking performance improvements brought from the proposed method are mainly due to the usage of the RNN-based prediction network.
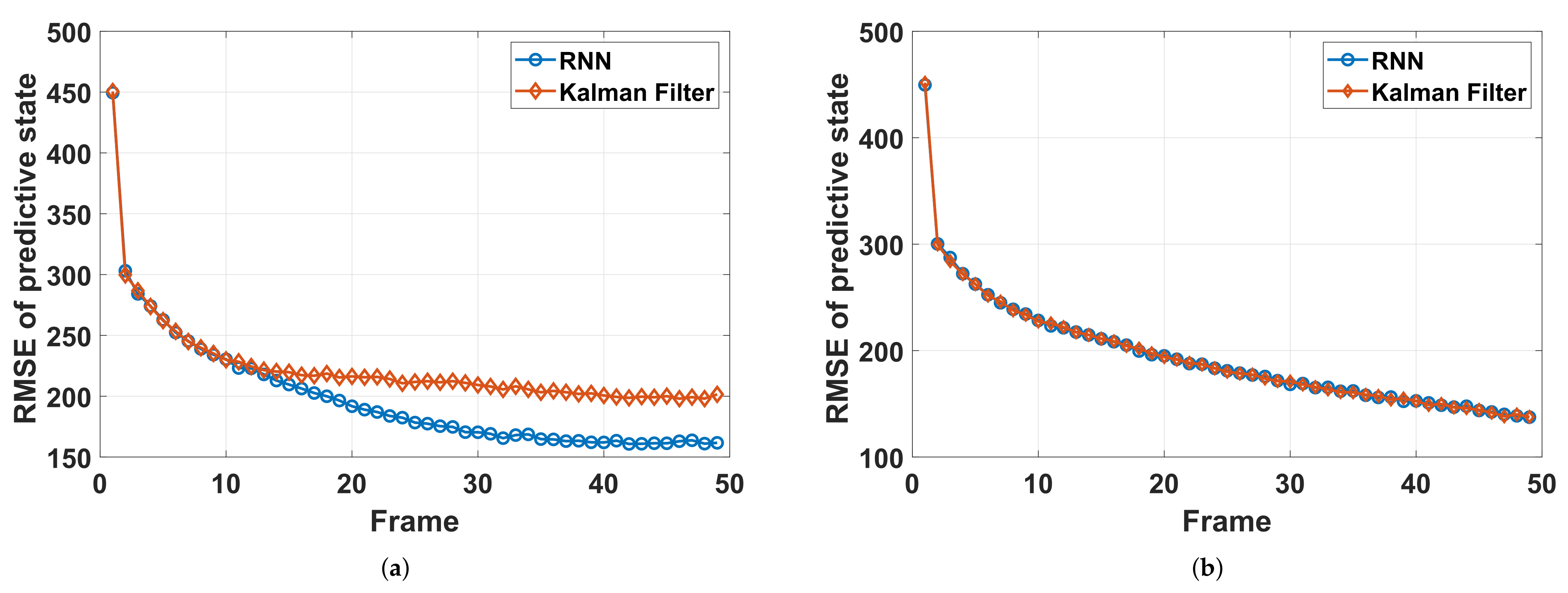
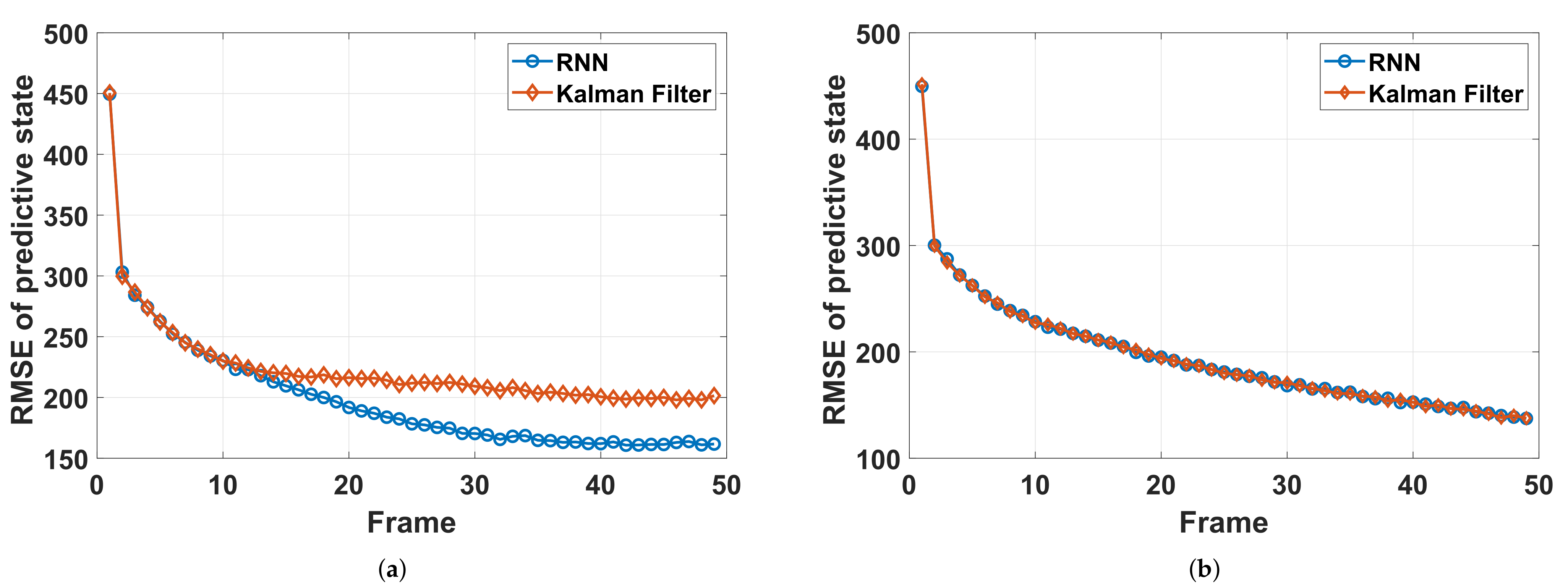
Furthermore, a prediction performance comparison of the RNN-based prediction network and the Kalman filter is given in
Figure 9, where the power is fixed during tracking. We first compare the RMSE of the predictive state of Target 2 (doing left turns) with the RNN and Kalman filter. The results are shown in
Figure 9a, in which the prediction performance of RNN is higher than that of Kalman filter with the CV model because the model mismatch problem is avoided to a certain extent. Additionally,
Figure 9b shows a comparison of the two methods of Target 3 (doing uniform linear motion). Here, Target 3 is taken in order to avoid the influence of model-mismatch. It can be seen that, different from that of Target 2, the RMSE curves of the two methods almost coincide, which implies that the performance of the RNN-based prediction network is very close (almost the same) to that of the Kalman filter with the true model (CV model), and thus, we believe that the RNN-based prediction network is able to replace the model-based prediction for target tracking in the applications of radar system resource allocation.
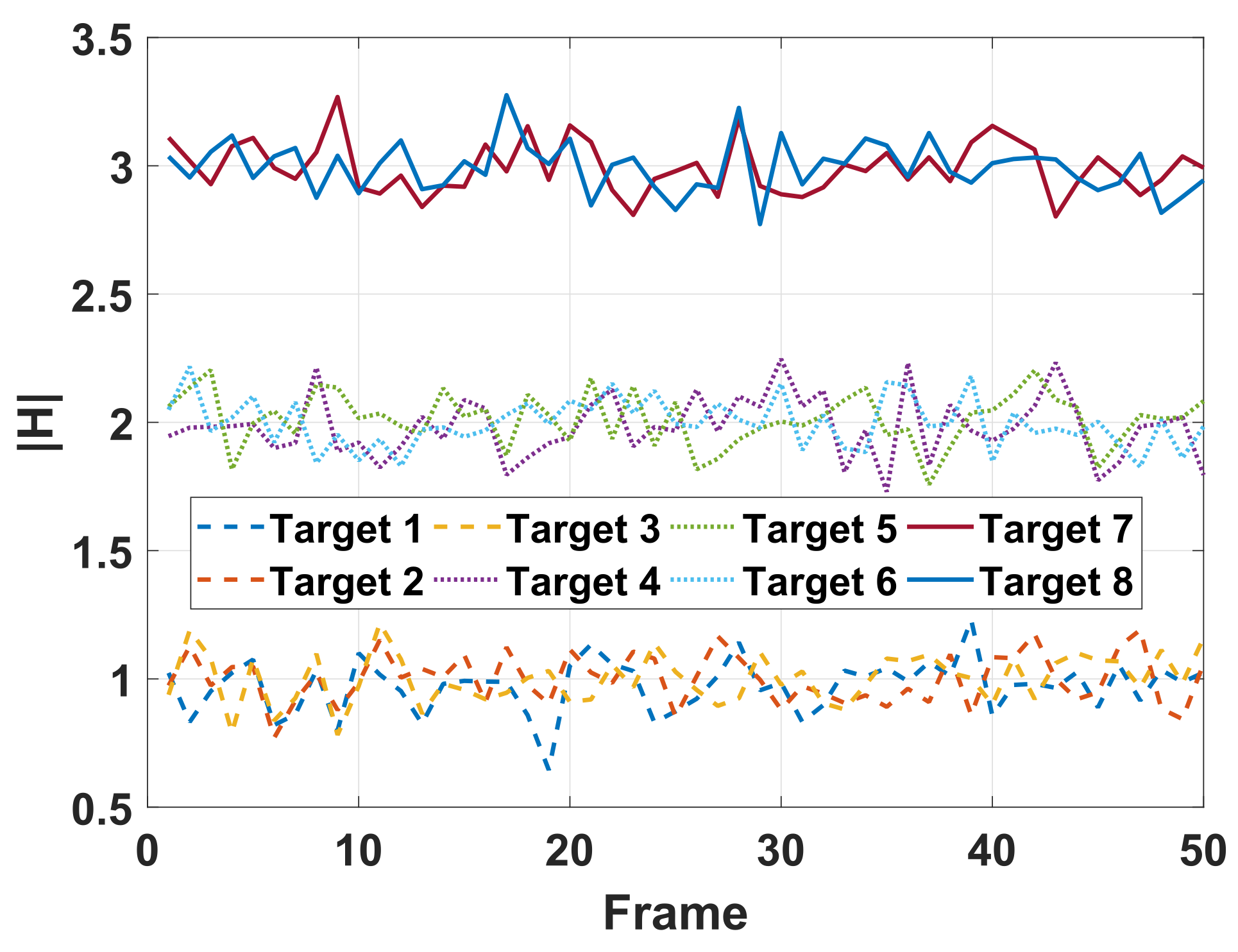
Next, we discuss the two methods with given RCS models. The amplitude sequences of RCS are given in
Figure 10. In
Figure 11, the curves labeled “
” and “
” are the worst tracking RMSEs averaged over 50 trails achieved with the optimization-based method and the proposed method, respectively. Similar to that in the first case, the tracking performance of the proposed data-driven-based method is also superior to that of the optimization-based method. In
Figure 12 and
Figure 13, we present the tracking RMSE and the corresponding resource allocation results of each target with the two methods. In
Figure 12, the tracking RMSE curves of targets given by the proposed method is closer than that of the optimization-based method. This indicates that the resource utilization efficiency of the optimization-based method is lower than that of the proposed method. Comparing the resource allocation results of Target 1, Target 2 and Target 3 in
Figure 13a, we observe that the revisit frequency of radar for Target 3 is higher than that of the other two. This phenomenon can be explained in that a high revisit frequency benefits the tracking performance improvement of the targets with a larger radial speed. On the other hand, more power and beam resource tend to be allocated to these targets with smaller RCS amplitude, i.e., Target 1, Target 2 and Target 3, which aim to improve SNR of echoes such that the worst-case tracking performance among multiple targets is maximized.
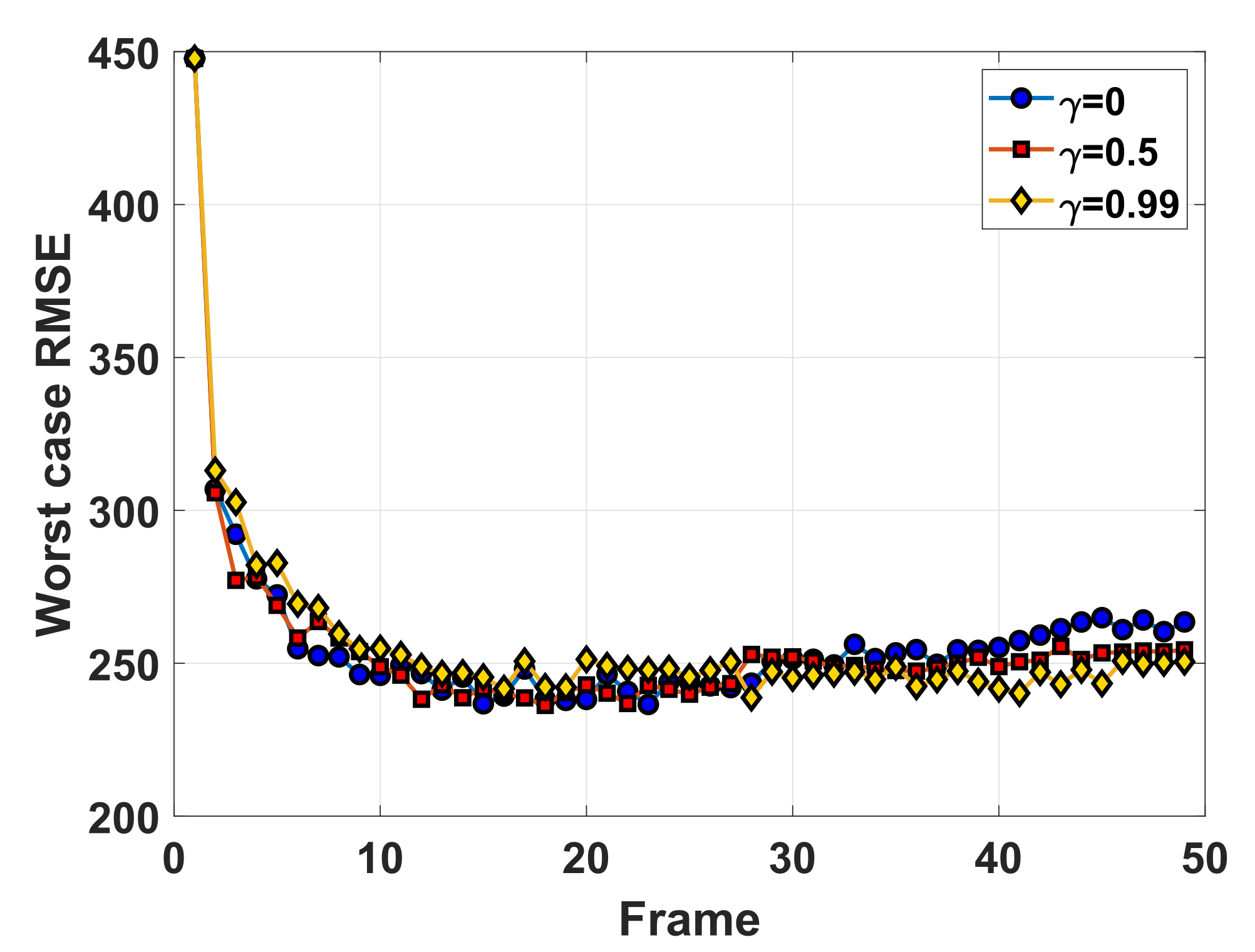
Simulation 2: In this section, we investigate the effect of the discounted factor on the resource allocation results and the tracking performance. Theoretically, taking cumulative discounted tracking accuracy into the resource allocation problem is more reasonable, especially as maneuvering targets are involved. Without loss of generality, three conditions are discussed, i.e., , and . The target parameters are set the same as that in simulation 1 and the amplitude of the target reflectivity is also set to 1.
The worst-case tracking RMSEs with different
are shown in
Figure 14, where the result with
is lower than that with
and
at the beginning, and later surpasses them with frame number increasing. This phenomenon is consistent with that the discounted factor controls the importance of the future tracking accuracy on the current resource allocation solution. Particularly, if taking a small discounted factor, the learned policy tends to improve the performance of the nearer future tracking time step at a cost of a performance loss of the farther future tracking time. In
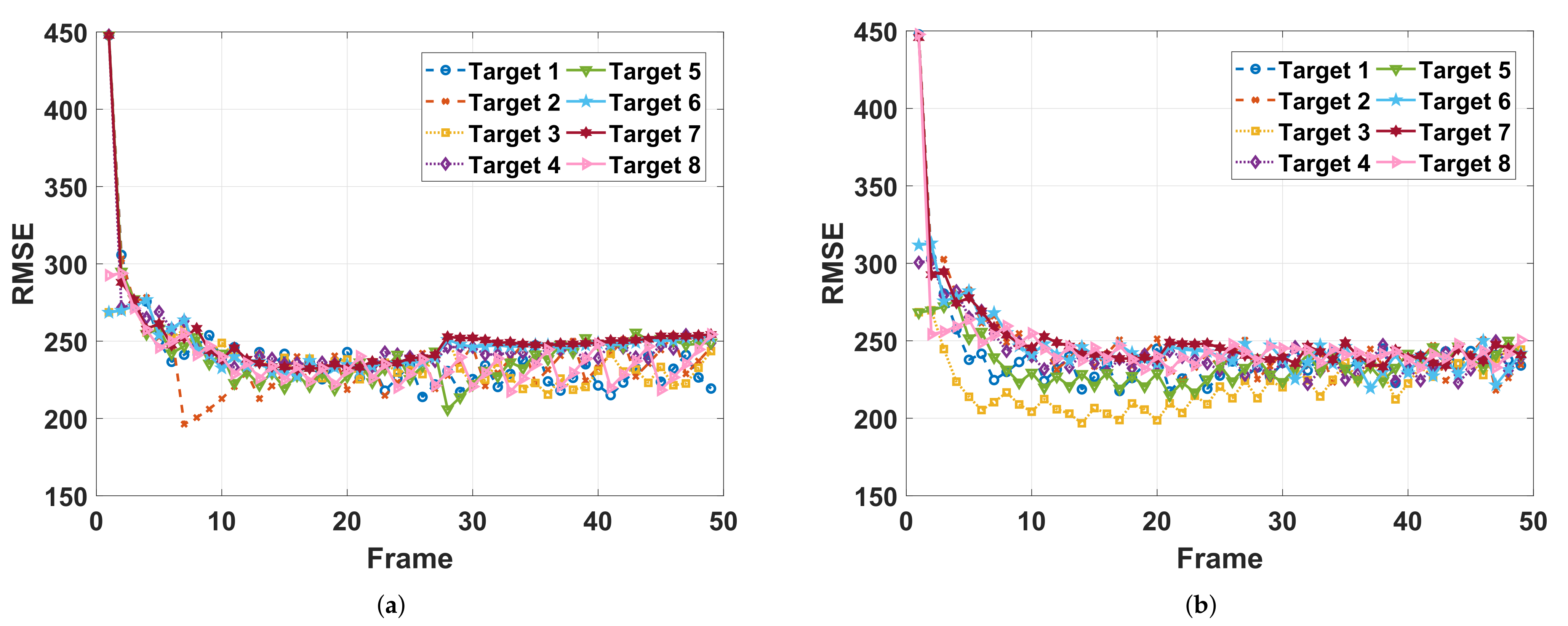
Figure 15, the tracking RMSE curves with
are more compact than that with
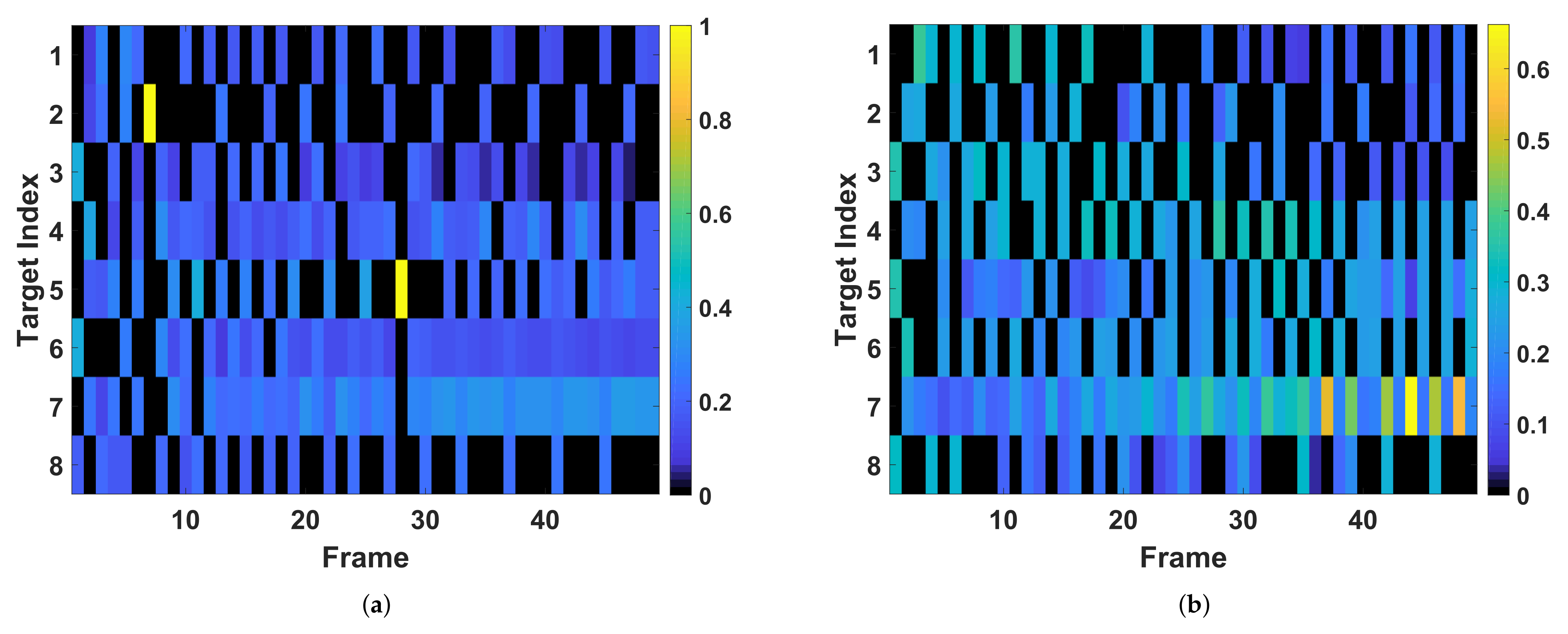
before frame 30 in order to reduce the worst-case tracking RMSE of the nearer future tracking time, which is the opposite after frame 30. The corresponding resource allocation results are presented in
Figure 16. In
Figure 16a, more power and beam resource are allocated to the beam pointing to target 4, target 5, target 6, and target 7, which are moving away from radar such that a larger gain of future tracking performance can be achieved. Meanwhile, increasing the revisit frequency of Target 3 aims to preventing from future larger BCRLB due to its larger radial speeds, which is the same as the result of
. By comparing the tracking performance curves in
Figure 14, it is easy to see that the tracking RMSE curves of non-zero discounted factors are lower than that of
within frame [30, 50], which indicates that the usage of non-zero discounted factors makes the resource allocation policy improve the performance of farther tracking time. In this case, as shown in
Figure 16b, in order to improve the worst-case tracking RMSE of farther tracking time as
, Target 7 (it moves away from the radar with the largest radial speed) is illuminated all the time even at the beginning of tracking, and takes up most of the power at the end of tracking. This phenomenon is different from the results with
that cares more about nearer future tracking performance.
In all, the usage of a larger contributes to a more stable and effective allocation policy in the case of considering farther future tracking performance. However, in this case, a performance loss of the early tracking stage would not be avoided. In other words, there is a trade-off between the current tracking performance and the future tracking performance about .



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}