
Efficient Occluded Road Extraction from High-Resolution Remote Sensing Imagery

Abstract
:
1. Introduction
- (1)
- We propose a novel MAU-Net method to extract roads from high-resolution remote sensing images. With the use the of the attention mechanism module in the feature extraction and feature fusion, the network can adaptively adjust its attention to different regions, and weaken the influence of the interference area while highlighting the key areas. Thus, the road extract ability of network is improved. Experiments show that the proposed method has distinct advantages over existing methods on a benchmark dataset.
- (2)
- A data enhancement method aiming at occlusions is applied. Beyond the conventional method, this paper focuses on the situation of a road occluded by other ground objects, and the quality of the dataset is improved by generating an occlusion mask. This method can improve the network’s extraction ability towards occluded roads.
- (3)
- After analyzing the problems existing in the road semantic segmentation results, a geometric topology reconstruction algorithm based on connected domain analysis is established, and it can further weaken or eliminate the fracture phenomenon and remove the errors of extracted spots in the road extraction results. Compared with other post-processing methods, this algorithm is easy to realize and can achieve a better visual effect.
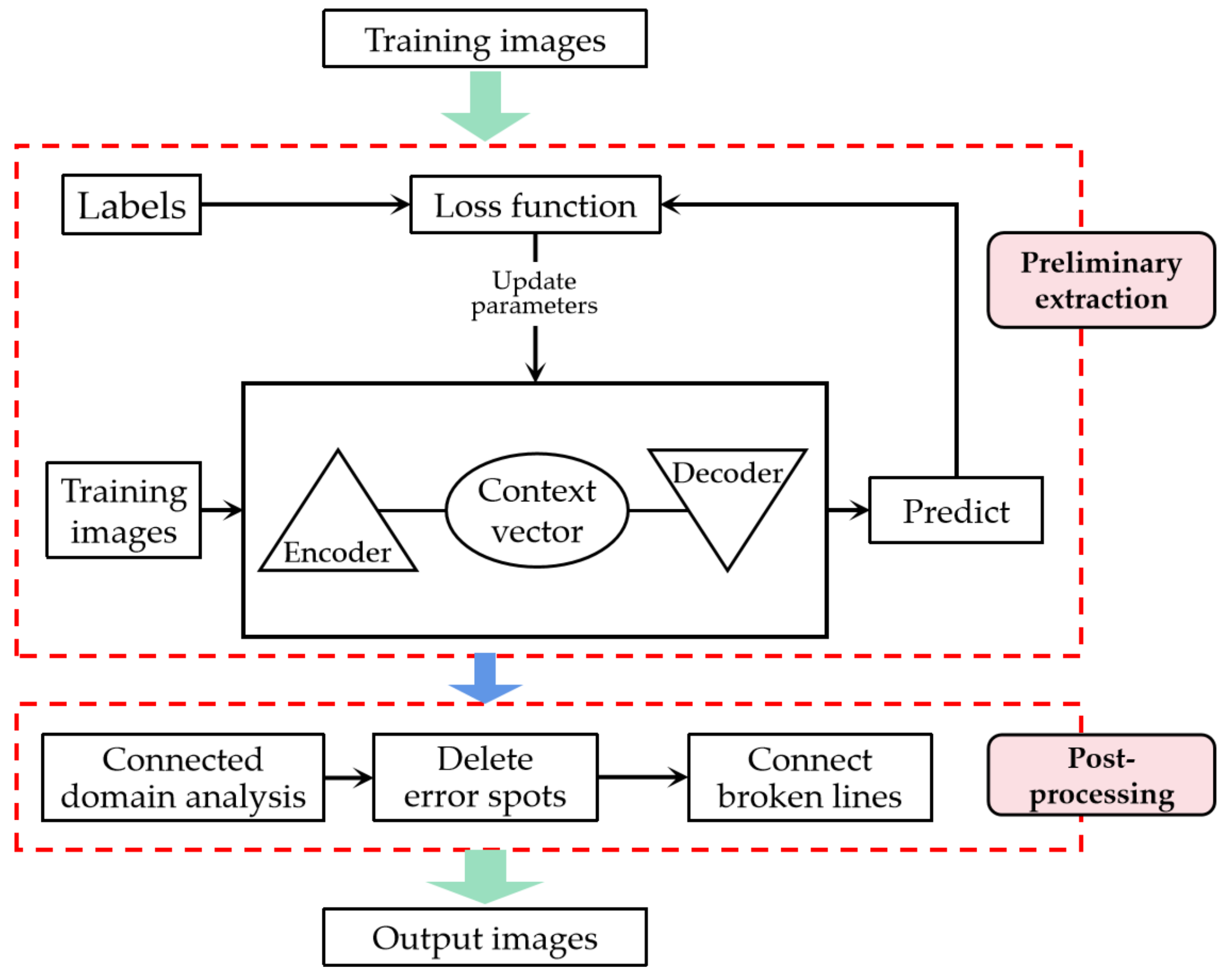
2. Methods
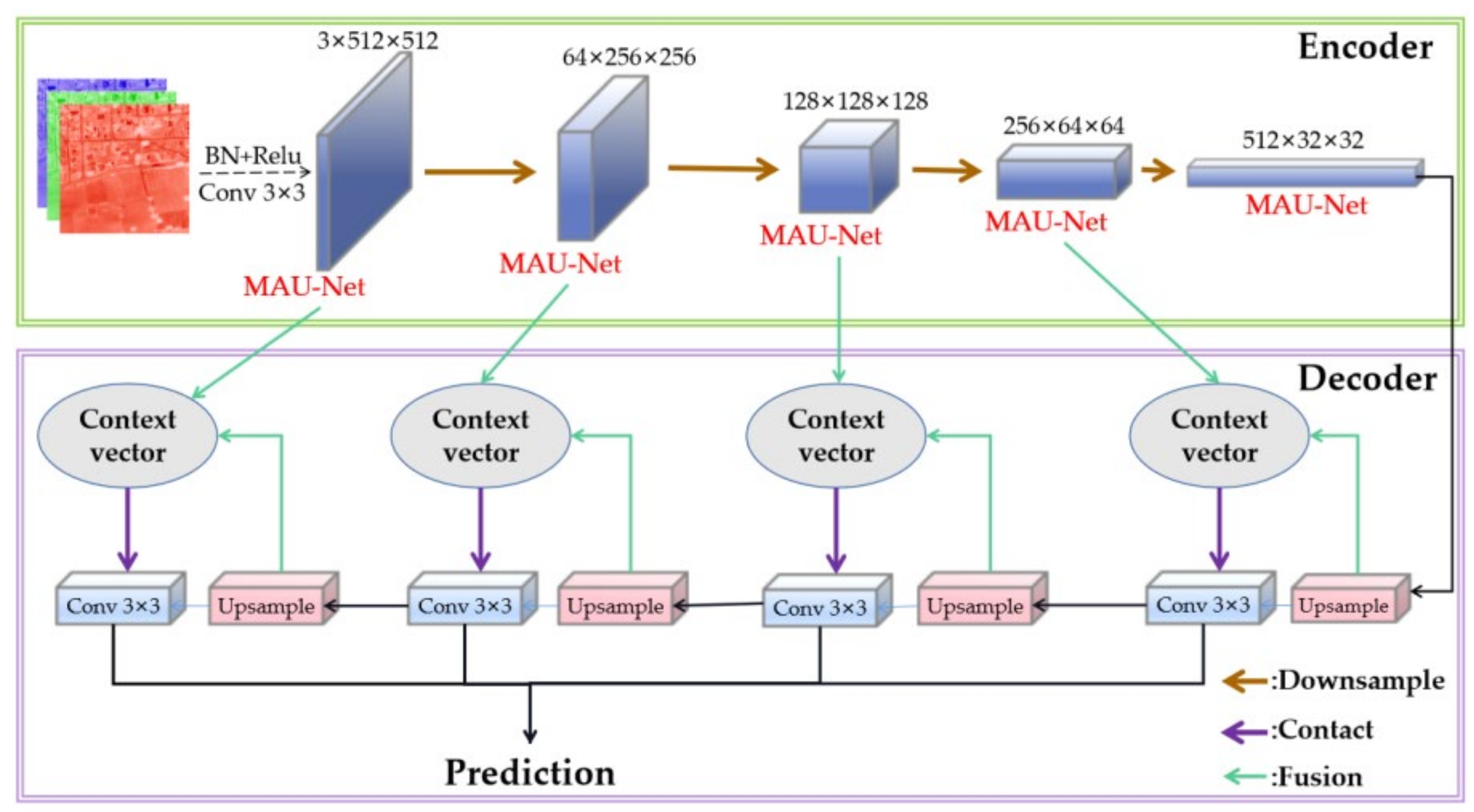
2.1. Road Extraction Using Attention Convolutional Neural Network
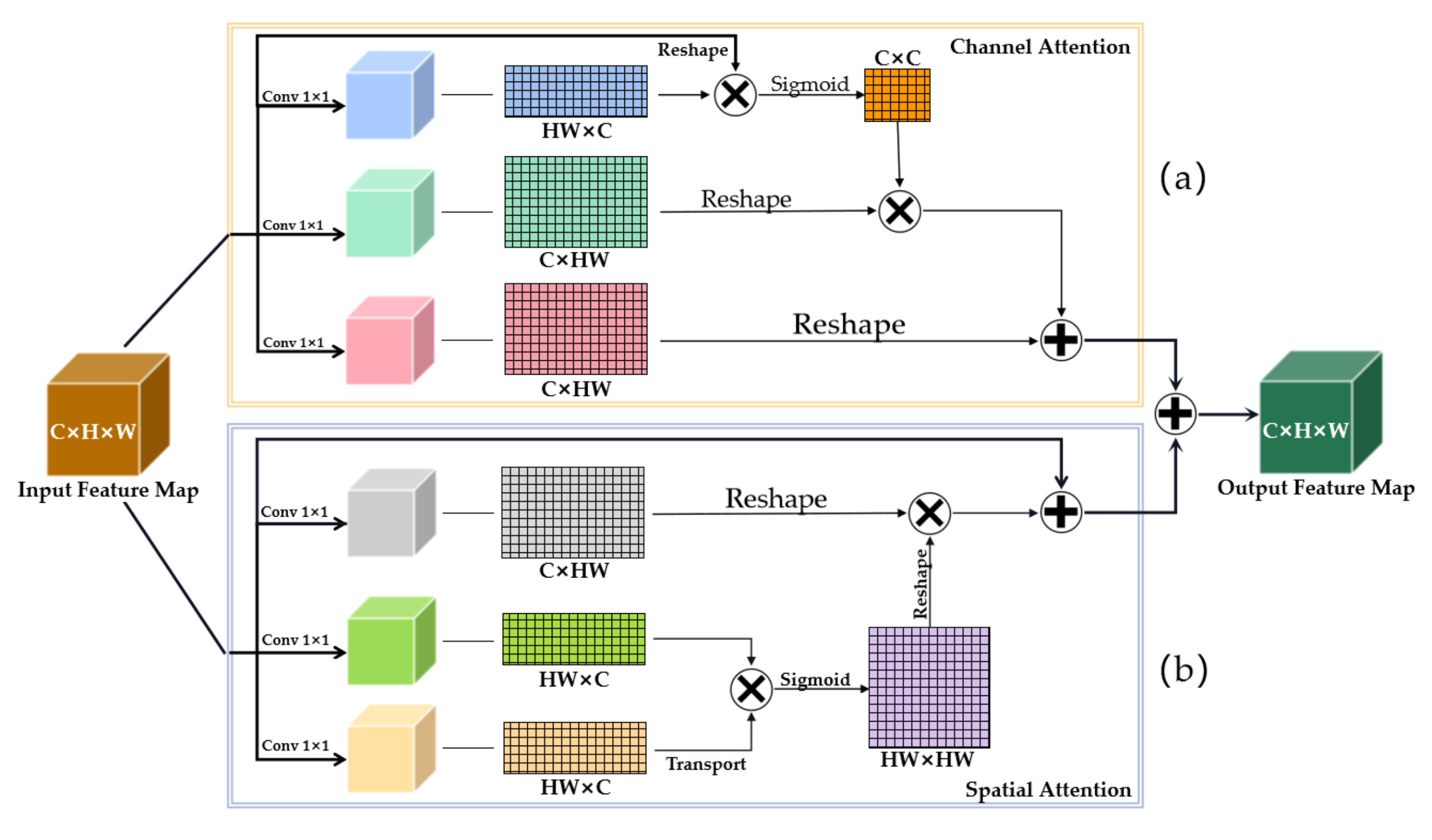
2.1.1. Enhanced Attention Module
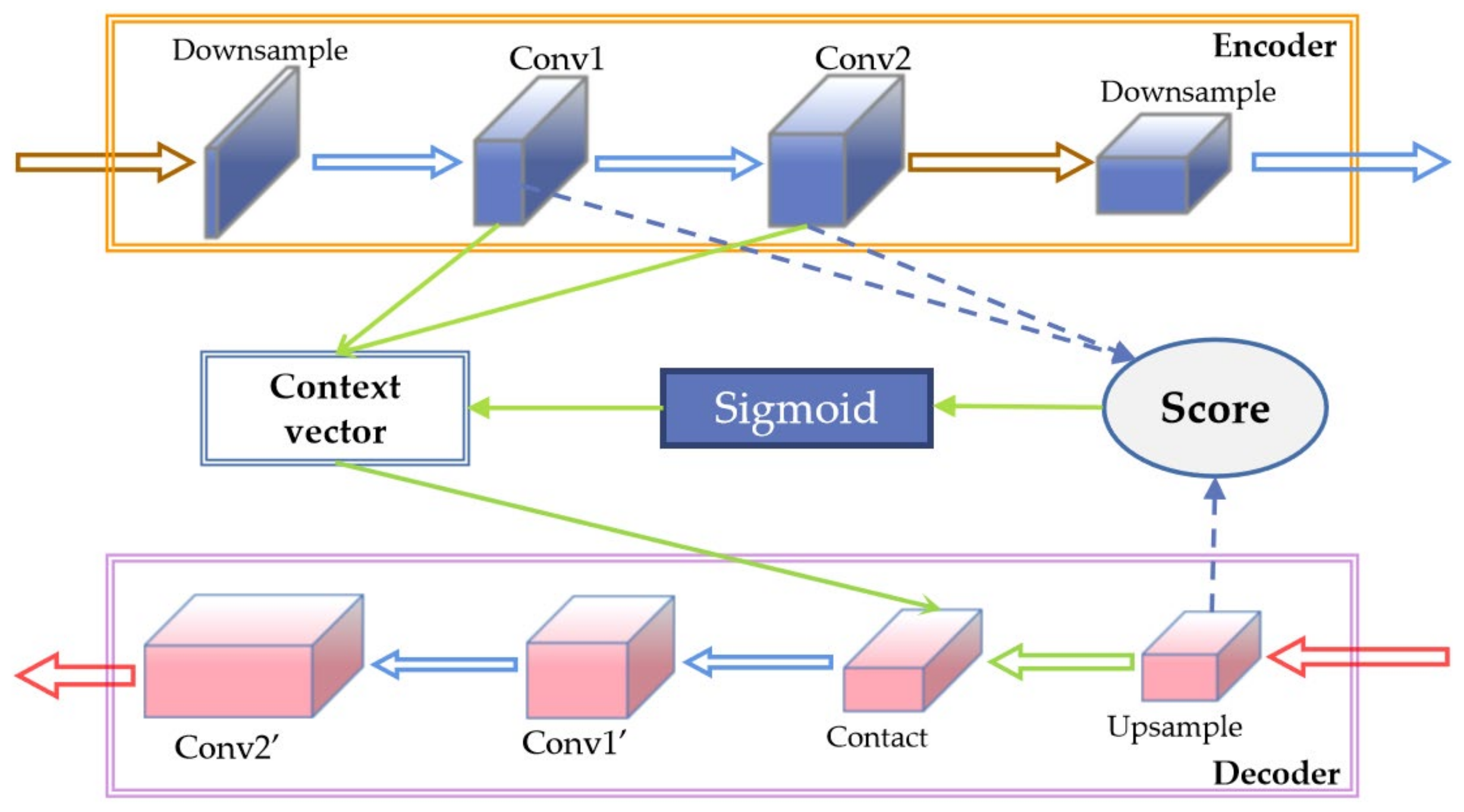
2.1.2. Feature Fusion Based on Attention Mechanism
2.1.3. Multi-Scale Aggregate Output
2.2. Post-Processing Based on Connected Domain Analysis
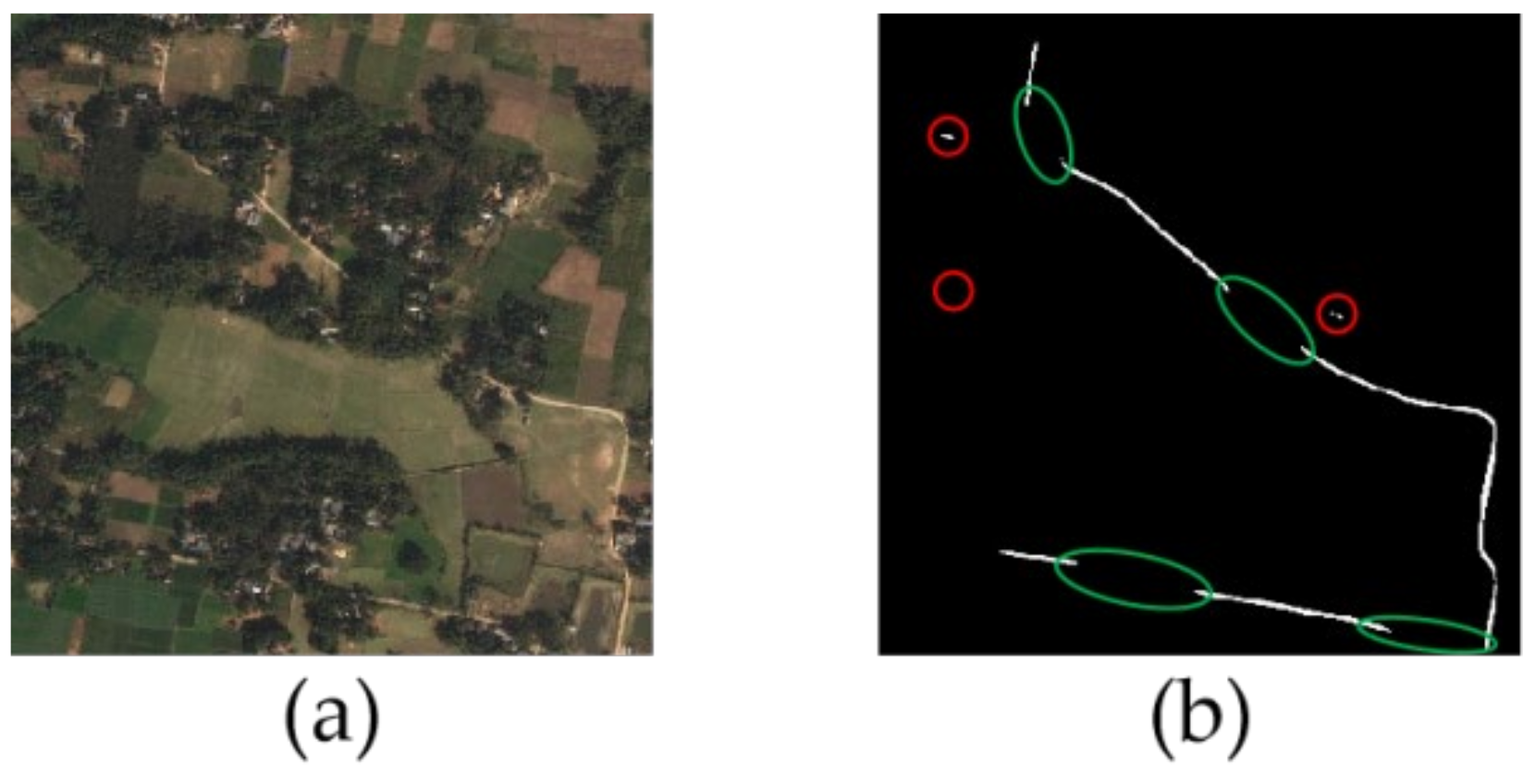
2.2.1. Problems in Road Extraction
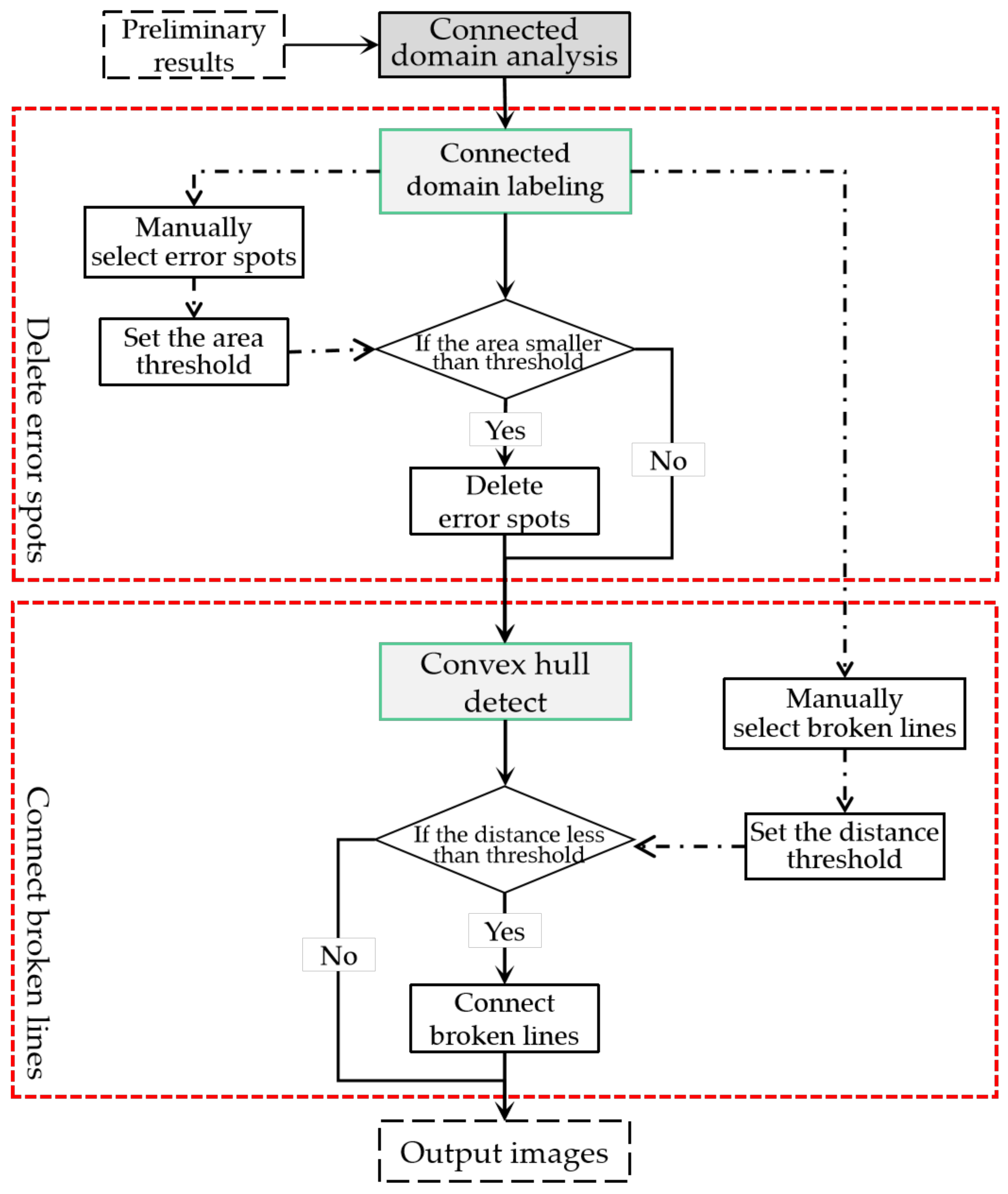
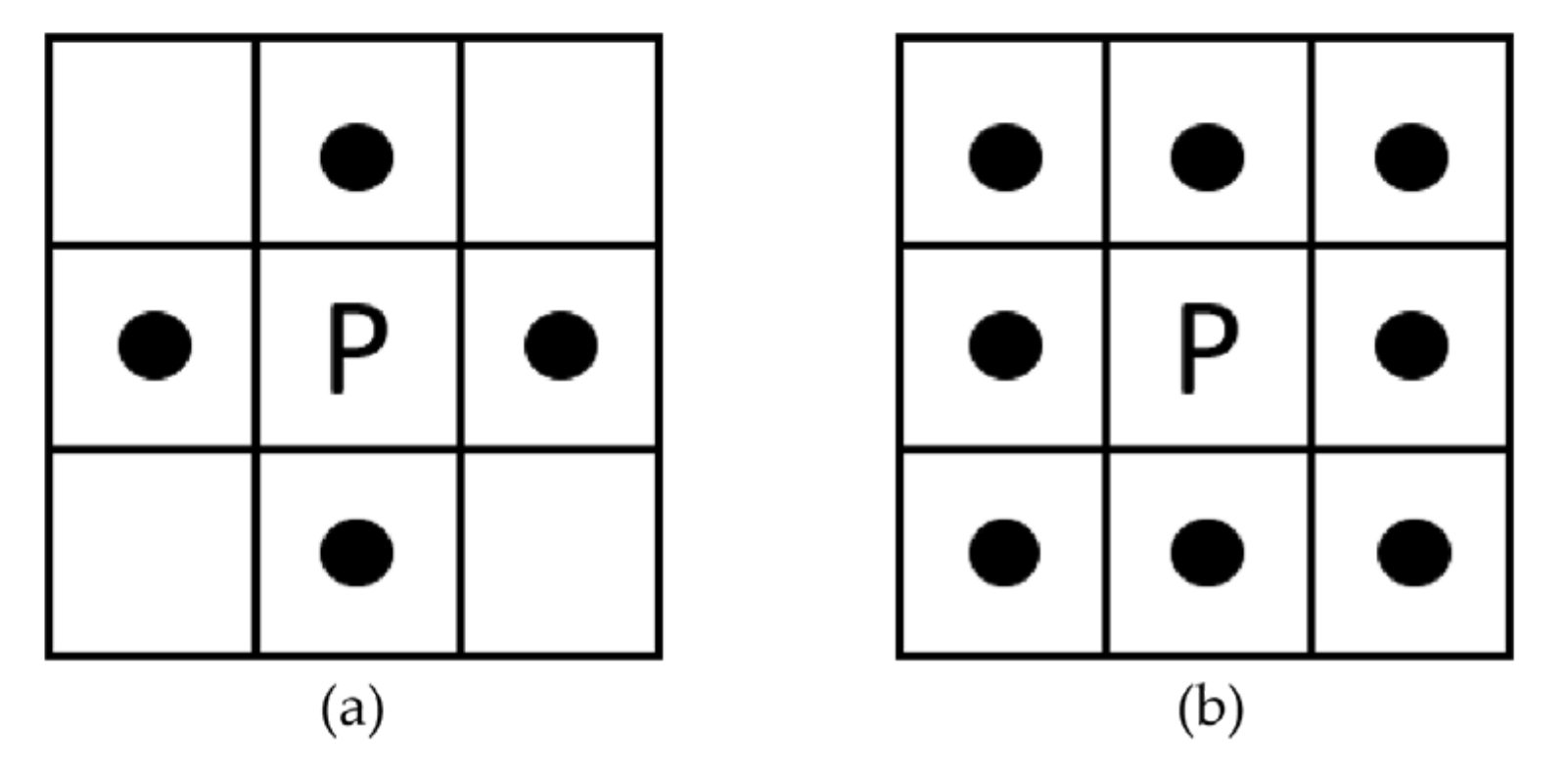
2.2.2. Post-Processing Algorithm
- (1)
- Connected domain labeling
- (2)
- Connected domain-based post-processing
- (3)
- Schematic diagram of post-processing
3. Dataset Descriptions and Experimental Configuration
3.1. Dataset Descriptions
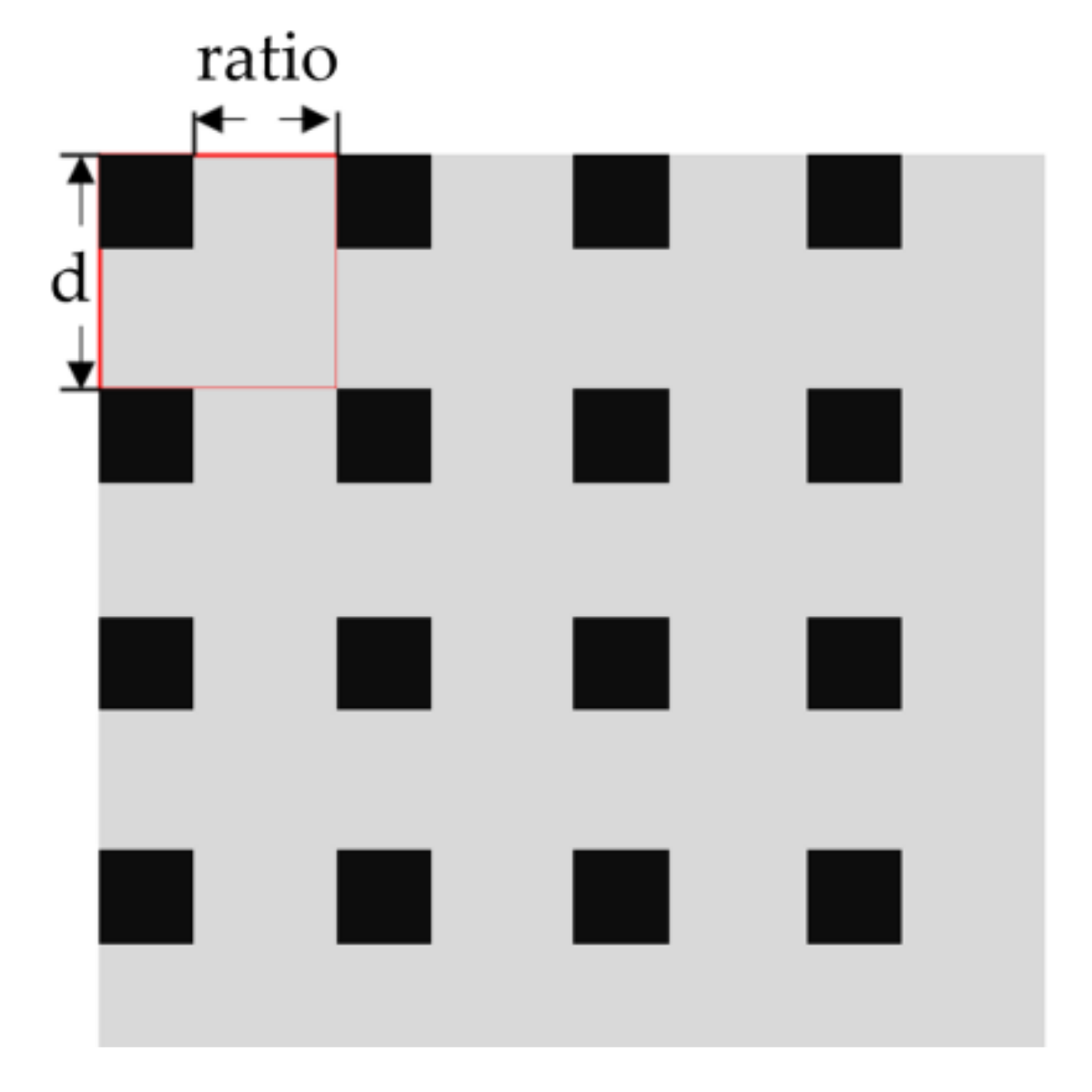
3.2. Mask Based Data Enhancement against Occluded Information
3.3. Experimental Configuration
3.3.1. Training Environment Description
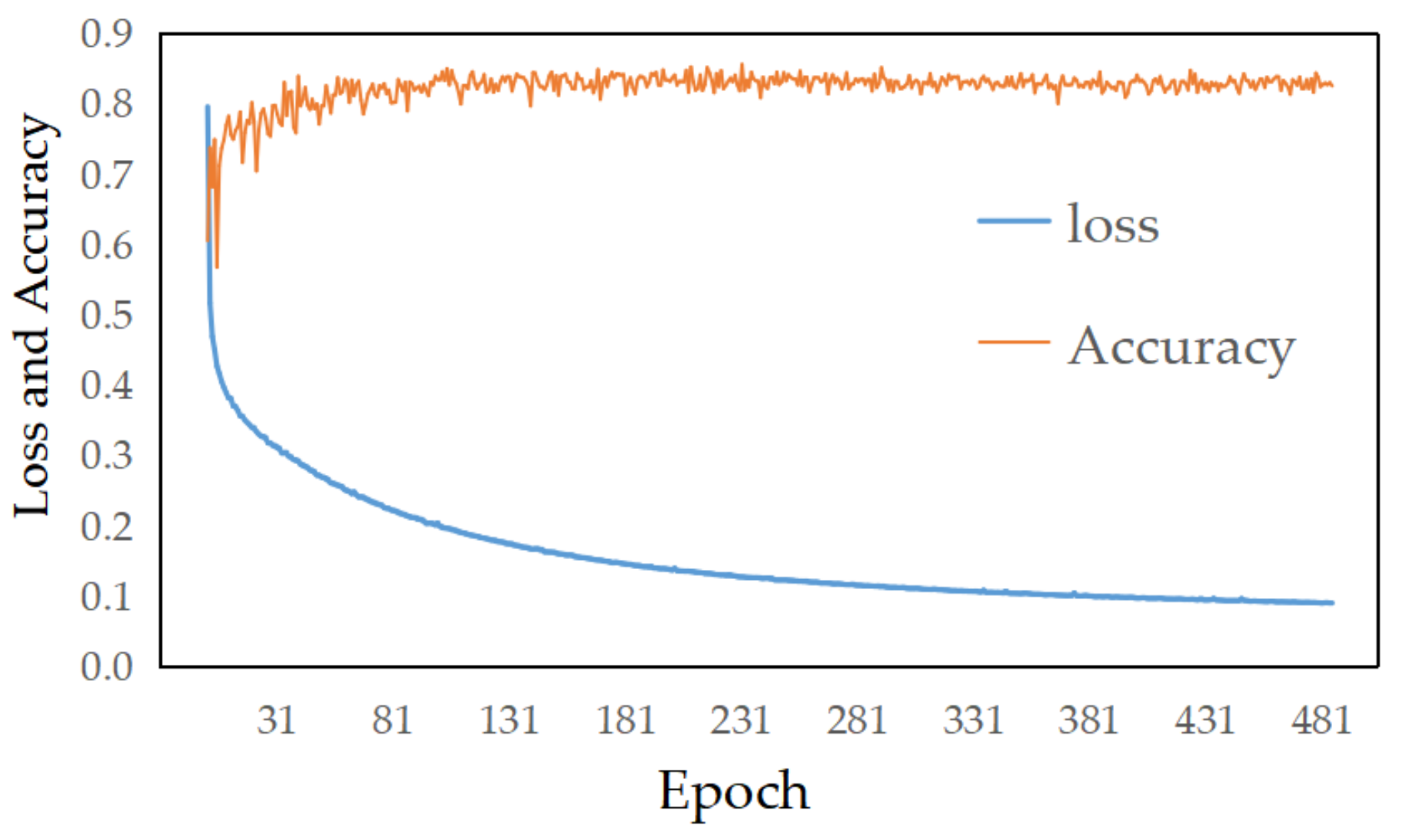
3.3.2. Hyper-Parameter Settings
3.4. Evaluation Metrics




4. Experimental Results and Discussion
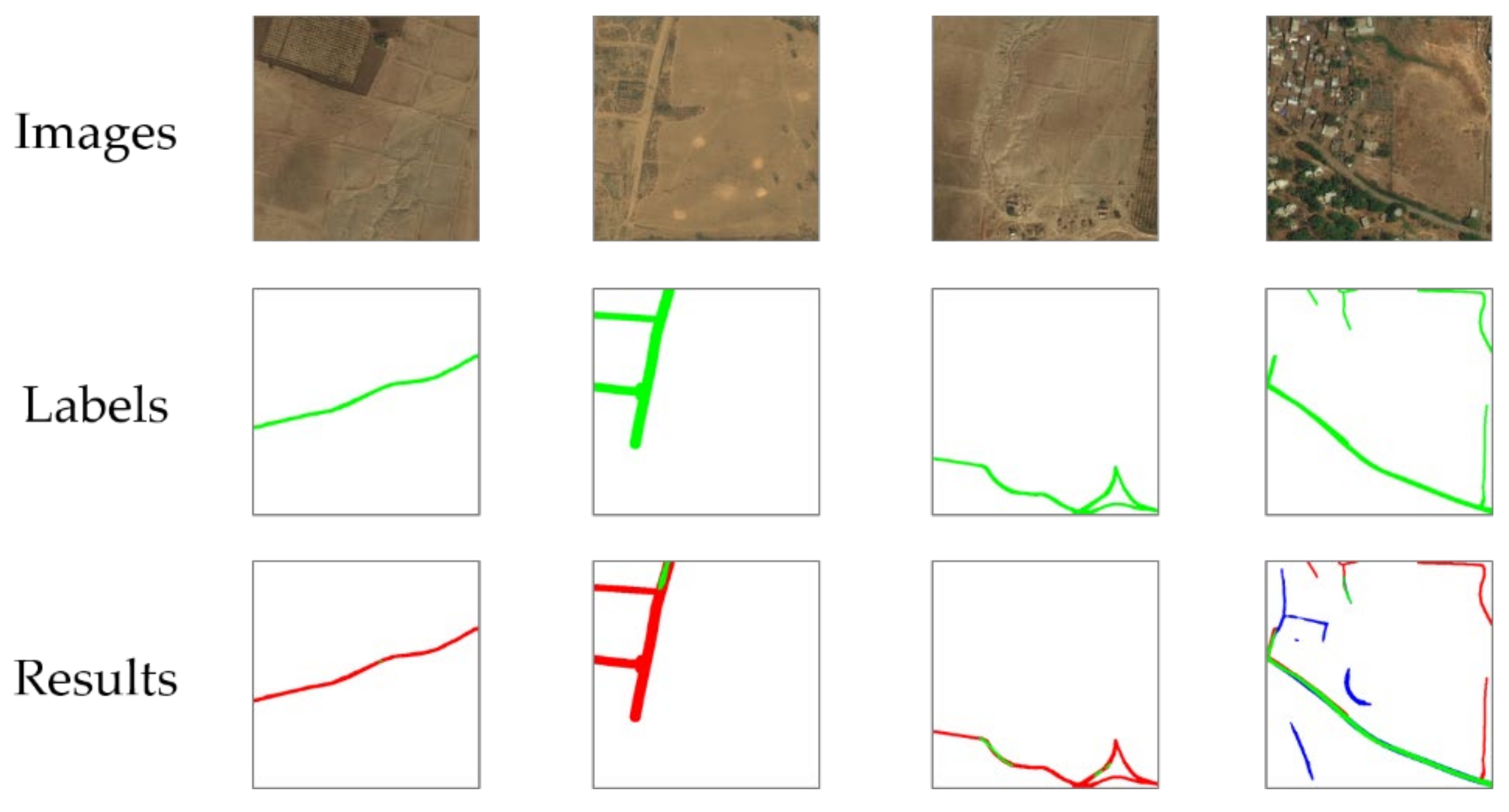
4.1. Qualitative Analysis
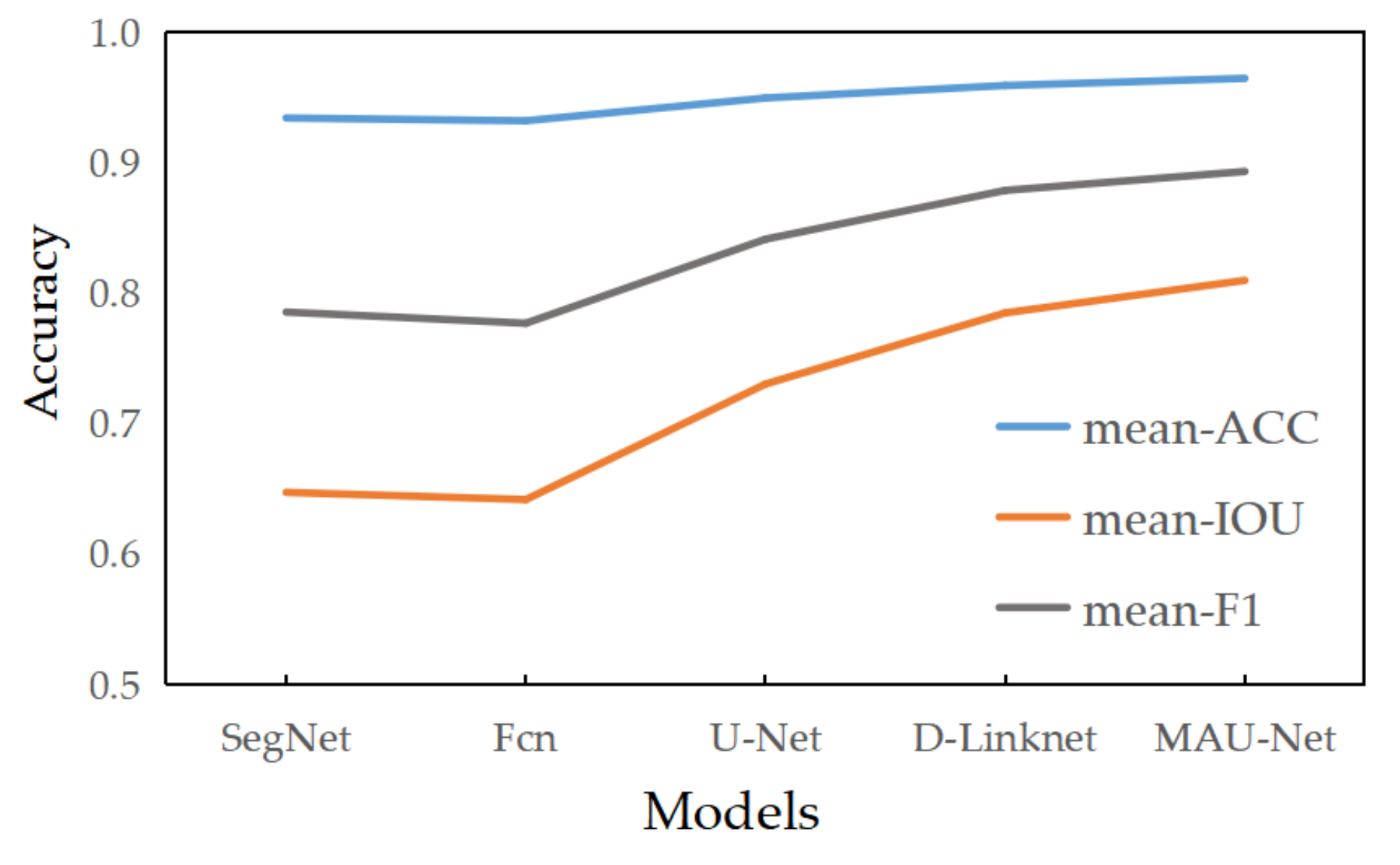
4.2. Quantitative Analysis
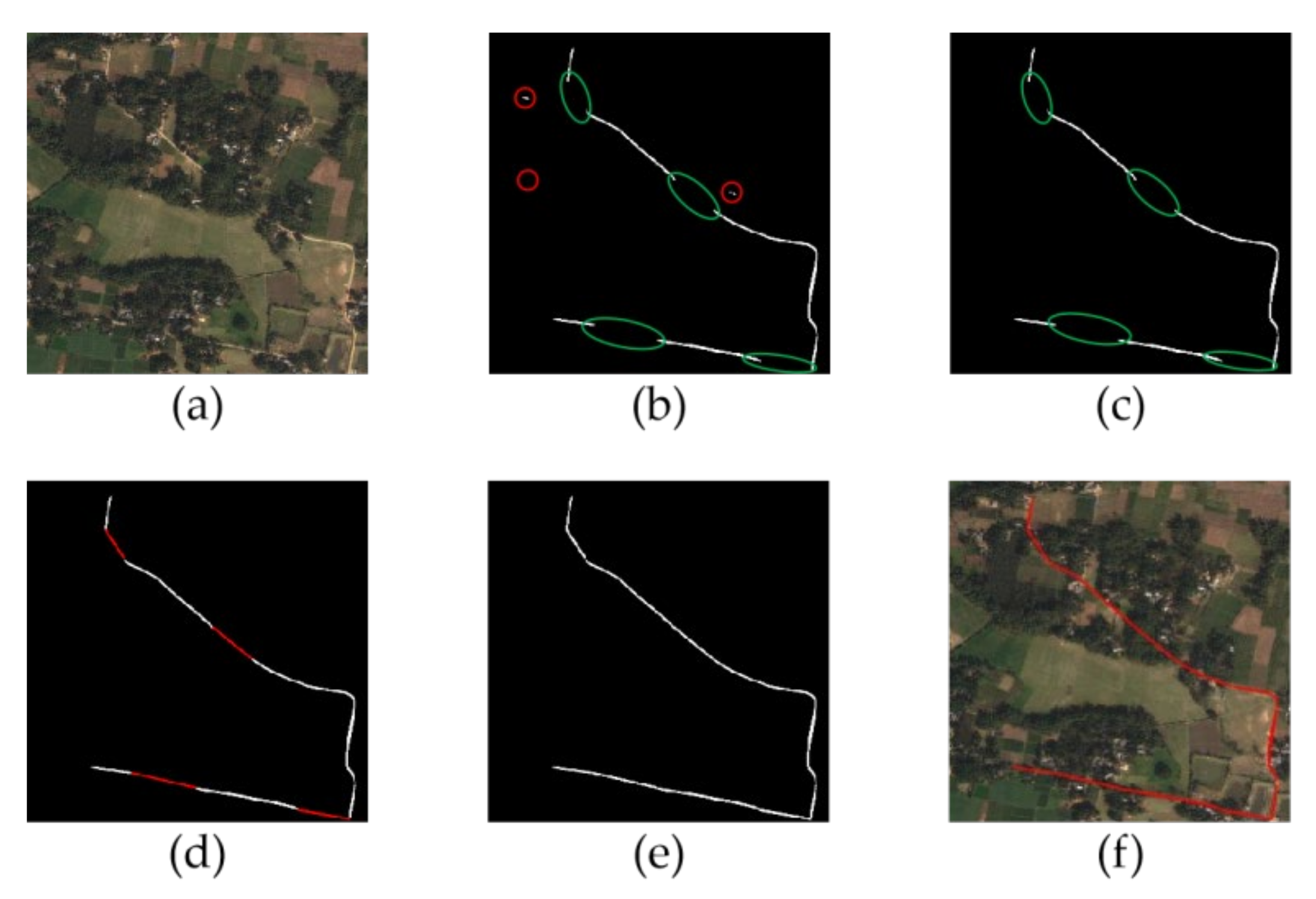
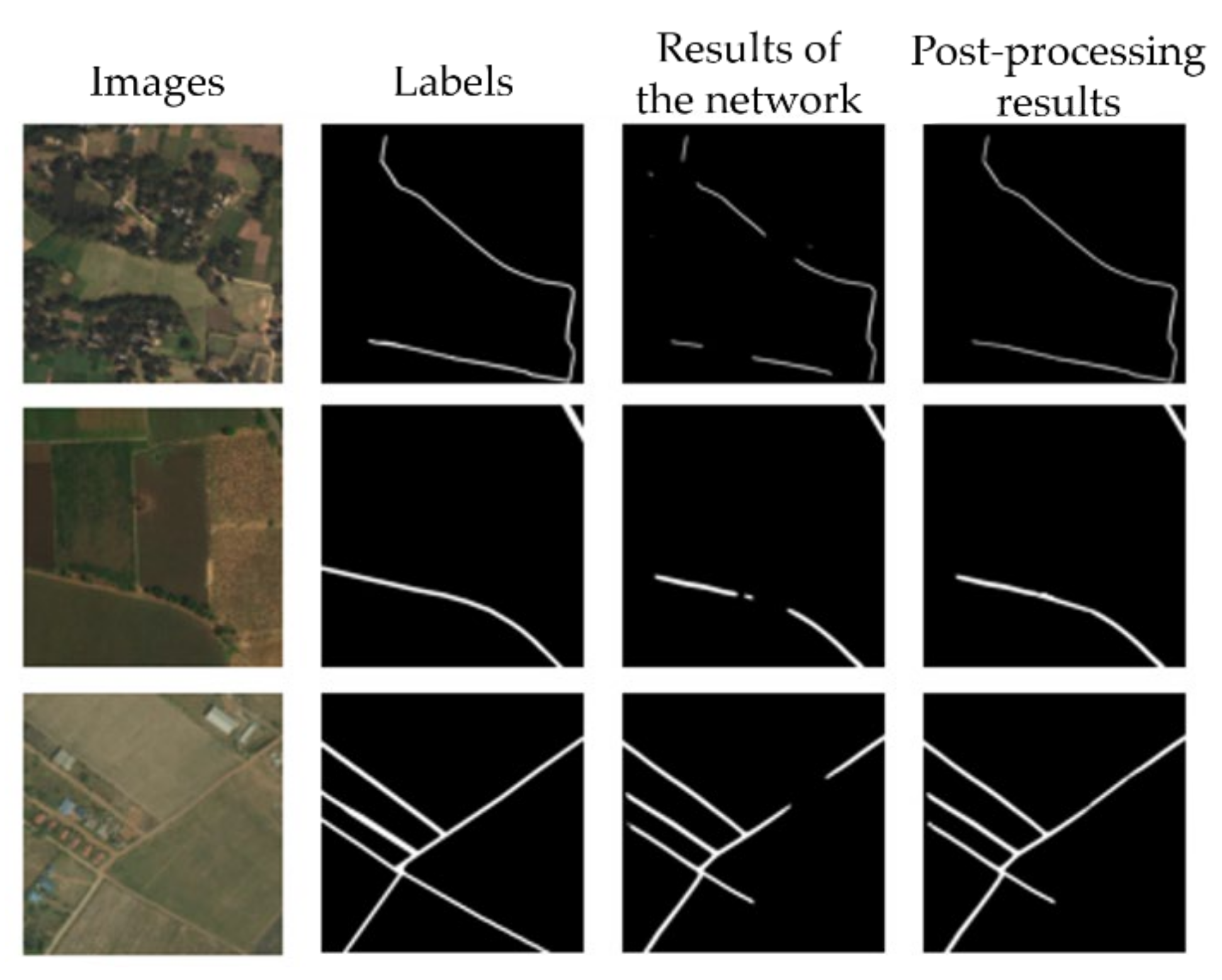
4.3. Post-Processing Analysis
4.4. Discussion of the Proposed Method
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Z.; Feng, R.; Wang, L.; Zhong, Y.; Cao, L. D-Resunet: Resunet and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3927–3930. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, W.; Li, C.; Wu, J.; Tang, X.; Jiao, L. Fully convolutional network-based ensemble method for road extraction from aerial images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1777–1781. [Google Scholar] [CrossRef]
- Li, D.; Deng, L.; Cai, Z.; Yao, X. Intelligent transportation system in Macao based on deep self-coding learning. IEEE Trans. Ind. Inf. 2018, 14, 3253–3260. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, C.; Li, J.; Xie, N.; Han, Y.; Du, J. Reconstruction bias U-Net for road extraction from optical remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 2284–2294. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B. Integrated technique of segmentation and classifification methods with connected components analysis for road extraction from orthophoto images. Expert Syst. Appl. 2021, 176, 114908. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, W.; Zhong, B.; Li, J.; Du, J.; Wang, C. Corse-to-fifine road extraction based on local Dirichlet mixture models and multiscale-high order deep learning. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4283–4293. [Google Scholar] [CrossRef]
- Soni, P.K.; Rajpal, N.; Mehta, R. Semiautomatic road extraction framework based on shape features and LS-SVM from high-resolution images. J. Indian Soc. Remote Sens. 2020, 48, 513–524. [Google Scholar] [CrossRef]
- Cheng, J.; Liu, T.; Zhou, Y.; Xiong, Y. Road junction identification in high resolution urban SAR images based on SVM. In International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing; Barolli, L., Xhafa, F., Hussain, O., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 994, pp. 597–606. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous extraction of road surface and road centerline in complex urban scenes from very high-resolution images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Luo, Q.; Yin, Q.; Kuang, D. Research on Extracting Road Based on Its Spectral Feature and Shape Feature. Remote Sens. Technol. Appl. 2011, 22, 339–344. [Google Scholar] [CrossRef]
- Wang, J.; Qin, Q.; Yang, X.; Wang, J.; Ye, X.; Qin, X. Automated road extraction from multi-resolution images using spectral information and texture. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 533–536. [Google Scholar] [CrossRef]
- Barzohar, M.; Cooper, D.B. Automatic finding main roads in aerial image by using geometric-stochastic models and estimation. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 707–721. [Google Scholar] [CrossRef]
- Hu, J.; Razdan, A.; Femiani, J.C.; Cui, M.; Wonka, P. Road network extraction and intersection detection from aerial images by tracking road footprints. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4144–4157. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Debayle, J. An integrated method for urban main-road centerline extraction from optical remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3359–3372. [Google Scholar] [CrossRef]
- Mu, H.; Zhang, Y.; Li, H.; Guo, Y.; Zhuang, Y. Road extraction base on Zernike algorithm on SAR image. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 1274–1277. [Google Scholar] [CrossRef]
- Ghaziani, M.; Mohamadi, Y.; Bugra Koku, A.; Konukseven, E.I. Extraction of unstructured roads from satellite images using binary image segmentation. In Proceedings of the 2013 21st Signal Processing and Communications Applications Conference, Haspolat, Turkey, 24–26 April 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Ma, H.; Cheng, X.; Wang, X.; Yuan, J. Road information extraction from high resolution remote sensing images based on threshold segmentation and mathematical morphology. In Proceedings of the 2013 6th International Congress on Image and Signal Processing, Hangzhou, China, 16–18 December 2013; pp. 626–630. [Google Scholar] [CrossRef]
- Shanmugam, L.; Kaliaperumal, V. Junction-aware water flow approach for urban road network extraction. IET Image Process. 2016, 10, 227–234. [Google Scholar] [CrossRef]
- Ma, S.; Xu, Y.; Yue, W. Numerical solutions of a variable-order fractional financial system. J. Appl. Math. 2012, 2012, 1–16. [Google Scholar] [CrossRef]
- Sirmacek, B.; Unsalan, C. Road network extraction using edge detection and spatial voting. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3113–3116. [Google Scholar] [CrossRef]
- Gaetano, R.; Zerubia, J.; Scarpa, G.; Poggi, G. Morphological road segmentation in urban areas from high resolution satellite images. In Proceedings of the 2011 17th International Conference on Digital Signal Processing, Corfu, Greece, 6–8 July 2011; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Anil, P.N.; Natarajan, S. Road extraction using topological derivative and mathematical morphology. J. Indian Soc. Remote Sens. 2013, 41, 719–724. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, X.; Liu, L.; Shi, J. A method of road extraction from high resolution remote image based on delaunay algorithms. In Proceedings of the 2018 International Conference on Robots & Intelligent System, Changsha, China, 26–27 May 2018; pp. 127–130. [Google Scholar] [CrossRef]
- Yager, N.; Sowmya, A. Support vector machines for road extraction from remotely sensed images. In Proceedings of the Computer Analysis of Images and Patterns: 10th International Conference, Groningen, The Netherlands, 25–27 August 2003; pp. 285–292. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic object-based image analysis–towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, M.; Singh, R.K.; Raju, P.L.N.; Krishnamurthy, Y.V.N. Road network extraction from high resolution multispectral satellite imagery based on object oriented techniques. Remote Sens. Spat. Inf. Sci. 2014, 2, 107–110. [Google Scholar] [CrossRef] [Green Version]
- Herumurti, D.; Uchimura, K.; Koutaki, G.; Uemura, T. Urban road extraction based on hough transform and region growing. In Proceedings of the 19th Korea-Japan Joint Workshop on Frontiers of Computer Vision, Incheon, Korea, 30 January–1 February 2013; pp. 220–224. [Google Scholar] [CrossRef]
- Lu, P.; Du, K.; Yu, W.; Wang, R.; Deng, Y.; Balz, T. A new region growing-based method for road network extraction and its application on different resolution SAR Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 4772–4783. [Google Scholar] [CrossRef]
- Miao, Z.; Wang, B.; Shi, W.; Zhang, H. A semi-automatic method for road centerline extraction from VHR images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1856–1860. [Google Scholar] [CrossRef]
- Li, M.; Stein, A.; Bijker, W.; Zhan, Q. Region-based urban road extraction from VHR satellite images using binary partition tree. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 217–225. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Luus, F.P.S.; Salmon, B.P.; Van Den Bergh, F.; Maharaj, B.T.J. Multiview deep learning for land-use classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards realtime object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. Comput. Sci. 2017. Available online: https://arxiv.org/abs/1706.05587v3 (accessed on 29 October 2021).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. Lect. Notes Comput. Sci. 2018, 11211, 833–851. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the 11th European Conference on Computer Vision, Part VI. Heraklion, Crete, Greece, 5–11 September 2010; pp. 210–223. [Google Scholar] [CrossRef]
- Gao, J.; Qi, W.; Yuan, Y. Embedding structured contour and location prior in siamesed fully convolutional networks for road detection. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 219–224. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, H.; Jiao, J.; Fu, K. An end-to-end neural network for road extraction from remote sensing imagery by multiple feature pyramid network. IEEE Access 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for effificient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing, St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Zhang, C.; Wu, M. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yan, H.; Lu, X. High-resolution remote sensing image road extraction method for improving U-Net. Remote Sens. Technol. Appl. 2020, 35, 741–748. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.K.; Zhang, X.F.; Huang, X.H. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 59, 7209–7220. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Sofla, R.A.D.; Alipour-Fard, T.; Arefi, H. Road extraction from satellite and aerial image using SE-Unet. J. Appl. Remote Sens. 2021, 15, 014512. [Google Scholar] [CrossRef]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A dual-attention capsule U-Net for road extraction from remote sensing imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Lin, Y.; Wan, L.; Zhang, H.; Wei, S.; Ma, P.; Li, Y.; Zhao, Z. Leveraging optical and SAR data with a UU-Net for large-scale road extraction. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102498. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. Lect. Notes Comput. Sci. 2018, 11211, 3–19. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Accuracy (%) | P (%) | R (%) | F1 (%) | IOU (%) |
|---|---|---|---|---|---|
| SegNet | 97.61 | 83.41 | 64.05 | 72.46 | 56.81 |
| FCN | 97.32 | 75.10 | 67.80 | 71.26 | 55.36 |
| U-Net | 97.76 | 83.22 | 67.99 | 74.84 | 59.79 |
| D-Linknet | 97.94 | 80.06 | 77.29 | 78.65 | 64.81 |
| MAU-Net | 98.14 | 80.97 | 81.15 | 81.06 | 68.16 |
| Accuracy (%) | IOU (%) | F1 (%) | |
|---|---|---|---|
| Results of the network | 98.68 | 61.53 | 75.95 |
| Post-processing results | 98.83 | 69.69 | 82.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, D.; Shen, X.; Xie, Y.; Liu, Y.; Wang, J. Efficient Occluded Road Extraction from High-Resolution Remote Sensing Imagery. Remote Sens. 2021, 13, 4974. https://doi.org/10.3390/rs13244974
Feng D, Shen X, Xie Y, Liu Y, Wang J. Efficient Occluded Road Extraction from High-Resolution Remote Sensing Imagery. Remote Sensing. 2021; 13(24):4974. https://doi.org/10.3390/rs13244974
Chicago/Turabian StyleFeng, Dejun, Xingyu Shen, Yakun Xie, Yangge Liu, and Jian Wang. 2021. "Efficient Occluded Road Extraction from High-Resolution Remote Sensing Imagery" Remote Sensing 13, no. 24: 4974. https://doi.org/10.3390/rs13244974
APA StyleFeng, D., Shen, X., Xie, Y., Liu, Y., & Wang, J. (2021). Efficient Occluded Road Extraction from High-Resolution Remote Sensing Imagery. Remote Sensing, 13(24), 4974. https://doi.org/10.3390/rs13244974