Obtaining Urban Waterlogging Depths from Video Images Using Synthetic Image Data


 , and
, and
Abstract
1. Introduction
- (1)
- To the best of our knowledge, this is the first work to utilize synthetic images of urban flooding as training data for CNN-based reference object detection models that can be used at a city scale.
- (2)
- Images containing reference objects and images about urban flooding are used to generate synthetic image data. Multiple data augmentation techniques are utilized to ensure the diversity and amount of synthetic image data.
- (3)
- The effectiveness of synthetic image data on training the reference object detection model is evaluated.
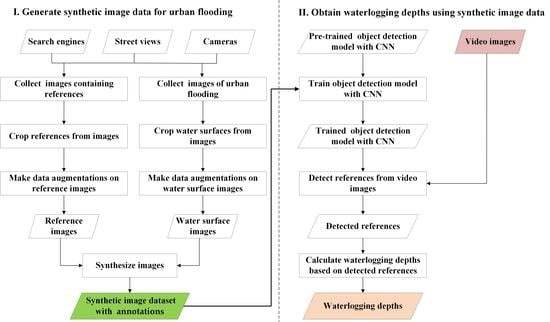
2. Method and Its Further Application
2.1. Method of Generating Synthetic Image Dataset
2.1.1. Collection of Original Images, Cropping References, and Water Surfaces
2.1.2. Data Augmentations on Images of Reference Objects and Water Surfaces
2.1.3. Generating Synthetic Image Dataset with Annotations
2.2. Further Application of the Method: Using the Synthetic Image Dataset to Obtain Waterlogging Depths
2.2.1. Training an Object Detection Model
2.2.2. Detection of Reference Objects from Video Images
2.2.3. Calculation of Waterlogging Depths
3. Materials
3.1. Video Image Dataset
3.2. Computing Environment and SSD Model
4. Results
4.1. Synthetic Image Dataset
4.2. Accuracy and Efficiency
4.2.1. Accuracy of Heights of Detected Reference Objects
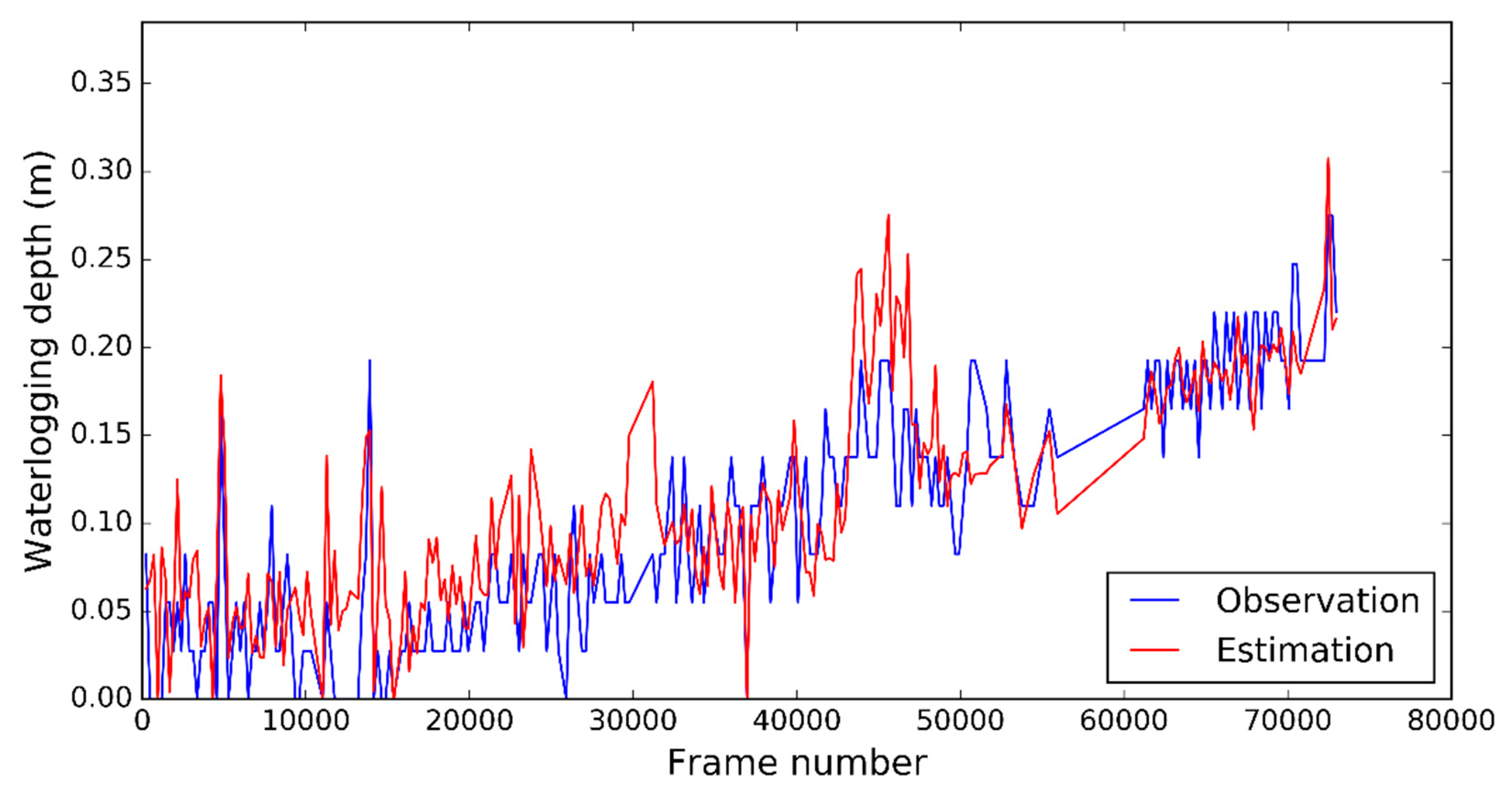
4.2.2. Accuracy of Waterlogging Depths
4.2.3. Efficiency of Labelling Reference Objects
5. Discussion
5.1. Comparison with the Sensitivity Analysis Based on an Edge Detection Method
5.2. Evaluation on an Artificial Image Dataset
5.3. Comparison Between the Synthetic Image Dataset and the Training Dataset of the Real Video Images
5.4. Effects of Data Augmentation Methods on the Effectiveness of Synthetic Datasets
5.5. Comparison with Other Related Research
5.6. Some Potential Issues
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mousa, M.; Zhang, X.; Claudel, C. Flash flood detection in urban cities using ultrasonic and infrared sensors. IEEE Sens. J. 2016, 16, 7204–7216. [Google Scholar] [CrossRef]
- Byun, Y.; Han, Y.; Chae, T. Image fusion-based change detection for flood extent extraction using bi-temporal very high-resolution satellite images. Remote. Sens. 2015, 7, 10347–10363. [Google Scholar] [CrossRef]
- Li, L.; Xu, T.; Chen, Y. Improved urban flooding mapping from remote sensing images using generalized regression neural network-based super-resolution algorithm. Remote. Sens. 2016, 8, 625. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, A.S.; Fu, G.; Djordjević, S.; Zhang, C.; Savić, D.A. An integrated framework for high-resolution urban flood modelling considering multiple information sources and urban features. Environ. Model. Softw. 2018, 107, 85–95. [Google Scholar] [CrossRef]
- Wang, R.Q.; Mao, H.; Wang, Y.; Rae, C.; Shaw, W. Hyper-resolution monitoring of urban flooding with social media and crowdsourcing data. Comput. Geosci. 2018, 111, 139–147. [Google Scholar] [CrossRef]
- Le Coz, J.; Patalano, A.; Collins, D.; Guillén, N.F.; García, C.M.; Smart, G.M.; Bind, J.; Chiaverini, A.; Le Boursicaud, R.; Dramais, G.; et al. Crowdsourced data for flood hydrology: Feedback from recent citizen science projects in Argentina, France and New Zealand. J. Hydrol. 2016, 541, 766–777. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, J.; Qin, C.Z.; Wang, D. Extraction of urban waterlogging depth from video images using transfer learning. Water 2018, 10, 1485. [Google Scholar] [CrossRef]
- Bhola, P.K.; Nair, B.B.; Leandro, J.; Rao, S.N.; Disse, M. Flood inundation forecasts using validation data generated with the assistance of computer vision. J. Hydroinform. 2019, 21, 240–256. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, J.; Cheng, C.; Huang, J.; Xue, A. Automatic Estimation of Urban Waterlogging Depths from Video Images Based on Ubiquitous Reference Objects. Remote Sens. 2019, 11, 587. [Google Scholar] [CrossRef]
- De Vitry, M.M.; Kramer, S.; Wegner, J.D.; Leitão, J.P. Scalable flood level trend monitoring with surveillance cameras using a deep convolutional neural network. Hydrol. Earth Syst. Sci. 2019, 23, 4621–4634. [Google Scholar] [CrossRef]
- Diakakis, M.; Deligiannakis, G.; Pallikarakis, A.; Skordoulis, M. Identifying elements that affect the probability of buildings to suffer flooding in urban areas using Google Street View. A case study from Athens metropolitan area in Greece. Int. J. Disaster Risk Reduct. 2017, 22, 1–9. [Google Scholar] [CrossRef]
- Schnebele, E.; Cervone, G.; Waters, N. Road assessment after flood events using non-authoritative data. Nat. Hazards Earth Syst. Sci. 2014, 14, 1007–1015. [Google Scholar] [CrossRef]
- Fohringer, J.; Dransch, D.; Kreibich, H.; Schröter, K. Social media as an information source for rapid flood inundation mapping. Nat. Hazards Earth Syst. Sci. 2015, 15, 2725–2738. [Google Scholar] [CrossRef]
- Liu, L.; Liu, Y.; Wang, X.; Yu, D.; Liu, K.; Huang, H.; Hu, G. Developing an effective 2-d urban flood inundation model for city emergency management based on cellular automata. Nat. Hazards Earth Syst. Sci. 2015, 15, 381–391. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Gilmore, T.E.; Birgand, F.; Chapman, K.W. Source and magnitude of error in an inexpensive image-based water level measurement system. J. Hydrol. 2013, 496, 178–186. [Google Scholar] [CrossRef]
- Nguyen, L.S.; Schaeli, B.; Sage, D.; Kayal, S.; Rossi, L. Vision-based system for the control and measurement of wastewater flow rate in sewer systems. Water Sci. Technol. 2009, 60, 2281–2289. [Google Scholar] [CrossRef]
- Peng, X.; Sun, B.; Ali, K.; Saenko, K. Learning deep object detectors from 3d models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1278–1286. [Google Scholar]
- Wang, K.; Gou, C.; Zheng, N.; Rehg, J.M.; Wang, F.Y. Parallel vision for perception and understanding of complex scenes: Methods, framework, and perspectives. Artif. Intell. Rev. 2017, 48, 299–329. [Google Scholar] [CrossRef]
- Zhan, F.; Lu, S.; Xue, C. Verisimilar image synthesis for accurate detection and recognition of texts in scenes. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 257–273. [Google Scholar]
- Alhaija, H.A.; Mustikovela, S.K.; Mescheder, L.; Geiger, A.; Rother, C. Augmented reality meets computer vision: Efficient data generation for urban driving scenes. Int. J. Comput. Vis. 2018, 126, 961–972. [Google Scholar] [CrossRef]
- Gaidon, A.; Lopez, A.; Perronnin, F. The reasonable effectiveness of synthetic visual data. Int. J. Comput. Vis. 2018, 126, 899–901. [Google Scholar] [CrossRef]
- Pepik, B.; Benenson, R.; Ritschel, T.; Schiele, B. What is holding back convnets for detection? In Proceedings of the German Conference on Pattern Recognition, Aachen, Germany, 7–10 October 2015; pp. 517–528. [Google Scholar]
- Mayer, N.; Ilg, E.; Fischer, P.; Hazirbas, C.; Cremers, D.; Dosovitskiy, A.; Brox, T. What makes good synthetic training data for learning disparity and optical flow estimation? Int. J. Comput. Vis. 2018, 126, 942–960. [Google Scholar] [CrossRef]
- Chen, W.; Wang, H.; Li, Y.; Su, H.; Wang, Z.; Tu, C.; Lischinski, D.; Cohen-Or, D.; Chen, B. Synthesizing training images for boosting human 3D pose estimation. In Proceedings of the International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 479–488. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 102–118. [Google Scholar]
- Rahmani, H.; Mian, A. Learning a non-linear knowledge transfer model for cross-view action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2458–2466. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Synthetic Datasets | Size (Pixels) | Truncation Range (Pixels) | Ways of Pasting | RMSE (Pixels) |
|---|---|---|---|---|
| S1 | 26 × 40 | 0 | Direct Pasting | 12.223 |
| S2 | 26 × 40 | 0 | Blending | 9.847 |
| S3 | 26 × 40 | 0~19 | Direct Pasting | 6.403 |
| S4 | 26 × 40 | 0~19 | Blending | 4.427 |
| S5 | 19 × 30 | 0 | Direct Pasting | 6.694 |
| S6 | 19 × 30 | 0 | Blending | 5.849 |
| S7 | 19 × 30 | 0~14 | Direct Pasting | 6.078 |
| S8 | 19 × 30 | 0~14 | Blending | 3.441 |
| S9 | 13 × 20 | 0 | Direct Pasting | 4.319 |
| S10 | 13 × 20 | 0 | Blending | 1.733 |
| S11 | 13 × 20 | 0~9 | Direct Pasting | 3.806 |
| S12 | 13 × 20 | 0~9 | Blending | 2.794 |
| S13 | 10 × 15 | 0 | Direct Pasting | 4.622 |
| S14 | 10 × 15 | 0 | Blending | 2.286 |
| S15 | 10 × 15 | 0~4 | Direct Pasting | 4.043 |
| S16 | 10 × 15 | 0~4 | Blending | 2.775 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Qin, C.-Z.; Yu, J.; Cheng, C.; Liu, J.; Huang, J. Obtaining Urban Waterlogging Depths from Video Images Using Synthetic Image Data. Remote Sens. 2020, 12, 1014. https://doi.org/10.3390/rs12061014
Jiang J, Qin C-Z, Yu J, Cheng C, Liu J, Huang J. Obtaining Urban Waterlogging Depths from Video Images Using Synthetic Image Data. Remote Sensing. 2020; 12(6):1014. https://doi.org/10.3390/rs12061014
Chicago/Turabian StyleJiang, Jingchao, Cheng-Zhi Qin, Juan Yu, Changxiu Cheng, Junzhi Liu, and Jingzhou Huang. 2020. "Obtaining Urban Waterlogging Depths from Video Images Using Synthetic Image Data" Remote Sensing 12, no. 6: 1014. https://doi.org/10.3390/rs12061014
APA StyleJiang, J., Qin, C.-Z., Yu, J., Cheng, C., Liu, J., & Huang, J. (2020). Obtaining Urban Waterlogging Depths from Video Images Using Synthetic Image Data. Remote Sensing, 12(6), 1014. https://doi.org/10.3390/rs12061014