MRFF-YOLO: A Multi-Receptive Fields Fusion Network for Remote Sensing Target Detection

Abstract
1. Introduction
2. Introduction to YOLO
2.1. The Fundamental of YOLO
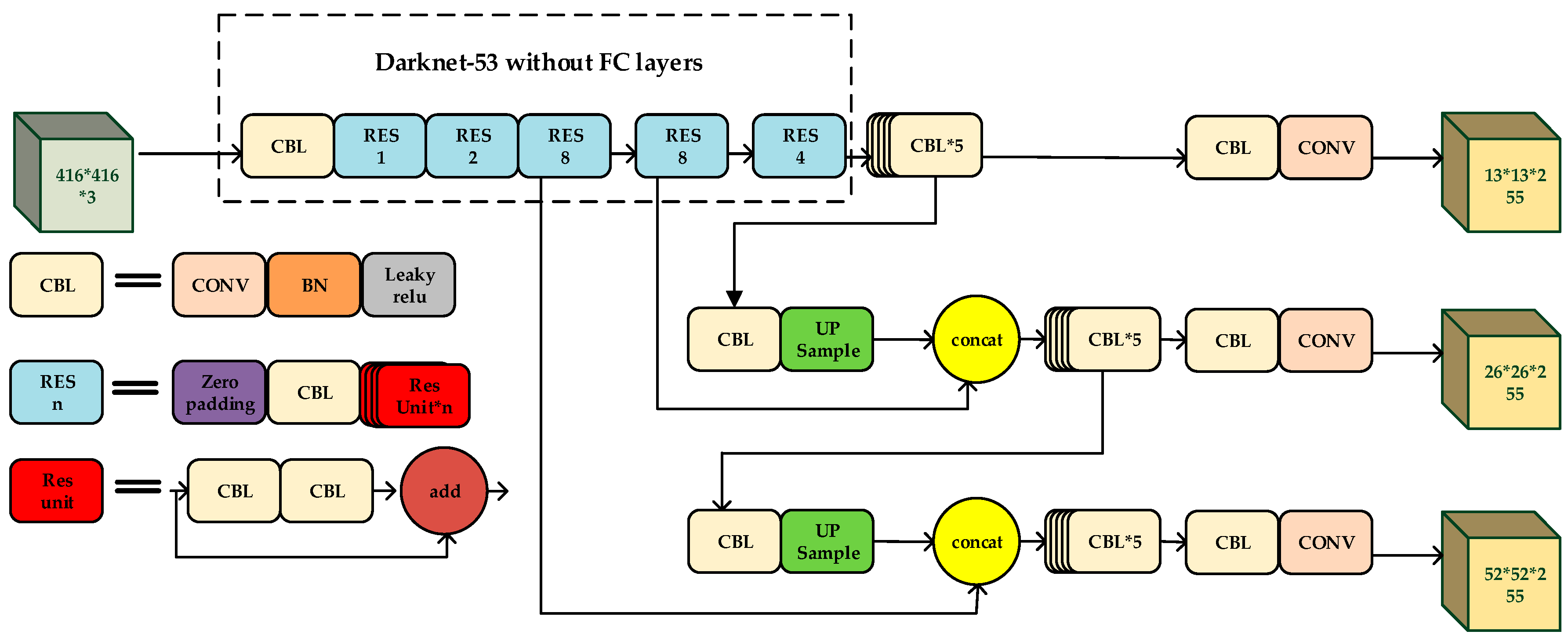
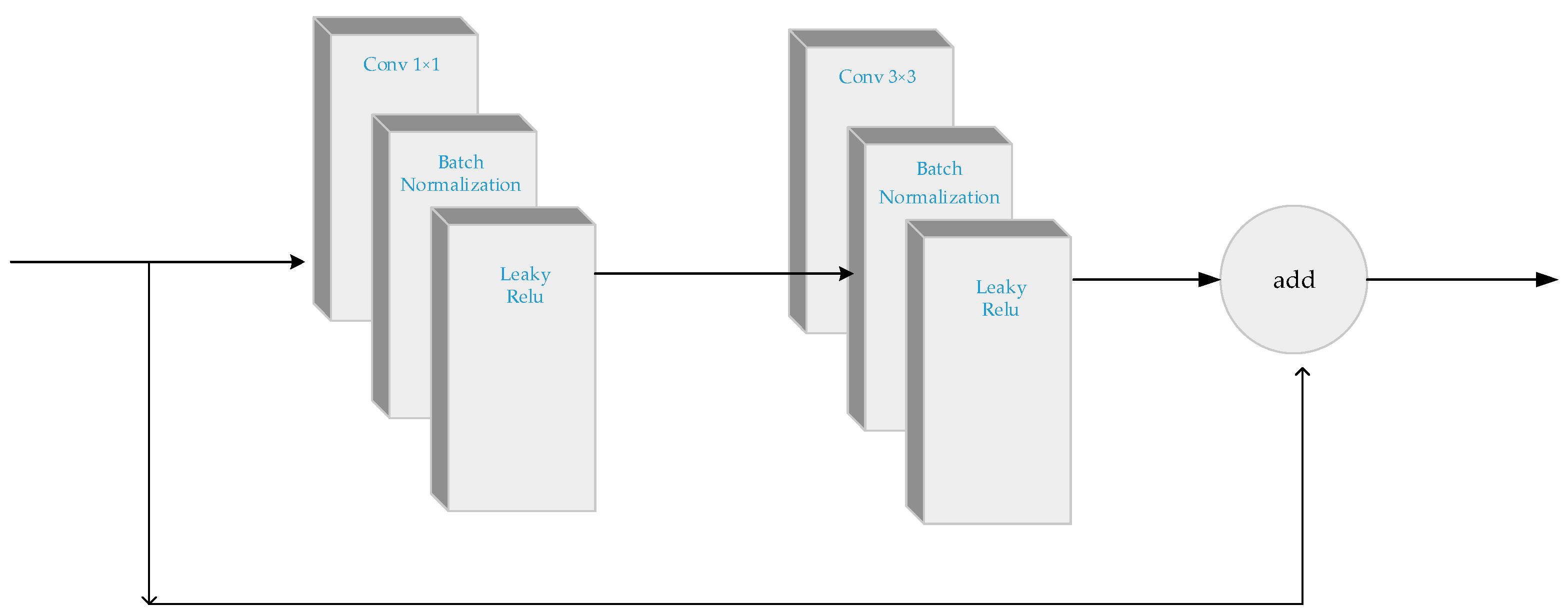
2.2. The Principle of YOLO-V3
3. Methodology
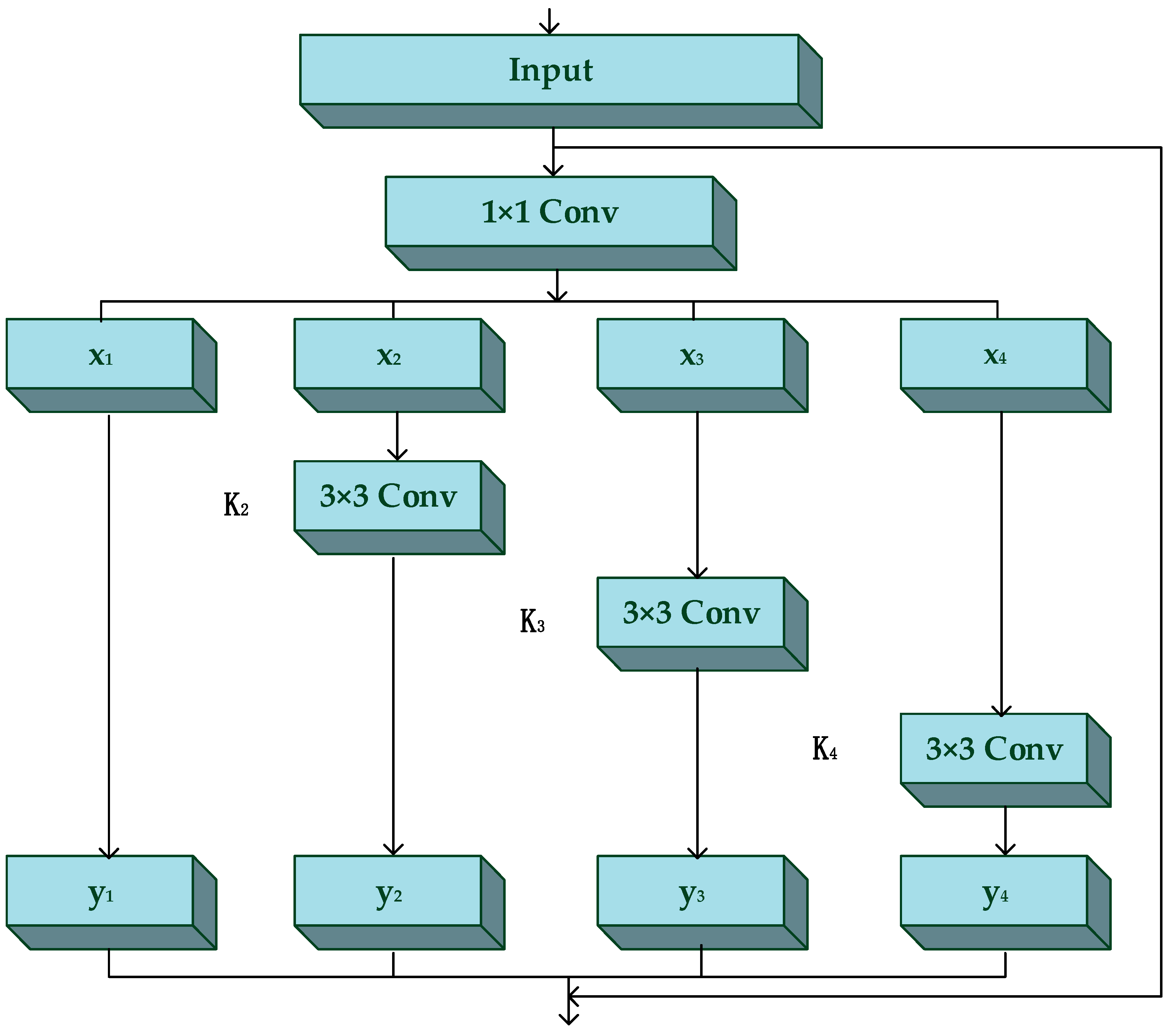
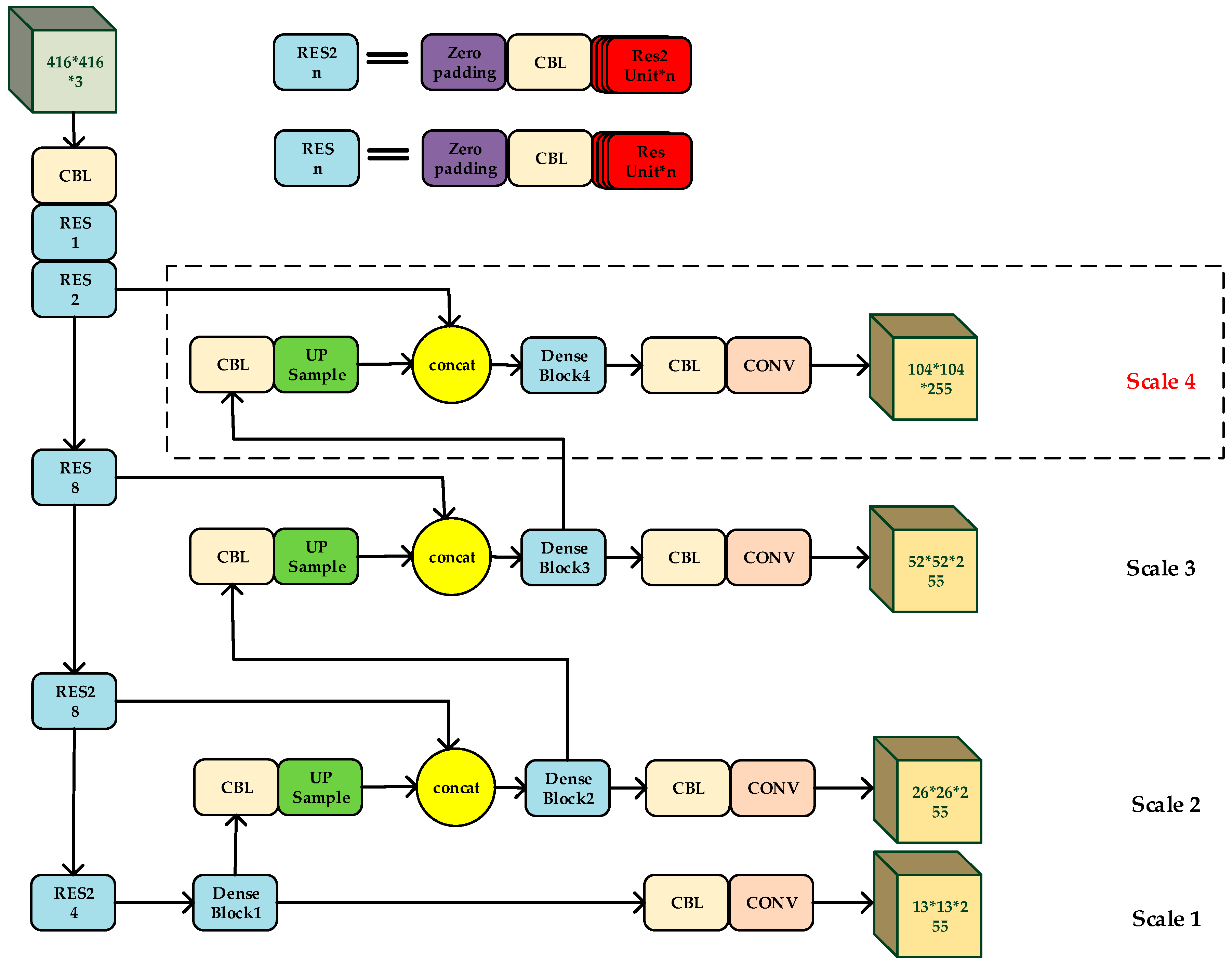
3.1. The Feature Extractor Based on Res2Net
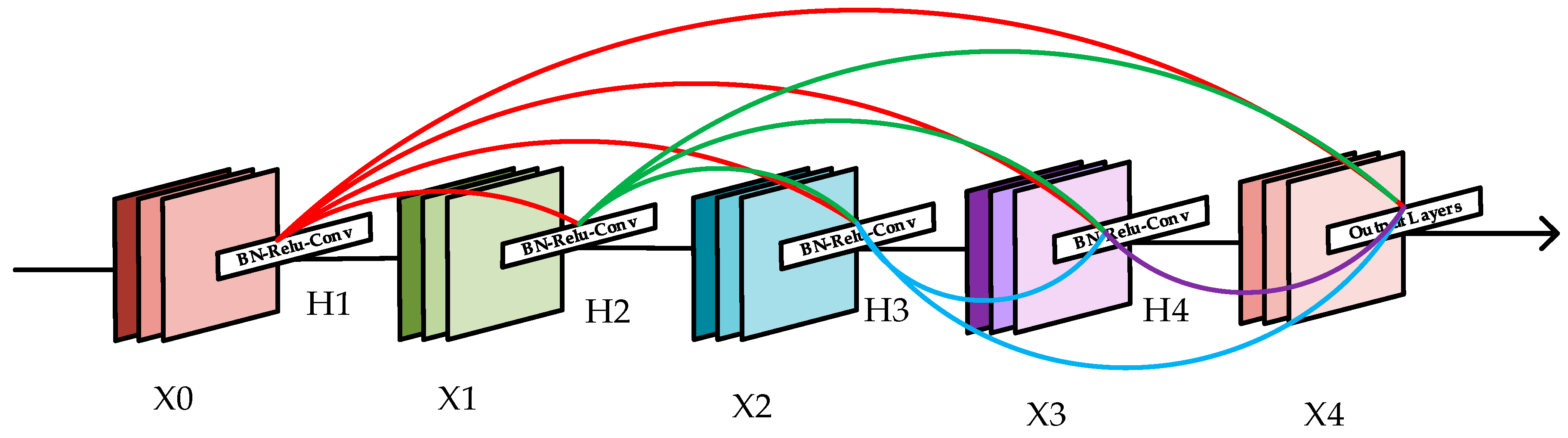
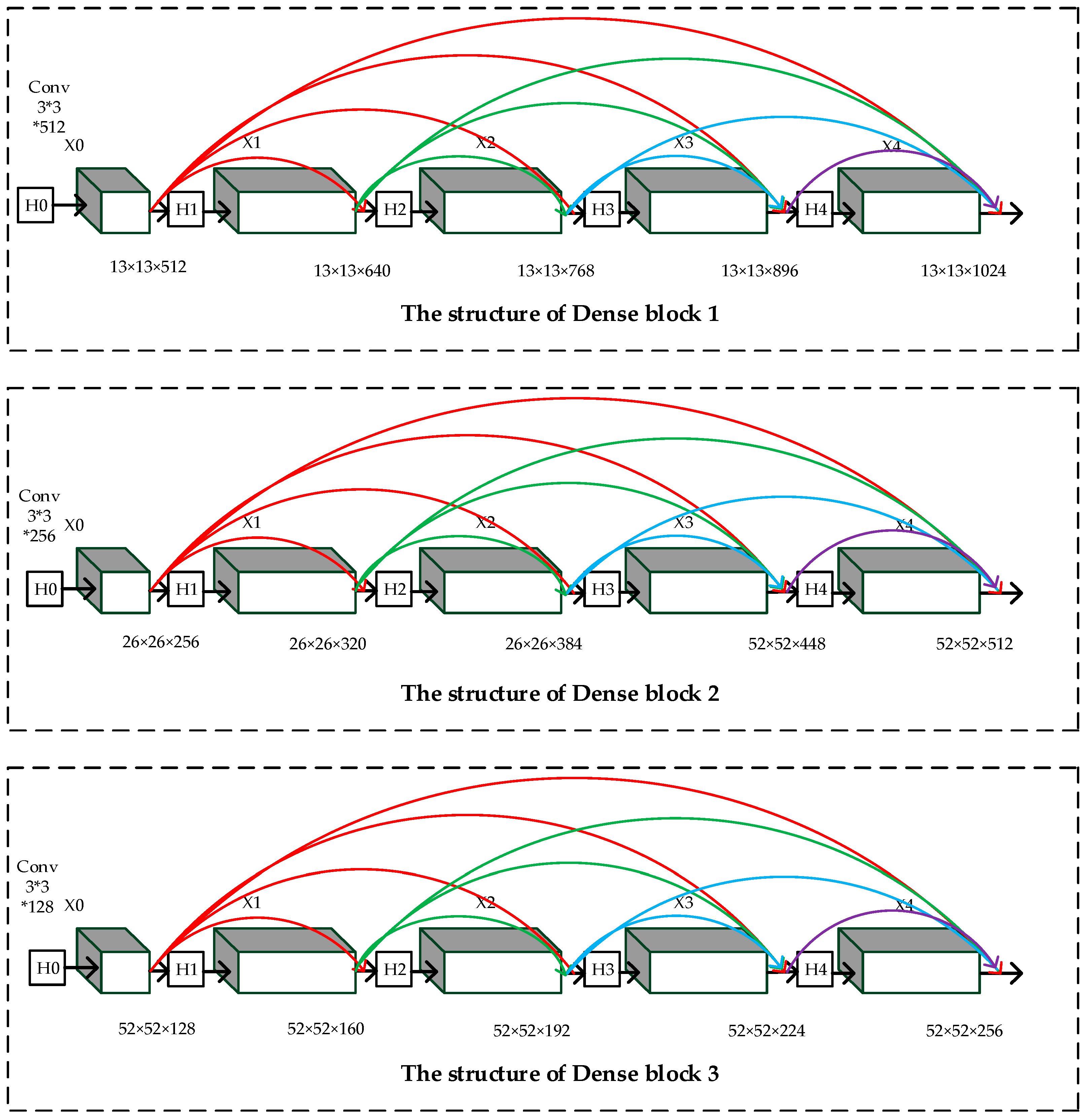
3.2. Densely Connected Network for Detecting Layers
3.3. Multi-Scale Detecting Layers
3.4. Our Model
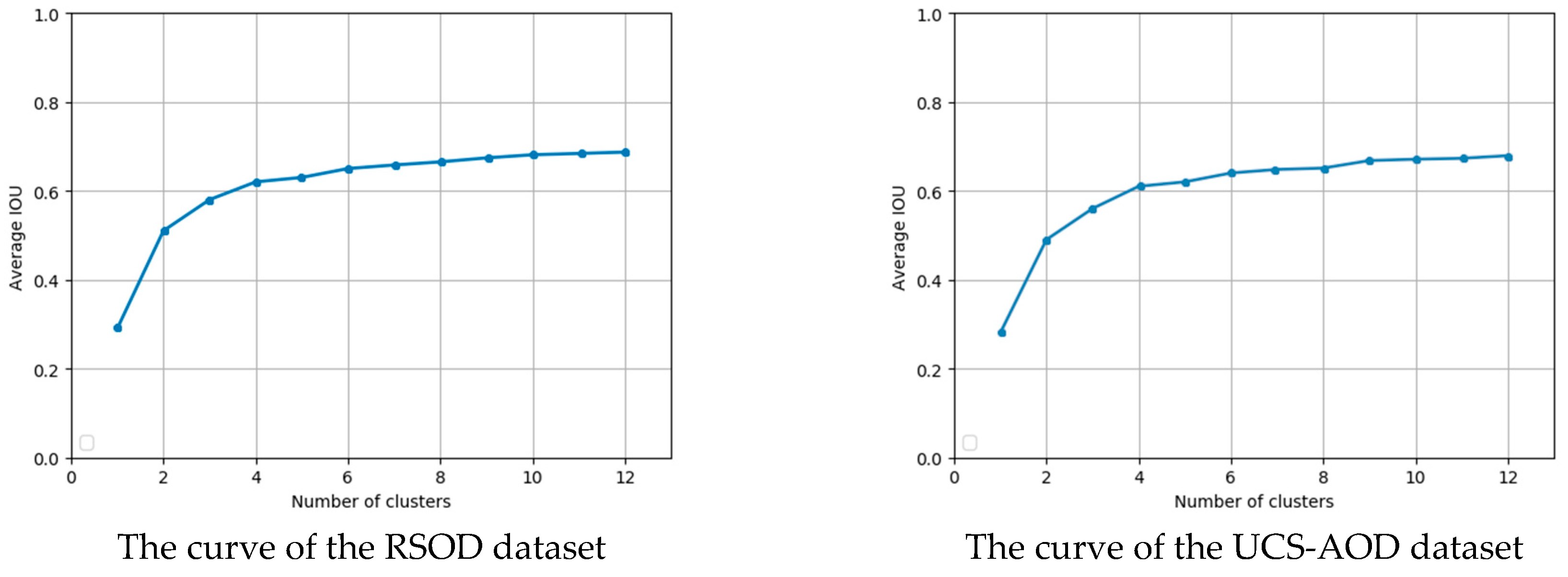
3.5. K-Means for Anchor Boxes
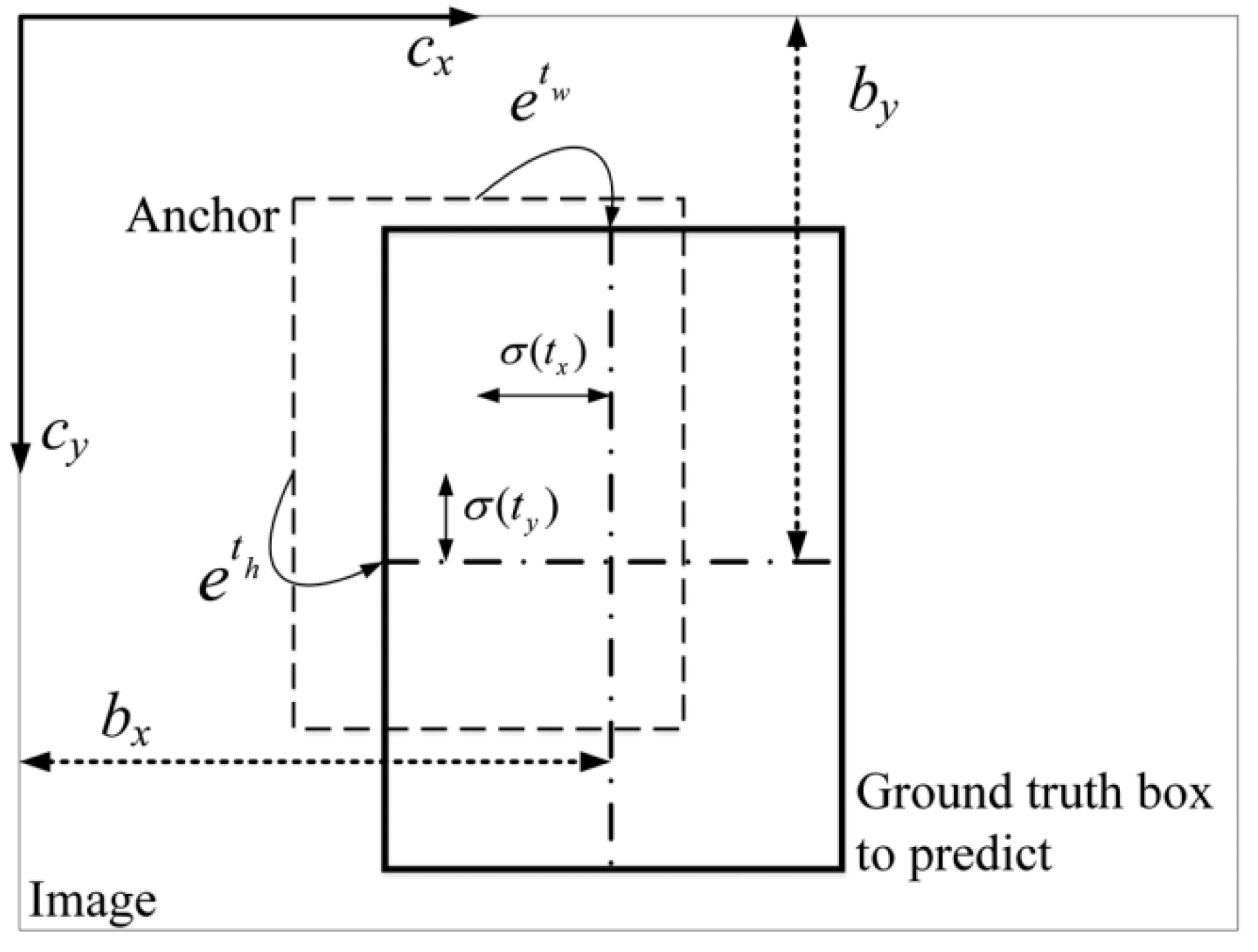
3.6. Decoding Process
3.7. Remove Redundant Bounding Boxes
| Algorithm 1 The pseudocode of NMS |
| Original Bounding Boxes: |
| , , |
| refers to the list of the bounding boxes generated by the network |
| refers to the list of the confidences corresponding to the bounding boxes in |
| Detection result: |
| refers to the list of the final bounding boxes |
| 1: |
| 2: while do: |
| 3: |
| 4: ; ; |
| 5: for do: |
| 6: if |
| 7: ; |
| 8: end |
| 9: end |
| 10: end |
4. Results
4.1. Anchor Boxes of Our Model
4.2. The Evaluation Indicators
4.3. Experimental Process and Analysis
4.3.1. Experimental Results and Comparative Analysis
4.3.2. Ablation Experiments
4.3.3. Comparison of Detection Effect
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| MRFF | Multi-Receptive Fields Fusion |
| CV | Computer Version |
| IOU | Intersection-Over-Union |
| FC | Full Connected Layer |
| FCN | Full Convolutional Network |
| CNN | Convolutional Neural Network |
| GT | Ground Truth |
| RPN | Region Proposal Network |
| FPN | Feature Pyramid Network |
| ResNet | Residual Network |
| DenseNet | Densely Connected Network |
| UAV | Unmanned Aerial Vehicle |
| SPP | Spatial Pyramid Pooling |
| NMS | Non-Maximum Suppression |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| TN | True Negative |
| AP | Average Precision |
| mAP | Mean Average Precision |
| FPS | Frames Per Second |
References
- Kohlus, J.; Stelzer, K.; Mueller, G.; Smollich, S. Mapping seagrass (Zostera) by remote sensing in the Schleswig-Holstein Wadden Sea. Estuar. Coast. Shelf Sci. 2020, 238. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, J.; Zhao, J. Adaptive conditional random field classification framework based on spatial homogeneity for high-resolution remote sensing imagery. Remote Sens. Lett. 2020, 11, 515–524. [Google Scholar] [CrossRef]
- Xu, G.; Zhu, X.; Tapper, N. Using convolutional neural networks incorporating hierarchical active learning for target-searching in large-scale remote sensing images. Int. J. Remote Sens. 2020, 41, 4057–4079. [Google Scholar] [CrossRef]
- Yang, N.; Li, J.; Mo, W.; Luo, W.; Wu, D.; Gao, W.; Sun, C. Water depth retrieval models of East Dongting Lake, China, using GF-1 multi-spectral remote sensing images. Glob. Ecol. Conserv. 2020, 22. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, G.; Yang, W. Aircraft detection in remote sensing imagery with lightweight feature pyramid network. Proc. SPIE 2020, 11429, 114290W. [Google Scholar] [CrossRef]
- Vivone, G.; Addesso, P.; Ziemann, A. Editorial for Special Issue “Remote Sensing for Target Object Detection and Identification”. Remote Sens. 2020, 12, 196. [Google Scholar] [CrossRef]
- Li, X.; Huang, R.; Niu, S.; Cao, Z.; Zhao, L.; Li, J. Local similarity constraint-based sparse algorithm for hyperspectral target detection. J. Appl. Remote Sens. 2019, 13. [Google Scholar] [CrossRef]
- Larsen, S.O.; Salberg, A.-B. Vehicle Detection and Roadside Tree Shadow Removal in High Resolution Satellite Images. In Geobia 2010: Geographic Object-Based Image Analysis; Addink, E.A., VanCoillie, F.M.B., Eds.; Copernicus Gesellschaft Mbh: Ghent, Belgium, 2010; Volume 38-4-C7. [Google Scholar]
- Yokoya, N.; Iwasaki, A. Object Detection Based on Sparse Representation and Hough Voting for Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2053–2062. [Google Scholar] [CrossRef]
- Buck, H.; Sharghi, E.; Guilas, C.; Stastny, J.; Morgart, W.; Schalcosky, B.; Pifko, K. Enhanced ship detection from overhead imagery. In Optics and Photonics in Global Homeland Security Iv; Halvorson, C.S., Lehrfeld, D., Saito, T.T., Eds.; Spie-Int Soc Optical Engineering: Orlando, FL, USA, 2008; Volume 6945. [Google Scholar]
- Chen, J.-H.; Tseng, Y.J. Different molecular enumeration influences in deep learning: An example using aqueous solubility. Brief. Bioinform. 2020. [Google Scholar] [CrossRef]
- Guenard, G.; Morin, J.; Matte, P.; Secretan, Y.; Valiquette, E.; Mingelbier, M. Deep learning habitat modeling for moving organisms in rapidly changing estuarine environments: A case of two fishes. Estuar. Coast. Shelf Sci. 2020, 238. [Google Scholar] [CrossRef]
- Heinonen, R.A.; Diamond, P.H. Turbulence model reduction by deep learning. Phys. Rev. E 2020, 101. [Google Scholar] [CrossRef]
- Ballester, P.; Araujo, R.M. On the Performance of GoogLeNet and AlexNet Applied to Sketches; Assoc Advancement Artificial Intelligence: Phoenix, AZ, USA, 2016; pp. 1124–1128. [Google Scholar]
- Xiao, L.; Yan, Q.; Deng, S. Scene Classification with Improved AlexNet Model; IEEE: Piscataway, NJ, USA; Nanjing, China, 2017. [Google Scholar]
- Seker, A. Evaluation of Fabric Defect Detection Based on Transfer Learning with Pre-trained AlexNet; IEEE: Piscataway, NJ, USA, 2018; p. 4. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Li, X.; Shang, M.; Qin, H.; Chen, L. Fast Accurate Fish Detection and Recognition of Underwater Images with Fast R-CNN; IEEE: Piscataway, NJ, USA, 2015; pp. 921–925. [Google Scholar]
- Qian, R.; Liu, Q.; Yue, Y.; Coenen, F.; Zhang, B. Road Surface Traffic Sign Detection with Hybrid Region Proposal and Fast R-CNN; IEEE: Piscataway, NJ, USA, 2016; pp. 555–559. [Google Scholar]
- Wang, K.; Dong, Y.; Bai, H.; Zhao, Y.; Hu, K. Use Fast R-CNN and Cascade Structure for Face Detection; IEEE: Piscataway, NJ, USA, 2016; p. 4. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; IEEE: Piscataway, NJ, USA, 2015; Volume 28. [Google Scholar]
- Mhalla, A.; Chateau, T.; Gazzah, S.; Ben Amara, N.E.; Assoc Comp, M. PhD Forum: Scene-Specific Pedestrian Detector Using Monte Carlo Framework and Faster R-CNN Deep Model; IEEE: Piscataway, NJ, USA, 2016; pp. 228–229. [Google Scholar] [CrossRef]
- Zhai, M.; Liu, H.; Sun, F.; Zhang, Y. Ship Detection Based on Faster R-CNN Network in Optical Remote Sensing Images; Springer: Singapore, 2020; pp. 22–31. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Zhao, T.; Yang, Y.; Niu, H.; Wang, D.; Chen, Y. Comparing U-Net Convolutional Network with Mask R-CNN in the Performances of Pomegranate Tree Canopy. In Multispectral, Hyperspectral, and Ultraspectral Remote Sensing Technology, Techniques and Applications Vii; Larar, A.M., Suzuki, M., Wang, J., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10780. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Zhang, X.; Qiu, Z.; Huang, P.; Hu, J.; Luo, J. Application Research of YOLO v2 Combined with Color Identification. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Zhengzhou, China, 18–20 October 2018; pp. 138–141. [Google Scholar] [CrossRef]
- Itakura, K.; Hosoi, F. Automatic Tree Detection from Three-Dimensional Images Reconstructed from 360 degrees Spherical Camera Using YOLO v2. Remote Sens. 2020, 12, 988. [Google Scholar] [CrossRef]
- Bi, F.; Yang, J. Target Detection System Design and FPGA Implementation Based on YOLO v2 Algorithm; IEEE: Singapore, 2019; pp. 10–14. [Google Scholar]
- Huang, R.; Gu, J.; Sun, X.; Hou, Y.; Uddin, S. A Rapid Recognition Method for Electronic Components Based on the Improved YOLO-V3 Network. Electronics 2019, 8, 825. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, W.; Tang, X.; Liu, J. A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3. Sensors 2018, 18, 4308. [Google Scholar] [CrossRef] [PubMed]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition Using One Stage Improved Model; IEEE: Piscataway, NJ, USA, 2020; pp. 687–694. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—Eccv 2016, Pt I; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Wang, S.; Wu, L.; Wu, W.; Li, J.; He, X.; Song, F. Optical Fiber Defect Detection Method Based on DSSD Network; IEEE: Piscataway, NJ, USA, 2019; pp. 422–426. [Google Scholar] [CrossRef]
- Yang, J.; Wang, L. Feature Fusion and Enhancement for Single Shot Multibox Detector; IEEE: Piscataway, NJ, USA, 2019; pp. 2766–2770. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, B.; Cao, Y.; Lu, M. SFSSD: Shallow Feature Fusion Single Shot Multibox Detector; Springer: Singapore, 2020; pp. 2590–2598. [Google Scholar] [CrossRef]
- Tang, Q.; Zhou, J.; Xin, J.; Zhao, S.; Zhou, Y. Autoregressive Model-Based Structural Damage Identification and Localization Using Convolutional Neural Networks. Ksce J. Civ. Eng. 2020, 24, 2173–2185. [Google Scholar] [CrossRef]
- Baker, N.; Lu, H.; Erlikhman, G.; Kellman, P.J. Local features and global shape information in object classification by deep convolutional neural networks. Vis. Res. 2020, 172, 46–61. [Google Scholar] [CrossRef] [PubMed]
- Moon, W.K.; Lee, Y.-W.; Ke, H.-H.; Lee, S.H.; Huang, C.-S.; Chang, R.-F. Computer -aided diagnosis of breast ultrasound images using ensemble learning from convolutional neural networks. Comput. Methods Programs Biomed. 2020, 190. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Mbouembe, P.L.T.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef]
- Li, J.; Gu, J.; Huang, Z.; Wen, J. Application Research of Improved YOLO V3 Algorithm in PCB Electronic Component Detection. Appl. Sci.-Basel 2019, 9, 3750. [Google Scholar] [CrossRef]
- Peng, H.; Zhang, Y.; Yang, S.; Song, B. Battlefield Image Situational Awareness Application Based on Deep Learning. IEEE Intell. Syst. 2020, 35, 36–42. [Google Scholar] [CrossRef]
- Gao, S.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P.H.S. Res2Net: A New Multi-scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Yan, Q.-R.; Wang, Y.-F.; Yang, Y.-B.; Wang, Y.-H. A binary sampling Res2net reconstruction network for single-pixel imaging. Rev. Sci. Instrum. 2020, 91. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Huang, L.; Ren, K.; Fan, C.; Deng, H. A Lite Asymmetric DenseNet for Effective Object Detection Based on Convolutional Neural Networks (CNN). In Optoelectronic Imaging and Multimedia Technology Vi; Dai, Q., Shimura, T., Zheng, Z., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11187. [Google Scholar]
- Tran, T.-H.; Tran, X.-H.; Nguyen, V.-T.; Nguyen-An, K. Building an Automatic Image Tagger with DenseNet and Transfer Learning; IEEE: Piscataway, NJ, USA, 2019; pp. 34–41. [Google Scholar] [CrossRef]
- Yuan, Y.; Qin, W.; Guo, X.; Buyyounouski, M.; Hancock, S.; Han, B.; Xing, L. Prostate Segmentation with Encoder-Decoder Densely Connected Convolutional Network (Ed-Densenet); IEEE: Piscataway, NJ, USA, 2019; pp. 434–437. [Google Scholar] [CrossRef]
- Li, Z.; Wang, W.; Li, T.; Liu, G.; Li, Z.; Tian, Y. Defect diagnosis technology of typical components on transmission line based on Fully Convolutional Network. J. Phys. Conf. Ser. 2020, 1453, 012108. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172. [Google Scholar] [CrossRef]
- Zheng, L.; Fu, C.; Zhao, Y. Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network. In Tenth International Conference on Digital Image Processing; Jiang, X., Hwang, J.N., Eds.; SPIE: Bellingham, WA, USA, 2018; Volume 10806. [Google Scholar]
- Fan, D.; Liu, D.; Chi, W.; Liu, X.; Li, Y. Improved SSD-Based Multi-Scale Pedestrian Detection Algorithm; Springer: Singapore, 2020; pp. 109–118. [Google Scholar] [CrossRef]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-Fused SSD: Fast Detection for Small Objects. In Ninth International Conference on Graphic and Image Processing; Yu, H., Dong, Y., Eds.; SPIE: Bellingham, WA, USA, 2018; Volume 10615. [Google Scholar]
- Huang, Z.; Wang, J. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLO-V3 | ||
|---|---|---|
| Conv(3 × 3/2 × 32)-BN-ReLU | Convolutional | |
| Conv(3 × 3/2 × 64)-BN-ReLU | Convolutional | |
| RES × 1 | Conv(1 × 1 × 32)-BN-ReLU-Conv(3 × 3 × 64)-BN-ReLU | Residual |
| Conv(3 × 3/2 × 128)-BN-ReLU | Convolutional | |
| RES × 2 | Conv(1 × 1 × 64)-BN-ReLU-Conv(3 × 3 × 128)-BN- ReLU | Residual |
| Conv(3 × 3/2 × 256)-BN-ReLU | Convolutional | |
| RES × 8 | Conv(1 × 1 × 128)-BN-ReLU-Conv(3 × 3 × 256)-BN-ReLU | Residual |
| Conv(3 × 3/2 × 512)-BN- ReLU | Convolutional | |
| RES × 8 | Conv(1 × 1 × 256)-BN-ReLU-Conv(3 × 3/ × 512)-BN-ReLU | Residual |
| Conv(3 × 3/2 × 1024)-BN-ReLU | Convolutional | |
| RES × 4 | Conv(1 × 1 × 512)-BN-ReLU-Conv(3 × 3 × 1024)-BN-ReLU | Residual |
| MRFF-YOLO | ||
|---|---|---|
| Conv(3 × 3/2 × 32)-BN-ReLU | Convolutional | |
| Conv(3 × 3/2 × 64)-BN-ReLU | Convolutional | |
| RES × 1 | Conv(1 × 1 × 32)-BN-ReLU-Conv(3 × 3 × 64)-BN-ReLU | Residual |
| Conv(3 × 3/2 × 128)-BN-ReLU | Convolutional | |
| RES × 2 | Conv(1 × 1 × 64)-BN-ReLU-Conv(3 × 3 × 128)-BN-ReLU | Residual |
| Conv(3 × 3/2 × 256)-BN-ReLU | Convolutional | |
| RES × 8 | Conv(1 × 1 × 128)-BN-ReLU-Conv(3 × 3 × 256)-BN-ReLU | Residual |
| Conv(3 × 3/2 × 512)-BN-ReLU | Convolutional | |
| RES2 × 8 | Conv(1 × 1 × 256)-BN-ReLU | Residual |
| Concat | ||
| : Conv(3 × 3 × 128)-BN-ReLU | ||
| : Conv(3 × 3 × 128)-BN-ReLU | ||
| : Conv(3 × 3 × 128)-BN-ReLU | ||
| Conv(3 × 3/2 × 1024)-BN-ReLU | Convolutional | |
| RES2 × 4 | Conv(1 × 1 × 512)-BN-ReLU | Residual |
| Concat | ||
| : Conv(3 × 3 × 256)-BN-ReLU | ||
| : Conv(3 × 3 × 256)-BN-ReLU | ||
| s: Conv(3 × 3 × 256)-BN-ReLU | ||
| The K-Means Clustering for Anchor Boxes |
| 1: Set random cluster center points: . represent the width and height of each anchor box. |
| 2: Then, we calculated the distance between each ground truth and each cluster center: . Since the position of the anchor box is not fixed, the center point of each ground truth is coincident with the clustering center. |
| 3: Recalculate the cluster center for each cluster: . |
| 4: Repeat step 2 and step 3 until the clusters converge. |
| Input Size | Batch Size | Momentum | Learning Rate | Training Step |
|---|---|---|---|---|
| 416 × 416 | 8 | 0.9 | 0.001–0.00001 | 50,000 |
| Dataset | RSOD | UCS-AOD | |
|---|---|---|---|
| Anchors | Scale 1 | (232, 214), (241, 203), (259, 271) | (225, 201), (231, 212), (268, 279) |
| Scale 2 | (109, 114), (121, 153), (169, 173) | (101, 124), (118, 147), (152, 167) | |
| Scale 3 | (51, 54), (61, 88), (82, 91) | (49, 52), (63, 86), (80, 92) | |
| Scale 4 | (21, 24), (25, 31), (33, 41) | (19, 22), (23, 29), (31, 38) | |
| Actual | Predicted | Confusion Matrix |
|---|---|---|
| Positive | Positive | TP |
| Negative | Positive | FP |
| Positive | Negative | FN |
| Negative | Negative | TN |
| Dataset | Class | Image | Instances | Target Amount | ||
|---|---|---|---|---|---|---|
| Small | Medium | Large | ||||
| Training set | Aircraft | 446 | 4993 | 3714 | 833 | 446 |
| Oil tank | 165 | 1586 | 724 | 713 | 149 | |
| Overpass | 176 | 180 | 0 | 0 | 180 | |
| Playground | 189 | 191 | 0 | 12 | 179 | |
| Test set | Aircraft | 176 | 1257 | 741 | 359 | 157 |
| Oil tank | 63 | 567 | 257 | 213 | 97 | |
| Overpass | 36 | 41 | 0 | 0 | 41 | |
| Playground | 49 | 52 | 0 | 0 | 52 | |
| Dataset | Class | Image | Instances |
|---|---|---|---|
| Training set | Aircraft | 600 | 3591 |
| Car | 310 | 4475 | |
| Test set | Aircraft | 400 | 3891 |
| Car | 200 | 2639 |
| Method | Backbone | AP (%) | FPS | ||||
|---|---|---|---|---|---|---|---|
| Aircraft | Oil Tank | Overpass | Playground | mAP (IOU = 0.5) | |||
| Faster RCNN | VGG-16 | 85.85 | 86.67 | 88.15 | 90.35 | 87.76 | 6.7 |
| SSD | VGG-16 | 69.17 | 71.20 | 70.23 | 81.26 | 72.97 | 62.2 |
| DSSD [52] | ResNet-101 | 72.12 | 72.49 | 72.10 | 83.56 | 75.07 | 6.1 |
| ESSD [53] | VGG-16 | 73.08 | 72.94 | 73.61 | 84.27 | 75.98 | 37.3 |
| FFSSD [54] | VGG-16 | 72.95 | 73.24 | 73.17 | 84.08 | 75.86 | 38.2 |
| YOLO | GoogleNet | 52.71 | 49.58 | 51.06 | 62.17 | 53.88 | 61.4 |
| YOLO-V2 | DarkNet19 | 62.35 | 67.74 | 68.38 | 78.51 | 69.25 | 35.6 |
| YOLO-V3 | DarkNet53 | 74.30 | 73.85 | 75.08 | 85.16 | 77.10 | 29.7 |
| YOLO-V3 tiny | DarkNet19 | 54.14 | 56.21 | 59.28 | 64.20 | 58.46 | 69.8 |
| UAV-YOLO [41] | Figure 1 in [41] | 74.68 | 74.20 | 76.32 | 85.96 | 77.79 | 30.12 |
| DC-SPP-YOLO [55] | Figure 5 in [55] | 73.16 | 73.52 | 74.82 | 84.82 | 76.58 | 33.5 |
| MRFF-YOLO | (Table 2) | 87.16 | 86.56 | 87.56 | 92.05 | 88.33 | 25.1 |
| Method | Backbone | AP (%) | Leak Detection Rate (%) | ||
|---|---|---|---|---|---|
| Small | Medium | Large | |||
| Faster RCNN | VGG-16 | 84.73 | 87.87 | 89.18 | 11.8 |
| SSD | VGG-16 | 70.38 | 73.41 | 77.51 | 21.1 |
| DSSD [52] | ResNet-101 | 74.42 | 75.18 | 77.70 | 15.2 |
| ESSD [53] | VGG-16 | 75.12 | 75.84 | 78.12 | 16.5 |
| FFSSD [54] | VGG-16 | 72.62 | 74.78 | 82.56 | 18.2 |
| YOLO | GoogleNet | 52.25 | 51.68 | 60.35 | 33.6 |
| YOLO-V2 | DarkNet19 | 63.20 | 68.53 | 69.28 | 24.3 |
| YOLO-V3 | DarkNet53 | 74.52 | 75.63 | 76.14 | 19.5 |
| YOLO-V3 tiny | DarkNet19 | 55.26 | 56.47 | 60.17 | 31.4 |
| UAV-YOLO [41] | Figure 1 in [41] | 75.45 | 75.15 | 76.85 | 17.1 |
| DC-SPP-YOLO [55] | Figure 5 in [55] | 75.41 | 74.67 | 76.41 | 15.9 |
| MRFF-YOLO | (Table 2) | 87.76 | 88.42 | 91.85 | 8.5 |
| Method | Backbone | AP (%) | FPS | |||
|---|---|---|---|---|---|---|
| Aircraft | Car | Leak Detection Rate (%) | mAP (IOU = 0.5) | |||
| Faster RCNN | VGG-16 | 87.31 | 86.48 | 13.8 | 86.90 | 6.1 |
| SSD | VGG-16 | 70.24 | 72.61 | 23.7 | 71.43 | 61.5 |
| DSSD [52] | ResNet-101 | 73.17 | 74.19 | 16.1 | 73.68 | 5.2 |
| ESSD [53] | VGG-16 | 73.62 | 75.06 | 15.9 | 74.34 | 33.2 |
| FFSSD [54] | VGG-16 | 71.15 | 74.63 | 17.6 | 72.89 | 34.6 |
| YOLO | GoogleNet | 54.57 | 57.70 | 47.6 | 56.14 | 64.2 |
| YOLO-V2 | DarkNet19 | 63.17 | 68.42 | 23.0 | 65.80 | 34.3 |
| YOLO-V3 | DarkNet53 | 75.71 | 75.62 | 18.5 | 75.67 | 27.6 |
| YOLO-V3 tiny | DarkNet19 | 57.58 | 56.35 | 35.2 | 56.97 | 65.3 |
| UAV-YOLO [41] | Figure 1 in [41] | 75.12 | 75.60 | 16.5 | 75.36 | 28.4 |
| DC-SPP-YOLO [55] | Figure 5 in [55] | 76.52 | 74.61 | 17.4 | 75.57 | 30.4 |
| MRFF-YOLO | (Table 2) | 91.23 | 90.28 | 9.1 | 90.76 | 24.3 |
| RES2 8 | RES2 4 | AP (%) | FPS | |||||
|---|---|---|---|---|---|---|---|---|
| Aircraft | Oil tank | Overpass | Playground | mAP (IOU = 0.5) | ||||
| 1 | 74.30 | 73.85 | 75.08 | 85.16 | 77.10 | 29.7 | ||
| 2 | √ | 75.05 | 74.37 | 75.61 | 85.82 | 77.71 | 30.2 | |
| 3 | √ | 74.86 | 74.12 | 75.85 | 85.73 | 77.64 | 30.1 | |
| 4 | √ | √ | 75.21 | 74.86 | 76.27 | 86.12 | 78.12 | 31.5 |
| RES2 8 | RES2 4 | AP (%) | FPS | |||||
|---|---|---|---|---|---|---|---|---|
| Aircraft | Oil Tank | Overpass | Playground | mAP (IOU = 0.5) | ||||
| 1 | 84.72 | 84.81 | 85.07 | 90.41 | 86.25 | 22.8 | ||
| 2 | √ | 85.31 | 85.26 | 85.27 | 90.81 | 86.66 | 23.3 | |
| 3 | √ | 85.58 | 85.39 | 85.12 | 90.52 | 86.65 | 23.3 | |
| 4 | √ | √ | 86.51 | 85.71 | 86.16 | 91.57 | 87.49 | 23.5 |
| mAP | FPS | Dense Block 1 | Dense Block 2 | Dense Block 3 | Dense Block 4 |
|---|---|---|---|---|---|
| 87.49 | 23.5 | ||||
| 87.54 | 23.8 | √ | |||
| 87.69 | 24.3 | √ | √ | ||
| 88.13 | 24.8 | √ | √ | √ | |
| 88.33 | 25.1 | √ | √ | √ | √ |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, D.; Wu, Y. MRFF-YOLO: A Multi-Receptive Fields Fusion Network for Remote Sensing Target Detection. Remote Sens. 2020, 12, 3118. https://doi.org/10.3390/rs12193118
Xu D, Wu Y. MRFF-YOLO: A Multi-Receptive Fields Fusion Network for Remote Sensing Target Detection. Remote Sensing. 2020; 12(19):3118. https://doi.org/10.3390/rs12193118
Chicago/Turabian StyleXu, Danqing, and Yiquan Wu. 2020. "MRFF-YOLO: A Multi-Receptive Fields Fusion Network for Remote Sensing Target Detection" Remote Sensing 12, no. 19: 3118. https://doi.org/10.3390/rs12193118
APA StyleXu, D., & Wu, Y. (2020). MRFF-YOLO: A Multi-Receptive Fields Fusion Network for Remote Sensing Target Detection. Remote Sensing, 12(19), 3118. https://doi.org/10.3390/rs12193118