Abstract
Filter banks transferred from a pre-trained deep convolutional network exhibit significant performance in heightening the inter-class separability for hyperspectral image feature extraction, but weakening the intra-class consistency simultaneously. In this paper, we propose a new superpixel-based relational auto-encoder for cohesive spectral–spatial feature learning. Firstly, multiscale local spatial information and global semantic features of hyperspectral images are extracted by filter banks transferred from the pre-trained VGG-16. Meanwhile, we utilize superpixel segmentation to construct the low-dimensional manifold embedded in the spectral domain. Then, representational consistency constraint among each superpixel is added in the objective function of sparse auto-encoder, which iteratively assist and supervisedly learn hidden representation of deep spatial feature with greater cohesiveness. Superpixel-based local consistency constraint in this work not only reduces the computational complexity, but builds the neighborhood relationships adaptively. The final feature extraction is accomplished by collaborative encoder of spectral–spatial feature and weighting fusion of multiscale features. A large number of experimental results demonstrate that our proposed method achieves expected results in discriminant feature extraction and has certain advantages over some existing methods, especially on extremely limited sample conditions.
1. Introduction
Hyperspectral imagery (HSI) contains abundant spectral and spatial features, and records pixel, structure, object and other multiscale information about the target domain, which provides a lot of bases for object detection and recognition. However, in the face of high-dimensional nonlinearity in hyperspectral data, shallow structural model of traditional methods have some limitations in the representation of high-order nonlinear functions and the generalization ability of complex classification problems. In other words, it is sometimes difficult to achieve the optimal balance between discriminability and robustness in these priori knowledge-driven or hand-designed low-level feature extraction methods.
A deep network, which is different from traditional machine learning methods, has comparative advantage of hierarchical features learning ability [1,2]. It is a powerful data representation tool to layer-wise learn higher-level semantic features from shallow ones, which means learning distributed feature representation of data from diverse perspectives. With this pattern, a deep model can build a nonlinear network structure and realize approximation of complex functions, so as to improve its generalization capacity and deal with complex classification tasks. Therefore, lots of deep learning-based methods have emerged in the field of HSIC.
Deep learning-based pixel-level HSIC is mainly comprised of three parts: data input, model training, and classification. Among them, the input data can be spectral, spatial or both, while the spatial feature usually gets from the object-centered neighboring patches; the deep network structure includes supervised model (such as CNN [3,4]), unsupervised model (such as stacked auto-encoder [5,6,7,8,9,10], deep belief network [11,12,13,14]), and other self-defined structures [15,16,17,18,19]; the classification step utilizes features learned from the deep model to complete the pixel-level classification, where generally contains two classifiers, one is the hard classification [20,21,22,23] that directly takes learned features as input of one classifier to get class prediction, the other is soft classification [5,11,24,25] that uses the label information to carry out the supervision and fine-tuning of the pre-trained network while predicting the label by a probability classification model. However, existing deep learning-based methods for HSIC usually remain following drawbacks to be solved:
(1) Deep networks usually need a great number of training samples to optimize the model parameters [26]. However, HSI labeling often requires lots of manpower and resources. Even though, it is difficult to ensure the accuracy of sample marking, especially for pixel-level segmentation. Thus, many deep learning-based methods choose small network structures or generate fake datas to cope with the small sample problems. Though achieve certain effects, those methods still poor in high dimensional nonlinear problem. Theoretically, although a network with relatively shallow structure but sufficient number of neurons may fully approximate arbitrary multivariate non-linear function, its computing unit will present exponential growth than a network with more one depth layer [27,28]. Therefore, it is difficult to learn ‘compact’ expression by a shallow network in a finite sample condition, so as to lower nonlinear simulation ability and generalization.
(2) CNN is a special multi-layer distributed perception or feedforward neural network model to extract more abstract and deep discriminative semantic features. Such model integrates the idea of ‘receptive field’, in which a large number of neurons are connected locally and shared weights, and respond to overlapping areas of the visual field in a certain organizational form. For pixel-level semantic segmentation of HSI, most of the existing methods take pixel-centered neighboring patches as the network input for feature learning [19,21,29,30,31]. This fixed neighborhood limits the flexibility of global information reasoning, and can not be adaptive to the boundary region. Besides, the data block partition produces a lot of repeated calculations.
(3) CNN, inspired by the mammalian visual system, is a biophysical model designed for two-dimensional spatial information learning. Its operating pattern from shallow to deep follows the inference rules from general to special, where the general features mainly include lines, textures, and shapes, etc, while special information refers to expression of more complex contour and even objects. CNN is of great significance in learning potential geometric features of HSI, but easy to ignore its unique high resolution spectral features.
Deep spatial feature (DSaF), which is extracted by the filter banks transferred from a pre-trained deep CNN, exhibits significant performance for HSIC, while fusing it with the raw spectral feature (SeF) further enhances its discrimination [20,32]. However, from the visualization in Figure 1, SeF shows obvious intra-class manifold but weak inter-class separability, while DSaF does just the reverse. Collaborative auto-encoder (CAE), as did in [32], greatly combines both of their advantages and shows excellent performance. Nevertheless, the excessive intra-class discretization in DSaF caused the fusion processing difficult to preserve the potential manifold in SeF. Such pixel-level unsupervised feature learning will be very sensitive to noises and outliers in the training set, and thus interfere with the classification accuracy, especially with small samples. This phenomenon also illustrates that filter banks pre-trained by large-scale datasets with higher spatial resolution will not be fit for feature learning of geodetic coordinate-based HSIs. So modification of DSaF will promote discriminative feature learning. In this paper, we try to utilize the significant manifold structure in SeF to adaptively enhance the intra-class consistency of DSaF, and further improve the classification performance and finer processing of boundary region.

Figure 1.
Visualization of features before and after collaborative fusion by t-SNE [33]: (a) raw spectral feature (SeF) (b) deep spatial feature (DSaF), and (c) deep spectral–spatial fusion feature (DSF). Take the University of Pavia dataset as example.
Manifold learning aims to keep the local neighborhood information of input space to the hidden space. Liao et al. [34] added graph regularized constraint in the auto-encoder model and proposed graph regularized auto-encoder (GAE) to maintain a certain spatial coherency of learning features. On the basis of GAE, we present a novel superpixel-based relational auto-encoder (S-RAE) for discriminant feature learning. As in the previous analysis, DSaF shows poor aggregation within the same class, but SeF present higher manifold. Therefore, intra-class consistency constraint, which is accomplished by graphical model structured in spectral domain, is added in S-RAE during the auto-encoder process of DSaF in the first layer before spectral–spatial fusion, so as to enhance its intra-class consistency. For the following defects of traditional graphical model: (1) pixel-level graph construction needs large matrix storage (which means the measurement matrix will be 21,025 × 21,025 for an image with size ); (2) sparse matrix that only consider neighborhood similarity is insensitive to boundary region; and (3) optimization of graph regularized constraint suffers high computational complexity. We utilize superpixel segmentation to reconstruct and optimize of graph regular term, which keeps the manifold in spectral domain, reduces the computational complexity, enhances boundary adaptability, and improves classification robustness.
The final feature extraction is completed by a collaborative auto-encoder of spectral and spatial features, and weighting fusion of multiscale features, so as to achieve feature presentation with high intra-class aggregation and inter-class difference. A large number of experimental results shows that S-RAE achieves desired effects in cohesive DSaF learning, meanwhile admirably assists spectral–spatial fusion and mutliscale feature extraction for more precise and finer target recognition.
The remainder of this paper is organized as follows. We introduce graph regular auto-encoder (GAE) in Section 2. Section 3 outlines our proposed S-RAE, containing model establishment and optimization solution. Section 4 introduces spectral–spatial fusion and the final mutliscale feature fusion (MS-RCAE). Section 5 gives experimental design, parameter analysis and method comparison in detail. Conclusion is involved in Section 6.
2. Graph Regularized Auto-Encoder (GAE)
Graph regularized auto-encoder (GAE) [34] assumes that if neighborhood pixels and are close to each other in low-dimensional manifold, their corresponding hidden representation and should also be close too. Thus, GAE adds a local invariant constraint to the cost function of auto-encoder (AE). Let the reconstruction cost of AE be:
where t is the total amount of input samples, , and are all the training parameters in AE. is the weight penalty term and is a balance parameter. The encoder and decoder is presented as
Thus, the cost function of GAE is
where is the weighting coefficient for graph regularization term, records the distance between input variables and . The closer the two variables in the input space, the larger the distance measurement , and thus forcing the greater similarity between and in the hidden representational layer.
Let be a adjacency graph composed of the similarity measurement. Generally, V is constructed as a sparse matrix, which means only few neighbors (according to given scale) are connected in order to reduce storage. Here, the connectivity between samples can be given by kNN-graph or ϵ-graph method, etc., and weight between two connected samples be calculated by binary or heat kernel method, etc. [34].
Finally, the cost function can be expressed in the following matrix form:
where is the trace of a matrix, L is the laplacian matrix, , and are diagonal matrices with diagonal elements and , respectively.
The parameter of can be solved by the stochastic gradient descent based iterative optimization algorithm.
where and correspond to the parameters in encoding and decoding. Details please refer to [34].
3. Superpixel-Based Relational Auto-Encoder
DSaF, extracted by pre-trained filter banks in VGG-16, presents excellent inter-class separability, but also suffer terrible intra-class consistency. This phenomenon can hardly be compensated by the spectral–spatial fusion strategy. Amending DSaF with the manifold in spectral domain could effectively weaken this problem. GAE is a good method in capturing local manifolds, but the graph regular term in GAE contains a graph matrix V, which occupies plenty of storage, and increases the computational complexity in network training, even if batch processing under neighborhood pixels (as proposed in [34]). Additionally, a fixed-size neighborhood of randomly selected samples is prone to error in the boundary region. In order to avoid the calculation of graph matrix and interference of fixed neighborhood in GAE, we propose a superpixel-based relational auto-encoder (S-RAE) network. In this method, we firstly extract DSaFs by the transferred filter banks in VGG-16, and upsample them to have the same spatial dimension. Meanwhile, HSI, after spectral reduction and spatial downsampling, is segmented into superpixels in the spectral domain. We enhance the intra-class consistency of DSaFs by interrelationship constraints in each superpixel, which not only retain manifold well, but also consume little running time. A detailed process of our proposed S-RAE is summarized in Algorithm 1.
| Algorithm 1: S-RAE. |
| Input: HSI data; Hidden size, sparsity , regular parameter , for ; Superpixel clusters number and weight coefficient for ; weighting parameter and for MS-RCAE. |
| 1. The first three principal components from PCA of HSI are reserved as the inputs of VGG16; |
| 2. Extract DSaF from the pre-trained filter banks in VGG16; |
| 3. Upsample feature maps in the last pooling layer with 4 pixels stride by bilinear interpolation operation; |
| 4. Normalize the raw spectral data and downsample with 8 pixels stride by average pooling; |
| 5. Reserve the maximum principal component of the downsampled image after PCA, and do superpixel segmentation; |
| 6. Separate the cross-region superpixels in the segmented image by connected graph method; |
7. Learning cohesive DSaF by S-RAE
|
| 8. Upsample the learned features of hidden layer to have a same scale with the input maps. |
| Output: Feature maps |
3.1. Model Establishment
With the assumption that if two pixels, and , are close in the raw spectral domain, their corresponding lower-dimensional representation of DSaF, and , should present high similarity with great possibility as well. Thus, based on the loss function of sparse auto-encoder (SAE), we add one relational constraint in the hidden layer coding of DSaF to enhance its intra-class consistency, which is expressed as
where Equation (8) is the loss function of SAE. KL (Kullback–Leibler) distance is introduced here for sparsity constraint,
in which is the average activation of all inputs in the j-th neuron. The proposed relational constraint is defined as in Equation (9). To establish neighborhood relationship adaptively, we utilize over-segmented superpixels, and do the relational constraint in each superpixel. In Equation (9), is a set of pixels in the k-th superpixel, is a set consisting of all the superpixels, and means dectorial of the elements number of .
Superpixel is usually defined as a region with consistent perception in the image, and is composed of the same target, which provides spatial support for region-based feature calculation [35]. In this paper, we build the spatial relationships by Liu et al.’s proposed clustering-based superpixel segmentation method [35], which includes two terms in its loss function: (1) Entropy rate of random walk on constructed graphs to obtain compact and homogeneous clusters, and (2) Balance term that encourages all the clusters with similar sizes. This method processes segmentation as a clustering problem, while our target is for consistency constraint of a neighborhood. Thus, a connected graph is utilized here and does a simple reprocessing for the segmented superpixels, which forces each superpixel block only containing pixels in contiguous region but not the cross-region. The superpixel segmentation is achieved on the maximum principal component of the original HSI after principal component analysis (PCA). With experimental verification, connected graph operation makes a parameter setting in superpixel segmentation extremely robust.
Figure 2 shows the difference between traditional AE, GAE, and our proposed S-RAE. Compared with GAE, S-RAE does not build neighborhood relationships with the input data. As analyzed in Section 1, DSaF extracted by transferred deep filter banks presents strong inter-class separability, but poor intra-class aggregation, while the spectral feature can just compensate for this deficiency. Thus, in this paper, we build neighborhood relations in the spectral domain (represented by blue dots in Figure 2), and do the neighborhood consistency constraint for spatial feature. Besides, the metric matrix V in the loss function (4) of GAE is canceled from the relational constraint term in Equation (9), and relationships in S-RAE only involve pixels in each superpixels, instead of crossing between them. The purpose of relational auto-encoder in this paper is to learn spatial features with highly intra-class consistency, thus we only need to guarantee a minimum difference of the hidden layer features within each superpixel, but without any additional measurement of their similarity. Meanwhile, DSaF has stronger inter-class difference, so there is no need for further constraint or optimization.
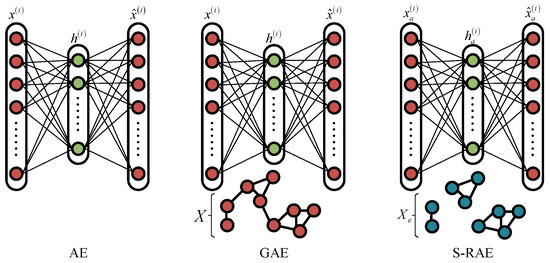
Figure 2.
Comparison of AE, GAE, and our proposed S-RAE.
3.2. Model Optimization
The parameters optimization of and in Equation (7) could be achieved by gradient descent algorithm. For the parameter in the encoder part, we have
where is in the reconstitution of ,
the weight penalty term , and the constraint of hidden layer ,
We use sigmoid as their activation function in all the encoder and decoder part, and its derivation can be expressed as
Thus, in the part of SAE, we have
where is the sparsity of n neurons in hidden layer, , and ⊙ represents dot product operation of matrix. The derivative of with respect to can be obtained as
For the relational constraint part, we rewrite the loss function (9) as
Thus the partial derivation of could be
Even if the neighborhood relationship is established within the superpixel, measuring distance per pixel is still computationally expensive. Therefore, we relax the pixel-wise similarity constraint to a minimum of mean deviation (M.D.) in each superpixel block. Thus, the derivative of Equation (20) can be approximated as
where
Likewise, we can obtain the derivative of with respect to as
The relational regularization and sparse constraint in Equation (7) are mainly directed at neurons in the hidden layer. Thus, the optimization of parameter set is only relevant to , so we have
and
Finally, all parameters are updated and optimized by the following iterative formula,
4. Multiscale Spectral-Spatial Feature Fusion
Neighborhood constraint in S-RAE makes DSaF with strong intra-class consistency. However, transferring pre-trained (by natural images) deep network parameters still hard to keep the raw spectral features of hyperspectral images. Therefore, as we do in [32], one layer of collaborative sparse AE is added to the hidden layer of the proposed S-RAE network for fusing the spectral–spatial feature, which is abbreviated as S-RCAE and given by
where is the normalization of hidden layer in S-RAE, and is the spectral features.
Besides, we still use the last three convolution modules in VGG-16 network to extract multiscale DSaFs and do spectral–spatial fusion by S-RCAE in each scale. Finally, we get the highly discriminant spectral–spatial features through the multiscale weighting fusion. Let , , be spectral–spatial features obtained from the three scales, pool5, pool4, and pool3, respectively. Thus, the weighting fusion of them can be represented as
where and are weighting parameters. X is the final discriminant feature obtained by our proposed MS-RCAE. Figure 3 gives the algorithm flow.
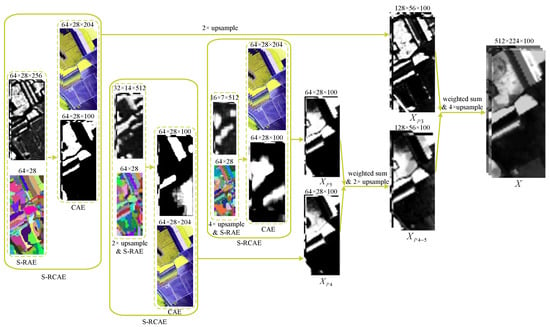
Figure 3.
Illustration of the proposed MS-RCAE (All the sizes are subject to the digital markers). A case of the Salinas dataset.
5. Experiments
5.1. Data Sets and Quantitative Metrics
In this section, we introduce four public databases to experimentally confirm the advantages of our proposed MS-RCAE for HSIC. They respectively are:
Indian Pines: This data consists image of size with spatial resolution of 20 m per pixel and 200 spectral bands (20 water absorption bands be removed) in the wavelength range from to 2.5 m. The ground truth available contains 16 classes.
University of Pavia: This data includes image of size with geometric resolution of 1.3 m and spectral coverage ranging from to 0.86 m. The ground truth available differentiates 9 classes.
Salinas: This data consists of image of size with high spatial resolution of 3.7 m per pixel, and the spectral reflectance bands is 204 after 20 water absorption bands moved. 16 classes is available in the ground truth.
Kennedy Space Center (KSC): This data consists image of size with spatial resolution of 18 m per pixel and 176 spectral bands (removed water absorption and low SNR bands) in 10 nm width with center wavelengths from to 2.5 m. 13 classes is available in the ground truth.
Figure 4 shows the pseudocolor image and corresponding ground truth of those datasets, respectively. To evaluate the proposed MS-RCAE method qualitatively, we select support vector machine (SVM) [36] as classifier for all the feature learning-based method, and use linear kernel function with penalty factor uniformly equal to 10. Overall accuracy (OA), average accuracy (AA), and Kappa coefficient are adopted to statistical evaluation of the results. All experiments in this paper are repeated 20 times with randomly selected train samples from the labeled pixels in each dataset, and we report the average accuracy across the 20 folds.

Figure 4.
Pseudo-color and ground references for the following datasets. (a) Indian Pines; (b) University of Pavia; (c) Salinas; (d) KSC.
5.2. Parameters Analysis
In our proposed S-RAE and MS-RCAE methods, the parameters to be set empirically mainly include: the number of superpixel clusters and the weight coefficient for relational regular term in Equation (9), and the weighting parameters in Equation (32) for multiscale fusion. To analyze the influence of parameter setting on classification accuracy, we randomly select 5% labeled samples from Indian Pines dataset for model training, and the rest 95% as test samples. For other three datasets, we randomly select 10 labeled pixels from each class as training samples, and all the others for testing.
We chose the number of superpixel clusters in the range from 10 to 80, weight coefficient from 0 to 30, and analyze the two parameters simultaneously here. Since the size of Indian Pines data is too small after downsampling, and the over-segmentation is extremely unbalanced when the number of clusters over 30. Therefore, this group of parameter analysis is primarily conducted on the other three datasets. To further illustrate the parameter robustness, we do the dimension reduction of DSaF by S-RAE under different parameters at the pool5 and pool3 layer of VGG-16, respectively. Then, the processed features are upsampled by corresponding scales, and classified by SVM. The experimental results are shown in Figure 5, and features extracted at different layers are annotated as S-RAE-P5 and S-RAE-P3, respectively. As seen from the results, S-RAE achieves relatively stable classification accuracy when the value of is greater than 15, and there is no significant influence when the number of clusters is set between 10 and 80. Therefore, we set the number of clusters at 60 and the regular parameter in all experiments, except for Indian Pines data with 30 clusters.
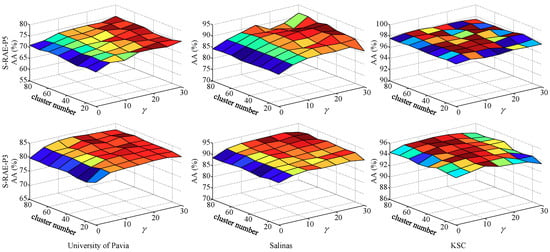
Figure 5.
Effect of initial superpixel clusters number and weight coefficient on classification accuracy.
We further examine how the proposed MS-RCAE behaves when the weighting parameters and in Equation (32) change from 0.2 to 0.7. As the results shown in Figure 6, images with finer spatial texture will be more beneficial to the shallow local feature descriptor, while those with smooth distribution but complex semantic information can be more inclined to the deep global descriptor, such as the University of Pavia data benefits from a larger weight on features from pool4, Salinas and KSC data prefer to pool5, while Indian Pine depends equally on the three scale layers. Thus, we set for Indian Pine, , for University of Pavia, for Salinas and KSC, respectively.
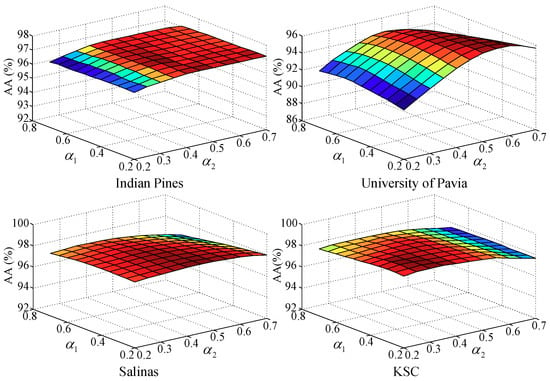
Figure 6.
Effect of weighting parameters and on classification accuracy.
5.3. Stepwise Evaluation of the Proposed Strategies
The main innovation in this paper is S-RAE for more discriminative feature learning. In order to verify its effectiveness, we severally compare the classification accuracy of DSaF processed by S-RAE and SAE, as well as deep spectral–spatial fusion feature by S-RCAE and CAE in [32], respectively. All experiments here are conducted on three experimental datasets except Indian Pines. To enhance the persuasiveness, we present the results of an increasing number of training samples from 3 to 50.
To analyze the effectiveness of our proposed S-RAE, SAE and S-RAE are compared to reduce the dimension of deep spatial features extracted from the last three convolutional modules in VGG-16, all of which are abbreviated as SAE-P5, SAE-P4, SAE-P3, and S-RAE-P5, S-RAE-P4, S-RAE-P3, respectively. Classification results, as shown in Figure 7, show that S-RAE gets great improvement on each scale features and all the datasets compared with the traditional SAE. This experiment strongly indicates that using the potential manifold in the spectral domain as a consistency constraint effectively improves the intra-class aggregation of the deep spatial feature, and thus the high discriminability of each target
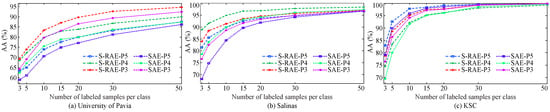
Figure 7.
Comparison of classification results from deep spatial feature preprocessed by SAE and S-RAE on datasets of (a) University of Pavia, (b) Salinas, and (c) KSC.
In addition, we further demonstrate the superiority of S-RAE from comparison of the spectral–spatial fusion features extracted by S-RCAE and CAE in [32]. Here, we also do the experiment on three scale layers, which are named as S-RCAE-P5, S-RCAE-P4, S-RCAE-P3, and correspondingly compared with CAE-P5, CAE-P4, CAE-P3, as well as the final method MS-RCAE. From the experimental results as in Figure 8, we can conclude that modification of DSaF by S-RAE could assist the collaborative network more effectively learning commonalities between spatial and spectral features in each scale, and excellently enhancing discriminability and robustness of learned features, such as more precise classification accuracy with a few training samples. Meanwhile, weighting fusion of multiscale features further improves their classification accuracy, particularly outstanding on University of Pavia dataset.

Figure 8.
Comparison of classification results from spectral–spatial feature learned by CAE, S-RCAE, and multiscale feature by MS-RCAE on datasets of (a) University of Pavia, (b) Salinas, and (c) KSC.
5.4. Comparison with Other Feature Extraction Algorithm
In this section, we compare our proposed method MS-RCAE with existing unsupervised feature extraction and deep learning-based methods through quantitative analysis and visual comparison, including recursive filtering (RF) [37] and intrinsic image decomposition (IID) [38] based unsupervised feature extraction method, joint-sparse auto-encoder (J-SAE) [5], guided filter-fast sparse auto-encoder (GF-FSAE) [8], 3-D CNN based method (3D-CNN) [4], deep spatial distribution prediction (MSFE) algorithm [20], and deep multiscale spectral–spatial feature fusion (DMSF) [32]. The parameters of all comparison methods in this section are set according to the corresponding references.
Table 1, Table 2, Table 3 and Table 4 respectively counts the classification accuracy of all comparison methods on the four experimental datasets, while Figure 9, Figure 10, Figure 11 and Figure 12 shows the corresponding classification maps of all the pixels. Numerical experiments demonstrate that our proposed method, compared with other methods, achieves the highest accuracy on Indian Pines, University of Pavia, and KSC datasets, though it does not achieve the best results on every category, the accuracy almost above 95%. Although the results on Salinas data are still relatively worse than IID, it is comparable to the best results, and has more promotion compared with DMSF. This well illustrates the effectiveness of our proposed superpixel-based neighborhood consistency constraint. As can be seen from the classification maps, besides reasonable semantic recognition, our method completes finer and more accurate edge segmentation, such as finer marsh recognition across the sea in KSC, more regular boundaries in Salinas data that with more adjacent boundary marking.

Table 1.
Classification accuracies of the Indian Pines dataset obtained by each comparison methods. The best results are highlighted in bold font.
Table 2.
Classification accuracies of University of Pavia dataset obtained by each comparison methods. The best results are highlighted in bold font.
Table 3.
Classification accuracies of the Salinas dataset obtained by each comparison methods. The best results are highlighted in bold font.
Table 4.
Classification accuracies of the KSC dataset obtained by each comparison methods. The best results are highlighted in bold font.
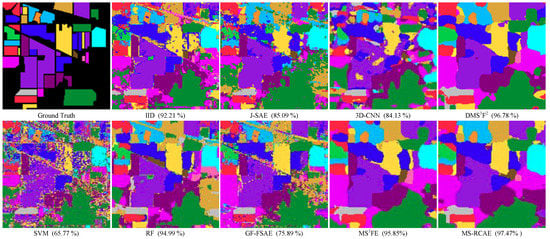
Figure 9.
Classification maps of the Indian Pine dataset obtained by different methods (AA).

Figure 10.
Classification maps of the University of Pavia dataset obtained by different methods (AA).

Figure 11.
Classification maps of the Salinas dataset obtained by different methods (AA).
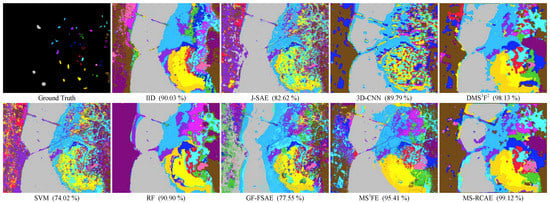
Figure 12.
Classification maps of the KSC dataset obtained by different methods (AA).
Our method is mainly based on auto-encoder network, so we further compare the execution time of our proposed MS-RCAE with the SAE-based method, J-SAE [5], GF-FSAE [8], and DMSF [32], as well as two CNN-based method, 3D-CNN [4] and MSFE [20]. As Table 5 shows, 3D-CNN needs training lots of convolutional parameters, so it consume the most time and is recorded on the order of minutes. MSFE extract deep features by the pre-trained FCN that with no training, so spend the least amount of time. To learn more discriminant feature, J-SAE and GF-FSAE all construct four hidden layers, while DMSF and our method MS-RCAE only need two hidden layers with less neurons and iteration (though contain three submodules for multiscale fusion), they take almost twice as long time than the latter. From the results, we can conclude that superpixel-based relational constraint only adds a slight computational burden to MS-RCAE compared with DMSF, but significant improvement in classification accuracy.
Table 5.
Execution Time of Different Methods on the Four Data Sets.
To verify the stability advantages of our method, we further exhibit how classification accuracy changes with the increasing number of training samples on the University of Pavia, Salinas, and KSC datasets (see Figure 13, Figure 14 and Figure 15). Here, we randomly select training samples from each class, and let the number gradually increase from 3 to 50. The experimental results show that our proposed MS-RCAE method is superior to other comparison methods, especially in the case of small samples. Accuracy on Salinas data is still slightly worse than method IID. However, compared to other auto-encoder-based methods, such as J-SAE, GF-FSAE, and DMSF, our method shows significant advantages, particularly gets a big boost under less sample training conditions, which further illustrate that superpixel-based relational auto-encoder has a certain contribution to the discriminant feature extraction. In addition, although IID method achieves the highest classification accuracy on Salinas, it is not outstanding on the other datasets, and lower than our method by at least 5 percent, while our proposed MS-RCAE is only about 0.2 percent below IID on Salinas. This further indicates that our proposed method has certain universality.
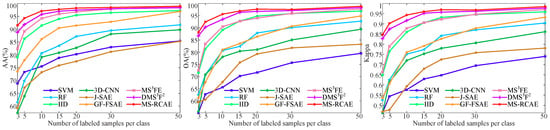
Figure 13.
Effect of the number of training samples on classification accuracy for the University of Pavia dataset.
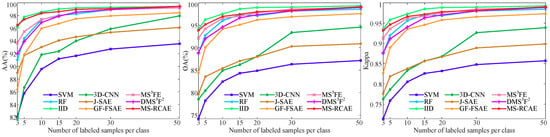
Figure 14.
Effect of the number of training samples on classification accuracy for the Salinas dataset.
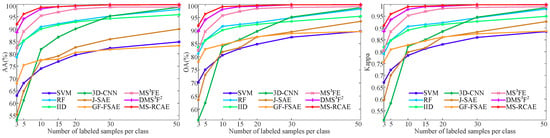
Figure 15.
Effect of the number of training samples on classification accuracy for the KSC dataset.
6. Conclusions
In this paper, we propose a superpixel-based relational auto-encoder method to learn deep spatial features with high intra-class consistency. Firstly, we transferred the pre-trained filter banks in VGG-16 to extract deep spatial information of HSI. Then, the proposed S-RAE is utilized to reduce the dimensionality of the extracted deep feature. Based on the spectral feature with high intra-class consistency and deep spatial features with strong inter-class separability, we utilize the manifold relations in the spectral domain, and build a superpixel-based consistency constraint on the deep spatial feature to enhance its intra-class consistency. In addition, the obtained deep feature is further fused with the raw spectral feature by a collaborative auto-encoder, and the multiscale spectral–spatial features learned from the last three convolution modules in VGG-16 are weighting fused to achieve the final feature representation (MS-RCAE). To evaluate the proposed method in this paper qualitatively, we utilize SVM as a unified classifier to classify the extracted features. Extensive experiments on four public datasets demonstrate the superior performance of our proposed method, especially under the condition of small samples.
There is still plenty of room for improvement, such as more reasonable multiscale feature fusion strategies to maximize the advantages of each scale, more concise steps in representative feature learning, and a parallel computing strategy to speed up the calculation efficiency and enhance the demands of real-time performance.
Author Contributions
Conceptualization, M.L.; Methodology, M.L.; Software, M.L.; Writing-Original Draft Preparation, M.L.; Writing-review and editing, M.L. and Z.M.; Data Curation, Z.M.; Validation, Z.M.; Formal Analysis, L.J.; Funding Acquisition, M.L.; Supervision, L.J.; Project Administration, M.L.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 61901198, in part by the National Natural Science Foundation of China under Grant 61871306, and in part by the Doctoral Scientific Research Foundation of Jiangxi University of Science and Technology under Grant jxxjbs19006.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Jiao, L.; Zhao, J.; Yang, S.; Liu, F. Deep learning, Optimization and Recognition; Tsinghua University Press: Beijing, China, 2017. [Google Scholar]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 1–12. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Xing, C.; Ma, L.; Yang, X. Stacked denoise autoencoder based feature extraction and classification for hyperspectral images. J. Sens. 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Zheng, J.; Zhao, H.; Qing, C.; Yang, Z.; Du, P.; Marshall, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, J.; Liu, P.; Choo, K.K.R.; Huang, F. Spectral–spatial multi-feature-based deep learning for hyperspectral remote sensing image classification. Soft Comput. 2017, 21, 213–221. [Google Scholar] [CrossRef]
- Jiao, L.; Liu, F. Wishart deep stacking network for fast POLSAR image classification. IEEE Trans. Image Process. 2016, 25, 3273–3286. [Google Scholar] [CrossRef]
- Guo, Y.; Jiao, L.; Wang, S.; Wang, S.; Liu, F. Fuzzy Sparse Autoencoder Framework for Single Image Per Person Face Recognition. IEEE Trans. Cybern. 2018, 48, 2402–2415. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Zhong, P.; Gong, Z.; Li, S.; Schönlieb, C.B. Learning to diversify deep belief networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3516–3530. [Google Scholar] [CrossRef]
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR Image Classification Based on Wishart DBN and Local Spatial Information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Zhao, Z.; Jiao, L.; Zhao, J.; Gu, J.; Zhao, J. Discriminant deep belief network for high-resolution SAR image classification. Pattern Recognit. 2017, 61, 686–701. [Google Scholar] [CrossRef]
- Zhou, Y.; Wei, Y. Learning Hierarchical Spectral-Spatial Features for Hyperspectral Image Classification. IEEE Trans. Cybern. 2017, 46, 1667–1678. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X. MugNet: Deep learning for hyperspectral image classification using limited samples. ISPRS J. Photogramm. Remote Sens. 2017, 145, 108–119. [Google Scholar] [CrossRef]
- Santara, A.; Mani, K.; Hatwar, P.; Singh, A.; Garg, A.; Padia, K.; Mitra, P. BASS Net: Band-adaptive spectral–spatial feature learning neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5293–5301. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral image classification with deep feature fusion network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Jiao, L.; Liang, M.; Chen, H.; Yang, S.; Liu, H.; Cao, X. Deep fully convolutional network-based spatial distribution prediction for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5585–5599. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Hou, J.; Li, X.; Du, Q. Learning sensor-specific spatial–spectral features of hyperspectral images via convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4520–4533. [Google Scholar] [CrossRef]
- Lin, Z.; Chen, Y.; Zhao, X.; Wang, G. Spectral–spatial classification of hyperspectral image using autoencoders. In Proceedings of the International Conference on Information, Communications & Signal Processing (ICICS), Tainan, Taiwan, 10–13 December 2013; pp. 1–5. [Google Scholar]
- Zhang, X.; Liang, Y.; Li, C.; Huyan, N.; Jiao, L.; Zhou, H. Recursive Autoencoders-Based Unsupervised Feature Learning for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1928–1932. [Google Scholar] [CrossRef]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhao, Y.Q.; Chan, J.C.W. Learning and Transferring Deep Joint Spectral–Spatial Features for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4729–4742. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Hastad, J.; Goldmann, M. On the power of small-depth threshold circuits. Comput. Complex. 1991, 1, 113–129. [Google Scholar] [CrossRef]
- Li, L.; Zhang, T.; Shan, C.; Liu, Z. Deep Learning: Mastering Convolutional Neural Networks from Beginner; China Machine Press: Beijing, China, 2018. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral—Spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Contextual deep CNN based hyperspectral classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3322–3325. [Google Scholar]
- Liang, M.; Jiao, L.; Yang, S.; Liu, F.; Hou, B.; Chen, H. Deep Multiscale Spectral-Spatial Feature Fusion for Hyperspectral Images Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 2911–2924. [Google Scholar] [CrossRef]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Research 2008, 9, 2579–2605. [Google Scholar]
- Liao, Y.; Wang, Y.; Liu, Y. Graph regularized auto-encoders for image representation. IEEE Trans. Image Process. 2017, 26, 2839–2852. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Feature extraction of hyperspectral images with image fusion and recursive filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3742–3752. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Fang, L.; Benediktsson, J.A. Intrinsic image decomposition for feature extraction of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2241–2253. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).