Abstract
We present a simple, and efficient approach to fusing MODIS and Landsat images. It is well known that MODIS images have high temporal resolution and low spatial resolution, whereas Landsat images are just the opposite. Similar to earlier approaches, our goal is to fuse MODIS and Landsat images to yield high spatial and high temporal resolution images. Our approach consists of two steps. First, a mapping is established between two MODIS images, where one is at an earlier time, t1, and the other one is at the time of prediction, tp. Second, this mapping is applied to map a known Landsat image at t1 to generate a predicted Landsat image at tp. Similar to the Spatial and Temporal Adaptive Reflectance Fusion Model (STARFM), SpatioTemporal Image-Fusion Model (STI-FM), and the Flexible Spatiotemporal DAta Fusion (FSDAF) approaches, only one pair of MODIS and Landsat images is needed for prediction. Using seven performance metrics, experiments involving actual Landsat and MODIS images demonstrated that the proposed approach achieves comparable or better fusion performance than that of STARFM, STI-FM, and FSDAF.
1. Introduction
Fusing high spatial resolution/low temporal resolution Landsat images with low spatial resolution/high temporal resolution MODIS images will have many applications, such as drought monitoring, fire damage assessment, flood damage monitoring, etc. In [1], a fusion approach known as Spatial and Temporal Adaptive Reflectance Fusion Model (STARFM) was proposed and demonstrated. The STARFM has been used to generate daily time-series vegetation index and evapotranspiration for crop condition and drought monitoring [1,2]. Several alternative algorithms [3,4] were published to further improve the fusion performance. The Bayesian prediction approach [5,6,7], which was also proposed for fusing satellite images with complementary characteristics, can be an alternative fusion method for Landsat and MODIS. According to the survey paper [8], the STAARCH [3] approach can handle abrupt changes, but requires two pairs of MODIS and Landsat images. The ESTARFM [4] algorithm focuses on enhancing the performance of mixed pixels. Similar to STAARCH, ESTARFM also requires two pairs of images. As a result, both STAARCH and ESTARFM may not be suitable for forward prediction.
Recently, the Flexible Spatiotemporal DAta Fusion (FSDAF) algorithm can use one pair of MODIS and Landsat images for forward prediction [9]. The method has six steps, including land cover classification, grouping of neighboring pixels, etc. The computational load is heavy, as one prediction may take more than one hour to finish for an image size of 1200 × 1200. Moreover, since there are multiple steps in the prediction process, it is hard to grasp which step contributes the most to the prediction performance. A relatively simple and more efficient algorithm, the SpatioTemporal Image-Fusion Model (STI-FM) [10] applies clustering to the images first, and, for each cluster, performs a separate prediction. In addition to the above algorithms, some alternative fusion ideas [11,12,13,14,15,16] were proposed and evaluated. Interested readers can find concise reviews for these alternative methods in [10]. In this paper, we present a simple approach to fusing MODIS and Landsat images for forward prediction. Our approach was motivated by our recent pansharpening work for synthesizing a high resolution hyperspectral image by fusing a high resolution color image with a low resolution hyperspectral image cube [17]. Our approach is called hybrid color mapping (HCM), which has also been applied to enhance Mastcam images [18] in the Curiosity rover and Mars satellite imagers THEMIS and TES [19]. The HCM is simple, intuitive, and computationally efficient, as compared to other algorithms in the literature. Most importantly, it has high performance because numerous recent comparative studies [18,19,20] have demonstrated its efficacy. Similar to STARFM, STI-FM, and FSDAF, only one pair of MODIS and Landsat images is needed for prediction.
Our paper is organized as follows. Section 2 introduces our approach. Section 3 presents the experimental results. Two types of real images have been used. One type is homogeneous and the other is the more challenging type of heterogeneous images. Discussions are included in Section 4. Finally, the conclusions and future directions are given in Section 5.
2. Materials and Methods
Our approach is simple, intuitive, and has two steps. First, a mapping is established between two MODIS images where one is at an earlier time, t1, and the other one is at the time of prediction, tp. To achieve better prediction results, it is necessary to divide the images into small patches, which can be either overlapping or non-overlapping. The mapping is then obtained for each patch. It should be noted that the mapping is between a pixel vector in one image and another pixel vector in another image. Second, this mapping is applied to a known Landsat image at t1 to generate a predicted Landsat image at tp.
2.1. A Simple Motivating Example of Our Approach
We will use one band of MODIS and LANDSAT to illustrate our approach. Figure 1 shows two pairs of MODIS (M1 and M2) and Landsat (L1 and L2) images. The pairs, (M1, L1) and (M2, L2) were collected on the same days. From Figure 1, we have two observations. First, the MODIS images can be treated as blurred versions of their Landsat counterparts. Second, the intensity relationship between the MODIS pixels is somewhat similar to that of those Landsat pixels. For example, the middle of L1 is darker than the rest of the scene, and this can be easily seen in M1 as well. Similarly, the middle part of L2 is slightly brighter than the rest and one can see the same in M2. The above observations indicate that the heterogeneous landscape information is captured in the MODIS images. If we can capture the intensity mapping between the MODIS images at two different times, then we can use that mapping to predict the Landsat image at time using Landsat image at . It turns out that, although the above idea is simple and intuitive, the prediction results using this idea are quite accurate in previous experiments [19,20].


Figure 1.
Relationship between two pairs of MODIS and Landsat images. One band is shown here. (a,b) are MODIS images collected at two different times; (c,d) are Landsat images collected at two different times.
To further substantiate the above observations, we include some statistics (Table 1) from four pairs of MODIS and Landsat images. Days 128 and 144 belong to homogeneous regions and Days 214 and 246 are heterogeneous regions. It can be easily seen that the means and the standard deviations of MODIS and Landsat images are indeed very close, corroborating the visual observations in Figure 1.

Table 1.
Mean and standard deviation of MODIS and Landsat images at different dates.
2.2. Proposed Approach Based on Hybrid Color Mapping (HCM)
Figure 2 illustrates our proposed prediction approach. Based on the available MODIS images that were collected at and , we learn the pixel by pixel mapping between the two images. The learned matrix F is then applied in the prediction step. Using similar notations in related work [1], the prediction of Landsat image at can be achieved by
where denotes a pixel vector (up to Q with Q being the number of bands) for this application and is a pixel to pixel mapping/transformation matrix with appropriate dimensions. can be determined by using the following relationship
where denotes a pixel vector (Q bands). To account for the intensity differences between two images, a variant of (2) can be described as
where is a vector of constants.
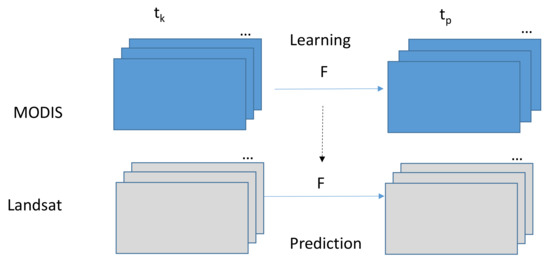
Figure 2.
Proposed prediction approach.
With no loss of generality, let us focus on the determination of F in (2). Now, let us denote as the set of all of the multispectral pixels for all the pixels in the image at and as the set of all the multispectral pixels in the image at . Q is the number of bands. Since and are vectors, and can be expressed as
where and are the numbers of rows and columns, respectively.
We call the mapping F in (2) the global version and all of the pixels in and are used in estimating F. To estimate F, we will use the least square approach, which minimizes the error
where .
Following the definition of Frobenius norm [21], (6) is equivalent to
Solving F in (7) involves the following. Since
Differentiating (8) with respect to F yields [22]
Setting the above to zero will yield
Unlike normal image mapping, such as the 3 × 3 image transform matrices (a rotation or perspective transformation), which maps between the spatially distributed patches, it should be noted that F is a pixel to pixel mapping between two multispectral pixels.
To avoid instability, we can add a regularization term in (7). That is,
where is a regularization parameter and the optimal F becomes
with I an identity matrix with the same dimension as .
Remark 1.
Difference between the HCM in this paper and the HCM in [17].
Although the mathematical derivations are the same, the proposed HCM in this paper is different from that in [17]. The key difference is the implementation. In [17], the mapping is between a downsampled high resolution image and a low resolution hyperspectral image, whereas here the mapping is between two low resolution MODIS images.
Remark 2.
Addition of a bias term.
If the means of the two MODIS images are different, we can easily extend the above derivation to arrive at a new expression for and in (3). This can be done by rewriting (3) as
that is, we simply augment the vector M by one more row of 1. After that, the derivation will be the same as before.
Remark 3.
Local Mapping.
Based on our observations in some cases, prediction results will be more accurate if we divide the images into patches. Each patch will have its own mapping matrix. Figure 3 illustrates the local prediction approach. The patches can be overlapped or non-overlapped. In this paper, overlapped patches were used for homogeneous areas and non-overlapped patches were used for the heterogeneous areas.
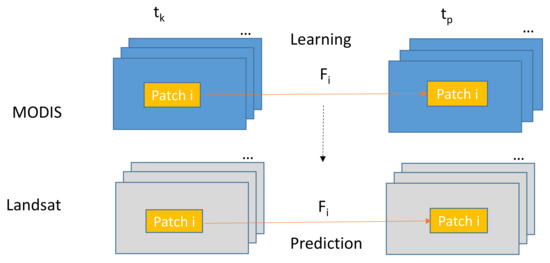
Figure 3.
Proposed prediction approach based on local mapping.
Remark 4.
Band by band mapping.
It should be noted that the derivations for the forward prediction are done jointly for all of the bands. Actually, the mapping can also be done band by band.
Remark 5.
Only one pair of MODIS and Landsat images.
Unlike STAARCH and ESTARFM, our approach does not require two pairs of MODIS and Landsat images for prediction. This will be ideal for forward prediction, where only past measurements of Landsat images are available.
Remark 6.
One mapping per cluster.
One can also perform image clustering/segmentation first and then use HCM for each individual cluster. We implemented this approach and the results are similar to that of the non-clustering approach. Discussions on this clustering approach will be summarized in Section 4.
2.3. Evaluation Metrics
We evaluate the performance of algorithms using the following seven objective metrics. Moreover, computational times are also used in our comparative studies.
- Absolute Difference (AD). The AD of two vectorized images (ground truth) and (prediction) is defined aswhere Z is the number of pixels in each image. The ideal value of AD is 0 if the prediction is perfect.
- RMSE (Root Mean Squared Error). The RMSE of two vectorized images (ground truth) and (prediction) is defined aswhere Z is the number of pixels in each image. The ideal value of RMSE is 0 if the prediction is perfect.
- CC (Cross-Correlation). We used the codes from Open Remote Sensing website (https://openremotesensing.net/). The ideal value of CC is 1 if the prediction is perfect.
- ERGAS (Erreur Relative. Globale Adimensionnelle de Synthese). We used the codes from [23]. The ERGAS is defined asfor some constant d depending on the resolution and is the mean the ground truth image. The ideal value of ERGAS is 0 if a prediction algorithm flawlessly reconstructs the Landsat bands.
- SSIM (Structural Similarity). It is a metric to reflect the similarity between two images. An equation of SSIM can be found in [9]. The ideal value of SSIM is 1 for perfect prediction.
- SAM (Spectral Angle Mapper) [23]. The spectral angle mapper measures the angle between two vectors. The ideal value of SAM is 0 for perfect reconstruction.
- Q2n: A definition for Q2n can be found in [24,25]. The ideal value of Q2n is 1. The codes can be downloaded from Open Remote Sensing website.
3. Results
In this section, we present extensive experimental results. Since our main interest is in forward prediction, we only compare with STARFM, STI-FM, and FSDAF.
3.1. Data Set 1: Scene Contents Are Homogeneous
Data set 1 is the Boreal Ecosystem–Atmosphere Study (BOREAS) southern study area (54.6°N, 105.8°W) that has been used by Gao et al. [26] in the data fusion test. This is a relatively homogeneous area. The major land cover type is forest, with subsidiary fen and spare vegetation. Land cover patches are large. Landsat and MODIS data have been reprocessed using the latest available collections when we started this study. Landsat surface reflectance images (L1T) were ordered from U.S. Geological Survey (USGS). MODIS daily surface reflectance products (MOD09GA, Collection 6) [27] were corrected to nadir BRDF-adjusted reflectance (NBAR) using MODIS BRDF products (MCD43A1, Collection 5) [26]. Note that the Collection 6 of daily MODIS NBAR at 500 m resolution is now available and can be directly used. Co-registration between Landsat and MODIS was applied to all of the Landsat-MODIS image pairs using maximum correlation approach [27]. Four Landsat-MODIS image pairs (day 128, 144, 192 and 224) on 2001 were re-processed for the study. Each image has six bands. We can perform six forward prediction experiments.
The parameters of our prediction algorithm for the first data set are as follows. Band to band prediction was used and no bias term was introduced. The images are divided into patches with a patch size of 80 Landsat pixels. The regularization term was chosen to be 0.001. The overlapping window size for patches is 40.
Table 2, Table 3 and Table 4summarize the forward prediction results of using Landsat image 128 to predict Landsat image 144, Landsat image 144 to predict Landsat image 192, Landsat image 192 to predict Landsat image 224, respectively. The tables are arranged in a similar manner as that of [9]. The first block of each table compares the source Landsat image and the ground truth Landsat image to be predicted. We have applied cloud masks in calculating those values in the tables. In Table 2, one can see that our prediction results in terms of AD, RMSE, CC, ERGAS, SSIM, and Q2n metrics are better than that of STARFM, STI-FM, and FSDAF in almost all of the bands. In the false color image (formed by treating NIR, Red, and Green as Red, Green, and Blue, respectively) that is shown in Figure 4, if one looks at the zoomed-in area inside the red circles, one can see that our results can recover more fine details as compared to that of STARFM and are comparable to that of FSDAF and STI-FM. From Table 3, it can be seen that our results have similar trends as Table 2. This is reflected in Figure 5, as it can be seen that, inside the red circles, our results can preserve the color information slightly better than that of STARFM and STI-FM, and are comparable to FSDAF. From Table 4, our results also give better performance metrics in almost all of the metrics as compared to those of STARFM, STI-FM, and FSDAF. In Figure 6, one can see that the STARFM image has an area in the center/bottom half (inside the white circle) that seems to have some spectral distortion, while our predicted image looks much more like the actual image. Table 4 also shows that our prediction, especially the NIR band, is a lot closer to the ground truth image.
Table 2.
Comparison of forward prediction results of using Landsat image 128 to predict Landsat image 144.
Table 3.
Comparison of forward prediction results of using Landsat image 144 to predict Landsat image 192.
Table 4.
Comparison of forward prediction results of using Landsat image 192 to predict Landsat image 224.

Figure 4.
Comparison of forward prediction results of using Landsat image 128 to predict Landsat image 144. (a) Actual image; (b) Spatial and Temporal Adaptive Reflectance Fusion Model (STARFM); (c) Flexible Spatiotemporal Data Fusion (FSDAF); (d) SpatioTemporal Image-Fusion Model (STI-FM); (e) hybrid color mapping (HCM).

Figure 5.
Comparison of forward prediction results of using Landsat image 144 to predict Landsat image 192. (a) Actual image; (b) STARFM; (c) FSDAF; (d) STI-FM; (e) HCM.

Figure 6.
Comparison of forward prediction results of using Landsat image 192 to predict Landsat image 224. (a) Actual image; (b) STARFM; (c) FSDAF; (d); STI-FM; and, (e) HCM.
3.2. Data Set 2: Scene Contents Are Heterogeneous
Data set 2 is a rain-fed agricultural area in central Iowa (42.4°N, 93.4°W). The major crops were corn and soybean. They were planted at different times and had different crop phenology. This is a relatively heterogeneous area. Same data processing procedures that were used in Data set 1 were applied. Three Landsat-MODIS image pairs (day 144, 182, and 224) on 2002 were processed.
MODIS daily NBAR were resampled to match Landsat 30 m resolution using the bi-linear interpolation approach. Both data sets have the image size of 1200 by 1200. For each time, one image-pair was used to predict Landsat observation for another pair date and then compared to the actual Landsat reflectance. There are three pairs of MODIS and Landsat images in this data set. Each image has six bands. We can perform two forward prediction experiments.
The parameters of our prediction algorithm for the second data set are as follows. The learning and prediction were performed band by band. For heterogeneous contents, we observed that we need to pick small patch sizes in order to achieve good prediction performance. Patches with a size of two were used and there is no overlapping between the patches. The regularization term was chosen to be 0.001.
Table 5 summarizes the forward prediction results from Landsat image 182 to Landsat image 214. It can be seen that FSDAF has the best performance, followed by STI-FM, HCM, and STARFM. In terms of subjective comparisons, one can see from the false color image in Figure 7, which is created by using the order of near infrared (NIR), red, and green bands, as the RGB bands, that our results are slightly closer to the ground truth image in terms of color. Table 6 summarizes the prediction results from Landsat image 214 to Landsat image 246. Although our results are comparable to those of STARFM and STI-FM, and slightly inferior to those of FSDAF, the numbers are close. This is also reflected in the images shown in Figure 8 where the predictions results using STARFM, STI-FM, FSDAF, and our approach are all very close visually.
Table 5.
Comparison of forward prediction results of using Landsat image 182 to predict Landsat image 214.

Figure 7.
Comparison of forward prediction results of using Landsat image 182 to predict Landsat image 214. (a) Actual image; (b) STARFM; (c) FSDAF; (d) STI-FM; and, (e) HCM.
Table 6.
Comparison of forward prediction results of using Landsat image 214 to predict Landsat image 246.

Figure 8.
Comparison of forward prediction results of using Landsat image 214 to predict Landsat image 246. (a) Actual image; (b) STARFM; (c) FSDAF; (d) STI-FM; and, (e) HCM.
4. Discussions
The STARFM algorithm is the pioneering work on the fusion of MODIS and Landsat images. The FSDAF incorporates land cover classification and some additional processing steps and yields better performance over the STARFM in heterogeneous areas. When comparing the proposed HCM with the FSDAF method, our method is much simpler and efficient. In fact, HCM is comparable to that of STI-FM in terms of computational complexity. One may think that, since the resolution between Landsat and MODIS is 16 to 1, the proposed HCM based mapping may not be effective. It turns out that we have applied HCM to enhance images with even greater resolution differences: Worldview-2 (25 to 1) [20] and THEMIS and TES (30 to 1) [19]. The results in [19,20] as well as the results in this paper clearly demonstrate that the HCM algorithm is a very competitive method for fusing different types of satellite images. More supporting arguments are presented in the following paragraphs.
4.1. Additional Simulation Studies Using Synthetic Data to Address 16:1 Resolution Concern for HCM
To further validate the performance HCM, we have carried out some additional studies. Similar to the FSDAF paper, we used a synthetic data set, as shown in Figure 9 below. There are three areas besides the background, which has a magnitude of 0.5. A small Gaussian noise (0.001) was added to the image. The pixel magnitudes in Landsat image at t1 are as follows: 0.01 in the circle (radius: 56 pixels), 0.3 in the rectangle and the line. The pixel magnitudes in Landsat image at t2 are: 0.05 in the circle (radius: 72 pixels), 0.2 in the rectangle and the line. The circles in the two Landsat images are to emulate gradual changes (phenology), and the lines and rectangle are to emulate land cover type changes. The MODIS images were generated by averaging 16 × 16 blocks in the Landsat images.
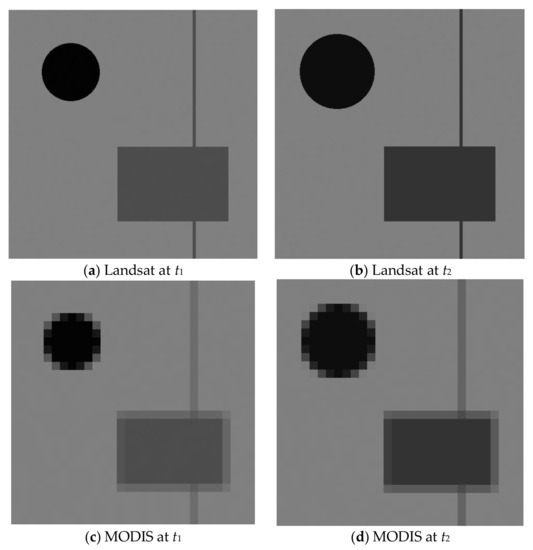
Figure 9.
Synthetic data for Landsat and MODIS at two different times. The image size is 480 × 480. (a,b) are synthetic Landsat images at two different times; (c,d) are synthetic MODIS images at two different times.
Now, we summarize the prediction results below in Figure 10. Table 7 summarizes four performance metrics. It can be seen that the FSDAF results have smaller prediction errors than those of HCM. The HCM results have some blurry peripherals. Because this synthetic data set is somewhat similar to the heterogeneous landscape, the FSDAF method performed well. However, this simple example also substantiates that our HCM does not have any “grave” issues; it just performs slightly worse than FSDAF in the heterogeneous cases. We did not include the STI-FM results here, as thorough comparisons have been carried out earlier in Section 3.

Figure 10.
Comparison of FSDAF and HCM prediction results. (a) is the Landsat image at t2; (b) and (c) are the prediction images using FSDAF and HCM, respectively.
Table 7.
Comparison of FSDAF and HCM for the synthetic data.
4.2. Performance of HCM for Applications with 25:1 Resolution Difference
To further alleviate the concern that our proposed HCM method may not work for large spatial resolution applications, we would like to mention some of the fusion results where we have 25:1 resolution difference between two images. The 25 to 1 resolution difference application is for enhancing the eight SWIR bands (7.5 m resolution) using the pan band (0.31 m resolution) in Worldview-3 images. A paper has been published [20]. See Table 5 in [20]. It can be seen that our HCM results are slightly better than other state-of-the-art methods in the literature using three performance metrics, even if the resolution difference is 25:1.
4.3. Performance of HCM for Applications with 30:1 Resolution Difference
Here, we mention one more application of HCM to image fusion where the spatial resolution difference between the two images is 30:1. The 30 to 1 resolution difference application is for the fusion of THEMIS (100 m resolution) and TES (3 km resolution) images for NASA’s Mars exploration. A paper was presented in 2017 IGARSS [19]. The performance of HCM was also excellent for this application. See Figure 4 and Table 1 in [19] for details. Those results clearly demonstrated that HCM can still perform well in 30:1 resolution difference application). Table 1 in [19] indicates that HCM actually has the best performance in this application.
4.4. Necessity and Importance of Having Diverse Methods for Image Fusion
We would like to argue that no one method could perform well under all of the conditions in many remote sensing applications. For example, a recent research by our team focused on the fusion of Planet and Worldview images. In this application, the resolution of Planet images is actually uncertain because its resolution is much worse than the declared resolution of 3.125 m. There are both homogeneous and heterogeneous regions in the images. We carried out three case studies in that paper. It was observed that none of the three methods (STARFM, FSDAF, and HCM) can outperform others in all cases. This shows that it is important to have more diversity in the fusion methods. HCM is simple and efficient, and hence may be more suitable for near real-time applications. On the other hand, FSDAF and STARFM require more computational times and may be suitable for batch, off-line processing applications. The bottom line is that the remote sensing community needs to have some freedom in choosing the most appropriate fusion method that can meet each individual’s specific needs. In this respect, HCM offers a reasonable alternative.
4.5. Combine HCM with Image Clustering
We have implemented a general clustering approach, which does not require the cluster maps at different times to be the same. To perform the clustering, we use k-means for MODIS images at tk and tp. The clusters can be dramatically different at two different times. Let us use Figure 11 below to illustrate our idea. At tk, there are three clusters and at tp, there are four clusters. When we overlay the cluster maps, we will have six combinations of clusters. If there are N clusters at tk and M clusters at tp, then there will be at most NM clusters in total. In each cluster, we estimate a matrix F. We applied this clustering approach to two cases. The results are shown below.
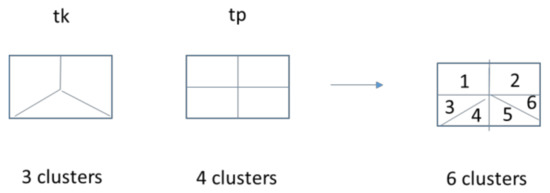
Figure 11.
Illustration of clustering combinations.
4.5.1. Example in Homogeneous Area
We used Day 128 to predict Day 144. We tried three cluster combinations: 50 × 50; 20 × 20; and, 5 × 5, where the first number indicates the number of clusters at time tk and the second number is the number of clusters at tp. From Table 8, it can be seen that the local HCM approach is slightly better than the cluster based approach.
Table 8.
Comparison of cluster based HCM with different cluster sizes and local based HCM for homogeneous areas. Bold numbers indicate high performing methods.
4.5.2. Example in Heterogeneous Area
We used Day 214 to predict Day 246. We tried three cluster combinations: 50 × 50; 20 × 20; and, 5 × 5. Again, from Table 9, it can be seen that the two approaches have very close performances and the local based method has a very slight edge over the cluster based approach.
Table 9.
Comparison of cluster based HCM with different cluster sizes and local based HCM for heterogeneous areas. Bold numbers indicate high performing methods.
When comparing the cluster-based HCM with non-cluster/local based HCM, we see that the results are mixed. We do see some cases where the cluster-based approach is slightly better, but in other cases, the non-cluster based HCM performs well. A simple explanation is that our non-cluster based HCM is local in nature. Since we normally set the patch size to be small for heterogeneous areas, the pixels within those small patches generally do not have much variation.
We would also like to mention that there is another clustering based method (STI-FM) [10]. The idea is to use the ratio of MODIS pixels at two different times to perform clustering. We implemented that algorithm and included the results in this paper. See Table 2, Table 3, Table 4, Table 5 and Table 6 in Section 3.
In short, the use of clustering based approach could be a good future research direction, especially in the case of heterogeneous images.
4.6. General Comments and Observations
For homogeneous regions, our proposed HCM algorithm performed the best in terms of objective evaluations using seven performance metrics. See Table 2, Table 3 and Table 4 for details. Those seven performance metrics are widely used in the literature to compare image fusion and pansharpening algorithms.
In terms of subjective visualization for homogeneous regions, one can see that our results are comparable or better than others. Some details in Figure 4, Figure 5 and Figure 6 clearly show more closeness to the ground truth by using the proposed method.
For heterogeneous regions, the proposed HCM method is slightly inferior to that of FSDAF, which explicitly incorporates land cover classification. However, in some bands, such as SW1 and SW2, our results are comparable or better than that of FSDAF in terms of objective metrics. In terms of subjective comparisons, our prediction performance is comparable to that of the other methods.
In terms of computational complexity, STARFM completes the prediction of one image in less than 3 min, while FSDAF completes the prediction of one image in about 1.5 h for both datasets. There is a fast variant of FSDAF in that package. However, the prediction performance is not as good as the slow version. STI-FM completes a forward prediction in about 2 s for both of the datasets. The computational time for HCM is comparable to that of STI-FM, but varies depending on which dataset is used since different parameters were used for each dataset. For the homogenous dataset, the computational time for a single prediction is roughly 10 s, while for the heterogeneous dataset, the computational time is about 8 min.
Since none of the prediction methods can work well under all situations, it might be better to adopt a hybrid approach for Landsat and MODIS image fusion. That is, we propose to use HCM for homogeneous areas and FSDAF or STI-FM for heterogeneous areas.
One future research is to incorporate the high temporal resolution fused images into a remote sensing data product, such as fire damage assessment. Another potential research direction is to apply deep learning approach to learn the mapping between the MODIS images and then use that mapping for Landsat image prediction. A third direction is to utilize the high temporal and high spatial resolution images for anomaly detection, border monitoring, and target detection.
5. Conclusions
In this paper, we present a simple, and high performance forward prediction approach to generating Landsat images with high temporal resolution. The idea is based on learning a mapping between MODIS images. Once the mapping is learned, it is then applied to a Landsat image that is collected at an earlier time in order to predict a future Landsat image. When compared to other fusion approaches, such as STAARCH and ESTARFM, our approach does not require two pairs of MODIS and Landsat images, and hence it is more appropriate for forward prediction. Experiments using actual MODIS and Landsat images demonstrated that the proposed approach achieves a comparable performance as that of STARFM, STI-FM, and FSDAF. The comparisons were done at least after the three digits of the decimal point. Consequently, the outcomes were similar in comparison to the other methods. In addition, computationally, the proposed HCM and STI-FM were found to be relatively simpler in comparison to the other two methods.
Author Contributions
Chiman Kwan conceived the overall approach. Bence Budavari and Chiman Kwan generated all the figures in this paper. Feng Gao provided the data sets in the experiments and the STARFM results. Xiaolin Zhu provided the synthetic data set as well as the FSDAF results.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar]
- Gao, F.; Anderson, M.; Zhang, X.; Yang, Z.; Alfieri, J.; Kustas, B.; Mueller, R.; Johnson, D.; Prueger, J. Mapping crop progress at field scales using Landsat and MODIS imagery. Remote Sens. Environ. 2017, 188, 9–25. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, A.M.; Coops, N.C.; Linke, J.; McDermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial- and temporal-resolution mapping of forest disturbance based on Landsat and MODIS. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Addesso, P.; Conte, R.; Longo, M.; Restaino, R.; Vivone, G. Sequential Bayesian methods for resolution enhancement of TIR image sequences. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 233–243. [Google Scholar] [CrossRef]
- Addesso, P.; Conte, R.; Longo, M.; Restaino, R.; Vivone, G. A sequential Bayesian procedure for integrating heterogeneous remotely sensed data for irrigation management. In Proceedings of the Remote Sensing for Agriculture, Ecosystems, and Hydrology XIV, Edinburgh, UK, 19 October 2012; Volume 8531, p. 85310C. [Google Scholar]
- Agam, N.; Kustas, W.P.; Anderson, M.C.; Li, F.; Neale, C.M. A vegetation index based technique for spatial sharpening of thermal imagery. Remote Sens. Environ. 2007, 107, 545–558. [Google Scholar] [CrossRef]
- Gao, F.; Hilker, T.; Zhu, X.; Anderson, M.; Masek, J.; Wang, P.; Yang, Y. Fusing Landsat and MODIS Data for Vegetation Monitoring. IEEE Geosci. Remote Sens. Mag. 2015, 3, 47–60. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Hazaymeh, K.; Hassan, Q.K. Spatiotemporal image-fusion model for enhancing temporal resolution of Landsat-8 surface reflectance images using MODIS images. J. Appl. Remote Sens. 2015, 9, 096095. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Lewis, P.; Schaaf, C.; Gao, F.; Hansen, M.; Lindquist, E. Multi-temporal MODIS–Landsat data fusion for relative radiometric normalization, gap filling, and prediction of Landsat data. Remote Sens. Environ. 2008, 112, 3112–3130. [Google Scholar] [CrossRef]
- Fu, D.; Chen, B.; Wang, J.; Zhu, X.; Hilker, T. An improved image fusion approach based on enhanced spatial and temporal the adaptive reflectance fusion model. Remote Sens. 2013, 5, 6346–6360. [Google Scholar] [CrossRef]
- Wu, M.; Niu, Z.; Wang, C.; Wu, C.; Wang, L. Use of MODIS and Landsat time series data to generate high-resolution temporal synthetic Landsat data using a spatial and temporal reflectance fusion model. J. Appl. Remote Sens. 2012, 6, 063507. [Google Scholar]
- Zhang, W.; Li, A.; Jin, H.; Bian, J.; Zhang, Z.; Lei, G.; Qin, Z.; Huang, C. An enhanced spatial and temporal data fusion model for fusing Landsat and MODIS surface reflectance to generate high temporal Landsat-like data. Remote Sens. 2013, 5, 5346–5368. [Google Scholar] [CrossRef]
- Huang, B.; Song, H. Spatiotemporal reflectance fusion via sparse representation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3707–3716. [Google Scholar] [CrossRef]
- Song, H.; Huang, B. Spatiotemporal satellite image fusion through one-pair image learning. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1883–1896. [Google Scholar] [CrossRef]
- Zhou, J.; Kwan, C.; Budavari, B. Hyperspectral image super-resolution: A hybrid color mapping approach. J. Appl. Remote Sens. 2016, 10, 035024. [Google Scholar] [CrossRef]
- Kwan, C.; Budavari, B.; Dao, M.; Ayhan, B.; Bell, J.F. Pansharpening of Mastcam images. In Proceedings of the 2017 IEEE International IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Kwan, C.; Ayhan, B.; Budavari, B. Fusion of THEMIS and TES for Accurate Mars Surface Characterization. In Proceedings of the 2017 IEEE International IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Kwan, C.; Budavari, B.; Bovik, A.C.; Marchisio, G. Blind Quality Assessment of Fused WorldView-3 Images by Using the Combinations of Pansharpening and Hypersharpening Paradigms. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1835–1839. [Google Scholar] [CrossRef]
- Balgopal, R. Applications of the Frobenius Norm Criterion in Multivariate Analysis; University of Alabama: Tuscaloosa, AL, USA, 1996. [Google Scholar]
- Matrix Calculus. Available online: http://www.psi.toronto.edu/matrix/calculus.html (accessed on 20 November 2017).
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A Critical Comparison among Pansharpening Algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2565–2586. [Google Scholar] [CrossRef]
- Alparone, L.; Baronti, S.; Garzelli, A.; Nencini, F. A global quality measurement of pan-sharpened multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 313–317. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F. Hypercomplex quality assessment of multi-/hyper-spectral images. IEEE Geosci. Remote Sens. Lett. 2009, 6, 662–665. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Wofe, R.; Huang, C. Building consistent medium resolution satellite data set using moderate resolution imaging spectroradiometer products as reference. J. Appl. Remote Sens. 2010, 4, 043526. [Google Scholar]
- Vermote, E.F.; El Saleous, N.Z.; Justice, C.O. Atmospheric correction of MODIS data in the visible to middle infrared: First results. Remote Sens. Environ. 2002, 83, 97–111. [Google Scholar] [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).