
A Study on the Speed Decision Control of Agricultural Vehicles in a Collaborative Multi-Machine Operation Scenario
 , ,
, ,
Abstract
1. Introduction
2. Preliminaries
2.1. Constrained Markov Decision-Making (CMDP)
2.2. Actor–Critic Architecture (AC)
2.3. Policy Gradient (PG)
2.4. Proximal Policy Optimization Algorithm (PPO)
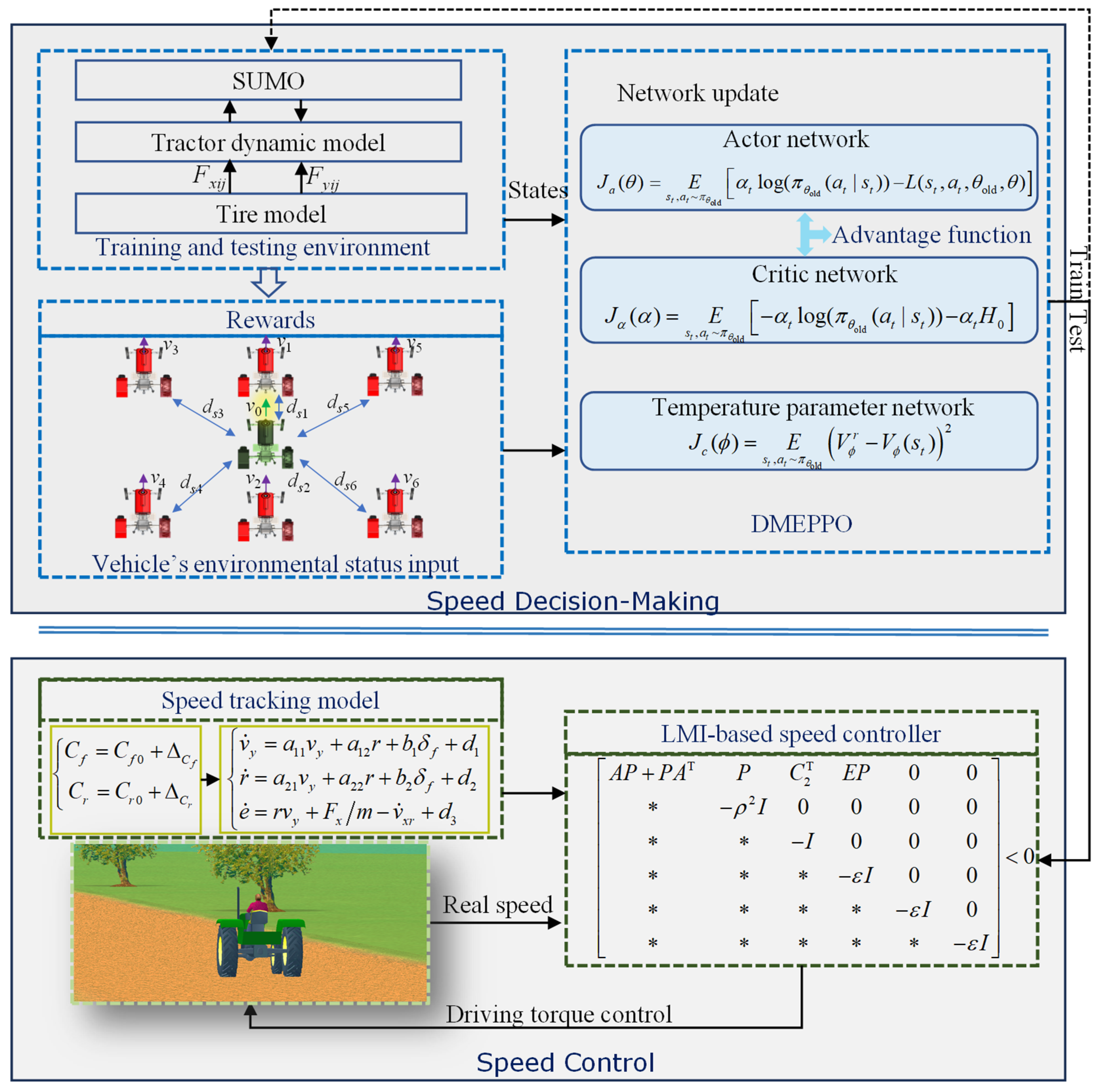
3. Speed Control Modeling for Driverless Agricultural Vehicles
4. Speed Decision-Making and Control Design
4.1. Deep Maximization Entropy-Constrained Reinforcement Learning
| Algorithm 1. DMEPPO pseudocodes. |
| Input: Environment ε; Heuristic target entropy threshold H0 |
| Initialize: Parameters θ, ϕ, ϑ |
| for do |
| Run the strategy T times and collect |
| Estimating the dominant function: |
| for do |
| Updating parameters with gradient descent θ, ϕ, ϑ |
| end for |
| end for |
4.2. Multi-Target Speed Rewards and Network Settings
4.2.1. Consider the Rewards of Operational Efficiency
4.2.2. Consider Fuel Economy Rewards
4.2.3. Consider the Rewards of Safety
4.2.4. Consider the Rewards of Smooth Driving
4.2.5. Multi-Objective Awards
4.2.6. Network Settings
4.3. Design of LMI-Based Speed Tracking Controller
- (1)
- S < 0;
- (2)
- If S11 < 0, then ;
- (3)
- If S22 < 0, then .
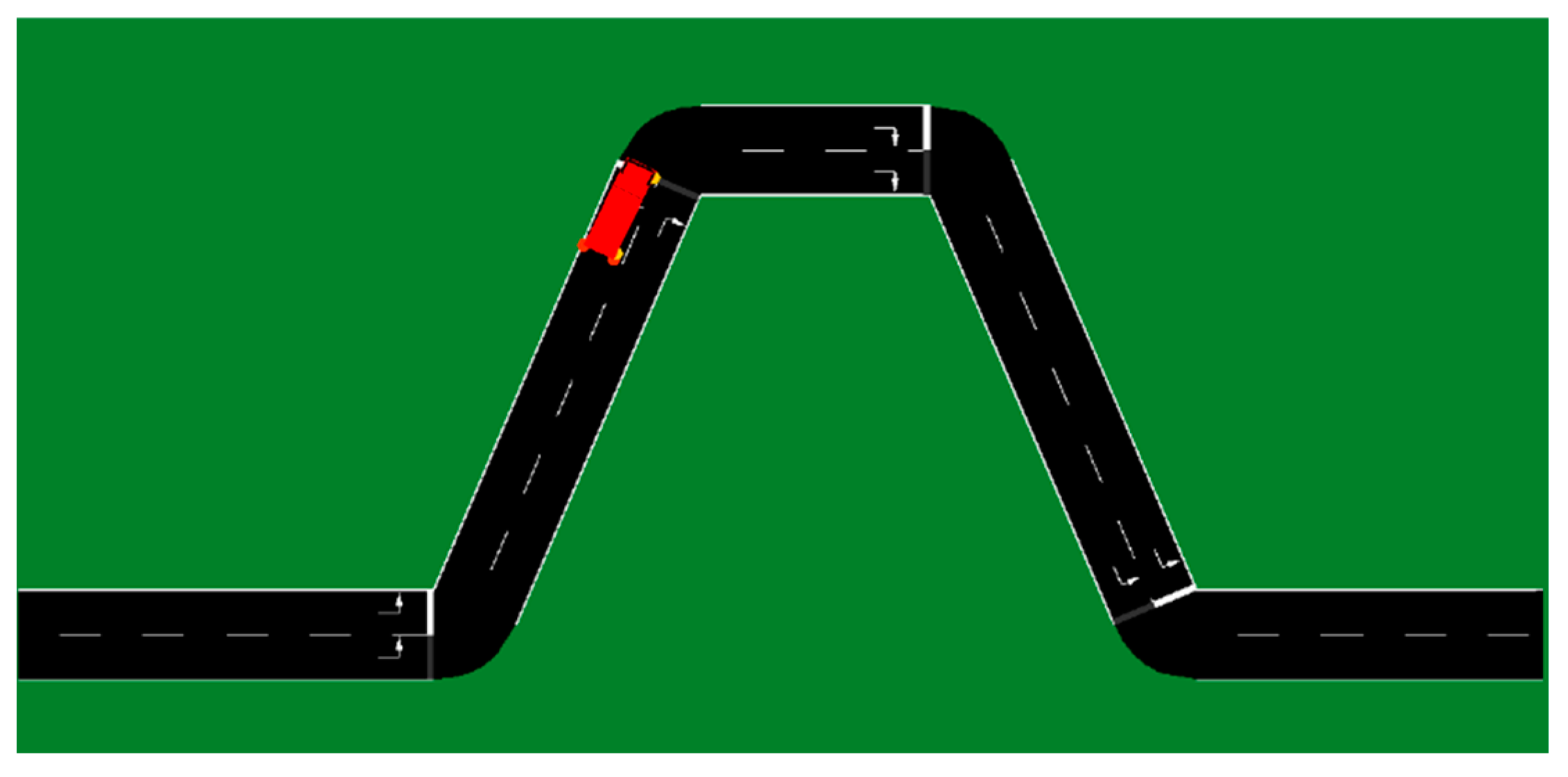
5. Experimental Method
6. Results and Discussion
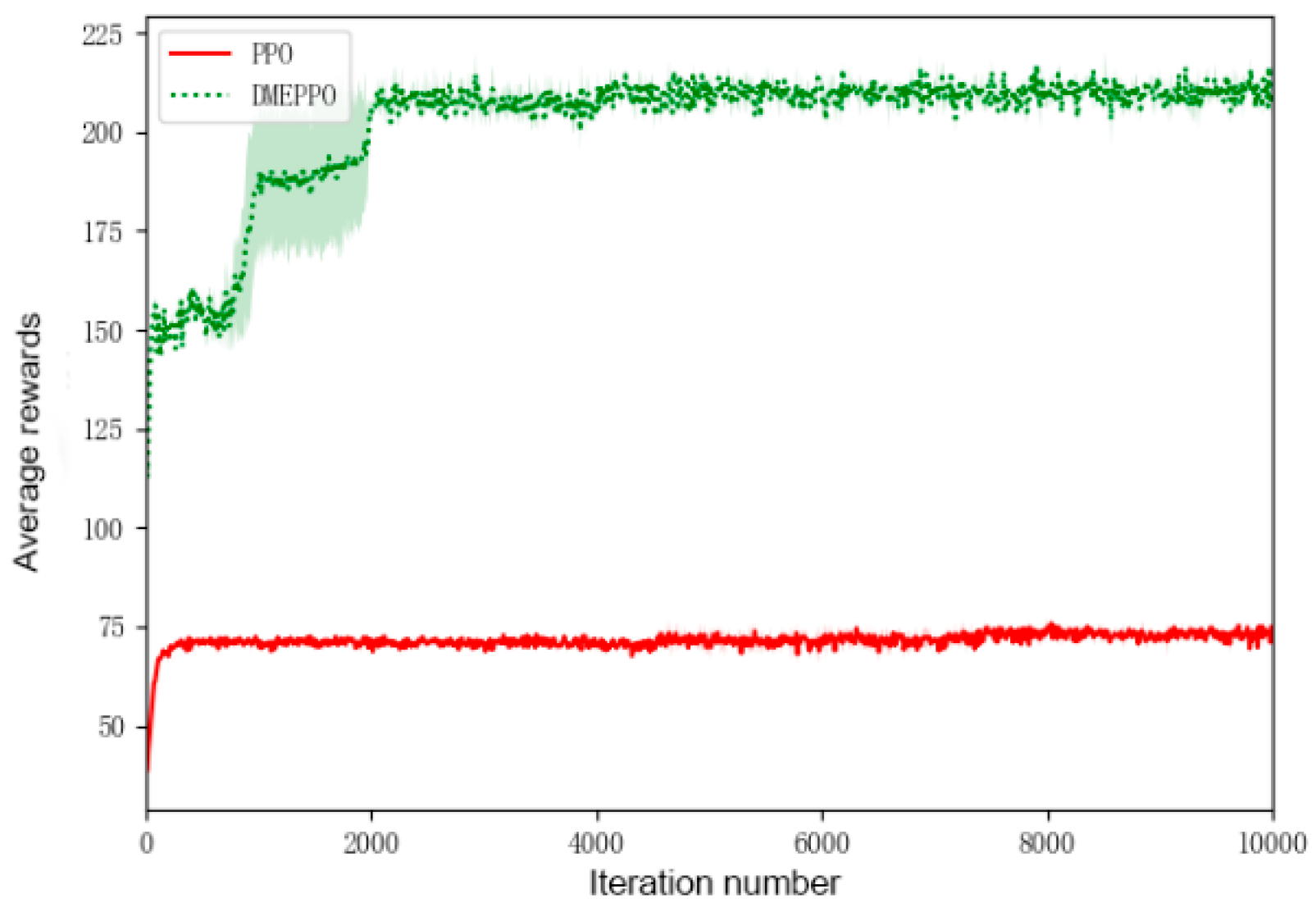
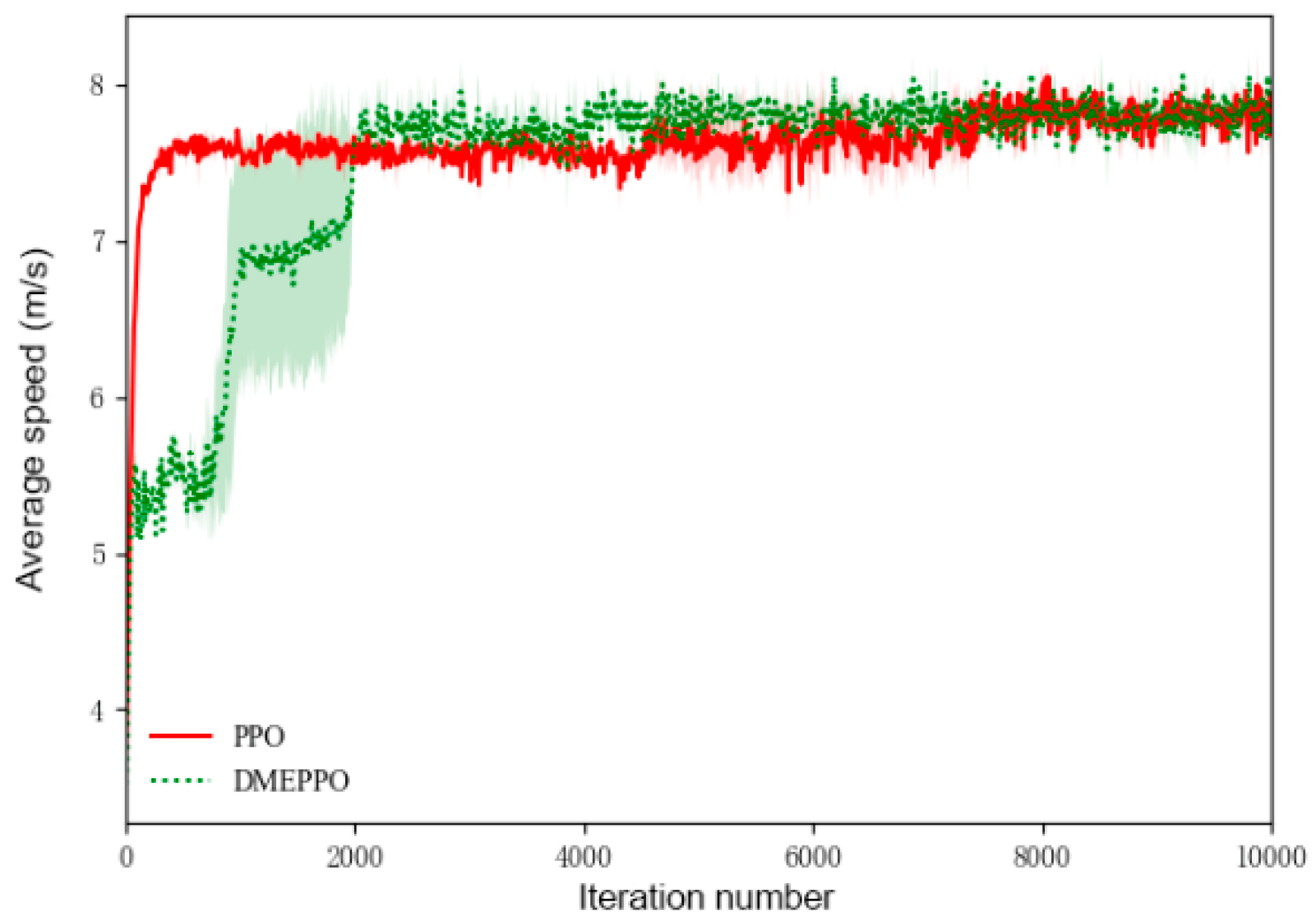
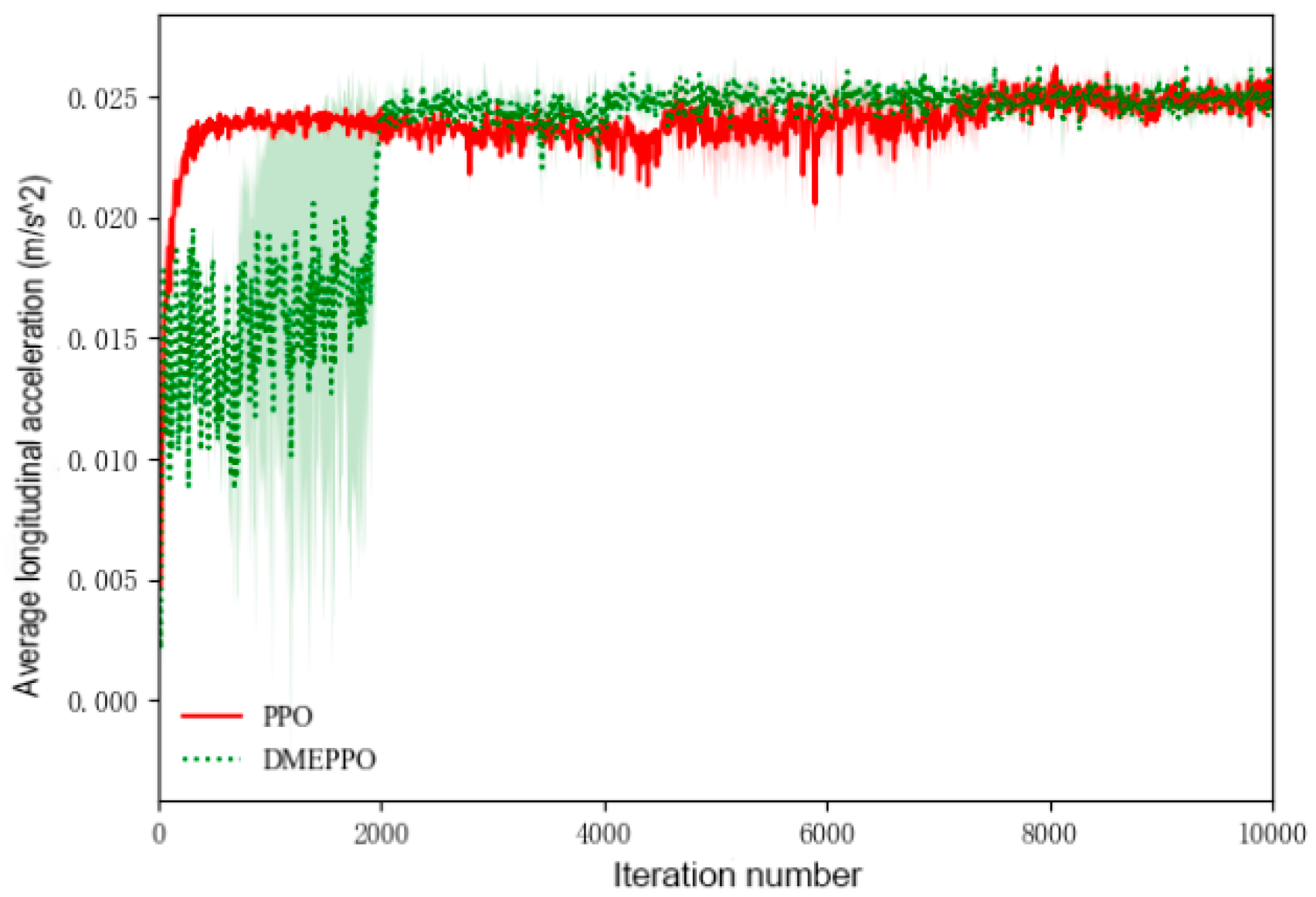
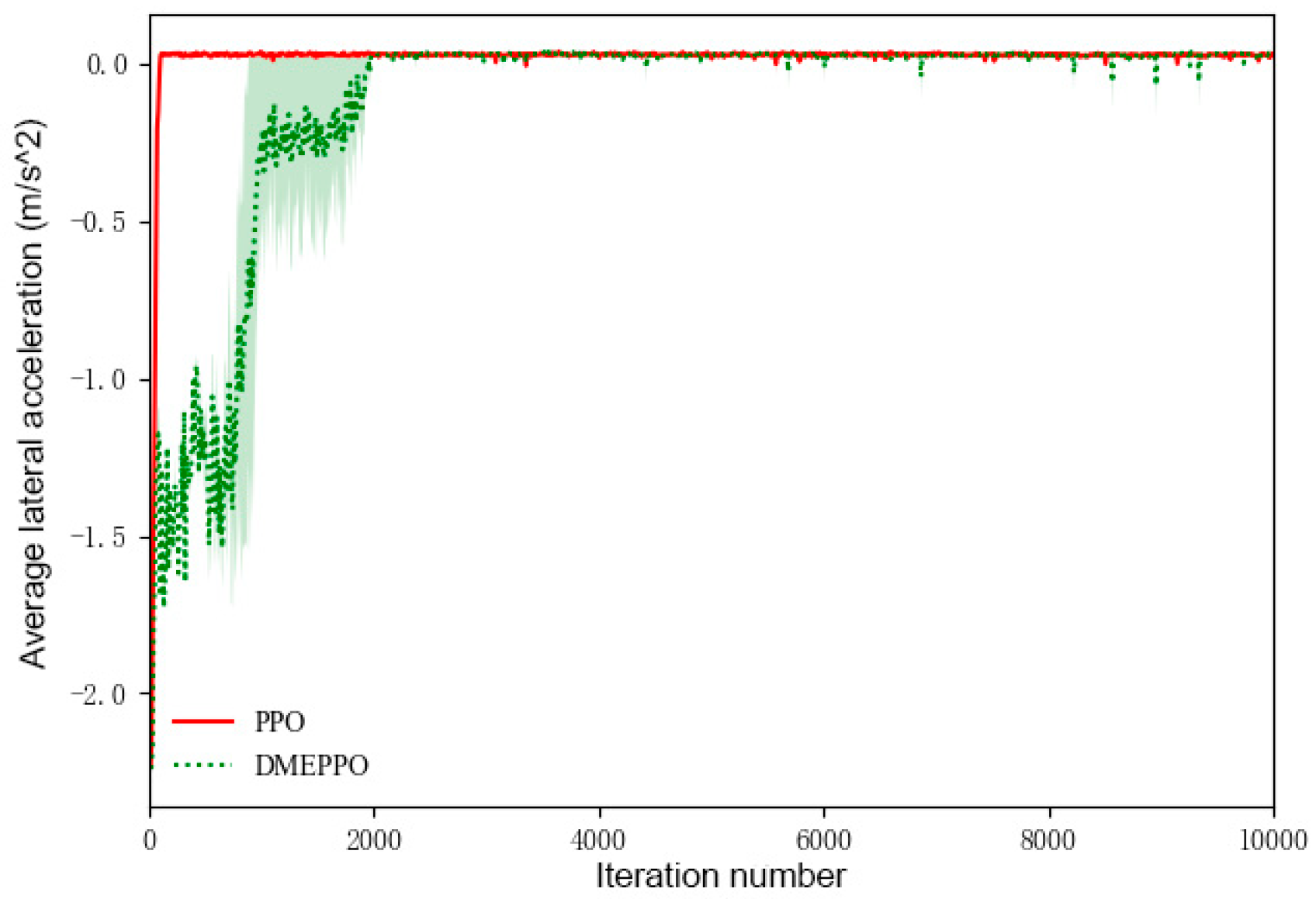
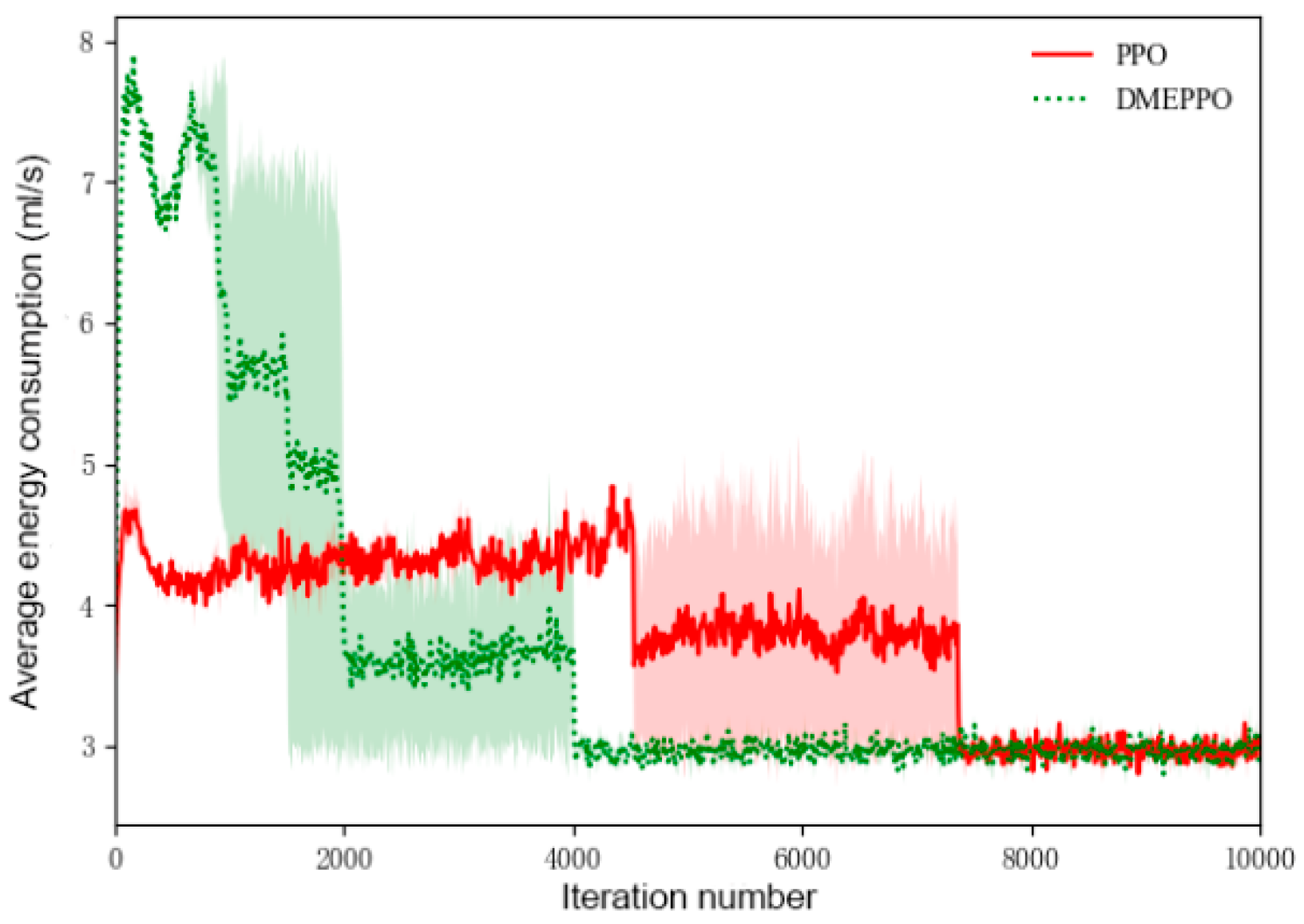
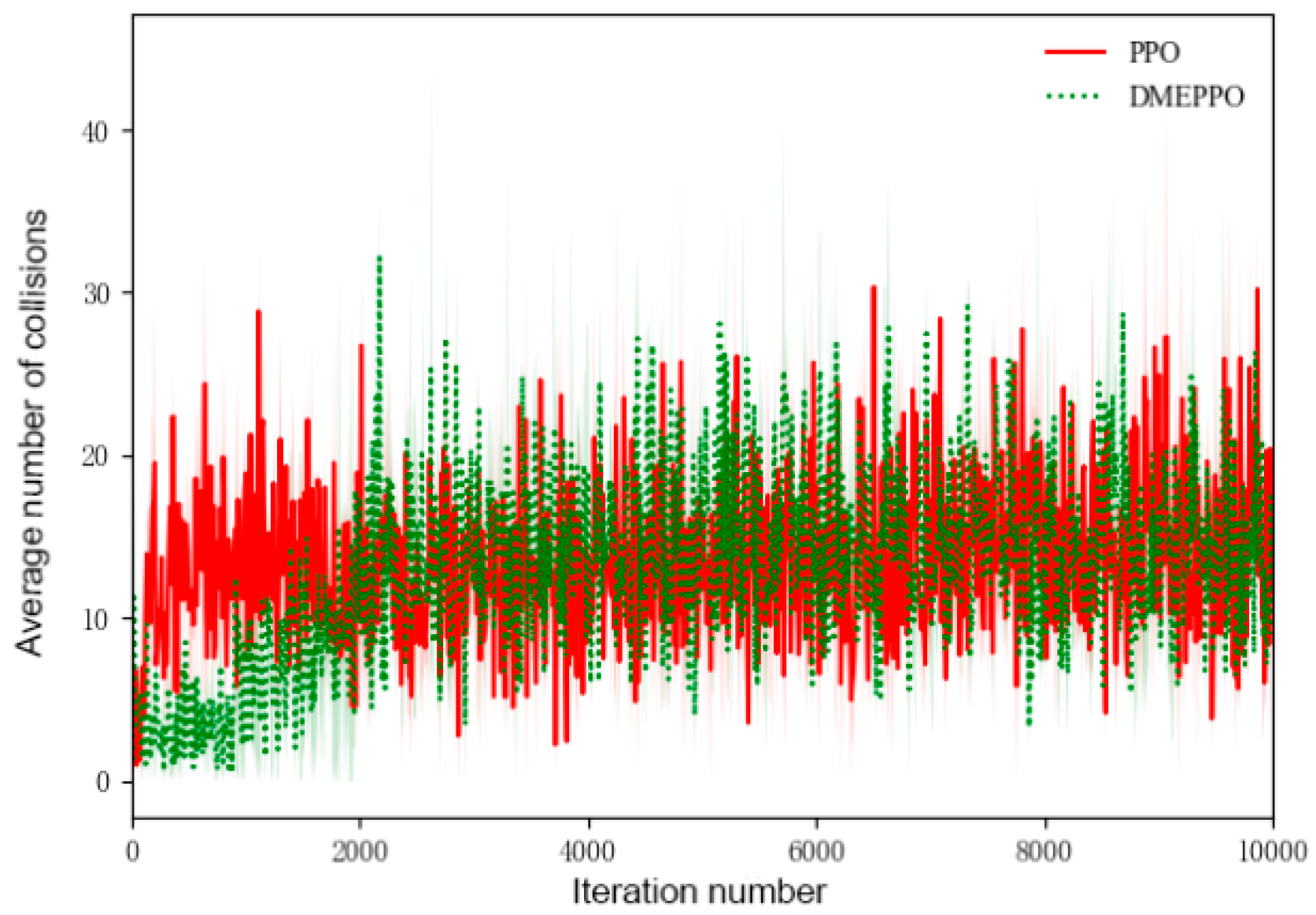
6.1. Speed Decision-Making Training Experiment
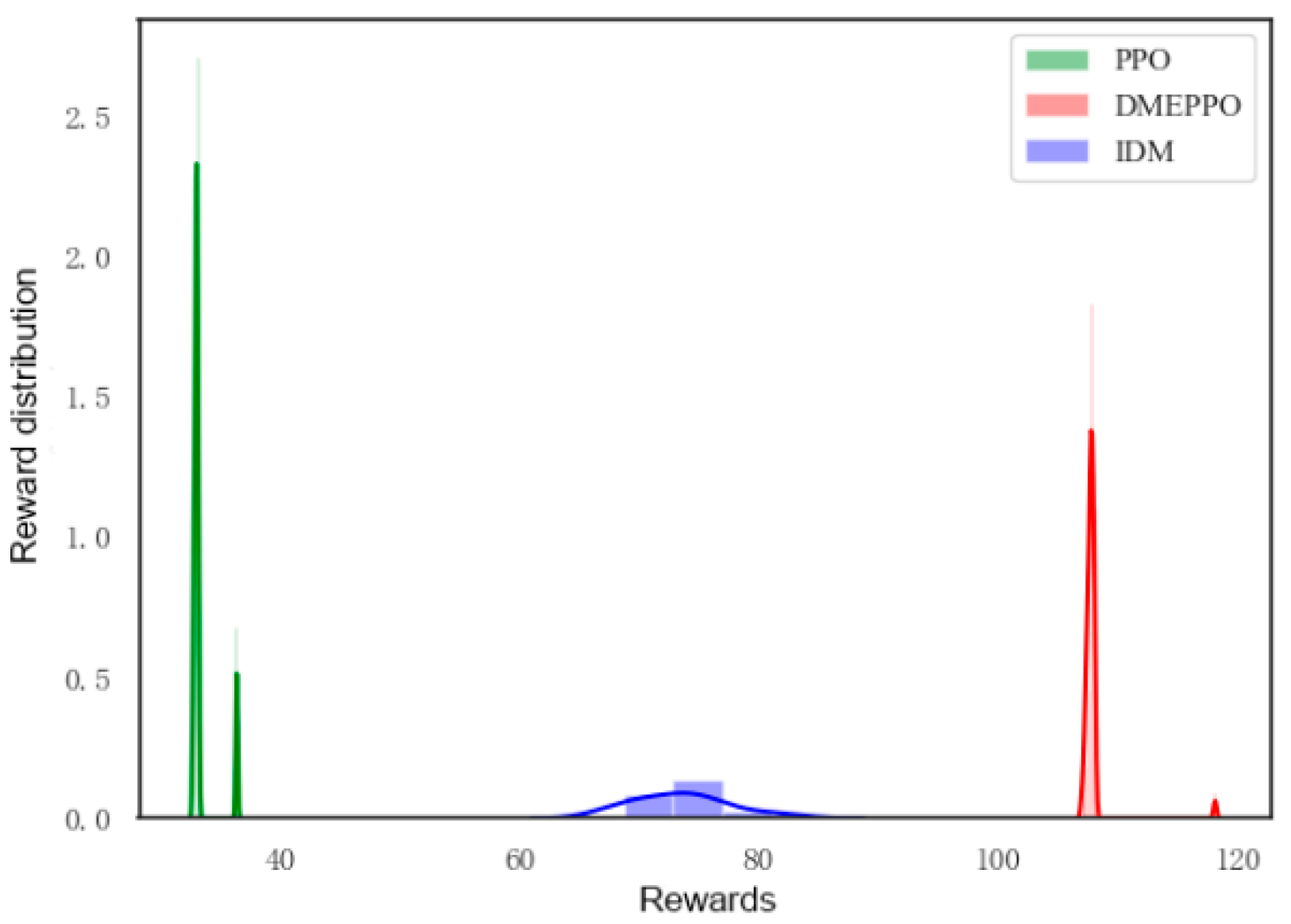
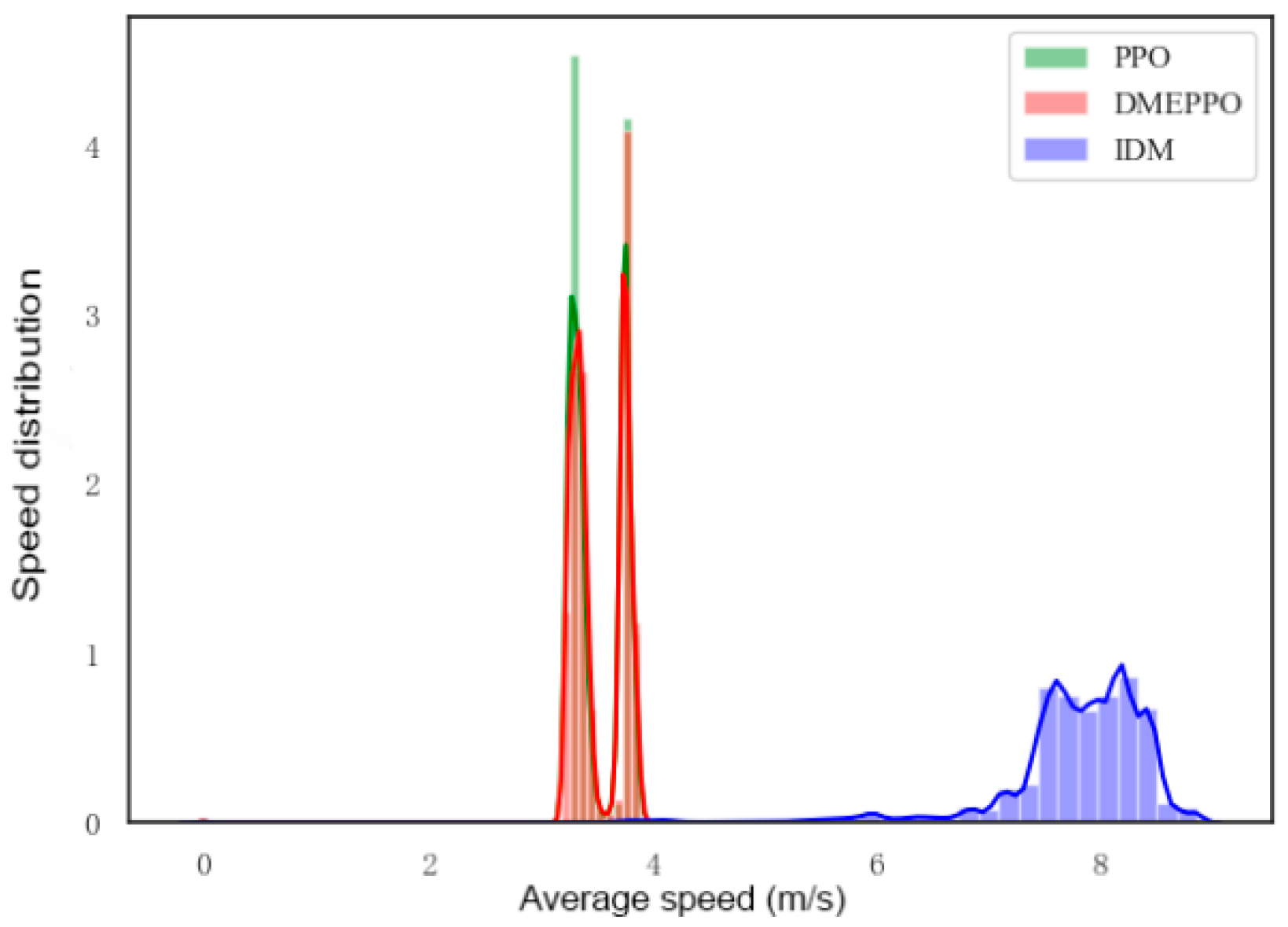
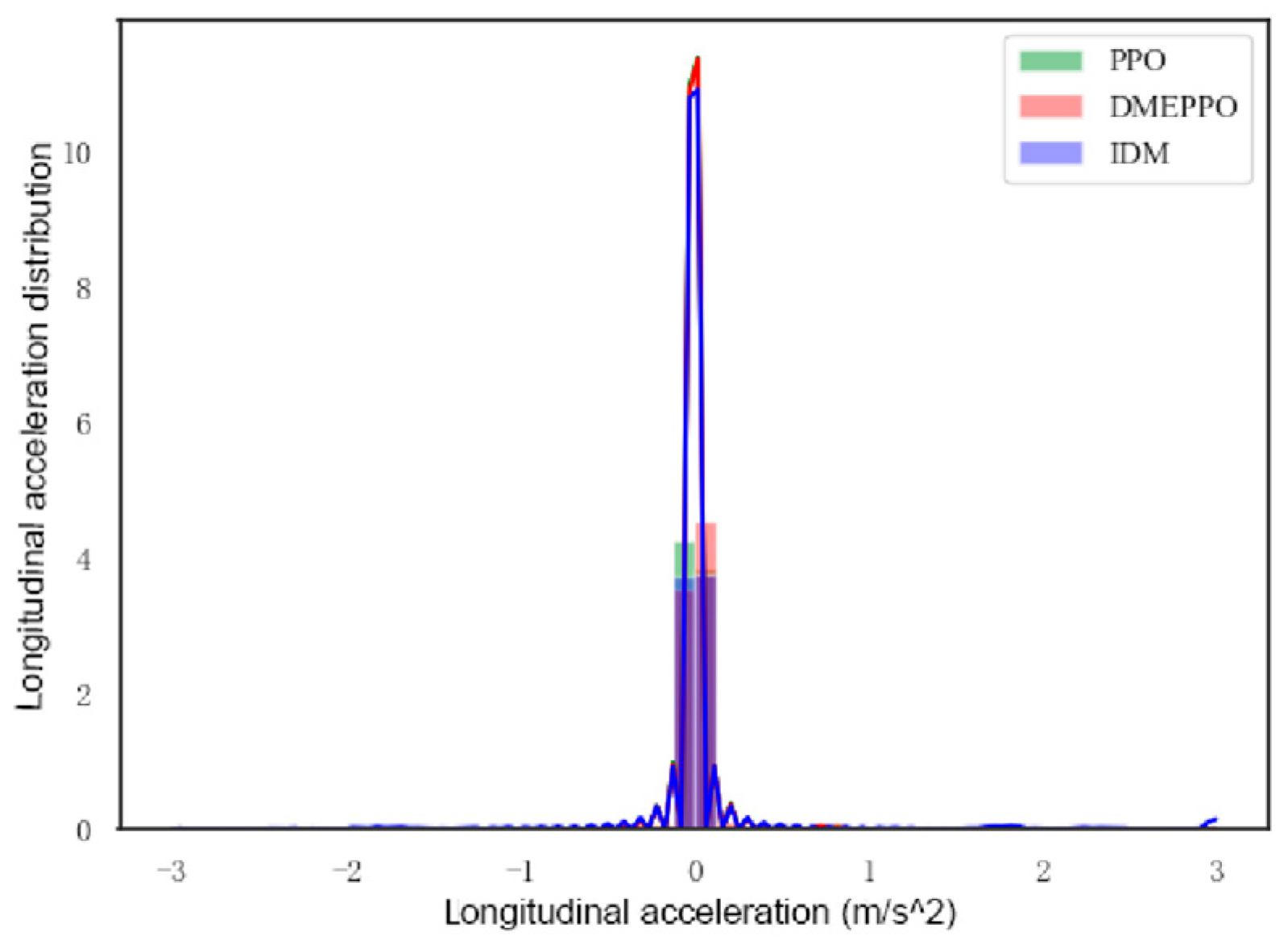
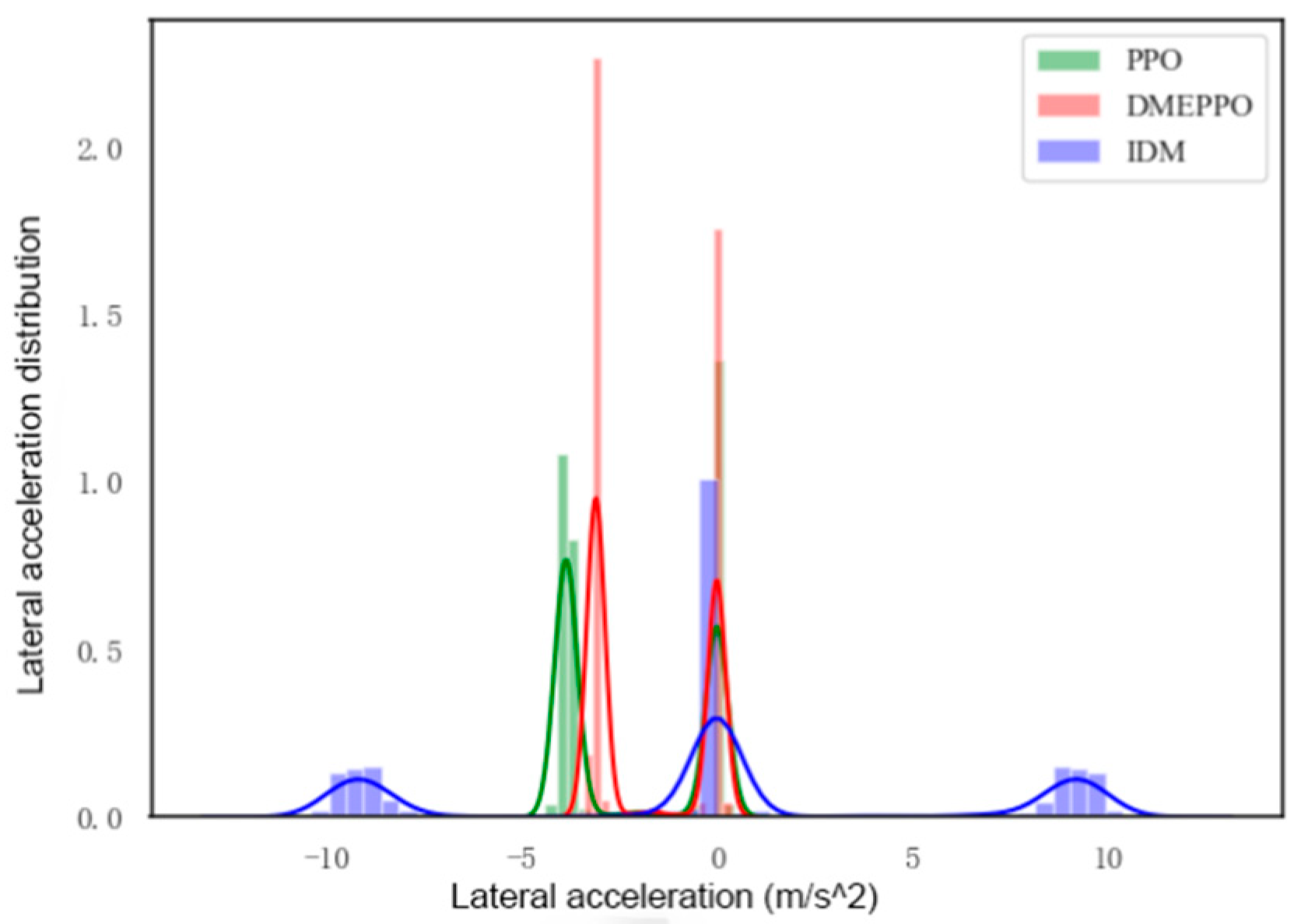
6.2. Speed Decision-Making Test Experiment
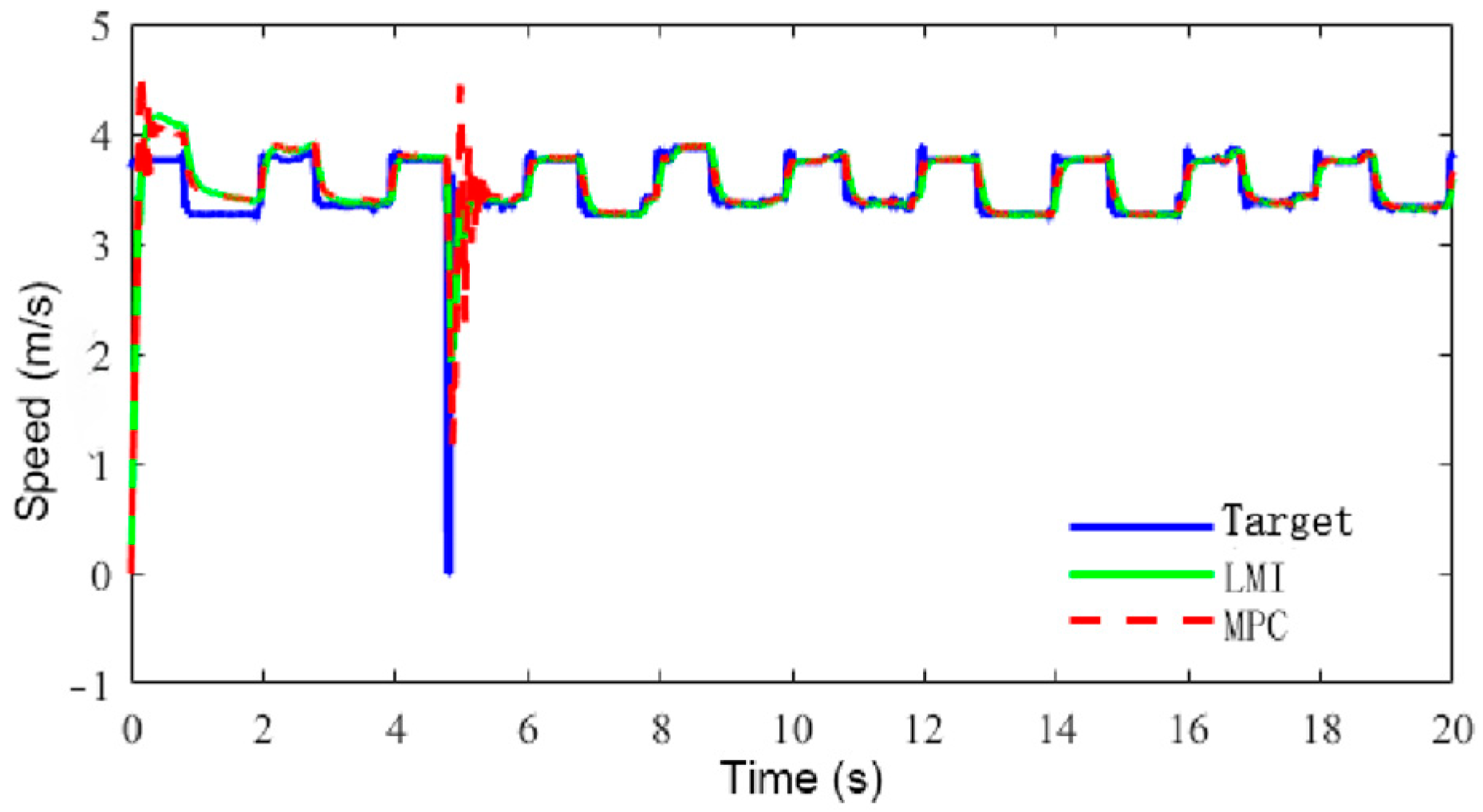
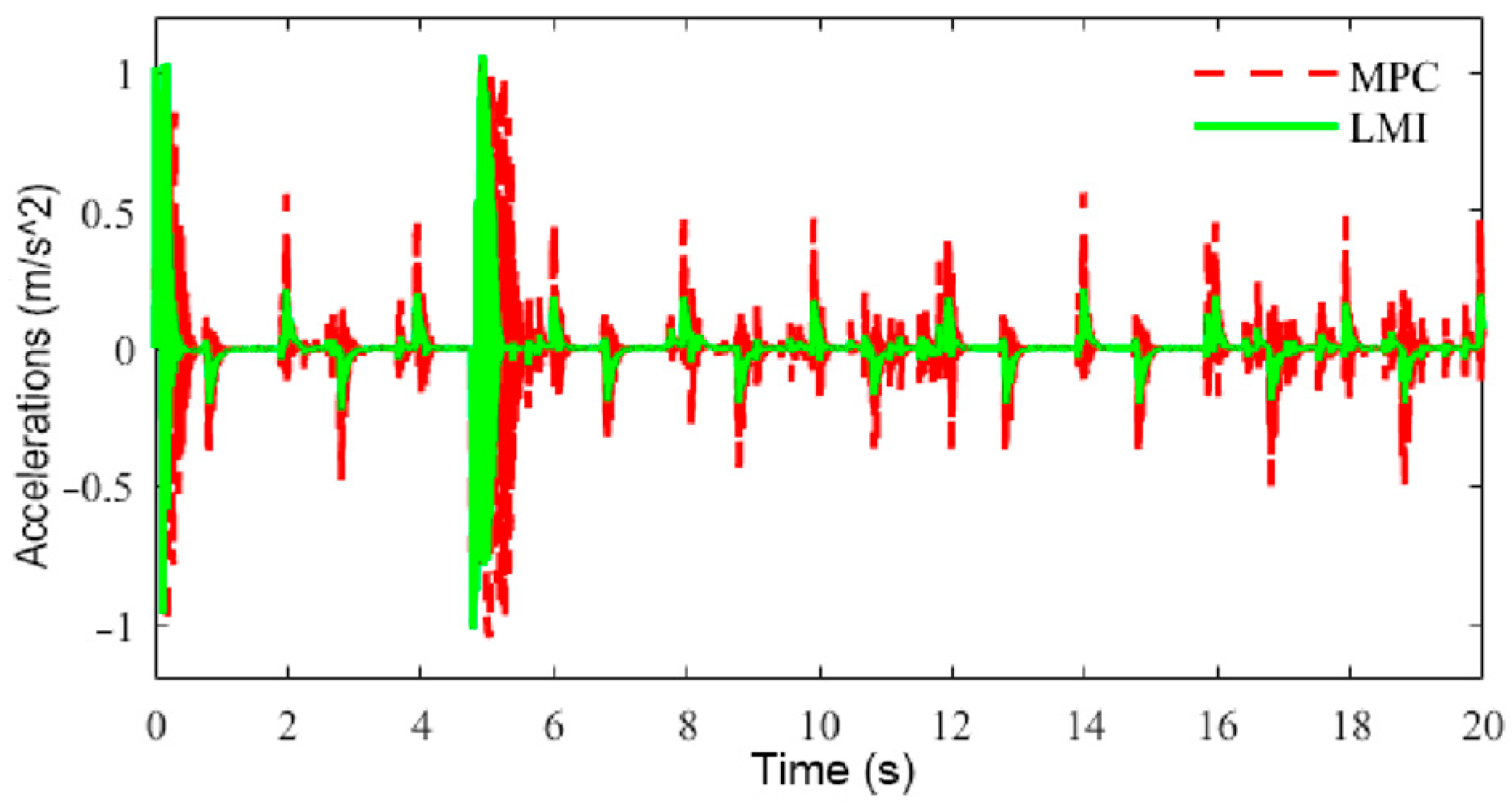
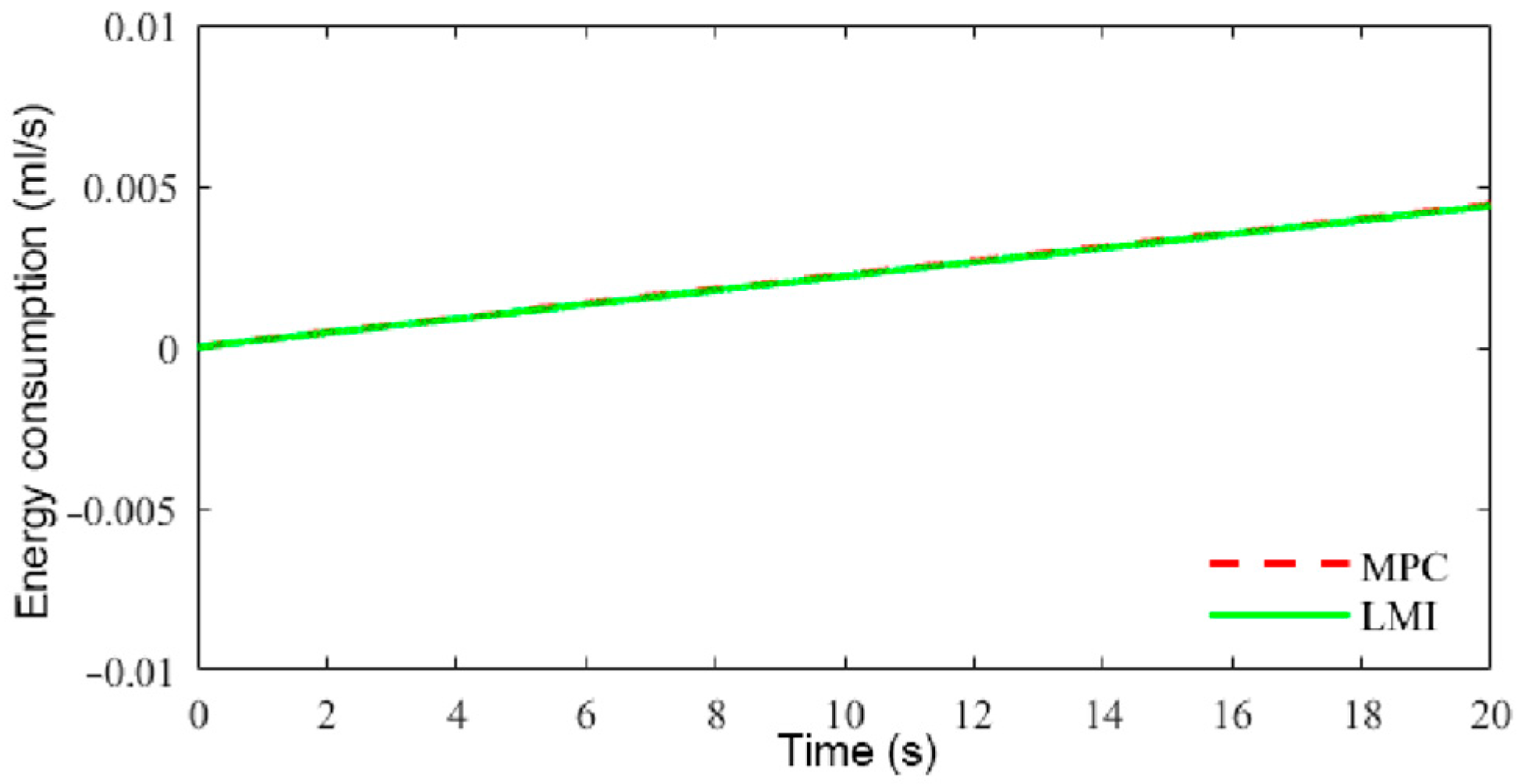
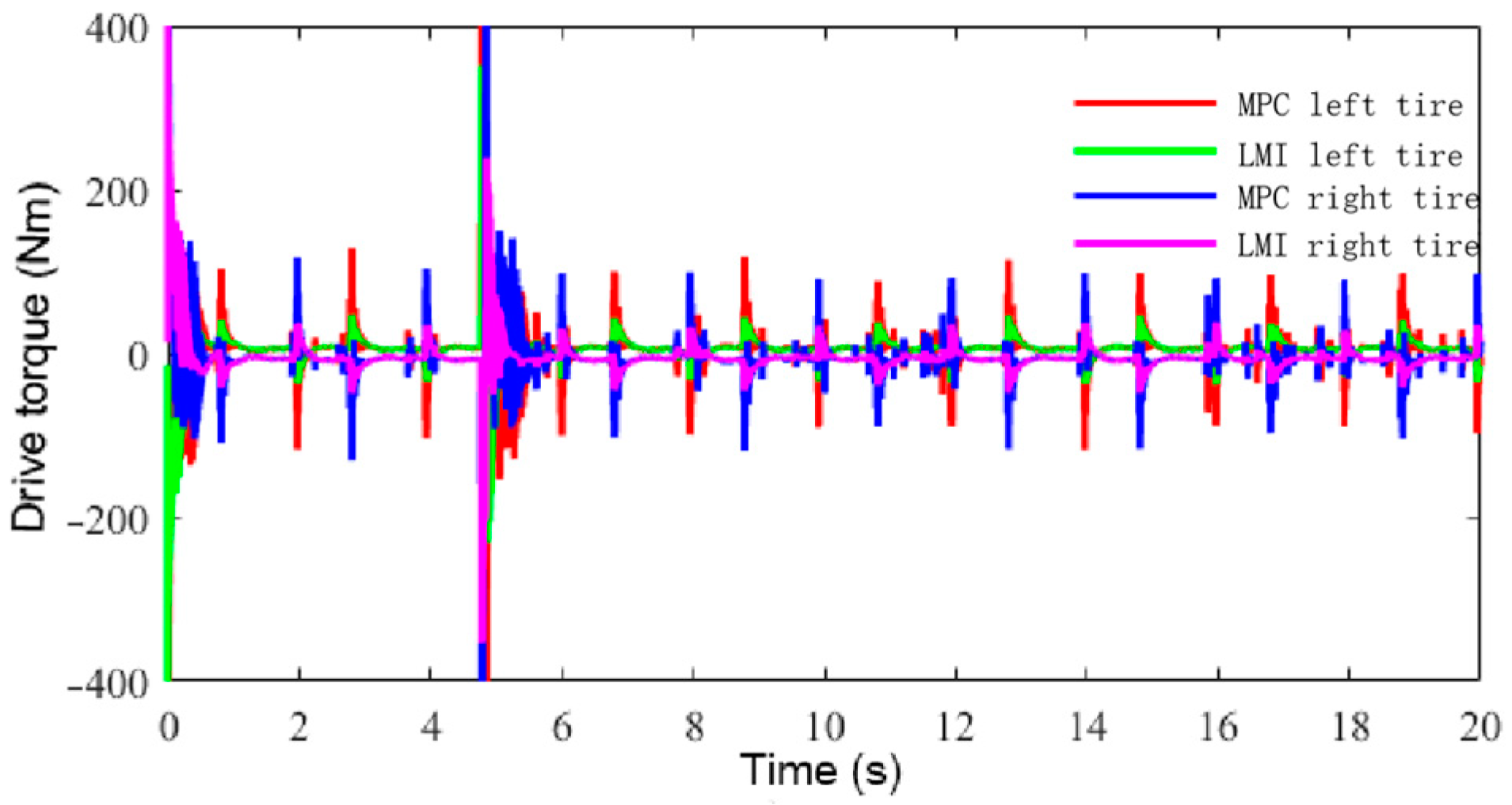
6.3. Speed Tracking Control HIL Simulation Test
7. Conclusions
- (1)
- It could be seen from the training and testing of the DMEPPO speed decision-making strategy that the trained speed decision-making model is able to converge quickly within 2000 iterations and was able to complete decision-making when facing multi-objective tasks in the test.
- (2)
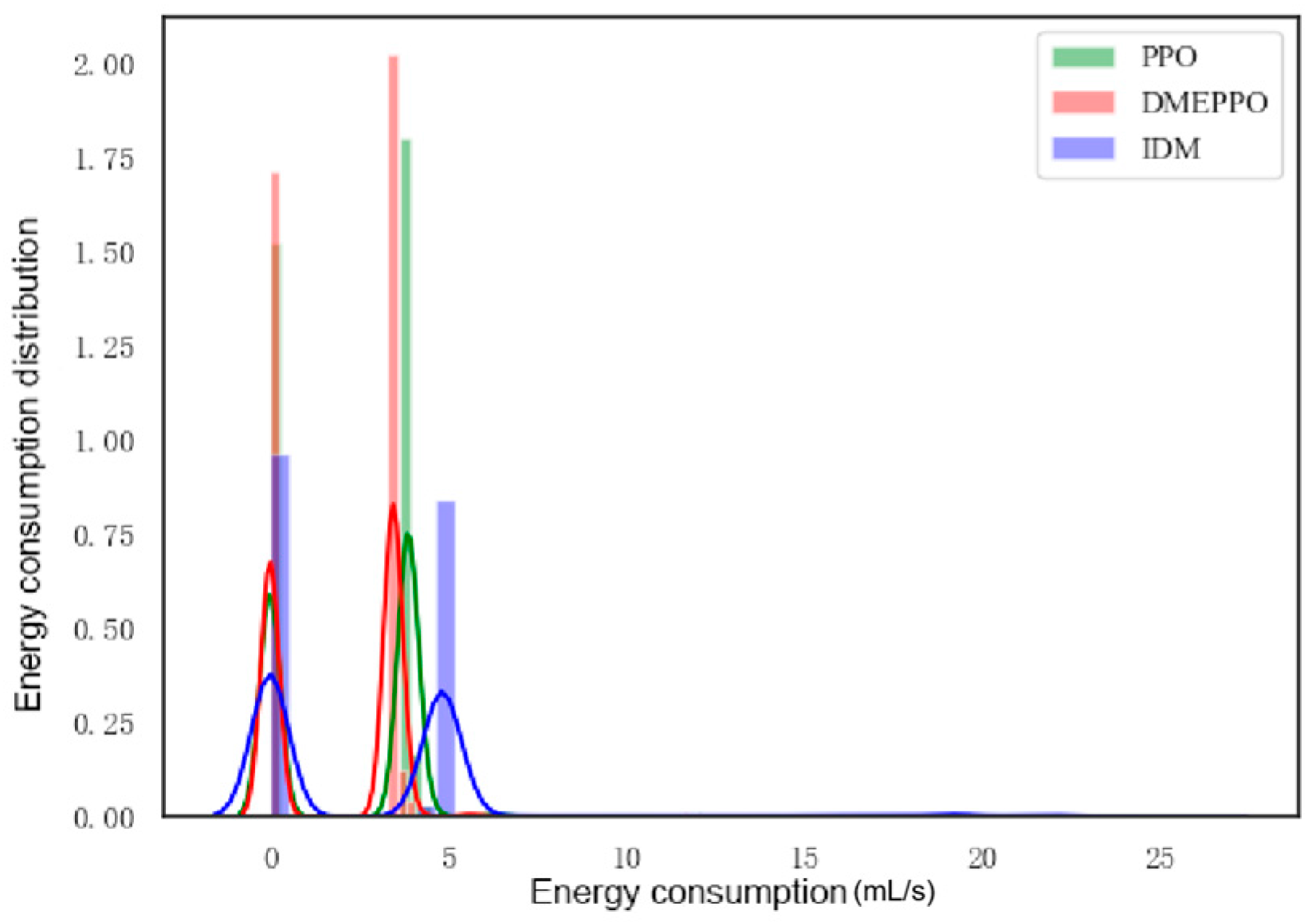
- The suggested LMI-based speed controller effectively maintained the robust tracking of the intended speed amidst uncertainty and disturbances. The comprehensive performance of the controller resulted in robustness to uncertainties and disturbances, smooth driving with frequent acceleration and deceleration, low power consumption, and good output responsiveness.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Lai, J.; Li, P.; Awad, O.I.; Zhu, Y. Prediction horizon-varying model predictive control (MPC) for autonomous vehicle control. Electronics 2024, 13, 1442. [Google Scholar] [CrossRef]
- Zhao, S.; Leng, Y.; Shao, Y. Explicit model predictive control of multi-objective adaptive cruise of vehicle. J. Transp. Eng. 2020, 20, 206–216. [Google Scholar]
- Moser, D.; Schmied, R.; Waschl, H.; del Re, L. Flexible spacing adaptive cruise control using stochastic model predictive control. IEEE Trans. Control Syst. Technol. 2017, 26, 114–127. [Google Scholar] [CrossRef]
- Jin, J.; Li, Y.; Huang, H.; Dong, Y.; Liu, P. A variable speed limit control approach for freeway tunnels based on the model-based reinforcement learning framework with safety perception. Accid. Anal. Prev. 2024, 201, 107570. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, J.; Zhou, H.; Chng, C.B.; Chui, C.K.; Zhao, S. Comprehensive evaluation of deep reinforcement learning for permanent magnet synchronous motor current tracking and speed control applications. Eng. Appl. Artif. Intell. 2025, 149, 110551. [Google Scholar] [CrossRef]
- Goodall, N.J.; Lan, C.L. Car-following characteristics of adaptive cruise control from empirical data. J. Transp. Eng. Part A Syst. 2020, 146, 04020097. [Google Scholar] [CrossRef]
- Melson, C.L.; Levin, M.W.; Hammit, B.E.; Boyles, S.D. Dynamic traffic assignment of cooperative adaptive cruise control. Transp. Res. Part C Emerg. Technol. 2018, 90, 114–133. [Google Scholar] [CrossRef]
- Liu, H.; Wang, H.; Niu, K.; Zhu, R.; Zhang, Z. Research on car-following models and platoon speed guidance based on real datasets in connected and automated environments. Transp. Lett. 2025, 1–15. [Google Scholar] [CrossRef]
- Wang, C.; Gong, S.; Zhou, A.; Li, T.; Peeta, S. Cooperative adaptive cruise control for connected autonomous vehicles by factoring communication-related constraints. Transp. Res. Part C Emerg. Technol. 2020, 113, 124–145. [Google Scholar] [CrossRef]
- Li, T.; Chen, D.; Zhou, H.; Laval, J.; Xie, Y. Car-following behavior characteristics of adaptive cruise control vehicles based on empirical experiments. Transp. Res. Part B Methodol. 2021, 147, 67–91. [Google Scholar] [CrossRef]
- You, Z. Design of automotive mechanical automatic transmission system based on torsional vibration reduction. J. Vibroeng. 2023, 25, 683–697. [Google Scholar] [CrossRef]
- Geng, G.; Jiang, F.; Chai, C.; Wu, J.; Zhu, Y.; Zhou, G.; Xiao, M. Design and experiment of magnetic navigation control system based on fuzzy PID strategy. Mech. Sci. 2022, 13, 921–931. [Google Scholar] [CrossRef]
- Wang, L.; Li, L.; Wang, H.; Zhu, S.; Zhai, Z.; Zhu, Z. Real-time vehicle identification and tracking during agricultural master-slave follow-up operation using improved YOLO v4 and binocular positioning. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2023, 237, 1393–1404. [Google Scholar] [CrossRef]
- Chu, L.; Li, H.; Xu, Y.; Zhao, D.; Sun, C. Research on longitudinal control algorithm of adaptive cruise control system for pure electric vehicles. World Electr. Veh. J. 2023, 14, 32. [Google Scholar] [CrossRef]
- Mehraban, Z.; Zadeh, A.Y.; Khayyam, H.; Mallipeddi, R.; Jamali, A. Fuzzy adaptive cruise control with model predictive control responding to dynamic traffic conditions for automated driving. Eng. Appl. Artif. Intell. 2024, 136, 109008. [Google Scholar] [CrossRef]
- Yin, X.; Wang, Y.; Chen, Y.; Jin, C.; Du, J. Development of autonomous navigation controller for agricultural vehicles. Int. J. Agric. Biol. Eng. 2020, 13, 70–76. [Google Scholar] [CrossRef]
- Wu, Z.; Xie, B.; Li, Z.; Chi, R.; Ren, Z.; Du, Y.; Inoue, E.; Mitsuoka, M.; Okayasu, T.; Hirai, Y. Modelling and verification of driving torque management for electric tractor: Dual-mode driving intention interpretation with torque demand restriction. Biosyst. Eng. 2019, 182, 65–83. [Google Scholar] [CrossRef]
- Saeed, M.A.; Ahmed, N.; Hussain, M.; Jafar, A. A comparative study of controllers for optimal speed control of hybrid electric vehicle. In Proceedings of the 2016 International Conference on Intelligent Systems Engineering (ICISE), Islamabad, Pakistan, 15–17 January 2016; IEEE: New York, NY, USA, 2016; pp. 1–4. [Google Scholar]
- Zhu, M.; Chen, H.; Xiong, G. A model predictive speed tracking control approach for autonomous ground vehicles. Mech. Syst. Signal Process. 2017, 87, 138–152. [Google Scholar] [CrossRef]
- Tanaka, T.; Nakayama, S.; Wasa, Y.; Hirata, K.; Hatanaka, T. A continuous-time primal-dual algorithm with convergence speed guarantee utilizing constraint-based control. SICE J. Control. Meas. Syst. Integr. 2025, 18, 2485496. [Google Scholar] [CrossRef]
- He, X.; Fei, C.; Liu, Y.; Yang, K.; Ji, X. Multi-objective longitudinal decision-making for autonomous electric vehicle: A entropy-constrained reinforcement learning approach. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Xiao, B.; Yang, W.; Wu, J.; Walker, P.D.; Zhang, N. Energy management strategy via maximum entropy reinforcement learning for an extended range logistics vehicle. Energy 2022, 253, 124105. [Google Scholar] [CrossRef]
- He, X.; Huang, W.; Lv, C. Trustworthy autonomous driving via defense-aware robust reinforcement learning against worst-case observational perturbations. Transp. Res. Part C Emerg. Technol. 2024, 163, 104632. [Google Scholar] [CrossRef]
- He, X.; Hao, J.; Chen, X.; Wang, J.; Ji, X.; Lv, C. Robust Multiobjective Reinforcement Learning Considering Environmental Uncertainties. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 6368–6382. [Google Scholar] [CrossRef] [PubMed]
- Tang, C.Y.; Liu, C.H.; Chen, W.K.; You, S.D. Implementing action mask in proximal policy optimization (PPO) algorithm. ICT Express 2020, 6, 200–203. [Google Scholar] [CrossRef]
- Liang, J.; Feng, J.; Fang, Z.; Lu, Y.; Yin, G.; Mao, X.; Wu, J.; Wang, F. An energy-oriented torque-vector control framework for distributed drive electric vehicles. IEEE Trans. Transp. Electrif. 2023, 9, 4014–4031. [Google Scholar] [CrossRef]
- Feng, J.; Yin, G.; Liang, J.; Lu, Y.; Xu, L.; Zhou, C.; Peng, P.; Cai, G. A Robust Cooperative Game Theory based Human-machine Shared Steering Control Framework. IEEE Trans. Transp. Electrif. 2023, 10, 6825–6840. [Google Scholar] [CrossRef]
- Bui, V.H.; Mohammadi, S.; Das, S.; Hussain, A.; Hollweg, G.V.; Su, W. A critical review of safe reinforcement learning strategies in power and energy systems. Eng. Appl. Artif. Intell. 2025, 143, 110091. [Google Scholar] [CrossRef]
- Park, I.S.; Park, C.E.; Kwon, N.K.; Park, P. Dynamic output-feedback control for singular interval-valued fuzzy systems: Linear matrix inequality approach. Inf. Sci. 2021, 576, 393–406. [Google Scholar] [CrossRef]
- Thabet, A.S.M.; Zengin, A. Optimizing Dijkstra’s Algorithm for Managing Urban Traffic Using Simulation of Urban Mobility (Sumo) Software. Ann. Math. Phys. 2024, 7, 206–213. [Google Scholar]
- Xu, G.; Chen, M.; He, X.; Liu, Y.; Wu, J.; Diao, P. Research on state-parameter estimation of unmanned Tractor—A hybrid method of DEKF and ARBFNN. Eng. Appl. Artif. Intell. 2024, 127, 107402. [Google Scholar] [CrossRef]
- Naseri, K.; Vu, M.T.; Mobayen, S.; Najafi, A.; Fekih, A. Design of linear matrix inequality-based adaptive barrier global sliding mode fault tolerant control for uncertain systems with faulty actuators. Mathematics 2022, 10, 2159. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Variable | Input Meaning | Units |
|---|---|---|---|
| 1 | v0 | The speed of the trained agricultural vehicle | m/s |
| 2 | v1 | Speed of the machine in front of the agricultural vehicle | m/s |
| 3 | v2 | Speed of the machine behind the agricultural vehicle | m/s |
| 4 | v3 | Speed of the machine in front of and on the left side of the agricultural vehicle | m/s |
| 5 | v4 | Speed of the machine behind and on the left side of the agricultural vehicle | m/s |
| 6 | v5 | Speed of the machine to the right and in front of the agricultural vehicle | m/s |
| 7 | v6 | Speed of the machine to the right and at the rear of the agricultural vehicle | m/s |
| 8 | ds1 | Distance between agricultural vehicle and machine in front | m |
| 9 | ds2 | Distance between agricultural vehicle and machine behind | m |
| 10 | ds3 | Distance between the agricultural vehicle and the machine in front of it on the left-hand side | m |
| 11 | ds4 | Distance between agricultural vehicle and machine to left and at rear | m |
| 12 | ds5 | Distance between the agricultural vehicle and the machine in front of it on the right-hand side | m |
| 13 | ds6 | Distance between agricultural vehicle and machine to the right and at rear | m |
| 14 | ni | Number of paths | |
| 15 | as0 | Training the longitudinal acceleration of the agricultural vehicle | m/s2 |
| 16 | r0 | Training the agricultural vehicle’s yaw speed | rad/s |
| 17 | mi | Agricultural vehicle operating mode weights |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, G.; Feng, J.; Wang, Q.; Xu, D.; Sun, J.; Chen, M.; Wu, J. A Study on the Speed Decision Control of Agricultural Vehicles in a Collaborative Multi-Machine Operation Scenario. Sustainability 2025, 17, 4326. https://doi.org/10.3390/su17104326
Xu G, Feng J, Wang Q, Xu D, Sun J, Chen M, Wu J. A Study on the Speed Decision Control of Agricultural Vehicles in a Collaborative Multi-Machine Operation Scenario. Sustainability. 2025; 17(10):4326. https://doi.org/10.3390/su17104326
Chicago/Turabian StyleXu, Guangfei, Jiwei Feng, Quanjin Wang, Dongxin Xu, Jingbin Sun, Meizhou Chen, and Jian Wu. 2025. "A Study on the Speed Decision Control of Agricultural Vehicles in a Collaborative Multi-Machine Operation Scenario" Sustainability 17, no. 10: 4326. https://doi.org/10.3390/su17104326
APA StyleXu, G., Feng, J., Wang, Q., Xu, D., Sun, J., Chen, M., & Wu, J. (2025). A Study on the Speed Decision Control of Agricultural Vehicles in a Collaborative Multi-Machine Operation Scenario. Sustainability, 17(10), 4326. https://doi.org/10.3390/su17104326