Abstract
Urban metro cross-section flow is the passenger flow that travels through a metro section. Its volume is a critical parameter for planning operation diagrams and improving the service quality of urban subway systems. This makes it possible to better plan the drive for the sustainable development of a city. This paper proposes an improved model for predicting urban metro section flow, combining time series decomposition and a generative adversarial network. First, an urban metro section flow sequence is decomposed using EMD (Empirical Mode Decomposition) into several IMFs (Intrinsic Mode Functions) and a trend function. The sum of all the IMF components is treated as the periodic component, and the trend function is considered the trend component, which are fitted by Fourier series function and spline interpolation, respectively. By subtracting the sum of the periodic and trend components from the urban metro section flow sequence, the error is regarded as the residual component. Finally, a GAN (generative adversarial network) based on the fusion graph convolutional neural network is used to predict the new residual component, which considers the spatial correlation between different sites of urban metro sections. The Chengdu urban metro system data in China show that the proposed model, through incorporating EMD and a generative adversarial network, achieves a 15–20% improvement in prediction accuracy at the cost of a 10% increase in the calculation time, meaning it demonstrates good prediction accuracy and reliability.
1. Introduction
1.1. Forecast Methods
With the increasing scale of rail transit in developing countries, rail transit has officially entered the network operation stage. Accurate section flow prediction makes a reasonable rail vehicle traffic scheduling plan, selects the emergency rescue location, improves the passenger transportation efficiency, and reduces costs. It is also conducive to the sustainable development of cities [1]. Over decades, scholars have conducted in-depth research on the forecasting problem [2]. Short-term traffic forecasting models are mainly divided into three types: parametric models, non-parametric models, and hybrid models. Parametric models, including the ARIMA (Autoregressive Integrated Moving Average) model [3] and Kalman filtering [4], are usually based on statistical theory, and in the context of these models, it is a prerequisite that the time series data are stationary. Non-parametric models, such as k-proximity algorithms [5], artificial neural networks [6,7,8], SVMs (Support Vector Machines) [9], and language models [10], include a large number of families. Their main advantage is that they avoid setting some unnecessary parameters, thus avoiding noise impacts. Their main disadvantage is that the training model process is not transparent and requires a large amount of historical data and time. Hybrid models, on the other hand, can combine different models, overcoming the shortcomings of using a single model and making the resulting model more robust [11]. Among hybrid models [12,13], time series decomposition has become a very popular method in recent years. Time series decomposition extracts several relatively simple sub-sequences from raw data, and each component is fitted with the best suitable model, and the final accumulation is carried out to improve accuracy. Based on this approach, Huang et al. [14] invented the Hibert transform. In contrast to the wavelet and Fourier transforms, which have many limitations when processing complex signals, this transform can theoretically decompose any type of signal into a connotative-mode IMF [15], which can present a variety of frequencies, trends, and residual components. The earliest time series decomposition was applied to the short-term forecasting of temperature [16], finance [17,18], electricity loads [19], and hydrology [20,21], with good forecasting results being observed. However, combined time series decomposition models such as ARIMA and LSTM focus on a single series and rarely take into account the correlation of predicted samples. The advantages and disadvantages of the various models are shown in Table 1.

Table 1.
Advantages and disadvantages of forecasting methods.
In order to solve the problem regarding the fact that sample correlation is not considered in time series decomposition, we decided to use a hybrid model that fuses EMD and GANs and is based on an STGCN (Space Time Graph Convolutional Network). We call the hybrid model STGCN-GAN, and through using EMD to separate the periodic part and the trend part of an original sequence and using GAN to predict the remaining unstable residual sequence due to the adversarial generation of GANs, it can predict complex sequences. First, this paper describes the extraction of passenger trip’s OD data from the subway automatic fare collection system and the calculation of the hourly passenger flow crossing each section according to the logit allocation method, carried out to obtain the time series of all the cross-sectional flows . Symbol is the number of sections between two adjacent stations in the urban metro system. Second, we decompose the original sequence into several IMF components and a trend component, treating the sum of all IMF components as periodic components. Third, the periodic component refers to the cyclical fluctuation of the cross-sectional flows in a certain period of time. So, we used Fourier series for prediction. Fourth, the trend component represents the long-term characteristics of the railway-sectional passenger demand can be predicted by spline interpolation. It is assumed here that the seasonal and trend components are intrinsic for each railway section. Finally, the prediction error is regarded as the remaining components minus the seasonal and trend components from the original sequence . The residual part is much more difficult to predict than the seasonal and trend components due to its irregularities, and this has a great impact on passenger flows in adjacent down-sections. Therefore, it is more appropriate to use non-parametric methods to deal with the resident component individually in order to catch its long-term uncertainties. Due to the powerful ability of GAN learning complex distributions [22], we built a GAN model based on graph convolutional neural networks to predict the passenger volume of the railway sections. Figure 1 shows the framework for the prediction model proposed in this paper.
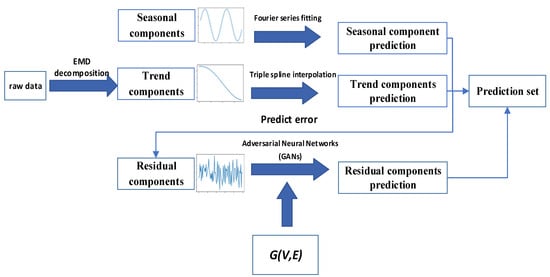
Figure 1.
STGCN-GAN prediction model framework based on EMD.
The highlights of this article are summarized as follows:
- (1)
- An STGCN-GAN (Space Time Graph Convolutional Network–Generative Adversarial Network) hybrid prediction model based on EMD is proposed.
- (2)
- The model uses cross-sectional traffic data to make predictions, and the results show that the performance of the model is better than that of other baseline models such as those based on GCNs (Graph Convolutional Networks) and LSTM (Long Short-Term Memory), Bi-LSTM, STGCN, and STGCN-GAN. The prediction accuracy is generally improved at 15–50%.
- (3)
- The model achieved a 15–20% improvement in prediction accuracy at the cost of a 10% increase in the calculation time, meaning it demonstrates good prediction accuracy and reliability.
This article is divided into seven sections: The first section mainly discusses the advantages and disadvantages of various methods. Section 2 describes the details of the EMD time series decomposition method and seasonal, trend, and residual components. Section 3 focuses on datasets and data processing. Section 4 describes the use of Fourier series to predict seasonal components. Section 5 introduces the use of cubic spline interpolation to predict trend components. Section 6 presents the use of STGCN-GAN to predict the residual component. Section 7 presents the forecast results and formulates the train schedule based on the forecast results, and future directions for research and the conclusions that can be derived from the work described in this paper are also noted in this section.
1.2. Related Work
(a) Time series decomposition
EMD is a method used to decompose time series data into different components and then model and forecast these components independently [23]. Hamad et al. [15] were the first to use EMD to predict vehicle speeds on Fairfax highways to infer travel times. Chen et al. [24] directly treated time series as seasonal components and performed the Hibert transform, observing dynamic fluctuations in passenger flow through the time–frequency energy distribution revealed by Hilbert’s spectrum and achieving good predicting results. Yang et al. [9] used a time series forecasting hybrid model based on EMD and a SAE (Superimposed Auto Encoder), EMD-SAE, to predict traffic flow. They found that the SAE method, used to process all decomposed IMFs and residuals, may be able to solve the end effect problem. Huang [25] applied EMD to extract the intrinsic mode function of the traffic flow recorded by four adjacent sensors on a highway and intuitively presented the seasonal mode in the form of frequency through the Hilbert transform. The seasonal components can then be described as Fourier series based on the obtained frequencies, which improves the prediction accuracy of the seasonal components and predicts the remaining components by using a Bi-LSTM (Bi-directional Long Short-Term Memory) neural network.
(b) Generative adversarial networks
The GAN model was originally proposed by Goodfellow [26]. Originally, GANs were used for image recognition and generation. But more recently, GANs have been used to fit complex sequences. Alkilane [27] combined GANs and GCNs to predict short-term traffic flow. Several GCNs were constructed within a generator based on different perspectives such as similarity, correlation, and spatial distance, and remarkable results were obtained. Liang [28] proposed a SATP-GAN model based on self-attention and the generative adversarial network mechanism which showed improved prediction performance compared to a baseline model. Kun [29] proposed a generative adversarial model (GAN) with Long Short-Term Memory (LSTM) as the generator and deep multilayer perceptron (MLP) as the discriminator to predict a network traffic time series.
2. Methodology
2.1. Time Series Decomposition
Figure 1 shows the process through which the original cross-section flow time series can be decomposed into three component types: seasonal components, a trend component, and a residual component. Then, the seasonal components and trend component are fitted using the Fourier function and triple spline interpolation, respectively. The new residual component equals the original cross-section flow time series minus the addition of the Fourier function and triple spline interpolation, which is forecasted by the adversarial neural network; therefore, prediction results can be obtained from the Fourier function, triple spline interpolation, and the new residual component forecasted by the adversarial neural network.
Since the cross-sectional flow sequence on urban metro sections has a seasonal, trendy character, the time series is decomposed into several IMF components, a trend component and residual component, via EMD. The process can be modelled as shown in Formula (1):
where is the seasonal components, is the trend component, and is the residual component. The original sequence and the residual component are relevant to a certain urban metro section, so these functions are not only relevant to time but also space, while the seasonal component and the trend component are treated as functions of time only. For the sake of brevity, here, we ignore the space variant in the original sequence and residual component temperately.
EMD can handle non-linear and non-stationary data. The main idea behind EMD is to decompose the original time series of raw data into a limited number of oscillation modes based on its own local characteristic time scale. Each oscillation mode is similar to a harmonic function and is represented by an IMF. The IMFs must meet the following two conditions:
- (a)
- Throughout the data segment, the number of extremum points and the number of zero crossing points must be equal or have one difference.
- (b)
- At any moment, the average value of the upper envelope formed by the local maxima point and the lower envelope formed by the local maxima point is zero, that is, the upper and lower envelopes are locally symmetrical relative to the time axis.
First, all the extremum points in the sequence are identified, and all the maximal and minimum points are fitted with cubic spline interpolation to form the upper and lower envelopes as and , respectively. The average envelope is as follows:
In the second step, the intermediate signal is obtained by subtracting the average envelope from the original sequence , which is the jth IMF if both conditions (a) and (b) are met. If not, let replace for a second screening.
where is the average envelope of . Repeat both steps (3) and (4) until satisfies conditions (a) and (b). Then, the jth IMF will equal .
The trend components , after the th IMF has been obtained, can be expressed as follows:
Revert as the original signal and repeat Formulas (1)–(4) until the SD (Standard Deviation) is less than the threshold of 0.2.
The original signal can be expressed as Formula (9):
In this way, we decompose the original sequence into n IMF modal functions and a trend. Now, perform a Hilbert transform on each IMF to find the instantaneous frequency of each IMF. The Hilbert transform is shown in Formula (10):
The solution of the amplitude angle is shown in Formula (11):
The instantaneous frequency and cycle are shown in Formulas (12) and (13):
The seasonalic component can be reverted to Formula (14):
The trend component is the cubic spline interpolation fitting of the trend component , represented by , and the residual component is the original sequence needed to remove the seasonal component and the trend components due to the fact that the original sequence is relevant to a certain urban metro section ; so, we add variant as and the residual component as :
2.2. GAN Methodology
The principle and structure of a generative adversarial network (GAN) is introduced in this section. The GAN model was originally proposed by Goodfellow [26] and usually consists of two parts: generator G and discriminator D. The GAN structure is shown in Figure 2. Generator G learns how to generate real data until the discriminator is indistinguishable from real data. The goal of the discriminator is to accurately identify whether the input sample is real or not from the generator. In this way, G and D constitute a dynamic “game process”.
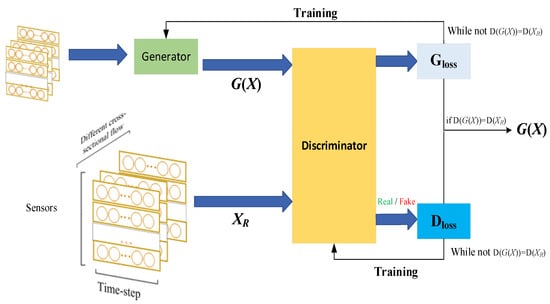
Figure 2.
The architecture of the STGCN-GAN.
The purpose of G’s loss function in Equation (23) is to maximize the probability that will accept that the data generated by G are real.
The training of the discriminator D is a binary classification, and the goal is to distinguish between the real data and the generated data; that is, the D output of the real data is close to 1. So, the discriminator uses cross-entropy as the loss function, as shown in Equation (24). represents the real dataset. is the forecasting dataset.
During the training of the GAN model, the two neural networks D(·) and G(·) are alternately optimized. The generator continuously optimizes itself based on the gap between the generated sample and the real sample. As the number of iterations increases, the samples generated by the generator gradually more closely resemble the real sample. When the discriminator cannot distinguish whether the sample is real or not, the two networks reach equilibrium.
3. Data Processing
We considered Chengdu Metro card data as an example for our research. In this study, automatic card swiping data from the Chengdu Metro pertaining to a period ranging from 12 April to 5 May 2021 were collected. The Chengdu Metro dataset has sufficient temporal and spatial coverage to cover working days and weekends during holidays. The original data format is shown in Table 2.
Table 2.
Partial raw data.
Based on the raw data, it is possible to sort out the time-to-hour passenger traffic for each OD (Origin-Destination) pair. Since there is more than one interchange station in a line, this results in a path is not unique between an OD pair. Therefore, it is difficult to directly calculate the path flow of each OD pair and urban metro across-section flow. However, these can be obtained using the network passenger flow assignment method. This method involves the following: First, according to the passenger smart card data, the OD demand between two stations pair in the subway network is calculated. Then, based on the travel time of each section between the two adjacent stations, we find the k-shortest path between any OD pair in the subway network. Second, we use a polynomial logit model to calculate the probability that each route will be chosen and assign the travel demands to each route based on the probability.
where represents an OD pair, and is the OD demand in the OD pair . and are paths between the OD pair , and , is the path set of OD pair . represents the probability of choosing the path in the OD pair . represents the travel time cost of path between OD pair ; represents the passenger flow assigned to path between OD pair ; is a variable of 0–1; equals 1 if the path contains an urban subway section between two stations (otherwise, equals 0); and belongs to the section set .
Finally, by statistically summarizing the passenger flow of all paths, the cross-sectional traffic of the subway network can be obtained. The cross-sectional flow calculation formula is as follows:
After carrying out the logit assignment process using Formulas (19)–(22), a passenger volume time series consisting of 323 sections of Chengdu Metro data is obtained.
Taking the Chunxi road–Tianfu Square cross-sectional passenger flow as an example, the time series is decomposed according to Formulas (1)–(8) until the termination conditions (8) are met. As shown in Figure 3, the passenger flow time series is decomposed into nine IMFs and trends, and the parameters of the instantaneous frequency and cycle, according to Formulas (9)–(12) and for each IMF, respectively, are listed in Table 3.
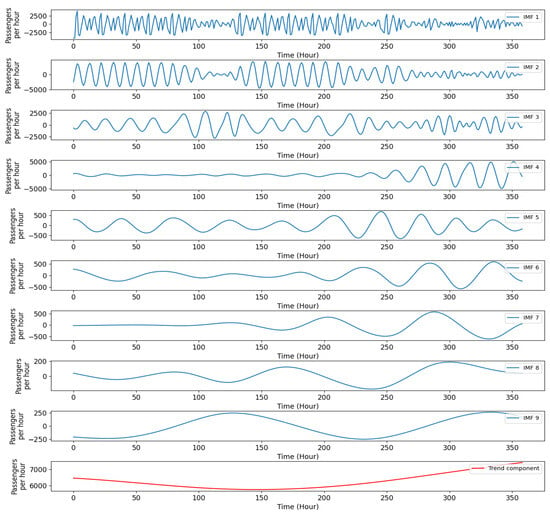
Figure 3.
EMD of the time series of the Chunxi Road–Tianfu Square cross-sectional flow.
Table 3.
Section flow time series.
As can be seen from Table 4, the IMF instantaneous frequency of IMF1 and IMF2 in the time series represent short-term patterns, with cycles of about 1 h and 2 h, respectively. IMF3, IMF4, and IMF5 illustrate the peak hour modes, and the seasonal cycles are about 3.7 h, 6 h, and 9.3 h, respectively. IMF6, IMF7, and IMF8 stand for the daily service model, with seasonal cycles of about 13.6 h, 19.8 h, and 24 h, respectively. IMF9 describes a half-week service model with a seasonal cycle of about 50 h. The following two subsections will introduce how to fit and predict these components.
Table 4.
IMF instantaneous frequency and cycle.
4. Seasonal Components Prediction
The time series of the urban metro across-section passenger flow is split into two parts: the first part, the origin set, includes 60% of the data, and the rest, the test set, has 40% of the data. After removing the from the original sequence, a difference series can be obtained, and it can be seen that the extremum points are basically distributed symmetrically around the zero-horizon line. Nine IMF functions decomposed from the first part’s data (the origin set) are fitted by the seasonal Fourier function, the parameters of which are shown in Table 5. The difference series and the addition of nine fitted seasonal Fourier functions are plotted in Figure 4. We can also see the forecasting periodic component predicted by the Fourier series in Figure 4.
Table 5.
Parameters of the seasonal Fourier function.
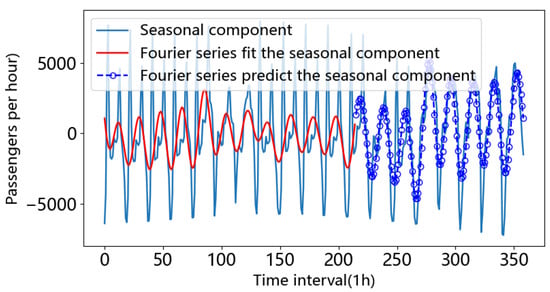
Figure 4.
Fourier fitting function and predicting the seasonal part.
5. Trend Component Prediction
The trend component , which is the deterministic part of the urban metro sectional passenger flow, is the lowest frequency component obtained by EMD, and it is not affected by variations in the occasional commuting mode and can be fitted by spline interpolation. Based on Figure 5, the spline interpolation fitting of the remaining components and their predictions are pretty good.
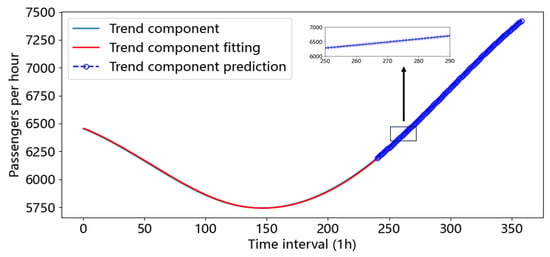
Figure 5.
Fitting and prediction of spline interpolation components.
6. Prediction of Residual Component
In this section, we will introduce the architecture and modules of the STGCN-GAN model, including graphs of time convolutional networks and the training process of adversarial neural networks.
6.1. Definition of Predictive Model
From Equation (16), we obtain the residual component and build a predictive model, as shown in Equation (23):
where represents the argument to the function . Symbol indicates the last item of the first part including 60% of the origin data. represents the node graph structure of the metro system, and and represent the set of sections (or parking station or train maintenance base) and railway sections between two adjacent stations, respectively. represents the length of the predicted series, and m represents the length of the first part of the origin set. The crux of this equation is to use the observations of the previous m time intervals to predict the data for the time intervals in the future.
Forecasting passenger flow for all the cross-sections is a demanding task in terms of computational burden. There are a total of 352 cross-sections in the Chengdu urban metro network. Firstly, we calculate the average passenger flow of each cross-section in all periods, and then the cross-sections with the average passenger flow located in the first 40 percent are picked up, meaning 142 sections are selected, including 2 sections with the same average passengers flow. Finally, the Poisson correlation coefficient between the passenger flows of different two sections is calculated among these selected sections, which constitutes the correlation coefficient matrix .
This defines the adjacency matrix , where each element equals 0 if the correlation coefficient value is less than the threshold ; othervise, element equals 1. In this study, the value is set as 0.75. is defined as shown in Equation (24):
6.2. The Architecture of the STGCN-GAN
The generator adopts a graph neural network STGCN to capture the spatial and temporal dependencies between nodes and generate future cross-sectional traffic. The discriminator also adopts a graph neural network GCN which takes two sets of samples generated by the generator STGCN and the corresponding true flow as inputs in order to determine which sample is real and which sample is false. The next section describes the components of the model in detail.
(a) The STGCN as a generator
The STGCN generator consists of two time–space blocks and an output layer. Each time–space block consists of two time domain convolutions and a spatial convolution. The output layer consists of a time convolutional layer and a fully connected layer, and a time domain convolutional block is shown in Figure 6.
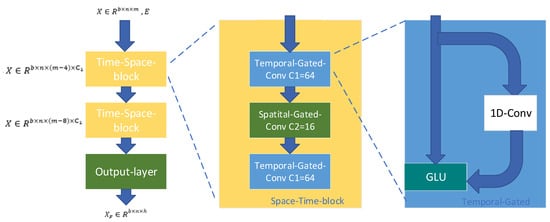
Figure 6.
The architecture of the generator in detail.
The input and output of the generator: The network input is the vector of the graph with b batch size; the dimension stands for the number of sections, and m time stands for steps. The network output is the feature vector used to indicate the graph in the next m time steps.
Graph Convolutional Networks: In order to obtain complex spatial dependencies of urban rail sections, we use Graph Convolutional Networks (GCNs). The GCN recursion formula is defined as follows (25) [30]:
In Equation (25), each row of the matrix represents each section’s time series of cross-section traffic . “ is the sigmoid activation function. is the graph adjacency matrix. can be calculated as . is the identity matrix. is the degree matrix of and can be calculated as . stands for the weight matrix to be learned. Each row of the matrix represents the output with the prediction of each section.
Time–space blocks: The time domain convolutional layer contains convolution kernels , and the input vector is convolved along the time dimension. After performing GLU activation, the output is produced.
Spatial convolution is performed on the graph at each time step and contains convolution kernels . The input is , and the output is shown in (25). Namely, .
After a space–time convolutional block, the vector dimension and the time step dimension will be shortened 2 × (k − 1). So, after two space–time convolutional blocks, the vector becomes .
The output layer: The output layer consists of a time domain convolutional layer and a fully connected layer. The input vectors reshaped into are mapped through the fully connected layer into .
(b) The GCN as a discriminator
We use the GCN model as a discriminator to identify and learn characteristics of traffic data . The discriminator input is the output of the generator or the real traffic for the corresponding period . The output of the discriminator is . We expect that if the input is real traffic data or close to real traffic data, the value of is large; otherwise, is small. The structure of the discriminator is shown in Figure 7, which depicts the GCN, self-attention mechanism, and fully connected layers, as well as the probability matrix The self-attention calculation mechanism is as follows (26)–(29):
where are all weight matrices; is the result of the linear transformation of or . is the output of the self-attention layer. Then, we flatten into and pass it through the weight matrix of the fully connected layer into .

Figure 7.
The architecture of the discriminator in detail.
6.3. Training Methodology
The parameters are updated with the gradient-decreasing loss functions of (23) and (24), where G and D are trained alternately until convergence. The training pseudocode for STGCN-GAN is shown in Table 6.
Table 6.
The STGCN-GAN pseudocode.
After several rounds of training, it was found that the loss functions of both the generator and the discriminator converge to ln2, as shown in Figure 8, because the discriminator and generator loss functions are minimized under the conditions .
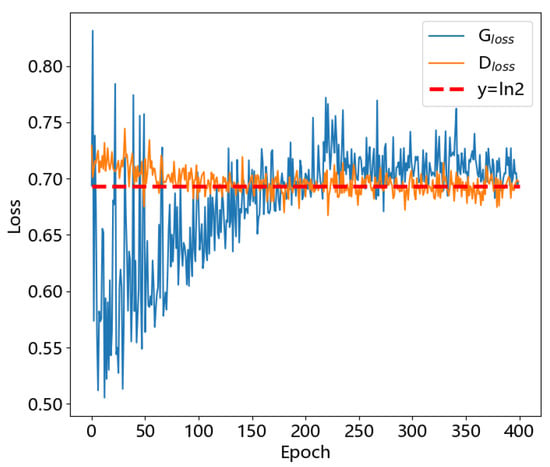
Figure 8.
The loss functions of the generator and discriminator.
6.4. Residual Component Prediction Results and Analysis
(a) Baseline methods for comparison
To verify the predictive performance of the model proposed in this paper, we selected evaluation indicators such as mean absolute error (MAE) and root mean squared error (RMSE).
In order to verify the effectiveness of the proposed method, the following prediction methods were selected to compare their prediction effects with that of the proposed model: (1) Autoregressive Moving Average (ARIMA), (2) Long Short-Term Memory (LSTM), (3) Bi-directional Long Short-Term Memory (BiLSTM), (4) a spatio-temporal graph convolutional network (STGCN).The prediction effect is shown in Figure 9.
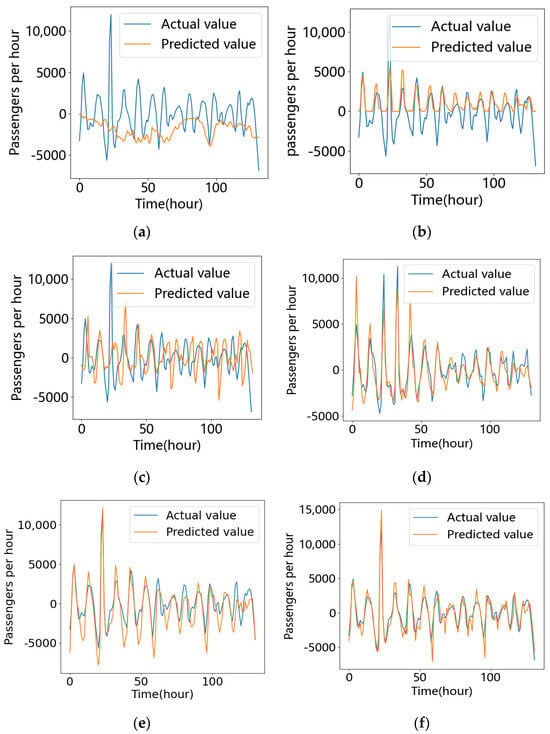
Figure 9.
Visualizations of the prediction results derived from the different models: (a) ARIMA, (b) GCN, (c) LSTM, (d) BiLSTM, (e) STGCN, (f) STGCN-GAN.
Table 7 presents the evaluation index of the residual components of different models. It is clear that the traditional ARIMA model is inadequate for forecasting non-stationary time series. Although the GCN considered in this study can capture spatial information, it also performs poorly. We suspect that while the residual component is influenced by fluctuations in passenger flow, it is primarily related to time. The most successful predictors were Bi-LSTM, STGCN, and STGCN-GAN. The Bi-LSTM structure consists of two independent LSTMs that extract features from the input sequence in positive and reverse order. The Bi-LSTM model aims to incorporate information from both past and future time series into the feature data obtained at each time point. The experimental results indicate that this model outperforms single LSTM models in capturing the characteristics of previous time series.
Table 7.
Comparison of the indicators of the residual components predicted by different models.
However, when considering passenger flow on metro lines, STGCN-GAN outperforms Bi-LSTM, with STGCN-GAN being the best performer overall, improving MAE performance by 27% and RMSE performance by 9% compared to Bi-LSTM.
In addition, we also tried to experiment with other neural networks as discriminators, and the results are shown in Table 8 below: In addition to a GCN, MLP works best as a discriminator, but there are disadvantages, as the training is unstable, and the generator and discriminator can never achieve equilibrium results. The MLP loss function is shown in Figure 10.
Table 8.
Comparison of the performance of different models as discriminators.
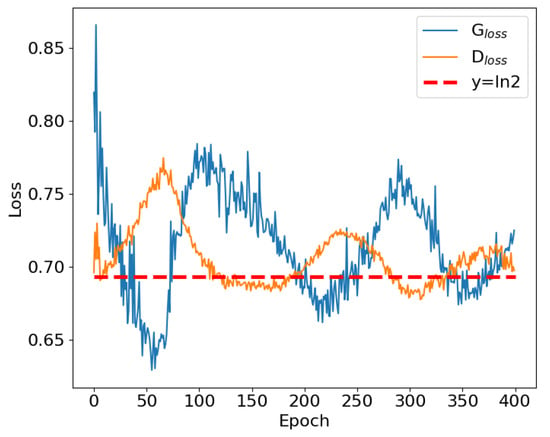
Figure 10.
Using MLP as a discriminator led to GD training loss.
(b) Ablation study
To verify the effect of EMD on prediction accuracy, we added a model without EMD as a baseline model. The prediction performance results are shown in Table 9, which depicts a comparison of the results achieved by the temporal models and hybrid models.
Table 9.
Comparison of the results achieved by the temporal models and hybrid models.
We noticed that all models achieved improved performance with EMD-based decomposition. The increase is about 15–20%. However, when using CEEMDAN decomposition, the prediction performance becomes worse than it originally was. Our guess is that CEEMDAN may have overdecomposed the signal, dissolving noise or irrelevant patterns into the IMFs as well. These additional patterns can interfere with predictions, making them more complex and less accurate.
(c) Time cost analysis
From Figure 11, we can see that predicting the residual components took about 80% of the time for the hybrid model, mainly because deep learning training involves high hardware requirements and long training times. In contrast, EMD did not take too long. EMD brings a significant improvement in predictive performance because EMD can, to a certain extent, remove noise from the data, allowing the neural network to make better predictions. Compared with Bi-LSTM, graph neural networks take longer to train because Bi-LSTM trains a single sequence, while graph neural networks train multidimensional sequences, but models that consider cross-sectional spatiotemporal correlations predict better. STGCN-GAN is acceptable, despite a slight increase in time cost, because of its guaranteed improved performance. The detailed forecast time of each part is shown in Table 10.
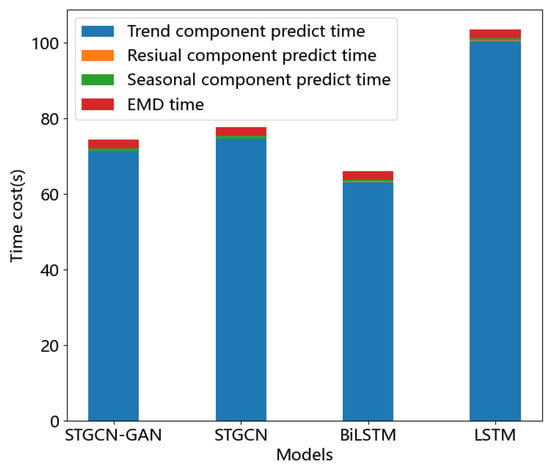
Figure 11.
Time cost values for the different models.
Table 10.
Time cost values for the different models.
(d) Analysis of the number of trains running
However, it is not enough to predict cross-sectional flow; cross-sectional flow forecasting needs to provide a valuable reference for train demand forecasting. Based on the prediction of cross-sectional flow, we can predict the number of trains required per hour on each line, which can be calculated as shown in (30):
In this formula, refers to the number of trains in different periods, refers to the maximum cross-sectional flow in the line, and refers to the maximum capacity of train; according to the Chengdu metro train model, the is about 1500. refers to the full load factor, which is set as 0.9. refers to the minimum departure interval, which is about 90 s. refers to the maximum departure interval, which is regarded as 600 s.
According to Formula (28), the figure for calculating the number of trains required to run on each line and the diagonal error is shown in Figure 12.
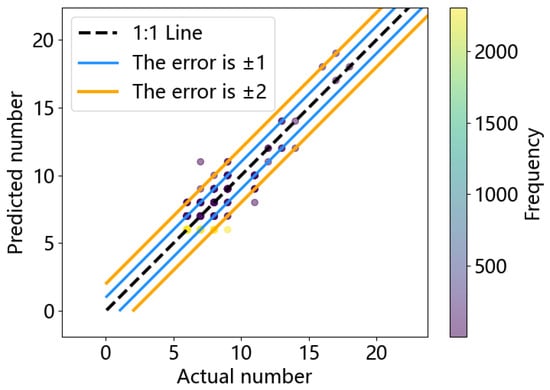
Figure 12.
Diagonal error plot of train demand.
Based on Figure 12 and Figure 13, the error of predicting train demand is controlled within 2, and the prediction accuracy is about 95%.And the prediction accuracy of the STGCN-GAN model is better than that of the other baseline models. However, it can be seen that the main error sources in the three models are the same as the flat-peak period and the low-peak period, and in the future, we will study the passenger flow synergy of multiple traffic modes to avoid wasting resources.
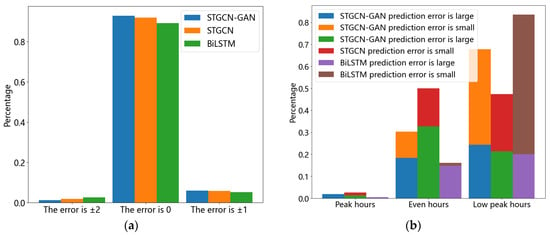
Figure 13.
(a) The proportion of train errors in the top three forecasting methods; (b) statistics on the sources of the errors at different periods.
7. Conclusions and Future Work
In this paper, the Chengdu Metro’s across-section traffic flow was predicted by using a hybrid prediction method named STGCN-GAN, which is based on a combination of EMD and a graph convolutional neural network. The STGCN-GAN method predicts the residual component better than other baseline models, and the improvement range is between 15% and 50%. It also predicted the number of trains on different lines per hour in the next 7 days with an accuracy rate of about 95%. Although our proposed method has achieved significant improvements in some aspects, we should also note its limitations. In our experiments, we observed a 10% increase in computation time. Future work could explore the possibility of further optimizing the algorithm to reduce computation time while maintaining stability in terms of model performance, and we will work on the coordination of passenger flow control in multiple modes of transportation.
Author Contributions
Conceptualization, M.L. and C.Z.; methodology, M.L.; software, C.Z.; validation, M.L. and C.Z.; formal analysis, M.L.; investigation, M.L.; resources, M.L.; data curation, M.L.; writing—original draft preparation, M.L.; writing—review and editing, C.Z.; visualization, C.Z; supervision, M.L.; project administration, M.L.; funding acquisition, M.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ortúzar, J.d.D. Future transportation: Sustainability, complexity and individualization of choices. Commun. Transp. Res. 2021, 1, e100010. [Google Scholar] [CrossRef]
- Hussain, E.; Bhaskar, A.; Chung, E. Transit OD matrix estimation using smartcard data: Recent developments and future research challenges. Transp. Res. Part C Emerg. Technol. 2021, 125, 103044. [Google Scholar] [CrossRef]
- Wang, X.; Kang, Y.; Hyndman, R.J.; Li, F. Distributed ARIMA models for ultra-long time series. Int. J. Forecast. 2022, 39, 1163–1184. [Google Scholar] [CrossRef]
- Zhao, J.; Yu, Z.; Yang, X.; Gao, Z.; Liu, W. Short term traffic flow prediction of expressway service area based on STL-OMS. Phys. A Stat. Mech. Its Appl. 2022, 595, 126937. [Google Scholar] [CrossRef]
- Lin, G.; Lin, A.; Gu, D. Using support vector regression and K-nearest neighbors for short-term traffic flow prediction based on maximal information coefficient. Inf. Sci. 2022, 608, 517–531. [Google Scholar] [CrossRef]
- Zhao, J.; Yan, Z.; Chen, X.; Han, B.; Wu, S.; Ke, R. k-GCN-LSTM: A k-hop Graph Convolutional Network and Long–Short-Term Memory for ship speed prediction. Phys. A Stat. Mech. Its Appl. 2022, 606, 128107. [Google Scholar] [CrossRef]
- Yu, B.; Lee, Y.; Sohn, K. Forecasting road traffic speeds by considering area-wide spatio-temporal dependencies based on a graph convolutional neural network (GCN). Transp. Res. Part C Emerg. Technol. 2020, 114, 189–204. [Google Scholar] [CrossRef]
- Lee, K.; Rhee, W. DDP-GCN: Multi-graph convolutional network for spatiotemporal traffic forecasting. Transp. Res. Part C Emerg. Technol. 2022, 134, 103466. [Google Scholar] [CrossRef]
- Yang, H.-F.; Chen, Y.-P.P. Hybrid deep learning and empirical mode decomposition model for time series applications. Expert Syst. Appl. 2019, 120, 128–138. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, F.; Liu, Z.; Wang, K.; Wang, F.; Qu, X. Can language models be used for real-world urban-delivery route optimization? Innovation 2023, 4, 100520. [Google Scholar] [CrossRef] [PubMed]
- Tselentis, D.I.; Vlahogianni, E.I.; Karlaftis, M.G. Improving short-term traffic forecasts: To combine models or not to combine? IET Intell. Transp. Syst. 2015, 9, 193–201. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Haghani, A. A hybrid short-term traffic flow forecasting method based on spectral analysis and statistical volatility model. Transp. Res. Part C Emerg. Technol. 2014, 43, 65–78. [Google Scholar] [CrossRef]
- Mao, Y.; Yu, X. A hybrid forecasting approach for China’s national carbon emission allowance prices with balanced accuracy and interpretability. J. Environ. Manag. 2023, 351, 119873. [Google Scholar] [CrossRef]
- Huang, H. Introduction to the HILBERT–HUANG Transform And Its Related MathmaticalL Problems. Hilbert Huang Transform. Its Appl. 2003, 1–26. [Google Scholar] [CrossRef]
- Wei, Y.; Chen, M.-C. Forecasting the short-term metro passenger flow with empirical mode decomposition and neural networks. Transp. Res. Part C Emerg. Technol. 2012, 21, 148–162. [Google Scholar] [CrossRef]
- Yu, X.; Shi, S.; Xu, L. A spatial–temporal graph attention network approach for air temperature forecasting. Appl. Soft Comput. 2021, 113, 107888. [Google Scholar] [CrossRef]
- He, K.; Chen, Y.; Tso, G.K.F. Price forecasting in the precious metal market: A multivariate EMD denoising approach. Resour. Policy 2017, 54, 9–24. [Google Scholar] [CrossRef]
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Its Appl. 2019, 519, 127–139. [Google Scholar] [CrossRef]
- Huang, Y.; Hasan, N.; Deng, C.; Bao, Y. Multivariate empirical mode decomposition based hybrid model for day-ahead peak load forecasting. Energy 2022, 239, 122245. [Google Scholar] [CrossRef]
- Hao, W.; Sun, X.; Wang, C.; Chen, H.; Huang, L. A hybrid EMD-LSTM model for non-stationary wave prediction in offshore China. Ocean Eng. 2022, 246, 110566. [Google Scholar] [CrossRef]
- Song, C.; Chen, X.; Wu, P.; Jin, H. Combining time varying filtering based empirical mode decomposition and machine learning to predict precipitation from nonlinear series. J. Hydrol. 2021, 603, 126914. [Google Scholar] [CrossRef]
- Duan, J.-H.; Li, W.; Zhang, X.; Lu, S. Forecasting fine-grained city-scale cellular traffic with sparse crowdsourced measurements. Comput. Netw. 2022, 214, 109156. [Google Scholar] [CrossRef]
- Wu, G.; Zhang, J.; Xue, H. Long-Term Prediction of Hydrometeorological Time Series Using a PSO-Based Combined Model Composed of EEMD and LSTM. Sustainability 2023, 15, 13209. [Google Scholar] [CrossRef]
- Chen, M.-C.; Wei, Y. Exploring time variants for short-term passenger flow. J. Transp. Geogr. 2011, 19, 488–498. [Google Scholar] [CrossRef]
- Huang, H.; Chen, J.; Sun, R.; Wang, S. Short-term traffic prediction based on time series decomposition. Phys. A Stat. Mech. Its Appl. 2022, 585, 126441. [Google Scholar] [CrossRef]
- Goodfellow, I. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27, Montreal, QB, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Khaled, A.; Elsir, A.M.T.; Shen, Y. TFGAN: Traffic forecasting using generative adversarial network with multi-graph convolutional network. Knowl. Based Syst. 2022, 249, 108990. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Shen, J.; Chen, M.; Wang, R.; Zhou, X.; Xu, C.; Yao, Q.; Wu, Q. SATP-GAN: Self-attention based generative adversarial network for traffic flow prediction. Transp. B Transp. Dyn. 2021, 9, 552–568. [Google Scholar] [CrossRef]
- Zhou, K.; Wang, W.; Huang, L.; Liu, B. Comparative study on the time series forecasting of web traffic based on statistical model and Generative Adversarial model. Knowl. Based Syst. 2021, 213, 106467. [Google Scholar] [CrossRef]
- Thomas, K. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; p. 14. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).