Abstract
Smart healthcare using the cloud and the Internet of Things (IoT) allows for remote patient monitoring, real-time data collection, improved data security, and cost-effective storage and analysis of healthcare data. This paper proposes an information-centric dissemination scheme (ICDS) for smart healthcare services in smart cities. The proposed scheme addresses the time sensitiveness of healthcare data and aims to ensure consistent dissemination. The ICDS uses decision-tree learning to classify requests based on time-sensitive features, allowing prioritization of access. The scheme also involves segregating sensitive information and distributing digital health data within the classified time to retain time sensitiveness and prioritize access. The learning is then modified for the leaves based on data significance and minimum resources to reduce waiting times and improve availability.
1. Introduction
The IoT is widely used in smart cities, maximizing the performance range in communication and interaction services. The IoT provides various services that reduce the complexity rate in smart cities. Healthcare data containing important health-related information is collected from healthcare centers [1]. Healthcare data distribution is a complicated task to perform in smart cities. Healthcare data distribution provides relevant information to users and reduces the latency range in providing healthcare services. A smart healthcare system framework is used in smart cities that distribute healthcare data from one end to another [2]. An organizational business model in the healthcare framework identifies healthcare data’s essential features and principles. Every healthcare center manages an electronic health record (EHR) containing the patients’ exact healthcare data. The organizational model uses EHRs, reducing the time and energy consumption ratio in the classification and identification process [3]. EHRs are used in smart cities to reduce the paperwork range and latency ratio in visiting hospitals. IoT-based wireless sensor networks (WSN) are also used in smart cities that distribute healthcare data among users. WSNs reduce the error rate distribution, which enhances accuracy in the decision-making process [4].
Time-sensitive healthcare request classification is a complicated task to perform in healthcare centers. Healthcare requests have various conditions and situations that require a proper classification system. The classification process classifies the requests based on health priorities and conditions [5] using machine learning (ML) techniques. ML techniques are mainly used here to improve the classification accuracy in the detection processes. EHRs are first analyzed by healthcare centers as they contain important information about a patient’s health condition [6]. EHRs reduce latency and error range in request classification systems. EHRs produce the necessary information to service access that provides required services to users. Convolutional neural networks (CNNs) are a deep learning method initially utilized for image feature extraction. Due to its high learning speed and accuracy, the CNN extracts text features, referred to as Text-CNN [7]. It inputs a pre-trained word vector and generates the appropriate word embedding. Compared to conventional CNNs, the width of the convolution kernel must be the same as the word vector dimension. Text-CNN models are utilized to extract the text features in EHRs. The classification is based on user and EHR requests [8,9,10,11].
This study makes the following significant contributions.
- A new paradigm for smart healthcare services in smart cities using IoT and cloud architecture is proposed. The following key features were developed to ensure data time sensitivity and consistent dissemination: the decision tree (DT) method is adopted to classify and segregate the time-sensitivity data; prioritization of access and segregation of sensitive features is developed; assigning priorities based on the time sensitivity is customized and incorporated in the ICDS framework.
- The simulation environment is developed to validate the proposed model by populating end-to-end data. A sequential increment snippet program is introduced to analyze the proposed work.
- The performance of the ICDS is compared with two other landmark schemes in which the ICDS enhanced service distribution and availability by 9.03% and 8.91%, respectively, and reduced waiting time, allocation time, and failures by 11.77%, 9.46%, and 8.61%, respectively.
The remainder of the document is structured as follows. Section 2 discusses the related research and Section 3 suggests a strategy to accomplish the goals. Section 4 discusses the findings and outcomes of the comparative analysis. The work is concluded in Section 5, which focuses on the work’s significant contribution and its future course.
2. Related Works
In this section, we discuss related works and outline the differences with the contribution proposed in this paper. Table 1 summarizes these works.
Xu et al. [12] introduced a device-agonistic cloud-based sleep-care platform (CSCP) for sleep disorder diagnosis and management systems. The platform uses the Sleep Care Alliance Network (SCAN) to identify disorders and coordinates diagnosis. CSCP leverages data analytics to predict important features and characteristics from the database. It reduces the error and latency ratio in identification, improving the systems’ feasibility. The introduced CSCP increases the accuracy of sleep disorder detection and enhances the efficiency range in diagnosis. Sabokbar et al. [13] proposed a fuzzy inference system (FIS) based spatial model for accessibility measurement in healthcare centers. The main aim of the proposed model is to evaluate and address the healthcare services provided to patients. Healthcare service requires high accessibility that reduces the error range in the diagnosis process. The proposed model increases accuracy in accessibility to the prediction that provides relevant data to further processes, compared with other models.
Abdelmoneem et al. [14] designed a mobility-aware heuristic-based scheduling and allocation approach using cloud and fog computing architecture. The proposed approach mostly allocates resources required to perform certain tasks in healthcare centers. The cloud–fog network detects spatial and temporal factors, which provide relevant data to the scheduling process. Issues will be critical during the data communication between the healthcare device and infrastructure handoff. The author has considered this issue and developed a method based on the traditional HHO mechanism, which uses the base on signal strength estimation. Hands-off-based decision policy is introduced to smoothly switch the devices without any interruption. The scheduling model is developed based on a mobility-aware MBAR algorithm which allocates the job based on sensitive information. The proposed approach reduces computation latency and energy consumption with the strategy, improving the healthcare center’s performance and effectiveness range.
Gouveia et al. [15] proposed a consistent traveling salesman problem with positional consistency constraints (CTSP). The proposed architecture is mainly used in healthcare applications. CTSP solves salesman problems which occur during optimization and computation processes. CTSP reduces the latency ratio in providing healthcare services to users. Experimental results show that the proposed model maximizes healthcare services’ efficiency and performance.
Similarly, Zgheib et al. [16] developed a scalable semantic framework for the Internet of Things (IoT) based healthcare applications. The proposed framework aims to identify patients’ daily activities that provide feasible data for the diagnosis process. The semantic reasoning technique is used here to identify the complex data that must be presented in the database. The complex data is processed with the Esper CEP library, where the event proximity is considered based on the magnitude of the activities. Symptom indicators are introduced in this work to characterize the activities based on specific symptoms. The CEP engine will identify the most important events. Based on a 24-h window, the query is raised. By this method, the framework increases detection and prediction accuracy, improving the feasibility and mobility of IoT-based healthcare applications.
Kumar et al. [17] developed posture-based classifier cloud architecture for end-to-end healthcare systems. The classifier identifies and preserves the healthcare system user data during communication between the end-user device and cloud infrastructure. The energy and delay-aware computational offloading scheme are proposed to minimize end-user devices’ uncertainty and energy consumption. Prediction-based priorities are provided by the cloud system, which is used to help emergency patients to diagnose quickly and securely. Similarly, Amjad R et al. [18] proposed smart healthcare systems using a regression for IoT communication with cloud infrastructure. The regression prediction will provide quality awareness services for the patient and intelligent methods to tolerate the delay using a mobile agent. In an addition to the scheme, the cryptographic technique is applied to ensure data communication security.
Waibel et al. [19] designed tiers of service framework for children’s healthcare systems. The main aim of the proposed framework is to provide operational planning for healthcare centers. The proposed framework identifies the key factors and symptoms presented in the database. Organizing services is a complicated task to perform in healthcare centers. The proposed framework maximizes the quality and feasibility range of services provided to the patients. Li et al. [20] introduced a Q-learning algorithm-based optimal scheduling approach for cloud healthcare systems. Q-learning is mainly used here to solve optimization problems during the scheduling process. The optimal scheduling approach reduces both cost and time consumption range in computation. The proposed method increases scheduling accuracy, enhancing healthcare systems’ performance and effectiveness. Elshahed et al. [21] proposed a new prioritized sorted task-based allocation (PSTBA) for healthcare monitoring systems. The virtual machine is used here to perform a particular task in monitoring systems. PSTBA reduces the expected processing time (EPT) by performing specific functions that enhance the feasibility range of the systems. When compared with other traditional methods, the proposed PSTBA method achieves high efficiency in providing healthcare services to the users.

Table 1.
Summary of research related to healthcare services using IoT and cloud architecture.
Table 1.
Summary of research related to healthcare services using IoT and cloud architecture.
| Study | Platform/Model | Aim | Key Features | Impact on Healthcare |
|---|---|---|---|---|
| Xu et al. [12] | CSCP | Sleep disorder diagnosis and management | Device-agonistic, uses SCAN and data analytics | Increases accuracy and efficiency of sleep disorder detection |
| Sabokbar et al. [13] | FIS-based spatial model | Accessibility measurement in healthcare centers | Evaluates and addresses healthcare services provided to patients | Increases the accuracy of accessibility predictions and improves healthcare service accessibility |
| Abdelmoneem et al. [14] | Mobility-aware heuristic-based scheduling and allocation approach | Allocate resources in healthcare centers | Uses cloud and fog computing architecture, detects spatial and temporal factors | Reduces computation latency and energy consumption to improve the performance and effectiveness of healthcare centers |
| Gouveia et al. [15] | CTSP | Optimization and computation in healthcare applications | Solves traveling salesman problems, imposes positional consistency constraints | Reduces latency and improves efficiency and performance of healthcare services |
| Zgheib et al. [16] | Scalable semantic framework for IoT-based healthcare | Identify patients’ daily activities for diagnosis | Uses semantic reasoning technique, detects complex data for database | Increases in detection and prediction accuracy improve the feasibility and mobility of IoT-based healthcare applications |
| Waibel et al. [19] | Tiers of service framework for children’s healthcare | Provide operational planning for healthcare centers | Identifies key factors and symptoms in the database, organizes services | Maximizes quality and feasibility of services provided to patients |
| Li et al. [20] | Q-learning algorithm-based optimal scheduling approach | Scheduling in cloud healthcare systems | Solves optimization problems, reduces cost and time consumption | Increases accuracy of scheduling, enhances the performance and effectiveness of healthcare systems |
| Elshahed et al. [21] | PSTBA | Healthcare monitoring systems | Uses virtual machine, reduces expected processing time by performing specific functions | Achieves high efficiency in providing healthcare services compared to traditional methods |
3. Materials and Methods
3.1. Information-Centric Discrimination Scheme
The proposed ICDS for smart healthcare services utilizing the IoT is designed to address the time sensitivity of healthcare data and ensure consistent discrimination. The scheme is intended to be implemented in smart cities, where many healthcare requests are generated and must be processed efficiently.
The ICDS is based on the concept of digital resource availability and allocation. It utilizes IoT technology to monitor and collect data from various healthcare devices and sources, such as medical sensors, wearable devices, and electronic health records. This data is then used to discriminate heterogeneous healthcare requests and allocate resources accordingly. For example, requests for emergency care or critical patient information would be given priority over less urgent requests.
One of the key features of the ICDS is its use of decision-tree learning to classify requests and prioritize access to sensitive health data. Decision-tree algorithms are known for their intelligibility and simplicity, making them well-suited for this application. In this scheme, the root node represents the time sensitivity of the healthcare data and the leaves represent the access granted. This allows for a clear and transparent system for allocating resources and accessing sensitive information.
The ICDS also facilitates sharing of EHRs across healthcare centers. EHRs are digital collections of patient information that can support clinical decision-making, improve patient outcomes, and reduce costs. By sharing EHRs, the ICDS enables healthcare providers to access a patient’s complete medical history, regardless of where they received care. This can improve the continuity of care and reduce the risk of medical errors.
In summary, the ICDS is proposed for smart healthcare services that utilize the IoT to discriminate and allocate resources for healthcare requests in smart cities. It utilizes decision-tree learning to classify requests, prioritize access to sensitive health data, and facilitate sharing of electronic health records across healthcare centers. The sequence flow, flowchart, and scheme are represented in Figure 1a–c.
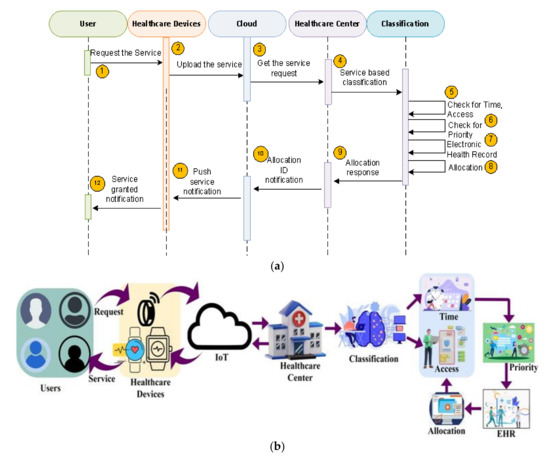
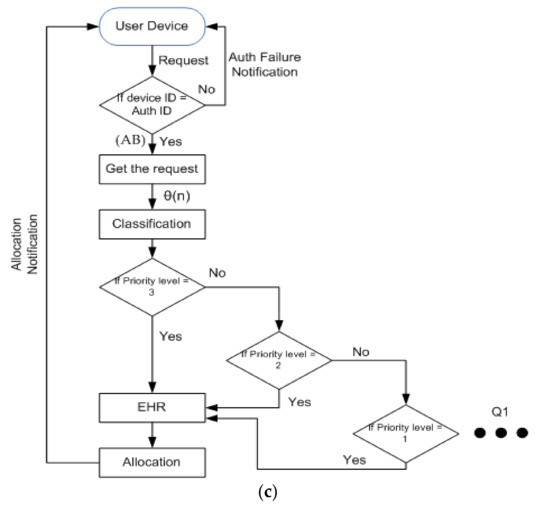
Figure 1.
(a). Sequence flow of ICDS. (b). ML-based ICDS architecture. (c). Flow chart of ICDS.
In this method, the user request is given to the healthcare center through the IoT-cloud gateway. The healthcare device is responsible for generating the current status of the user through inbuilt sensors such as electrocardiogram (ECG), blood pressure, oxygen levels, etc. Based on the request, data, and the EHR, the classification is carried out. The methodology used for classification relies on applying the decision tree (DT) algorithm. DT is a robust multi-criteria algorithm well known in decision theory. We choose this method because of its flexibility which enables us to vary the weight assigned to each feature of the request according to the situation.
The time and access are considered for classification, where the root is considered as time sensitiveness of the data and leaves can be represented as the access, which has the minimum waiting time. The priorities are given based on the waiting time. Based on the preferences and EHRs, the allocation token is raised. The service response will reach the user upon the allocation token through the IoT-cloud gateway. The proposed scheme identifies spontaneous availability and healthcare data access resources post the request generation. Here, the requested service is used to supervise the patient’s health and help in emergency care.
3.2. Decision-Tree (DT) Algorithm
Decision tree (DT) learning in healthcare for the classification process can be used in situations with uncertain treatments, such as high levels of sickness. Hence, with the sensitivity of the sickness and the waiting time, the request can be classified using this decision-tree learning algorithm. The following equation explains the process of sending a request for the classification.
where . = . .
θ(n) denotes the request sent by the user, (AB) denotes the output of the request from the healthcare devices, (α, β, γ) is the request when sent by the use of IoT, (K) denotes the patients’ information. Now the classification process takes place based on time and access. Based on time, the classification takes place. In this tree classification, the root is considered to be the time sensitivity of the data. The proposed scheme identifies spontaneous availability and healthcare data access resources post the request generation. Dissemination for heterogeneous healthcare requests relies on digital resource availability and allocation. If the user request is sensitive and highly needs the response, it will be prioritized first. If the user has any emergencies such as a heart attack or asthma attack, it can be given priority and less waiting time. The classification process is illustrated in Figure 2.
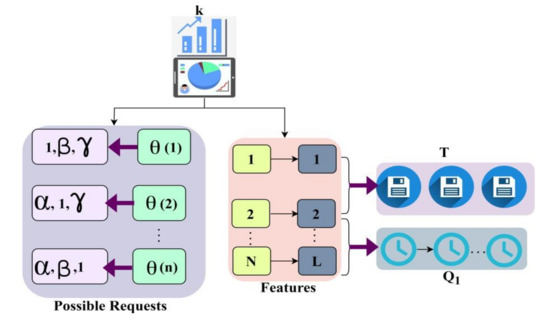
Figure 2.
Classification illustration using the decision-tree method.
3.2.1. Classification Based on Time
The classification is based on user variations (α, β, γ) that represent K. Based on (N, L), this implies Q1 and Q2 to prevent AB failures (Figure 2). Priority must be given to the decision-tree learning classification based on how time sensitive the request data is and the response will be provided right away. If there is an emergency for the patients, then it is considered time-sensitive data of the user. The response from the healthcare facility is classified as soon as the request is sent to determine its sensitivity. This decision-tree learning gives its intelligibility and simplicity features to the device to prioritize the production of the data requested by the users. Then, after the classification process, the time sensitiveness of the user data can be found. Immediately, the response will be given first to sensitive data from the user. The priority will be given first to those sensitive data requests from the user through healthcare centers. Time-sensitive data requires additional care as they undergo an emergency, so it is classified under the tree classification. The following equation explains the process of classification based on time-sensitive data through the classifier given below.
where . = . . where (Q2) denotes the time-sensitive data request, , denote the features of sensitive data, and (T) denotes the resources of the request. Now, the classification is based on the access that takes place. This will have the common availability of the response and time is considered the tree structure’s leaf in the tree classification. The sensitive information is segregated for access and digital health data is distributed within the classified time. Decision-tree learning is used to minimize the distribution time and helps in prioritized allocations. This will have less waiting time if they don’t have any serious data to be prioritized first. This can give some late responses which have minimum waiting time. The user request response is frequently available due to the access to the leaves of the tree structure in the tree classification.
3.2.2. Classification Based on Access
The classification based on access is represented in the leaves of the tree structure. This access classification of the user request has some minimum waiting time and better response availability. The learning is employed wherein the roots are constructed using allocation and the leaves are distinguished using allocation time. This access in the leaves is based on the waiting time of the request. The learning is modified for the leaves based on data significance and minimum resource time. If it has sensitive data content, the waiting-time sensitivity is less and the responsibility for that data will be prioritized first. However, if it does not have that serious problem in the request, it can be considered that the leaves are based on waiting time. The process of classification based on access with common availability is explained by the following equation.
where
where σ (n) denotes the request classified under access data and denotes the calculation of the waiting time of the request.
3.2.3. Assigning Priority
Time sensitiveness is retained through time and access to prioritized allocation. The requested data will be prioritized according to its significance and waiting time. Priority is assigned based on the outcomes of the user request via IoT in the healthcare center. If the request has the weightage data for the process, it must be responded to primarily based on the waiting time. Time-sensitive data from users should be represented as the root of the tree structure in the classification, which is considered essential data to be processed first. The priority assignment is illustrated in Figure 3.
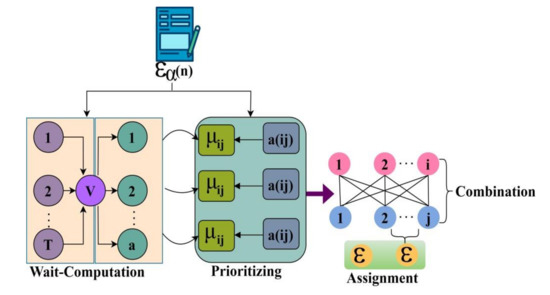
Figure 3.
Priority assignment.
The priority of the data request depends on the weightage of the data request from the user. Then it will be checked and the importance will be considered to give priority to the data from the user. The prioritizing occurs in the healthcare system where requirements and indigence exceed resources. It can be meant as the healthcare preferences during the allocation process from the user request. The priority is given to the emergency data to get the resources from the digital data. Their time of wait should not be exceeded by more than the given period due to their contingency. The request for more juncture ballgames should be paramount. Access to classified data will be given less priority in the process as it has common availability of the response. This decision-tree learning puts the waiting time in the process of the healthcare center. The service distribution expertly uses this decision-tree learning algorithm for user requests through the healthcare center’s IoT. The process of prioritizing the output of the classification procedure is explained by the following equation.
where (µij) denotes the calculation of the time-sensitive data from the classification process, (ε) denotes the prioritized data from the classification process, and (a) denotes the contingency of the request. Now, the prioritized request is sent to the electronic health records (EHRs) to determine the needed information of the patient. This record is the one that has the patients’ information and their characteristics in digital format. It will have every individual’s record containing data about their health in the healthcare center; thus, it allows the data to be instantly available when needed. It also has the treatment plans for the prioritized data request the user sends to the healthcare center. Thus, the needed information the user requests will be sent to them after the process of allocation. The following equations explain the information imparted by the EHR for the prioritized data by the user.
where a(i,j) is the information derived from the classification process for the prioritized data.
3.3. Allocation Process
The sensitive information is segregated for access and digital health data is distributed within the classified time. Therefore, time sensitiveness is retained through time and access prioritized allocations. The allocations are based on the importance of the user’s request via IoT in the healthcare center. The record information will be allocated according to the importance of the data requested by the user and then it will be sent to the user. After the classification process by the tree classifier algorithm, the data can be classified based on time and access. The time-sensitive data is then given a priority designation and the user is given access to the information from the digital record. The following equations illustrate the process used to allocate EHR information.
where (ηR) is the calculation of the information from the electronic records and ψQ is the information allocation for the requested data. The allocation processes are illustrated in Figure 4.
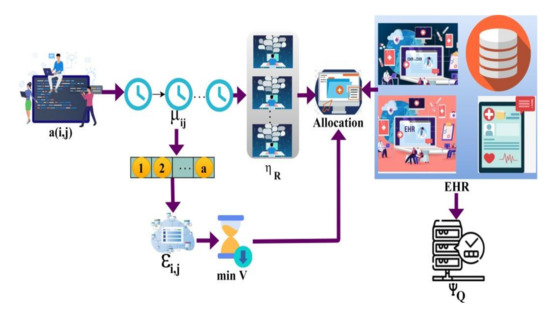
Figure 4.
Allocation process.
Following the procedure, the user in the smart healthcare center receives the information in response to their request. The proposed scheme identifies spontaneous availability and healthcare data access resources post the request generation. This method increases the service distribution in a lesser waiting time. It increases the availability of resources and decreases the allocation time by using the tree classifier algorithm for classification.
4. Results and Discussion
The results and discussion present a comparative analysis of the metrics of service distributions, availability, waiting time, allocation time, and failures. In this analysis, the requests vary from 100 to 1100 and the average time out varies from 300 s to 3000 s. The comparison is performed between SSF [13] and PSTBA [18].
4.1. Service Distribution
The proposed scheme identifies spontaneous availability and healthcare data access resources post the request generation. The requests are classified using time-sensitive features for prioritizing their access. The DT learning provides its intelligibility and simplicity features to the device to prioritize the production of the data requested by the users. Then, after the classification process, the time sensitiveness of the user data can be found. Immediately, the response will be given first to sensitive data from the user. The priority will be given first to those sensitive data requests from the user through healthcare centers. The service distribution is calculated based on the request triggered by the user in the selected timeframe. Figure 5 illustrates the average time out service distribution. To do this a number of requests are generated using the sequential increment snippet program.

Figure 5.
Average time out—service distribution analysis.
4.2. Service Availability
The service availability is fitter in this process by using the decision-tree learning algorithm in the classification process. The service availability is high during the classification of the data request to provide the information to the user from the EHR. The prioritized request is sent to the electronic record to determine the needed information of the patient. The priority of the data request depends on the weightage of the data request from the user. Then, it will be checked and the importance is considered to give priority to the data from the user. The prioritizing occurs in the healthcare system where requirements and indigence exceed resources. This record is the one that has the patients’ information and their characteristics in digital format. It will have every individual’s record containing the health data in the healthcare center, thus giving the instant availability of the data when needed. It also has the treatment plans for the prioritized data request sent by the user to the healthcare center (refer to Figure 6 and Figure 7).
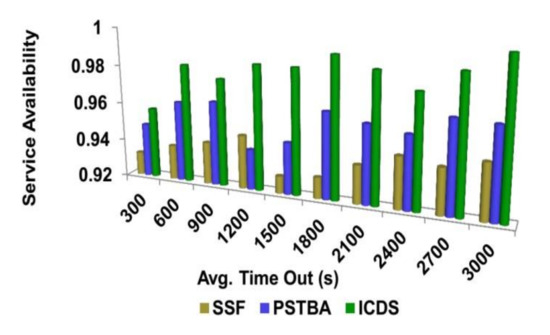
Figure 6.
Average time out—service availability analysis.
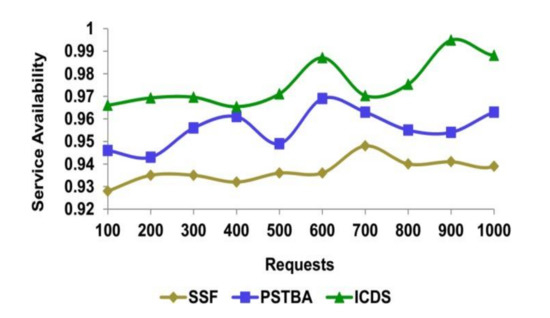
Figure 7.
Request—service availability analysis.
4.3. Waiting Time
The waiting time of the process is subordinate to using decision-tree learning in the classification process. The classification process takes place based on time and access. Based on time, the classification takes place. The sensitive information is segregated for access and digital health data is distributed within the classified time. Therefore, time sensitiveness is retained through time and access prioritized allocations. Then, priorities are given to the time-sensitivity data and the information from the digital record is allocated to the user. The learning is modified for the leaves based on data significance and minimum resource waiting time. The process occurs immediately based on the significance of the data request by the user. The service distribution is expert in lowering waiting time by using this decision-tree learning algorithm for user requests through the healthcare center’s IoT. The proposed scheme identifies spontaneous availability and healthcare data access resources post the request generation. This method increases the service distribution with less waiting time (refer to Figure 8 and Figure 9).
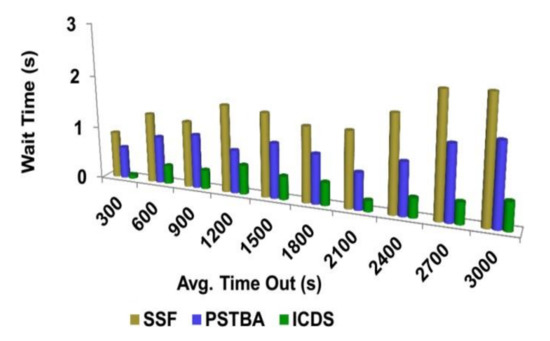
Figure 8.
Average time out—wait time analysis.
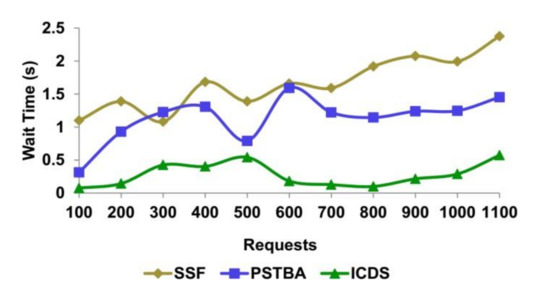
Figure 9.
Request—wait time analysis.
4.4. Allocation Time
The time taken for the allocation process from the EHR information is less in this healthcare procedure. The allocation process for significant data can take place. The sensitive information is segregated for access and digital health data is distributed within the classified time. The data the user requests will be assigned based on its significance and sent to them. After the classification process by the tree classifier algorithm, the data can be classified based on time and access. Therefore, time sensitiveness is retained through time and access prioritized allocations. Dissemination for heterogeneous healthcare requests relies on digital resource availability and allocation. Decision-tree learning is employed in this classification wherein the roots are constructed using allocation and the leaves are distinguished using allocation time. The sensitive information is segregated for access and digital health data is distributed within the classified time. Therefore, the time sensitiveness is retained through time and access prioritized allocations (refer to Figure 10 and Figure 11).
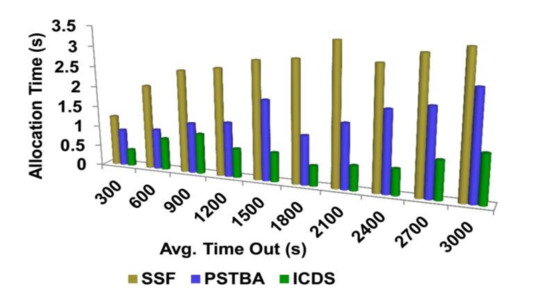
Figure 10.
Average time out—allocation time analysis.
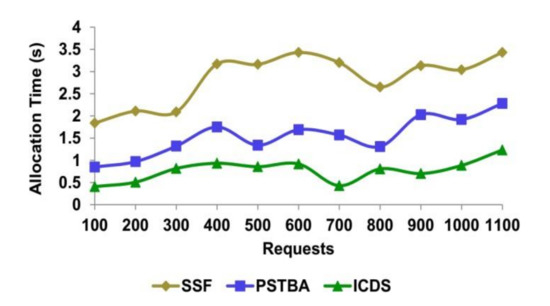
Figure 11.
Request—allocation time analysis.
4.5. Failure
The failures are fewer in this method by using the IoT in the process of the healthcare center where the user sends the request. In this method, the user request is given to the healthcare center through the IoT, which is used in healthcare devices. Then, the request can be classified by using the decision-tree learning algorithm. That request can be classified based on time and based on access. By this classification, the priority can be identified based on the waiting time and then the output is given to the EHR for the process allocation. Then the response to the request is sent to the user after the process. The user sends the request to the healthcare device with the IoT and then sends it to the healthcare center. Dissemination for heterogeneous healthcare requests relies on digital resource availability and allocation. The proposed scheme identifies spontaneous availability and healthcare data access resources post request generation and the shortcomings of the information provided. This process is shorter for the user through the healthcare center from digital data. The summary of the above comparison is presented in Table 2 and Table 3 for varying requests and average time out (refer to Figure 12 and Figure 13).

Figure 12.
Average time out—failures.

Figure 13.
Request—failures.
Table 2.
Comparison summary for varying requests.
Table 2.
Comparison summary for varying requests.
| Metrics | SSF | PSTBA | ICDS |
|---|---|---|---|
| Service Distribution (%) | 91.673 | 93.513 | 95.602 |
| Service Availability | 0.954 | 0.968 | 0.9907 |
| Waiting Time (s) | 2.375 | 1.452 | 0.5722 |
| Allocation Time (s) | 3.43 | 2.28 | 1.234 |
| Failures | 0.075 | 0.054 | 0.0358 |
Summary: The proposed scheme improves service distribution and availability by 9.03% and 8.91%, respectively. This scheme reduces waiting time, allocation time, and failures by 11.77%, 9.46%, and 8.61%, respectively.
Table 3.
Comparison summary for average time out.
Table 3.
Comparison summary for average time out.
| Metrics | SSF | PSTBA | ICDS |
|---|---|---|---|
| Service Distribution (%) | 90.555 | 92.941 | 95.659 |
| Service Availability | 0.949 | 0.967 | 0.9995 |
| Waiting Time (s) | 2.311 | 1.532 | 0.5241 |
| Allocation Time (s) | 3.45 | 2.61 | 1.189 |
| Failures | 0.076 | 0.047 | 0.0362 s |
Summary: The proposed scheme improves service distribution and availability by 11.73% and 12.45%, respectively. This scheme reduces waiting time, allocation time, and failures by 12.12%, 10.13%, and 7.59%, respectively.
5. Conclusions
To improve the service dissemination of smart healthcare backboned by the IoT, this article introduced an information-centric dissemination scheme. The proposed scheme classifies the user requests as time-sensitive and access-centric for providing wait-timeless services. The classification uses decision-tree learning, wherein the roots are consistently modified for the time and access features. The proposed scheme identifies priority requests and resource availability features such that the waiting time is considerably less. Therefore, the prioritized data classification and information calculation from the service providers’ end improve service dissemination for time-sensitive healthcare data requests. The proposed scheme enhances service distribution and availability by 9.03% and 8.91%, respectively. This scheme reduces waiting time, allocation time, and failures by 11.77%, 9.46%, and 8.61%, respectively. The proposed architecture will integrate with the smartwatch by developing a mobile application and checking service distribution, reliability, and availability for real-time scenarios.
Author Contributions
V.K.K. and S.G. conceived and planned the conceptualization and writing of the original draft preparation, performed the experiments, and visualization. A.Y., R.S. and M.B. contributed to the proposal of the methodology, investigation, and validation. M.B., B.Q. and A.K. contributed to the analysis and interpretation of the results, writing—reviewing, editing, and analysis. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Acknowledgments
The authors would like to acknowledge the support of Prince Sultan University for paying the article processing charges (APC) of this publication.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, J.; Yang, Y.; Liu, X.; Ma, J. An efficient blockchain-based hierarchical data sharing for Healthcare Internet of Things. IEEE Trans. Ind. Inform. 2022, 18, 7139–7150. [Google Scholar] [CrossRef]
- Blanken, M.; Mathijssen, J.; Nieuwenhuizen, C.V.; Raab, J.; Oers, O.V. Actors’ awareness of network governance in Child Welfare and Healthcare service networks. Health Policy 2023, 127, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Kiross, G.T.; Chojenta, C.; Barker, D.; Loxton, D. Optimum maternal healthcare service utilization and infant mortality in Ethiopia. BMC Pregnancy Childbirth 2021, 21, 390. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Ma, S.; Chen, S. Healthcare service configuration based on project scheduling. Adv. Eng. Inform. 2020, 43, 101039. [Google Scholar] [CrossRef]
- Tuli, S.; Basumatary, N.; Gill, S.S.; Kahani, M.; Arya, R.C.; Wander, G.S.; Buyya, R. HealthFog: An ensemble deep learning based Smart Healthcare System for Automatic Diagnosis of Heart Diseases in integrated IoT and fog computing environments. Future Gener. Comput. Syst. 2020, 104, 187–200. [Google Scholar] [CrossRef]
- Zhang, C.; Cho, H.H.; Chen, C.Y. Emergency-level-based healthcare information offloading over fog network. Peer-Peer Netw. Appl. 2020, 13, 16–26. [Google Scholar] [CrossRef]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- Quy, V.K.; Hau, N.V.; Anh, D.V.; Ngoc, L.A. Smart healthcare IoT applications based on fog computing: Architecture, applicationsand challenges. Complex Intell. Syst. 2022, 8, 3805–3815. [Google Scholar] [CrossRef] [PubMed]
- Rehman, A.; Saba, T.; Haseeb, K.; Alam, T.; Lloret, J. Sustainability model for the internet of health things (IoHT) using reinforcement learning with Mobile edge secured services. Sustainability 2022, 14, 12185. [Google Scholar] [CrossRef]
- Rehman Khan, A.; Saba, T.; Sadad, T.; Hong, S.P. Cloud-based framework for COVID-19 detection through feature fusion with bootstrap aggregated extreme learning machine. Discret. Dyn. Nat. Soc. 2022, 2022, 3111200. [Google Scholar] [CrossRef]
- Du, G.; Tian, Y.; Ouyang, X. Multi-resources co-scheduling optimization for home healthcare services under the constraints of service time windows and green transportation. Appl. Soft Comput. 2022, 131, 109746. [Google Scholar] [CrossRef]
- Xu, L.Q.; Gao, H. A device-agnostic cloud-based platform enabling tiered service provisioning for sleep disorders diagnosis and management. In Encyclopedia of Sleep and Circadian Rhythms; Elsevier: Amsterdam, The Netherlands, 2022; pp. 88–99. [Google Scholar]
- Sabokbar, H.F.; Mohammadi, H.; Tahmasbi, S.; Rafii, Y.; Hosseini, A. Measuring spatial accessibility and equity to healthcare services using fuzzy inference system. Appl. Geogr. 2021, 136, 102584. [Google Scholar] [CrossRef]
- Abdelmoneem, R.M.; Benslimane, A.; Shaaban, E. Mobility-aware task scheduling in cloud-Fog IoT-based healthcare architectures. Comput. Netw. 2020, 179, 107348. [Google Scholar] [CrossRef]
- Gouveia, L.; Paias, A.; Ponte, M. The travelling salesman problem with positional consistency constraints: An Application to healthcare services. Eur. J. Oper. Res. 2022, 308, 960–989. [Google Scholar] [CrossRef]
- Zgheib, R.; Kristiansen, S.; Conchon, E.; Plageman, T.; Goebel, V.; Bastide, R. A scalable semantic framework for IoT healthcare applications. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1735–1762. [Google Scholar] [CrossRef]
- Kumar, C.S.; Kumar, K.V. Integrated Privacy Preserving Healthcare System Using Posture-Based Classifier in Cloud. Intell. Autom. Soft Comput. 2023, 35, 2893–2907. [Google Scholar] [CrossRef]
- Rehman, A.; Saba, T.; Haseeb, K.; Singh, R.; Jeon, G. Smart health analysis system using regression analysis with iterative hashing for IoT communication networks. Comput. Electr. Eng. 2022, 104, 108456. [Google Scholar] [CrossRef]
- Waibel, S.; Williams, J.; Tuff, Y.; Shum, J.; Scarr, J.; Donnell, M. Development of the Tiers of Service framework to support system and operational planning for children’s healthcare services. BMC Health Serv. Res. 2021, 21, 693. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Wang, H.; Wang, N.; Zhang, T. Optimal scheduling in cloud healthcare system using Q-learning algorithm. Complex Intell. Syst. 2022, 8, 4603–4618. [Google Scholar] [CrossRef] [PubMed]
- Elshahed, E.M.; Abdelmoneem, R.M.; Shaaban, E.; Elzahed, H.A.; Al-Tabbakh, S.M. Prioritized scheduling technique for healthcare tasks in cloud computing. J. Supercomput. 2022, 79, 4895–4916. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).