1. Introduction
The South Korean government has recently focused on environmental protection efforts to improve water quality which has been degraded by nonpoint sources (NPSs) of water pollution from runoff because of runoff transporting sediment from NPSs. These efforts have been undertaken to improve instream conditions for aquatic organisms, reduce the costs of drinking water treatment, and prevent the excessive sedimentation of dams and hydroelectric energy production facilities. A large amount of sediment control has focused on agricultural fields using a wide range of hydraulic structures, such as debris barriers, sediment filters and sediment chambers [
1]. Of these approaches, vegetative filter strips (VFS) has been popular and suggested as the best management practices (BMPs) for reducing contaminant in surface runoff [
2].
VFS is an area of vegetation next to a waterway designed to remove pollutants and sediment from runoff water through particle settling, water infiltration, and nutrient uptake. The VFS also provides a way to control erosion rates and keep soils in the field rather than letting the soils be carried off the field into drainage water. The VFS approach consists of a strip of land planted with vegetation on a relatively low angle cross-slope portion of the field between the site agricultural erosion sources and a water body. The VFS approach is designed to mimic natural sediment traps on the landscape, and therefore, slow the speed of runoff by filtration, deposition and infiltration to filter a substantial amount of NPS water pollution from agricultural runoff. Thus, VFS is effective at trapping sediment [
3]. VFS also provides soil conservation management by reducing soil erosion in agricultural fields. Overall, vegetative filter strips (VFSs) can be an effective, long-term, economical approach for environmental management [
4,
5].
VFSs have been considered to be the BMP for effective sediment control, and proper design of VFS is often the most important consideration for the effective application of VFS. In order to evaluate the effectiveness of a certain design of VFS using various design elements (e.g., slope, vegetation type and condition, soil condition, strip width, monitoring, etc.), VFS-related physically-based computational models are needed because it is difficult to set various design elements in the field, as well as to conduct monitoring frequently which is direct measurement of sediment load. For these reasons, the vegetative filter strip modeling system (VFSMOD-W) has been widely used to evaluate the impact of VFS on hydrology, sediment and pollutant transport, and VFSMOD-W performs well [
6,
7,
8].
While the VFSMOD-W works well, it takes a large amount of work to carry out site simulations, and there is a need to find faster and more efficient approaches and machine learning may provide an efficient alternative to simulation modeling [
6,
7,
8]. Also, machine learning can improve beyond the capability of physically-based modeling by simply adding as new data which are principle components representing VFS. In agricultural fields, big data analysis is used for precision agriculture to achieve optimal productivity and minimize costs [
9,
10]. In addition to the applications of precision agriculture, machine learning models (e.g., ANN [Artificial Neural Network], GRNN [Generalized Regression Neural Network] and ANFIS [Adaptive neuro-fuzzy inference system]) has been widely used to estimate nonlinear hydrologic processes [
11,
12,
13,
14,
15,
16].
There have been many applications of machine learning in diverse disciplines in environmental engineering. In hydrology and water resources areas, Thirumalaiah and Deo [
17] applied for Neural Networks (NNs) with three alternative methods (e.g., error backpropagation, conjugate gradient and cascade correlation) to forecast stream flows and flood during storms. Thirumalaiah and Deo [
17] found NNs with cascade correlation forecasted flood better than with other alternative methods. Dawson and Wilby [
18] used artificial neural networks (ANNs) for flow forecasting in two flood-prone UK catchments. This study showed based on the optimized data preprocessing the ability of the ANN outperformed conventional lumped or semi-distributed flood forecasting models. Coulibaly and Anctil [
19] forecasted real-time short-term natural water inflows using Recurrent Neural Networks (RNNs). The results indicated using RNN to forecast natural inflows into hydropower reservoirs outperformed the traditional stochastic and conceptual models. Adnan et al. [
20] predicted the flood water level using Back Propagation Neural Network (BPN) for flood disaster mitigation. BPN with an extended Kalman filter showed significant improvement to the prediction of the flood water level.
In soil science and agronomy areas, Soil and Water Assessment Tool (SWAT) enables to predict soil and water components in agriculture, such as runoff and agricultural chemical movement, was applied for flow estimation by using together ANN and Self Organizing Map (SOM) [
21]. Machine learning applications, such as ANN and SOM exhibited good performance in prediction of water flow. Adnan et al. [
20] mentioned nonlinear models, such as support vector regression (SVR) outperformed linear models or time series models in the prediction of streamflow.
As machine learning models can quickly and accurately estimate runoff and soil erosion without the application of a complex physically-based model, such as SWAT, it was necessary to examine whether VFSMOD-W can be replaced with machine learning models in the evaluation of sediment trapping efficiency in VFS.
The objective of this study is to develop an efficient machine learning model to estimate sediment trapping efficiencies simply and accurately considering agricultural characteristics for agricultural fields in South Korea. Data construction for training, validation and testing is an important process for developing a machine learning model. Data to build a machine learning model were constructed by using VFSMOD-W input and output. Model validation was carried out with observed data retrieved from the literature, as well as simulated results from VFSMOD-W.
In a nutshell, this study suggests a simple and accurate machine learning model without using a complex physically-based model to estimate sediment trapping efficiencies in agricultural fields in South Korea. Such machine learning models can be used to evaluate sediment trapping efficiency without complicated physically-based model design and high computational cost. Thus, decision makers, such as developers, planners, engineers, local units of government can maximize the quality of their outputs by minimizing their efforts.
3. Results and Discussion
3.1. Development of Machine Learning Models
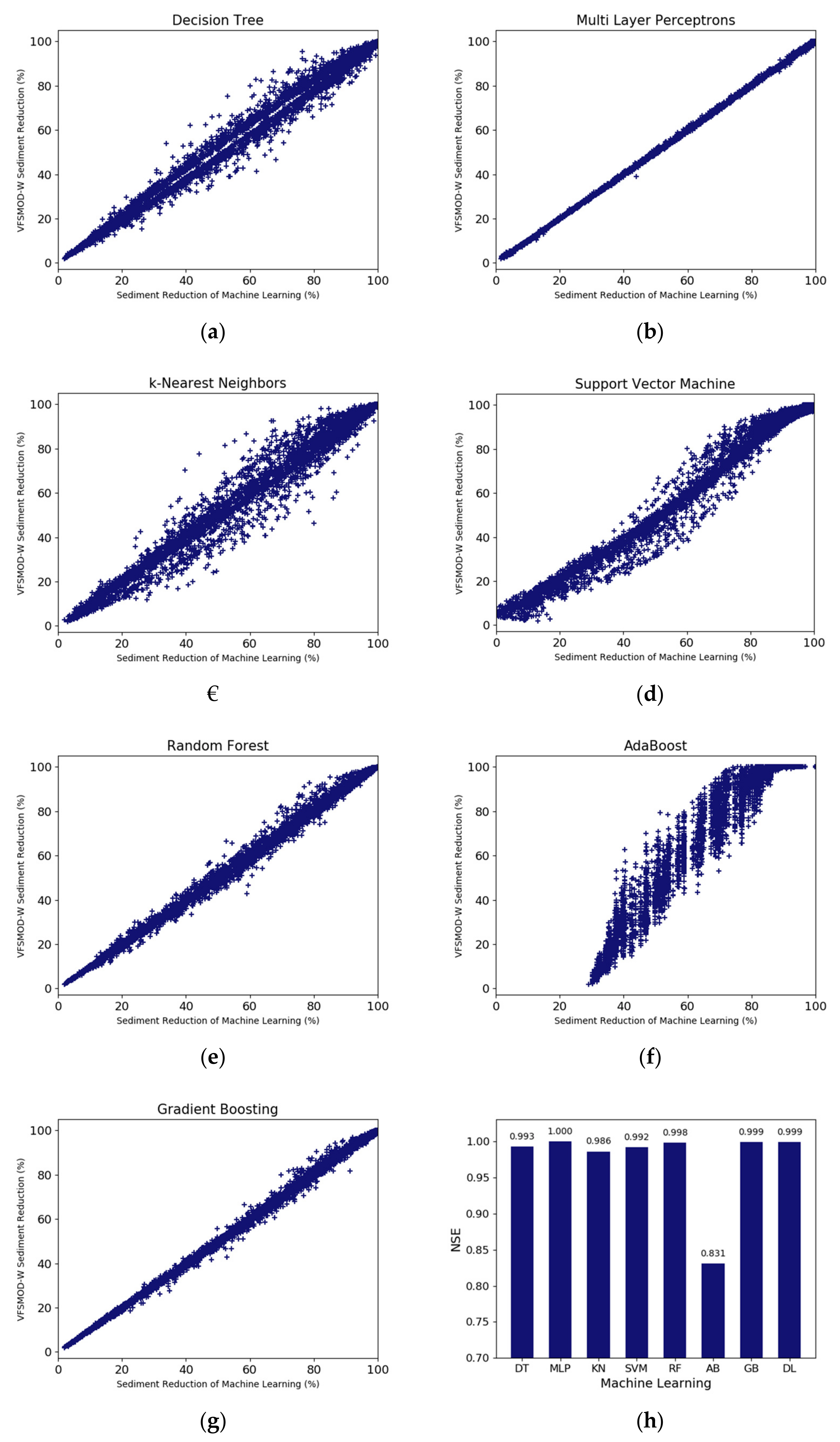
Overall, the machine learning models tested in this study were highly successful in replicating the results of the VFSMOD-W simulations across a wide range of conditions.
Table 11 shows prediction accuracy results (NSE, RMSE and MAPE) of seven machine learning models compared to the sediment trapping efficiencies of VFSMOD-W. The results from MLP and gradient boosting models showed high prediction accuracy indicating MLP with NSE of 1, RMSE of 0.37% and MAPE of 0.53% and gradient boosting with NSE of 0.99, RMSE of 0.89% and MAPE of 0.78%. Thus, these two models would be suggested in this study. MLP and gradient boosting are the most powerful and widely used models in supervised learning and appear to have led to high accuracy by adjusting the hyperparameters using the hidden layers of MLP and the depth of the gradient boosting [
27,
36].
The results of this analysis show a large overall variation in the success of the machine learning models tested against the VFSMOD-W simulation results. Among the seven machine learning models, AdaBoost showed the lowest performance with NSE of 0.83, RMSE of 10.78% and MAPE of 21.81% as the boosting tends to focus on misclassified samples (data) Also, because the boosting is too dependent on training data, it was too easy to overfit depending on the training data, indicating a rather low accuracy [
41]. However, other machine learning models (e.g., decision trees, KNN, SVM and random forest regression models) all showed high performance above 0.98. Using these machine learning models, it is expected that the similar results of sediment trapping efficiencies in VFS can be estimated well.
The most successful machine learning approach tested here was the MLP model. The test data were used to calculate the sediment trapping efficiencies of each machine learning model and the efficiency values calculated in the VFSMOD-W were compared to the efficiencies estimated by machine learning models (
Figure 2a–g).
Figure 2a–g shows that the sediment trapping efficiency calculated by the MLP regression model is most similar to that of VFSMOD-W.
Figure 2h shows a bar graph for easy comparison of NSE of seven machine learning models, which indicates that the results of MLP, gradient boosting and random forest are excellent. Especially MLP has the best results among the seven machine learning models. Since single perceptron classification can be performed with only one straight line, it cannot solve the problem that cannot be divided into straight lines. In MLP, however, it is possible to bend the line by creating a hidden layer. Thus, more flexible prediction can be carried out, and since the hidden layer consists of three layers with 50 nodes each, it is more flexible to predict the sediment trapping efficiency.
The AdaBoost model showed the most different result from the sediment trapping efficiency calculated by VFSMOD-W, and NSE was 0.82. The gradient boosting regression model increased NSE to 0.999 by changing ‘max_depth’ to 10 than the gradient boosting regression model was estimated with the fixed hyperparameter, and it can be seen that the hyperparameter setting can increase the predictive performance. However, when looking at the correlation distribution with the result of VFSMOD-W, the gradient boosting is slightly more distributed than MLP.
As shown in the results, it was found that not only is certain machine learning superior, but also there would be a more suitable model (in terms of prediction) according to the data characteristics, and that the predictive performance can be sufficiently increased by the setting and tuning of hyperparameters.
3.2. Validation of Machine Learning Models
Seven machine learning models were developed in this study to calculate the sediment trapping efficiency of VFS, and the models were validated that the sediment trapping efficiencies can be easily and conveniently calculated without using a physically-based hydrological model, such as VFSMOD-W. However, it is necessary to verify how well the seven machine learning models can predict the sediment trapping efficiency of VFS in real situations.
The observations in VFS from the literature review were used to apply the actual situation, and all the machine learning models developed in this study were applied. The study area of VFS in Barfield et al. [
44] is a naturally formed karst watershed area. As the input data for the machine learning models, the rainfall was 63.5 mm/hr, and soil texture was specified as loam. The slope was 9%, the area ratio of VFS to a field size was 4.8%, field area was 0.001 ha, the USLE P-factor was 1.0, the USLE C-factor was 0.3, and the CN was 74. The sediment trapping efficiencies predicted in the machine learning models were compared with the observations from Barfield et al. [
44] (
Figure 3).
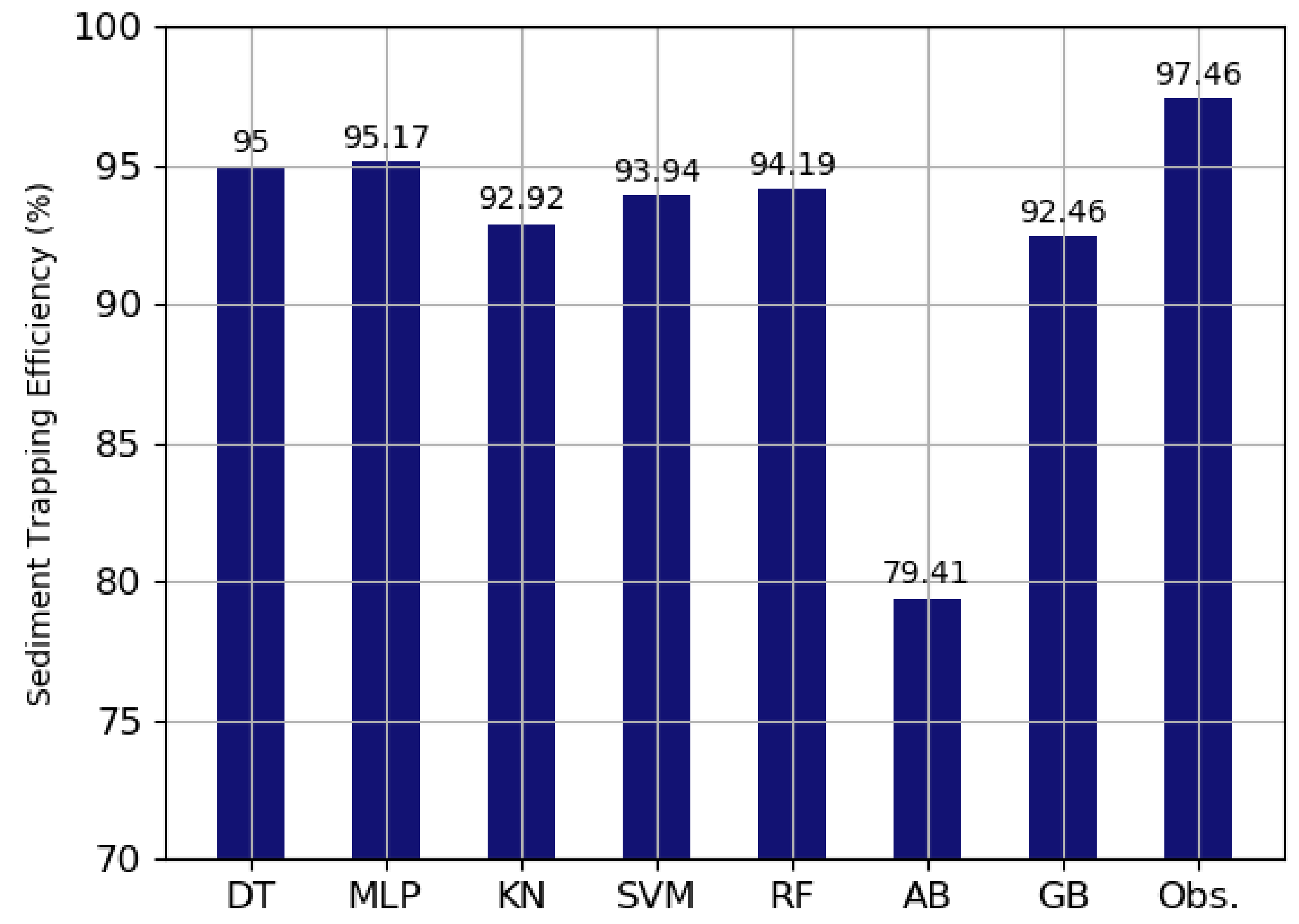
The validation results showed MLP and the decision tree were reliable and useful models.
Figure 3 showed that the sediment trapping efficiencies calculated by the decision tree, MLP, KNN, SVM, random forest, AdaBoost, gradient boosting were 95%, 95.17%, 92.92%, 93.94%, 94.19%, 79.41%, 92.46%, respectively, and actual sediment trapping efficiency indicated 97.46% which was most similar to the result from MLP and decision tree. The prediction results of MLP and the decision tree showed a percentage error between actual observations and the two models ranged from 2.34 to 2.52%. Thus, the two models (i.e., MLP and the decision tree) are verified as robust models.
3.3. Data Analysis to Develop Machine Learning Models
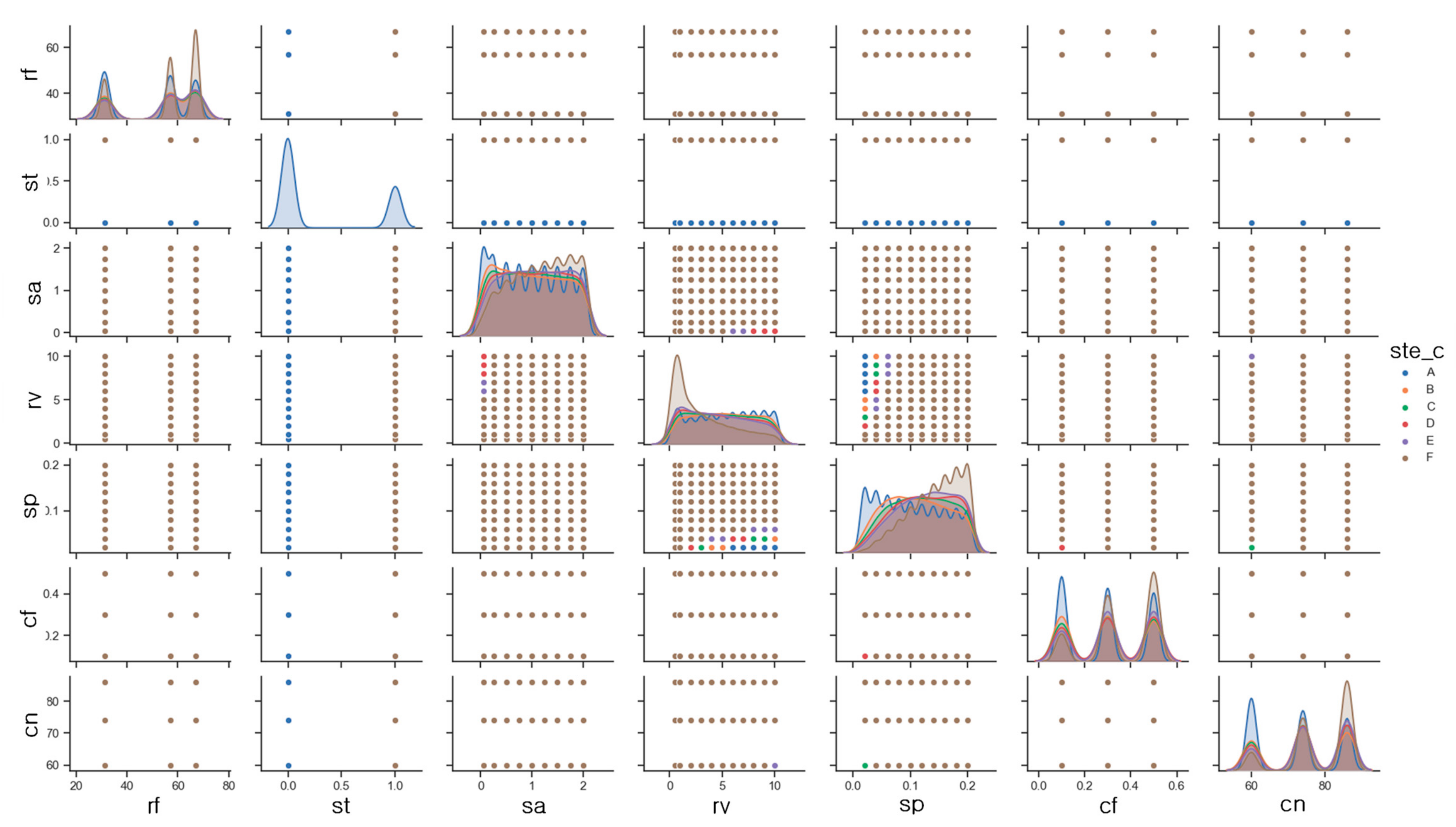
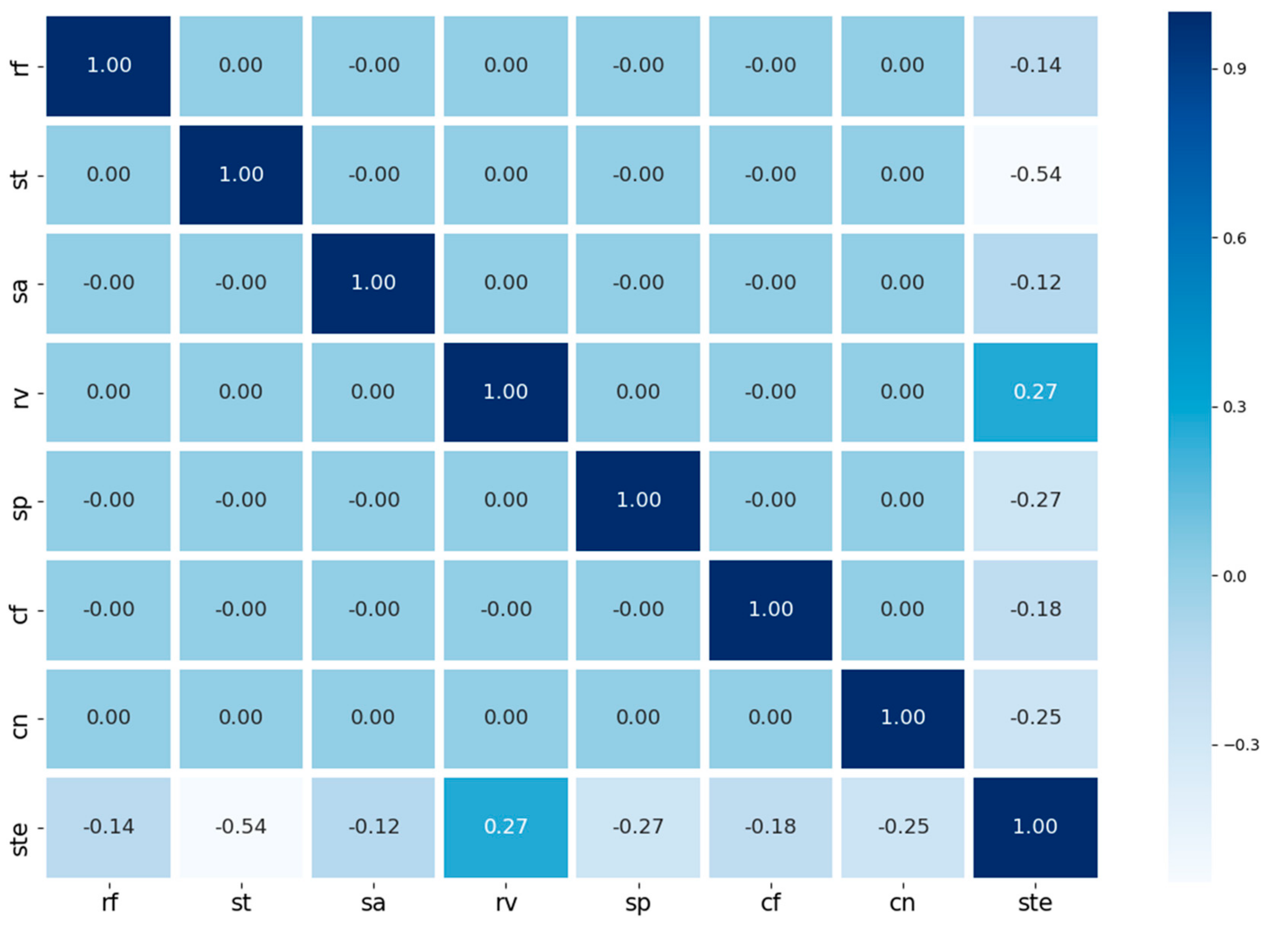
Many parameters related to VFS were used to develop machine learning models. For the development of machine learning models in an effective way, parameters for machine learning models should be analyzed and understood. Using a scatter plot matrix and heat map, correlation analysis between sediment trapping efficiency and model attributes (i.e., rf [rainfall], st [soil texture], sa [source area], rv [ratio of VFS area to source area], sp [slope], cf [USLE C-factor], cn [curve number] and ste [sediment trapping efficiency]) were analyzed. Soil texture (st), the ratio of VFS area to source area (rv) and slope (sp) indicated a strong relationship with sediment trapping efficiency.
Figure 4 is a scatterplot matrix which shows that the sediment trapping efficiency and the correlation between each property at the same time. It is expected that
Figure 4 can improve readability by presenting the legend in a categorical form with the sediment trapping efficiency. The sediment trapping efficiency category (ste_c) of VFS is assigned as A for more than 90% of the sediment trapping efficiency, B for 80–90%, C for 70–80%, D for 60–70% and E for 50–60%. If the sediment trapping efficiency is less than 50%, we specify an F category value, and we can see the correlation between these categories and each attribute and the histogram of each attribute (
Figure 4). The results showed that A and F classes were distributed mostly with 86.7% of the total, and the frequency of B ~ E classes with the remaining 13.3% was low. The class is randomly assigned, so it may be a good idea to take a look at the scattering matrix repeatedly by resetting the sensitively changing classes.
In the scatter plot matrix, it is necessary to look at the histogram of each property. Because the specified attribute values are categorical data rather than continuous data, the distribution also shows a normalized distribution around each category. When the rainfall (rf) is 67 mm, the result shows the sediment trapping efficiency class (ste_c) is mostly F class, whereas, at 31 mm, it shows the highest grade distribution. Through these results, it can be estimated that the more rainfall, the lower the sediment trapping efficiency.
According to
Figure 4 and
Figure 5, there is a positive strong relationship between the ratio of VFS area to source area (rv) and sediment trapping efficiency. The more rv, the higher the sediment trapping efficiency. This explains that bigger areas of vegetation developed to remove sediment work better for sediment trapping efficiency. The F class is densely distributed in the small VFS to agricultural field area ratio, and the A grade is distributed variously over the entire interval. In the case of the slope (sp), the distribution of the F class is high when the slope is high, and the distribution of the A grade is high in the low slope region. In the case of other attributes, it can be seen that all categories show various classes, and the correlation with the sediment trapping efficiency can be analyzed in the upper distribution.
In the end, however, it is difficult to quantify the correlations only by looking at the correlation between the properties and the sediment trapping efficiency class of VFS. Therefore, the correlation between each input data, including the sediment trapping reduction (ste) of VFS which is continuous numerical data was analyzed using a heat map (
Figure 5). Soil texture played a major role in controlling sediment trapping efficiency. The heat map shows that the soil texture (st) of VFS has the strongest influence on the sediment trapping efficiency (ste) with −0.54, and The VFS area ratio (rv) is 0.27 with a positive correlation and the slope (sp) has a negative correlation of −0.27. The sediment trapping efficiency (ste) was statistically significant in the paired T-test results from each attribute (
p < 0.001). Multicollinearity does not occur when there are strong correlations between independent variables (
Table 2).
3.4. Sensitivity Analysis of Model Hyperparameters
In the seven machine learning regression models, experiments were conducted to set the critical hyperparameters proposed by Müller and Guido [
27].
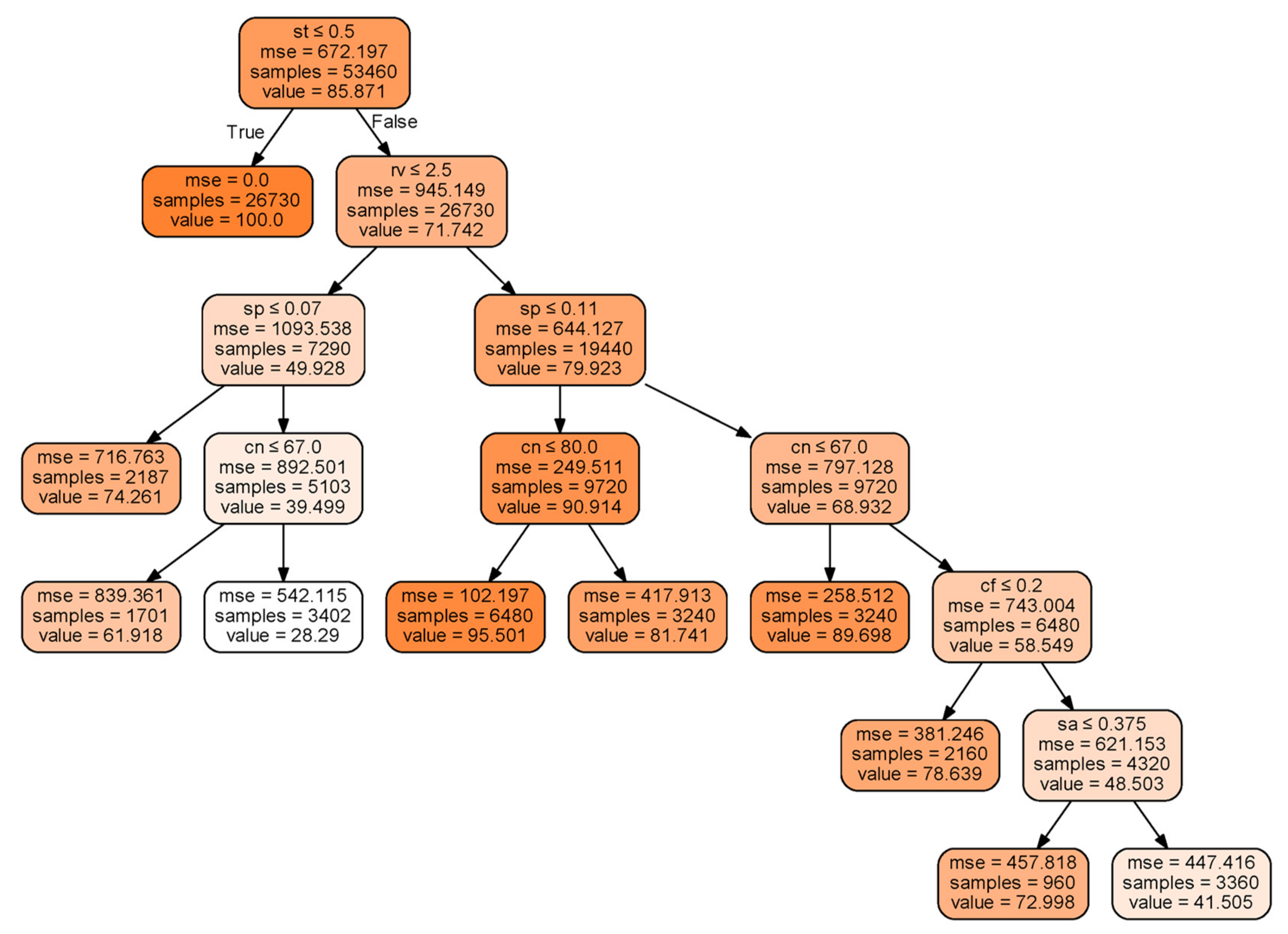
Figure 6 examines how the decision tree method is used to predict the sediment trapping efficiency of VFS. If the maximum number of branches of the decision tree is not determined, a huge distribution with many branches is created. Therefore, in this study, the maximum number of branches (max_leaf_nodes) is set to 10. The mean squared error, which is the classification condition, was calculated to generate a decision tree diagram.
The decision tree diagram is not about predicting the class of data, but rather about the process of predicting consecutive numeric values. As shown in the decision tree diagram, the most influential attribute is soil texture (st), which is the first to be classified in the decision tree classifier. If the criterion of soil texture is less than 0.5, it is classified as true only if it is sandy loam. The next is classified whether the VFS area ratio (rv) is less than or equal to 2.5. If the VFS area ratio (rv) is true, the classification is made under the condition that the slope (sp) is 0.07 or less. As such, it is helpful to understand a decision tree regression based on the criteria of classification.
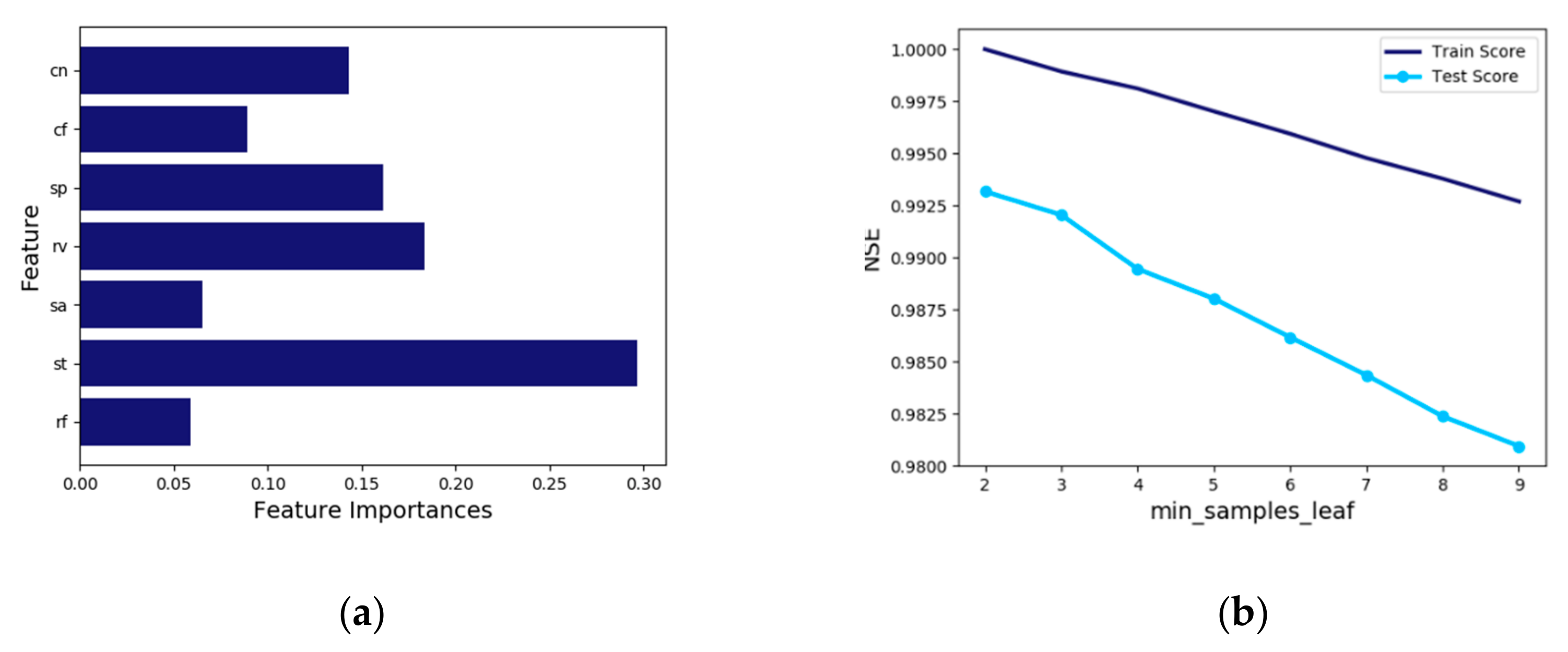
In addition, the influential components are presented in
Figure 7a. The most influential property is soil texture (st) which is 0.30. Then, the VFS area ratio (rv) is 0.18, and the third important property is the slope (sp) which is 0.16. This result indicates the same as the order of the decision tree diagram in
Figure 6.
Determining the minimum number of samples required to be at a leaf node (Min_samples_leaf) was conducted to prevent overfitting in the regression function (
Figure 7b). When ‘min_samples_leaf’ is 2, the best learning is achieved, and the NSE (coefficient of determination) for test is 0.993. This hyperparameter value stops the tree before the decision tree is completely built by pre-pruning. If ‘min_samples_leaf’ goes over 2, the result shows a tendency to sharply decrease in accuracy.
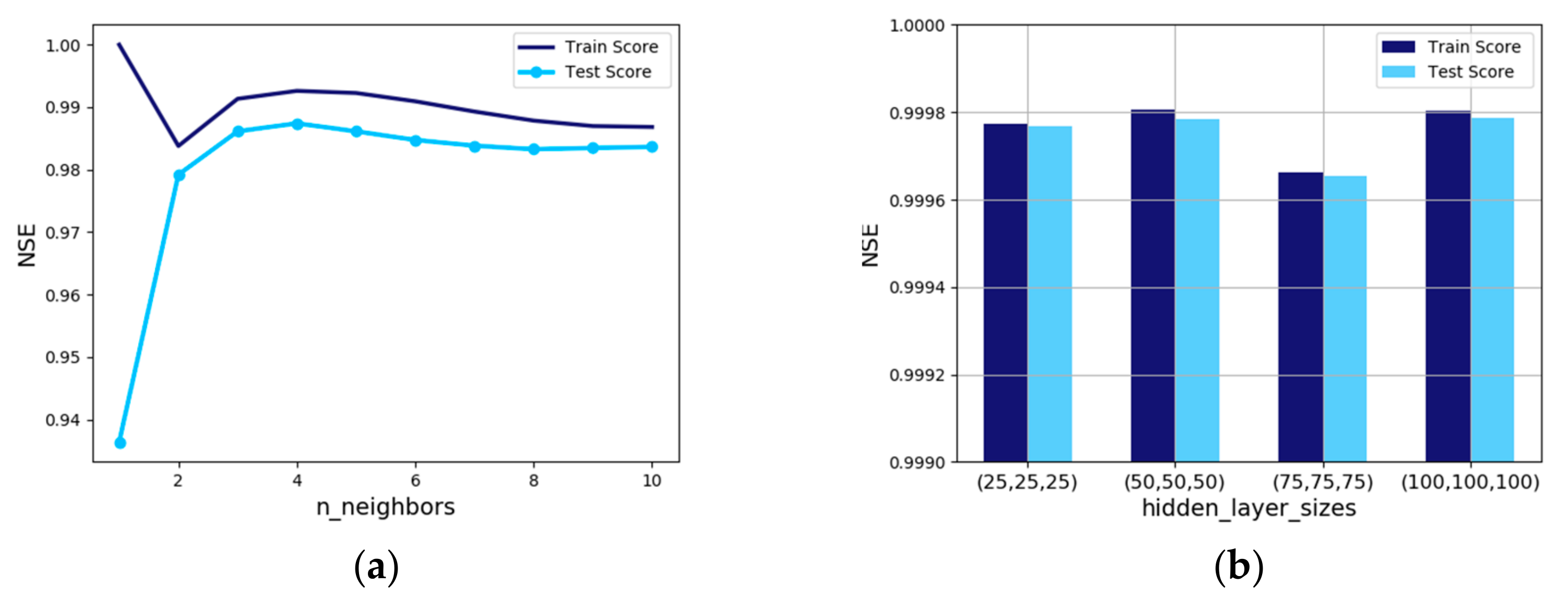
In the k-nearest neighbors model, the use of a large number of neighbors usually does not fit well with the training data, but tends to yield more stable predictions which are a way to prevent overfitting [
36]. Therefore, it is important to determine the optimal number of neighbors in the k-nearest neighbors model.
Figure 8a indicates that when four neighbors were used, both the training and test show the best results, and the test result shows NSE of 0.987.
An important hyperparameter in the multilayer perceptron regression model (MLPRegressor) is the hidden layer size. In this study, various tests to determine the optimal hidden layers and nodes were conducted, and the results of the four cases are represented in
Figure 8b. The best results were obtained by setting three hidden layers with 50 nodes and hyperparameters were set to the same hidden layer and node size.
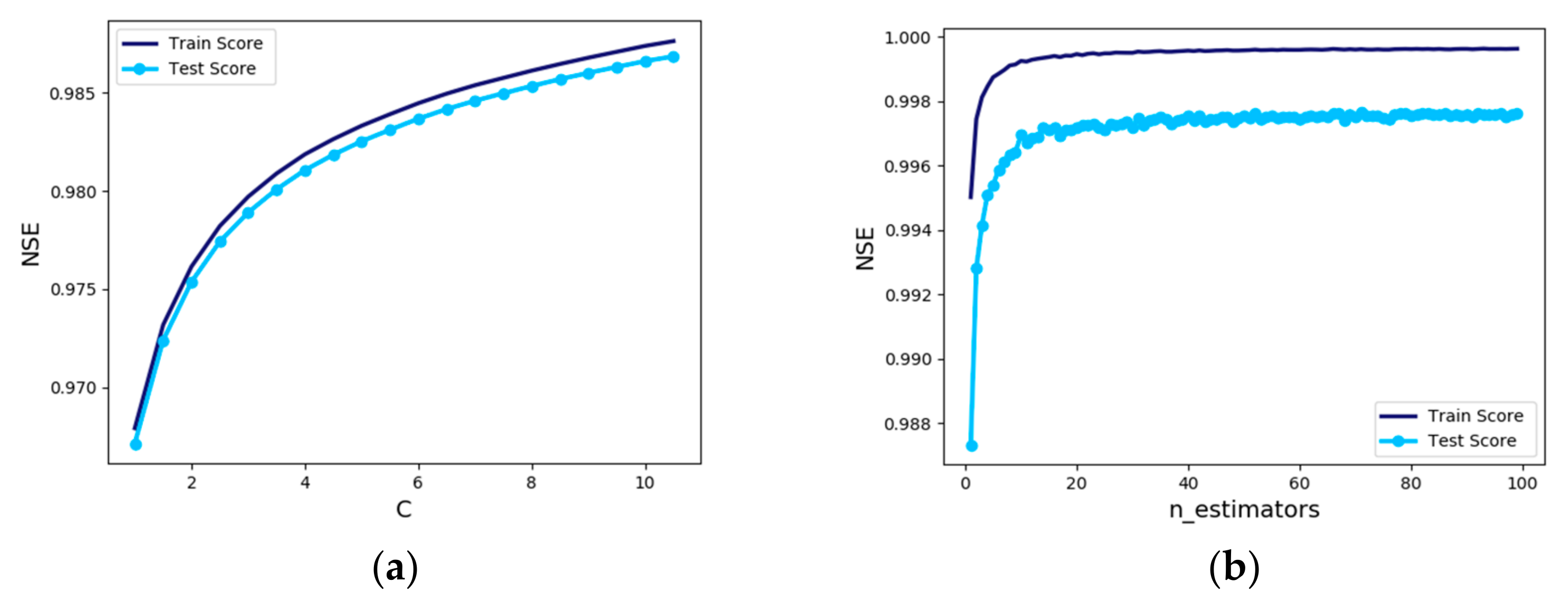
In the support vector machine regression model, a C value was set to 50 because when NSE showed 0.992 in the test data, a C value was 50 (
Figure 9a). Since the accuracy of the model increases as the C value increases, the C value is set large. C values determine how many data samples are allowed to be placed in different classes. Lower C values increase the likelihood that there are outliers to find a general decision boundary, while higher C values narrow the likelihood of outliers and more precisely determine the decision boundary. Increasing the C value as much as possible for the fine decision boundary showed good results. In this study, the C value was set to 50, considering calculation speed and overfitting issues.
In order to get the best results of ‘n_estimators’ which is tree numbers and is the sensitive hyperparameter in the random forest regression model, we experimented with varying the settings from 1 to 100. In the case of the test data, no significant change was observed from 20 or more, but the maximum value was set to 52 in this model because the tree number 52 showed an NSE of 0.998 which resulted in the best results (
Figure 9b).
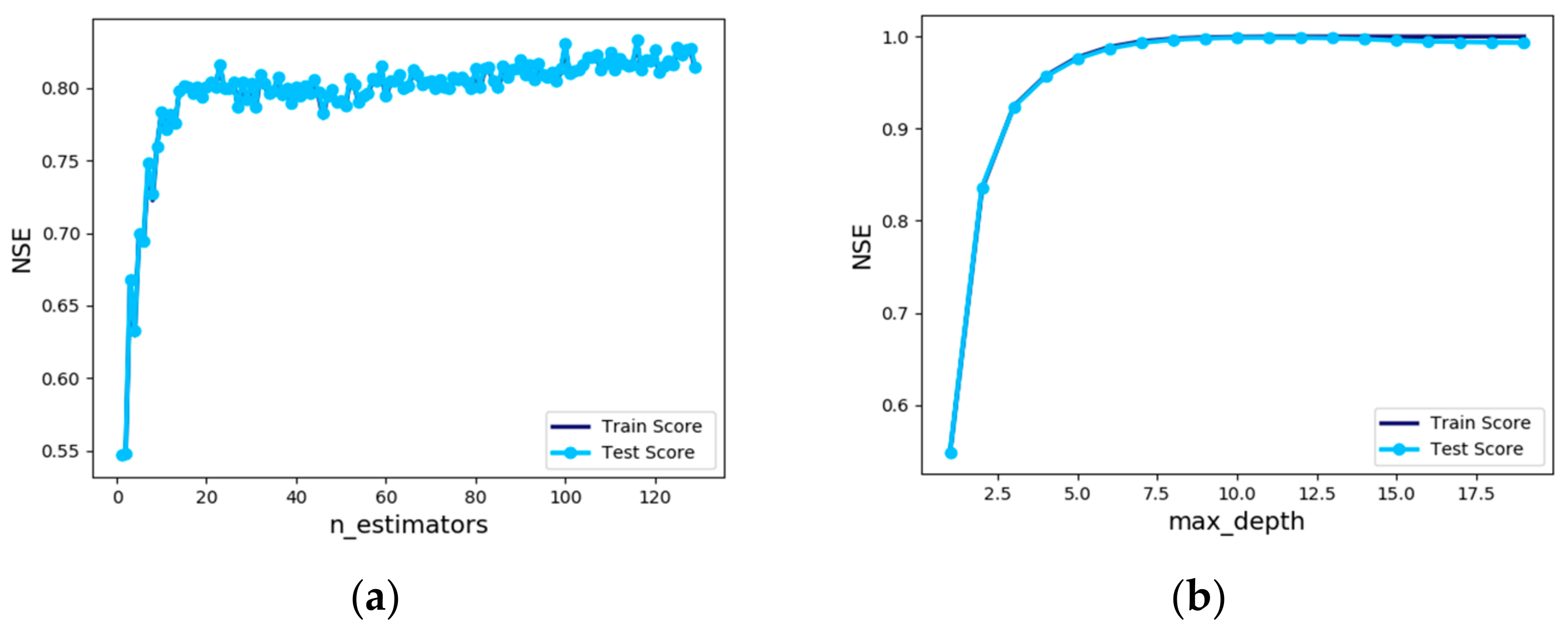
Sensitivity analysis of “n_estimators”, a hyperparameter of the AdaBoost Regressor, was performed. To obtain the most accurate model, the analysis of “n_estimators” was carried out by changing the value from 1 to 129, and the training and test data results showed almost the same trend. When “n_estimators” was validated using the test data, the result showed NSE of 0.831 with 126 learners. Therefore, ‘n_estimators’ of 126 would be appropriate (
Figure 10a). In the case of AdaBoost, it is necessary to adjust the ‘learning_rate’ because it shows somewhat lower accuracy by only tuning “n_estimators”. However, the learning rate is adjusted by showing the best NSE of 0.804 at 0.4 and 1 of ‘learning_rate’. The result shows that the accuracy increase cannot be expected greatly. In future studies, it is necessary to study how to produce better results by constructing various combinations of hyperparameters rather than adjusting only a couple of independent hyperparameters.
The critical hyperparameters in the gradient boosting regression model (GradientBoostingRegressor) are ‘n_estimators’ which specify the number of trees and ‘learning_rate’ which compensates for errors in the previous tree [
36]. These two parameters are so closely related that lowering ‘learning_rate’ requires adding more trees to create a model of similar complexity.
Sensitivity analysis of two hyperparameters was conducted, and because of the accuracy of up to 0.95, no good results are comparable to MLP. Sensitivity analysis was also carried out by changing the depth of ‘max_depth’ which reduces the complexity of the tree. Setting the value of ‘max_depth’ to 10 increased the accuracy of the gradient boosting regression model, and NSE of the test data was 0.999.
Usually, setting the ‘max_depth’ value to 5 does not make the tree deeper in the gradient boosting model. However, for the data used in this study, it was not unreasonable to use this value to derive the maximum accuracy of the gradient boosting model when the depth value was changed to 10 (
Figure 10b).
4. Conclusions
The fundamental objective for estimating the sediment trapping efficiency by VFS is to protect water quality and soil environment. We consider that machine learning is a feasible alternative method of VFSMOD-W to evaluate VFSs efficiently. The machine learning models developed in this study can readily provide robust estimates within the domain of the training and validation data with the appropriate data processing.
For the optimal machine learning model generation, a sensitivity analysis was conducted first to determine most sensitive hyperparameters, and the models were developed by tuning the hyperparameters that were trained and validated in each model through sensitivity analysis. A total of seven machine learning models were tested herein, such as decision tree, MLP, KNN, SVM, random forest, AdaBoost and gradient boosting. The MLP model showed the best results with NSE of 1, RMSE of 0.37% and MAPE of 0.53%, followed by gradient boosting, random forest, decision tree, SVM, KNN and AdaBoost models. Also, all models showed good results with NSE above 0.83.
A particular model is not considered to be superior, and it is possible to improve the learning ability in each model according to the user parameter setting of the algorithm in the model (i.e., the hyperparameter tuning). The results showed that using the appropriate data processing, as well as the training and validation of the model is very important to build robust machine learning models.
In order to build great potential machine learning models to create readily applicable VFSMOD-W models, a couple of further studies is needed. First, impact of data processing (e.g., data pre- and post-processing) and various validation techniques (e.g., k-fold cross validation, leave-one-out cross validation [LOOCV] and bootstrapping) on the accuracy of machine learning models need to be tested. Second, various input data combinations (e.g., soils, land use/land cover, climate, management and topographic information) should be applied to the global extent.
Machine learning models developed in this study can evaluate sediment trapping efficiency without complicated physically-based model design and high computational cost. Thus, machine learning models would be popular among decision makers, such as developers, planners, engineers, local units of government, and decision makers can maximize the quality of their outputs by minimizing their efforts.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}