
Assessing OpenStreetMap Data Using Intrinsic Quality Indicators: An Extension to the QGIS Processing Toolbox

Abstract
:1. Introduction
2. Data Quality Parameters and Related Work in OSM
2.1. Completeness
2.2. Attribute Accuracy
2.3. Semantic Accuracy
3. Methodology: Extending the Processing Toolbox
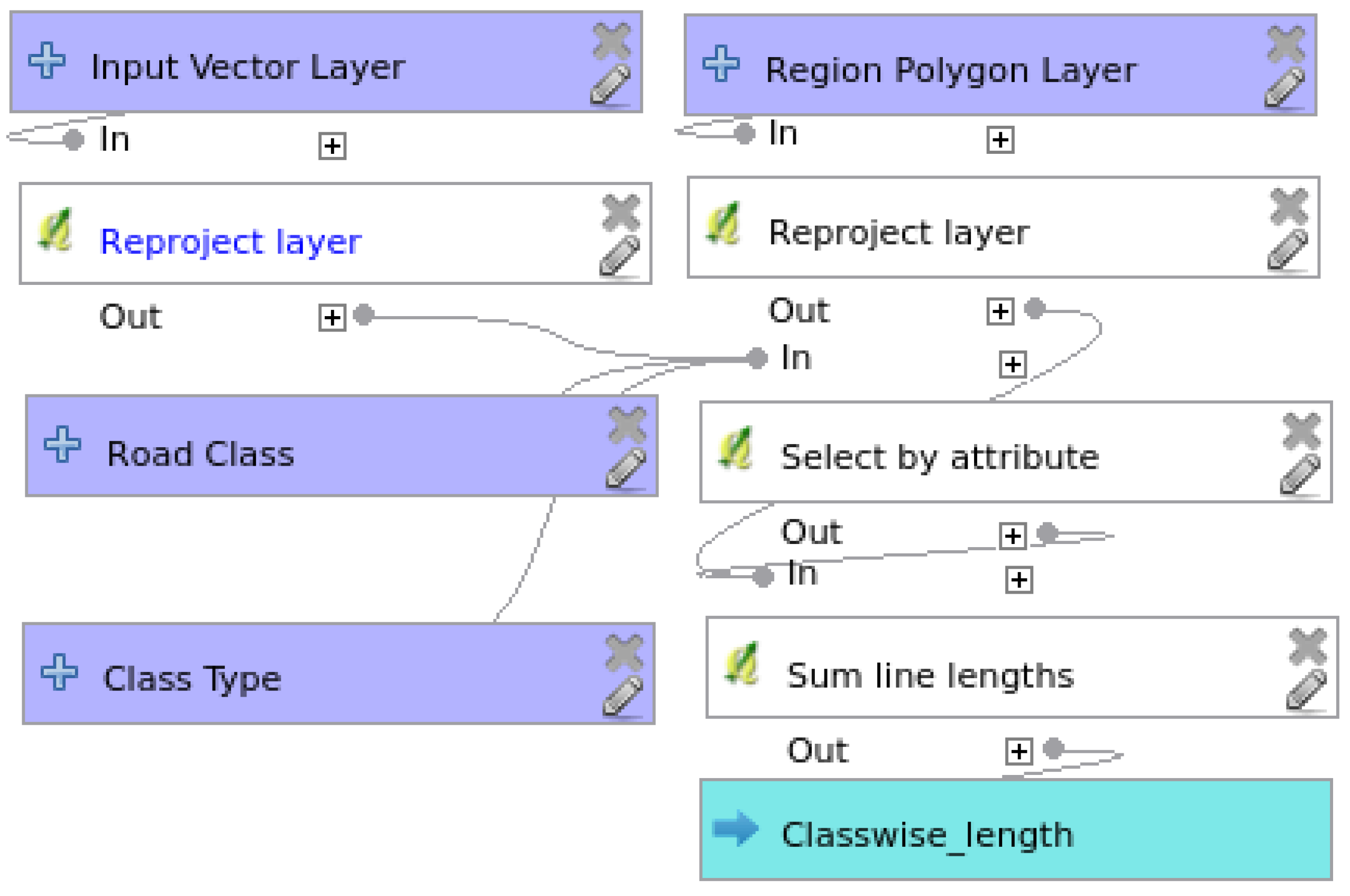
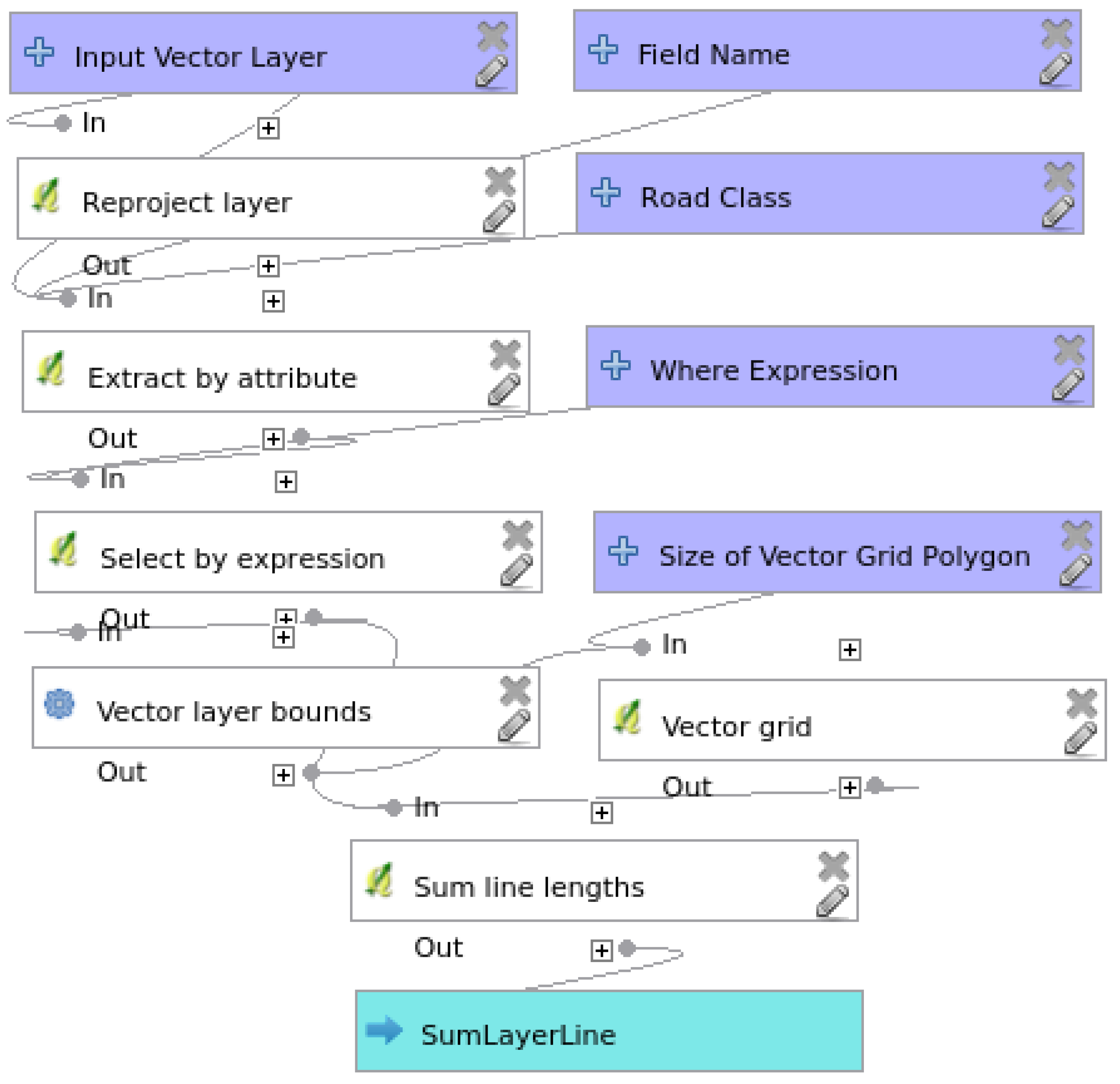
3.1. Network Length Completeness Model
3.2. Attribute Completeness Model
3.3. Semantic Accuracy Assessment Model
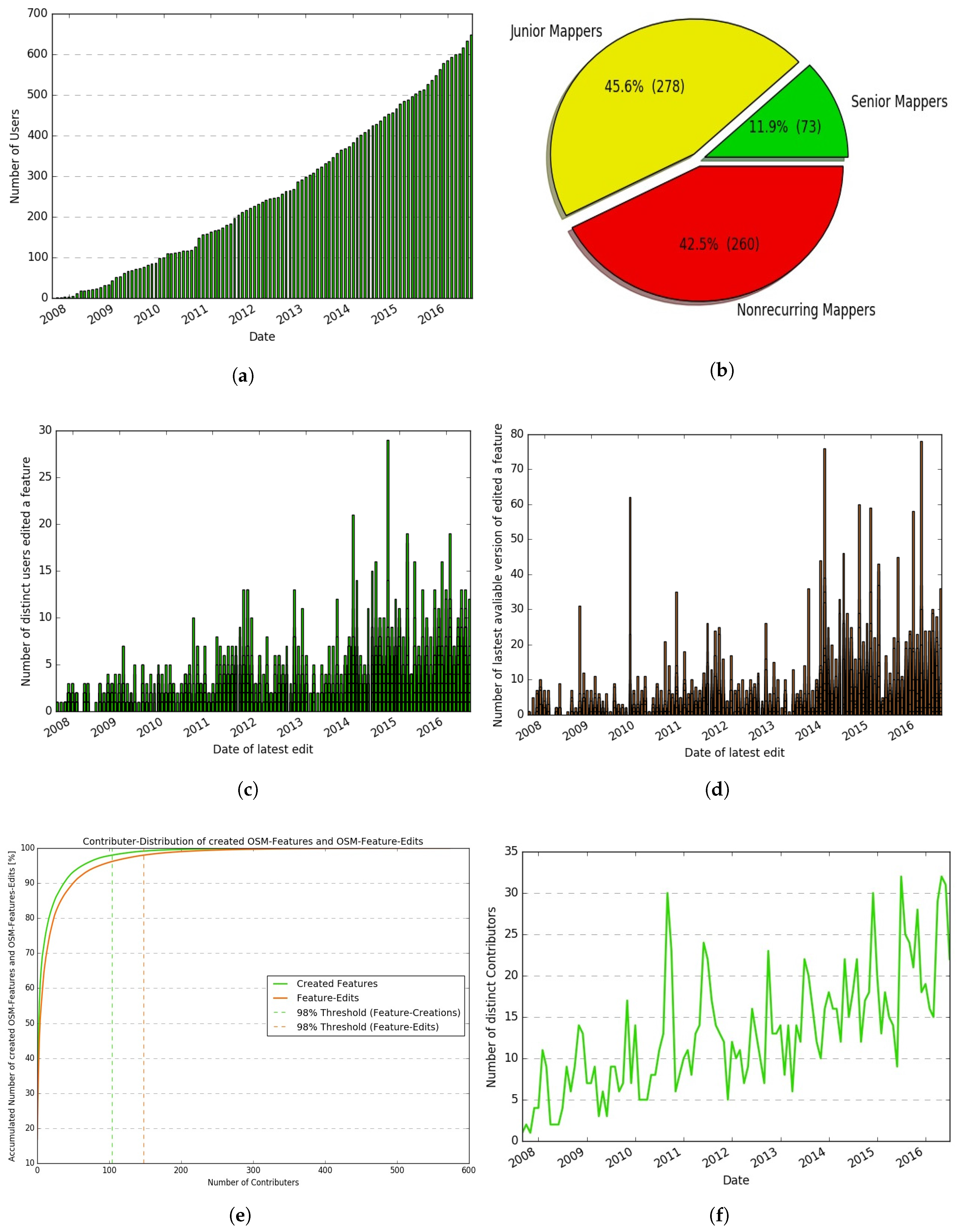
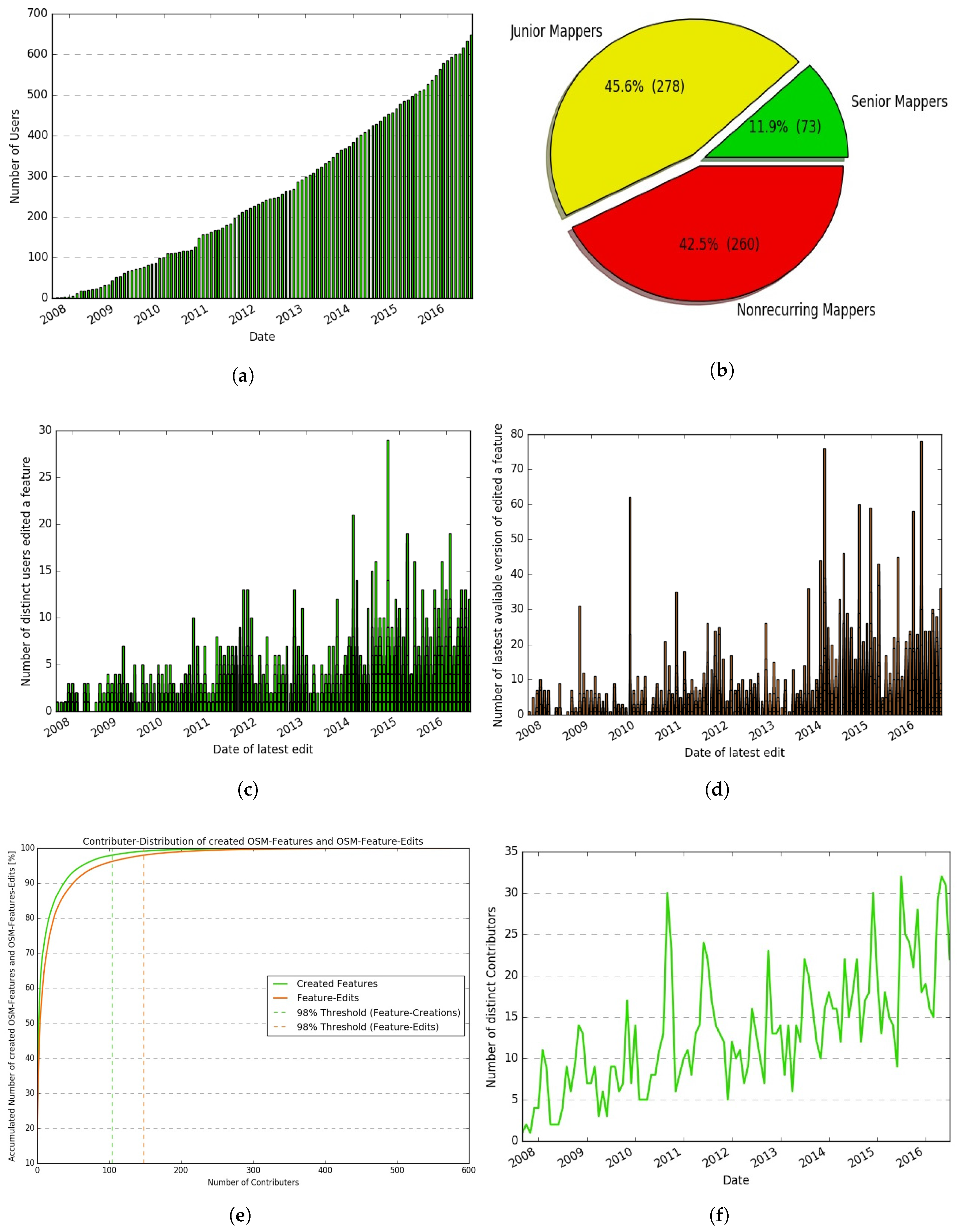
- How many contributors have made contributions to OSM data?
- What classes of contributors have edited the area under examination?
- How many distinct users have contributed chronologically to develop a feature?
- How has a feature developed over time, and what is its latest version number?
- How many distinct active contributors edited OSM data?
- Contributor-distribution of created OSM-features and OSM-feature-edits.
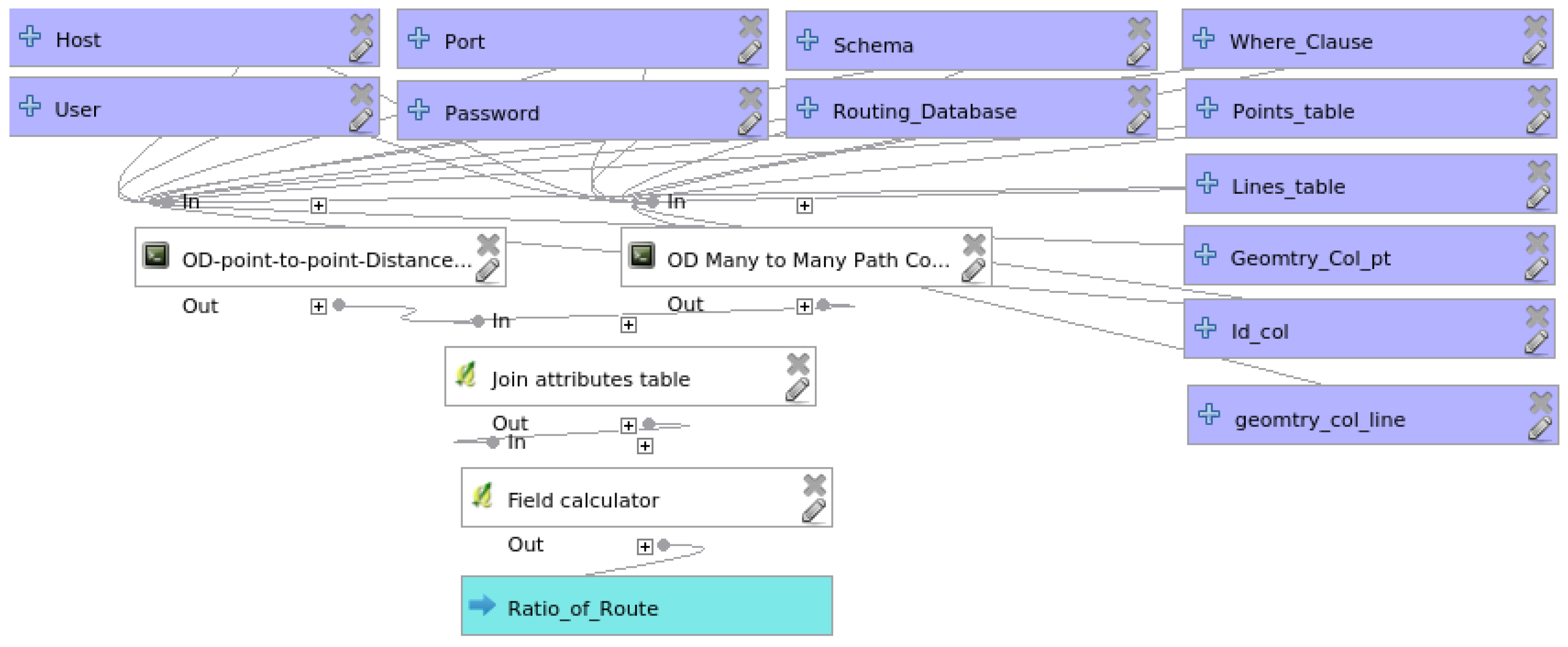
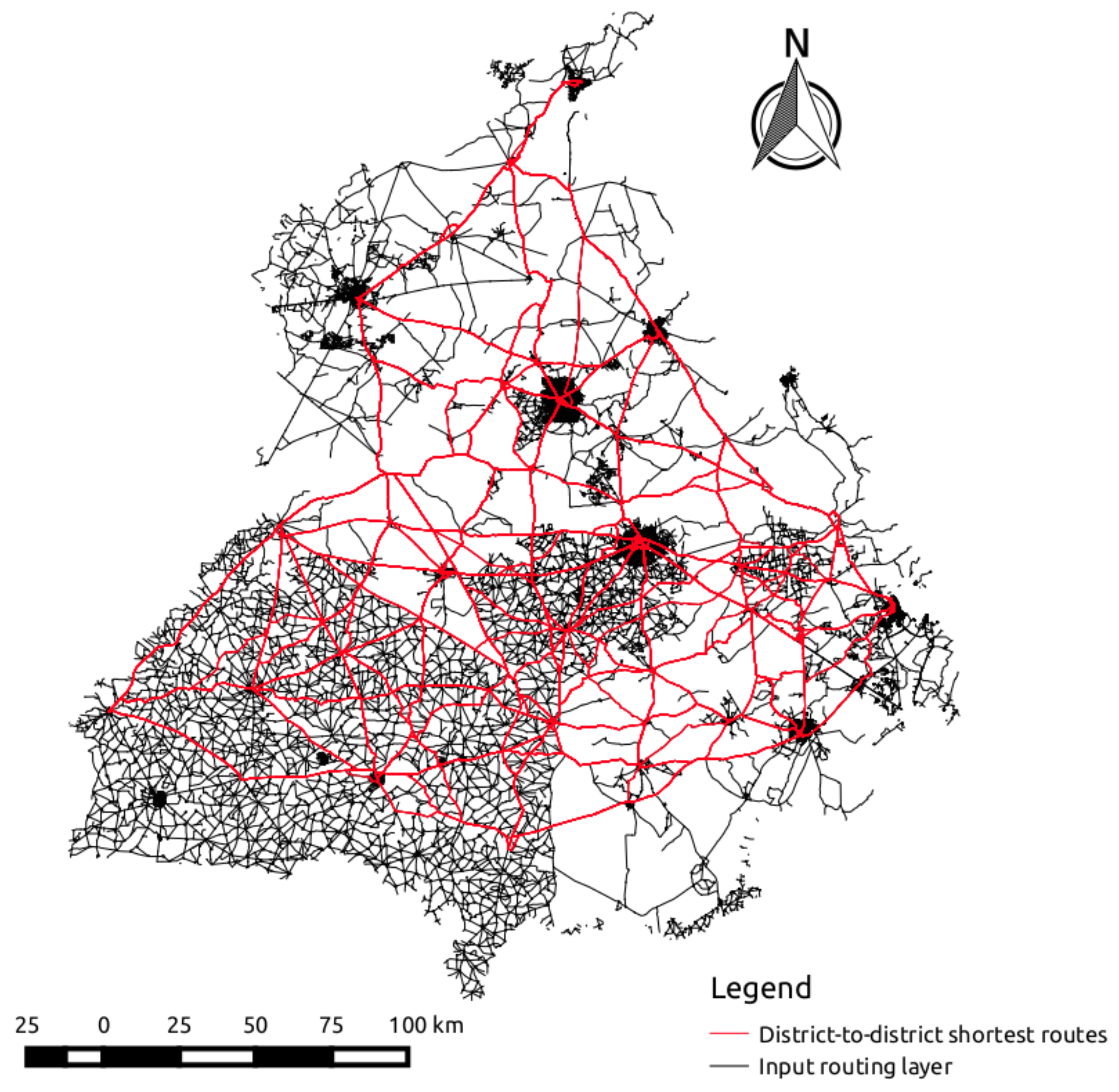
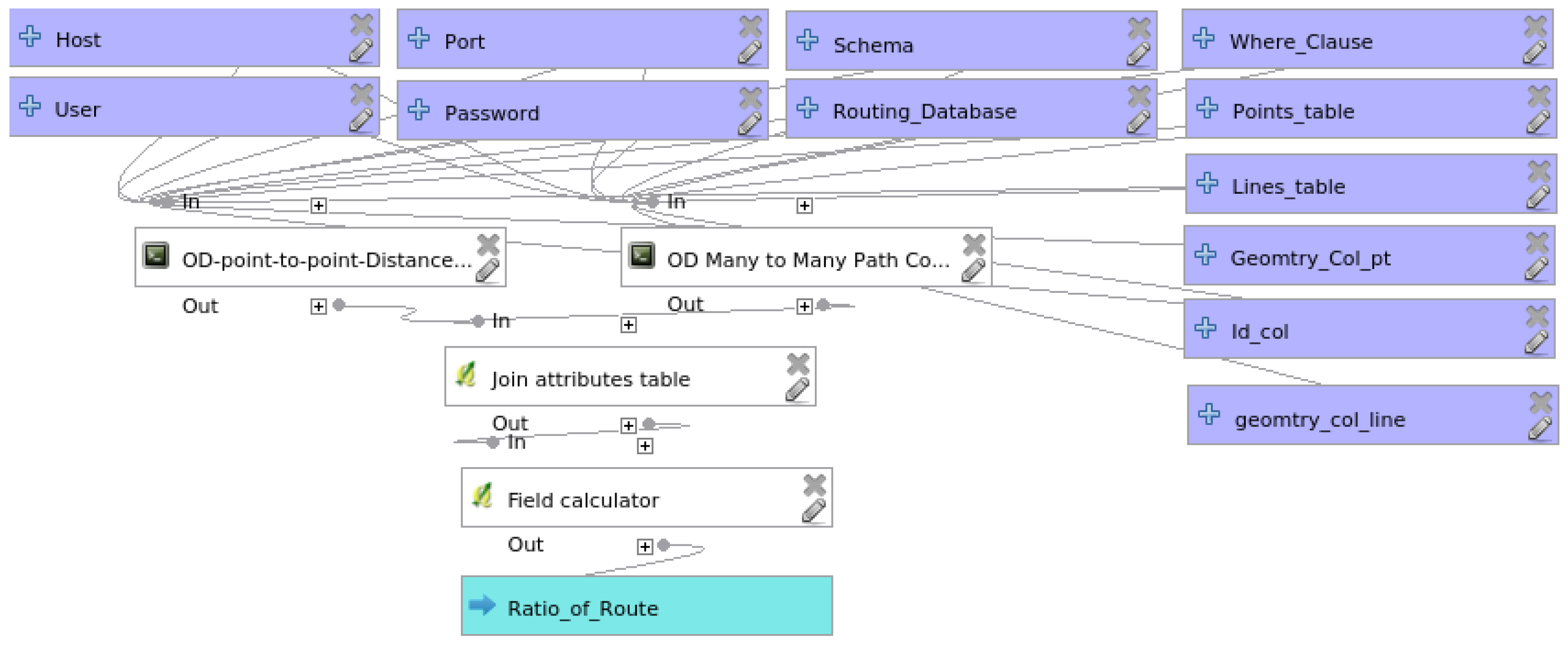
3.4. Route Navigability Assessment Model
4. Case Study of Punjab OSM Data
4.1. Data Preparation and Tools
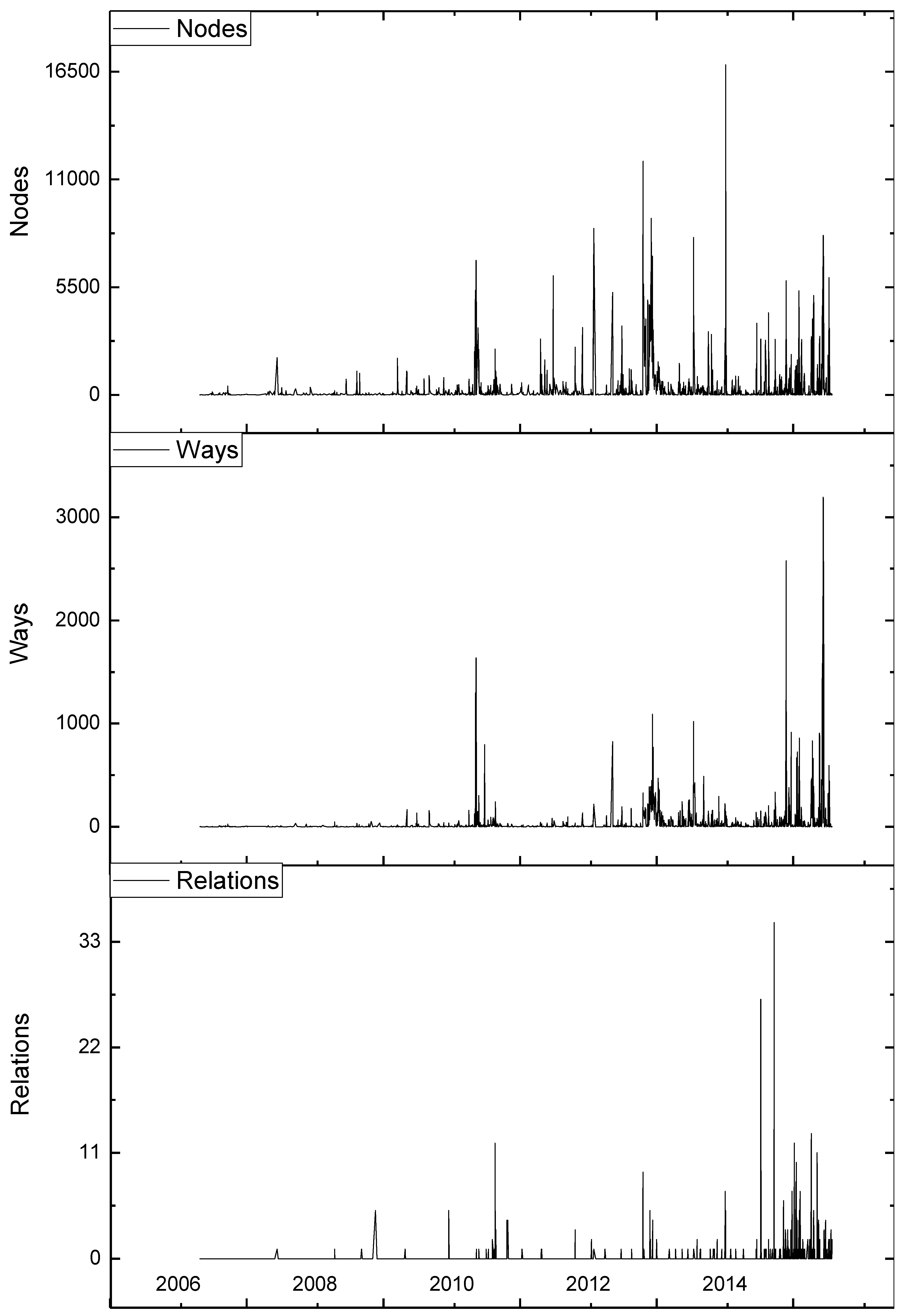
4.1.1. History Data Preparation
4.1.2. Routing Graph Preparation
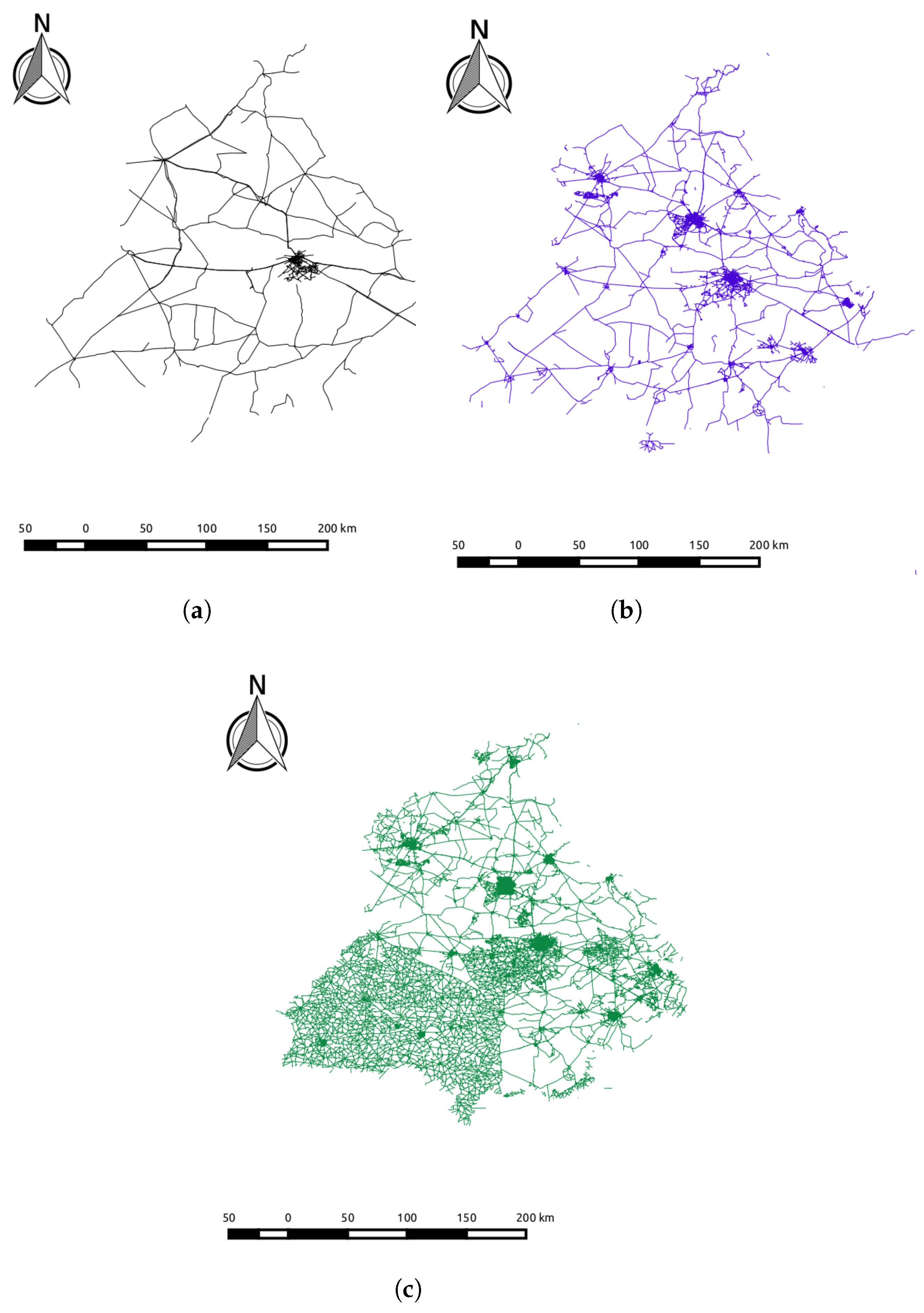
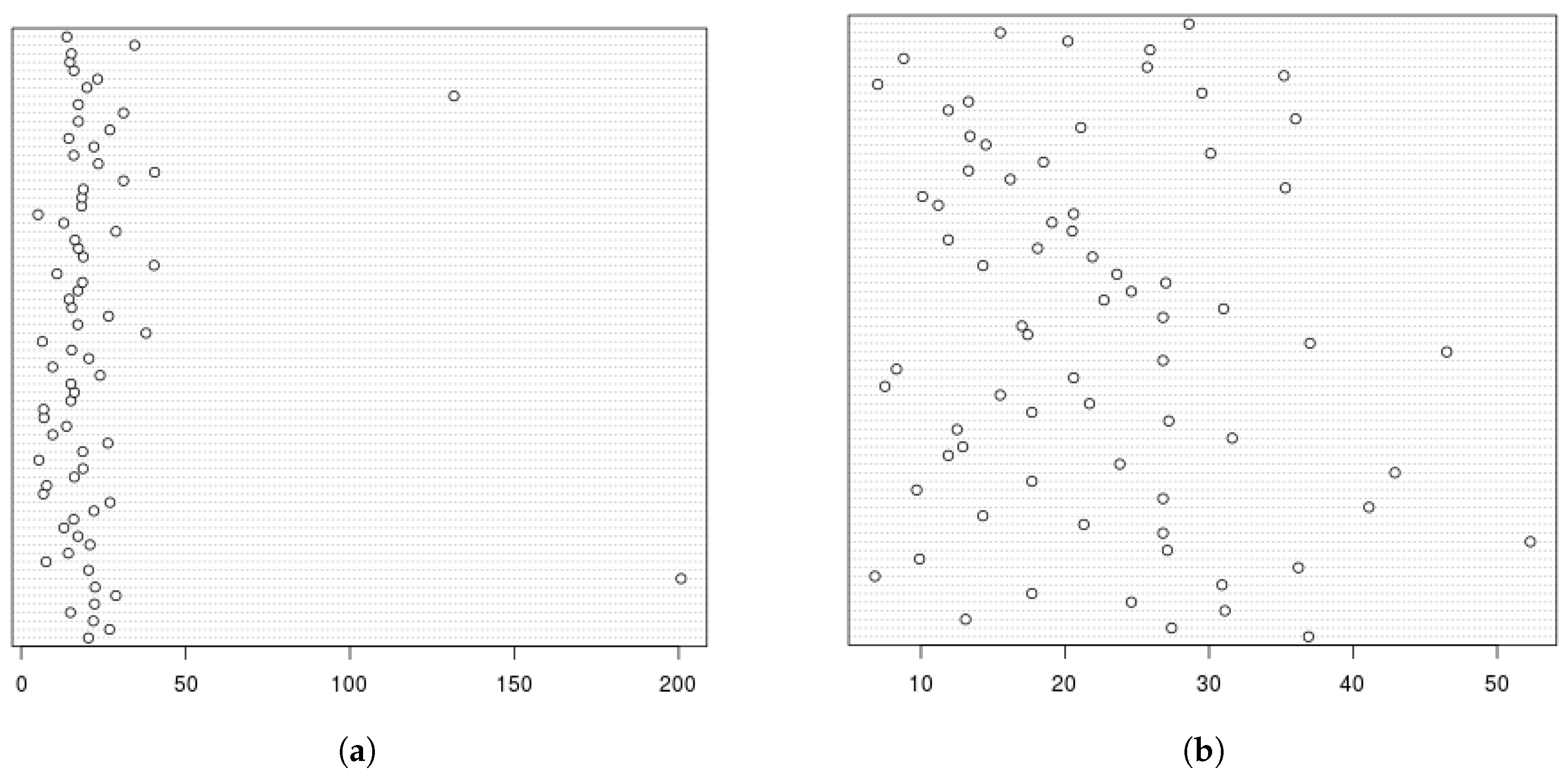
4.2. Results
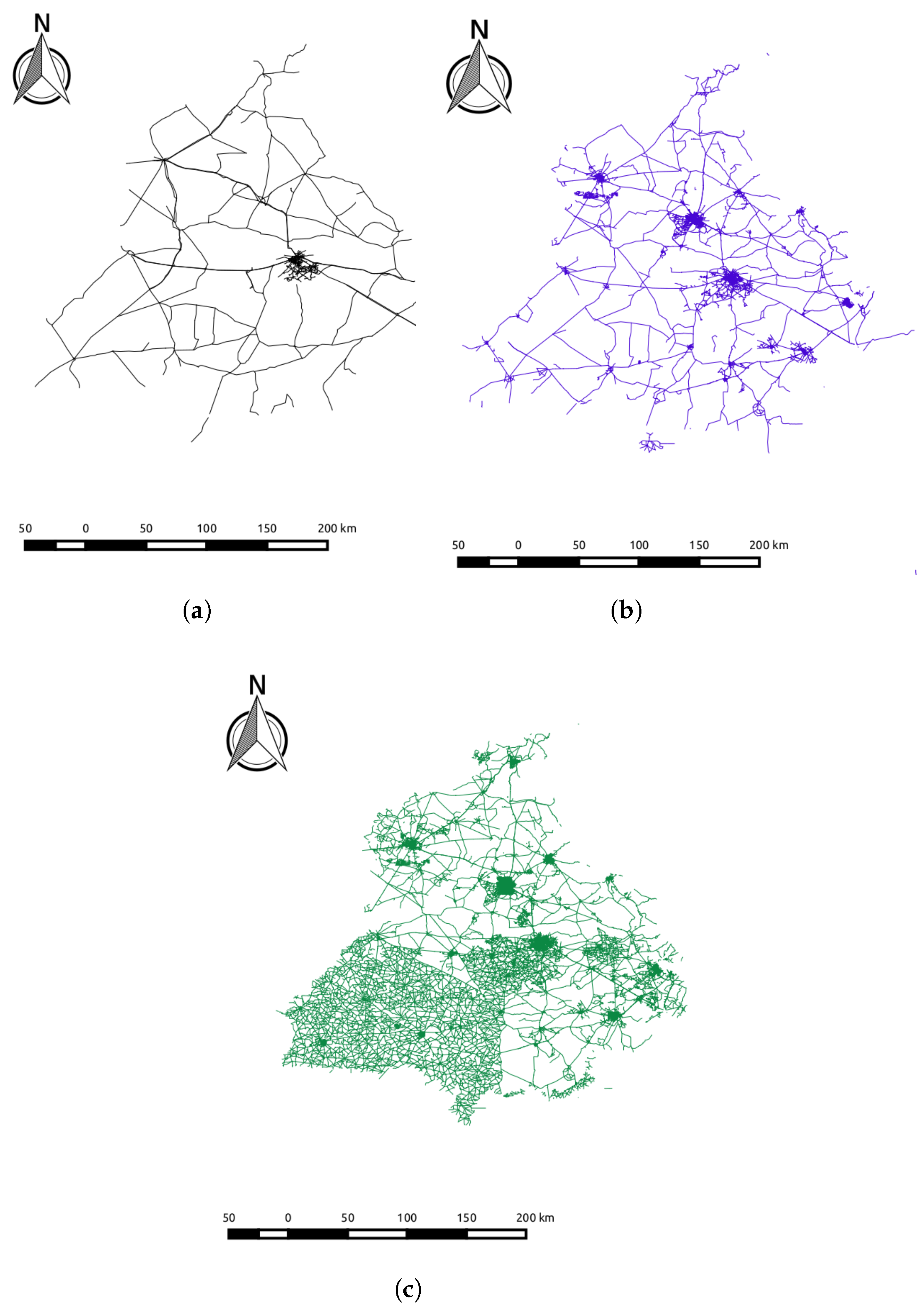
4.2.1. Network Length Completeness
4.2.2. Attribute Completeness
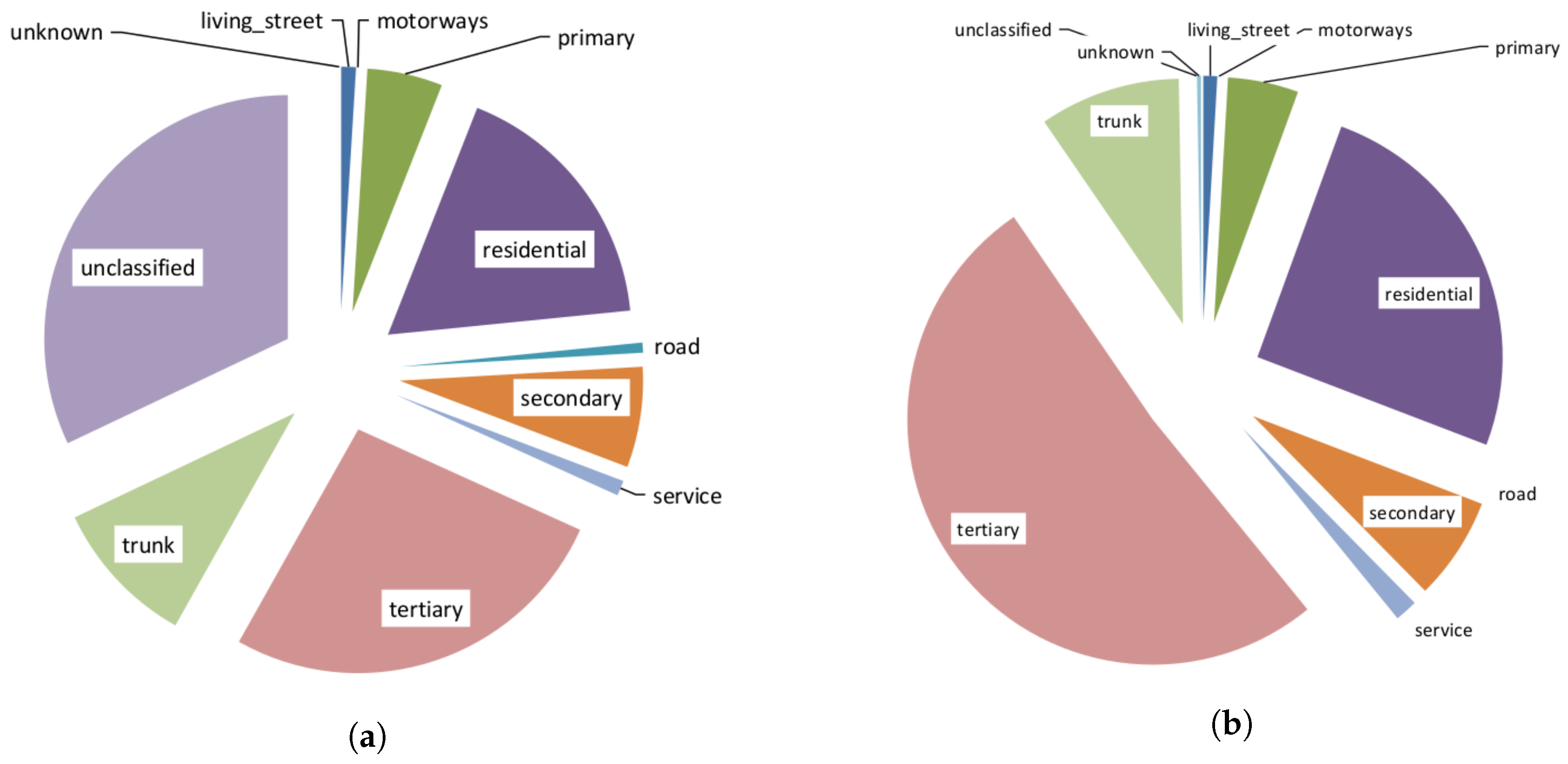
4.2.3. Semantic Accuracy
4.2.4. Route Navigability Assessment
5. Limitations of the Study
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| GI | Geographic information |
| VGI | Volunteered geographic information |
| OSM | OpenStreetMap |
| QGIS | Quantum geographic information system |
References
- Goodchild, M.; Li, L. Assuring the Quality of Volunteered Geographic Information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Haklay, M. Citizen science and volunteered geographic information: Overview and typology of participation. In Crowdsourcing Geographic Knowledge; Chapter Crowdsourcing Geographic Knowledge; Sui, D., Elwood, S., Goodchild, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 105–122. [Google Scholar]
- Sehra, S.S.; Singh, J.; Rai, H.S. A systematic study of openstreetmap data quality assessment. In Proceedings of the IEEE 11th International Conference on Information Technology: New Generations (ITNG), Las Vegas, NV, USA, 7–9 April 2014; pp. 377–381. [Google Scholar]
- Vandecasteele, A.; Devillers, R. Improving volunteered geographic information quality using a tag recommender system: The case of OpenStreetMap. In OpenStreetMap in GIScience; Arsanjani, J.J., Zipf, A., Mooney, P., Helbich, M., Eds.; Springer: Cham, Switzerland, 2015; pp. 59–80. [Google Scholar]
- Antoniou, V.; Skopeliti, A. Measures and Indicators of VGI Quality: An Overview. ISPRS Int. Soc. Photogramm. Remote Sens. 2015, II-3/W5, 345–351. [Google Scholar] [CrossRef]
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How Many Volunteers Does It Take to Map an Area Well the Validity of Linus’ Law to Volunteered Geographic Information. Cartogr. J. World Mapp. 2010, 47, 315–322. [Google Scholar] [CrossRef]
- ODC Open Database License (ODbL), Version 1.0. Available online: https://opendatacommons.org/licenses/odbl/ (accessed on 30 March 2017).
- OpenStreetMap. Available online: http://www.openstreetmap.org/stats/data_stats.html (accessed on 30 March 2017).
- Poser, K.; Dransch, D. Volunteered geographic information for disaster management with application to rapid flood damage estimation. Geomatica 2010, 64, 89–98. [Google Scholar]
- Quattrone, G.; Capra, L.; Meo, P.D. There’s no such thing as the perfect map: Quantifying bias in spatial crowd-sourcing datasets. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing-CSCW’15, Vancouver, BC, Canada, 14–18 March 2015. [Google Scholar]
- Quattrone, G.; Dittus, M.; Capra, L. Work Always in Progress: Analysing Maintenance Practices in Spatial Crowd-sourced Datasets. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing-CSCW’17, Portland, OR, USA, 25 February–1 March 2017. [Google Scholar]
- Chen, H.; Zhang, W.C.; Deng, C.; Nie, N.; Yi, L. Volunteered Geographic Information for Disaster Management with Application to Earthquake Disaster Databank and Sharing Platform. IOP Conf. Ser. Earth Environ. Sci. 2017, 57, 012015. [Google Scholar] [CrossRef]
- Hashemi, P.; Abbaspour, R.A. Assessment of logical consistency in openstreetmap based on the spatial similarity concept. In OpenStreetMap in GIScience; Arsanjani, J.J., Zipf, A., Mooney, P., Helbich, M., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer: Cham, Switzerland, 2015; pp. 19–36. [Google Scholar]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M.M. A Review of Volunteered Geographic Information Quality Assessment Methods. Int. J. Geogr. Inf. Sci. 2016, 31, 1–29. [Google Scholar] [CrossRef]
- Rak, A. Legal Issues and Validation of Volunteered Geographic Information; Technical Report; Department of Geodesy and Geomatics Engineering, University of New Brunswick: Fredericton, NB, Canada, 2013. [Google Scholar]
- Ballatore, A.; Wilson, D.C.; Bertolotto, M. A survey of volunteered open geo-knowledge bases in the semantic web. In Quality Issues in the Management of Web Information; Pasi, G., Bordogna, G., Jain, L.C., Eds.; Springer: Heidelberg, Germany, 2013; Volume 50, pp. 93–120. [Google Scholar]
- Ali, A.L.; Schmid, F. Data quality assurance for volunteered geographic information. In Proceedings of the Geographic Information Science: 8th International Conference (GIScience 2014), Vienna, Austria, 24–26 September 2014; Duckham, M., Pebesma, E., Stewart, K., Frank, A.U., Eds.; Springer Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2014; Volume 8728, pp. 126–141. [Google Scholar]
- Mooney, P.; Corcoran, P.; Winstanley, A.C. Towards quality metrics for openstreetmap. In Proceedings of the 18th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems (GIS ’10), San Jose, CA, USA, 3–5 November 2010; pp. 514–517. [Google Scholar]
- Graser, A.; Straub, M.; Dragaschnig, M. Is osm good enough for vehicle routing a study comparing street networks in vienna. In Progress in Location-Based Services 2014; Gartner, G., Huang, H., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer: Cham, Switzerland, 2015; pp. 3–17. [Google Scholar]
- Zhang, X.; Ai, T. How to model roads in OpenStreetMap a method for evaluating the fitness-for-use of the network for navigation. In Advances in Spatial Data Handling and Analysis; Harvey, F., Leung, Y., Eds.; Select Papers from the 16th IGU Spatial Data Handling Symposium; Springer Advances in Geographic Information Science; Springer: Cham, Switzerland, 2015; pp. 143–162. [Google Scholar]
- ISO. ISO 19157:2013: Geographic Information—Data Quality; Technical Report; International Organization for Standardization (ISO): Geneva, Switzerland, 2013. [Google Scholar]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. (Eds.) Geographical Information Systems: Principles, Techniques, Management and Applications, 2nd ed.; Abridged, Wiley: Chichester, UK, 2005. [Google Scholar]
- Guptill, S.; Morrison, J. (Eds.) Elements of Spatial Data Quality, 1st ed.; Elsevier Science Ltd.: Exeter, UK, 1995. [Google Scholar]
- Joksić, D.; Bajat, B. Elements of Spatial Data Quality As Information Technology Support for Sustainable Development Planning. Spatium 2004, 11, 77–83. [Google Scholar] [CrossRef]
- Servigne, S.; Ubeda, T.; Puricelli, A.; Laurini, R. A Methodology for Spatial Consistency Improvement of Geographic Databases. GeoInformatica 2000, 4, 7–34. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Minghini, M.; Molinari, M.; Mooney, P. Towards an Automated Comparison of Openstreetmap with Authoritative Road Datasets. Trans. GIS 2016, 21, 191–206. [Google Scholar] [CrossRef]
- Keßler, C.; de Groot, R.T.A. Trust as a Proxy Measure for the Quality of Volunteered Geographic Information in the Case of OpenStreetMap. In Geographic Information Science at the Heart of Europe; Vandenbroucke, D., Bucher, B., Crompvoets, J., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer: Cham, Switzerland, 2013; pp. 21–37. [Google Scholar]
- De Groot, R.T.A. Evaluation of a Volunteered Geographical Information Trust Measure in the Case of OpenStreetMap. Mater’s Thesis, Institute of Formal Methods in Computer Science, University of Stuttgart, Brussels, Belgium, 2012. [Google Scholar]
- Mooney, P.; Corcoran, P. Characteristics of Heavily Edited Objects in Openstreetmap. Future Internet 2012, 4, 285–305. [Google Scholar] [CrossRef]
- Barta, D. Project OpenStreetMap as open and free source of geodata and maps. In Proceedings of the Eight International Symposium (GIS Ostrava 2011), Ostrava, Czech Republic, 24–26 January 2011; Jiri, H., Tomas, H., Jan, R., Lena, H., Otakar, C., Eds.; Technical University of Ostrava: Ostrava, Czech Republic; pp. 23–26. [Google Scholar]
- Graser, A.; Straub, M.; Dragaschnig, M. Towards an Open Source Analysis Toolbox for Street Network Comparison: Indicators, Tools and Results of a Comparison of Osm and the Official Austrian Reference Graph. Trans. GIS 2014, 18, 510–526. [Google Scholar] [CrossRef]
- Morrison, J.L. Spatial data quality. In Elements of Spatial Data Quality; Guptill, S.C., Morrison, J.L., Eds.; Elsevier Science Ltd.: Exeter, UK, 1995; Chapter one; pp. 1–12. [Google Scholar]
- Veregin, H. Data quality parameters. In Geographical Information Systems: Principles, Techniques, Management and Applications; Longley, P.A., Goodchild, M.F., Maguire, D.J., Rhind, D.W., Eds.; Wiley: Chichester, UK, 2005; Chapter twelve; pp. 177–189. [Google Scholar]
- Lopez-Pellicer, F.J.; Barrera, J. D19.1 Call 2: Linked Map Report on VGI Data Quality Factors; Technical Report; PlanetData: Zaragoza, Spain, 2014. [Google Scholar]
- Brassel, K.; Bucher, F.; Stephan, E.M.; Vckovski, A. Completeness. In Elements of Spatial Data Quality; Guptill, S.C., Morrison, J.L., Eds.; Elsevier Science Ltd.: Exeter, UK, 1995; Chapter five; pp. 81–108. [Google Scholar]
- Veregin, H. Quantifying Positional Error Induced by Line Simplification. Int. J. Geogr. Inf. Sci. 2000, 14, 113–130. [Google Scholar] [CrossRef]
- Oort, P.V. Spatial Data Quality: From Description to Application. Ph.D. Thesis, Wageningen University, Wageningen, The Netherlands, 2006. [Google Scholar]
- Salgé, F. Semantic accuracy. In Elements of Spatial Data Quality; Guptill, S.C., Morrison, J.L., Eds.; Elsevier Science Ltd.: Exeter, UK, 1995; Chapter seven; pp. 139–151. [Google Scholar]
- Kounadi, O. Assessing the Quality of OpenStreetMap Data. Mater’s Thesis, Department of Civil, Environmental and Geomatic Engineering, University College of London, London, UK, 2009. [Google Scholar]
- Ather, A. A Quality Analysis of OpenStreetMap. Mater’s Thesis, Department of Civil, Environmental & Geomatic Engineering, University College London, London, UK, 2009. [Google Scholar]
- Haklay, M. How Good Is Volunteered Geographical Information A Comparative Study of Openstreetmap and Ordnance Survey Datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Zielstra, D.; Zipf, A. Quantitative studies on the data quality of OpenStreetMap in Germany. In Proceedings of the Sixth International Conference on Geographic Information Science, Zürich, Switzerland, 14–17 September 2010; pp. 20–26. [Google Scholar]
- Zielstra, D.; Hochmair, H. Comparative Study of Pedestrian Accessibility to Transit Stations Using Free and Proprietary Network Data. Transp. Res. Rec. J. Transp. Res. Board 2011, 145–152. [Google Scholar] [CrossRef]
- Ciepluch, B.; Mooney, P.; Jacob, R.; Zheng, J.; Winstanley, A.C. Assessing the Quality of Open Spatial Data for Mobile Location-based Services Research and Applications. Arch. Photogramm. Cartogr. Remote Sens. 2011, 1, 105–116. [Google Scholar]
- Hagenauer, J.; Helbich, M. Mining Urban Land-use Patterns from Volunteered Geographic Information by Means of Genetic Algorithms and Artificial Neural Networks. Int. J. Geogr. Inf. Sci. 2012, 26, 963–982. [Google Scholar] [CrossRef]
- Wang, A.; Hoang, C.D.V.; Kan, M.Y. Perspectives on Crowdsourcing Annotations for Natural Language Processing. Lang. Resour. Eval. 2013, 47, 9. [Google Scholar] [CrossRef]
- Zheng, S.; Zheng, J. Assessing the completeness and positional accuracy of OpenStreetMap in China. In Thematic Cartography for the Society; Bandrova, T., Konecny, M., Zlatanova, S., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer: Cham, Switzerland, 2014; pp. 171–189. [Google Scholar]
- Neis, P.; Zipf, A. Analyzing the Contributor Activity of a Volunteered Geographic Information Project the Case of OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012, 1, 146–165. [Google Scholar] [CrossRef]
- Ludwig, I.; Voss, A.; Krause-Traudes, M. A comparison of the street networks of Navteq and OSM in Germany. In Advancing Geoinformation Science for a Changing World; Geertman, S., Reinhardt, W., Toppen, F., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer-Verlag: Berlin, Germany, 2011; Volume 1, pp. 65–84. [Google Scholar]
- Koukoletsos, T.; Haklay, M.; Ellul, C. Assessing Data Completeness of Vgi through an Automated Matching Procedure for Linear Data. Trans. GIS 2012, 16, 477–498. [Google Scholar] [CrossRef]
- Will, J. Development of an Automated Matching Algorithm to Assess the Quality of the OpenStreetMap Road Network. Mater’s Thesis, Department of Physical Geography and Ecosystem Science, Lund University, Sölvegatan, Sweden, 2014. [Google Scholar]
- Abdolmajidi, E.; Mansourian, A.; Will, J.; Harrie, L. Matching Authority and Vgi Road Networks Using an Extended Node-based Matching Algorithm. Geo-Spat. Inf. Sci. 2015, 18, 65–80. [Google Scholar] [CrossRef]
- Zielstra, D.; Hochmair, H. Using Free and Proprietary Data to Compare Shortest-path Lengths for Effective Pedestrian Routing in Street Networks. Transp. Res. Rec. J. Transp. Res. Board 2012, 2299, 41–47. [Google Scholar] [CrossRef]
- Mullen, W.F.; Jackson, S.P.; Croitoru, A.; Crooks, A.; Stefanidis, A.; Agouris, P. Assessing the Impact of Demographic Characteristics on Spatial Error in Volunteered Geographic Information Features. GeoJournal 2014, 80, 587. [Google Scholar] [CrossRef]
- Mashhadi, A.; Quattrone, G.; Capra, L. The impact of society on volunteered geographic information: The case of OpenStreetMap. In OpenStreetMap in GIScience; Arsanjani, J.J., Zipf, A., Mooney, P., Helbich, M., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer International Publishing: Cham, Switzerland, 2015; pp. 125–141. [Google Scholar]
- Camboim, S.P.; Bravo, J.V.M.; Sluter, C.R. An Investigation into the Completeness of, and the Updates to, Openstreetmap Data in a Heterogeneous Area in Brazil. ISPRS Int. J. Geo-Inf. 2015, 4, 1366. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Vaz, E. An Assessment of a Collaborative Mapping Approach for Exploring Land Use Patterns for Several European Metropolises. Int. J. Appl. Earth Obs. Geoinf. 2015, 35 Pt B, 329–337. [Google Scholar] [CrossRef]
- Jackson, S.P.; Mullen, W.; Agouris, P.; Crooks, A.; Croitoru, A.; Stefanidis, A. Assessing Completeness and Spatial Error of Features in Volunteered Geographic Information. ISPRS Int. J. Geo-Inf. 2013, 2, 507. [Google Scholar] [CrossRef]
- Törnros, T.; Dorn, H.; Hahmann, S.; Zipf, A. Uncertainties of Completeness Measures in Openstreetmap—A Case Study for Buildings in a Medium-sized German City. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3-W5, 353–357. [Google Scholar]
- Hecht, R.; Kunze, C.; Hahmann, S. Measuring Completeness of Building Footprints in Openstreetmap Over Space and Time. ISPRS Int. J. Geo-Inf. 2013, 2, 1066. [Google Scholar] [CrossRef]
- Fan, H.; Zipf, A.; Fu, Q.; Neis, P. Quality Assessment for Building Footprints Data on Openstreetmap. Int. J. Geogr. Inf. Sci. 2014, 28, 700–719. [Google Scholar] [CrossRef]
- Dorn, H.; Törnros, T.; Zipf, A. Quality Evaluation of VGI Using Authoritative Data—A Comparison with Land Use Data in Southern Germany. ISPRS Int. J. Geo-Inf. 2015, 4, 1657–1671. [Google Scholar] [CrossRef]
- Van Exel, M.; Dias, E.; Fruijtier, S. The impact of crowdsourcing on spatial data quality indicators. In Proceedings of the Sixth International Conference on Geographic Information Science, Zürich, Switzerland, 14–17 September 2010; p. 213. [Google Scholar]
- Devillers, R.; Gervais, M.; Bédard, Y.; Jeansoulin, R. Spatial data quality: From metadata to quality indicators and contextual end-user manual. In Proceedings of the OEEPE/ISPRS Joint Workshop on Spatial Data Quality Management, Istanbul, Turkey, 21–22 March 2002; pp. 45–55. [Google Scholar]
- Devillers, R.; Bédard, Y.; Jeansoulin, R.; Moulin, B. Towards Spatial Data Quality Information Analysis Tools for Experts Assessing the Fitness for Use of Spatial Data. Int. J. Geogr. Inf. Sci. 2007, 21, 261–282. [Google Scholar] [CrossRef]
- Razniewski, S.; Nutt, W. Assessing the completeness of geographical data. In Big Data; Springer Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7968, pp. 228–237. [Google Scholar]
- Bégin, D.; Devillers, R.; Roche, S. Assessing Volunteered Geographic Information VGI Quality Based on Contributors’ Mapping Behaviours. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-2/W1, 149–154. [Google Scholar]
- Gröchenig, S.; Brunauer, R.; Rehrl, K. Estimating completeness of VGI datasets by analyzing community activity over time periods. In Connecting a Digital Europe Through Location and Place; Huerta, J., Schade, S., Granell, C., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer: Cham, Switzerland, 2014; pp. 3–18. [Google Scholar]
- Ballatore, A.; Zipf, A. Spatial Information Theory; A Conceptual Quality Framework for Volunteered Geographic Information; Springer Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9368, pp. 89–107. [Google Scholar]
- Forghani, M.; Delavar, M.R. A Quality Study of the Openstreetmap Dataset for Tehran. ISPRS Int. J. Geo-Inf. 2014, 3, 750. [Google Scholar] [CrossRef]
- Girres, J.F.; Touya, G. Quality Assessment of the French Openstreetmap Dataset. Trans. GIS 2010, 14, 435–459. [Google Scholar] [CrossRef]
- Navarro, G. A Guided Tour to Approximate String Matching. Comput. Surv. 2001, 33, 31–88. [Google Scholar] [CrossRef]
- Koukoletsos, T. A Framework for Quality Evaluation of VGI Linear Datasets. Ph.D. Thesis, University College London (UCL), London, UK, 2012. [Google Scholar]
- Barron, C.; Neis, P.; Zipf, A. A Comprehensive Framework for Intrinsic Openstreetmap Quality Analysis. Trans. GIS 2014, 18, 877–895. [Google Scholar] [CrossRef]
- Congalton, R.G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1994, 20, 37–46. [Google Scholar] [CrossRef]
- Fan, H.; Zipf, A.; Fu, Q. Estimation of building types on openstreetmap based on urban morphology analysis. In Connecting a Digital Europe Through Location and Place; Huerta, J., Schade, S., Granell, C., Eds.; Springer Lecture Notes in Geoinformation and Cartography; Springer: Castellon, Spain, 2014; pp. 19–35. [Google Scholar]
- Al-Bakri, M.; Fairbairn, D. Assessing Similarity Matching for Possible Integration of Feature Classifications of Geospatial Data from Official and Informal Sources. Int. J. Geogr. Inf. Sci. 2012, 26, 1437–1456. [Google Scholar] [CrossRef]
- Jilani, M.; Corcoran, P.; Bertolotto, M. Automated highway tag assessment of openstreetmap road networks. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas/Fort Worth, TX, USA, 4–7 November 2014; pp. 449–452. [Google Scholar]
- Mülligann, C.; Janowicz, K.; Ye, M.; Lee, W.C. Analyzing the spatial-semantic interaction of points of interest in volunteered geographic information. In Spatial Information Theory, Proceedings of the 10th International Conference, COSIT 2011, Belfast, ME, USA, 12–16 September 2011; Egenhofer, M., Giudice, N., Morat, R., Worboys, M., Eds.; Springer Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6899, pp. 350–370. [Google Scholar]
- Flanagin, A.J.; Metzger, M.J. The Credibility of Volunteered Geographic Information. GeoJournal 2008, 72, 137. [Google Scholar] [CrossRef]
- Rehrl, K.; Gröchenig, S.; Hochmair, H.; Leitinger, S.; Steinmann, R.; Wagner, A. A conceptual model for analyzing contribution patterns in the context of VGI. In Progress in Location-Based Services; Krisp, J.M., Ed.; Springer Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2013; pp. 373–388. [Google Scholar]
- Goodchild, M. Citizens as Sensors: The World of Volunteered Geography. GeoJournal 2007, 69, 211. [Google Scholar] [CrossRef]
- Budhathoki, N.R. Participants’ Motivations to Contribute Geographic Information in an Online Community. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Urbana, IL, USA, 2010. [Google Scholar]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234. [Google Scholar] [CrossRef]
- Auer, S.; Lehmann, J.; Hellmann, S. Linkedgeodata: Adding a spatial dimension to the web of data. In Proceedings of the Semantic Web—ISWC 2009, Chantilly, VA, USA, 25–29 October 2009; Bernstein, A., Karger, D.R., Heath, T., Feigenbaum, L., Maynard, D., Motta, E., Thirunarayan, K., Eds.; Springer Lecture Notes in Computer Science. Springer: Chantilly, VA, USA, 2009; Volume 5823, pp. 731–746. [Google Scholar]
- Ballatore, A.; Wilson, D.C.; Bertolotto, M. The similarity jury: Combining expert judgements on geographic concepts. In Advances in Conceptual Modeling, Proceedings of the ER 2012 Workshops CMS, ECDM-NoCoDA, MoDIC, MORE-BI, RIGiM, SeCoGIS, WISM, Florence, Italy, 15–18 October 2012; Castano, S., Vassiliadis, P., Lakshmanan, L.V., Lee, M.L., Eds.; Springer Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7518, pp. 231–240. [Google Scholar]
- Codescu, M.; Horsinka, G.; Kutz, O.; Mossakowski, T.; Rau, R. DO-ROAM: Activity-oriented search and navigation with openstreetmap. In GeoSpatial Semantics, Proceedings of the 4th International Conference, GeoS 2011, Brest, France, 12–13 May 2011; Claramunt, C., Levashkin, S., Bertolotto, M., Eds.; Springer Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6631, pp. 88–107. [Google Scholar]
- Hopf, K.; Dageförde, F.; Wolter, D. Identifying the geographical scope of prohibition signs. In Spatial Information Theory, Proceedings of the 12th International Conference, COSIT 2015, Santa Fe, NM, USA, 12–16 October 2015; Fabrikant, I.S., Raubal, M., Bertolotto, M., Davies, C., Freundschuh, S., Bell, S., Eds.; Springer Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9368, pp. 247–267. [Google Scholar]
- Haklay, M. Haiti—How Can VGI Help? Comparison of OpenStreetMap and Google Map Maker. 2010. Available online: https://povesham.wordpress.com/2010/01/18/haiti-how-can-vgi-help-comparison-of-openstreetmap-and-google-map-maker/ (accessed on 10 April 2017).
- Poiani, T.H.; dos Santos Rocha, R.; Degrossi, L.C.; de Albuquerque, J.P. Potential of collaborative mapping for disaster relief: A case study of OpenStreetMap in the Nepal earthquake 2015. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016. [Google Scholar]
- Mahabir, R.; Stefanidis, A.; Croitoru, A.; Crooks, A.; Agouris, P. Authoritative and Volunteered Geographical Information in a Developing Country: A Comparative Case Study of Road Datasets in Nairobi, Kenya. ISPRS Int. J. Geo-Inf. 2017, 6, 24. [Google Scholar] [CrossRef]
- Ahmouda, A.; Hochmair, H.H. Using Volunteered Geographic Information to measure name changes of artificial geographical features as a result of political changes: A Libya case study. GeoJournal 2017. [Google Scholar] [CrossRef]
- Rehrl, K.; Gröchenig, S. A Framework for Data-centric Analysis of Mapping Activity in the Context of Volunteered Geographic Information. ISPRS Int. J. Geo-Inf. 2016, 5, 37. [Google Scholar] [CrossRef]
- QGIS Development Team. QGIS Geographic Information System. Open Source Geospatial Foundation, 2016. Available online: http://qgis.org/ (accessed on 10 April 2016).
- Graser, A.; Olaya, V. Processing: A Python Framework for the Seamless Integration of Geoprocessing Tools in QGIS. ISPRS Int. J. Geo-Inf. 2015, 4, 2219–2245. [Google Scholar] [CrossRef]
- Government of Punjab. Know Punjab. Available online: http://punjab.gov.in/know-punjab (accessed on 4 April 2017).
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Dijkstra’s algorithm. In Introduction to Algorithms, 2nd ed.; MIT Press: Cambridge, MA, USA, 2001; Section 24.3; pp. 595–601. [Google Scholar]
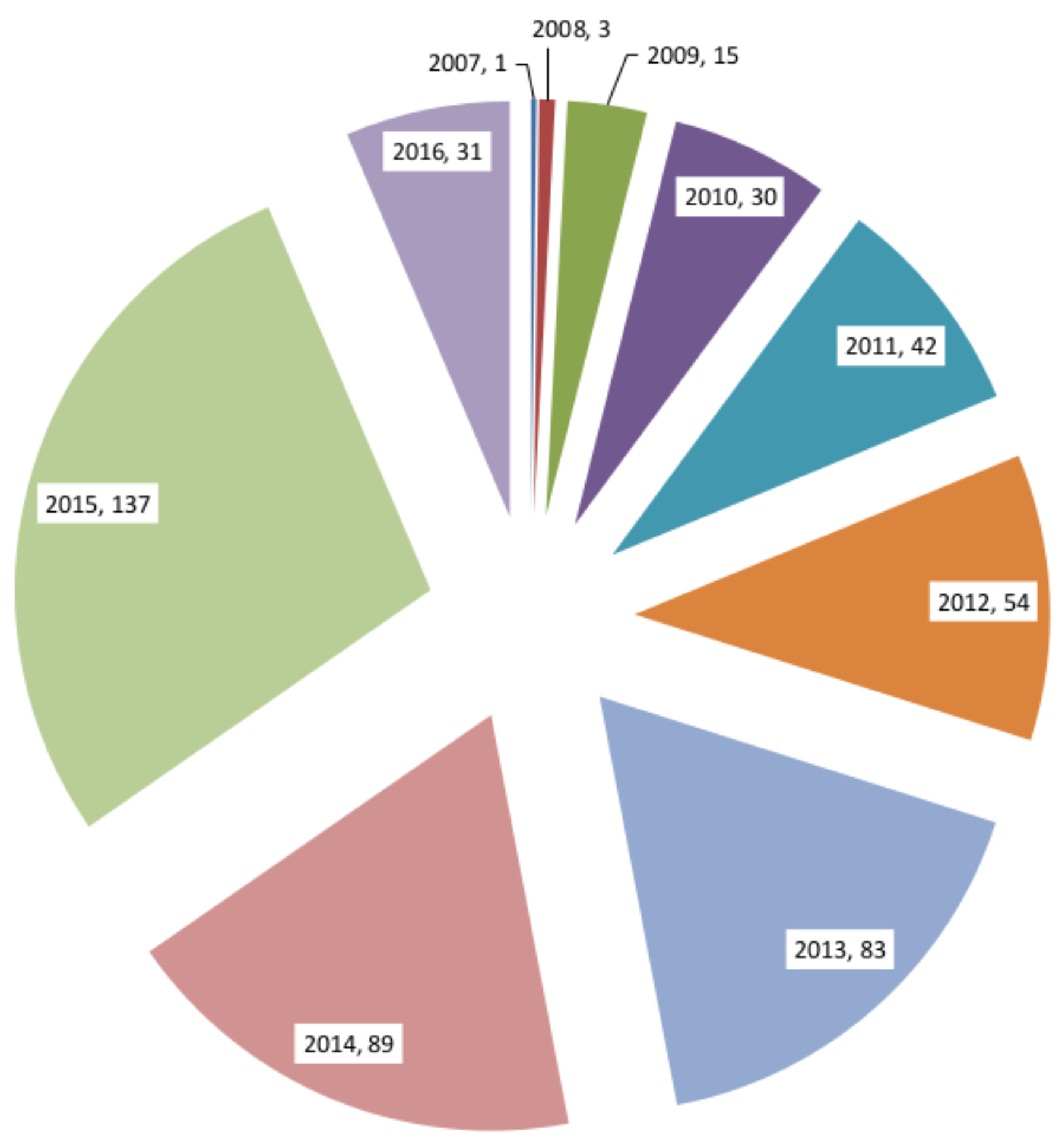
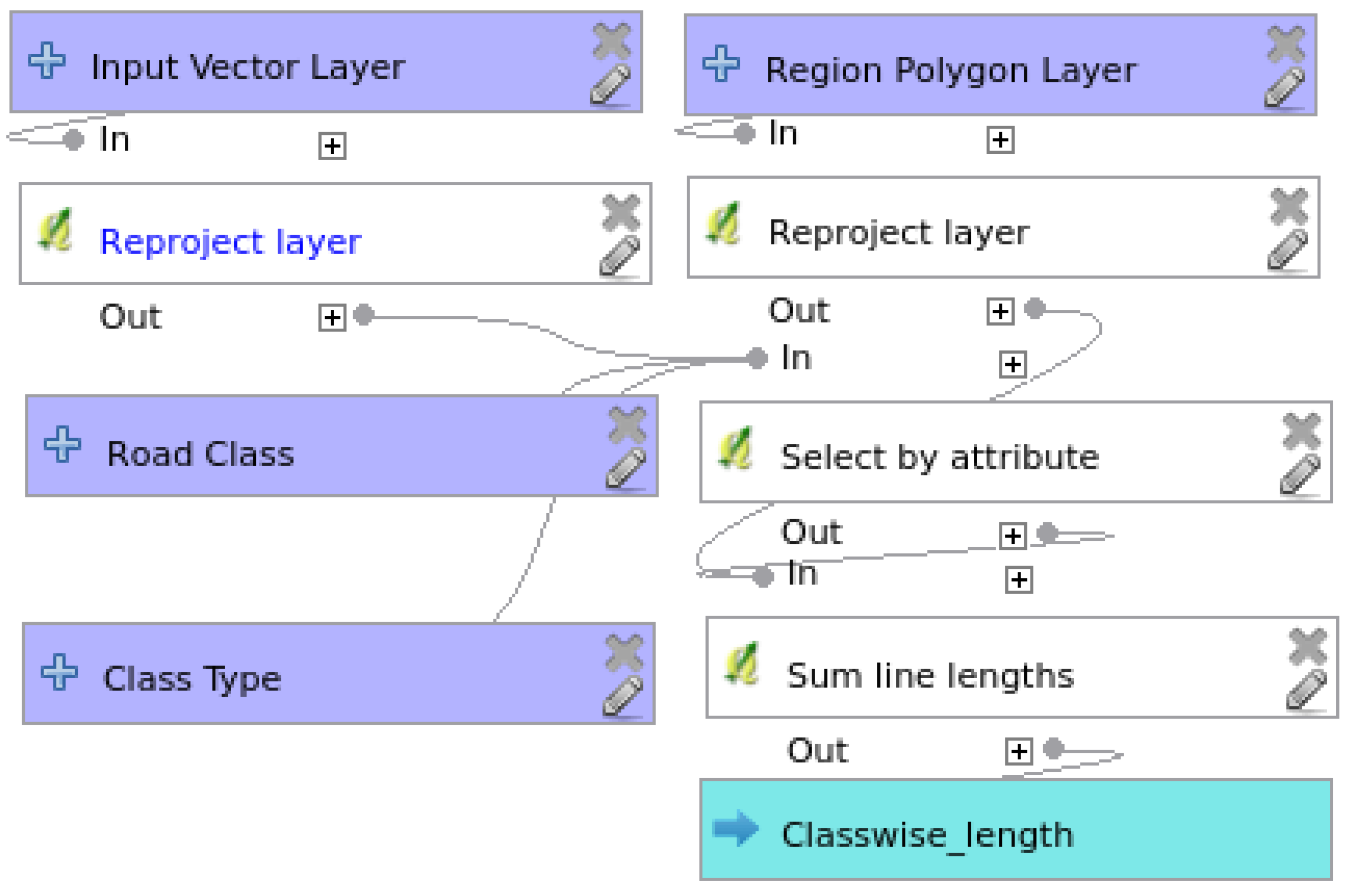
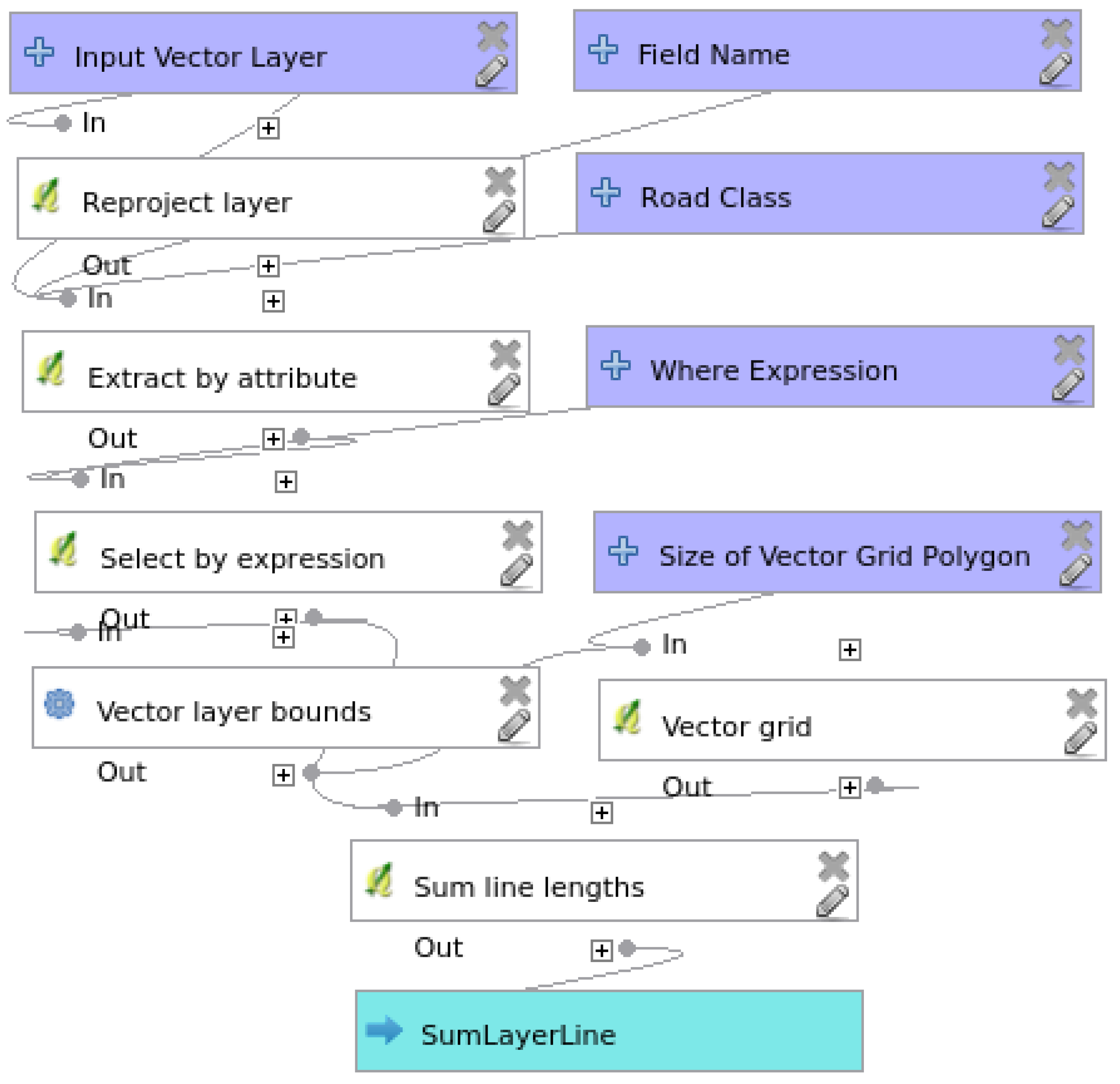
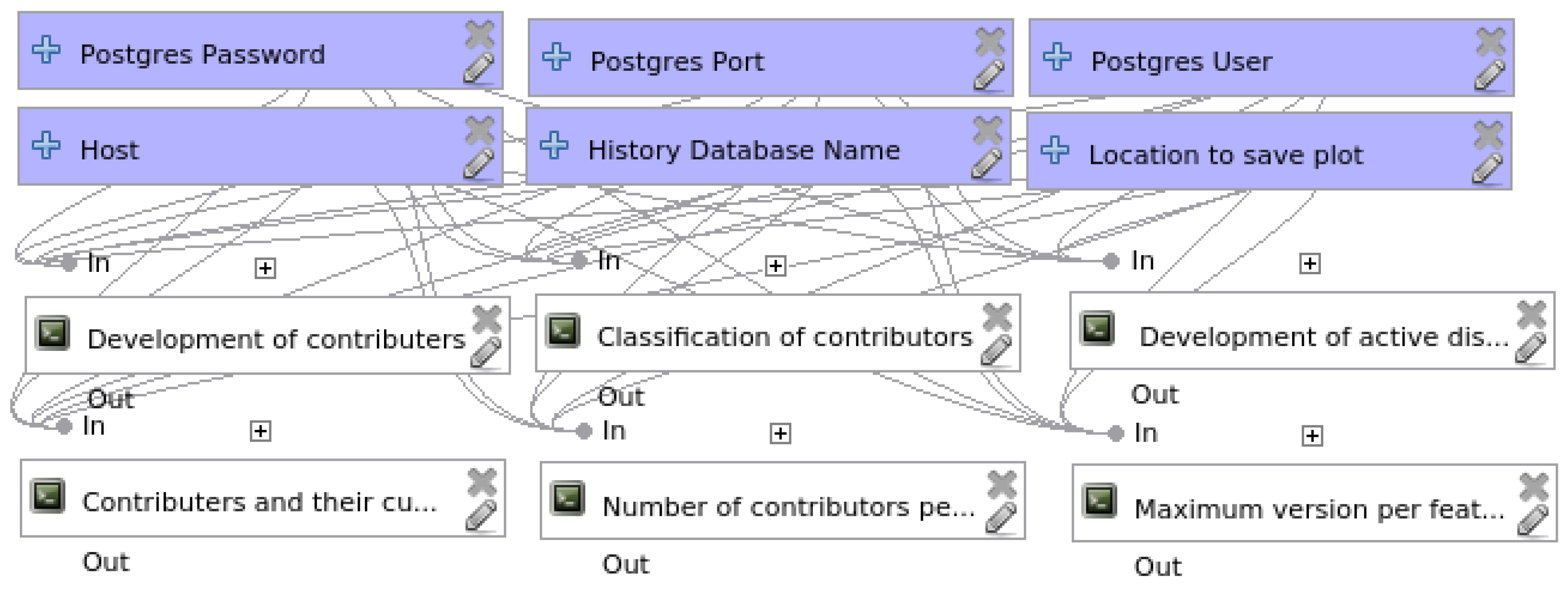

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Researcher | Reference Datasets | Description |
|---|---|---|
| Kounadi [39], Ather [40] | OSM (Heathrow, U.K.) | The study analyzed road features without names in the attribute tables, and the total length of these roads was calculated and presented as a percentage. |
| Keßler and de Groot [27] | OSM (Altstadt, Heidelberg, Germany) | The research employed term frequency-inverse distance frequency measure (tf-idf) to evaluate the importance of tags related to the feature type. |
| Bégin et al. [67] | OSM (Canada) | The study used concave hulls for defining contributor’s editing sessions for producing an image of contribution. |
| Razniewski and Nutt [66] | OSM (Lübbenau, Germany) | In this study, spatial operations were applied on the metadata of the spatial dataset, e.g., star join, to extract “data completeness” of the area. |
| Gröchenig et al. [68] | OSM (London, U.K.) | The study used methodology to assess regional data completeness by analyzing changes in community activity over time periods. |
| Forghani and Delavar [70] | OSM (Tehran, Iran) | The authors assessed OSM based on metrics such as minimum bounding geometry area and directional distribution (standard deviational ellipse) and applied fuzzy logic to identify the completeness of OSM data in gridded cells |
| Ballatore and Zipf [69] | OSM (Selected regions of Germany and U.K.) | The study developed a conceptual framework for analyzing the completeness and other quality attributes of data based on intrinsic indicators. |
| Sr. No. | Type | Data Till January 2016 | Data Till February 2017 |
|---|---|---|---|
| 1 | living_street | (15,410.22 m) 4.75% | (15,921.75 m) 4.99% |
| 2 | primary | (892,920.07 m) 54.01% | (881,872.72 m) 54.22% |
| 3 | primary_link | (6821.38 m) 76.35% | (6821.38 m) 92.49% |
| 4 | residential | (299,629.34 m) 5.17% | (317,655.36 m) 3.58% |
| 5 | road | (2406.07 m) 1.09% | - |
| 6 | secondary | (619,726.5 m) 28% | (664,109.17 m) 27.88% |
| 7 | secondary_link | (930.66 m) 23% | (930.66 m) 80.66% |
| 8 | service | (24,643.08 m) 7.37% | (25,239.91 m) 4.79% |
| 9 | tertiary | (2,890,667.47 m) 33.72% | (3,039,071.22 m) 17.07% |
| 10 | tertiary_link | (13,970.34 m) 7.11% | (14,594.31 m) 6.94% |
| 11 | trunk | (1,474,286.38 m) 46.08% | (1,508,242.11 m) 46.74% |
| 12 | trunk_link | (34,432.64 m) 58.89% | (7624.25 m) 20.13% |
| 13 | unclassified | (237,603.93 m) 2.23% | - |
| 14 | motorway | - | (657.65 m) 100% |
| 15 | unknown | - | (3212.6 m) 3.38% |
| 16 | Total | (6,513,448.09 m) 19.60% | (6,485,953.07 m) 18.48% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sehra, S.S.; Singh, J.; Rai, H.S. Assessing OpenStreetMap Data Using Intrinsic Quality Indicators: An Extension to the QGIS Processing Toolbox. Future Internet 2017, 9, 15. https://doi.org/10.3390/fi9020015
Sehra SS, Singh J, Rai HS. Assessing OpenStreetMap Data Using Intrinsic Quality Indicators: An Extension to the QGIS Processing Toolbox. Future Internet. 2017; 9(2):15. https://doi.org/10.3390/fi9020015
Chicago/Turabian StyleSehra, Sukhjit Singh, Jaiteg Singh, and Hardeep Singh Rai. 2017. "Assessing OpenStreetMap Data Using Intrinsic Quality Indicators: An Extension to the QGIS Processing Toolbox" Future Internet 9, no. 2: 15. https://doi.org/10.3390/fi9020015
APA StyleSehra, S. S., Singh, J., & Rai, H. S. (2017). Assessing OpenStreetMap Data Using Intrinsic Quality Indicators: An Extension to the QGIS Processing Toolbox. Future Internet, 9(2), 15. https://doi.org/10.3390/fi9020015