1. Introduction: Policy Failures as Failures of Knowledge
In a talk given in 2005, while presenting the
Committee on Global Thought (New York, NY, USA, 14 December 2005), a commission intended to build an international program for the study of globalization and its issues, Lee Bollinger, the Dean of Columbia University said:
“The forces affecting societies around the world and creating a global community are powerful and novel. The spread of global market systems, the rise of (and resistance to) various forms of democracy, the emergence of extraordinary opportunities for increased communication and of an increasingly global culture, and the actions of governments and nongovernmental organizations are all reshaping our world and our sense of responsibility for it and, in the process, raising profound questions. These questions call for the kinds of analyses and understandings that academic institutions are uniquely capable of providing. Too many policy failures are fundamentally failures of knowledge…”
As suggested by Bollinger’s words, humankind is dealing with a series of novel and global challenges spanning from the depletion of natural resources to migrations; from financial, institutional and economic instability to the spreading of epidemics; from international terrorism to corruption or illegal use of data. We live in a complex world in which the interactions between technological, economic, social and political systems are becoming ever more frequent and mazy: in our hyperconnected society, any event can produce effects that spread rapidly from one system to another through cycles of nonlinear feedback that are extremely difficult to predict and to control [
2].
In this scenario, the ambitious project of a “smart society” [
3], the vision of a socio-technical ecosystem exploiting advanced information and communication technologies to build resilient institutions [
4], improve the quality of life and solve the severe challenges of modernity, encounters serious difficulties. Recent global financial and economic crises have casted grave misgivings on the robustness and the scientific basis of policy-makers’ choices emphasizing the inadequacy of our understanding of the mechanisms governing social complexity.
Often characterized by a naively mechanistic vision of reality and by the underestimation of the interaction between public choices and individual decision-making, the conventional approaches to policy modeling show huge limitations in terms of efficacy [
5]. On a closer examination, the situation appears to be the result of different factors, two of which are particularly relevant for our analysis insofar as expression of the theoretical and scientific deficiencies of conventional policy-making.
The first one [
6] is represented by the difficulty to grasp the logic underlying human decision-making. Individuals do not necessarily behave in the linear ways predicted by rational choice theory [
7], which still is the main source of inspiration for policy-makers. Even when dealing with the same information or the same payoffs, human beings show behaviors that are often hard to anticipate.
The second reason has to do with the fact that, differently from what is predicted by economic theory, the preferences of individuals are continuously altered by the interaction with others. Even knowing in advance the reaction of an individual to a policy change, it is impossible to foresee the evolution of his behavior as the response depends also on the reaction of the other members of the same group and on learning mechanisms that are anything but linear. Strongly amplified by the interactions taking place in real time on large-scale communication networks, the adaptive component of social behaviors generates tricky implications that are difficult to deal with [
5].
Luckily, in the last two decades, the scientific understanding of the social and economic world has started to make relevant progress with respect to the above-mentioned issues. Social scientists have begun to investigate social systems with new theoretical and technological tools allowing innovative approaches to social research. A fundamental role has been played, in this vein, by two different scientific advancements. If, on the one hand, Behavioral economics and Economic psychology [
8,
9] started to offer new insights into how individuals and groups decide, interact and react to changes, on the other hand [
6], the conceptual framework offered by complexity theory, the data deluge [
10] and the computational evolution of science have paved the way to an unprecedented leap in the comprehension of social phenomena.
This paper discusses how the advancements of social sciences can contribute to the challenge of a smarter society providing policy analytics with a new theoretical and instrumental framework. The attention is focused, in particular, on the scientific and methodological acquisitions gained in the emerging area of Computational Social Sciences (CSS), a data- and computation-driven research field that is going to play (this our main claim) a crucial role in promoting a more scientifically-grounded approach to policy design and a systemic vision of public choices.
The article is structured as follows. The first section briefly introduces, in general terms, the computational evolution of science. The second and the third sections analyze the computational social science paradigm and its main research methodologies. The fourth section discusses the intersections between computational social science and policy modeling, while the fifth is focused on the role that can be played, in this scenario, by social simulation models. The last section concludes the paper, sketching some final considerations.
2. The Data (and Computation)-Driven Future of Science
The advancement of science has always been strongly influenced by the features of the research tools used by the scientist. For a long time supported only by the direct observation of reality, the scientific endeavor has been over the centuries mediated by increasingly complex artifacts capable of offering new and more realistic representations of the world. As a matter of fact, research is an “instrument-enabled” [
11] activity, the result of an iterative process in which technological development is at the same time an enabling factor and an outcome of scientific progress. On this process depended the birth of entire research areas: the nano-sciences, to give just a recent example, would not have come into being without the invention of the electronic microscope.
Much the same applies to information technology. Digitization, the key prerequisite allowing a computer to process information, is a decisive element for scientific research in the broadest sense understood, and we are going through a period of dramatic growth of digital information. In the era of Big Data, a process fueled by the web and social media, as well as by the spread of smartphones, surveillance devices and increasingly large networks of sensors, the collection of a huge amount of data is allowed, from which you can extract knowledge with effects that take place both on the scientific and the application level [
12,
13].
This circumstance is highlighted in a recent report by the Royal Society of London (London, England) [
14], the oldest British scientific association, which analyzes the increasingly close link between science and the massive analysis of digital data. By leveraging the growing computational power today available and algorithms capable of more and more reliable inferences, computational sciences allow one to extract knowledge existing only implicitly within large datasets. In this scenario, data are used not only to validate theories and hypotheses, but also to identify regularities and correlations that are useful both to better understand reality and to make predictions about the future.
We are facing what has already been defined [
15] as a new research paradigm that is adding to the existing ones. Since the 17th century, scientists have identified in theory and in experimentation the two basic scientific paradigms allowing human beings to understand nature. In last few decades, computer simulations have become the third paradigm of science, the standard way to explore phenomena that are inaccessible to theory and experiments, from climate change to the evolution of galaxies.
Today, “data-led” science, the science that exploits the analysis of huge amounts of data to produce knowledge [
16], represents the fourth scientific paradigm, an emerging approach that can already count on innovative practices that span from “data mining” (the discovery of pattern and regularities within large sets of digital data) to “information integration” (the merging of information coming from heterogeneous sources with differing conceptual, contextual and typographical representations), from speech to image recognition.
3. From Nature to Social Facts: Computational Social Science
The above described development is not going to remain within the borders of the physical and natural sciences that are, for understandable reasons, more familiar with data analysis and computation. Only six years ago,
Science published a position paper [
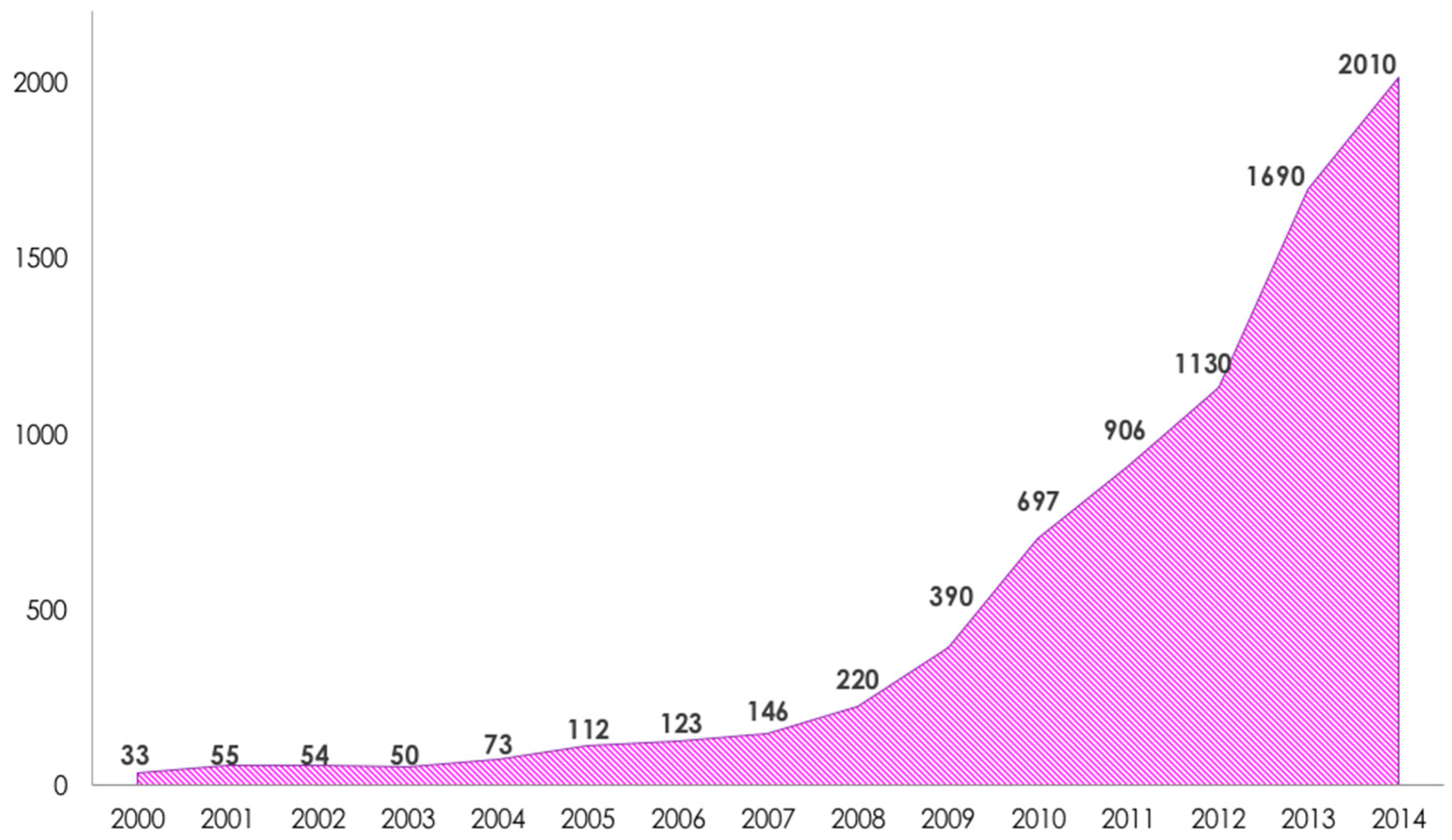
17] that identified in the digital information flood and in the rise of computer capacities the starting point for a scientific and methodological renewal expected to heavily impact social sciences. In the perspective of “Computational Social Sciences” (CSS), a research area that has experienced an almost exponential growth over the last 10 years (see
Figure 1), the analysis of data generated by our interactions with digital technologies, the use of quantitative and computational methods of investigation together with new forms of experimentation push human sciences to the cumulativeness and the rigor that have historically characterized the study of the physical and biological world.
The new ICT-enabled study of society is grounded in a strongly interdisciplinary approach to the investigation of social systems: scientists belonging to different research areas ranging from cognitive and behavioral science to physics and economics strictly cooperate to come up with innovative models of social phenomena. On the one hand, they take advantage of massive ICT data representing traces of almost all kinds of activities of individuals. On the other, they exploit the growth of computational power and the modelling instruments made available by ICT to produce predictive and explanatory models of social systems [
18,
19].
Although relatively new, computational social science is already [
11,
19] a well-established research area organized in an international and active community that by now covers many topics. The computational modeling of social phenomena and the analyses of huge datasets obtained from mobile social networks, phone calls or online commercial interactions have already started to shed new light onto extremely various subjects like political opinions [
20,
21], the evolution of individual tastes [
22], the relationships between the structure of society and the intensity of relationships [
23], the spread of pandemic diseases [
24] or the speed of communication [
25].
From a theoretical and epistemological point of view [
26,
27], computational social science, the “integrated, interdisciplinary pursuit of social inquiry with emphasis on information processing and through the medium of advanced computation” [
11], is grounded on a scientific perspective in which different research traditions flow into one (see
Figure 2). The CSS scientific background is extremely varied and encompasses contributions from complexity science, general system theory, cybernetics, information theory, computer science, mathematics, economics, sociology, political science and many more. The theoretical foundations of the area can be therefore traced back to the seminal works of heterogeneous scientists, like Ross Ashby, Claude Shannon, Norbert Wiener, Herbert Simon, Ludwig von Bertalanffy, Harold Guetzkow and Thomas Schelling [
28].
From a methodological standpoint, computational social science can rely on an already mature framework that encompasses different research methods with several specialized sub-branches. According to Cioffi-Revilla [
19], if we drop for now visualization [
29], visual analytics [
30] and sonification [
31], which will likely become autonomous research practices in the near future, we can identify five main CSS methods that contribute in different ways to the computational investigation of social matter: information extraction; complexity models; social network analysis; geographic information systems; social simulation models. Several combinations among the main five methods (like network analysis, GIS and social simulation; see, just for instance, [
31]) are already common. Others, since the field is still young, have yet to be explored. As we briefly highlight here below, each of the mentioned methods offers specific insights allowing to see beyond the scope of traditional social science research practices or even beyond the results offered by earlier statistical approaches.
Making sense of data: information extraction and data mining. The extraction of semantically-meaningful information from unstructured documents and data sources is probably the keystone of computation-driven science. The identification of unsuspected pattern, regularities and correlations within huge amounts of data allows not only to produce new knowledge by means of inferences and predictions, but is also a powerful incentive for theory making. Born as the application of parsing and marking (semantic encoding) techniques to textual database, information extraction has evolved into the increasingly sophisticated computational analysis of audio, images and videos. A significant step forward in this direction has been made with artificial intelligence methods that are already producing promising results. Automated textual analysis represents a valuable strategy in all of the areas of the social sciences in which the understanding of the text has a crucial scientific role. One of the primary uses of automated information extraction is the production of series of
events data, a stream of historical, social or economic information that can be analyzed through methodologies spanning from more traditional statistical [
32] time series to event lifecycle analysis [
32]. Another relevant application of automated text mining [
33] is the generation of network data structures analyzable with social network analysis techniques (see, for instance, [
34]). In applied research fields, automated information extraction can be used not only for the detection of anomalies and early warning, but also to analyze trends of social and economic dynamics. This feature could turn out to be useful to monitor the impact of policy intervention, especially when dealing with real-time data streams (e.g., stock exchange data).
Grasping (and predicting) the behavior of complex systems. In the last twenty years, complexity theory has provided social science with powerful methods for the analysis of non-equilibrium dynamics that are quite often found in many social phenomena [
35,
36,
37]. Based on mathematical concepts and principles, complexity-theoretic models illuminate the rules underlying the behavior of social systems that, like all complex systems, are characterized by non-linear and hardly predictable dynamics. Social scientists are provided with the opportunity to draw important inferences about the potential evolution of social dynamics that are neither available nor reliable on the basis of data or plain observation [
37]. These inferences include (but are not limited to) the risk of extreme events, the fragility of unstable conditions or the early-warning indicators of incumbent drastic changes. Patterns observed in terrorist attacks, in the distribution of poverty and wealth of developing countries, political instability or, again, the dynamics of the encounter between supply and demand in the labor market are typical examples of nonlinear and non-equilibrium processes. Complexity models allow one to find the regularity of these dynamics, to understand and often predict their evolution [
38]. That is why many relevant social dynamics have been investigated by means of the “complexity-inspired” approach from market fluctuations [
39] to extremist religious opinions [
40] through a process that is gradually extending to many other social issues.
From (social) structure to function: social network analysis. The networks, structures made of entities (nodes) and relations between entities (links) each of which is defined by specific properties, are recurring in a large amount of social phenomena. Communities, groups, political parties, criminal organizations and international alliances are common examples of networks of interest to social scientists. Social Network Analysis (SNA) is a research methodology rooted in social psychology and in the mathematical theory of graphs that exploits formal and computational methods to investigate the structural and functional properties of social networks. Thanks to a large family of metrics and methods, SNA allows to extract insightful information and to make meaningful inferences about the features of a social network simply starting from the analysis of its structural pattern of nodes and relations [
41]. The investigation develops in two phases: the construction of a graphical representation (graph) of data related to the target social phenomenon and the quantitative analysis of the graph based on standard methods and metrics. Through this process, network properties, such as resilience, vulnerability and functionality, can be inferred in a way that is not even conceivable with plain observation or more traditional social science methods (surveys, questionnaires or even statistical analysis). As emerges by a growing literature, SNA has already had large applications across the social sciences, providing a deeper understanding of many different social phenomena: language diffusion; opinion dynamics; belief systems (e.g., political ideologies); treaty systems and their historical evolution; international and transnational organizations like terrorist networks [
42,
43]. Moreover, SNA can be applied to the design of robust and sustainable networks in areas of primary importance for policy-makers, like infrastructures and public transport, security and health.
Spatial analysis of social phenomena. Geographic Information Systems (GIS) are systems designed to store, integrate, analyze, share and display information placed in spatially-/geographically-referenced contexts. GIS were first introduced in social research by social geographers to visualize and analyze spatially-referenced data about the social world. Nowadays,
SocialGIS allows one to investigate the spatial dimension of social phenomena being applied in various fields of social sciences, from criminology [
31] to the regional economy [
44], often in conjunction with other quantitative techniques. In general terms, the methodology is characterized by the capacity to offer a synoptic view of various categories of social data thanks to the superposition of several levels of information (as occurs, for example, in Google Earth). Thanks to these features,
SocialGIS can be a valuable ally for the policy-maker, as it enables one to monitor in innovative ways the scenarios object of intervention and the impact of public choices.
Reproduce to explain (and predict): social simulation models. Scientific explanation is strictly connected with experiments. They not only push to explicitly formulate hypotheses about the factors and the processes that can causally explain a given phenomenon, but also allow one to validate the assumption by means of the comparison between the experiments’ results and the empirical predictions made by the researcher. Social simulations are computational models that provide social scientists with the opportunity to explain in experimental terms and to predict the evolution of complex social phenomena reproducing the real-world processes that generate the social reality. The two main simulation techniques used today in social research are
Systems dynamics [
45] and
Agent-Based Models (ABM) [
46,
47].
System dynamics models are based on the idea that the evolution of a social system can be represented as the result of complex cycles of action and feedback which can be described in mathematical terms. On this assumption are grounded simulations in which the phenomenon under investigation is represented as a set consisting of variables (
stocks) and rates of change (
flows) associated with them. Today, these models are the basis for many applications in the industrial sector, managerial and social sciences.
Agent-based simulation models are led by the theoretical assumption that the macro-level social phenomena (e.g., the emergence of social norms or the spread of racial segregation) are the result deriving from the interactions occurring, at the micro-level, between individuals and between individuals and the environment. ABMs typically include a set of heterogeneous artificial agents simulating real-world actors and their behaviors, a set of rules of interaction and an environment in which both dynamic, organizational and spatial characteristics are defined. As highlighted in the next section, social simulation provides policy-makers with the ability to run a
what-
if analysis allowing to observe the effects potentially deriving from different choices by means of well-developed models of a given “target system” (see, for example, the effects of social stressors on patterns of political instability [
48]).
4. Computational Social Science and Policy Design: Making Smarter Public Choices
The implications of the scenario so far described go beyond the scientific dimension. By increasing our ability to understand and predict social dynamics, computational social science is preparing the ground to innovative and more rooted in science approaches to policy design. Thanks to the capacity of bringing together in innovative ways theory and computation, data and laboratory experiments, computational social science offers policy makers and legislators a clearer idea of complex socio-economic processes and an opportunity to increase the effectiveness of public choices. CSS methodologies are particularly suited to the study of non-linear phenomena that are, at the same time, difficult to understand with conventional mathematical and statistical tools and also often poorly understood by traditional policy-making procedures. That is why, in recent years, the scientific community has paid a growing attention to the intersections between computational social sciences and policy modeling [
2,
12,
19].
As evidence of this, we can cite some research projects that explore the potential impact of computational methodologies in policy-making and try to promote what the EU defines as “
scientific evidence-based policy making” [
49], drawing attention to the need for policy-makers to ground their decisions in science.
FuturICT [
50] is a research project presented in response to the FP7 Flagship Call ICT aiming to bring together complexity science, social sciences and information technologies to support the understanding and the management of complex global issues spanning from epidemics to crime, ecological disasters and financial crises. Largely inspired by CSS research, the core of the project is represented by the
Living Earth Platform, an advanced simulation, visualization and participation platform designed to support decision-making of policy-makers, business people and citizens. A similar issue, the understanding and the prediction of systemic risk and global financial instabilities is the main topic of
FOC -
Forecasting Financial Crises [
51], a project financed by the Future Emerging Technologies OPEN Scheme aiming, on the one hand, to offer a theoretical framework to measure risks in global financial market and, on the other hand, to deliver an ICT collaborative platform for monitoring systemic fragility and the propagation of financial distress across markets around the world.
Dealing with the economy is also
Eurace [
52], FP6 European research that involved researchers from various backgrounds to build an agent-based simulation model of the European economy. The research tackles the complexity generated by the interplay between different macroeconomic policies (fiscal and monetary strategies, R&D incentives,
etc.) pursuing objectives that unfold on both the scientific and the societal level. From the scientific point of view, the main goal was the development of multi-agent models reproducing the emergence of global features of the economic system from the complex pattern of interactions among heterogeneous individuals. From the social point of view, the goal was to support EU policy design capabilities by means of simulation enabling one to perform what-if analysis, optimizing the impact of regulatory decisions that will be quantitatively based on the European economy scenario.
FUPOL (FUture POLicy modelling) [
53], finally, is an FP7 project that aimed to provide a new approach to politics building on major innovations like multichannel social computing, crowd sourcing and social simulation. The project developed a governance model to support the policy design and implementation lifecycle by a system combining two CSS techniques: information extraction and social simulations. The first was used to collect, analyze and interpret the opinions expressed online by citizens, in order to give governments a better understanding of their needs. The latter aimed to simulate the effects of policies in order to assist governments throughout the process of their development.
Beyond the albeit significant scientific results, marked by a consistent number of relevant publications [
2,
19,
54,
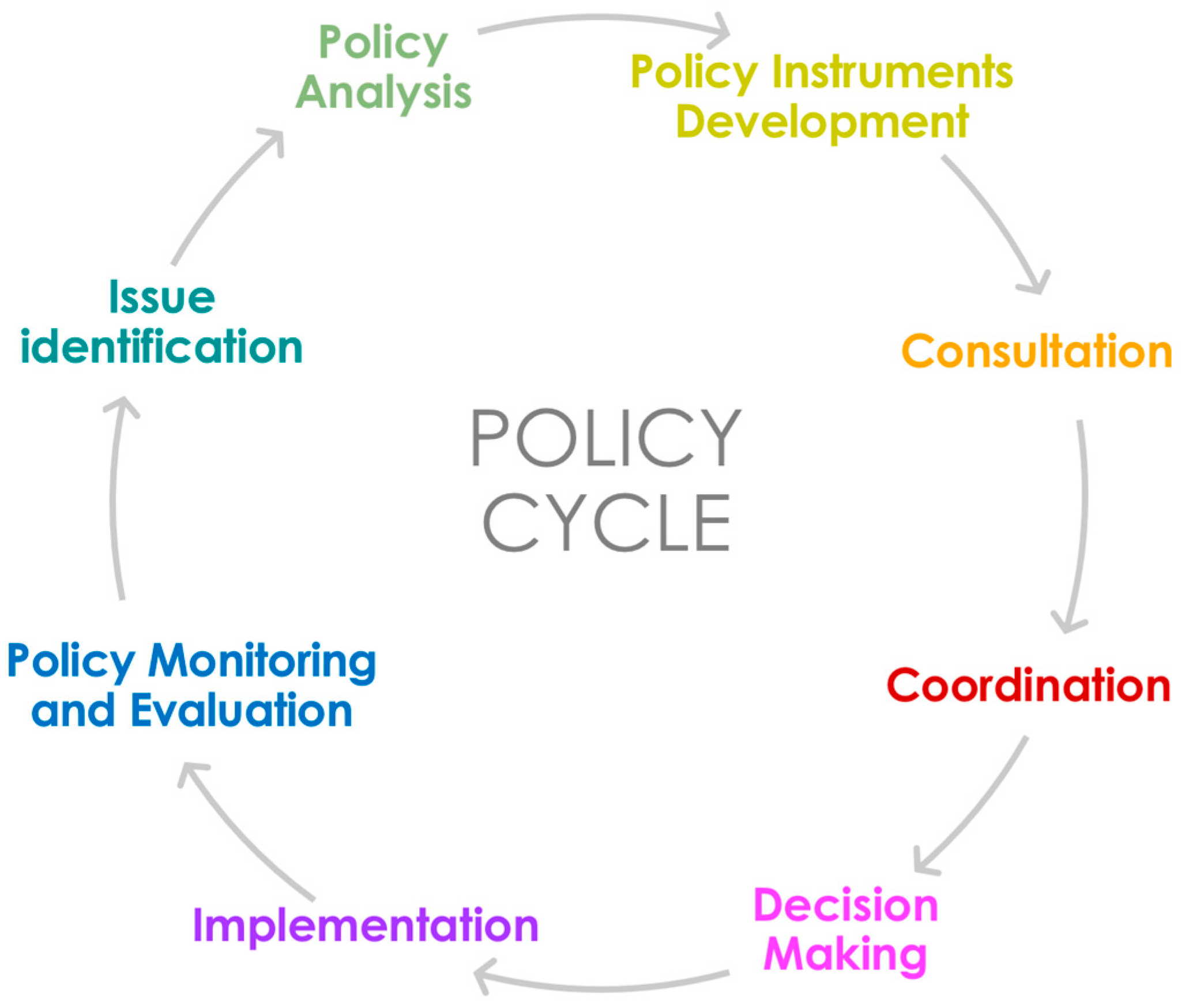
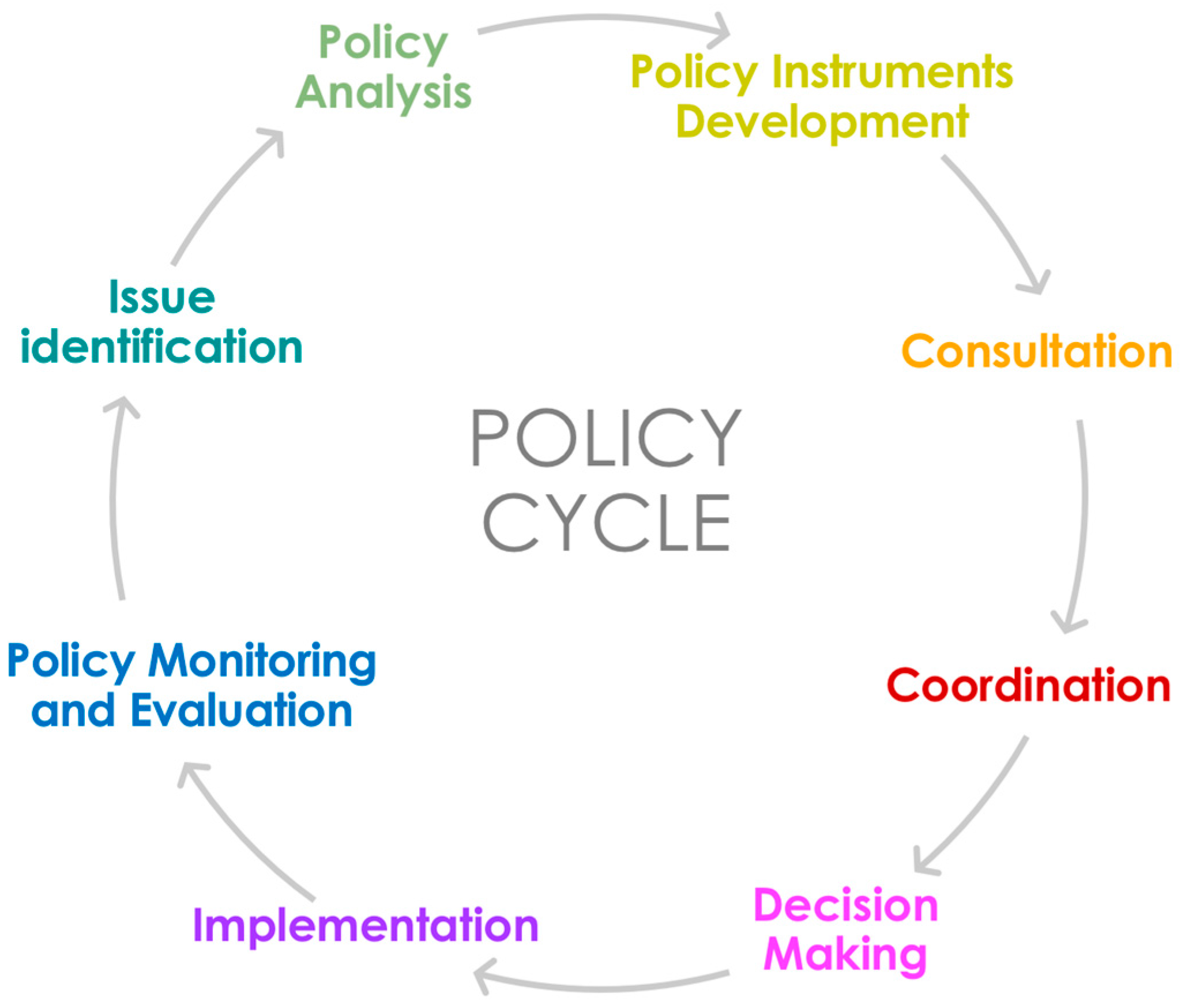
55], the above-mentioned projects share the credit of enhancing the debate over the intersections between policy modeling and science promoting, at the same time, the creation of an interdisciplinary research community. As the result of their activities somehow shows, CSS research is gradually driving a deep innovation in policy design. The methodologies and the tools developed by computational social scientists seem indeed to be helpful in different fundamental steps of the policy cycle from the identification of the solutions that are more appropriate to implement the policy to decision-making and
evaluation (see
Figure 3), opening up new prospects and new scenarios.
A reasonable question at this point is: how can the insights potentially deriving from CSS methodologies concretely be implemented into the policy design process? A crucial role is expected to be played, in this vein, by the rule-making procedures and, in more detail, by the legal mechanisms regulating the formulation and evaluation of public policies.The issue is strictly connected with the goal of a higher ‘quality of regulation’ [
57], an increasingly important concern on the agenda of national and international institutions.
In the last twenty years, the Organisation for Economic Co-operation and Development (OECD) has produced several documents on the topic adopting, in 2012, a document (“
Recommendation on regulatory policy and governance”) [
58] that contains detailed international guidelines on the quality of regulation. The EU, in its turn, has been moving in the same direction actively promoting the creation of tools to ensure the the quality of norms discussing, since the early 1990s, new ideas and practices to assess the impact of both policies and rules implementing them. More recently, the subject has been widely analyzed within the context of the White Paper on Governance [
59] in which the European Commission expressly emphasizes the need to improve the quality, the simplicity and the effectiveness of regulatory acts.
The concept of ‘quality regulation’, the idea of a regulation capable, among other things, of clearly identifying policy goals and being effective in achieving them, involves both the process that leads to the adoption of norms and their results. With reference to the rule-making process, three different instruments are relevant in our perspective: the regulatory impact analysis, citizens’ involvement and the ex post evaluation.
Regulatory Impact Analysis (RIA) is a methodology aiming to evaluate the potential impact of a given piece of legislation before its adoption. The RIA translates into a socio-economic assessment aiming to compare the effect on citizens, enterprises and public administrations potentially deriving from different hypotheses of regulatory intervention. The analysis aims to guide policy-makers to the adoption of more efficient and effective choices while making more explicit the reasons for the choices made. Based on qualitative analysis and, where possible, on the collection of quantitative data, the RIA is also a tool to ensure the coherence and integration of policies, as it requires decision-makers to assess the impact of sectorial policies in other contexts.
Citizens‘ involvement in the design of public policy is typically achieved through consultations, in particular through the notice and comments mechanism that consists in seeking public comments on the specific issues to be settled. The collection and the analysis of information about the way in which a regulation is perceived by the citizens helps governments to refine policies, so as to address problems deemed most important by the community and to better define the priorities (i.e., focusing on the areas in which the regulatory intervention is more urgent or, conversely, identifying areas in which the adjustment could be unnecessarily burdensome).
For the ex post evaluation, the assessment of regulatory measures already in place, an evaluation is made considering the effects, the impact on the relevant needs and the resources employed. The evaluation produces information that is essential to plan, design and implement new policies, as it allows one to answer essential questions about the relevance, the effectiveness and the cost-benefit ratio of the envisaged rules.
Scientific and methodological results achieved in the CSS research area appear to be supporting the effectiveness of the above-mentioned policy-making instruments mainly in three ways: providing new scientific knowledge about the social phenomena affecting (and affected by) the policy choices; extracting relevant and useful information from the huge amount of digital data available today; offering tools and predictive techniques for the what-if analysis.
RIA and
ex post evaluation can find useful support in simulation models. The statistical/mathematical simulations enabled by
system dynamics and
microsimulation models have been already used in the past (the first experiences date back to the 1950s) with reference to specific policy issues, like the prediction of the effects of changes in tax laws on government finances [
60]. As we will highlight in the next section, a more powerful tool, in this perspective, is however represented by agent-based simulation models that are particularly suited to study social dynamics strongly influenced by the interactions between agents and other factors (individual motivations, cultural mechanisms, cognitive processes) that are difficult to treat in exclusively mathematical-statistical terms.
As to citizens’ involvement, CSS methods seem to be potentially useful to overcome the limits affecting today e-consultation, an activity that is intrinsically connected with the problem of extracting meaningful knowledge from citizens’ contributions. Online discussions and feedback contain valuable opinions about the effects of policy decisions and an essential knowledge about the societal needs that the policy tries to address. This information asset is today exploited only to a limited extent by policy-makers due to the variety and the growing amount of information available. Alongside the first web-based e-consultation tools, accepting only textual contributions (e.g., online voting and survey or discussion forums), there are more recent solutions allowing increasingly advanced contributions that span from posts on social media to comments on YouTube videos [
61,
62,
63,
64].
The problem is that while a limited number of textual contributions can be effectively interpreted by means of statistical methods, the same is not true when the information grows and is spread over different media. In this case, it becomes ever more difficult if not impossible to extract crucial information like the attitudes of the citizens and the main issues they raise (e.g., strengths and weaknesses of the policies under discussion; the effects of implemented decisions; suggestions about potential improvements). This not only results in a loss of knowledge that would be extremely useful to design more contextualized and accepted policies, but prevents from giving citizens automatic feedback about the way in which their opinions have been taken into account, a choice that would help promote government openness and accountability, avoiding disappointment and mistrust in e-consultation processes.
It is no accident that the first OECD report about e-consultation [
58] claims that one of the most relevant challenges for the application of the electronic participation model is the automated and cost-efficient extraction of information from the huge amount of unstructured information contained in citizens’ contributions. The report explicitly mentions the use of “appropriate technologies” and all of their potential uses: support “the summarization and content analysis of contributions’; help highlighting areas of agreement and disagreement”; “identify the participants main concerns, their level of support for any draft proposals, or their suggestions” [
58].
Information extraction research so far has generated several opinion mining methods variously tested in the commercial domain to analyze judgements and reviews posted on the web by customers. These methods today may produce innovative solutions to assess citizens’ sentiments (positive, negative or neutral) towards the policies and also to extract the main issues they raise.
Sentiment analysis [
64] is a particularly promising technique in this perspective. The application of computational techniques to determine the attitude of the author of a text (an entire document or even single sentences within it) with respect to a particular topic or, more generally, his or her state of mind is going to offer more insightful knowledge compared to that achievable through the methods that are more traditionally used to evaluate the perception of policies (e.g., the surveys based on the Worldwide Governance Indicators defined by the World Bank to measure the perception of citizens, companies and experts about the quality of governance using six distinct dimensions).
The reasons of the interest toward computational approaches to policy-making should be now clearer. CSS methods could enhance the tools supporting the quality of regulations with positive effects both on the implementation of the legal principles that govern the activity of policy-makers (transparency, accountability, legality, proportionality) and on the overall effectiveness of public policies.
5. In Silico Management of Social Complexity: Agent-Based Models and Policy Design
Among the different CSS methodologies so far tested in policy-making, social simulation occupies a very special place. The opportunity, offered by the simulations, to better understand and, above all, to somehow predict the evolution of complex socio-economic phenomena has long attracted the attention of scholars with different scientific backgrounds for various reasons who are interested in policy issues.
In an frequently cited essay published in 1998 [
65], the American economist Steven Durlauf provides an effective representation of the reasons that should prompt policymakers to look at the scientific paradigm and the investigative methods (simulations in particular) offered by computational social science: social systems and economic dynamics show all of the features of complex phenomena [
5,
66]. Generated by feedback loops, evolutionary processes and interactions between individuals who constantly change their behavior, the social and economic phenomena are complex, nonlinear and difficult to predict through the most common methods of analysis. However useful, the scientific tools usually supporting policy modeling, mainly based on predictive statistical analyses, show inherent limitations because of their inability to account for the role that the individual and the local dimension plays in determining the overall development of social dynamics. The causal role played, in the evolution of social phenomena, by the individual preferences, by psychological, cognitive and cultural factors or, again, by the reactions of different social actors to political decisions is a puzzle that is difficult to solve with traditional approaches.
The circumstance is confirmed, with specific reference to economic policy, in a statement made by the former European Central Bank president Jean-Claude Trichet in November 2010:
“When the crisis came, macro models failed to predict the crisis and [...] to explain what was happening [...] in the face of crisis, we felt abandoned by conventional tools [...] The key lesson [...] is the danger of relying on a single tool, methodology or paradigm.”
What is needed, in this scenario, is a research methodology allowing one to capture the microfoundations of macro-social outcomes, and the above-mentioned agent-based models represent the most promising solution to this end. Trichet’s speech contains a meaningful statement in this regard:
“A large number of aspects of the observed behavior of financial markets is hard to reconcile with the efficient market hypothesis. But a determinedly empirical approach—Which places a premium on inductive reasoning based on the data, rather than deductive reasoning grounded in abstract premises or assumptions—lies at the heart of These methods [...] simulations will play a helpful role. Agent-based modeling [...] Allows for more complex interactions between agents.”
Having been designed to illuminate and predict the micro-level processes at the root of social macro-phenomena, agent-based models were soon considered as a possible tool to support policy-makers. The focus on this research perspective has grown considerably over the last ten years [
67,
68,
69], transcending the boundaries of the scientific world and, as shown by the Trichet’s speech, reaching the world of institutions.
The issues addressed by the research conducted in this area are very heterogeneous, ranging from the management of environmental resources to the impact of land use decisions, from the effects of economic policies to that of retirements [
70,
71,
72]. Following the classification proposed in [
73] (see, also, for a more detailed analysis, [
74]), social simulation models conceived for policy design can be divided into two categories characterized by different theoretical premises and development methods: the
prescriptive and the
participatory models, two categories on which it is interesting to offer some detail also in view of the considerations that will be proposed later on.
Prescriptive models are inspired by the idea that the scientific explanation of the mechanisms underlying social phenomena can be somehow translated into recommendations for policy-makers. The goal of the researcher (somewhat analogous to that pursued in the legislative sphere through the above-mentioned Regulatory Impact Analysis) is to develop a preliminary analysis allowing the policy-makers to understand the phenomenon object of intervention and to make an ex ante evaluation of the effects potentially deriving from different policy choices. The core of the research, in this kind of model, consists of theories and scientific evidence related to the target phenomena, elements that are taken into account to create models showing the implications of different choices and to evaluate different solutions before the choice takes place. Studies related to this kind of approach are numerous.
An emblematic and particularly interesting example of this kind of research (because of its connection with public decision-making issues) is the work published by Rouchier and Thoyer in 2003 [
75]. The authors use a multi-agent model to study the effects of new decision-making procedures introduced by the EU legislator in the field of genetically-modified organisms, procedures characterized, compared to the previous legislation, by a wider use of public consultation. The aim, in more detail, is to check the impact of the reform on two different aspects of the investigated phenomenon: on the one hand, the level of the influence on political choices deriving from pressure groups and from organizations representing collective interests; secondly, the acceptability to the public of new rules for the regulation of such a delicate matter.
Another interesting example of prescriptive model [
76] simulates the negotiation process that, according to the French law, needs to be activated to regulate the use of water within river basins. The model, designed taking into account the different categories of stakeholders involved (farmers, advocacy groups, payers, water companies) and all of the variables relevant for trading (irrigation quotas, price of the water, size of available dams,
etc.), allows one to estimate the benefits related to different solutions of the negotiation process and to assess the overall impact of the negotiation on the final results of the procedure considered. The purpose is typical of prescriptive models: to provide an information framework to stakeholders in order to improve the quality of policy choices.
Participatory models. In this second category of simulations, the development of the model is not only the result of theoretical assumptions or scientific evidences, but derives from a collaborative process in which the recipients of the policies under scrutiny are directly involved. The predictive purposes and decision support are added, in this case, for two other objectives: on the one hand, to achieve a greater degree of adherence of the model to reality; on the other, the beginning of a participatory process and the relevant trading plan for the legitimacy of the choices [
77,
78]. In participatory modeling process, decision-makers and stakeholders share information and integrate scientific knowledge with the representation of the concrete interests at stake. The models are designed based on observation and developed through an empirical validation process in which the stakeholders are involved directly in the definition of the theme of research and the evaluation of the results. The benefits of participatory methods are different: the acquisition of otherwise inaccessible knowledge; the ability to identify research issues of important practical significance; and above all, a greater likelihood that stakeholders will be sufficiently motivated in the future to implement in their ordinary activity the solutions emerging from the research.
After an initial phase in which policy recipients were involved only for the
ex post validation of the model, we went, thanks to the spread of online collaboration tools, to more active forms of participation. An interesting example is represented by the
CORMAS (COmmon-pool Resources and Multi-Agent Simulations) simulation platform developed at the CIRAD (Centre de coopération internationale en recherche agronomique pour le développement), the French research center for the development of agriculture [
79] to allow the implementation of participatory simulations intended to support the design and the study of policies relating to the environment and agriculture. To encourage user involvement, participatory simulation exploits different techniques: on the one hand, it uses approaches emerging from the social sciences since the advent of the web (extraction of information from social networks and, more generally, from all of the interactions mediated by the web, online questionnaires,
etc.); on the other hand, it uses online games as a strategic tool to extract from end users knowledge and information about their needs [
80]. Even in the case of participatory models, the experiences to be mentioned are already numerous. Studies conducted so far are mainly linked to sustainable development issues in which the interactions between environmental dynamics, policies, production factors and other economic and social aspects generate complexity that is often difficult to govern [
81,
82].
A particularly interesting experience [
83] is related to the implementation of a multi-agent system developed to stimulate the development, the discussion and comparison of different land management strategies in the Causse Mejean, a limestone plateau in southern France characterized by a delicate ecosystem of grasslands and threatened by an invasion of pines. To allow the identification and comparative assessment of different strategic decisions concerning the location of farms and forest management, the researchers translated the different options into different simulation models defined step-by-step with the direct participation of stakeholders and the use of detailed empirical data concerning the agents involved and the characteristics of the environment.
In the initial phase of the project, the key stakeholders (foresters, farmers, rangers of Cevennes National Park) were invited to contribute to the design of the model through a statement of their views and the proposition of different natural resource management scenarios. Once the model was implemented, the execution of the simulations allowed to assess the impact of each scenario on the production plan (number of sheep to rear, wood growth), on the environment (species in danger of extinction, landscape protection), as well as on other considered relevant territorial entities (forests, farms, grasslands, etc.).
The different options have been examined together by all participants in the project passing through the implementation of new scenarios postulated during the discussion. The iteration of the procedure facilitated the identification of a set of compromise solutions based on a shared management of the forests of pines and innovative farming practices protecting the ecosystem.
6. Conclusions
In one of his most famous aphorisms Francis Bacon declares: “
human knowledge and human power meet in one; for where the cause is not known the effect cannot be produced. Nature to be commanded must be obeyed” [
84]: in order to master nature (and take advantage of it), we must understand it before. Almost four centuries later, the intuition of the English philosopher, scientist and jurist is more topical than ever, even when applied to the policy-making domain.
Virtually every relevant phenomenon for the decision-maker, from the dynamics of the labor market to the financial crises, from international outbreaks to migratory flows, poses the urgency of a better understanding of real world dynamics. To be more effective and properly contextualized, policy-making need to be increasingly rooted in science. As argued in a growing literature (see, among others, [
5,
19,
68,
85,
86,
87]), the time is ripe to bridge the gap between the public policies and scientific-methodological advancements that are illuminating social phenomena and the individual processes underlying them.
Mixing social theory and computation, data and laboratory experiments in an innovative way, the computational social science paradigm can contribute to a clearer vision of social processes and, therefore, to the quality of public choices integrating the more traditional quantitative approaches already practiced in social science. However important, statistical analysis is unable by itself to account for the generative processes at the root of social and economic dynamics: being mainly devoted to descriptive purposes and to the discovery of correlations and regularities rather than to the development of scientific hypotheses and theories, statistics may offer a partial view of reality that may well be supplemented by analytical computational social science methods.
As a matter of fact, the computational paradigm is pushing forward our ability to deal with social complexity. It not only takes advantage of unprecedented amounts of ICT data about potentially any kind of human interaction, but is also exploiting computation to inspire, formalize and implement new and more complex theories about real socio-economic systems. It is on the back of these features that CSS promises to turn social science into applicable tools that can inform decision-makers about issues of major concern [
19]. New policy analytics could considerably benefit from advanced ICT data mining and analyses, tools that are going to become ever more essential to transform policy in an adaptive, experimental and collaborative process.
Based on the above, the need of a cultural, political and scientific shift becomes clear. If, on the one hand, it is necessary to bring together science and policy design, on the other, it will be essential to promote the cross-fertilization between all of the different cultures, disciplines and research areas involved in the computational social science endeavor, from computer and complexity science to law and economics, from sociology to cognitive and behavioral sciences. In the same perspective, it will be necessary to foster an issue-oriented and interdisciplinary approach to research overcoming a cultural resistance that still appears far from being broken down. As already highlighted, computational social science shares with other emerging inter-disciplinary research areas like cognitive science, the need to develop a paradigm for training new scholars [
17]. Universities, research institutes and editorial boards need to understand and reward the effort to work across disciplines.
The stakes are high and deserve major effort: the possibility to successfully cope with the challenges of the contemporary world depends to a significant extent on the capacity to promote a new paradigm for the study of social phenomena and, through it, new practices for policy design. Ten years after Bollinger’s talk, the way to go to establish a more strict relationship between science and policy-making is still far from over. Computational social science certainly is not the only solution to the problem, but, for sure, is an important part of our future.



{kind=link}
{kind=link}
{kind=link}