
Information Is Not a Virus, and Other Consequences of Human Cognitive Limits


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
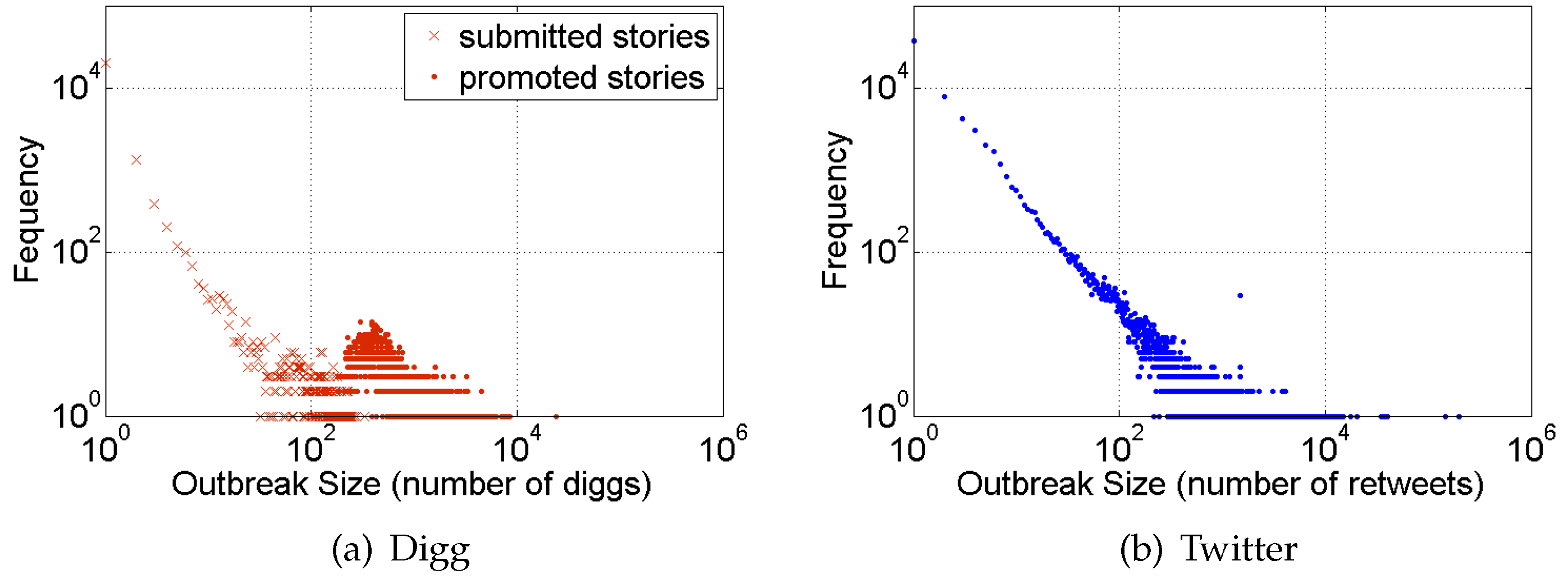
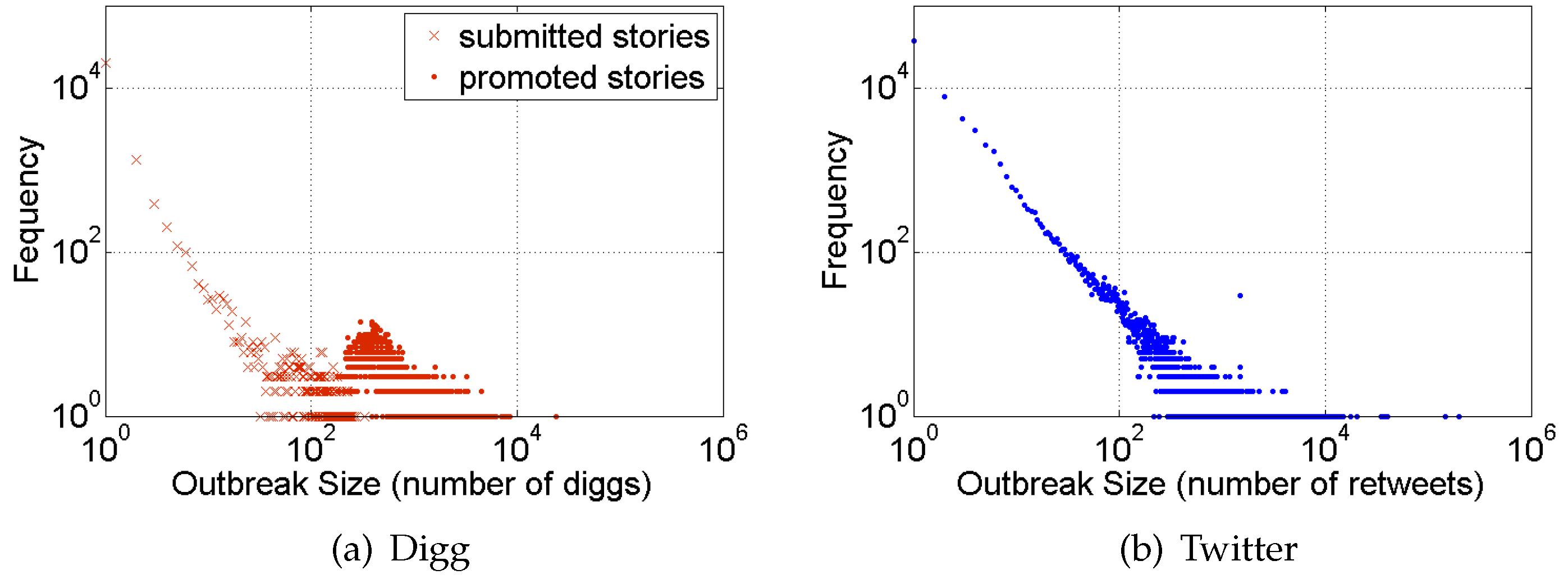
2. Size of Social Contagions
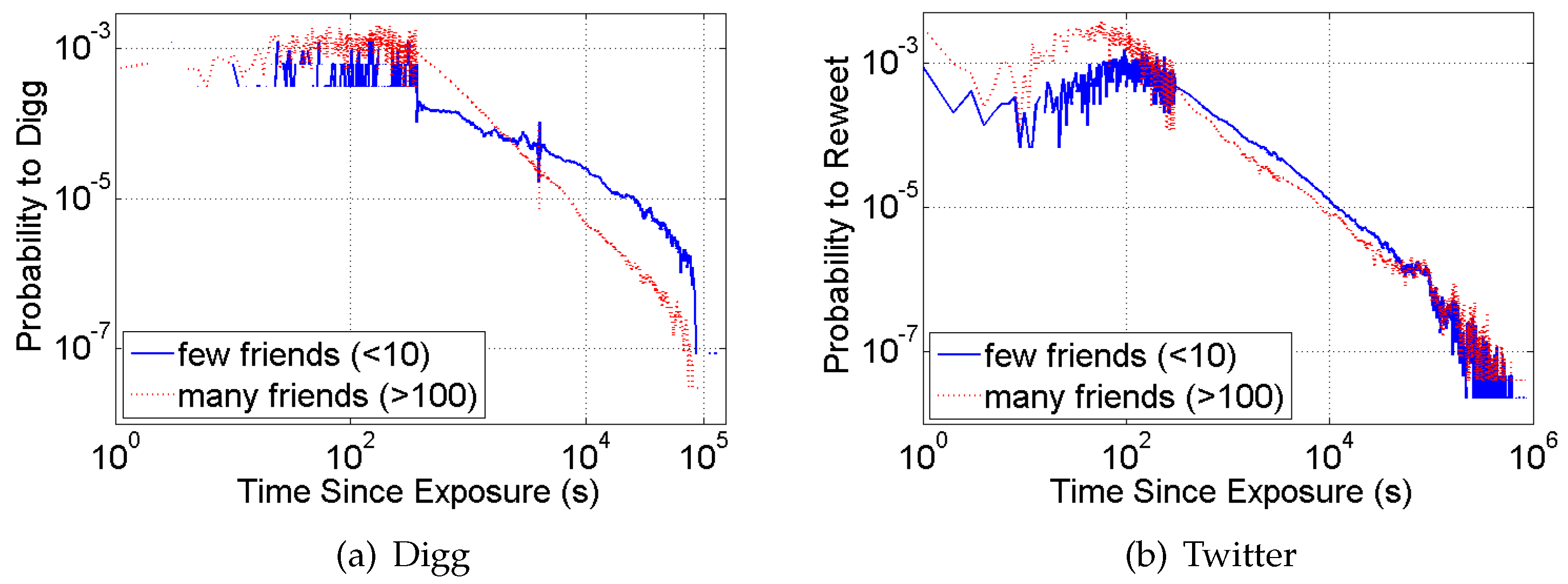
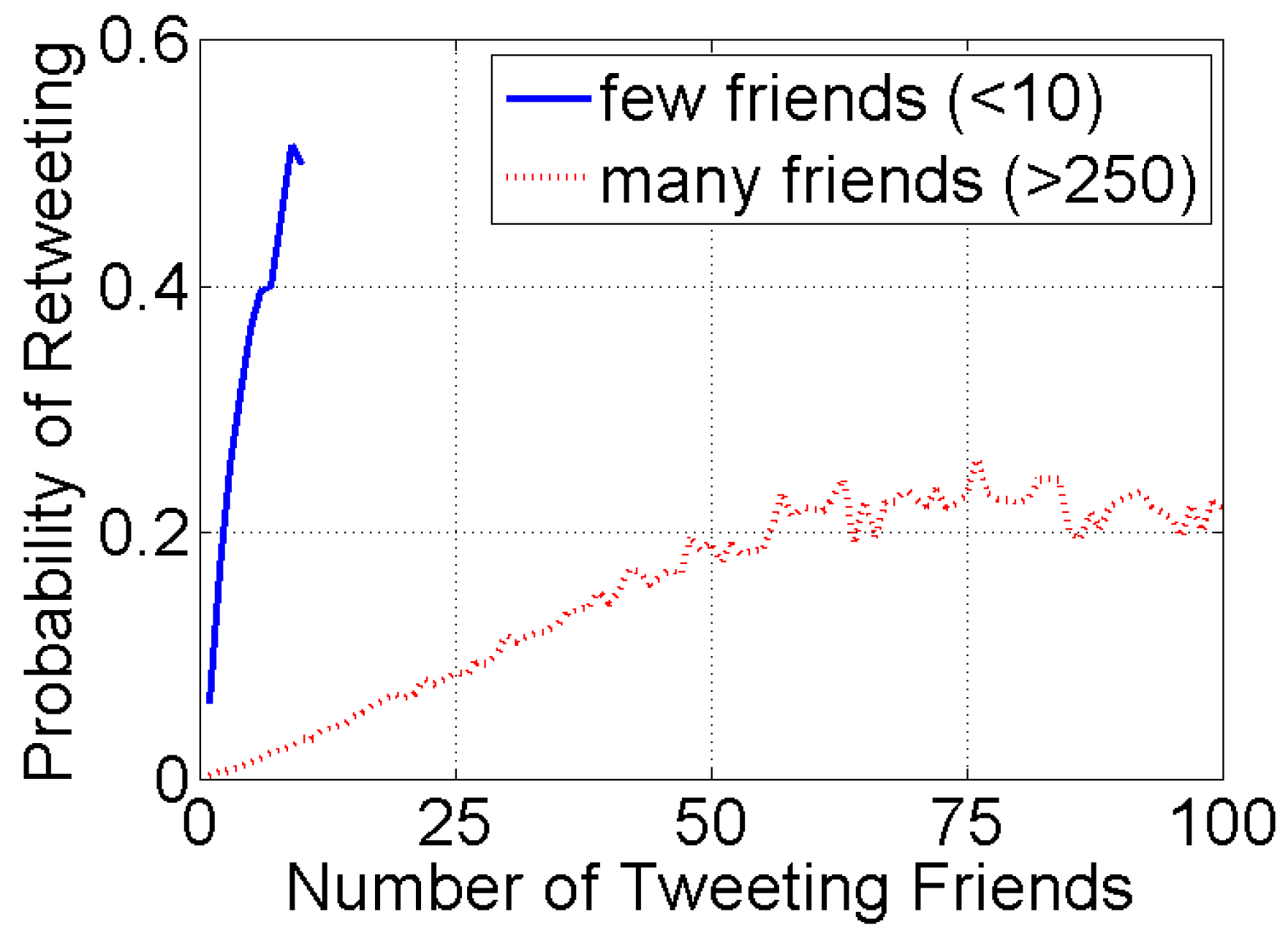
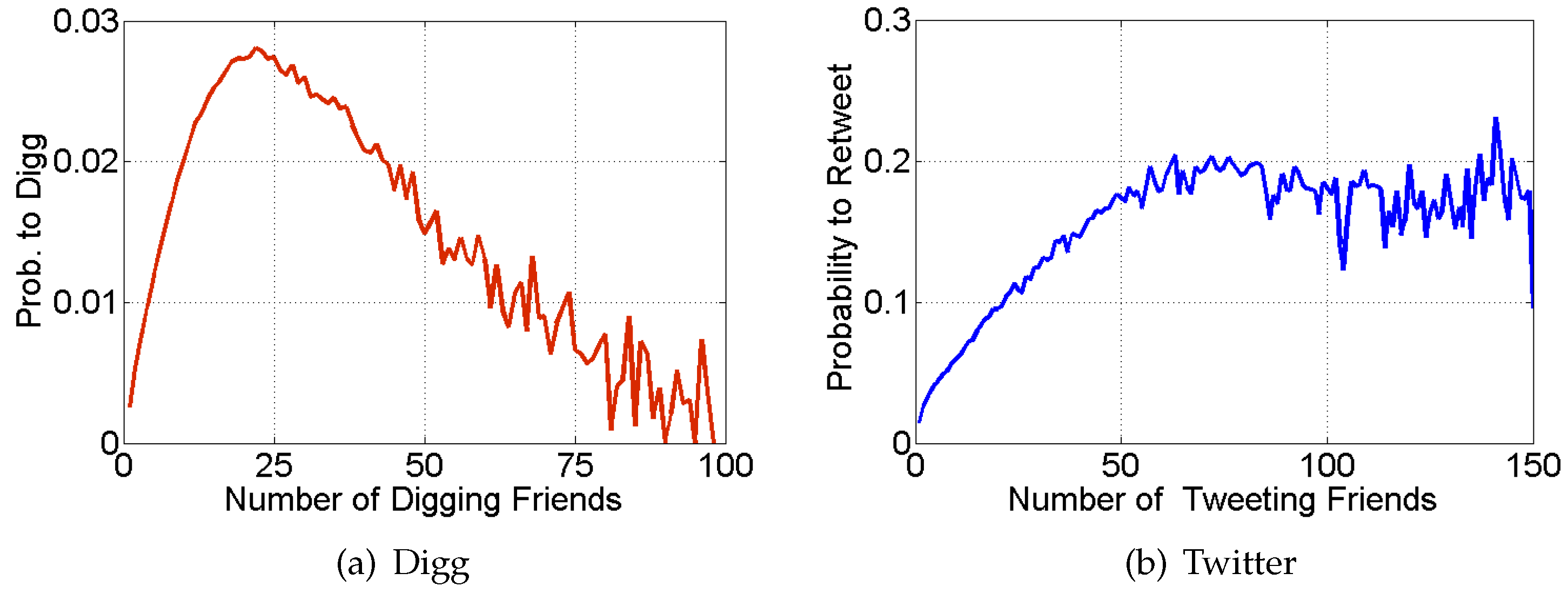
3. Mechanics of Contagion: Exposure Response
- Subcriticality
- The vast majority of information spread is sub-critical, with transmissibility below the epidemic threshold. As a result, information is unlikely to spread upon exposure, and can be considered uninteresting. This hypothesis is easy to dismiss, since it is difficult to imagine that all the information shared on many different social media platforms is uninteresting.
- Load balancing
- Social media users may modulate transmissibility of information to prevent too many pieces of information from spreading and creating information overload. This hypothesis is difficult to evaluate, though it is not very credible, since such wide-scale coordination would be difficult to achieve. Moreover, it would require users to correctly estimate the popularity of different pieces of information in their local neighborhood, a measurement that is easily skewed in networks [23].
- Novelty decay
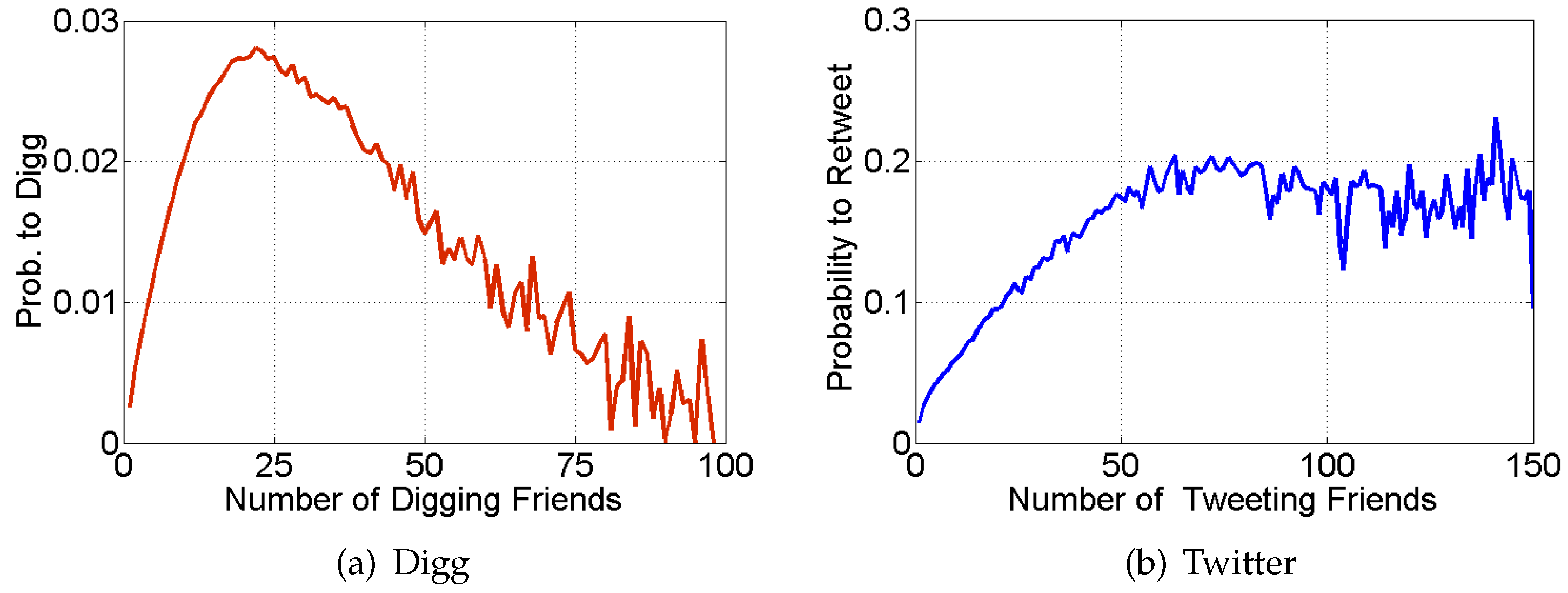
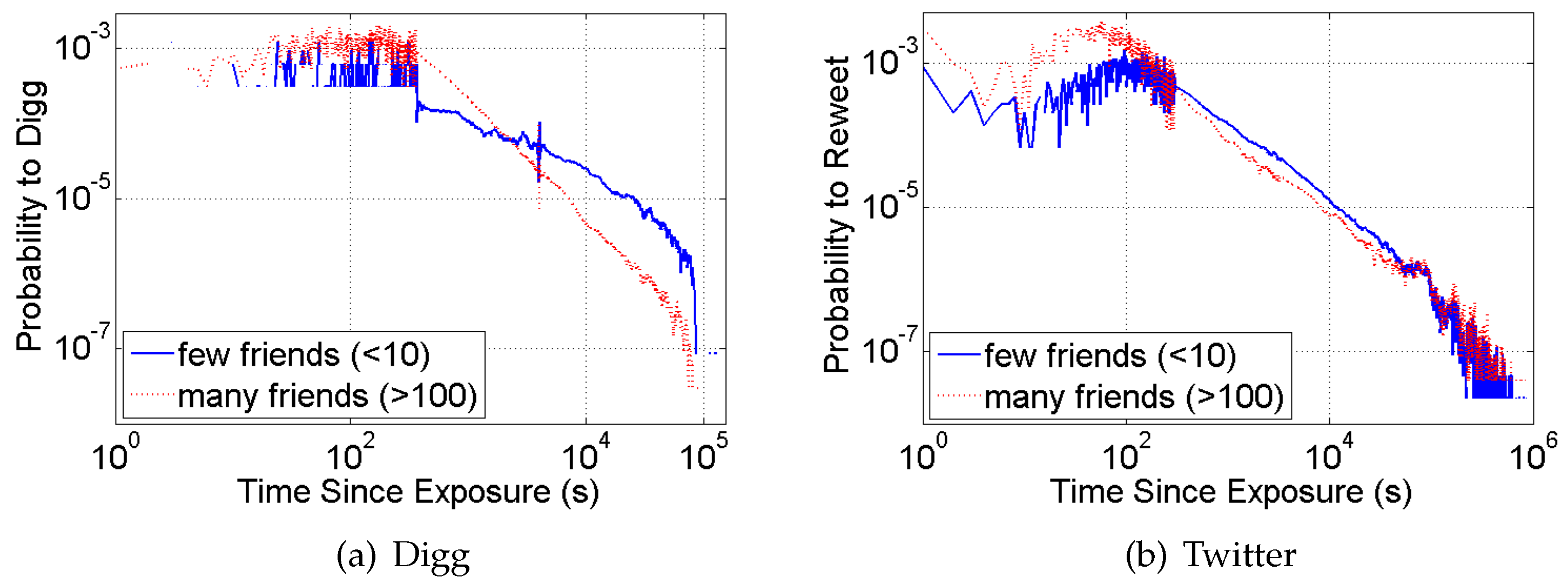
- Transmissibility of information could diminish over time as information loses novelty. A study [24] explicitly addressed this hypothesis, and found that the probability to retweet information on Twitter does not depend on its absolute age, but only the time it first appeared in a user’s social feed.
- Network structure
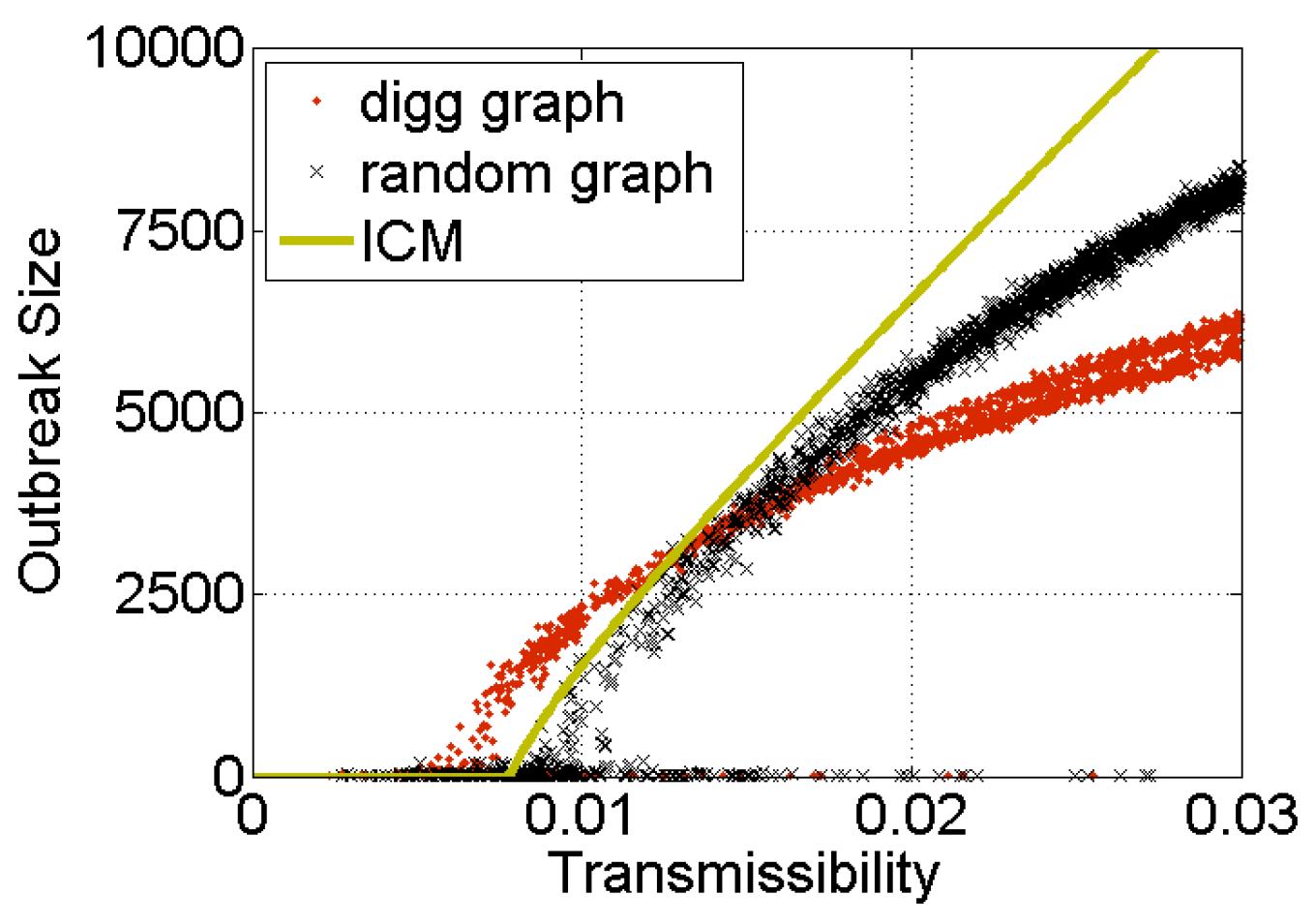
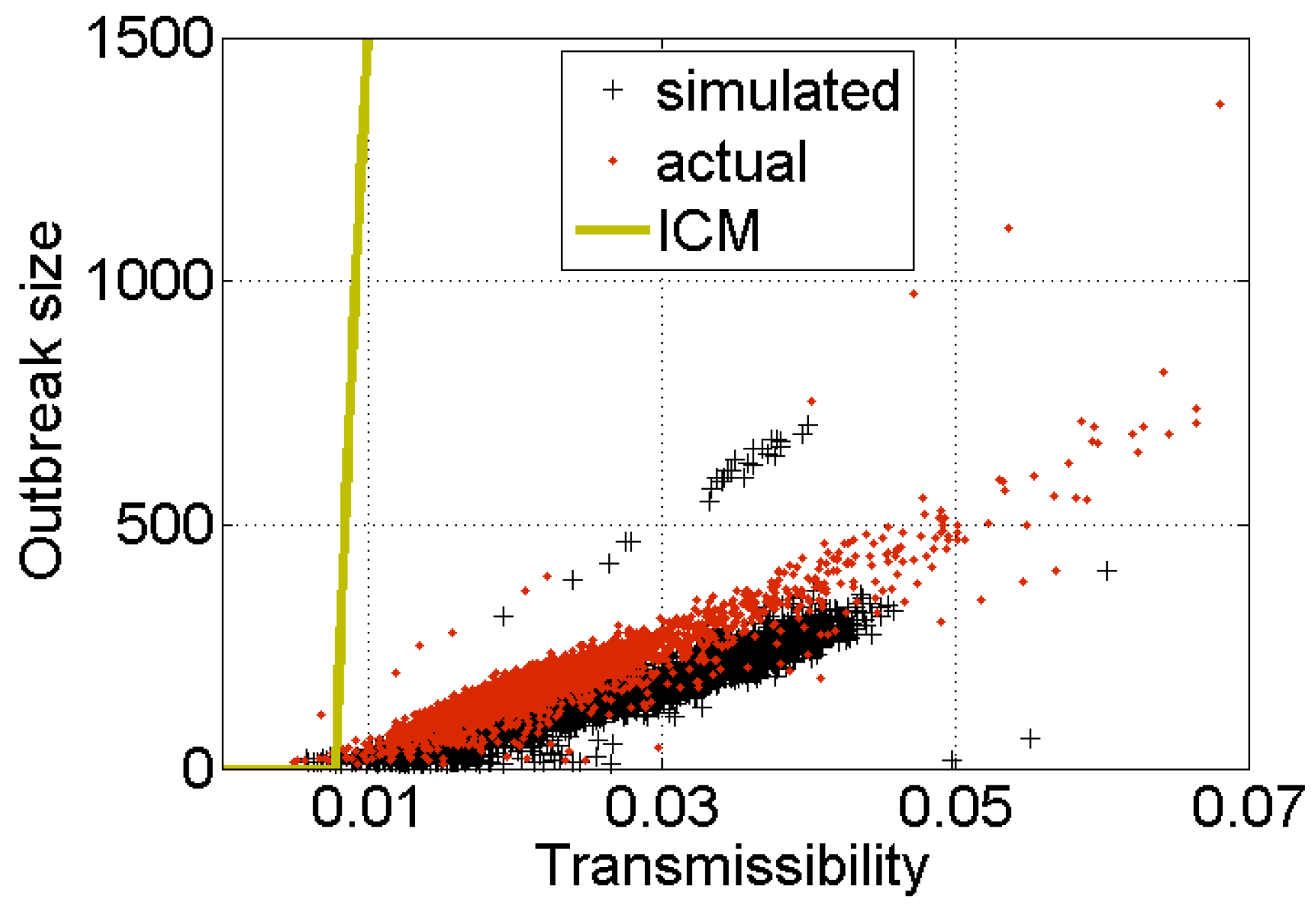
- Although it is conceivable that network structure (e.g., clustering or communities) could limit the spread of information, this hypothesis was ruled out [14]. As can be seen in Figure 1, the structure of the actual Digg follower graph somewhat reduces the size of outbreaks, but not nearly enough to explain empirical observations.
- Contagion mechanism
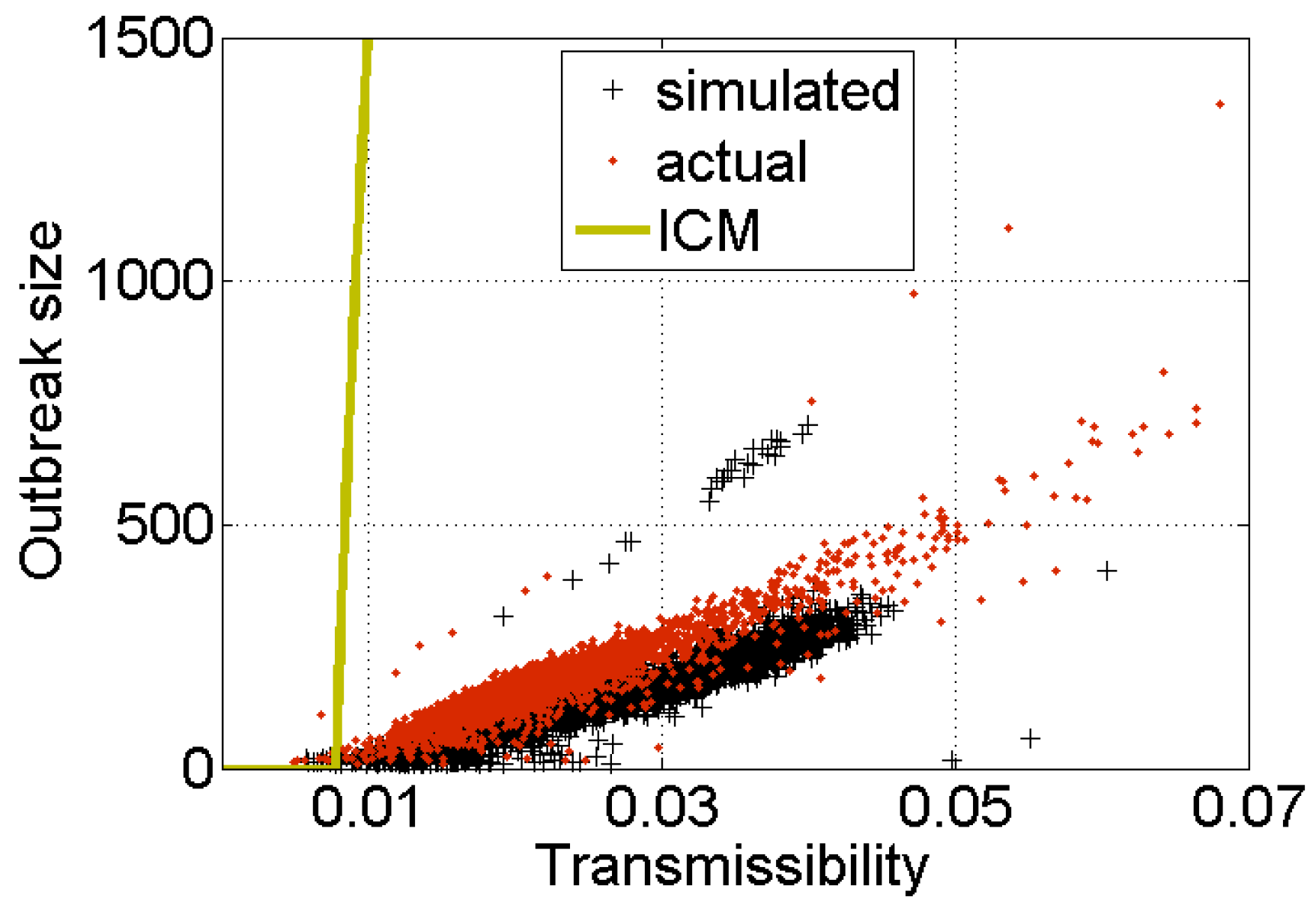
- The decisions people make to vote for a story on Digg or retweet a URL on Twitter, once their friends have shared, could differ substantially from the ICM. These differences could prevent information from spreading [14].
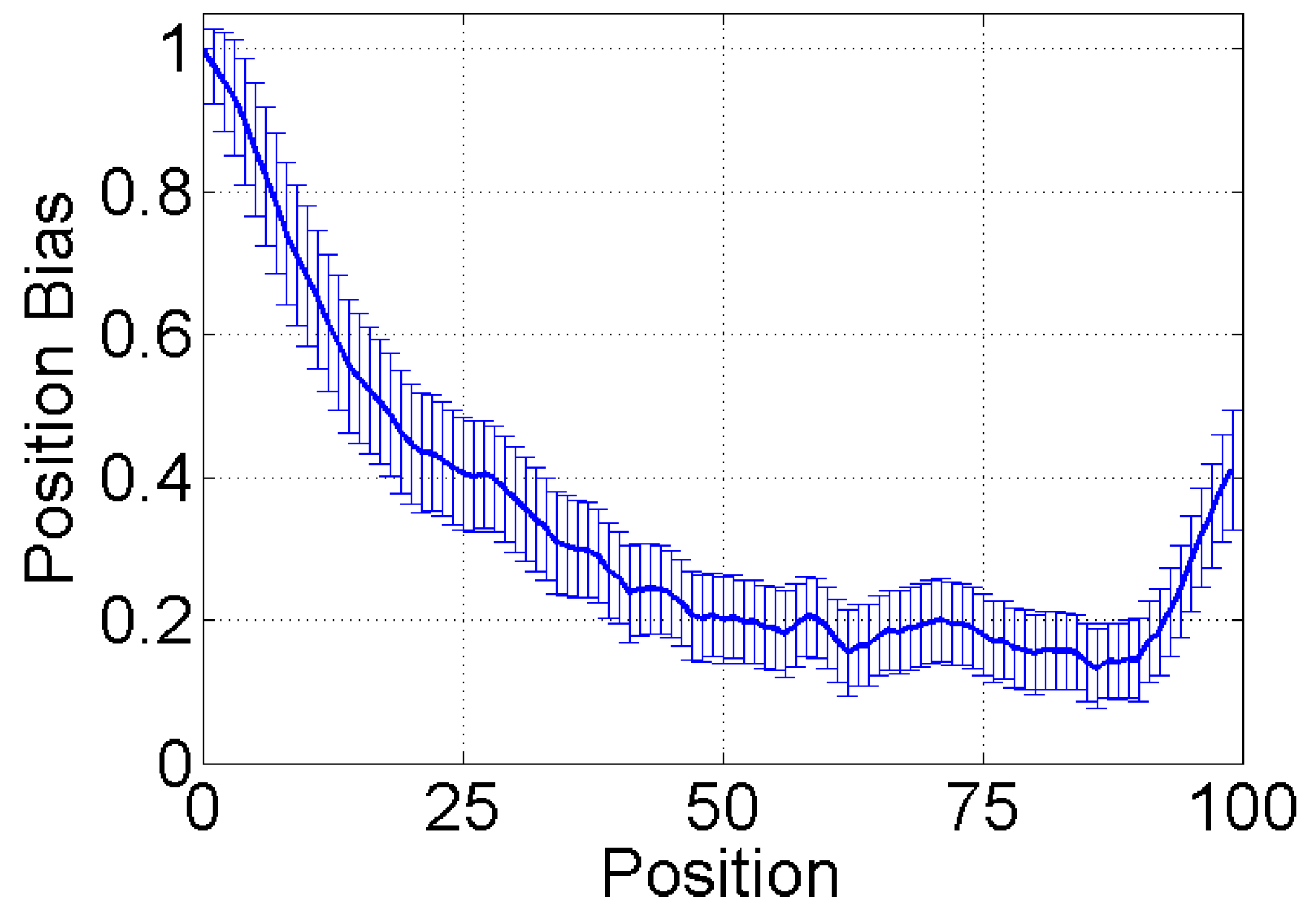
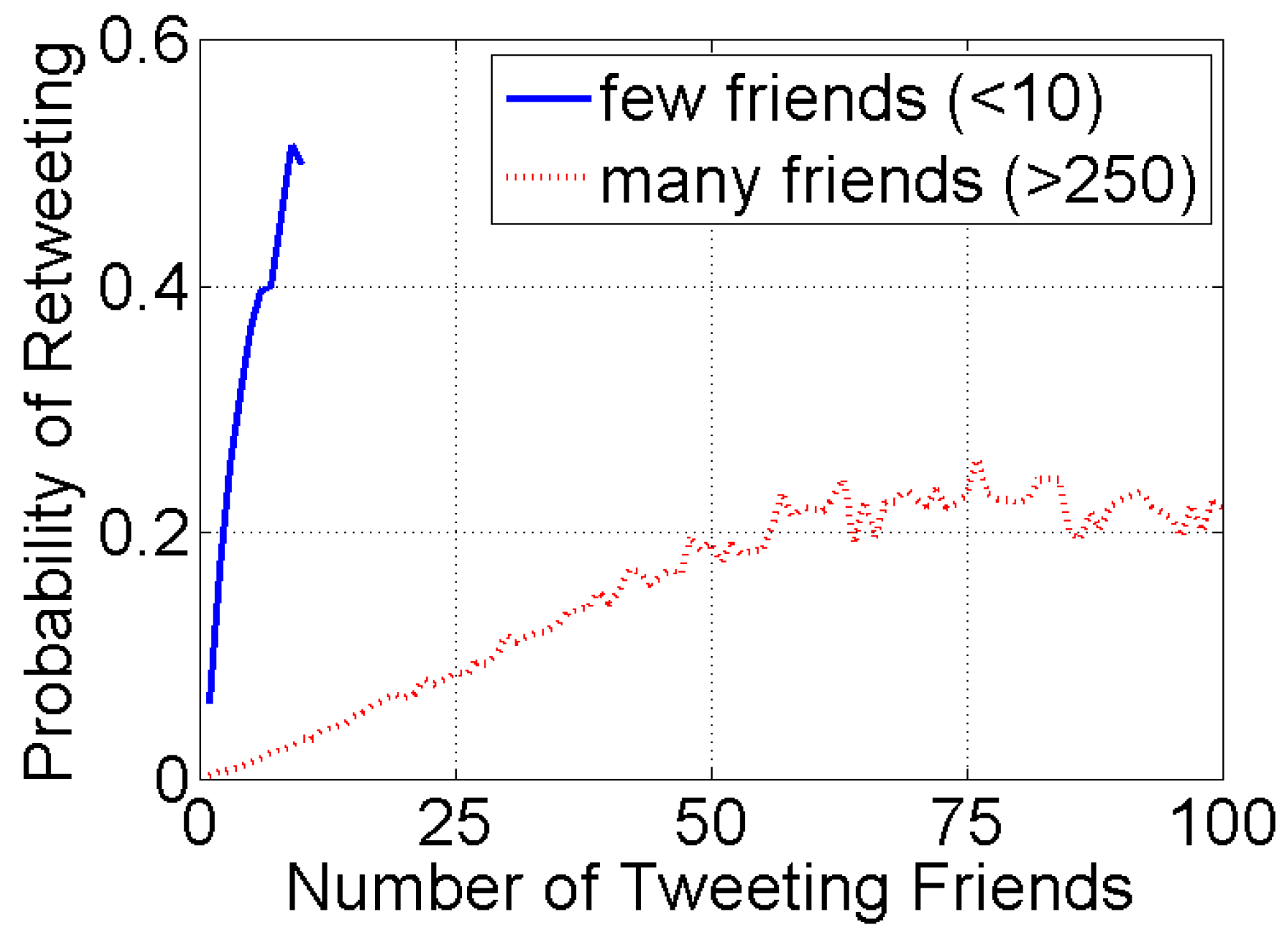
4. Limited Attention and Cognitive Heuristics
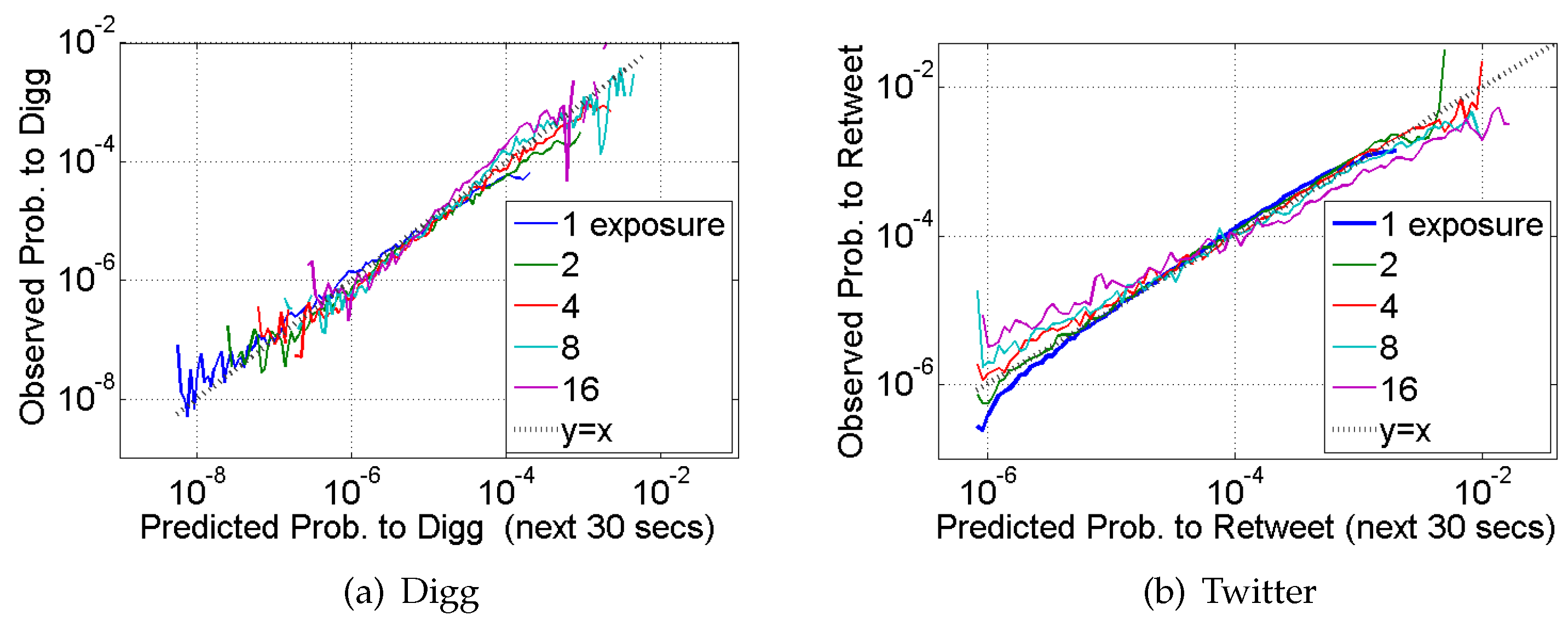
5. Predicting Social Contagions
6. Discussion
Acknowledgments
Conflicts of Interest
References
- Kempe, D.; Kleinberg, J.; Tardos, E. Maximizing the spread of influence through a social network. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’03), Washington, DC, USA, 24–27 August 2003; ACM Press: New York, NY, USA, 2003; pp. 137–146. [Google Scholar]
- Leskovec, J.; Adamic, L.A.; Huberman, B.A. The dynamics of viral marketing. In Proceedings of the 7th ACM Conference on Electronic Commerce, EC ’06, Ann Arbor, MI, USA, 11–15 June 2006; ACM: New York, NY, USA, 2006; pp. 228–237. [Google Scholar]
- Leskovec, J.; Krause, A.; Guestrin, C.; Faloutsos, C.; VanBriesen, J.; Glance, N. Cost-effective Outbreak Detection in Networks. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’07, San Diego, CA, USA, 21–24 August 2011; ACM: New York, NY, USA, 2007; pp. 420–429. [Google Scholar]
- Gruhl, D.; Guha, R.; Nowell, D.L.; Tomkins, A. Information diffusion through blogspace. In Proceedings of the 13th International Conference on World Wide Web, WWW ’04, New York, NY, USA, 17–22 May 2004; ACM: New York, NY, USA, 2004; pp. 491–501. [Google Scholar]
- Castellano, C.; Fortunato, S.; Loreto, V. Statistical physics of social dynamics. Rev. Mod. Phys. 2009, 81, 591–646. [Google Scholar] [CrossRef]
- Newman, M.E.J. Spread of epidemic disease on networks. Phys. Rev. E 2002, 66. [Google Scholar] [CrossRef] [PubMed]
- Anagnostopoulos, A.; Kumar, R.; Mahdian, M. Influence and correlation in social networks. In Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’08, Las Vegas, NV, USA, 24–27 August 2008; ACM: New York, NY, USA, 2008; pp. 7–15. [Google Scholar]
- Gomez Rodriguez, M.; Leskovec, J.; Krause, A. Inferring Networks of Diffusion and Influence. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’10, Washington, DC, USA, 25–28 July 2010; ACM: New York, NY, USA, 2010; pp. 1019–1028. [Google Scholar]
- Rodriguez, M.G.; Leskovec, J.; Balduzzi, D.; Schölkopf, B. Uncovering the structure and temporal dynamics of information propagation. Netw. Sci. 2014, 2, 26–65. [Google Scholar] [CrossRef]
- Myers, S.; Zhu, C.; Leskovec, J. Information Diffusion and External Influence in Networks. In Proceedings of the KDD, Beijing, China, 12–16 August 2012.
- Hethcote, H.W. The Mathematics of Infectious Diseases. SIAM Rev. 2000, 42, 599–653. [Google Scholar] [CrossRef]
- Goldenberg, J.; Libai, B.; Muller, E. Talk of the Network: A Complex Systems Look at the Underlying Process of Word-of-Mouth. Mark. Lett. 2001, 12, 211–223. [Google Scholar] [CrossRef]
- Gruhl, D.; Liben-Nowell, D.; Guha, R.; Tomkins, A. Information diffusion through blogspace. SIGKDD Explor. Newsl. 2004, 6, 43–52. [Google Scholar] [CrossRef]
- Steeg, G.V.; Ghosh, R.; Lerman, K. What stops social epidemics? In Proceedings of the 5th International Conference on Weblogs and Social Media, Catalonia, Spain, 17–21 July 2011.
- Moreno, Y.; Pastor-Satorras, R.; Vespignani, A. Epidemic outbreaks in complex heterogeneous networks. Eur. Phys. J. B 2002, 26, 521–529. [Google Scholar] [CrossRef]
- Wang, Y.; Chakrabarti, D.; Wang, C.; Faloutsos, C. Epidemic Spreading in Real Networks: An Eigenvalue Viewpoint. In Proceedings of the 22nd International Symposium on Reliable Distributed Systems, Florence, Italy, 6–18 October 2003; pp. 25–34.
- Chakrabarti, D.; Wang, Y.; Wang, C.; Leskovec, J.; Faloutsos, C. Epidemic Thresholds in Real Networks. ACM Trans. Inf. Syst. Secur. 2008, 10, 13. [Google Scholar] [CrossRef]
- Ghosh, R.; Lerman, K. A Parameterized Centrality Metric for Network Analysis. Phys. Rev. 2011, E 83. [Google Scholar] [CrossRef]
- Goel, S.; Watts, D.J.; Goldstein, D.G. The Structure of Online Diffusion Networks. In Proceedings of the 13th ACM Conference on Electronic Commerce, Valencia, Spain, 4–8 June 2012.
- Bakshy, E.; Hofman, J.M.; Mason, W.A.; Watts, D.J. Everyone’s an influencer: Quantifying influence on twitter. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011.
- Lerman, K.; Ghosh, R. Information Contagion: An Empirical Study of Spread of News on Digg and Twitter Social Networks. In Proceedings of the 4th International Conference on Weblogs and Social Media (ICWSM), Washington, DC, USA, 23–26 May 2010.
- Hogg, T.; Lerman, K. Social Dynamics of Digg. EPJ Data Sci. 2012, 1. [Google Scholar] [CrossRef]
- Lerman, K.; Yan, X.; Wu, X.Z. The “Majority Illusion” in Social Networks. PLoS ONE 2016, 11, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Hodas, N.O.; Lerman, K. How Limited Visibility and Divided Attention Constrain Social Contagion. In Proceedings of the ASE/IEEE International Conference on Social Computing, Amsterdam, The Netherlands, 11 May 2012.
- Romero, D.M.; Meeder, B.; Kleinberg, J. Differences in the Mechanics of Information Diffusion Across Topics: Idioms, Political Hashtags, and Complex Contagion on Twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011.
- Granovetter, M. Threshold Models of Collective Behavior. Am. J. Sociol. 1978, 83, 1420–1443. [Google Scholar] [CrossRef]
- Watts, D.J. A simple model of global cascades on random networks. Proc. Natl. Acad. Sci. USA 2002, 99, 5766–5771. [Google Scholar] [CrossRef] [PubMed]
- Centola, D.; Macy, M. Complex contagions and the weakness of long ties1. Am. J. Sociol. 2007, 113, 702–734. [Google Scholar] [CrossRef]
- Centola, D. The spread of behavior in an online social network experiment. Science 2010, 329, 1194–1197. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, M.G.; Gummadi, K.; Schoelkopf, B. Quantifying Information Overload in Social Media and its Impact on Social Contagions. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014.
- Kahneman, D. Attention and Effort; Prentice Hall: Englewood Cliffs, NJ, USA, 1973. [Google Scholar]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus and Giroux: New York, NY, USA, 2011. [Google Scholar]
- Payne, S.L. The Art of Asking Questions; Princeton University Press: Princeton, NJ, USA, 1951. [Google Scholar]
- Salganik, M.J.; Dodds, P.S.; Watts, D.J. Experimental Study of Inequality and Unpredictability in an Artificial Cultural Market. Science 2006, 311, 854–856. [Google Scholar] [CrossRef] [PubMed]
- Hogg, T.; Lerman, K. Disentangling the Effects of Social Signals. Hum. Comput. J. 2015, 2, 189–208. [Google Scholar] [CrossRef]
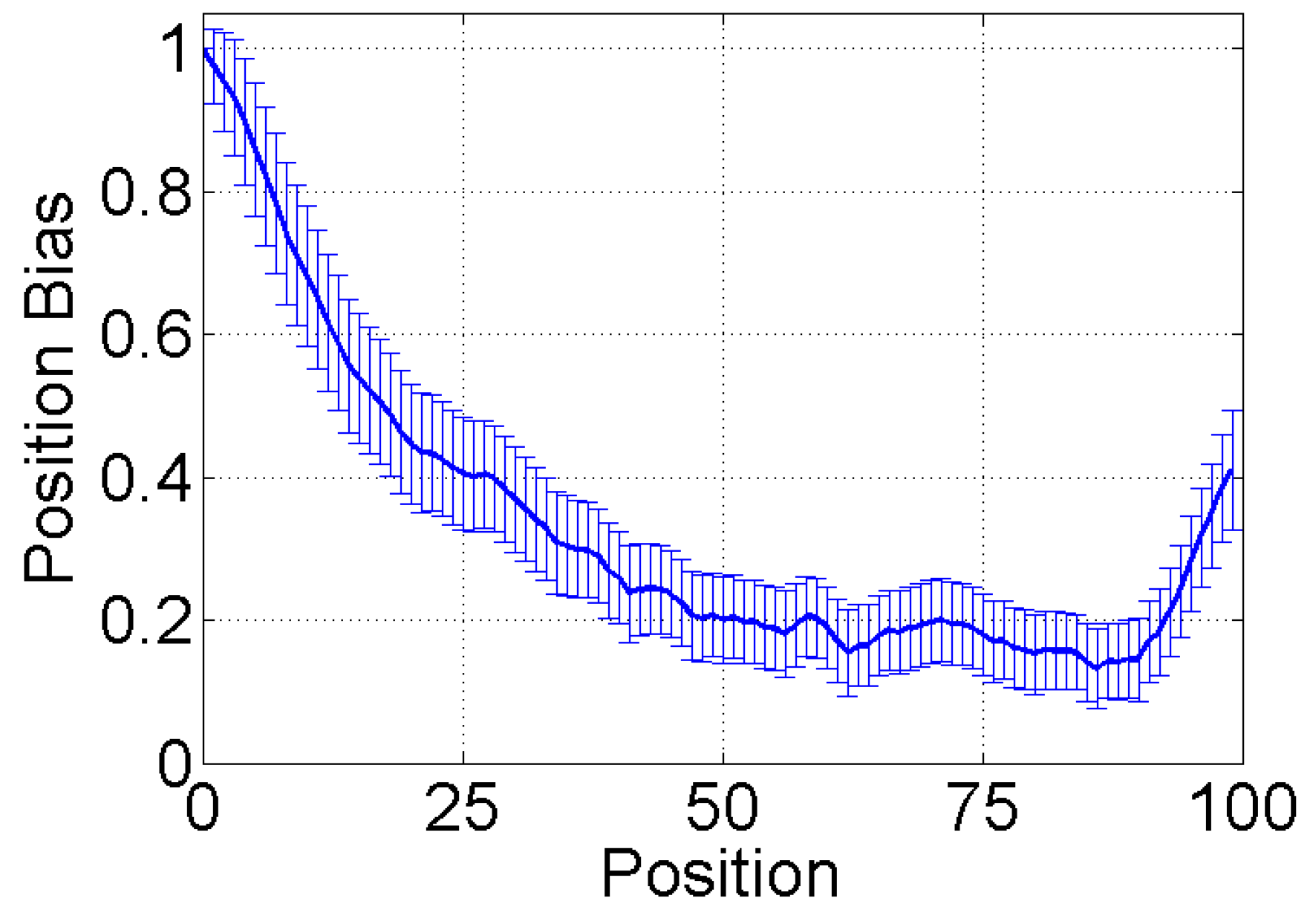
- Lerman, K.; Hogg, T. Leveraging position bias to improve peer recommendation. PLoS ONE 2014, 9. [Google Scholar] [CrossRef] [PubMed]
- Vaupel, J.W.; Yashin, A.I. Heterogeneity’s ruses: Some surprising effects of selection on population dynamics. Am. Stat. 1985, 39, 176–185. [Google Scholar] [PubMed]
- Kooti, F.; Lerman, K.; Aiello, L.M.; Grbovic, M.; Djuric, N.; Radosavljevic, V. Portrait of an Online Shopper: Understanding and Predicting Consumer Behavior. In Proceedings of the 9th ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016.
- Hodas, N.O.; Lerman, K. The Simple Rules of Social Contagion. Sci. Rep. 2014, 4. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Lerman, K. User Effort and Network Structure Mediate Access to Information in Networks. In Proceedings of the 9th International AAAI Conference on Weblogs and Social Media (ICWSM), Oxford, UK, 26–29 May 2015.
- Hogg, T.; Lerman, K.; Smith, L.M. Stochastic Models Predict User Behavior in Social Media. ASE Hum. 2013, 2. Available online: http://arxiv.org/abs/1308.2705 (accessed on 8 May 2016). [Google Scholar]
- Weng, L.; Flammini, A.; Vespignani, A.; Menczer, F. Competition among memes in a world with limited attention. Sci. Rep. 2012, 2. [Google Scholar] [CrossRef] [PubMed]
- Feld, S.L. Why Your Friends Have More Friends than You Do. Am. J. Sociol. 1991, 96, 1464–1477. [Google Scholar] [CrossRef]
- Hodas, N.O.; Kooti, F.; Lerman, K. Friendship Paradox Redux: Your Friends Are More Interesting Than You. In Proceedings of the 7th International AAAI Conference On Weblogs And Social Media (ICWSM), Cambridge, MA, USA, 8–11 July 2013.
- Kooti, F.; Hodas, N.O.; Lerman, K. Network Weirdness: Exploring the Origins of Network Paradoxes. In Proceedings of the International Conference on Weblogs and Social Media (ICWSM), Ann Arbor, MI, USA, 1–4 June 2014.
- Aral, S.; Van Alstyne, M.W. The Diversity-Bandwidth Tradeoff. Am. J. Sociol. 2011, 117, 90–171. [Google Scholar] [CrossRef]
- Granovetter, M.S. The Strength of Weak Ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef]
- Burt, R. Structural Holes: The Social Structure of Competition; Harvard University Press: Cambridge, MA, USA, 1995. [Google Scholar]


© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lerman, K. Information Is Not a Virus, and Other Consequences of Human Cognitive Limits. Future Internet 2016, 8, 21. https://doi.org/10.3390/fi8020021
Lerman K. Information Is Not a Virus, and Other Consequences of Human Cognitive Limits. Future Internet. 2016; 8(2):21. https://doi.org/10.3390/fi8020021
Chicago/Turabian StyleLerman, Kristina. 2016. "Information Is Not a Virus, and Other Consequences of Human Cognitive Limits" Future Internet 8, no. 2: 21. https://doi.org/10.3390/fi8020021
APA StyleLerman, K. (2016). Information Is Not a Virus, and Other Consequences of Human Cognitive Limits. Future Internet, 8(2), 21. https://doi.org/10.3390/fi8020021