
Privacy-Preserving Federated Unlearning with Ontology-Guided Relevance Modeling for Secure Distributed Systems


Abstract
1. Introduction
- Efficiency—storing historical gradients or performing calibration rounds imposes high storage/server costs [8].
- Contextual blindness—uniform treatment of data points during unlearning risks unnecessary accuracy loss by disregarding semantic relevance [9].
- Verifiability—clients cannot independently confirm complete data erasure [10].
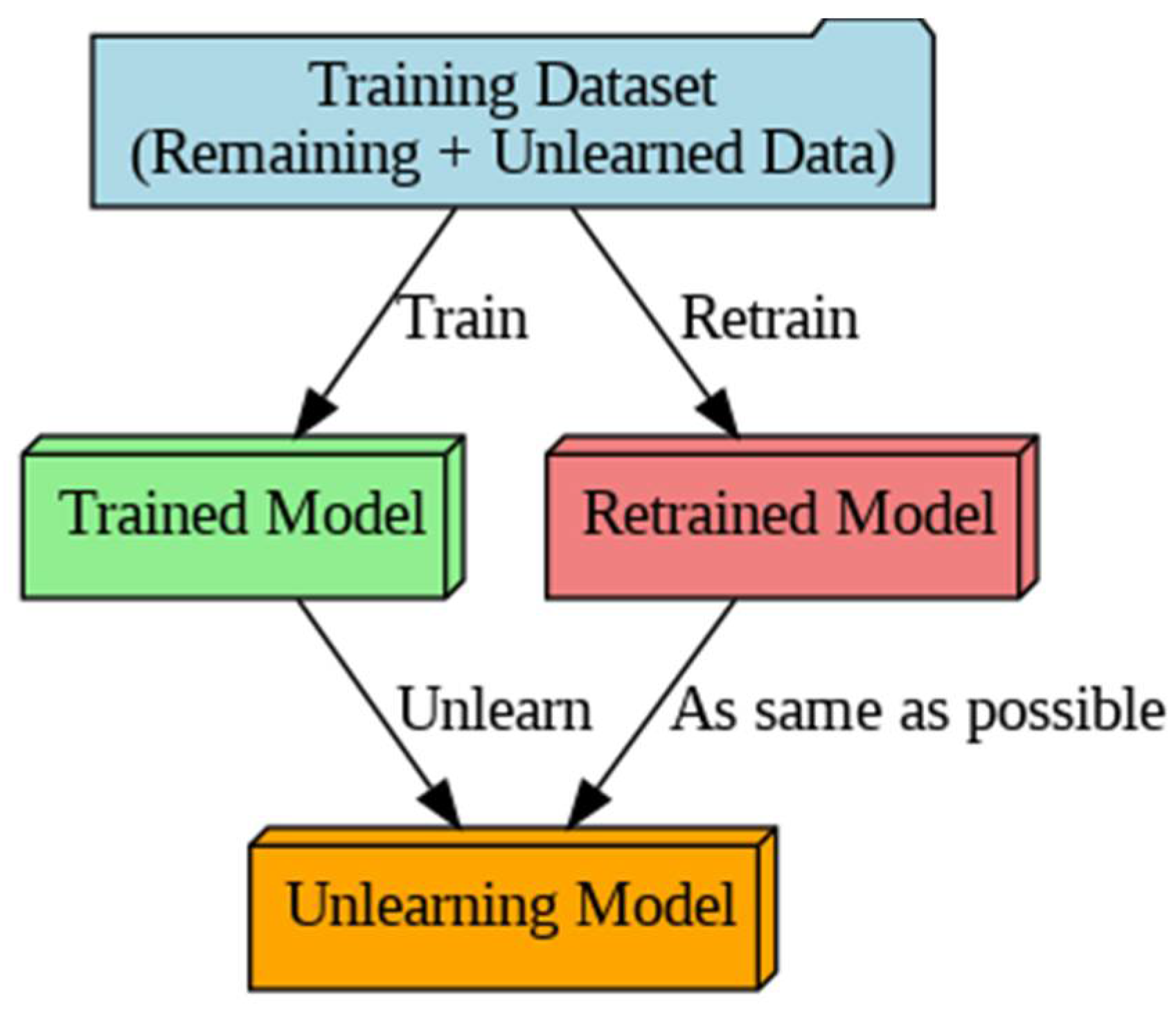
- EG-FedUnlearn—A gradient-based approach that analytically reverses target clients’ contributions from aggregated model parameters. By applying negative gradient updates derived from local data samples, it achieves “exact unlearning” (equivalent to retraining) under standard FL assumptions, eliminating retraining costs and minimizing communication.
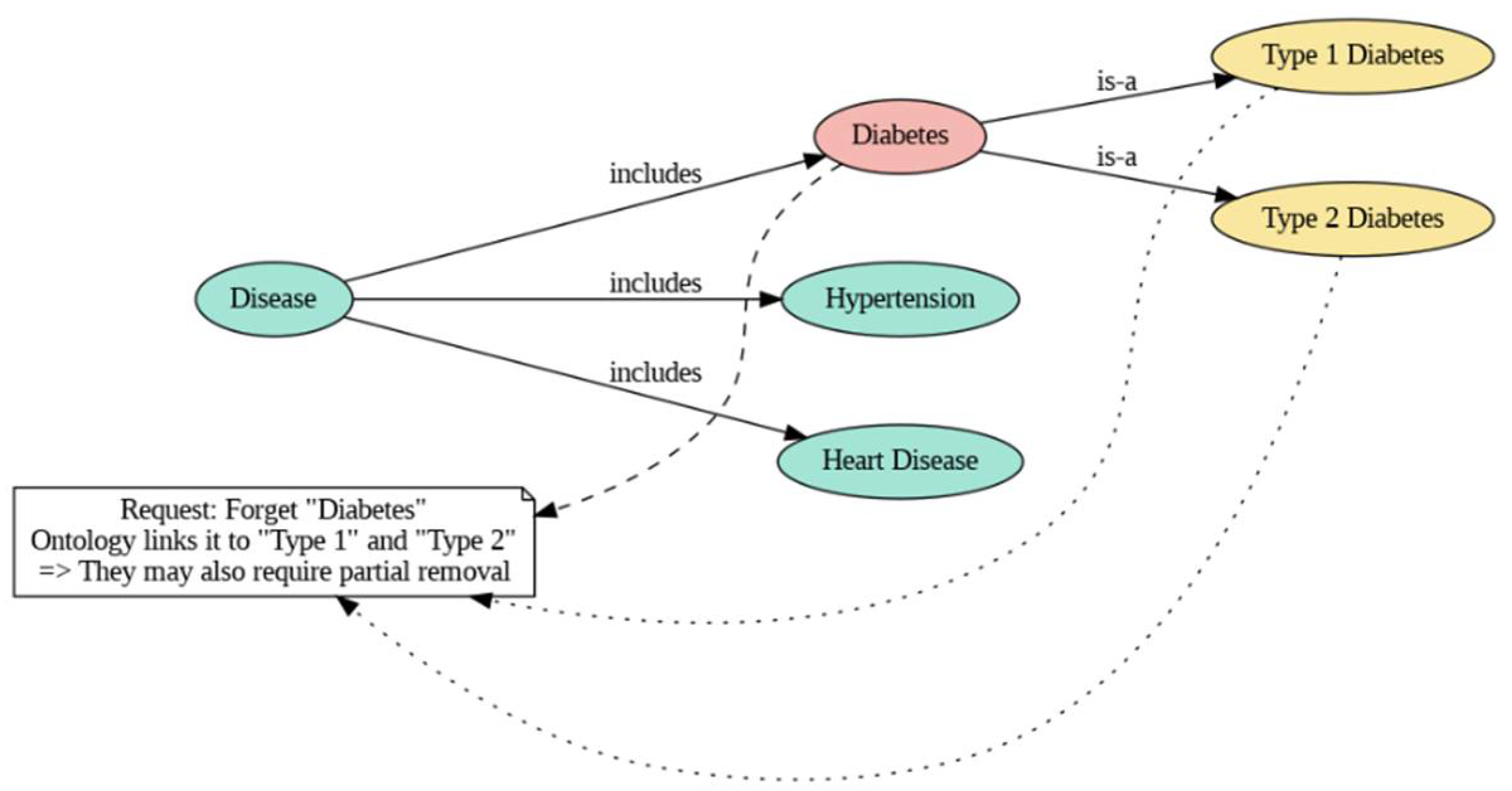
- OFU-Ontology—The first method to integrate domain ontologies into federated unlearning. It assigns semantic relevance scores to data points using structured knowledge representations (e.g., symptom–diagnosis relationships in healthcare). Low-relevance data is prioritized for unlearning via weighted gradient negation, preserving high-impact knowledge and reducing accuracy degradation.
- Proposing EG-FedUnlearn, a fast and storage-efficient unlearning method that removes a target client’s influence from the federated model without requiring full model retraining. We also propose OFU-Ontology, the first ontology-enhanced federated unlearning approach, which utilizes domain ontologies to guide the unlearning process and protect the remaining useful model knowledge.
- Providing an analysis of the proposed methods to demonstrate that the target client’s data contributions are eliminated from the model. We prove that EG-FedUnlearn achieves the same effect as excluding the client’s data from training (equivalent to retraining) under certain assumptions, thus guaranteeing exact unlearning. We also discuss how the ontology in OFU-Ontology helps avoid unintended forgetting of unrelated knowledge. We also analyze security and privacy implications to show that our approaches do not introduce any new privacy leaks and that these techniques can be used in conjunction with verifiability techniques to assure clients of successful unlearning.
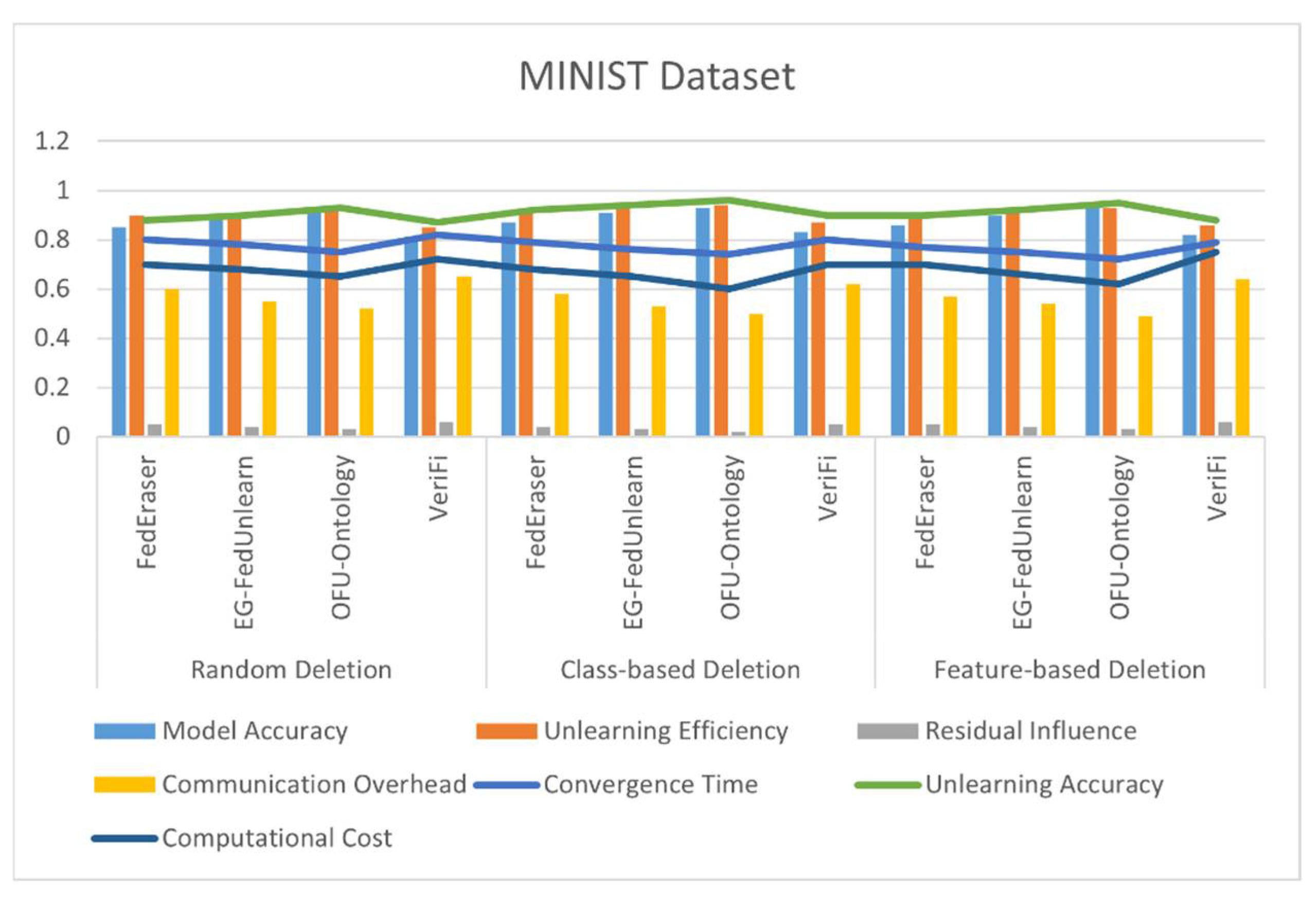
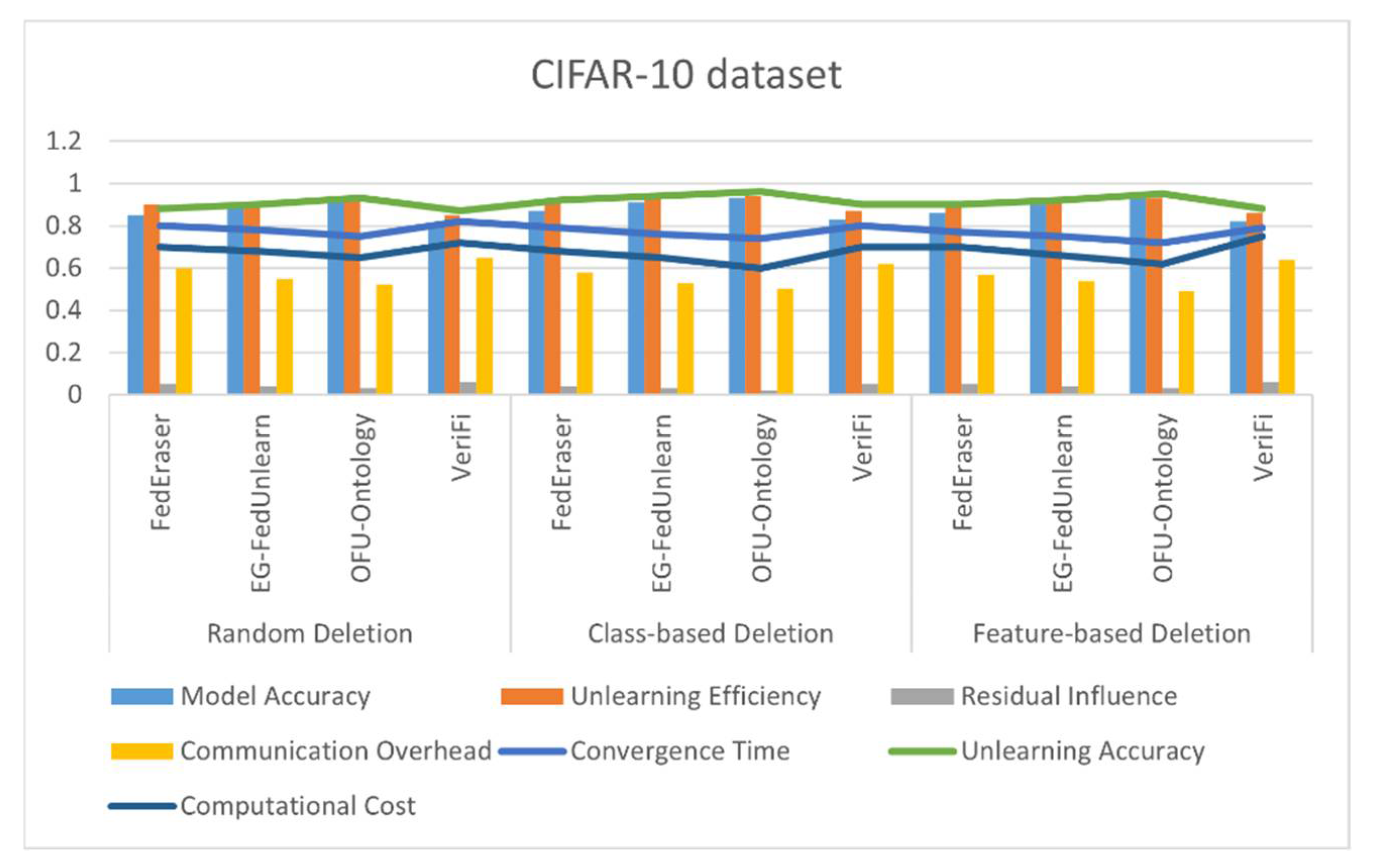
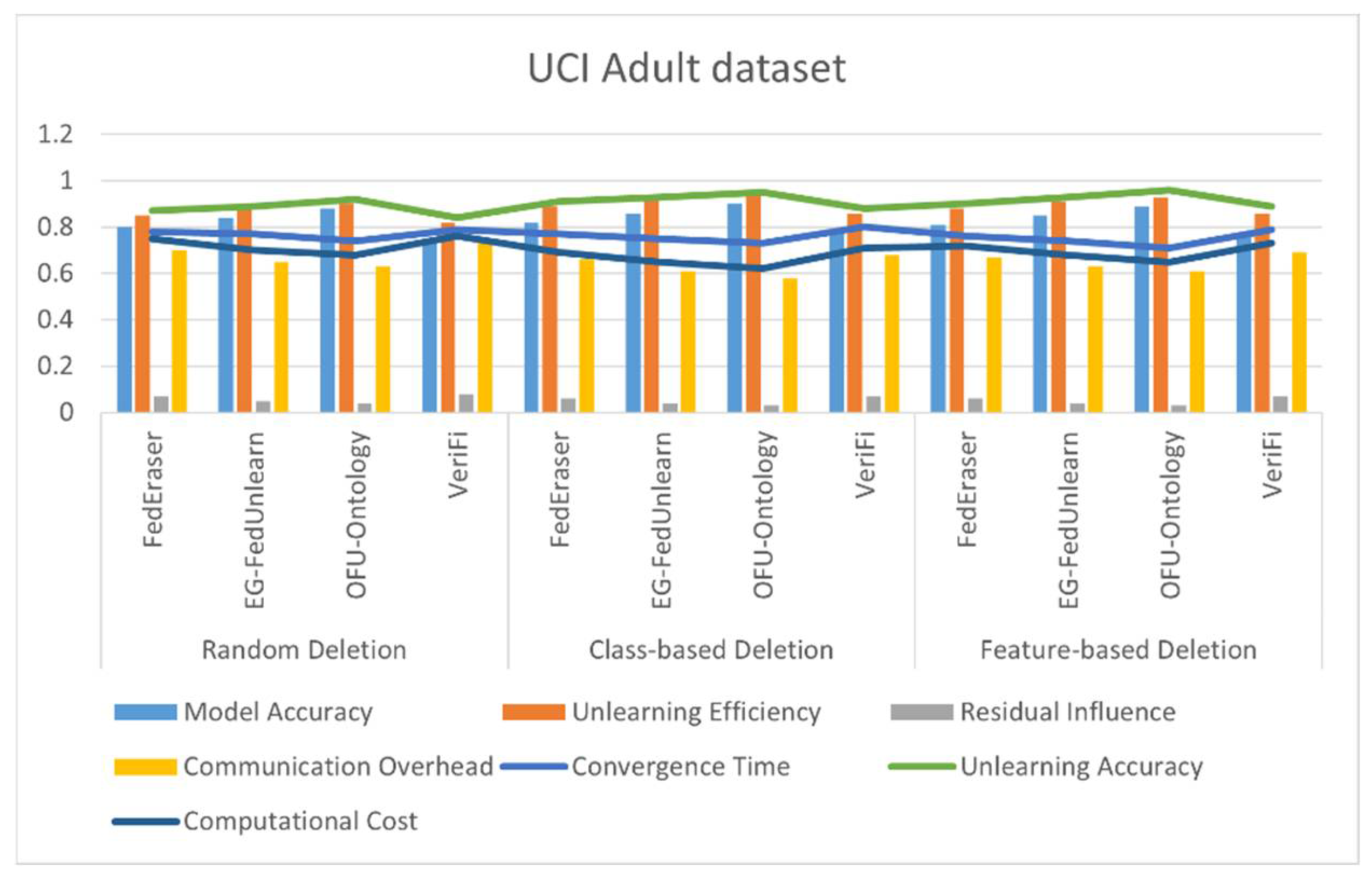
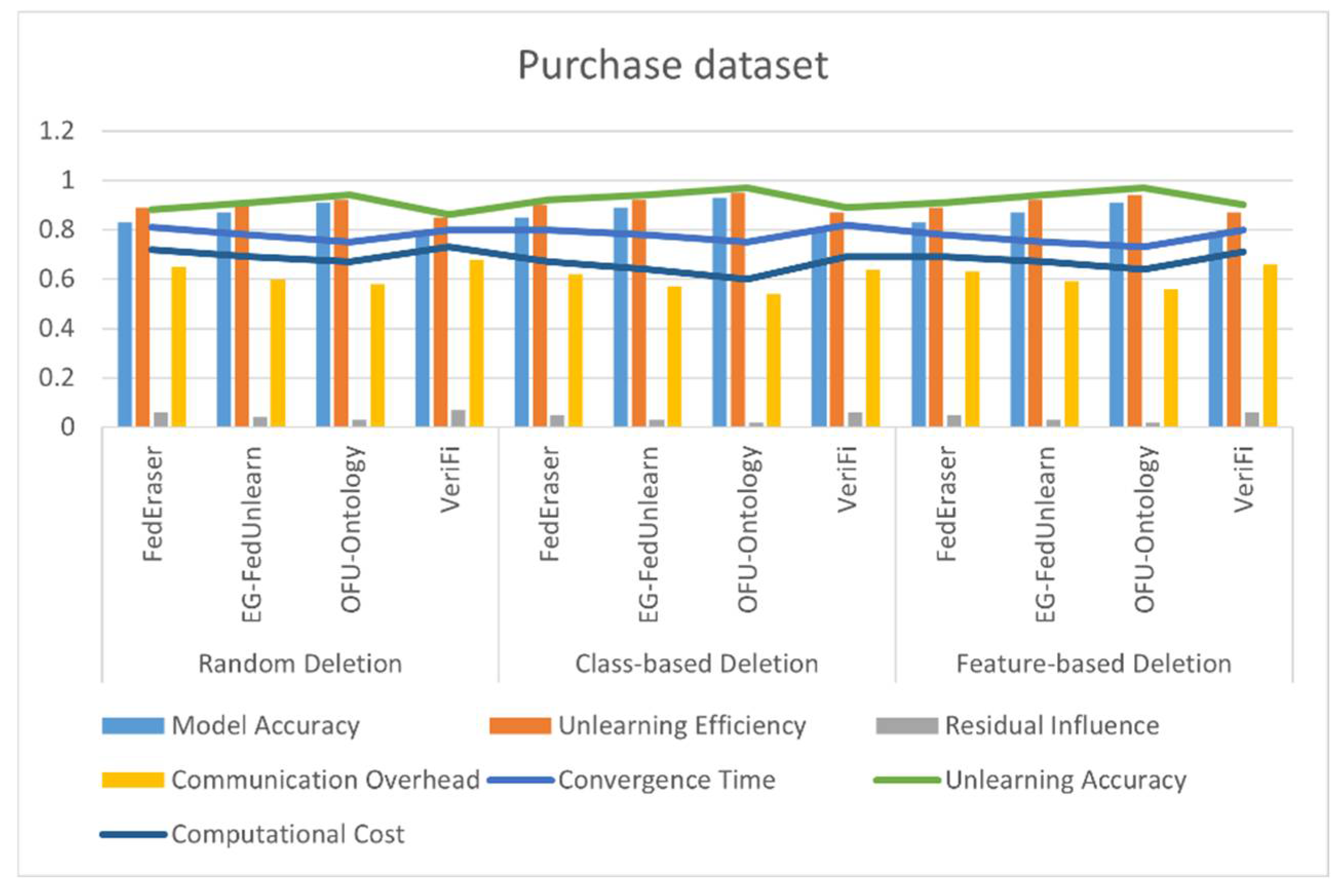
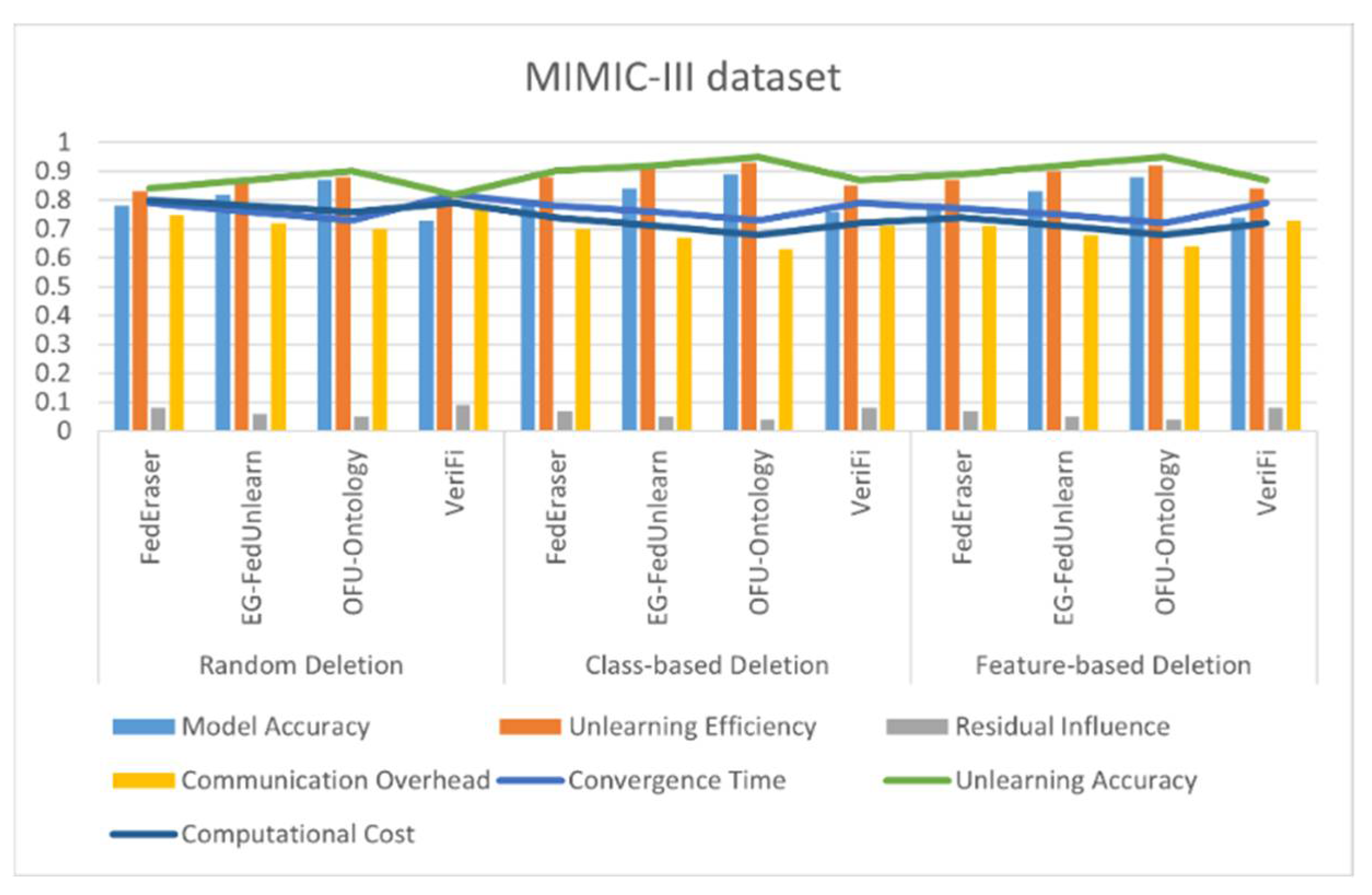
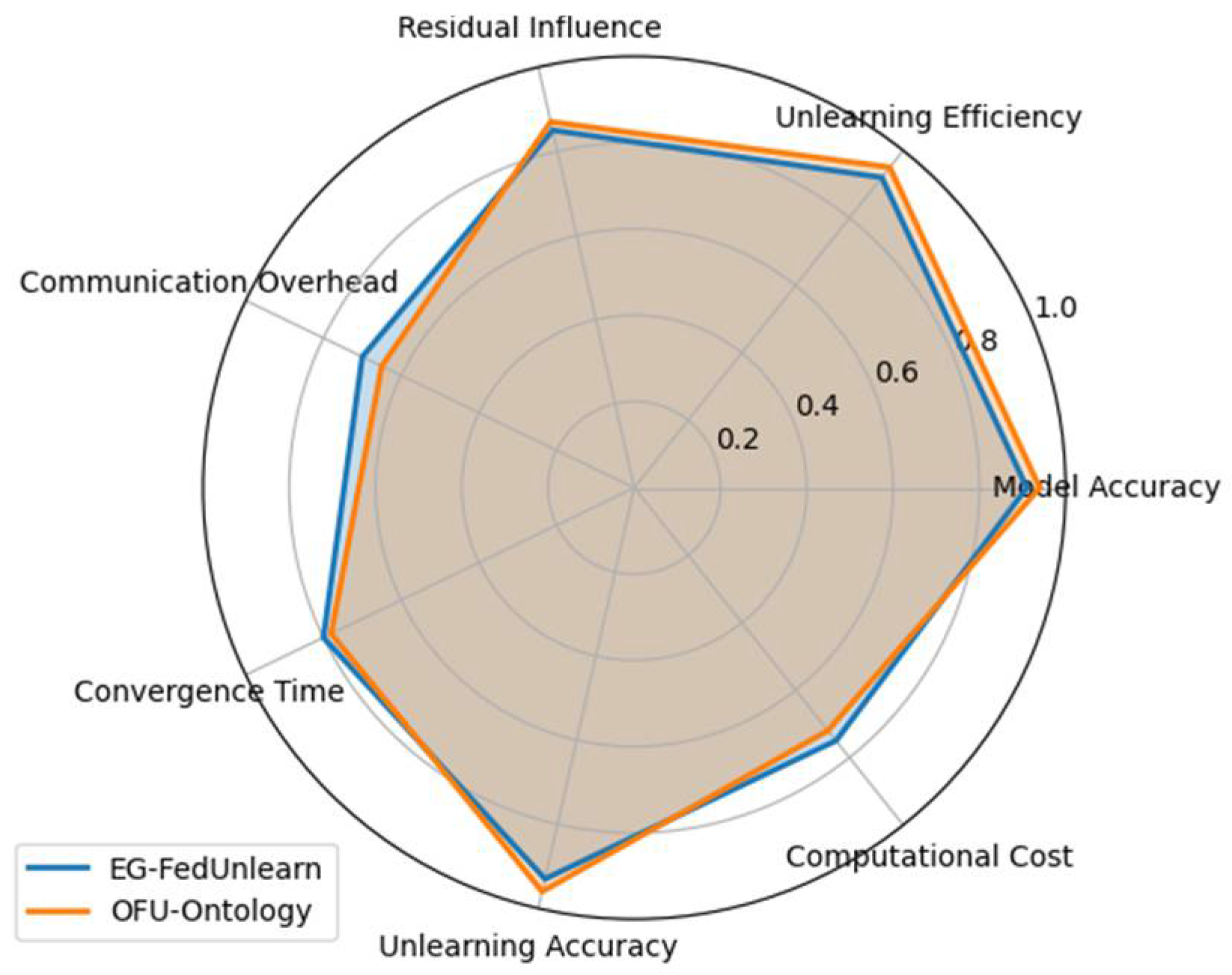
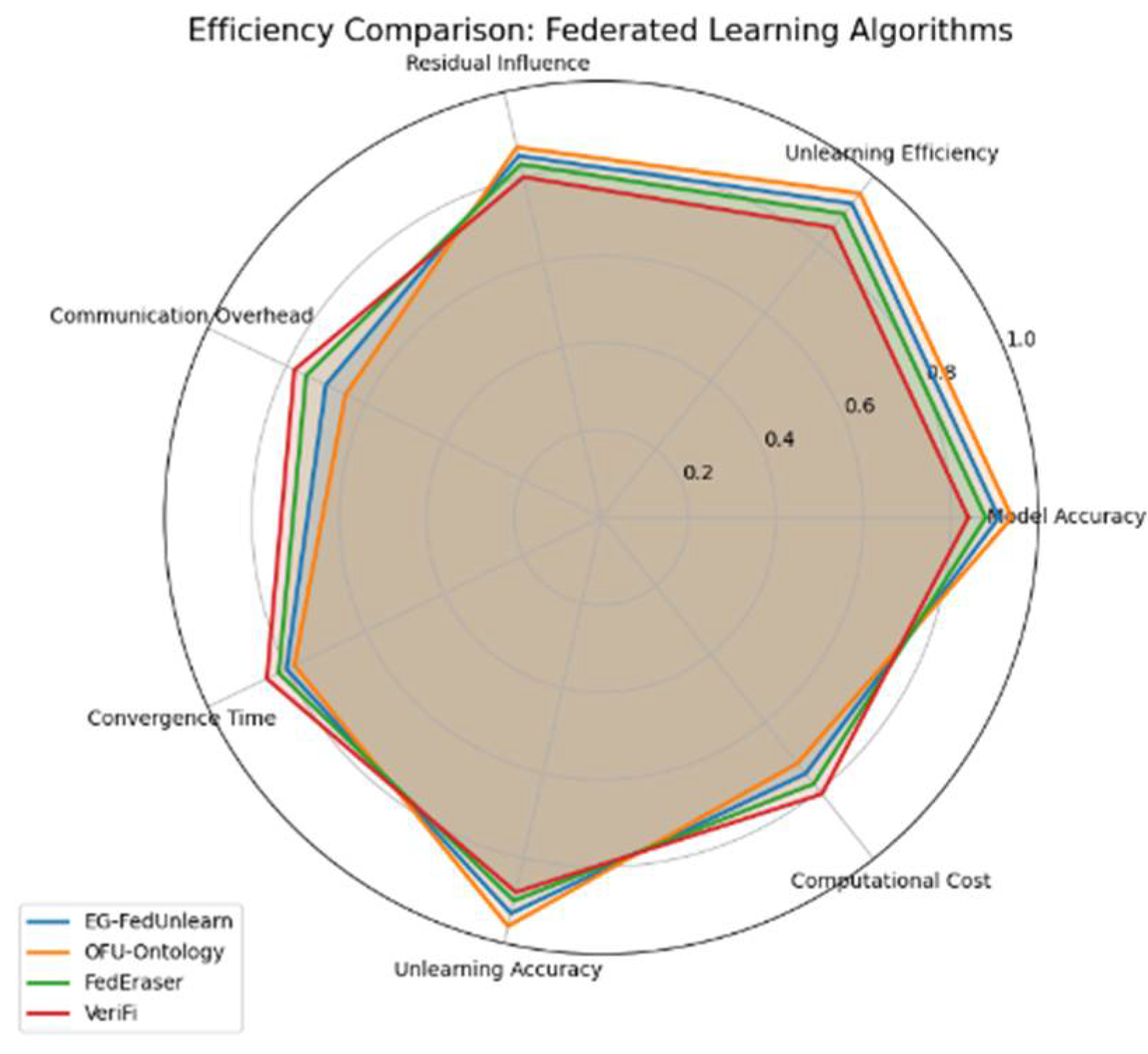
- Performing experiments on benchmark FL datasets to assess methods such as EG-FedUnlearn and OFU-Ontology. The results indicate that our techniques substantially enhance the performance of unlearning, standing far apart from FedEraser and VeriFi. In terms of model unlearning, our approach takes less time (approximately one-tenth the computation and communication overhead of the baselines) and better retains the model (higher remaining accuracy on test data after unlearning). We demonstrate that OFU-Ontology maintains model utility especially well—the global model suffers a much smaller accuracy drop on non-forgotten data, thanks to ontology-guided knowledge preservation. These improvements illustrate the practical benefit of our contributions to enable efficient, reliable, and accurate federated unlearning in real-world scenarios.
2. Literature Review
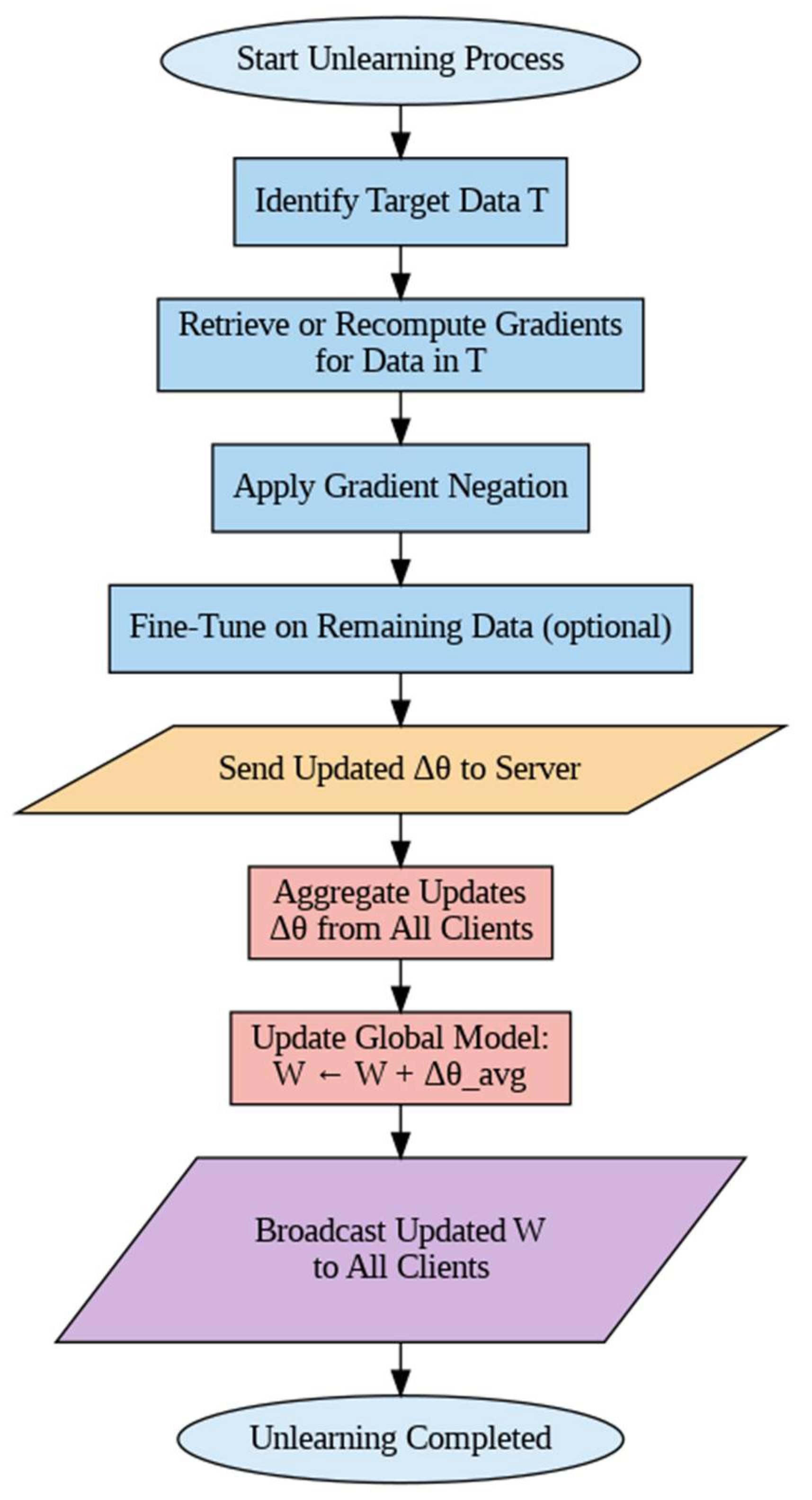
3. Methodology
3.1. Efficient Gradient-Based Federated Unlearning (EG-FedUnlearn)
| Algorithm 1: Pseudocode for EG-FedUnlearn |
| Input: Local datasets {} for each client , Target data point to be unlearned, Number of communication rounds Output: Updated global model without influence from T 1. Initialize global model 2. For each communication round do: 3. Each client receives the global model from the server 4. Each client checks if a. If is in : i. Recalculate local updates by removing from ii. Train the local model using \ b. Else: i. Train the local model using 5. Send local model updates to the server 6. Server aggregates local updates to compute the new global model: = Aggregate ( for all ) 7. Return the updated global model |
3.2. Ontology-Integrated Federated Unlearning (OFU-Ontology) Algorithm
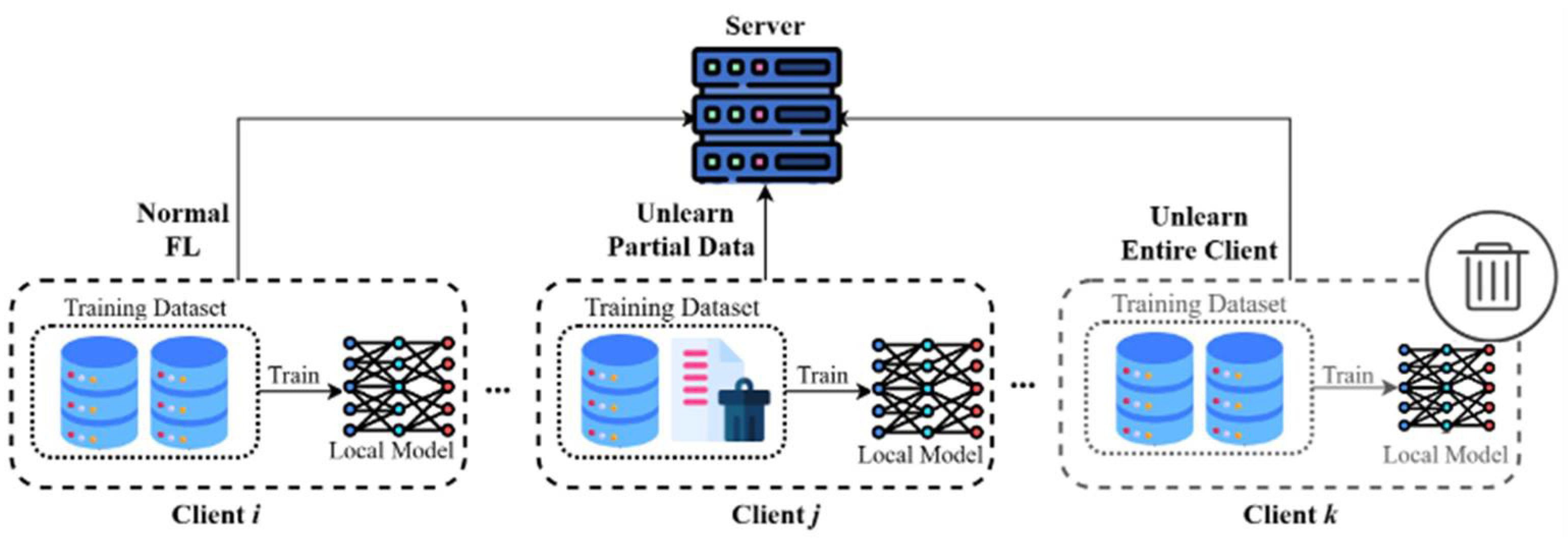
3.2.1. System Architecture
- Federated nodes: Each federated node locally stores its dataset and maintains a copy of the model. Federated nodes train the model locally on data unique to them and communicate updates of their models to the central server. At each node, there is also storage of gradient information for each data point during training, later to be used for unlearning.
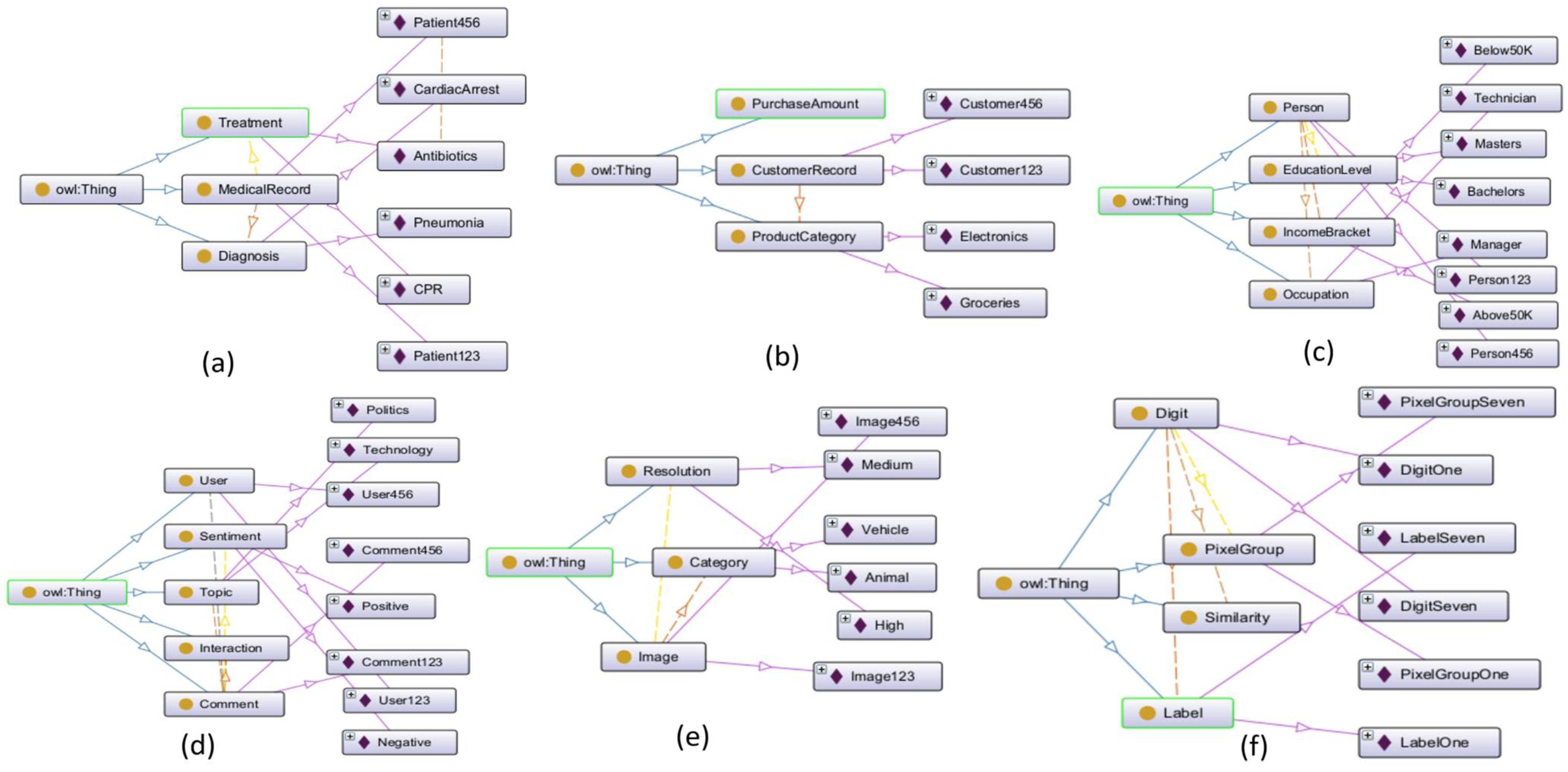
- Ontology module: The ontology module describes inter-entity relationships and relevance hierarchies among different types of data entities. This module assigns relevance scores to data points on the basis of domain knowledge, with higher scores implying higher importance and lower scores suggesting that a data point can be prioritized for unlearning with the least possible effect on the model quality. The ontology module can either be embedded locally at each node, or it can be housed centrally and accessed on unlearning requests. The ontology model is used for representing relationships and hierarchies within the data and hence forms a basis for assigning relevance scores to data points. The ontology is built using the following:
- Entities represent key features or data elements in the domain. For instance, in healthcare, entities might include “symptom”, “diagnosis”, “treatment”, etc.
- Attributes are properties of entities that provide additional detail. For example, the “symptom” entity may have attributes such as severity, duration, and frequency.
- Relationships define the connections between entities. For instance, “symptom” might be related to “diagnosis” through a “leads to” relationship.
- Importance hierarchy indicates that the ontology includes a hierarchical structure that defines the importance of different entities and relationships.
- 3.
- Central coordinating server: The central coordinating server aggregates the updates received from the nodes and synchronizes with the global model. It also facilitates the federated unlearning by managing relevance-weighted updates and calibration training to minimize knowledge permeation from unlearned data.
3.2.2. Ontology Construction and Integration
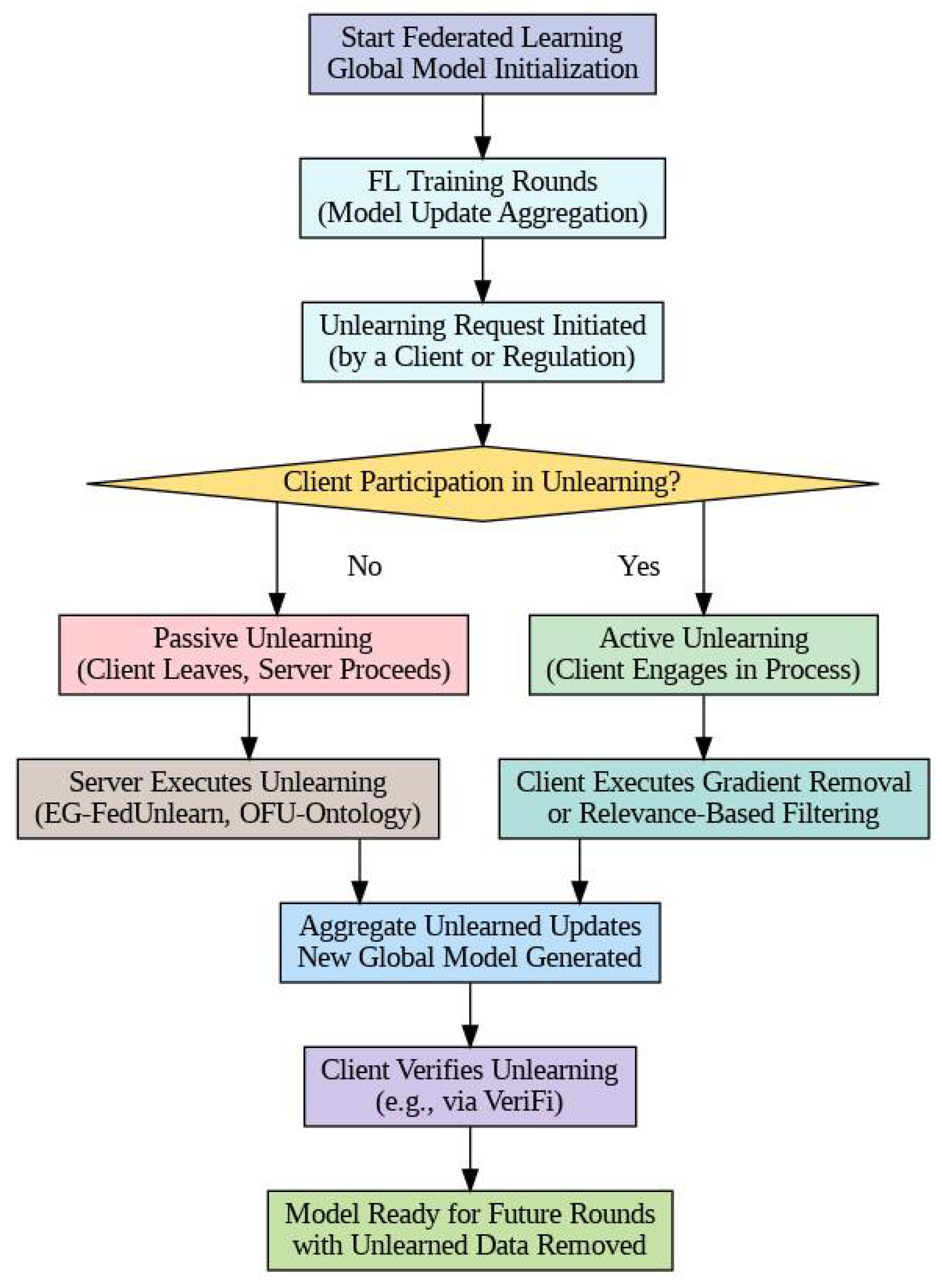
3.2.3. Workflow of OFU-Ontology
- By considering low-relevance data points as applying for unlearning, the computational overhead and communication overhead are decreased.
- The ontology-based approach does not allow important data to be needlessly exposed or removed, thereby retaining federated learning’s privacy-preserving properties.
- Calibration using historical updates mitigates knowledge permeation by ensuring that the unlearned data’s influence is correctly removed from all clients.
- By allowing updates of the ontology module with changes in data relevance, the system could be made to adapt to changing privacy and regulatory requirements.
| Algorithm 2: Pseudocode for OFU-Ontology |
| Input: Local datasets {} for each client , Target data point to be unlearned, Number of communication rounds Output: Updated global model without influence from T 1. Initialize global model 2. For each communication round do: 3. Each client receives the global model from the server 4. Each client checks if a. If is in : i. Recalculate local updates by removing from ii. Train the local model using \ b. Else: i. Train the local model using 5. Send local model updates to the server 6. Server aggregates local updates to compute the new global model: = Aggregate ( for all ) 7. Return the updated global model |
4. Experimental Results
4.1. Datasets
4.2. Evaluation Metrics
- Communication overhead () represents how much data is exchanged between the nodes and the server of the central during the process of unlearning [4].
- Convergence time () is measured as the number of rounds required by the global model to restore its stability following unlearning [27].
- Unlearning accuracy (UA) measures the precision with which the unlearning procedure has erased the influence of a particular datum. It is measured by assessing how the model output differs with and without the particular datum. Unlearning accuracy determines whether the unlearning mechanism has indeed reversed the model influence of the requested data points or otherwise negatively affected the remaining model [28].
- Computational cost (CC) concerns the computational requirement to unlearn; it comprises computation time and memory utilization [12].
4.3. Deletion Strategies
- (a)
- Random deletion strategy—A random portion of the training data is chosen using this method to be eliminated. The idea is to simulate a situation where a random user requests that data be deleted. This simple method evaluates the model’s ability to extract random patterns from the dataset. For example, randomly deleting images from various classes or arbitrary removal of a subset of numbers (e.g., 100 random photos) [5].
- (b)
- Class-based deletion strategy—This method aims to remove all data points that belong to a specific class (or category). This facilitates the evaluation of the model’s ability to retain knowledge of other classes despite forgetting entire datasets. It is useful for removing entire categories from the dataset, such all images of a particular item or all evaluations that express a particular emotion. Examples are removing all images of cars, all images of the number seven, and all reviews that are labelled as “positive” [29].
- (c)
- Feature-based deletion strategy—With such an approach, data points are identified instead of labels or classes. For instance, the data in the UCI Adult dataset may not contain any data points with certain demographic features (such as gender or level of education). This type of method is truly useful with tabular datasets (e.g., deleting data belonging to a certain demographic class) and can be used as a guard to comply with data privacy laws. Examples are to wipe away all those data items with the attribute “education” set to “Bachelors” or a value of “White” for the attribute “race” [29].
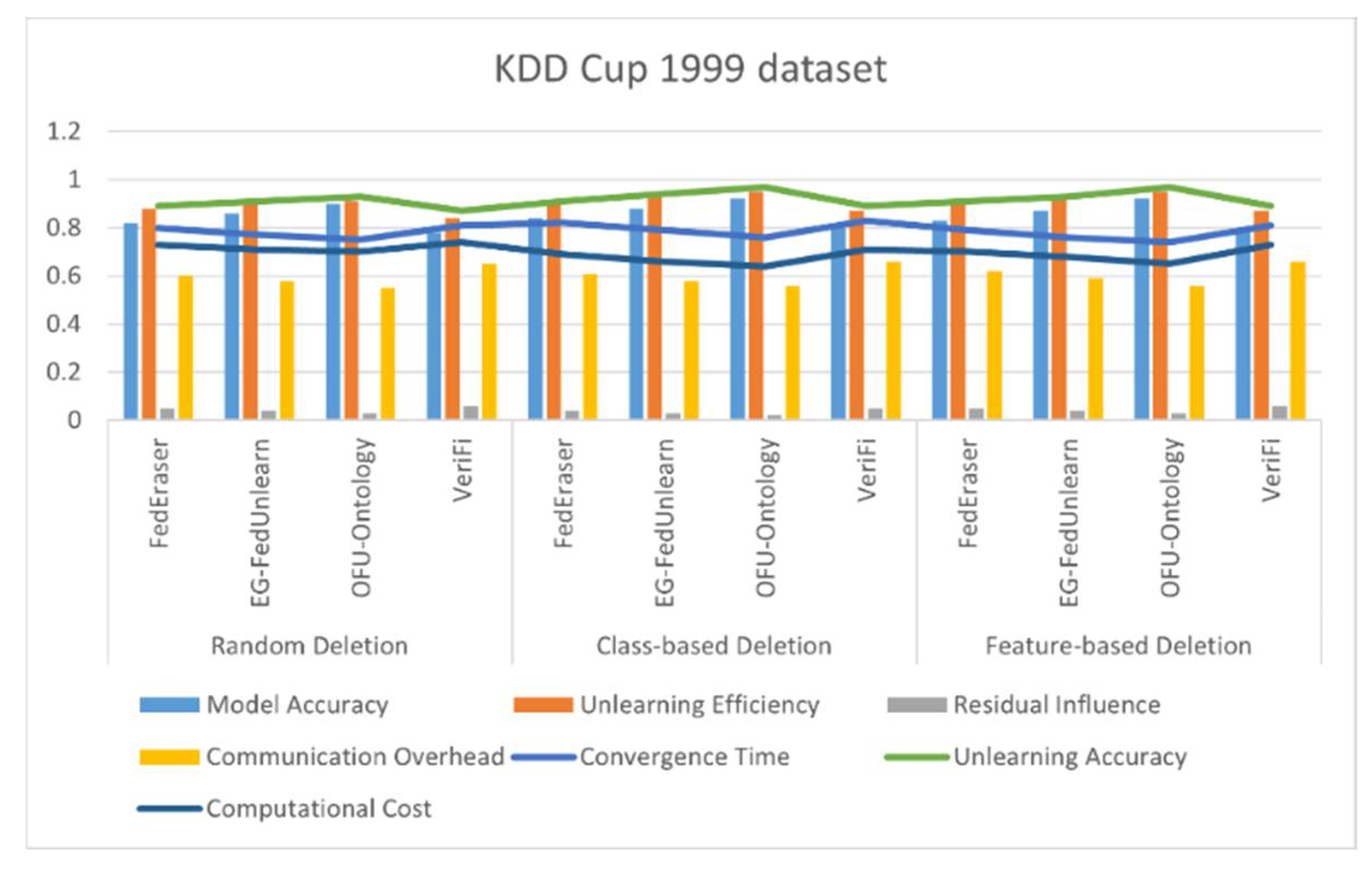
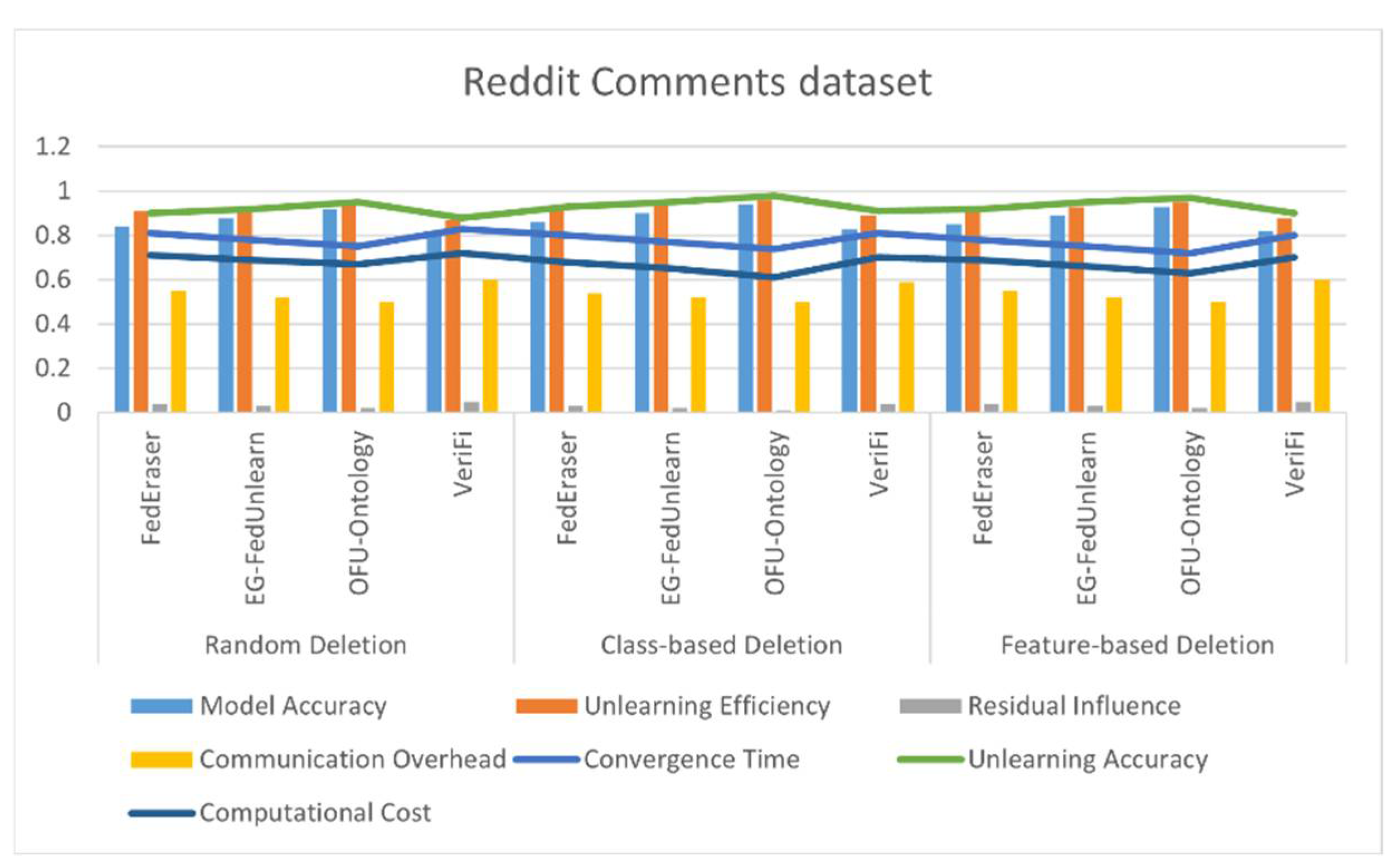
4.4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Deletion Strategy | Algorithm | Model Accuracy | Unlearning Efficiency | Residual Influence | Communication Overhead | Convergence Time | Unlearning Accuracy | Computational Cost |
|---|---|---|---|---|---|---|---|---|
| Random Deletion | FedEraser | 0.88 | 0.92 | 0.03 | 0.5 | 0.82 | 0.9 | 0.65 |
| EG-FedUnlearn | 0.91 | 0.93 | 0.02 | 0.45 | 0.80 | 0.93 | 0.6 | |
| OFU-Ontology | 0.94 | 0.95 | 0.01 | 0.4 | 0.78 | 0.95 | 0.58 | |
| VeriFi | 0.85 | 0.87 | 0.04 | 0.52 | 0.83 | 0.89 | 0.66 | |
| Class-based Deletion | FedEraser | 0.89 | 0.93 | 0.03 | 0.48 | 0.81 | 0.94 | 0.63 |
| EG-FedUnlearn | 0.92 | 0.95 | 0.02 | 0.42 | 0.78 | 0.96 | 0.6 | |
| OFU-Ontology | 0.95 | 0.97 | 0.01 | 0.38 | 0.75 | 0.98 | 0.55 | |
| VeriFi | 0.86 | 0.88 | 0.04 | 0.50 | 0.82 | 0.91 | 0.68 | |
| Feature-based Deletion | FedEraser | 0.87 | 0.91 | 0.04 | 0.47 | 0.80 | 0.92 | 0.64 |
| EG-FedUnlearn | 0.91 | 0.94 | 0.03 | 0.43 | 0.77 | 0.95 | 0.61 | |
| OFU-Ontology | 0.94 | 0.96 | 0.02 | 0.39 | 0.74 | 0.97 | 0.57 | |
| VeriFi | 0.84 | 0.88 | 0.05 | 0.51 | 0.81 | 0.90 | 0.70 |
| Deletion Strategy | Algorithm | Model Accuracy | Unlearning Efficiency | Residual Influence | Communication Overhead | Convergence Time | Unlearning Accuracy | Computational Cost |
|---|---|---|---|---|---|---|---|---|
| Random Deletion | FedEraser | 0.85 | 0.9 | 0.05 | 0.6 | 0.8 | 0.88 | 0.7 |
| EG-FedUnlearn | 0.89 | 0.91 | 0.04 | 0.55 | 0.78 | 0.9 | 0.68 | |
| OFU-Ontology | 0.92 | 0.92 | 0.03 | 0.52 | 0.75 | 0.93 | 0.65 | |
| VeriFi | 0.81 | 0.85 | 0.06 | 0.65 | 0.82 | 0.87 | 0.72 | |
| Class-based Deletion | FedEraser | 0.87 | 0.91 | 0.04 | 0.58 | 0.79 | 0.92 | 0.68 |
| EG-FedUnlearn | 0.91 | 0.93 | 0.03 | 0.53 | 0.76 | 0.94 | 0.65 | |
| OFU-Ontology | 0.93 | 0.94 | 0.02 | 0.50 | 0.74 | 0.96 | 0.6 | |
| VeriFi | 0.83 | 0.87 | 0.05 | 0.62 | 0.80 | 0.9 | 0.7 | |
| Feature-based Deletion | FedEraser | 0.86 | 0.90 | 0.05 | 0.57 | 0.77 | 0.90 | 0.70 |
| EG-FedUnlearn | 0.90 | 0.92 | 0.04 | 0.54 | 0.75 | 0.92 | 0.66 | |
| OFU-Ontology | 0.93 | 0.93 | 0.03 | 0.49 | 0.72 | 0.95 | 0.62 | |
| VeriFi | 0.82 | 0.86 | 0.06 | 0.64 | 0.79 | 0.88 | 0.75 |
| Deletion Strategy | Algorithm | Model Accuracy | Unlearning Efficiency | Residual Influence | Communication Overhead | Convergence Time | Unlearning Accuracy | Computational Cost |
|---|---|---|---|---|---|---|---|---|
| Random Deletion | FedEraser | 0.80 | 0.85 | 0.07 | 0.7 | 0.78 | 0.87 | 0.75 |
| EG-FedUnlearn | 0.84 | 0.88 | 0.05 | 0.65 | 0.77 | 0.89 | 0.7 | |
| OFU-Ontology | 0.88 | 0.90 | 0.04 | 0.63 | 0.74 | 0.92 | 0.68 | |
| VeriFi | 0.75 | 0.82 | 0.08 | 0.73 | 0.79 | 0.84 | 0.76 | |
| Class-based Deletion | FedEraser | 0.82 | 0.89 | 0.06 | 0.66 | 0.77 | 0.91 | 0.69 |
| EG-FedUnlearn | 0.86 | 0.92 | 0.04 | 0.61 | 0.75 | 0.93 | 0.65 | |
| OFU-Ontology | 0.90 | 0.94 | 0.03 | 0.58 | 0.73 | 0.95 | 0.62 | |
| VeriFi | 0.78 | 0.86 | 0.07 | 0.68 | 0.80 | 0.88 | 0.71 | |
| Feature-based Deletion | FedEraser | 0.81 | 0.88 | 0.06 | 0.67 | 0.76 | 0.90 | 0.72 |
| EG-FedUnlearn | 0.85 | 0.91 | 0.04 | 0.63 | 0.74 | 0.93 | 0.68 | |
| OFU-Ontology | 0.89 | 0.93 | 0.03 | 0.61 | 0.71 | 0.96 | 0.65 | |
| VeriFi | 0.77 | 0.86 | 0.07 | 0.69 | 0.79 | 0.89 | 0.73 |
| Deletion Strategy | Algorithm | Model Accuracy | Unlearning Efficiency | Residual Influence | Communication Overhead | Convergence Time | Unlearning Accuracy | Computational Cost |
|---|---|---|---|---|---|---|---|---|
| Random Deletion | FedEraser | 0.83 | 0.89 | 0.06 | 0.65 | 0.81 | 0.88 | 0.72 |
| EG-FedUnlearn | 0.87 | 0.91 | 0.04 | 0.6 | 0.78 | 0.91 | 0.69 | |
| OFU-Ontology | 0.91 | 0.92 | 0.03 | 0.58 | 0.75 | 0.94 | 0.67 | |
| VeriFi | 0.79 | 0.85 | 0.07 | 0.68 | 0.80 | 0.86 | 0.73 | |
| Class-based Deletion | FedEraser | 0.85 | 0.90 | 0.05 | 0.62 | 0.80 | 0.92 | 0.67 |
| EG-FedUnlearn | 0.89 | 0.92 | 0.03 | 0.57 | 0.78 | 0.94 | 0.64 | |
| OFU-Ontology | 0.93 | 0.95 | 0.02 | 0.54 | 0.75 | 0.97 | 0.6 | |
| VeriFi | 0.81 | 0.87 | 0.06 | 0.64 | 0.82 | 0.89 | 0.69 | |
| Feature-based Deletion | FedEraser | 0.83 | 0.89 | 0.05 | 0.63 | 0.78 | 0.91 | 0.69 |
| EG-FedUnlearn | 0.87 | 0.92 | 0.03 | 0.59 | 0.75 | 0.94 | 0.67 | |
| OFU-Ontology | 0.91 | 0.94 | 0.02 | 0.56 | 0.73 | 0.97 | 0.64 | |
| VeriFi | 0.79 | 0.87 | 0.06 | 0.66 | 0.80 | 0.90 | 0.71 |
| Deletion Strategy | Algorithm | Model Accuracy | Unlearning Efficiency | Residual Influence | Communication Overhead | Convergence Time | Unlearning Accuracy | Computational Cost |
|---|---|---|---|---|---|---|---|---|
| Random Deletion | FedEraser | 0.78 | 0.83 | 0.08 | 0.75 | 0.79 | 0.84 | 0.80 |
| EG-FedUnlearn | 0.82 | 0.86 | 0.06 | 0.72 | 0.76 | 0.87 | 0.78 | |
| OFU-Ontology | 0.87 | 0.88 | 0.05 | 0.70 | 0.73 | 0.90 | 0.76 | |
| VeriFi | 0.73 | 0.81 | 0.09 | 0.77 | 0.82 | 0.82 | 0.79 | |
| Class-based Deletion | FedEraser | 0.80 | 0.88 | 0.07 | 0.70 | 0.78 | 0.90 | 0.74 |
| EG-FedUnlearn | 0.84 | 0.91 | 0.05 | 0.67 | 0.76 | 0.92 | 0.71 | |
| OFU-Ontology | 0.89 | 0.93 | 0.04 | 0.63 | 0.73 | 0.95 | 0.68 | |
| VeriFi | 0.76 | 0.85 | 0.08 | 0.71 | 0.79 | 0.87 | 0.72 | |
| Feature-based Deletion | FedEraser | 0.79 | 0.87 | 0.07 | 0.71 | 0.77 | 0.89 | 0.74 |
| EG-FedUnlearn | 0.83 | 0.90 | 0.05 | 0.68 | 0.75 | 0.92 | 0.71 | |
| OFU-Ontology | 0.88 | 0.92 | 0.04 | 0.64 | 0.72 | 0.95 | 0.68 | |
| VeriFi | 0.74 | 0.84 | 0.08 | 0.73 | 0.79 | 0.87 | 0.72 |
| Deletion Strategy | Algorithm | Model Accuracy | Unlearning Efficiency | Residual Influence | Communication Overhead | Convergence Time | Unlearning Accuracy | Computational Cost |
|---|---|---|---|---|---|---|---|---|
| Random Deletion | FedEraser | 0.82 | 0.88 | 0.05 | 0.6 | 0.8 | 0.89 | 0.73 |
| EG-FedUnlearn | 0.86 | 0.90 | 0.04 | 0.58 | 0.77 | 0.91 | 0.71 | |
| OFU-Ontology | 0.90 | 0.91 | 0.03 | 0.55 | 0.75 | 0.93 | 0.7 | |
| VeriFi | 0.78 | 0.84 | 0.06 | 0.65 | 0.81 | 0.87 | 0.74 | |
| Class-based Deletion | FedEraser | 0.84 | 0.91 | 0.04 | 0.61 | 0.82 | 0.91 | 0.69 |
| EG-FedUnlearn | 0.88 | 0.93 | 0.03 | 0.58 | 0.79 | 0.94 | 0.66 | |
| OFU-Ontology | 0.92 | 0.95 | 0.02 | 0.56 | 0.76 | 0.97 | 0.64 | |
| VeriFi | 0.80 | 0.87 | 0.05 | 0.66 | 0.83 | 0.89 | 0.71 | |
| Feature-based Deletion | FedEraser | 0.83 | 0.90 | 0.05 | 0.62 | 0.79 | 0.91 | 0.70 |
| EG-FedUnlearn | 0.87 | 0.92 | 0.04 | 0.59 | 0.76 | 0.93 | 0.68 | |
| OFU-Ontology | 0.92 | 0.95 | 0.03 | 0.56 | 0.75 | 0.96 | 0.65 | |
| VeriFi | 0.80 | 0.87 | 0.06 | 0.66 | 0.81 | 0.89 | 0.73 |
| Deletion Strategy | Algorithm | Model Accuracy | Unlearning Efficiency | Residual Influence | Communication Overhead | Convergence Time | Unlearning Accuracy | Computational Cost |
|---|---|---|---|---|---|---|---|---|
| Random Deletion | FedEraser | 0.84 | 0.91 | 0.04 | 0.55 | 0.81 | 0.90 | 0.71 |
| EG-FedUnlearn | 0.88 | 0.92 | 0.03 | 0.52 | 0.78 | 0.92 | 0.69 | |
| OFU-Ontology | 0.92 | 0.94 | 0.02 | 0.50 | 0.75 | 0.95 | 0.67 | |
| VeriFi | 0.81 | 0.87 | 0.05 | 0.60 | 0.83 | 0.88 | 0.72 | |
| Class-based Deletion | FedEraser | 0.86 | 0.92 | 0.03 | 0.54 | 0.80 | 0.93 | 0.68 |
| EG-FedUnlearn | 0.90 | 0.94 | 0.02 | 0.52 | 0.77 | 0.95 | 0.65 | |
| OFU-Ontology | 0.94 | 0.96 | 0.01 | 0.50 | 0.74 | 0.98 | 0.61 | |
| VeriFi | 0.83 | 0.89 | 0.04 | 0.59 | 0.81 | 0.91 | 0.70 | |
| Feature-based Deletion | FedEraser | 0.85 | 0.91 | 0.04 | 0.55 | 0.78 | 0.92 | 0.69 |
| EG-FedUnlearn | 0.89 | 0.93 | 0.03 | 0.52 | 0.75 | 0.95 | 0.66 | |
| OFU-Ontology | 0.93 | 0.95 | 0.02 | 0.50 | 0.72 | 0.97 | 0.63 | |
| VeriFi | 0.82 | 0.88 | 0.05 | 0.60 | 0.80 | 0.90 | 0.70 |
Appendix B
| SPARQL B1: Query for MNIST Ontology |
| SELECT ?digit ?similarityScore WHERE { ?digit rdf:type :Digit. ?digit :isSimilarTo ?similarDigit. ?digit :hasComplexityScore ?complexityScore. FILTER(?complexityScore > 0.5) } |
| SPARQL B2: Query for CIFAR-10 Ontology |
| SELECT ?image ?category ?relevanceScore WHERE { ?image rdf:type :Image. ?image :hasCategory ?category. ?category :hasRelevanceScore ?relevanceScore. FILTER(?category IN (:Vehicle, :Animal)) } |
| SPARQL B3: Query for UCI Adult Ontology |
| SELECT ?individual ?incomeLevel ?educationLevel WHERE { ?individual rdf:type :Person. ?individual :hasIncomeLevel ?incomeLevel. ?individual :hasEducationLevel ?educationLevel. FILTER(?incomeLevel = “High” && ?educationLevel = “Bachelors”) } |
| SPARQL B4: Query for Purchase Ontology |
| SELECT ?customer ?productCategory ?purchaseFrequency WHERE { ?customer rdf:type :Customer. ?customer :hasPurchased ?productCategory. ?customer :purchaseFrequency ?purchaseFrequency. FILTER(?purchaseFrequency > 5) } |
| SPARQL B5: Query for MIMIC-III Ontology |
| SELECT ?patient ?diagnosis ?treatment WHERE { ?patient rdf:type :Patient. ?patient :hasDiagnosis ?diagnosis. ?patient :receivedTreatment ?treatment. FILTER(?diagnosis IN (:Cardiac, :Respiratory)) } |
| SPARQL B6: Query for KDD Cup 1999 Ontology |
| SELECT ?event ?attackType ?severity WHERE { ?event rdf:type :NetworkEvent. ?event :isAnomalous ?attackType. ?event :hasSeverity ?severity. FILTER(?severity > 0.7) } |
| SPARQL B7: Query for Reddit Comments Ontology |
| SELECT ?comment ?user ?sentiment WHERE { ?comment rdf:type :Comment. ?comment :hasSentiment ?sentiment. ?comment :belongsToTopic ?topic. FILTER(?sentiment = “Negative” && ?topic IN (:Politics, :Religion)) } |
References
- General Data Protection Regulation (GDPR), 2018.
- California Consumer Privacy Act (CCPA), California Legislative Information. 2018. Available online: https://leginfo.legislature.ca.gov (accessed on 25 June 2025).
- Song, M.; Wang, Z.; Zhang, Z.; Song, Y.; Wang, Q.; Ren, J.; Qi, H. Analyzing User-Level Privacy Attack Against Federated Learning. IEEE J. Sel. Areas Commun. 2020, 38, 2430–2444. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017; Google, Inc.: Seattle, WA, USA, 2017. [Google Scholar]
- Ginart, A.A.; Guan, M.Y.; Valiant, G.; Zou, J. Making AI Forget You: Data Deletion in Machine Learning. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Liu, G.; Ma, X.; Yang, Y.; Wang, C.; Liu, J. FedEraser: Enabling Efficient Client-Level Data Removal from Federated Learning Models. In Proceedings of the 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), Tokyo, Japan, 25–28 June 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Wu, L.; Guo, S.; Wang, J.; Hong, Z.; Zhang, J.; Ding, Y. Federated Unlearning: Guarantee the Right of Clients to Forget. IEEE Netw. 2022, 36, 129–135. [Google Scholar] [CrossRef]
- Xie, C.; Huang, K.; Chen, P.-Y.; Li, B. DBA: Distributed Backdoor Attacks Against Federated Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Liu, G.; Ma, X.; Yang, Y.; Wang, C.; Liu, J. Federated Unlearning. arXiv 2021. [Google Scholar] [CrossRef]
- Guarino, N.; Oberle, D.; Staab, S. What Is an Ontology? In Handbook on Ontologies, 2nd ed.; Staab, S., Studer, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–17. [Google Scholar] [CrossRef]
- Zhu, N.; Chen, B.; Wang, S.; Teng, D.; He, J. Ontology-Based Approach for the Measurement of Privacy Disclosure. Inf. Syst. Front. 2022, 24, 1689–1707. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan; Brendan, H.; Brendan, A. Advances and Open Problems in Federated Learning; Now Foundations and Trends: Norwell, MA, USA, 2021; Volume 14, pp. 1–210. [Google Scholar]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A Hybrid Approach to Privacy-Preserving Federated Learning. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; Volume 42, pp. 356–357. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, Y.; Shen, J.; Peng, M.; Lam, K.-Y.; Yuan, X.; Liu, X. A Survey on Federated Unlearning: Challenges, Methods, and Future Directions. ACM Comput. Surv. 2024, 57, 2. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Tarun, A.K.; Chundawat, V.S.; Mandal, M.; Kankanhalli, M. Fast Yet Effective Machine Unlearning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 35, 13046–13055. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C.; Burges, C.J.C. MNIST Handwritten Digit Database. AT&T Labs. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 12 November 2024).
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 28 September 2024).
- Dua, D.; Graff, C. UCI Machine Learning Repository: Adult Data Set; University of California, Irvine: Irvine, CA, USA, 2019. [Google Scholar]
- Yeh, I.C.; Yang, K.J.; Ting, T.M. Knowledge discovery on RFM model using Bernoulli sequence. Expert. Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.-W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef]
- Stolfo, S.J.; Fan, W.; Lee, W.; Prodromidis, A.L.; Chan, P.K. Cost-based modeling for fraud and intrusion detection: Results from the JAM project. In Proceedings of the DARPA Information Survivability Conference and Exposition, DISCEX’00, Hilton Head, SC, USA, 25–27 January 2000; Volume 2, pp. 130–144. [Google Scholar] [CrossRef]
- Baumgartner, J.; Zannettou, S.; Keegan, B.; Squire, M.; Blackburn, J. The Pushshift Reddit Dataset. In Proceedings of the Fourteenth International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2019; The Association for the Advancement of Artificial Intelligence: Washington, DC, USA, 2020; Volume 14, pp. 830–839. [Google Scholar]
- Aldaghri, N.; Mahdavifar, H.; Beirami, A. Coded Machine Unlearning. IEEE Access 2021, 9, 88137–88150. [Google Scholar] [CrossRef]
- Sekhari, A.; Acharya, J.; Kamath, G.; Suresh, A.T. Remember what you want to forget: Algorithms for machine unlearning. Adv. Neural Inf. Process. Syst. 2021, 34, 18075–18086. [Google Scholar]
- Chundawat, V.S.; Tarun, A.K.; Mandal, M.; Kankanhalli, M. Zero-Shot Machine Unlearning. IEEE Trans. Inf. Forensics Secur. 2022, 18, 2345–2354. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. On the Convergence of Federated Optimization in Heterogeneous Networks. arXiv 2018. [Google Scholar] [CrossRef]
- Gu, H.; Zhu, G.; Zhang, J.; Zhao, X.; Han, Y.; Fan, L.; Yang, Q. Unlearning during Learning: An Efficient Federated Machine Unlearning Method. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI-24), Jeju, Republic of Korea, 3–9 August 2024; pp. 4035–4043. Available online: https://gdpr-info.eu/art-17-gdpr/ (accessed on 25 June 2025).
- Bourtoule, L.; Chandrasekaran, V.; Choquette-Choo, C.A.; Jia, H.; Travers, A.; Zhang, B.; Lie, D.; Papernot, N. Machine unlearning. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 24–27 May 2021; pp. 141–159. [Google Scholar] [CrossRef]

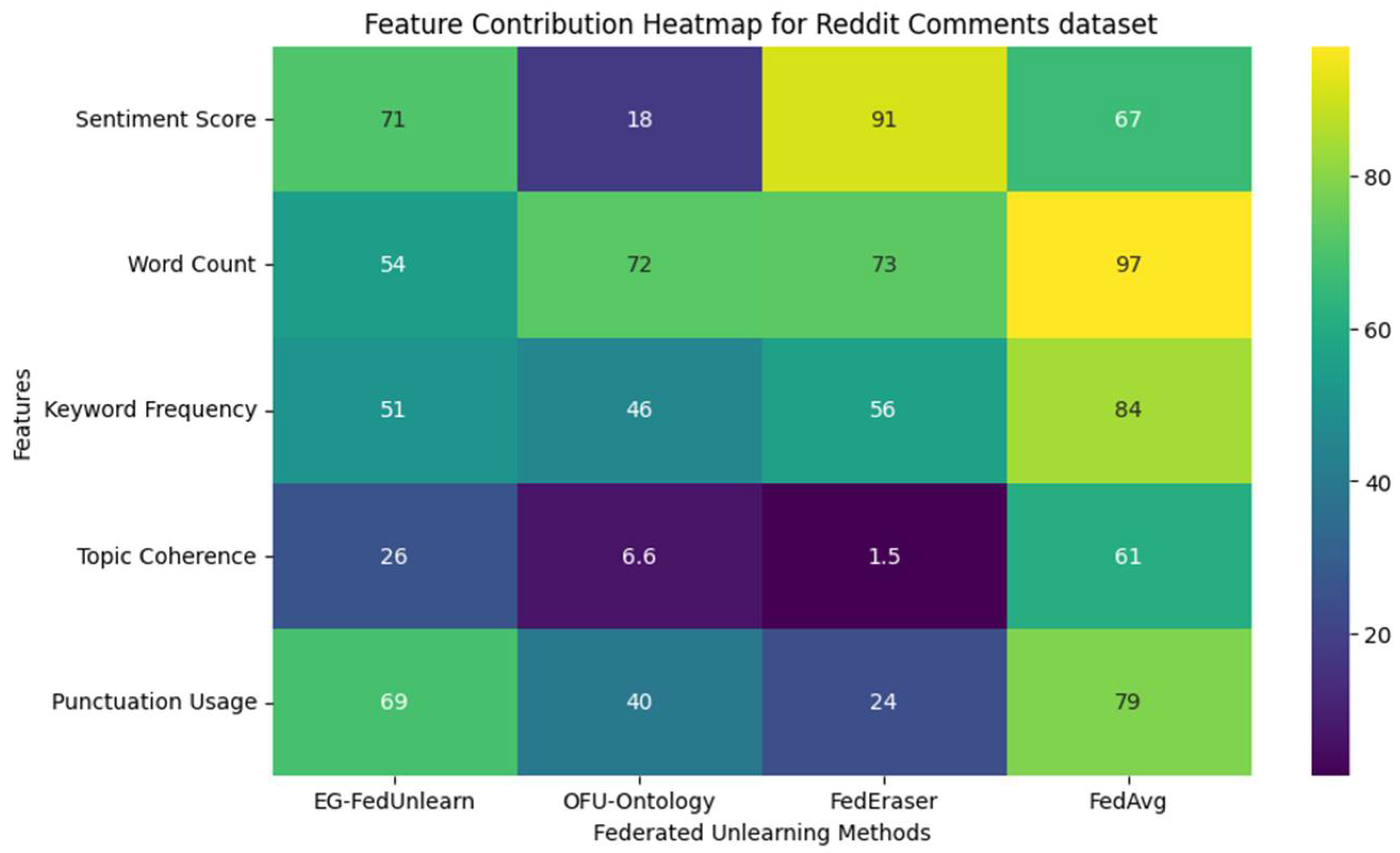
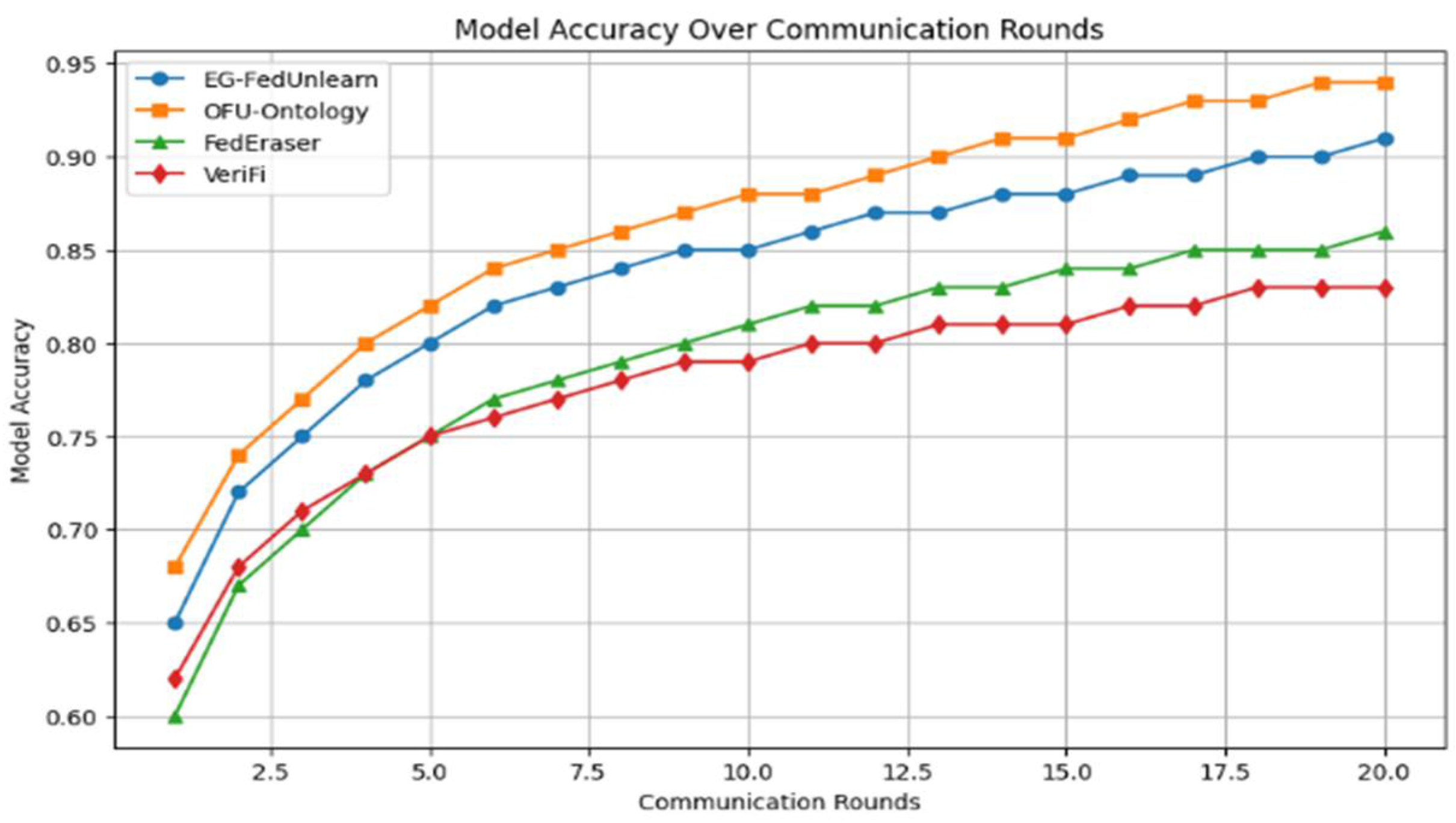
| Dataset | Type | Number of Samples | Features | Dataset Size | Use Case | Relevance for Unlearning |
|---|---|---|---|---|---|---|
| MNIST [17] | Image Classification | 70,000 | 28 × 28 grayscale images (784 features) | ~50 MB | Used to test image classification algorithms. It is simple, well-balanced, and often used as a benchmark for machine learning and federated learning techniques. | The simplicity of the dataset makes it suitable for testing the efficiency of both EG-FedUnlearn and OFU-Ontology. It helps illustrate the basic performance and computational overhead of using ontology integration in a low-complexity setting. |
| CIFAR-10 [18] | Image Classification | 60,000 | 32 × 32 color images (3072 features) | ~163 MB | CIFAR-10 is more complex compared to MNIST, with color images and multiple categories. | CIFAR-10 is ideal for testing the efficiency of ontology-based unlearning. Ontology can help prioritize images based on their impact on classification accuracy. |
| UCI Adult Census [19] | Tabular Data | 48,842 | 14 features (age, education, etc.) | ~4 MB | The dataset is typically used for income classification tasks and serves as a benchmark for machine learning algorithms dealing with tabular data. | This dataset allows us to evaluate how both algorithms handle unlearning across different data types, including numerical and categorical features. Ontology can prioritize the unlearning of sensitive features (e.g., gender and race). |
| Purchase [20] | Transactional Data | 197,324 | Product ID, category, store, transaction | ~20 MB | Purchase data is often used in recommendation systems and market basket analysis to derive customer buying patterns. | The dataset is highly suitable for evaluating the ability of unlearning algorithms to handle transactional data. OFU-Ontology can be used to prioritize unlearning less significant purchases, while EG-FedUnlearn can be used for a more generalized unlearning approach. |
| MIMIC-III [21] | Medical Diagnosis | ~58,000 hospital admissions | Patient demographics, vitals, medications | ~60 GB | MIMIC-III is widely used for predictive modeling in healthcare, such as predicting mortality, length of stay, and treatment outcomes. | Evaluating unlearning in this context helps to assess how well OFU-Ontology can prioritize unlearning of less critical clinical information while retaining essential features that significantly affect the model’s predictions. |
| KDD Cup 1999 [22] | Network Security Data | 4,898,431 | 41 features (protocol type, service, etc.) | ~743 MB | The dataset is used for network intrusion detection tasks to classify network traffic as normal or malicious. It has a combination of continuous and categorical features. | This dataset allows us to assess how efficiently the algorithms can handle unlearning while ensuring that the model retains the ability to accurately detect intrusions. OFU-Ontology’s relevance scoring can help identify and unlearn low-impact traffic data. |
| Reddit Comment [23] | Text Data | ~100 million comments | Comment text, metadata (author, subreddit) | ~50 GB | This dataset is often used for sentiment analysis, topic modeling, or text classification tasks. | The Reddit Comment dataset is suitable for evaluating the algorithms in terms of content moderation and privacy-related requests (e.g., users requesting removal of comments). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghannam, N.E.; Mahareek, E.A. Privacy-Preserving Federated Unlearning with Ontology-Guided Relevance Modeling for Secure Distributed Systems. Future Internet 2025, 17, 335. https://doi.org/10.3390/fi17080335
Ghannam NE, Mahareek EA. Privacy-Preserving Federated Unlearning with Ontology-Guided Relevance Modeling for Secure Distributed Systems. Future Internet. 2025; 17(8):335. https://doi.org/10.3390/fi17080335
Chicago/Turabian StyleGhannam, Naglaa E., and Esraa A. Mahareek. 2025. "Privacy-Preserving Federated Unlearning with Ontology-Guided Relevance Modeling for Secure Distributed Systems" Future Internet 17, no. 8: 335. https://doi.org/10.3390/fi17080335
APA StyleGhannam, N. E., & Mahareek, E. A. (2025). Privacy-Preserving Federated Unlearning with Ontology-Guided Relevance Modeling for Secure Distributed Systems. Future Internet, 17(8), 335. https://doi.org/10.3390/fi17080335