Abstract
The rapid loss of biodiversity significantly impacts birds’ environments and behaviors, highlighting the importance of analyzing bird behavior for ecological insights. With the growing adoption of Machine Learning (ML) algorithms in the Internet of Things (IoT) domain, edge computing has become essential to ensure data privacy and enable real-time predictions by processing high-dimensional data, such as video streams, efficiently. This paper introduces a set of dimensionality reduction techniques tailored for video sequences based on cutting-edge methods for this data representation. These methods drastically compress video data, reducing bandwidth and storage requirements while enabling the creation of compact ML models with faster inference speeds. Comprehensive experiments on bird behavior classification in rural environments demonstrate the effectiveness of the proposed techniques. The experiments incorporate state-of-the-art deep learning techniques, including pre-trained video vision models, Autoencoders, and single-frame feature extraction. These methods demonstrated superior performance to the baseline, achieving up to a 6000-fold reduction in data size while reaching a classification accuracy of 60.7% on the Visual WetlandBirds Dataset and obtaining state-of-the-art performance on this dataset. These findings underline the potential of using dimensionality reduction to enhance the scalability and efficiency of bird behavior analysis.
1. Introduction
The accelerating pace of global biodiversity loss necessitates efficient environmental management strategies to mitigate its impacts [1]. Bird behavior, closely influenced by environmental conditions, weather, and surrounding ecosystems, serves as a valuable indicator of ecological health [2]. Analyzing bird behavior provides critical insights for researchers and ecologists, enabling the identification of behavioral changes and anomalies that may signal environmental shifts [3,4]. As highly sensitive species, birds can detect subtle changes in their habitats, making them indispensable in monitoring and conservation efforts [5].
Video classification can be used for automating the study of bird behavior. However, this task can be resource-intensive, requiring the analysis of both visual and temporal data, which presents significant challenges in terms of time and effort. Additionally, it presents several challenges inherent to the task itself. The main one is the high dimensionality of the data the models have to process. This leads to a sparse data distribution due to the curse of dimensionality [6], requiring lots of samples to train a classifier without significant overfitting. Moreover, the high dimensionality significantly increases the number of trainable parameters in the classifiers, which in turn demands greater computational resources for both training and inference. In the context of bird behavior recognition, resources are often highly constrained due to deployment in rural environments.
To address these challenges, we present a study focused on reducing the dimensionality of video recordings by transforming them into smaller and more compact representations while preserving the most relevant features for classification. To achieve this, we employ various state-of-the-art deep learning techniques, including the employment of embeddings obtained from large video vision models, such as 3D Convolutional Neural Networks (3DCNNs) [7,8] or Video Transformers [9,10]. In addition, other techniques are proposed, including Autoencoders and extracting visual features from a single frame within the sequence. We present a comprehensive ablation study to identify the most effective methods and parameters. Our results demonstrate that the proposed methodologies can reduce video representations by a factor of 6000, while these compact representations outperform the baseline model. All experiments were carried out on the Visual WetlandBirds Dataset [11], yielding up to a 60.7% accuracy increase over the test set and presenting new state-of-the-art performance. Furthermore, they significantly reduce training time due to the smaller data size. In summary, our key contributions are as follows:
- We proposed three different approaches to dimensionality reduction for the specific task of action classification from videos of birds in natural environments. These methods can reduce the size of a video by up to 6000 times for much faster training and inference.
- Additionally, the new classifiers trained with the reduced representations outperformed the previously proposed baselines, achieving state-of-the-art results on this specific dataset. In this particular task, characterized by a limited number of samples, our reduced representation has proven more effective in capturing differences between classes.
- Finally, we performed an exhaustive ablation study of the different proposed methods to determine parameter selection and the importance of each of them. This process allowed us to establish the capabilities and limitations of each method.
The remainder of this paper is structured as follows: Section 2 reviews the most relevant related work within this field. Section 3 outlines the methodology employed in this study. Section 4 presents the experimental results. Section 5 discusses and interprets the results obtained from this study. Finally, Section 6 discusses the conclusions drawn from this work, along with potential directions for future research.
2. Related Work
Deep learning techniques excel at identifying and analyzing patterns in heterogeneous, high-dimensionality data. However, certain data modalities and scenarios benefit from reduced representations. For instance, video data present challenges due to their high spatial and temporal dimensionality. Similarly, in scenarios like the Internet of Things (IoT), where computational resources are limited and low inference times are critical, using reduced data representations leads to smaller models with lower computational costs and faster inference times.
In this context, dimensionality reduction involves mapping a set of input features to a smaller set while retaining meaningful information that can still be used for the same tasks as the original representation [12,13,14,15]. Two main approaches are commonly discussed in the literature [12]: feature selection and feature extraction.
Feature selection focuses on identifying and retaining a subset of the original features that preserve the most information. These features remain in their original form, and the methods prioritize selecting them based on specific criteria. This approach is particularly useful in scenarios with low-sample, high-dimensionality tabular data, where noise and feature redundancy are prevalent.
In contrast, feature extraction transforms the initial features into a lower-dimensional representation, making it more suitable for unstructured data such as images and videos. Traditional linear approaches aim to achieve this transformation through linear methods. Examples include techniques based on variances and contribution ratios, such as Principal Component Analysis (PCA) [16,17], Linear Discriminant Analysis (LDA) [18], and Factor Analysis (FA). Other linear feature extraction methods include Independent Component Analysis (ICA), Multi-Dimensional Scaling (MDS) [19], and Singular Value Decomposition (SVD) [20]. However, these linear methods are limited in their ability to address the inherent non-linearity and complexity of video data.
Non-linear feature extraction algorithms provide flexibility to handle complex, non-linear relationships in data that linear methods fail to capture effectively. Examples include Kernel Principal Component Analysis (KPCA) [21], which uses kernel functions to project data into higher-dimensionality spaces where linear separation is feasible, and Locally Linear Embedding (LLE) [22], which maintains local neighborhood relationships while embedding data into a low-dimensionality space. Isometric Mapping (ISOMAP) [23] is another prominent approach, extending classical MDS by preserving geodesic distances between data points, effectively capturing the manifold structure of complex data. Non-negative Matrix Factorization (NMF) [24] offers a part-based representation of data by imposing non-negativity constraints, making it highly interpretable in fields such as text mining and facial recognition. These non-linear methods provide improved capability to represent the complexity and inherent non-linear nature of video and image data compared to traditional linear approaches.
Dimensionality reduction using deep learning can be categorized into supervised [25], unsupervised, and semi-supervised methods. Supervised methods, such as Convolutional Neural Networks (CNNs) [26] and Transformer [27] models, effectively reduce feature dimensions by capturing both local and global features present in data. These methods work particularly well for structured tasks where labeled data are available, enabling the extraction of key information while minimizing irrelevant details. On the other hand, unsupervised methods, like Deep Autoencoders [28,29,30,31] and Deep Belief Networks (DBNs) [32], focus on compressing high-dimensional data into lower-dimensional representations without relying on labels, making them suitable for discovering hidden structures and patterns in unstructured data.
Semi-supervised approaches leverage the strengths of both supervised and unsupervised learning by combining unsupervised pre-training with labeled data to improve generalization. For instance, pre-training with unlabeled data helps the model learn meaningful representations, while fine-tuning with labeled data refines its accuracy. This combination is particularly valuable when labeled data are scarce, enhancing the model’s ability to generalize effectively. Overall, deep learning-based dimensionality reduction methods can handle the complexity and non-linearity of high-dimensionality data [33], providing efficient and meaningful feature representations for tasks like image, video, and sensor data analysis.
Dimensionality reduction is crucial for handling video data due to their high computational complexity and memory requirements and the challenge of extracting effective spatio-temporal features. Unlike static data, videos involve a temporal dimension, which requires specialized approaches for the efficient management of both spatial and temporal aspects [12]. Various methods have been developed to reduce dimensionality, making video data more manageable while maintaining the quality of extracted features. Techniques like the Spatio-temporal Prompting Network (STPN) [34], Regularized Deep Neural Networks (rDNNs) [35], and lightweight optimization for frame interpolation [36] exemplify how dimensionality reduction can enhance performance in video classification, detection, and segmentation tasks. These methods focus on reducing redundancy, preserving essential information, and improving computational feasibility.
Dimensionality reduction also finds applications beyond video classification, such as human action recognition, medical video analysis, and human detection. For action recognition, local CNN features are aggregated to create global representations, addressing GPU memory limitations while preserving performance [37]. In medical video analysis, particularly gastrointestinal endoscopy, hybrid feature extraction techniques reduce computational costs while retaining critical diagnostic information [38,39]. Additionally, incremental Principal Component Analysis (PCA) has been used to improve human detection by reducing the dimensionality of CoHOG features [40]. Overall, dimensionality reduction plays an essential role in making video data analysis practical and improving efficiency, memory management, and accuracy across various video-related applications.
In the study of animal behavior [41,42,43] and, more specifically, in bird-related research [44,45,46,47], videos serve as a primary data structure for analysis and insight generation. However, to the best of our knowledge, no prior work has applied dimensionality reduction techniques to this specific domain, making our approach the first to explore and integrate these methods for analyzing video data in the context of animal behavior and avian studies.
When considering datasets for training deep learning algorithms, there is a notable scarcity of resources focused on bird behavior recognition. For instance, the VB100 dataset [48], which consists of video recordings of birds in their natural environments, is annotated only with bird species and lacks labels for the actions being performed. Consequently, this dataset is not suitable for behavior recognition tasks. Similarly, the AnimalKingdom dataset [49] contains video recordings of various animals and includes annotations of their corresponding actions. However, as this dataset encompasses a wide range of animal species, including but not limited to birds, it is not suitable for focused bird behavior recognition. The Visual WetlandBirds Dataset [11] provides video recordings exclusively of birds, making it the most appropriate dataset for this study. In addition, other datasets, such as Birds525 (https://huggingface.co/datasets/chriamue/bird-species-dataset, accessed on 18 January 2024), CUB-200-2011 [50], and NABirds [51], offer images of different bird species, but these datasets lack temporal or behavioral annotations. As a result, they are unsuitable for tasks requiring such information.
3. Materials and Methods
In this section, we present the methodology proposed for this study. The main scope of this study and the proposed pipeline are formulated to capture the most relevant information within video frames while converting videos into lower-dimensionality representations.
The proposed techniques aim to generate lower-dimensionality representations of the video input. Each technique includes a final Multi-Layer Perceptron (MLP) designed to classify and evaluate the effectiveness of the representations. An ablation study was conducted to identify the most suitable technique and the optimal parameters for training and the MLP. As a result, the configuration of the final MLP may vary depending on the employed method. All code developed for this project is publicly available in our GitHub repository (https://github.com/3dperceptionlab/DimensionalityReductionBirdBehaviours, accessed on 1 December 2024).
3.1. Dataset
The Visual WetlandBirds Dataset [11] consists of videos of birds from the Valencian region, each depicting different actions. The dataset consists of 2765 video frames and is distributed into 1834 samples for training, 440 for validation, and 491 for testing. This distribution was designed taking into consideration the bird species in the video, as well as the action performed in it. Furthermore, this division was not limited to bird species and actions but also considered the original video source, which was segmented into smaller video frames. This approach ensures that videos are separated based on factors such as the recording camera, the day of recording, and the time of day. These videos are annotated with the bird species and the actions performed. The videos encompass 16 frames, with three color channels per frame and a resolution of 224 × 224 pixels. This dataset establishes a baseline for the classification of bird behaviors using 3DCNNs and Video Transformers. The models trained end-to-end include ResNet3D, S3D, Video Swin Transformer, and MViTv2.
3.2. Features
With the advent of deep learning technologies, a wide range of pre-trained models are available for various modalities and purposes. For instance, in Natural Language Processing (NLP), models such as BERT [52], LLaMA [53], and Gemini [54] have been developed. These models are trained on extensive datasets and can capture and encode the most relevant information from an input, leveraging the knowledge acquired during their training phase.
Similarly, for video analysis, several large pre-trained models can be used for feature extraction and classification tasks. These models have been trained on the Kinetics Dataset [55], enabling them to learn general patterns that can be effectively leveraged for transfer to other tasks, for example, bird behavior classification. These models rely on diverse backbone architectures, such as 3DCNNs [56] and Video Transformers [57]. Examples of 3DCNNs include ResNet3D [7] and Video S3D [8], while Video Transformers include models like Video Swin Transformer [9] and MViTv2 [10].
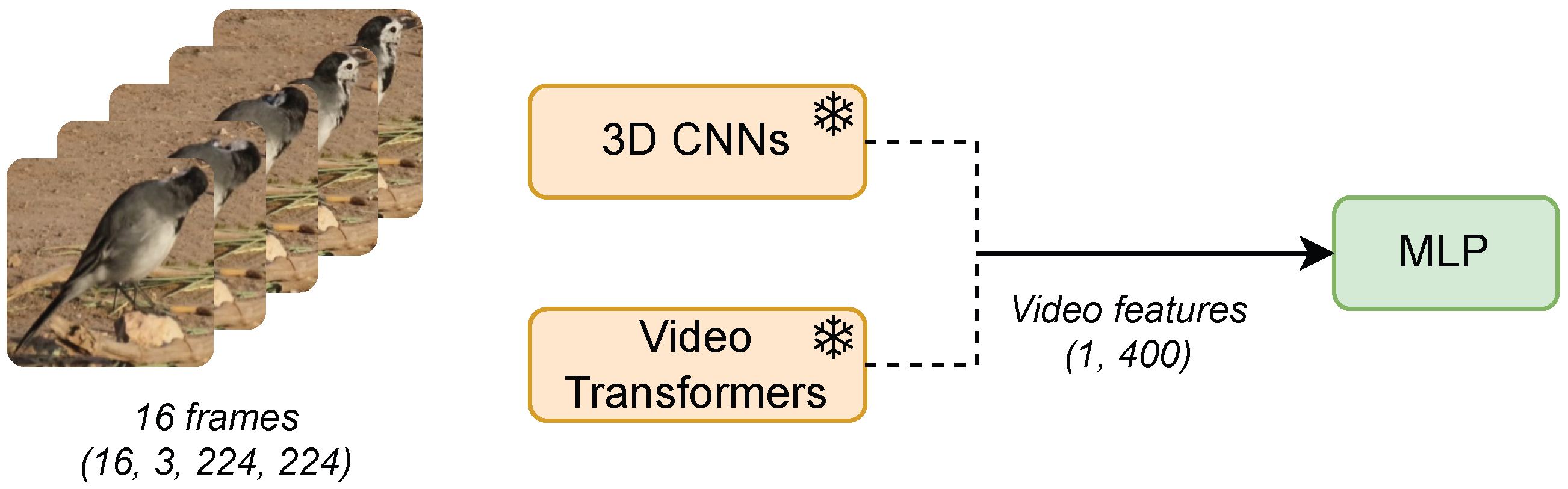
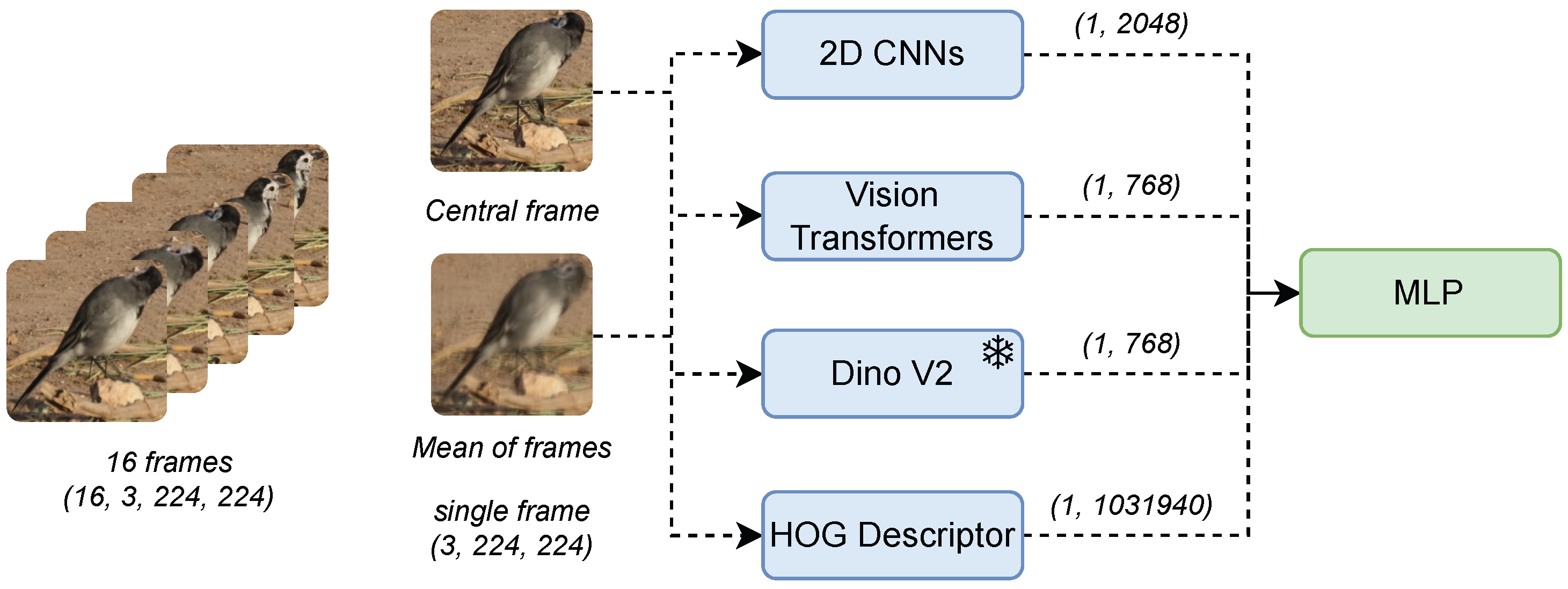
The Features dimensionality reduction technique involves utilizing these models to extract internal representations of videos, generating embeddings that encapsulate essential features. These embeddings serve as input into an MLP for the final classification task. This architecture processes a sequence of 16 frames, each with dimensions of 16 × 3 × 224 × 224, and transforms it into a single embedding with a size of 400. This transformation achieves a dimensionality reduction of over 6000 times compared to the original video sequence, substantially decreasing the input size while preserving critical information. An overview of the proposed architecture is shown in Figure 1.

Figure 1.
Overview of the Baseline Feature Method: The architecture utilizes the internal representations of the proposed models in conjunction with an MLP. Discontinued lines indicate that only one of the models is selected for use in each experiment. The snowflake symbol denotes a frozen model.
3.3. Autoencoder
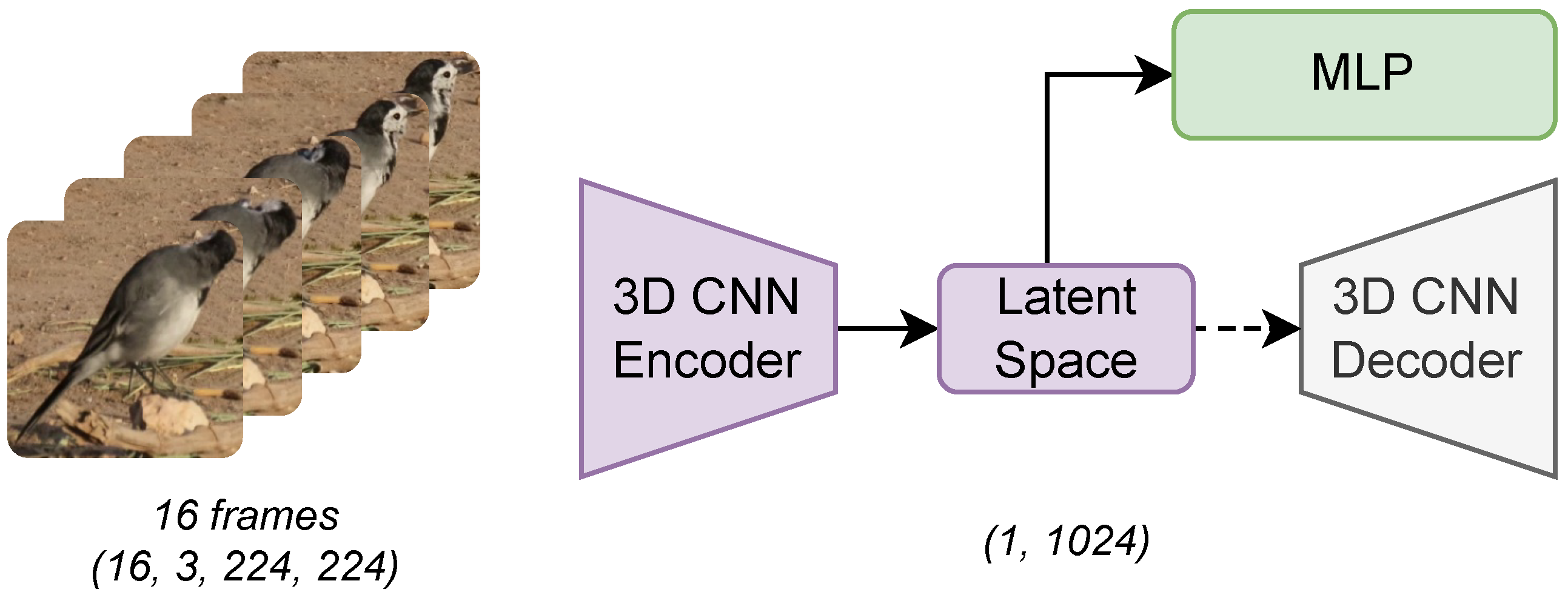
An alternative methodology proposed in this study utilizes Autoencoders, designed to reduce the dimensionality of input data and reconstruct them from a latent space. This approach allows the model to compress the input into a lower-dimensionality representation while retaining its essential features. An Autoencoder is composed of two primary components: an encoder, which reduces the dimensionality of the input data, and a decoder, which reconstructs the input data to their original form [31,58,59].
During the training process, the Autoencoder learns to effectively represent the input data within the latent space and reconstruct them. Once trained, the decoder is removed from the pipeline. The latent space representation is used for downstream tasks. This study employs this latent space representation and an MLP to classify bird behaviors.
The spatio-temporal Autoencoder architecture is designed to process video data by utilizing 3D convolutions to capture spatial and temporal features. The encoder comprises four 3D convolutional layers that progressively reduce the spatial and temporal dimensions of the input. Each convolutional layer is followed by batch normalization and ReLU activation to enhance convergence and improve model robustness. The output of the encoder is flattened and passed through a fully connected layer, compressing the data into a 1024-dimensional latent space. The decoder is structured to mirror the encoder, employing transposed 3D convolutions to reconstruct the video data from the latent representation. However, after the training process, the decoder is discarded, and representations from the latent space are used to reduce the dimensionality of video inputs. The learning rate for the training process is set to 0.0001, and the Adam optimizer is employed. Training is conducted over 100 epochs with a batch size of 32. The Mean Squared Error (MSE) loss function is utilized to minimize the pixel-wise difference between the input videos and their reconstructions in alignment with the Autoencoder’s objective. During training, the performance is periodically evaluated by saving the model state every 20 epochs, providing progress checkpoints, and facilitating recovery if needed.
This method allows for a significant reduction in data size, compressing a 16 × 3 × 224 × 224 input into a single embedding of size 1024—a reduction of more than 2350 times the original data volume. Figure 2 provides an overview of the proposed architecture.
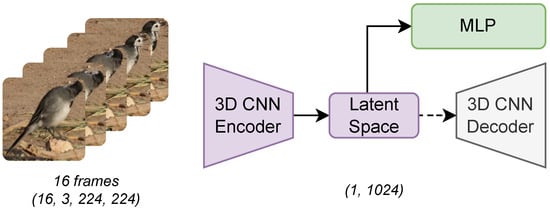
Figure 2.
Overview of the Autoencoder Method: An Autoencoder is pre-trained to reconstruct video frames. Following the training process, the decoder is discarded, and the latent space representation is combined with an MLP. Discontinued lines indicate that the decoder is discarded after being trained, and only the latent space is used to classify the bird action.
3.4. Single Frame
The final dimensionality reduction technique implemented in this study involves using a single frame for the task, thereby discarding the temporal information contained within the video. The selected architecture processes a single frame, utilizing both the environmental context and the bird-specific features captured at that moment to perform the classification. We propose two primary approaches to extract a single frame from the video sequence. The first one is selecting the central frame of the sequence, while the second is computing the mean pixel values across the sequence to generate a representative frame. This selection serves as the first step in dimensionality reduction, reducing the input dimensions from 16 × 3 × 224 × 224 to a single frame of 3 × 224 × 224, effectively achieving a 16-fold reduction in size.
Following this initial dimensionality reduction step and drawing on methodologies used in previously proposed architectures, we employed pre-trained models such as 2D CNNs, Vision Transformers, the DINOv2 [60,61] model, and a Histogram of Oriented Gradients (HOG) [62]. The 2D CNNs utilized include ResNet [63], MobileNet [64], DenseNet [65], and VGG [66], while the implemented Vision Transformer models include ViT [67] and Swin Transformer [68]. The primary objective of this methodology is to leverage CNN kernels and transformer layers to extract meaningful patterns and features from images for classification tasks. The extent of dimensionality reduction achieved depends on the chosen model. For example, using ResNet, which delivers the most promising results among the 2D CNNs, we obtained embeddings of size 2048, achieving a reduction of over 1100 times. Other 2D CNNs produce varying reduction rates based on their internal representation sizes. For Vision Transformers and the DINOv2 model, the embedding size is 768, resulting in a reduction of more than 3100 times in size. HOG features were computed to extract complementary information [69,70], with these features yielding a reduction size of 1,031,940, corresponding to a more modest reduction of slightly over two times. As in prior methodologies, the extracted representations were combined with an MLP for final classification. Figure 3 illustrates the overall architecture.
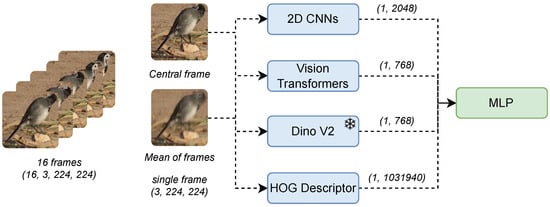
Figure 3.
Overview of single-frame methods. The initial dimensionality reduction step involves selecting either the central frame or the mean pixel values of the frames. Subsequently, visual embeddings are obtained using 2D CNNs, Vision Transformers, or DinoV2. Finally, classification is performed using an MLP. Discontinued lines indicate that only one of the models and frames are selected for use in each experiment.
4. Results
In this section, we present quantitative experimentation with the methods previously introduced in this work. In Table 1, we can observe the evaluation of the different proposed approaches and their reduction rates. By analyzing the results, we can observe that the method labeled Features is the best concerning reduction and metrics, even outperforming the original metrics obtained by the baseline.

Table 1.
Quantitative evaluation of the proposed dimensionality reduction techniques, including their performance metrics and the reduction achieved relative to the original input size. Evaluations were conducted 5 times to mitigate the effects of randomness. The symbol ± indicates the 95% confidence interval.
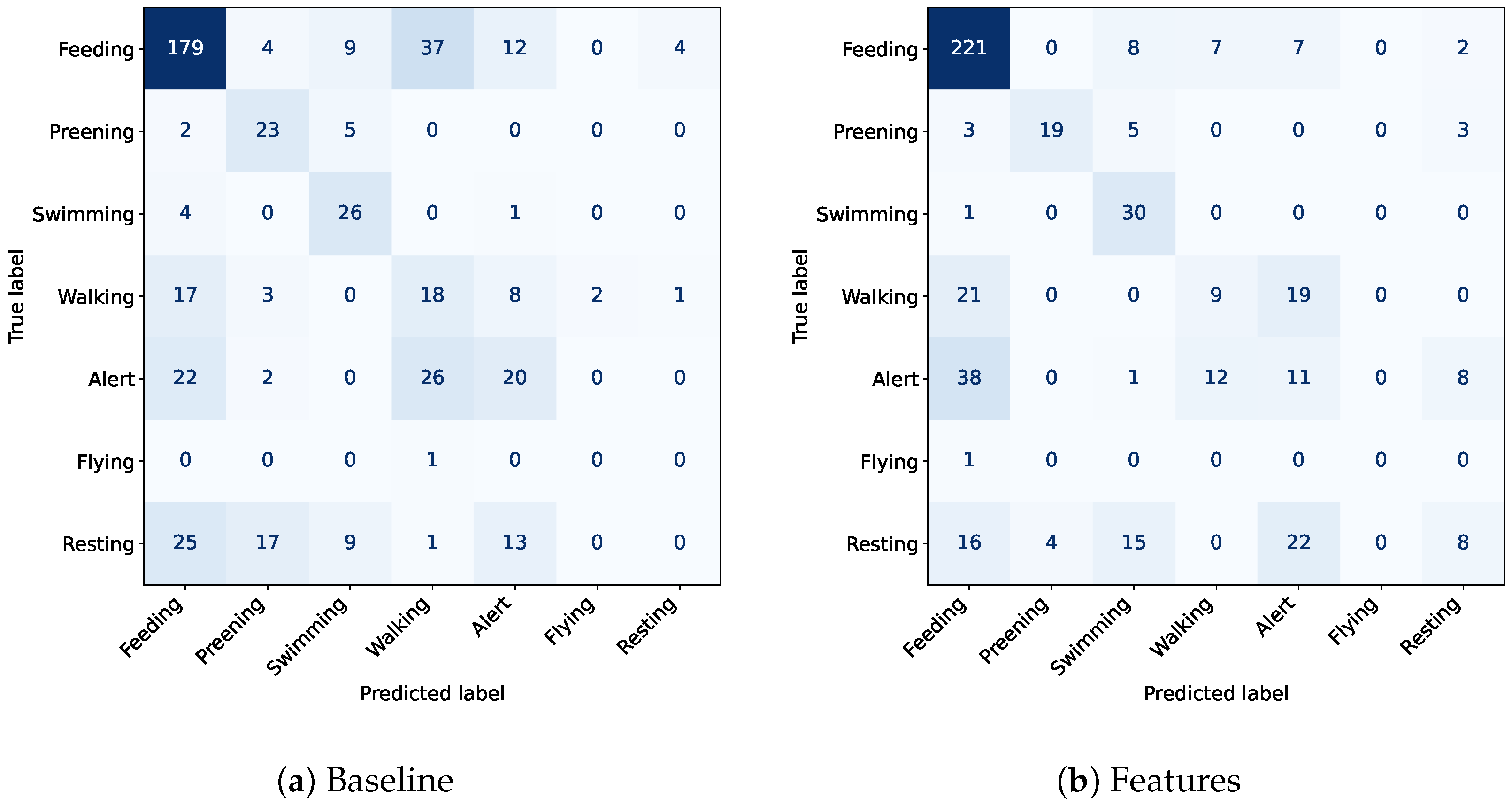
The experiments demonstrate that the most relevant features were obtained by extracting embeddings from large pre-trained video models. These embeddings effectively capture high-level information from prior tasks, reducing the representation size by more than 6000 times while improving performance across various metrics. While this method is highly efficient for training, its benefits are more limited during the inference time due to the time required to extract the embeddings from the pre-trained models. The effectiveness of this method can be graphically observed in Figure 4.
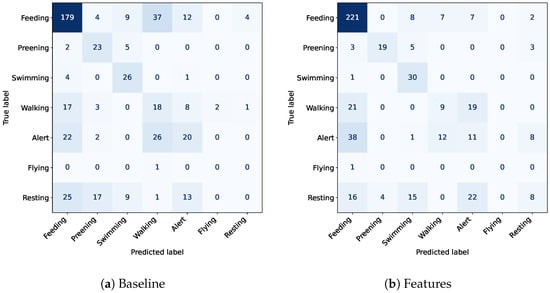
Figure 4.
Confusion matrix comparing the baseline approach with the proposed best dimensionality reduction method on the Visual WetlandBirds Dataset test set.
The second-best method involves removing temporal information by processing only a single frame from each video sequence. We tested two strategies for selecting this single frame: The first was picking the central frame and calculating the mean frame pixel-wise across the entire sequence. The results indicate that using the mean frame leads to slightly better performance than using the central frame, likely because it retains some contextual information from the entire sequence. Features are extracted from the single frame using pre-trained image models, being a more lightweight process than the previous method in the video processing stage. As such, this could be the most suitable option in resource-constrained environments. Despite removing temporal information, this method achieves highly competitive performance metrics.
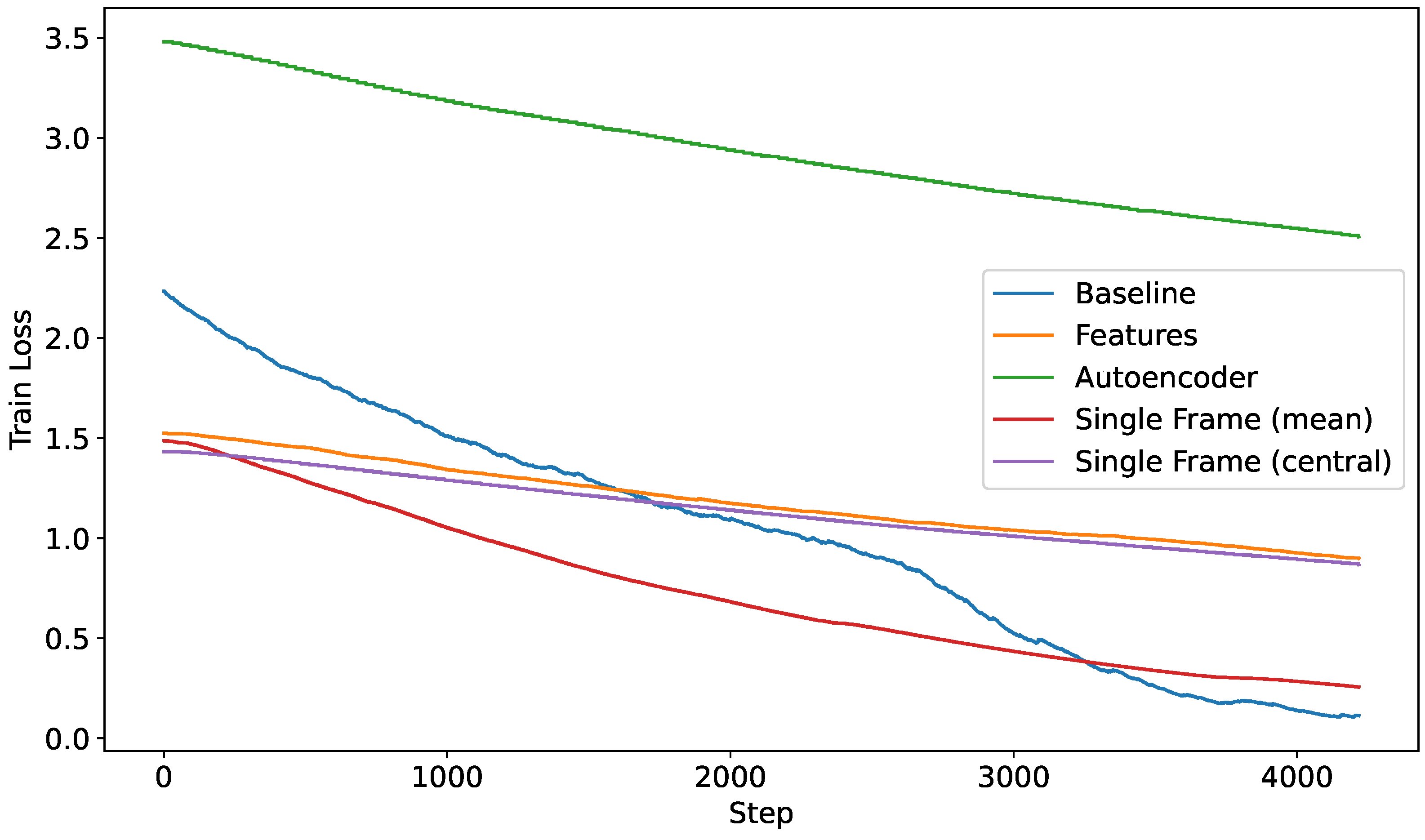
Among the methods we proposed, the one based on Autoencoders performed the worst. Its lack of effectiveness can be attributed to overfitting, which occurred due to the limited availability of large datasets for this particular task. Figure 5 shows the learning curves for the loss functions for the different proposed methods.
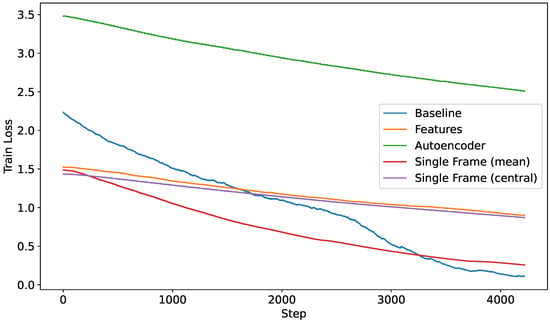
Figure 5.
Loss curves over the training procedure for each of the proposed methods.
5. Discussion
In this work, we proposed using various dimensionality reduction techniques to classify bird behaviors through videos. To evaluate the performance of the resulting representations, we performed an ablation study, where the most relevant methods were identified. In the following subsections, we will analyze the ablation carried out with the different features and parameters tested from the different dimensionality reduction methods we proposed.
5.1. Features
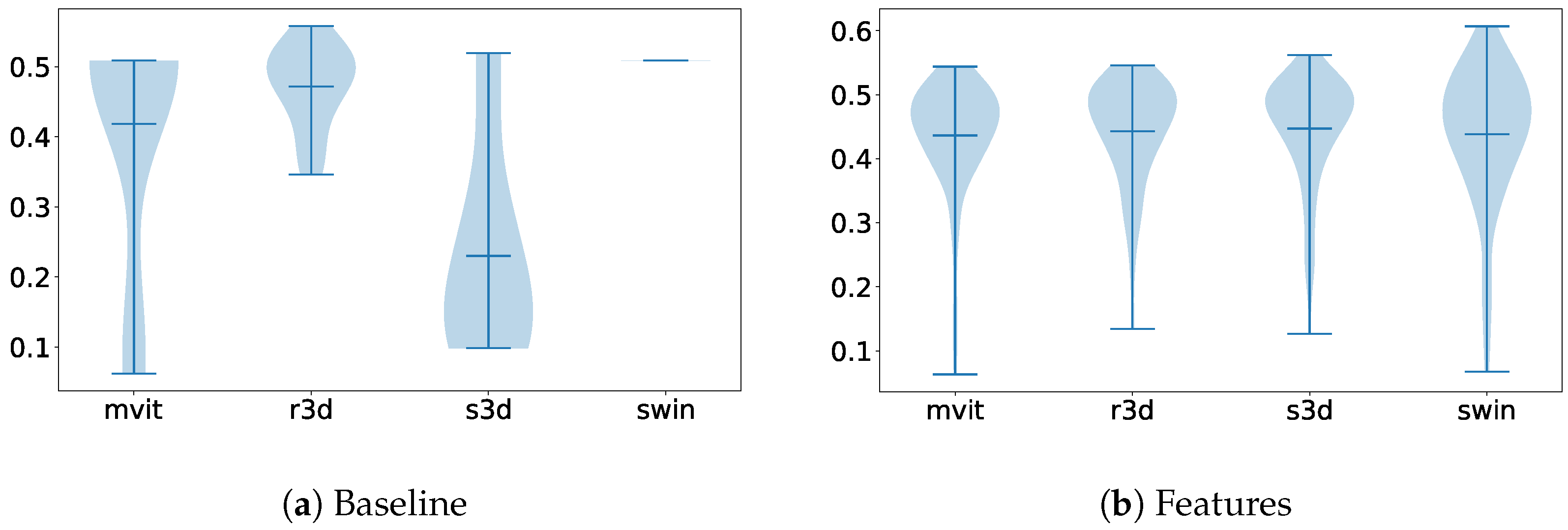
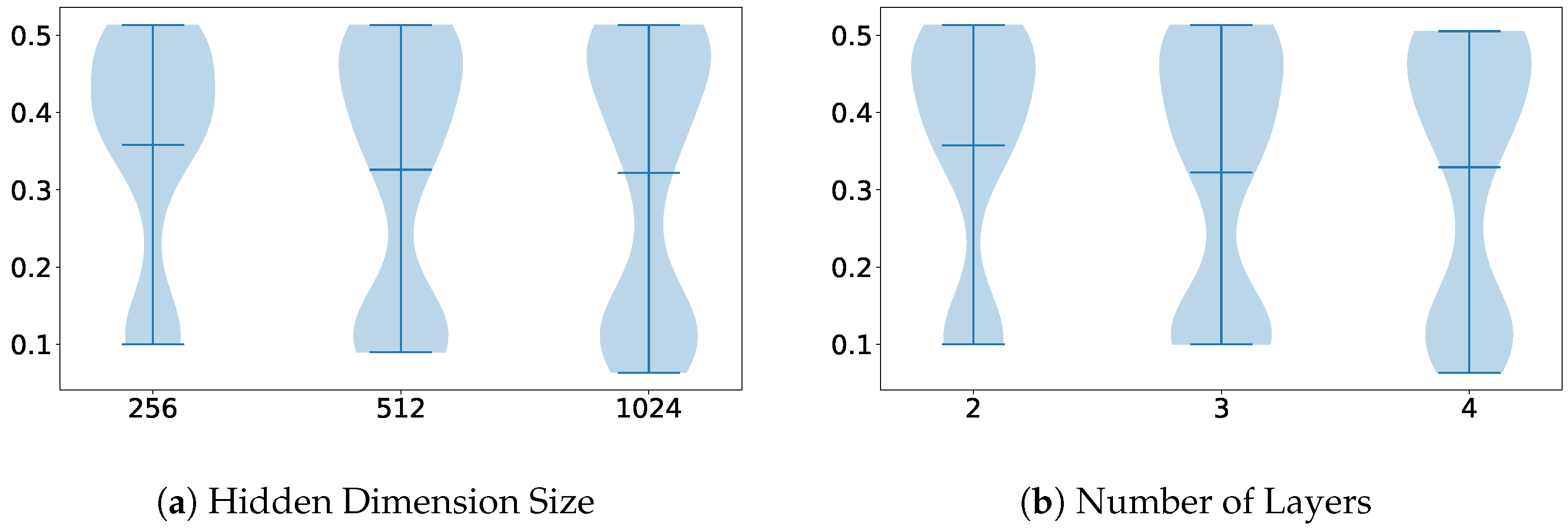
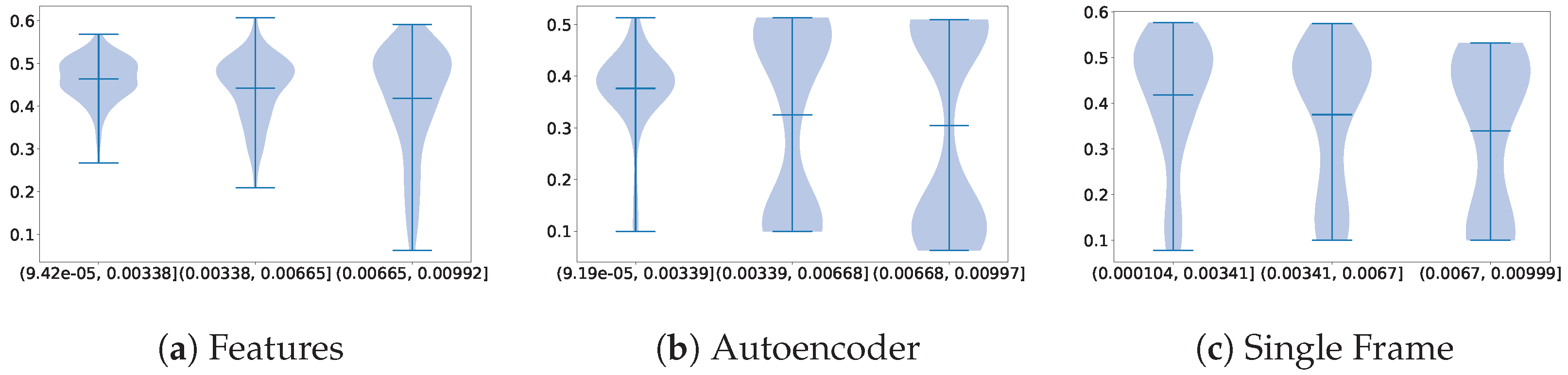
The first comparison we made was between the dataset’s baselines and the method labeled Features, where we proposed the use of the architectural backbones of the baseline to extract some features that would later be classified using an MLP. In the comparison shown in Figure 6, we can observe that while the best architecture for the baseline was ResNet3D, the backbone that obtained the most meaningful features was the Swin Transformer.
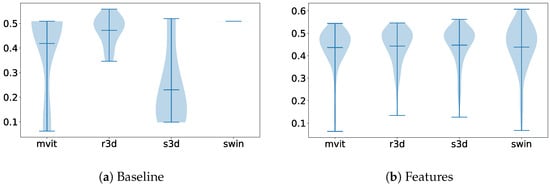
Figure 6.
Violin plots illustrating the distribution of parameter importance, comparing the dimensionality reduction method labeled Features with the overall performance of the other methods on the Visual WetlandBirds Dataset test set.
5.2. Autoencoder
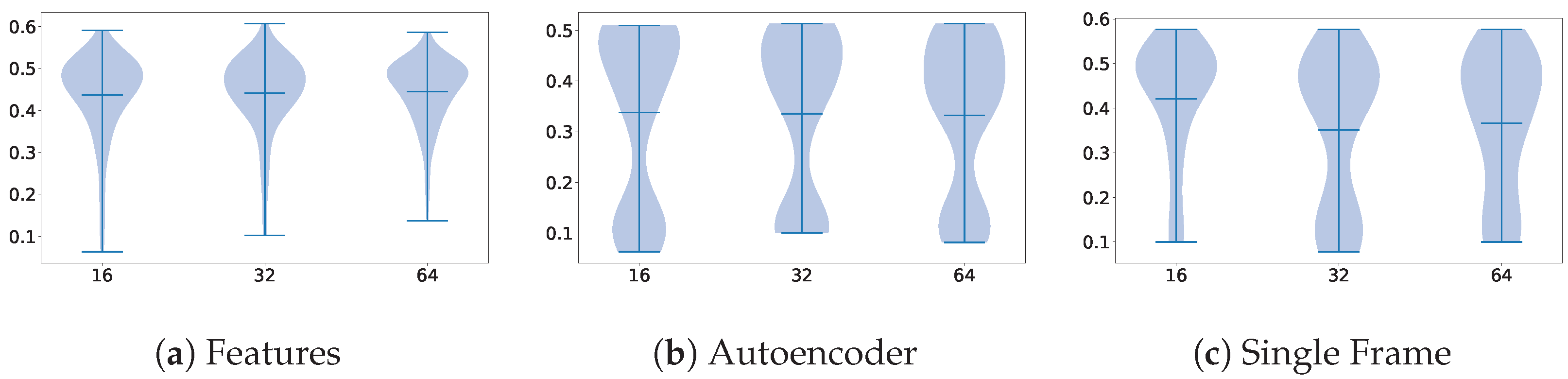
For the Autoencoder technique, in Figure 7, we can observe a correlation between certain architecture components and their performance. The information that can be extracted from these plots is that the smaller the encoder, the better performance. As the number of samples in the dataset that we used was not too high, smaller models can better capture insights from the data without massive amounts of overfitting, which hinders the quality of the extracted features.
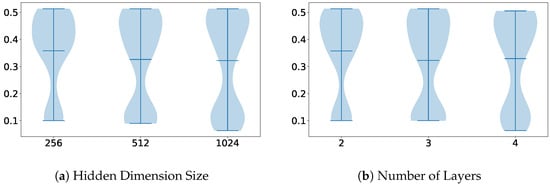
Figure 7.
Violin plots illustrating the distribution of parameter importance, comparing the Autoencoder dimensionality reduction method with the overall performance of the other methods on the Visual WetlandBirds Dataset test set.
However, even with the smaller models, the performance remains the lowest among all the approaches, exhibiting significant overfitting. Unlike the other methods, which benefitted from pre-trained weights, training the Autoencoder from scratch on this limited dataset led to its failure in adequately capturing the distribution of diverse actions.
5.3. Single Frame
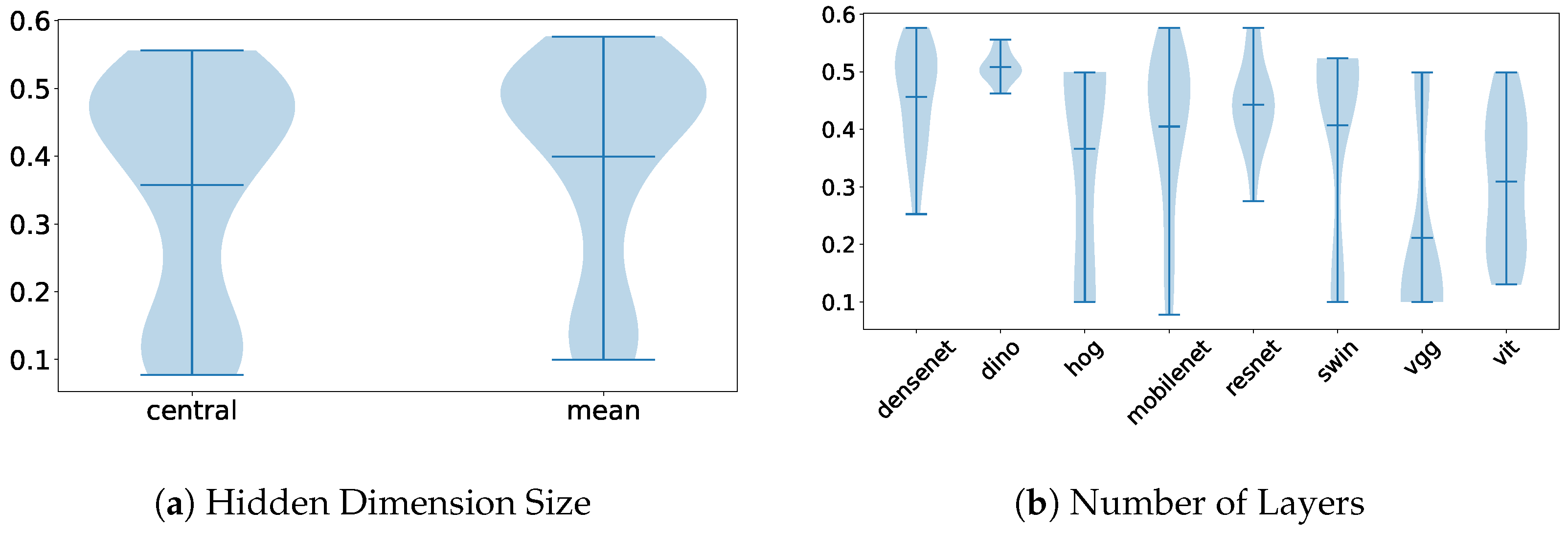
For the single-frame technique, Figure 8 illustrates the impact of the method used to select the single frame and the choice of image model on feature extraction. As shown, the mean image provides more information and achieves slightly better performance. Among the image feature extractors, the ResNet architecture produced the best accuracy on the test set.
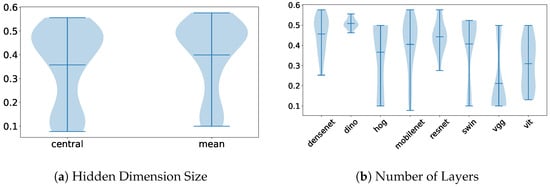
Figure 8.
Violin plots illustrating the distribution of parameter importance, comparing the single-frame dimensionality reduction method with the overall performance of the other methods on the Visual WetlandBirds Dataset test set.
Although temporal information was lost, this approach demonstrates strong performance, even achieving the best results in certain metrics. Furthermore, while the reduction in data size was not the most substantial, the computation of the reduced representation was significantly faster, as it relied on a single image rather than processing an entire video sequence.
5.4. Other Parameters
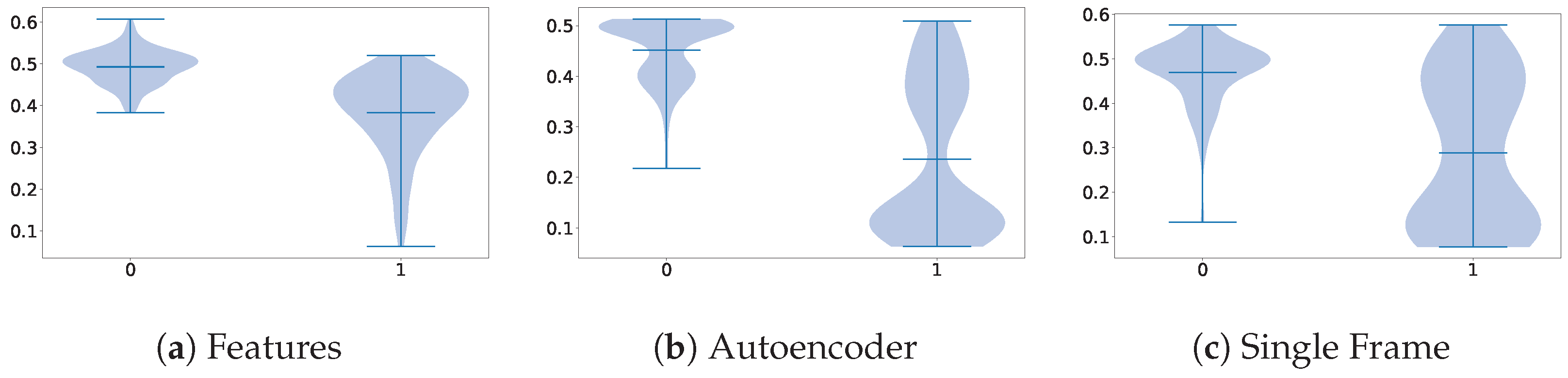
Finally, Figure 9, Figure 10 and Figure 11 display the effect of different parameters on the performance of the different dimensionality reduction techniques that we proposed. Concerning the batch size, we can observe that the differences are minimal, with the smallest being slightly better overall. Choosing not to assign class weights to the losses during training led to higher performance across all the methods. And, concerning learning rates, the smallest ones seem to work better with this particular combination of methods and dataset.
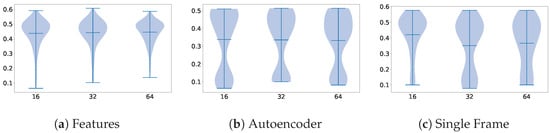
Figure 9.
Impact of batch size on the performance of each proposed method.
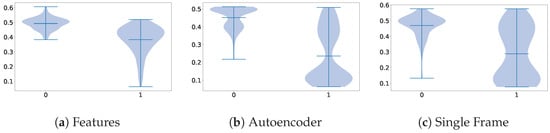
Figure 10.
Impact of class weight on the performance of each proposed method.
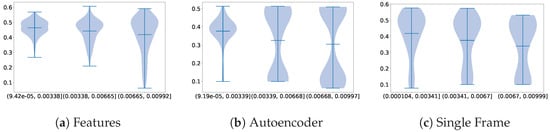
Figure 11.
Impact rate on the performance of each proposed method.
6. Conclusions
We explored various methods to reduce the dimensionality of videos from the Visual WetlandBirds Dataset for bird action classification. Among the approaches we proposed, the most effective in terms of accuracy and dimensionality reduction utilizes a feature extractor based on a Swing Transformer pre-trained on the Kinetics 400 dataset. This method outperformed the current state-of-the-art techniques while achieving a remarkable reduction in the classifier input size of over 6000 times. As a result, it significantly decreased both the training time and the computational resources required.
While our study was specifically tailored to the Visual WetlandBirds Dataset, the principles we introduced can be applied to other datasets featuring similar challenges—namely, fast movements in noisy natural environments. This flexibility makes our approach well suited for a wide range of animal action videos captured in real-world settings. Consequently, our work opens up promising avenues for future research, especially as new comparable datasets emerge and bring forth fresh challenges in action detection and classification.
Although we conducted an exhaustive ablation study of the methods we tested, several topics for future work remain open. While we implemented various dimensionality reduction techniques, there are other traditional methods we have yet to explore. Additionally, combining the reduced representations we proposed could further enhance the classifiers’ performance. Finally, even though it is beyond the scope of this paper, applying these reduced representations to the entire pipeline of action detection and classification could offer valuable insights into the quality of the reduction techniques that we proposed.
Author Contributions
Conceptualization, P.R.-P. and D.O.-P.; methodology, P.R.-P., D.O.-P. and J.G.-R.; software, P.R.-P., D.O.-P., D.M.-P., M.B.-L. and J.R.-J.; validation, P.R.-P., D.O.-P., D.M.-P., M.B.-L., H.H.-L. and A.I.; formal analysis, P.R.-P., D.O.-P., D.M.-P. and M.B.-L.; investigation, P.R.-P., D.O.-P. and J.G.-R.; resources, J.G.-R., S.K., D.V. and D.N.; data curation, P.R.-P., D.O.-P., H.H.-L. and A.I.; writing—original draft preparation, P.R.-P., D.O.-P., D.M.-P., M.B.-L. and J.R.-J.; writing—review and editing, P.R.-P., D.O.-P., D.M.-P., M.B.-L., J.R.-J., H.H.-L., A.I., J.G.-R., S.K., D.V. and D.N.; validation, P.R.-P., D.O.-P., D.M.-P. and M.B.-L.; visualization, P.R.-P., D.O.-P., H.H.-L., J.R.-J. and A.I.; supervision, J.G.-R., S.K., D.V. and D.N.; project administration, J.G.-R., S.K., D.V. and D.N.; funding acquisition, J.G.-R., S.K., D.V. and D.N. All authors have read and agreed to the published version of the manuscript.
Funding
We would like to thank “A way of making Europe” European Regional Development Fund (ERDF) and MCIN/AEI/10.13039/501100011033 for supporting this work under the “CHAN-TWIN” project (grant TED2021-130890B-C21. HORIZON-MSCA-2021-SE-0 action number: 101086387, REMARKABLE, Rural Environmental Monitoring via ultra wide-ARea networKs And distriButed federated Learning). This work is part of the HELEADE project (TSI-100121-2024-24), funded by the Spanish Ministry of Digital Processing and by the European Union NextGeneration EU. This work was also supported by three Spanish national and two regional grants for PhD studies, FPU21/00414, FPU22/04200, FPU23/00532, CIACIF/2021/430 and CIACIF/2022/175.
Data Availability Statement
The dataset used during this study is publicly available at https://doi.org/10.5281/zenodo.14355257 (accessed on 15 December 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- O’Riordan, T. Environmental Science for Environmental Management; Longman: London, UK, 1995. [Google Scholar]
- Nichols, J.D.; Williams, B.K. Monitoring for conservation. Trends Ecol. Evol. 2006, 21, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Margules, C.; Usher, M. Criteria used in assessing wildlife conservation potential: A review. Biol. Conserv. 1981, 21, 79–109. [Google Scholar] [CrossRef]
- Smallwood, K.S.; Beyea, J.; Morrison, M.L. Using the best scientific data for endangered species conservation. Environ. Manag. 1999, 24, 421–435. [Google Scholar] [CrossRef] [PubMed]
- Fraixedas, S.; Lindén, A.; Piha, M.; Cabeza, M.; Gregory, R.; Lehikoinen, A. A state-of-the-art review on birds as indicators of biodiversity: Advances, challenges, and future directions. Ecol. Indic. 2020, 118, 106728. [Google Scholar] [CrossRef]
- Bellman, R.; Bellman, R.; Corporation, R. Dynamic Programming; Rand Corporation Research Study; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Li, Y.; Wu, C.Y.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. Mvitv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LO, USA, 18–24 June 2022; pp. 4804–4814. [Google Scholar]
- Rodriguez-Juan, J.; Ortiz-Perez, D.; Benavent-Lledo, M.; Mulero-Pérez, D.; Ruiz-Ponce, P.; Orihuela-Torres, A.; Garcia-Rodriguez, J.; Sebastián-González, E. Visual WetlandBirds Dataset: Bird Species Identification and Behavior Recognition in Videos. arXiv 2025, arXiv:2501.08931. [Google Scholar]
- Guo, C.; Wu, D. Feature Dimensionality Reduction for Video Affect Classification: A Comparative Study. In Proceedings of the 2018 First Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ayesha, S.; Hanif, M.K.; Talib, R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf. Fusion 2020, 59, 44–58. [Google Scholar] [CrossRef]
- Reddy, G.T.; Reddy, M.P.K.; Lakshmanna, K.; Kaluri, R.; Rajput, D.S.; Srivastava, G.; Baker, T. Analysis of Dimensionality Reduction Techniques on Big Data. IEEE Access 2020, 8, 54776–54788. [Google Scholar] [CrossRef]
- Zebari, R.; Abdulazeez, A.; Zeebaree, D.; Zebari, D.; Saeed, J. A Comprehensive Review of Dimensionality Reduction Techniques for Feature Selection and Feature Extraction. J. Appl. Sci. Technol. Trends 2020, 1, 56–70. [Google Scholar] [CrossRef]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinburgh Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Cohen, J. Applied multiple regression. In Correlation Analysis for the Behavioral Sciences/Hillsdale; Lawrence Erlbaum Associates, Inc., Publishers: Mahwah, NJ, USA, 1983; p. 07430. [Google Scholar]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964, 29, 1–27. [Google Scholar] [CrossRef]
- Klema, V.; Laub, A. The singular value decomposition: Its computation and some applications. IEEE Trans. Autom. Control 1980, 25, 164–176. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; Silva, V.d.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Sra, S.; Dhillon, I. Generalized nonnegative matrix approximations with Bregman divergences. Adv. Neural Inf. Process. Syst. 2005, 18, 283–290. [Google Scholar]
- Chao, G.; Luo, Y.; Ding, W. Recent Advances in Supervised Dimension Reduction: A Survey. Mach. Learn. Knowl. Extr. 2019, 1, 341–358. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation, parallel distributed processing, explorations in the microstructure of cognition, ed. de rumelhart and j. mcclelland. vol. 1. 1986. Biometrika 1986, 71, 6. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Dong, G.; Liao, G.; Liu, H.; Kuang, G. A review of the autoencoder and its variants: A comparative perspective from target recognition in synthetic-aperture radar images. IEEE Geosci. Remote Sens. Mag. 2018, 6, 44–68. [Google Scholar] [CrossRef]
- Li, P.; Pei, Y.; Li, J. A comprehensive survey on design and application of autoencoder in deep learning. Appl. Soft Comput. 2023, 138, 110176. [Google Scholar] [CrossRef]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Kiarashinejad, Y.; Abdollahramezani, S.; Adibi, A. Deep learning approach based on dimensionality reduction for designing electromagnetic nanostructures. npj Comput. Mater. 2020, 6, 12. [Google Scholar] [CrossRef]
- Sun, G.; Wang, C.; Zhang, Z.; Deng, J.; Zafeiriou, S.; Hua, Y. Spatio-temporal Prompting Network for Robust Video Feature Extraction. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 4–6 October 2023; pp. 13541–13551. [Google Scholar] [CrossRef]
- Jiang, Y.G.; Wu, Z.; Wang, J.; Xue, X.; Chang, S.F. Exploiting Feature and Class Relationships in Video Categorization with Regularized Deep Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 352–364. [Google Scholar] [CrossRef]
- Nottebaum, M.; Roth, S.; Schaub-Meyer, S. Efficient Feature Extraction for High-resolution Video Frame Interpolation. arXiv 2022, arXiv:2211.14005. [Google Scholar] [CrossRef]
- Lan, Z.; Zhu, Y.; Hauptmann, A.G.; Newsam, S. Deep local video feature for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–7. [Google Scholar]
- Ali, H.; Sharif, M.; Yasmin, M.; Rehmani, M.H.; Riaz, F. A survey of feature extraction and fusion of deep learning for detection of abnormalities in video endoscopy of gastrointestinal-tract. Artif. Intell. Rev. 2020, 53, 2635–2707. [Google Scholar] [CrossRef]
- Abdulhussain, S.H.; Rahman Ramli, A.; Mahmmod, B.M.; Iqbal Saripan, M.; Al-Haddad, S.; Baker, T.; Flayyih, W.N.; Jassim, W.A. A Fast Feature Extraction Algorithm for Image and Video Processing. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Pang, Y.; Yan, H.; Yuan, Y.; Wang, K. Robust CoHOG Feature Extraction in Human-Centered Image/Video Management System. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2012, 42, 458–468. [Google Scholar] [CrossRef]
- Zin, T.T.; Kobayashi, I.; Tin, P.; Hama, H. A General Video Surveillance Framework for Animal Behavior Analysis. In Proceedings of the 2016 Third International Conference on Computing Measurement Control and Sensor Network (CMCSN), Matsue, Japan, 20–22 May 2016; pp. 130–133. [Google Scholar] [CrossRef]
- Fan, J.; Jiang, N.; Wu, Y. Automatic video-based analysis of animal behaviors. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, 26–29 September 2010; pp. 1513–1516. [Google Scholar] [CrossRef]
- Stern, U.; He, R.; Yang, C.H. Analyzing animal behavior via classifying each video frame using convolutional neural networks. Sci. Rep. 2015, 5, 14351. [Google Scholar] [CrossRef]
- Can, C.; Yan, X.; Baoping, Y. Morphology classification and behaviors identification of birds in scientific video. In Proceedings of the 3rd International Conference on Multimedia Technology (ICMT-13), Guangzhou, China, 29 November 2013; Atlantis Press: Paris, France, 2013; pp. 1449–1457. [Google Scholar] [CrossRef]
- Lin, C.W.; Chen, Z.; Lin, M. Video-based bird posture recognition using dual feature-rates deep fusion convolutional neural network. Ecol. Indic. 2022, 141, 109141. [Google Scholar] [CrossRef]
- Saito, T.; Kanezaki, A.; Harada, T. IBC127: Video dataset for fine-grained bird classification. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Atanbori, J.; Duan, W.; Shaw, E.; Appiah, K.; Dickinson, P. Classification of bird species from video using appearance and motion features. Ecol. Inform. 2018, 48, 12–23. [Google Scholar] [CrossRef]
- Ge, Z.; McCool, C.; Sanderson, C.; Wang, P.; Liu, L.; Reid, I.; Corke, P. Exploiting Temporal Information for DCNN-based Fine-Grained Object Classification. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications, Gold Coast, Australia, 30 November–2 December 2016. [Google Scholar]
- Ng, X.L.; Ong, K.E.; Zheng, Q.; Ni, Y.; Yeo, S.Y.; Liu, J. Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 19023–19034. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2023. [Google Scholar]
- Van Horn, G.; Branson, S.; Farrell, R.; Haber, S.; Barry, J.; Ipeirotis, P.; Perona, P.; Belongie, S. Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 595–604. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Gemini Team Google. Gemini: A Family of Highly Capable Multimodal Models. arXiv 2024, arXiv:2312.11805.
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Selva, J.; Johansen, A.S.; Escalera, S.; Nasrollahi, K.; Moeslund, T.B.; Clapes, A. Video Transformers: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12922–12943. [Google Scholar] [CrossRef]
- Tschannen, M.; Bachem, O.; Lucic, M. Recent advances in autoencoder-based representation learning. arXiv 2018, arXiv:1812.05069. [Google Scholar]
- Zhang, Y. A better autoencoder for image: Convolutional autoencoder. In Proceedings of the ICONIP17-DCEC. 2018. Available online: https://users.cecs.anu.edu.au/~Tom.Gedeon/conf/ABCs2018/paper/ABCs2018_paper_58.pdf (accessed on 23 March 2017).
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.V.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Darcet, T.; Oquab, M.; Mairal, J.; Bojanowski, P. Vision Transformers Need Registers. arXiv 2023, arXiv:2309.16588. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Déniz, O.; Bueno, G.; Salido, J.; De la Torre, F. Face recognition using histograms of oriented gradients. Pattern Recognit. Lett. 2011, 32, 1598–1603. [Google Scholar] [CrossRef]
- Bhattarai, B.; Subedi, R.; Gaire, R.R.; Vazquez, E.; Stoyanov, D. Histogram of oriented gradients meet deep learning: A novel multi-task deep network for 2D surgical image semantic segmentation. Med. Image Anal. 2023, 85, 102747. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).