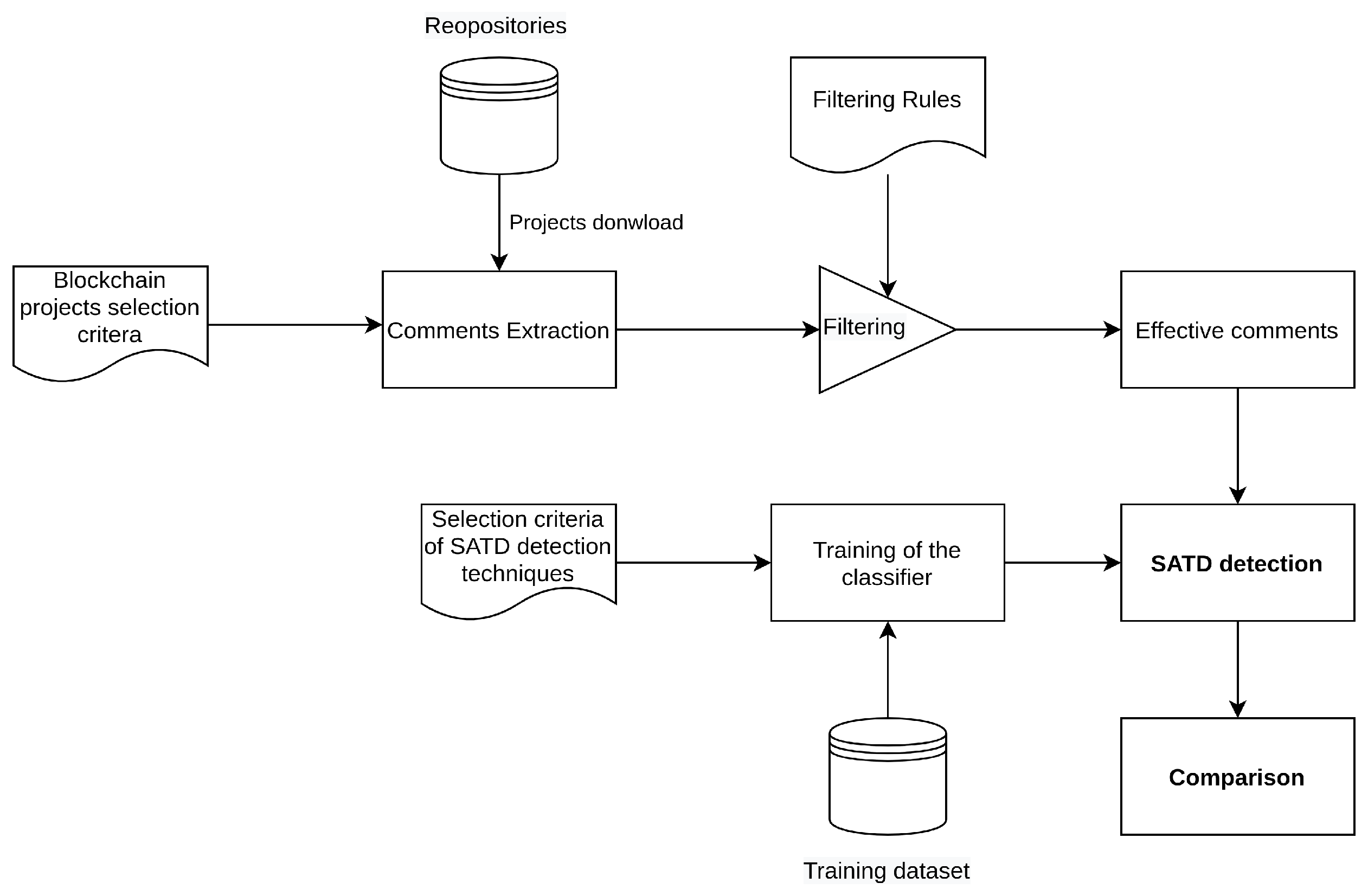
3.1. Selection of Open-Source Blockchain Projects
To conduct our study on self-admitted technical debt in blockchain projects, we focused on the top ten open-source blockchain projects in terms of market capitalization and relevance in terms of repository content. Projects that do not provide source code have been rejected.
At the end of the selection, the following projects were chosen: Bitcoin, Ethereum, USD Coin, Binance, Terra, Xrp, Polkadot, Cardano, Avalanche, and Solana. These projects correspond to the cryptocurrencies among those with the highest capitalization and include the most relevant projects in terms of repository content. For each project, we describe the main features below.
3.1.1. Bitcoin
The introduction of Bitcoin in 2009 began a revolution in the world of digital assets by allowing users to send and receive funds without the use of central intermediaries. Each block in the bitcoin blockchain contains a set of transactions and an encryption that binds it to the previous block. This structure gives rise to the term blockchain and is characterized by being secure and immutable. Posted transactions cannot be edited or deleted later. The verification of the transactions on the blockchain is carried out by all the nodes of the network, and the registration of new transactions is entrusted to the miners, encouraged through proof-of-work consensus by the possibility of earning Bitcoins. The block time is about 10 min on average. Bitcoin is also the first cryptocurrency in terms of capitalization.
3.1.2. Ethereum
Ethereum is a blockchain designed for the development of decentralized applications and is the most widely used blockchain 2.0, i.e., a blockchain that can be programmed through the use of smart contracts and can be used in different scenarios. The blockchain is public and permissionless, and it employs a consensus algorithm that was initially based on Proof of Work and is now based on Proof of Stake, with an average block time of around 15 s. Ethereum has its own currency, Ether (ETH), which is the second cryptocurrency in terms of capitalization and the first in terms of daily volume.
3.1.3. Xrp (Ripple)
Ripple is a peer-to-peer protocol created by Ripple Labs 53 in 2012 for the secure, instantaneous, and low-cost global transfer of funds. Conceived to be used by banks and financial institutions, it is defined by Ripple itself as “an infrastructure technology for interbank transactions”. The native currency used in the protocol is the XRP token. Major Ripple partnerships include Accenture, American Express, Deloitte, Santander, UBS, and Unicredit. Ripple aims to solve some of the biggest problems facing banks and financial institutions in globally transferring money, especially for cross-border payments.
3.1.4. USD Coin
USD Coin is the most popular of the cryptocurrencies that fall under the definition of stablecoin, i.e., those cryptocurrencies designed to maintain a stable value over time based on the value of other currencies or commodities such as USD, gold, etc. The value of USDC is backed by collateral that equals the number of outstanding USDC, in this case, US dollars, and the value of 1 USDC always equals the value of 1 US dollar. The USD coin project aims for full financial interoperability, and for this reason, the USD coin implementation is available on several blockchain platforms, including Ethereum, Solana, and Avalanche. The issuance of USDC is reserved for the Circle consortium.
3.1.5. Cardano
Cardano is a blockchain platform for executing smart contracts released in 2017 and built through peer-reviewed research. It uses a proof-of-stake consensus protocol called Ouroboros, and its blockchain is structured on different levels, each focused on particular characteristics such as scalability or security. Cardano is part of the projects trying to solve some intrinsic problems of the first generation of blockchains, such as the scalability and speed of transactions. The focus is therefore on building a more sustainable and balanced blockchain ecosystem.
3.1.6. Terra
Terra is a blockchain designed to provide a stable and scalable infrastructure for payments and financial apps. It was designed to be used as a platform for e-commerce financial applications and offers an efficient solution for low-cost peer-to-peer transactions. Terra is also a decentralized and secure system that uses blockchain technology to ensure the transparency and security of transactions. The native cryptocurrency is the stablecoin of the same name, which is associated with a reserve asset cryptocurrency called Luna.
3.1.7. Polkadot
Polkadot is a multi-chain blockchain designed to provide an infrastructure for building different blockchains and interconnecting them. Polkadot was designed to overcome the limitations of single blockchains, such as scalability and interoperability, by providing a flexible infrastructure for building many decentralized applications. The Polkadot blockchain uses a relay chain system to connect to different blockchains, making them able to exchange information and currencies with each other. This makes it possible to create an interconnected ecosystem of different blockchains and applications, paving the way for many new opportunities for blockchain technology. Additionally, Polkadot offers a secure and scalable platform for developing new blockchain and decentralized technologies.
3.1.8. Avalanche
Avalanche is a blockchain platform launched in 2020 with the aim of ensuring scalability and high performance with up to 6500 transactions per second. Conceived to be a platform for decentralized applications, it stands out for guaranteeing predictable and specific fees. The Avalanche network consists of three different blockchains: the X-Chain, C-Chain, and P-Chain. In addition, the Avalanche platform allows developers to build application-specific blockchains (called subnets). The consensus protocol is Proof of Stake.
3.1.9. Binance
Binance is a platform for financial services and cryptocurrency exchanges. In addition to offering an exchange platform, Binance has also launched its own blockchain, known as Binance Chain. Binance Chain was designed to provide a highly efficient and decentralized solution for exchanging digital tokens. Originally known as Binanche chain, the system is now called Build N Build chain (BNB chain) and is the blockchain used by Binance services. This is composed of two blockchains, the Beacon chain for block validation and governance and the Smart Chain, which is EVM-compatible and therefore capable of run smart contracts.
3.1.10. Solana
Solana is an open-source blockchain platform that uses a consensus protocol called Proof-of-History (PoH) to increase the speed and efficiency of transactions. Solana is designed to be a high-performance platform for building Apps (Decentralized Applications) and DeFi (Decentralized Finance). The smart contract programming language is rust.
Table 1 summarizes the blockchain projects chosen for SATD analysis, with the related programming languages used in the project and the links to the repositories
3.2. Comment Extraction
This phase includes extracting the comments from the source files, serializing the comments into csv files, and filtering the comments to remove sources of noise.
To extract comments, a copy of each project’s code was downloaded first. The following step was to extract the comments from the source code. In terms of the programming languages used, each blockchain project turned out to be a diverse set. For the reason that there are so many languages, a tool (available at
github.com/StefanoOr/RecuperoCommentiDeBitoTecnio, accessed on 10 June 2023) was developed by us for this work that extrapolates the comments for any language in
Table 1. The tool allows the extraction of comments and their characterization in terms of length, number of lines, position in the file.
The operation of the extractor is as follows:
Once the path of the folder containing the repository has been assigned, the program recursively enters all the subdirectories, and whenever it finds a code file (recognized through a list of extensions), the file is read, and the comments are extrapolated based on the types of syntax of language comments.
Whenever a file with a specific extension is found, the program reads the file line by line, and when it finds a comment based on the syntax of the language, it inserts the comment into a structured list.
After reading the source file, the list contains all extracted comments, and for each comment contains information about the line number, column number, and length of the comment.
Once the previous operation is finished, a CSV file is created with the same name as the source file, to which the “.csv” extension is added. It contains all the comments extrapolated from the file and some relevant information, such as the position of the comment within the file. The newly created file will be placed in a specific folder.
The result of this operation is a number of CSV files equal to the number of source files present for each repository, and each CSV file will contain all the comments of the corresponding source file. The set of CSV files represents our initial dataset to analyze.
For the SATD analysis, once all the comments from all the files have been extracted, the files are merged into a single file using a script created for the purpose. The script recursively takes the “.csv” files and, for each file containing the comments extracted above, removes the character structures used in the syntax of the language to indicate the comments (for example, ‘//’ or ‘/ *’ and ‘*/’), punctuation characters (for example, ‘,’, ‘…’, ‘;’, ‘:’), and any extra white space characters (for example, ‘ ’, ‘\t’, ‘\n’), and finally we convert all the comments to lowercase, the comment once it has been cleaned of punctuation marks is placed in another CSV file. However, we have decided not to remove the exclamation and question marks. These specific punctuations are helpful when identifying comments with SATD. Once this process is finished, we will have, as a final result, a single CSV file per project that contains all the comments of the repository.
Table 2 shows an example of the contents of each CSV file. The “Line” and “Column” data indicate where the comment is located within the source file, and the “Number of lines” indicates how many lines the comment consists of (in the case of multiline comments).
Multi-line comments were also processed. Most programming languages support multi-line comments. However, developers can use a single-line comment set to leave a single comment. These multi-line comments often need to be combined to represent the final intention of the developer. For our study, these comments were collected and merged into a single comment.
3.4. Choice of Detection Technique and Configuration
The choice of detection technique is essentially based on considering two main aspects. The first regards the possibility of replicating the process in existing studies, i.e., accessing the method and the training dataset and the second regards having comparable results about the presence of the SATD in open source projects, which we can take as a reference for the results that will be obtained in this study. Among the techniques presented in
Section 2.2, we decided to use the technique used in [
11], as the authors provide the tool specifications and the training dataset, and discuss the results of the detection of the SATD in a selection of open source projects. We will then use NLP techniques and the Stanford Classifier, which is a Java implementation of a maximum entropy classifier [
36].
The Stanford Classifier is a machine learning tool developed by Stanford University designed to perform text classification. The classification algorithm used by this tool is based on the Maximum Entropy (MaxEnt) method [
37]. The algorithm uses several binary functions (features) that correspond to specific properties or attributes of the input text that are distinctive enough with respect to the class it belongs to. In other words, features are elementary pieces of evidence that link the fact that we observe a given d (for example, a word) with a category c that we want to predict for a new text. Examples of features are: previous word, current word; presence of suffixes; type of word (adjective, noun, verb, etc.); presence of capital letters in a specific order; tags that precede or follow the word (in, to) [
38]. The learning phase of the algorithm consists of optimizing the weights of the characteristic functions in order to maximize the joint probability of the observed data and the corresponding class labels. This process is usually completed using an optimization algorithm, such as gradient descent or coordinate optimization. The underlying principle of the MaxEnt algorithm is to find the probability distribution model that maximizes entropy (a concept related to the degree of uncertainty in a distribution) subject to specific given constraints. In other words, we try to find the most uniform model possible that is consistent with the observed information. Once trained, the Stanford Classifier can be used to assign class labels to new data based on the learned probability distribution model. The algorithm calculates the probability of each possible class label given the observation and selects the one with the highest probability as the predicted label.
To that end, a tool capable of configuring the classifier via property files, training the classifier via the training dataset, and processing the data collected in the CSV files to detect the presence of SATD in the comments has been developed. The tool takes as input the configuration property file for the classifier, the training set, and the CSV file containing the comments extracted from each repository. The classifier, once trained, will be used to assign a class label to each comment in our comments dataset. The tool makes use of the “ColumnDataClassifier” belonging to the library “edu.stanford.nlp.classify”, which allows the processing of labeled structured data organized into columns, as in the case of our csv file-based dataset.
The training dataset described in ref. [
11] is composed of 57,676 source code comments, manually categorized into SATD classification labels. Although the set pf dataset labels includes multiple categories of SATD, in order to avoid an excessive imbalance, we decide to consider only the three most represented categories: “design”, “requirements” and “withoutclassification” (i.e., absence of SATD), where “design” indicates that the comment refers to suboptimal design, including workarounds and features that need to be extended to support more features, and “requirement” indicates that the comment refers to some software requirements that have not been fully satisfied by the implementation. The training phase was repeated several times, and at each training of the classifier, the training dataset was randomly divided into two sets, training set (90% of labeled comments) and the test set (the remaining 10%).
The configuration of the classifier consists of the selection of the NLP properties the classifier has to use in its training. A configuration file (named prop) consists of a series of properties described in the “ColumnDataClassifier” class [
36].
In our study, we defined two different props. A first prop was extracted from the reference study [
11], while we created the second prop aiming to optimize training performance, i.e., to reach the highest possible score of the “Micro-averaged accuracy/F1” and “Macro-average F1”, These two configuration files describe the configuration of two different SATD detection models. The two configurations differ in that in the configuration used in ref. [
11], the use of N-Grams is set to false and the use of lowercase words is set to true, while in the prop we created, the use of N-Grams is set to true, the use of split words is set to true, and the length of the N-Grams is limited between 1 and 5. In summary, the main differences between the two configuration files are the use of N-Grams, the form of the split words, and the length of the N-Grams.
For each class, the results show the number of true positives (TP), false negatives (FN), false positives (FP), and true negatives (TN). True positives are cases where the maximum entropy classifier correctly identifies, while true negatives are comments without technical debt that are classified as such. The table also shows the accuracy, precision, recall and F1 measure for each class. The classes in question are the three classes present in the dataset, namely WITHOUTCLASSIFICATION, REQUIREMENT and DESIGN.
Using the TP, TN, FP, and FN values, we are able to evaluate the performance of different classifier configurations. Performances are evaluated in terms of
The Micro-averaged F1 score is used to evaluate the overall performance of a classifier and has a value between 0 and 1.
Table 4 lists the performance of the training by using the same configuration as in [
11], while
Table 5 lists the performance of the training obtained using the optimized configuration.
We can see from tables that the performances obtained through the optimized configuration outperform those of the reference configuration. This is essentially given by a reduction in false positives and this is reflected in a substantial reduction in the number of comments classified as SATD compared with what was obtained using the reference configuration.
Although our configuration has better results in terms of score, we felt it necessary to make some considerations. As mentioned, the optimized classifier uses a different model than the reference study. By running a test classification on one of the blockchain projects under review (Avalanche) with both classifiers, the results obtained highlight the differences between the two models. In particular, as shown in
Table 6, the optimized classifier detects a number of comments with a SATD 85% lower than the classifier of the reference configuration.
Additionally, if we manually examine comments that were classified as SATD using the reference setup but not the optimized configuration, we discover that these are not necessarily false positives. For example, comments that have keywords like TODO, FIXME, and XXX are labeled “WITHOUT CLASSIFICATION” by the classifier with the optimized configuration. The same comments are detected as SATD by the classifier with the reference configuration. Some of these comments and their classification labels are shown in
Table 7.
As a further consideration, we must mention that this study aims to compare the presence of SATD in blockchain projects with that in other open-source projects. Having chosen the study in [
11] as a reference, the same configuration must be maintained.
Both considerations lead us to decide to use the reference configuration in [
11] for SATD detection in blockchain projects.








{kind=link}