
Zero-Inflated Patent Data Analysis Using Generating Synthetic Samples



Abstract
:
1. Introduction
2. Research Background
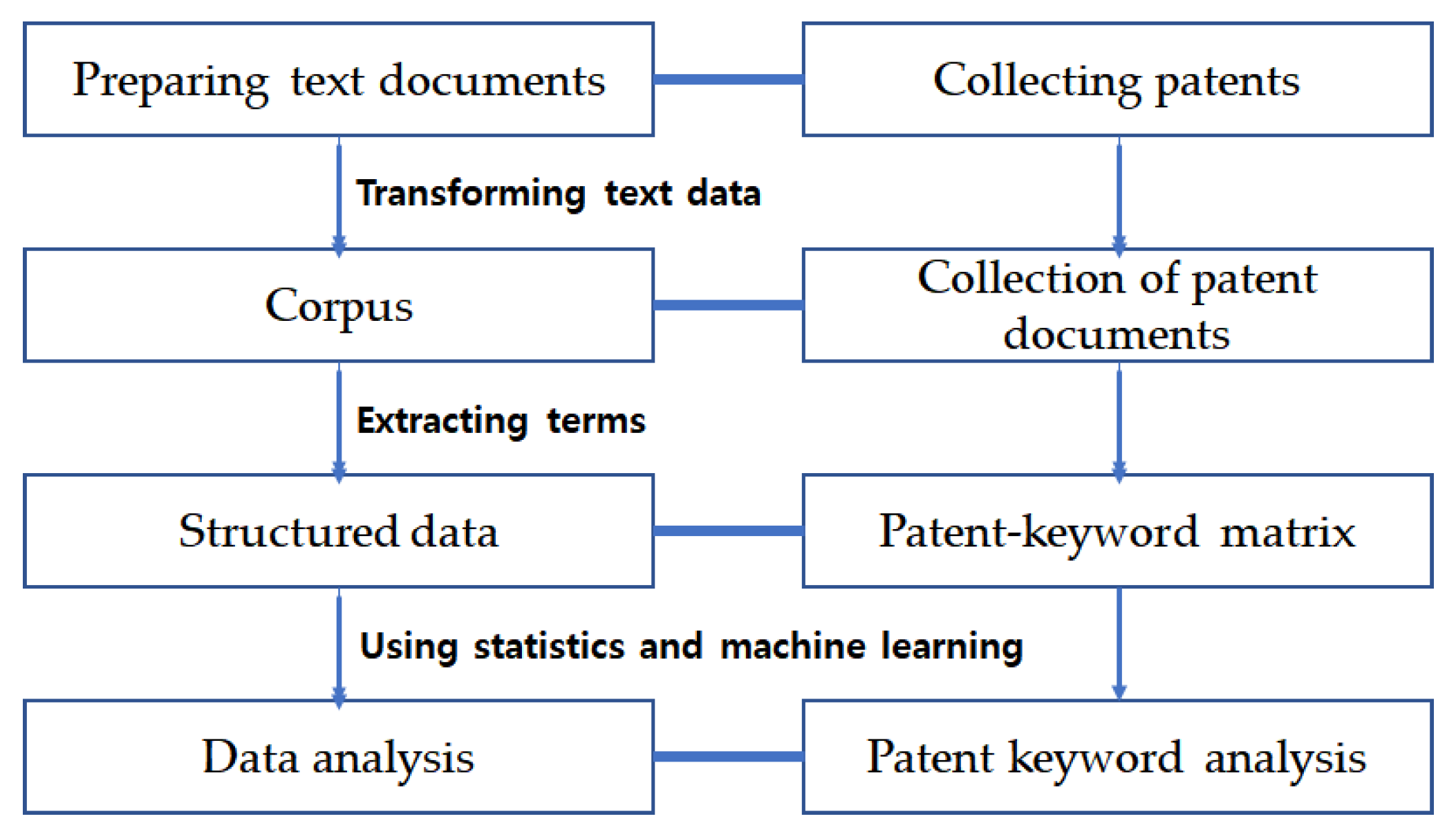
2.1. Patent Data
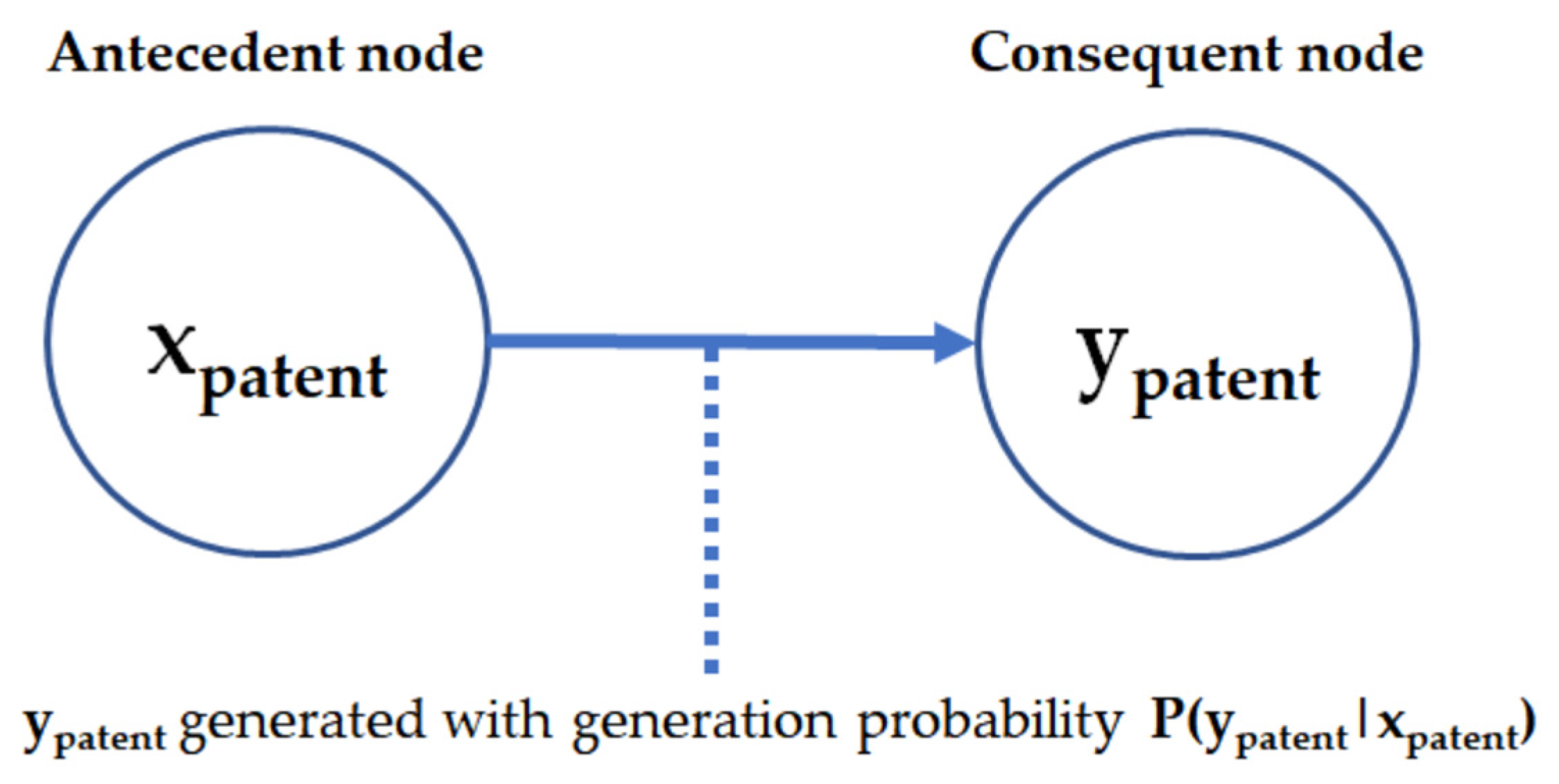
2.2. Zero-Inflated Problems in Text Data
3. Methods
4. Results
4.1. Experimental Result Using Patent Big Data
4.2. Simulation Study with Zero-Inflated Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cameron, A.C.; Trivedi, P.K. Regression Analysis of Count Data, 2nd ed.; Cambridge University Press: New York, NY, USA, 2013. [Google Scholar]
- Kim, J.M.; Jun, S. Zero-Inflated Poisson and Negative Binomial Regressions for Technology Analysis. Int. J. Softw. Eng. Appl. 2016, 10, 431–448. [Google Scholar] [CrossRef]
- Feng, C.X. A comparison of zero-inflated and hurdle models for modeling zero-inflated count data. J. Stat. Distrib. Appl. 2021, 8, 8. [Google Scholar] [CrossRef]
- Carvalho, F.J.; de Santana, D.G.; Sampaio, M.V. Modeling overdispersion, autocorrelation, and zero-inflated count data via generalized additive models and Bayesian statistics in an Aphid population study. Neotrop. Entomol. 2020, 49, 40–51. [Google Scholar] [CrossRef]
- Hilbe, J.M. Negative Binomial Regression, 2nd ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Hilbe, J.M. Modeling Count Data; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Hunt, D.; Nguyen, L.; Rodgers, M. Patent Searching Tools & Techniques; Wiley: Hoboken, NJ, USA, 2007. [Google Scholar]
- Roper, A.T.; Cunningham, S.W.; Porter, A.L.; Mason, T.W.; Rossini, F.A.; Banks, J. Forecasting and Management of Technology; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Kim, S.; Yoon, B. Patent infringement analysis using a text mining technique based on SAO structure. Comput. Ind. 2021, 125, 103379. [Google Scholar] [CrossRef]
- Wang, H.C.; Chi, Y.C.; Hsin, P.L. Constructing patent maps using text mining to sustainably detect potential technological opportunities. Sustainability 2018, 10, 3729. [Google Scholar] [CrossRef] [Green Version]
- Feng, X.; Fuhai, L. Patent Text Mining and Informetric-based Patent Technology Morphological Analysis: An Empirical Study. Technol. Anal. Strateg. Manag. 2021, 24, 467–479. [Google Scholar] [CrossRef]
- Feinerer, I.; Hornik, K.; Meyer, D. Text mining infrastructure in R. J. Stat. Softw. 2008, 25, 1–54. [Google Scholar] [CrossRef] [Green Version]
- Feinerer, I.; Hornik, K. Package ‘tm’ Ver. 0.7–8, Text Mining Package. Available online: https://cran.microsoft.com/web/packages/tm/tm.pdf (accessed on 1 March 2022).
- R Development Core Team. R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing. Available online: http://www.R-project.org (accessed on 1 March 2022).
- Nowok, B.; Raab, G.M.; Dibben, C. synthpop: Bespoke Creation of Synthetic Data in R. J. Stat. Softw. 2016, 74, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: Waltham, MA, USA, 2012. [Google Scholar]
- Nowok, B.; Raab, G.M.; Snoke, J.; Dibben, C.; Nowok, M.B. Package ‘synthpop’ Ver. 1.7–0, Generating Synthetic Versions of Sensitive Microdata for Statistical Disclosure Control. Available online: https://cran.r-project.org/web/packages/synthpop/synthpop.pdf (accessed on 1 March 2022).
- Raab, G.M.; Nowok, B.; Dibben, C. Practical Data Synthesis for Large Samples. J. Priv. Confid. 2018, 7, 67–97. [Google Scholar] [CrossRef] [Green Version]
- Reiter, J.P. Using CART to Generate Partially Synthetic Public Use Microdata. J. Off. Stat. 2005, 21, 441–462. [Google Scholar]
- Snoke, J.; Raab, G.M.; Nowok, B.; Dibben, C.; Slavkovic, A. General and specific utility measures for synthetic data. J. R. Stat. Soc. Ser. A 2018, 181, 663–688. [Google Scholar] [CrossRef] [Green Version]
- Bruce, P.; Bruce, A.; Gedeck, P. Practical Statistics for Data Scientists; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Theodoridis, S. Machine Learning A Bayesian and Optimization Perspective; Elsevier: London, UK, 2015. [Google Scholar]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- USPTO, The United States Patent and Trademark Office. Available online: http://www.uspto.gov (accessed on 1 March 2022).
- KIPRIS, Korea Intellectual Property Rights Information Service. Available online: www.kipris.or.kr (accessed on 1 March 2022).
- Jun, S.; Park, S.; Jang, D. Document Clustering Method Using Dimension Reduction and Support Vector Clustering to Overcome Sparseness. Expert Syst. Appl. 2014, 41, 3204–3212. [Google Scholar] [CrossRef]
- Amatya, A.; Demirtas, H. Simultaneous generation of multivariate mixed data with Poisson and normal marginals. J. Stat. Comput. Simul. 2015, 85, 3129–3139. [Google Scholar] [CrossRef]
- Amatya, A.; Demirtas, H. PoisNor: An R package for generation of multivariate data with Poisson and normal marginals. Commun. Stat. Simul. Comput. 2017, 46, 2241–2253. [Google Scholar] [CrossRef]
- Li, H.; Demirtas, H.; Chen, R. RNGforGPD: An R Package for Generation of Univariate and Multivariate Generalized Poisson Data. R J. 2020, 12, 173–188. [Google Scholar] [CrossRef]
- Li, H.; Chen, R.; Nguyen, H.; Chung, Y.; Gao, R.; Demirtas, H. Package ‘RNGforGPD’ Ver. 1.1.0, Random Number Generation for Generalized Poisson Distribution. Available online: https://cran.r-project.org/web/packages/RNGforGPD/RNGforGPD.pdf (accessed on 1 March 2022).
- Vernic, R. A multivariate generalization of the generalized Poisson distribution. ASTIN Bulletin. J. Int. Actuar. Assoc. 2000, 30, 57–67. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistic | Fire | Temperature | Wind | Pressure |
|---|---|---|---|---|
| Min. | 0 | 0 | 0 | 0 |
| Median | 0 | 0 | 0 | 0 |
| Mean | 0.1146 | 0.6642 | 0.4925 | 0.4427 |
| Max. | 42 | 70 | 88 | 49 |
| Method | Parameter | Temperature | Wind | Pressure | AIC |
|---|---|---|---|---|---|
| Original | b | 0.0284 | −0.0013 | 0.0053 | 58193.7 |
| SE (b) | 0.0034 | 0.0030 | 0.0045 | ||
| With noise (SD = 0.1) | b | 0.0284 | −0.0014 | 0.0055 | 58193.7 |
| SE (b) | 0.0034 | 0.0030 | 0.0045 | ||
| With noise (SD = 0.5) | b | 0.0276 | −0.0017 | 0.0060 | 58194.9 |
| SE (b) | 0.0034 | 0.0030 | 0.0045 | ||
| With noise (SD = 1) | b | 0.0256 | −0.0020 | 0.0063 | 58199.2 |
| SE (b) | 0.0034 | 0.0030 | 0.0045 | ||
| Zero-inflated Negative Binomial | b | 0.0556 | −0.0461 | −0.0301 | 4537.4 |
| SE (b) | 0.0304 | 0.0293 | 0.0293 | ||
| Zero-inflated Poisson | b | 0.0211 | −0.0391 | −0.0092 | 6177.7 |
| SE (b) | 0.0033 | 0.0118 | 0.0086 | ||
| Synthetic sample | b | 0.0036 | −0.0021 | −0.0037 | 1647.4 |
| SE (b) | 0.0047 | 0.0055 | 0.0085 |
| Simulation | Statistic | Variable | X1 | X2 | X3 | X4 |
|---|---|---|---|---|---|---|
| Data 1 | Mean | 1.0 | 3.0 | 4.0 | 2.0 | |
| X2 | 0.352 | 0.265 | 0.342 | |||
| Correlations | X3 | 0.152 | 0.352 | |||
| X4 | 0.265 | |||||
| Data 2 | Mean | 1.0 | 1.0 | 2.0 | 2.0 | |
| X2 | 0.200 | −0.300 | 0.002 | |||
| Correlations | X3 | 0.001 | 0.003 | |||
| X4 | 0.004 |
| Simulation | Statistic | Variable | X1 | X2 | X3 | X4 |
|---|---|---|---|---|---|---|
| Data 1 | Min. | 0 | 0 | 0 | 0 | |
| Median | 1 | 3 | 4 | 2 | ||
| Mean | 1.004 | 3.000 | 3.992 | 1.994 | ||
| Max. | 7 | 12 | 14 | 10 | ||
| Variances (diagonal) & Correlations | X1 | 0.993 | 0.348 | 0.263 | 0.335 | |
| X2 | 3.026 | 0.145 | 0.355 | |||
| X3 | 4.000 | 0.256 | ||||
| X4 | 2.001 | |||||
| Data 2 | Min. | 0 | 0 | 0 | 0 | |
| Median | 1 | 1 | 2 | 2 | ||
| Mean | 1.011 | 1.015 | 1.995 | 2.006 | ||
| Max. | 7 | 7 | 11 | 10 | ||
| Variances (diagonal) & Correlations | X1 | 1.010 | 0.185 | −0.318 | −0.005 | |
| X2 | 1.022 | −0.009 | −0.004 | |||
| X3 | 2.024 | 0.012 | ||||
| X4 | 2.009 |
| Method | Parameter | X2 | X3 | X4 | AIC |
|---|---|---|---|---|---|
| Original | b | 0.1442 | 0.0874 | 0.1414 | 52,133.6 |
| SE (b) | 0.0039 | 0.0033 | 0.0049 | ||
| With noise (sigma = 0.1) | b | 0.1444 | 0.0873 | 0.1412 | 52,340.2 |
| SE (b) | 0.0039 | 0.0033 | 0.0049 | ||
| With noise (sigma = 0.5) | b | 0.1356 | 0.0869 | 0.1272 | 57,671.4 |
| SE (b) | 0.0042 | 0.0036 | 0.0052 | ||
| With noise (sigma = 1) | b | 0.1163 | 0.0814 | 0.0983 | 68,623.9 |
| SE (b) | 0.0049 | 0.0043 | 0.0057 | ||
| Zero-inflated Negative Binomial | b | 0.1204 | 0.0776 | 0.1111 | 48,333.9 |
| SE (b) | 0.0044 | 0.0037 | 0.0054 | ||
| Zero-inflated Poisson | b | 0.1204 | 0.0776 | 0.1111 | 48,331.9 |
| SE (b) | 0.0044 | 0.0037 | 0.0054 | ||
| Synthetic sample | b | 0.0077 | −0.0005 | −0.0221 | 2907.6 |
| SE (b) | 0.0190 | 0.0161 | 0.0235 |
| Method | Parameter | X2 | X3 | X4 | AIC |
|---|---|---|---|---|---|
| Original | b | 0.1809 | −0.2232 | −0.0008 | 54,081.8 |
| SE (b) | 0.0065 | 0.0046 | 0.0047 | ||
| With noise (sigma = 0.1) | b | 0.1796 | −0.2215 | −0.0013 | 54,329.7 |
| SE (b) | 0.0066 | 0.0047 | 0.0047 | ||
| With noise (sigma = 0.5) | b | 0.1450 | −0.1965 | 0.0021 | 59,454.2 |
| SE (b) | 0.0067 | 0.0050 | 0.0050 | ||
| With noise (sigma = 1) | b | 0.0915 | −0.1469 | 0.0035 | 69,674.9 |
| SE (b) | 0.0068 | 0.0056 | 0.0056 | ||
| Zero-inflated Negative Binomial | b | 0.1515 | −0.2418 | −0.0010 | 49,648.4 |
| SE (b) | 0.0074 | 0.0060 | 0.0054 | ||
| Zero-inflated Poisson | b | 0.1515 | −0.2418 | −0.0010 | 49,646.4 |
| SE (b) | 0.0074 | 0.0060 | 0.0054 | ||
| Synthetic sample | b | −0.0278 | −0.0174 | 0.0190 | 2772.0 |
| SE (b) | 0.0301 | 0.0219 | 0.0210 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uhm, D.; Jun, S. Zero-Inflated Patent Data Analysis Using Generating Synthetic Samples. Future Internet 2022, 14, 211. https://doi.org/10.3390/fi14070211
Uhm D, Jun S. Zero-Inflated Patent Data Analysis Using Generating Synthetic Samples. Future Internet. 2022; 14(7):211. https://doi.org/10.3390/fi14070211
Chicago/Turabian StyleUhm, Daiho, and Sunghae Jun. 2022. "Zero-Inflated Patent Data Analysis Using Generating Synthetic Samples" Future Internet 14, no. 7: 211. https://doi.org/10.3390/fi14070211
APA StyleUhm, D., & Jun, S. (2022). Zero-Inflated Patent Data Analysis Using Generating Synthetic Samples. Future Internet, 14(7), 211. https://doi.org/10.3390/fi14070211