
HealthFetch: An Influence-Based, Context-Aware Prefetch Scheme in Citizen-Centered Health Storage Clouds

 , ,
, , 
Abstract
:1. Introduction
2. Related Works
2.1. Data Prefetching, Caching, and Data Replication
2.2. Cloud Solutions for Health Data Storage
2.3. Advancements beyond the Related Work
3. Materials and Methods
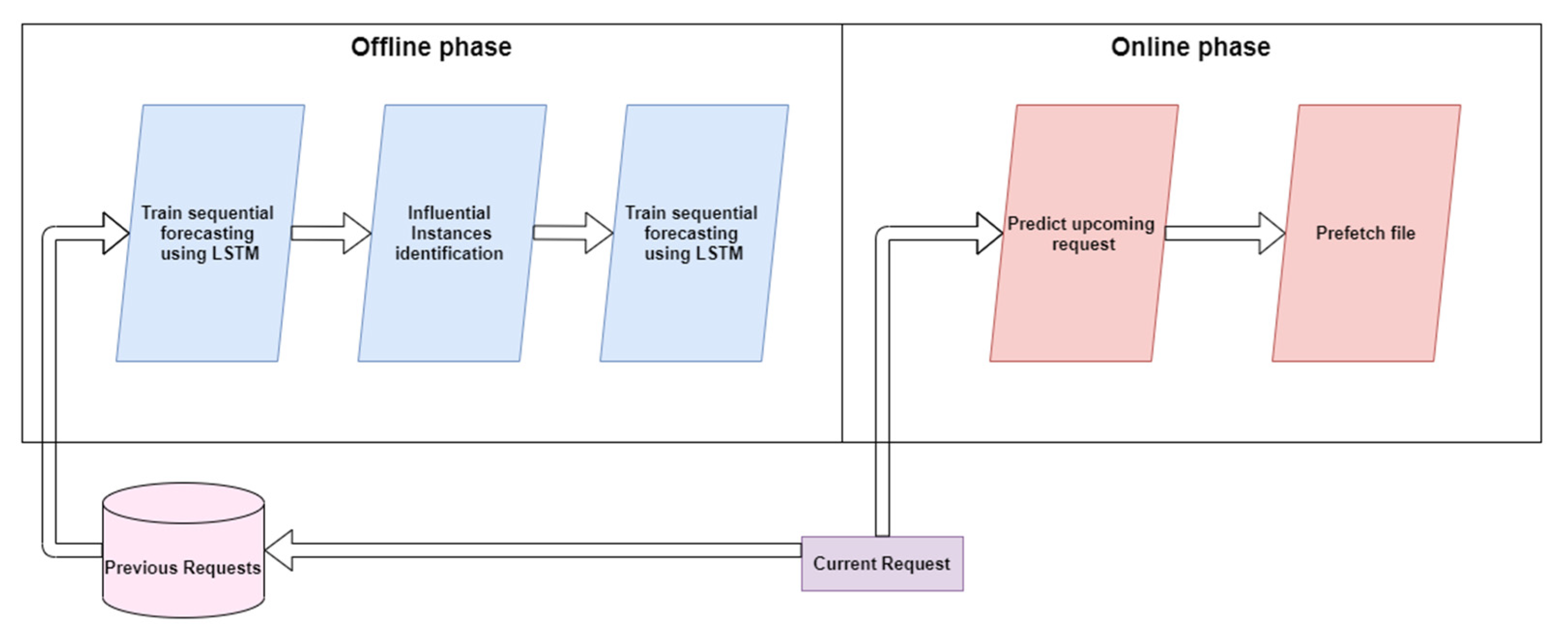
3.1. The Context-Aware Prefetch Scheme
3.1.1. The Offline Phase
| Algorithm 1 Prefetch scheme workflow |
| Input: HTTP requests data set from HCPs in the form of time series () Auxiliary Variables: , Output: Predicted health record to be prefetched () Begin HealthFetch
|
3.1.2. The Online Phase
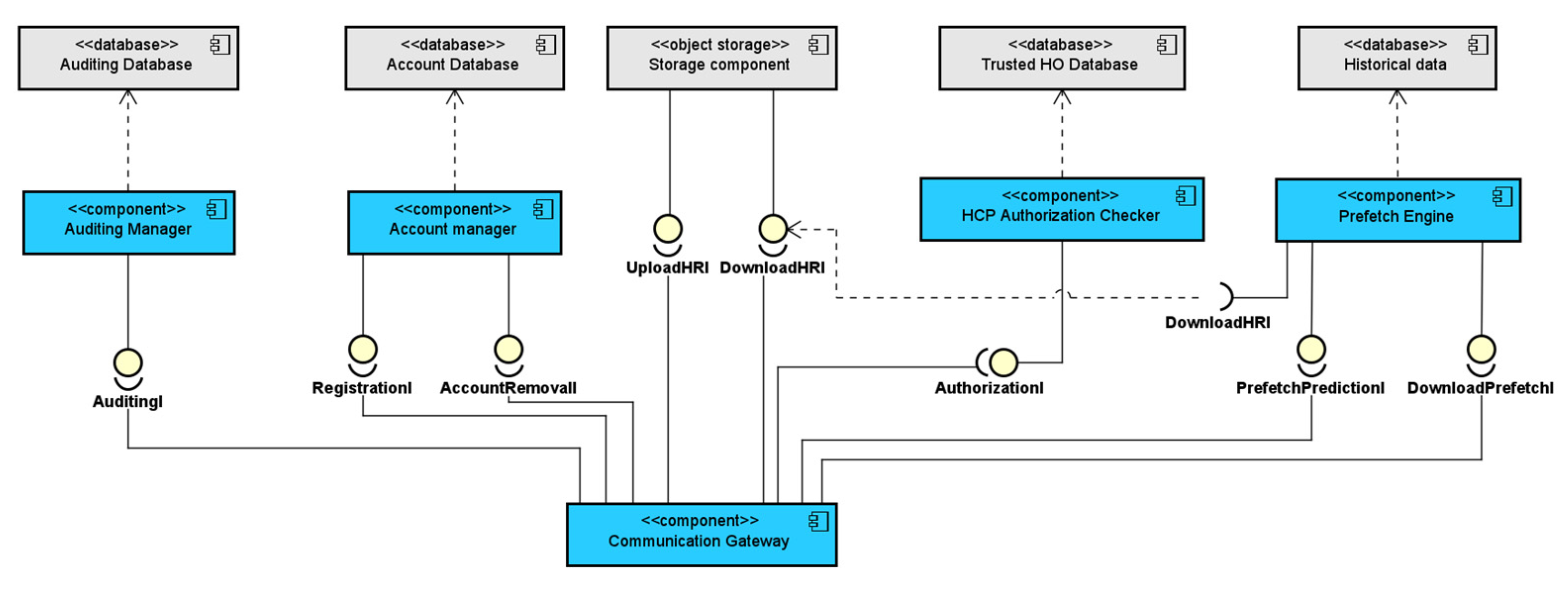
3.2. The Health Storage Cloud
- The Account Management Component, which was used for the management of the citizens’ accounts and account policies, along with the management of the healthcare institutions’ temporary account creation during emergency situations;
- The Storage Component, which was used for the storage of the citizens’ health data;
- The HCP Authorization Component, which was used for the authorization of healthcare institutions during emergency situations;
- The Auditing Manager Component, which was used for keeping logs of all actions performed by any user of the storage cloud (i.e., both citizens and healthcare professionals from authorized institutions);
- The Communication Gateway Component, which handled all incoming requests from the client side (i.e., both citizens and healthcare professionals);
- The Prefetch Engine Component, which regarded the implementation of the proposed prefetch scheme that predicted the upcoming requests from the users and prefetched the corresponding health data.
3.2.1. The Account Management Component
3.2.2. The Storage Component
3.2.3. The HCP Authorization Component
3.2.4. The Auditing Component
- List of uploads of encrypted health data performed by the citizen, including a timestamp;
- List of downloads of encrypted health data performed by the citizen, including a timestamp;
- List of approved requests by healthcare institutions;
- List of healthcare professionals and physicians that were granted access to the storage cloud through the temporary account of the healthcare institution he or she is working for;
- List of rejected requests and who they were from;
- List of downloads of encrypted health data performed by physicians from a trusted healthcare institution, including a timestamp;
- List of uploads of encrypted health data performed by physicians from a trusted healthcare institution, including a timestamp.
3.2.5. The Communication Gateway Component
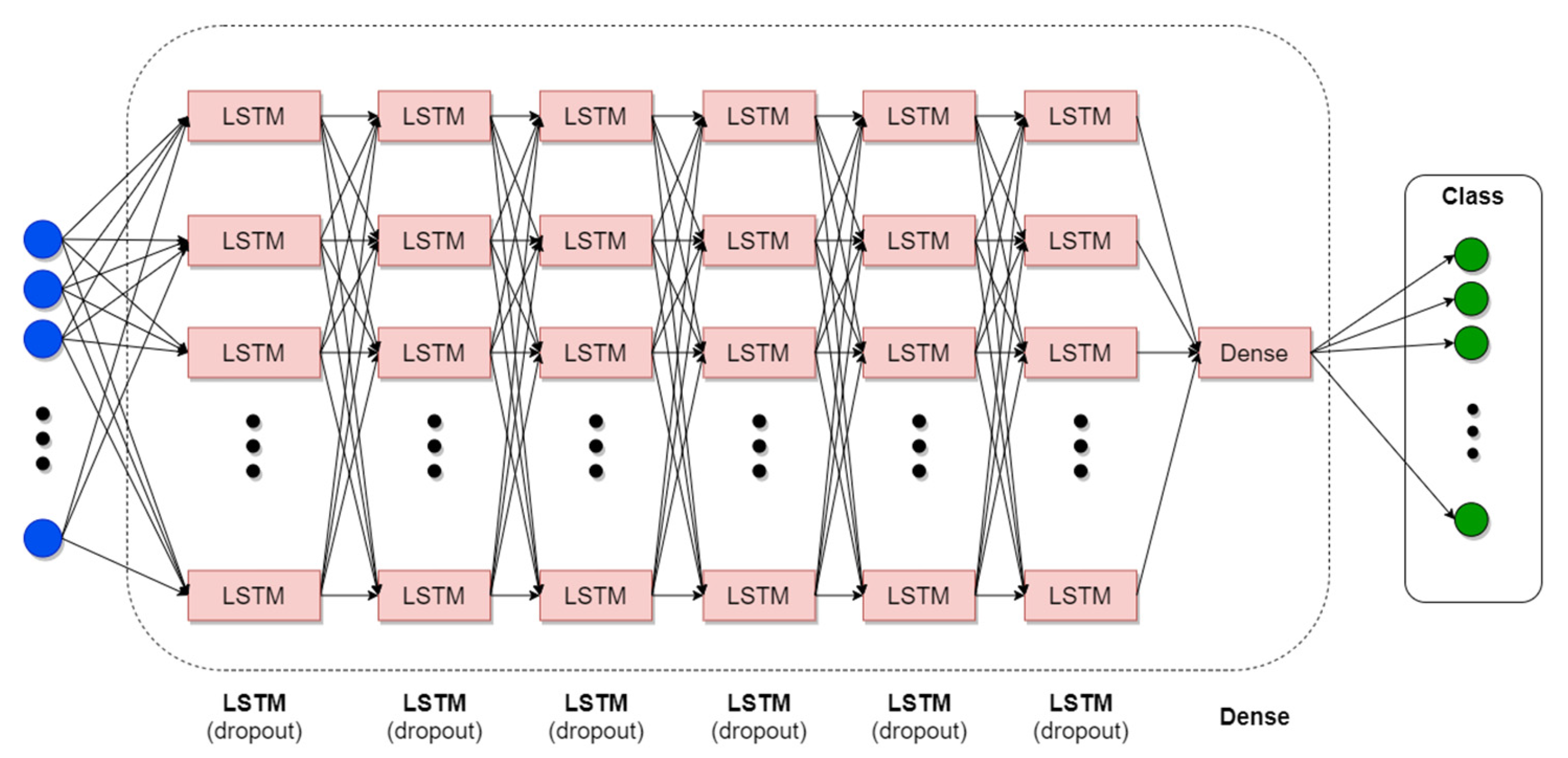
3.2.6. The Prefetch Engine Component
4. Results
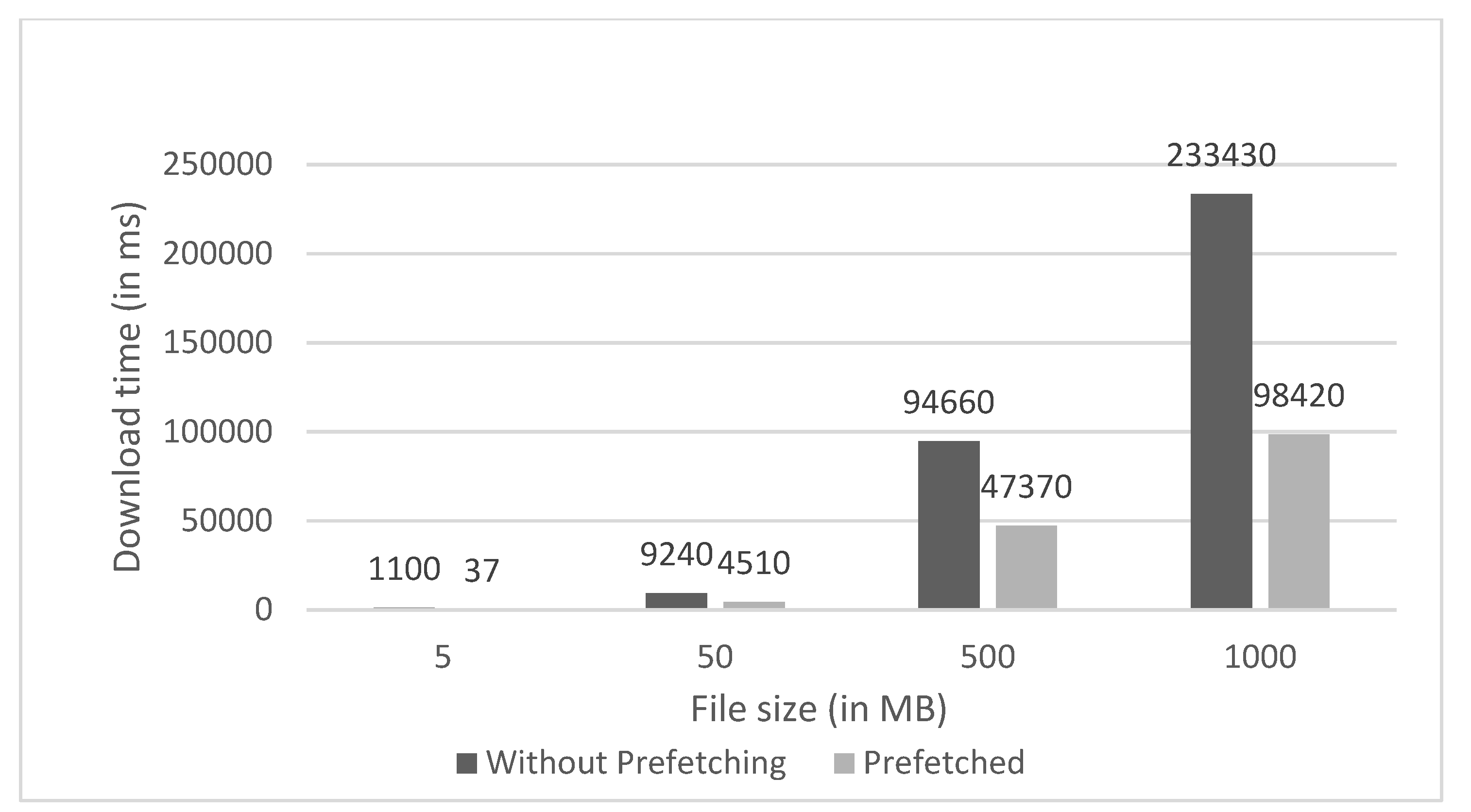
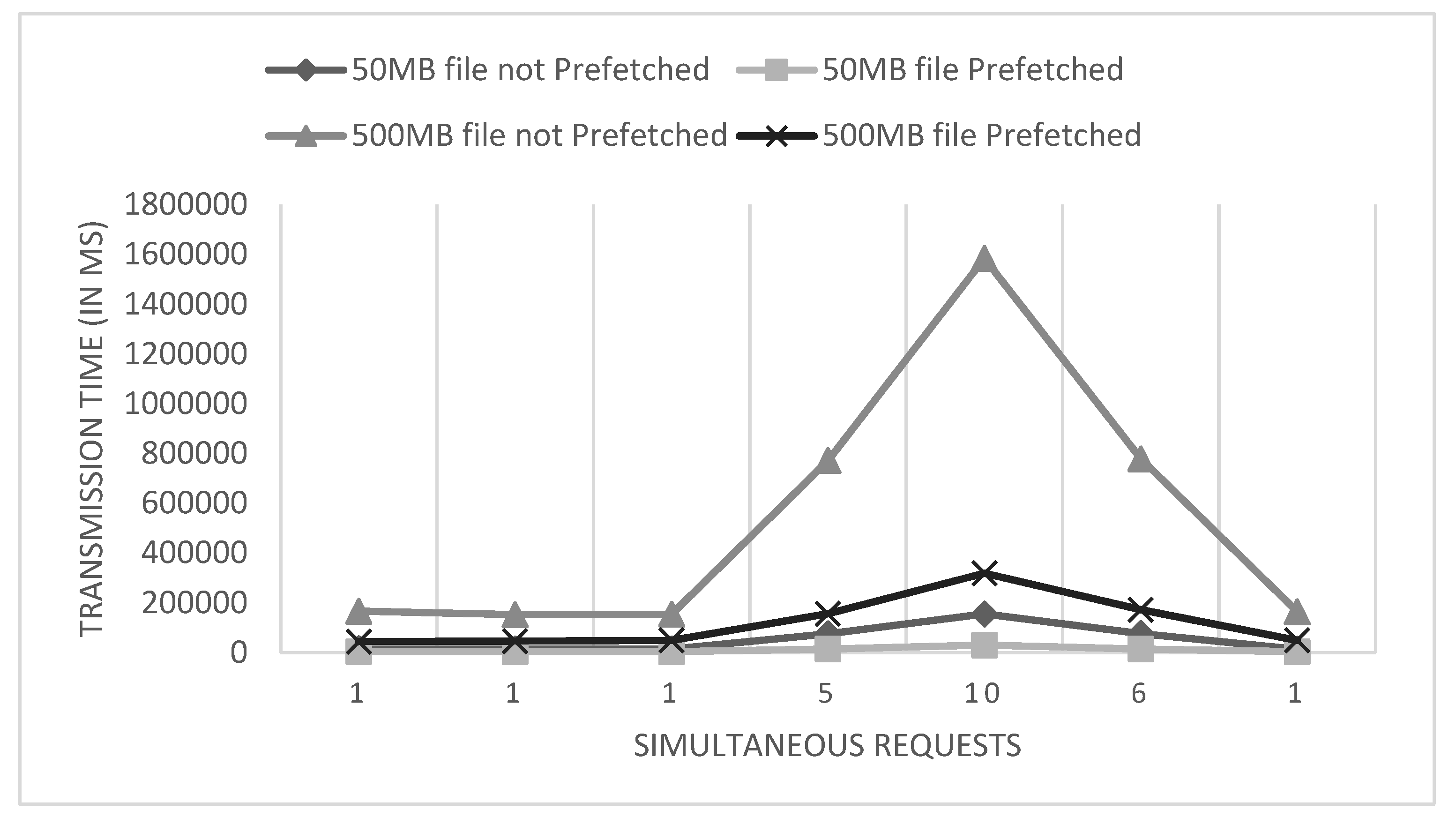
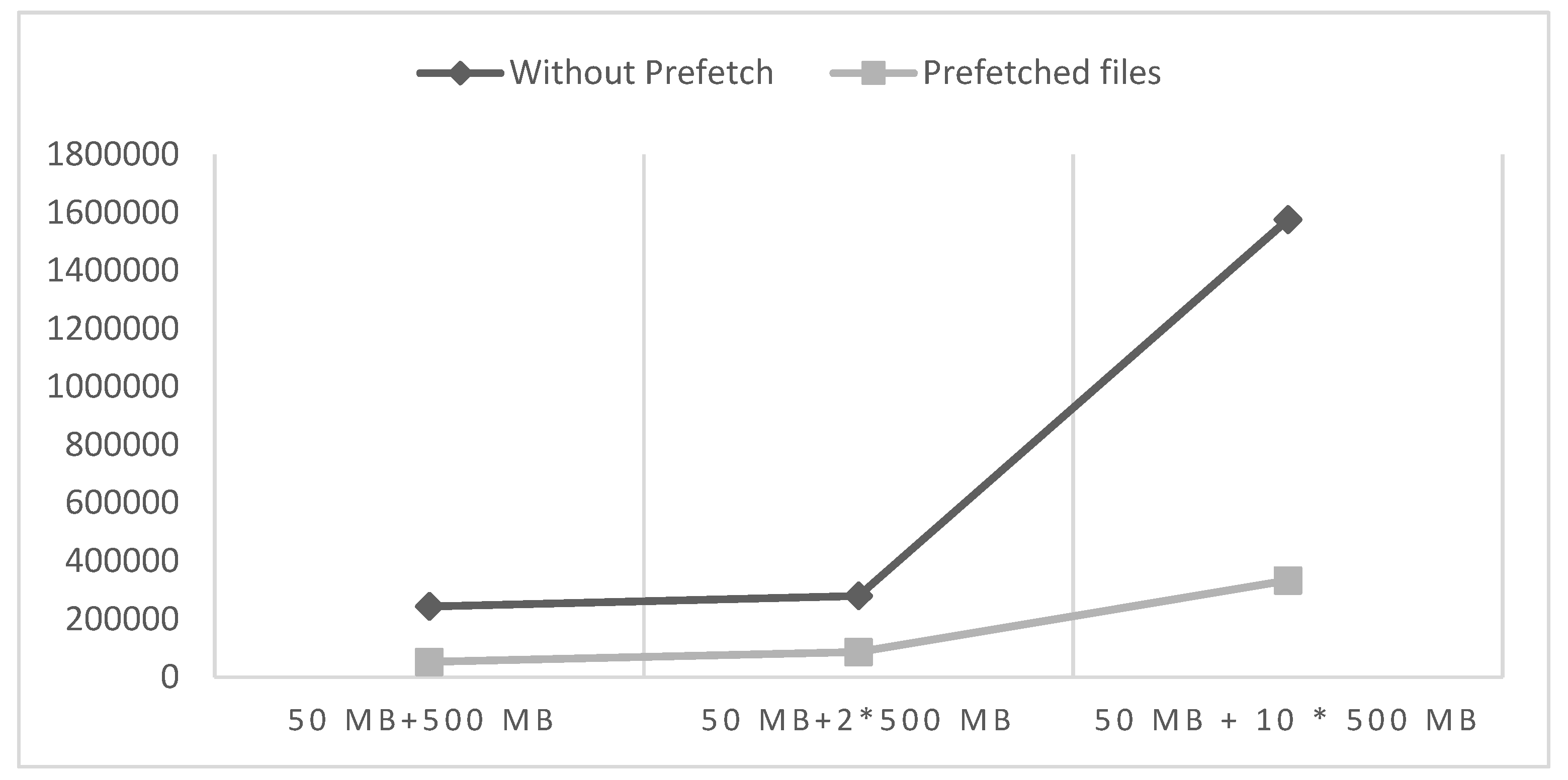
4.1. Performance Evaluation
4.2. Model Optimization Using Prefetch Scheme Evaluation
4.3. Discussion of Results and Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maufe, Z. Financial Services, Cloud Adoption, Regulators. Google Cloud. 12 August 2021. Available online: https://cloud.google.com/blog/topics/inside-google-cloud/new-study-shows-cloud-adoption-increasing-in-financial-services (accessed on 19 January 2022).
- Ezell, S.B.S. How Cloud Computing Enables Modern Manufacturing. Information Technology & Innovation Foundation (ITIF). 22 June 2017. Available online: https://itif.org/publications/2017/06/22/how-cloud-computing-enables-modern-manufacturing (accessed on 19 January 2022).
- Bai, C.; Dallasega, P.; Orzes, G.; Sarkis, J. Industry 4.0 technologies assessment: A sustainability perspective. Int. J. Prod. Econ. 2020, 229, 107776. [Google Scholar] [CrossRef]
- Sonin, J.; Lakey Becker, A.; Nipp, K. It’s Time for Individuals—Not Doctors or Companies—To Own Their Health Data. STAT. 12 November 2021. Available online: https://www.statnews.com/2021/11/15/its-time-for-individuals-not-doctors-or-companies-to-own-their-health-data/ (accessed on 19 January 2022).
- McCurry, C. People Should Have Ownership of Personal Health Data, Says Patients’ Group. Independent. 7 September 2021. Available online: https://www.independent.ie/breaking-news/irish-news/people-should-have-ownership-of-personal-health-data-says-patients-group-40824715.html (accessed on 19 January 2022).
- Google Health. Google Health. 2021. Available online: https://health.google/ (accessed on 19 January 2022).
- Microsoft. Cloud for Healthcare. 2021. Available online: https://www.microsoft.com/en-us/industry/health/microsoft-cloud-for-healthcare (accessed on 19 January 2022).
- Estonian Central Health Information System and Patient Portal. CEF Digital. 26 July 2019. Available online: https://ec.europa.eu/cefdigital/wiki/display/CEFDIGITAL/2019/07/26/Estonian+Central+Health+Information+System+and+Patient+Portal (accessed on 19 January 2022).
- IBM. Watson Health Citizen Engagement–Details. 2021. Available online: https://www.ibm.com/products/citizen-engagement/details (accessed on 19 January 2022).
- Amazon Web Services, Inc. AWS for Health. 2021. Available online: https://aws.amazon.com/health/ (accessed on 19 January 2022).
- Health Cloud. Salesforce. 2021. Available online: https://www.salesforce.com/eu/products/health-cloud/overview/ (accessed on 19 January 2022).
- Esteves, S.; Silva, J.N.; Veiga, L. Palpatine: Mining Frequent Sequences for Data Prefetching in NoSQL Distributed Key-Value Stores. In Proceedings of the 2020 IEEE 19th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 24–27 November 2020; pp. 1–10. [Google Scholar]
- Chen, Y.; Zhang, Y.; Wu, J.; Wang, J.; Xing, C. Revisiting Data Prefetching for Database Systems with Machine Learning Techniques. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2165–2170. [Google Scholar]
- Singh, T.B.; Chitra, S. Prefetching of Web Objects For Effective Retrieval Process Through Data Mining Techniques. 2021. Available online: https://assets.researchsquare.com/files/rs-266666/v1/ef3494ab-9c7c-4cb1-979e-4d7ea8a465d9.pdf?c=1631881773 (accessed on 19 January 2022).
- Hussien, N.; Sulaiman, S. Web pre-fetching schemes using machine learning for mobile cloud computing. Int. J. Adv. Soft Comput. Appl. 2017, 9, 154–187. [Google Scholar]
- Konstantinidis, A.; Irakleous, P.; Georgiou, Z.; Zeinalipour-Yazti, D.; Chrysanthis, P.K. IoT data prefetching in indoor navigation SOAs. ACM Trans. Internet Technol. 2018, 19, 1–21. [Google Scholar] [CrossRef]
- Shakarami, A.; Ghobaei-Arani, M.; Shahidinejad, A.; Masdari, M.; Shakarami, H. Data replication schemes in cloud computing: A survey. Clust. Comput. 2021, 24, 2545–2579. [Google Scholar] [CrossRef]
- Mansouri, N.; Javidi, M.M. A new prefetching-aware data replication to decrease access latency in cloud environment. J. Syst. Softw. 2018, 144, 197–215. [Google Scholar] [CrossRef]
- Liang, Y.; Hu, Z.; Zhang, X.; Xiao, H. Correlation-aware replica prefetching strategy to decrease access latency in edge cloud. China Commun. 2021, 18, 249–264. [Google Scholar] [CrossRef]
- Alyami, M.A.; Almotairi, M.; Aikins, L.; Yataco, A.R.; Song, Y.T. Managing personal health records using meta-data and cloud storage. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 265–271. [Google Scholar]
- Patra, D.; Ray, S.; Mukhopadhyay, J.; Majumdar, B.; Majumdar, A.K. Achieving e-health care in a distributed EHR system. In Proceedings of the 2009 11th International Conference on e-Health Networking, Applications and Services (Healthcom), Sydney, Australia, 16–18 December 2009; pp. 101–107. [Google Scholar]
- Sun, J.; Fang, Y. Cross-domain data sharing in distributed electronic health record systems. IEEE Trans. Parallel Distrib. Syst. 2009, 21, 754–764. [Google Scholar]
- Bahga, A.; Madisetti, V.K. A cloud-based approach for interoperable electronic health records (EHRs). IEEE J. Biomed. Health Inform. 2013, 17, 894–906. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Deyu, T.; Yi, Z. A distributed storage model for EHR based on Hbase. In Proceedings of the 2011 International Conference on Information Management, Innovation Management and Industrial Engineering, Shenzhen, China, 26–27 November 2011; Volume 2, pp. 369–372. [Google Scholar]
- Apache Hbase. Apache Hbase. 2021. Available online: https://hbase.apache.org/ (accessed on 19 January 2022).
- Apache Hadoop. Apache Hadoop. 2021. Available online: https://hadoop.apache.org/ (accessed on 19 January 2022).
- Zheng, X.; Mukkamala, R.R.; Vatrapu, R.; Ordieres-Mere, J. Blockchain-based personal health data sharing system using cloud storage. In Proceedings of the 2018 IEEE 20th International Conference on e-Health Networking, Applications and Services (Healthcom), Ostrava, Czech Republic, 17–20 September 2018; pp. 1–6. [Google Scholar]
- Song, Y.T.; Hong, S.; Pak, J. Empowering patients using cloud based personal health record system. In Proceedings of the 2015 IEEE/ACIS 16th International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Takamatsu, Japan, 1–3 June 2015; pp. 1–6. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access 2017, 6, 1662–1669. [Google Scholar] [CrossRef]
- Webby, R.; O’Connor, M. Judgemental and statistical time series forecasting: A review of the literature. Int. J. Forecast. 1996, 12, 91–118. [Google Scholar] [CrossRef]
- Ho, S.L.; Xie, M. The use of ARIMA models for reliability forecasting and analysis. Comput. Ind. Eng. 1998, 35, 213–216. [Google Scholar] [CrossRef]
- Zhang, J.; Man, K.F. Time series prediction using RNN in multi-dimension embedding phase space. In Proceedings of the SMC’98 Conference Proceedings. 1998 IEEE International Conference on Systems, Man, and Cybernetics (Cat. No. 98CH36218), San Diego, CA, USA, 14 October 1998; Volume 2, pp. 1868–1873. [Google Scholar]
- Gers, F.A.; Eck, D.; Schmidhuber, J. Applying LSTM to time series predictable through time-window approaches. In Neural Nets WIRN Vietri-01; Springer: London, UK, 2002; pp. 193–200. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies. 2001. Available online: https://www.researchgate.net/profile/Y-Bengio/publication/2839938_Gradient_Flow_in_Recurrent_Nets_the_Difficulty_of_Learning_Long-Term_Dependencies/links/546cd26e0cf2193b94c577c2/Gradient-Flow-in-Recurrent-Nets-the-Difficulty-of-Learning-Long-Term-Dependencies.pdf (accessed on 19 January 2022).
- Kwon, B.C.; Choi, M.J.; Kim, J.T.; Choi, E.; Kim, Y.B.; Kwon, S.; Sun, J.; Choo, J. Retainvis: Visual analytics with interpretable and interactive recurrent neural networks on electronic medical records. IEEE Trans. Vis. Comput. Graph. 2018, 25, 299–309. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Huang, X.; Ye, Y.; Xiong, L.; Lau, R.Y.; Jiang, N.; Wang, S. Time series k-means: A new k-means type smooth subspace clustering for time series data. Inf. Sci. 2016, 367, 1–13. [Google Scholar] [CrossRef]
- Senin, P. Dynamic Time Warping Algorithm Review; Information and Computer Science Department University of Hawaii at Manoa: Manoa, HI, USA,, 2008; Volume 855, p. 40. [Google Scholar]
- Symvoulidis, C.; Kiourtis, A.; Mavrogiorgou, A.; Kyriazis, D. Healthcare Provision in the Cloud: An EHR Object Store-based Cloud Used for Emergency. In Proceedings of the HEALTHINF, Online Streaming, 11–13 February 2021; pp. 435–442. [Google Scholar]
- Symvoulidis, C.; Mavrogiorgou, A.; Kiourtis, A.; Marinos, G.; Kyriazis, D. Facilitating Health Information Exchange in Medical Emergencies, In Proceedings of the 2021 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 18–19 November 2021.
- MinIO, Inc. MinIO|High Performance, Kubernetes Native Object Storage. MinIO. 2021. Available online: https://min.io/ (accessed on 19 January 2022).
- Pramukantoro, E.S.; Bakhtiar, F.A.; Bhawiyuga, A. A Semantic RESTful API for Heterogeneous IoT Data Storage. In Proceedings of the 2019 IEEE 1st Global Conference on Life Sciences and Technologies (LifeTech), Osaka, Japan, 12–14 March 2019; pp. 263–264. [Google Scholar]
- Goli-Malekabadi, Z.; Sargolzaei-Javan, M.; Akbari, M.K. An effective model for store and retrieve big health data in cloud computing. Comput. Methods Programs Biomed. 2016, 132, 75–82. [Google Scholar] [CrossRef] [PubMed]
- Pandey, M.K.; Subbiah, K. A novel storage architecture for facilitating efficient analytics of health informatics big data in cloud. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology (CIT), Nadi, Fiji, 8–10 December 2016; pp. 578–585. [Google Scholar]
- MongoDB. MongoDB: 2021. The Application Data Platform. Available online: https://www.mongodb.com/ (accessed on 19 January 2022).
- Flask. Flask. 2021. Available online: https://flask.palletsprojects.com/en/2.0.x/ (accessed on 19 January 2022).
- FHIR. Patient. 2021. Available online: https://www.hl7.org/fhir/patient.html (accessed on 19 January 2022).
- FHIR. Bundle. 2021. Available online: https://www.hl7.org/fhir/bundle.html (accessed on 19 January 2022).
- FHIR. Composition. Available online: https://www.hl7.org/fhir/composition.html (accessed on 19 January 2022).
- DICOM. 2022. Available online: https://www.dicomstandard.org/ (accessed on 19 January 2022).
- Koh, P.W.; Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1885–1894. [Google Scholar]
- InteropEHRate. InteropEHRate. 2019. Available online: https://www.interopehrate.eu/ (accessed on 19 January 2022).
- Koutsoukos, K.; Symvoulidis, C.; Kiourtis, A.; Mavrogiorgou, A.; Dimopoulou, S.; Kyriazis, D. Emergency Health Protocols Supporting Health Data Exchange, Cloud Storage, and Indexing. In Proceedings of the 15th International Conference on Health Informatics-HEALTHINF 2022, Vienna, Austria, 9–11 February 2022; pp. 597–604. [Google Scholar]
- Fondazione Toscana Gabriele Monasterio. Fondazione Toscana Gabriele Monasterio. 2022. Available online: https://www.monasterio.it (accessed on 19 January 2022).
- CHU de Liège. CHU de Liège. 2022. Available online: https://www.chuliege.be (accessed on 19 January 2022).
- Emergency Hospital Bagdasar-Arseni. Emergency Hospital Bagdasar-Arseni. 2022. Available online: https://www.bagdasar-arseni.ro (accessed on 19 January 2022).
- General Data Protection Regulation (GDPR) Compliance Guidelines Proton Technologies AG. 2022. Available online: https://gdpr.eu/ (accessed on 19 January 2022).
- Diastema Diastema. 2022. Available online: https://diastema.gr/ (accessed on 19 January 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prefetch Scheme Used | # of Observations in Train Set | RMSE | R2 |
|---|---|---|---|
| N | 650 | 0.06 | 0.954 |
| Y | 535 | 0.048 | 0.943 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Symvoulidis, C.; Marinos, G.; Kiourtis, A.; Mavrogiorgou, A.; Kyriazis, D. HealthFetch: An Influence-Based, Context-Aware Prefetch Scheme in Citizen-Centered Health Storage Clouds. Future Internet 2022, 14, 112. https://doi.org/10.3390/fi14040112
Symvoulidis C, Marinos G, Kiourtis A, Mavrogiorgou A, Kyriazis D. HealthFetch: An Influence-Based, Context-Aware Prefetch Scheme in Citizen-Centered Health Storage Clouds. Future Internet. 2022; 14(4):112. https://doi.org/10.3390/fi14040112
Chicago/Turabian StyleSymvoulidis, Chrysostomos, George Marinos, Athanasios Kiourtis, Argyro Mavrogiorgou, and Dimosthenis Kyriazis. 2022. "HealthFetch: An Influence-Based, Context-Aware Prefetch Scheme in Citizen-Centered Health Storage Clouds" Future Internet 14, no. 4: 112. https://doi.org/10.3390/fi14040112
APA StyleSymvoulidis, C., Marinos, G., Kiourtis, A., Mavrogiorgou, A., & Kyriazis, D. (2022). HealthFetch: An Influence-Based, Context-Aware Prefetch Scheme in Citizen-Centered Health Storage Clouds. Future Internet, 14(4), 112. https://doi.org/10.3390/fi14040112