
A Dynamic Cache Allocation Mechanism (DCAM) for Reliable Multicast in Information-Centric Networking


Abstract
:1. Introduction
2. Related Work
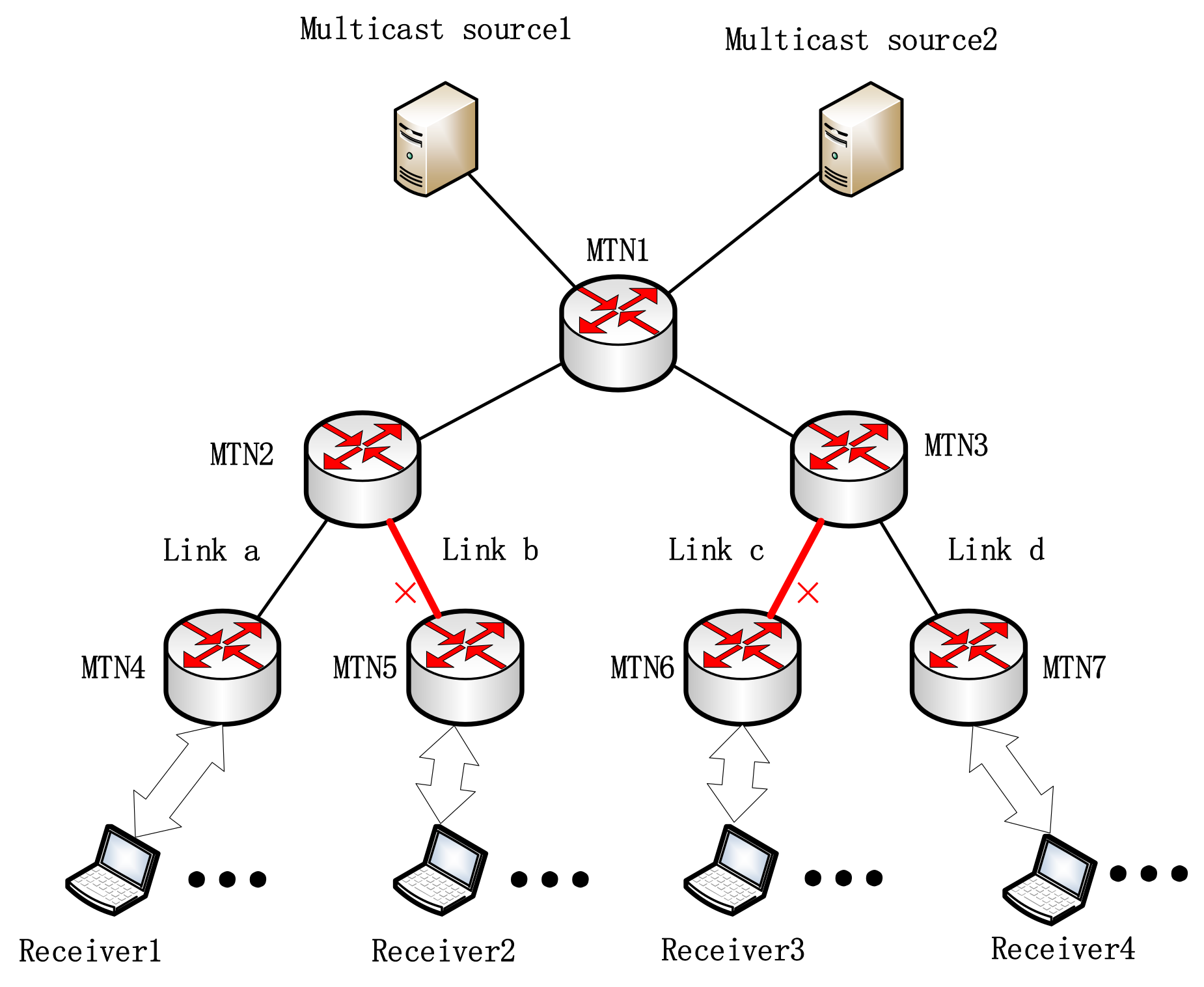
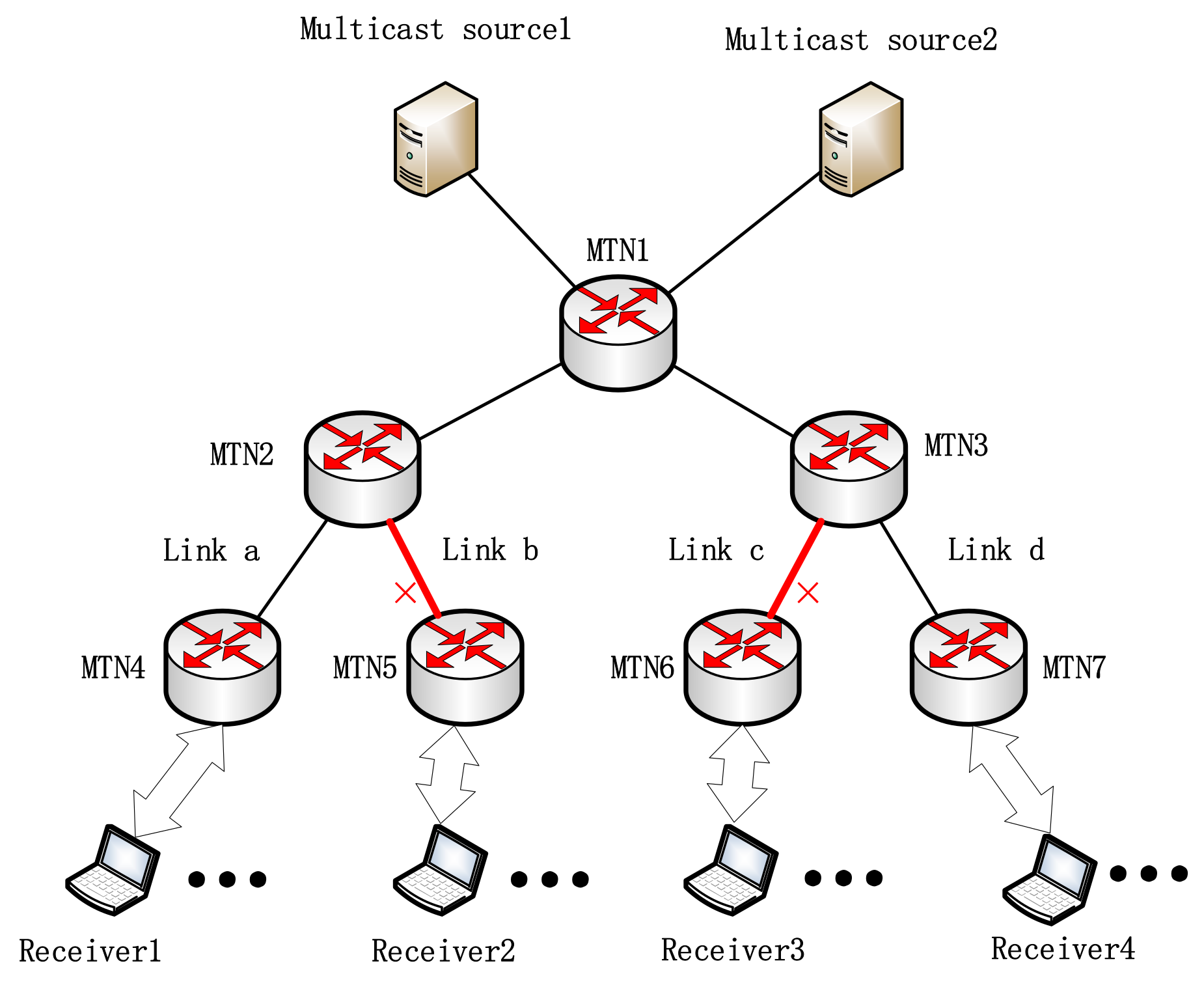
3. Problem Description
4. Design of Dynamic Cache Allocation Mechanism
| Algorithm 1. The Dynamic Cache Allocation Mechanism |
| Input:, , , |
Output:
|
4.1. Weight Definition
4.1.1. Definition 1: NACK Weight
4.1.2. Definition 2: Distance Weight
4.1.3. Definition 3: Rate Weight
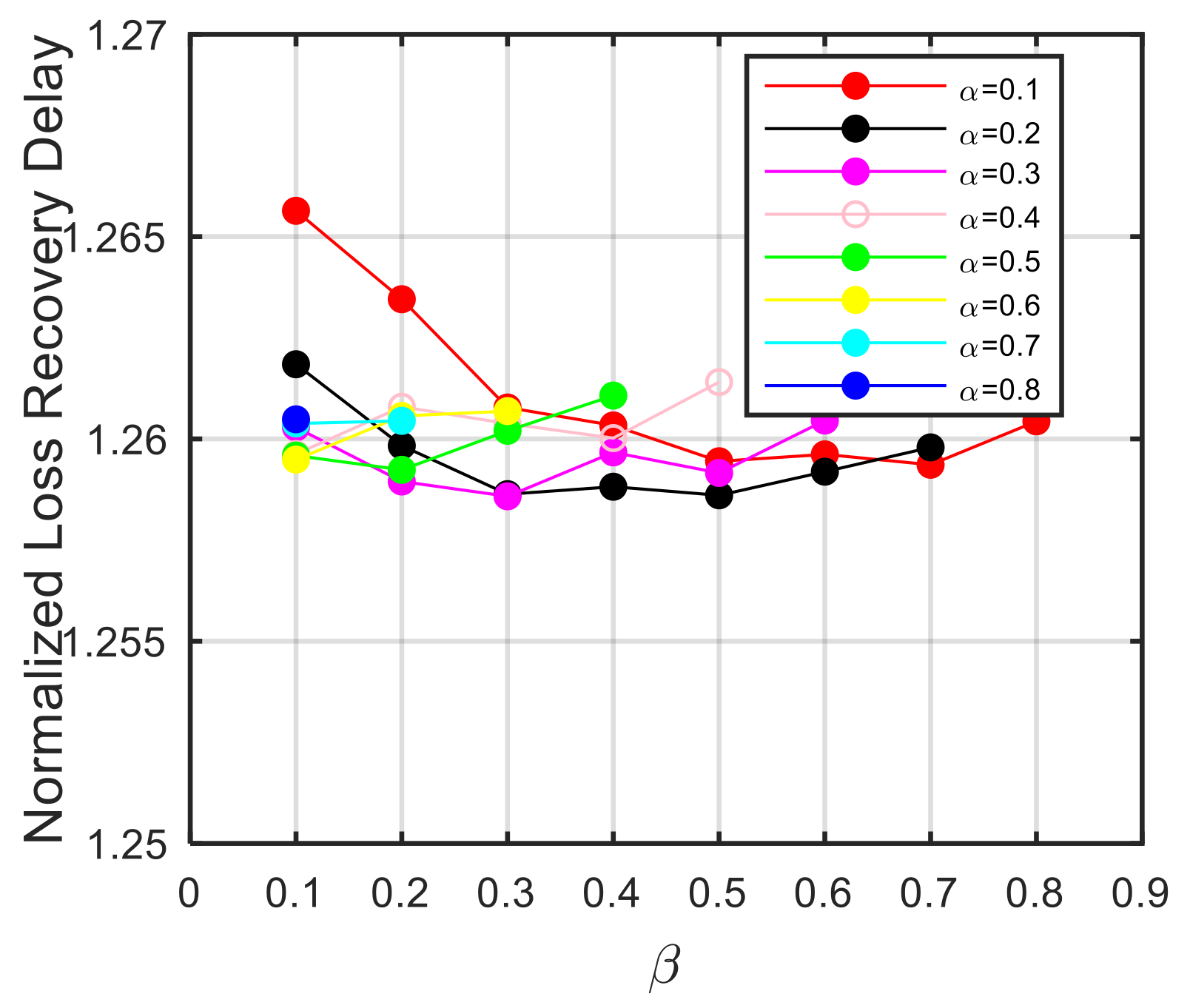
4.2. Normalized Weight and Cache Allocation
5. Evaluation
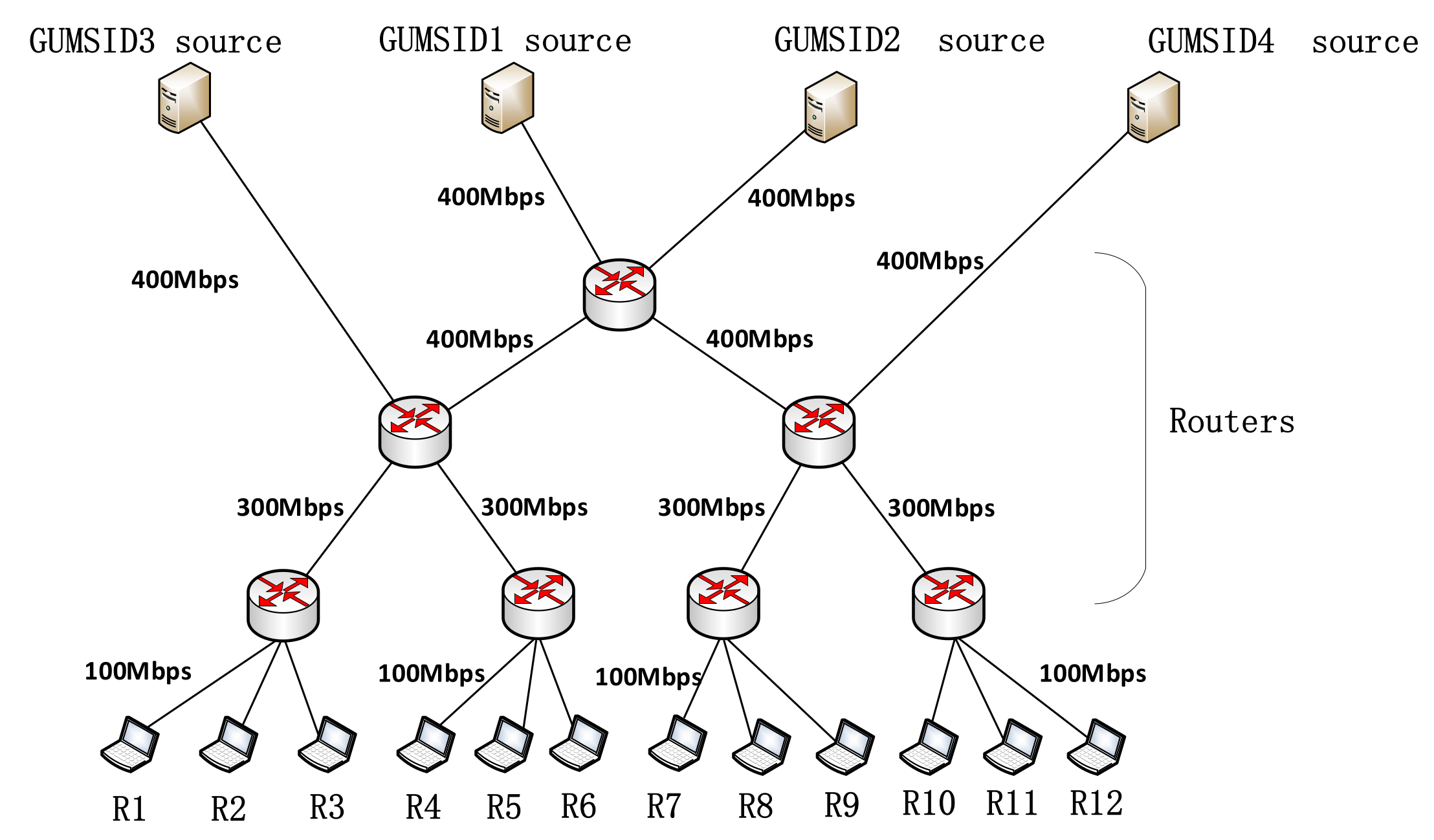
5.1. Simulation Setup
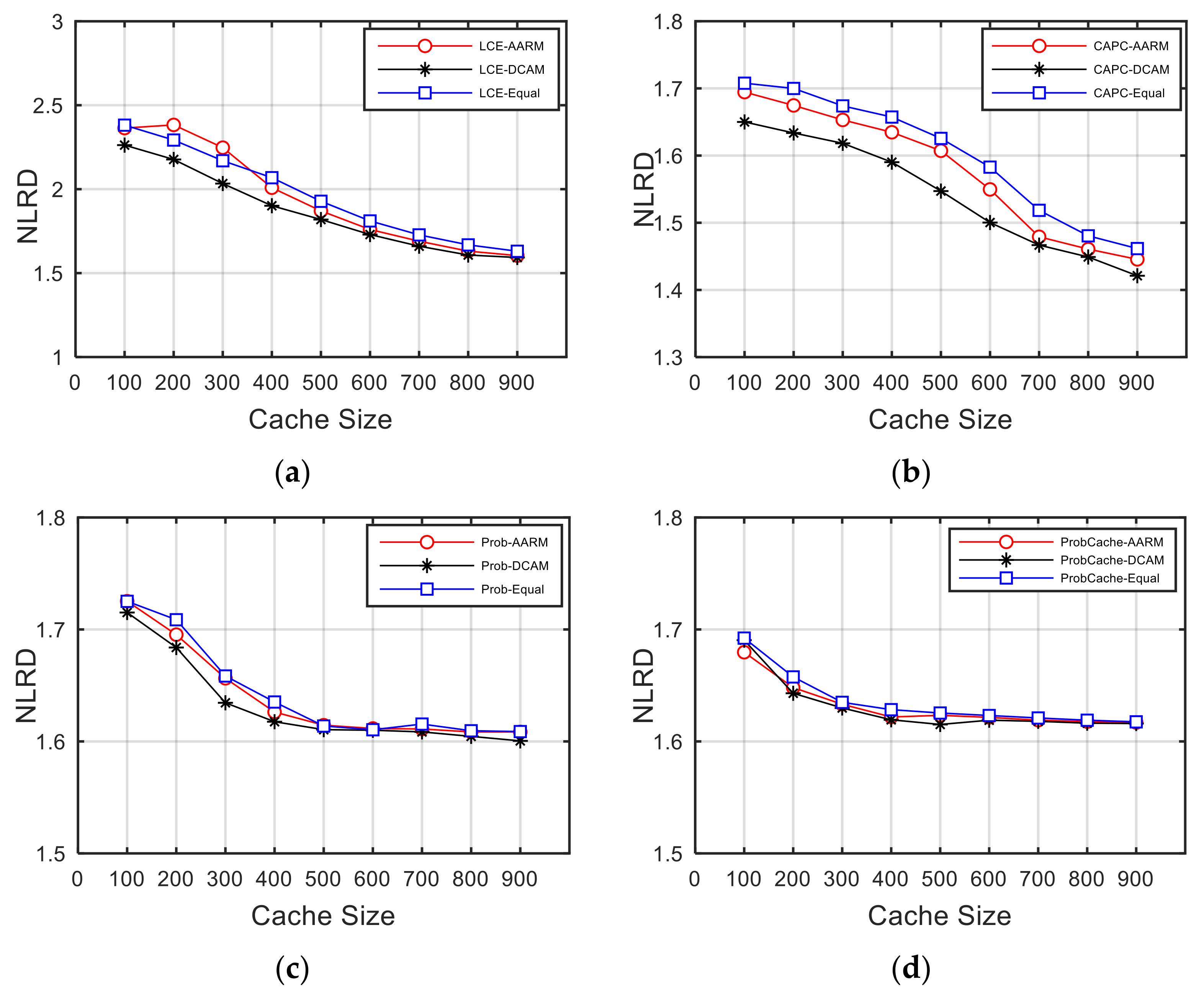
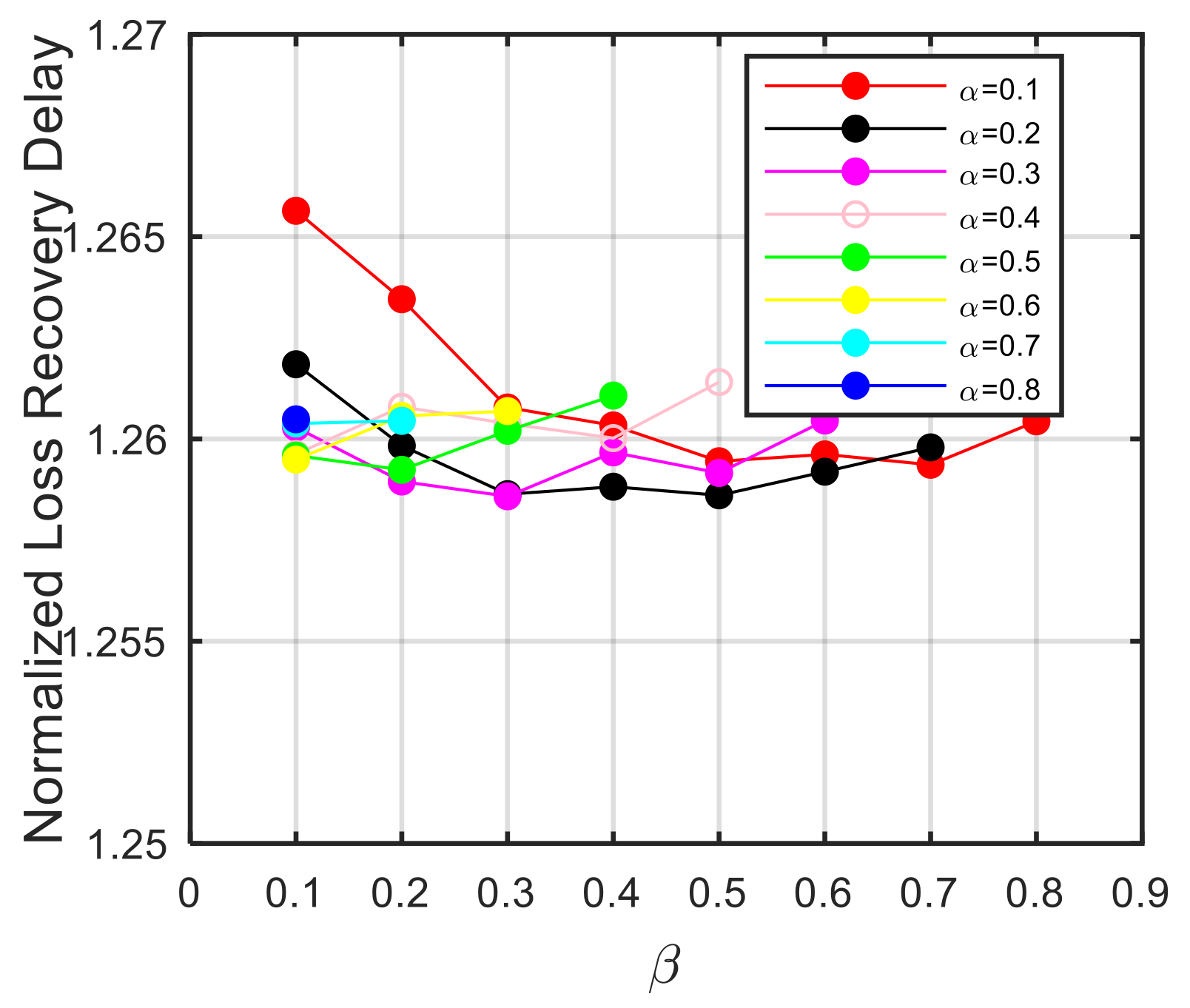
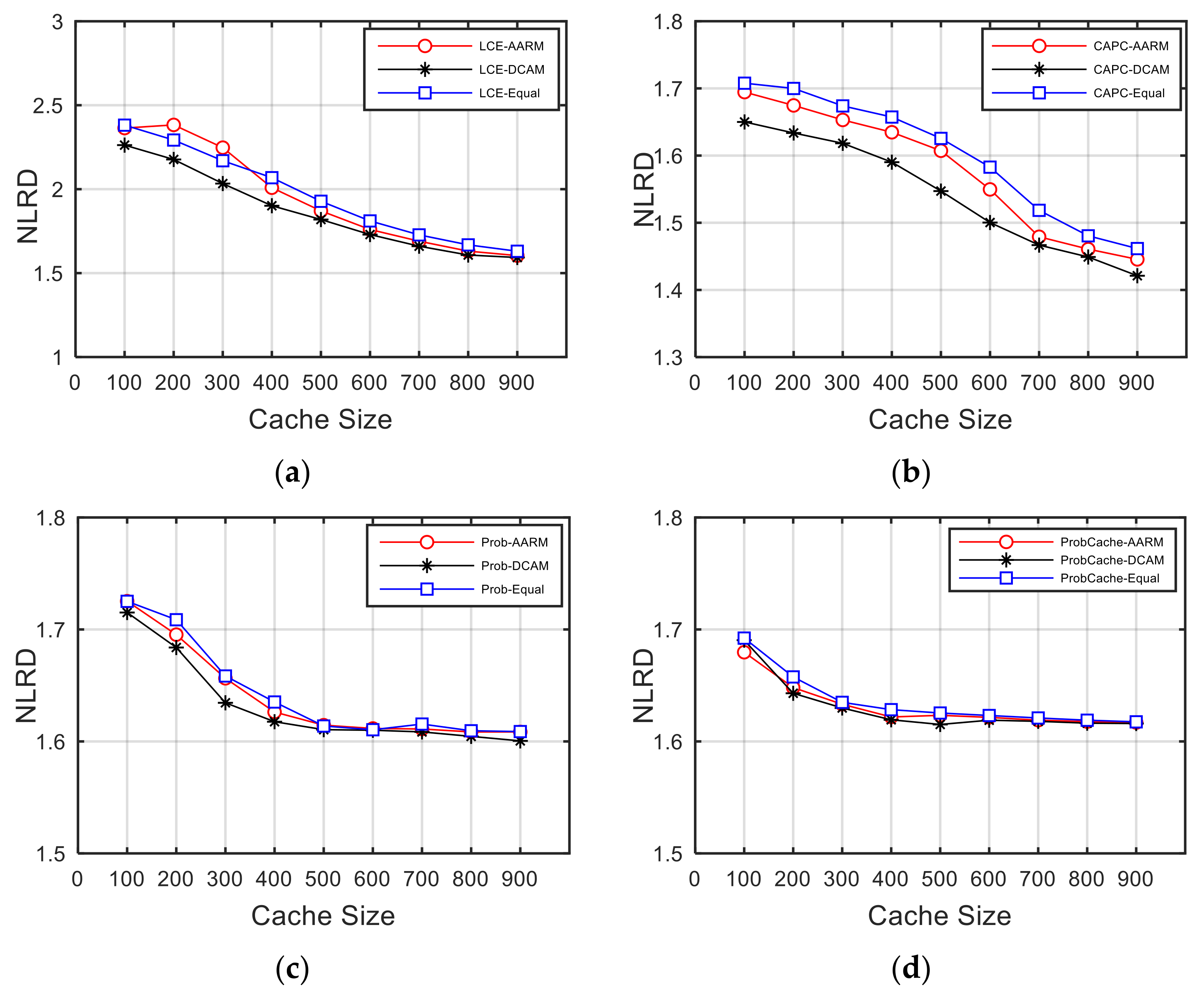
5.2. Loss Recovery Delay
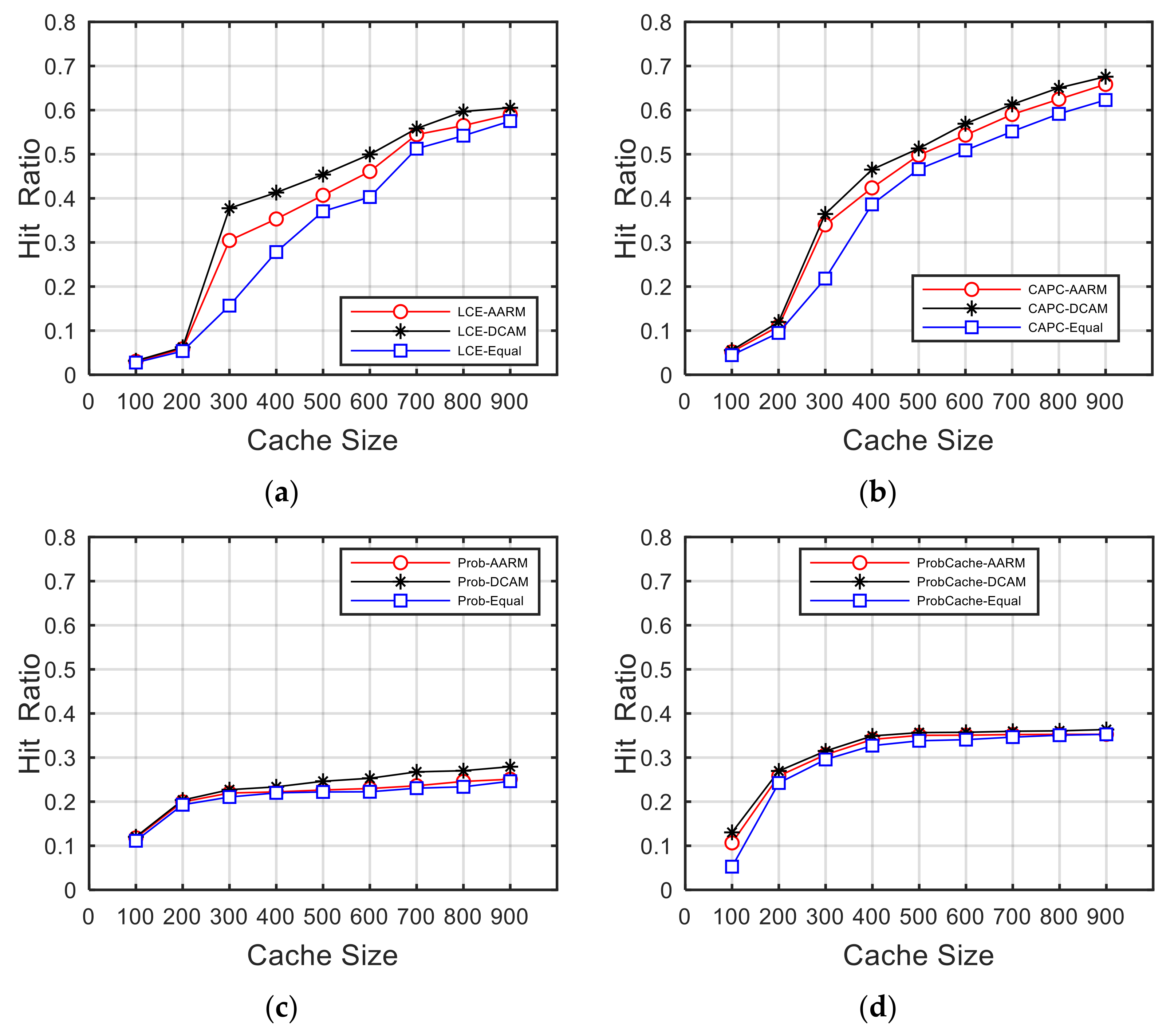
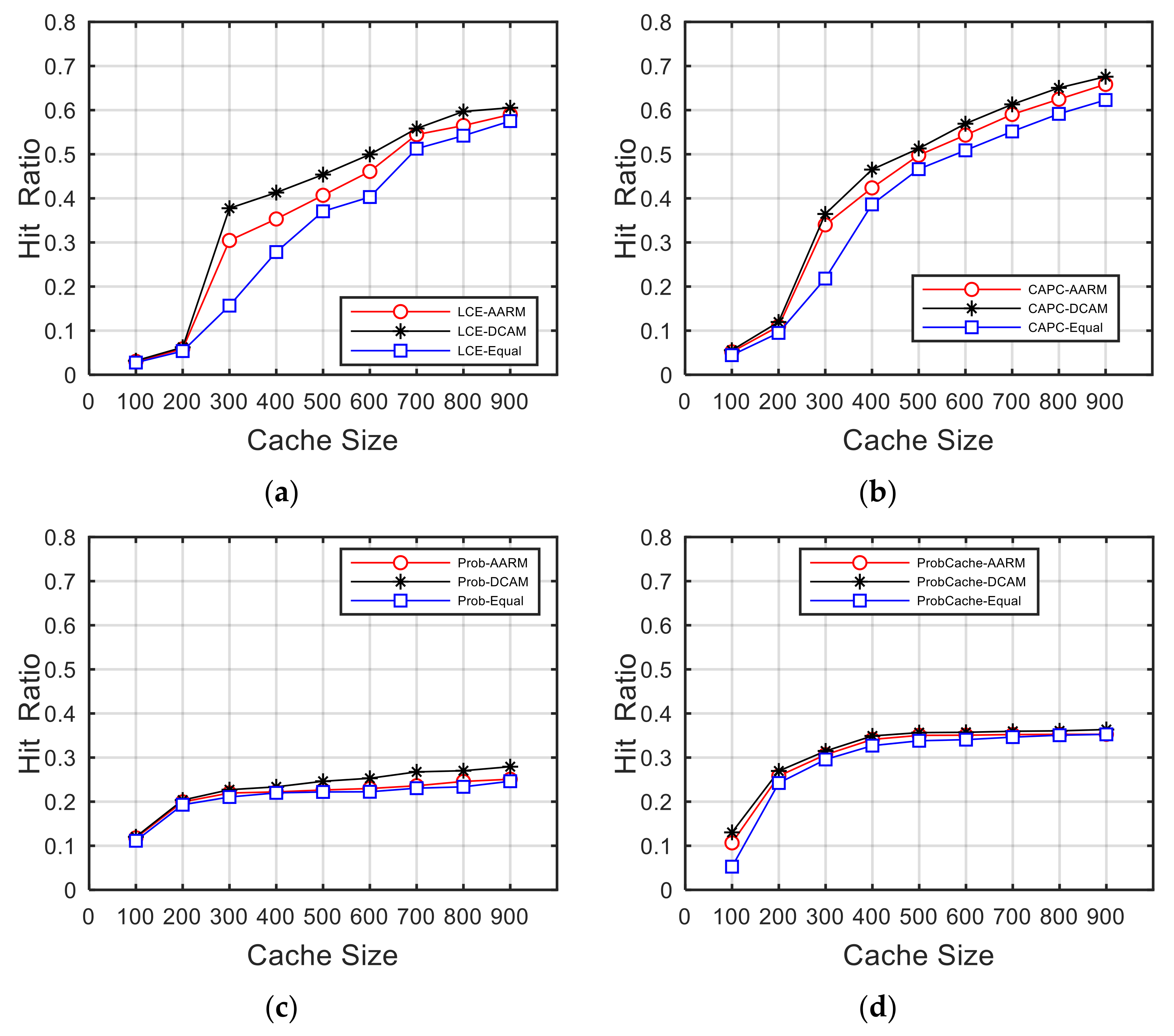
5.3. Average Cache Hit Ratio
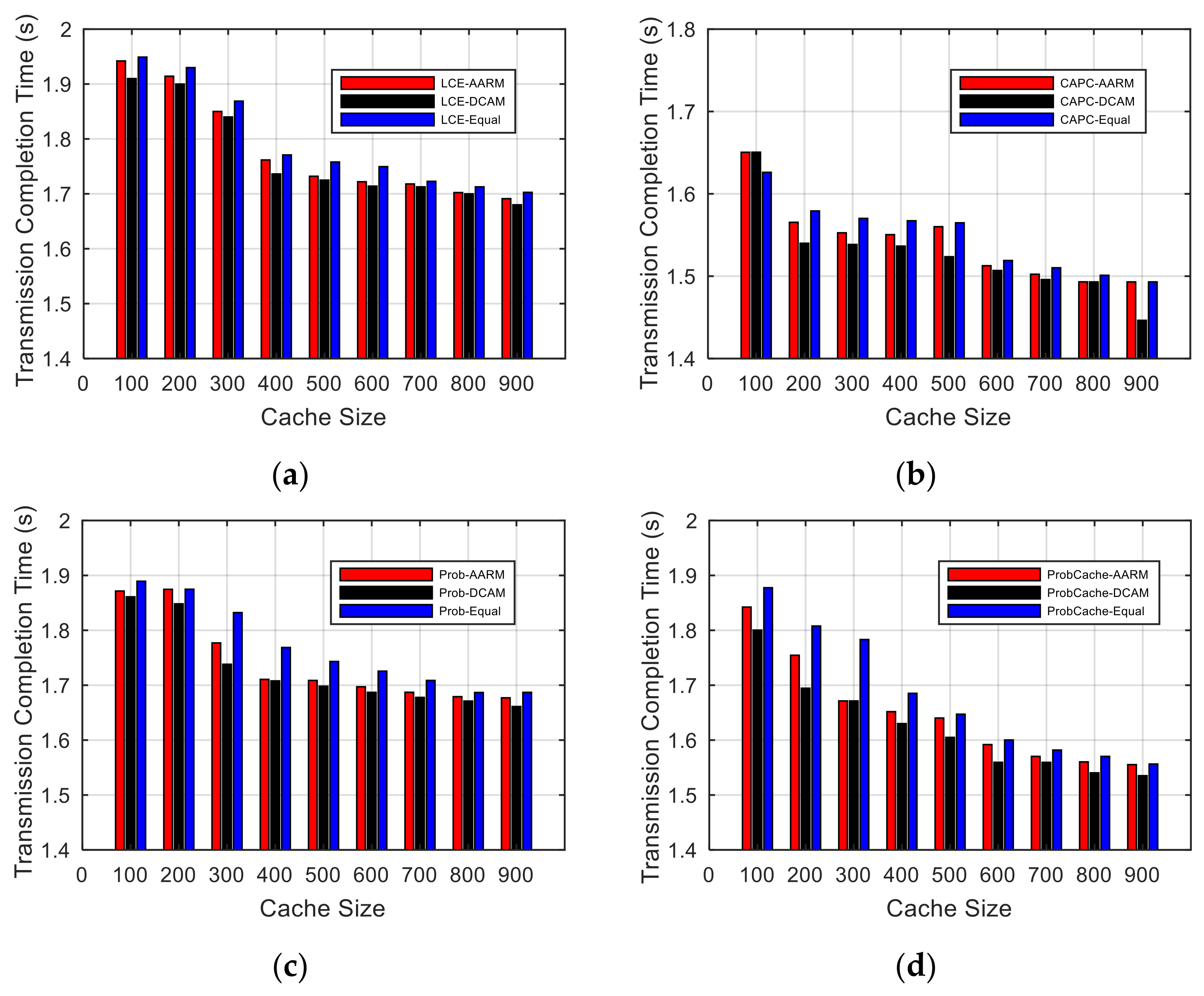
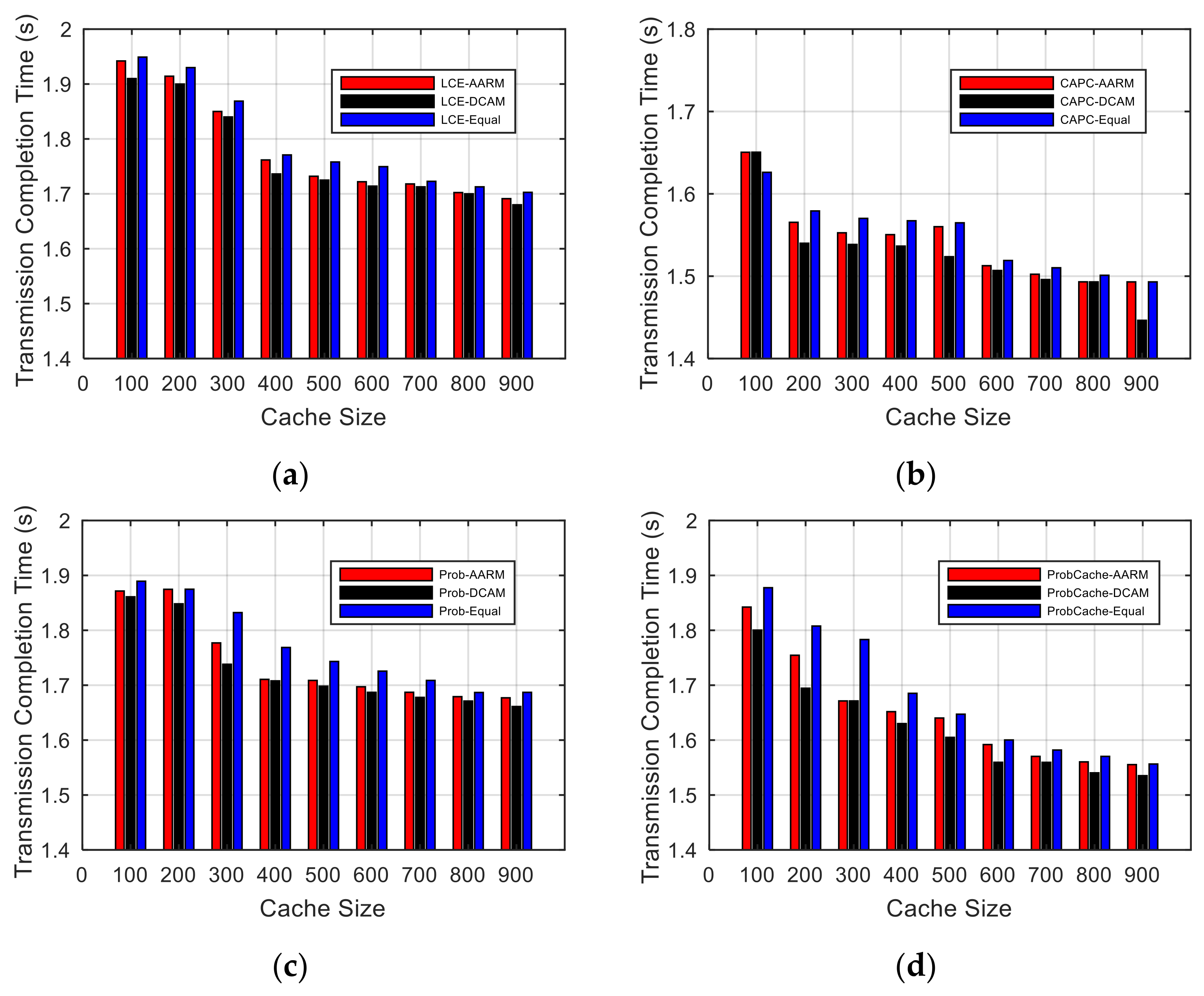
5.4. Average Transmission Completion Time
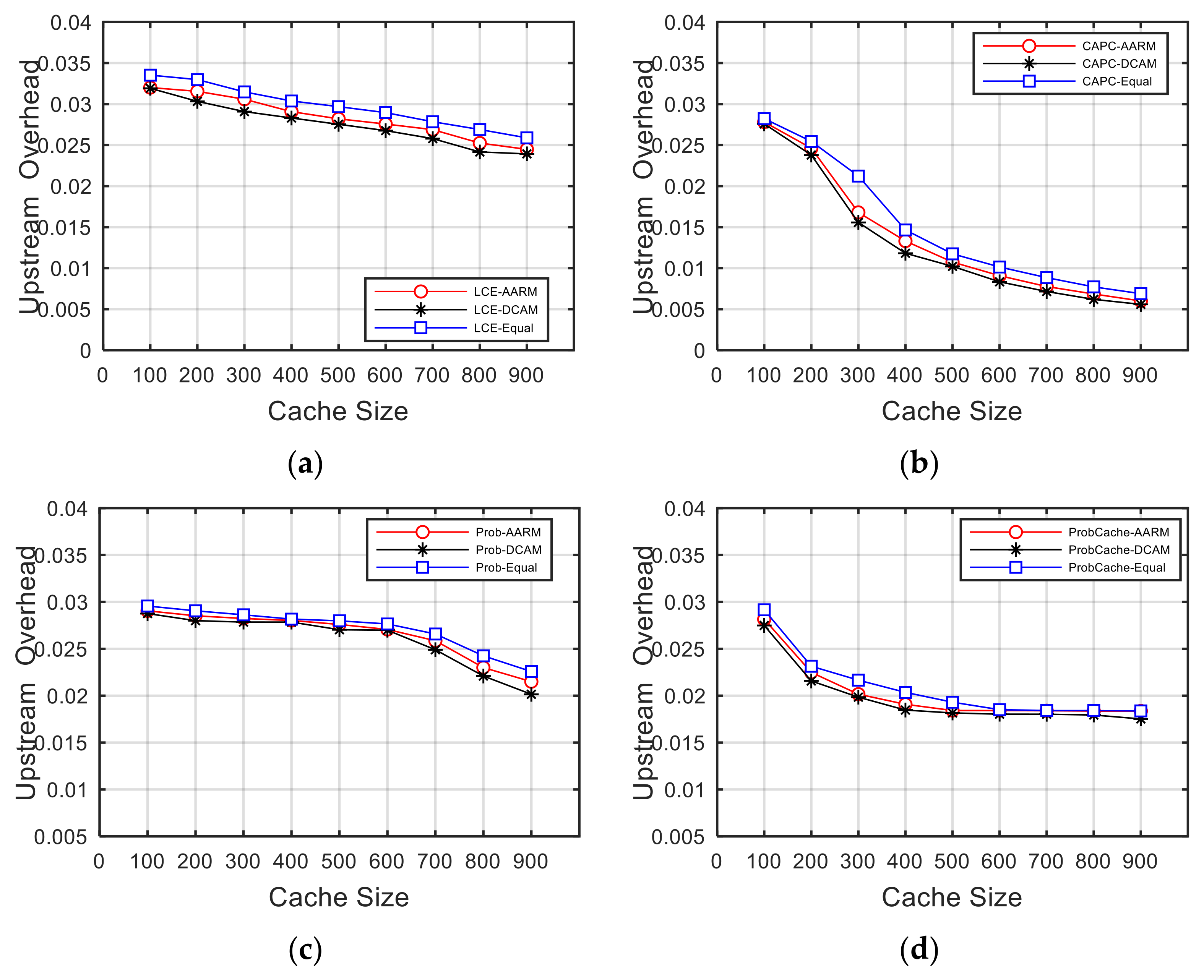
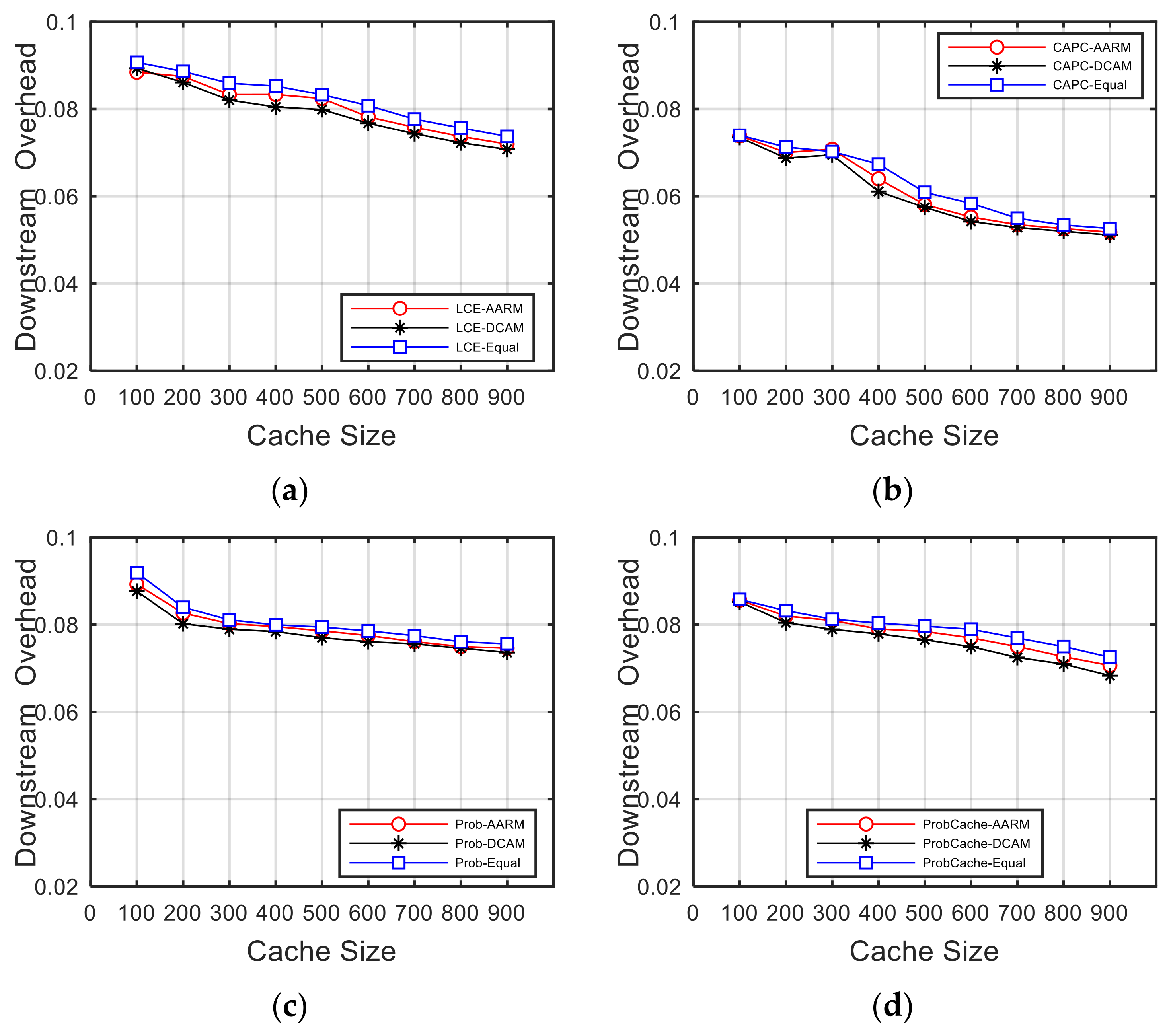
5.5. Overhead Evaluation
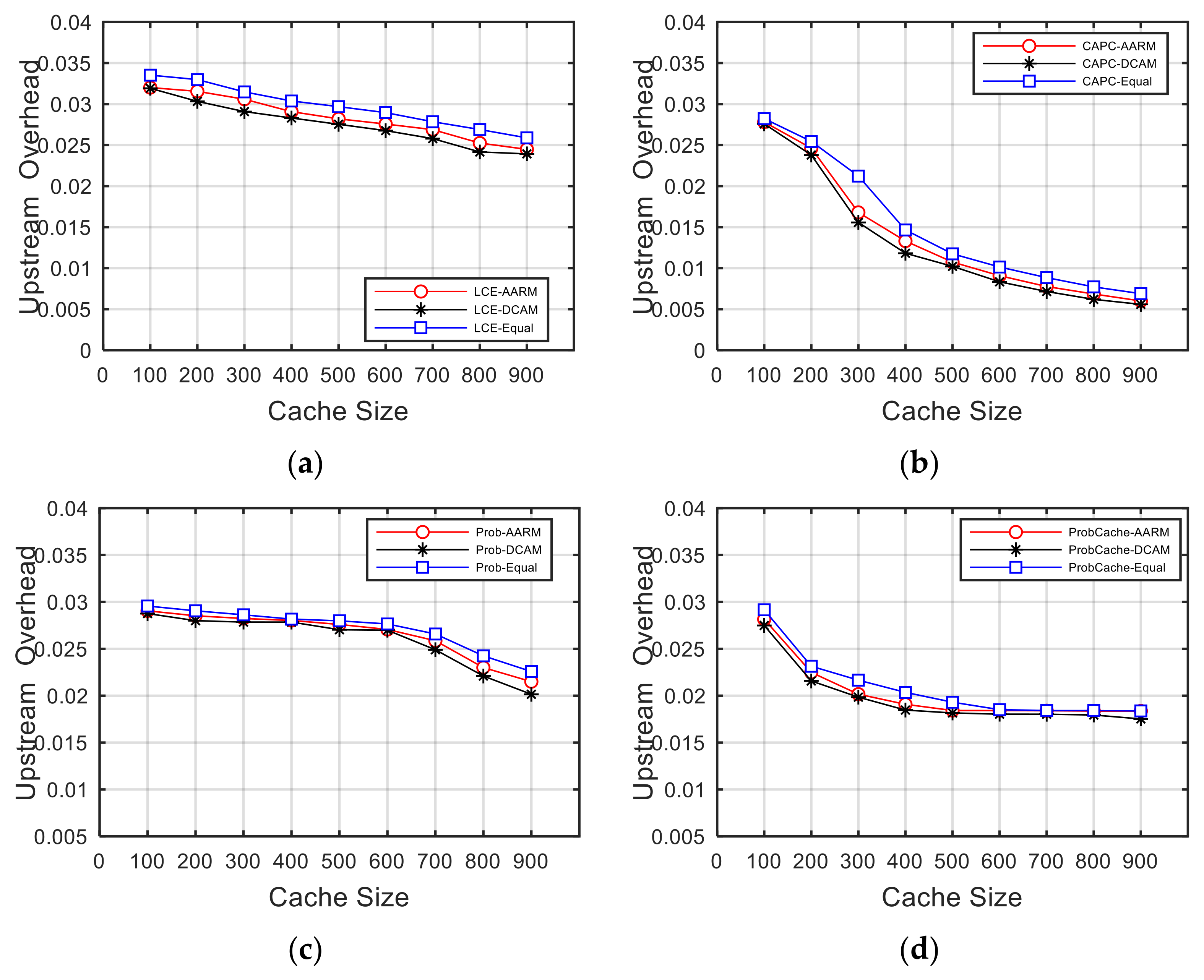
5.5.1. Upstream Overhead
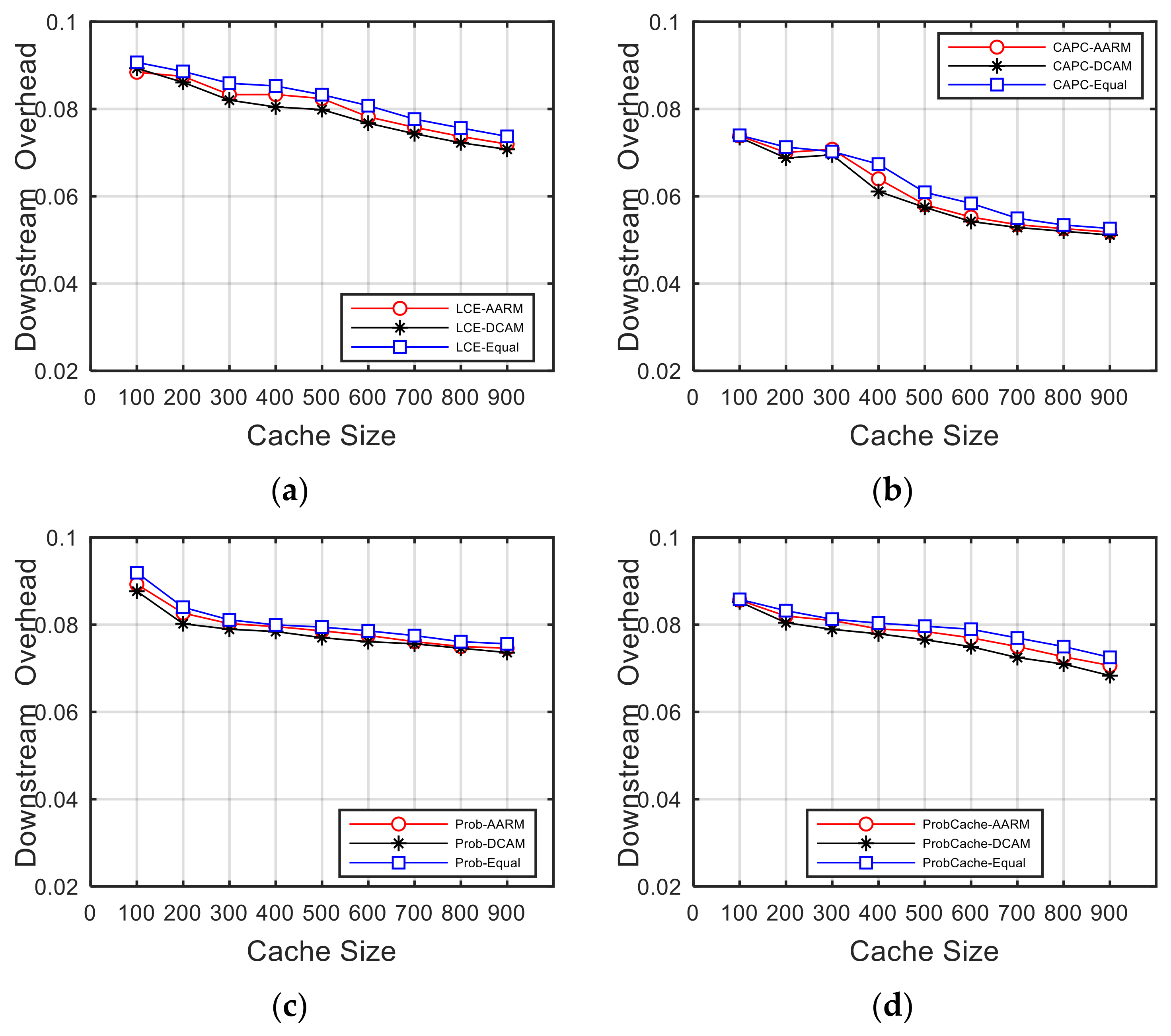
5.5.2. Downstream Overhead
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pan, J.; Paul, S.; Jain, R. A survey of the research on future internet architectures. IEEE Commun. Mag. 2011, 49, 26–36. [Google Scholar] [CrossRef]
- Xylomenos, G.; Ververidis, C.N.; Siris, V.A.; Fotiou, N.; Tsilopoulos, C.; Vasilakos, X.; Katsaros, K.V.; Polyzos, G.C. A survey of information-centric networking research. IEEE Commun. Surv. Tutor. 2013, 16, 1024–1049. [Google Scholar] [CrossRef]
- Ahlgren, B.; Dannewitz, C.; Imbrenda, C.; Kutscher, D.; Ohlman, B. A survey of information-centric networking. IEEE Commun. Mag. 2012, 50, 26–36. [Google Scholar] [CrossRef]
- Jiang, X.; Bi, J.; Nan, G.; Li, Z. A survey on information-centric networking: Rationales, designs and debates. China Commun. 2015, 12, 1–12. [Google Scholar] [CrossRef]
- Liao, Y.; Sheng, Y.; Wang, J. Summary of Research on ICN Name Resolution Technology. J. Netw. New Media. 2020, 9, 9. [Google Scholar]
- Adhatarao, S.S.; Chen, J.; Arumaithurai, M.; Fu, X.; Ramakrishnan, K.K. Comparison of naming schema in ICN. In Proceedings of the 2016 IEEE international symposium on local and metropolitan area networks (LANMAN), Rome, Italy, 13–15 June 2016; pp. 1–6. [Google Scholar]
- Yamamoto, M. A survey of caching networks in content oriented networks. IEICE Trans. Commun. 2016, 99, 961–973. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Chen, X.; Xie, J.; Li, S.; Zhang, Y.; Yang, J. Multicast Design for the MobilityFirst Future Internet Architecture. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 88–93. [Google Scholar]
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Claffy, K.C.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named data networking. ACM SIGCOMM Comp. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Wang, J.; Chen, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-site, Elastic, Autonomous Network. J. Netw. New Media 2020, 9, 8. [Google Scholar]
- Raychaudhuri, D.; Nagaraja, K.; Venkataramani, A. Mobilityfirst: A robust and trustworthy mobility-centric architecture for the future internet. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2012, 16, 2–13. [Google Scholar] [CrossRef]
- AbdAllah, E.G.; Hassanein, H.S.; Zulkernine, M. A survey of security attacks in information-centric networking. IEEE Commun. Surv. Tutorials 2015, 17, 1441–1454. [Google Scholar] [CrossRef]
- Chakraborty, D.; Chakraborty, G.; Shiratori, N. A dynamic multicast routing satisfying multiple QoS constraints. Int. J. Netw. Management. 2003, 13, 321–335. [Google Scholar] [CrossRef]
- Kawasumi, R.; Hirota, Y.; Murakami, K.; Tode, H. Multicast distribution system with functions of time-shift and loss-recovery based on in-network caching and openflow control. In Proceedings of the 8th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Compiegne, France, 28–30 October 2013; pp. 641–646. [Google Scholar]
- Whetten, B.; Vicisano, L.; Kermode, R.; Handley, M.; Floyd, S.; Luby, M. Reliable multicast transport building blocks for one-to-many bulk-data transfer. RFC 3048. Available online: https://tools.ietf.org/html/rfc3048 (accessed on 1 January 2020).
- Zhang, J.; Li, Z.; Chen, Y.; Cheng, Y.; Ding, G. AACP: Adaptive Active Cache Management Protocol in Reliable Multicast Networks. J. Sichuan Univ. 2010, 42, 179–184. [Google Scholar]
- Xu, C.; Lv, S. Research on Cache Size Allocation Scheme Based on Node Weight in ICN. Res. Comput. Appl. 2017, 34, 214–216. [Google Scholar]
- Zhang, J.; Li, Z.; Chen, L. Dynamic cache allocation algorithm and replacement policy for reliable multicast network. In Proceedings of the 5th International Conference on Wireless Communications, Networking and Mobile Computing, Beijing, China, 24–26 September 2009; pp. 1–5. [Google Scholar]
- Yeung, K.L.; Wong, H.-L.T. Caching policy design and cache allocation in active reliable multicast. Comput. Netw. 2003, 43, 177–193. [Google Scholar] [CrossRef]
- Duan, Y.; Ni, H.; Zhu, X. Reliable Multicast Based on Congestion-Aware Cache in ICN. Electronics 2021, 10, 1579. [Google Scholar] [CrossRef]
- Psaras, I.; Chai, W.K.; Pavlou, G. Probabilistic in-network caching for information-centric networks. In Proceedings of the 2nd Edition of the ICN Workshop on Information-Centric Networking, Helsinki, Finland, 17 August 2012; pp. 55–60. [Google Scholar]
- Laoutaris, N.; Syntila, S.; Stavrakakis, I. Meta algorithms for hierarchical web caches. In Proceedings of the IEEE International Conference on Performance, Computing, and Communications, Phoenix, AZ, USA, 15–17 April 2004; pp. 445–452. [Google Scholar]
- Feng, G.; Zhang, J.; Xie, F.; Siew, C.K. Buffer management for local loss recovery of reliable multicast. In Proceedings of the IEEE Global Telecommunications Conference, Dallas, TX, USA, 29 November–3 December 2004; pp. 1152–1156. [Google Scholar]
- Wang, J.; Li, C.; Huang, J. A Survey of Research on the Strategies for Setting the Cache Size of Routers. Comput. Sci. 2009, 36, 12–16. [Google Scholar]
- Ge, G.; Guo, Y.; Lan, J.; Liu, C. Dynamic Secondment Mechanism of Cache Space Based on Replacement Rate in CCN. J. Commun. 2015, 36, 120. [Google Scholar]
- Cheng, D.; Liu, Z. A New Cache Space Dynamic Allocation Mechanism and Its Packet Loss Rate Analysis. Electron. J. 2001, 29, 634. [Google Scholar]
- Maravelakis, P.E.; Castagliola, P. An EWMA chart for monitoring the process standard deviation when parameters are estimated. Comput. Stat. Data Anal. 2009, 53, 2653–2664. [Google Scholar] [CrossRef]
- NS-2 Simulator [EB/OL]. Available online: https://www.isi.edu/nsnam/ns/ns-build.html (accessed on 1 March 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| ) | 700 packets |
| ) | |
| ) | |
| Cache size | 100–900 |
| Chunk size | 10 packets |
| Packet size | 1032 bytes |
| for DCAM | 0.9 |
| The cache allocation cycle | 0.07 s |
| ) for CAPC | 0.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, Y.; Ni, H.; Zhu, X. A Dynamic Cache Allocation Mechanism (DCAM) for Reliable Multicast in Information-Centric Networking. Future Internet 2022, 14, 105. https://doi.org/10.3390/fi14040105
Duan Y, Ni H, Zhu X. A Dynamic Cache Allocation Mechanism (DCAM) for Reliable Multicast in Information-Centric Networking. Future Internet. 2022; 14(4):105. https://doi.org/10.3390/fi14040105
Chicago/Turabian StyleDuan, Yingjie, Hong Ni, and Xiaoyong Zhu. 2022. "A Dynamic Cache Allocation Mechanism (DCAM) for Reliable Multicast in Information-Centric Networking" Future Internet 14, no. 4: 105. https://doi.org/10.3390/fi14040105
APA StyleDuan, Y., Ni, H., & Zhu, X. (2022). A Dynamic Cache Allocation Mechanism (DCAM) for Reliable Multicast in Information-Centric Networking. Future Internet, 14(4), 105. https://doi.org/10.3390/fi14040105