1. Introduction
The development of the Web according to a semantic paradigm, usually addressed as Semantic Web, represents an essential precondition to the definition of new scenarios for the future Internet, aimed at the creation of an interoperability environment for distributed and ubiquitous networks, where software agents, devices and humans can effectively interact as producers or consumers of resources and services.
The Internet, in particular the Web, represents nowadays the main source of the Law, therefore the development of the Semantic Web in the legal domain is a perspective of particular interest for the specialized nature of legal information, the complexity of legislative workflow, and the peculiarities of user information needs. Such development is foreseen to affect all the players of the legal information scenario: public administrations, publishers, legal professionals, scholars, as well as citizens.
In this scenario the Publications Office of the European Union (OP) is a key player, having a two-fold role: public institution department and legal publisher. In these two roles it is aimed to provide information services (in particular legal information) able to guarantee accessibility, maintainability and re-usability of legal information resources. These services are already, and will be more in the near future, highly affected by the evolution of the Web which will be more and more characterized as provider of semantically qualified pieces of information. This evolution presents specific technological challenges, addressed in strategic objectives to be achieved by the OP in the next decade.
This paper presents a review of the evolution of the Semantic Web in the legal domain, as well as a discussion on its possible developments, whose strategic objectives the OP is being prepared to achieve. In particular, in
Section 2 a brief recall is given of the main phases of the Web evolution until the Semantic Web, focused in particular on the legal domain and related users’ information needs. In
Section 3 the top-down approach to the Semantic Web is described, leading to the current bottom-up trend described in
Section 4. Within this scenario, in
Section 5 the strategic objectives of the OP are presented. Finally, in
Section 6 possible developments towards the Web 4.0 in the legal domain are discussed, and in
Section 7 some conclusions are reported, as well as further possible developments of the Web 5.0.
2. From the Web 1.0 to the Web 3.0 (Or Semantic Web)
The World Wide Web (WWW) is characterized by a continuous evolution which is necessary to respond to the increasing specialization of the users’ information needs.
The beginning of the Web era (early 1990s) is commonly known as “Web 1.0”, namely the Web phase characterized by static information; a document-centric platform, including mainly text, images and hyperlinks, with limited interaction with the users. It made massive use of HTML as language to describe contents (a mix of contents and presentation features), including very little semantics. Information search and retrieval services were firstly developed to meet user’s needs, hence the success of search engines, such as Altavista, Bing, Yahoo and Google. However, such retrieval services were (and nowadays are still mainly) characterized by keyword indexing, so that queries are mainly based on keywords while semantics is usually inferred by contexts (query refinement by other related keywords) as well as by algorithms able to infer semantics from contexts.
The second phase of the Web (from early-mid 2000’s) is commonly known as “Web 2.0” or Collaborative Web, namely the phase characterized by the possibility for the users to interact and share contents, as well as create them in a collaborative fashion. Success stories of this phase are services such as Facebook, Twitter, Google+, Wikipedia, Myspace, LinkedIn, Foursquare, etc. This second generation of the Web introduced dynamic and interactive contents which need “semantics”, namely explicit qualified concepts and relations able to describe contents and users’ roles, as well as their relationships (examples are the “friendship” or the “following/follower” relationships in social networks).
In this evolutive process the Web has become the main source of information not only for generic users but also for specialized ones, like scholars and professionals, holders of specific information needs. This is even more felt in the legal domain where users look for advanced information retrieval and reasoning services on legal materials. They are not only interested in legal documents matching certain keywords, but they are also interested in specific information, as for example the following expressed according to an increasing degree of complexity:
Which version of law n. [NN] issued on [date1] was in force on [date2] > [date1]?
In which laws Mr. [XY] is the first signer?
Which laws on consumer protection do apply in a [specific region]?
Which are the Rights of the Consumer according to the EU law?
None of the current general-purpose search engines provides facilities able to respond to such specialized information needs. To implement advanced services able to meet such requirements, the semantics of the information has to be understandable not only by humans (as in the Web 1.0 and 2.0) but also understandable and processable by the machines.
This is actually what the Web 3.0 (or Semantic Web) is: an evolution of the Web characterized by information understandable by both humans and machines. If endowed with semantically qualified data (Smart Data), the Web becomes the effective environment where distributed machines will be able to work together, as well as generate and distribute useful information tailored to the users’ needs.
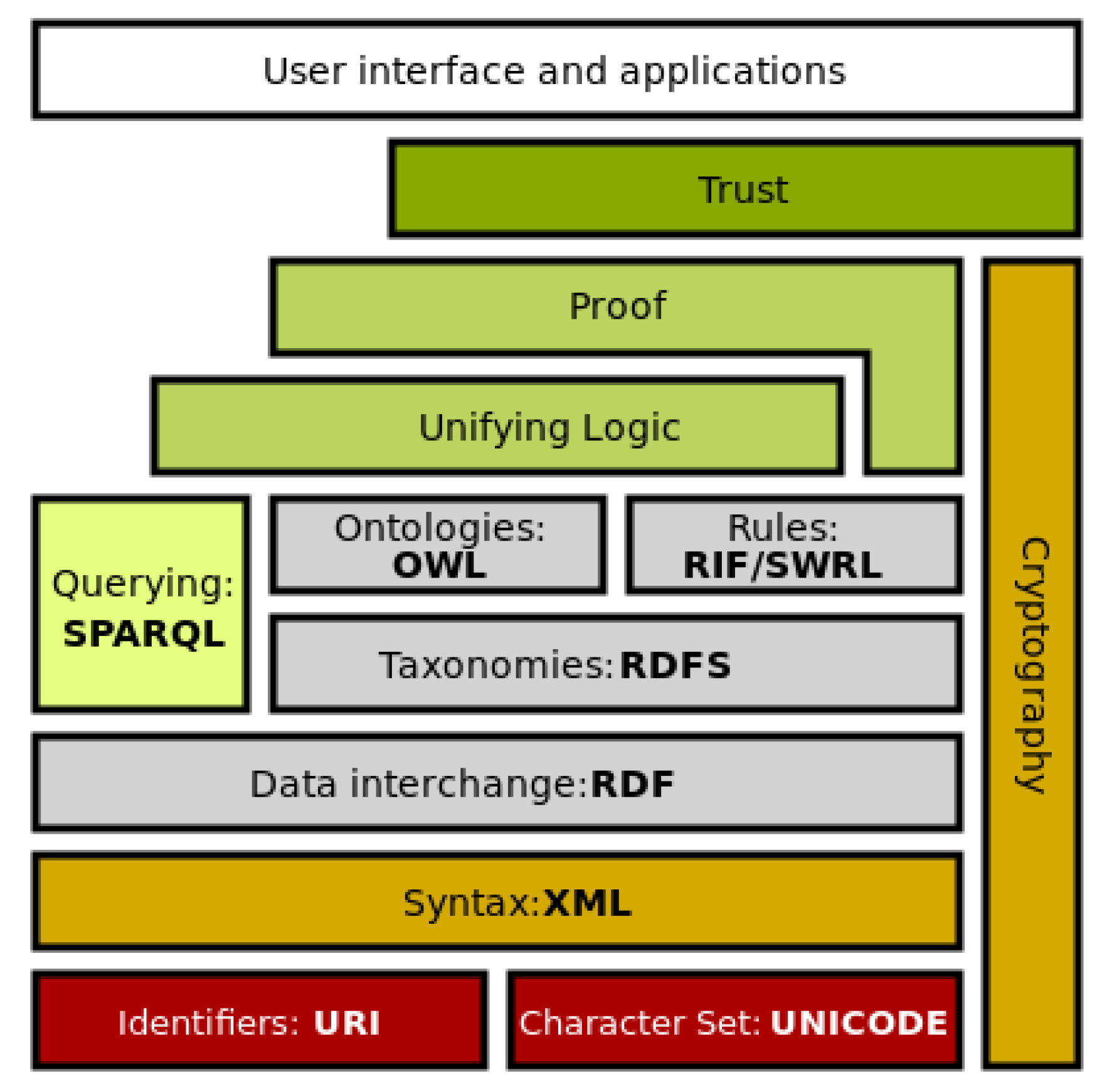
We are nowadays on the edge of this important evolution whose main objective is the development of advanced information access and management services. In this regard, the W3C has promoted a hierarchy of standards (see
Figure 1) for the identification of information resources, as well as the description of their structure and semantics. The basic level of this hierarchy involves digital encoding of information by using the Unicode standard as well as uniform resources identification (URI). Using the eXtensible Mark-up Language (XML) syntax you can then define markup languages that describe the structure of such resources; in particular, the Resource Description Framework (RDF) has been defined as a language able to describe the semantics of information resources, as well as the relationships between them, through subject-predicate-object statements (a part from the RDF/XML serialization, other RDF serializations are Turtle, N-Triples, N-Quads, JSON-LD, N3).
Through RDF Schema and OWL (Ontology Web Language), you can also define vocabularies, organized into hierarchies of classes and properties, which provide meaning to the statements. The upper layers of the W3C standard hierarchy introduce languages for rules (layer
Logic with languages such as RIF (Rule Interchange Format) or SWRL (Semantic Web Rule Language), for describing the source of information (layer
Proof with languages, like the Open Provenance Model (
http://openprovenance.org), that can specify how information has been derived, on which data, by whom), and finally for the ways in which parties establishing communication can be reliable (layer
Trust, an example of are specific techniques for the implementation of digital signatures or the Blockchain technique).
The principles of the Semantic Web have a natural application in specialized domains such as the legal one. Legal information has particular characteristics:
legal documents (in particular legislative ones) have well-defined characteristics with regard to their structure and semantics;
the legislative process, in particular the legislative documents production, is characterized by a well-structured and defined workflow that involves legislative offices in parliaments and public administrations;
legal information systems are not only intended to provide advanced search tools for users, but also to organize the legal order, to monitor the impact of the new rules on the regulation, to manage documents life-cycle and different versions chronology;
users are mostly interested in accessing individual norms rather than simply documents, in knowing relationships between them, and having support for legal reasoning.
The peculiarities of legal information, coupled with the complexity of the user’s information needs, make the management of the legal information on the Web a challenge. For example, there is a growing need of having access to search engines able to simulate the interpretative process of legal experts on regulatory provisions: this actually requires a specialized representation of legal information supporting automatic legal reasoning. For these reasons the principles of the Semantic Web, for exchanging smart data on the Web, have been applied to legal information since early 2000’s, especially in projects developed at institutional levels.
3. The Semantic Web: The Top-Down Model
The first experiences, aimed at introducing the Semantic Web principles in the legal domain, followed an approach that we can define top-down. According to this approach, the semantic enrichment of legal information originates from an intense work of definition and harmonization of standards and vocabularies, to be shared and used to describe the sources of law and favor its interoperability.
Several initiatives were launched at national levels. In Italy, for example, the Ministry of Justice, launched in 2001 the “NormeInRete” (NIR) project with the aim of creating a distributed architecture, based on document identification standards and content descriptors, with the purpose of creating a single point of access to legal documents equipped with advanced query tools and a stable mechanism for their linking [
1]. In this scenario, the project adopted the Web Semantic principles in a top-down approach using URIs for document identification (URN-NIR), as well as XML (XML-NIR) and RDF/OWL standards for representing the structure and the semantics of documents contents.
The NormeInRete project was one of the first experiences where the Semantic Web principles were applied to the legal domain, thus becoming an international reference in the field [
2]. URN-LEX [
3] is the direct international extension of the URN-NIR standard, under approval as the IETF (Internet Engineering Task Force (
http://www.ietf.org)) official standard for legal documents. It is designed to be sufficiently general and flexible to permit the identification of legal documents of various kinds (legislation, case-law and administrative acts) issued in any country or by any authority. One of the main URN-LEX implementations is represented by the publication service of United Kingdom legislation, managed by the UK National Archive. This service uses URN-LEX for back office document management services, while it exposes http-based identifiers following the Linked Open Data principles (see
Section 4).
One of the pioneer administrations to join the URN model was the Senado Federal do Brazil, that developed a law enforcement service (LexML Brazil) [
4] explicitly inspired by NormeInRete, based on the URN-LEX standard for the construction of document identifiers. Similarly, Zotero (Zotero (
http://www.zotero.org)) developed by Frank Bennet, Associate Professor at Nagoya University, Japan is a free and open-source service capable of capturing references from documents of legal publishers databases which cooperate with it. Moreover, this service manages references provided directly by users to create reusable libraries in scientific articles according to a user-selected bibliographic style. Zotero’s multilingual extension uses the URN-LEX standard, which permits better reference management and increased interoperability with other quotation services.
The conceptual model underlying the URN and XML standards in NormeInRete has inspired other legal Semantic Web initiatives at international level, such as the AkomaNtoso project (
http://www.akomantoso.org) promoted by UNDESA (the United Nations-Department of Economic and Social Affairs) designed to provide document formats and tools to support pan-African parliaments activities. This initiative was followed by the OASIS standardization process producing the so-called LegalDocML standard (
https://www.oasis-open.org/committees/tc_home.php?wg_abbrev=legaldocml).
In addition, the NormeInRete working groups have been an active part, along with a consortium of European research centers, in the definition of the CEN Metalex [
5] standard (
http://www.metalex.eu), a model for exchanging XML legislative document formats, promoted by the Leibniz Center for Law of the University of Amsterdam, approved by the European Standardization Office (CEN).
Such academic and institutional activities, described so far, were an essential point of reference in the development of other legal standards such as the LexDania project standards in Denmark, eLaw in Austria, CHLexML and the new version of the legislative standards being developed by the Publications Office of Swiss Federal Chancellery.
4. The Crisis of the Top-Down Model and the Linked Open Data
The top-down implementation of the Semantic Web was characterized by a broad coordination effort for defining and sharing standards describing the resources. In particular, the top-down approach in the legal domain produced relevant academic results, represented by the availability of document standards specialized in legal information description. However, the level of details with which information is represented in experiences as NormeInRete, AkomaNtoso and others, in the long run represented an obstacle to the development of large-scale access services to legal documents collections.
On the other hand, recently, a set of principles and technologies, known as “Linked Data”, was promoted as the basic infrastructure for the Semantic Web development, allowing data sharing and reuse in large-scale [
6]. These principles, introduced by Tim Berners-Lee in the note on Linked Data (
http://www.w3.org/DesignIssues/LinkedData.html), can be summarized as follows:
Use URIs as names for things;
Use HTTP URIs so that people can look up those names (namely they can find the associated resources);
When someone looks up a URI, provide useful information, using the standards RDF and SPARQL;
Include links to other URIs, so that they can discover more things.
The Linked Data approach does not alter the standard architecture which the Semantic Web philosophy is based on, but promotes an incremental, bottom-up approach, with the aim to foster data publication and management by using URIs for their identification and RDF to describe the available semantics by providing, or possibly exploiting, existing XML organization of the resources. The objective is to encourage data exposure at the available level of interoperability, leaving the effort of semantic enrichment and data interconnection to a virtuous trend that may be stimulated by the interest in their reuse.
This tendency has had a particular impetus in the context of OpenGovernment initiatives: the Memorandum on Transparency and Open Government published by the Obama’s administration in 2009 (
https://obamawhitehouse.archives.gov/the-press-office/transparency-and-open-government), the Open Gov (
http://data.gov.uk) Initiative in the UK and similar initiatives of the European Commission (
http://ec.europa.eu/information_society/events/cf/ict2010/). Such initiatives promote the opening of public data (license free by nature) as an instrument of transparency and citizen participation in the democratic game. From this perspective, the Public Administrations (as data publishers) are responsible for providing data to the best possible level of interoperability, leaving citizens and other public and private entities (as data consumers) the possibility of data exploitation and enrichment. The Linked Open Data (LOD) initiative is aimed at opening public data (hence the adjective
Open) for their bottom-up enrichment. In this respect the application of the Linked Data paradigm has had an immediate success.
One of the key examples of a Linked Open Data approach in the OpenGovernment domain is represented by the United Kingdom’s Open Data Service. This service is intended to publish UK government data in a Linked Data modality, using HTTP URIs to identify resources and RDF as standard for representing data. The main types of information published as Linked Data by the UK Government are:
references to the organizational structures that provided the data
data of administrative units
data on transport, including infrastructure and traffic data
data on the education system, including schools and kindergartens
government expenditure data
legislation.
In particular, legislation is published at “
www.legislation.gov.uk”, a web service managed by the National Archives on behalf of the Government, containing all the legislation issued in the United Kingdom since 1267, including its evolution over time: from the general and local acts of the United Kingdom to those of the national assemblies. Documents can be viewed in different formats (PDF, RDF, XML). The “
www.legislation.gov.uk” service also allows the users to select any type of legislation and to select a geographic area to see which types of laws are locally applicable. From a technical point of view, “
www.legislation.gov.uk” provides API (Application Program Interface) specifications for full and free access to the underlying data so that they can be reused in terms of the Open Government License (
http://data.gov.uk).
A specific initiative for providing HTTP URIs to identify European legislation has been promoted in the early 2010’s by the Luxembourgish Ministry of Justice. This initiative, called ELI (European Legislation Identifier), is supported by the e-Law Working Group of the European Council who invited Member States to implement such a standard in their institutional legal information systems [
7]. The ELI identification standard is based on the same metadata model of the URN-LEX initiative, with few syntax differences including the HTTP syntax serialization, which complies with the LOD guidelines.
A similar initiative has been promoted for the identification of case-law. In this domain in the late 2000’s the ECLI initiative was carried on with the aim to provide a naming convention jurisprudential resources [
8]. ECLI was firstly released as a URN serialization of case-law identification metadata; nowadays an http-based version of ECLI is being implemented.
The Semantic FinLex is a relevant example of a Linked Open Data service for Finnish legislation and case-law (
http://data.finlex.fi/). FinLex in fact has already adopted ELI and ECLI standards, both in their HTTP-based syntax form, to identify legal resources and provides access to legal information according a Linked Open Data approach. Several other initiatives are moving in this direction, so that the e-Council Working Group of the Council of the European Union has created a specific working group on Linked Open Data, with the aim of monitoring and coordinating initiatives to adopt this approach in the legal domain.
At European level, one of the main LOD initiative has been developed at the OP by providing a Linked Open Data dissemination service for the Cellar, semantic web content and metadata repository of legal and non-legal documents produced by the European institutions. Cellar includes about 150 millions of documents in 24 languages; metadata in as many languages are stored and described in RDF, resulting in about 800 millions of triples. Currently the Cellar SPARQL endpoint, recently exposed in order to complement linked open data services to potential consumers [
9], receives about 10 million requests per day (Cellar statistics dated April 2018). Cellar is also the source of information of the Eur-Lex portal (
http://www.eurlex.eu) which provides access to several types of legal resources including treaties, legislation, case-law and legislative proposals.
Based on a LOD approach, legal informatics research has also recently obtained relevant results not only in legal information accessibility, but also in legal reasoning (as for example Hohfeldian and deontic reasoning [
10,
11], as well as non-monotonic reasoning [
12,
13]). In this respect legal knowledge modeling is essential to implement advanced services: for this reason legal ontologies have been developed aiming to capture different aspects of the legal knowledge: from the core legal concepts [
14,
15,
16,
17,
18], including deontic ones [
10,
19], to domain concepts [
20,
21,
22,
23].
A LOD approach in the legal domain has not only to do with norms modeling (and related metadata) but also with enactment of rights and empowerment of people, thus contributing to transparency and accountability of the Public Administration. An example of this is the “LOD and e-Participation” pilot project promoted by the European Parliament and developed by the OP [
24]. This project aims to develop a web platform allowing citizens and other stakeholders to actively participate in the EU law-making by providing comments and amendments, as well expressing sentiments, on pre-legislative documents. To this aim a proper knowledge organization system has been developed including ontology modules for the semantic representation of legislative proposals, amendments and users’ activities.
As information resources, in particular legal ones, are mainly available on the Web without specific semantic qualification, it is essential developing tools able to process contents, extract semantics and represent them in a way amenable for computation. In this respect a wide literature exists including natural language processing and machine learning tools used to parse and qualify legal content [
25,
26,
27,
28,
29,
30]. From this point of view the state-of-the-art bridge between ontologies and lexicons is represented by the Ontolex-Lemon model [
31], which describes the linguistic roles of textual constituents and makes it easier the semantic mark-up of legal texts according to the available standards and knowledge models. This very model has been recently used by the OP within the PMKI (Public Multilingual Knowledge management Infrastructure) project [
32], aiming to create a web platform able to provide interoperability between multilingual classification systems (like thesauri) and other language resources, to be published as Linked Open Data.
5. The Strategic Objectives of the OP within the Semantic Web
The revolution of digital services carried by the advent of the Web and its developments, previously discussed, brings about challenges particularly sensitive for the legal domain, affecting legal information providers and their production channels. In this context, the Publications Office of the EU (OP), as main inter-institutional legal information service provider, has recently defined orientations to tackle such challenges at either technological, political or financial point of views [
33].
The technological changes are drivers of changes in the way how the OP will provide information services, on behalf of EU institutions, directly to the citizens and to businesses or other types of professional organizations. This holds in particular as regards reusing services for both commercial and non-commercial purposes. Such changes are strictly linked to the semantic evolution of the Web and the associated digital services, in particular Open Data ones. Therefore, OP has identified mid-term and long-term strategic objectives shaped around these technological changes and priorities.
Mid-term strategic objectives, to be achieved by 2020, can be summed up as follows [
33]:
- 1.
Exchange all legal data with institutions in a secure and automated way based on common standards (metadata and content in a structured format);
- 2.
Facilitate the rationalization of the publication contracts of the EU institutions and provide interoperable formats and collaborative production workflows for multichannel production of highly structured content;
- 3.
Focus linguistic quality-control processes on consistency, content analysis, data structuring and new media, including social media;
- 4.
Link the information available on the portals managed by the Office (ex: EUR-Lex, Publications Office portal, TED (tenders documentation), CORDIS (research and development information services), EU Open Data Portal) with other EU information available online, increase interoperability and provide federated search and access services (seamless navigation experience).
Long-term strategic objectives, to be achieved by 2025, are identified in the following [
33]:
- 5.
Implement act-by-act production of the Official Journal in order to achieve a more flexible, faster and simplified way of publishing;
- 6.
Be the reference production centre for the EU institutions for publication material (all content fully accessible for any device and fully accessible for disabled users);
- 7.
Implement a new distribution concept to achieve a zero-stock objective;
- 8.
Manage a single point of access (one-stop shop) for all services related to the management and publication of public procurement data, including procurement by EU institutions;
- 9.
Manage a fully operational legal deposit scheme for all publications of the EU institutions (preservation and access in digital format);
- 10.
Be the central point of access to and reuse of public sector information from EU institutions, thus contributing to the creation of innovative products and services by businesses.
Such objectives are highly influenced by the semantic evolution of the Web, and seem to be mainly driven by the dynamic nature of digital publications seen as a set of objects endowed with specific identity and meaning, as well as consumed on different media (considering the paper as just one and not principal medium), subject to specific modality of preservation and accessibility. On the other hand, OP strategic objectives foresee an evolution of the accessibility to legal information which is mainly influenced by the Linked Open Data approach to the Semantic Web, which considers information objects as a set of building-blocks for the development of added-value services, which derive from datasets mash-up and can leverage crowdsourcing in the social Web.
6. A Scenario for the Future Web: Towards the Web 4.0
The Linked Open Data approach is significantly fostering the development of the Web 3.0 or Semantic Web: it provides smart data, essential pre-conditions to support machine intelligence, paving the way for a new revolution of the Web that is about to come, the so-called “Web 4.0”.
Authors are now unanimous to identify Web 4.0 as the next evolution of the Web where autonomous software agents can interact one another, as well as interact with human minds in symbiosis. For this reasons some authors refers to Web 4.0 as
Symbiotic Web [
34].
The tendency to provide information consumers with software agents, able to manage relevant information with practical consequences for humans, is sometimes addressed in literature as
Pragmatic Web: it represents the specific aspect of the Web 4.0 or
Symbiotic Web which comprises the collection of practices and theories able to describe how people use information for social interaction, which creates understanding or commitments [
35,
36].
Being endowed with the ability of processing smart data, intelligent personal software agents can be developed. Having knowledge of users’ profile and needs, they will be able, for example, to book flights at the right moment to get the lowest price, as well as to re-protect a customer with the best flight option in case of flight cancellation; to select the news most interesting for the users; to make the best economic investment according to the users’ financial risk profile, and so on. Personal software agents will be always available, ready to cope with users’ requests as well as to be intuitive of the user’s needs. In such a scenario, where everything can be identified by a URI, as well as every device can be connected to the Internet through an IP address, our interaction with objects can be managed by such intelligence agents, for example allowing a self-driving car to drive users to the right place according to users’ agenda and schedule, or giving disabled people the possibility to control the movement of a prosthesis by just thinking a movement.
The legal domain will be not immune from this further evolution. As we are now about to use self-driving cars, we will be probably driven by such cars to respect speed-limits according to the laws of the specific jurisdiction where we are. This is a specific case of laws embedded in personal intelligent agents. As the law can be unclear in some cases, this might bring about problems of interpretation to the digital systems too [
37]: for example some states have a basic speed law imposing not to drive faster than weather conditions permit regardless of the speed limit. In these cases the law requires a judgement of a reasonable person which is a concept not easily translated for an artificial intelligence. Similar problems might arise in case of contradictory laws: which one should prevail?
A so-called
ex-ante [
38,
39,
40] semantic annotation of legislative rules, which consists in providing the Legislator with tools supporting the semantic description of norms during the legal drafting phase, may be a solution for making legislation amenable for computation in the Semantic Web (accessibility and reasoning), as well as for solving legal norms ambiguity at the source.
Legal professions will be highly affected by this kind of revolution: for example legal data mining and e-discovery will be no longer functions for lawyers but for intelligent agents endowed with knowledge of a specific disputed case and the law regulating that particular case [
41].
As in the Web 3.0 the Law can be understandable and processable by the machines, in the Web 4.0 nothing prevents us in principle to imagine a scenario where an intelligent agent with the function of a Judge, having knowledge of personal profiles, specific cases and related laws, can take the final decision on legal disputes. This is a scenario that can be considered disquieting by someone, and some recent regulations, as GDPR (
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=uriserv:OJ.L_.2016.119.01.0001.01.ENG) for example, prohibit automated individual decision-making, including profiling (where “automated individual decision-making” is a decision based solely on automated processing). In particular, in case of automated decisions involving personal data of the data subject, the GDPR obliges the data controller to provide the data subject with “meaningful information about the logic involved” (Articles 13 and 14) [
42]. This seems to place obstacles in the implementation of automatic decisions but, on the other hand, these limitations can be viewed as a contribution to transparency and accountability. On the other hand, the implementation of automatic decisions seem not too far when we consider, for example, the status of development of on-line dispute resolution systems, which provide, in small scale, similar legal advice services (
https://ec.europa.eu/info/live-work-travel-eu/consumers/resolve-your-consumer-complaint_en).
7. Conclusions and a Step Further: The Web 5.0
The evolution of digital services in the Semantic Web is a perspective affecting already our daily life and is about to determine a revolution especially in a technical and specialized domain as the legal one. Legal publishers and legal professionals are sectors particularly affected by such revolution. This is given by the possibility of reusing legal data for developing new services in the Web 3.0, envisaging symbiotic interaction between humans and machines in the Web 4.0 and leading profound changes in the legal domain, as in the perceptions and compliance with legal rules, as well as in the administration of Justice.
This trend received a significant promotion by the European legislation in this area, with Directive 2013/37/EU of the European Parliament and of the Council of 26 June 2013, which amends Directive 2003/98/EC on the re-use of public sector information. This directive aims to facilitate the re-use of public data accessible to citizens and businesses, for example by introducing the obligation for public administrations to allow data access and re-use.
Modeling legal knowledge is therefore essential for the implementation of Semantic Web oriented services. In the Linked Data context, this modeling provides the pre-condition for that semantic refinement level, made of standardization, classification and conceptual mapping, capable of increasing the degree of data interoperability. In this framework the role of the scientific research is essential: in fact, it can contribute with knowledge modeling in different domains, can provide guidelines and tools for the implementation of advanced legal information services [
10], effective pre-conditions to machine intelligence.
This appears to be the current status of the evolution of the Web in general, and in the legal domain in particular. Semantic Web and smart data (Web 3.0) are paving the way to the Symbiotic Web (Web 4.0) where real world and humans will be more and more interconnected and indistinguishable. Moreover, thanks to smart data, machines will be able to develop their intelligence. In this symbiosis a further question can be raised: what will distinguish interaction between humans from human-machine interactions? Currently the Web is
emotionally neutral [
34]: information systems exposed on the Web do not feel the user perceives. Therefore, it seems fascinating to envisage human-machine interaction comprising emotions in the Web 5.0 or
Emotional Web. In this context, humans will be able to communicate their emotions to systems able to perceive and elaborate them, thus responding to this special case of users’ needs. The same holds for the legal domain, where not only legal information but also emotions will play a meaningful role in human-machine interaction, as it happens today in the interaction between humans: in this scenario, how will you be able to persuade a digital Judge?


{kind=link}
