Abstract
Lidar-based models rely on an optimal relationship between the field and the lidar data for accurate predictions of forest attributes. This relationship may be altered by the variability in the stand growth conditions or by the temporal discrepancy between the field inventory and the lidar survey. In this study, we used lidar data to predict the timber merchantable volume (MV) of five sites located along a bioclimatic gradient of temperature and elevation. The temporal discrepancies were up to three years. We adjusted a random canopy height coefficient (accounting for the variability amongst sites), and a growth function (accounting for the growth during the temporal discrepancy), to the predictive model. The MV could be predicted with a pseudo-R2 of 0.86 and a residual standard deviation of 24.3 m3 ha−1. The average biases between the field-measured and the predicted MVs were small. The variability of MV predictions was related to the bioclimatic gradient. Fixed-effect models that included a bioclimatic variable provided similar prediction accuracies. This study suggests that the variability amongst sites, the occurrence of a bioclimatic gradient and temporal discrepancies are essential in building a generalized lidar-based model for timber volume.
1. Introduction
Forest stands often develop a diversity of canopy structures across space and time. The diversity may result from the natural dynamics in stands through time (e.g., growth, mortality, succession, stand composition), the variability of biophysical factors (e.g., soil, climate, elevation) or human activities [1,2]. Boucher et al. [1] for example, stated that disturbance regimes and climate have an effect on canopy structures. Laflèche et al. [3] showed that site characteristics, species composition, and climate influence site productivity.
Canopy structures can be described through forest attributes measured during field inventories (e.g., canopy cover, height, diameter, stand volume) or through remote sensing tools such as the light detection and ranging (lidar) [4]. Lidar is an active sensor which uses pulses of laser light to measure the distance to a target and record the strength of light backscattering from this target. It generates a point cloud which is a three-dimensional representation of the volumetric interaction between pulse photons and the target. It has been extensively used in forestry to describe the vertical structure of stands [5,6,7]. Metrics can be calculated from the point clouds to statistically describe them (e.g., height metrics, canopy cover metrics). They are often used as explanatory variables to model forest attributes such as basal area, timber merchantable volume, biomass, etc. [8,9,10,11].
Spatially extensive acquisitions of lidar datasets are now possible, making this tool attractive for large-scale inventories [12,13]. Such inventories often require several lidar surveys. Combining the resulting datasets is challenging, especially when there is variability amongst the sites distributed across a given survey area, or when time has elapsed between the field inventory and the lidar survey (temporal discrepancy). In this situation, it is difficult to transfer a site-specific model to another location and therein obtain the same prediction accuracy.
Recent research has ways to accurately predict forest attributes from lidar over large-scale areas. Hansen et al. [2] for example, included biophysical variables (climate, topography, and soil) in their model when predicting lidar canopy height and canopy cover for five ecoregions located along a 4000 km transect. Næsset and Gobakken [14] and Nilsson et al. [15] calibrated site-specific models to predict forest attributes from lidar and combined the models’ outputs to make predictions at a large-scale. Their approach allowed for accurate predictions locally but required several models for working at the large-scale level. and opted for a general mixed-effect model to predict timber volume, biomass or dominant height of multiple sites. Both authors obtained an overall goodness comparable to the site-specific (local) models. This approach offered the advantage of building a single predictive model which could be adapted to the specific conditions found in the different sites.
Several questions remain when predicting forest attributes of different sites in an operational context, including the following: (1) Does the combination of multiple lidar datasets in a generalized predictive model increase the bias at each site? (2) Does accounting for the variability in sites limit the model biases at each site? (3) How should forest attributes be predicted outside the range of the studied sites? and (4) Do temporal discrepancies between field and lidar acquisitions have an effect on the model prediction accuracy? This study, therefore, aims at analyzing the effects of variability amongst sites and temporal discrepancies on the prediction accuracy of timber merchantable volume of sites located along a bioclimatic gradient.
2. Materials and Methods
2.1. Study Sites
Various bioclimatic domains exist throughout the province of Quebec, Eastern Canada [16]. Five study sites populated by balsam fir (Abies balsamea (L.) Mill) were selected along a bioclimatic gradient of temperature, precipitation, elevation and growing degree days (calculated with a 5 °C reference temperature), Figure 1. The Mauricie_south and Mauricie_north sites are located in the Mauricie region in central Quebec (47.0° N, 73.0° W). The Mauricie_south covers an area of 4364 km2. It is part of the sugar maple (Acer saccharum Marshall)/yellow birch (Betula alleghaniensis Britt.) domain. The Mauricie_north site covers an area of 4630 km2. It is part of the balsam fir/yellow birch domain which is a transition zone between the temperate and the boreal forests. The Montmorency site is located in central Quebec (47.3° N, 71.1° W). It covers an area of 66 km2. It is part of the balsam fir/white birch (Betula papyrifera Marshall) domain. Two other sites are located in the Saguenay-Lac-St-Jean (SLSJ) region in northern Quebec (49.7° N, 71.5° W). The SLSJ_south covers an area of 5937 km2. It is part of the balsam fir/white birch and the black spruce (Picea mariana (Mill.) Britton, Sterns & Poggenburg)/moss (Bryophyta) domains. The SLSJ_north site covers an area of 6093 km2. It is part of the black spruce/moss domain where balsam fir stands are preferentially located on the slope of hills.
Figure 1.
Location of the study sites.
The field and the lidar data were obtained from the Quebec provincial forest ministry - Ministère des Forêts, de la Faune et des Parcs (MFFP) and the Montmorency Research Forest [17,18,19]. The field data were acquired following a uniform inventory protocol while the lidar data were generated through surveys with variable acquisition parameters.
2.2. Field Plot Data
The field data were collected in circular plots (radius = 11.28 m, area = 400 m2). The plot center positions were georeferenced using a precision GPS + Glonass receiver. Field plots were selected following these criteria: (1) balsam fir was the dominant species (>50%); and (2) the dominant height was above 7 m. The resulting sample was comprised of 295 plots, with 40 plots inventoried at the Mauricie_south site (in 2012), 55 at the Mauricie_north (in 2012), 93 at the Montmorency forest (between 2009–2013), 74 at the SLSJ_south (in 2016), and 33 at the SLSJ_north (in 2016). Trees with a diameter at breast height (dbh) above 9 cm (merchantable trees) were measured using a diameter tape. Tree height was calculated using a height–diameter based-equation following Bégin and Raulier [20]:
where is the total height of the tree of the plot, the diameter at breast height, the model parameters, the k explanatory variables, and the error term and the plot random coefficients.
The height-diameter ratio (H–D ratio) of each plot was calculated by dividing the average plot height (weighted against the basal area) by the average plot dbh (weighted against the basal area). This ratio accounts for the tree morphology resulting from growth conditions [21]. The field merchantable volume (MV) defined as the volume under bark for stems greater than 9 cm diameter excluding the stump and tip, was calculated following Fortin et al. [22]. The climatic data (temperature, precipitation, growing degree days (gdds)) were derived from the MFFP forest inventory database using the BioSIM software [19]. Table 1 provides a summary of the field data for the study sites.

Table 1.
Summary of the field data a.
2.3. Lidar Data and Variable Generation
The lidar surveys were conducted in leaf-on conditions in 2014 at the Mauricie_south and Mauricie_north sites, 2011 at the Montmorency site, 2013 at the SLSJ_south site, and 2013–2014 at the SLSJ_north site. They were supplied by various survey providers. Ground-classified returns were interpolated to construct a digital terrain model (dtm) using LAStools software (version 150526 unlicensed, rapidlasso GmbH, Gilching, Germany) [23]. The height of returns was normalized by measuring the elevation difference relative to the underlying terrain model. A 2 m threshold was applied to remove non-canopy returns [9,14]. Point clouds were clipped to the extent of each field plot boundary. Metrics describing them were calculated using the USFS’s FUSION software (version 3.42, US Forest Service, Salt Lake City, UT, USA) [24]. They were classified into three standard groups of variables: canopy height CH variables (percentiles of heights, averages), canopy density CD variables (percentage of first returns above or below a 2 m, 5 m or 7 m threshold), canopy structural heterogeneity CSH variables (standard deviation of height, variance of height, coefficient of variation). The average elevation of each plot was also calculated from the lidar raw data. The elevation and the climatic data were included in a fourth group of variables, identified as BIO variables. Table 2 provides a summary of the lidar data for the study sites.
Table 2.
Summary of the lidar data a.
2.4. Data Analysis
2.4.1. Merchantable Volume Modeling
Several generalized MV models were tested. The simplest model (Model 1) ignored the effects of site, growth, and the bioclimatic gradient, while the most complex model (Model 6) included all of these. All possible combinations of candidate metrics (one variable per standard group) were tested in a 3-metric model (Model 1) adapted from Yoga et al. [25]. We selected this model as it has been specifically developed for balsam fir stands and was successfully tested at the Montmorency site:
where is the merchantable volume of the jth field plot of study site m, the canopy height, the canopy height intercept (mean height adjustment where = 0), the canopy density, CSHjm the canopy structural heterogeneity, the model parameters, and the error term. Each 3-metric subset was tested separately for each study site. The model’s mean square error (MSE) was then calculated. The candidate subset with the smallest MSE across all study sites was selected as the best subset and then used to elaborate the more complex models.
Temporal discrepancies existed amongst the field inventories and the corresponding lidar surveys (Table 2). Equation (3) describes a growth adjustment function (G), based on Pothier and Savard [26] yield tables, that can be used to account for the discrepancies:
where TD is the temporal discrepancy between the field and the lidar data acquisitions (in years), H a height variable, and the model parameters. A time-corrected model MV model (Model 2) was then built by adding Equation (3) to Equation (2):
The effect of site variability was accounted by using a random coefficient regression [27,28]. Site random coefficients were either added to all the model parameters (, Model 3) or to the canopy height parameter only (, Model 4):
Bioclimatic variables were added iteratively to Model 4 to account for the bioclimatic gradient (Model 5):
Finally, the site random coefficient of Model 5 was ignored to specifically analyze the accuracy of the resulting bioclimatic fixed-effect model (Model 6):
All the models were fitted by maximum likelihood. The statistical analyses were carried out using the “nlme” package [29] of the R software [30]. The residual heteroscedasticity was taken into account by adding a variance function to the models following Yoga et al. [25]. In that study, the variance function was comprised of variables describing the average height and the spatial distribution of returns. In our present study, the lidar data were acquired with different settings. We, therefore, opted to omit the return spacing variable of Yoga et al. [25] when accounting for the heteroscedasticity. The random error term , therefore, had the following form:
where is the residual variance, havgfjm the variance the average height of first returns above 2 m and the variance parameter.
2.4.2. Model Validation
The best models were selected based on the Akaike Information Criterion AIC (lowest), the residual standard deviation RSD (lowest), the coefficient of determination (pseudo-R2, highest), the level of significance (p-value) and the standard deviation of the random coefficients (rstd, lowest). The leave-one-out cross-validation (LOOCV) was used to assess the models’ accuracy [31]. A new dataset was created by removing one field observation from any site. The MV model was fitted to the new dataset (training data) and used to predict the MV of the removed observation (test data). The procedure was repeated until predicted values were obtained for all the field observations.
3. Results
3.1. Optimal Subset of Explanatory Variables
The subset of lidar-derived variables, which generated the smallest MSE, included the average height of first returns above 2 m (havgf), the percentage of first returns above 2 m (p2f) and the standard deviation of the height of first returns above 2 m (hstdf). Figure 2 presents the correlation between the field MV and each of the explanatory variables per study site. They were of 0.87, 0.41 and 0.41 respectively.
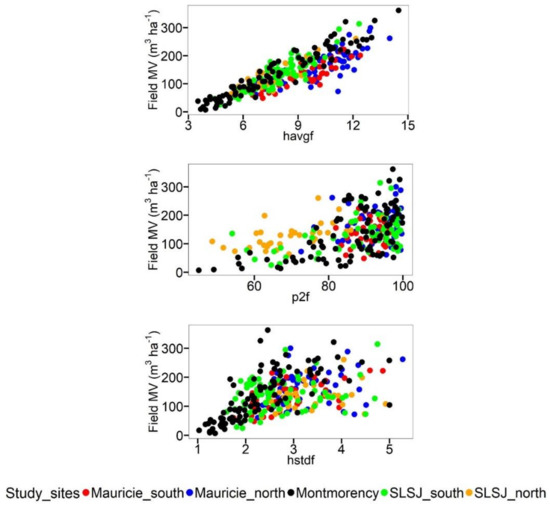
Figure 2.
Scatter plots of the field merchantable volume (MV) against the explanatory variables. Field plots of each study site are represented by a dot. havgf = average height of first returns above 2 m; p2f = percentage of first returns above 2 m; hstdf = standard deviation of the height of first returns above 2 m.
3.2. General MV Models
Table 3 presents a model comparison amongst the MV models. Model 1 was built with the best subset of lidar-derived variables only. It was significantly improved by including the growth adjustment function (Model 2: p-value < 0.0001). The AIC decreased from 2861.8 to 2774.9 and the RSD from 33.3 to 27.2 m3 ha−1 while the pseudo-R2 increased from 0.75 to 0.83. Table 4 presents the average biases between the field and the predicted merchantable volumes before (Model 1) and after (Model 2) the addition of the growth adjustment function. The absolute biases decreased for all sites except the SLSJ_south.
Table 3.
Anova comparisons amongst candidate merchantable volume (MV) models.
Table 4.
Average biases of the merchantable volume (MV) models per study site.
Model 2 was further improved by accounting for the variability amongst sites (Models 3 and 4: pseudo-R2 = 0.86). Similar improvements were obtained between Model 3 (built with multiple random coefficients) and Model 4 (built with the canopy height random coefficient). Model 4, however, had the smallest AIC (2722.7 versus 2746.9). The RSD was 24.3 m3 ha−1 initially and 25.0 m3 ha−1 after cross-validation (see also Table 4 for site biases). However, the model residuals were heteroscedastic. The RSD was estimated as 2.8 m3 ha−1 multiplied by the variance function when accounting for the heteroscedasticity.
The fixed coefficients of Model 4 are presented in Table 5 and the random coefficients, in Table 6. The random coefficients were negative for the Mauricie_south, Mauricie_north and SLSJ_south sites (−0.48 m, −0.37 m, −0.36 m) and positive for the Montmorency and SLSJ north sites (0.70 m and 0.51 m). Their standard deviation was of 0.56 m. It decreased further with the MV models built with the 95th percentile of height (rstd = 0.47). However, these models were less accurate (pseudo-R2 = 0.82). The rstd decreased substantially when a bioclimatic variable was added to Model 4 (Table 6: Models 5a and 5b, random coefficients ~ 0 m). The models included the gdd and the elevation variable respectively. The AICs were smaller (Table 3: 2699.5 and 2687.9).
Table 5.
Fixed coefficients of candidate merchantable volume models.
Table 6.
Canopy height random coefficients of candidate merchantable volume models.
Model 4 random coefficients were plotted against the H–D ratio and the bioclimatic variables (Figure 3). The Mauricie_south, Mauricie_north, and SLSJ_south, which had low elevations but high gdds and H–D ratios, also had a lower random coefficient. Conversely, the Montmorency and SLSJ_north sites, which had high elevations but low gdds and H–D ratios also, had a higher random coefficient.
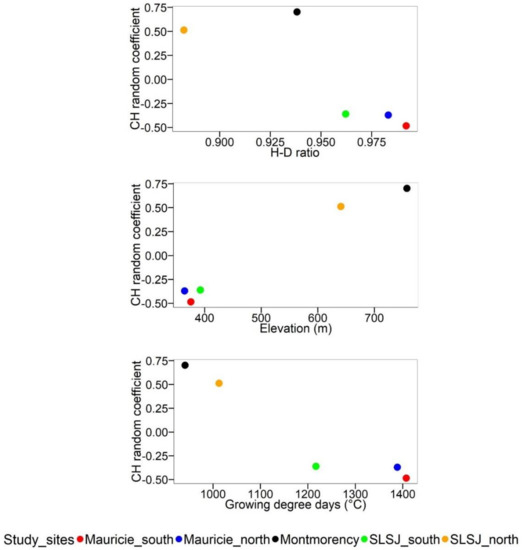
Figure 3.
Scatter plots of Model 4 canopy height (CH) random coefficients plotted against the height–diameter ratio (H–D ratio), the elevation, and the growing degree day variables presented by study site.
The fixed-effect models (Models 6a and 6b) produced similar accuracies as Model 4 (pseudo-R2 = 0.86). Model 6b which included the elevation variable had the lowest AIC value (2688.9). The average biases remained small (Table 4). The RSD was of 24.2 initially and of 24.8 m3 ha−1 after cross-validation. It was estimated to 2.1 m3 ha−1 multiplied by the variance function when accounting for the heteroscedasticity.
4. Discussion
Our study aimed at building a generalized lidar-based model to predict the timber merchantable volume of various study sites located along a gradient of bioclimatic factors. The field and the lidar data were acquired at different dates. We opted for a nonlinear random coefficient model to predict the MV as several studies have shown that mixed-effect models can accurately predict forest attributes both at small and large-scale levels [32,33,34]. The model needed to be adjusted given the variability amongst study sites and the temporal discrepancies.
A crucial step in building the MV models was the search of optimal explanatory variables. The combination of havgf, p2f and hstdf provided the best subset of variables. The addition of a growth adjustment function improved the model significantly (p-value < 0.0001). This function accounted for the MV growth that occurred during the temporal discrepancy. It also enabled us to accurately combine the different lidar datasets. It included a height variable (havgf) as the effect of time on merchantable volume varies with the stand development stage. This result confirms the need to adjust predictive models when temporal discrepancies occur [35].
Models 4 and 6b were the best candidate models. Model 4 contained a site random coefficient () accounting for the variability amongst sites. The model performed as efficiently as Model 3, which contained several coefficient adjustments (p-value = 0.9913). This result showed that a local adjustment of canopy height was therefore enough to account for the variability amongst sites. This can be explained by the fact that the correlation between the MV and havgf was high compared to the other explanatory variables (Figure 2). It was of 0.87 versus 0.41 for p2f and hstdf. Modifying havgf only would, therefore, have a comparable effect to modifying all the model parameters.
Model 4 random coefficients varied with the characteristics of the study sites: they were positive at the Mauricie_south, Mauricie_north and SLSJ_south sites and negative at the Montmorency and the SLSJ_north sites. The Mauricie_south, Mauricie_north and SLSJ_south sites also had higher H–D ratios (H–D = 0.99, 0.98, 0.96; Table 1) compared to the Montmorency and the SLSJ_north sites (H–D = 0.94 and 0.88). Thinner stems are characterized by higher H–D ratios and have lower merchantable volumes. For a given height, trees were therefore possibly thinner at the Mauricie_south, Mauricie_north and SLSJ_south sites compared to the Montmorency and the SLSJ_north sites. For a given average height, canopy density and canopy structural heterogeneity, havgf needed to be decreased at the Mauricie_south, Mauricie_north and SLSJ_south sites and increased at the Montmorency, SLSJ_north sites when predicting the MV with the same equation.
Table 1 shows a gradient of bioclimatic factors amongst study sites: higher temperatures and gdds were observed at the Mauricie_south, Mauricie_north and SLSJ_south sites compared to the Montmorency and SLSJ_north sites. The random coefficient values (Models 5a and 5b) decreased substantially when a bioclimatic variable was added to the canopy height parameter. This result suggests a correlation between the site variability and the bioclimatic gradient in this case study. The fixed-effect Model 6b which included the elevation variable had a similar prediction accuracy to Model 4 but a lower AIC value. The relationship between the environmental conditions of a study area and the canopy structure variability has also been assessed in other studies [2,36]. Gdd is an indicator of accumulated heat and can be correlated with tree growth [37]. Warmer temperatures and longer growing seasons have a positive effect on tree height growth [38] as well as lower elevations [39]. Trees will, therefore, have a higher H–D ratio and a lower merchantable volume for a given height. Conversely, lower gdds or higher elevations have a negative effect on tree height growth. Trees will have a lower H–D ratio and a higher merchantable volume for a given height. The H–D ratio was smallest at the SLSJ_north site and Montmorency sites.
The canopy variability may be due to other factors such as tree mortality, fire disturbance, site species composition, lidar sensor settings, return density, etc. Sites were composed of similar species, predominantly balsam fir and spruce (Table 1). We tested Models 4 and 6b on a sample of field plots where the proportion of balsam fir was > 60% (256 plots). We obtained similar MV predictions (pseudo-R2 = 0.87 and 0.86; RSD = 24.4 m3 ha−1 and 24.5 m3 ha−1 respectively). We, therefore, considered that the species composition had little effect on the MV predictions in this case study.
Several studies have also demonstrated that the lidar settings can have an effect on the precision of derived forest attributes [40,41,42]. The lidar data were acquired separately and with variable acquisition settings in this case study (Table 2). We could not analyze the settings’ effects on the MV models as we did not have enough datasets to draw conclusions. However, their effects would likely be minor compared to the bioclimatic gradient, which had a direct effect on the MV. Further research should be done on this issue.
Our study has several practical uses in an operational context. It suggests flexible models to predict the merchantable volume in study sites where spatial and temporal variabilities are observed. The proposed models are adaptable enough to combine lidar datasets acquired at different time periods. They can accurately predict the merchantable volume both at local (site-specific) and large-scale levels (multiple sites). Using a random coefficient model, such as Model 4, is more advantageous than building several local lidar-based models when predicting forest attributes at a large-scale level. When the variability amongst sites is related to a bioclimatic gradient, a simpler fixed-effect model, such as Model 6b, could then be used with a similar prediction accuracy. The fixed-effect models offer the advantage to be generalizable to other sites of known gdd/elevation, even when field inventory has not been done. As lidar data will be available for the entire province of Quebec by 2021, new lidar study sites could be tested to confirm the relationship between the bioclimatic gradient and the MV variation. The data could also be combined with satellite data to predict the MV at large scale [43,44].
5. Conclusions
Canopy structure variations can be caused by natural forest dynamics occurring over time or by variations of bioclimatic factors (including temperature and elevation). We tested a lidar-based model to predict the merchantable volume (MV) of balsam fir sites located along a bioclimatic gradient of temperature and elevation. Temporal discrepancies up to three years also existed between the field inventory and the lidar data acquisitions. A random coefficient model was adjusted to include a random canopy height coefficient (accounting for site variability) and a growth function (accounting for growth during the temporal discrepancy). The pseudo-R2 was of 0.86 and the RSD of 24.3 m3 ha−1. The model performed as efficiently as a model with adjustments on all the parameters (p-value = 0.9913). The site variability was found to be related to the bioclimatic gradient. Fixed-effect models built with bioclimatic variables produced similar prediction accuracies (pseudo-R2 = 0.86, RSD ≤ 24.5 m3 ha−1). The effects of site variability, bioclimatic gradients, and temporal discrepancies were found to be essential to generalized lidar-based modelings.
Acknowledgments
The authors would like to thank the Fonds de recherche du Québec-Nature et technologies (FRQNT) and the MFFP for the financial support of this research work. We would like to thank the Forest Inventory Branch (Direction des Inventaires Forestiers DIF) of the MFFP and the Montmorency Forest for access to the data used in this study. We are also grateful to the Applied Geomatics Research Group (AGRG, Nova Scotia Community College, Middleton, NS, Canada), the Canadian Consortium for lidar Environmental Applications Research (C-CLEAR, Centre of Geographic Sciences, Lawrencetown, NS, Canada) and Christopher Hopkinson (University of Lethbridge, Lethbridge, AB, Canada), for providing the lidar data at a reduced cost. Special thanks to Antoine Leboeuf (Direction des Inventaires Forestiers DIF, Quebec City, QC, Canada) for facilitating our partnership with the DIF and to Rémi St-Amant (Canadian Forest Service CFS, Quebec City, QC, Canada) for his assistance with the climatic data. We are also grateful to Mrs. Marie Coyea for the English translation of this work and to the anonymous reviewers for their valuable comments on the manuscript.
Author Contributions
Sarah Yoga, Jean Bégin, and Benoît St-Onge proposed the theoretical framework of the study. Martin Riopel carried out the processing of the field data and the height–diameter modeling. Sarah Yoga conducted the processing of the lidar data and the statistical analyses. Jean Bégin and Gaétan Daigle contributed statistical expertise. Sarah Yoga wrote the manuscript. All authors contributed to the interpretation of results and the editing of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Boucher, D.; de Grandpré, L.; Gauthier, S. Development of a tool for classifying forest stand structure and comparison of two black spruce forest regions in Quebec. For. Chron. 2003, 79, 318–328. [Google Scholar] [CrossRef]
- Hansen, A.J.; Phillips, L.B.; Dubayah, R.; Goetz, S.; Hofton, M. Regional-scale application of lidar: Variation in forest canopy structure across the southeastern US. For. Ecol. Manag. 2014, 329, 214–226. [Google Scholar] [CrossRef]
- Laflèche, V.; Bernier, S.; Saucier, J.-P.; Gagné, C. Indices de Qualité de Station des Principales Essences Commerciales en Fonction des Types Écologiques du Québec Méridional—Site Indices of the Main Commercial Species Following the Ecological Types of Southern Quebec; Gouvernement du Québec, Ministère des Ressources naturelles, Direction des inventaires forestiers Québec: Ville de Québec, QC, Canada, 2013; p. 115. [Google Scholar]
- McRoberts, R.E.; Tomppo, E.O. Remote sensing support for national forest inventories. Remote Sens. Environ. 2007, 110, 412–419. [Google Scholar] [CrossRef]
- Magnussen, S.; Eggermont, P.; LaRiccia, V.N. Recovering tree heights from airborne laser scanner data. For. Sci. 1999, 45, 407–422. [Google Scholar]
- Maltamo, M.; Packalén, P.; Yu, X.; Eerikäinen, K.; Hyyppä, J.; Pitkänen, J. Identifying and quantifying structural characteristics of heterogeneous boreal forests using laser scanner data. For. Ecol. Manag. 2005, 216, 41–50. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Renaud, J.-P. Generalizing predictive models of forest inventory attributes using an area-based approach with airborne LiDAR data. Remote Sens. Environ. 2015, 156, 322–334. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Treitz, P.; Lim, K.; Woods, M.; Pitt, D.; Nesbitt, D.; Etheridge, D. LiDAR sampling density for forest resource inventories in Ontario, Canada. Remote Sens. 2012, 4, 830–848. [Google Scholar] [CrossRef]
- Yoga, S.; Bégin, J.; St-Onge, B.; Gatziolis, D. Lidar and multispectral imagery classifications of balsam fir tree status for accurate predictions of merchantable volume. Forests 2017, 8, 253. [Google Scholar] [CrossRef]
- Nord-Larsen, T.; Schumacher, J. Estimation of forest resources from a country wide laser scanning survey and national forest inventory data. Remote Sens. Environ. 2012, 119, 148–157. [Google Scholar] [CrossRef]
- Næsset, E. Airborne laser scanning as a method in operational forest inventory: Status of accuracy assessments accomplished in Scandinavia. Scand. J. For. Res. 2007, 22, 433–442. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T. Estimation of above-and below-ground biomass across regions of the boreal forest zone using airborne laser. Remote Sens. Environ. 2008, 112, 3079–3090. [Google Scholar] [CrossRef]
- Nilsson, M.; Nordkvist, K.; Jonzén, J.; Lindgren, N.; Axensten, P.; Wallerman, J.; Egberth, M.; Larsson, S.; Nilsson, L.; Eriksson, J. A nationwide forest attribute map of Sweden predicted using airborne laser scanning data and field data from the National Forest Inventory. Remote Sens. Environ. 2017, 194, 447–454. [Google Scholar] [CrossRef]
- MRN. Vegetation Zones and Bioclimatic Domains in Quebec; Ministère des Ressources Naturelles, Direction des Inventaires Forestiers: Québec, QC, Canada, 2001. [Google Scholar]
- MFFP. Données Descriptives des Placettes-Échantillons Temporaires - Descriptive Data of the Temporary Sample Plots; Ministère des Forêts, de la Faune et des Parcs, Direction Des Inventaires Forestiers: Québec, QC, Canada, 2016.
- MFFP. Guide d’utilisation des Produits Intégrés de l’inventaire écoforestier du Québec Méridional - User Guide of the Southern Quebec Ecoforest Inventory Database; Ministère des Forêts, de la Faune et des Parcs, Direction des Inventaires Forestiers, Gouvernement du Québec: Québec, QC, Canada, 2017; p. 47.
- Régnière, J.; Saint-Amant, R.; Béchard, A. BioSIM 10 – User’s Manual; Natural Resources Canada, Canadian Forest Service: Québec, QC, Canada, 2014; LAU-X-137E; p. 72. [Google Scholar]
- Bégin, J.; Raulier, F. Comparaison de différentes approches, modèles et tailles d’échantillons pour l’établissement de relations hauteur-diamètre locales—A comparison of different methods, models and sample sizes for the establishment of local height-diameter relationships. Can. J. For Res. 1995, 25, 1303–1312. [Google Scholar] [CrossRef]
- Sumida, A.; Miyaura, T.; Torii, H. Relationships of tree height and diameter at breast height revisited: Analyses of stem growth using 20-year data of an even-aged Chamaecyparis obtusa stand. Tree Physiol. 2013, 33, 106–118. [Google Scholar] [PubMed]
- Fortin, M.; DeBlois, J.; Bernier, S.; Blais, G. Mise au point d’un tarif de cubage général pour les forêts québécoises: une approche pour mieux évaluer l’incertitude associée aux prévisions - Establishing a general cubic volume table for Québec forests: an approach to better assess prediction uncertainties. For. Chron. 2007, 83, 754–765. [Google Scholar]
- Isenburg, M. “LAStools-Efficient LiDAR Processing Software” (Version 150526, Unlicensed). Available online: http://rapidlasso.com/LAStools (accessed on 1 August 2017).
- McGaughey, R.J. FUSION/LDV: Software for LIDAR Data Analysis and Visualization; Version 3.42; US Department of Agriculture, Forest Service, Pacific Northwest Research Station: Seattle, WA, USA, 2014; p. 175. [Google Scholar]
- Yoga, S.; Bégin, J.; St-Onge, B.; Riopel, M. Modeling the effect of the spatial pattern of airborne Lidar returns on the prediction and the uncertainty of timber merchantable volume. Remote Sens. 2017, 9, 808. [Google Scholar] [CrossRef]
- Pothier, D.; Savard, F. Actualisation des Tables de Production pour les Principales Espèces Forestières du Québec—Yield Tables Updates for The Main Forest Species of Quebec; Ministère des Ressources Naturelles: Québec, QC, Canada, 1998; p. 183. [Google Scholar]
- Longford, N.T. Random coefficient models. In Handbook of Statistical Modeling for the Social and Behavioral Sciences; Springer: New York, NY, USA, 1995; pp. 519–570. [Google Scholar]
- Pinheiro, J.; Bates, D. Mixed-Effects Models in S and S-PLUS; Springer-Verlag: New York, NY, USA, 2000. [Google Scholar]
- Pinheiro, J.; Bates, D.; DebRoy, S.; Sarkar, D.; R Core Team. nlme: Linear and Nonlinear Mixed Effects Models. R Package Version 3.1–117. 2014. Available online: http://CRAN. R-project. org/package= nlme (accessed on 21 March 2018).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. In Encyclopedia of Database Systems; Springer: Berlin, Germany, 2009; pp. 532–538. [Google Scholar]
- Breidenbach, J.; Kublin, E.; McGaughey, R.; Andersen, H.-E.; Reutebuch, S. Mixed-effects models for estimating stand volume by means of small footprint airborne laser scanner data. Photogramm. J. Finl. 2008, 21, 4–15. [Google Scholar]
- Kotivuori, E.; Korhonen, L.; Packalen, P. Nationwide airborne laser scanning based models for volume, biomass and dominant height in Finland. Silva Fenn. 2016, 50. [Google Scholar] [CrossRef]
- Suvanto, A.; Maltamo, M. Using mixed estimation for combining airborne laser scanning data in two different forest areas. Silva Fenn. 2010, 44, 91–107. [Google Scholar] [CrossRef]
- Bright, B.C.; Hudak, A.T.; McGaughey, R.; Andersen, H.E.; Negrón, J. Predicting live and dead tree basal area of bark beetle affected forests from discrete-return lidar. Can. J. Remote Sens. 2013, 39, S99–S111. [Google Scholar] [CrossRef]
- Ashiq, M.W.; Anand, M. Spatial and temporal variability in dendroclimatic growth response of red pine (Pinus resinosa Ait.) to climate in northern Ontario, Canada. For. Ecol. Manag. 2016, 372, 109–119. [Google Scholar]
- McMaster, G.S.; Wilhelm, W. Growing degree-days: one equation, two interpretations. Agric. For. Meteorol. 1997, 87, 291–300. [Google Scholar] [CrossRef]
- Fortin, M.; Bernier, S.; Saucier, J.-P.; Labbé, F. Une Relation Hauteur-Diamètre Tenant Compte de L’influence de la Station et du Climat Pour 20 Espèces Commerciales du Québec—A Height-Diameter Relationship Which Takes into Account the Influence of the Quality Station and the Climate for 20 Commercial Species in Quebec; Gouvernement du Québec, Direction de la recherche forestière: Québec, QC, Canada, 2009.
- Coomes, D.A.; Allen, R.B. Effects of size, competition and altitude on tree growth. J. Ecol. 2007, 95, 1084–1097. [Google Scholar] [CrossRef]
- Ehlert, D.; Heisig, M. Sources of angle-dependent errors in terrestrial laser scanner-based crop stand measurement. Comput. Electron. Agric. 2013, 93, 10–16. [Google Scholar] [CrossRef]
- Keränen, J.; Maltamo, M.; Packalen, P. Effect of flying altitude, scanning angle and scanning mode on the accuracy of ALS based forest inventory. Int. J. Appl. Earth Observ. Geoinform. 2016, 52, 349–360. [Google Scholar] [CrossRef]
- Næsset, E. Effects of different sensors, flying altitudes, and pulse repetition frequencies on forest canopy metrics and biophysical stand properties derived from small-footprint airborne laser data. Remote Sens. Environ. 2009, 113, 148–159. [Google Scholar] [CrossRef]
- Chasmer, L.; Barr, A.; Hopkinson, C.; McCaughey, H.; Treitz, P.; Black, A.; Shashkov, A. Scaling and assessment of GPP from MODIS using a combination of airborne lidar and eddy covariance measurements over jack pine forests. Remote Sens. Environ. 2009, 113, 82–93. [Google Scholar] [CrossRef]
- Hudak, A.T.; Lefsky, M.A.; Cohen, W.B.; Berterretche, M. Integration of lidar and Landsat ETM+ data for estimating and mapping forest canopy height. Remote Sens. Environ. 2002, 82, 397–416. [Google Scholar] [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).