
Research on a Real-Time Monitoring System for Campus Woodland Fires via Deep Learning


Abstract
1. Introduction
2. Forest Fire Detection Algorithm Based on the Improved YOLOv5
2.1. Basic Structure of YOLOv5
2.2. The Improvement of the YOLOv5 Network
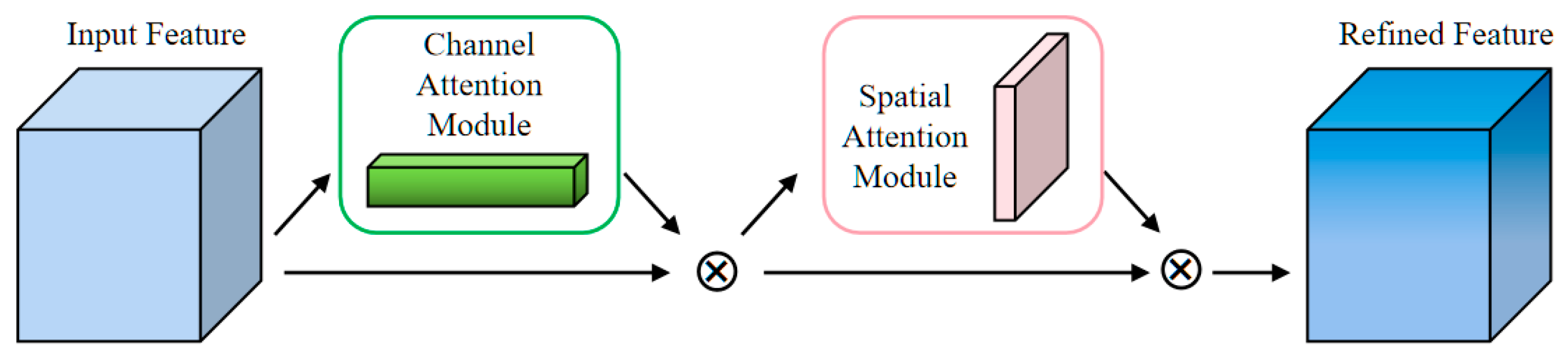
2.2.1. Mix the Attention Mechanism
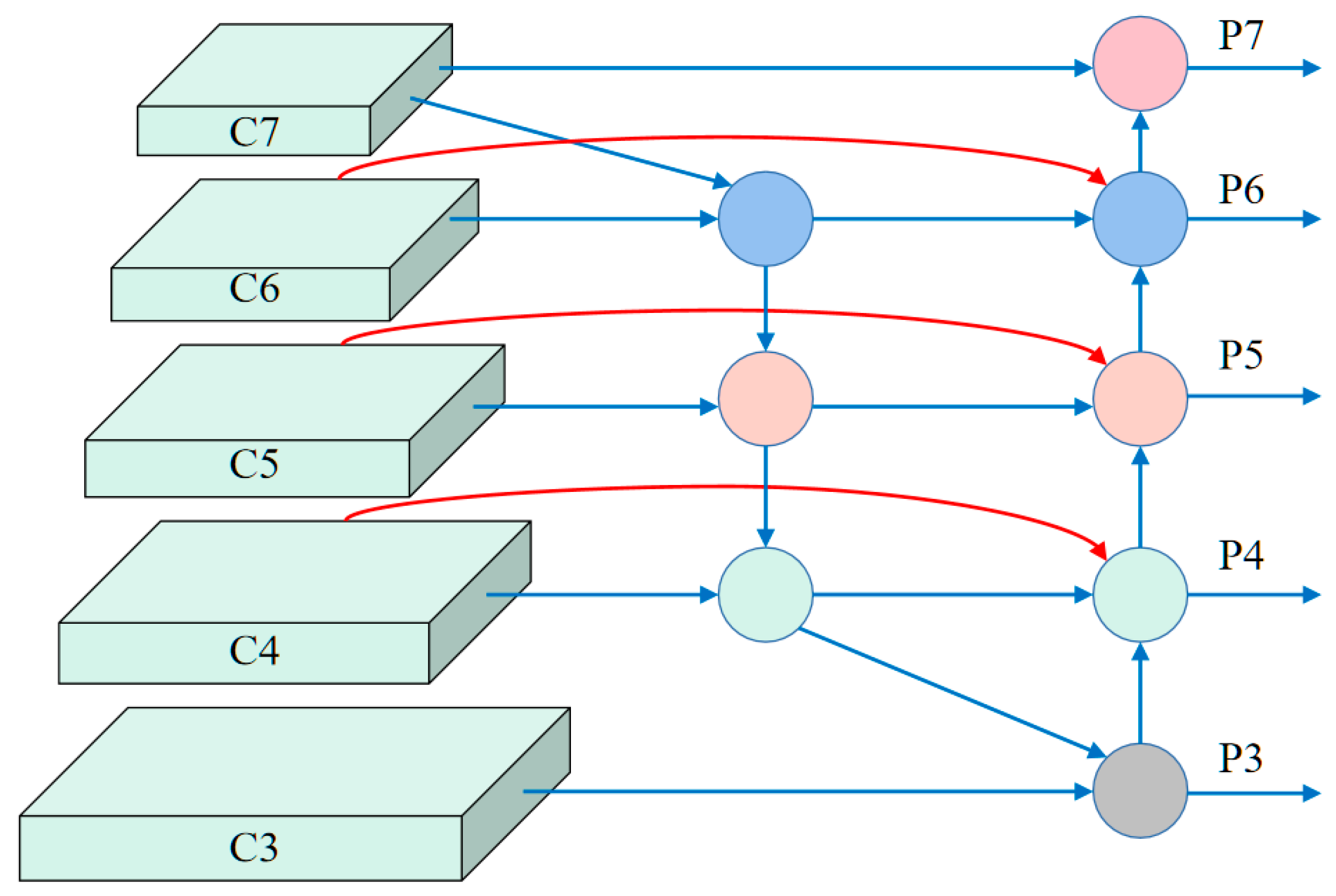
2.2.2. Integrate the BiFPN Structure
2.2.3. Lightweight Improvement Model Combined with GhostNet
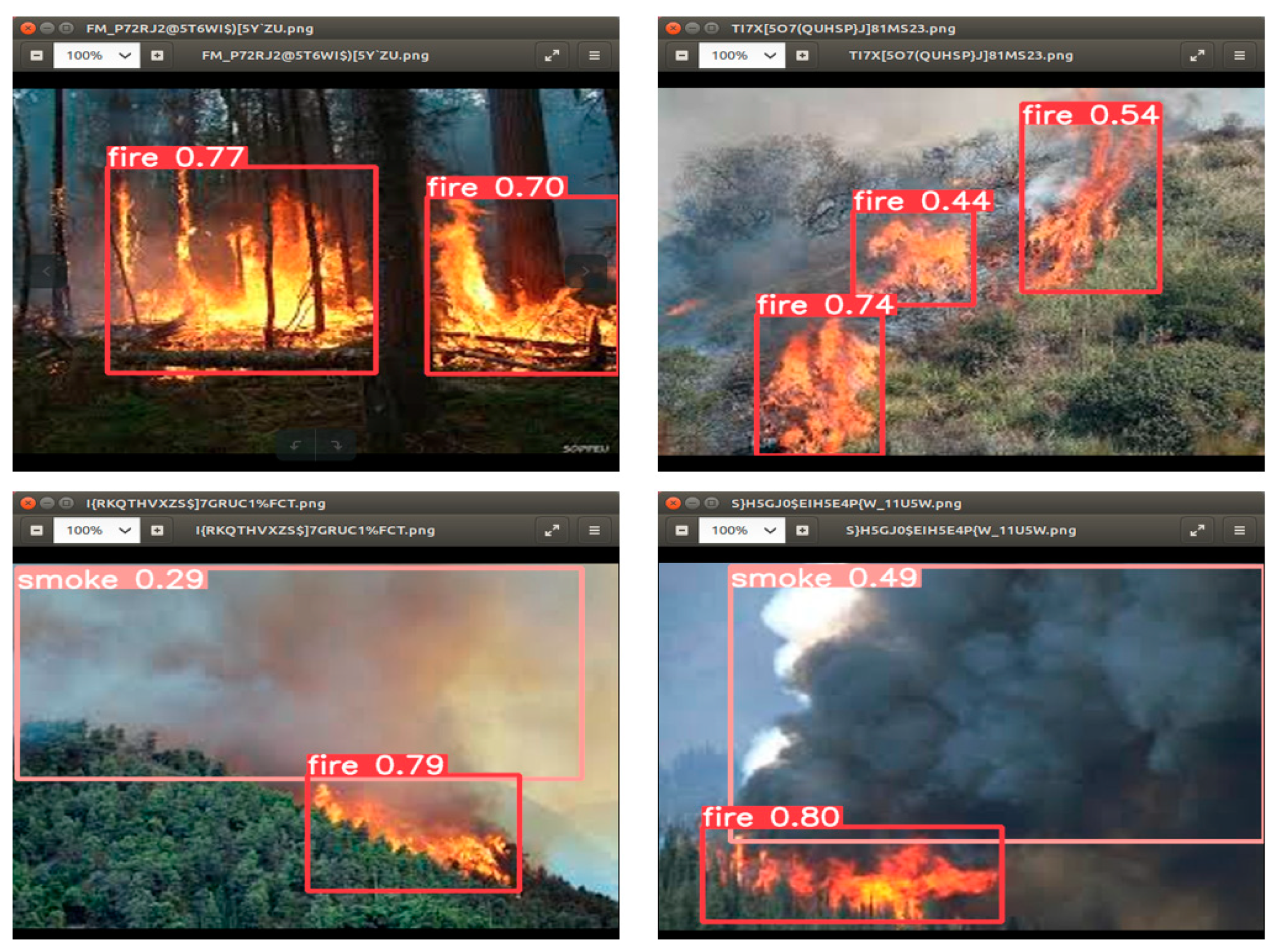
2.3. Forest Fire Dataset
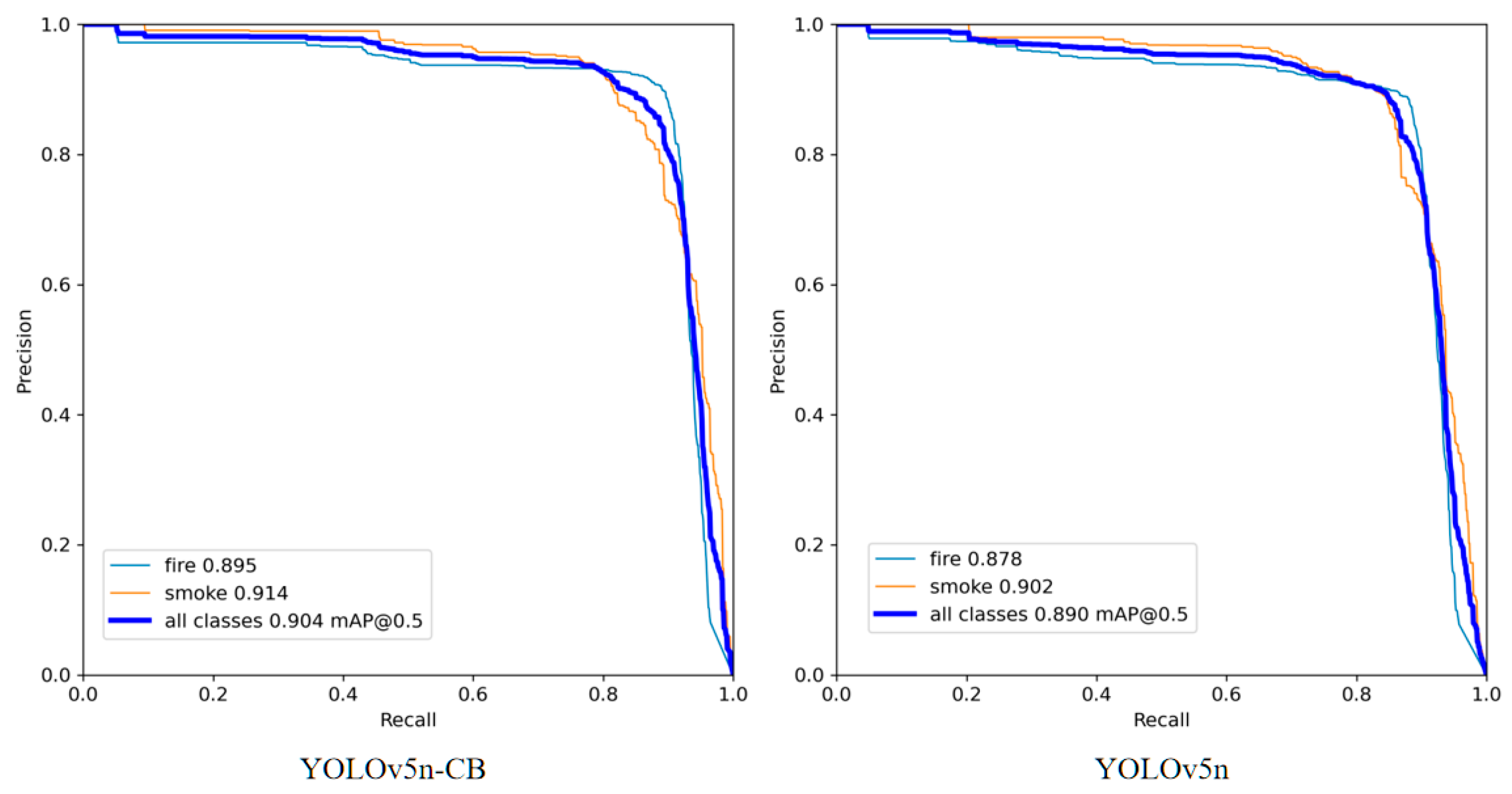
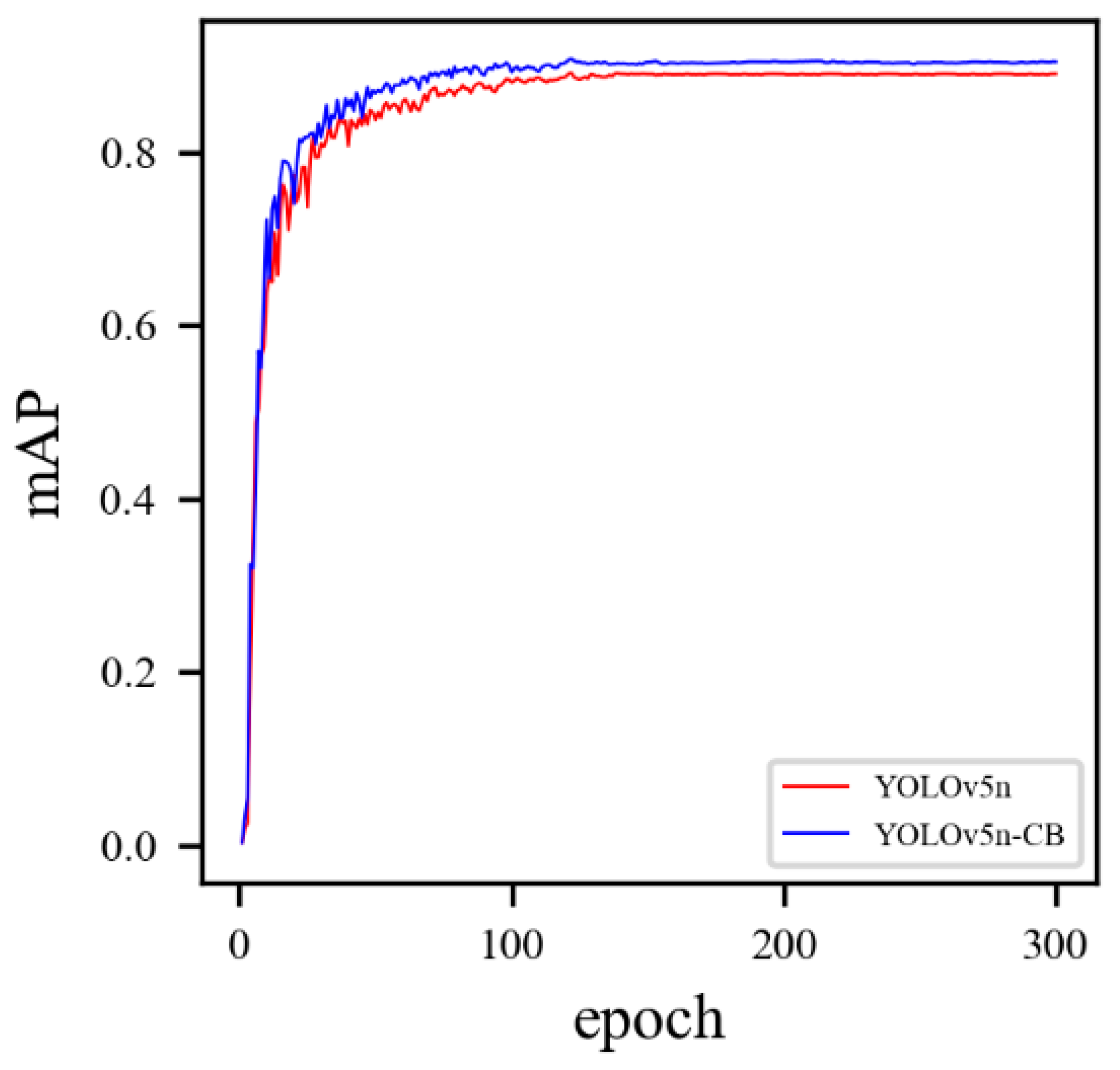
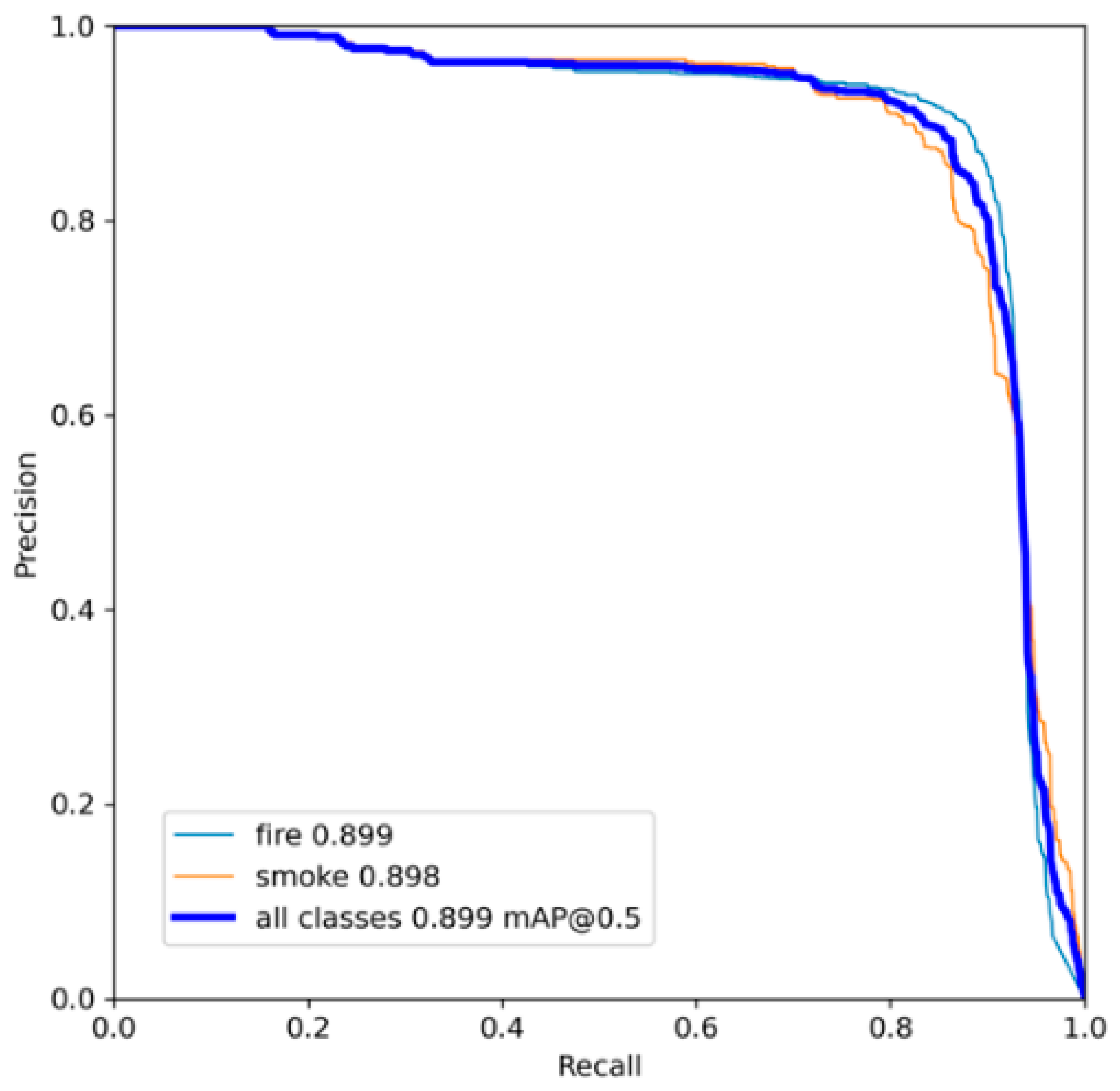
2.4. Analysis of the Multi-Stage Improvement Results of YOLOv5
2.4.1. Test Environment and Results Analysis
2.4.2. Performance Analysis of YOLOv5n-CB Algorithm after Multi-Stage Improvement
3. Improve the Lightweight and Model Deployment of the YOLOv5 Network
3.1. Performance Analysis of Improved G-YOLOv5-CB Network Model
3.2. Jetson Nano Model Deployment and Testing
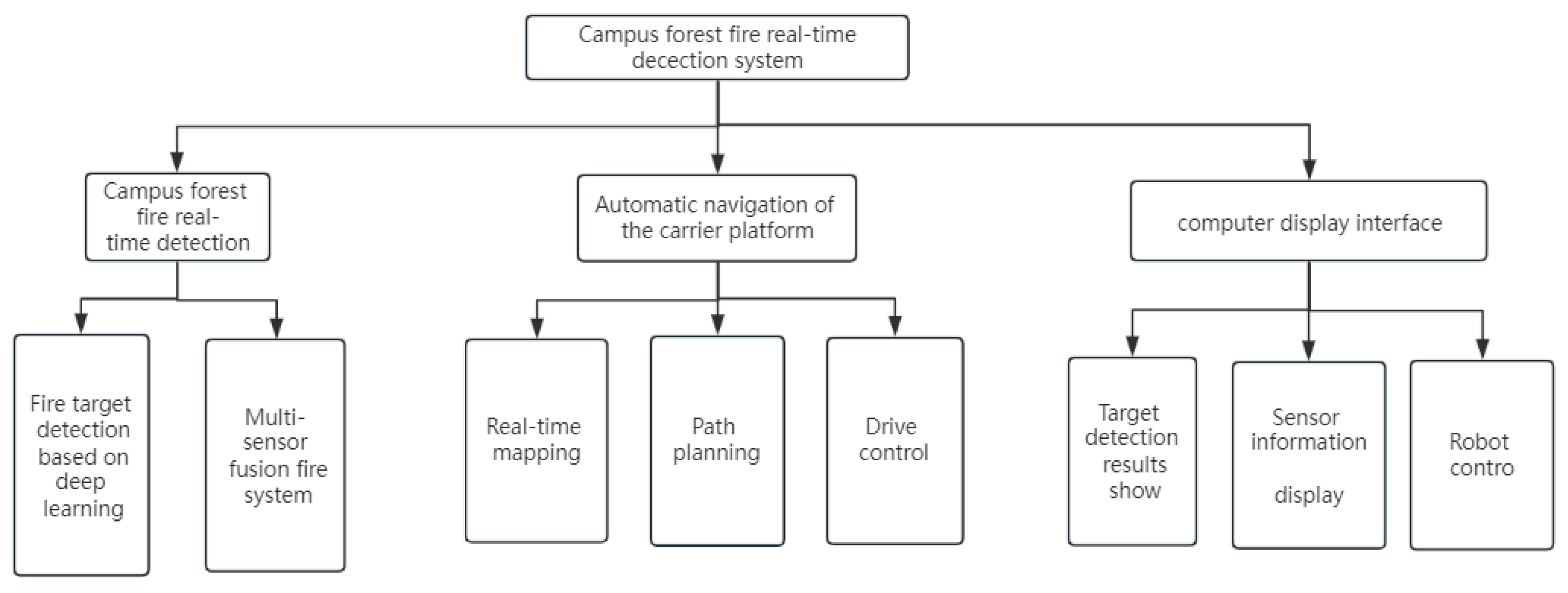
4. Design of Campus Forest Fire Real-Time Monitoring System
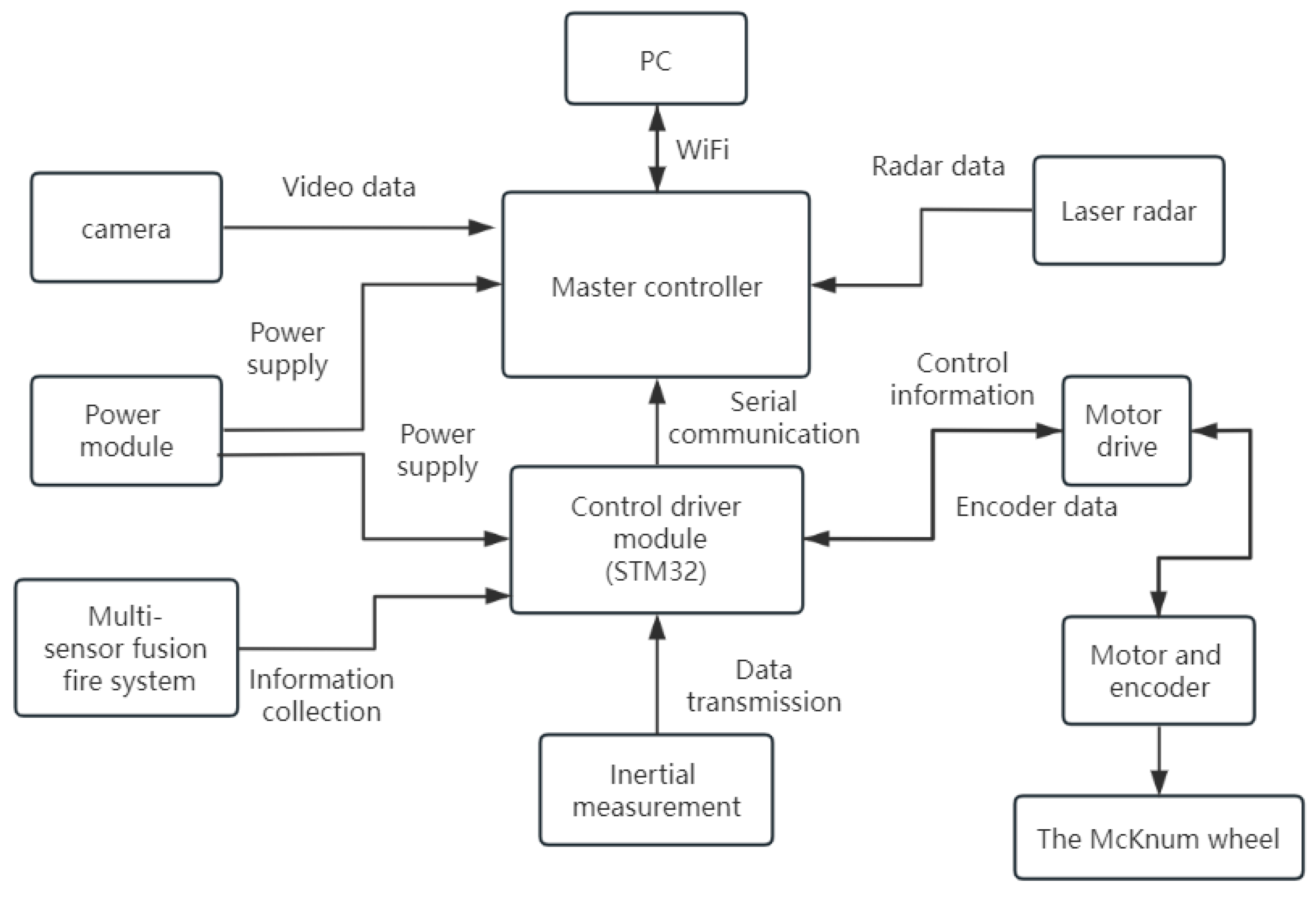
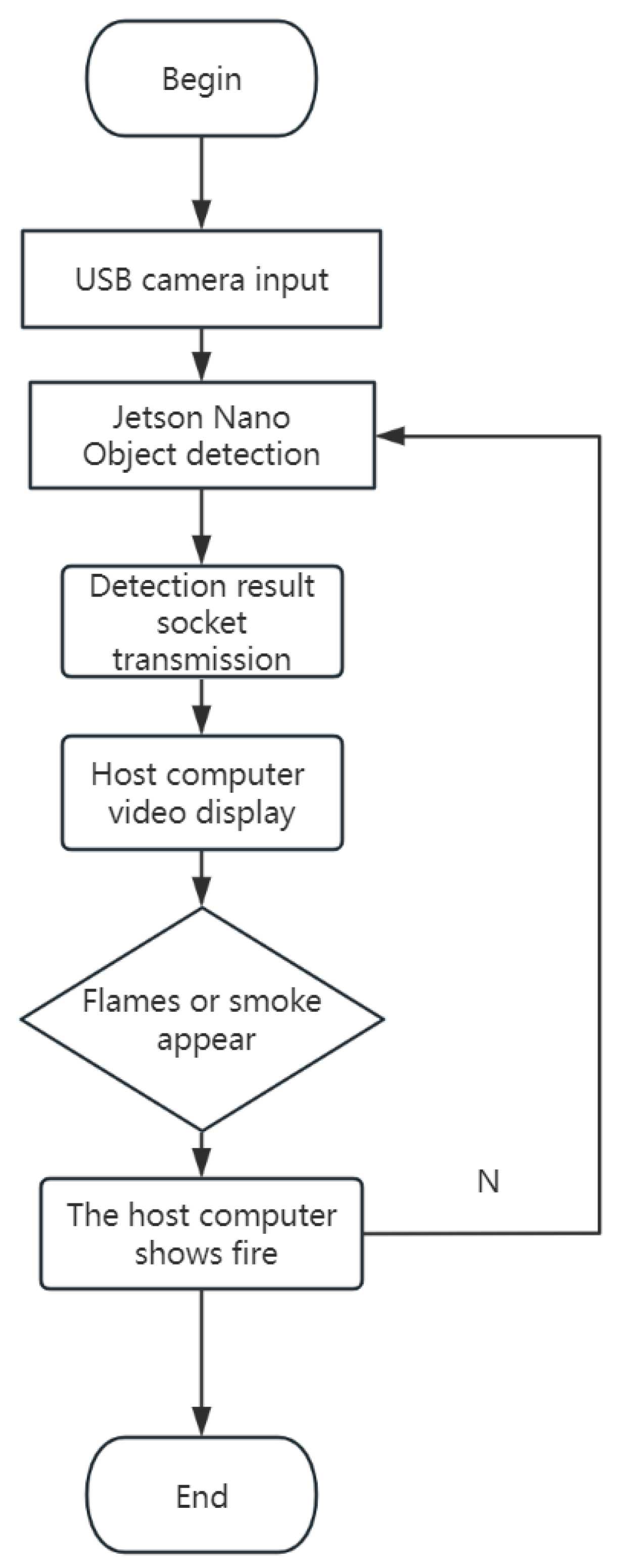
4.1. Design of Campus Forest Fire Detection Module
4.2. Automatic Navigation System Design
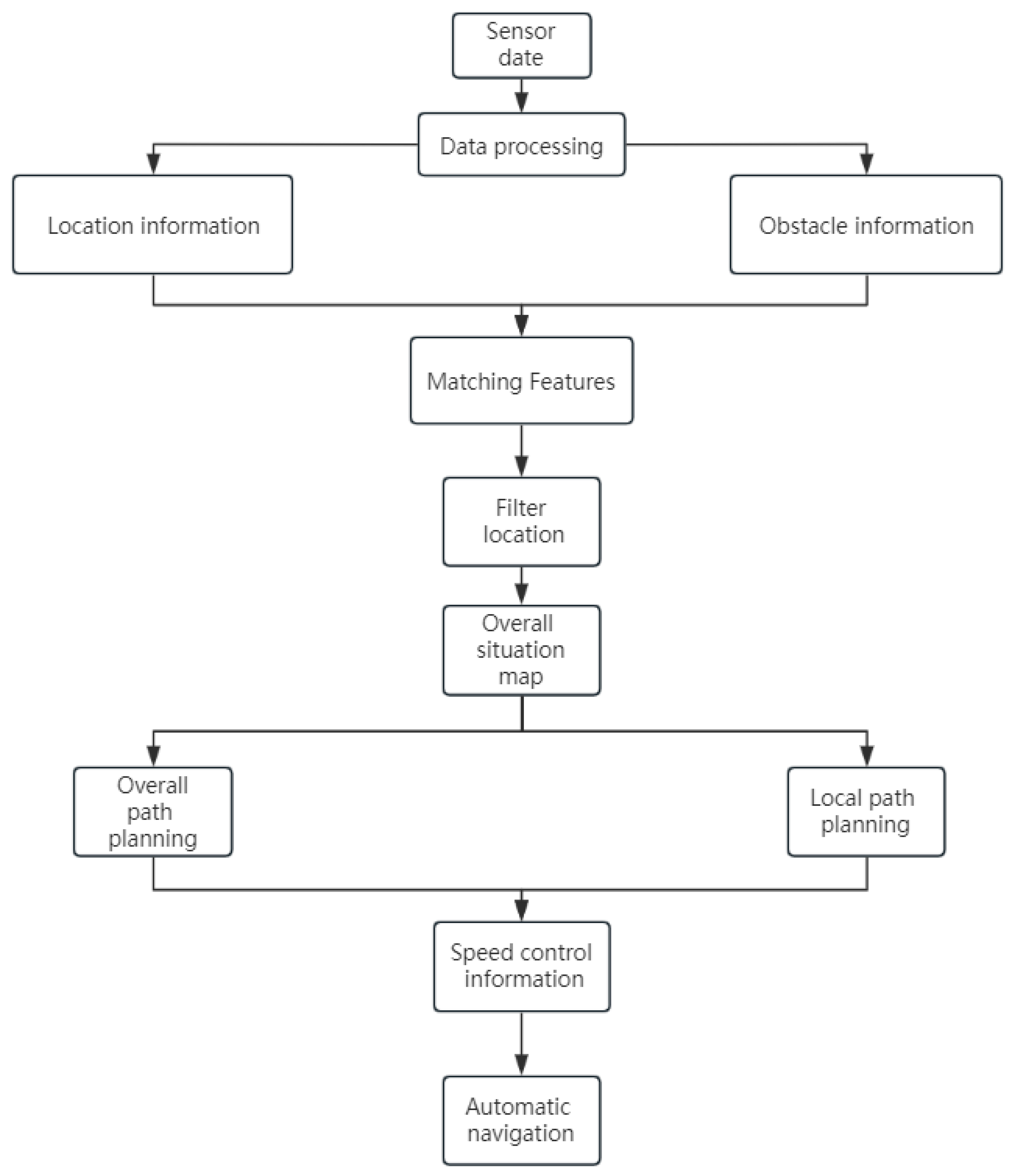
4.2.1. Overall Design of Automatic Navigation Function Module
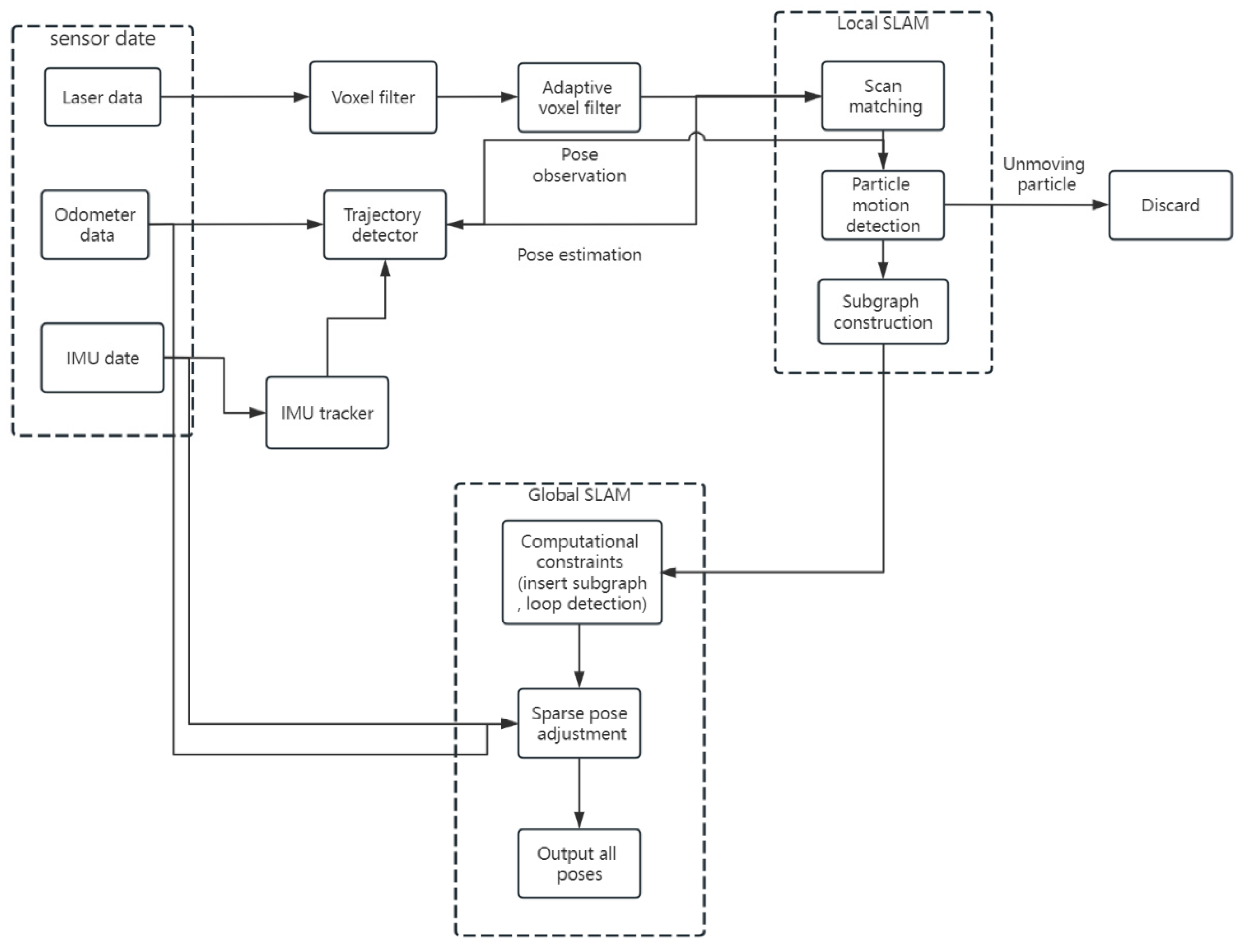
4.2.2. Navigation Map Construction
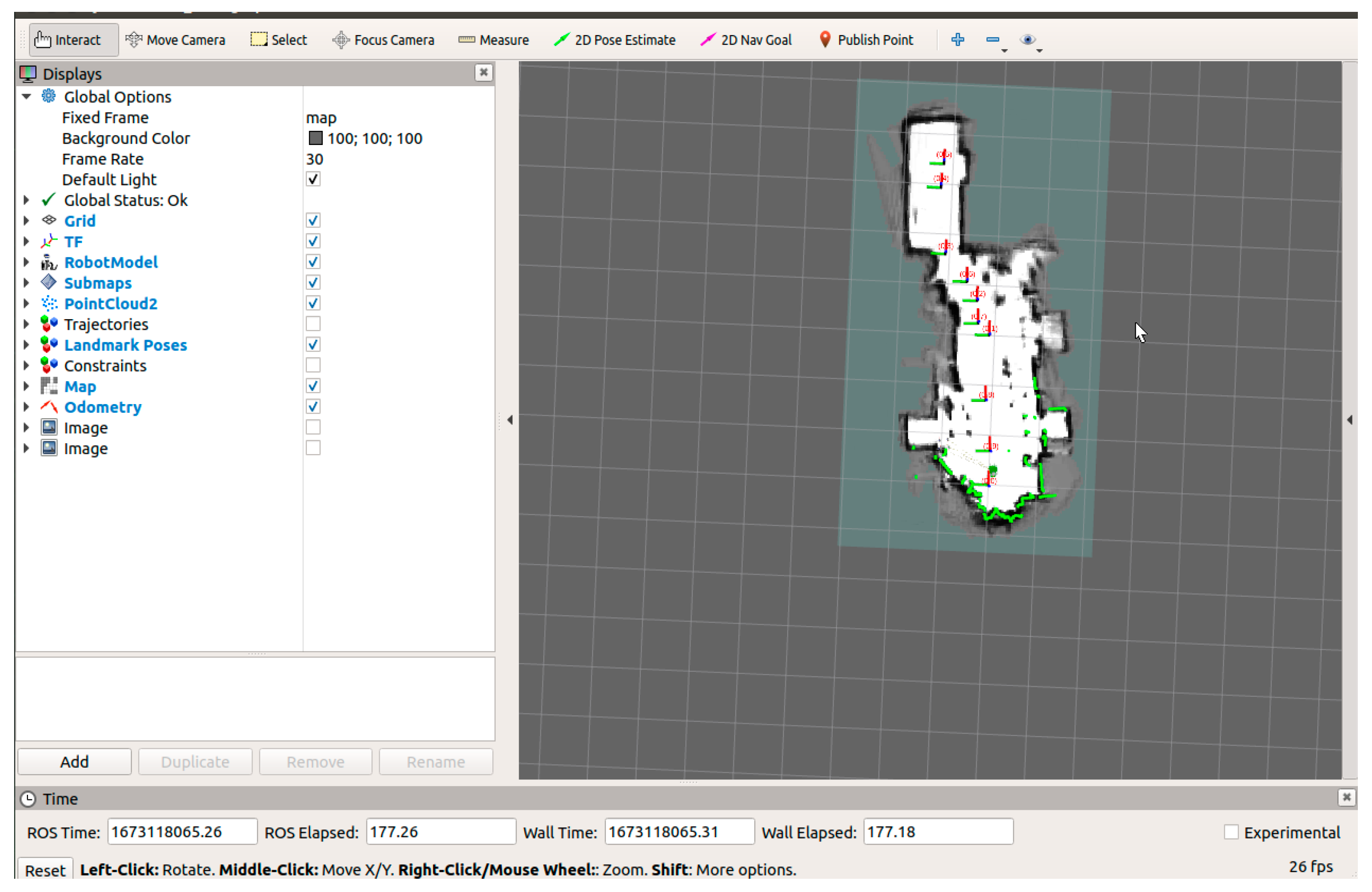
4.2.3. Map Construction Experiment
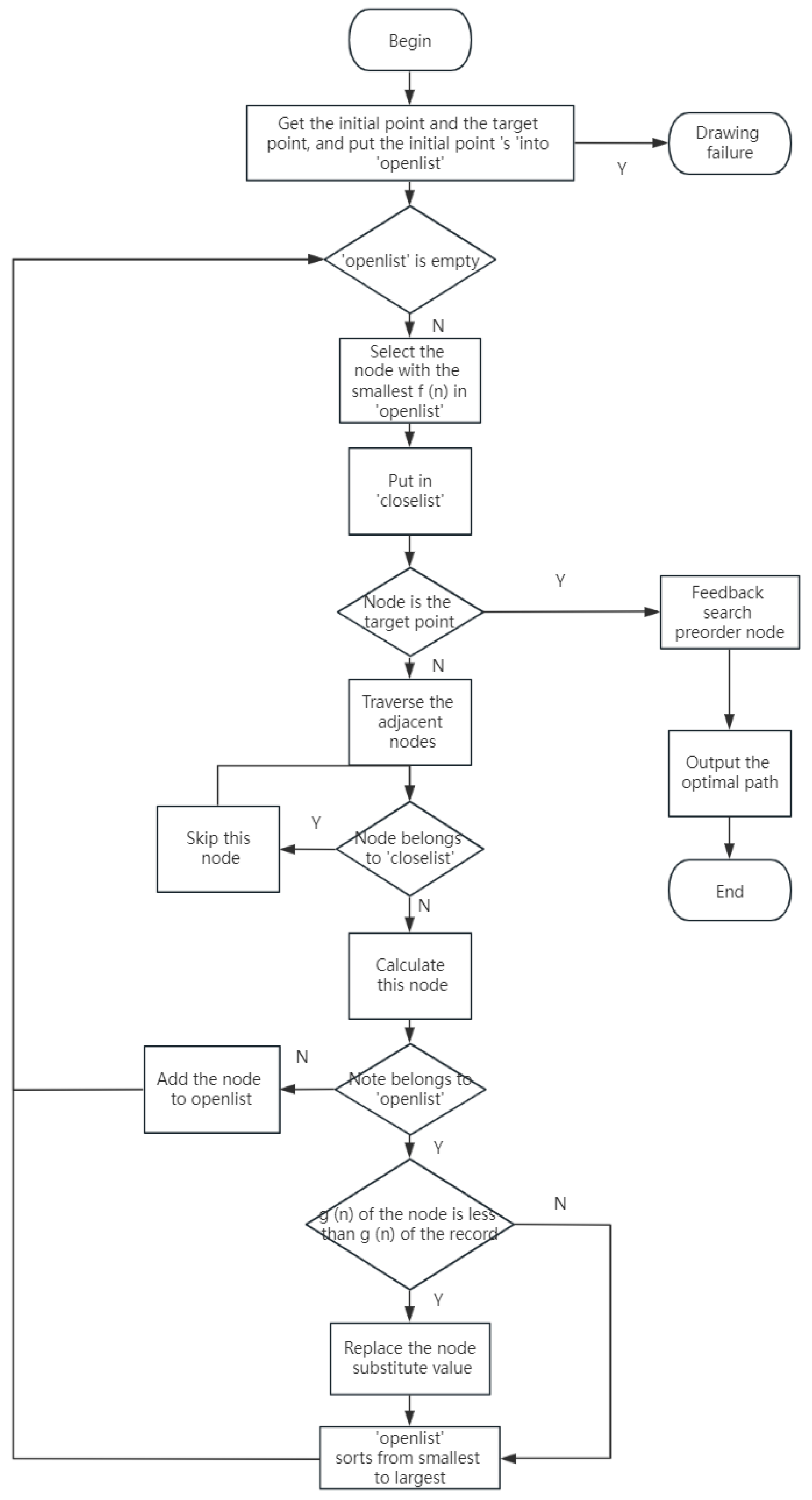
4.2.4. Path Planning
4.2.5. Local Path Planning
4.2.6. AMCL Positioning Algorithm
4.2.7. Navigation Test
5. Test of Campus Forest Fire Real-Time Monitoring System
5.1. Upper Computer Interface Design
5.2. Automatic Navigation Function Test in Campus Woodland Scene
6. Conclusions
- A forest fire dataset is constructed. The forest fire image data are obtained through the Internet, and the images are annotated by the Make Sense tool. A total of 8000 pictures containing fire and smoke are made to convey the fire information, and the forest fire dataset for the test is completed.
- A YOLOv5n-CB algorithm with higher detection accuracy is proposed. Based on the YOLOv5n model, the CBAM attention mechanism is introduced at the junction of the backbone and neck to improve network performance effectively while introducing only a small number of parameters. The idea of a weighted bidirectional feature pyramid network (BiFPN) is introduced to enhance the neck part and strengthen the feature extraction of the target. Experiments have shown that the YOLOv5n-CB model integrated with the CBAM attention mechanism and BiFPN structure has a higher accuracy and recall rate than the original model, the mAP value index on the forest fire dataset has increased by 1.4%, and the network performance has been significantly improved.
- Aiming at the problem of large volume and complex calculation of the algorithm model, the G-YOLOv5n-CB algorithm is proposed, and it can be deployed on the Jetson Nano platform for real-time forest fire detection. The MobileNetV3 network and GhostNet network are used to improve the lightweight feature extraction network of the original algorithm. The test shows that integrating the lightweight strategy of GhostNet reduces the number of parameters and the amount of computation and keeps the drop in detection accuracy of the mAP value index at only 0.5%. By comparing it with other in-depth models, the effectiveness of the proposed algorithm is verified.
- The G-YOLOv5n-CB model is deployed on the Jetson Nano platform, and the operating environment of the model is configured. According to the experiment, the detection speed of the model reaches 15 FPS, which meets the real-time requirements of the system.
- The global path planning algorithm A* and local path planning algorithm DWA are used in the automatic navigation system of the carrier platform of this system to plan the path of the robot, which realizes the target point navigation and obstacle avoidance functions of the robot in the campus woodland scene.
- Based on PyQt5, the upper computer interface of the system is developed to realize real-time display of detection results and action control of the robot. The comprehensive test shows that the system can carry out the real-time monitoring of campus forest fires accurately.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zahra, P.; Shervan, F.; Loris, N. Fabric defect detection based on completed local quartet patterns and majority decision algorithm. Expert Syst. Appl. 2022, 198, 116827. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q. Efficientnet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, Y.; Yin, B.; Zou, Q.; Xu, Y. Design of forest fire monitoring system based on UAV. Agric. Equip. Veh. Eng. 2022, 60, 105–108. (In Chinese) [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Computer Society Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. arXiv 2019, arXiv:1901.01892. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level Accuracy with 50x Fewer Parameters and <0.5MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Yang, Q. Fire image recognition algorithm based on improved DenseNet deep network. Comput. Appl. Softw. 2019, 36, 258–263. (In Chinese) [Google Scholar]
- Pi, J.; Liu, Y.; Li, J. Research on lightweight forest fire detection algorithm based on YOLOv5s. J. Graph. 2023, 44, 26–32. (In Chinese) [Google Scholar]
- Avula, S.B.; Badri, S.J.; Reddy, G. A Novel Forest Fire Detection System Using Fuzzy Entropy Optimized Thresh holding and STN-based CNN. In Proceedings of the International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2020. [Google Scholar]
- Zhang, Y.; Liu, M.; Xu, S.; Ma, Y.; Qiang, H. Substation fire detection based on Mobile Netv3-Large-YOLOv3. Guangdong Electr. Power 2021, 34, 123–132. [Google Scholar]
- Zhang, R.; Zhang, W. Fire Detection Algorithm Based on Improved GhostNet-FCOS. J. Zhejiang Univ. (Eng. Technol. Ed.) 2022, 56, 1891–1899. [Google Scholar]
- Yandouzi, M.; Grari, M.; Berrahal, M.; Idrissi, I.; Moussaoui, O.; Azizi, M.; Ghoumid, K.; Elmiad, A.K. Investigation of Combining Deep Learning Object Recognition with Drones for Forest Fire Detection and Monitoring. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2023, 14, 25–29. [Google Scholar] [CrossRef]
- Zhang, Q.-J.; Zheng, E.-G.; Xu, L.; Xu, W. Research on forest fire prevention UAV system design and forest fire recognition algorithm. Electron. Meas. Technol. 2017, 40, 6. [Google Scholar]
- Ma, Y. Research and implementation of fire monitoring system based on intelligent sensor. J. Taiyuan Univ. (Nat. Sci. Ed.) 2022, 40, 31–37. [Google Scholar]
- Li, Y. Research on Indoor Omnidirectional Autonomous Navigation Robot Based on ROS; China University of Mining and Technology: Xuzhou, China, 2020. [Google Scholar]
- Di, Y.; Ma, X.; Dong, G. Front-end matching optimized algorithm of cartographer with multi-resolution layered search strategy. Int. J. Model. Identif. Control. 2022, 40, 336–342. [Google Scholar]
- Dwijotomo, A.; Abdul Rahman, M.A.; Mohammed Ariff, M.H.; Zamzuri, H.; Wan Azree, W.M. Cartographer SLAM Method for Optimization with an Adaptive Multi-Distance Scan Scheduler. Appl. Sci. 2020, 10, 347. [Google Scholar] [CrossRef]
- Chen, X.; Ji, J.; Jiang, J.; Jin, G.; Wang, F.; Xie, J. Developing high-level cognitive functions for service robots. In Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2010), Toronto, ON, Canada, 10–14 May 2010. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | Parameter (PCS) | mAP@0.5 (%) | GFLOPs |
|---|---|---|---|---|---|
| YOLOv5n | 87.8 | 85.7 | 1,766,623 | 89 | 4.2 |
| YOLOv5n + SE | 88.2 | 86 | 1,774,815 | 89.4 | 4.2 |
| YOLOv5n + ECA | 86.9 | 86.6 | 1,766,626 | 89.5 | 4.2 |
| YOLOv5n + CBAM | 88.1 | 87.6 | 1,774,913 | 89.7 | 4.2 |
| YOLOv5n + BiFPN | 87.5 | 87.1 | 1,783,007 | 89.6 | 4.3 |
| Model | Precision (%) | Recall (%) | Parameter (PCS) | mAP@0.5 (%) | GFLOPs |
|---|---|---|---|---|---|
| YOLOv5n | 87.8 | 85.7 | 1766623 | 89 | 4.2 |
| YOLOv5n-CB | 88.6 | 87.7 | 1791297 | 90.4 | 4.3 |
| Model | Parameter | Weight File Size (MB) | mAP@0.5 (%) |
|---|---|---|---|
| YOLOv5n | 17.66 × 106 | 3.65 | 89 |
| YOLOv3-tiny | 21.73 × 106 | 16.7 | 79.4 |
| YOLOv5s | 70.25 × 106 | 13.7 | 90.6 |
| Faster R-CNN | 28.32 × 106 | 108.4 | 85.2 |
| G-YOLOv5-CB | 9.68 × 106 | 2.2 | 89.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, D.; Chen, J.; Wu, Q.; Wang, Z. Research on a Real-Time Monitoring System for Campus Woodland Fires via Deep Learning. Forests 2024, 15, 483. https://doi.org/10.3390/f15030483
Xu D, Chen J, Wu Q, Wang Z. Research on a Real-Time Monitoring System for Campus Woodland Fires via Deep Learning. Forests. 2024; 15(3):483. https://doi.org/10.3390/f15030483
Chicago/Turabian StyleXu, Dengwei, Jie Chen, Qi Wu, and Zheng Wang. 2024. "Research on a Real-Time Monitoring System for Campus Woodland Fires via Deep Learning" Forests 15, no. 3: 483. https://doi.org/10.3390/f15030483
APA StyleXu, D., Chen, J., Wu, Q., & Wang, Z. (2024). Research on a Real-Time Monitoring System for Campus Woodland Fires via Deep Learning. Forests, 15(3), 483. https://doi.org/10.3390/f15030483