

Using the Error-in-Variable Simultaneous Equations Approach to Construct Compatible Estimation Models of Forest Inventory Attributes Based on Airborne LiDAR


Abstract
1. Introduction
2. Materials and Methods
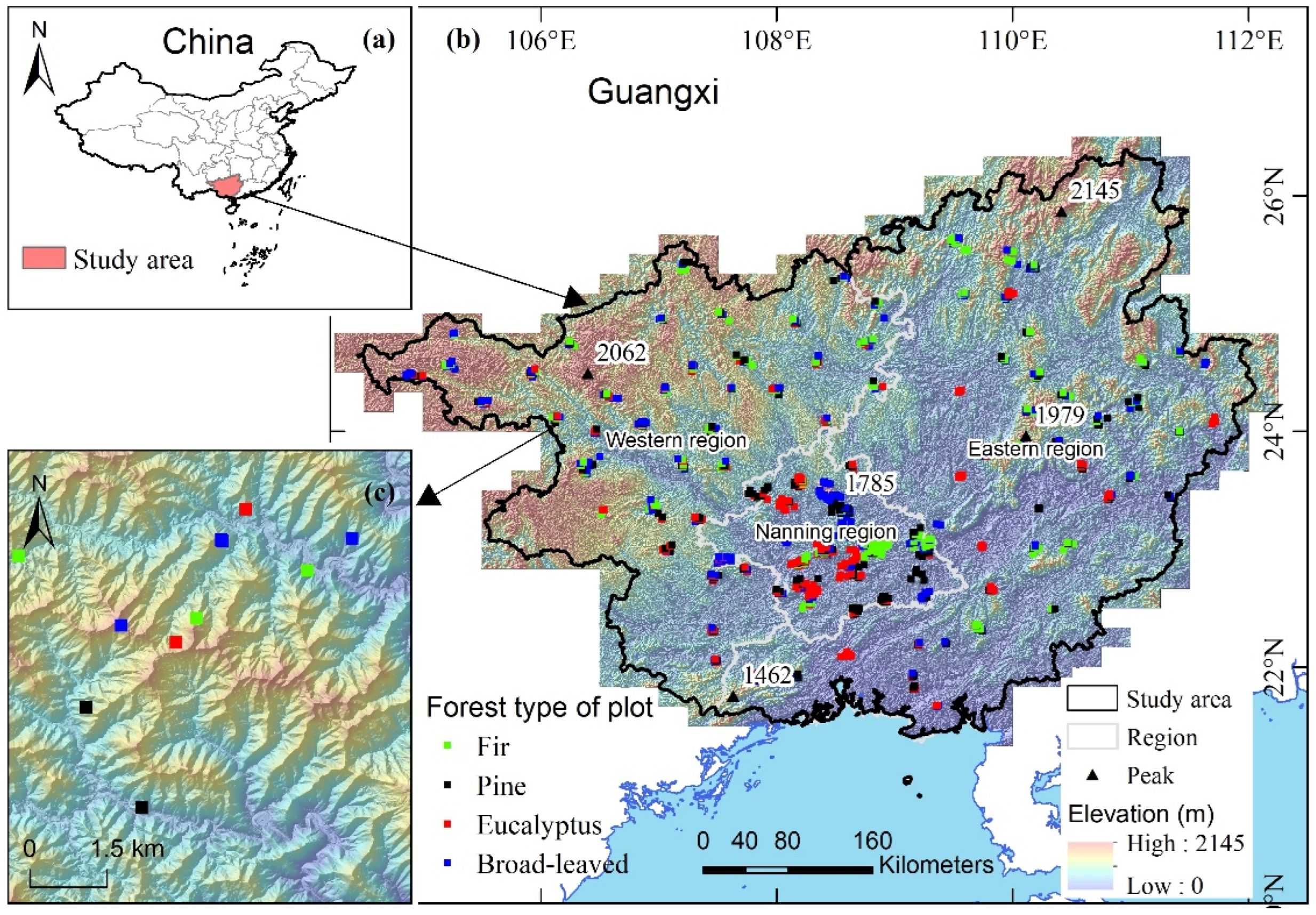
2.1. Study Site
2.2. Field Plot Data
2.3. LiDAR Data
2.4. Independence Model
- (1)
- The variable combination scheme: 1–2 height variables + 1–2 density variables +/1 vertical structure variable.
- (2)
- The model must comprise at least one primary height variable (Hmean or hp95) and one primary density variable (CC). When two height variables are selected, one primary and one secondary height variable (Hstdev or Hcv) can be included. When two density variables are selected, one secondary density variable is selected in addition to the CC.
- (3)
- Each variable in the group of vertical structure variables can appear in the model separately.
- (4)
- When the model comprises two variables, Equation (5) consists of one primary height variable and one primary density variable. When the model comprises three variables, Equation (5) consists of one primary height variable, one primary density variable, and one vertical structure variable. When the model comprises four variables, Equation (5) consists of one primary height variable, one secondary height variable, one primary density variable, and one vertical structure variable. When the model comprises five variables, Equation (5) consists of one primary height variable, one secondary height variable, one primary density variable, one secondary density variable, and one vertical structure variable.
2.5. Error-in-Variable Simultaneous Equations
3. Result
3.1. Performance of the Independence Model
3.2. Performance of the Simultaneous Equations
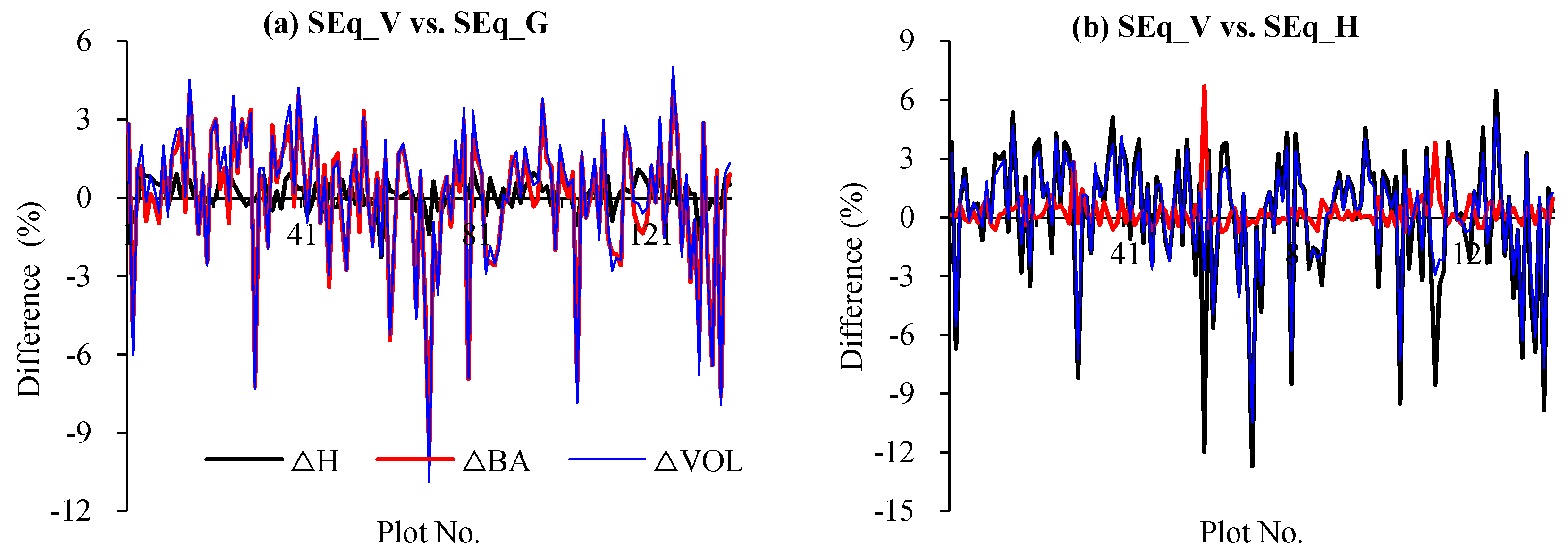
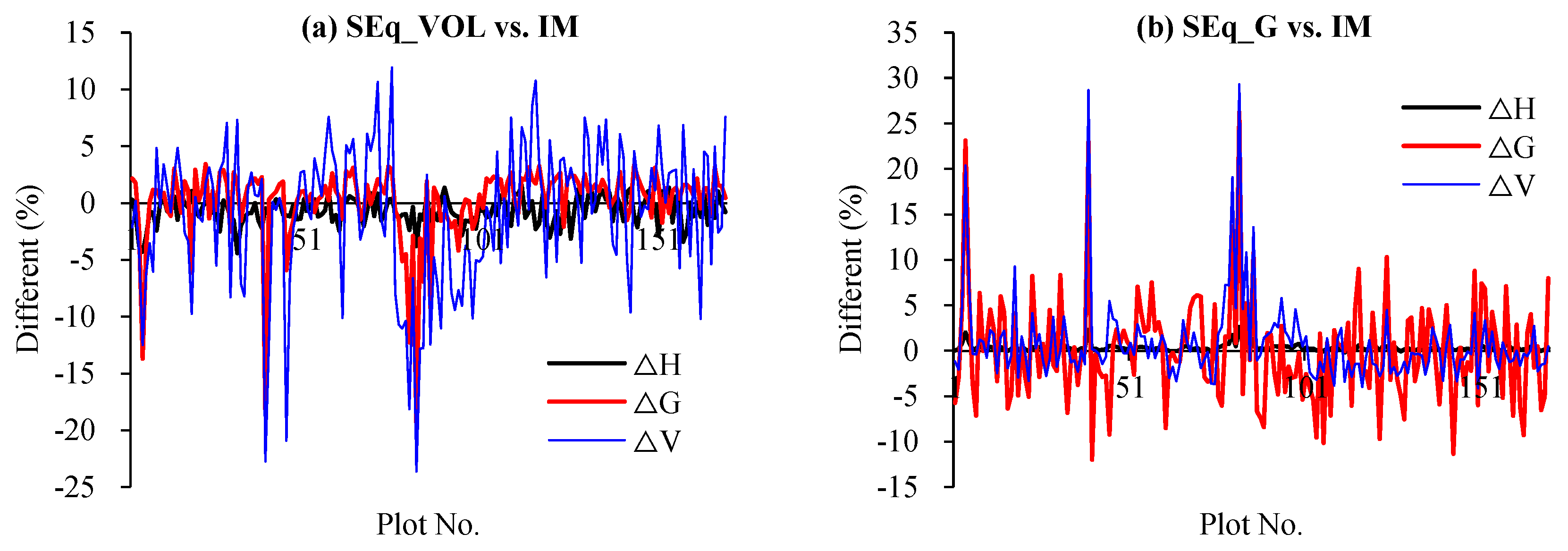
3.3. Comparison of the Simultaneous Equations and Independence Model
4. Discussion
5. Conclusions
- (1)
- Both IMs and SEqs can achieve good estimation results for all forest parameters of all forest types. The SEqs performed slightly worse than the IMs; however, the difference was not obvious.
- (2)
- The SEqs maintain the definite mathematical relationships among various forest attributes, which are consistent with the principle of forest mensuration. The estimation results are useful for forest resource management.
- (3)
- For the Chinese fir, pine, and broad-leaved forests, the SEqs using the mean stand height, and basal area as the endogenous variables to estimate stand volume performed slightly better than the other two SEqs. For the eucalyptus forests, the SEqs with the diameter at breast height, mean stand height, and stand volume as the endogenous variables to estimate basal area (SEq_G) outperformed the other three SEqs.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAO. Global Forest Resources Assessment 2020: Main Report; FAO: Rome, Italy, 2020. [Google Scholar] [CrossRef]
- Means, J.E.; Acker, S.A.; Fitt, B.J.; Renslow, M.; Emerson, L.; Hendrix, C.J. Predicting forest stand characteristics with airborne scanning lidar. Photogramm. Eng. Remote Sens. 2000, 66, 1367–1371. [Google Scholar]
- Torre-Tojal, L.; Bastarrika, A.; Boyano, A.; Lopez-Guede, J.M.; Graña, M. Above-ground biomass estimation from LiDAR data using random forest algorithms. J. Comput. Sci. 2022, 58, 101517. [Google Scholar] [CrossRef]
- Coops, N.C.; Tompalski, P.; Goodbody, T.R.; Queinnec, M.; Luther, J.E.; Bolton, D.K.; White, J.C.; Wulder, M.A.; van Lier, O.R.; Hermosilla, T. Modelling lidar-derived estimates of forest attributes over space and time: A review of approaches and future trends. Remote Sens. Environ. 2021, 260, 112477. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Tomppo, E.O.; Næsset, E. Advances and emerging issues in national forest inventories. Scand. J. For. Res. 2010, 25, 368–381. [Google Scholar] [CrossRef]
- Johnson, K.D.; Birdsey, R.; Finley, A.O.; Swantaran, A.; Dubayah, R.; Wayson, C.; Riemann, R. Integrating forest inventory and analysis data into a LiDAR-based carbon monitoring system. Carbon Balance Manag. 2014, 9, 11. [Google Scholar] [CrossRef]
- Straub, C.; Tian, J.; Seitz, R.; Reinartz, P. Assessment of Cartosat-1 and WorldView-2 stereo imagery in combination with a LiDAR-DTM for timber volume estimation in a highly structured forest in Germany. Forestry 2013, 86, 463–473. [Google Scholar] [CrossRef]
- Mora, B.; Wulder, M.A.; White, J.C.; Hobart, G. Modeling stand height, volume, and biomass from very high spatial resolution satellite imagery and samples of airborne LiDAR. Remote Sens. 2013, 5, 2308–2326. [Google Scholar] [CrossRef]
- Fekety, P.A.; Falkowski, M.J.; Hudak, A. Temporal transferability of LiDAR-based imputation of forest inventory attributes. Can. J. For. Res. 2015, 45, 422–435. [Google Scholar] [CrossRef]
- Frank, B.; Mauro, F.; Temesgen, H. Model-based estimation of forest inventory attributes using Lidar: A comparison of the area-based and semi-individual tree crown approaches. Remote Sens. 2020, 12, 2525. [Google Scholar] [CrossRef]
- Asner, G.P.; Clark, J.K.; Mascaro, J.; Galindo García, G.A.; Chadwick, K.D.; Navarrete Encinales, D.A.; Paez-Acosta, G.; Cabrera Montenegro, E.; Kennedy-Bowdoin, T.; Duque, Á.; et al. High-resolution mapping of forest carbon stocks in the Colombian Amazon. Biogeosciences 2012, 9, 2683–2696. [Google Scholar] [CrossRef]
- Morsdorf, F.; Kötz, B.; Meier, E.; Itten, K.I.; Allgöwer, B. Estimation of LAI and fractional cover from small footprint airborne laser scanning data based on gap fraction. Remote Sens. Environ. 2006, 104, 50–61. [Google Scholar] [CrossRef]
- Naesset, E. Accuracy of forest inventory using airborne laser scanning: Evaluating the first nordic full-scale operational project. Scand. J. Res. 2004, 19, 554–557. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T.; Holmgren, J.; Hyyppä, H.; Hyyppä, J.; Maltamo, M.; Nilsson, M.; Olsson, H.; Persson, Å.; Söderman, U. Laser scanning of forest resources: The Nordic experience. Scand. J. Res. 2004, 19, 482–499. [Google Scholar] [CrossRef]
- White, J.C.; Tompalski, P.; Vastaranta, M.; Wulder, M.A.; Saarinen, N.; Stepper, C.; Coops, N.C. A Model Development and Application Guide for Generating an Enhanced Forest Inventory Using Airborne Laser Scanning Data and an Area-Based Approach; CWFC Information Report FI-X-018; Natural Resources Canada, Canadian Forest Service, Pacific Forestry Centre: Victoria, BC, Canada, 2017. [Google Scholar] [CrossRef]
- Næsset, E.; Bjerknes, K.-O. Estimating tree heights and number of stems in young forest stands using airborne laser scanner data. Remote Sens. Environ. 2001, 78, 328–340. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Næesset, E.; Bollandsas, O.M.; Gobakken, T.; Gregoire, T.G.; Stahl, G. Model-assisted estimation of change in forest biomass over an 11 year period in a sample survey supported by airborne LiDAR: A case study with post-stratification to provide “activity data”. Remote Sens. Environ. 2013, 128, 299–314. [Google Scholar] [CrossRef]
- Packalén, P.; Maltamo, M. The k-MSN method for the prediction of species-specific stand attributes using airborne laser scanning and aerial photographs. Remote Sens. Environ. 2007, 109, 328–341. [Google Scholar] [CrossRef]
- Hudak, A.T.; Crookston, N.L.; Evans, J.S.; Hall, D.E.; Falkowski, M.J. Nearest neighbour imputation of species-level, plot-scale forest structure attributes from LiDAR data. Remote Sens. Environ. 2008, 112, 2232–2245. [Google Scholar] [CrossRef]
- Woods, M.; Pitt, D.; Penner, M.; Lim, K.; Nesbitt, D.; Etheridge, D.; Treitz, P. Operational implementation of a LiDAR inventory in Boreal Ontario. For. Chron. 2011, 87, 512–528. [Google Scholar] [CrossRef]
- Penner, M.; Pitt, D.G.; Woods, M.E. Parametric vs. nonparametric LiDAR models for operational forest inventory in Boreal Ontario. Can. J. Remote Sens. 2013, 39, 426–443. [Google Scholar] [CrossRef]
- Penner, M.; Woods, M.; Pitt, D. A comparison of airborne laser scanning and image point cloud derived tree size class distribution models in Boreal Ontario. Forests 2015, 6, 4034–4054. [Google Scholar] [CrossRef]
- Montealegre, A.L.; Lamelas, M.T.; de la Riva, J.A.; García-Martín, A.; Escribano, F. Use of low point density ALS data to estimate stand-level structural variables in Mediterranean Aleppo pine forest. Forestry 2016, 89, 373–382. [Google Scholar] [CrossRef]
- Zhang, Z.; Cao, L.; She, G. Estimating forest structural parameters using canopy metrics derived from airborne LiDAR data in subtropical forests. Remote Sens. 2017, 9, 940. [Google Scholar] [CrossRef]
- Xu, C.; Manley, B.; Morgenroth, J. Evaluation of modelling approaches in predicting forest volume and stand age for small-scale plantation forests in New Zealand with RapidEye and LiDAR. Int. J. Appl. Earth Obs. 2018, 73, 386–396. [Google Scholar] [CrossRef]
- Van Ewijk, K.; Treitz, P.; Woods, M.; Jones, T.; Caspersen, J. Forest site and type variability in ALS-based forest resource inventory attribute predictions over three Ontario forest sites. Forests 2019, 10, 226. [Google Scholar] [CrossRef]
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Renaud, J.P. Generalizing predictive models of forest inventory attributes using an area-based approach with airborne LiDAR data. Remote Sens. Environ. 2015, 156, 322–334. [Google Scholar] [CrossRef]
- Dube, T.; Siban, M.; Shoko, C.; Mutanga, O. Stand-volume estimation from multi-source data for coppiced and high forest Eucalyptus spp. silvicultural systems in Kwa Zulu-Natal, South Africa. ISPRS J. Photogram. 2017, 132, 162–169. [Google Scholar] [CrossRef]
- Giannico, V.; Lafortezza, R.; John, R.; Sanesi, G.; Pesola, L.; Chen, J. Estimating stand volume and above-ground biomass of urban forests using LiDAR. Remote Sens. 2016, 8, 339. [Google Scholar] [CrossRef]
- Yang, T.-R.; Kershaw, J.A., Jr.; Ducey, M.J. The development of allometric systems of equations for compatible area-based LiDAR-assisted estimation. Forestry 2021, 94, 36–53. [Google Scholar] [CrossRef]
- Asner, G.P.; Mascaro, J.; Muller-Landau, H.C.; Vieilledent, G.; Vaudry, R.; Rasamoelina, M.; Hall, J.S.; Van Breugel, M. A universal airborne LiDAR approach for tropical forest carbon mapping. Oecologia 2012, 168, 1147–1160. [Google Scholar] [CrossRef]
- Jenkins, J.C.; Chojnacky, D.C.; Heath, L.S.; Birdsey, R.A. National-scale biomass estimators for United States tree species. For. Sci. 2003, 49, 12–35. [Google Scholar]
- Hill, T.C.; Williams, M.; Bloom, A.A.; Mitchard, E.T.A.; Ryan, C.M. Are inventory based and remotely sensed above-ground biomass estimates consistent? PLoS ONE 2013, 8, e74170. [Google Scholar] [CrossRef]
- Sharma, M.; Oderwald, R.G. Dimensionally compatible volume and taper equations. Can. J. Res. 2001, 31, 797–803. [Google Scholar] [CrossRef]
- Buckman, R.E. Growth and Yield of Red Pine in Minnesota; Technical Bulletin 1272; USDA Forest Service: Washington, DC, USA, 1962; 50p, Available online: https://babel-hathitrust-org-s.vpn.gxu.edu.cn:8118/cgi/pt?id=uiug.30112019334355&view=1up&seq=3 (accessed on 10 May 2022).
- Clutter, J.L. Compatible growth and yield models for loblolly pine. For. Sci. 1963, 9, 354–371. [Google Scholar]
- Fang, Z.; Giley, R.L.; Shiver, B.D. A multivariate simultaneous prediction system for stand growth and yield with fixed and random effects. For. Sci. 2001, 47, 550–562. [Google Scholar]
- Wang, Y.; Huang, S.; Yang, R.C.; Tang, S. Error-in-variable method to estimate parameters for reciprocal base-age invariant site index models. Can. J. Res. 2004, 34, 1929–1937. [Google Scholar] [CrossRef]
- Fu, L.; Lei, Y.; Wang, G.; Bi, H.; Tang, S.; Song, X. Comparison of seemingly unrelated regressions with error-invariable models for developing a system of nonlinear additive biomass equations. Trees 2016, 30, 839–857. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, D.-L.; Huang, G.-S.; Zeng, W.-S. Developing aboveground biomass equations Both compatible with tree volume equations and additive systems for single-trees in Poplar plantations in Jiangsu Province, China. Forests 2016, 7, 32. [Google Scholar] [CrossRef]
- Zeng, W.; Zhang, L.; Chen, X.; Cheng, Z.; Ma, K.; Li, Z. Construction of compatible and additive individual-tree biomass models for Pinus tabulaeformis in China. Can. J. Res. 2017, 47, 467–475. [Google Scholar] [CrossRef]
- Sakici, O.E.; Kucuk, O.; Ashraf, M.I. Compatible above-ground biomass equations and carbon stock estimation for small diameter Turkish pine (Pinus brutia Ten.). Environ. Monit. Assess 2018, 190, 285. [Google Scholar] [CrossRef]
- Fu, L.; Liu, Q.; Sun, H.; Wang, Q.; Li, Z.; Chen, E.; Pang, Y.; Song, X.; Wang, G. Development of a system of compatible individual tree diameter and aboveground biomass prediction models using error-in-variable regression and airborne LiDAR data. Remote Sens. 2018, 10, 325. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, Q.; Luo, P.; Ye, Q.; Duan, G.; Sharma, R.P.; Zhang, H.; Wang, G.; Fu, L. Prediction of individual tree diameter and height to crown base using nonlinear simultaneous regression and airborne LiDAR data. Remote Sens. 2020, 12, 2238. [Google Scholar] [CrossRef]
- Kangas, A.S. Effect of errors-in-variables on coefficients of a growth model and on prediction of growth. For. Ecol. Manag. 1998, 102, 203–212. [Google Scholar] [CrossRef]
- Tang, S.; Li, Y.; Wang, Y. Simultaneous equations, error-in-variable models, and model integration in systems ecology. Ecol. Model. 2001, 142, 285–294. [Google Scholar] [CrossRef]
- Kinane, S.M.; Montes, C.R.; Albaugh, T.J.; Mishra, D.R. A model to estimate leaf area index in loblolly pine plantations using Landsat 5 and 7 images. Remote Sens. 2021, 13, 1140. [Google Scholar] [CrossRef]
- Liao, Z.; Huang, D. Forest Inventory Handbook of Guangxi, China; Forestry Department of Guangxi Zhuang Autonomous Region: Nanning, China, 1986. (In Chinese) [Google Scholar]
- Harding, D.J.; Lefsky, M.A.; Parker, G.G.; Blair, J.B. Laser altimeter canopy height profiles methods and validation for closed-canopy, broadleaf forests. Remote Sens. Environ. 2001, 76, 283–297. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Maltamo, M.; McRoberts, R.E.; Næsset, E. Introduction to Forestry Applications of Airborne Laser Scanning. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Managing Forest Ecosystems, 27; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Springer: Dordrechtc, The Netherlands, 2014; Volume 464, pp. 1–18. [Google Scholar]
- Li, C.; Li, Z. Generalizing predictive models of sub-tropical forest inventory attributes using an area-based approach with airborne LiDAR data. Sci. Silvae Sin. 2021, 57, 23–35. (In Chinese) [Google Scholar] [CrossRef]
- Tang, S.; Wang, Y. A parameter estimation program for the errors-in-variable model. Ecol. Model. 2002, 156, 225–236. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: https://www.R-project.org/ (accessed on 20 August 2020).
- Zolkos, S.G.; Goetz, S.J.; Dubayah, R. A meta-analysis of terrestrial aboveground biomass estimation using lidar remote sensing. Remote Sens. Environ. 2013, 128, 289–298. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forest Type | Sample Size | Stem Density (Stems ha−1) | Diameter at Breast Height (D) | Stand Height (H) | Basal Area (G) | Stand Volume (V) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean (cm) | CV (%) | Mean (m) | CV(%) | Mean (m2ha−1) | CV (%) | Mean (m3ha−1) | CV (%) | |||
| Fir | 139 | 683–6883 | 11.8 | 26.2 | 10.65 | 27.76 | 33.32 | 30.20 | 205.67 | 46.73 |
| Pine | 170 | 350–3967 | 19.5 | 28.0 | 14.32 | 27.26 | 28.57 | 32.30 | 206.91 | 47.95 |
| Eucalyptus | 267 | 517–3350 | 11.2 | 21.4 | 16.10 | 20.63 | 17.14 | 33.87 | 141.14 | 44.58 |
| Broad-leaved | 206 | 233–4800 | 13.6 | 34.5 | 10.49 | 27.25 | 19.27 | 40.62 | 110.13 | 58.88 |
| Acronym | Explanation of Metric | Structural Aspect | Predictor (Px) |
|---|---|---|---|
| H | Mean stand height (m) | Target variable | - |
| D | Diameter at breast height (cm) | Target variable | - |
| V | Stand volume (m3 ha−1) | Target variable | - |
| G | Basal area (m2 ha−1) | Target variable | - |
| Hmean | Mean height of point clouds (m) | Canopy height | Phm |
| hp95 | 95th height percentile | Canopy height | Phm |
| Hstdev | Standard difference of point height distribution (m) | Canopy height | Ph |
| Hcv | Coefficient of variation of point height distribution | Canopy height | Ph |
| CC | Canopy cover | Canopy density | Pdm |
| dp50 | 50th density percentile | Canopy density | Pd |
| dp75 | 75th density percentile | Canopy density | Pd |
| LADmean | Mean of vertical leaf area density (LAD) profile | Vertical heterogeneity | Pv |
| LADstdev | Standard difference of vertical LAD profile | Vertical heterogeneity | Pv |
| LADcv | Coefficient of variation of vertical LAD profile | Vertical heterogeneity | Pv |
| VFPmean | Mean of vertical foliage profile (VFP) | Vertical heterogeneity | Pv |
| VFPstdev | Standard difference of VFP | Vertical heterogeneity | Pv |
| VFPcv | Coefficient of variation of VFP | Vertical heterogeneity | Pv |
| Forest Type | Model Type | Attribute | Variables and Their Parameter Estimates | Fitting Statistic | Validation Statistic | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a0 | Hmean | hp95 | Hstdev | Hcv | CC | dp50 | dp75 | LADmean | LADstdev | LADcv | VFPmean | VFPstdev | VFPcv | R2 | RMSE(%) | R2 | RMSE(%) | |||
| Fir | IM | V | 5.0365 | 1.2623 | −0.3574 | 1.2661 | 0.03870 | 0.867 | 15.96 | 0.858 | 15.99 | |||||||||
| H | 1.4389 | 0.7897 | 0.02164 | 0.2902 | 0.08133 | 0.05820 | 0.858 | 10.07 | 0.850 | 10.08 | ||||||||||
| G | 8.1460 | 0.7273 | −0.1939 | 0.9878 | 0.03551 | 0.692 | 15.86 | 0.673 | 15.77 | |||||||||||
| SEq_G | V | 4.1305 | 1.2945 | −0.3923 | 0.9746 | 0.04636 | 0.863 | 16.21 | 0.853 | 16.22 | ||||||||||
| H | 1.3651 | 0.8040 | 0.005625 | 0.18520 | 0.06160 | 0.06417 | 0.856 | 10.14 | 0.847 | 10.14 | ||||||||||
| G | 0.689 | 15.93 | 0.671 | 15.80 | ||||||||||||||||
| SEq_V | V | 0.864 | 16.14 | 0.854 | 16.16 | |||||||||||||||
| H | 1.4038 | 0.8016 | 0.01272 | 0.19910 | 0.06775 | 0.04897 | 0.857 | 10.12 | 0.848 | 10.13 | ||||||||||
| G | 6.9021 | 0.7962 | −0.2401 | 0.8014 | 0.04387 | 0.685 | 16.03 | 0.666 | 15.90 | |||||||||||
| SEq_H | V | 4.1094 | 1.2942 | −0.3979 | 0.9664 | 0.04423 | 0.863 | 16.22 | 0.853 | 16.23 | ||||||||||
| H | 0.840 | 10.70 | 0.829 | 10.74 | ||||||||||||||||
| G | 7.0148 | 0.7866 | −0.2254 | 0.8740 | 0.04492 | 0.686 | 16.00 | 0.667 | 15.87 | |||||||||||
| Pine | IM | V | 6.1982 | 1.4577 | 0.4028 | −0.06050 | 0.825 | 19.30 | 0.824 | 19.01 | ||||||||||
| H | 0.7293 | 1.0751 | −0.01010 | 0.1209 | 0.895 | 8.69 | 0.889 | 8.73 | ||||||||||||
| G | 6.6866 | 0.7472 | −0.04336 | 0.2011 | 0.3149 | −0.1095 | 0.702 | 17.25 | 0.700 | 17.01 | ||||||||||
| SEq_G | V | 5.9387 | 1.4838 | 0.6551 | −0.04736 | 0.821 | 19.50 | 0.821 | 19.14 | |||||||||||
| H | 0.7407 | 1.0697 | 0.007975 | 0.1112 | 0.894 | 8.70 | 0.889 | 8.74 | ||||||||||||
| G | 0.675 | 18.02 | 0.673 | 17.73 | ||||||||||||||||
| SEq_V | V | 0.833 | 18.85 | 0.832 | 18.53 | |||||||||||||||
| H | 0.7596 | 1.0588 | −0.01068 | 0.07242 | 0.893 | 8.77 | 0.887 | 8.80 | ||||||||||||
| G | 7.0295 | 0.7428 | −0.03240 | 0.3490 | 0.3502 | −0.1117 | 0.697 | 17.39 | 0.696 | 17.10 | ||||||||||
| SEq_H | V | 6.1386 | 1.4617 | 0.6392 | −0.03340 | 0.822 | 19.47 | 0.822 | 19.11 | |||||||||||
| H | 0.893 | 8.77 | 0.888 | 8.78 | ||||||||||||||||
| G | 4.8815 | 0.8090 | −0.08092 | 0.5478 | 0.1012 | −0.01289 | 0.689 | 17.63 | 0.688 | 17.33 | ||||||||||
| Eucalyptus | IM | V | 5.6930 | 1.3300 | −0.01835 | 0.2280 | 0.3609 | −0.1124 | 0.777 | 20.99 | 0.769 | 20.92 | ||||||||
| H | 2.0316 | 0.7329 | 0.006645 | −0.1352 | 0.08831 | −0.01158 | 0.764 | 9.95 | 0.757 | 9.76 | ||||||||||
| G | 2.9668 | 0.8470 | −0.05055 | 0.2734 | 0.2742 | −0.1500 | 0.657 | 19.83 | 0.650 | 19.71 | ||||||||||
| D | 1.5173 | 0.7018 | 0.04169 | −0.1269 | 0.07403 | −0.01798 | 0.694 | 11.77 | 0.683 | 11.62 | ||||||||||
| SEq_G | V | 4.6363 | 1.3431 | 0.007167 | −0.003278 | 0.3653 | −0.07611 | 0.773 | 21.20 | 0.765 | 21.12 | |||||||||
| H | 2.3845 | 0.6689 | 0.02462 | −0.20860 | 0.1018 | −0.01090 | 0.761 | 10.02 | 0.755 | 9.85 | ||||||||||
| G | 0.655 | 19.90 | 0.649 | 19.77 | ||||||||||||||||
| D | 1.8010 | 0.6344 | 0.05877 | −0.1909 | 0.08666 | −0.01665 | 0.691 | 11.83 | 0.682 | 11.69 | ||||||||||
| SEq_V | V | 0.773 | 21.20 | 0.765 | 21.12 | |||||||||||||||
| H | 2.3393 | 0.6708 | 0.02836 | −0.2194 | 0.1019 | −0.001516 | 0.759 | 10.05 | 0.753 | 9.89 | ||||||||||
| G | 2.4802 | 0.8435 | −0.01378 | 0.1630 | 0.2884 | −0.08184 | 0.654 | 19.91 | 0.648 | 19.78 | ||||||||||
| D | 1.7722 | 0.6337 | 0.06019 | −0.1975 | 0.08687 | −0.009687 | 0.690 | 11.85 | 0.680 | 11.73 | ||||||||||
| SEq_H | V | 4.1199 | 1.3622 | 0.01500 | 0.008849 | 0.3622 | −0.04535 | 0.773 | 21.19 | 0.765 | 21.11 | |||||||||
| H | 0.759 | 10.06 | 0.753 | 9.90 | ||||||||||||||||
| G | 2.3542 | 0.8584 | −0.01386 | 0.1857 | 0.2851 | −0.07427 | 0.655 | 19.90 | 0.649 | 19.77 | ||||||||||
| D | 1.7558 | 0.6368 | 0.05998 | −0.2179 | 0.08665 | −0.01231 | 0.689 | 11.86 | 0.680 | 11.73 | ||||||||||
| SEq_D | V | 4.9610 | 1.3252 | 0.008399 | −0.006183 | 0.3712 | −0.08210 | 0.773 | 21.20 | 0.765 | 21.12 | |||||||||
| H | 2.3575 | 0.6678 | 0.02798 | −0.2306 | 0.1033 | −0.002148 | 0.759 | 10.06 | 0.753 | 9.91 | ||||||||||
| G | 2.6718 | 0.8236 | −0.01287 | 0.1580 | 0.2936 | −0.08883 | 0.654 | 19.91 | 0.648 | 19.78 | ||||||||||
| D | 0.671 | 12.20 | 0.661 | 12.11 | ||||||||||||||||
| Broad-leaved | IM | V | 5.0340 | 1.2488 | 0.2287 | 0.07030 | 0.678 | 31.38 | 0.669 | 31.41 | ||||||||||
| H | 2.2698 | 0.6531 | −0.07921 | 0.09380 | 0.620 | 15.76 | 0.610 | 15.74 | ||||||||||||
| G | 3.7473 | 0.7143 | 0.4489 | 0.06407 | 0.507 | 27.21 | 0.501 | 27.22 | ||||||||||||
| SEq_G | V | 4.5078 | 1.2782 | 0.2167 | 0.08187 | 0.677 | 31.42 | 0.667 | 31.45 | |||||||||||
| H | 2.5117 | 0.6072 | −0.08318 | 0.01247 | 0.617 | 15.82 | 0.606 | 15.80 | ||||||||||||
| G | 0.488 | 27.71 | 0.483 | 27.69 | ||||||||||||||||
| SEq_V | V | 0.688 | 30.91 | 0.678 | 30.92 | |||||||||||||||
| H | 2.1363 | 0.6785 | −0.07103 | 0.11390 | 0.619 | 15.78 | 0.609 | 15.75 | ||||||||||||
| G | 3.1293 | 0.7583 | 0.3296 | 0.11350 | 0.496 | 27.51 | 0.492 | 27.46 | ||||||||||||
| SEq_H | V | 4.5103 | 1.2779 | 0.2220 | 0.08284 | 0.677 | 31.42 | 0.667 | 31.45 | |||||||||||
| H | 0.608 | 16.00 | 0.598 | 15.99 | ||||||||||||||||
| G | 3.2912 | 0.7501 | 0.2817 | 0.07504 | 0.503 | 27.32 | 0.498 | 27.30 | ||||||||||||
| Forest Type | Equation/Model for Comparison | ∆H | ∆G | ∆V | ∆D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean (m) | Mean (%) | Std. (m) | Mean (m2ha−1) | Mean (%) | Std. (m2ha−1) | Mean (m3ha−1) | Mean (%) | Std. (m3ha−1) | Mean (cm) | Mean (%) | Std. (cm) | ||
| Fir | SEq_V vs. SEq_G | 0.02 *** | 0.16 | 0.05 | 0.02 ns | −0.05 | 0.73 | 0.54 ns | 0.09 | 4.58 | |||
| SEq_V vs. SEq_H | 0.02 ns | 0.03 | 0.33 | 0.06 *** | 0.24 | 0.19 | 0.89 * | 0.28 | 4.57 | ||||
| SEq_G vs. SEq_H | 0.00 ns | −0.12 | 0.31 | 0.04 ns | 0.29 | 0.75 | 0.35 *** | 0.19 | 0.53 | ||||
| Pine | SEq_V vs. SEq_D | −0.02 * | −0.36 | 0.15 | 0.08 ns | 0.19 | 1.38 | 0.47 ns | −0.07 | 10.17 | |||
| SEq_V vs. SEq_H | −0.04 ns | −0.38 | 0.53 | 0.14 ns | 0.00 | 1.04 | 0.54 ns | −0.29 | 10.04 | ||||
| SEq_G vs. SEq_H | −0.02 ns | −0.02 | 0.53 | 0.06 ns | −0.19 | 0.85 | 0.08 ns | −0.22 | 1.28 | ||||
| Eucalyptus | SEq_V vs. SEq_D | 0.01 ns | 0.08 | 0.09 | 0.00 ns | −0.09 | 0.08 | 0.00 ns | 0.06 | 0.06 | 0.03 * | −0.02 | 0.18 |
| SEq_V vs. SEq_H | 0.00 ns | −0.04 | 0.09 | −0.03 *** | −0.09 | 0.07 | 0.00 * | −0.05 | 0.04 | −0.25 *** | −0.12 | 0.87 | |
| SEq_V vs. SEq_D | 0.00 ns | −0.02 | 0.03 | −0.01 ** | −0.10 | 0.05 | −0.03 ns | −0.31 | 0.29 | −0.03 ns | −0.09 | 0.49 | |
| SEq_G vs. SEq_H | −0.01 ns | −0.12 | 0.12 | −0.03 *** | 0.00 | 0.12 | −0.01 ** | −0.11 | 0.06 | −0.28 *** | −0.09 | 0.86 | |
| SEq_G vs. SEq_D | −0.01 ns | −0.10 | 0.10 | −0.01 ns | −0.02 | 0.08 | −0.03 ns | −0.38 | 0.30 | −0.06 * | −0.07 | 0.41 | |
| SEq_H vs. SEq_D | 0.00 ns | 0.02 | 0.08 | 0.02 ** | −0.01 | 0.11 | −0.02 ns | −0.27 | 0.26 | 0.22 ** | 0.02 | 1.18 | |
| Broad-leaved | SEq_V vs. SEq_D | 0.00 ns | −0.01 | 0.17 | −0.03 ns | −0.26 | 0.37 | −0.16 ns | −0.27 | 3.59 | |||
| SEq_V vs. SEq_H | 0.02 ns | 0.18 | 0.39 | −0.07 * | −0.55 | 0.53 | −0.30 ns | −0.39 | 3.56 | ||||
| SEq_G vs. SEq_H | 0.02 ns | 0.19 | 0.30 | −0.04 ns | −0.29 | 0.51 | −0.13 *** | −0.11 | 0.15 | ||||
| Forest Type | Equation/Model for Comparison | Sample Size | ∆H | ∆G | ∆V | ∆D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean (m) | Mean (%) | Std. (m) | Mean (m2 ha−1) | Mean (%) | Std. (m2ha−1) | Mean (m3ha−1) | Mean (%) | Std. (m3ha−1) | Mean (cm) | Mean (%) | Std. (cm) | |||
| Fir | SEq_G vs. IM | 139 | 0.01 nc | −0.27 | 0.12 | −0.43 *** | 1.34 | 0.95 | −1.88 *** | 1.16 | 5.42 | |||
| SEq_V vs. IM | 0.03 *** | 0.43 | 0.10 | −0.40 *** | −1.39 | 0.68 | −1.34 ** | −1.07 | 7.13 | |||||
| SEq_H vs. IM | 0.02 ns | −0.39 | 0.39 | −0.46 *** | 1.63 | 0.53 | −2.23 *** | 1.35 | 5.46 | |||||
| Pine | SEq_G vs. IM | 166 | −0.04 *** | 0.33 | 0.04 | −0.11 ns | 0.04 | 1.26 | −0.82 ns | 0.87 | 6.23 | |||
| SEq_V vs. IM | −0.07 *** | −0.69 | 0.13 | 0.15 ** | 0.15 | 0.64 | 0.81 ns | −0.94 | 9.35 | |||||
| SEq_H vs. IM | −0.01 ns | 0.31 | 0.47 | −0.14 ns | −0.15 | 1.05 | −0.54 ns | 0.65 | 5.90 | |||||
| Eucalyptus | SEq_G vs. IM | 267 | 0.04 ** | 0.44 | 0.21 | −0.11 *** | −0.54 | 0.30 | −1.12 *** | −0.42 | 4.12 | 0.04 *** | 0.54 | 0.14 |
| SEq_V vs. IM | 0.05 ** | 0.52 | 0.25 | −0.12 *** | −0.62 | 0.28 | −1.10 *** | −0.45 | 4.09 | 0.04 *** | 0.60 | 0.17 | ||
| SEq_H vs. IM | 0.05 ** | 0.56 | 0.28 | −0.09 *** | −0.53 | 0.26 | −0.85 *** | −0.33 | 4.09 | 0.05 *** | 0.65 | 0.18 | ||
| SEq_D vs. IM | 0.05 ** | 0.27 | 0.27 | −0.11 *** | −0.26 | 0.29 | −1.07 *** | −0.18 | 4.11 | 0.07 ** | 0.46 | 0.40 | ||
| Broad-leaved | SEq_G vs. IM | 206 | −0.03 *** | 0.41 | 0.14 | −0.14 * | 0.70 | 0.81 | −0.96 *** | 1.36 | 1.51 | |||
| SEq_V vs. IM | −0.03 *** | −0.42 | 0.05 | −0.17 ** | −0.97 | 0.77 | −1.13 *** | −1.64 | 4.00 | |||||
| SEq_H vs. IM | −0.05 ** | 0.60 | 0.37 | −0.10 ** | 0.41 | 0.48 | −0.83 *** | 1.25 | 1.61 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Yu, Z.; Zhou, X.; Zhou, M.; Li, Z. Using the Error-in-Variable Simultaneous Equations Approach to Construct Compatible Estimation Models of Forest Inventory Attributes Based on Airborne LiDAR. Forests 2023, 14, 65. https://doi.org/10.3390/f14010065
Li C, Yu Z, Zhou X, Zhou M, Li Z. Using the Error-in-Variable Simultaneous Equations Approach to Construct Compatible Estimation Models of Forest Inventory Attributes Based on Airborne LiDAR. Forests. 2023; 14(1):65. https://doi.org/10.3390/f14010065
Chicago/Turabian StyleLi, Chungan, Zhu Yu, Xiangbei Zhou, Mei Zhou, and Zhen Li. 2023. "Using the Error-in-Variable Simultaneous Equations Approach to Construct Compatible Estimation Models of Forest Inventory Attributes Based on Airborne LiDAR" Forests 14, no. 1: 65. https://doi.org/10.3390/f14010065
APA StyleLi, C., Yu, Z., Zhou, X., Zhou, M., & Li, Z. (2023). Using the Error-in-Variable Simultaneous Equations Approach to Construct Compatible Estimation Models of Forest Inventory Attributes Based on Airborne LiDAR. Forests, 14(1), 65. https://doi.org/10.3390/f14010065