1. Introduction
Clustering is a fundamental machine learning [
1] approach for extracting useful information from the data of such application domains as pattern recognition, image segmentation, text analysis, medicine, bioinformatics, and Artificial Intelligence. K-Means [
2,
3,
4] is a classical clustering algorithm often used due to its simplicity and efficiency.
The aim of K-Means is to partition data points , e.g., , in , with , subsets (said clusters) by ensuring that points belonging to the same cluster are similar to one another, and points in different clusters are dissimilar. The Euclidean distance between data points usually expresses the similarity. Every cluster is represented by its central point or centroid. K-Means aims to optimize (minimize) the Sum-of-Squared Errors () cost, a sort of internal variance (or distortion) in clusters.
Recently, K-Means properties have been studied in depth [
5,
6,
7]. A crucial aspect is the procedure which initializes the centroids (
seeding method). In fact, the accuracy of a clustering solution strongly depends on the initial centroids. A basic limitation of K-Means is the adoption of a
local strategy for managing centroids, which determines the algorithm often blocks in a sub-optimal solution. Random Swap [
8,
9] and genetic/evolutionary approaches [
10,
11,
12] are examples of more sophisticated clustering algorithms that try to remedy this situation by adopting a
global strategy of centroid management. At each iteration of Random Swap, a centroid is randomly selected and replaced by a randomly chosen data point of the dataset. The
of the new configuration is then compared to that of the previous centroids’ configuration and, if it is diminished, the configuration becomes current for the next iteration. The algorithm can be iterated a maximum number of times. Random Swap has been demonstrated to approach, in many cases, the obtainment of a solution
close to the optimal one, even with a possible increase in the computational time.
The contribution of this paper is the development of two new clustering algorithms by extending the K-Means and Random Swap through an evolutionary technique [
10,
13] and careful seeding. The two algorithms are Population-Based K-means (
PB-KM) and Population-Based Random Swap (PB-RS). They borrow ideas from the evolutionary algorithms underlying GA-K-Means [
10] and Recombinator-K-Means [
11,
12] and consist of two steps. In the first step, a population of candidate centroid solutions is initially built, by executing
times the Lloyd’s K-Means or Random Swap along with the Greedy-K-Means++ (GKM++) [
11,
12,
14] seeding method, which is effective for producing a careful configuration of centroids with a reduced
cost. In the second step, PB-KM and PB-RS start from a configuration of centroids extracted by using GKM++ on the candidate centroids of the population. Then, they recombine centroids until a satisfying solution minimizes the
cost.
The greater the number of repetitions is during the second step (independent restarts of PB-KM, the number of swap iterations of PB-RS), the higher the possibility of getting a combined solution near the best one is.
Regarding reliability and accuracy, PB-KM significantly enhances the classical Lloyd’s repeated K-Means in globular, spherical, and Gaussian-shaped clusters [
5,
6]. PB-RS is better suited for studying general datasets with an irregular distribution of points. A common issue of PB-KM and PB-RS, though, is the assumption that good clustering follows by minimizing the
cost. Unfortunately, this is not true for some challenging datasets [
9] which can only be approximated through the proposed and similar tools.
To cope with large datasets,
PB-KM and PB-RS systematically use parallel computing. Currently, the two algorithms are developed in Java using lambda expressions and parallel streams [
15,
16]. This way, it is possible to exploit today’s multi/many-core machines transparently.
This paper extends the preliminary paper [
17] presented at the Simultech 2023 conference, where the basic idea of PB-KM was introduced. Differences from the conference paper are indicated in the following.
A more complete description of the evolutionary approach, which is the basis of the proposed clustering algorithms, is provided.
PB-KM now includes a mutation operation in the second step of recombination.
An original development of PB-RS is presented which, with respect to standard Random Swap [
8,
9], is more apt to move directly to a good clustering solution.
More details about the Java implementations are furnished.
All previous execution experiments were reworked, and new challenging case studies were added to the experimental framework, exploiting synthetic (benchmark) and real-world datasets.
The paper first describes the evolutionary approach of PB-KM and PB-RS, then reports the experimental results of applying them to several datasets. The simulation results confirm that the new algorithms can ensure accurate clustering and good execution times.
The paper is structured as follows.
Section 2 reviews the related work about the K-Means and methods for seeding. It also overviews the fundamental aspects of Random Swap, the evolutionary clustering of GA-K-means and Recombinator-K-Means, which inspired the algorithms proposed here. The section also describes some external measures suited to assess the clustering quality. The operations of the PB-KM and PB-RS algorithms are presented in
Section 3. Some implementation issues in Java are discussed in
Section 4.
Section 5 reports the chosen experimental setup made up of synthetic datasets and real-world ones, and the experimental results tied to the practical applications of the developed tools. The execution performance of the new algorithms is also demonstrated. Finally, conclusions are drawn together with an indication of ongoing and future work.
2. Related Work
This section provides a review of the clustering concepts and operation of K-Means [
2,
3,
4,
7], Genetic K-Means (GA-K-Means) [
10], Random Swap [
8,
9] and the evolutionary Recombinator-K-Means [
11,
12], which are at the basis of the development of the two algorithms this paper proposes.
2.1. Lloyd’s K-Means
Algorithm 1 illustrates the operation of classical K-Means. In step 1, the data points of the dataset to assume as the initial centroids are established by a seeding procedure (e.g., uniform random, see also
Table 1 of basic notations).
In step 2, the data points are partitioned according to current centroids. In particular, each point
is assigned to the cluster
, of which the representative centroid,
, is nearest to
:
where
expresses the Euclidean distance between
and
data points. In step 3, centroids get updated as the mean of the clusters’ belonging points:
Steps 2 and 3 are re-executed until a stop condition holds. For example, when the updated centroids
practically “coincide” (according to a certain numeric tolerance) with the previous ones
the K-Means exits for reached convergence, otherwise, the stop condition occurs after the maximum number of iterations of steps 2 and 3 is finished. In any case, the new centroids
become the current centroids,
.
| Algorithm 1. The Lloyd’s K-Means |
Input: the dataset and the number of clusters .
Output: final centroids and corresponding partitions.
1. Initialization. Use some seeding method (e.g., uniform random) to choose data in as initial centroids.
2. Partitioning. Assign data points of to clusters according to the nearest centroid rule.
3. Update. Redefine centroids as the mean points of the clusters resulting from step 2.
4. Check termination. If the termination condition does not hold, repeat from 2. |
The goal of K-Means is minimizing the
cost:
In the practical case, the normalized mean value of
, named
and here also referred to as the
distortion index, can be used (see
Table 1):
In general, optimizing the
function cost is very difficult. This is due to the highly non-convex character of the
. In addition, a good clustering of some datasets does not necessarily follow from the minimization of the
(see, e.g., [
9]). Therefore, clustering solutions are usually approximations of the optimal solution.
2.2. The Random Swap Clustering Algorithm
The behavior of K-Means is heavily dependent on its initial seeding. Centroid points are then subsequently refined locally. The global movement of centroids is, in many cases, forbidden. For example, the seeding procedure can sometimes associate multiple centroids with the same big real cluster, which is in turn well-separated from smaller clusters with no centroid associated with them. Consequently, the big cluster can get wrongly split into multiple sub-clusters because its centroids cannot move to smaller clusters without a centroid. This bad situation is favored when the two kinds of clusters are far away from each other [
6]. What could help is the adoption of a global strategy governing the movement of centroids.
Random Swap [
8] is a clustering algorithm based on such a global strategy. It starts by defining initial centroids via uniform random seeding. After that, it executes a certain number of
swap iterations. At each swap, a centroid is randomly chosen in the vector of centroids, which is then replaced by a random point selected in the dataset:
In the case the resultant centroid configuration, preliminarily refined by a few K-Means iterations (e.g., 5), has an cost lesser than the previous configuration, it is accepted as the new current solution and the algorithm goes on by starting the next swap iteration. The previous configuration and associated partitioning are otherwise restored, and the new swap is launched. The algorithm terminates when the required maximum number of iterations are executed.
Given its modus operandi, Random Swap is naturally capable of exploring all the data space and ending up, in many practical cases [
9], with a clustering solution close to the optimal one, provided an adequate number of iterations are executed.
2.3. Centroids Initialization Methods
As has been pointed out, e.g., in [
5,
6,
7], initial centroids should be defined in such a way to not coincide with outliers or noise data points. In addition, centroids should be far away from one another. This requirement avoids splitting a big real cluster into multiple smaller clusters. Different seeding methods for the initialization of centroids are defined in the literature. A few of these methods are described in the following.
. The uniform random seeding is the default method K-Means and Random Swap use. Centroids are initialized through a uniform random selection of
distinct points of the dataset
:
is simple to apply, but it does not guarantee the properties mentioned above of centroids are fulfilled. Only when centroids are selected near the optimal positions, the clustering solution delivered by K-Means locates close to the optimal one. Consequently, using K-Means with seeding typically requires the algorithm to be repeated a certain number of times (Repeated K-Means or K-Means with Restarts). The more the independent repetitions are, the higher the chance of finding a solution near the optimal one is. In any case, if are the repetitions of the K-Means, the solution that minimizes the objective cost is identified as the “best” one among the runs.
Let, in the following, be the minimal distance of point from the currently defined centroids, .
The first centroid is established by selecting a point in the dataset by uniform random. Each subsequent centroid is a point with maximal from the currently defined centroids. The method is continued until all the centroids are defined. Similarly to K-Means++ (see below), the method tends to define centroids far away from one another and with a similar linear computational cost ().
K-Means++. This seeding method [
18] initializes centroids incrementally and probabilistically, as shown in Algorithm 2.
| Algorithm 2. The K-Means++ seeding method. |
| 1. Establish the first centroid through a uniform random selection: |
| |
| 2. For each point define the probability of being chosen as the next centroid as: |
| |
Use a random switch based on the newly computed values of , for choosing a
point , not previously selected, as the next centroid |
| |
| 3. If , repeat from step 2. |
K-Means++ is known to be a good seeding method. It tends to distribute the centroids in the data space more evenly, ensuring that they are located far away from each other.
-
Means++. This method is a refinement of
K-Means++ [
11,
12,
14]. Its operation is illustrated in Algorithm 3.
| Algorithm 3. The Greedy_K-Means++ (GKM++) seeding method. |
,
a point as candidate centroid, using the K-Means++ method
according to that is assign points to clusters according
to the function
|
A uniform random choice in the dataset defines the first centroid. From the second centroid onward, attempts are executed to ensure the next candidate centroid is not only distinct and far away from the already chosen points but will also contribute with a minimal cost increment (the greedy step) in the centroid configuration.
As suggested in [
11], in our work too, the adopted value of the parameter
is
, which represents a trade-off between careful seeding and the required computational cost
.
It is worth noting that, although the improved seeding, GKM++ has a greater computational cost than K-Means++ and, unfortunately, it cannot guarantee that the chosen centroids hit the optimal positions. However, as an important benefit confirmed experimentally, some centroids (“exemplars”), in different configurations, can be positioned close to ground truth centroids. All of this can then be exploited to improve the accuracy of a clustering solution (see later in this paper).
2.4. Evolutionary Algorithm Concepts
Genetic and evolutionary algorithms (GEA) [
19] try to mimic the behavior of real-life individuals of a population by moving through subsequent generations of the population using selection, survival and disappearing genetic operations. When interpreted in the context of clustering [
10,
12,
13], individuals are solutions <
> that are cluster centroids and corresponding data partition labels. The partition label of a data point
can be denoted as
, that is the index, in the centroids vector, of the nearest centroid
. At each new generation, the best solution can be identified that improves at subsequent generations toward, at the end of the algorithm, the obtainment of the proposed solution, hopefully close to the optimal one. Despite its flexibility and accuracy, GEA-based clustering algorithms can be disadvantaged by, in general, an expensive computational time.
2.4.1. GA-K-Means
The genetic algorithm developed by P. Franti in [
10], referred to as GA-K-Means, represents a fundamental influencing work. GA-K-Means starts by defining an initial population,
, with
solutions, each one achieved by choosing
data points (centroids) from the dataset
by uniform random, and by executing the partitioning step 2 (see Algorithm 1) of Lloyd’s K-Means.
GA-K-Means depends on an elitist approach. Only an subset of the best solutions (according to the or index) in is considered for the crossover operations, which will transform into the next generation . In a case, it can happen that ; that is, all the solutions in the population are the best solutions.
In particular, starting from , for times, first a pair of solutions and (parents) in are chosen, then the two solutions are crossed with each other to define an offspring solution which is added to : . The number of possible solution pairs is .
The crossing operation is realized by first establishing a solution of clusters/centroids <> where is , and is the corresponding optimal partitioning. Then, the new solution is reduced to elements by deterministic iterations of the Pairwise Nearest Neighbor () technique, that is, by subsequent merging operations. At each iteration of the , the two clusters in are identified whose merging would increase the distortion least. The centroid is then defined for the resultant merged cluster. Finally, the partitions of the remaining clusters in are updated accordingly to the merged cluster, and their centroids are redefined by executing step 3 of Lloyd’s K-Means (see Algorithm 1). Only a part of the remaining clusters needs to be updated: those containing points which now have as nearest the centroid of the merged cluster. The centroids and the partitions must be redefined only for these clusters.
The offspring solution can be affected by a
mutation operation to improve the population’s genetic variation. As in the Random Swap (see
Section 2.2), with a given probability, a randomly selected centroid in the solution is possibly replaced by a randomly chosen dataset point.
Finally, Lloyd’s K-Means is executed to refine the offspring solution.
GA-K-Means is characterized by the efficient support of the
technique. For example, the pair of clusters
and
to merge can be found by anticipating the distortion increase
, which would follow the merging operation by using only the centroids
of the two originating clusters and the cluster sizes
,
:
In addition, the centroid of the new merged cluster can also be computed by using only the centroids and the cluster sizes:
2.4.2. Concepts of Recombinator K-Means
Recombinator-K-Means is an evolutionary algorithm [
12] that manages a population of individuals (solutions), which is initially made coincident, to the entire dataset. Subsequent generations are then established by using a
recombination technique always followed by Lloyd’s K-Means local optimization, until a convergence condition is fulfilled.
At each generation,
centroid configurations (solutions) are first created by repeating
times Lloyd’s K-Means together with GKM++ seeding applied to the population. The original dataset
is instead always used to evaluate the
cost during the execution of GKM++ for choosing the candidate centroids and qualifying the cost of a complete centroid configuration. An adapted version of GKM++, which employs a weighting (priority) mechanism, is used. Each centroid configuration, as in the Random Swap algorithm (see
Section 2.2), is then refined by a small number of iterations of Lloyd’s K-Means, and maintained paired with its
cost. After that, the population gets modified by retaining the
best solutions from the previous and newly generated solutions.
Priorities are attached to configurations through weights initialized by a uniform vector. Following each generation, weights get updated and affect the selection of the next centroid in GKM++.
Processing a generation has the effect of (re)combining centroid points of different solutions, thus determining new configurations with a smaller cost.
The resultant approach is characterized by the average cost of the population solutions, which decreases monotonically during the evolution of the generations. In addition, the population definitely tends to collapse (up to a numerical tolerance) around a single solution. This behavior naturally furnishes the termination criterion.
Recombinator-K-Means was implemented by his author in Julia and positively experimented with using synthetic and real-world datasets.
2.5. External Measures of Clustering Accuracy
Besides the
or
internal cost, the quality of a clustering solution can often also be assessed by some external measure, like the Adjusted Rand Index (
) [
20,
21], which compares similarity/dissimilarity between an achieved clustering solution and a reference solution (ground truth). In this paper, the Cluster Index (
) proposed in [
22] is used, which was felt to be more sound for capturing the clustering accuracy.
is best suited to quantify the clustering accuracy of synthetic datasets equipped with ground truth
information (centroids and/or partition labels).
quantifies the degree to which a clustering solution, , achieved by a certain clustering algorithm is close to . First (), centroids of are mapped onto the centroids of , which, in general, could also be different in numbers. Every centroid of maps on the particular centroid of which has minimal distance from it. As a measure of the dissimilarity in the mapping , the number of centroids in (said “orphans”) which were not associated with any centroid of are counted.
In the second step,
centroids are mapped onto
centroids (
) and the number of orphans determined in
is counted. The
value is the maximum number of orphans in the two directions of mapping:
characterizes a “correct” clustering solution, that is, one where clusters and clusters are structurally very similar to one another. A indicates the number of centroids incorrectly determined by the clustering algorithm.
If the dataset comes with partition labels as ground truth [
23], the Jaccard distance [
9] between partitions (sets of labels or cluster indexes) belonging to the emerged solution and the ground truth solution can be exploited for realizing the mapping and determining the number of orphans in the two mapping directions.
It is worth noting that, normally, real-world datasets come without ground truth information. However, a “golden” solution determined using an advanced clustering algorithm can sometimes exist. Also, in these cases (see later in this paper), it becomes possible to check, with the , the accuracy of a solution obtained by applying a given clustering algorithm.
3. Population-Based Clustering Algorithms
3.1. PB-KM
The proposed Population-Based K-Means (PB-KM) algorithm was inspired by the operation of both Recombinator-K-Means [
11,
12] and GA-K-Means [
10]. The design is based on a more simple, yet effective, clustering approach. PB-KM is organized into two steps (see Algorithm 4). The first step is devoted to the initialization of the population. The second step recombines the centroids of the population toward a final accurate clustering solution.
As in GA-K-Means, an elitist approach is usually used for managing the population. solutions achieved via Lloyd’s K-Means seeded by GKM++ are used to initialize the population, thus containing points. Each initial solution is the best one, which emerges after repetitions of the K-Means. In the case , the population is set as in Recombinator-K-Means. A value allows for the population to be preliminarily established with “best” solutions, as can happen with GA-K-Means. It is worth noting that, unlike Recombinator-K-Means, PB-KM rests on the basic GKM++ seeding without using a weighting mechanism.
The evolutionary iterations in the second step of PB-KM consist of repetitions of K-Means, fed by GKM++ seeding applied to the population instead of the dataset. The clustering result is the emerging best solution among the executions of K-Means. In other words, the crossover operation coincides with applying the GKM++ seeding followed by the optimization of K-Means. If the emerged solution has an value less than that of the current best solution, it becomes the current one and the obtained centroids are replaced (mutation operation) in the population by the centroid configuration which was selected by GKM++.
Algorithm 4 describes the two steps of PB-KM which depend on three parameters:
and
. In step 1 the writing run (K-Means, GKM++,
) expresses that K-Means is executed with the GKM++ seeding method applied to the data points of the dataset
. In step 2, K-Means is seeded by GKM++ applied to the centroid points of the population
. The
cost, though, is always computed on the entire
dataset, partitioned according to the candidate solution (
cand) suggested by K-Means.
| Algorithm 4. The PB-KM operation. |
1. Setup population
repeat times{
costBest←∞, candBest←?
repeat times{
cand←run(K-Means,GKM++,)
cost←SSE(cand,)
if(cost<costBest){
costBest←cost
candBest←cand
}
}
{candBest}
2. Recombination
costBest←∞
candBest←?
repeat times{
cand←run(K-Means,GKM++,)
cost←SSE(cand,)
if(cost<costBest){
costBest←cost
candBest←cand
replace in the GKM++ selected centroids by cand centroids
}
check candBest accuracy by clustering indexes
} |
Generally, following GKM++ seeding in step 1, each identified solution has limited chances of aligning precisely with the optimal solution. However, as discussed in
Section 2.3, it may encompass “exemplars”, i.e., centroids near the optimal ones. These exemplars tend to aggregate in dense regions surrounding the ground truth centroids. In step 2, the likelihood of selecting an exemplar by GKM++ in a peak is influenced by the density of that area. Conversely, when an exemplar is chosen, the probability of selecting a point in the same peak area or its vicinity as a subsequent centroid is minimal, thanks to GKM++ ensuring that candidate centroids are far from one another. Consequently, the
repetitions in step 2 have a favorable prospect of detecting a solution closely resembling the optimal one in practical scenarios (as shown later in this paper).
The parameters , and depend on the handled dataset and the number of clusters . In many cases, a value was found to be sufficient in approaching an accurate solution. For regular datasets, e.g., with spherical clusters regularly located in the data space, even can be adopted. A small or moderate value, e.g., , can be used in more complex datasets. Generally speaking, the greater the value of is, the higher the chance of hitting a solution close to the optimal one is.
The computational cost of the two steps of PB-KM is directly derived from the Repeated K-Means behavior and the use of GKM++. In particular, the first step has a linear cost whereby in the squared brackets, there is first the GKM++ cost, then the K-Means cost (is the number of iterations for reaching the convergence) and finally the cost for computing the value. The second step has a similar cost when one considers that the seeding is fed by the population, which has points: .
3.2. PB-RS
The setup population step of PB-RS consists of running
times the parallel version of Random Swap described in [
9], each run continued for
swap iterations (e.g.,
) and storing in the population
each emerged solution.
Algorithm 5 shows the recombination step of PB-RS. An initial configuration of
centroids is set up by applying GKM++ to population
. The corresponding partition of dataset points is then built and its
cost is defined as the current cost. Then,
swap iterations are executed. The value of
depends on the dataset and the number of clusters
.
| Algorithm 5. The PB-RS recombination step. |
cand←GKM++()
partition data points according to cand
cost←SSE()
repeat times{
save cand
cand’←swap(cand), that is: cs←pj, pj, s←unif_rand(1.. K), j←unif_rand(
refine cand’ by a few K-Means iterations (e.g., 5)
new_cost←SSE(cand’)
if(new_cost<cost){
accept cand’, cand←cand’
cost←new_cost
}
else{
restore saved cand and its previous partitioning
}
}
check the accuracy of candBest by further clustering indexes. |
At each swap iteration, a centroid in the current configuration () is randomly selected and replaced by a randomly chosen candidate point taken from the population.
It is worth noting that the population remains unaltered during the swap iterations under PB-RS. The initial selection of centroids via GKM++ triggers mutation and crossover operations, respectively, represented by swap operation and K-Means refinement.
The cost of the first step of PB-RS can be summarized as where for each of the solutions, first the cost of GKM++ is accounted, then the cost of partitioning the dataset according to the initial centroids is considered; after that, the cost of the swap iterations is added. is the small number of iterations of K-Means executed at each swap to optimize the new centroid configuration and is the probability of accepting the new centroid configuration. If the new configuration is rejected, is the cost of restoring the previous centroids and associated partitioning. The cost of the second step of PB-RS is similar to that of the first step by considering one single run of Random Swap () and that the single seeding of GKM++ is fed from the population and costs . The number of swap iterations, , is expected to depend on the particular adopted dataset.
With respect to the standard Random Swap operation [
8,
9], PB-RS recombination tends to move more “directly”, experimentally confirmed, toward a good clustering solution by avoiding many unproductive iterations. This is because at each swap iteration, only a candidate centroid in the population, not a point in the whole dataset, is considered for the replacement of a centroid in the current vector of centroids.
4. JAVA Implementation Notes
The realized Java implementation of PB-KM was designed to tackle the important task of facilitating the parallel execution of recurring operations. These include the partitioning and centroids update steps of K-Means (refer to Algorithm 1), the computation of the SSE cost, and the fundamental operations of GKM++, among others. To achieve this, parallel streams and lambda expressions [
9,
15,
16,
20] were leveraged. A parallel stream is orchestrated by the fork/join mechanism, allowing for arrays/collections like datasets, populations, centroid vectors and so forth, to be divided into multiple segments. Separate threads are then spawned to process these segments independently, and the results are eventually combined. Lambda expressions serve as functional units specifying operations on a data stream concisely and efficiently.
While the use of such popular parallelism can be straightforward in practical scenarios, it necessitates caution from the designer to avoid using shared data in lambda expressions, as this could introduce subtle data inconsistency issues, rendering the results meaningless.
Supporting classes for PB-KM/PB-RS encompass a foundational environmental
class, exposing global data (see
Table 1), such as
(dataset numerosity),
(number of data point coordinates or dimensions),
(number of clusters/centroids),
(GKM++ accuracy degree),
(population size), available seeding methods, methods for loading the dataset into memory, ground truth information (centroids or partition labels), if there are any, population and more. The helper
class enables common operations on data points like the Euclidean distance and offers some method references (equivalent to lambda expressions) employed in point stream operations.
To illustrate the Java programming style, Algorithm 6 presents a snippet of the K-means++/greedy K-means++ methods operating on a source, which can be the entire dataset or the population. The operations pertain to calculating of the common denominator (see Algorithm 2) of the probabilities of the data points being chosen as the next centroid.
| Algorithm 6. Code fragment of K-Means++/Greedy_K-Means++ operating on a source of data points. |
…
final int l=L;//turn L into a final variable l
Stream<DataPoint> pStream=
(PARALLEL) ? Arrays.stream(source).parallel(): Arrays.stream(source);
DataPoint ssd=pStream//sum of squared distances
.map(p->{
p.setDist(Double.MAX_VALUE);
for(int k=0; k<l; ++k) {//existing centroids
double d=p.distance(centroids[k]);
if(d<p.getDist()) p.setDist(d);
}
return p; })
.reduce(new DataPoint(), DataPoint::add2Dist, DataPoint::add2DistCombiner);
double denP=ssd.getDist();
//common denominator of points probability
…
//random switch
… |
Initially, a stream (a view, not a copy of the data) is extracted from the source of data points. The value of the G’s PARALLEL parameter determines whether pStream should be operated in parallel. In the following, it is normally assumed that PARALLEL = true.
The intermediate map() operation on processes the points of the in parallel by recording the minimal distance to existing centroids (indexes from ) into each point . This is achieved as part of the Function’s lambda expression of the map() operation. Notably, each point only modifies itself and avoids modifications to any shared data.
The operation yields a new stream operated by the terminal operation. The reduce() operation concretely initiates parallel processing, including the map executions. It instructs the underlying threads to add the squared point distances, utilizing the method reference of the class. The partial results from the threads are ultimately combined by the method reference of , adding them and producing a new , of which the distance field contains the desired calculation ().
Following the calculations in Algorithm 6, a random switch based on point probabilities finally selects the next (not yet chosen) centroid.
Parallel streams are also used to implement K-Means (see also [
9,
15]), particularly for the concretization of the basic steps 2 and 3 of Algorithm 1. In addition, parallelism is exploited for computing the
cost and in many similar operations.
Algorithm 7 illustrates the function which computes the
cost of a given centroid configuration (current contents of the
vector) and its corresponding partitioning of the dataset points. First, the squared distance to its nearest centroid is stored into each point. Then, all the squared distances are accumulated in a point
, through a
operation which receives a neutral point (located in the origin of data points) and a lambda expression that creates and returns a new point with the sum of the squared distances of the two parameter points p1 and p2. In Algorithm 7, all the dataset points can be processed in parallel.
| Algorithm 7. Java function which calculates the the cost of a given partitioning. |
Stream<DataPoint> pStream=
(PARALLEL) ? Stream.of(dataset).parallel(): Stream.of (dataset);
DataPoint s=pStream
.map(p ->{
int k=p.getCID();//retrieve partition label (centroid index) of p
double d=p.distance(centroids[k]);
p.setDist(d*d);//store locally to p the squared distance of p to its (nearest) centroid
return p;
} )
.reduce(new DataPoint(),
(p1,p2)->{ DataPoint ps=new DataPoint(); ps.setDist(p1.getDist()+p2.getDist());
return ps; }
);
return s.getDist(); |
The systematic use of the parallelism in PB-KM/PB-RS purposely reduces the time required, e.g., for computing all the distances between the points and associated centroids which, in turn, can significantly reduce the program execution time on a multi-core machine.
5. Experimental Framework
For comparison purposes with Recombinator-K-Means, all the synthetic (benchmark) and real-world datasets used in [
11,
12], plus others, were chosen to test the behavior of PB-KM/PB-RS. The datasets are split into four groups.
The first group (see
Table 2) contains some basic benchmark datasets taken from [
24], often used to check the clustering capabilities of algorithms based on K-Means. All the datasets come with ground truth centroids and will be processed, as in [
11,
12], by scaling down the data entries by the overall maximum. A brief description of the datasets is shown in
Table 2.
The
dataset comprises
2-d points distributed across 50 spherical clusters.
admits 5000 2-d points divided into 15 Gaussian distributed clusters with limited overlap. As discussed in [
5,
6], cluster overlapping is the key factor which can favor centroid movement during K-Means refinement, and then the obtainment of an accurate clustering.
is an example of a dataset with high-dimensional points. It contains 1024 Gaussian-distributed points in 16 well-separated clusters.
is made up of 6500 2-d points split into eight Gaussian clusters, articulated in two neatly separated groups of clusters containing 2000 and 100 points, respectively.
datasets contain 10
5 2-dimensional points distributed into 100 clusters. In particular,
places its clusters on a 10 × 10 grid.
, instead, puts the clusters on a sine curve.
and
have spherical clusters of the same size.
The synthetic datasets presented in
Table 2 can be studied using classical Repeated K-Means and careful seeding. However, in many cases, only an imperfect solution will emerge from the experiments (see
Section 5.1).
The second group of datasets (see
Table 3) includes two real-world datasets taken from the UCI Repository [
25].
concerns a molecule identification problem, whether it is musk or not. Although limited in the number of data points,
, and the number of clusters,
, the dataset admits a high number,
, of features (coordinates) per point, which complicates the identification problem. The
dataset, instead, regards a signals identification problem, whether they are neutrinos or background. In this case, the challenge is represented by both high values of
and
. The two datasets were also used in [
14]. In particular, the solutions documented in [
14] will be assumed in this paper as “golden” solutions, from which ground truth centroids are inferred and used to qualify the correctness of the solutions achieved via PB-KM/PB-RS. For comparison purposes with the results in [
14], the two datasets will be processed by first scaling all the data entries via min–max normalization.
The third group of datasets (see
Table 4) contains three synthetic datasets achieved from [
24] whose good clustering does not necessarily follow from the minimization of the
cost (see also [
9]).
(see
Figure 1) differs from the regular
and
because it admits clusters with a random size and randomly located in the data space.
(see
Figure 2) is composed of 35 clusters with 2-dimensional data points.
is characterized by 25 clusters with data points with 64 dimensions. The geometrical shapes of the worm datasets are determined by starting at a random position and moving in a random direction. At any moment, the points follow a Gaussian distribution, whereby the variance gradually increases step-by-step. In addition, movement direction is continually changed according to an orthogonal direction. In
, though, the orthogonal direction gets randomly re-defined at every step.
Clustering of worm datasets was investigated in [
26] using an enhanced and careful density peak-based algorithm [
27].
was analyzed, e.g., in [
9,
11,
12]. Such previous results will be used as a reference to assess the accuracy of the clustering solutions documented in this paper. To compare with the results in [
11,
12], the three datasets will be processed by first scaling down the data entries by the overall maximum.
The fourth group (see
Table 5) comprises some challenging real-world datasets, many of which are without ground truth information. Clustering difficulties arise from the large number of data points,
, the number of point features,
, and the number of needed clusters,
.
The non-binarized version of the
dataset, the 8 bits per color version of the
dataset, and the frame 1 vs. 2 version of
dataset, were downloaded from the [
24] repository. They all refer to image data processing.
The image facial recognition problem of the dataset, from the AT&T Laboratories Cambridge, handles human subjects, each portrayed in different poses. Every facial photo is stored by pixels.
The
is a large dataset consisting of geographical coordinates of car accidents in Great Britain’s urban areas. The dataset can be downloaded from [
28].
The solutions for the
and
reported in [
11,
12] were used to infer “ground truth” information about the datasets. In all the cases, though, the
cost and its evolution vs. the real time can be used for comparison purposes.
As in [
11,
12], the datasets of the fourth group are processed without scaling, except for the
where the first dimension of the data entries are scaled down by a factor of
.
The following simulation experiments were executed on a Win11 Pro platform, Dell XPS 8940, Intel i7-10700 (8 physical cores), CPU@2.90 GHz, 32GB RAM and Java 17.
5.1. Clustering the A3 Dataset
For a preliminary study, the
dataset was chosen (see
Table 2 and
Figure 3). The goal was to compare the performance of classical Repeated K-Means driven by different seeding methods, to that it was achievable with PB-KM. In particular,
was first clustered via Repeated K-Means
separately fed by uniform random
K-Means++ (RKM
KM++) and Greedy K-Means++
seeding procedure.
Then, 10
4 repetitions of K-Means were executed and the following quantities monitored: (a) the minimal value of the
cost
(b) the corresponding Cluster Index
value (see
Section 2.5) (
), (c) the minimal value of the observed
(
) and the corresponding value of the
cost (
), (d) the emerging average
value (
) and (e) the
, that is, the number of runs which ended with a
, divided by 10
4. In addition, the Parallel Execution Time (
), in sec, needed by Repeated K-Means to complete its runs was also observed.
Table 6 collects all the achieved results.
The experimental data in
Table 6 clearly confirm the superior behavior ensured by GKM++ seeding, which makes
capable of outperforming the scenarios where K-Means++ (KM++) or the uniform random (Unif) centroids initialization is adopted. The observed average
and the
are worth being noted. As one case see in
Table 6, it always happens that the minimum
value occurs at the minimum
cost.
The
results in
Table 6 comply with the results reported, e.g., in [
9,
11].
Table 7 collects the results observed when using PB-KM with the parameter values
and
adopted in the first step (see Algorithm 4), and the value
used for the second step. Only the
was annotated for the first step, which creates the population of candidate solutions. The second-step results clearly confirm that PB-KM is able to correctly solve the
dataset. In fact, a
of 100% and
were observed. The
minimal value coincides with that obtained with
in
Table 6.
Results in
Table 7 also show how the execution time of PB-KM outperforms that achievable by straight Repeated K-Means (see
Table 6). The same results of minimal
and
and a 100%
were also observed when using
. In reality, one single recombination iteration is sufficient for obtaining the minimal
and
. All of this was precisely confirmed by using the PB-RS recombination on the same population created by PB-KM.
The following sections report the experimental results collected by applying PB-KM/PB-RS to the four groups of selected datasets. A common point of all the experiments concerns using the GKM++ seeding method both in the first step of the population set-up and in the second step of recombination.
5.2. First Group of Synthetic Datasets (Table 2)
Table 8 shows the experimental results collected when applying PB-KM to all the benchmark datasets reported in
Table 2 (entries are preliminary scaled down by the overall maximum). It is worth noting that all these datasets have a
of
when clustered by Repeated K-Means together with uniform random seeding, as also documented in [
5]. The experimental results confirm that
always occurs at the minimum value of the objective
cost.
The
,
and
datasets were studied using
and
for the first step (three independent repetitions of K-Means are used for defining each solution of the population), and by
for the second step (see Algorithm 4). Due to the higher number of clusters
,
and
were instead studied by using
and
for the first step, and
for the second step.
Table 8 reports the Parallel Elapsed Time (
) in sec, required by the first and second step of PB-KM.
In reality, PB-KM was capable of detecting the “best” solution, that is, one with a minimal
and
, just after a few iterations (in some cases after 1 iteration) of the recombination step. All of this was also confirmed by PB-RS recombination. The results (e.g., CI = 0) in
Table 8 are the same as reported in [
9], where Random Swap was used, and in [
11] where the Recombinator-K-Means tool was exploited.
5.3. Second Group of Real-World Datasets (Table 3)
The
and
real-world datasets (data entries preliminarily scaled by min-max normalization), together with the ground truth information inferred from the solutions reported in [
14], were easily clustered using PB-KM with
and
for the first step, and
for the second step. The results, which coincide with those reported in [
11,
12,
14], are shown in
Table 9. Very few iterations of PB-RS also confirmed them.
5.4. Third Group of Synthetic Datasets (Table 4)
All the entries of datasets in
Table 4 were preliminarily scaled by the overall maximum. The datasets of this group were processed via PB-RS because it provided the most accurate results. The initial population of
was built using
and
swap iterations of Random Swap always seeded by GKM++, requiring a parallel elapsed time of
s. The recombination step was carried out using
10,000 iterations.
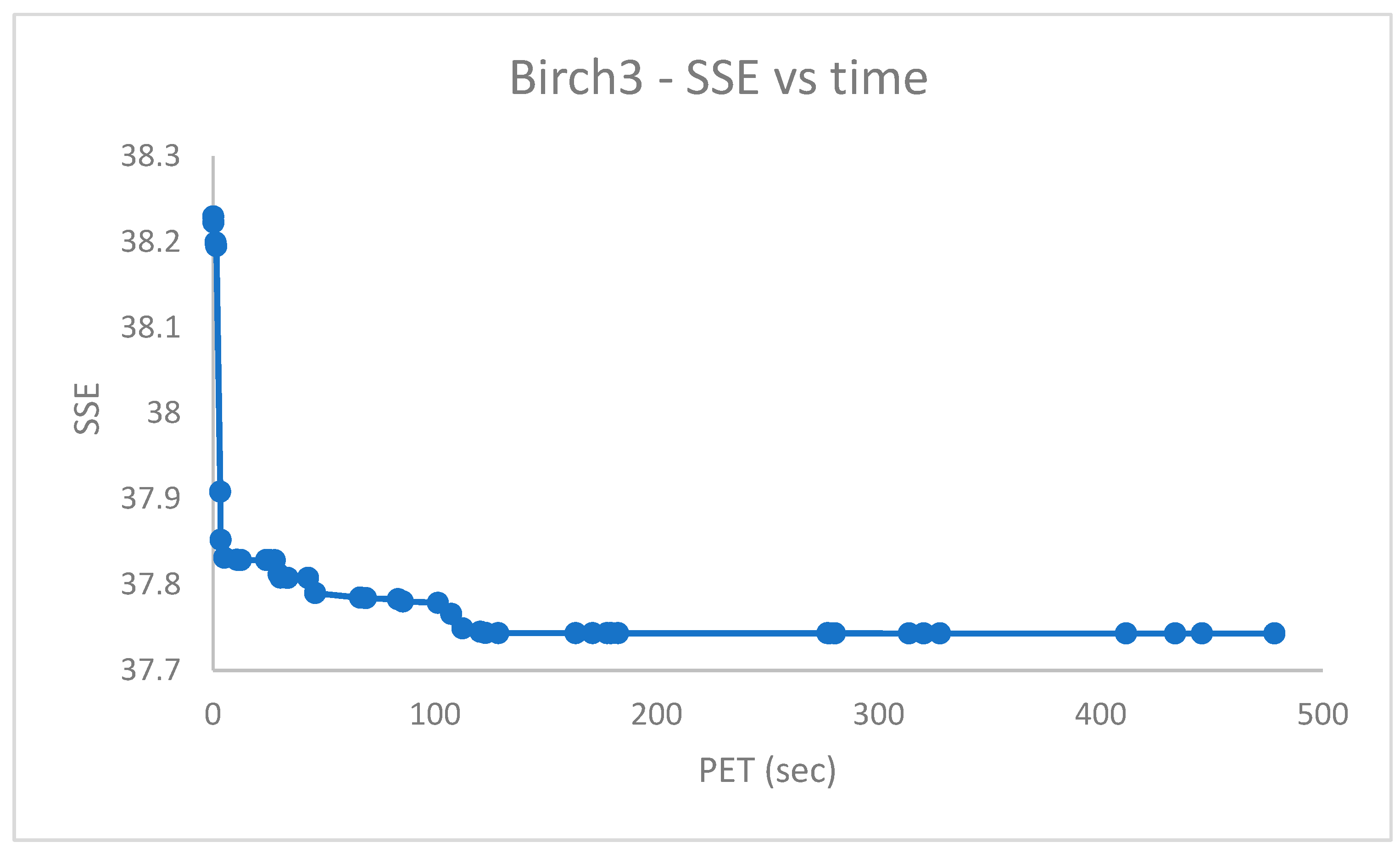
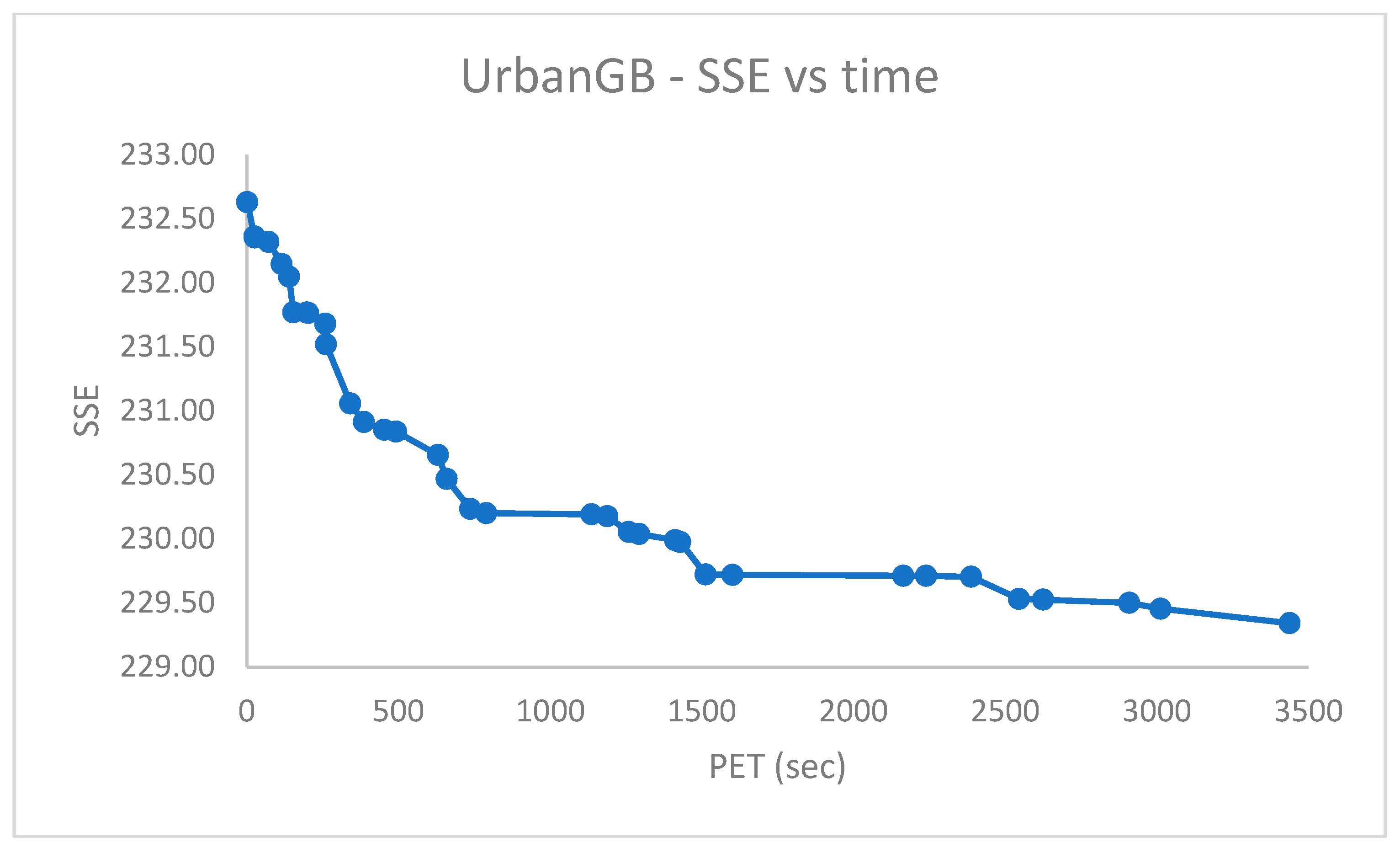
Figure 4 depicts the
vs. the real-time PET (s).
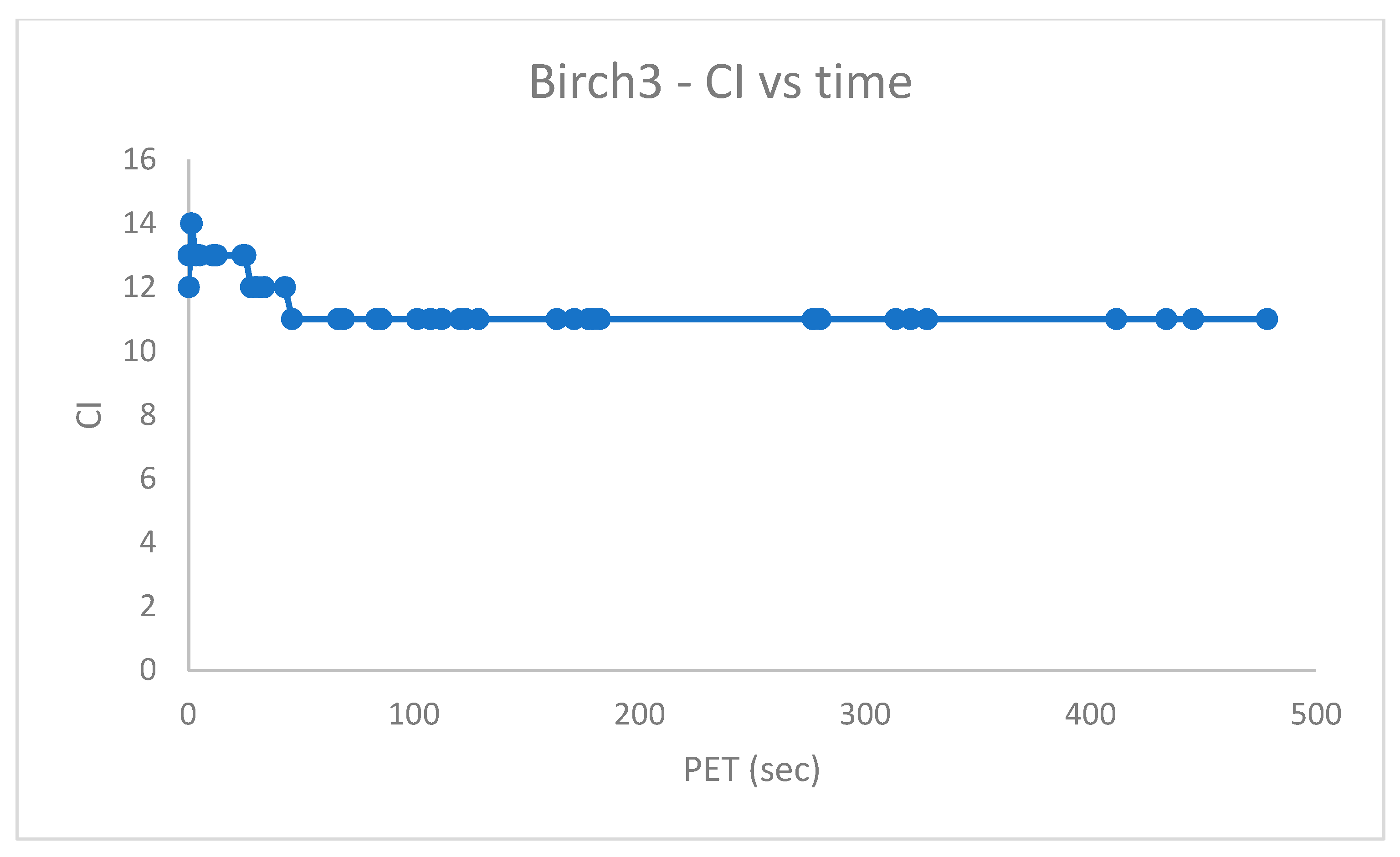
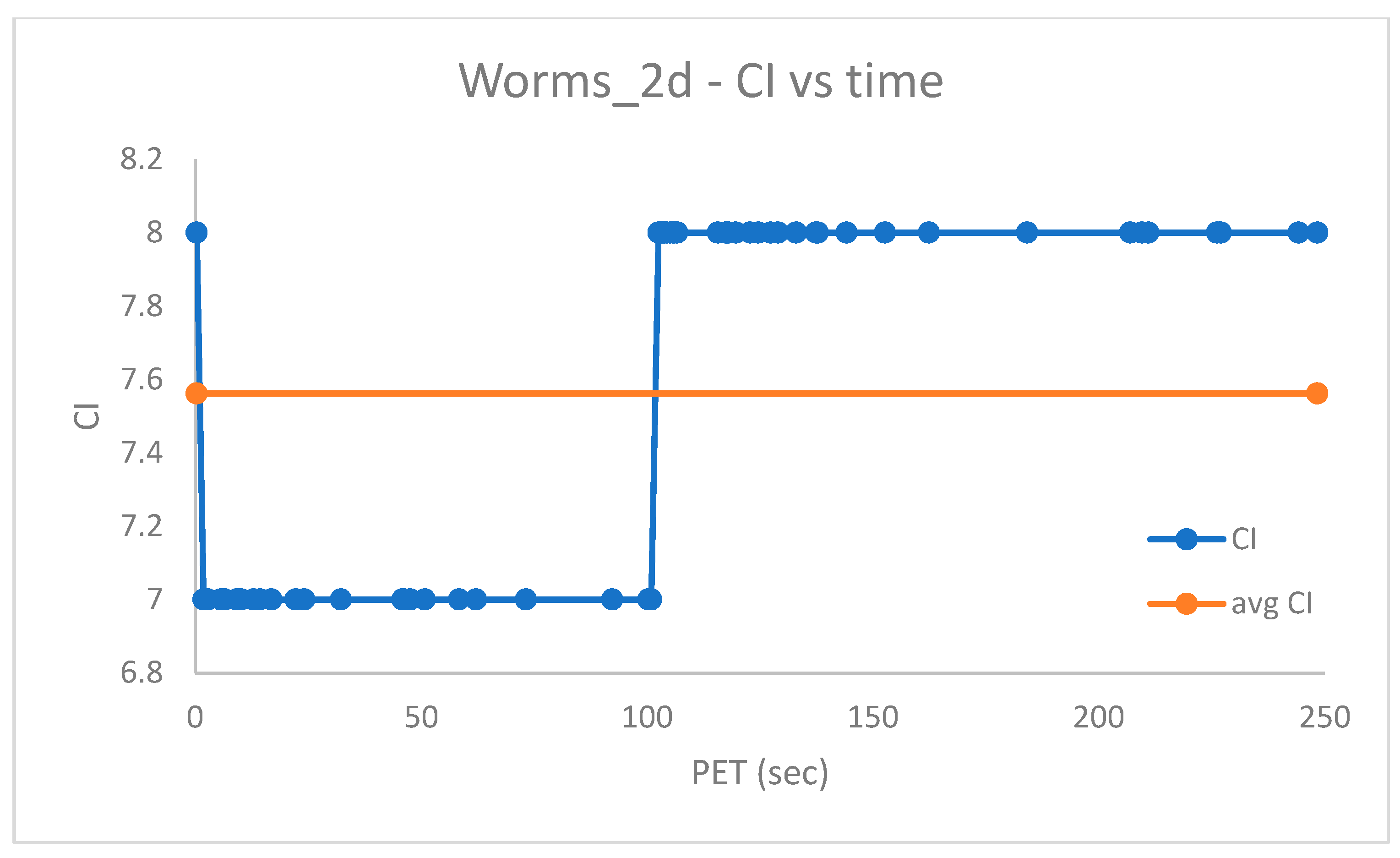
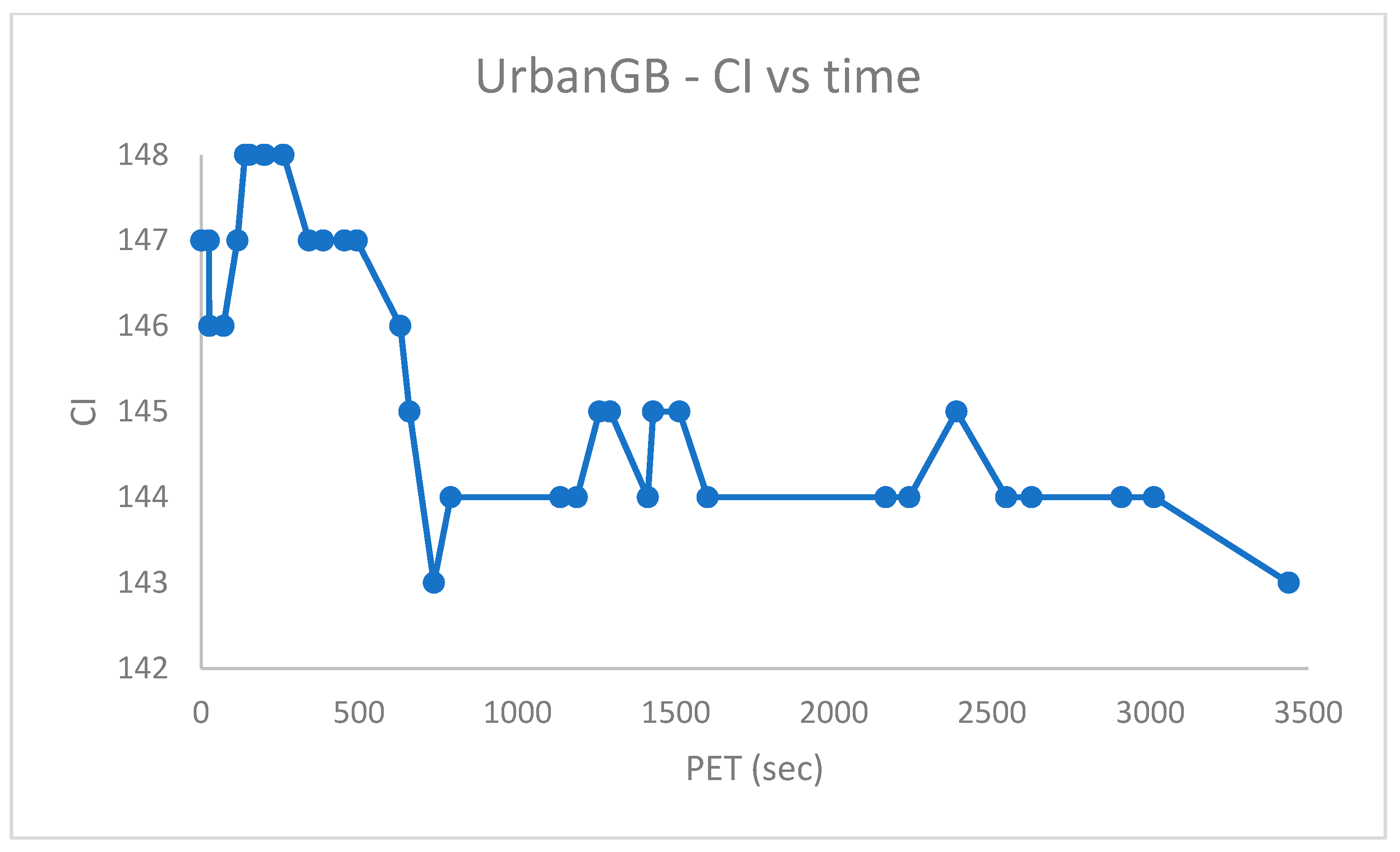
Figure 5 shows the Cluster Index (recall
comes with ground truth centroids, see also
Section 2.5)
vs. real-time PET (s).
Notably, a
was estimated in [
9] by using standard Parallel Random Swap executed for
iterations, requiring a
.
Figure 5 suggests a final value of
, after a significantly smaller time.
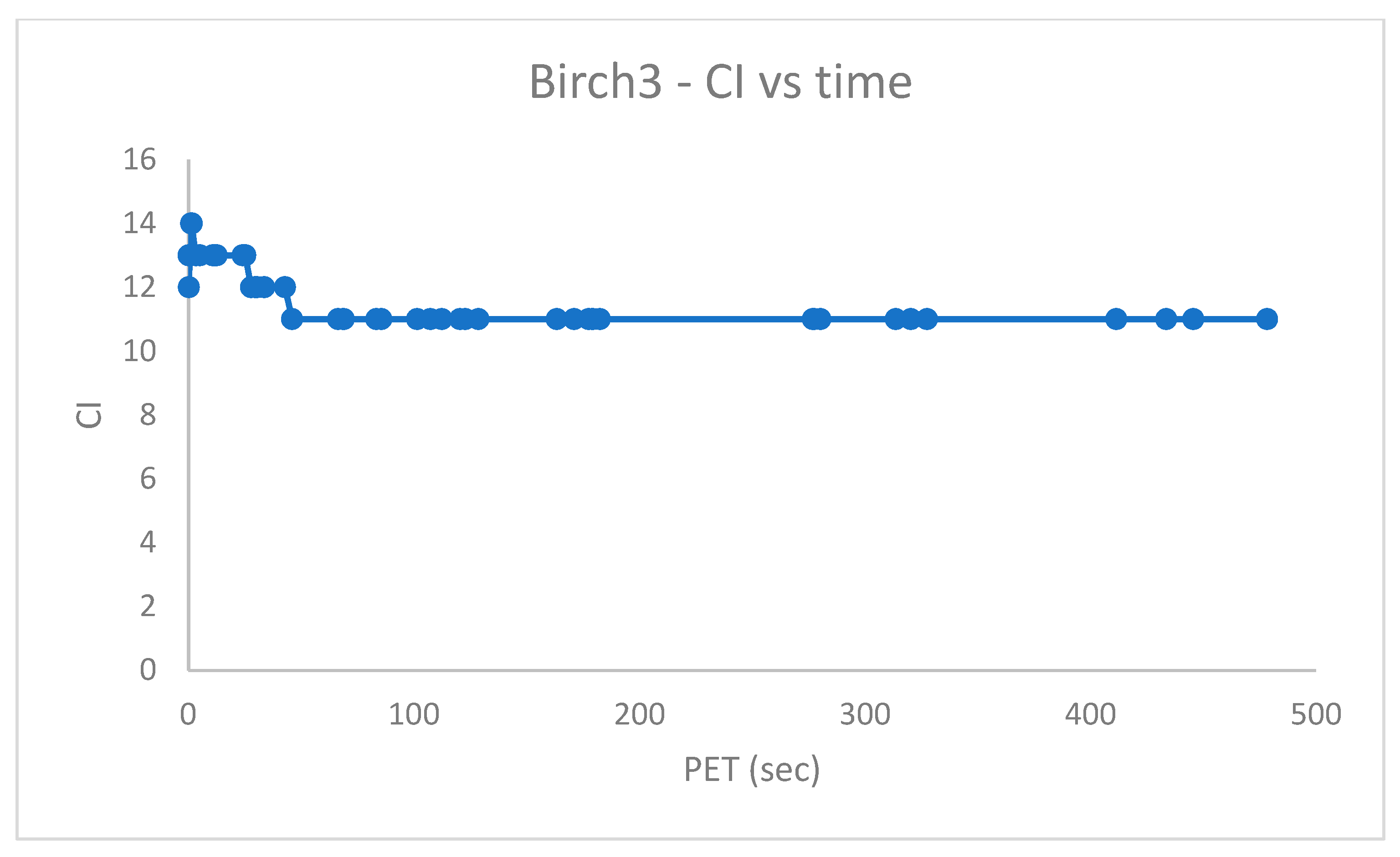
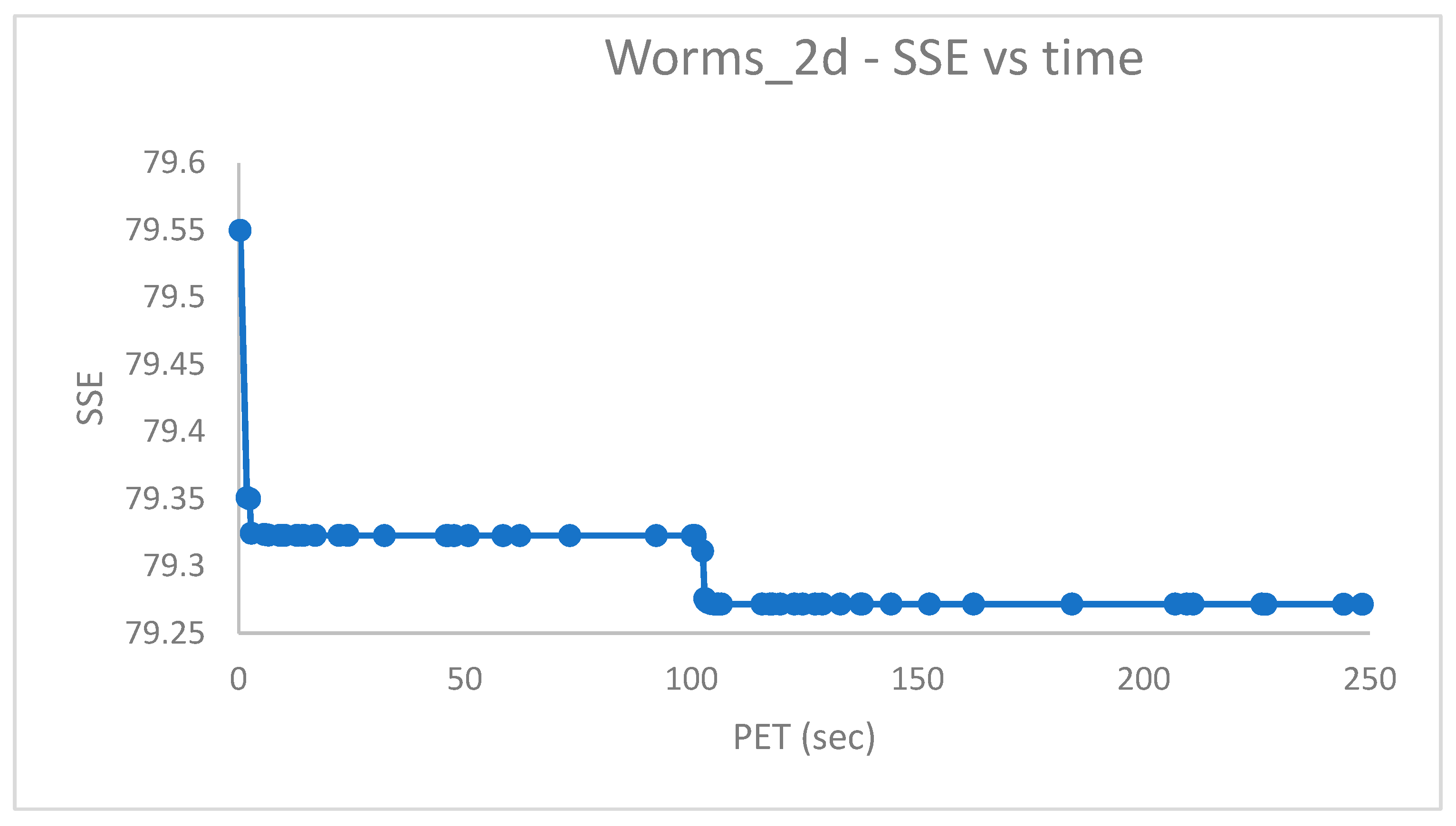
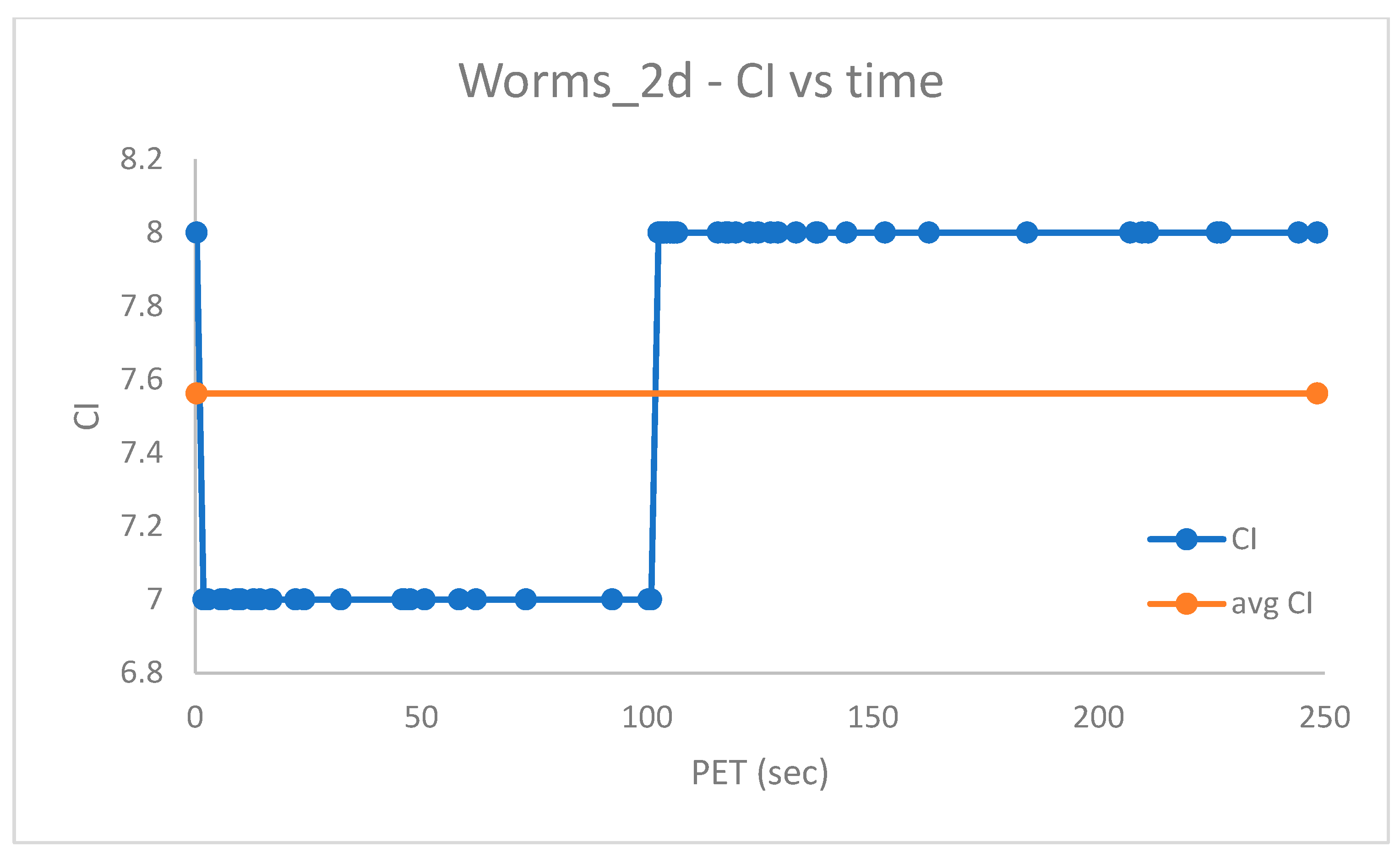
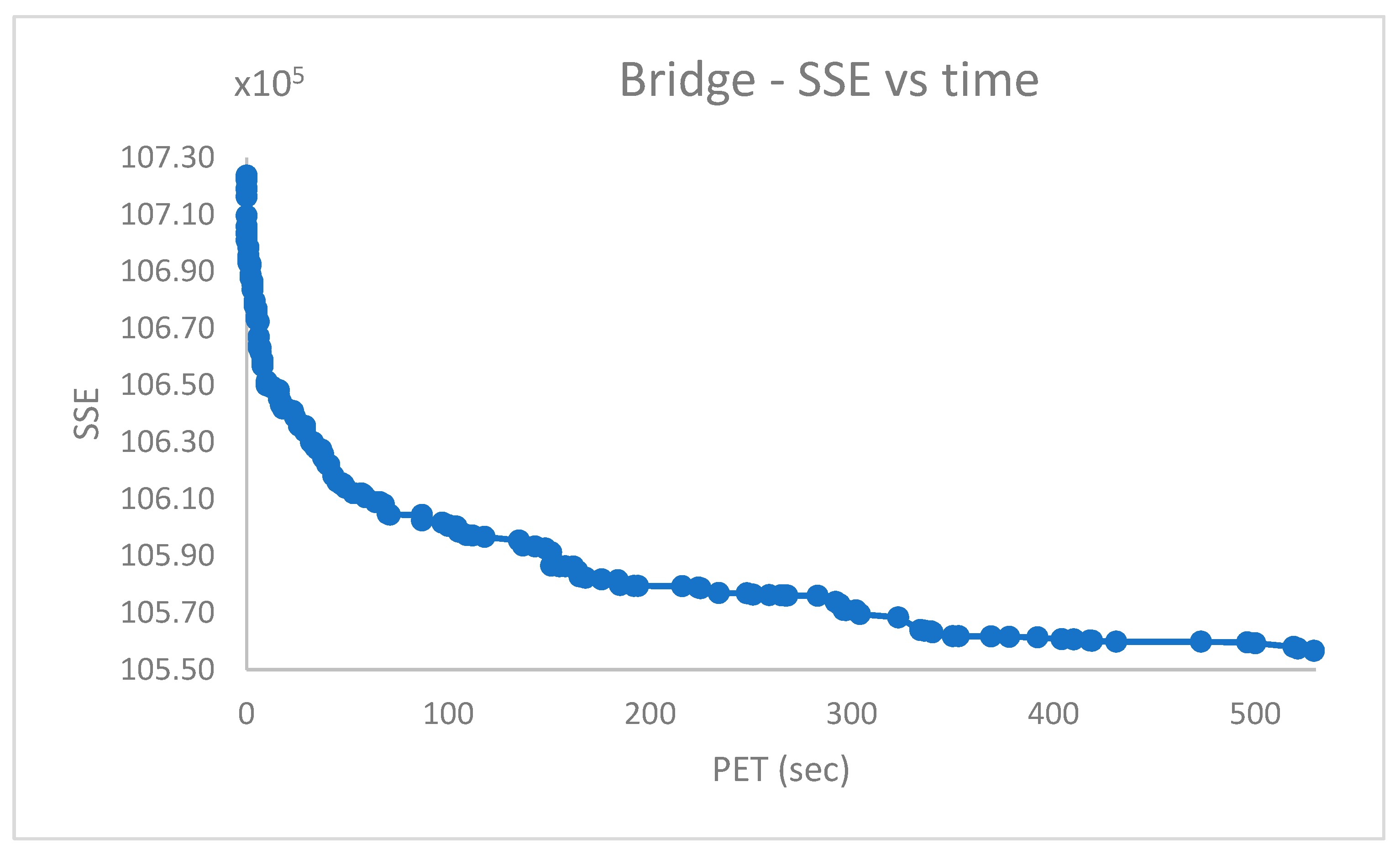
To ensure a proper number of candidate centroids for the datasets which have and clusters, respectively, a population with solutions and swap iterations was preliminarily created with PB-RS, requiring sec for , and a population of solutions and with PB-KM, requiring for .
The PB-RS recombination step lasts after
iterations for
.
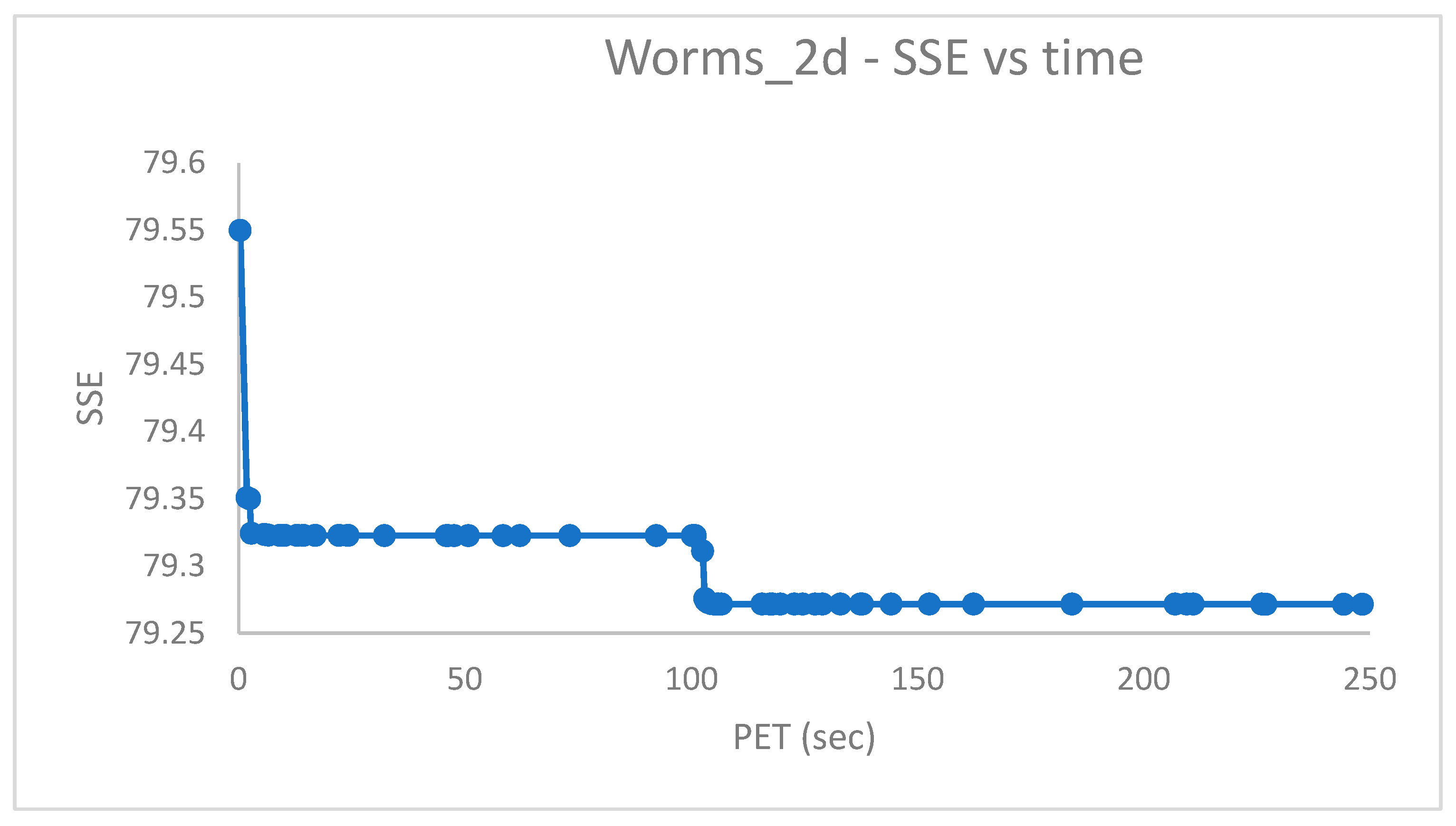
Figure 6 and
Figure 7 show the measured
vs. time and the
vs. time for
, respectively. Since the worm datasets come with partition labels as ground truth, the
is, in reality, a Generalized
[
23] based on the Jaccard distance among the partitions (see also [
9])).
Figure 6 confirms that for a dataset like
, the minimization of the
cost does imply the most accurate solution to be achieved (here assessed according to the Cluster Index
). In fact, for lower values of the
(see
Figure 6), the
increases. The average value
in
Figure 7 complies with a similar result documented in [
26].
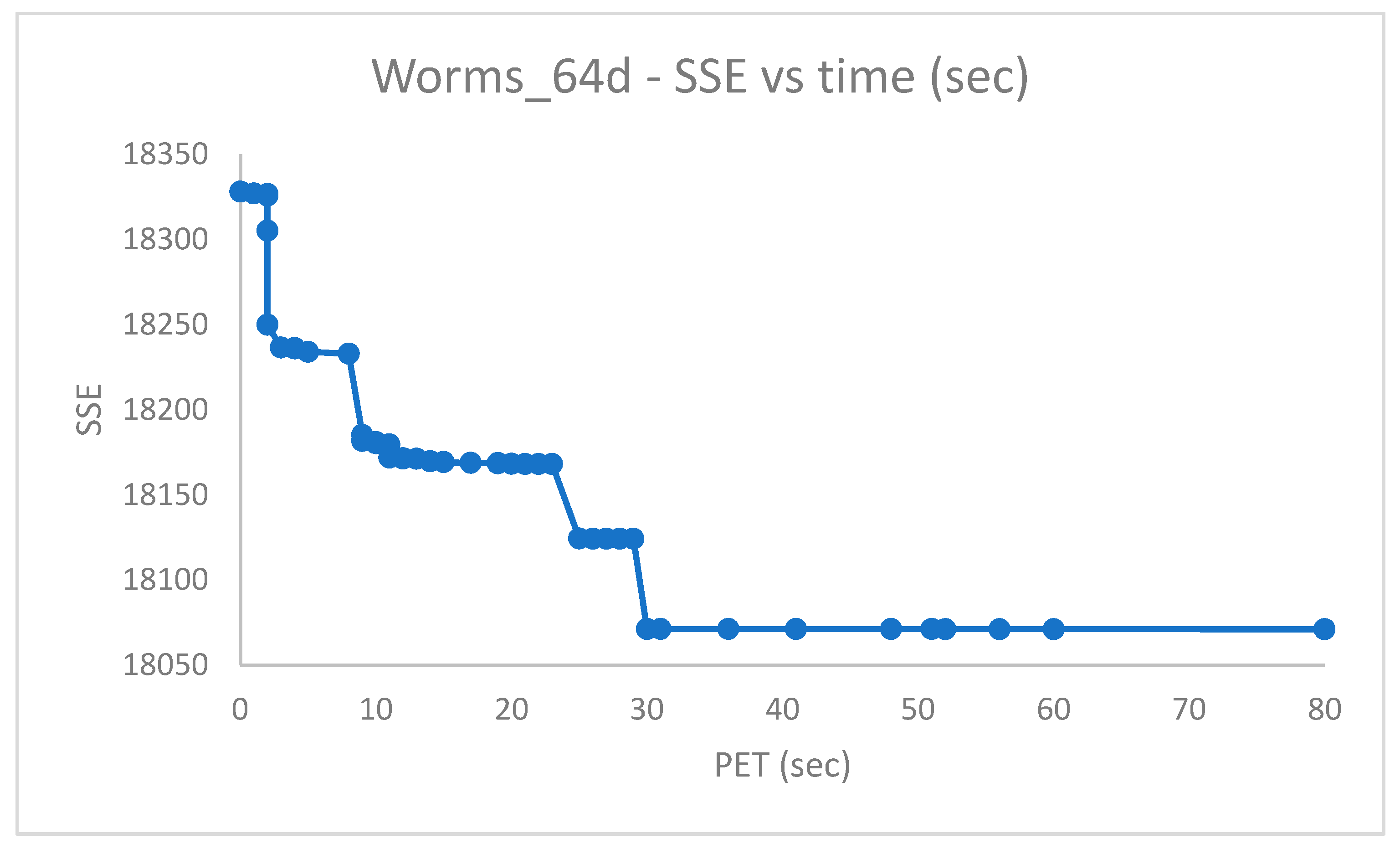
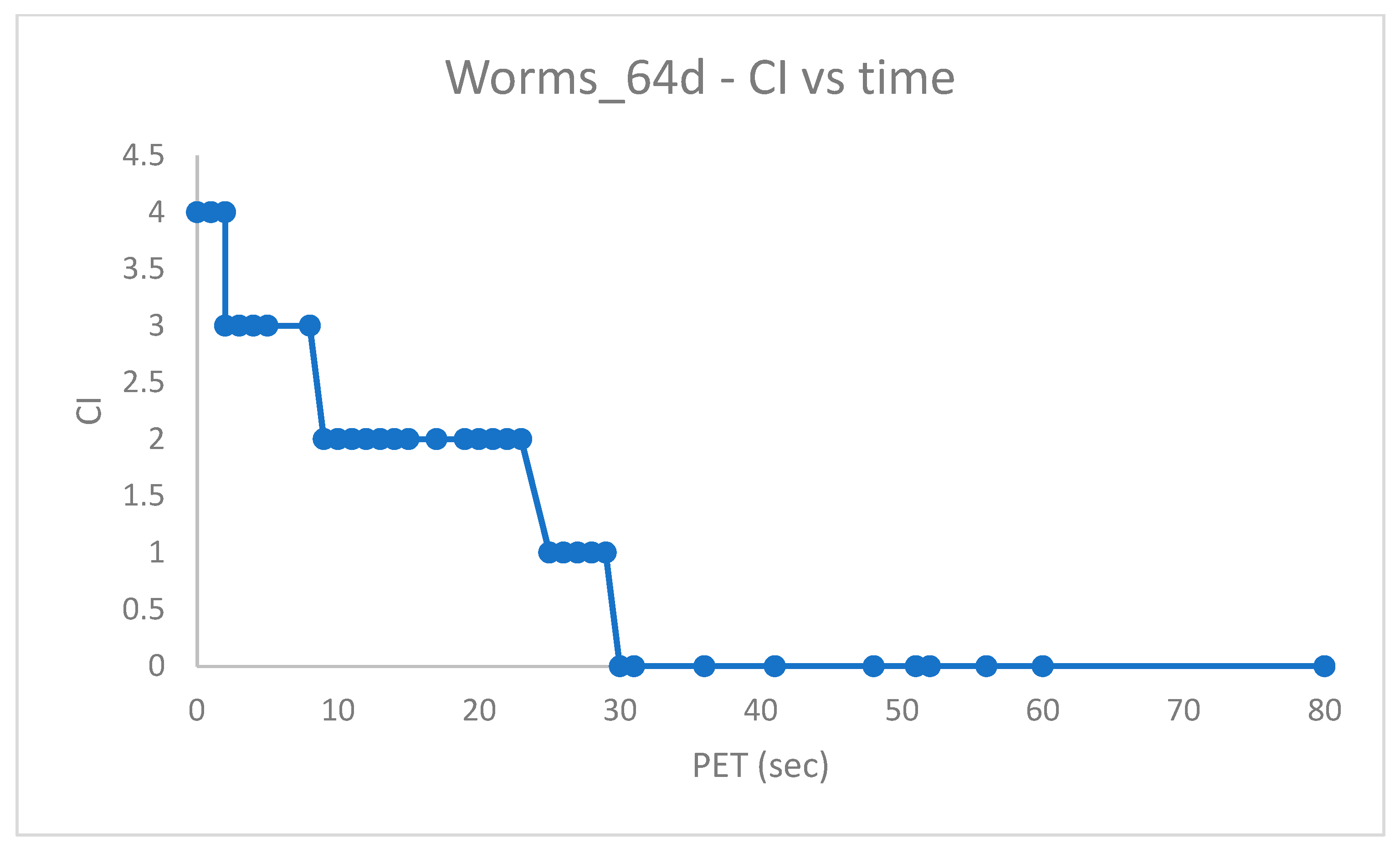
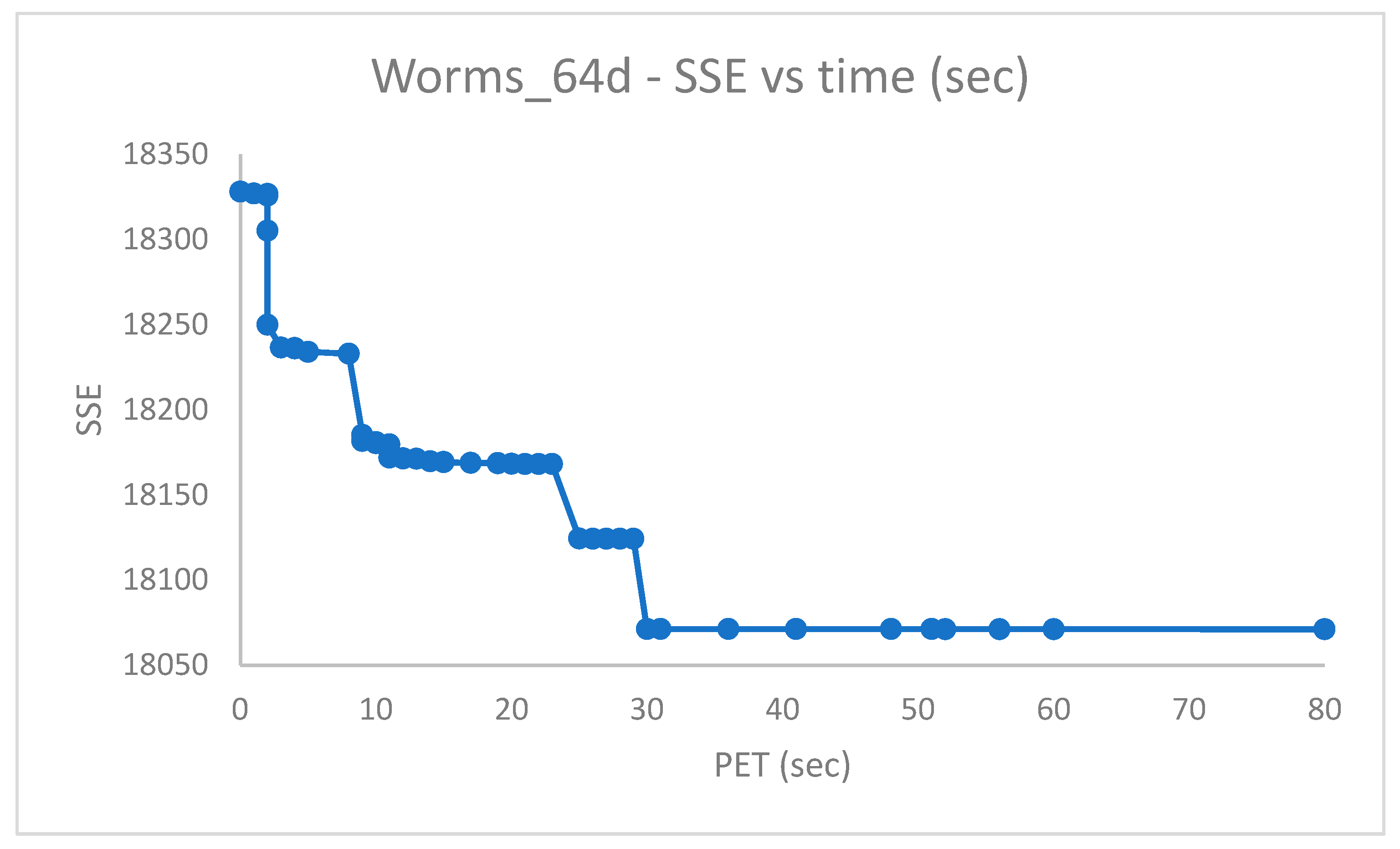
As discussed in [
9], the
, despite the higher dimensionality w.r.t.
, is more amenable to clustering and can be correctly solved via Random Swap. This was confirmed using PB-RS with a recombination step of
swap iterations (fewer iterations could have been used as well).
Figure 8 and
Figure 9 show the
vs. time and the
vs. time for
, respectively. As shown in
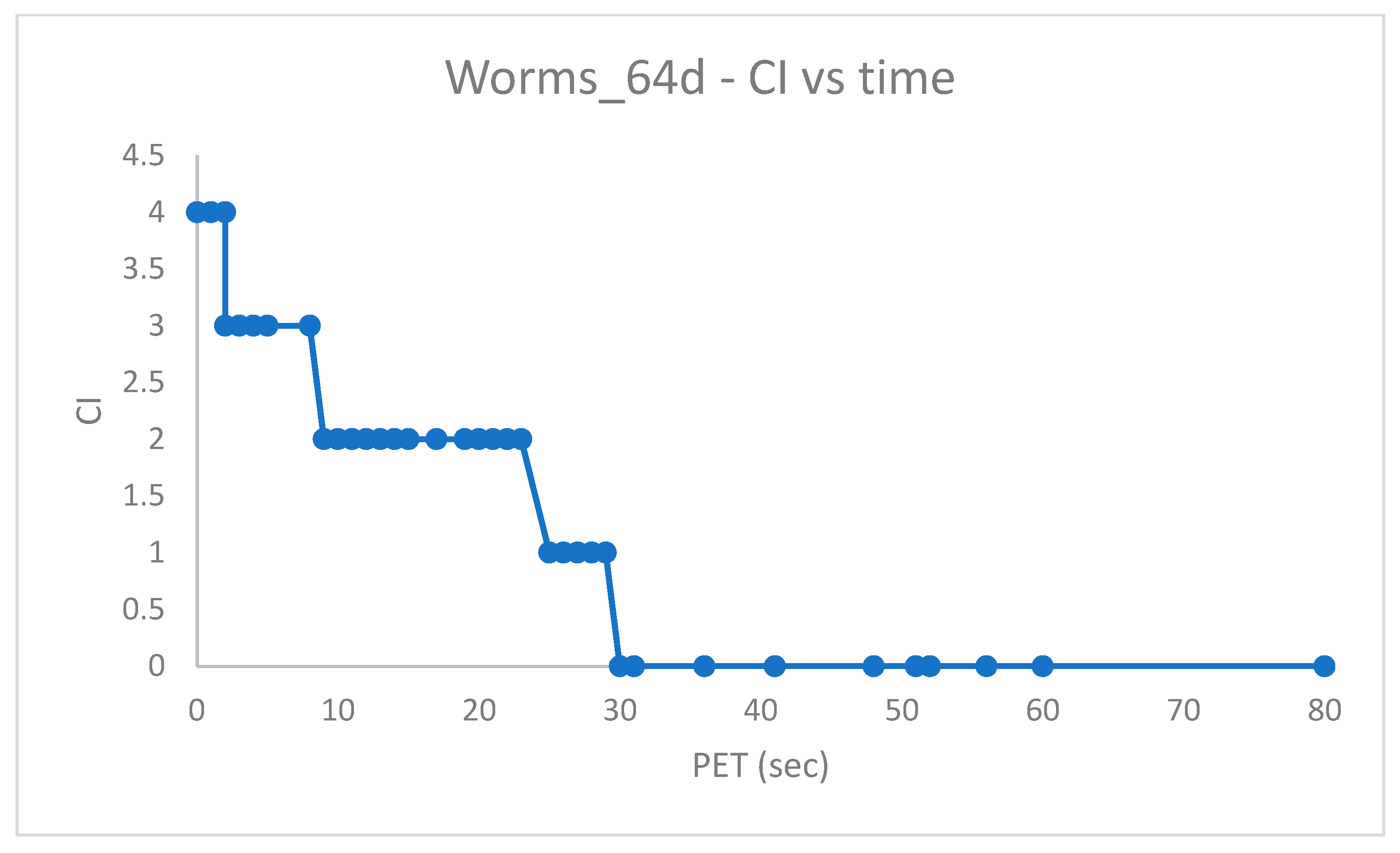
Figure 9, the ultimate value of
is 0, which starts occurring at the minimum
(see
Figure 8), thus witnessing the obtainment of a solution with correctly structured clusters.
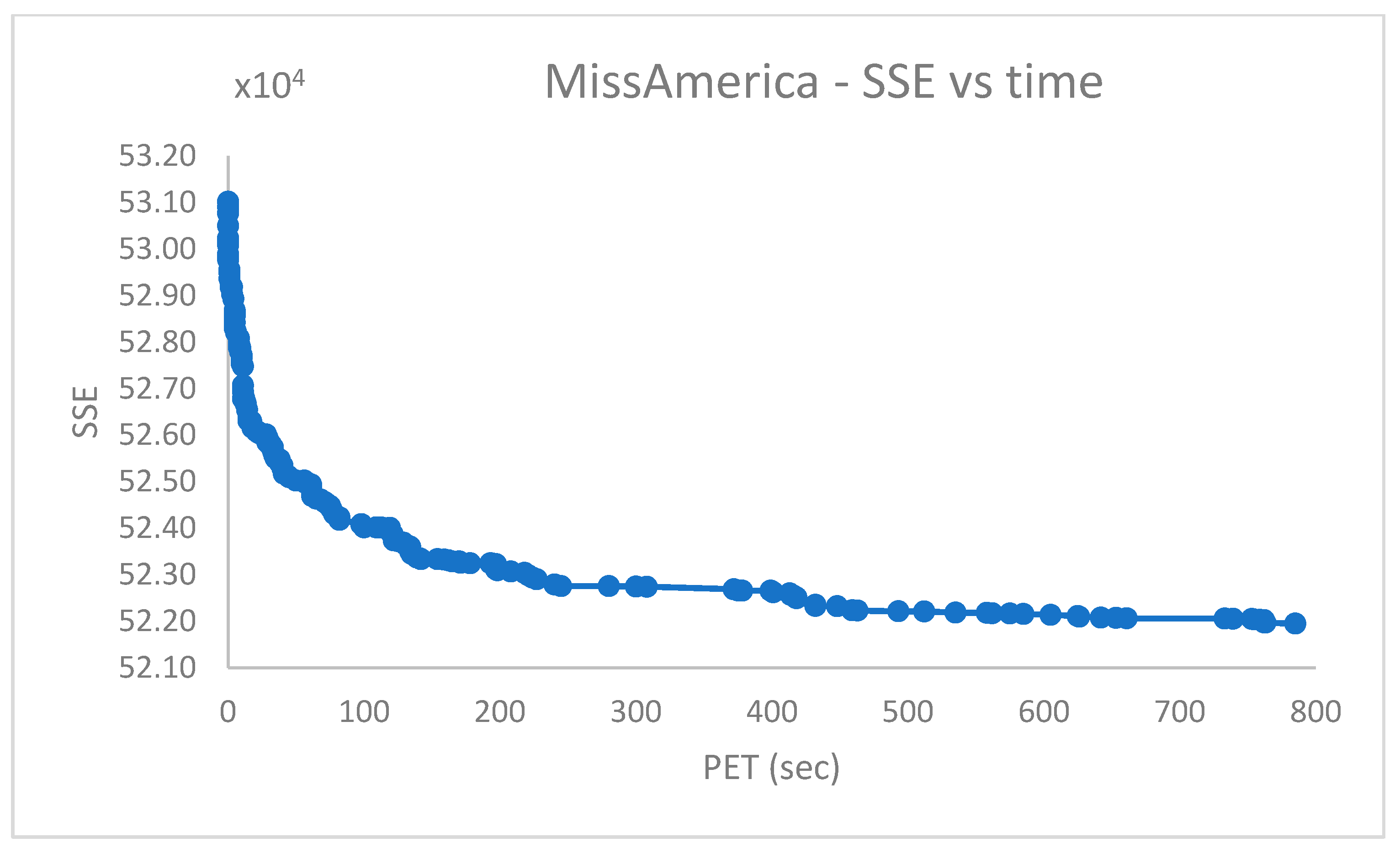
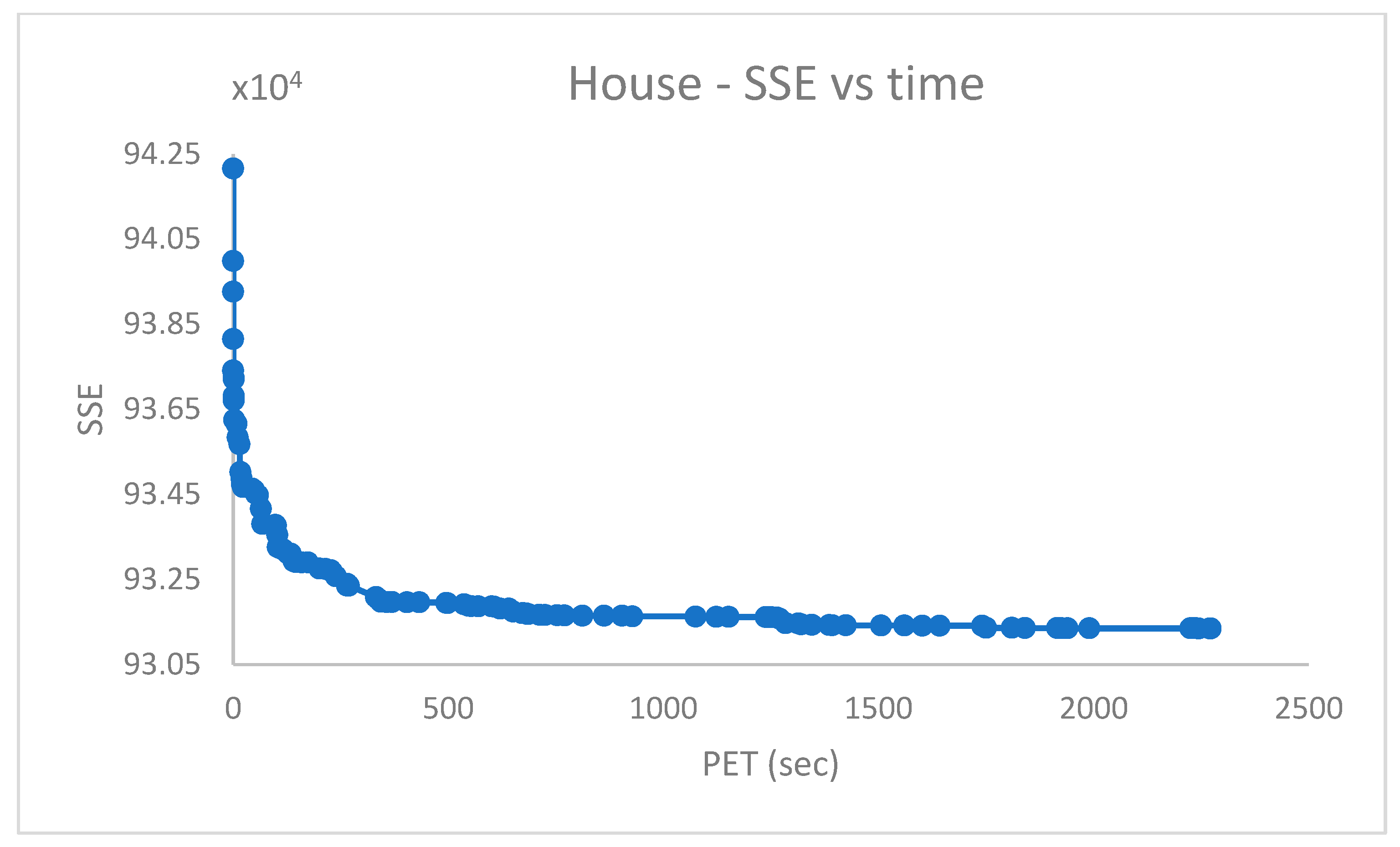
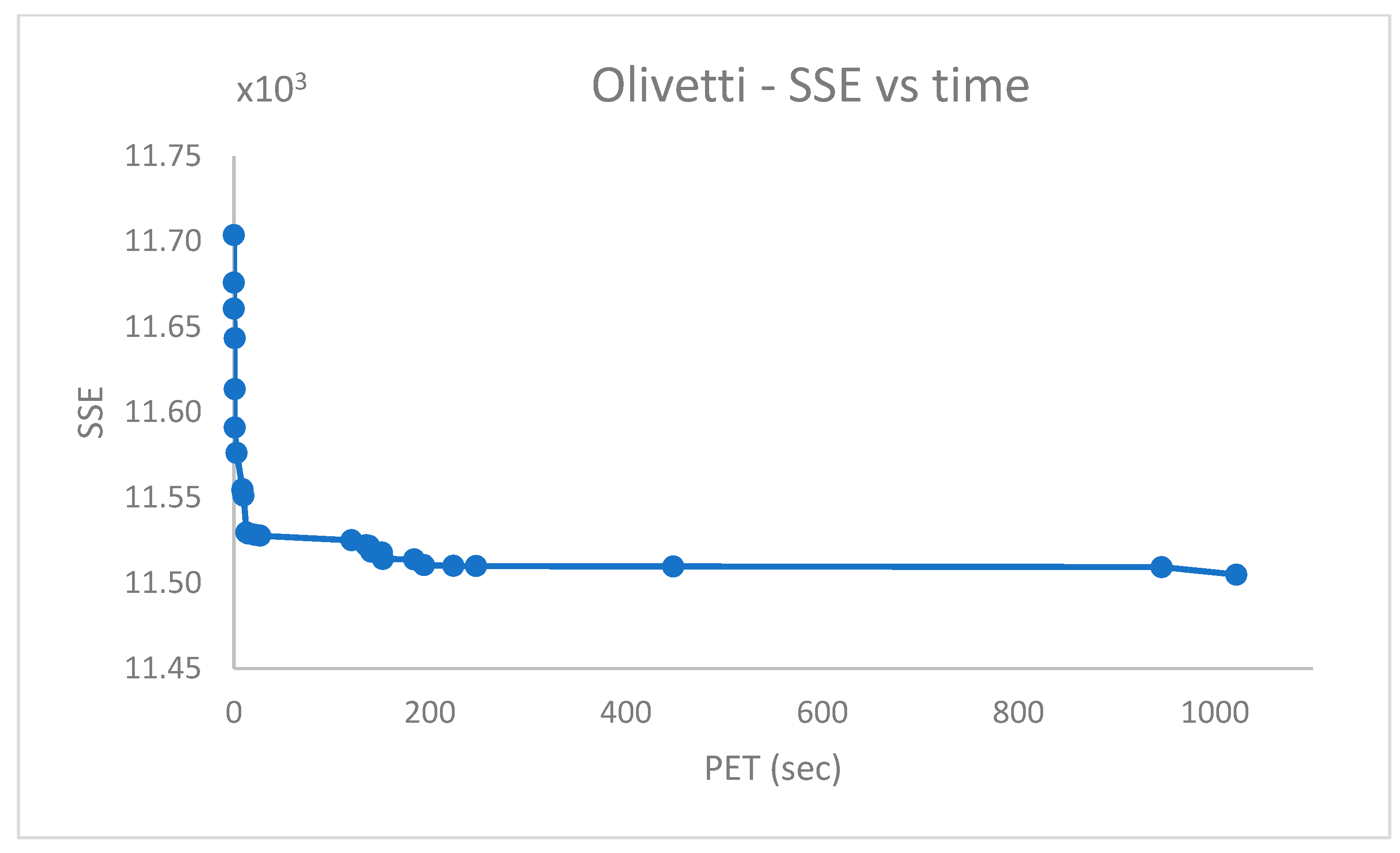
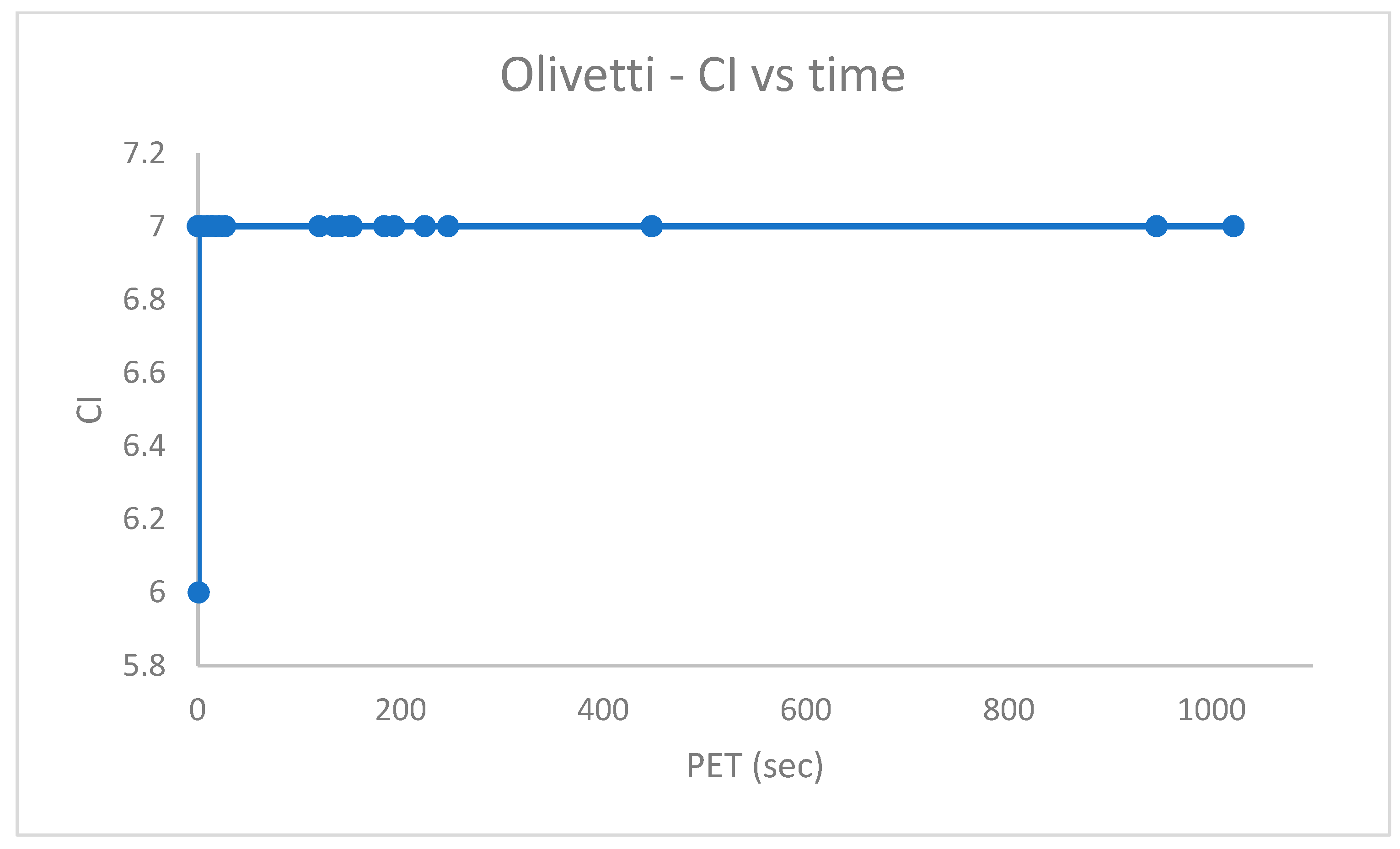
5.5. Fourth Group of Real-World Datasets (Table 5)
The challenging real-world datasets in
Table 5, which have many clusters, were clustered by PB-RS by preparing a population of
solutions each emerging after
iterations of Random Swap. PB-RS was chosen because it provided better experimental results (in terms of accuracy and time efficiency) w.r.t. PB-KM.
The dataset entries were used without scaling, except for the . In the , instead, the first dimension of the data entries is preliminarily scaled down by a factor of . The recombination step lasts after iterations. However, it can be terminated when the current cost differs from the previous one of a quantity less than a given numerical threshold (e.g., ).
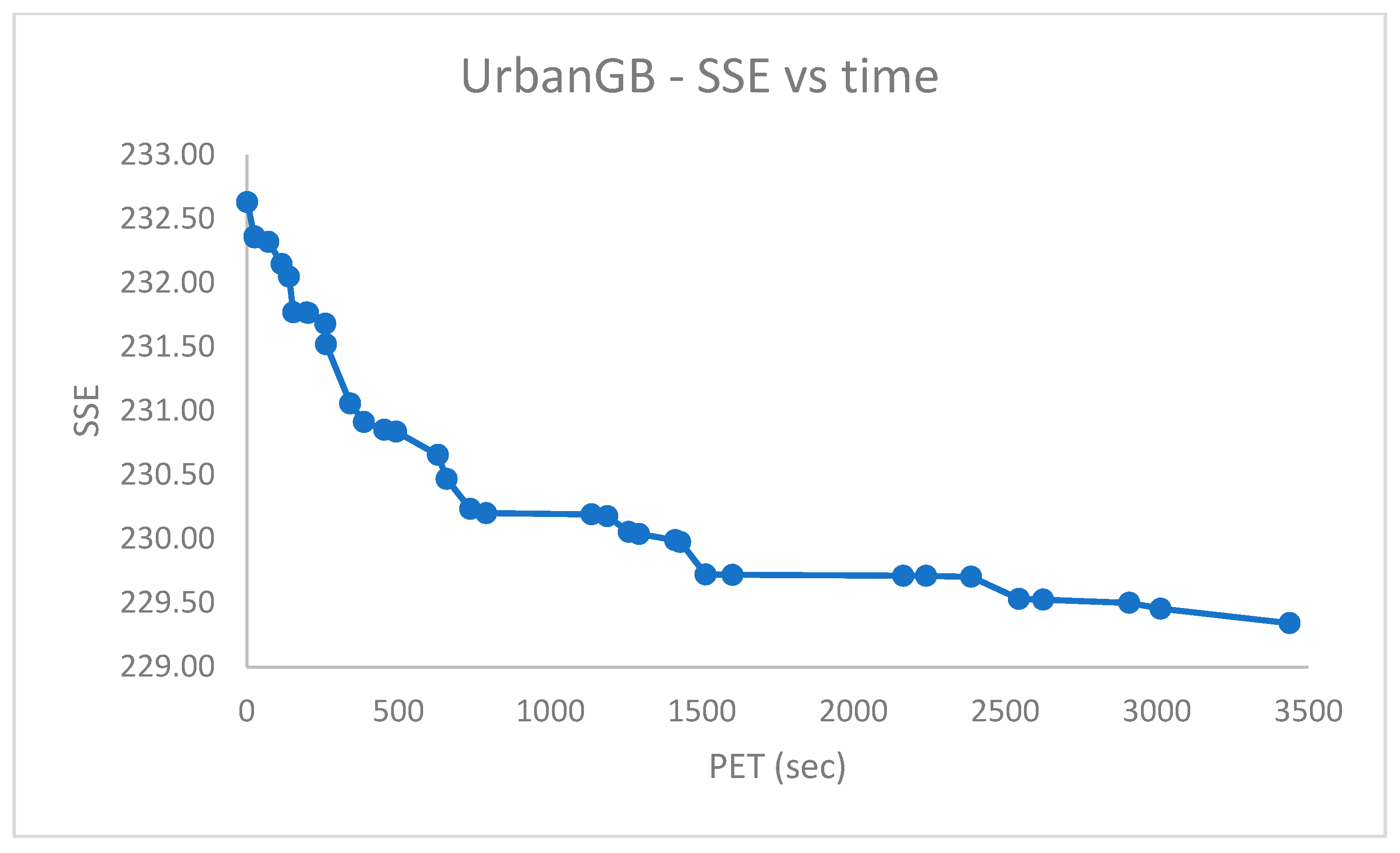
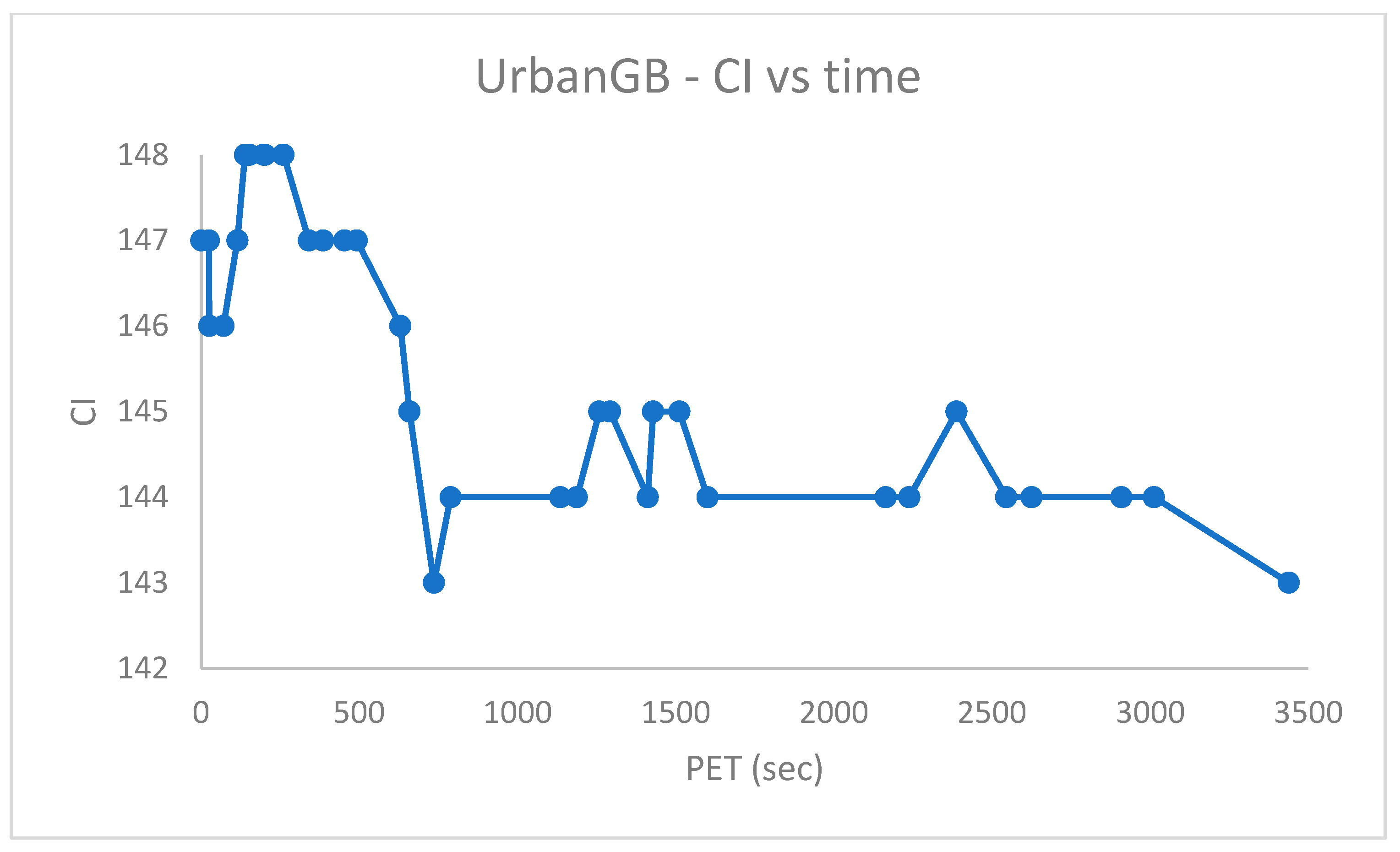
Figure 10,
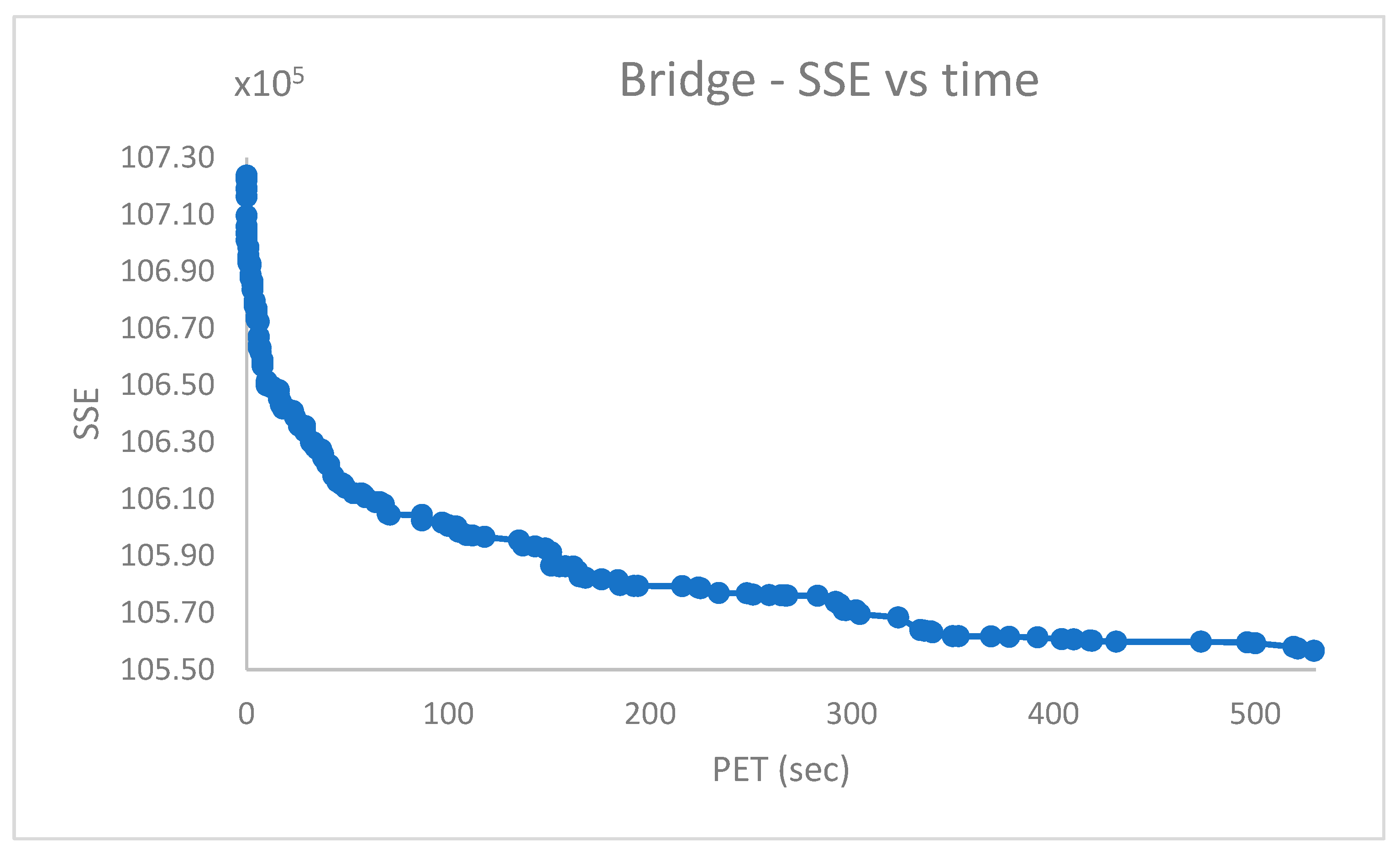
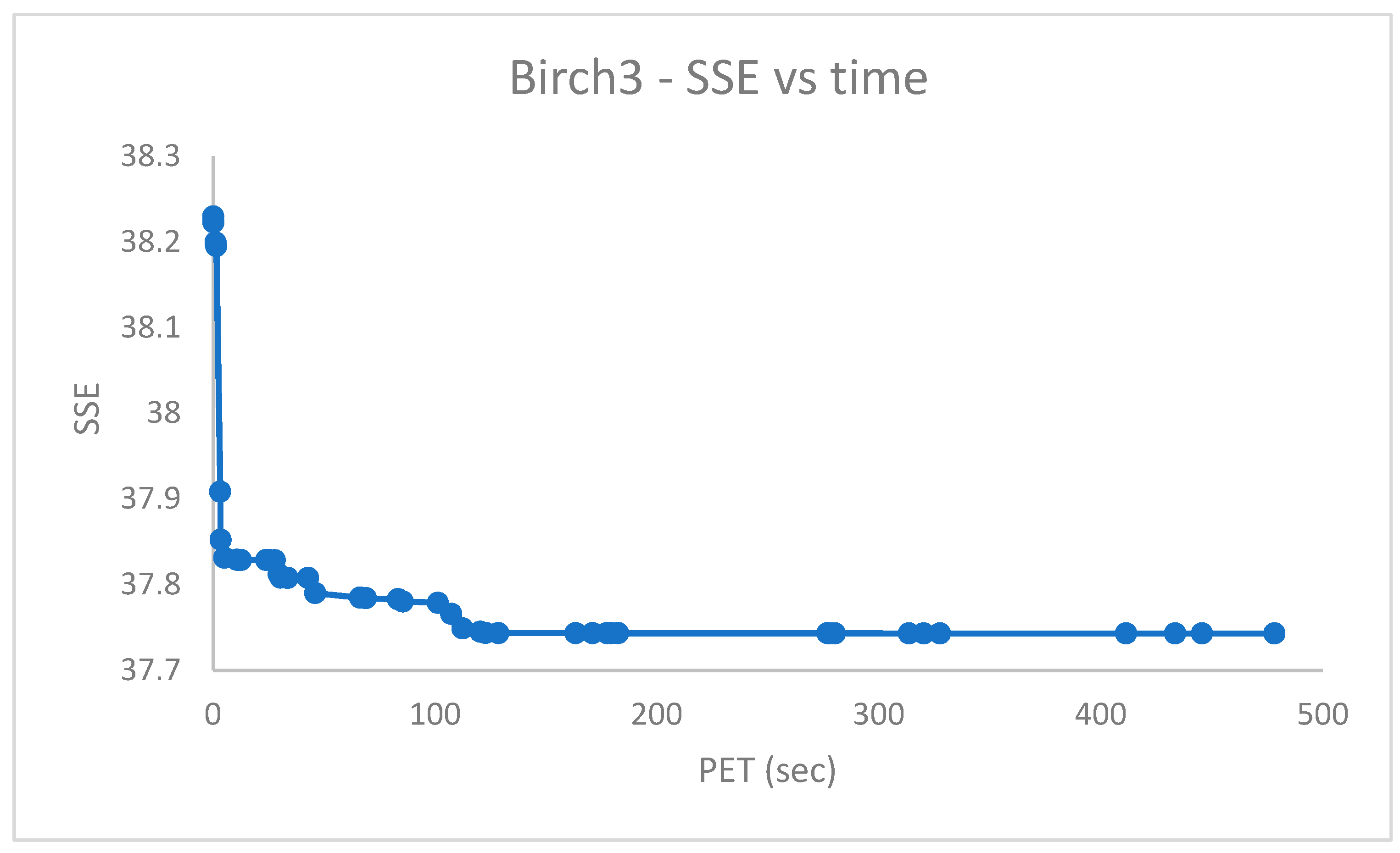
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16 report the performance curves (the
cost vs. time and, when possible, the
vs. time) observed for the
,
,
,
and
[
28] datasets. Since
and
are provided with ground truth information (both centroid and partition labels),
Figure 14 and
Figure 16 portray the observed centroid index
vs. time, respectively, for
and
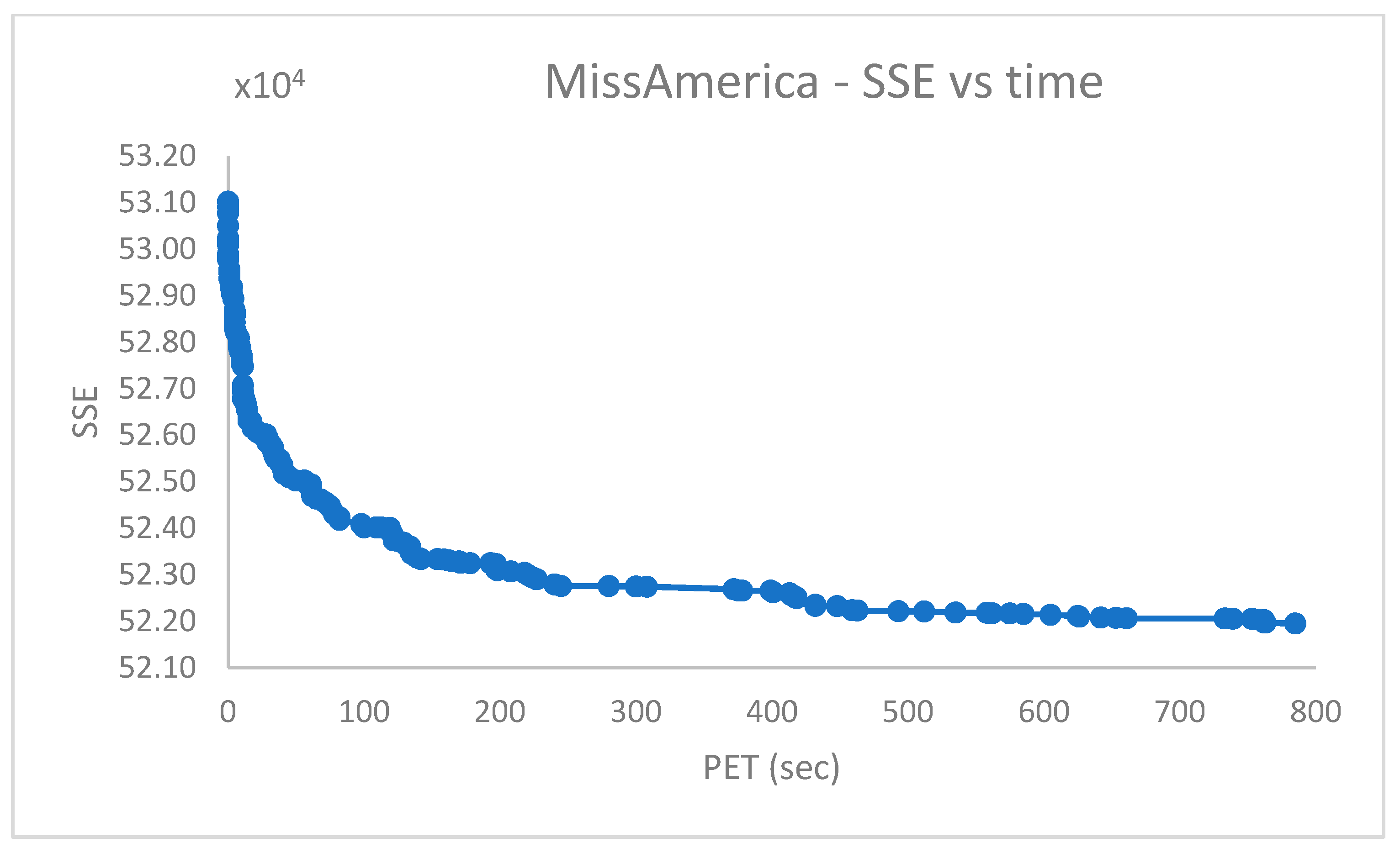
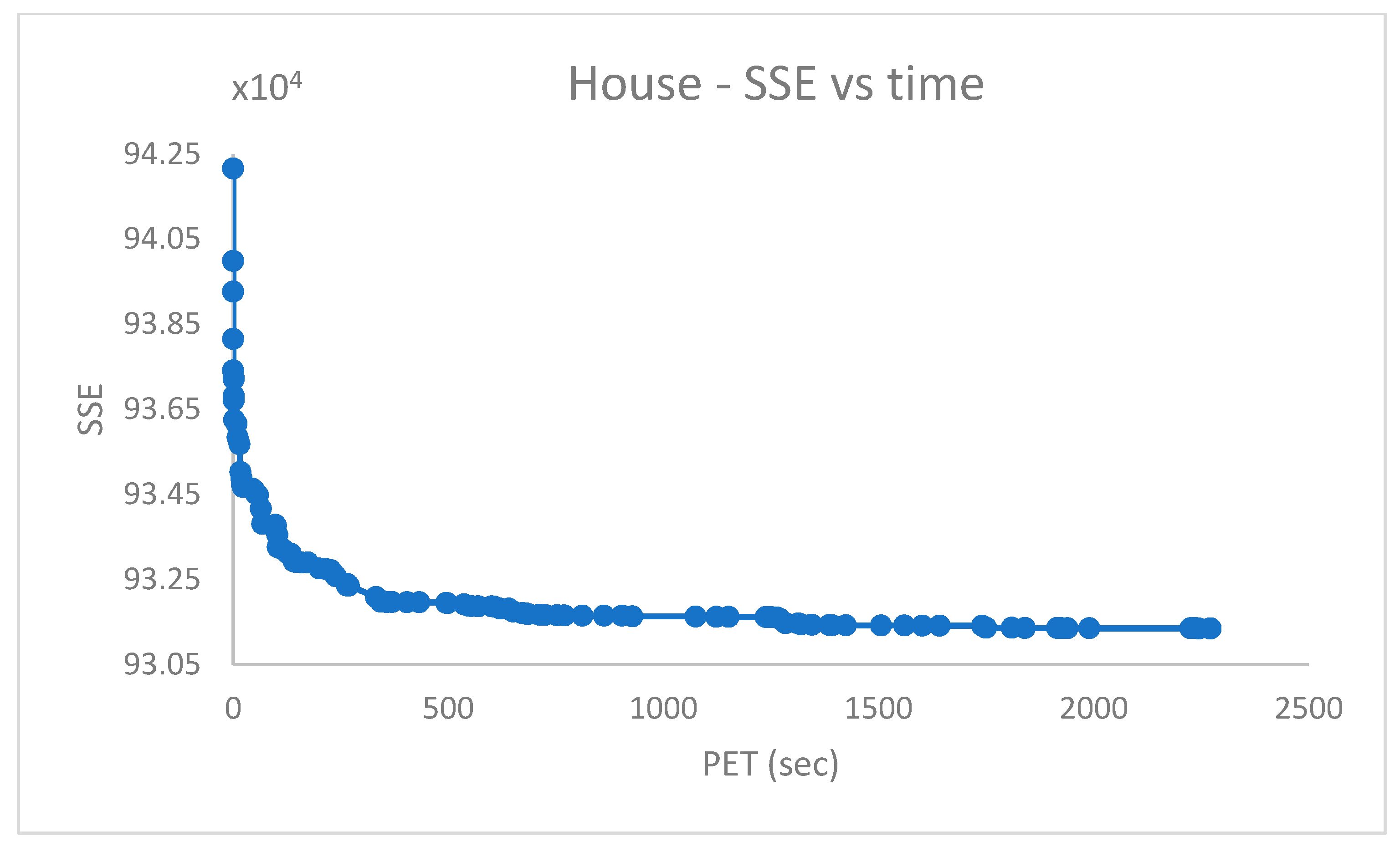
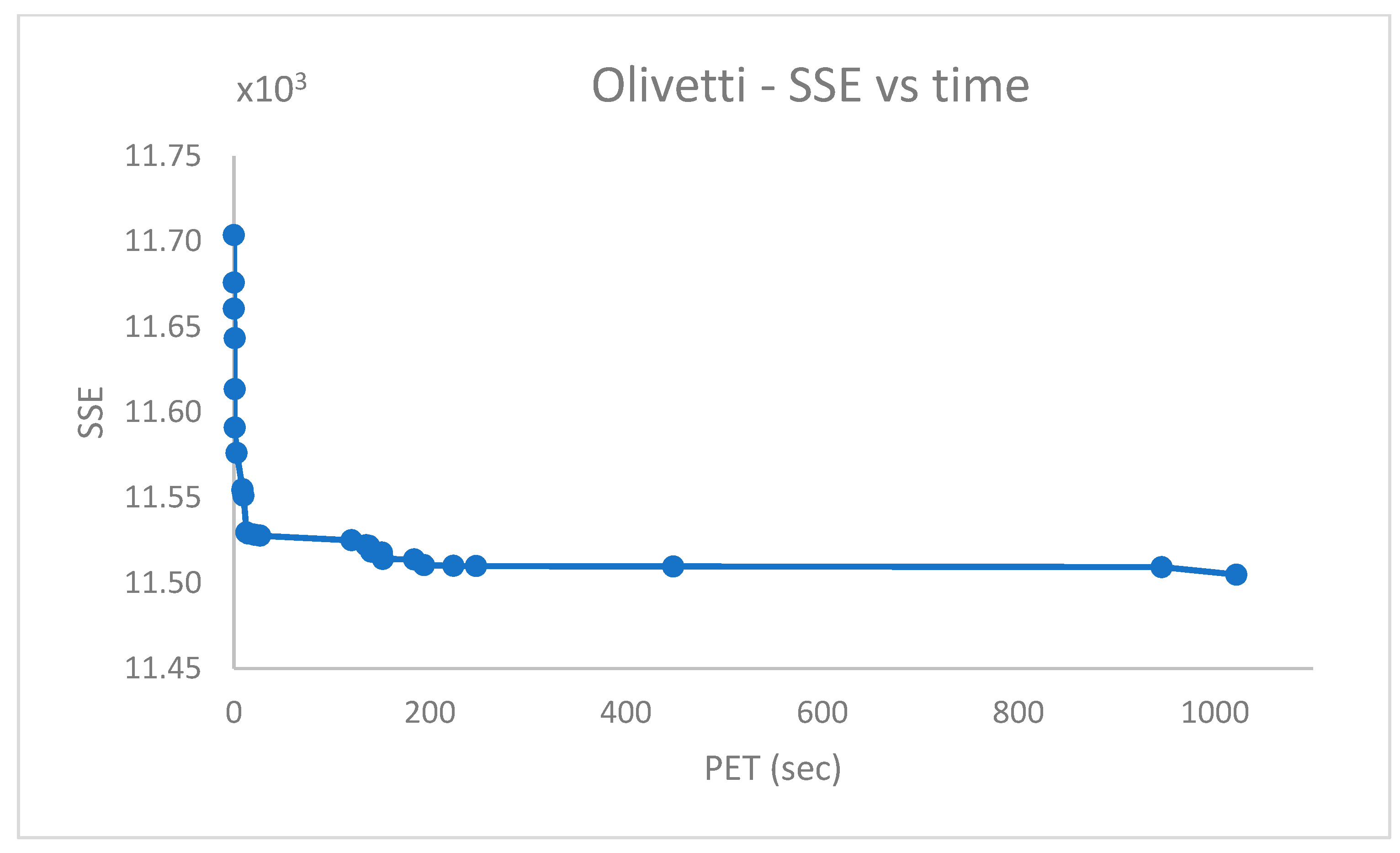
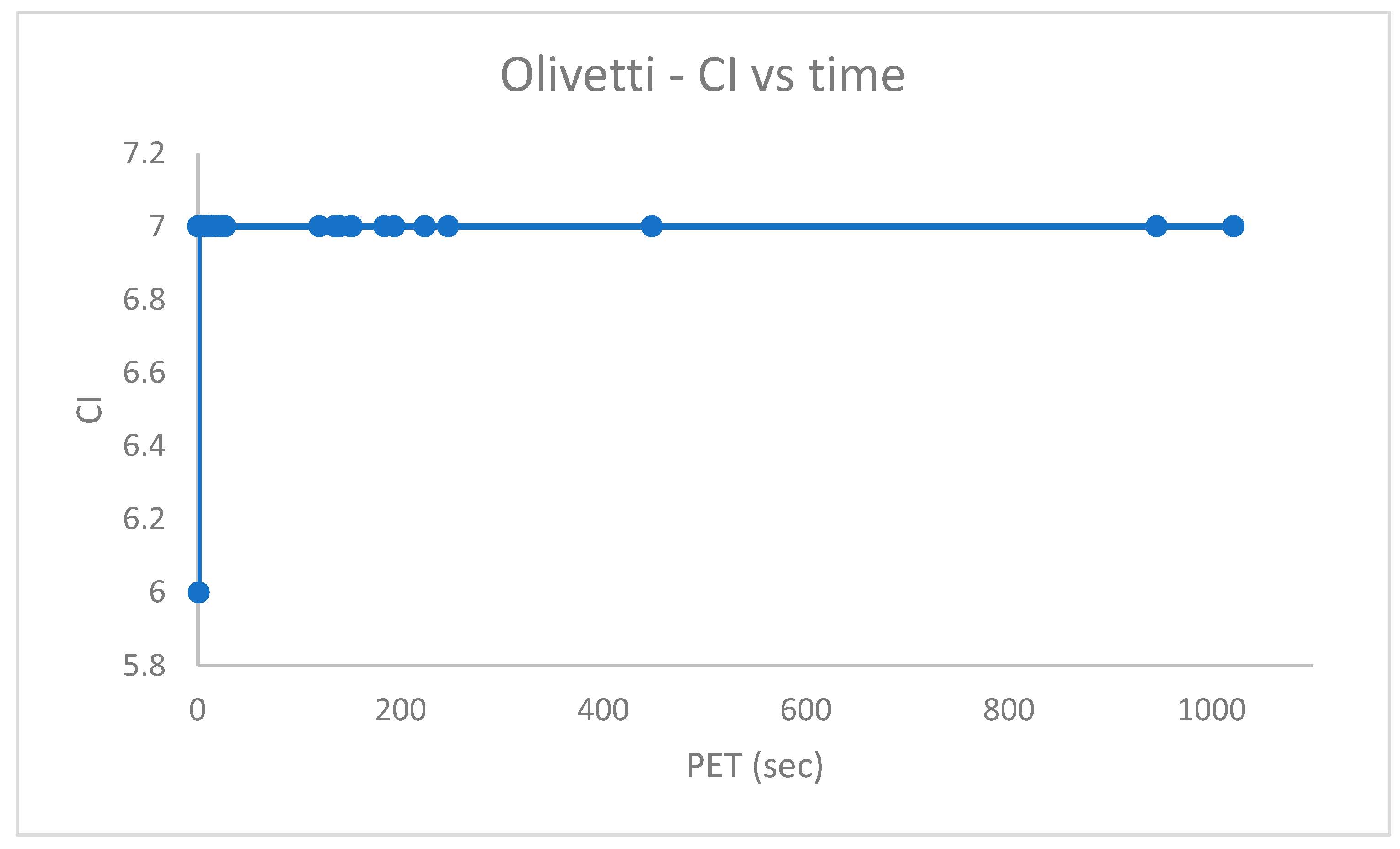
.
From
Figure 14, it emerges that the clustering algorithm could not recognize
faces out of
. Similarly, the results in
Figure 16 indicate that, in the best case,
of
cases were not correctly handled in the
dataset.
The shown experimental results agree with those reported in [
11,
12].
5.6. Time Efficiency of PB-KM
The computational efficiency of the developed tools was assessed, in a case, using the PB-KM recombination step on the
dataset (see
Table 4), via the GKM++ seeding method, with
and
repetitions, separately in parallel (the parameter
and sequential
modes. The total elapsed time
(in msec) for the serial (
) and parallel (
) case needed by PB-KM recombination to complete were measured, together with the total number of executed K-Means iterations (respectively
), as reported in
Table 10.
From the data in
Table 10, the average elapsed time per iteration was computed as
and
, and the speedup was estimated as
6. Conclusions
This paper proposes two evolutionary-based clustering algorithms: Population-Based K-Means (PB-KM) and Population-Based Random Swap (PB-RS). The two algorithms were inspired by the Recombinator-K-Means [
11,
12] and the Genetic Algorithm of P. Franti [
10], plus the use of the careful seeding ensured by the Greedy K-Means++ (GKM++) method [
11,
14].
However, PB-KM and PB-RS are based on a simpler, yet effective, approach which rests on two steps. In the first step, a population of
candidate “best” centroid solutions is created. The second step recombines the population’s centroids toward obtaining a careful solution. This is achieved in PB-KM through a number of independent repetitions of Lloyd’s K-Means [
2,
3,
4], and in PB-RS by a certain number of iterations of Random Swap [
8,
9]. In both cases the starting point is a centroid configuration achieved by applying GKM++ to the population. Refinement of the initial solution is then controlled by partitioning the points of the dataset and moving toward minimizing the
Sum of Squared Errors (
) cost.
A key factor of PB-KM and PB-RS concerns their implementation in Java, which is based on parallel streams [
9,
15,
16], which enables the exploitation of the parallel computing potential of modern multi/many-core machines.
The paper documents the reliable and efficient clustering capabilities of PB-KM and PB-RS by applying them to a collection of challenging benchmark and real-world datasets.
Ongoing and future work aims to address the following points.
First, it aims to experiment with the two developed algorithms for clustering sets [
20,
29] and more in general categorical and text-based datasets.
Second, it aims to port the implementations on top of the efficient Theatre actor system [
30], which allows for better control and exploitation of the parallel resources of a multi/many-core machine.
Third, the aim is to adapt PB-KM by replacing Lloyd’s K-Means with the Hartigan and Wong variation of K-Means [
31,
32]. The idea is to experiment with an incremental technique which constrains the switching of a data point from its source cluster to a destination cluster also on the basis of its Silhouette coefficient [
33]. The goal is to favor the definition of well-separated clusters.
The fourth aim is to compare the two developed algorithms to affinity propagation clustering [
34] algorithms, e.g., for studying the seismic consequences caused by earthquakes [
35]. In addition, the influence of the method about point distributions in the hypersphere [
36] on our described clustering work deserves particular attention.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}