
Improving Clustering Accuracy of K-Means and Random Swap by an Evolutionary Technique Based on Careful Seeding


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
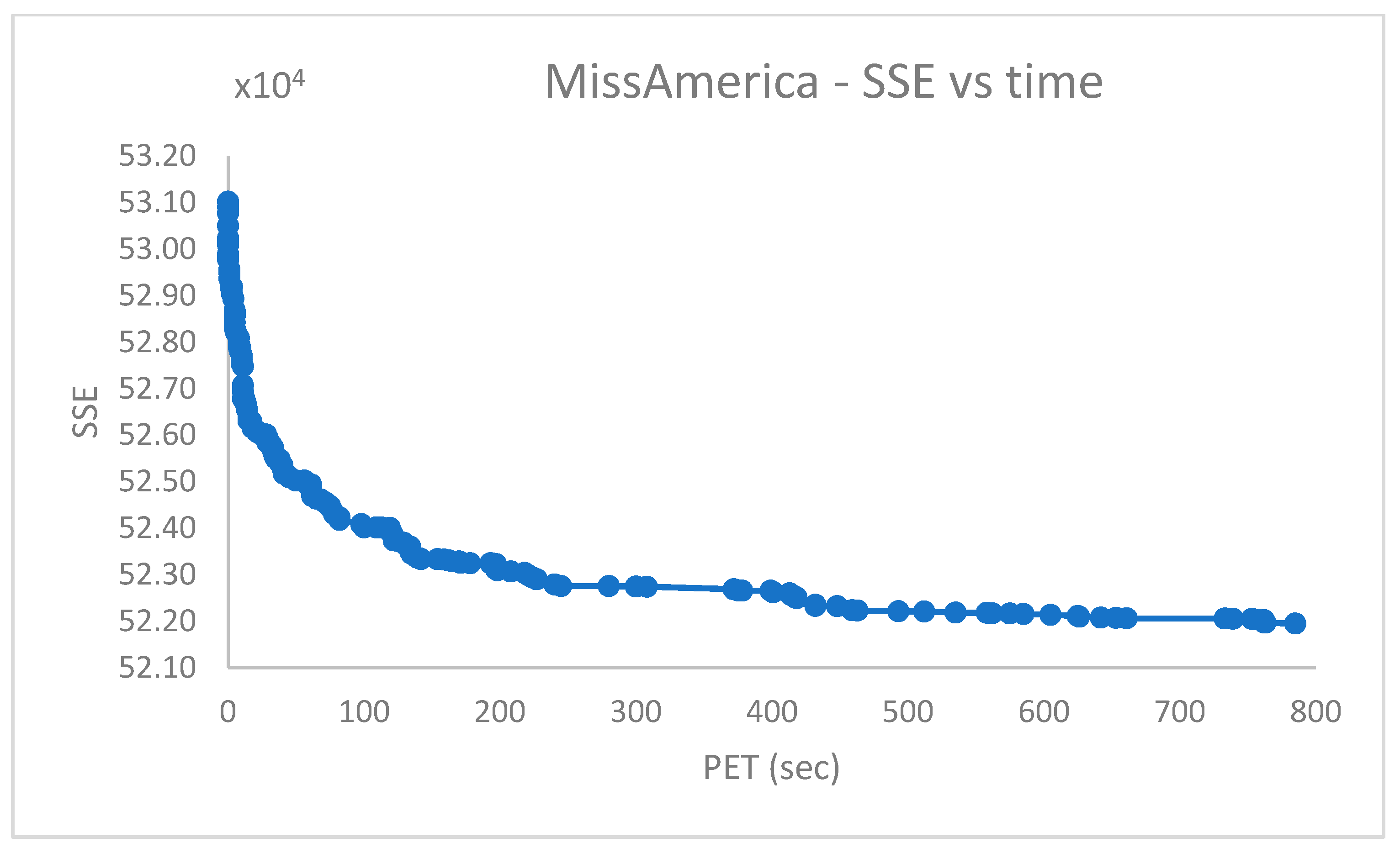
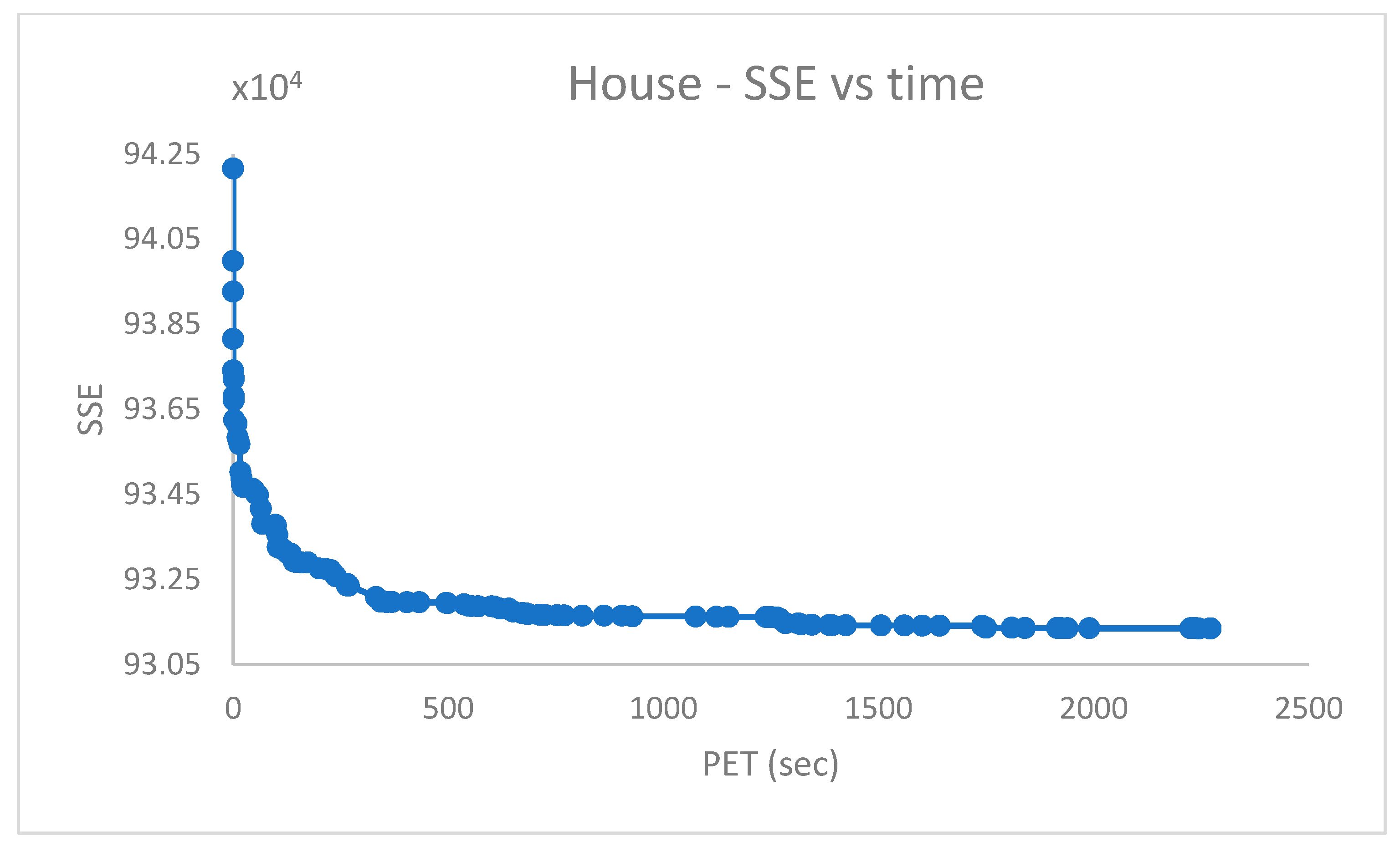
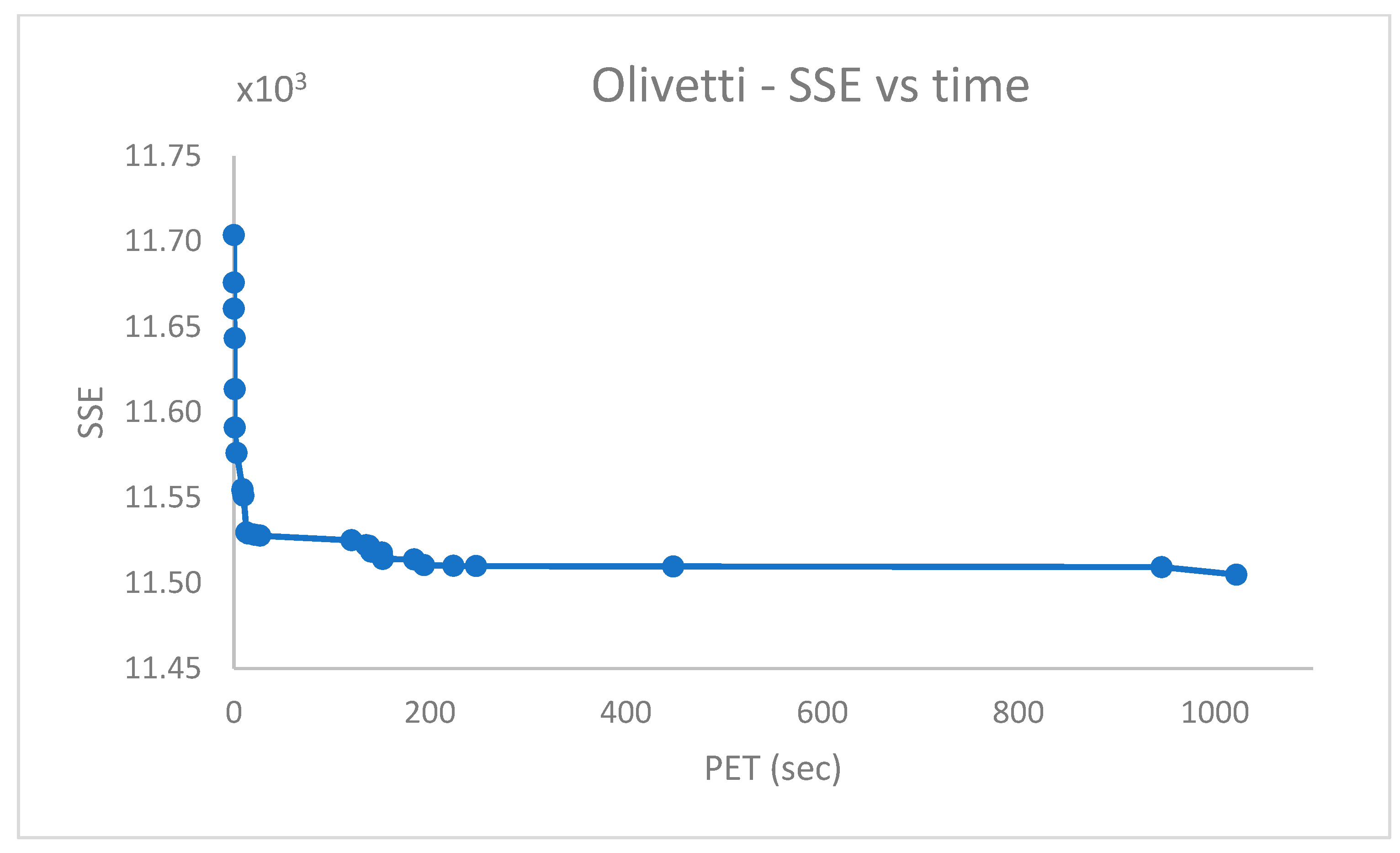
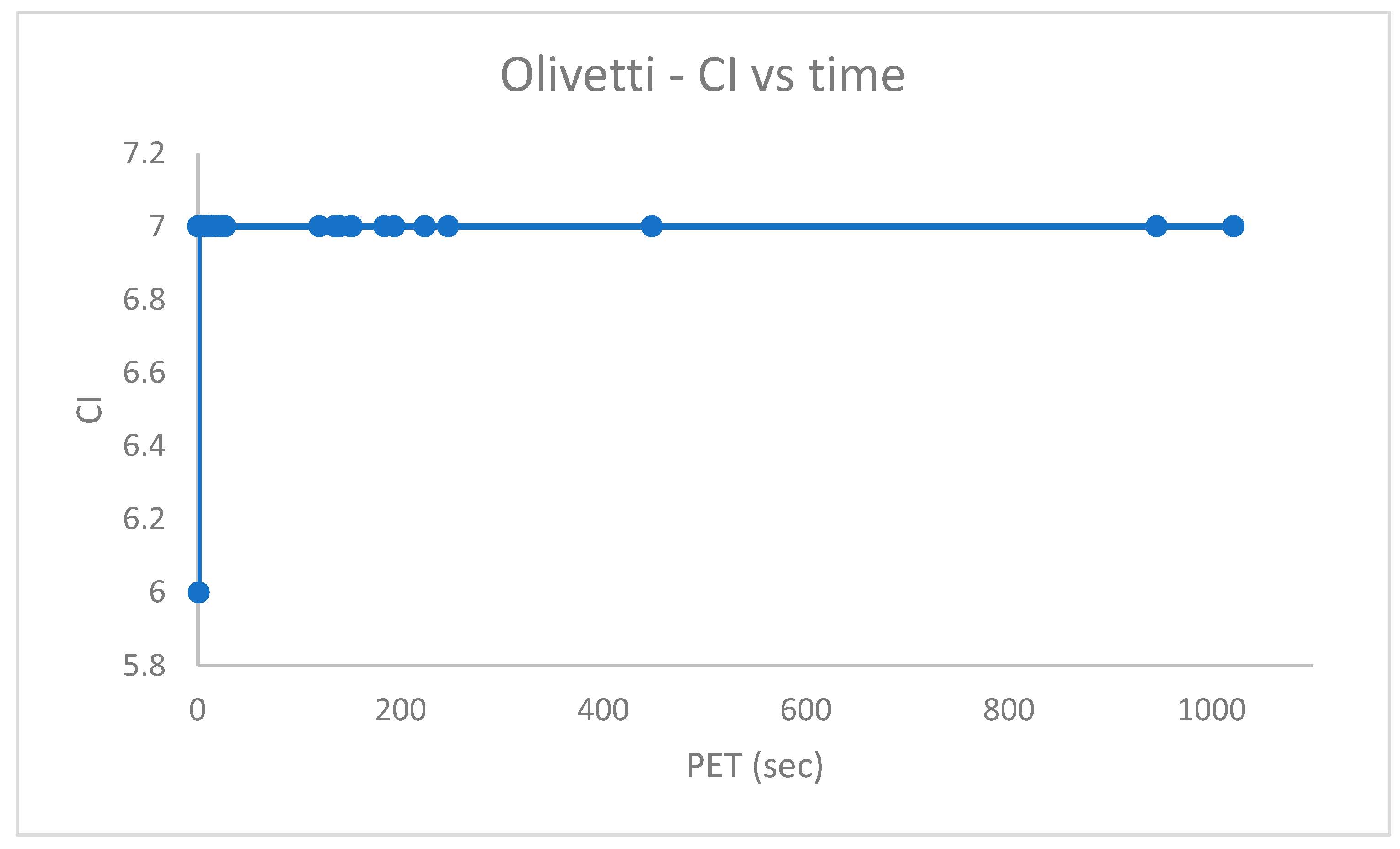
Abstract
Share and Cite
Nigro, L.; Cicirelli, F. Improving Clustering Accuracy of K-Means and Random Swap by an Evolutionary Technique Based on Careful Seeding. Algorithms 2023, 16, 572. https://doi.org/10.3390/a16120572
Nigro L, Cicirelli F. Improving Clustering Accuracy of K-Means and Random Swap by an Evolutionary Technique Based on Careful Seeding. Algorithms. 2023; 16(12):572. https://doi.org/10.3390/a16120572
Chicago/Turabian StyleNigro, Libero, and Franco Cicirelli. 2023. "Improving Clustering Accuracy of K-Means and Random Swap by an Evolutionary Technique Based on Careful Seeding" Algorithms 16, no. 12: 572. https://doi.org/10.3390/a16120572
APA StyleNigro, L., & Cicirelli, F. (2023). Improving Clustering Accuracy of K-Means and Random Swap by an Evolutionary Technique Based on Careful Seeding. Algorithms, 16(12), 572. https://doi.org/10.3390/a16120572