



Deep Error-Correcting Output Codes




Abstract
:1. Introduction
- We integrate an online learning method into the ECOC coding, which improves the efficiency of ECOC, especially for large-scale applications.
- We employ ECOC as building blocks of deep networks, which sufficiently utilizes the available label information of data and improves the effectiveness and efficiency of previous deep learning algorithms.
- We propose the DeepECOCs model, which combines the ideas of ensemble learning, online learning and deep learning.
2. Related Work
3. Deep Error-Correcting Output Codes (DeepECOCs)
3.1. The ECOC Framework
3.2. Incremental Support Vector Machines (Incremental SVMs)
3.2.1. KKT Conditions
3.2.2. Incremental Learning Procedure
- (1)
- Initialize to 0, then calculate ;
- (2)
- If , terminate (a is not a margin or error vector);
- (3)
- If , apply the largest possible increment so that one of the following conditions occurs:
- (a)
- : add a to margin set , terminate;
- (b)
- : add a to error set , terminate;
- (c)
- Elements of migrate across , and ; update membership of elements, and if changes, update accordingly.
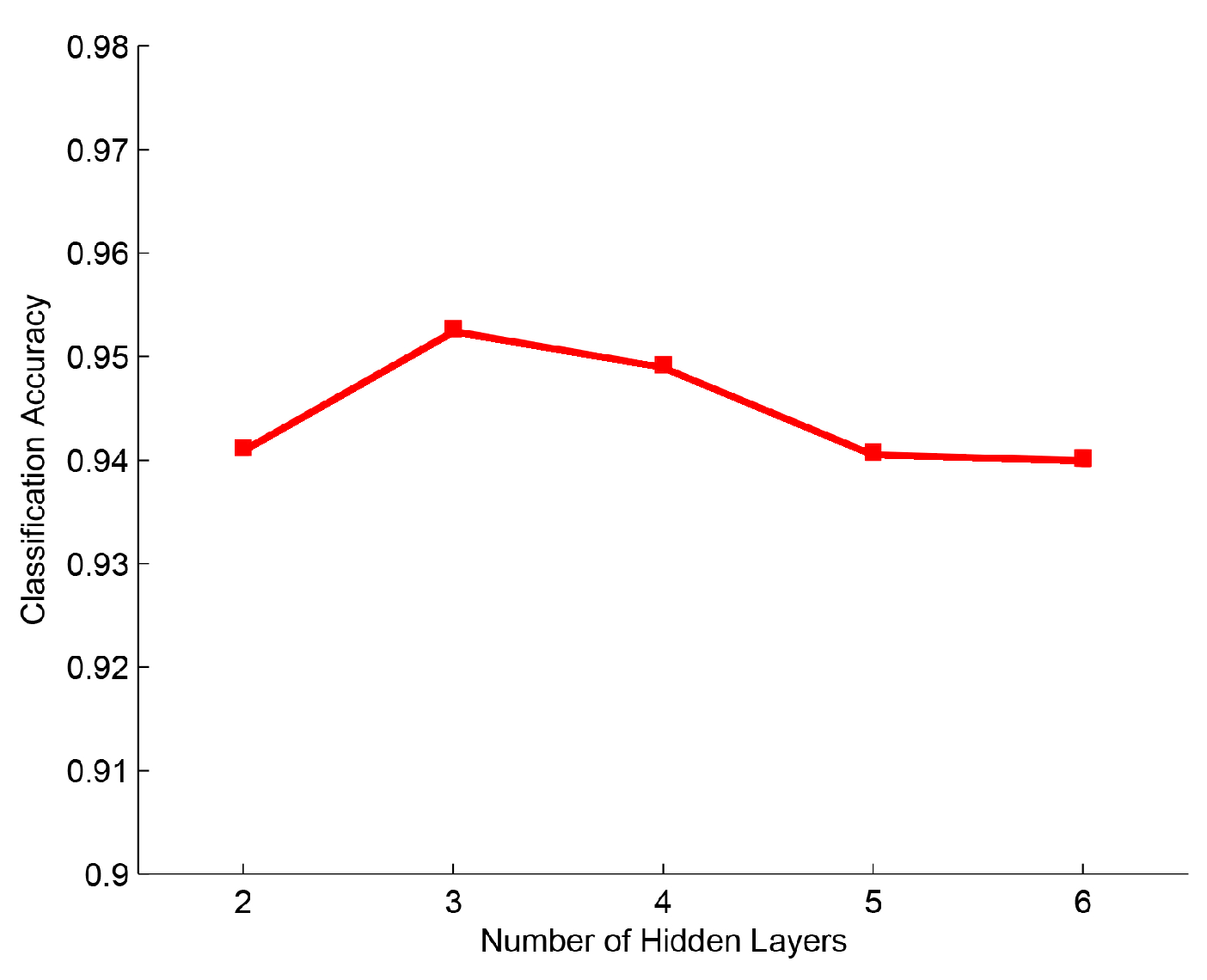
3.3. DeepECOCs
| Algorithm 1 The training procedure of DeepECOCs; L is the number of layers, I-SVM() is the incremental SVM binary classifier, is the sigmoid function, and is the softmax function. |
| Require: |
The set of training samples ; |
The labels corresponding to training samples . |
| Ensure: |
Parameters and . |
1: Initialize the first layer input ; |
2: for to do |
3: Initialize the weights and bias of i-th ECOC module; |
4: ; |
5: Pre-train process (ECOC coding step): |
6: (1) Learn the ECOC matrix with a coding strategy, and obtain (binary case) or (ternary case); |
7: (2) Train the incremental SVM binary classifiers according to : |
8: for to P do |
9: I-SVM; |
10: ; |
11: end for |
12: ; |
13: ; |
14: ; |
15: end for |
16: . |
17: Use the back-propagation algorithm for fine-tuning. |
18: return and , . |
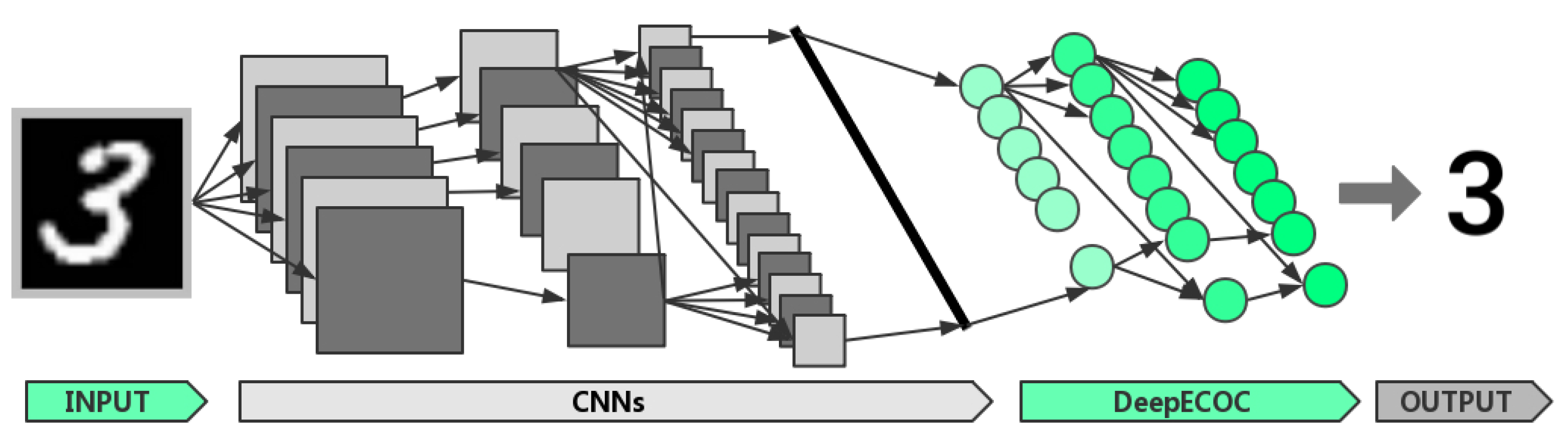
3.4. Combining Convolutional Neural Networks (CNNs) with DeepECOCs
4. Experiments
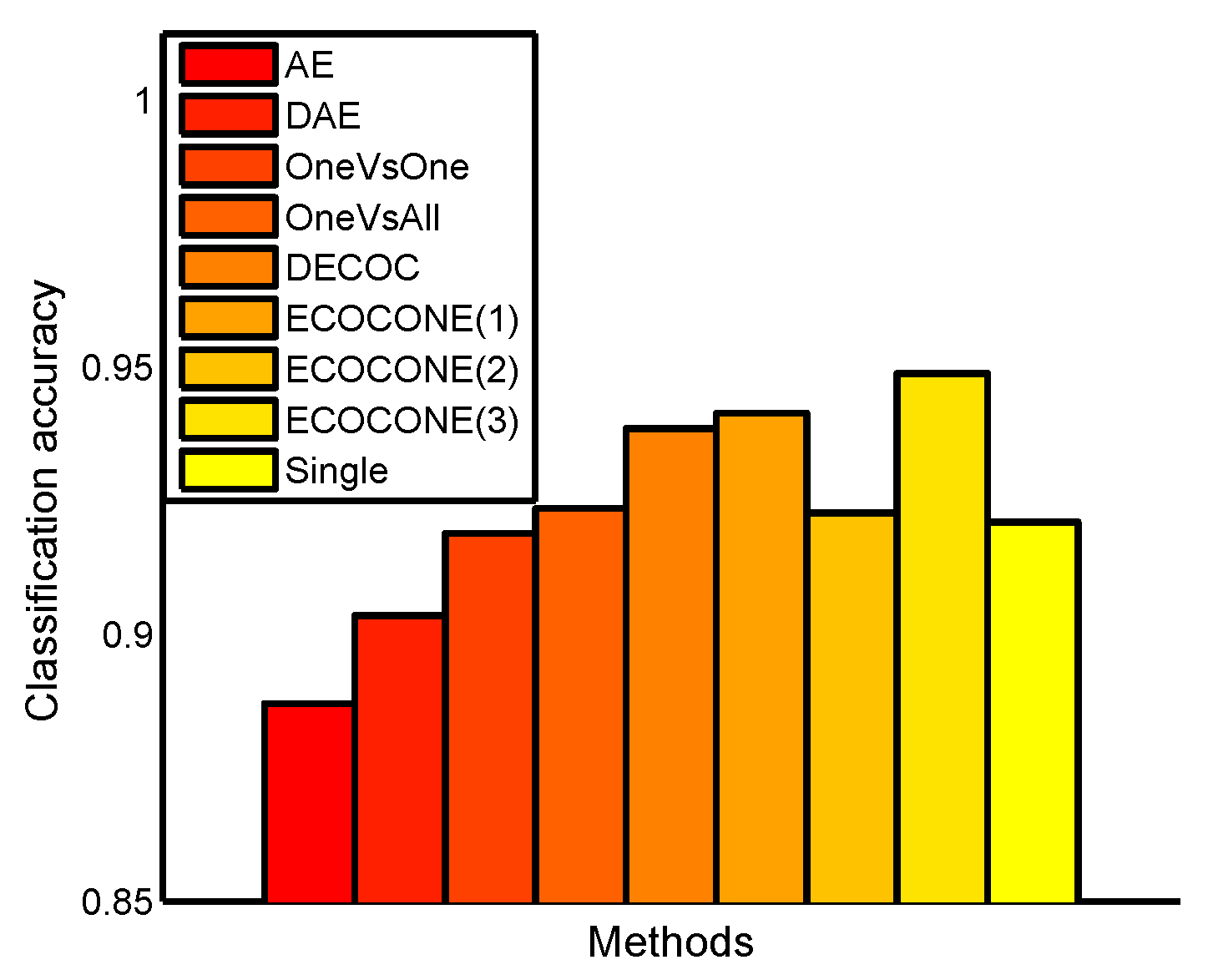
4.1. Classification on 16 UCI Data Sets
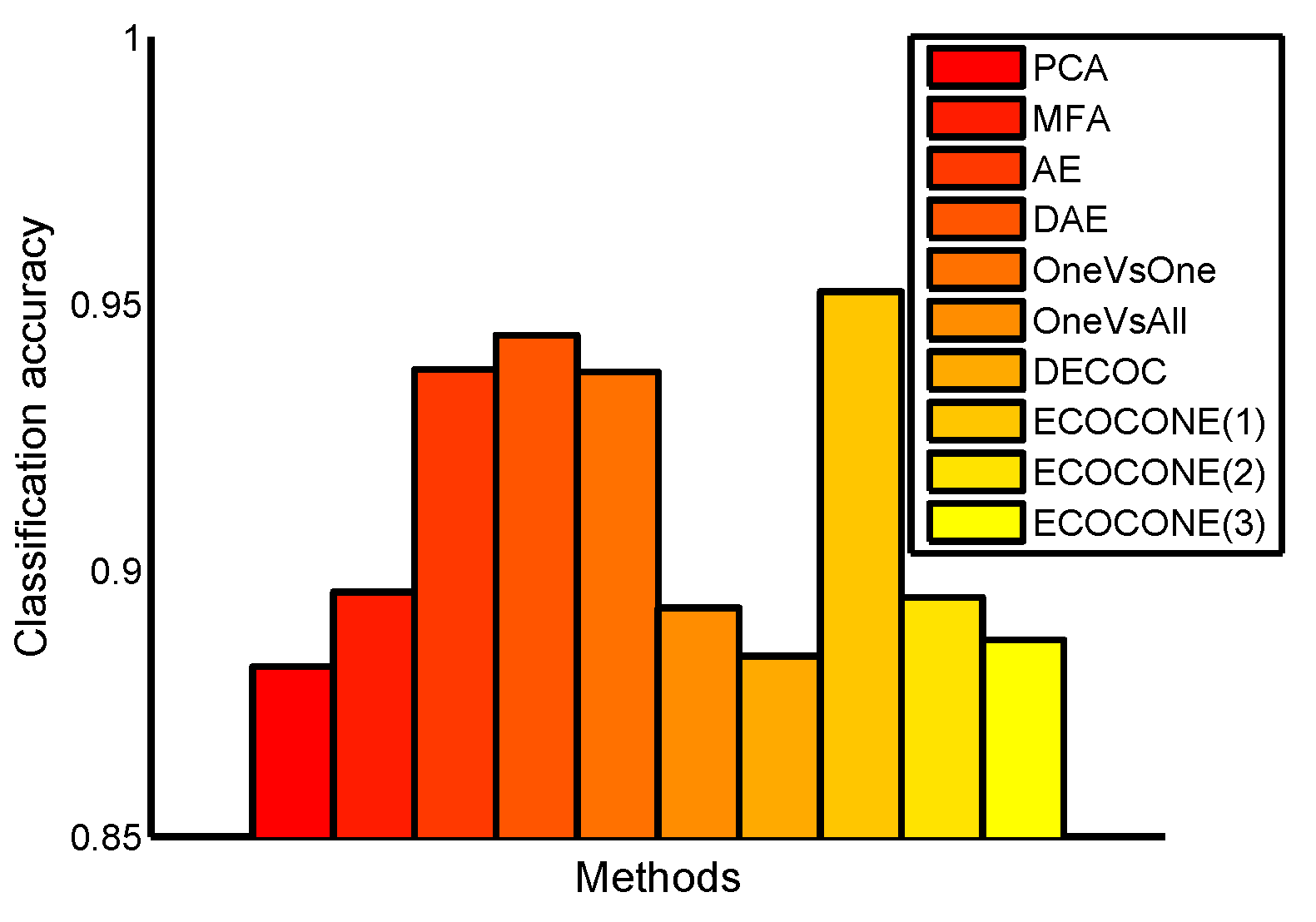
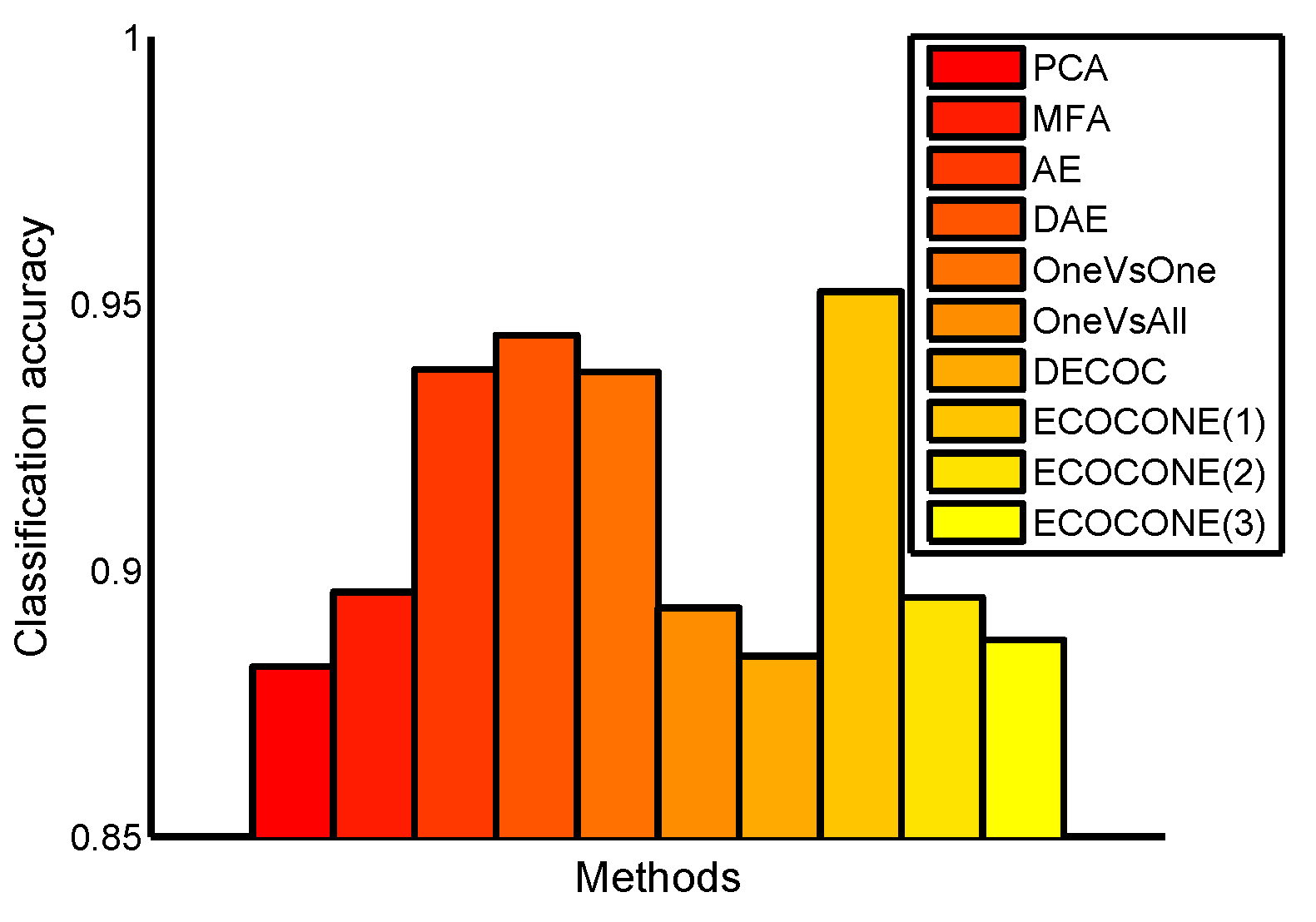
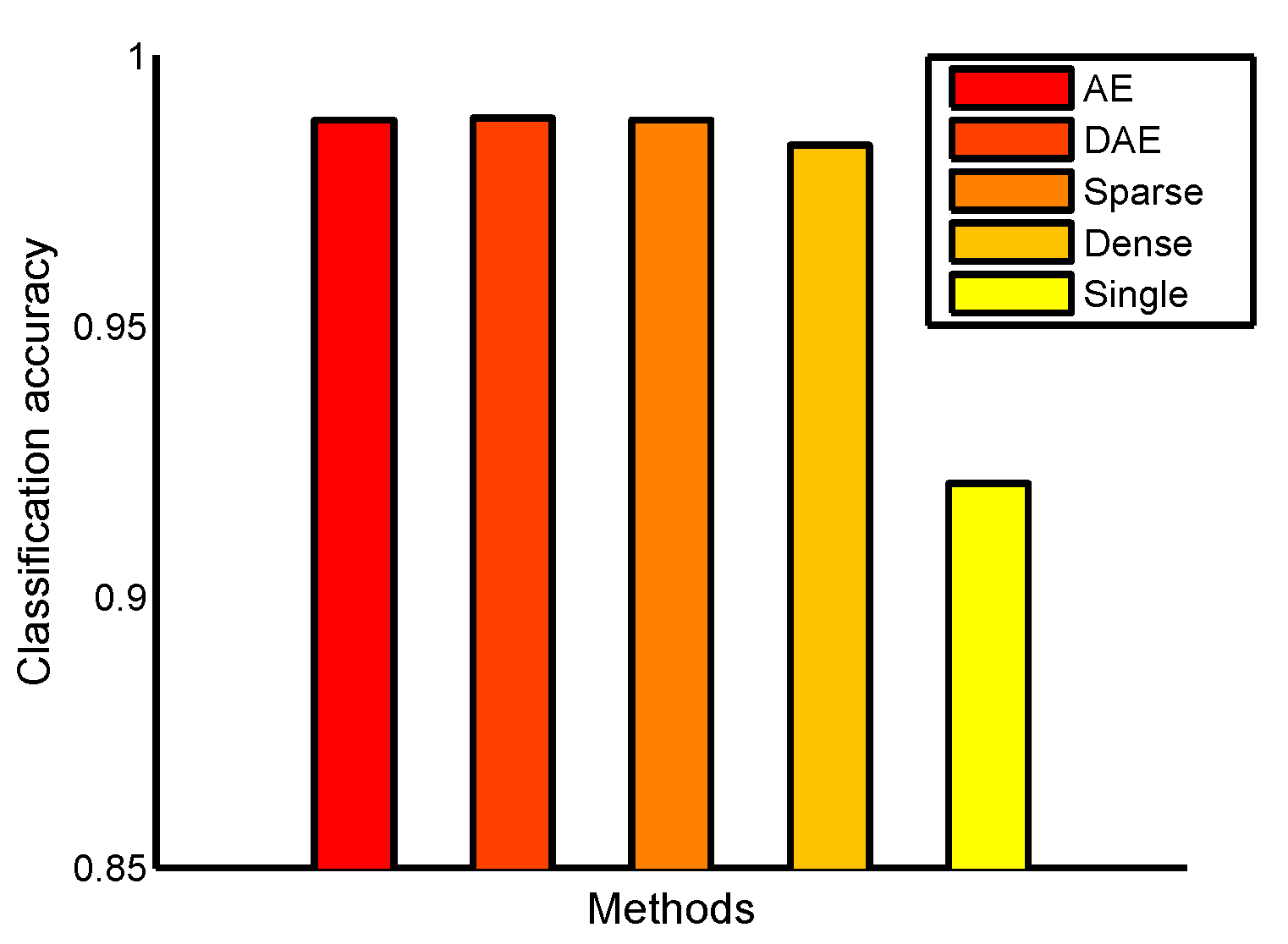
4.2. Classification on the USPS Data Set
4.3. Classification on the MNIST Data Set
4.4. Classification on the CMU Mocap Data Set
4.5. Classification on the CIFAR-10 Data set
4.6. Combining CNNs with DeepECOCs
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dietterich, T.G.; Bakiri, G. Solving multiclass learning problems via error-correcting output codes. J. Artif. Intell. Res. 1995, 2, 263–286. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Schapire, R.E. A Brief Introduction to Boosting. IJCAI 2010, 14, 377–380. [Google Scholar]
- Kumar, A.; Kaur, A.; Singh, P.; Driss, M.; Boulila, W. Efficient Multiclass Classification Using Feature Selection in High-Dimensional Datasets. Electronics 2023, 12, 2290. [Google Scholar] [CrossRef]
- Saeed, M.M.; Saeed, R.A.; Abdelhaq, M.; Alsaqour, R.; Hasan, M.K.; Mokhtar, R.A. Anomaly Detection in 6G Networks Using Machine Learning Methods. Electronics 2023, 12, 3300. [Google Scholar] [CrossRef]
- Zhong, G.; Liu, C.L. Error-correcting output codes based ensemble feature extraction. Pattern Recognit. 2013, 46, 1091–1100. [Google Scholar] [CrossRef]
- Ghani, R. Using error-correcting codes for text classification. In Proceedings of the ICML ’00: Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; pp. 303–310. [Google Scholar]
- Escalera, S.; Masip, D.; Puertas, E.; Radeva, P.; Pujol, O. Online error correcting output codes. Pattern Recognit. Lett. 2011, 32, 458–467. [Google Scholar] [CrossRef]
- Escalera, S.; Pujol, O.; Radeva, P. On the decoding process in ternary error-correcting output codes. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 120–134. [Google Scholar] [CrossRef]
- Nilsson, N.J. Learning Machines; McGraw-Hill: New York, NY, USA, 1965. [Google Scholar]
- Hastie, T.; Tibshirani, R. Classification by pairwise coupling. Ann. Stat. 1998, 26, 451–471. [Google Scholar] [CrossRef]
- Pujol, O.; Radeva, P.; Vitria, J. Discriminant ECOC: A heuristic method for application dependent design of error correcting output codes. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1007–1012. [Google Scholar] [CrossRef]
- Escalera, S.; Pujol, O.; Radeva, P. ECOC-ONE: A novel coding and decoding strategy. In Proceedings of the ICPR, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 578–581. [Google Scholar]
- Escalera, S.; Pujol, O.; Radeva, P. Separability of ternary codes for sparse designs of error-correcting output codes. Pattern Recognit. Lett. 2009, 30, 285–297. [Google Scholar]
- Allwein, E.L.; Schapire, R.E.; Singer, Y. Reducing multiclass to binary: A unifying approach for margin classifiers. J. Mach. Learn. Res. 2001, 1, 113–141. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the ICML, Machine Learning, Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. Acm Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal Process. Mag. IEEE 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Severyn, A.; Moschitti, A. Learning to rank short text pairs with convolutional deep neural networks. In Proceedings of the SIGIR ’15: 38th International ACM SIGIR Conference on Research and Development in Information, Santiago, Chile, 9–13 August 2015; pp. 373–382. [Google Scholar]
- Zheng, Y.; Cai, Y.; Zhong, G.; Chherawala, Y.; Shi, Y.; Dong, J. Stretching deep architectures for text recognition. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 236–240. [Google Scholar]
- Chitta, K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A. TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12878–12895. [Google Scholar] [CrossRef]
- Hinton, G.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the ICML ’08: 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Mak, H.W.L.; Han, R.; Yin, H.H.F. Application of Variational AutoEncoder (VAE) Model and Image Processing Approaches in Game Design. Sensors 2023, 23, 3457. [Google Scholar] [CrossRef]
- Sharif, S.A.; Hammad, A.; Eshraghi, P. Generation of whole building renovation scenarios using variational autoencoders. Energy Build. 2021, 230, 110520. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dirgova Luptakova, I.; Kubovcik, M.; Pospichal, J. Wearable Sensor-Based Human Activity Recognition with Transformer Model. Sensors 2022, 22, 1911. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Zhang, S.; Shi, R.; Yan, W.; Pan, X. Multi-Temporal Hyperspectral Classification of Grassland Using Transformer Network. Sensors 2023, 23, 6642. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Sabzevari, M.; Martínez-Muñoz, G.; Suárez, A. Vote-boosting ensembles. Pattern Recognit. 2018, 83, 119–133. [Google Scholar] [CrossRef]
- Claesen, M.; Smet, F.D.; Suykens, J.A.; Moor, B.D. EnsembleSVM: A library for ensemble learning using support vector machines. J. Mach. Learn. Res. 2014, 15, 141–145. [Google Scholar]
- Hu, C.; Chen, Y.; Hu, L.; Peng, X. A novel random forests based class incremental learning method for activity recognition. Pattern Recognit. 2018, 78, 277–290. [Google Scholar] [CrossRef]
- Sun, Y.; Tang, K.; Minku, L.; Wang, S.; Yao, X. Online Ensemble Learning of Data Streams with Gradually Evolved Classes. IEEE Trans. Knowl. Data Eng. 2016, 28, 1532–1545. [Google Scholar] [CrossRef]
- Wang, S.; Minku, L.L.; Yao, X. Resampling-Based Ensemble Methods for Online Class Imbalance Learning. IEEE Trans. Knowl. Data Eng. 2015, 27, 1356–1368. [Google Scholar] [CrossRef]
- Deng, L.; Platt, J.C. Ensemble deep learning for speech recognition. In Proceedings of the INTERSPEECH, Singapore, 14–18 September 2014; pp. 1915–1919. [Google Scholar]
- Zhou, X.; Xie, L.; Zhang, P.; Zhang, Y. An ensemble of deep neural networks for object tracking. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 843–847. [Google Scholar]
- Maji, D.; Santara, A.; Mitra, P.; Sheet, D. Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus Images. arXiv 2016, arXiv:1603.04833. [Google Scholar]
- Trigeorgis, G.; Bousmalis, K.; Zafeiriou, S.; Schuller, B. A deep semi-nmf model for learning hidden representations. In Proceedings of the ICML’14: 31st International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1692–1700. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the INTERSPEECH, Singapore, 14–18 September 2014; pp. 338–342. [Google Scholar]
- Poggio, T.; Cauwenberghs, G. Incremental and decremental support vector machine learning. NIPS 2001, 13, 409. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Cogn. Model. 1988, 5, 3. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Carballo, J.A.; Bonilla, J.; Fernández-Reche, J.; Nouri, B.; Avila-Marin, A.; Fabel, Y.; Alarcón-Padilla, D.C. Cloud Detection and Tracking Based on Object Detection with Convolutional Neural Networks. Algorithms 2023, 16, 487. [Google Scholar] [CrossRef]
- Mao, Y.J.; Tam, A.Y.C.; Shea, Q.T.K.; Zheng, Y.P.; Cheung, J.C.W. eNightTrack: Restraint-Free Depth-Camera-Based Surveillance and Alarm System for Fall Prevention Using Deep Learning Tracking. Algorithms 2023, 16, 477. [Google Scholar] [CrossRef]
- Il Kim, S.; Noh, Y.; Kang, Y.J.; Park, S.; Lee, J.W.; Chin, S.W. Hybrid data-scaling method for fault classification of compressors. Measurement 2022, 201, 111619. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Wiley Online Library: Hoboken, NJ, USA, 2002. [Google Scholar]
- Yan, S.; Xu, D.; Zhang, B.; Zhang, H.J.; Yang, Q.; Lin, S. Graph embedding and extensions: A general framework for dimensionality reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 40–51. [Google Scholar] [CrossRef]
- Lawrence, N.D.; Quionero-Candela, J. Local distance preservation in the GP-LVM through back constraints. In Proceedings of the ICML ’06: 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 513–520. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | ♯ of I | ♯ of A | ♯ of C | Problem | ♯ of I | ♯ of A | ♯ of C |
|---|---|---|---|---|---|---|---|
| Dermatology | 366 | 34 | 6 | Yeast | 1484 | 8 | 10 |
| Iris | 150 | 4 | 3 | Satimage | 6435 | 36 | 7 |
| Ecoli | 336 | 8 | 8 | Letter | 20,000 | 16 | 26 |
| Wine | 178 | 13 | 3 | Pendigits | 10,992 | 16 | 10 |
| Glass | 214 | 9 | 7 | Segmentation | 2310 | 19 | 7 |
| Thyroid | 215 | 5 | 3 | Optdigits | 5620 | 64 | 10 |
| Vowel | 990 | 10 | 11 | Shuttle | 14,500 | 9 | 7 |
| Balance | 625 | 4 | 3 | Vehicle | 846 | 18 | 4 |
| Problem | OneVsOne | OneVsAll | DECOC | ECOCONE | ||||
|---|---|---|---|---|---|---|---|---|
| LibSVM | I-SVM | LibSVM | I-SVM | LibSVM | I-SVM | LibSVM | I-SVM | |
| Dermatology | 0.9671 | 0.9770 | 0.7928 | 0.9605 | 0.9671 | 0.9638 | 0.9671 | 0.9770 |
| Iris | 0.9333 | 0.9333 | 0.7030 | 0.7030 | 0.9333 | 0.9333 | 0.9333 | 0.9333 |
| Ecoli | 0.5944 | 0.6507 | 0.3940 | 0.4553 | 0.5281 | 0.5828 | 0.5944 | 0.6556 |
| Wine | 0.9892 | 0.9892 | 0.9731 | 0.9731 | 0.9892 | 0.9731 | 0.9839 | 0.9892 |
| Glass | 0.4838 | 0.4189 | 0.3216 | 0.3270 | 0.2973 | 0.3486 | 0.3027 | 0.5378 |
| Thyroid | 0.5897 | 0.6239 | 0.5897 | 0.6239 | 0.5897 | 0.4017 | 0.5897 | 0.6239 |
| Vowel | 0.4187 | 0.4956 | 0.3953 | 0.6591 | 0.2736 | 0.3278 | 0.4476 | 0.4956 |
| Balance | 0.8927 | 0.8927 | 0.9042 | 0.9042 | 0.8927 | 0.8927 | 0.8927 | 0.8927 |
| Yeast | 0.4741 | 0.5744 | 0.2383 | 0.2760 | 0.3751 | 0.5693 | 0.4147 | 0.6000 |
| Satimage | 0.8361 | 0.8692 | 0.7620 | 0.8334 | 0.7411 | 0.8532 | 0.8305 | 0.8604 |
| Letter | 0.7443 | 0.8216 | 0.2166 | 0.4536 | 0.7530 | 0.8375 | 0.7440 | 0.8120 |
| Pendigits | 0.9688 | 0.9859 | 0.9021 | 0.9773 | 0.9065 | 0.9758 | 0.9691 | 0.9850 |
| Segmentation | 0.8595 | 0.8872 | 0.6187 | 0.6759 | 0.7969 | 0.6706 | 0.8601 | 0.8872 |
| OptDigits | 0.9492 | 0.9860 | 0.8866 | 0.9649 | 0.8793 | 0.9808 | 0.9492 | 0.9860 |
| Shuttle | 0.9178 | 0.9475 | 0.8312 | 0.9034 | 0.8352 | 0.9407 | 0.9179 | 0.9532 |
| Vehicle | 0.6324 | 0.7595 | 0.7378 | 0.4892 | 0.6054 | 0.7243 | 0.6324 | 0.7595 |
| Problem | Epoch | Problem | Epoch | ||
|---|---|---|---|---|---|
| Dermatology | 0.1 | 2000 | Yeast | 0.01 | 4000 |
| Iris | 0.1 | 400 | Satimage | 0.01 | 4000 |
| Ecoli | 0.1 | 2000 | Letter | 0.01 | 8000 |
| Wine | 0.1 | 2000 | Pendigits | 0.01 | 2000 |
| Glass | 0.01 | 4000 | Segmentation | 0.01 | 8000 |
| Thyroid | 0.1 | 800 | Optdigits | 0.01 | 2000 |
| Vowel | 0.1 | 4000 | Shuttle | 0.1 | 2000 |
| Balance | 0.1 | 4000 | Vehicle | 0.1 | 4000 |
| Problem | Single | AE | DAE | V1 | V2 | V3 | V4 |
|---|---|---|---|---|---|---|---|
| Dermatology | 0.9513 | 0.9429 ± 0.0671 | 0.9674 ± 0.0312 | 0.9731 ± 0.0314 | 0.8852 ± 0.0561 | 0.9722 ± 0.0286 | 0.8834 ± 0.0349 |
| Iris | 0.9600 | 0.9600 ± 0.0562 | 0.9333 ± 0.0889 | 0.8818 ± 0.0695 | 0.8137 ± 0.0768 | 0.9667 ± 0.0471 | 0.9667 ± 0.0471 |
| Ecoli | 0.8147 | 0.7725 ± 0.0608 | 0.8000 ± 0.0362 | 0.8275 ± 0.0427 | 0.7868 ± 0.0633 | 0.9102 ± 0.0701 | 0.9183 ± 0.0611 |
| Wine | 0.9605 | 0.9765 ± 0.0264 | 0.9563 ± 0.0422 | 0.9063 ± 0.0793 | 0.9625 ± 0.0604 | 0.9875 ± 0.0264 | 0.9625 ± 0.0437 |
| Glass | 0.6762 | 0.6669 ± 0.1032 | 0.6669 ± 0.0715 | 0.7563 ± 0.0653 | 0.6875 ± 0.0877 | 0.8013 ± 0.0476 | 0.7830 ± 0.0893 |
| Thyroid | 0.9210 | 0.9513 ± 0.0614 | 0.9599 ± 0.0567 | 0.8901 ± 0.1177 | 0.9703 ± 0.0540 | 0.9647 ± 0.0431 | 0.9560 ± 0.0633 |
| Vowel | 0.7177 | 0.6985 ± 0.0745 | 0.7101 ± 0.0756 | 0.7020 ± 0.0529 | 0.6563 ± 0.0721 | 0.7628 ± 0.0716 | 0.6874 ± 0.0438 |
| Balance | 0.8222 | 0.8036 ± 0.0320 | 0.8268 ± 0.0548 | 0.8528 ± 0.0534 | 0.8108 ± 0.0634 | 0.8879 ± 0.1331 | 0.9090 ± 0.0438 |
| Yeast | 0.5217 | 0.5641 ± 0.0346 | 0.5891 ± 0.0272 | 0.5861 ± 0.0318 | 0.5368 ± 0.0582 | 0.6080 ± 0.0385 | 0.5968 ± 0.0378 |
| Satimage | 0.8537 | 0.8675 ± 0.0528 | 0.8897 ± 0.0304 | 0.8763 ± 0.0576 | 0.8238 ± 0.0453 | 0.8977 ± 0.0752 | 0.9108 ± 0.0483 |
| Letter | 0.9192 | 0.9234 ± 0.0547 | 0.9381 ± 0.0641 | 0.9498 ± 0.0587 | 0.9322 ± 0.0251 | 0.9553 ± 0.0327 | 0.9465 ± 0.0414 |
| Pendigits | 0.9801 | 0.9831 ± 0.0123 | 0.9886 ± 0.0034 | 0.9828 ± 0.0047 | 0.9768 ± 0.0034 | 0.9917 ± 0.0021 | 0.9817 ± 0.0082 |
| Segmentation | 0.9701 | 0.9584 ± 0.0317 | 0.9596 ± 0.0211 | 0.9683 ± 0.0412 | 0.9567 ± 0.0527 | 0.9757 ± 0.0296 | 0.9724 ± 0.0371 |
| Optdigits | 0.9982 | 0.9785 ± 0.0101 | 0.9856 ± 0.0088 | 0.9882 ± 0.0104 | 0.9845 ± 0.0122 | 0.9934 ± 0.0027 | 0.9901 ± 0.0033 |
| Shuttle | 0.9988 | 0.9953 ± 0.0012 | 0.9976 ± 0.0014 | 0.9991 ± 0.0017 | 0.9983 ± 0.0018 | 0.9996 ± 0.0012 | 0.9993 ± 0.0010 |
| Vehicle | 0.7315 | 0.6987 ± 0.0521 | 0.7348 ± 0.0454 | 0.7128 ± 0.0384 | 0.6624 ± 0.0472 | 0.7466 ± 0.0481 | 0.7097 ± 0.0521 |
| Mean rank | 5.2500 | 6.3125 | 4.9375 | 4.3125 | 7.0625 | 1.4375 | 3.1875 |
| Problem | AE | DAE | V1 | V2 | V4 | V5 |
|---|---|---|---|---|---|---|
| CMU | 0.6171 | 0.6422 | 0.8030 | 0.6364 | 0.7652 | 0.6030 |
| Problem | AE | DAE | V1 | V2 |
|---|---|---|---|---|
| CIFAR(36) | 0.3501 | 0.3678 | 0.4530 | 0.3895 |
| CIFAR(256) | 0.4352 | 0.4587 | 0.4936 | 0.4521 |
| Problem | V3 | V4 | V5 | V6 |
| CIFAR(36) | 0.4031 | 0.5089 | 0.4517 | 0.4752 |
| CIFAR(256) | 0.5236 | 0.5588 | 0.4589 | 0.5224 |
| Methods | ResNet-Baseline | ResNet-DeepECOCs |
|---|---|---|
| Accuracy | 0.9098 | 0.9208 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.-N.; Wei, H.; Zheng, Y.; Dong, J.; Zhong, G. Deep Error-Correcting Output Codes. Algorithms 2023, 16, 555. https://doi.org/10.3390/a16120555
Wang L-N, Wei H, Zheng Y, Dong J, Zhong G. Deep Error-Correcting Output Codes. Algorithms. 2023; 16(12):555. https://doi.org/10.3390/a16120555
Chicago/Turabian StyleWang, Li-Na, Hongxu Wei, Yuchen Zheng, Junyu Dong, and Guoqiang Zhong. 2023. "Deep Error-Correcting Output Codes" Algorithms 16, no. 12: 555. https://doi.org/10.3390/a16120555
APA StyleWang, L.-N., Wei, H., Zheng, Y., Dong, J., & Zhong, G. (2023). Deep Error-Correcting Output Codes. Algorithms, 16(12), 555. https://doi.org/10.3390/a16120555