1. Introduction
Blood cancer affects children and adults [
1]. Blood cancer is also known as leukemia and it occurs due to changes in white blood cells [
1,
2]. Leukemia refers to the uncontrolled growth of blood cells [
3]. Acute leukemia and chronic leukemia are considered the most common types of blood cancer that occur often and are widely diagnosed around the world [
3,
4,
5]. Uncontrolled changes in white blood cells stimulate the birth of too many cells or generate unneeded behaviors [
6]. Recently, physicians named four types of leukemia: acute lymphoblastic leukemia (ALL), acute myeloid leukemia (AML), chronic lymphocytic leukemia (CLL), and chronic myeloid leukemia (CML) [
6,
7,
8,
9,
10,
11]. These types were categorized according to the intensity levels of tumor cells [
12,
13,
14].
Acute lymphoblastic leukemia (ALL) affects children and older adults (65 years old and over) [
1,
14,
15]. Pathologists and physicians consider acute myeloid leukemia (AML) the most fatal type since just under 30% of patients have survived in the past five years [
1,
16]. The National Cancer Institute in the United States of America reported that nearly 24,500 patients died in 2017 due to leukemia [
1,
17,
18,
19,
20]. In addition, leukemia was the main cause of 4.1.% reported cancers in the United States of America [
1].
Various known risk factors can cause leukemia. These factors include smoking, exposure to high levels of radiation and chemotherapy, a blood disorder, family history, and some genetic mutations [
21,
22]. In young patients, leukemia occurs often due to genetic mutations that take place in blood cells only [
23]. In addition, some genetic mutations can be inherited from parents and cause leukemia [
24,
25].
Acute lymphoblastic leukemia (ALL), acute myeloid leukemia (AML), chronic lymphocytic leukemia (CLL), and chronic myeloid leukemia (CML) are recognized by their intensity level and form of infected cells [
1]. Acute myeloid leukemia (AML) occurs in adults more often than children, and more specifically, in men more often than women. In addition, acute myeloid leukemia (AML) is the deadliest type of leukemia since its five-year survival rate is 26.9% [
1]. Chronic lymphocytic leukemia (CLL) affects men more than women, since two-thirds of the positive reported cases are men [
1]. Moreover, this type of leukemia occurs in people aged 55 years and over, and its survival rate between 2007 and 2013 was 83.2% according to [
1].
The evaluation of leukemia is determined by expert pathologists who have sufficient skills [
1]. Leukemia types are determined by Molecular Cytogenetics, Long-Distance Inverse Polymerase Chain Reaction (LDI-PCR), and Array-based Comparative Genomic Hybridization (ACGH) [
1]. These procedures require substantial effort and skills [
1]. Pathologists and physicians use smear blood and bone marrow tests to identify leukemia [
1,
2,
3]. However, these tests are expensive and time-consuming. In addition, interventional radiology is another procedure used to identify leukemia [
1]. Yet, the radiological procedures are limited by hereditary issues that are affected by the sensitivity and resolution of the imaging modality [
1].
At the moment, deep learning (DL) methods can be deployed in the medical field to support and provide aid for identifying infected leukemia cells or healthy ones. These approaches require datasets for training purposes. In this study, four datasets from Kaggle are used. Neural networks are widely used in image processing, detection, and categorization due to their rapid reputation for accuracy and effectiveness. Overfitting issues could occur for some reasons. To eliminate or minimize these issues, taking equal numbers of images from different samples is necessary. Various deep learning solutions for leukemia diagnosis and categorization were implemented with reasonable results. Therefore, obtaining greater accuracy is required.
1.1. Research Problem and Motivations
Numerous methods were developed to diagnose leukemia using neural networks, such as in [
1,
2,
3,
4,
5]. All methods, except those in [
1], implemented work to detect tumor cells without the capability of classifying these cells into their suitable types. Only the developed method in [
1] could classify leukemia into ALL, AML, CLL, and CML. However, this algorithm suffers from a drawback as some of its evaluated metrics did not exceed 98.5%. Therefore, another practical algorithm to detect leukemia and categorize it is required.
1.2. Research Contributions
A novel segmentation method based on new deep learning technology is proposed in this article. This segmentation is performed to detect leukemia cells and categorize these cells into their suitable types, ALL and AML, due to the availability of these two types in the utilized datasets. A newly implemented UNET model is used to extract the required features for classification purposes. The major contributions are:
- I.
Developing a novel segmentation process to detect leukemia based on a deep learning architecture according to a U-shaped architecture.
- II.
Implementing the UNET model to extract various characteristics for the categorization of the main two categories.
- III.
Using four datasets to evaluate the proposed approach.
- IV.
Calculating several performance quantities to evaluate the correctness and robustness of the presented algorithm.
The rest of the article is organized as follows: a literature review is presented in
Section 1.3 and
Section 2 provides a description of the proposed method.
Section 3 contains the evaluated performance metrics, their results, and the details of the conducted comparative analysis with some developed methods, and
Section 4 provides a discussion. The conclusion is given in
Section 5.
1.3. Related Work
Recently, Computer Vision (CV) was deployed in various leukemia models to identify and classify tumors.
N. Veeraiah et al., in [
1], developed a model to detect and categorize leukemia based on deep learning technology. A Generative Adversarial Network (GAN) was used for feature extraction purposes. In addition, a Generative Adversarial System (GAS) and the Principal Component Analysis (PCA) method were deployed on the extracted characteristics to distinguish suitable types of leukemia. Furthermore, the authors deployed some image preprocessing methods to segment the detected blood cells. The developed method achieved 99.8%, 98.5%, 99.7%, 97.4%, and 98.5% for accuracy, precision, recall, F-score, and DSC, respectively. These achieved results came from applying the model to one dataset. In contrast, the proposed model utilized the newly implemented segmented technique and the newly developed UNET model to detect and categorize leukemia according to the extracted features. The presented method used three datasets to test the algorithm and achieve an acceptable range of outcomes between 97% and 99%. The obtained findings imply that the model can be used by any hospital or healthcare provider to support pathologists and physicians in their diagnosis of leukemia properly and accurately. The proposed model produces better results than the developed method in [
1] in some cases, as its accuracy reached 99% when the number of iterations and epochs increased.
The authors in [
2] implemented a method to discover long noncoding RNA using a competitive network. This network was developed on endogenous RNA and utilized on a dataset that had long noncoding RNAs and mRNAs. In addition, the authors validated their outcomes using a reverse transcription quantitative real-time approach. Unfortunately, the authors provided no information about the achieved accuracy or any other metric, while the proposed method achieved 97.82% accuracy using the new segmentation technique.
In [
3], N. Veeraiah et al. proposed a method to detect leukemia based on a histogram threshold segmentation classifier. This method worked on the color and brightness variation of blood cells. The authors cropped the detected nucleus using arithmetic operations and an automated approximation technique. In addition, the active contour method was utilized to determine the contrast in the segmented white blood cells. The authors achieved 98% accuracy and reached more than 99% when combined with other classifiers on a single dataset. In contrast, the proposed algorithm utilized three datasets and achieved nearly an average of 98% accuracy. This accuracy increased to nearly 98.9% when enhancing the number of iterations and epochs as well.
The authors in [
4] implemented a model to discover malignant leukemia cells using a deep learning model. The authors used a Convolutional Neural Network (CNN) to spot ALL and AML. In addition, two blocks of the CNN model were hybridized together. The algorithm was evaluated on a public dataset that contained 4150 blood smear images. In addition, transforming the color images into grey ones was deployed to assist the model in segmentation purposes. Five different classifiers were utilized to evaluate the model to achieve 89.63% accuracy, which is considered to be a low outcome. In contrast, the presented approach in this article used new segmentation and classification methods to spot and categorize four subcategories of leukemia. Four datasets were utilized to attain 97.82% accuracy, which is better than the obtained outcomes in [
4].
G. Sriram et al., in [
6], implemented a model to categorize leukemia using the VGG-16 CNN model when applied to a single dataset of nearly 700 images. This model classified only two types, which were ALL and AML, and attained nearly 98% accuracy, which is less than what the proposed algorithm obtained on four datasets.
Table 1 offers a summary of what has been implemented to detect and categorize leukemia.
3. Results
This section contains the conducted experiments to evaluate the presented algorithm for leukemia identification and categorization. This study aims to design and implement a new trustworthy Computer-Aided Design (CAD) system for the diagnosis and categorization of leukemia using two models. These models are developed for segmentation, characteristics extraction, and classification purposes. This system was trained, validated, tested, and evaluated using four datasets as shown in
Table 2. The performed analysis shows the superiority of the presented system. The utilized images from the used datasets were allocated equally between the assigned three groups, which are training, validation, and testing. As shown in
Table 2, the first set contains 19,701 images, while the other sets contain 4222 in each.
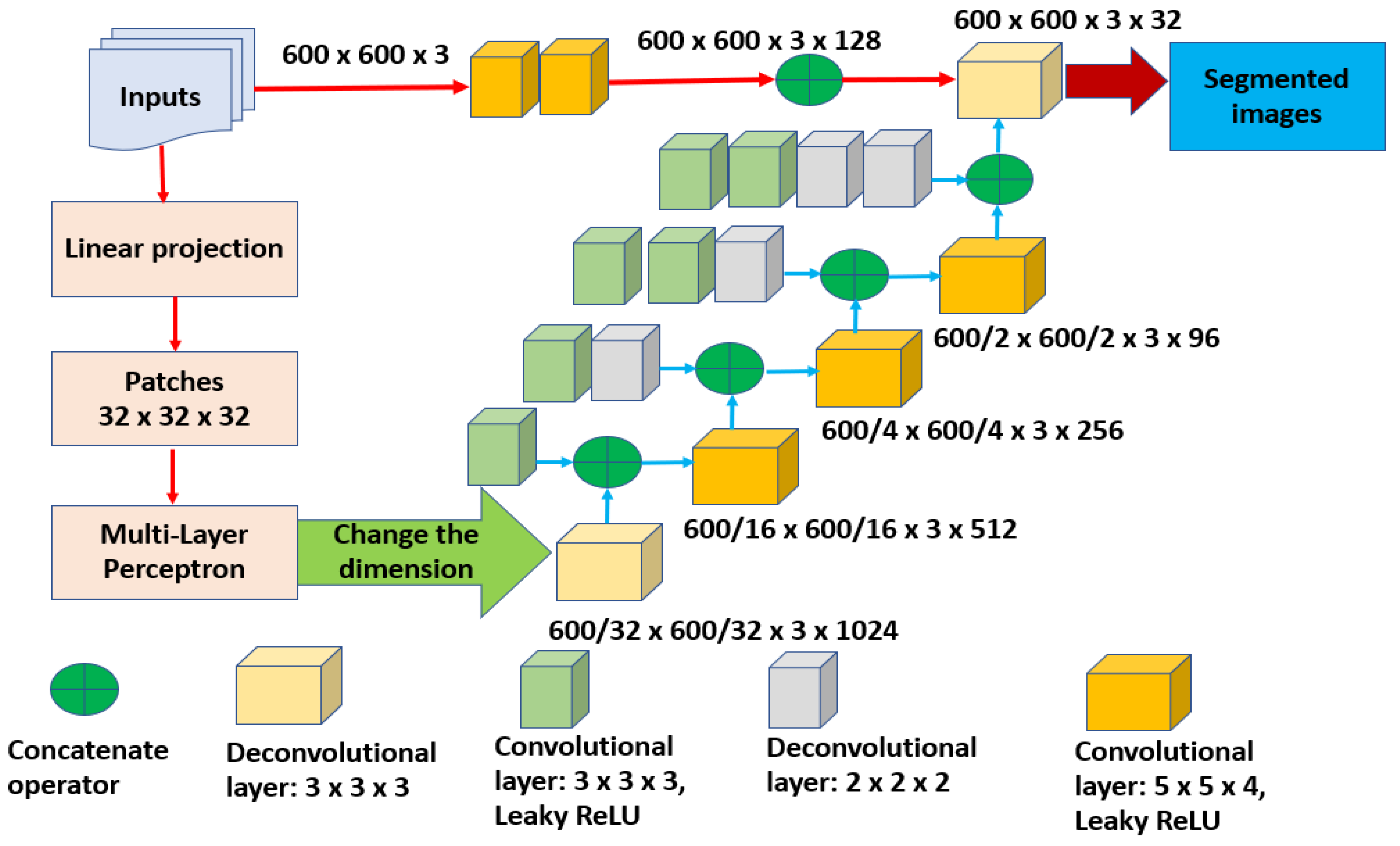
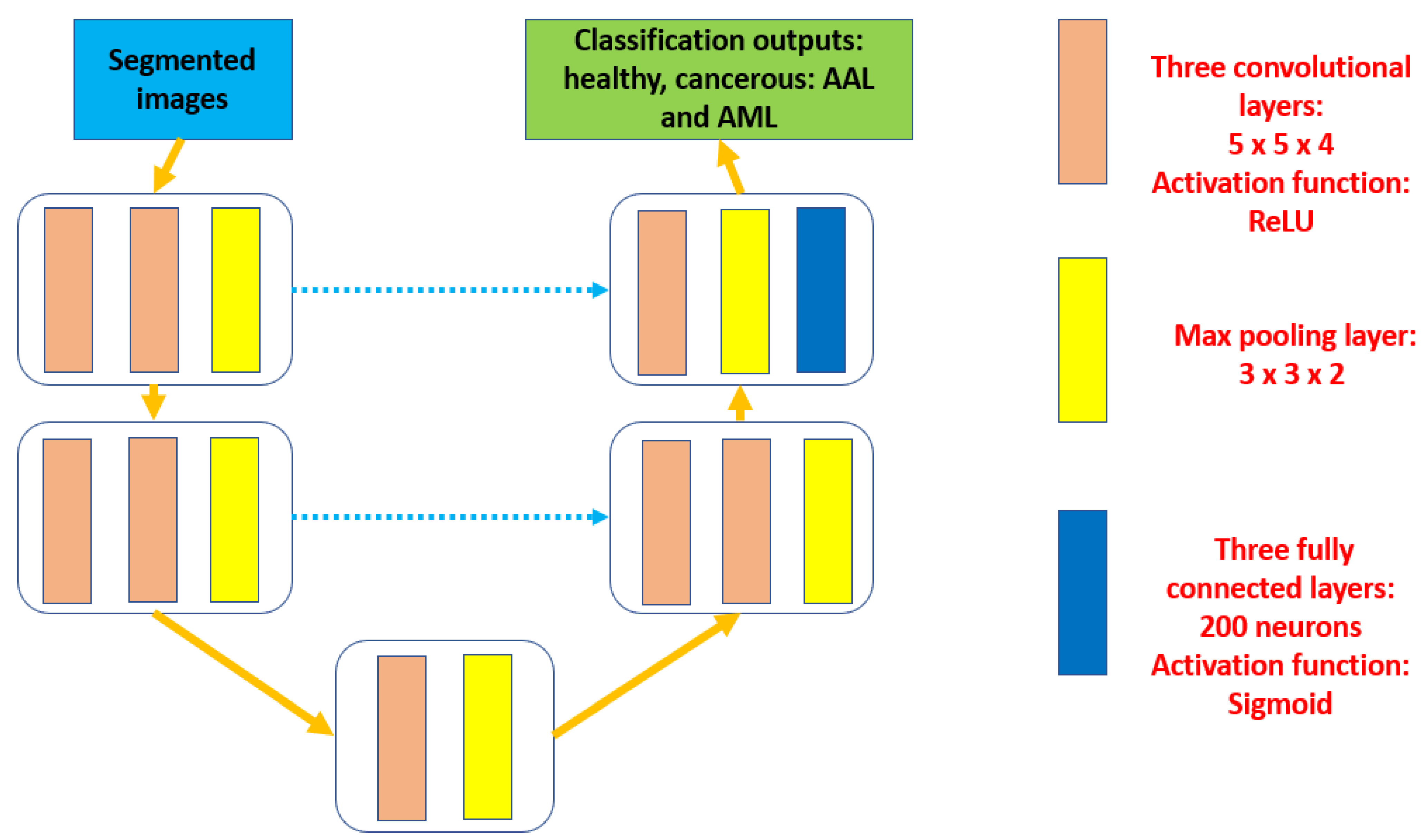
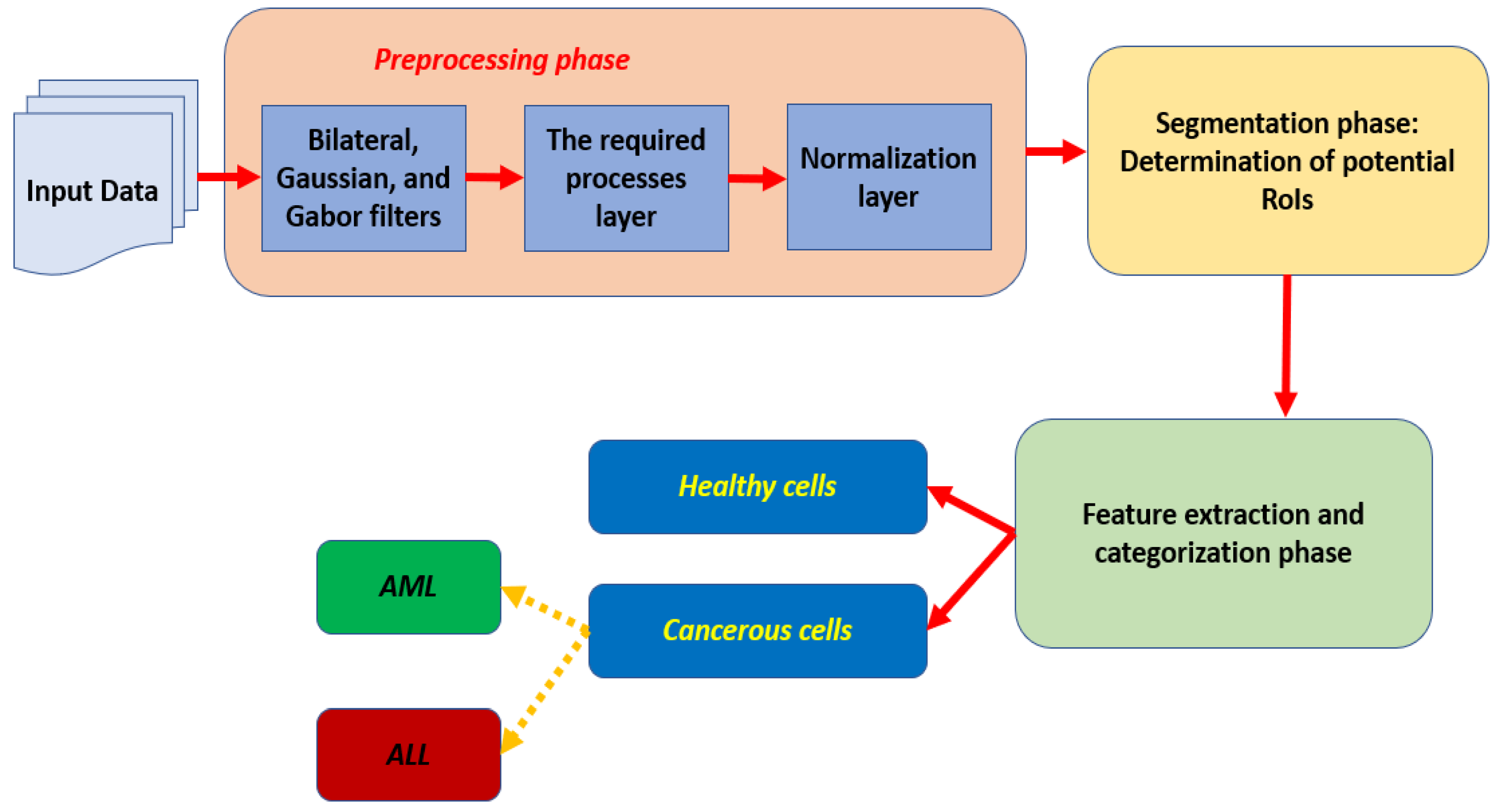
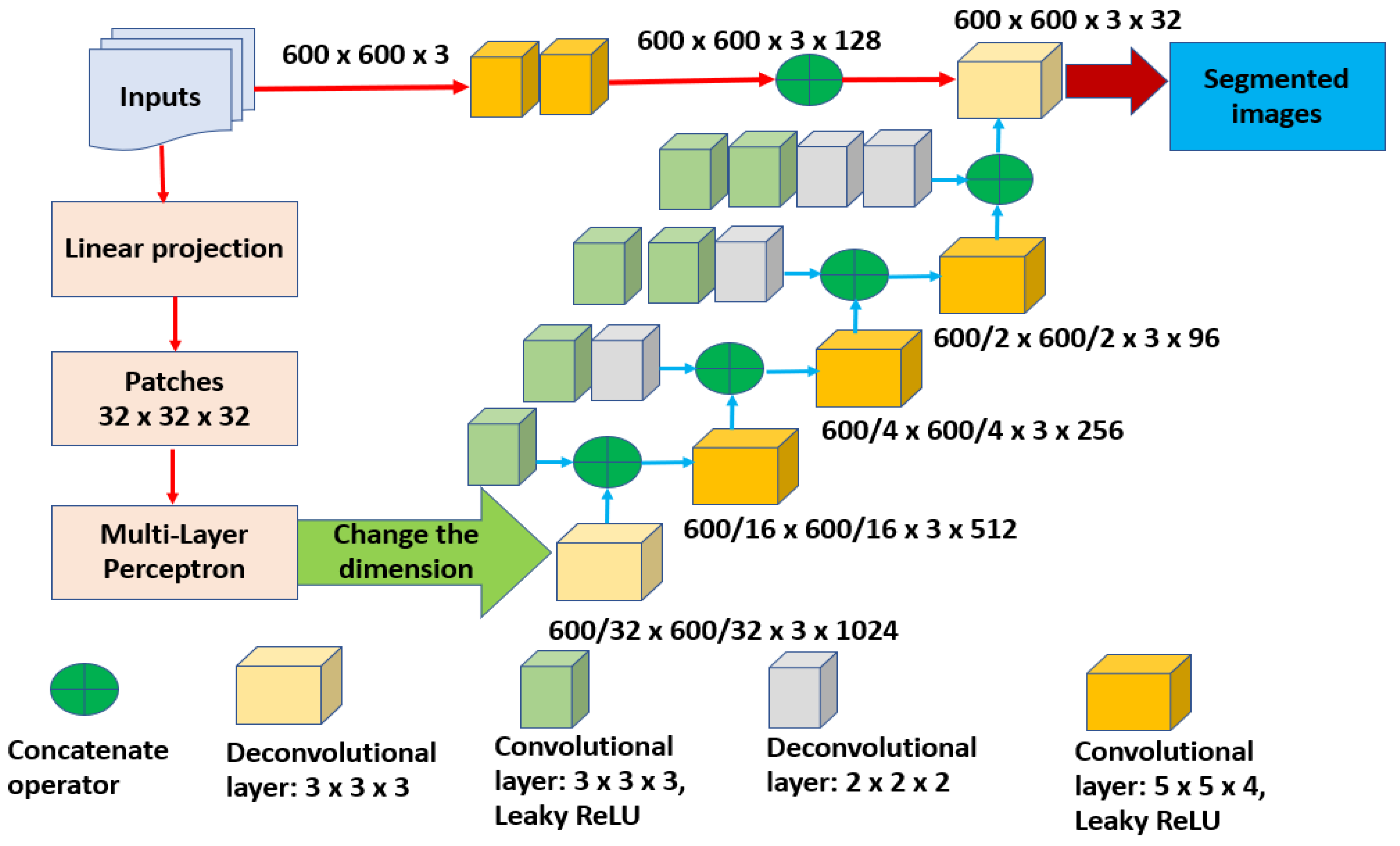
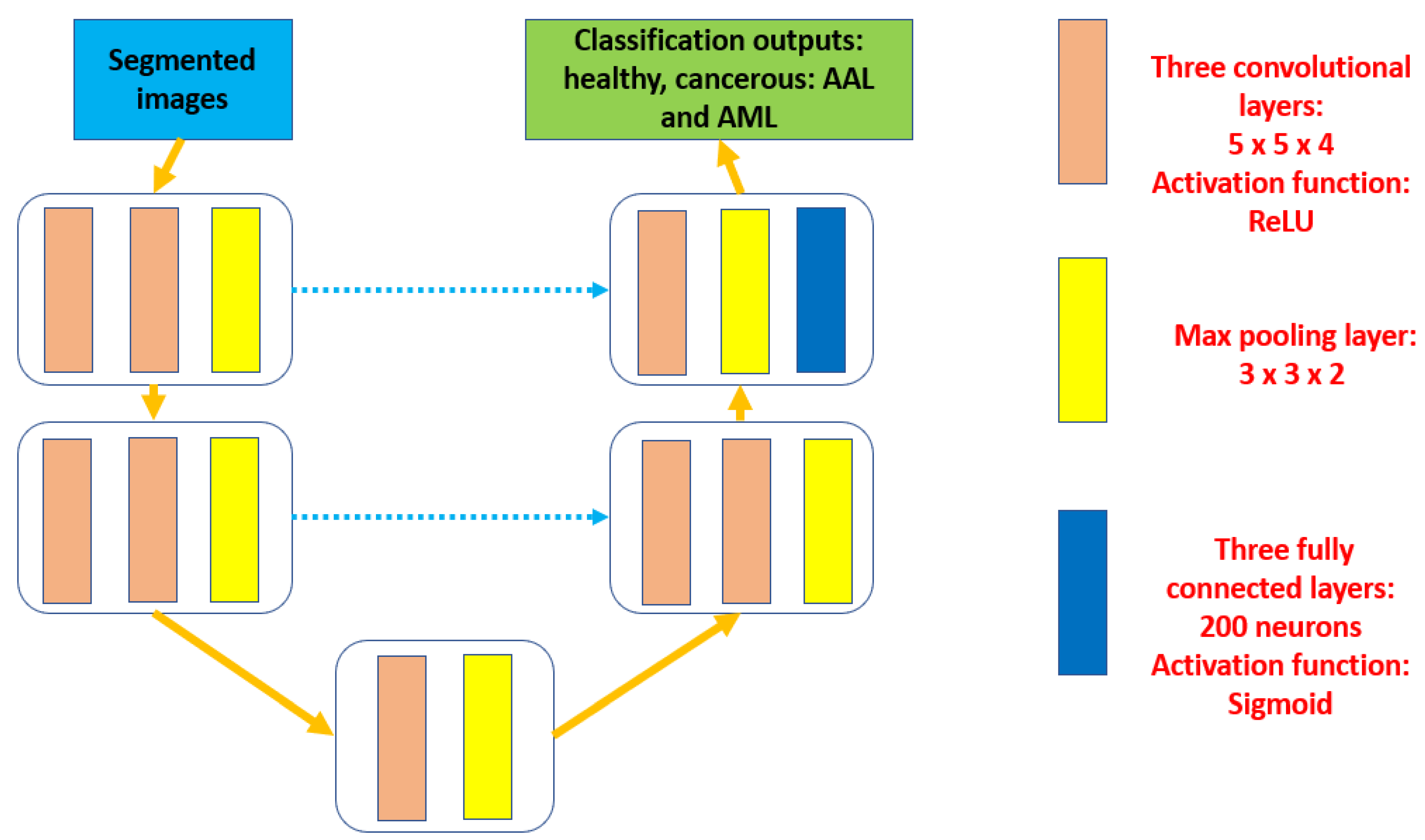
In this research, the proposed algorithm consists of three main components as depicted in
Figure 1. Each preprocessed input is segmented in the second phase to outline the potential RoIs and produce semantic outcomes. These segmented results are fed into the third stage to perform the extraction of the required characteristics and categorization procedures.
3.1. Experimental Setup
The conducted experiments were performed on a MATLAB that was installed on a machine with an Intel Core I7 8th Gen., 16 GB RAM, 64-bit Operating System, and 2 GHz. The machine operates using Windows 11 Pro.
3.2. Results
Numerous scenarios were performed to train and test the proposed approach using four datasets. A total of 19,701 images were used for training, whereas 4222 images were utilized for testing purposes. The success or failure of the segmentation stage depends mainly on the segmentation accuracy. As shown in
Table 4, different configurations were deployed to provide diverse evaluations.
Table 5 lists the achieved average accuracy from the second and third stages. In addition, it shows how accuracy was influenced and impacted by the optimizer.
Table 6 shows the obtained average outputs of the considered performance parameters with the use of the optimization tool and without it when the number of iterations ranged from 3000 to 8000.
Accuracy was impacted by the optimizer tool as it increased by 2.48%.
As shown in
Table 5 and
Table 6, the deployment of the optimizer tool had a significant role in the achieved results. The obtained results of the considered performance quantities were increased using the optimizer tool.
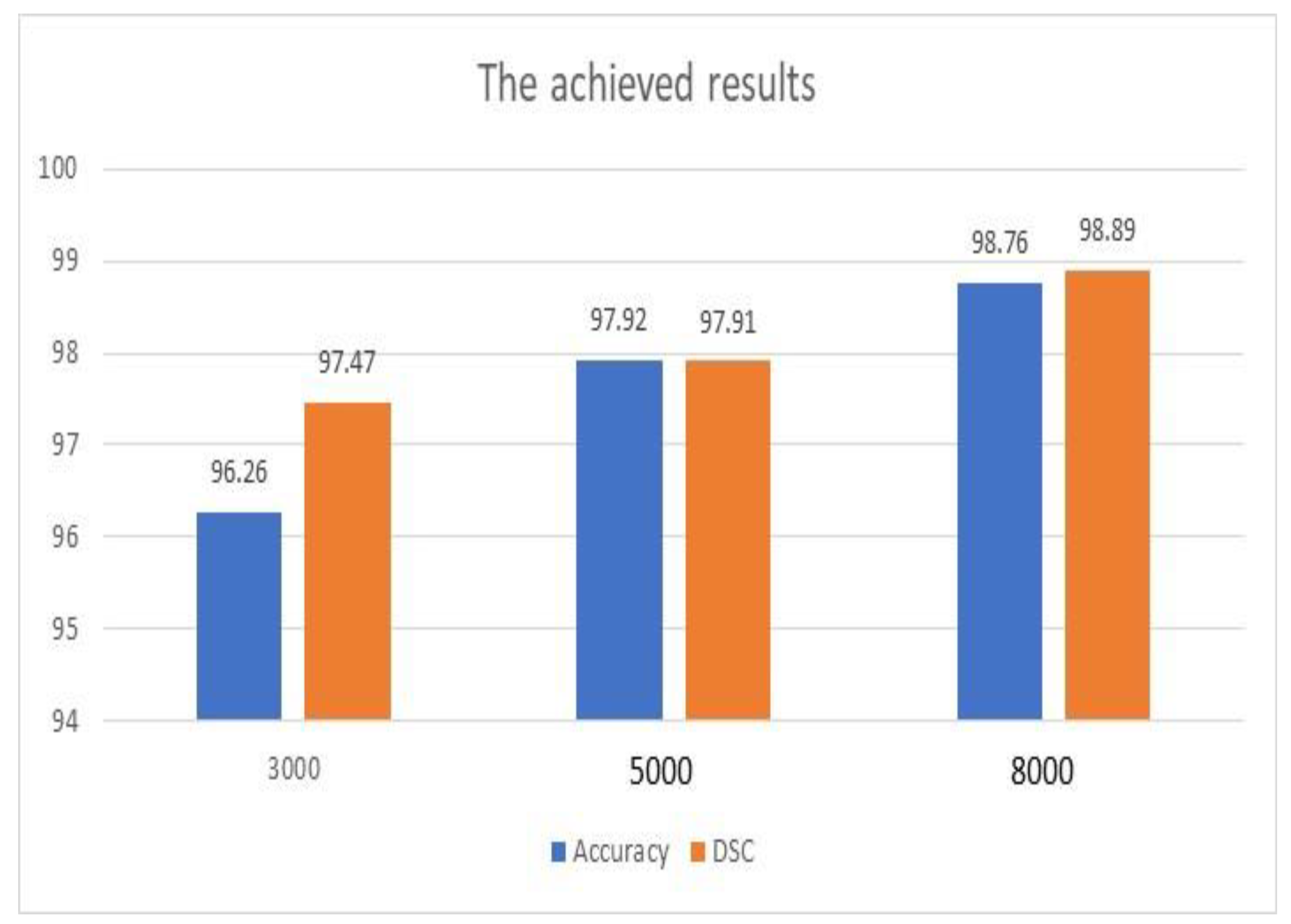
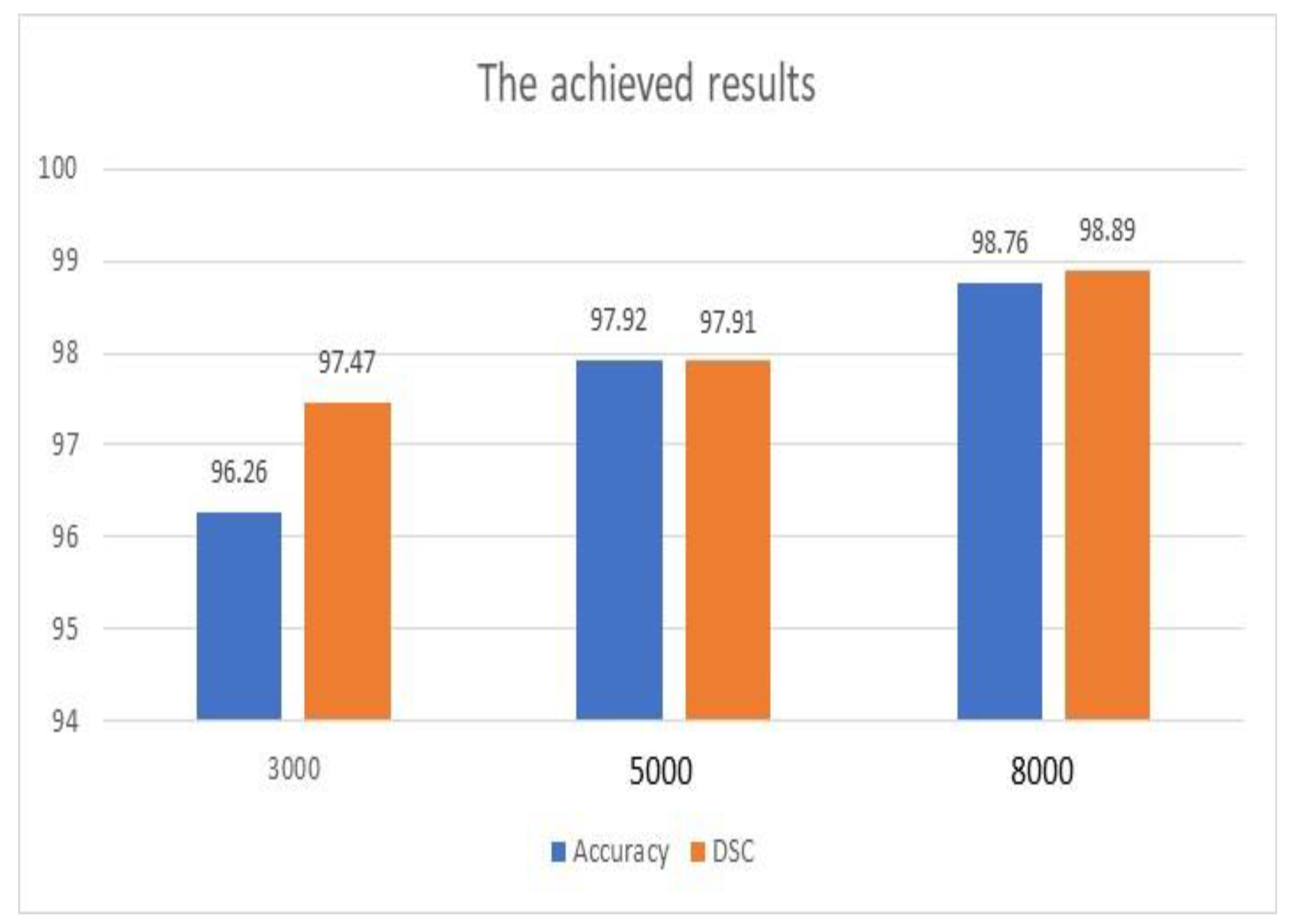
Figure 4 illustrates the achieved outputs of accuracy and DSC when different numbers of iterations were applied, as shown in
Table 4. In addition, these results were achieved with the use of the ADAM optimization tool. Both metrics improved significantly as the number of iterations increased. The enhancement of accuracy was 2.66%, while DSC improved by 1.43%. Furthermore, accuracy was improved when the scale of inputs was changed from 600 × 600 to 720 × 720 by approximately 8.21%. However, this improvement occurred with a penalty on the execution time.
Figure 4 and
Table 6 show that the achieved results of the proposed model are encouraging, and the system can be deployed to save lives and enhance the diagnosis procedures.
The execution time per input, also known as the processing time, the total number of utilized parameters, and the total number of Floating-Point Operations per Second (FLOPS) were evaluated. This evaluation was conducted according to the assigned size of images, which was 600 × 600, and a sliding window method.
Table 7 displays the attained results of these parameters. These outcomes indicate that the presented algorithm is highly computational. Nevertheless, acceptable and reasonable findings were obtained. FLOPS and the total number of parameters were found in millions.
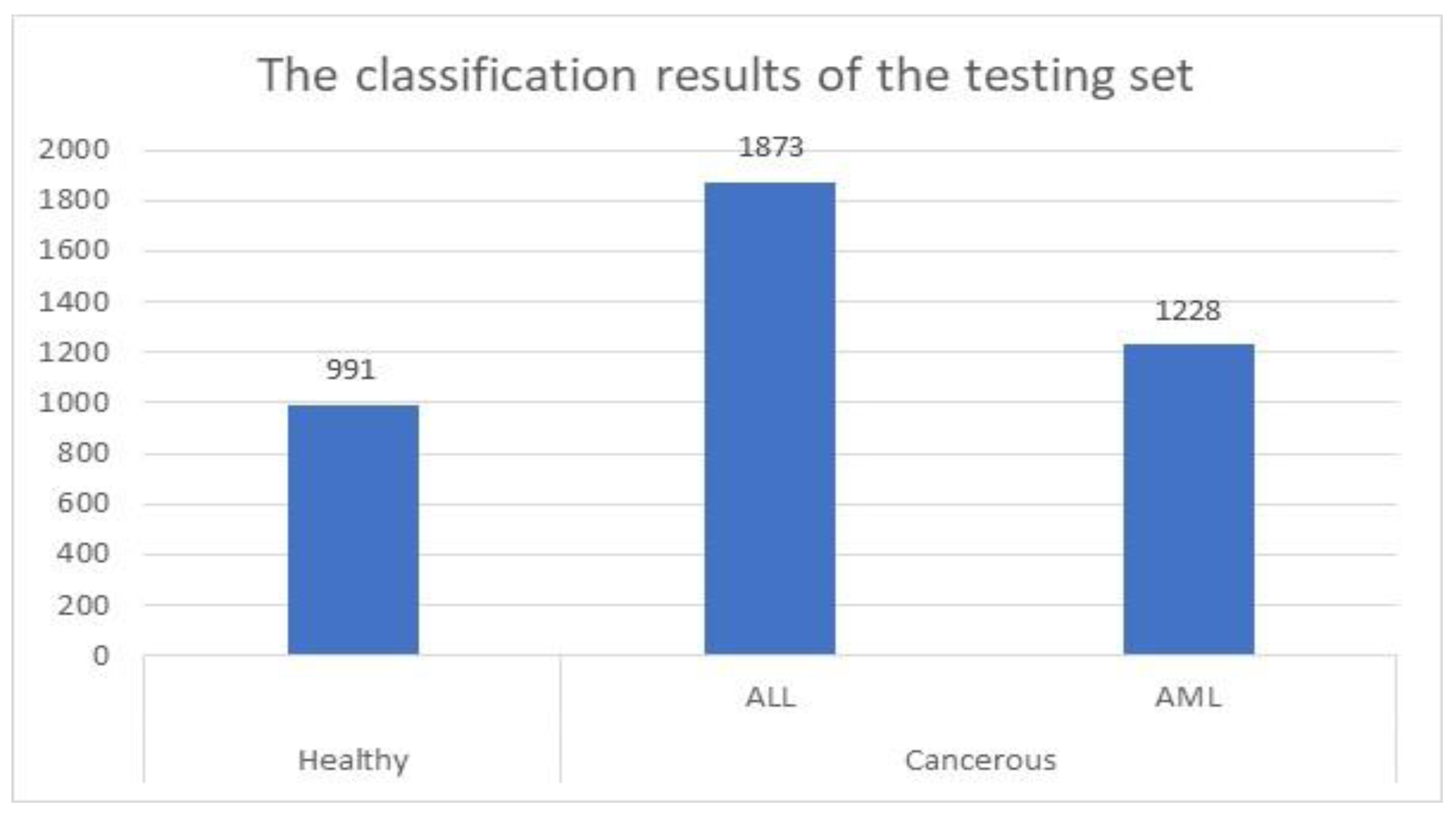
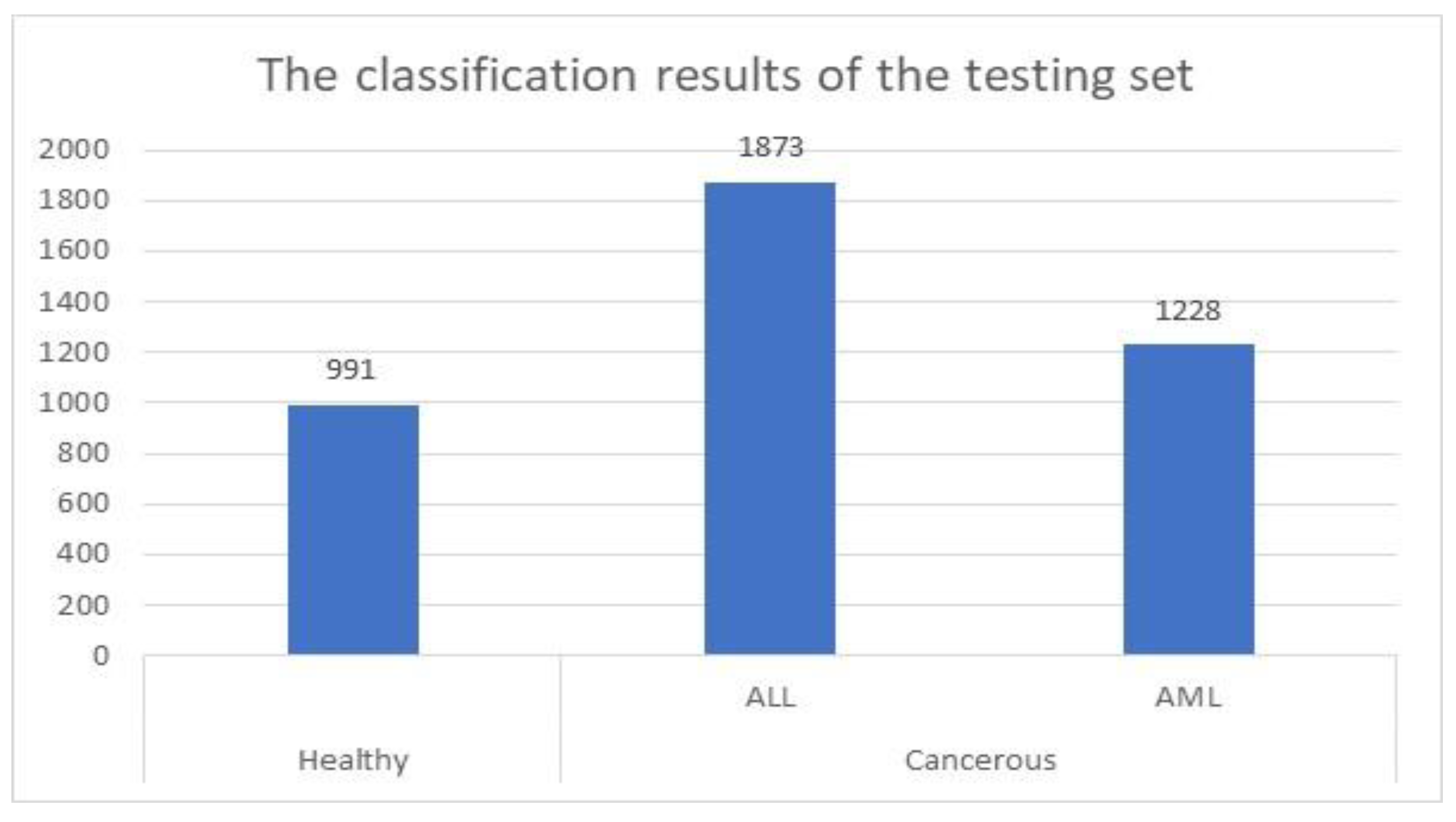
For the testing set, the proposed method was successfully identified and categorized 4092 images out of 4222, which represents approximately 97%. This set contained 1142 healthy cells and 3080 cancerous cells. These cells were 1731 ALL cells and 1349 AML cells. The presented system identified and categorized 991 healthy cells out of 1142 properly.
Figure 5 shows the achieved results when the model was applied to the testing set.
3.3. Comparative Assessment
An assessment evaluation between the proposed algorithm and some implemented methods in the literature was conducted to analyze the obtained outputs and efficiency and measure robustness. This comparative study included the number of used datasets, applied technology, obtained accuracy, and DSC.
Table 8 shows the performed comparative evaluation.
The presented approach performed better accuracy than the implemented methods in [
3,
6,
8,
12], while the approaches in [
1,
9] gave better results. However, both methods used a single dataset in each, while the proposed algorithm utilized four datasets. In addition, the number of used images in the proposed system was bigger than both models [
1,
9]. Nevertheless, the presented algorithm attained over 99% accuracy when the number of iterations exceeded 15000 and the value of learning changed from 0.001 to 0.01. Furthermore, the accuracy was enhanced by nearly 1.8% when the patch size decreased by half.
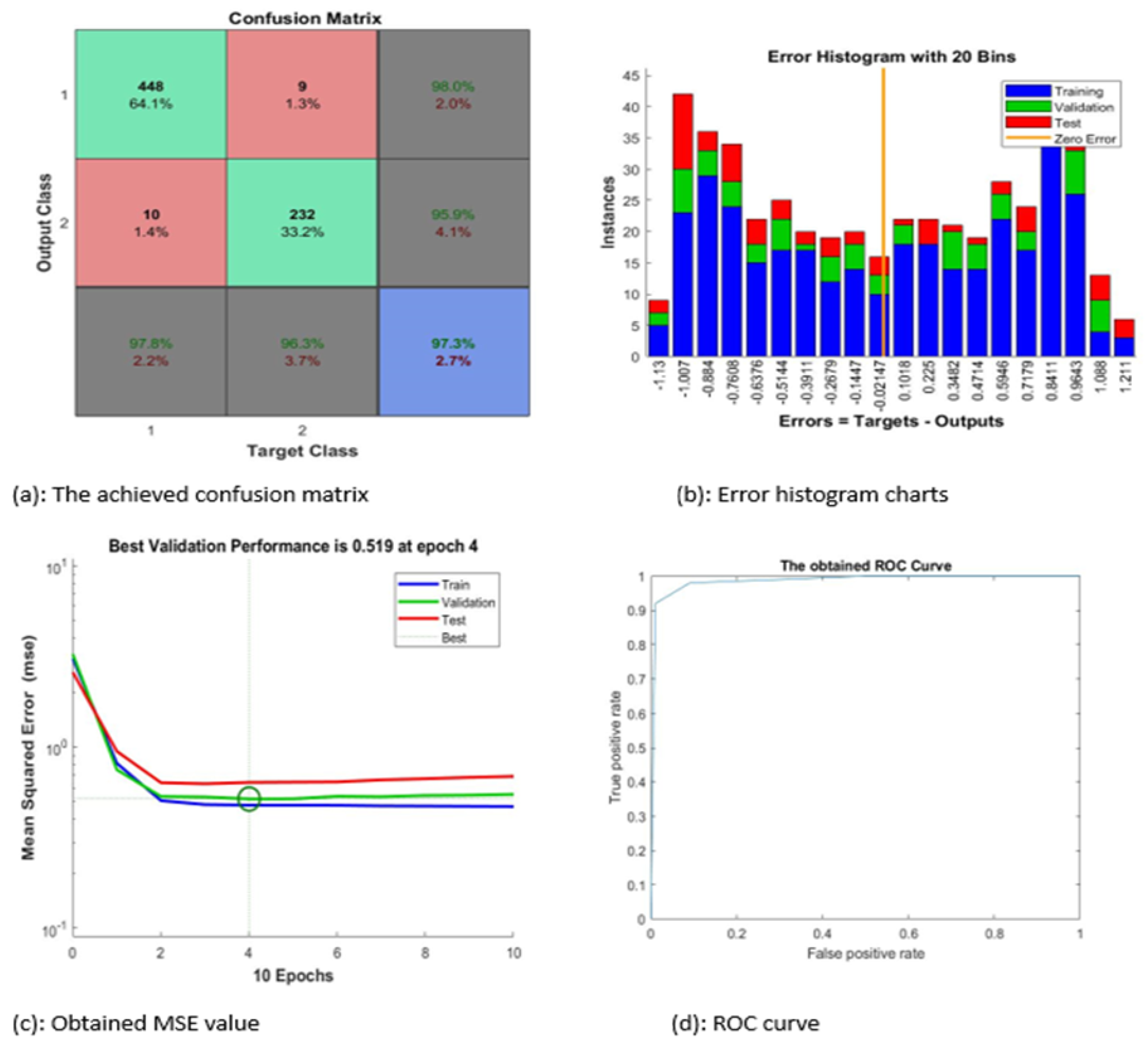
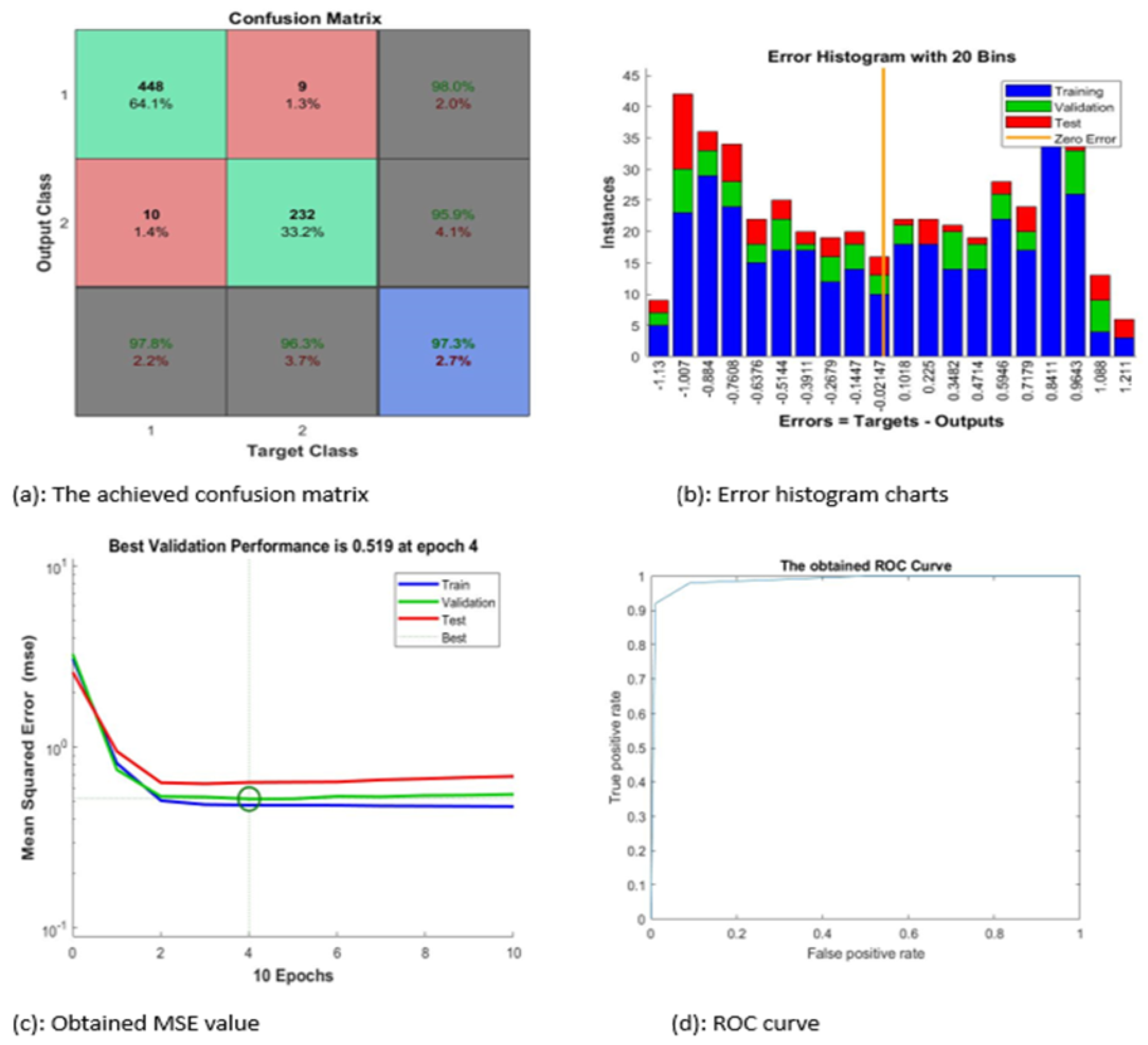
Figure 6 contains four subgraphs: (a) illustrates a confusion matrix for a sample of 700 images, (b) depicts an error histogram, (c) depicts a chart of Mean Squared Error (MSE), and (d) depicts a curve of Receiver Operating Characteristic (ROC). In
Figure 6a, class 1 denotes the ALL type and class 2 refers to the AML type.
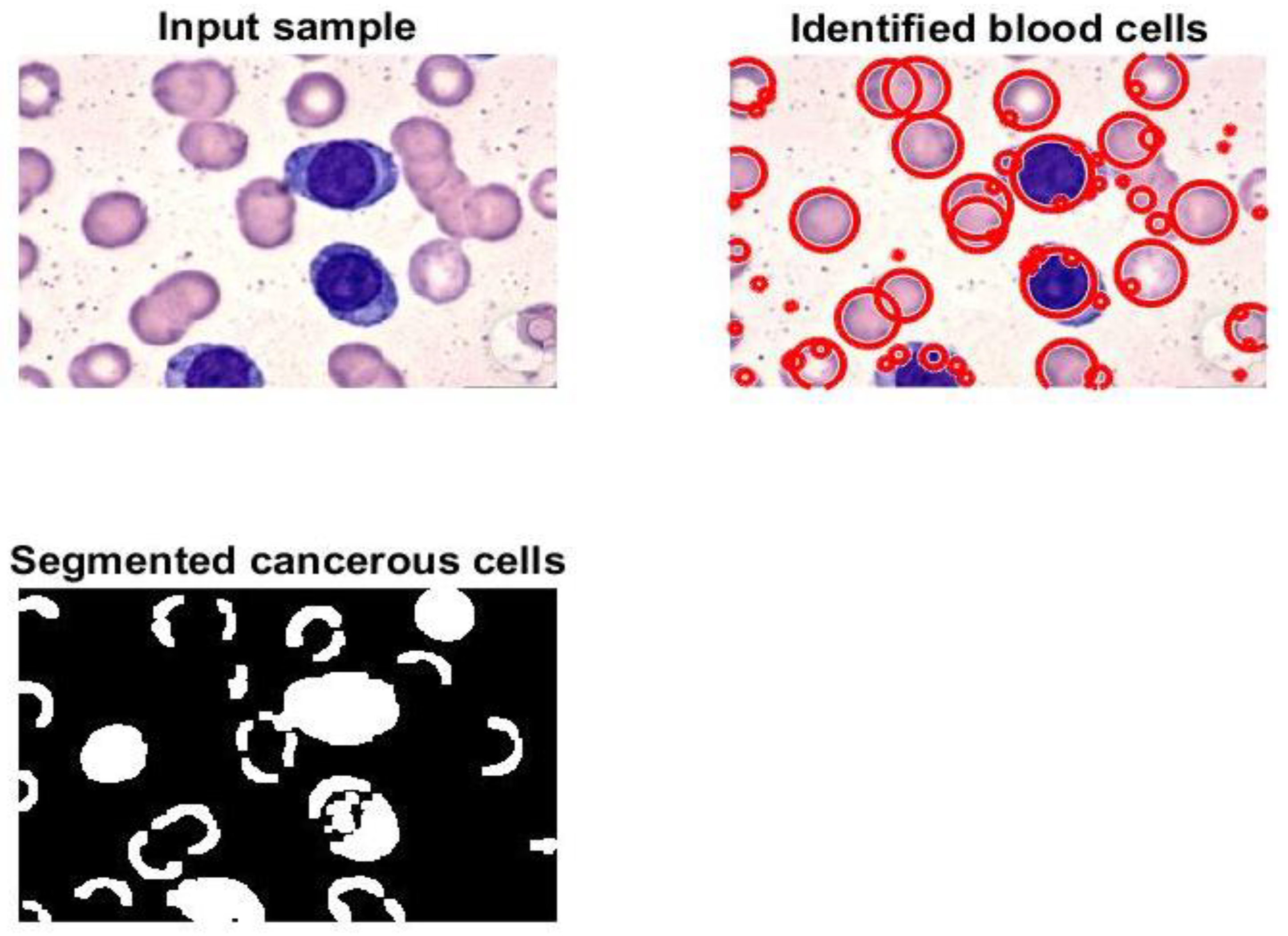
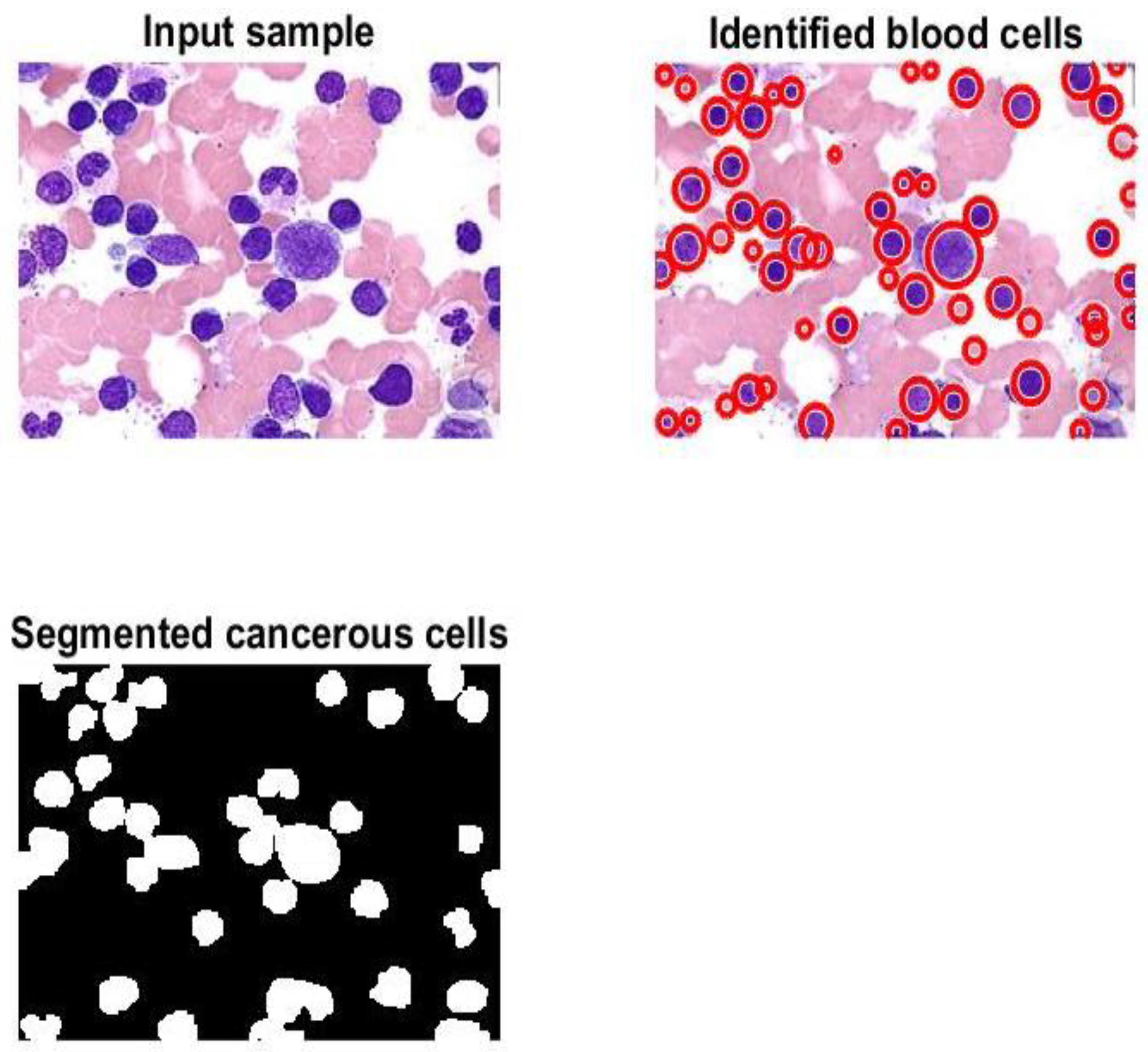
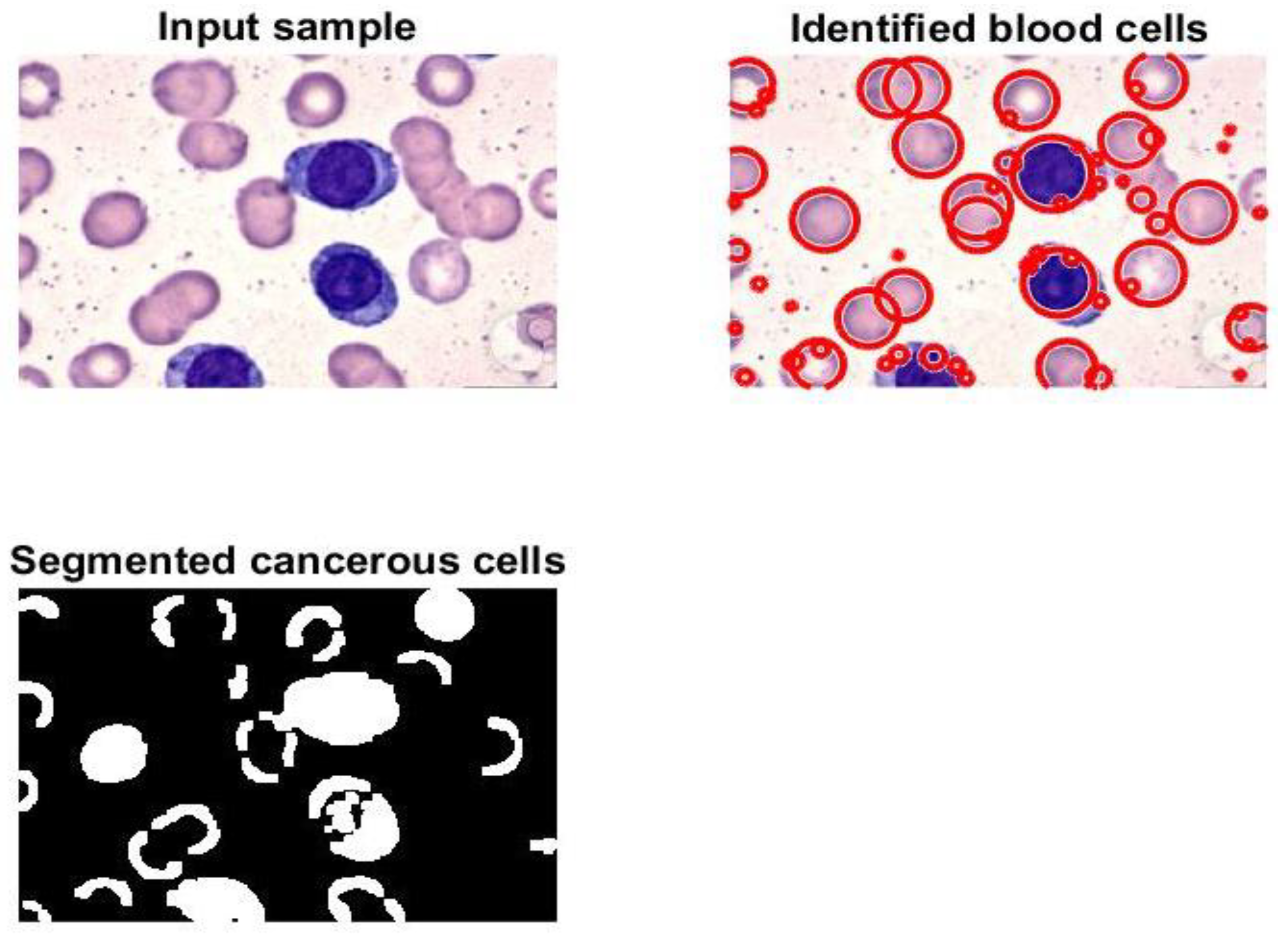
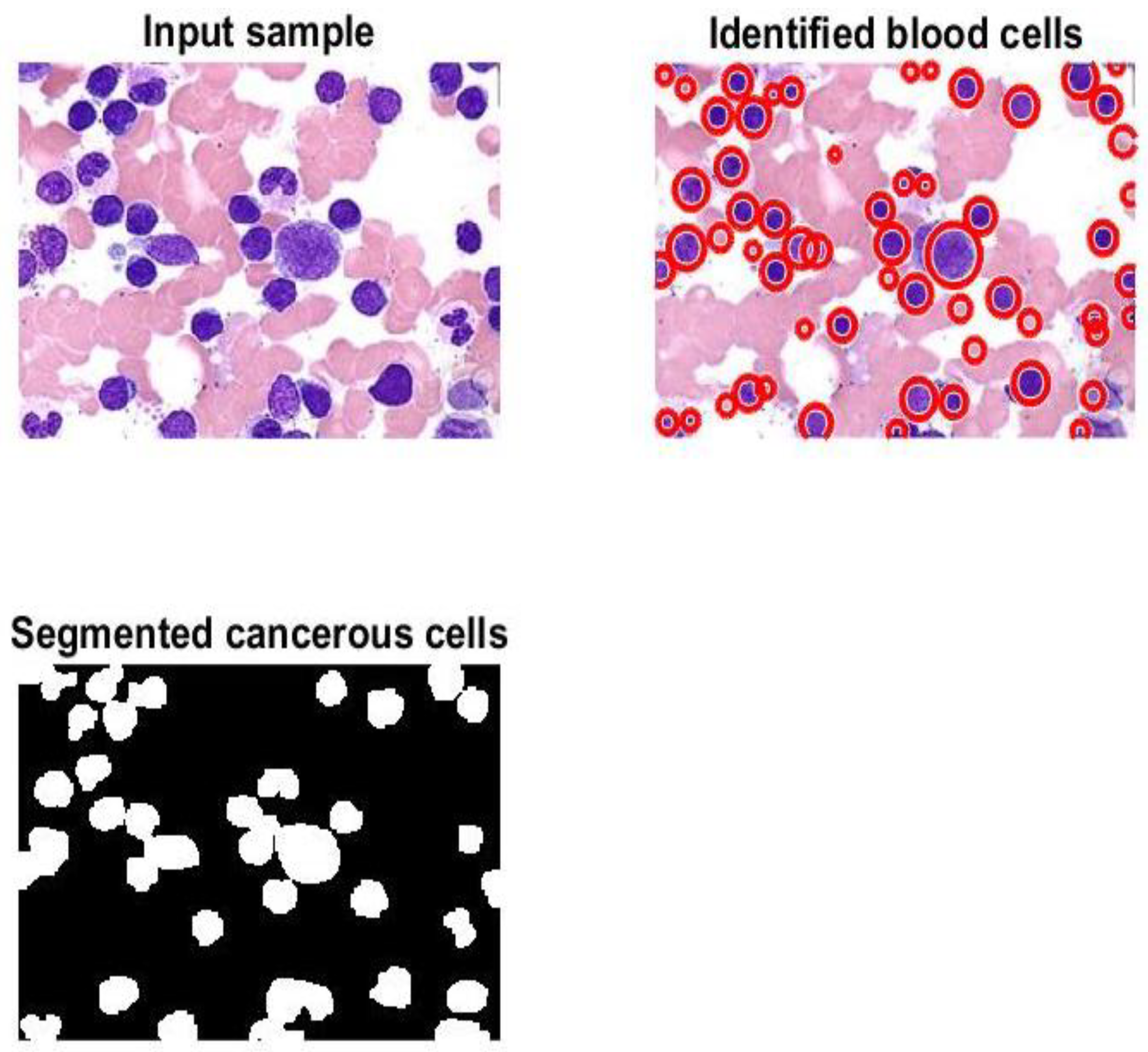
Figure 7 and
Figure 8 display samples of segmentation outcomes for two inputs. Both
Figure 7 and
Figure 8 contain three subgraphs in each. These subgraphs are original inputs, identified and outlined potentially infected cells, and binary segmented masks.
In
Figure 6, the proposed system categorized nearly 97.3% of the given sample accurately. The best value of MSE occurred at epoch 4 with a minimum value of 0.519.
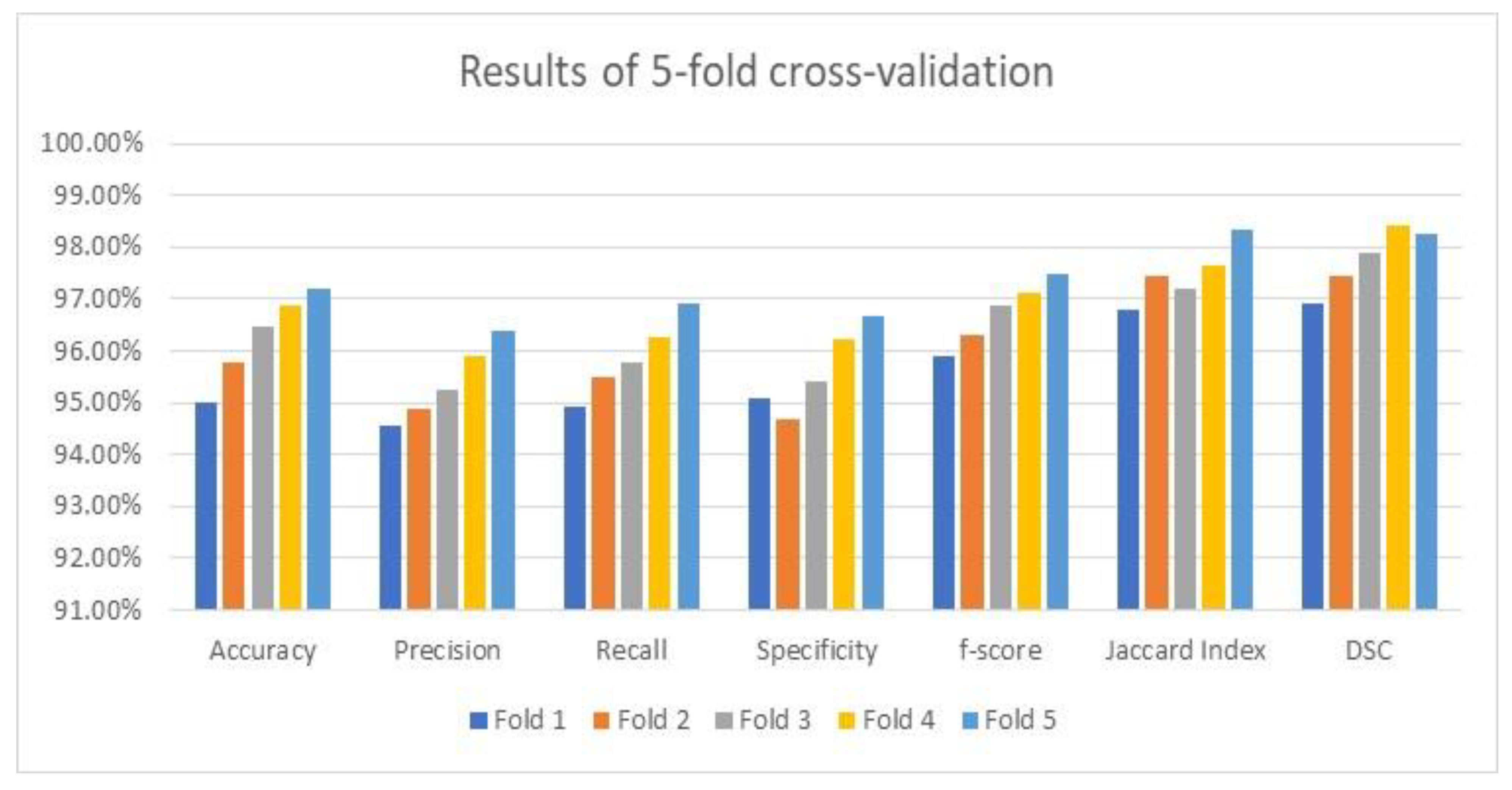
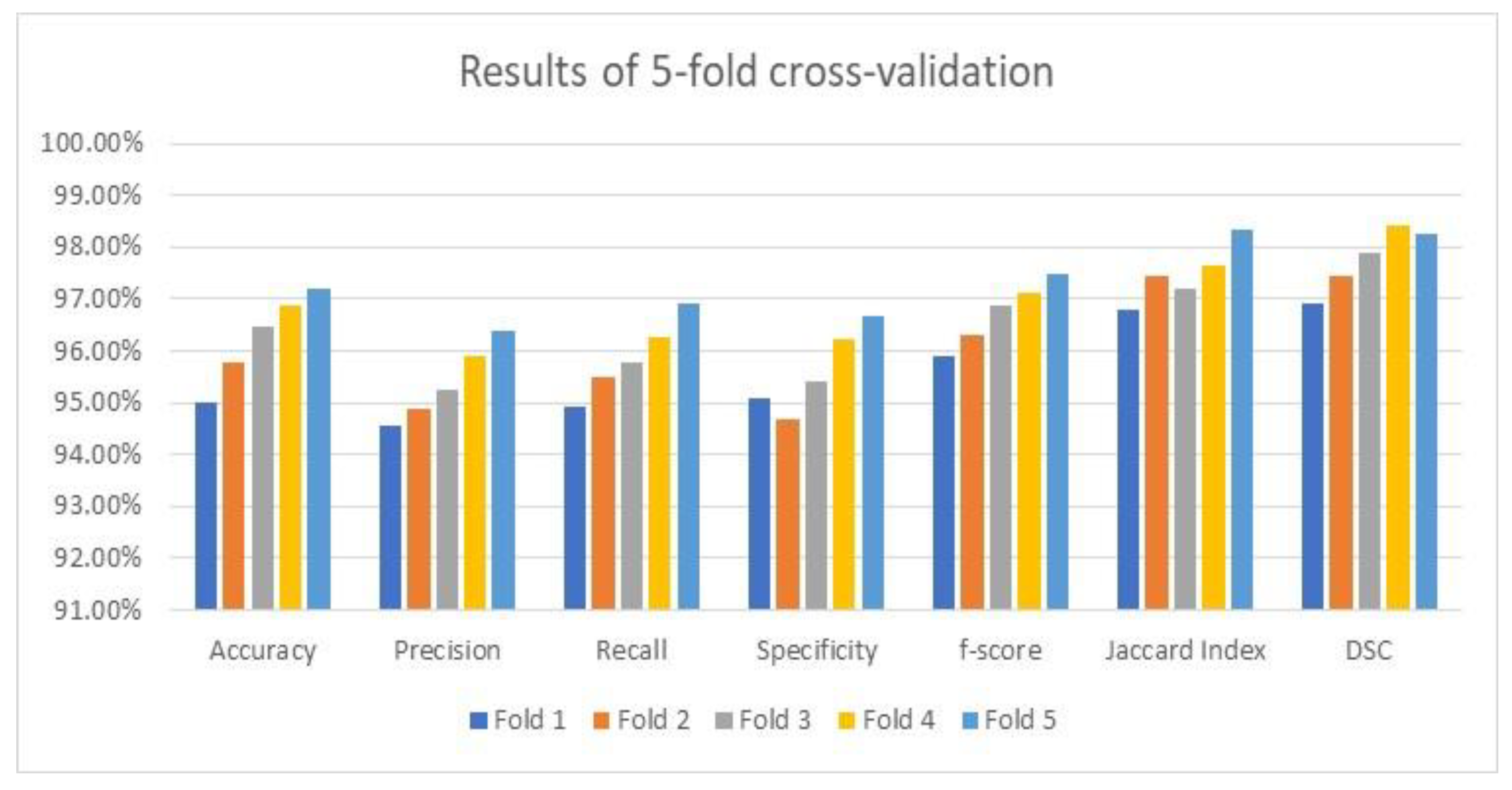
3.4. The Cross-Validation Results
As stated earlier, the utilized datasets were divided into three dependent sets: training, validation, and testing. The testing set was evaluated using an average value on the five-fold cross-validation methodology to prove its accuracy and robustness. The attained average results of the considered performance parameters and their averages by the suggested framework are illustrated in
Figure 9 using the applied optimizer. These results are exquisite and imply that the framework is reliable and trustworthy since accuracy, which is the main focused metric, increased after each fold as depicted in
Figure 9.
Figure 9 shows the visualization charts of the performance parameters using five-fold cross-validation.
3.5. The Influence of Modifying the Deployed Hyperparameters
As shown in
Table 7, the elapsed time for every input is nearly 8.5 s, which is considered higher than what was anticipated. Thus, the hosting machine started suffering from allocated hardware resources. Therefore, modifying or adjusting the applied configurations was required to reduce the execution time and minimize the required resources, such as memory. Thus, reducing the patch size to 6 was the optimal value to achieve the desired outputs. In addition, the decay factor was set to 0.25 to lower the learning rate by the decay factor if no enhancement in accuracy was noticed for seven consecutive epochs. Moreover, the proposed framework used an early stopping strategy to prevent overfitting from occurring. This forced the framework to halt or terminate if it detected an overfitting issue. These modifications improved the execution time by 34.87%, decreased to 5.536 s per image, and the number of total parameters went down by 24.1% and the number of FLOPS decreased by approximately 28%. Accuracy was positively affected since it was enhanced to nearly 98.76%.
3.6. The Statistical Analysis
A statistical analysis between the suggested framework and two traditional convolutional neural networks was performed based on the test based on a statistical parameter, which was the mean. These two convolutional neural networks were LeNet and Residual Neural Network (ResNet). Three performance indicators were measured, which were accuracy, F-score, and Jaccard Index.
Table 9 lists the obtained outcomes; these findings confirmed that the variations between the offered framework and other convolutional neural networks are statistically noticeable. The best results are bold. Moreover, the presented framework surpasses these networks.
4. Discussion
Various metrics of the presented algorithm were evaluated and analyzed. The comparison study in
Table 8 reveals that the model produces encouraging findings, and these results indicate that it is possible to apply the model in healthcare facilities to support physicians and pathologists. Saving patients’ lives can be achieved with support from the proposed method. This method can identify, outline, and segment the potential RoIs appropriately as shown in
Figure 7 and
Figure 8. Moreover, counting of the number of blood cells takes place in this algorithm. The presented framework’s performance was assessed as shown in
Table 6; the obtained results show that exquisite findings were reached and considered promising. In addition, this framework was compared against some developed works from the literature. This comparison is reported in
Table 8, and it shows that the implemented framework outperforms all models except those from [
1,
9]. This assessment demonstrates that the proposed framework shows higher performance than most of the current techniques.
Numerous experiments were performed in this research to exhibit and validate the attained performance results by the presented framework by modifying and adjusting the applied configurations of the hyperparameters and preprocessing methods. The execution time reduced from 8.5 s per image to 5.536 s, which means the improvement was nearly 34.87%. In addition, the number of the total parameters went down from 63.82 million to approximately 48.44 million; the percentage of this reduction is 24.1%. Moreover, the number of FLOPS decreased by approximately 28%. The performed changes affected the performance quantities positively, since accuracy was raised to nearly 98.76%, precision increased to 97.84%, recall went up to 98.02%, specificity enhanced to 97.47%, F-score was raised to nearly 99.21%, and Jaccard Index and DSC increased to 98.61% and 98.76%, respectively.
Investigating the effectiveness of data augmentation on the proposed framework was explored. This investigation showed that applying the framework without data augmentation affected its performance negatively since accuracy dropped to 94.11% due to limitations in capturing the complexities between data. Moreover, other metrics went down significantly. The lowest result was around 90.34% for specificity.
The major limitation/obstacle that this research faced was the availability of all leukemia types as the applied datasets contain only two types, ALL and AML, as stated earlier. In this regard, these datasets are believed to be difficult in many attributes. Firstly, only two types exist with different sizes, which require rescaling for each input. Secondly, rescaling all images takes time, and this results in the elapsed time by the framework. Lastly, these datasets entail multi-class classification on the pixel level of the binary image mode, which forces us to deploy various methodologies to reach the final findings.
5. Conclusions
This article proposes a new algorithm to identify and classify two types of leukemia, which are ALL and AML. This algorithm contains three main components, which are image preprocessing, segmentation, and classification. The segmentation part is developed using U-shaped architecture and the classification procedures are performed using a newly developed UNET. Four datasets were used to validate and test the model. These validation and testing operations were conducted using numerous experiments on the MATLAB platform. The proposed model reached an accuracy between 97% and 99%. However, reaching high accuracy requires increasing the number of iterations and decreasing the patch size. These two factors affect the execution significantly. This approach suffers from computational complexity since a huge number of parameters were involved. In addition, only two types of leukemia were identified and categorized because no public datasets for other types were found. These limitations can be resolved by having additional datasets for the remaining types and optimizing the proposed model to reduce the utilized number of parameters.
Improving classification accuracy, reducing computational complexity, and adding additional datasets will be considered in future work.



 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}