Abstract
The method of alternating projections for extracting low-rank signals is considered. The problem of decreasing the computational costs while keeping the estimation accuracy is analyzed. The proposed algorithm consists of alternating projections on the set of low-rank matrices and the set of Hankel matrices, where iterations of weighted projections with different weights are mixed. For algorithm justification, theory related to mixed alternating projections to linear subspaces is studied and the limit of mixed projections is obtained. The proposed approach is applied to the problem of Hankel low-rank approximation for constructing a modification of the Cadzow algorithm. Numerical examples compare the accuracy and computational cost of the proposed algorithm and Cadzow iterations.
1. Introduction
Problem. Consider the problem of extracting a signal from a noisy time series , where is governed by a linear recurrence relation (LRR) of order r: , , , is noise with zero expectation and autocovariance matrix . There is a well-known result that describes the set of time series governed by LRRs in parametric form: , where are polynomials in n (see, e.g., ([1], Theorem 3.1.1)). Methods based on the estimation of signal subspace (subspace-based methods), and in particular, singular spectrum analysis (see [2,3,4]), work well for the analysis of such signals.
The subspace-based approach starts from fixing a window length L, , putting and constructing the L-trajectory matrix for a series :
where denotes the bijection between and ; is the set of Hankel matrices of size with the equal values on the auxiliary diagonals .
We say that the time series is called a time series of rank r, if its trajectory matrix is rank-deficient and has rank r for any L, . The equivalent definition of series of rank r, , is that -trajectory matrix has rank r ([5], Corollary 5.1). Denote the set of time series of rank r and length N as .
Consider the problem of approximating a time series by series of rank r in a weighted Euclidean norm as the following non-linear weighted least-squares problem:
where , are time series of length N and is the weighted Euclidean norm generated by the inner product
is a symmetric positive-definite weight matrix and is the closure of the set .
The solution of the problem (1) can be used as a finite-rank estimate of the signal . Moreover, the obtained estimate allows one to solve many related problems: estimating the LRR coefficients and time series parameters, forecasting the time series, filling in the gaps (if any) and so on. Note that when , the resulting signal estimate assuming Gaussian noise is the maximum likelihood estimate.
Known solution. To solve the problem (1), consider the related problem of structured low-rank approximation (SLRA; see a review in [6]):
where is the matrix norm generated by the inner product described in [7]:
is the space of Hankel matrices of size ; is the set of matrices of rank not larger than r; and are positive-definite matrices; and and are the matrices related to (1) as and . Then, the estimate of the signal is .
There exists a relation between the weight matrix and the matrices and that provides the equivalence of the problems (1) and (3) [8] and thereby the coincidence of the corresponding signal estimates.
The algorithm for the numerical solution of the Hankel SLRA problem (3) is the Cadzow iterative method (introduced in [9]; see also [4]), which belongs to the class of alternating projection methods [10]. Let us define the following sequence of matrices starting from a given matrix :
where and are projectors on the corresponding sets in the matrix norm generated by the inner product (4). As a numerical solution we can take the value at T-th iteration, that is, , which can then be used as the initial value in local search methods, for example, in VPGN [11] and MGN [12] methods.
The problem of search of matrices and (let us call them “matrix weights” to differ from the weight matrix ) that would correspond to the matrix is already known. The choice is natural for a model with noise autocovariance matrix and leads to the maximum likelihood estimation of the signal. For the case of autoregressive noise (and for white noise in particular), it is shown in [8] that the equivalence of the problems (1) and (3) is possible, only if either the matrix or is degenerate; this is inappropriate when solving the problem with methods of the Cadzow type; see ([13], Remark 4). Thereby, nondegenerate matrices and , which give a matrix approximated by , have to be used. The papers [8,14] are devoted to solving the problems of finding such matrices.
The problem to be solved is parameterized by a parameter . Assume that the matrix is fixed and the matrix is subject to the following constraints: is diagonal, and its condition number is bounded—say, —that is, is the parameter regulating conditionality. By decreasing , we can achieve weights closer to the required weights of , but this reduces the convergence rate of the Cadzow method (5) [13]. Accordingly, by choosing close to or equal to 1, we get an iteration that converges faster, but the weights used are far from optimal, which leads to a loss of accuracy. The question arises: is there a way to modify the Cadzow iterations to obtain both fast convergence and high accuracy?
Proposed approach. We propose to consider “mixed Cadzow iterations” defined in the following way:
where and set the number of iterations performed with matrix weights and , respectively. The approach is to use different weights and that correspond to different to achieve an estimate of the signal that would be both sufficiently accurate and at the same time rapidly computable.
Main results. The main result consists of two parts. Theorem 2 contains the limit properties of (6) in the general case of alternating projections. Theorem 6, which is its corollary, is used to justify the proposed algorithm with mixed alternating projections for solving the problem (3). Section 5.2 demonstrates the capabilities of the proposed algorithm.
Paper’s structure. In this paper, we study general properties of alternating projections (Section 2) and mixed alternating projections (Section 3) and then apply them to Cadzow iterations with a justification of the choice of weights for the projectors participating in the mixed iterations. To do this, we consider a linearized version of the algorithm, where the projection on the set of rank-deficient matrices is replaced by the projection on the tangent subspace to the set of such matrices (Section 4). This allows us to apply the linear operator theory to the mixed iterations (Section 5). Section 5.1 discusses how the algorithm’s parameters affect the accuracy and rate of convergence. In Section 5.2, the obtained results are confirmed by a numerical experiment. Section 6 and Section 7 conclude the paper.
2. Alternating Projections
Consider the linear case where we are looking for a solution to an optimization problem
where and are linear subspaces of with a nonempty intersection of dimension .
The solution to the problem can be found using the method of alternating projections with an initial value of and the iteration step
The following statement is known.
Theorem 1
([15], Theorem 13.7).
that is, the limit of the iterations is equal to the projection on the intersection of the subspaces and .
This allows us to prove the following property. Denote .
Corollary 1.
All the eigenvalues of the matrix lie within the unit circle; the eigenvalue , which only has modulus 1, is semi-simple and has multiplicity equal to ; the corresponding eigenvectors form the basis of .
Proof.
The statement of the corollary is obviously true in the case of diagonalizable matrix , since by Theorem 1, tends to a projection matrix of rank m whose eigenvalues (1 of multiplicity m and 0 of multiplicity ) are the limits of the powers of the eigenvalues of . In the general case, the result is based on the statement “Limits of Powers” in ([16], page 630), which, among other things, states that the eigenvalue 1 is semi-simple—i.e., its algebraic and geometric multiplicities coincide. The geometric multiplicity m of the unit root follows from the fact that the vectors from (and only they) correspond to the eigenvalue 1 of the matrix . □
The following proposition establishes the convergence rate of alternating projections.
Proposition 1.
The following inequality holds:
where is some positive constant, is an arbitrarily small real number and is the largest non-unit (that is, -th) eigenvalue of the matrix .
Proof.
The theorem ([17], Theorem 2.12) implies that for a matrix , the convergence rate of to the limit matrix is determined by the spectral radius of the difference matrix. Namely, for any , there exists a constant C such that , where is the induced norm. By Corollary 1, both matrices and have eigenvalue one corresponding to the same eigenspace. Since the other eigenvalues of are zero, the spectral radius of the difference matrix is , which proves the statement. □
Thus, the convergence rate of the algorithm with iterations given by (8) is determined by the modulus of the eigenvalue : the closer it is to one, the slower the algorithm converges.
Remark 1.
Using the commutativity property and , the expression on the left side of the inequality (9) can be rewritten as
where , , , and are orthogonal complements of the in the subspaces and , respectively. Then is the largest absolute eigenvalue of the matrix .
Let us show the relation of to canonical correlations and principal angles between subspaces.
Proposition 2.
Let be the matrix consisting of a basis of the subspace as its columns and be the matrix consisting of a basis of the subspace as its columns. Then, the following is true:
Proof.
The formula (10) is obtained by multiplying the solutions of two least-squares approximation problems related to the subspaces and . □
Remark 2.
The matrix on the right side of the equality (10) arises in the problem of computing canonical correlations. The squares of canonical correlations are equal to the squares of cosines of the so-called principal angles between subspaces and , spanned by the columns of the matrices, and are calculated using the eigenvalues of this matrix.
Since we need only the leading principal angle, which is the angle between subspaces, we will use the simpler definition of the cosine of the angle between subspaces through the inner product.
Definition 1
([18]). Let and be two linear subspaces of a Hilbert space with inner product and the corresponding (semi-)norm . Then, the cosine of the angle between and is defined as
3. Mixed Alternating Projections
Suppose that different norms may be considered in the problem (7). For example, such a case arises if a weighted least-squares (WLS) problem is solved. Such a problem can be solved both with an optimal weight matrix in terms of the minimum error of WLS estimates and with some suboptimal ones.
Thus, consider two equivalent norms and assume that the application of the method of alternating projections in the first norm leads to a more accurate estimation of the solution, but the algorithm converges slowly, and alternating projections in the second norm, on the contrary, converge faster, but the accuracy of the solution is worse.
We propose a way to speed up the convergence of the algorithm using the first norm, almost without worsening the accuracy of the solution. Let us consider the projectors by two equivalent norms and denote the corresponding matrices and . This notation is introduced and implies both projections in one of the 1st or 2nd norms in the definition , .
The mixed alternating projections are defined as:
where . Since this formula uses only linear operators, we can prove the main theorem of this paper.
Theorem 2.
For the algorithm given by (11), the following relations are true, where convergence is in the operator norm:
- 1.
- if is fixed and .
- 2.
- There exists an equivalent third norm such that if is fixed and .
Proof.
The proof of the first statement follows from Theorem 1: as and also for any .
To prove the second statement, we first apply Theorem 1 to the matrix as , and then consider the matrix . It is sufficient to show that the matrix defines a projection—i.e., ; then, the required projection is in a third norm. By using direct substitution, we obtain:
Since for any , the second statement is proved. □
Theorem 2 has the following interpretation: if one first makes steps with projections in the first norm in the iteration (11), and then iterates with projections in the second norm, then the obtained result will still be a projection on the desired subspace (item 2), and the larger is, the closer this projection will be to the projection in the first norm (item 1). This implies that to achieve fast and accurate estimation, the first norm should correspond to a more accurate solution of the problem and possibly slower convergence of the alternating projections, and the second norm can correspond to a less accurate solution but faster iterations. The rate of convergence of the corresponding operators is explained by Proposition 1.
A general rule in optimization is that the accuracy of two successive optimization methods is inherited from the second method, so the first method is chosen to be fast and possibly inaccurate, and the second method to be more accurate. Theorem 2 shows that in alternating projections, the situation is in some sense the opposite. This can be explained as follows. Optimization methods use the target function at each step, and can therefore adjust the steps. In the case of alternating projections, initial data are used only to compute the first iteration. Therefore, it is important to perform the first iterations in the proper direction.
4. Linearized Cadzow Iterations in the Signal-Estimation Problem
In the next Section 5, we apply the approach proposed in Section 3 to solving the SLRA problem (3) to estimate signals in time series. Since this approach considers alternating projections to linear subspaces, we start with linearization of the Cadzow iteration (5). The Cadzow iteration is not linear because it uses the projection onto the nonconvex set of matrices of rank not larger than r, which is not a closed subspace but is a smooth manifold [19].
Let us sketch the way of linearization in the neighborhood of a time series of rank r. First, we consider the set in the neighborhood of the point . The projection in the neighborhood of this point is correctly defined if we solve the signal-estimation problem for a noisy time series of the form , where is a random vector with a zero mean and an autocovariance matrix proportional to , where the variances are small enough and is a given weight matrix. After that, we construct a linearized iteration by replacing the set with a tangent subspace at . Then, we can reduce the linearized iteration to a multiplication by a real matrix and find its properties. As a result, we obtain asymptotic relations for the linearization which explains the yield of the full Cadzow iteration (5).
4.1. Linearization of the Operator
Consider the matrix , and , where and is a series of rank r; hence, the matrix has rank r. In the neighborhood of the point , the set is a smooth manifold of dimension , and the tangent subspace at is expressed as follows [19]:
where and are arbitrary full-rank matrices such that and . Note that the definition is correct because depends only on and .
Let us denote by the projection on in the norm generated by (4). Then, the linearized Cadzow iteration in the neighborhood of the point has the following form:
Set , , . Then, we can rewrite (13) as
Note that each of the operators inside the brackets is linear. Hence, their composition is a linear operator and therefore can be written as a matrix, which we denote :
Formally, we can calculate the elements of the matrix by successive substituting N standard unit vectors into the composition of operators.
4.2. Intersection of Subspaces
For a compact representation of the further results, let us describe the intersection of the tangent subspace to the set of matrices of finite rank and the space of Hankel matrices .
Let us gather necessary definitions from [12].
Definition 2.
We say that a series is governed by a generalized linear recurrence relation (GLRR) with coefficients , where and , if . We denote by the subspace of time series governed by the GLRR().
Consider an equivalent form of . Denote by the operator defined as follows:
where . Then, can be represented in another form as
where [20].
Remark 3.
Since the columns and rows of the trajectory matrix of a time series in satisfy the same GLRR() as the original series does, we can take and as and in (12), respectively.
Definition 3.
Let . Denote by the acyclic convolution of the vector with itself:
As shown in [12], the tangent subspace to at coincides with , . The following theorem establishes the relation between the tangent subspaces to the manifold of time series governed by GLRRs and the manifold of their trajectory matrices.
Theorem 3.
Let ; i.e., let be a series of rank r, , and —i.e., let be governed by the GLRR() for a vector . Then, , where .
Proof.
Consider a matrix in the intersection of and . In particular, there exists : . Let us calculate the -th element of the matrix from (12) following Remark 3:
where are coefficients of the vector ; see definition (17). The values of , where i runs from 1 to and j runs from 1 to , cover the entire interval from 1 to , and therefore, (18) is equivalent to . Thus, according to (16), all such constitute . □
4.3. Limit Property of the Composition of Projections
First, consider the relation connecting the (semi-)norm generated by the inner product (2) and the (semi-)norm , which is generated by the inner product (4) (semi-norms arise if not to require nondegeneracy of the matrices , and ). The mapping preserves the norm if for any , where , and are matrix weights and is a weight matrix.
Define the convolution of the two matrices for , and as
where , and .
There is a known relation linking the weight matrix to the matrix weights.
Theorem 4
([8]). for any series if and only if .
All statements of the following theorem are a direct application of Theorem 1 and Proposition 1 with consideration to
and .
Theorem 5.
Let be a time series governed by a GLRR(), . Then
- 1.
- The following operator convergence takes place:that is, the limit of iterations is equal to the projection on the intersection of the subspaces and .
- 2.
- The following matrix convergence is valid:where denotes the matrix of projection on the linear subspace in the norm generated by the inner product (2) with the weight matrix .
- 3.
- All the eigenvalues of the matrix lie within the unit circle; the eigenvalue , which only has modulus 1, is semi-simple and has multiplicity equal to ; the corresponding eigenvectors form the basis of . If the weight matrix is nondegenerate,where C is some positive constant, is any small real number, is the largest non-unitary (that is, -th) eigenvalue of the matrix .
4.4. Influences of the Matrices and on the First Principal Angle and Convergence Rate of the Cadzow Method
Recall that if one wants to solve the problem (1) for a given weight matrix using the Cadzow method, one must require . To obtain the maximum likelihood estimate, the matrix is chosen as the inverse of the noise autocovariance matrix. However, for such weight matrices in the case of white or autoregressive noise, there are no nondegenerate matrix weights and . Therefore, the matrix weights and are sought numerically under the upper bound of the condition number of for a given .
The works [13,14] are devoted to the search for appropriate matrix weights. To find these weights, the matrix was fixed in some specific way, and the diagonal matrix was numerically found such that the measure of discrepancy considered in these papers was minimal: provided , where . Simulations have shown that the control of matrix conditionality by the parameter affects the convergence rate of the Cadzow method and the estimation accuracy. Decreasing increases the set on which the matrix is matched; this allows us to obtain a weight matrix with smaller values of and leads to improved accuracy of the signal estimate. However, decreasing also results in slower convergence of the iterations, which requires a theoretical explanation. A general theoretical dependence on could not be obtained, so we demonstrate the convergence rate when tends to zero.
We know from Theorem 5 that the convergence rate of the methods is affected by the -th eigenvalues of the matrix . From Remark 2, we know that this eigenvalue is equal to the squared cosine of the -th angle between the corresponding subspaces.
The calculation of the cosine of the -th principal angle between and can be reduced to finding the cosine between the orthogonal (in the inner product , given in (4)) complements to in and , respectively. Let us denote these complements and . Note that by Theorem 3, , and its rank equals . For brevity, we will omit in and .
The properties of the principal angles concerning Remark 1 lead directly to the following statement.
Proposition 3.
The cosine of the -th principal angle between the subspaces and is equal to .
4.4.1. Example of Bad Convergence as Tends to Zero
Using Proposition 3 and the fact that the cosine of the -th principal angle determines the convergence rate (Proposition 1), we show by a specific example that this cosine tends to one as tends to zero; this makes the convergence of the linearized Cadzow algorithm as slow as possible.
Let and . Let the matrix weights be the identity matrix, which corresponds to the case of white noise. For simplicity, we make the matrix equal to according to [13]. Numerical experiments show that similar matrix weights (up to multiplying a constant) are obtained when applying the method from [12] of finding weights for small . Consider the degenerate case studied in [13].
Proposition 4.
For any matrix , we can find a matrix such that .
Proof.
The inner product (4) of matrices and with the matrix weights and depends only on the first and last columns of these matrices due to the form of . Therefore, the required matrix can be written in the form , where the projection is calculated uniquely using the values from the first and last columns of the matrix . □
Corollary 2.
Let be an arbitrary matrix, , . Then, .
Proof.
The corollary is proved by the following substitution:
. □
Corollary 3.
Let . Denote and . Then, the following is fulfilled:
Proof.
Since , this expression is smooth in and uniquely defined when . The projection is also smooth in and uniquely defined at . Applying Corollary 2 for and , we obtain that ; this yields the statements of the corollary due to the smoothness of the left-side and right-side expressions. □
The declared result is described in the following proposition.
Proposition 5.
Let and . Then,
Proof.
Note that the cosine of the angle between a vector and a subspace (see Definition 1) is equal to the cosine between this vector and its projection to the subspace. Thus, we can use Corollary 3. It follows from Corollary 3 that the numerator and denominator in the definition of cosine are equal, and therefore, it is sufficient to prove that . The latter can be shown by constructing such a matrix from the trajectory matrix .
Let be a row of the matrix with a non-zero element at the first or last position (such a row always exists since ). Without loss of generality, we suppose that the first element of is not zero. Denote the mapping that truncates the vector to the first L coordinates. Then, let be a nonzero vector, which does not lie in , and . By construction, and have a nonzero first column, and therefore, . □
Thus, for a popular case , we have shown that the cosine of the -th principal angle can be as close to 1 as one wishes; hence, the convergence of the Cadzow method becomes as slow as one chooses with a small . Recall that the sense of choosing a small is to increase the estimation accuracy.
4.4.2. Numerical Example for the Dependence of Convergence on
Figure 1 shows the -th eigenvalue of the (the squared cosine of the -th principal angle between the corresponding subspaces) for the series with the common term and ; the window length is and the signal rank is . The values are taken from on the logarithmic scale, and the matrix is calculated using the weight search method from [14]. Figure 1 demonstrates that the eigenvalues are close to 1 for small ; however, they do not equal one; that is, the Cadzow iterations converge. This result explains the decrease in the convergence rate of the Cadzow method with decreasing values of the parameter , which was numerically demonstrated in [13,14].
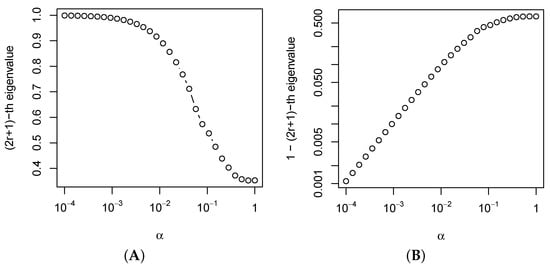
Figure 1.
(A) The -th eigenvalue of depending on ; (B) gap between 1 and -th eigenvalues of in the logarithmic scale.
5. Mixed Cadzow Iterations
5.1. Convergence of Linearized Mixed Iterations
Let us introduce a linearized analogue of the mixed Cadzow algorithm (6), using the matrix defined in (14). Instead of (6), we will study
where . Since this formula uses only linear operators, the following theorem follows directly from Theorem 2.
Theorem 6.
Let be a time series governed by the GLRR(). The following relations are true for iterations (20), where convergence is in the operator norm:
- 1.
- if is fixed and .
- 2.
- There is a symmetric positive-definite matrix such thatif is fixed and .
Thus, to achieve fast and accurate estimates, the weights should correspond to more accurate but possibly slower-converging Cadzow iterations, and the weights should correspond to less accurate but faster-converging iterations. The convergence rate of the corresponding operators is explained by Proposition 1. As follows from the discussion in Section 4.4, the pair of matrices is natural to choose as an approximation of the optimal weight matrix with a small parameter , and the pair corresponds to a larger value .
5.2. Numerical Experiments
In this section, we demonstrate the result of Theorem 6 through a numerical experiment. Consider the problem of estimating a finite-rank signal when it is corrupted by noise. As in Section 4.4.2, the signal has the form , where and . The observed time series is , where is Gaussian white noise with zero mean and standard deviation .
Let us apply iterations given in (6) for estimating the signal . Set and . Let us take iterations with one of three values of , 0.5, 0.1 and 0.01, and then iterations with . For the second iterations, we consider the identity matrices and (this choice corresponds to ). For the choice of , we set as the identity matrix, and for a given , we calculated the matrix of weights using the method described in [14].
We denote the results of the iterations and the signal estimate . For the linearized version (20), we can use the theoretical considerations. For the Cadzow mixed iterations (6), we have no theoretical results and estimated the error using simulations of time series with different realizations of noise. The accuracy of the estimate was measured by RMSE (root mean square error) and estimated as the square root of the sample mean of I realizations of .
The estimate of the signal using the linearized Cadzow algorithm has the form , where was taken from the second statement of Theorem 6 and GLRR() governs the signal . To calculate RMSE of , we consider its autocovariance matrix , where is the autocovariance matrix of . Then, RMSE can be calculated by taking the square root of the average value of the diagonal elements of , since the i-th element of the diagonal is the variance of .
The results are shown in Figure 2. The legend denotes the values of for obtaining the matrix weights , and which method was used (“Linear” corresponds to linearization (20), and “True” corresponds to the original Cadzow method (6)). To demonstrate the statement 2 of Theorem 6, we took a large , which numerically corresponds to the case .
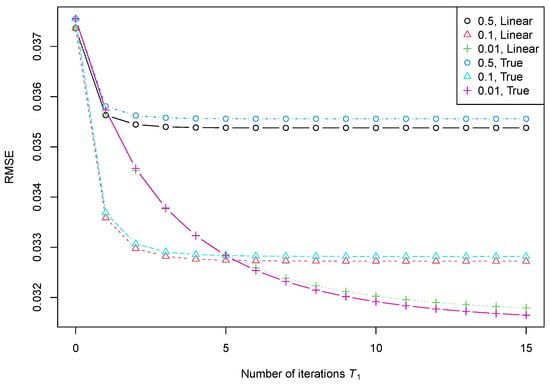
Figure 2.
RMSE (root mean square error) depending on and . The signal rank 2 and the target rank 2.
We see that the results predicted for the linearized Cadzow iterations and estimated by simulation for the original Cadzow iterations are similar.
To demonstrate that the proposed approach allows one to improve the computational costs while keeping the accuracy high, let us consider the dependence of RMSE on , where the total number of iterations changes from 1 to 10 and .
In Figure 3, the case (marked as “”) corresponds to the case of fast convergence but low accuracy for standard Cadzow iterations with . The case (“”) corresponds to the case of slow convergence but has good accuracy for Cadzow iterations with . The mixed iterations with two and four iterations with and then iterations with (“” and “” respectively) show their advantage in computational cost. One can see that one iteration of the second type is sufficient to almost achieve the limiting accuracy. Thereby, for example, four iterations with and one iteration with provide approximately the same accuracy and two-times faster than 10 iterations with .
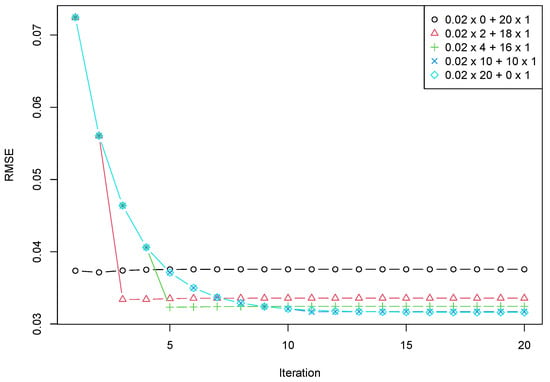
Figure 3.
RMSE depending on + . The signal rank 2 and the target rank 2.
6. Discussions
In the previous section, we demonstrated the potential advantage of mixed Cadzow iterations. The following questions arise for use in practice. The first important issue to discuss is the stability of the demonstrated effect. One source of perturbation is that the signal rank can be inaccurately estimated. Of course, if the rank is underestimated, most methods fail. The question is the robustness of the method to rank overestimation. Let us take the time series from Section 5.2 with a signal of rank 2 and consider a projection onto a subspace of rank 4 in alternating projections (target rank 4). Figure 4 shows that the general error behaviour is similar to that in Figure 3; the only differences are the convergence rate and the number of accurate steps required.
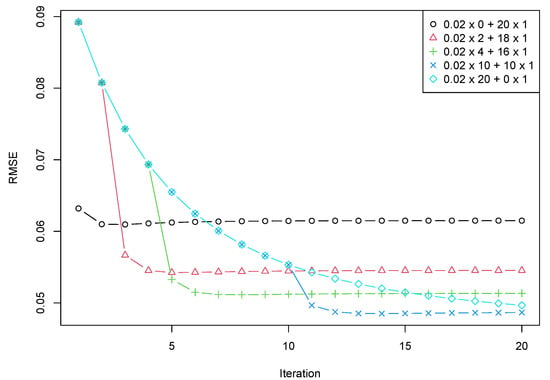
Figure 4.
RMSE depending on + . The signal rank 2 and the target rank 4.
The second example is related to the stability of the result concerning the signal rank. We changed the signal from the previous example to . Figure 5 demonstrates the same effect: similar behavior of the error dynamics and a lower rate of convergence. Note that the convergence for the case of rank 6 is much faster than for the overestimated rank 2.
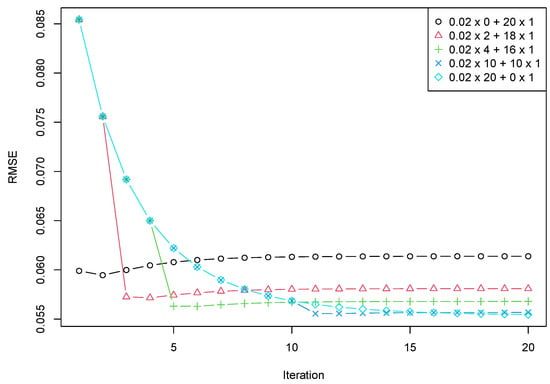
Figure 5.
RMSE depending on + . The signal rank 6 and the target rank 6.
Both examples show that the number of first accurate iterations depends on the structure of the series. Therefore, the choice of the number of accurate steps should be investigated in the future.
The next point of discussion is the possibility of speeding up the implementation of Cadzow iterations. Ideas from [21], including the randomized linear algebra approach [22,23], can be applied to Cadzow iterations. Combining the mixed alternating projection approach and approaches to single iteration acceleration may be a challenge for future research.
7. Conclusions
In this paper, an approach for improving the alternating projection method by combining the alternating projections in two equivalent norms was proposed and justified. The approach in general form was considered for the case of projections to linear subspaces (Theorem 2). Then, this approach was applied to the problem of Hankel low-rank approximation, which is considered for the estimation of low-rank signals and is not linear. The theoretical results were obtained using the linearization (13). Numerical experiments confirmed that the linearization provides the correct conclusions for the convergence of the mixed Cadzow iterations (6). Using the theory of principal angles, it was shown why improving the estimation accuracy leads to increasing the computational cost of the conventional Cadzow iterations (Section 4.4). Using the features of the projector compositions, it was shown how the signal estimation can be improved by a combination of iterations with different norms (Theorem 6).
As a result, the algorithm, which modifies the Cadzow weighted iterations by combining a good accuracy of slow iterations and a fast convergence of inaccurate iterations, was proposed.
The numerical example in Section 5.2 demonstrates the effectiveness of the elaborated approach. The examples are implemented in R using the R-package rhlra, which can be found at https://github.com/furiousbean/rhlra (accessed on 13 October 2022); see the R-code of the examples in Supplementary Materials.
Supplementary Materials
The R-code for producing the numerical results that are presented in the paper can be downloaded at https://www.mdpi.com/article/10.3390/a15120460/s1.
Author Contributions
Conceptualization, N.Z. and N.G.; methodology, N.G.; software, N.Z.; validation, N.Z. and N.G.; formal analysis, N.Z. and N.G.; investigation, N.Z. and N.G.; resources, N.G.; writing—original draft preparation, N.Z. and N.G.; writing—review and editing, N.Z. and N.G.; visualization, N.Z.; supervision, N.G.; project administration, N.G.; funding acquisition, N.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by RFBR, project number 20-01-00067.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We thank the two anonymous reviewers whose comments and suggestions helped to improve and clarify this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SLRA | Structured Low-Rank Approximation |
| (G)LRR | (Generalized) Linear Recurrence Relation |
| RMSE | Root Mean Square Error |
References
- Hall, M. Combinatorial Theory; Wiley-Interscience: Hoboken, NJ, USA, 1998. [Google Scholar]
- Van Der Veen, A.J.; Deprettere, E.F.; Swindlehurst, A.L. Subspace-based signal analysis using singular value decomposition. Proc. IEEE 1993, 81, 1277–1308. [Google Scholar] [CrossRef]
- Gonen, E.; Mendel, J. Subspace-based direction finding methods. In Digital Signal Processing Handbook; Madisetti, V., Williams, D., Eds.; CRC Press: Boca Raton, FL, USA, 1999; Volume 62. [Google Scholar]
- Gillard, J. Cadzow’s basic algorithm, alternating projections and singular spectrum analysis. Stat. Interface 2010, 3, 335–343. [Google Scholar] [CrossRef]
- Heinig, G.; Rost. Algebraic Methods for Toeplitz-like Matrices and Operators (Operator Theory: Advances and Applications); Birkhäuser Verlag: Basel, Switzerland, 1985. [Google Scholar]
- Gillard, J.; Usevich, K. Hankel low-rank approximation and completion in time series analysis and forecasting: A brief review. Stat. Interface 2022, accepted. [Google Scholar]
- Allen, G.I.; Grosenick, L.; Taylor, J. A generalized least-square matrix decomposition. J. Am. Stat. Assoc. 2014, 109, 145–159. [Google Scholar] [CrossRef]
- Golyandina, N.; Zhigljavsky, A. Blind deconvolution of covariance matrix inverses for autoregressive processes. Linear Algebra Appl. 2020, 593, 188–211. [Google Scholar] [CrossRef]
- Cadzow, J.A. Signal enhancement: A composite property mapping algorithm. IEEE Trans. Acoust. 1988, 36, 49–62. [Google Scholar] [CrossRef]
- Escalante, R.; Raydan, M. Alternating Projection Methods; SIAM: Philadelphia, PA, USA, 2011. [Google Scholar]
- Usevich, K.; Markovsky, I. Variable projection for affinely structured low-rank approximation in weighted 2-norms. J. Comput. Appl. Math. 2014, 272, 430–448. [Google Scholar] [CrossRef]
- Zvonarev, N.; Golyandina, N. Fast and stable modification of the Gauss–Newton method for low-rank signal estimation. Numer. Linear Algebra Appl. 2022, 29, e2428. [Google Scholar] [CrossRef]
- Zvonarev, N.; Golyandina, N. Iterative algorithms for weighted and unweighted finite-rank time-series approximations. Stat. Interface 2017, 10, 5–18. [Google Scholar] [CrossRef]
- Zvonarev, N.K. Search for Weights in the Problem of Finite-Rank Signal Estimation in the Presence of Random Noise. Vestn. St. Petersburg Univ. Math. 2021, 54, 236–244. [Google Scholar] [CrossRef]
- Von Neumann, J. Functional Operators: The Geometry of Orthogonal Spaces; Annals of Mathematics Studies, Princeton University Press: Princeton, NJ, USA, 1950. [Google Scholar]
- Meyer, C.D. Matrix Analysis and Applied Linear Algebra; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 2001. [Google Scholar]
- Bauschke, H.H.; Cruz, J.Y.B.; Nghia, T.T.A.; Phan, H.M.; Wang, X. Optimal Rates of Linear Convergence of Relaxed Alternating Projections and Generalized Douglas-Rachford Methods for Two Subspaces. Numer. Algorithms 2016, 73, 33–76. [Google Scholar] [CrossRef]
- Bjorck, A.; Golub, G.H. Numerical Methods for Computing Angles between Linear Subspaces. Math. Comput. 1973, 27, 579. [Google Scholar] [CrossRef]
- Lewis, A.S.; Malick, J. Alternating projections on manifolds. Math. Oper. Res. 2008, 33, 216–234. [Google Scholar] [CrossRef]
- Usevich, K. On signal and extraneous roots in Singular Spectrum Analysis. Stat. Interface 2010, 3, 281–295. [Google Scholar] [CrossRef]
- Wang, H.; Cai, J.F.; Wang, T.; Wei, K. Fast Cadzow’s Algorithm and a Gradient Variant. J. Sci. Comput. 2021, 88, 41. [Google Scholar] [CrossRef]
- Erichson, N.B.; Mathelin, L.; Kutz, J.N.; Brunton, S.L. Randomized Dynamic Mode Decomposition. SIAM J. Appl. Dyn. Syst. 2019, 18, 1867–1891. [Google Scholar] [CrossRef]
- Minster, R.; Saibaba, A.K.; Kar, J.; Chakrabortty, A. Efficient Algorithms for Eigensystem Realization Using Randomized SVD. SIAM J. Matrix Anal. Appl. 2021, 42, 1045–1072. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).