1. Introduction
Face recognition is a kind of biometric identification technology based on the facial features of people. A series of technologies relate to face recognition by using cameras to collect images or video streams containing faces, and automatically detect and track faces in the images. Face verification is a subfield of face recognition, which refers to several images containing faces to judge whether these faces belong to the same identity. The method is to extract facial features from the target image to be verified, and then traverse the database of the known identity of facial features.
Due to the popularity of camera technology and the upsurge of machine learning, the basic research of face recognition has been relatively mature. According to a 2020 study by MarketsandMarkets, the global biometric systems market is expected to be worth USD 36.6 billion by 2021, and grow to USD 68.6 billion by 2025, with a CAGR of 13.4% during the forecast period (2021–2025).
The application of neural networks improves the performance of face recognition to a new level. The development trend is to build a deeper and more complex network to achieve higher accuracy, but the storage space and speed causes difficulties when attempting to meet the requirements of universal application. Face recognition includes multiple subtasks, which is often inefficient when the neural network-based face recognition algorithm is run locally on common devices. There are disadvantages such as high delay and poor user experience, and to date no good solution has been found. To solve this problem, we researched the unified and efficient neural network algorithm for face recognition under the condition of a single camera, and propose a fast and efficient unified network: UFaceNet.
The paper [
1] points out that there is a certain quantifiable correlation between computer vision tasks, and that the reasonable use of the relationship between individual tasks can improve the performance of said tasks. There are many starting points for introducing multitasking in the network. From a biological point of view, multitasking is similar to the simulation of human learning processes; humans use the knowledge of related tasks to learn new tasks. From an educational point of view, learning a simple task can help people master more complex tasks faster. As for the neural network model, multi-task learning avoids bias to meet the requirement of its hypotheses which provide sparse solutions, and can learn from the solutions that can explain more tasks at the same time. The model has better generalization [
2].
UFaceNet uses Deep Detectable Convolutional Network as its model infrastructure to jointly learn, using this unified network, four subtasks: face detection, body detection, keypoint detection, and face verification. We hope to reduce the network time complexity while learning more advanced features with more generalizability. By sharing the shallow network between simple tasks and the deep network between complex tasks, the characteristics between tasks can be shared to reduce the amount of computing required by the network, and the model can be accelerated. At the same time, the attention mechanism is used to cut the feature level by using the basic face keypoints output in the network, so that the advanced tasks in the network (such as the accurate face keypoint detection and face verification) can focus on a specific space, making the model more robust and accurate.
Our main contributions are as follows:
(1) We proposed a unified model network integrating face recognition related subtasks (UFaceNet), which can effectively use multi-task information for supervised learning of the network and improve the network generalization ability.
(2) We have made use of the association between multiple subtasks in face recognition, designed inter-task dependencies to ensure network accuracy, used task fusion to improve network efficiency, and realized the acceleration of unified network learning and reasoning by sharing shallow convolution features among tasks.
(3) We have designed and completed the common training process of the multisource multitask dataset with the unified model for the case where there is no single dataset covering all face recognition-related subtask tags.
2. Related Work
Face detection works to find the position of all faces in an image. Generally, the input is an image, and the output is the coordinates of any rectangular frames that detect the faces. Face detection is the basis of various face image analyses, and it is also the first step in the overall face verification algorithm. The main difficulties in face detection include: the diversity of facial gestures and angles, the influence of illumination intensity and angle, the possibility of partial occlusion of the face, the proximity of the face position affects the size of the face, and the face may appear in various positions of the image. At present, face detection algorithms can be divided into three categories: VJ framework-based, DPM model-based, and convolutional neural network-based.
In [
3], the VJ framework was proposed by Viola and Jones in 2001. They used the integral graph to quickly calculate the Haar features of an image. The Haar features can reflect the contrast between parts of an image. The algorithm uses AdaBoost as a classifier and adopts a cascading structure, which greatly improves the detection efficiency. Under the hardware conditions at that time, the processing speed can reach 15 fps. However, the VJ framework also has some shortcomings. Haar features are too simple and have insufficient stability. Moreover, the use of decision trees as weak classifiers can easily lead to overfitting. It also does not work well when the face is partially obscured or has an exaggerated expression.
In [
4], Deformable Part Model (DPM) is a variable component model. At the time of detection, the model first calculates the DPM feature map of the input image, and then the input image is unsampled by Gaussian pyramid to obtain an image twice as large as the original, and the DPM feature map is calculated. The model then uses the root filter to obtain a response map for the DPM feature map. The model uses the part filter for the feature map of the upsampled image, and then performs Gaussian pyramid downsampling on the obtained response graph. Thus, the response maps obtained by the root filter and the part filter have the same resolution. Finally, the response graph is weighted and averaged to obtain the final response graph. The DPM-based method can achieve better face detection than the VJ-based method in complex scenes such as outdoors, but the DPM model is still hard to realize real-time detection due to the computational complexity of the model.
In [
5,
6,
7,
8,
9,
10], Cascade CNN is a convolutional neural network implementation of the VJ framework. Cascade CNN uses three CNN cascading structures. Cascade CNN first constructs a detection image pyramid, uses the primary network scan to remove most of the windows, and then adjusts the window position and size through a correction network, and uses the non-maximum suppression to merge the height coincidence window as the next level network input for further detection. Cascade CNN solves the problem of illumination and angle better than traditional methods. However, the performance of the method is affected to some extent by the fact that the first-level network still uses the dense sliding window. DenseBox uses a convolutional neural network to train images of different sizes, and finally directly predicts the position and confidence information of the face frame. DenseBox splices different convolutional layer outputs through upsampling and linear interpolation to achieve a multiscale fusion strategy and simultaneously locate keypoints, which improves the accuracy of detection. Faceness-Net inputs the images into five CNN networks, each of which outputs the position information of five different parts of the face, scores the information, and analyzes the scores of each part to obtain the face candidate frame. Face R-CNN is based on Faster R-CNN; it adds center loss to the last two classifications of the network to increase cohesion and adds the N largest samples of loss in each batch as a difficult case to the next training, which improves the classification ability of the entire network. This paper proposes an iterative algorithm for solving SDDLSp, which is suitable for training and testing images which are polluted by a large amount of noise. FHEDN is an end-to-end depth convolutional neural network, which uses a multiscale hierarchical feature pyramid fused with context prior-based information to detect faces in unconstrained scenes.
In face detection algorithms: (1) The VJ framework improves the detection performance by cascading, but the face detection effect for complex expressions and angles is not good. (2) The DPM model is less affected by noise, but is limited by the complex structure of the model. This leads to large calculations and poor real-time performance. (3) Neural network-based detection methods can obtain better facial features, but these algorithms generally have the disadvantages of low interpretation, difficult parameter adjustment, and long operation time.
Liveness detection refers to determining whether biological information comes from a legitimate user of living organism when obtaining biological information. The method of liveness detection mainly distinguishes biometrics forged by nonliving substances, such as photographs, silica gel, and plastic, by identifying physiological information on the organism as a feature. The paper [
11] divides the liveness detection technology into texture information analysis, motion information analysis, and living part analysis. The performance gap of the classifier based on the nonrigid motion of the authentic image, the noise difference, and the face background dependence are discussed. According to the input, liveness detection can be divided into single-frame input and continuous multi-frame input.
The paper [
12] proposes a liveness detection method that uses image distortion and color to construct feature vectors and uses SVM to perform two classifications. This method is not effective in the case where the forged facial image distortion is not serious. Color Texture [
13] believes that the living and nonliving are indistinguishable in RGB space, but there are significant texture differences in other color spaces. A method for obtaining a facial feature, by converting a facial image from RGB space to YCbCr space, and then using the SVM classifier for two classifications, is proposed. The method is simple and efficient. The paper [
14] implements liveness detection based on Lambertian Reflection and believes that a true facial living body and a nonliving body from a video or a photo are differently reflected under the same lighting conditions.
The paper [
15] enhances facial micromotion by inputting continuous multi-frame facial images, and then extracting dynamic texture features and histograms of oriented optical flow. Santosh Tirunagari et al. [
16] used the dynamic mode decomposition DMD to obtain the subspace map of the maximum motion energy, then perform texture analysis, and finally, input to the SVM classifier for binary classification. This method has a poor effect on forging the video or shaking a printed image. The paper [
17] introduces the liveness detection dataset PHOTO-ATTACK, which is extended based on PRINT-ATTACK, adding high-resolution screen images and mobile phone images. Furthermore, an optical flow-based analysis method is proposed to distinguish the authenticity of the image, which achieves a better performance.
These traditional methods are mainly based on feature engineering. They rely on image quality evaluation, illumination, smoothness, and moiré, and then obtain the test results through two classifications. In addition to traditional detection methods, some literature has begun to apply deep learning to liveness detection in recent years but, limited by the small number of samples, the performance struggles to exceed traditional methods. CNN-LSTM [
18] introduces deep learning to liveness detection earlier, and simulates traditional liveness detection through CNN, but the effect is not good. Yousef Atom et al. [
19] designed a depth framework to replace the two-category problem with a targeted feature monitoring problem. Song Xiao et al. [
20] used VGG16 as the basic network to directly add liveness detection to the face detection network. The detected bounding box includes three categories of confidence: background, living face, and nonliving face.
Liveness detection can be divided into traditional methods based on image quality, texture information, and deep learning-based methods. The former is not effective in some special cases, while the latter is limited by the small number of data samples, which makes the network training difficult to fit, and the performance struggles to surpass the traditional method.
Facial point detection refers to the image of a given face, finding the position and contour information of the key areas of the face. Facial point detection is roughly divided into three types: model-based, ASM and AAM methods; cascading shape regression; and deep learning-based methods.
Active Shape Model (ASM) [
21] first aligns the training images so that the images are rotated, scaled, and translated as close as possible to a selected reference image, and local features are constructed for each keypoint. When searching for shapes, ASM first calculates the position of the eye, aligns the faces with a simple scale and rotation change, and then searches for the vicinity of the aligned points to match the local keypoint, obtains the preliminary shape, and then corrects it using the average face model. Active Appearance Models (AAM) [
22] make improvements to ASM, which not only uses shape constraints but also adds texture features throughout the face area. Such linear models struggle to obtain better results under occlusion, special expressions, poses, and illumination changes, and their methods of searching for keypoints to exhaustive iterations similarly limit the computational efficiency of the method.
Cascaded waveform regression (CPR) [
23] specifies the initial prediction values and gradually refines them through a series of linear models. Each regression relies on the output of the previous regression to perform simple image operations. The entire system can automatically learn from the training samples. This algorithm is similar to random forest regression. It is a clear and simple regression algorithm. It can train a good model with a small amount of training data, but the model only detects three keypoints of the face. Dong Chen et al. [
24] inherited the idea of CPR using simple features and cascading tree structure to complete the classification and regression. It can do face detection and facial point detection at the same time. The calculation speed is fast, and the memory is small, but the model parameters are too numerous, and difficult to adjust. Local Binary Feature (LBF) [
25] is a tree-based method that learns the local binary features of each keypoint and then uses linear regression to detect keypoints by combining the features. The algorithm can be divided into three processes: feature extraction, LBF coding, and acquisition of shape increments. The model is fast and accurate, but the model only detects five keypoints on the face. Ensemble of Regression Tress (EERT) [
26] uses the GBDT algorithm to build a cascaded residual tree, and then gradually returns to the key point in the iteration. The model occupies less memory, and the calculation is fast, but the model is larger.
Sun et al. [
27] first applied CNN to facial point detection and proposed a cascaded CNN network DCNN (Deep Convolutional Network). This method belongs to the cascade regression method. It detects five facial keypoints by designing a three-layer convolutional neural network. It focuses on the depth of the first-level network. It believes that the deeper network structure can better extract the global features and improve the problem of local optimality caused by the initial inaccuracy, but the network does not detect well when the face is occluded. Erjin Zhou et al. [
28] made improvements on DCNN, proposing a four-level cascade network from coarse to fine facial point detection. It uses the image of the face area predicted by CNN as the input of the network, which improves the positioning accuracy of the latter stages. Similar to DCNN, this method also has the problem of complex network structure. Kaipeng Zhang et al. [
29] proposed the MTCNN (Multi-task Cascaded Convolutional Network), which can perform face detection and facial point detection simultaneously, making full use of the potential links between the two tasks. MTCNN has a certain improvement in speed and accuracy, but the network structure is complex and only detects five keypoints on the face. DAN, Deep Alignment Network [
30], is also a method based on cascaded neural networks. It introduces a keypoint heat map, and each level of the network uses the entire image as input. Model positioning is accurate, but the calculation speed still needs to be improved.
The main three algorithms of facial point detection are: (1) Model-based ASM and AAM models are simple, the architecture is clear and easy to understand and apply, but its exhaustive iterative search limits the performance of the method. (2) The calculation speed based on the cascading shape regression model is fast, but such models have problems that the parameters are difficult to adjust. (3) The method based on deep learning has a strong feature extraction ability of the convolutional neural network, and the detection is more accurate, but the network is more complicated, and the cascade structure limits the performance of the model.
The purpose of face recognition is to extract feature information from the face image and identify the identity based on the feature. The general face recognition process is divided into two steps. The first step is facial feature extraction and feature selection, and the second step is object classification.
Popular traditional recognition algorithms include principal component analysis using feature faces, linear discriminant analysis, the Fisherface algorithm, the hidden Markov model, etc. The method of identifying feature faces is developed by Sirovich and Kirby and used by Matthew Turk and Alex Pentland for face classification [
31]. The method takes the pixel points of the image as the original dimension unit and attempts to transform to another target space through one transformation, in which each face can be best distinguished. However, the performance of this method will decrease when the face is occluded. At the same time, the image analysis speed still needs to be optimized. The paper [
32] first applies the hidden Markov model to the face recognition algorithm. The method trains the HMM on the spatial sequence of multiple sample images and obtains the two-dimensional hidden Markov model based on the top-down and left-to-right structural features of the face according to the natural characteristics that the facial features are fixed. The algorithm of the Cove model uses DCT as the observation vector to obtain a good recognition effect, but its disadvantage is that the structure is complicated and the calculation amount is large.
In the past decade, Convolutional Neural Network (CNN) [
33] has become one of the most popular techniques for solving computer vision problems. Many visual tasks, such as image classification, object detection, and face recognition, benefit from CNN’s powerful learning and discriminative characterization. The CNN-based face recognition method usually regards CNN as a powerful feature extractor. DeepFace [
34] uses CNN as a feature extractor for the face to train on 4 million facial images, and obtains 67 base points to transform the triangulated face into a 3D model to depth information, and then turns the face back. Finally, it uses the 4096-dimensional feature vector output to find the classification result. It achieves an accuracy of 97.35% on the LFW dataset. DeepID [
35] uses CNN as a feature extractor to learn a 160-dimensional feature vector and finally uses various classifiers to obtain classification results. The main task of the DeepId network is to learn features, and its classification error rate is high. The input to FaceNet [
36] is a triple image with two identical identity images and one different identity. The network directly learns the separability between features: the feature distance between different identities should be as large as possible and the feature distance between the same identities should be as small as possible. FaceNet does not consider the face alignment problem. It only relies on a large amount of training data and a special objective function to obtain an accuracy of 99.63% on the LFW. Xiang Wu et al. [
37] proposed a Max-Feature-Map operation and used an MFM-based CNN model to learn facial information. MFM is an extension of the largest pooling. It suppresses the features with lower activation values by maximizing the characteristics of the same site on the adjacent two feature maps, and can effectively distinguish the noise data to make the model more robust. However, the samples used in the model training process are all aligned with facial patterns.
It can be seen that the traditional algorithms in face verification have a simple structure, but the ability to deal with occlusion and illumination changes is not good; the methods based on deep learning obtain good accuracy, but there is a widespread problem of a large amount of network computation.














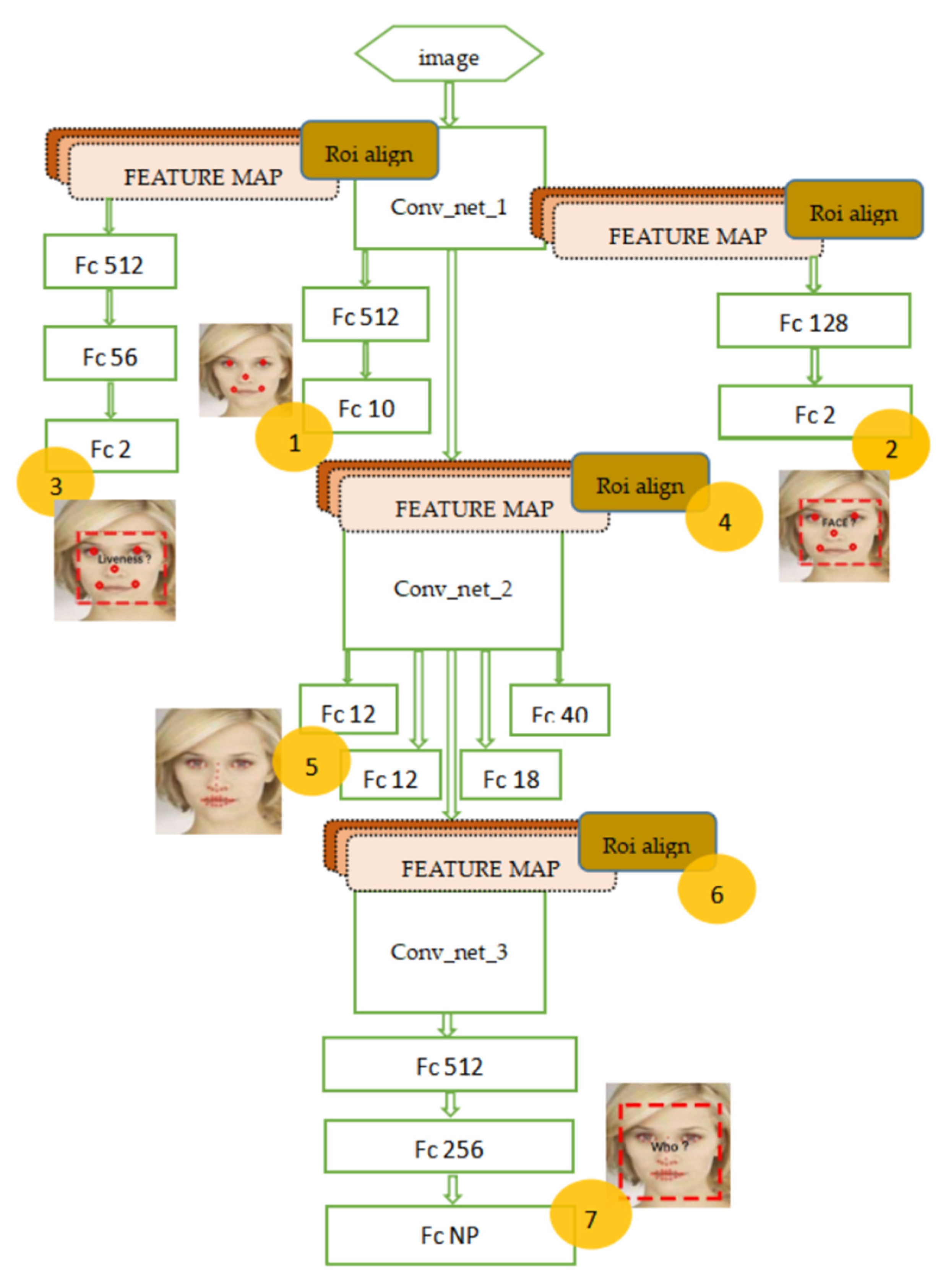{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
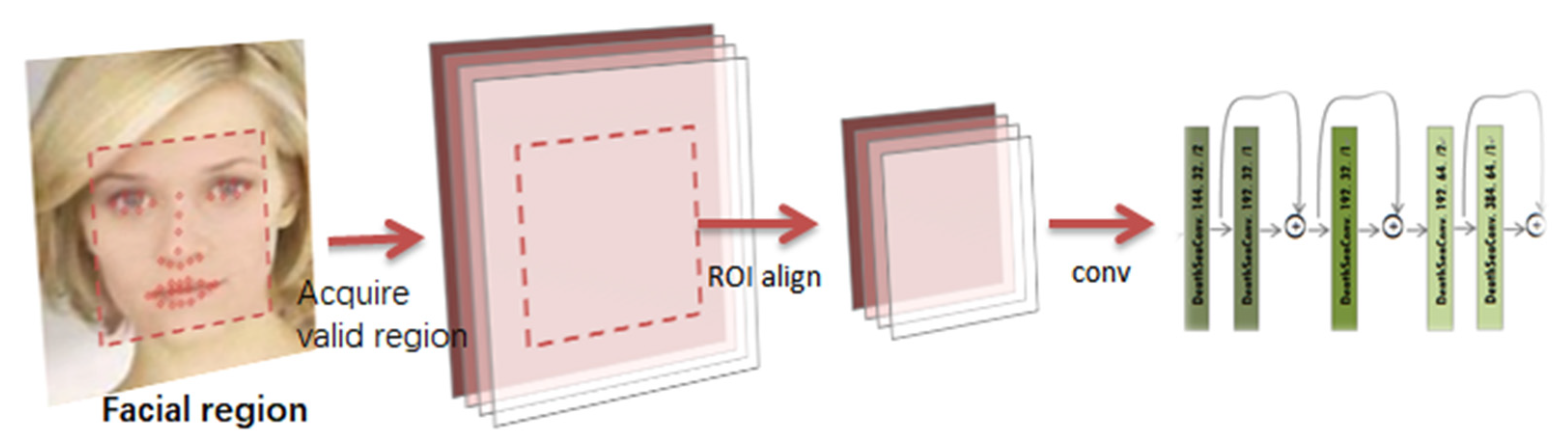{kind=link}
{kind=link}
{kind=link}
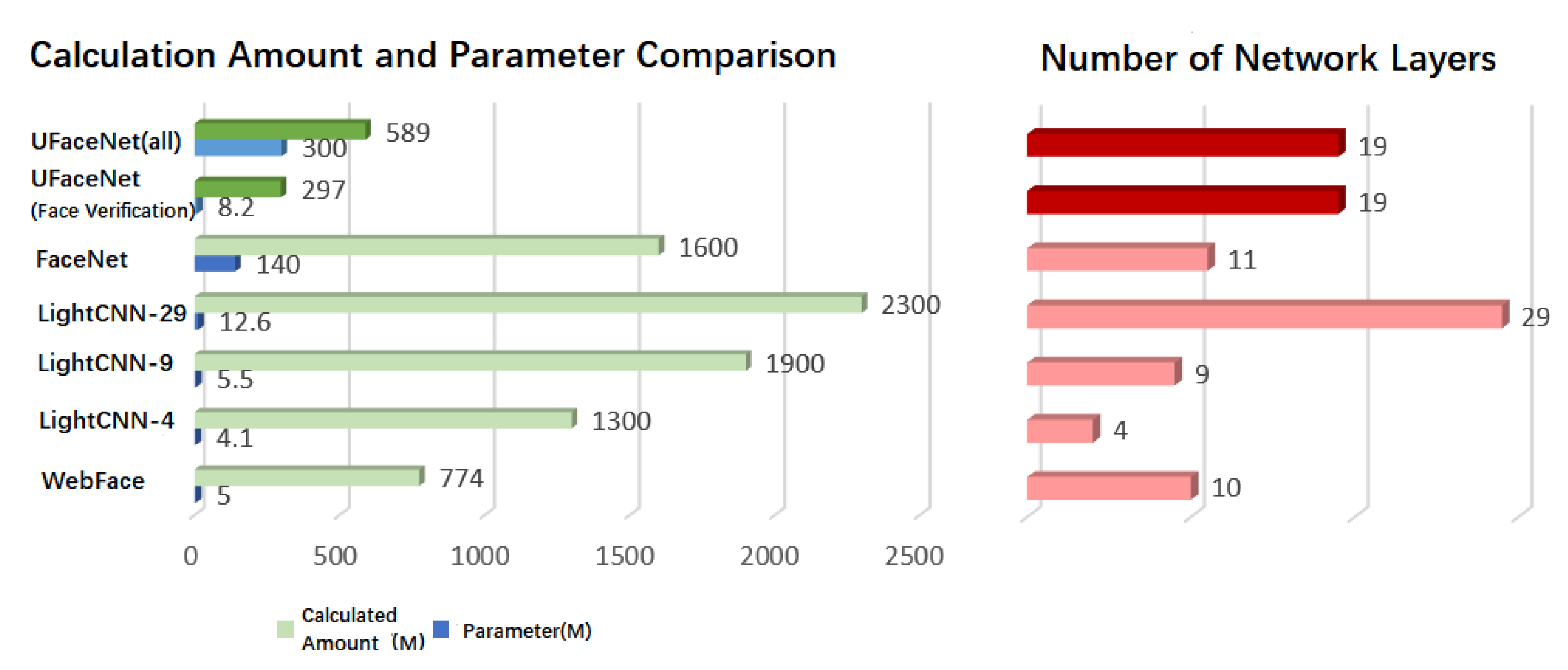{kind=link}