
Determinization and Minimization of Automata for Nested Words Revisited


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Nested Words
3. Nested Regular Expressions
3.1. Syntax and Semantics
3.2. XPath Example
| /site/closed_auctions/closed_auction[descendant::keyword]/date |
3.3. XPath Benchmark
4. Nested Word Automata
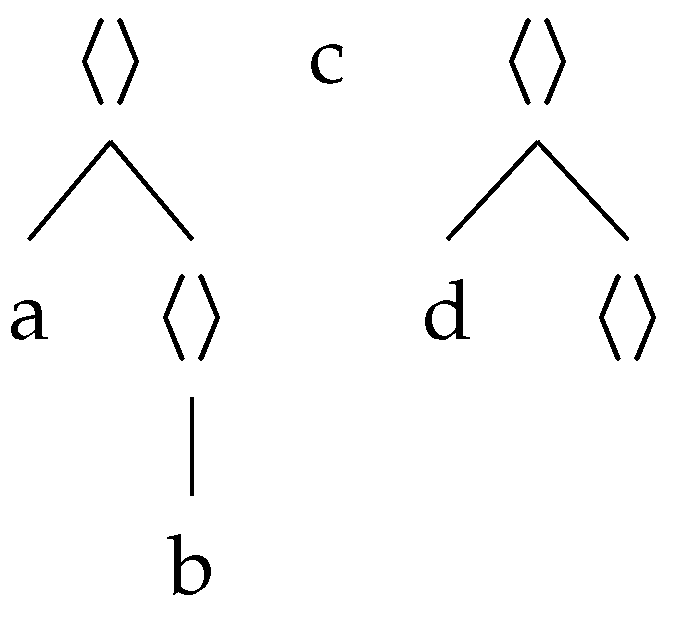
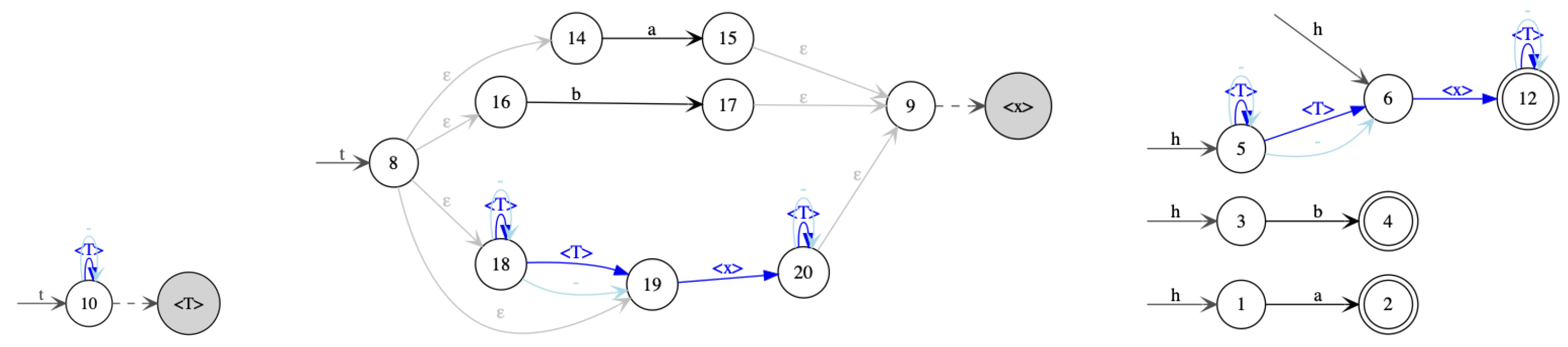
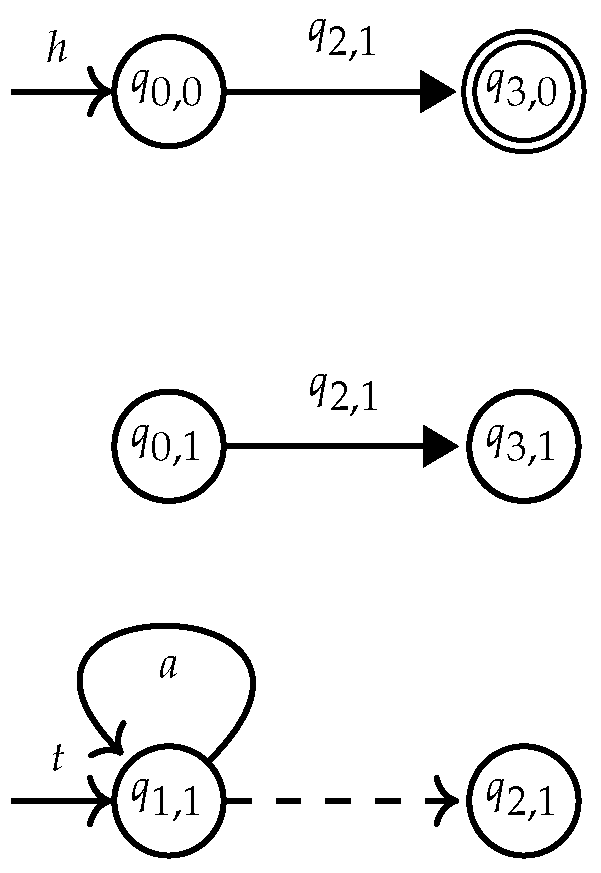
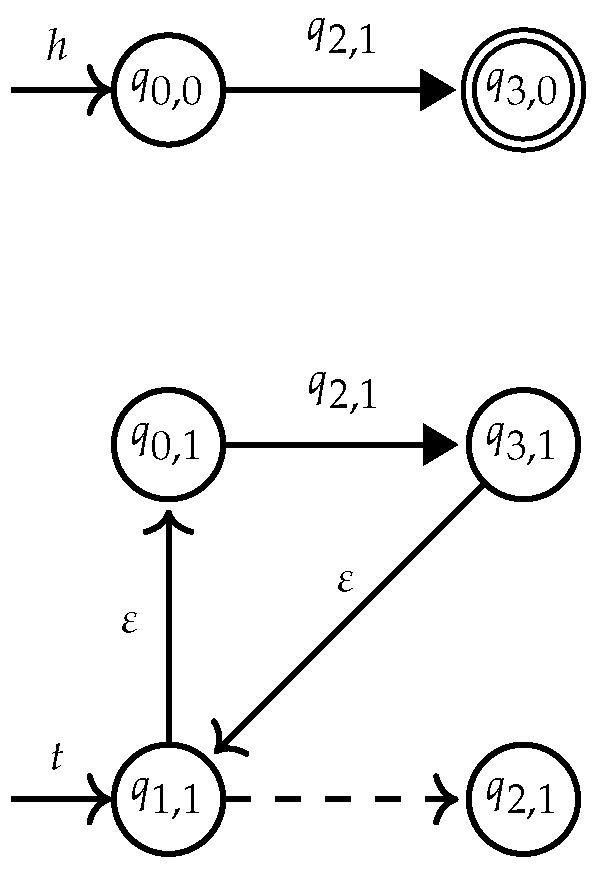
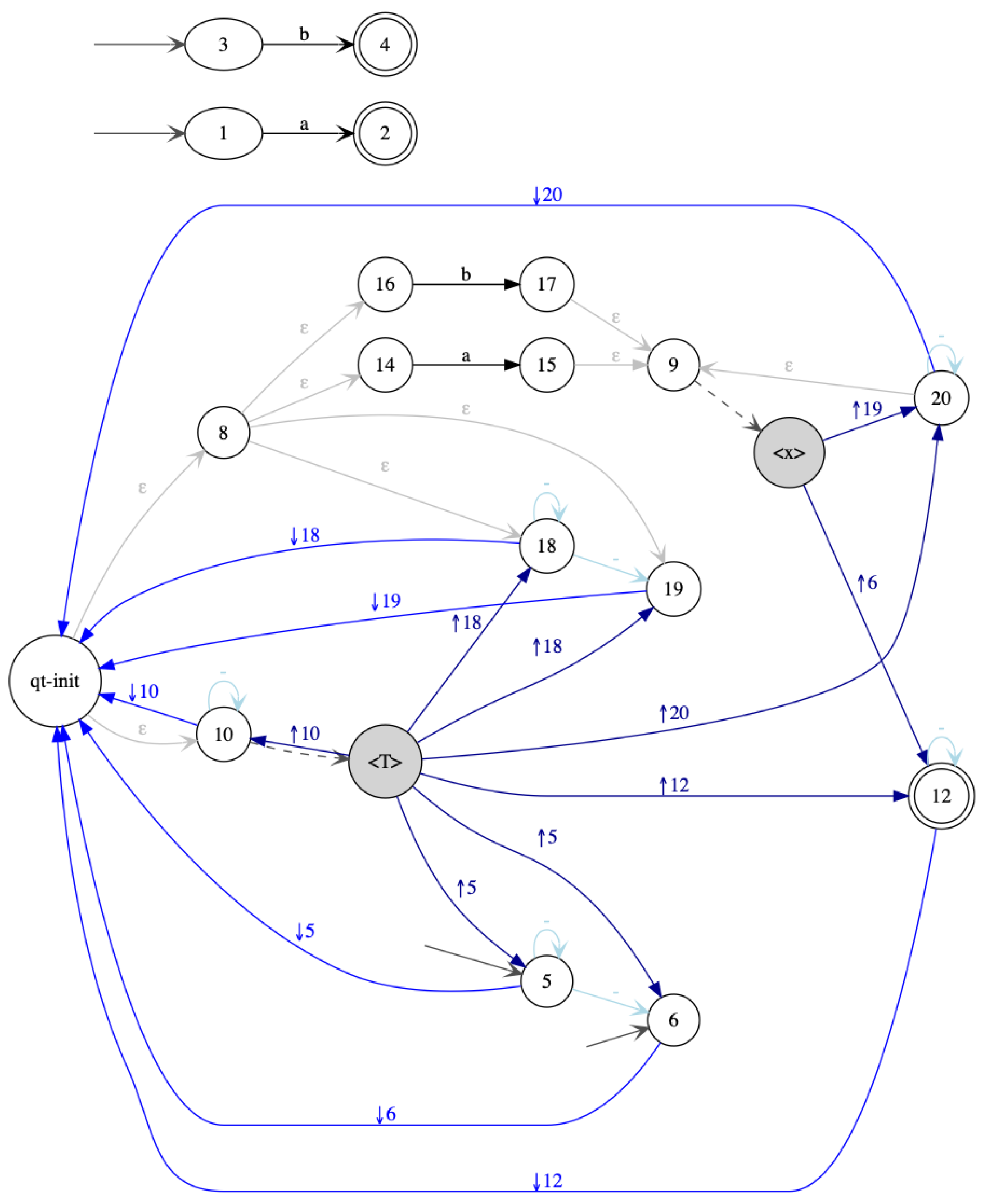
 , while hedge states are in unfilled circles . Initial states are drawn as and final states as
, while hedge states are in unfilled circles . Initial states are drawn as and final states as  . Hedge rules that have the form where are denoted by , while any tree rule is denoted . Opening rules are represented as and closing rules as .
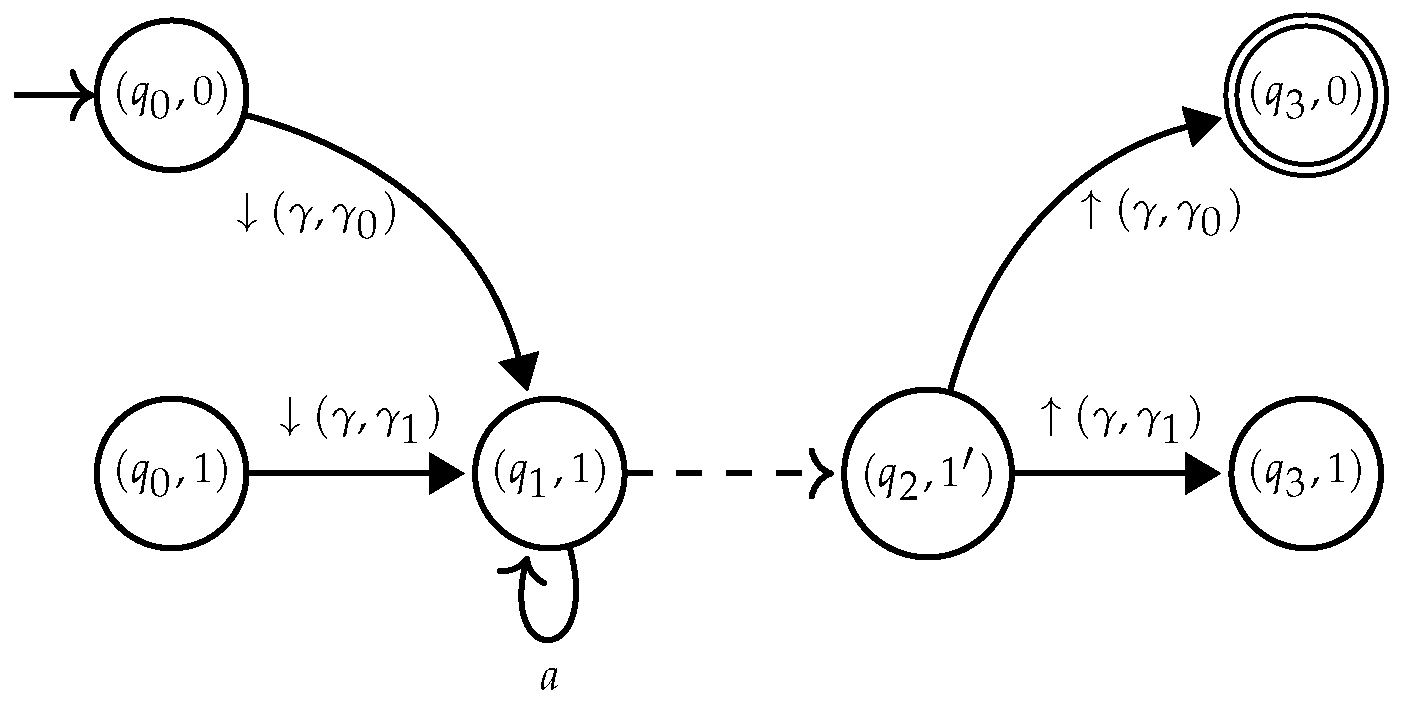
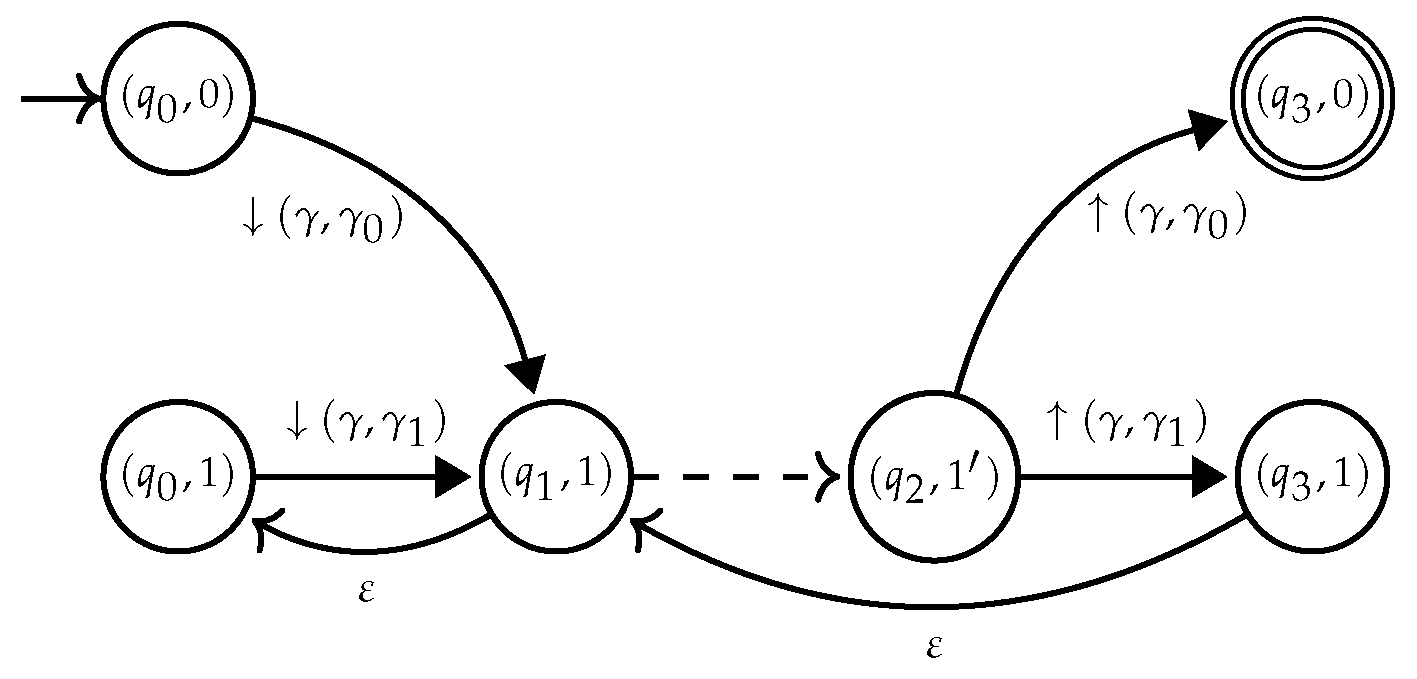
. Hedge rules that have the form where are denoted by , while any tree rule is denoted . Opening rules are represented as and closing rules as .4.1. Determinization of
- I contains at most one element;
- there is no epsilon rule, i.e., ,
- and are partial functions from to for all , and is a partial function from to ;
- for all and there exists a most one such that ; and
- is a partial function from to for all .
4.2. Multi-Module
4.3. Compilation of to
- Case :
- We use the McNaughton–Yamada–Thompson algorithm for composing the of and .
- Case :
- Let , , and be, respectively, the set of hedge states, tree states, and stack symbols of . We consider new hedge states and that are not in , a new tree state p not in and a new stack symbol not in . Then, is constructed by adding to opening rules for all the initial states q of , tree rules for all the final states of and a closing rule . Furthermore, we set as the only initial state of , and as its sole final state.
- Case :
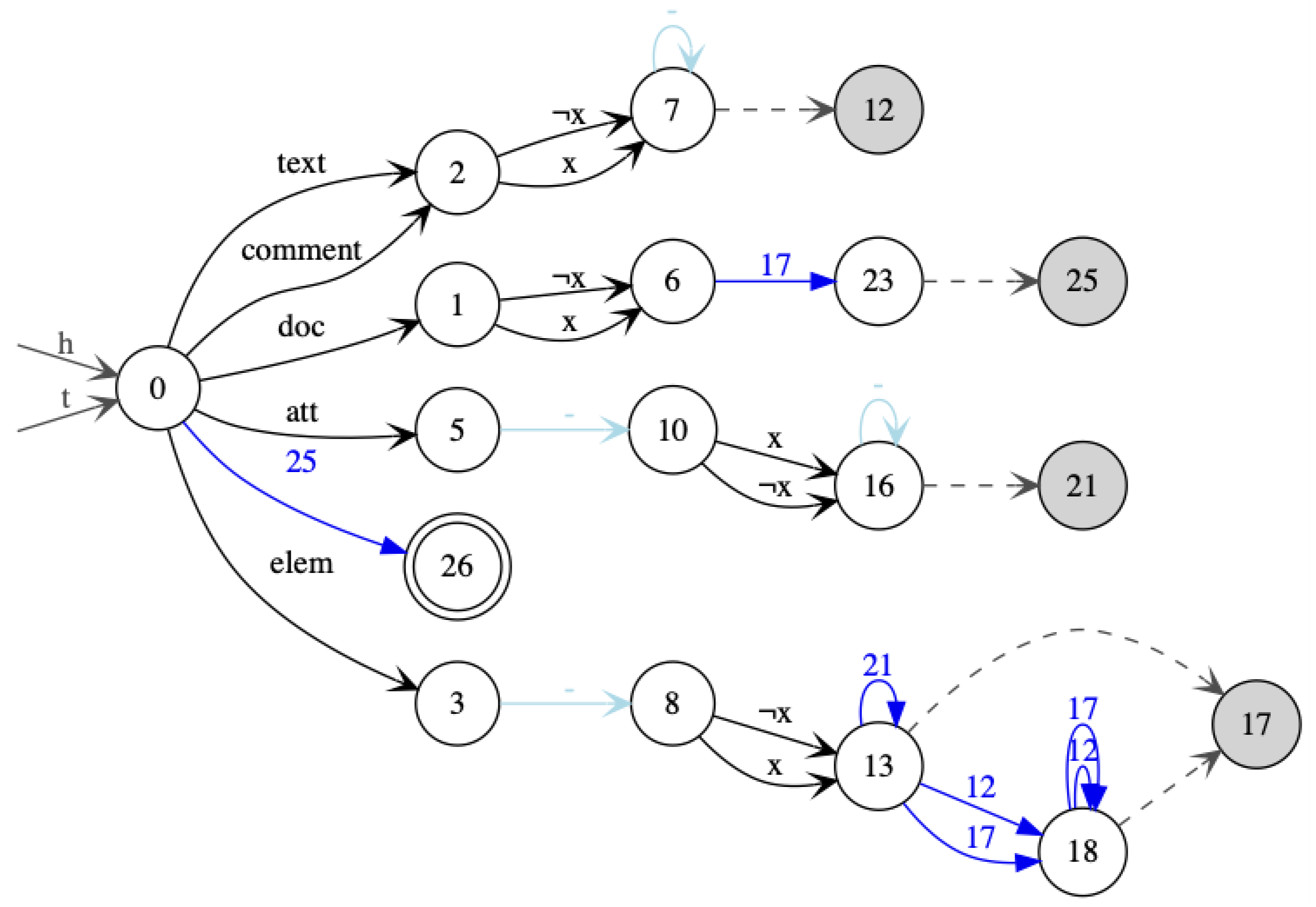
- Special care has to be given to repeat expression . First of all, the naive compilation approach for these expression turns out to be wrong. Second, fixing the problem in the simplest possible manner does not lead to a linear time algorithm.Note that we can assume w.l.o.g. that a occurs at most once in E by using the golden lemma of the calculus [37], stating for all names and expressions in which can appear free that . Our construction guarantees that all transitions of the form in will start with the same state q. The wrong naive construction would remove the transitions from and add -rules from q to all the initial states of , and from all final states of to . Unfortunately, the construction is not correct. For illustration, we consider the . The reader should be warned that constructing an for E is less trivial than it might seem at first sight. One has to start from the for which is given in Figure 8. Simply adding epsilon edges to capture the operator will not work though. It will lead to the wrong automaton in Figure 9. This automaton will wrongly accept the hedge , as this hedge does not belong to .If the for E is multi-module, then the naive construction of compiling can be made correct. Therefore, the simplest fix is to make the multi-moduled, before applying the naive construction. This can be achieved by typing the states of the automaton, by states of the in Figure 7. The added types yield the homomorphism of the constructed automaton to .The naive algorithm is then adapted as follows. Let be the multi-module obtained from the product of and . Note that we keep only the accessible top level states (type 0), but all nested states (type 1). In our example, this yields the in Figure 10. We then remove transition and add -rules from state to all states in , and from all states in to , where I and F are, respectively, the set of initial and final states of . Then, recognizes . The result obtained in the example is shown in Figure 11.The algorithm described so far makes the multi-moduled before compiling a -operator. For this, two copies of all states are introduced. This, however, could lead to an exponential construction if multiple -operators are nested. This problem can be avoided by preserving multi-moduledness as an invariant. Whenever a new state is created, it is created twice: once for the top level and once for the nested level. This information is maintained by typing the states, so that no further copies of the same state are produced later on.
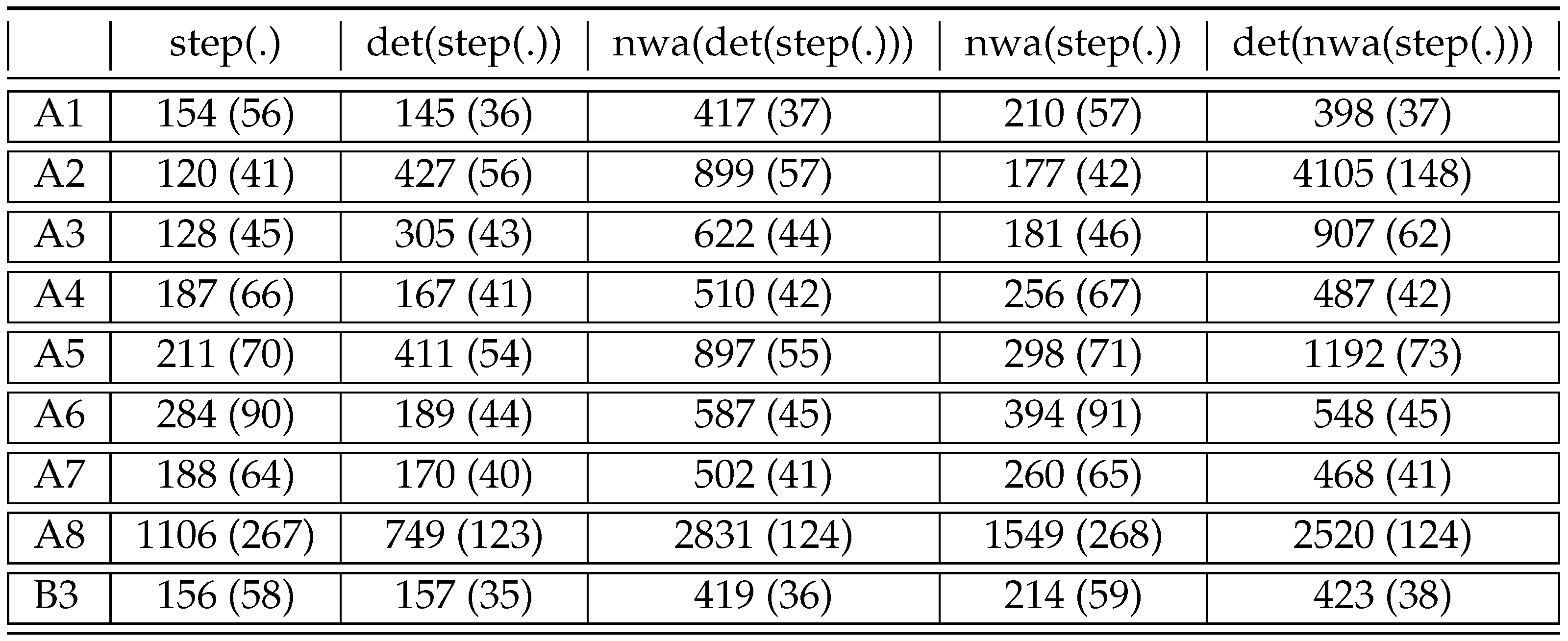
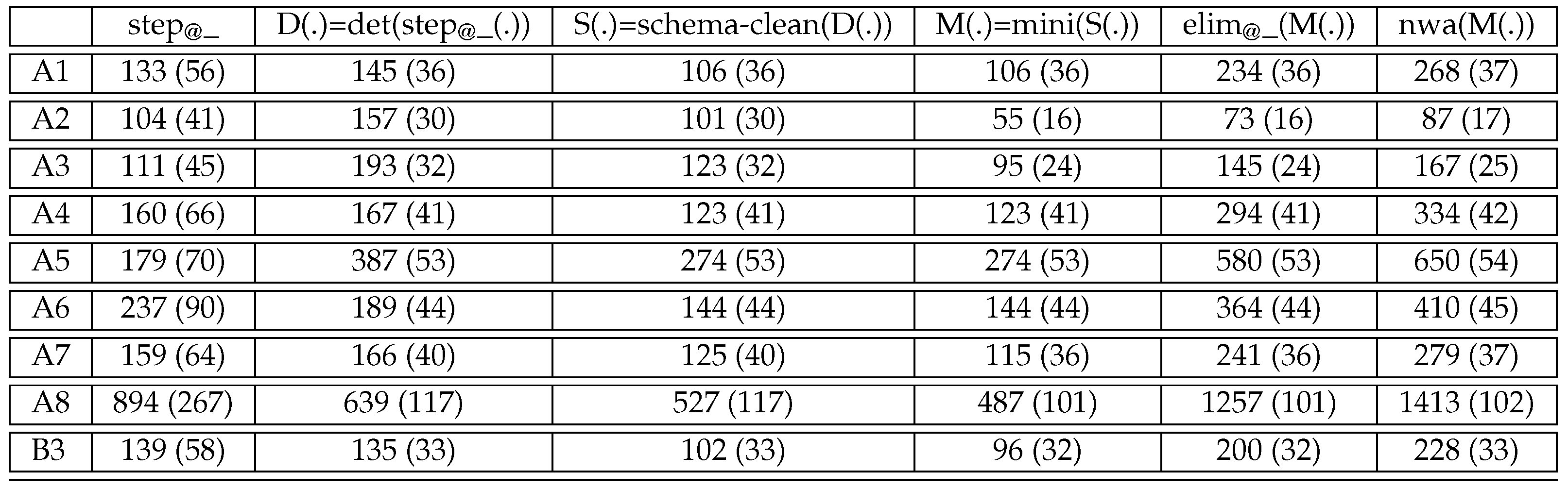
4.4. Experimental Results Starting with the Compiler
5. Stepwise Hedge Automata
, while the states of type hedge are drawn in unfilled circles . The right part of the graph is an Nfa which uses tree states as additional edge labels, while the left part is a stepwise tree automaton that defines the tree languages of these tree states.. A rule with an internal letter is denoted by stating that a hedge in state can be extended by the internal letter a leading to a hedge in state . Similarly, an epsilon rule is denoted by , and an else rule is denoted by . In the same spirit, a hedge rule —also called apply rule—is denoted by , stating that a hedge in state can be extended by a tree in state q leading to a hedge in state .5.1. Determinization of s
- I contains at most one element;
- contains at most one element;
- there is no epsilon transition, i.e., ;
- , are partial functions from to for all and ; and
- is a partial function from to .
5.2. Compilation of to s
- and
- the states in can reach only other states in via Δ.
- Case :
- We use McNaughton–Yamada–Thompson algorithm [36] for composing the multi-module Nfas of and . The stepwise tree automata of the subexpressions of type tree are preserved. For succinctness, if some subexpression occurs more than once, then only a single copy of is kept. References to states of the removed copy should be renamed to their equivalent counterparts.
- Case :
- We construct from . The initial states of are turned into tree initial states. We then add a new tree state and connect it to all final states of by a tree final rule . Furthermore, the previously final state q becomes non final. Finally we add a new initial state , a new final state and a transition rule .
- Case :
- The main idea of the construction is similar to the case of . The correctness argument relies on the invariant that only multi-module s are built.Again by the golden lemma of the -calculus, we can assume w.l.o.g. that a occurs at most once in . By using -rules, we can preserve the invariant that there will be at most one pair such that in . Furthermore, these transitions cannot be on top level, given that the occurrence of a in must be nested below parentheses. The automaton is obtained from by first copying the top level Nfa of , as in Figure 16. We thus obtain two versions for each state of the top level Nfa of : one referred to as the top level copy— and in Figure 16, and another one as the nested level – and in Figure 16. Only top level states may be initial or final. Then, we add -rules from q to the nested states that correspond to the initial states of , and from the nested states corresponding to the final states of to . Finally we remove the rule . The resulting automaton is shown in Figure 17.Note that every transition added for a state–top level or nested—in a subsequent step of the construction—except the -rules added for -expressions—must also be added for its copy.The construction is correct as the -bound name a is nested below parenthesis in . Therefore, it can be shown that the -edges introduced cannot be used to produce unwanted order in successful runs. Maintaining this invariant in polynomial time requires an additional argument. Instead of copying the top level parts of subexpressions, each state is introduced twice during the construction: one version for nesting, and another one for being part of top level parts. This way the size of the automaton is not doubled at each step, but only once.
5.3. Experimental Results Starting with the Compiler
6. NWAs versus SHAs
6.1. SHAs to NWAs
- if A is deterministic, the transformation returns A, and
- if A is nondeterministic with set of hedge states and transition relation , the transformation returns a new with set of hedge states where is a new hedge state, and set of transitions which equals except that and .
6.2. NWAs to SHAs

7. Optimizations
7.1. Minimization
- the subclass of multi-module s, and
- the subclass of s where the hedge and tree initial state are the same, i.e., .
7.2. Symbolic SHAs with Apply-Else Rules
7.3. Schema-Based Cleaning
7.4. Experimental Results for Optimizations
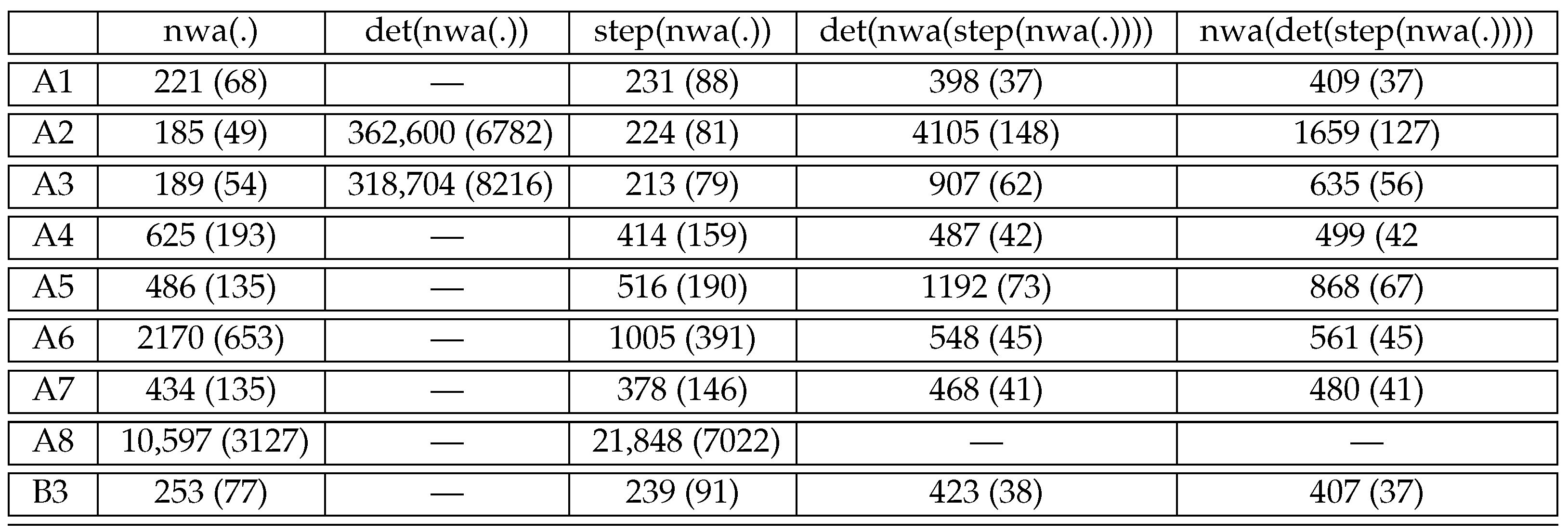
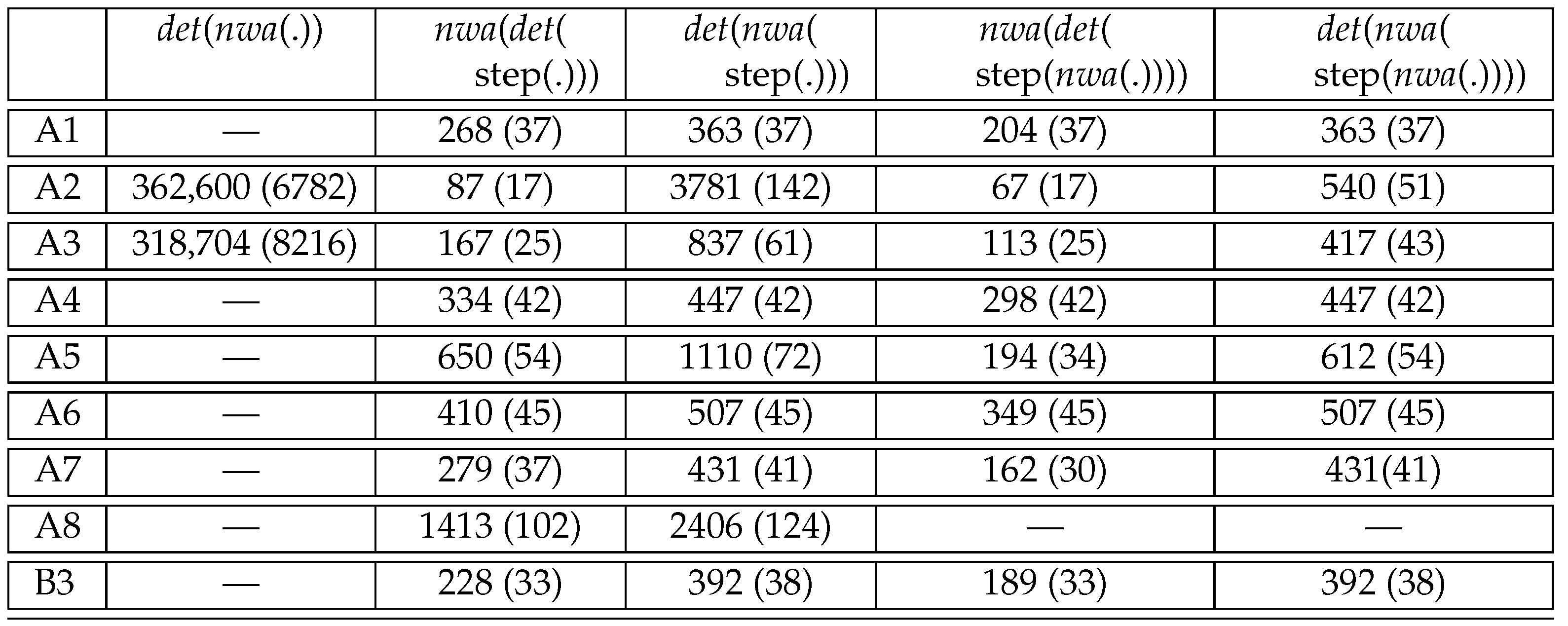
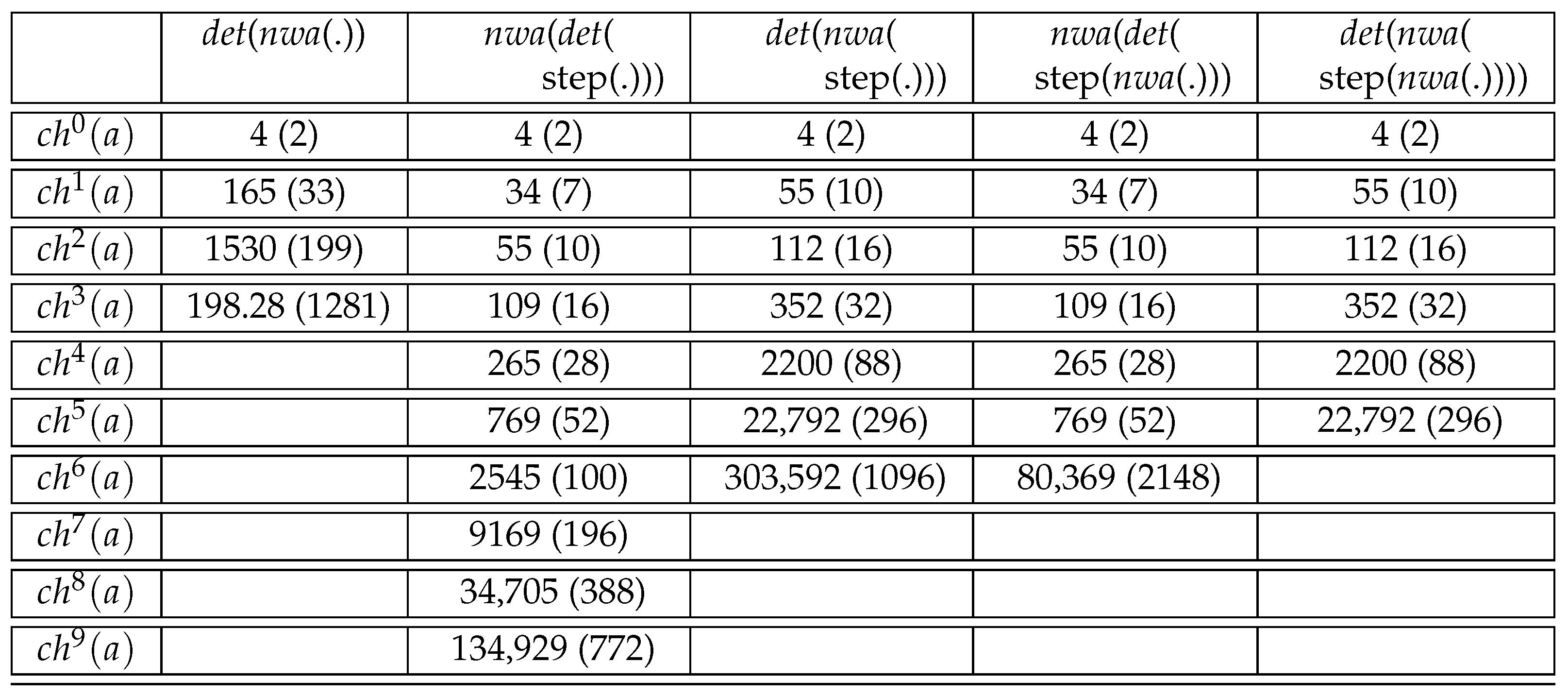
8. Summary of Experimental Results
9. Deterministic Nested Regular Expressions
10. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Determinization of NWAs

Appendix B. NREs for the XPathMark Benchmark

Appendix C. Some More Automata



References
- Mehlhorn, K. Pebbling Moutain Ranges and its Application of DCFL-Recognition. In Automata, Languages and Programming, Proceedings of the 7th Colloquium, Noordweijkerhout, The Netherlands, 14–18 July 1980; Lecture Notes in Computer Science; de Bakker, J.W., van Leeuwen, J., Eds.; Springer: Berlin/Heidelberg, Germany, 1980; Volume 85, pp. 422–435. [Google Scholar] [CrossRef]
- Von Braunmühl, B.; Verbeek, R. Input Driven Languages are Recognized in log n Space. North Holl. Math. Stud. 1985, 102, 1–19. [Google Scholar] [CrossRef]
- Alur, R. Marrying Words and Trees. In Proceedings of the 26th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Paris, France, 14–16 June 2004; ACM-Press: New York, NY, USA, 2007; pp. 233–242. [Google Scholar]
- Okhotin, A.; Salomaa, K. Complexity of input-driven pushdown automata. SIGACT News 2014, 45, 47–67. [Google Scholar] [CrossRef]
- Alur, R.; Madhusudan, P. Visibly pushdown languages. In Proceedings of the 36th ACM Symposium on Theory of Computing, Chicago, IL, USA, 13–16 June 2004; ACM-Press: New York, NY, USA, 2004; pp. 202–211. [Google Scholar]
- Neumann, A.; Seidl, H. Locating Matches of Tree Patterns in Forests. In Proceedings of the Foundations of Software Technology and Theoretical Computer Science, Chennai, India, 17–19 December 1998; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1530, pp. 134–145. [Google Scholar]
- Gauwin, O.; Niehren, J.; Roos, Y. Streaming Tree Automata. Inf. Process. Lett. 2008, 109, 13–17. [Google Scholar] [CrossRef]
- Thatcher, J.W. Characterizing derivation trees of context-free grammars through a generalization of automata theory. J. Comput. Syst. Sci. 1967, 1, 317–322. [Google Scholar] [CrossRef]
- Comon, H.; Dauchet, M.; Gilleron, R.; Löding, C.; Jacquemard, F.; Lugiez, D.; Tison, S.; Tommasi, M. Tree Automata Techniques and Applications. 2007. Available online: http://tata.gforge.inria.fr (accessed on 1 February 2021).
- Hosoya, H.; Pierce, B.C. XDuce: A statically typed XML processing language. ACM Trans. Internet Technol. 2003, 3, 117–148. [Google Scholar] [CrossRef]
- Mozafari, B.; Zeng, K.; Zaniolo, C. From Regular Expressions to Nested Words: Unifying Languages and Query Execution for Relational and XML Sequences. PVLDB 2010, 3, 150–161. [Google Scholar] [CrossRef]
- Pitcher, C. Visibly Pushdown Expression Effects for XML Stream Processing. Program. Lang. Technol. XML 2005, 1060, 1–14. [Google Scholar]
- Olteanu, D. SPEX: Streamed and Progressive Evaluation of XPath. IEEE Trans. Know. Data Eng. 2007, 19, 934–949. [Google Scholar] [CrossRef]
- Gauwin, O.; Niehren, J. Streamable Fragments of Forward XPath. In Proceedings of the International Conference on Implementation and Application of Automata, Blois, France, 13–16 July 2011; Lecture Notes in Computer Science; Markhoff, B.B., Caron, P., Champarnaud, J.M., Maurel, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6807, pp. 3–15. [Google Scholar] [CrossRef]
- Benedikt, M.; Jeffrey, A.; Ley-Wild, R. Stream Firewalling of XML Constraints. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; ACM-Press: New York, NY, USA, 2008; pp. 487–498. [Google Scholar]
- Gauwin, O.; Niehren, J.; Tison, S. Earliest Query Answering for Deterministic Nested Word Automata. In Proceedings of the 17th International Symposium on Fundamentals of Computer Theory, Wroclaw, Poland, 2–4 September 2009; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5699, pp. 121–132. [Google Scholar]
- Franceschet, M. XPathMark Performance Test. Available online: https://users.dimi.uniud.it/~massimo.franceschet/xpathmark/PTbench.html (accessed on 25 October 2020).
- Debarbieux, D.; Gauwin, O.; Niehren, J.; Sebastian, T.; Zergaoui, M. Early nested word automata for XPath query answering on XML streams. Theor. Comput. Sci. 2015, 578, 100–125. [Google Scholar] [CrossRef]
- Brüggemann-Klein, A. Regular Expressions into Finite Automata. Theor. Comput. Sci. 1993, 120, 197–213. [Google Scholar] [CrossRef]
- Brüggemann-Klein, A.; Wood, D. One-Unambiguous Regular Languages. Inf. Comput. 1998, 142, 182–206. [Google Scholar] [CrossRef]
- Carme, J.; Niehren, J.; Tommasi, M. Querying Unranked Trees with Stepwise Tree Automata. In Proceedings of the 19th International Conference on Rewriting Techniques and Applications, Paris, France, 26–28 June 2004; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3091, pp. 105–118. [Google Scholar]
- Alur, R.; Kumar, V.; Madhusudan, P.; Viswanathan, M. Congruences for Visibly Pushdown Languages. In Automata, Languages and Programming, Proceedings of the 32nd International Colloquium, Lisbon, Portugal, 11–15 July 2005; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3580, pp. 1102–1114. [Google Scholar] [CrossRef]
- Chervet, P.; Walukiewicz, I. Minimizing Variants of Visibly Pushdown Automata. In Mathematical Foundations of Computer Science 2007; Kučera, L., Kučera, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 135–146. [Google Scholar]
- Gauwin, O.; Muscholl, A.; Raskin, M. Minimization of visibly pushdown automata is NP-complete. Log. Methods Comput. Sci. 2020, 16. [Google Scholar] [CrossRef]
- Boneva, I.; Niehren, J.; Sakho, M. Nested Regular Expressions Can Be Compiled to Small Deterministic Nested Word Automata. In Computer Science—Theory and Applications, Proceedings of the 15th International Computer Science Symposium in Russia (CSR 2020), Yekaterinburg, Russia, 29 June–3 July 2020; Lecture Notes in Computer Science; Fernau, H., Ed.; Springer: Cham, Switzerland, 2020; Volume 12159, pp. 169–183. [Google Scholar] [CrossRef]
- Gottlob, G.; Koch, C.; Pichler, R. The complexity of XPath query evaluation. In Proceedings of the 22nd ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, San Diego, CA, USA, 9–12 June 2003; pp. 179–190. [Google Scholar]
- Libkin, L.; Martens, W.; Vrgoč, D. Querying Graph Databases with XPath. In Proceedings of the 16th International Conference on Database Theory (ICDT’13), Genoa, Italy, 18–22 March 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 129–140. [Google Scholar] [CrossRef]
- Fischer, M.J.; Ladner, R.E. Propositional Dynamic Logic of Regular Programs. J. Comput. Syst. Sci. 1979, 18, 194–211. [Google Scholar] [CrossRef]
- Mozafari, B.; Zeng, K.; Zaniolo, C. High-performance complex event processing over XML streams. In Proceedings of the SIGMOD Conference, Scottsdale, AZ, USA, 20–24 May 2012; Candan, K.S., Chen, Y., Snodgrass, R.T., Gravano, L., Fuxman, A., Eds.; ACM: New York, NY, USA, 2012; pp. 253–264. [Google Scholar] [CrossRef]
- Grez, A.; Riveros, C.; Ugarte, M. A Formal Framework for Complex Event Processing. In Proceedings of the 22nd International Conference on Database Theory (ICDT 2019), Lisbon, Portugal, 26–28 March 2019; Volume 127, pp. 5:1–5:18. [Google Scholar] [CrossRef]
- Bozzelli, L.; Sánchez, C. Visibly Rational Expressions. Acta Inf. 2014, 51, 25–49. [Google Scholar] [CrossRef][Green Version]
- Gécseg, F.; Steinby, M. Tree Automata; Akadémiai Kiadó: Budapest, Hungary, 1984. [Google Scholar]
- Scott, D.; de Bakker, J.W. A Theory of Programs; IBM: Vienna, Austria, 1969; Unpublished Manuscript. [Google Scholar]
- Stockmeyer, L.J.; Meyer, A.R. Word Problems Requiring Exponential Time. In Proceedings of the 5th ACM Symposium on Theory of Computing, Austin, TX, USA, 30 April–2 May 1973; pp. 1–9. [Google Scholar]
- Champavère, J.; Gilleron, R.; Lemay, A.; Niehren, J. Efficient Inclusion Checking for Deterministic Tree Automata and XML Schemas. Inf. Comput. 2009, 207, 1181–1208. [Google Scholar] [CrossRef][Green Version]
- Aho, A.V.; Lam, M.S.; Sethi, R.; Ullman, J.D. Compilers: Principles, Techniques, and Tools, 2nd ed.; Addison Wesley: Reading, MA, USA, 2006. [Google Scholar]
- Arnold, A.; Niwiński, D. Complete lattices and fixed-point theorems. In Rudiments of μ-Calculus; Studies in Logic and the Foundations of Mathematics; Elsevier: Amsterdam, The Netherlands, 2001; Volume 146. [Google Scholar]
- Martens, W.; Niehren, J. On the Minimization of XML-Schemas and Tree Automata for Unranked Trees. J. Comput. Syst. Sci. 2007, 73, 550–583. [Google Scholar] [CrossRef][Green Version]
- D’Antoni, L.; Alur, R. Symbolic Visibly Pushdown Automata. In Computer Aided Verification, Proceedings of the 26th International Conference (CAV, VSL 2014), Vienna, Austria, 18–22 July 2014; Lecture Notes in Computer Science; Biere, A., Bloem, R., Eds.; Springer: Cham, Switzerland, 2014; Volume 8559, pp. 209–225. [Google Scholar] [CrossRef]



























Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niehren, J.; Sakho, M. Determinization and Minimization of Automata for Nested Words Revisited. Algorithms 2021, 14, 68. https://doi.org/10.3390/a14030068
Niehren J, Sakho M. Determinization and Minimization of Automata for Nested Words Revisited. Algorithms. 2021; 14(3):68. https://doi.org/10.3390/a14030068
Chicago/Turabian StyleNiehren, Joachim, and Momar Sakho. 2021. "Determinization and Minimization of Automata for Nested Words Revisited" Algorithms 14, no. 3: 68. https://doi.org/10.3390/a14030068
APA StyleNiehren, J., & Sakho, M. (2021). Determinization and Minimization of Automata for Nested Words Revisited. Algorithms, 14(3), 68. https://doi.org/10.3390/a14030068