
A Linearly Involved Generalized Moreau Enhancement of ℓ2,1-Norm with Application to Weighted Group Sparse Classification


Abstract
:1. Introduction
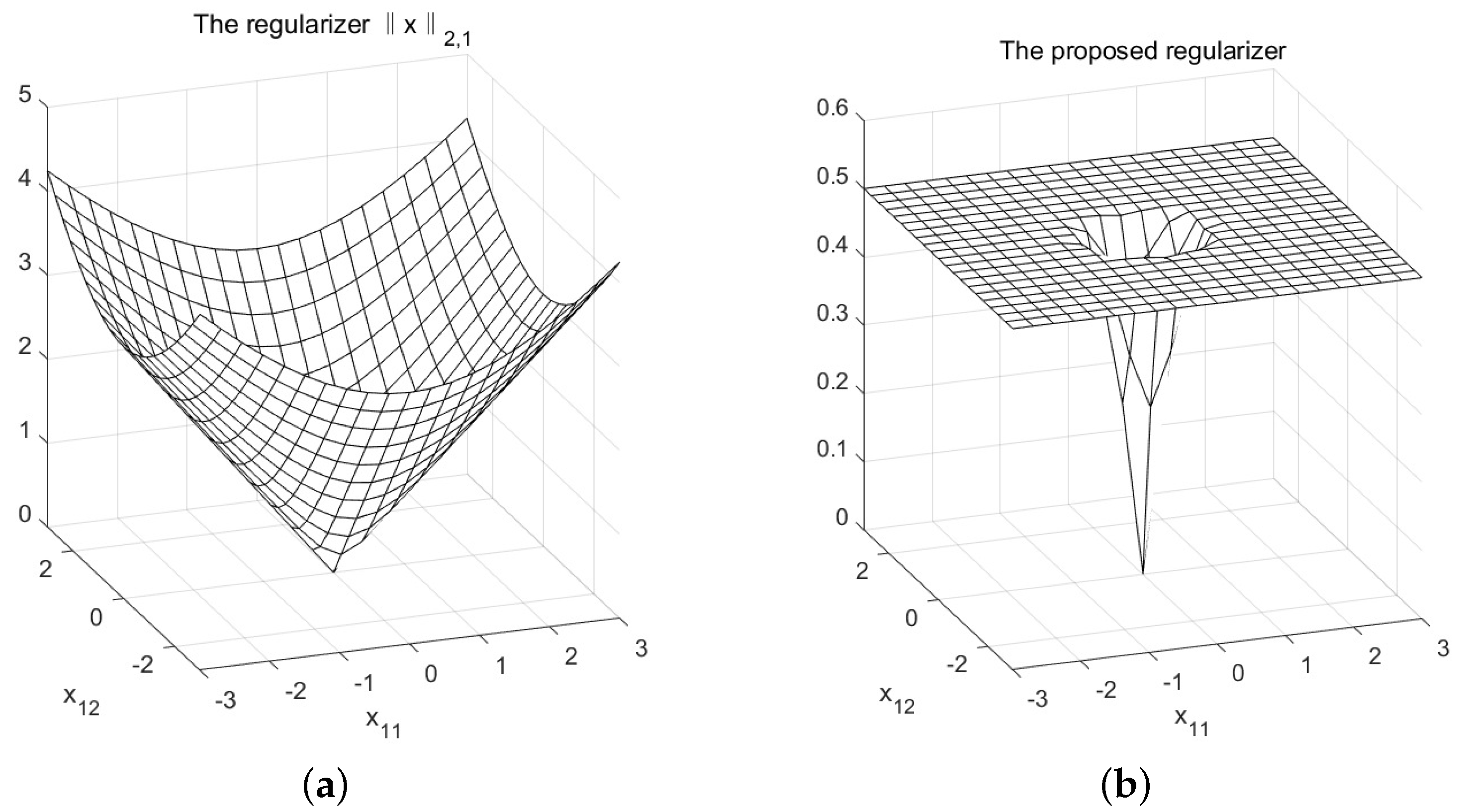
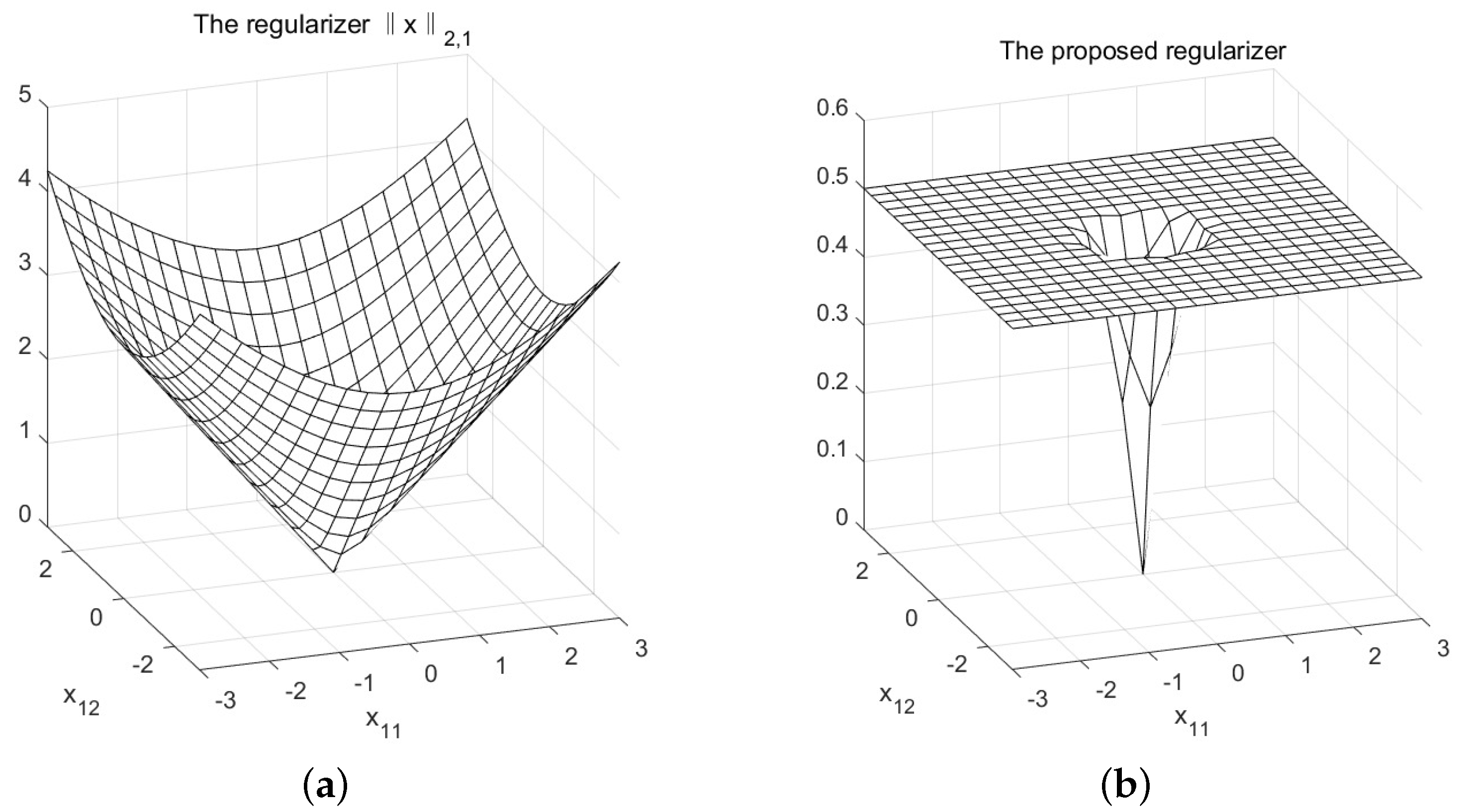
- We show in Proposition 2 that the generalized Moreau enhancement (GME) of , i.e., (see (11)), can bridge the gap between and . For the non-separable weighted , i.e., , its GME can be expressed as LiGME of in the case of weight matrix has full row-rank.
- We present a convex regularized least squares model with a nonconvex group sparsity promoting regularizer based on LiGME. It can be served as a unified model of many types of group sparsity related applications.
- We illustrate the unfairness of regularizer in unbalanced classification and then apply the proposed model to reduce the unfairness of it in GSC and weighted GSC (WGSC) [11].
2. Preliminaries
2.1. Review of Linearly Involved Generalized-Moreau-Enhanced (LiGME) Model
2.2. Basic Idea of Weighted Group Sparse Classification (WGSC)
3. LiGME Model for Group Sparse Estimation
3.1. GME of Weighted -Norm and Its Properties
3.2. LiGME of -Norm
4. Application to Classification Problems
4.1. Proposed Algorithm for Group-Sparsity Based Classification
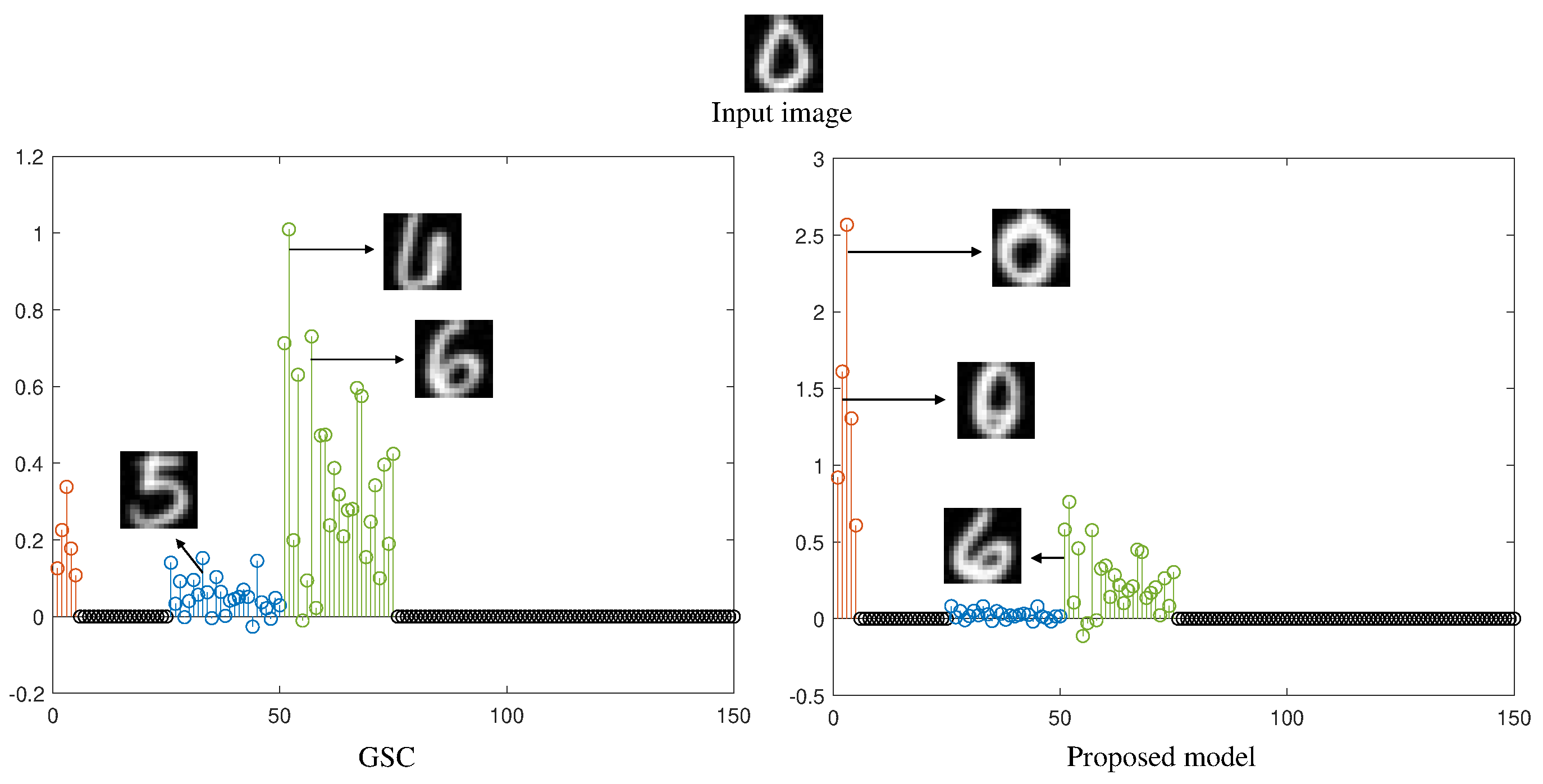
4.2. Experiments
| Algorithm 1: The proposed group-sparsity enhanced classification algorithm |
| Input: A matrix of training samples grouped by class information, a test sample vector , parameters , and . 1. Initialization: Let . Compute the weight matrix by (9). Choose satisfying . Choose satisfying 2. For , compute until the stopping criterion is fulfilled. 3. Compute the class label of by Output: The class label corresponding to . |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LASSO | Least Absolute Shrinkage and Selection Operator |
| SCAD | Smoothly Clipped Absolute Deviation) |
| MCP | Minimax Concave Penalty |
| GMC | Generalized Minimax Concave |
| GME | Generalized Moreau Enhancement |
| LiGME | Linearly involved Generalized-Moreau-Enhanced (or Enhancement) |
| SRC | Sparse Representation-based Classification |
| GSC | Group Sparse Classification |
| WGSC | Weighted Group Sparse Classification |
Appendix A. The Bias of ℓ2,1 Regularizer in Group Sparse Classification
- (a)
- If the number of samples in this class is doubled by duplication, the training set of class i becomes . Obviously, can also be well represented by , where () and . However, . That is, value of the first representation (before duplication) is greater than that of the second one (after duplication).
- (b)
- If the number of samples in this class is increased to by copying times (d > 1), the training set of class i becomes . Obviously, is a representation of , where and . Then .
Appendix B. Parameter Tuning and Proximal Splitting Algorithm for LiGME Model
- 1.
- , where .
- 2.
- Choose satisfyingwhere is the operator norm. Thenand is -averaged nonexpansive in the Hilbert space .
- 3.
- Assume the condition (A1) holds. Then, for any initial point , the sequence generated byconverges to a point and
References
- Theodoridis, S. Machine Learning: A Bayesian and Optimization Perspective; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Ma, S.; Song, X.; Huang, J. Supervised group Lasso with applications to microarray data analysis. BMC Bioinform. 2007, 8, 60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.; Chen, G.; Li, H. Group SCAD regression analysis for microarray time course gene expression data. Bioinformatics 2007, 23, 1486–1494. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zhong, Y.; Zhang, L.; Xu, Y. Spatial group sparsity regularized nonnegative matrix factorization for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6287–6304. [Google Scholar] [CrossRef]
- Drumetz, L.; Meyer, T.R.; Chanussot, J.; Bertozzi, A.L.; Jutten, C. Hyperspectral image unmixing with endmember bundles and group sparsity inducing mixed norms. IEEE Trans. Image Process. 2019, 28, 3435–3450. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Huang, T.Z.; Zhao, X.L.; Deng, L.J. Nonlocal tensor-based sparse hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6854–6868. [Google Scholar] [CrossRef]
- Qiao, B.; Mao, Z.; Liu, J.; Zhao, Z.; Chen, X. Group sparse regularization for impact force identification in time domain. J. Sound Vib. 2019, 445, 44–63. [Google Scholar] [CrossRef]
- Majumdar, A.; Ward, R.K. Classification via group sparsity promoting regularization. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 861–864. [Google Scholar]
- Elhamifar, E.; Vidal, R. Robust classification using structured sparse representation. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1873–1879. [Google Scholar]
- Huang, J.; Nie, F.; Huang, H.; Ding, C. Supervised and projected sparse coding for image classification. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Tang, X.; Feng, G.; Cai, J. Weighted group sparse representation for undersampled face recognition. Neurocomputing 2014, 145, 402–415. [Google Scholar] [CrossRef]
- Rao, N.; Nowak, R.; Cox, C.; Rogers, T. Classification with the sparse group lasso. IEEE Trans. Signal Process. 2015, 64, 448–463. [Google Scholar] [CrossRef]
- Tan, S.; Sun, X.; Chan, W.; Qu, L.; Shao, L. Robust face recognition with kernelized locality-sensitive group sparsity representation. IEEE Trans. Image Process. 2017, 26, 4661–4668. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Natarajan, B.K. Sparse approximate solutions to linear systems. SIAM J. Comput. 1995, 24, 227–234. [Google Scholar] [CrossRef] [Green Version]
- Argyriou, A.; Foygel, R.; Srebro, N. Sparse prediction with the k-support norm. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Siem Reap, Cambodia, 13–16 December 2018; Volume 1, pp. 1457–1465. [Google Scholar]
- Deng, W.; Yin, W.; Zhang, Y. Group sparse optimization by alternating direction method. In Wavelets and Sparsity XV; International Society for Optics and Photonics: Bellingham, WA, USA, 2013; Volume 8858, p. 88580R. [Google Scholar]
- Huang, J.; Breheny, P.; Ma, S. A selective review of group selection in high-dimensional models. Stat. Sci. A Rev. J. Inst. Math. Stat. 2012, 27. [Google Scholar] [CrossRef]
- Breheny, P.; Huang, J. Group descent algorithms for nonconvex penalized linear and logistic regression models with grouped predictors. Stat. Comput. 2015, 25, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Li, C.; Meng, K.; Qin, J.; Yang, X. Group sparse optimization via lp, q regularization. J. Mach. Learn. Res. 2017, 18, 960–1011. [Google Scholar]
- Jiang, L.; Zhu, W. Iterative Weighted Group Thresholding Method for Group Sparse Recovery. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 63–76. [Google Scholar] [CrossRef] [PubMed]
- Jiao, Y.; Jin, B.; Lu, X. Group Sparse Recovery via the ℓ0(ℓ2) Penalty: Theory and Algorithm. IEEE Trans. Signal Process. 2016, 65, 998–1012. [Google Scholar] [CrossRef]
- Chen, P.Y.; Selesnick, I.W. Group-sparse signal denoising: Non-convex regularization, convex optimization. IEEE Trans. Signal Process. 2014, 62, 3464–3478. [Google Scholar] [CrossRef] [Green Version]
- Abe, J.; Yamagishi, M.; Yamada, I. Linearly involved generalized Moreau enhanced models and their proximal splitting algorithm under overall convexity condition. Inverse Probl. 2020, 36, 035012. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Yamagishi, M.; Yamada, I. A Generalized Moreau Enhancement of ℓ2,1-norm and Its Application to Group Sparse Classification. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021. [Google Scholar]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Larsson, V.; Olsson, C. Convex low rank approximation. Int. J. Comput. Vis. 2016, 120, 194–214. [Google Scholar] [CrossRef]
- Blake, A.; Zisserman, A. Visual Reconstruction; MIT Press: Cambridge, MA, USA, 1987. [Google Scholar]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef] [Green Version]
- Nikolova, M.; Ng, M.K.; Tam, C.P. Fast nonconvex nonsmooth minimization methods for image restoration and reconstruction. IEEE Trans. Image Process. 2010, 19, 3073–3088. [Google Scholar] [CrossRef] [PubMed]
- Selesnick, I. Sparse regularization via convex analysis. IEEE Trans. Signal Process. 2017, 65, 4481–4494. [Google Scholar] [CrossRef]
- Yin, L.; Parekh, A.; Selesnick, I. Stable principal component pursuit via convex analysis. IEEE Trans. Signal Process. 2019, 67, 2595–2607. [Google Scholar] [CrossRef]
- Abe, J.; Yamagishi, M.; Yamada, I. Convexity-edge-preserving signal recovery with linearly involved generalized minimax concave penalty function. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4918–4922. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 210–227. [Google Scholar] [CrossRef] [Green Version]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, Y.; Quan, Y.; Luo, Y. Structured sparse coding for classification via reweighted ℓ2,1 minimization. In CCF Chinese Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2015; pp. 189–199. [Google Scholar]
- Zheng, J.; Yang, P.; Chen, S.; Shen, G.; Wang, W. Iterative re-constrained group sparse face recognition with adaptive weights learning. IEEE Trans. Image Process. 2017, 26, 2408–2423. [Google Scholar] [CrossRef]
- Zhang, C.; Li, H.; Chen, C.; Qian, Y.; Zhou, X. Enhanced group sparse regularized nonconvex regression for face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Bauschke, H.H.; Combettes, P.L. Convex Analysis and Monotone Operator Theory in Hilbert Spaces, 2nd ed.; Springer International Publishing: New York, NY, USA, 2017. [Google Scholar]
- Zhao, L.; Hu, Q.; Wang, W. Heterogeneous feature selection with multi-modal deep neural networks and sparse group lasso. IEEE Trans. Multimed. 2015, 17, 1936–1948. [Google Scholar] [CrossRef] [Green Version]
- Qin, Z.; Scheinberg, K.; Goldfarb, D. Efficient block-coordinate descent algorithms for the group lasso. Math. Program. Comput. 2013, 5, 143–169. [Google Scholar] [CrossRef]
- Hull, J.J. A database for handwritten text recognition research. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 550–554. [Google Scholar] [CrossRef]
- Samaria, F.S.; Harter, A.C. Parameterisation of a stochastic model for human face identification. In Proceedings of the1994 IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 5–7 December 1994; pp. 138–142. [Google Scholar]
- Cai, D.; He, X.; Hu, Y.; Han, J.; Huang, T. Learning a spatially smooth subspace for face recognition. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Method | Training Set Size (, ) | ||||||
|---|---|---|---|---|---|---|---|
| 10 | 25 | 50 | |||||
| 5 | 10 | 5 | 25 | 25 | 50 | ||
| GSC(with ) | 81.4% | 86.6% | 73.6% | 91.4% | 88.4% | 93.2% | |
| Proposed () | 82.0% | 87.2% | 79.0% | 92.2% | 89.4% | 93.0% | |
| Proposed () | 82.6% | 87.8% | 80.8% | 92.2% | 90.6% | 93.4% | |
| Method | Training Set Size (, ) | ||||||
|---|---|---|---|---|---|---|---|
| 4 | 6 | 8 | |||||
| 4 | 4 | 6 | 4 | 6 | 8 | ||
| GSC | 86.3% | 85.0% | 91.3% | 85.0% | 92.5% | 93.8% | |
| Proposed () | 88.8% | 86.3% | 93.8% | 86.3% | 93.8% | 95.0% | |
| WGSC | 90.6% | 87.5% | 95.0% | 88.8% | 93.8% | 96.3% | |
| Proposed ( by (9)) | 91.3% | 89.4% | 95.6% | 91.9% | 94.4% | 96.3% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Yamagishi, M.; Yamada, I. A Linearly Involved Generalized Moreau Enhancement of ℓ2,1-Norm with Application to Weighted Group Sparse Classification. Algorithms 2021, 14, 312. https://doi.org/10.3390/a14110312
Chen Y, Yamagishi M, Yamada I. A Linearly Involved Generalized Moreau Enhancement of ℓ2,1-Norm with Application to Weighted Group Sparse Classification. Algorithms. 2021; 14(11):312. https://doi.org/10.3390/a14110312
Chicago/Turabian StyleChen, Yang, Masao Yamagishi, and Isao Yamada. 2021. "A Linearly Involved Generalized Moreau Enhancement of ℓ2,1-Norm with Application to Weighted Group Sparse Classification" Algorithms 14, no. 11: 312. https://doi.org/10.3390/a14110312
APA StyleChen, Y., Yamagishi, M., & Yamada, I. (2021). A Linearly Involved Generalized Moreau Enhancement of ℓ2,1-Norm with Application to Weighted Group Sparse Classification. Algorithms, 14(11), 312. https://doi.org/10.3390/a14110312