Crowd Evacuation Guidance Based on Combined Action Reinforcement Learning


Abstract
1. Introduction
1.1. Crowd Simulation and Evacuation Guidance
1.2. Deep Reinforcement Learning
2. Methods
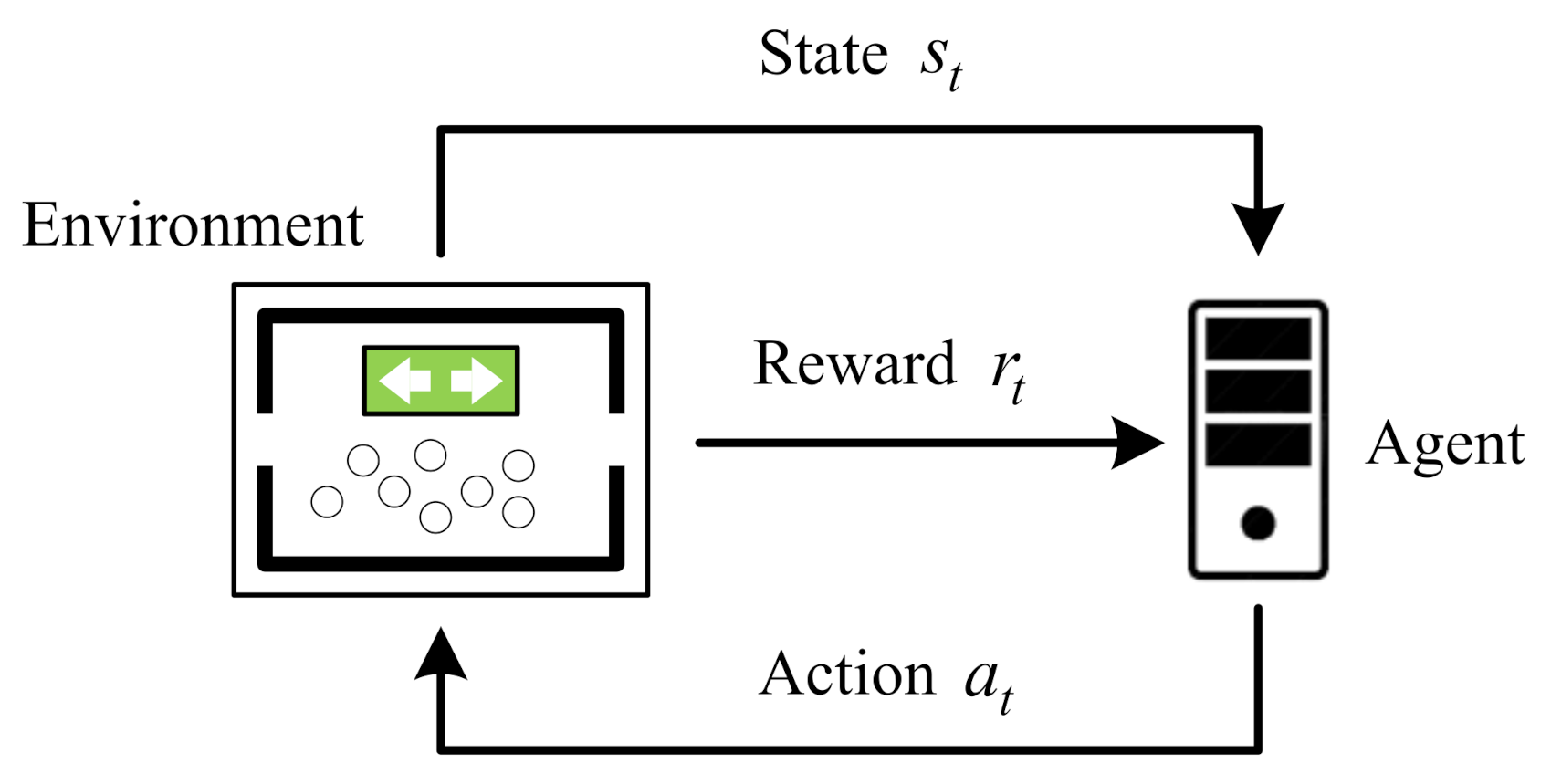
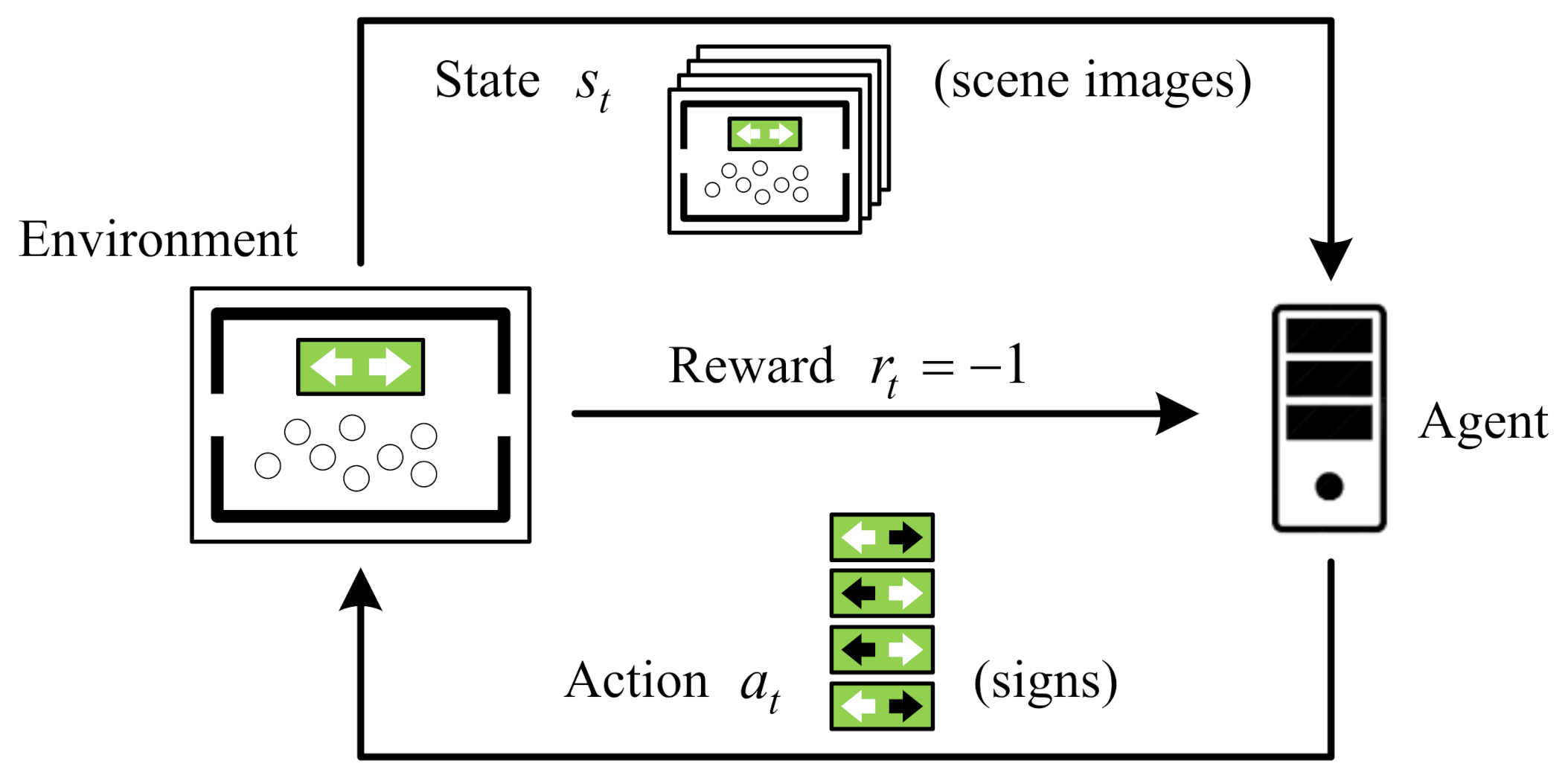
2.1. Reinforcement Learning Model for Crowd Evacuation Guidance
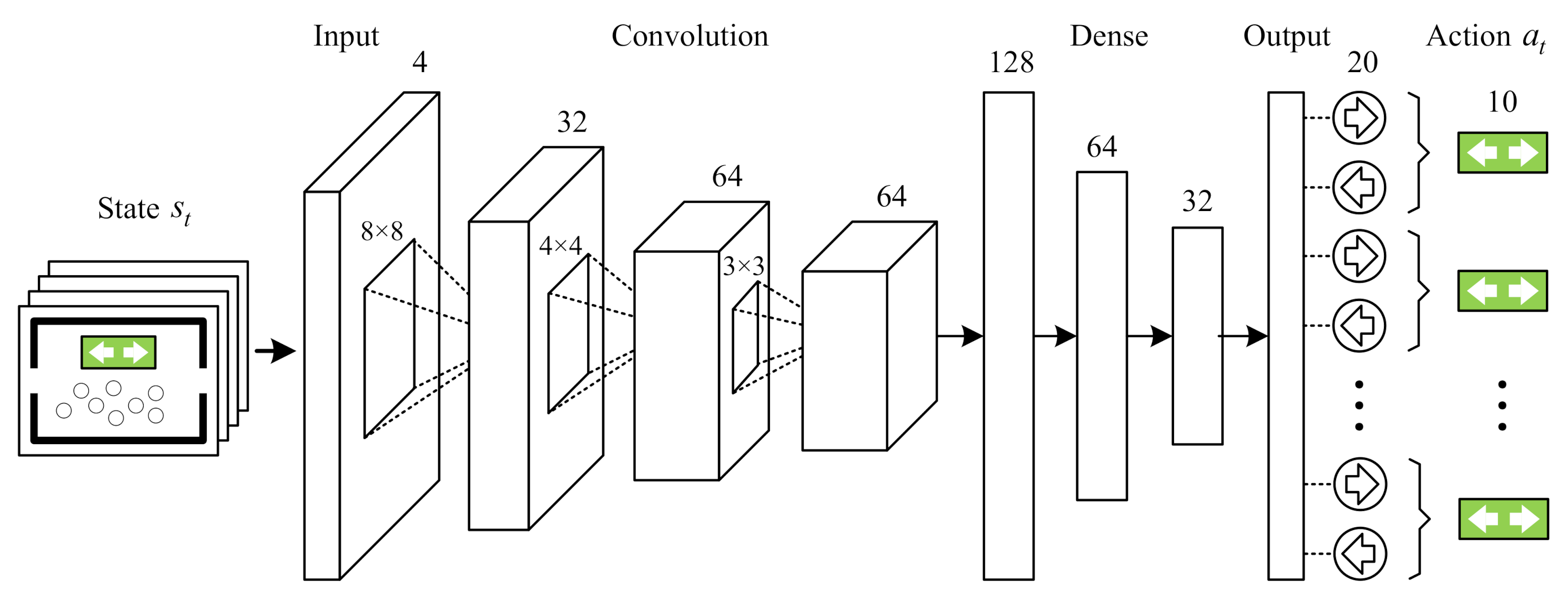
2.2. Combined Action Space DQN
2.3. Priority Experience Playback of CA-DQN
3. Results
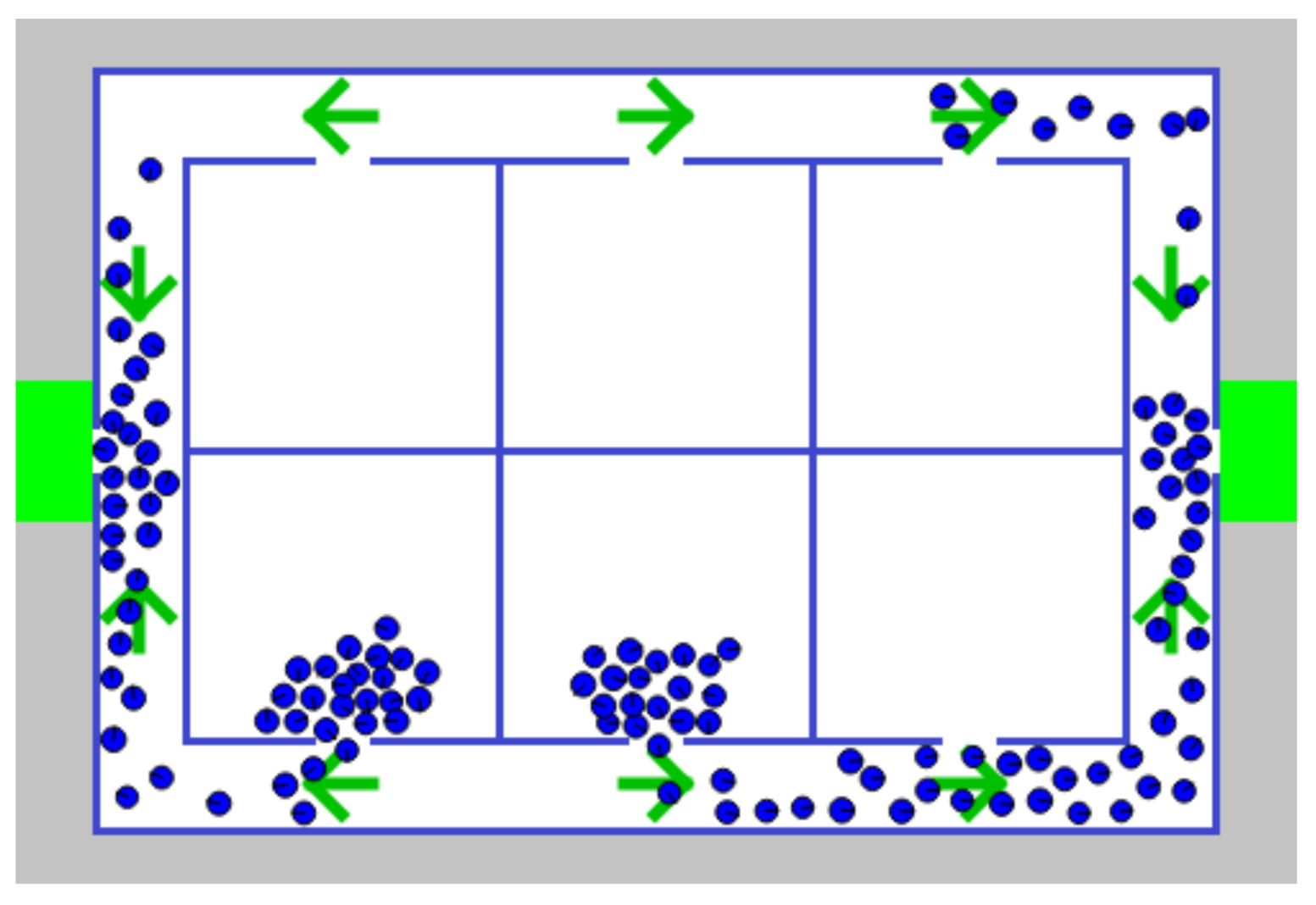
3.1. Experiment Design and Implementation
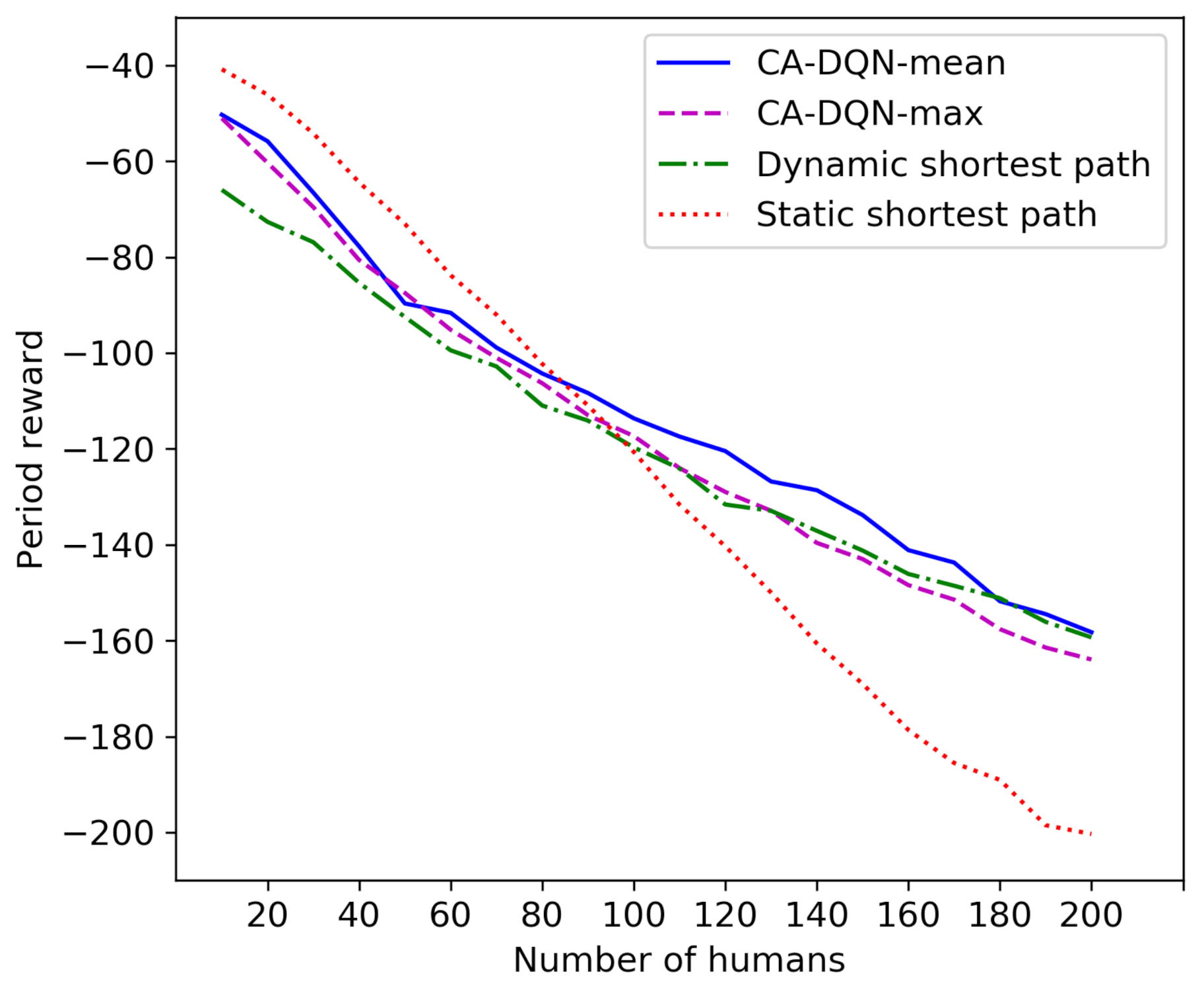
3.2. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ran, H.; Sun, L.; Gao, X. Influences of intelligent evacuation guidance system on crowd evacuation in building fire. Autom. Constr. 2014, 41, 78–82. [Google Scholar] [CrossRef]
- Desmet, A.; Gelenbe, E. Capacity based evacuation with dynamic exit signs. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communication Workshops (PERCOM WORKSHOPS), Budapest, Hungary, 24–28 March 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 332–337. [Google Scholar]
- Zhao, W.; Liu, C.; Lian, X.; Xue, Y.; Guo, Y. Simulation of crowd movement and design and implementation of evacuation optimization method. J. Syst. Simul. 2014, 26, 523–529. (In Chinese) [Google Scholar]
- Dong, H.; Ning, B.; Chen, Y.; Sun, X.; Wen, D.; Hu, Y.; Ouyang, R. Emergency management of urban rail transportation based on parallel systems. IEEE Trans. Intell. Transp. Syst. 2012, 14, 627–636. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Li, T.; Gong, X.; Peng, B.; Hu, J. A review on crowd simulation and modeling. Graph. Model. 2020, 111, 101081. [Google Scholar] [CrossRef]
- Xu, M.L.; Jiang, H.; Jin, X.G.; Deng, Z. Crowd simulation and its applications: Recent advances. J. Comput. Sci. Technol. 2014, 29, 799–811. [Google Scholar] [CrossRef]
- Muramatsu, M.; Irie, T.; Nagatani, T. Jamming transition in pedestrian counter flow. Phys. A Stat. Mech. Appl. 1999, 267, 487–498. [Google Scholar] [CrossRef]
- Bisagno, N.; Conci, N.; Zhang, B. Data-driven crowd simulation. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Xue, Y.; Liu, P.; Tao, Y.; Tang, X. Abnormal prediction of dense crowd videos by a purpose–driven lattice boltzmann model. Int. J. Appl. Math. Comput. Sci. 2017, 27, 181–194. [Google Scholar] [CrossRef]
- Helbing, D.; Molnar, P. Social force model for pedestrian dynamics. Phys. Rev. E 1995, 51, 4282. [Google Scholar] [CrossRef]
- Liu, H.; Xu, B.; Lu, D.; Zhang, G. A path planning approach for crowd evacuation in buildings based on improved artificial bee colony algorithm. Appl. Soft Comput. 2018, 68, 360–376. [Google Scholar] [CrossRef]
- Cuesta, A.; Abreu, O.; Balboa, A.; Alvear, D. Real-time evacuation route selection methodology for complex buildings. Fire Saf. J. 2017, 91, 947–954. [Google Scholar] [CrossRef]
- Zhou, M.; Dong, H.; Ioannou, P.A.; Zhao, Y.; Wang, F.Y. Guided crowd evacuation: Approaches and challenges. IEEE/CAA J. Autom. Sin. 2019, 6, 1081–1094. [Google Scholar] [CrossRef]
- Fu, L.; Cao, S.; Song, W.; Fang, J. The influence of emergency signage on building evacuation behavior: An experimental study. Fire Mater. 2019, 43, 22–33. [Google Scholar] [CrossRef]
- Yuan, Z.; Jia, H.; Zhang, L.; Bian, L. A social force evacuation model considering the effect of emergency signs. Simulation 2018, 94, 723–737. [Google Scholar] [CrossRef]
- Galea, E.R.; Xie, H.; Deere, S.; Cooney, D.; Filippidis, L. Evaluating the effectiveness of an improved active dynamic signage system using full scale evacuation trials. Fire Saf. J. 2017, 91, 908–917. [Google Scholar] [CrossRef]
- Cho, J.; Lee, G.; Lee, S. An automated direction setting algorithm for a smart exit sign. Autom. Constr. 2015, 59, 139–148. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Hasselt, H.v.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
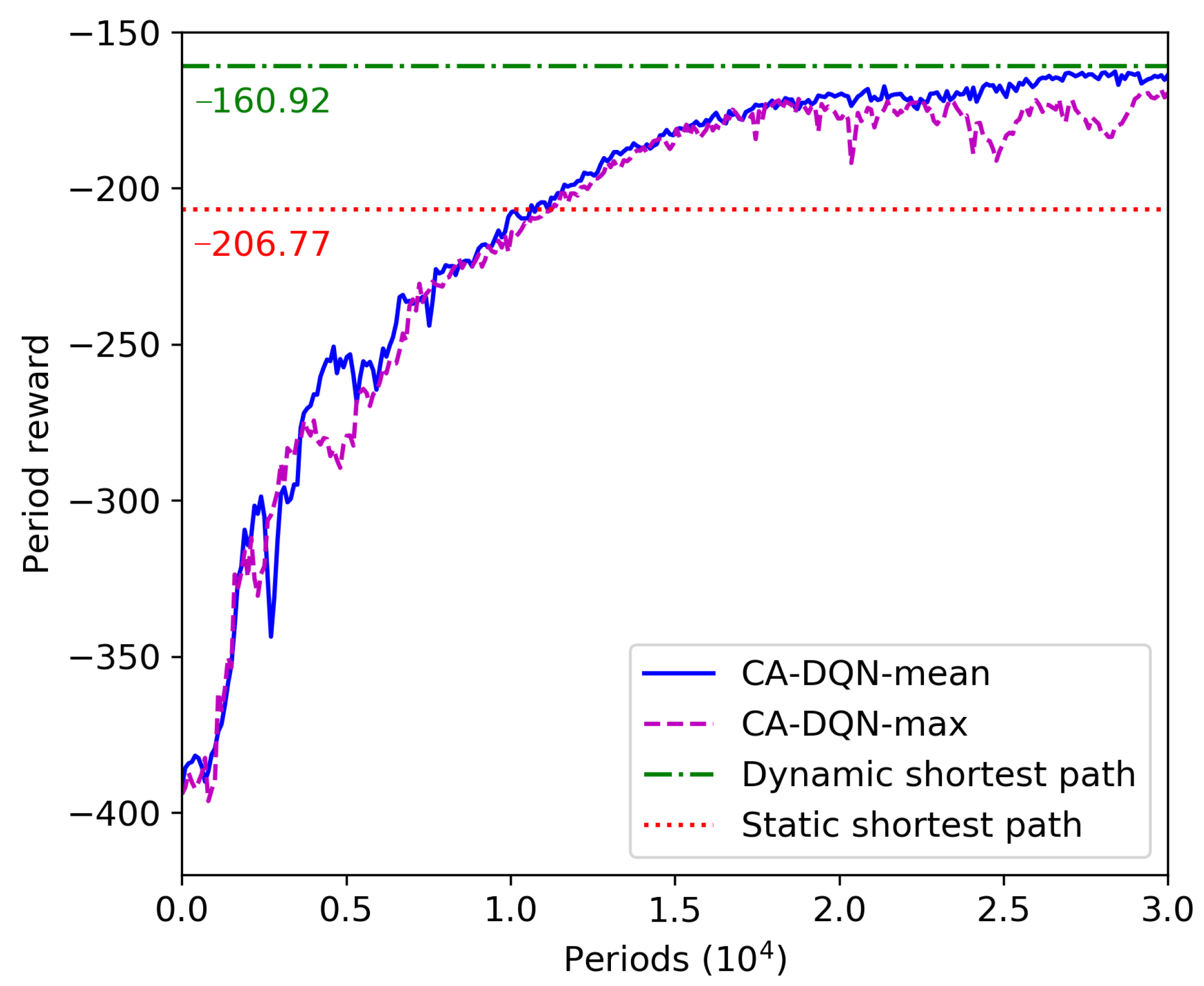
| Method | Period Reward | Evacuation Time (s) |
|---|---|---|
| Static sign | −206.77 | 41.35 |
| Dynamic shortest path | −160.92 | 32.18 |
| CA-DQN-mean | −158.25 | 31.65 |
| CA-DQN-max | −160.40 | 32.08 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, Y.; Wu, R.; Liu, J.; Tang, X. Crowd Evacuation Guidance Based on Combined Action Reinforcement Learning. Algorithms 2021, 14, 26. https://doi.org/10.3390/a14010026
Xue Y, Wu R, Liu J, Tang X. Crowd Evacuation Guidance Based on Combined Action Reinforcement Learning. Algorithms. 2021; 14(1):26. https://doi.org/10.3390/a14010026
Chicago/Turabian StyleXue, Yiran, Rui Wu, Jiafeng Liu, and Xianglong Tang. 2021. "Crowd Evacuation Guidance Based on Combined Action Reinforcement Learning" Algorithms 14, no. 1: 26. https://doi.org/10.3390/a14010026
APA StyleXue, Y., Wu, R., Liu, J., & Tang, X. (2021). Crowd Evacuation Guidance Based on Combined Action Reinforcement Learning. Algorithms, 14(1), 26. https://doi.org/10.3390/a14010026