Abstract
Deregulated electricity markets encourage firms to compete, making the development of renewable energy easier. An ordinary parameter of electricity markets is the electricity market price, mainly the day-ahead electricity market price. This paper describes a new approach to forecast day-ahead electricity market prices, whose methodology is divided into two parts as: (i) forecasting of the electricity price through autoregressive integrated moving average (ARIMA) models; and (ii) construction of a portfolio of ARIMA models per hour using stochastic programming. A stochastic programming model is used to forecast, allowing many input data, where filtering is needed. A case study to evaluate forecasts for the next 24 h and the portfolio generated by way of stochastic programming are presented for a specific day-ahead electricity market. The case study spans four weeks of each one of the years 2014, 2015 and 2016 using a specific pre-treatment of input data of the stochastic programming (SP) model. In addition, the results are discussed, and the conclusions are drawn.
1. Introduction
Electric energy systems have started being controlled by governments; since then, a constant search for improving such systems towards deregulation, seeking a competitive structure and attaining growth by satisfying the needs of society, has been pursued.
Electricity market prices have achieved a relevant importance as a consequence of the deregulation of the electricity sector. The importance of prices for the generation sector has been increasing in the last few years due to the high penetration of renewable energy sources, whose revenues come from selling the energy generated at market prices. Hence, price forecasting is still an active field of research, especially due to the incorporation of new technologies, such as wind and photovoltaic energy.
The high amount of renewable energies in the markets has decreased electricity market prices due to the fact that some renewable energies are offered in the market at zero price owing to their close-to-zero marginal costs. However, other effects in market prices can be observed since some generators could be working at a higher marginal cost to be used as reserves.
Literature Review and Contributions
Deregulation of electric energy systems started with the growth of the industry and the new demands for electricity [1,2]. After that, several research lines were created to reduce generation uncertainties, as presented in [3,4,5,6].
Thus, electricity market price forecasting has a high importance for generators, and electricity price forecasting is performed through different approaches [7], such as multi-agent, fundamental, reduced-form, statistical and computational intelligence methods.
Neural networks are presented in [8]. Another approach is based on a combinatorial neural network [9]. In addition, different models used for the Pennsylvania-New Jersey-Maryland (PJM) and Spanish electricity markets are compared in [10]. An artificial neural network with the preparation of input data through cluster algorithms is developed in [11]. The work in [12] combines an artificial neural network with a clustering algorithm. The works in [13,14,15] present time series analysis, forecasting and control models. Hence, [16] uses neural networks to forecast day-ahead market prices, while [17] forecasts through an autoregressive integrated moving average (ARIMA) model. Moreover, some models are based on forecasting the volatility [18] as a result of generalized autoregressive conditional heteroskedasticity (GARCH) models. In this way, forecasting trends of time series can be useful [19,20], as well as the use of filters [21].
Some forecasting methods are based on the combination or a portfolio of several models, as proposed by [22,23,24,25].
In this regard, an interesting procedure is presented in [26], proposing an enhanced hybrid approach composed of an innovative combination of wavelet transform, differential evolutionary particle swarm optimization and an adaptive neuro-fuzzy inference system to forecast electricity market price signals in the short-term through historical data.
Another work to estimate uncertainty uses a statistical approach for interval forecasting of the electricity price [27] based on a support vector machine (SVM) where some model parameters are estimated by means of maximum likelihood estimation (MLE). A possible accuracy gain from using factor models, quantile regression and forecast averaging to compute interval forecasts of electricity spot prices is evaluated in [28]. A general survey of support vector machines is shown in [29]. An ensemble method for weather conditions is described in [30].
This paper sets out a new stochastic programming model [31] combining many models whose forecasts are made by way of ARIMA models. Note that any forecast has an error because of future uncertainty.
In this paper, we propose a new stochastic programming model with many input data, which may help to reduce the error, where the combination of models comes from several forecasts. In contrast, perfect input data considering our forecast methodology could achieve a perfect forecast. However, this paper is only focused on the stochastic programming model and its features and not on the best input data for the model.
The main contributions of this paper are as follows:
- A new stochastic programming model to create a forecasting portfolio.
- A new combination approach using multiple input data in order to apply stochastic programming.
A description of the effects of input data on the created optimal forecasting portfolio is drawn. An application of forecasting in a real market with real-time series is also presented. A recent period is analyzed because the integration of renewable energy sources in the Spanish electricity market has produced a downward effect on the price from 2010 onwards, where the participation of renewable energy sources on some days (25 February 2015) was higher than 70%, as shown in [32].
2. Mathematical Model
The aim of the paper is to create a new model whose final error can be reduced by way of stochastic programming, after combining several forecasting models and their errors. The main decision made is the weight of each model per period seeking the lower error of the combination of forecasts.
A stochastic mixed integer linear programming model to combine the forecasting models and their portfolio (SP) is created. The variables of the stochastic programming model are .
subject to:
where the objective is to minimize the variables related to the errors (1), positive or negative , in each period p and scenario s. The error variables of (1) are both positive, as shown in (5) and (6); can be positive or negative, as shown in (3) and (4), which are not zero through binary variable ; depending on (5) or (6); if = 1, , whereas, if = 0, (negative). Constant m is a big enough value.
There are three input data, each one being a parameter, namely the forecasted errors , the forecasted trends and the forecasted prices .
The forecasted error (parameter) is an error that corrects the forecasted trends and the forecasted prices, i.e., . This parameter is the possible distance between the real price and the forecasted value. When the real price is lower than the forecasted price, is negative, and variable is positive (11), i.e., binary variable is zero, so . The opposite case is = 1 and , where is a positive variable, as shown in (10).
The forecasting portfolio is evaluated in (12), where is the parameter whose values are the forecasts made; one scenario for this parameter is a forecast per period, where variable is the final price of the portfolio created by the forecasts, , and the weight that has to be decided, , whose sum, , has to be equal to one, as shown in (13). could be different from one, even being an interval, and the model should decide what is the best value. In this paper, is used as in (13).
Equation (14) decides the value of variable; this variable comes from the multiplication of and the weight , being the final price from (12). Equation (14) reduces the error whose value is the difference between the variable and the parameters that are the input data of the model, such as , and . The parameter represents the trend of the price; thus, more forecasts provide more information for the possible behavior of the real unknown price. On the other hand, the differences between and can be corrected through parameter , but also, tries to reduce the imbalance between and the real unknown price. Therefore, the forecasting portfolio could improve the ordinary forecasts, but always following parameter .
To sum up, the stochastic programming model is composed of three kinds of input data. These input data are: (i) forecasted prices; (ii) errors of the forecasts that show the differences between the real price (unknown), forecasted price and the trend; and (iii) the trend of the prices (it could be obtained through more forecasts) in order to describe the possible evolution of the price. On the other hand, the variables of the model, , depend on the input data and can be calculated through different techniques.
Index p represents the hour, from Hour 1 spanning the time horizon of forecasting, and index s is the scenario of the stochastic programming model; nevertheless, each s scenario of each input datum can be achieved using any technique to forecast the prices, the error and the trend.
3. Case Study
The forecasts are obtained for the Spanish electricity market prices. The prices are quite different for each year; Table 1 shows a summary of the statistics, and Table 2 presents the correlation matrix of the Spanish electricity prices from 2010–2015 [33]. The high standard deviation of prices of years 2013 and 2014 is remarkable, whose values are €20.73/MWh and €21.14/MWh, respectively. These values are two-times the standard deviation of the prices of 2011. This analysis is made using ECOTOOL (2016) [34], a forecasting toolbox in MATLAB® (R2011b) [35].

Table 1.
Summary statistics of the Spanish electricity prices (€/MWh) of 2010–2015.
Table 2.
Correlation matrix of the Spanish electricity prices of 2010–2015.
Figure 1 portrays the scatter plots and the histograms of all of the hourly prices of each one of the six years. Red lines in the histograms indicate the shape of the normal distribution, whilst the green lines describe the real shape of the distribution that follows those data. Figure 2 depicts the sample of 2016, from 1 January–10 June 2016; the mean price is equal to €29.17/MWh, and the standard deviation of prices is €12.35/MWh. The time series of the day-ahead electricity market prices is transformed using a logarithmic transformation to make the dispersion constant.
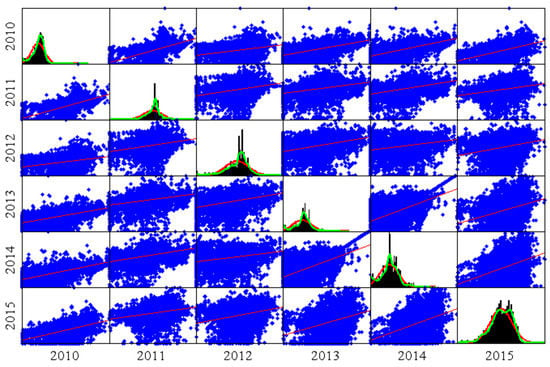
Figure 1.
Scatter plot of the Spanish electricity prices of 2010, 2011, 2012, 2013, 2014 and 2015.
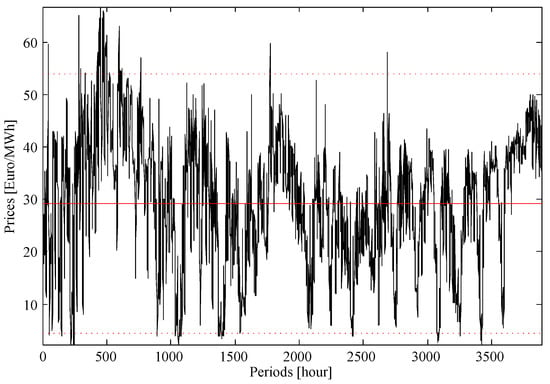
Figure 2.
Prices from 1 January–10 June 2016 of the Spanish electricity prices.
3.1. Input Data for the SP Model
As presented in Section 2, there are three input data: forecasted prices, forecasted errors and forecasted trends. This section shows how these input data are calculated to test the SP model, achieving a portfolio of the forecasted prices, which are input data.
Figure 3 shows the three input data: forecasted prices, forecasted errors and forecasted trends; all of them represent the information used in the SP model. Moreover, Figure 3 shows the main output data, i.e., the final forecasted prices.
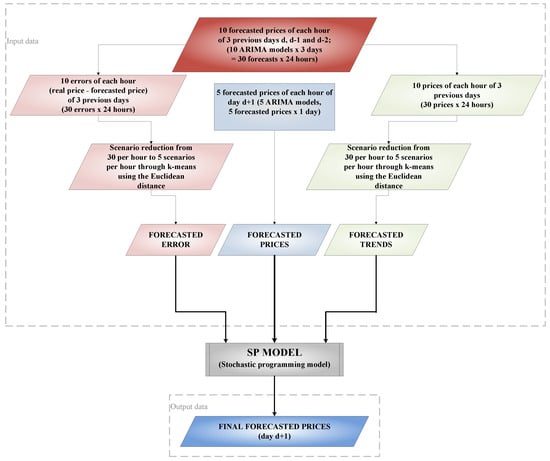
Figure 3.
Diagram of the input data of the SP model.
Figure 3 presents how the different inputs are calculated. There are two forecasting processes; first, some forecasts are made for the three days (d, , and ) previous to the final day () in order to have more information; and second, some forecasts are made only for the final day ().
The first forecasting process is used to determine the behavior of the errors and trends of the three days previous to day , where the models are similar to the models used in the second forecasting process. The three previous days are utilized because the real prices of these days are known; thus, the behavior of the errors and trends can be calculated from these forecasts. Thirty scenarios of trends and errors are attained for each hour of the day, 3 days × 10 models × 24 h. The 30 scenarios per hour are reduced to five scenarios per hour for the errors and trends. The scenario reduction from 30 scenarios per hour to five scenarios per hour is done by the k-means method using the Euclidean distance, where the centroid is the mean of the points of the cluster of the five scenarios.
The second forecasting process is applied to day , that is the real forecasted day, and five forecasted prices are obtained from the first five ARIMA models of Table 3. Five ARIMA models are used because the stochastic programming model presented in Section 2 is tested utilizing five scenarios.
Table 3.
Terms of the ARIMA models.
Note that the forecasting processes previous to the SP model can be done by means of neural networks, support vector machines, ensemble methods or by a mixture of all of them, with the possibility of including other methods.
The information of the input data comes from the use of ARIMA models. The behavior of previous days for each forecast is used in order to obtain the forecasted error and the forecasted trend.
3.2. ARIMA Models
The proposed general ARIMA formulation [34] is as follows:
where is the observed time series, is the residual term, , is a set of seasonal periods, , , are the differencing operators necessary to reduce the time series and to achieve mean stationary, and , are the AR and MA polynomials of the back shift operator B: of , and c is a constant.
Previously, the time series is transformed through logarithmic transformation to stabilize the variance; after that, ARIMA models can be applied.
Following the formulation of (16), the indexes of each term for every ARIMA model are shown in Table 3. The process to select each term of each ARIMA model is based on the evaluation of each autocorrelation function (ACF) and partial autocorrelation function (PACF) of the residual component, , of each ARIMA model, as shown in Figure 4 and Figure 5.
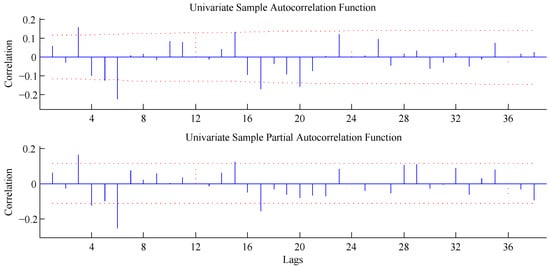
Figure 4.
Autocorrelation function (ACF) and partial ACF (PACF) of the residual component for the ARIMA 2 model of 5 June 2016.
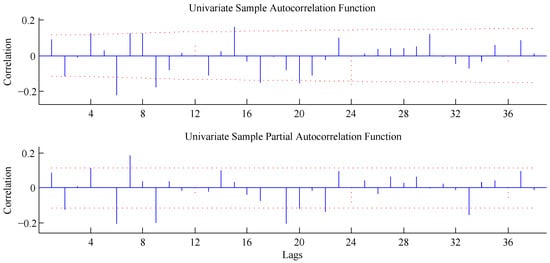
Figure 5.
ACF and PACF of the residual component for the ARIMA 2 model of 6 June 2016.
3.3. Forecasted Prices
Forecasted prices are obtained through ARIMA models; this case study uses five scenarios. These five scenarios for the input data of forecasted prices are ARIMA 1, ARIMA 2, ARIMA 3, ARIMA 4 and ARIMA 5, as presented in Table 3, where each ARIMA model represents one scenario. An econometric toolbox of MATLAB® [35], ECOTOOL [34], is used to obtain the forecasts. The sample used to forecast every day with each ARIMA model is 15 days, i.e., 360 h. A sample spanning 360 h has been selected because the sample changes every two or three weeks as a consequence of the price volatility. The computing time increases for a sample spanning more days.
The five scenarios of forecasted prices are depicted in Figure 6, where one week of forecasts is shown. The forecasted days span from the 4–10 June 2016. After this, the models are verified for one week of each season of 2014, 2015 and 2016, the forecasting horizon being 24 h using a 24-h rolling horizon window for the next day until every day of each week is evaluated.
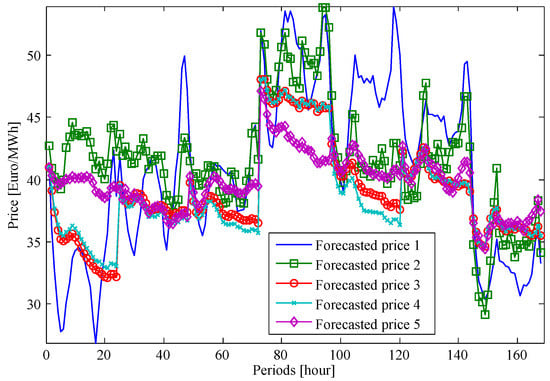
Figure 6.
Input data of forecasted prices.
3.4. Forecasted Errors
Errors are the differences between the real price and the forecasted price, being positive when the real price is higher than the forecasted price and negative otherwise. It is remarkable that, if for the forecasting day the real price are unknown, then the error is also unknown. However, the error can be calculated for previous days since the real price is known. Thus, the ten ARIMA models of Table 3 are used to make forecasts of the three previous days. As a consequence of using 10 ARIMA models in these three days, the number of scenarios of forecasted errors would be 30 (10 ARIMA models multiplied by three days), but they can be reduced to five scenarios. Scenario reduction is performed through the squared Euclidean distance, and each centroid is the mean of the points in the cluster for five scenarios, reducing them from 30 down to five. The input data forecasted errors are these five scenarios.
The five scenarios obtained from the 30 scenarios are shown in Figure 7.

Figure 7.
Input data of the forecasted errors.
3.5. Forecasted Trends
Forecasted trends are made through the 10 ARIMA models of Table 3. The forecasted trend is made for the three previous days, trying to recover some behaviors of previous days. Therefore, as happened for the forecasted error input data, the forecasted trend has 30 scenarios, three days multiplied by 10 forecasts of the 10 ARIMA models. The scenarios are reduced through the squared Euclidean distance as done for the forecasted error. The five scenarios of forecasted trends are depicted in Figure 8.

Figure 8.
Input data of the forecasted trends.
4. Results and Discussion
4.1. Results
This subsection shows the results obtained using this technique for the forecasting week. Firstly, the daily average errors (%) () of the week under study are calculated in (18), where is the real price, is the forecasted price and is the average real price of the 24 hours. Secondly, the errors (18) from 1–10 June 2016 are presented in Table 4. Several input data are calculated through the forecasts of the three previous days, and due to that, Days 1, 2 and 3 of June are presented in Table 4, as well.
Table 4.
Daily average error (%) of 1–10 June 2016, for ARIMA Models 1–10.
for the SP model of Table 5 can be lower and higher than the average price forecasting (AVG), but this depends on the forecasted errors and trends used as input data, where the final error is lower when the forecasted trend and forecasted error follow the forecasted price. The differences between forecasted price, trend and error can increase or reduce the final error.
Table 5.
Daily average error (%) of 4–10 June 2016, for the SP model, average, and ARIMA Models 1–5.
The forecasted week of June of 2016 is portrayed in Figure 9, and Table 6 shows the weight of each forecasted price, , introduced in the SP model for the second and third forecasted days, the best and worst forecasted day of the SP model, respectively.
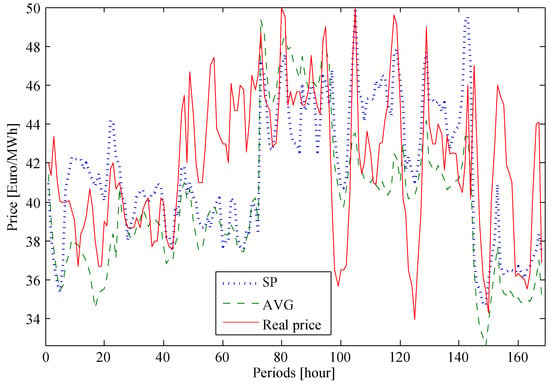
Figure 9.
Prices of the SP model, average forecasted price (AVG) and real prices for the week of 4–10 June 2016.
Table 6.
values in each scenario of the forecasted price for the second and third days of the week.
For this case study, , but this value could be different allowing for an increase or a decrease in the forecasted price weight. The main dissimilarity between of Table 6 is for the best day; the percentage of each forecasted price of the input data is more distributed between two scenarios of the input data.
After showing one week for the spring season of the current year, 2016, and in order to evaluate the forecasts per season, Table 7, Table 8, Table 9 and Table 10 show several error measures, such as , and the error variance. The studied seasons are winter, spring, summer and autumn for the last three years, 2014, 2015 and 2016. The SP model is presented together with the average of the first five ARIMA models of Table 5 and the naïve model (see [10]), whose forecasts for Monday, Saturday and Sunday are the previous Monday, Saturday and Sunday, respectively, while for Tuesday, Wednesday, Thursday and Friday, the forecasts are their previous days, respectively.
Table 7.
(%), and of winter of 2016, 2015 and 2014 for the SP model, average (AVG) and naïve models.
Table 8.
(%), and of spring of 2016, 2015 and 2014 for the SP model, average and naïve models.
Table 9.
(%), and of summer of 2016, 2015 and 2014 for the SP model, average and naïve models.
Table 10.
(%), and of autumn of 2016, 2015 and 2014 for the SP model, average and naïve models.
The naïve errors presented in the previous tables are neither very high, as in winter (January 2014), nor low, as in autumn (October 2016). The SP model displays a more stable error than the AVG and naïve models, i.e., lower volatility across several errors. Furthermore, the error variance shows lower values. For example, in Table 10, for Friday, autumn (October 2014), the SP model produces a higher error than the AVG model; nevertheless, is more than two-times lower than the AVG error variance. This behavior is present for some days of the representative weeks per season. Table 11 shows the average values of (%), and of each season for 2016, 2015 and 2014.
Table 11.
Average values of (%), and of each season for 2016, 2015 and 2014 in order to evaluate the SP model, average and naïve models.
The SP model has lower errors than the other models, and the errors are low in general. The naïve method has very low errors in some cases as a consequence of some days being very similar and with low prices [33].
4.2. Discussion
The forecasted prices of the SP model depend on the input data, where the main idea comes from Figure 10, which shows three lines: real price, forecasted price and forecasted trend of the real price. Thus, if we focus on Hour 13, Figure 10 shows the errors that are affecting the input data for the SP model. Hence, two errors are described, and . Thus, of Equation (14) is defined in (22). The final error could be increased or reduced; is evaluated from the forecasted trend, and comes from the forecasted price. In this way, if both errors tend to reduce the final error, the SP model will have a low final error, whilst if the error goes in the opposite way, in order to reduce the error, the SP model could produce a worse forecast with a high final error, as happens on the third day of the week studied, because the error will be the minimum of the sum of both errors, and .

Figure 10.
Description of .
A summary of the input data that affect the final error is presented as follows:
- : the real price is higher than the forecasted price:Final error > 0: where as a result of , and influence through .
- , otherwise:Final error < 0: where as a result of , and influence through .
In short, follows , whilst and influence , increasing or decreasing , the percentage of each forecasted price of the five ARIMA models.
For this reason, the input data can change the final forecasted price by means of β. Moreover, the value lies in the interval where each value per period depends on , and . If is equal to zero for a specific scenario and period, the contribution of that scenario as a forecasted price is null, whilst for , it can contribute to the final price, , and the sum of all terms for all scenarios has to be equal to one, as shown in (13).
5. Conclusions
In this paper, a new approach to improve the day-ahead electricity market price forecasting has been presented, where the error of the portfolio model can considerably reduce the final error, which depends on the quality of input data for the portfolio model. If the input data correctly follow the trend of prices and the error of the models used to create the portfolio, the final error may be very low. In contrast, with the average model, it would not be possible to achieve a perfect forecast. A portfolio approach could attain a zero final error if one input datum or a mix of forecasts closely follow the final error. Due to having more input data than the other models, this approach has higher flexibility. However, a drawback could be the incorrect creation of input data, increasing the final error. Hence, future work could be related to the creation of a better trend, error and forecasting data.
Acknowledgments
This work was supported in part by the Ministry of Economy and Competitiveness of Spain, under Project ENE2015-63879-R (MINECO/FEDER, UE), and the Junta de Comunidades de Castilla-La Mancha, under Project POII-2014-012-P.
Author Contributions
Agustín A. Sánchez de la Nieta and Javier Contreras proposed the methodology. Virginia González performed the simulations. All authors revised the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Larsen, E.R.; Bunn, D.W. Deregulation in electricity: Understanding strategic and regulatory risk. J. Oper. Res. Soc. 1999, 50, 337–344. [Google Scholar] [CrossRef]
- Rothwell, G.S.; Gómez, T. Electricity Economics: Regulation and Deregulation; Wiley-IEEE Press: New York, NY, USA, 2003; Volume 12. [Google Scholar]
- Pinson, P.; Chevallier, C.; Kariniotakis, G.N. Trading wind generation from short-term probabilistic forecasts of wind power. IEEE Trans. Power Syst. 2007, 22, 1148–1156. [Google Scholar] [CrossRef]
- Guerrero-Mestre, V.; Sánchez de la Nieta, A.A.; Contreras, J.; Catalão, J.P.S. Optimal bidding of a group of wind farms in day-ahead markets through an external agent. IEEE Trans. Power Syst. 2016, 31, 2688–2700. [Google Scholar] [CrossRef]
- Sánchez de la Nieta, A.A.; Contreras, J.; Muñoz, J.I. Optimal coordinated wind-hydro bidding strategies in day-ahead markets. IEEE Trans. Power Syst. 2013, 28, 798–809. [Google Scholar] [CrossRef]
- Sánchez de la Nieta, A.A.; Tavares, T.A.M.; Martins, R.F.M.; Matias, J.C.O.; Catalão, J.P.S.; Contreras, J. Optimal generic energy storage system offering in day-ahead electricity markets. In Proceedings of the 2015 IEEE Eindhoven IEEE PowerTech, Eindhoven, The Netherlands, 29 June–2 July 2015; pp. 1–6.
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast. 2014, 30, 1030–1081. [Google Scholar] [CrossRef]
- Haykin, S.; Network, N. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2004; Volume 2. [Google Scholar]
- Abedinia, O.; Amjady, N.; Shafie-Khah, M.; Catalão, J.P.S. Electricity price forecast using combinatorial neural network trained by a new stochastic search method. Energy Convers. Manag. 2015, 105, 642–654. [Google Scholar] [CrossRef]
- Conejo, A.; Contreras, J.; Espinola, R.; Plazas, M.A. Forecasting electricity prices for a day-ahead pool-based electric energy market. Int. J. Forecast. 2005, 21, 435–462. [Google Scholar] [CrossRef]
- Keles, D.; Scelle, J.; Paraschiv, F.; Fichtner, W. Extended forecast methods for day-ahead electricity spot prices applying artificial neural networks. Appl. Energy 2016, 162, 218–230. [Google Scholar] [CrossRef]
- Panapakidis, I.P.; Dagoumas, A.S. Day-ahead electricity price forecasting via the application of artificial neural network based models. Appl. Energy 2016, 172, 132–151. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- Pedregal, D.J.; Young, P.C. Statistical approaches to modelling and forecasting time series. In Companion to Economic Forecasting; John Wiley & Sons: New York, NY, USA, 2002; pp. 69–104. [Google Scholar]
- Wei, W.W.S. Time Series Analysis; Addison-Wesley: Boston, MA, USA, 1994. [Google Scholar]
- Amjady, N. Day-ahead price forecasting of electricity markets by a new fuzzy neural network. IEEE Trans. Power Syst. 2006, 21, 887–896. [Google Scholar] [CrossRef]
- Contreras, J.; Espinola, R.; Nogales, F.J.; Conejo, A.J. ARIMA models to predict next-day electricity prices. IEEE Trans. Power Syst. 2003, 18, 1014–1020. [Google Scholar] [CrossRef]
- Garcia, R.C.; Contreras, J.; van Akkeren, M.; Garcia, J.B.C. A GARCH forecasting model to predict day-ahead electricity prices. IEEE Trans. Power Syst. 2005, 20, 867–874. [Google Scholar] [CrossRef]
- Gardner, E.S., Jr.; McKenzie, E.D. Forecasting trends in time series. Manag. Sci. 1985, 31, 1237–1246. [Google Scholar] [CrossRef]
- Holt, C.C. Forecasting seasonals and trends by exponentially weighted moving averages. Int. J. Forecast. 2004, 20, 5–10. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Granger, C.W.J.; Ramanathan, R. Improved methods of combining forecasts. J. Forecast. 1984, 3, 197–204. [Google Scholar] [CrossRef]
- García-Martos, C.; Rodríguez, J.; Sánchez, M.J. Mixed models for short-run forecasting of electricity prices: Application for the Spanish market. IEEE Trans. Power Syst. 2007, 22, 544–552. [Google Scholar] [CrossRef]
- Bessler, D.A.; Brandt, J.A. Forecasting livestock prices with individual and composite methods. Appl. Econ. 1981, 13, 513–522. [Google Scholar] [CrossRef]
- Raviv, E.; Bouwman, K.E.; van Dijk, D. Forecasting day-ahead electricity prices: Utilizing hourly prices. Energy Econ. 2015, 50, 227–239. [Google Scholar] [CrossRef]
- Osório, G.J.; Gonçalves, J.N.D.L.; Lujano-Rojas, J.M.; Catalão, J.P.S. Enhanced Forecasting Approach for Electricity Market Prices and Wind Power Data Series in the Short-Term. Energies 2016, 9, 693. [Google Scholar]
- Zhao, J.H.; Dong, Z.Y.; Xu, Z.; Wong, K.P. A statistical approach for interval forecasting of the electricity price. IEEE Trans. Power Syst. 2008, 23, 267–276. [Google Scholar] [CrossRef]
- Maciejowska, K.; Nowotarski, J.; Weron, R. Probabilistic forecasting of electricity spot prices using Factor Quantile Regression Averaging. Int. J. Forecast. 2016, 32, 957–965. [Google Scholar] [CrossRef]
- Sapankevych, N.I.; Sankar, R. Time series prediction using support vector machines: A survey. IEEE Comput. Intell. Mag. 2009, 4, 24–38. [Google Scholar] [CrossRef]
- Taylor, J.W.; McSharry, P.E.; Buizza, R. Wind power density forecasting using ensemble predictions and time series models. IEEE Trans. Energy Convers. 2009, 24, 775–782. [Google Scholar] [CrossRef]
- Birge, J.R.; Louveaux, F. Introduction to Stochastic Programming; Springer: New York, NY, USA, 2011. [Google Scholar]
- Information System of the Spanish System Operator (esios). Available online: https://www.esios.ree.es/en (accessed on 13 December 2016).
- Operator of the Iberian Energy Market, Polo Español S.A. (OMIE). Available online: http://www.omie.es/files/flash/ResultadosMercado.swf (accessed on 13 December 2016).
- Pedregal, D.J.; Contreras, J.; Sánchez de la Nieta, A.A. ECOTOOL: A general MATLAB forecasting toolbox with applications to electricity markets. In Handbook of Networks in Power Systems I; Springer: New York, NY, USA, 2012; pp. 151–171. [Google Scholar]
- The Mathworks Inc., Matlab. Available online: http://www.mathworks.com (accessed on 13 December 2016).
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).