1. Introduction
With the recent emergence of the extended reality (XR) and tactile Internet technology, the demand for low-latency transmission and throughput increment has increased. Moreover, network bandwidth is expanding with the emergence of communication technologies, such as Gigabit Ethernet, 5G, and WiFi 6. Wired networks such as Gigabit Ethernet support throughput of tens of Gbps, while data rates of up to several Gbps are available in wireless networks such as 5G and WiFi 6 [
1,
2,
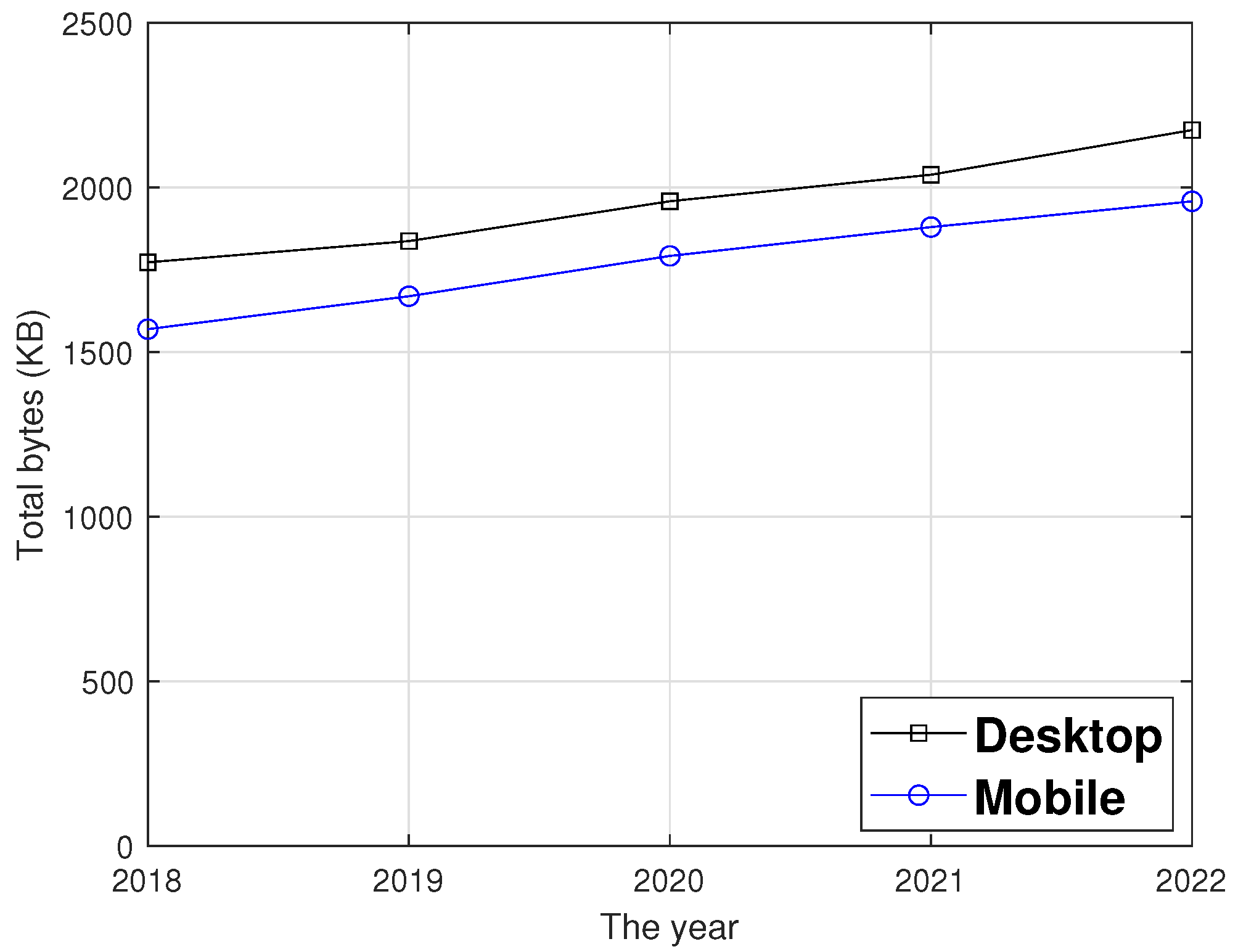
3]. With increasing network capability, the total bytes in a web page is also increasing, as shown in
Figure 1 [
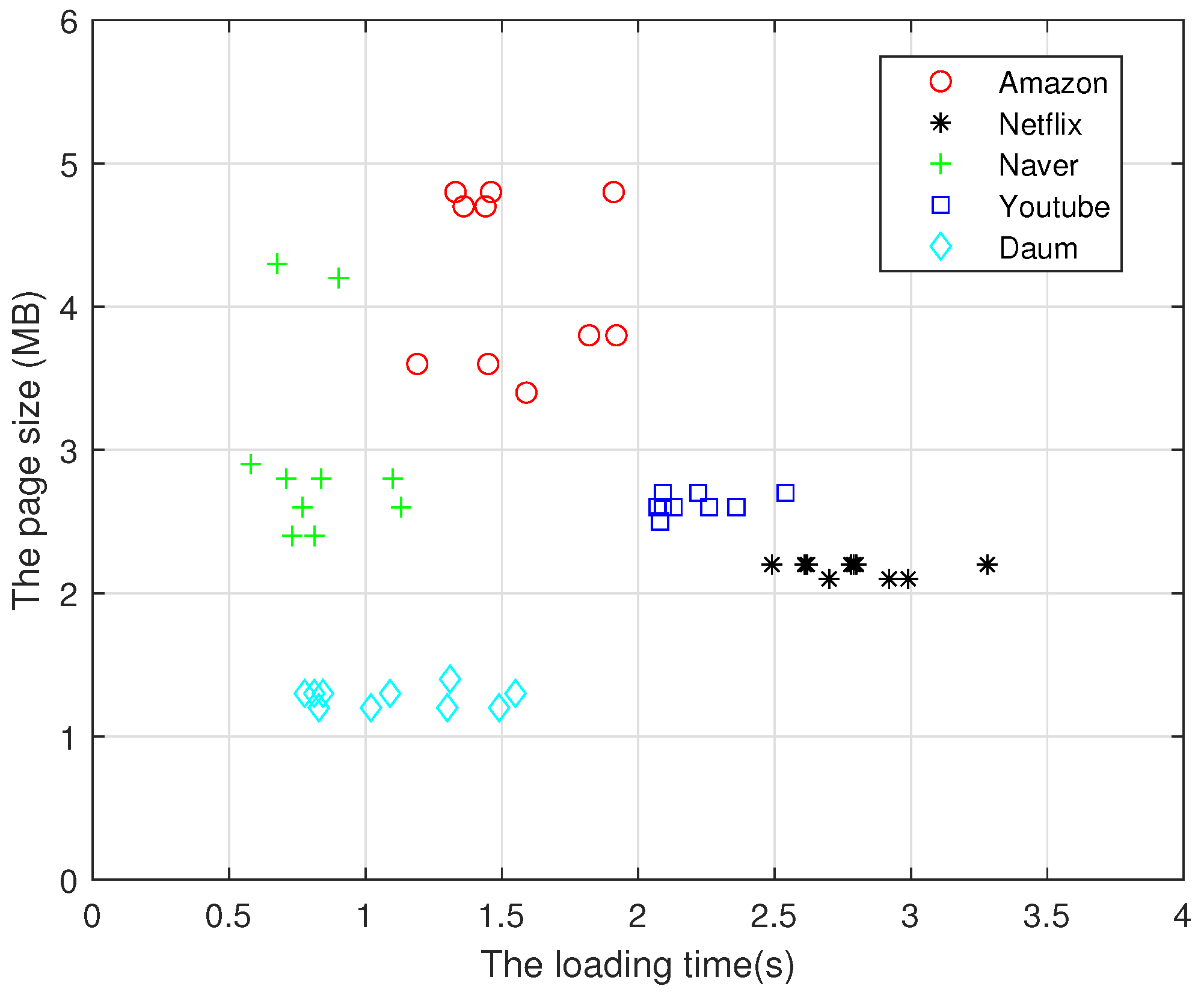
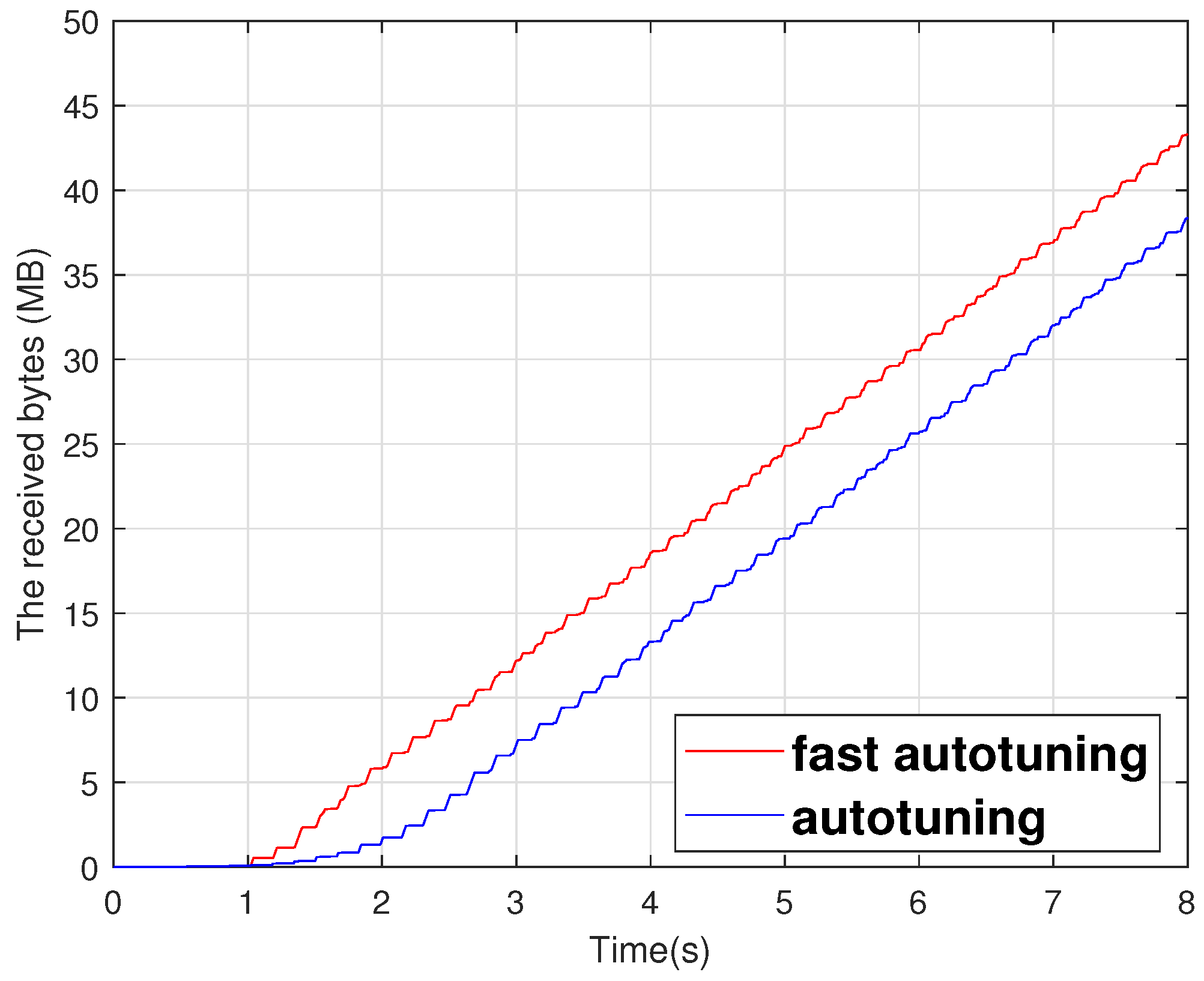
4]. The web data have increased by more than 20% in desktop and mobile environments, from 1772 and 1569 KB in 2018 to 2174 and 1957 KB in 2022, respectively. However, the reduction in transmission latency is negligible, despite the median size of a web page being roughly 2.2 MB, which is trivial in comparison to network capacity. We utilized Pingdom to analyze the web data size and page load time of the Amazon, Netflix, YouTube, Naver, and Daum sites [
5], and found that the average web page sizes are 4.2 MB, 2.1 MB, 2.6 MB, 2.9 MB, and 1.2 MB, and the average loading times are 1.547, 2.798, 2.219, 0.824, and 1.102 seconds, respectively, as shown in
Figure 2. The result indicates that the transmission delay is significant in comparison to the network capacity of Gbps.
Furthermore, 5G and WiFi 6 have been prepared to support low-latency communication [
6,
7,
8,
9]. In 5G, the 3GPP establishes three visions: enhanced mobile broadband (EMB), massive machine-type communications (MMTC), and ultra-reliable and low-latency communication (URLLC). Among them, URLLC aims for a delay time of less than 1 ms and transmission reliability of 99.99 % in radio access networks to meet the demand for low-latency communication [
6,
7]. In WiFi 6, several methods such as orthogonal frequency division multiple access (OFDMA) and spatial reuse (SR) have been proposed to improve user performance metrics such as reduced latency in heavily crowded areas [
8,
9].
Studies on the low-latency transmission of web content in transport and application layers have proposed using SPDY and Quick UDP Internet Connection (QUIC) protocols [
10]. SPDY, an application layer protocol, uses multiplexing, header compression, and server push to minimize the web page load time [
11]. The proposed features were included in the HTTP/2 standard, but SPDY support was phased out in 2016. The QUIC protocol is a novel transport layer protocol recently standardized by the Internet engineering task force (IETF) [
12,
13,
14]. For reduced transmission latency, QUIC employs 0-RTT to reduce the connection establishment time, multiple streams within a connection to avoid head of line (LOL) blocking from sequential TCP delivery, and a new packet number to eliminate retransmission ambiguity. Hence, for network-based services demanding an immediate response, the QUIC protocol is often used to provide low-latency service.
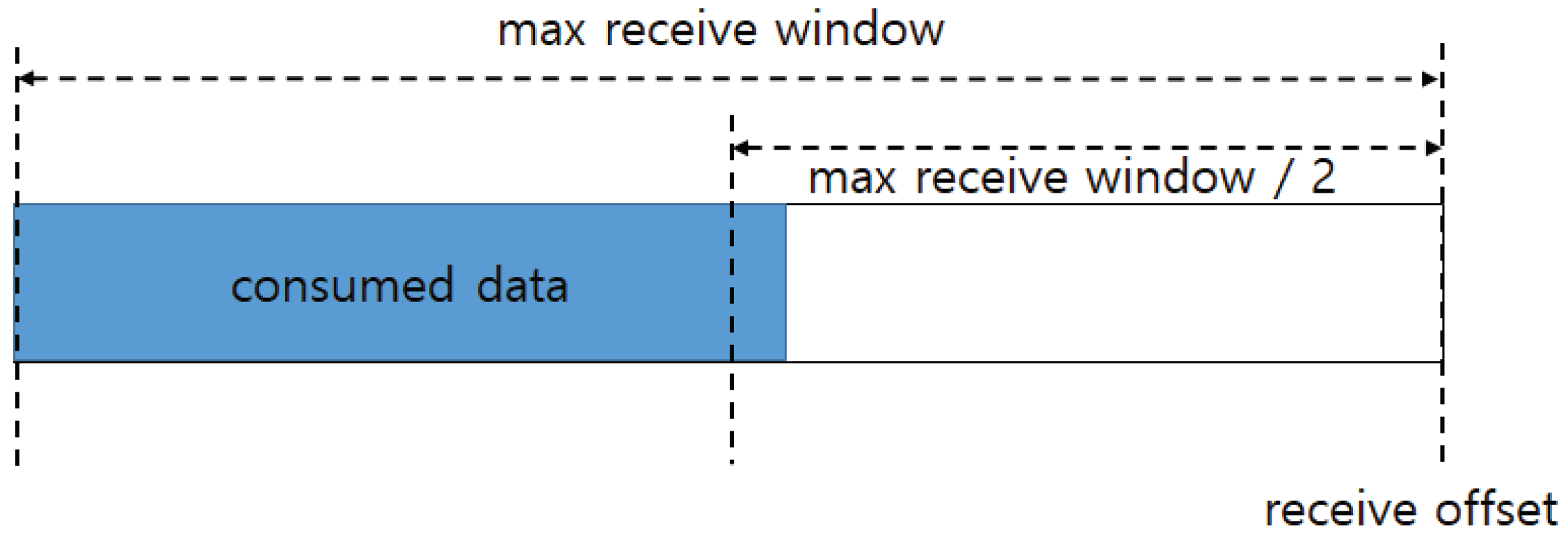
Flow control is disabled in TCP, because the buffer size is sufficiently large to accommodate the network-based service; moreover, packet errors caused by flow control are rare. However, the QUIC protocol allows for flow control to avoid buffer overflow, and employs static or autotuning allowances for flow control [
15]. The static allowance employs a fixed-size maximum receive window [
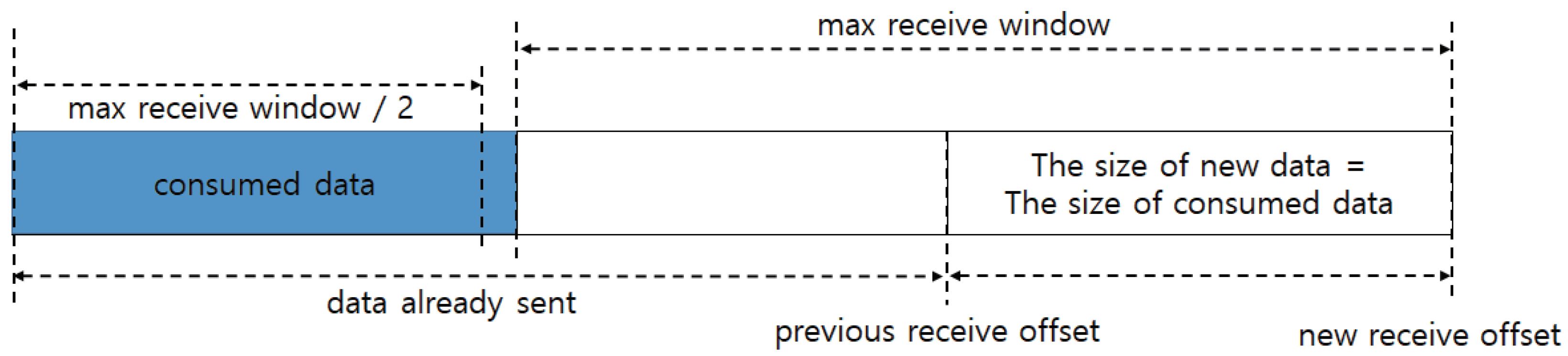
16]. The sender delivers data within the maximum receive window to avoid buffer overflow. The receiver notifies the sender of a receive window update by sending the MAX_STREAM_DATA frame when the upper layer protocol has read more than half of the maximum receive window, as shown in
Figure 3. Because the amount of remaining data in the receive window is not half, the receive window is not updated until new data arrive. After one RTT, the receiver receives new data, and half of the maximum receive window is then updated. This indicates that the sender can only transmit half of the receive window at each RTT [
17]. Google proposed autotuning allowance [
16]. The maximum receive window size is doubled if the receive window update period is shorter than a threshold. Moreover, the receive window is no longer increased after reaching the upper limit or the update cycle has stabilized. In contrast, autotuning requires time to find a suitable receive window size. Therefore, reducing the maximum receive window search time is important for low-latency transmission.
In this paper, we propose a fast autotuning scheme for low-latency transmission. The increase factor in fast autotuning is determined to be inversely proportional to the receive buffer occupancy. If the buffer occupancy is low, the increase factor is increased. Otherwise, the increase factor has been set to a low value. By rapidly widening the receive window while avoiding buffer overflow, the suggested approach can decrease transmission latency. We used the ns-3 simulator for performance evaluation [
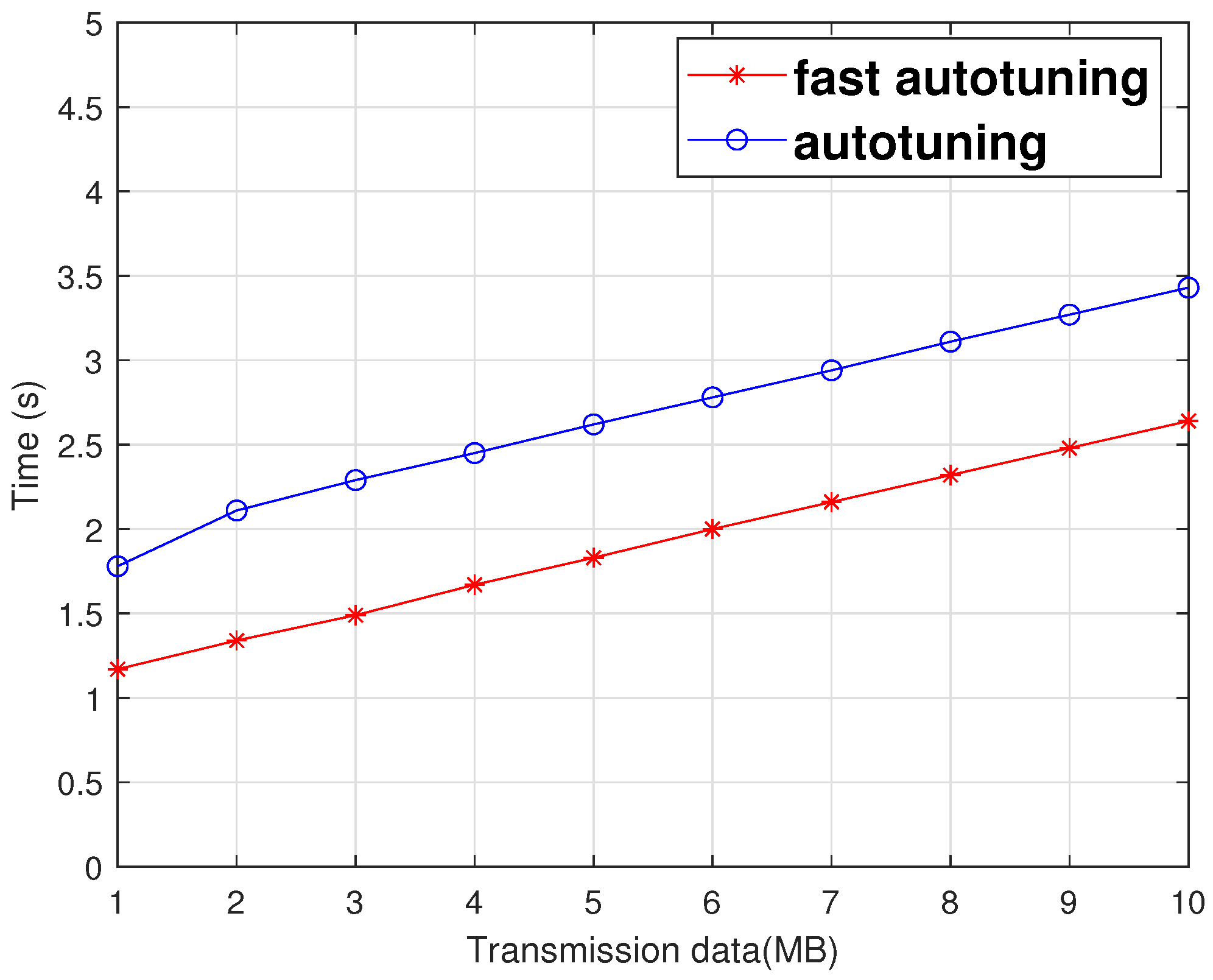
18]. Fast autotuning reduced transmission delays by 29% and increased throughput by 12% compared to autotuning in simulations employing a large buffer.
The rest of this paper is organized as follows: We present related works along with the motivation of this work in
Section 2. The proposed fast autotuning method is detailed in
Section 3. In
Section 4, we evaluate fast autotuning allowance based on extensive simulations. Finally, the conclusions are presented in
Section 5.
2. Related Works
The QUIC protocol suggests many approaches for reducing the web application data transmission time [
12,
13,
14]. To decrease the connection establishment time, QUIC employs two methods: 1-RTT and 0-RTT handshakes for the initial and reestablishment connections, respectively. When the client connects to the server for the first time, QUIC performs a 1-RTT handshake and exchanges data transmission information such as the maximum receive window for flow control. The 0-RTT handshake shortens the connection establishment when the client reestablishes the connection with the server. Additionally, QUIC uses stream multiplexing to avoid HOL blocking in a connection. When one stream experiences a transmission delay due to HOL, the other streams continue to transmit data normally, and minimize delay.
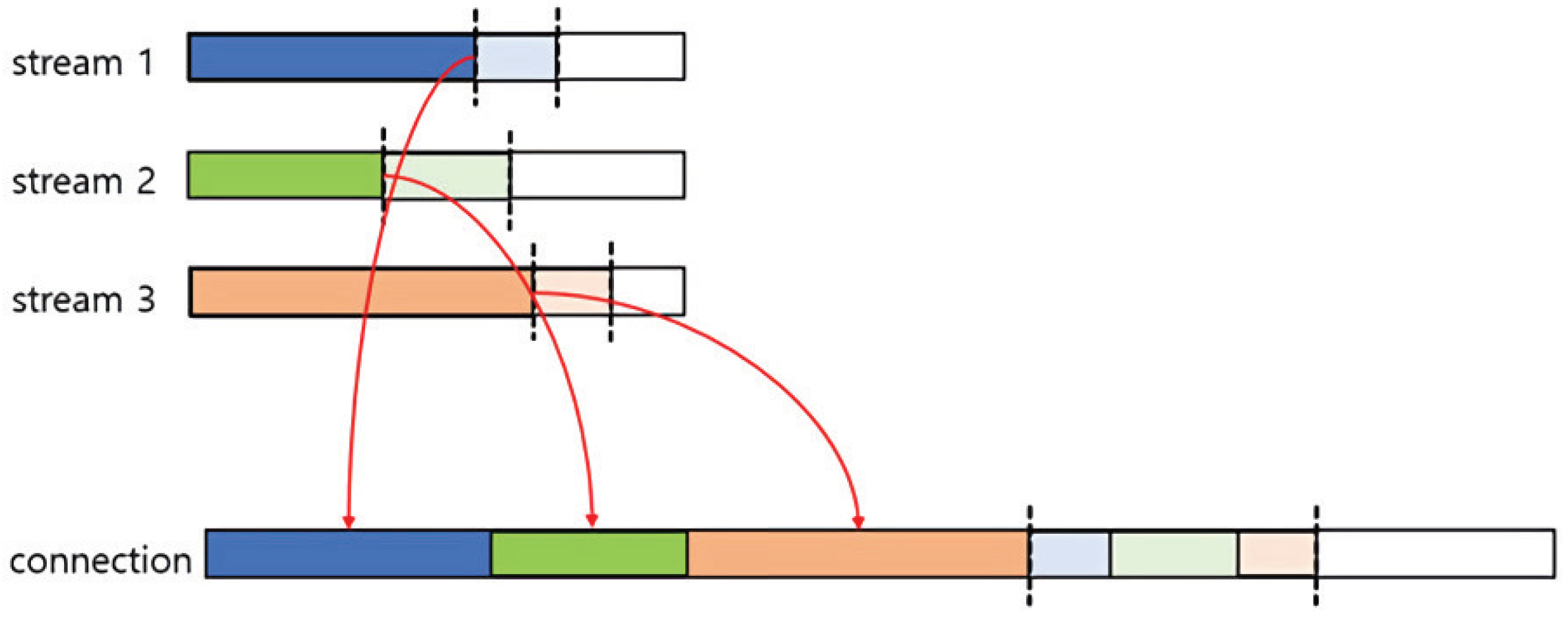
The QUIC protocol also uses flow control that limits bytes sent on a stream and connection to prevent buffer overflow. The maximum amount of transmission in a stream and connection is advertised during the 1-RTT handshake. A receiver sends the MAX_STREAM_DATA or MAX_DATA frame to advertise the new limit of the buffer. The MAX_STREAM_DATA frame represents one stream’s maximum transmission byte offset. If the sender has sent the maximum bytes in a stream, the transmission is blocked until the sender receives a MAX_STREAM_DATA frame from the receiver. The MAX_DATA frame represents the maximum transmission byte offset of the connection, equivalent to the total of all streams’ maximum transmission byte offsets, as shown in
Figure 4.
Google QUIC has proposed a static allowance for flow control [
16]. The receive window in a static allowance is allocated a fixed amount of memory. As shown in
Figure 3, the receiver transmits the MAX_STREAM_DATA frame if the consumed data, which are data read from the upper layer, exceed half of the maximum receive window. The receive offset grows by the maximum receive window from the consumed data after receiving the MAX_STREAM_DATA frame from the sender, as shown in
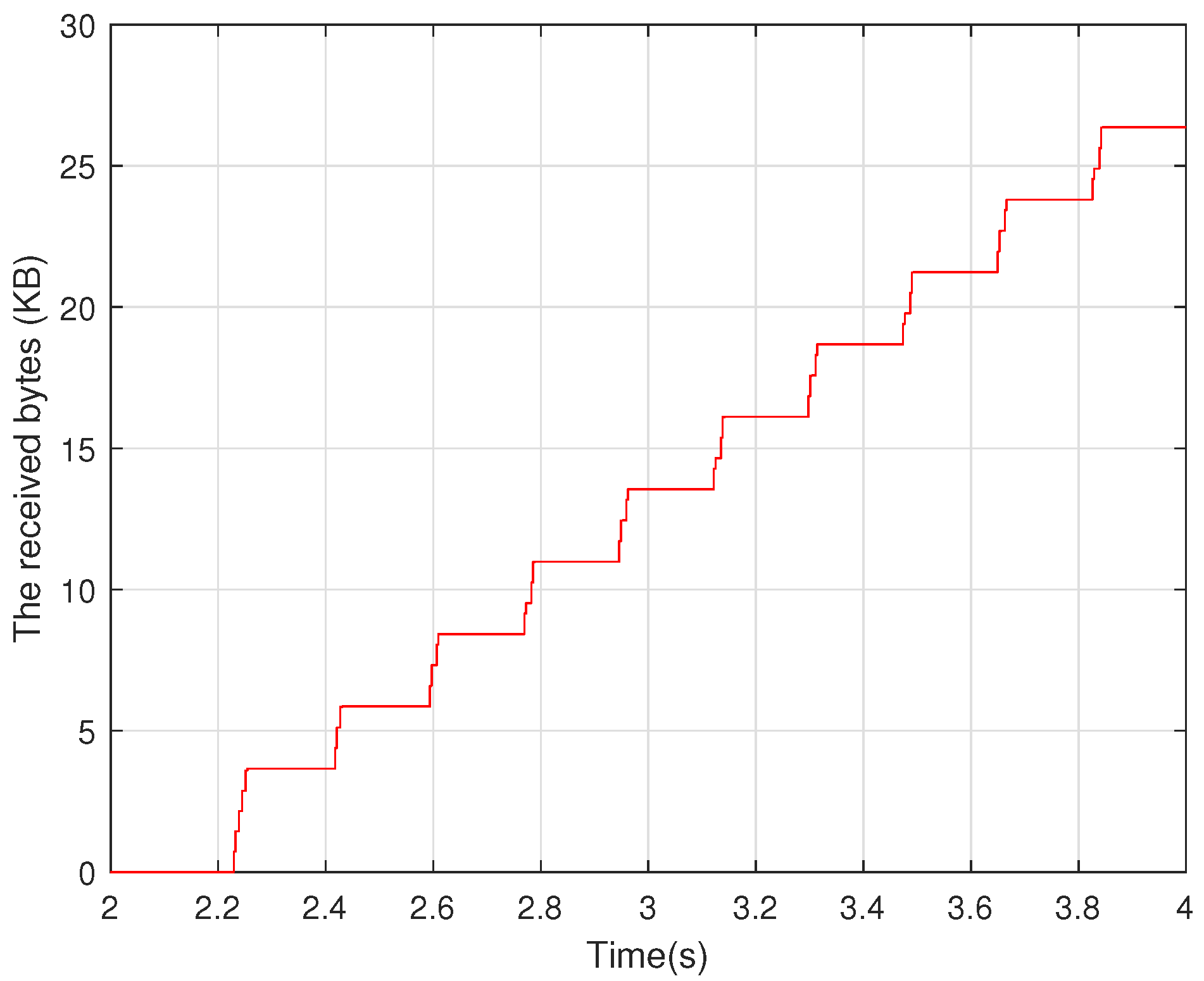
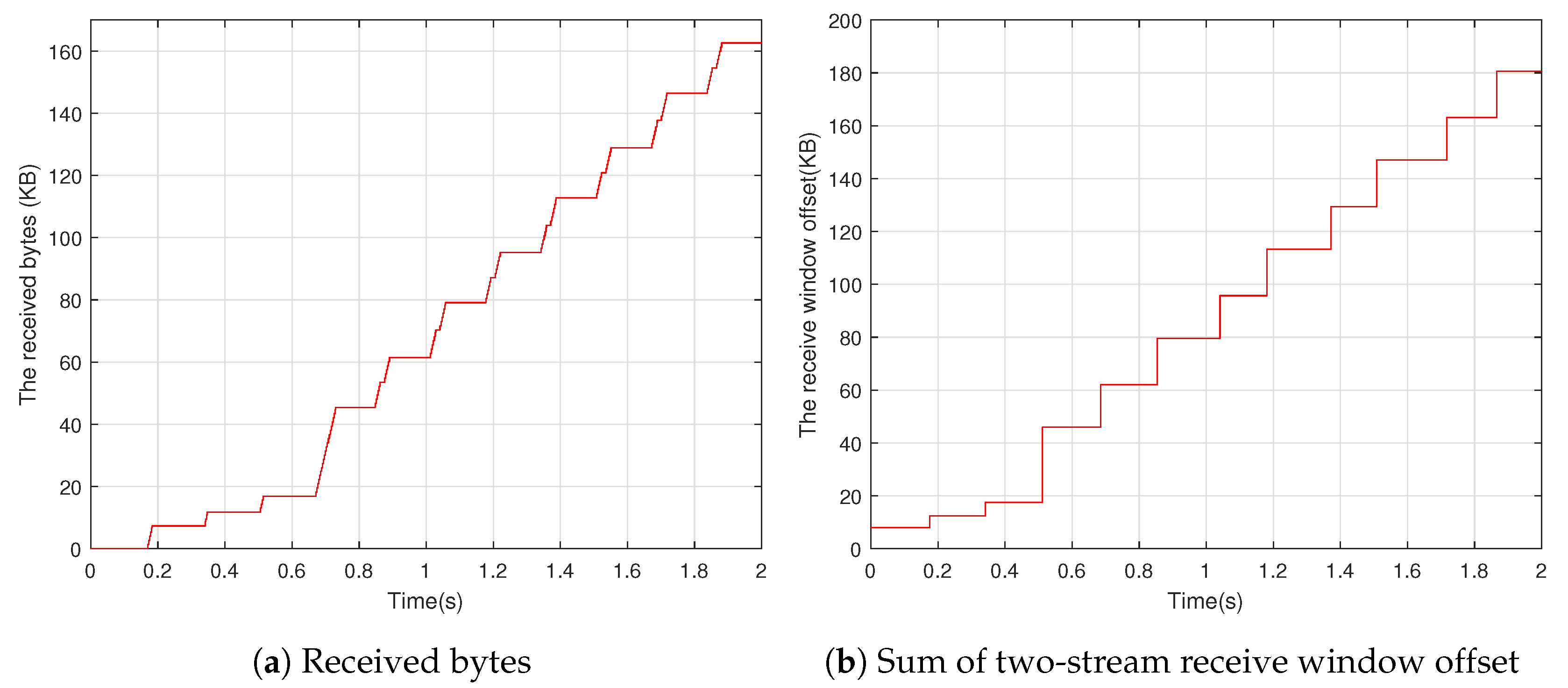
Figure 5. However, the sender can only transmit data equivalent to around half of the maximum receive window since the data have already been transferred in the previous transmission. After transmitting the MAX_STREAM_DATA frame, the receiver does not send the MAX_STREAM_DATA frame until new data arrive because the remaining receiver data size is less than half of the maximum receive window. The bytes received by a stream with a static allowance when two streams are transmitted in the ns-3 simulator are depicted in
Figure 6. The stream has 4 KB of the maximum receive window. After the initial data, the receiver receives around 2.5 KB of data on average every RTT, indicating that the sender uses half of the receive window to transmit data.
In [
17], the improved static allowance scheme was proposed to solve the throughput degradation in static allowance. The receiver transmits a MAX_STREAM_DATA frame if the amount of consumed data is larger than (threshold-MSS). Half of the maximum receive window is used as the threshold, and MSS is the maximum segment size. In other words, the MAX_STREAM_DATA frame is sent one packet earlier than the static allowance. The receive window updates occur twice within one RTT because the remaining data exceed (threshold-MSS). Thus, the sender transmits as many data as the maximum receive window allows in every RTT. Google has proposed autotuning allowance to search for an appropriate receive window [
16]. If the time interval between two MAX_STREAM_DATA frames is less than twice the RTT, the current receive window is identified as insufficient, and the maximum receive window is doubled. Moreover, an upper bound prevents indefinite increments in the receive window.
Compared to prior works, the proposed scheme aims to reduce the transmission delay caused by flow control. The improved static allowance uses the allocated receive window fully. However, if the maximum receive window is smaller than the transmission rate, the transmission is delayed until the MAX_STREAM_DATA frame is received, because the improved static allowance also utilizes a fixed memory size. The autotuning allowance increases the receive window size to prevent transmission interruption. However, to determine an adequate maximum receive window, the autotuning allowance requires several RTTs, increasing the transmission latency. Moreover, for small data sizes, an adequate receive window will not be identified until transmission completion. The proposed fast autotuning allowance reduces the search time for finding an adequate receive window. The receiver increases the receive window exponentially if free buffer space is sufficient; otherwise, the receive window is not enlarged to avoid buffer overflow. The computational overhead is minimal because of the low complexity of the proposed algorithm.
3. Proposed Scheme
This section details the proposed fast autotuning allowance strategy. We first present the calculation of the buffer occupancy, based on which an increase factor is determined. At time
t, the buffer occupancy of a stream,
, is expressed as Equation (
1).
and
are the upper bound and the current maximum receive window of the stream, respectively.
In the QUIC protocol, because a sender or a receiver can generate a stream if necessary, buffer occupancy calculations are required for both streams and connections. For a connection at time
t, the buffer occupancy of a connection,
, is calculated using Equation (
2).
is the upper bound of the buffer for a connection. The increase factor is determined based on the buffer occupancy after a receive window update.
The fast autotuning algorithm is described in Algorithm 1. By subtracting consumed bytes,
, from maximum receive window offset,
, the receiver calculates the available receive window,
. The receive window update is triggered if the available receive window is less than
; the receiver then delivers the MAX_STREAM_DATA frame for a stream (or MAX_DATA frame for a connection).
, the increase factor, is determined based on the buffer occupancy, if
, the time since the last window update, is less than 2RTT. The buffer occupancy is calculated using Equation (
1) for the stream and Equation (
2) for the connection. Because sufficient free buffer space is not available if the buffer occupancy is greater than 75%, the increase factor is set to 2. The increase factor is set to 4 if the buffer occupancy is between 50 and 75%, it is 8 if the occupancy is greater than 25% but less than 50%, and it is 16 if the free buffer space exceeds 75%. The maximum receive window is then determined by the smaller of (
) and
, the upper bound of the buffer. The maximum offset of the receive window is increased by (
), as depicted
Figure 5. The fast autotuning seeks to reach the maximum receive window as quickly as possible. As a result, since the autotuning allowance doubles the maximum receive window, the increase factor in Algorithm 1 increases by the power of 2 based on the buffer occupancy. The autotuning, for example, requires two buffer updates to raise the maximum receive window by four times, but the fast autotuning only requires one.
| Algorithm 1 Fast autotuning |
- 1:
- 2:
- 3:
ifthen - 4:
if then - 5:
if then - 6:
- 7:
else if then - 8:
- 9:
else if then - 10:
- 11:
else if then - 12:
- 13:
end if - 14:
- 15:
- 16:
end if - 17:
- 18:
- 19:
send MAX_STREAM_DATA (or MAX_DATA) - 20:
end if
|
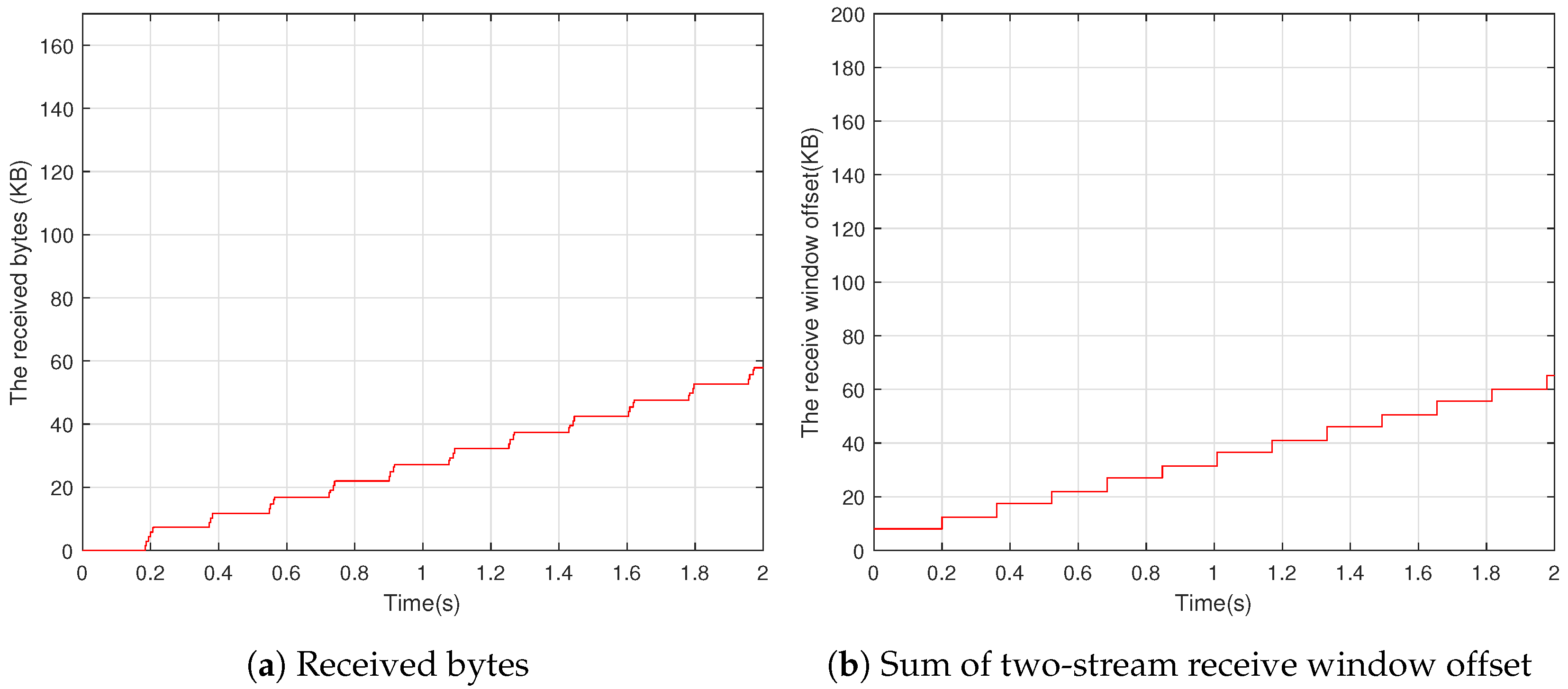
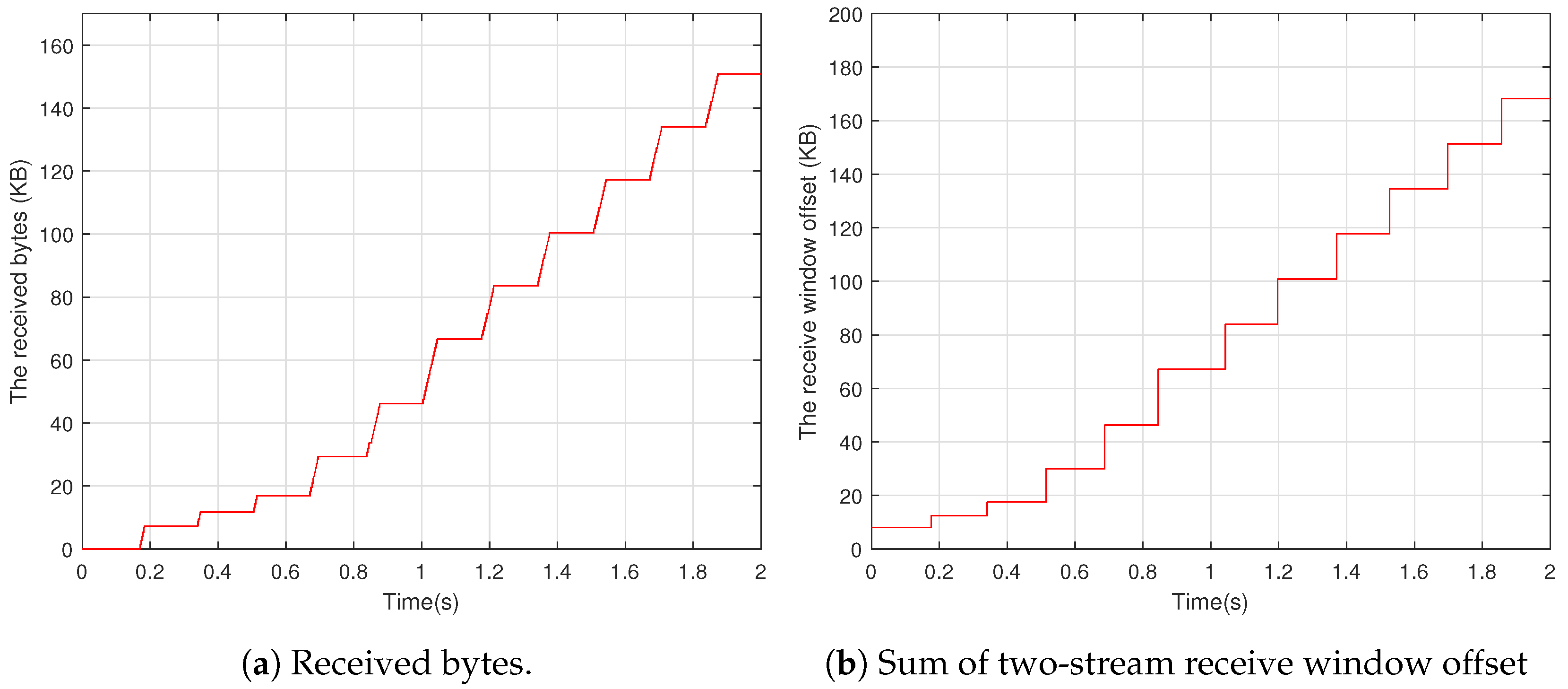
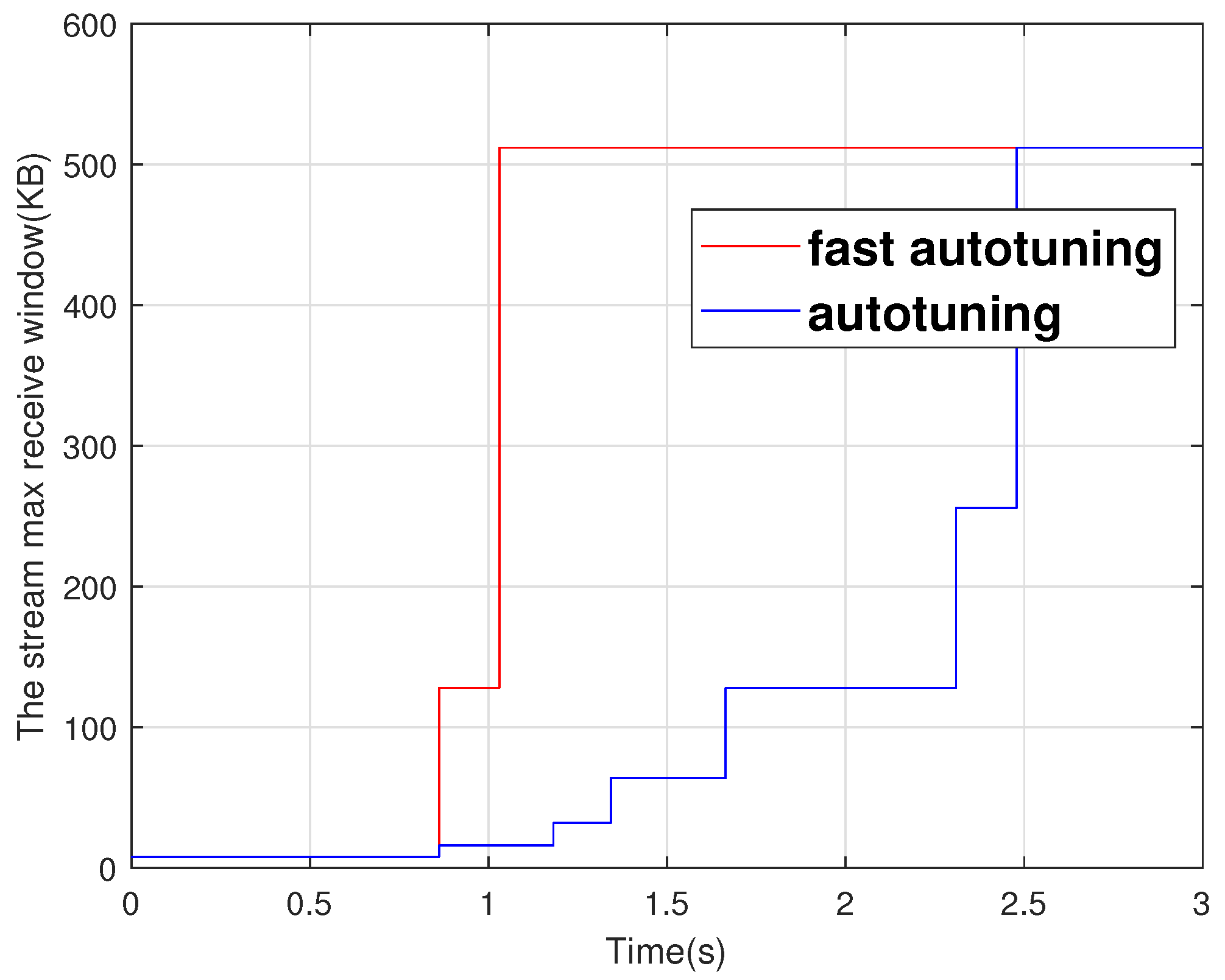
For example, a sender uses a QUIC connection with one stream to transfer data to a receiver. The upper bounds for the stream and the connection are 128 KB and 256 KB, respectively. The stream’s and connection’s initial maximum receive windows are 4 KB and 8 KB, respectively. Because the buffer occupancy is less than 25% of the stream upper bound when the first buffer update occurs, the increase factor is set to 16 and the maximum receive window is set to 64 KB. Because the buffer occupancy is 50%, the increase factor for the second buffer update is calculated to be 4. The maximum receive window, on the other hand, is set to 128 KB because the stream upper bound cannot be exceeded.
We implemented three flow control algorithms: static, autotuning, and fast autotuning allowances. First, we analyzed the ns-3 simulator with QUIC [
19], and then modified four classes: QuicL5Protocol, QuicSocketBase, QuicStreamBase, and QuicStreamRxBuffer classes. For example, Algorithm 1 should determine the available amount of data for a stream or connection. We modified AvailableWindow function in the QuicSocketBase class to calculate the available amount of data by subtracting CalculateAllRecv() from the m_max_data variable. In the function, m_max_data variable means the maximum amount of data that can be sent on the connection and CalculatedAllRecv() in the QuicL5Protocol class indicates the amount of received data.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}