
The Data-Driven Modeling of Pressure Loss in Multi-Batch Refined Oil Pipelines with Drag Reducer Using Long Short-Term Memory (LSTM) Network

 ,
, 
Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Calculation Methods | Applicable Conditions |
|---|---|
| Prandtl-Karman Law [6] | Newtonian fluid; turbulence flow; without drag reducer in the pipeline |
| Virk’s maximum drag reduction [11] | Newtonian fluid; turbulence flow; with drag reducer in the pipeline |
| General law of drag reduction [11] | Newtonian fluid; turbulence flow; with drag reducer in the pipeline |
| Karami’s method of calculating drag reduction for crude oil [13] | Non-Newtonian fluid; turbulence flow; with drag reducer in the pipeline |
| Karami’s method of calculating drag reduction for crude oil [15] | Non-Newtonian fluid; turbulence flow; with drag reducer in the pipeline |
| Zabihi’s method of calculating drag reduction for crude oil [21] | Non-Newtonian fluid; turbulence flow; with drag reducer in the pipeline |
| Moayedi’s method of calculating drag reduction for crude oil [22] | Non-Newtonian fluid; turbulence flow; with drag reducer in the pipeline |
- The data-driven modeling of pressure loss in multi-batch refined oil pipelines with drag reducer using the LSTM network is proposed, using the particle swarm optimization (PSO) algorithm for network hyperparameter tuning. The structure of the neural network model is designed and the input features of the proposed model are naturally inherited from the classical model and on adaptation to the multi-batch pipeline characteristics, which makes the proposed neural network model more easily interpreted and understood;
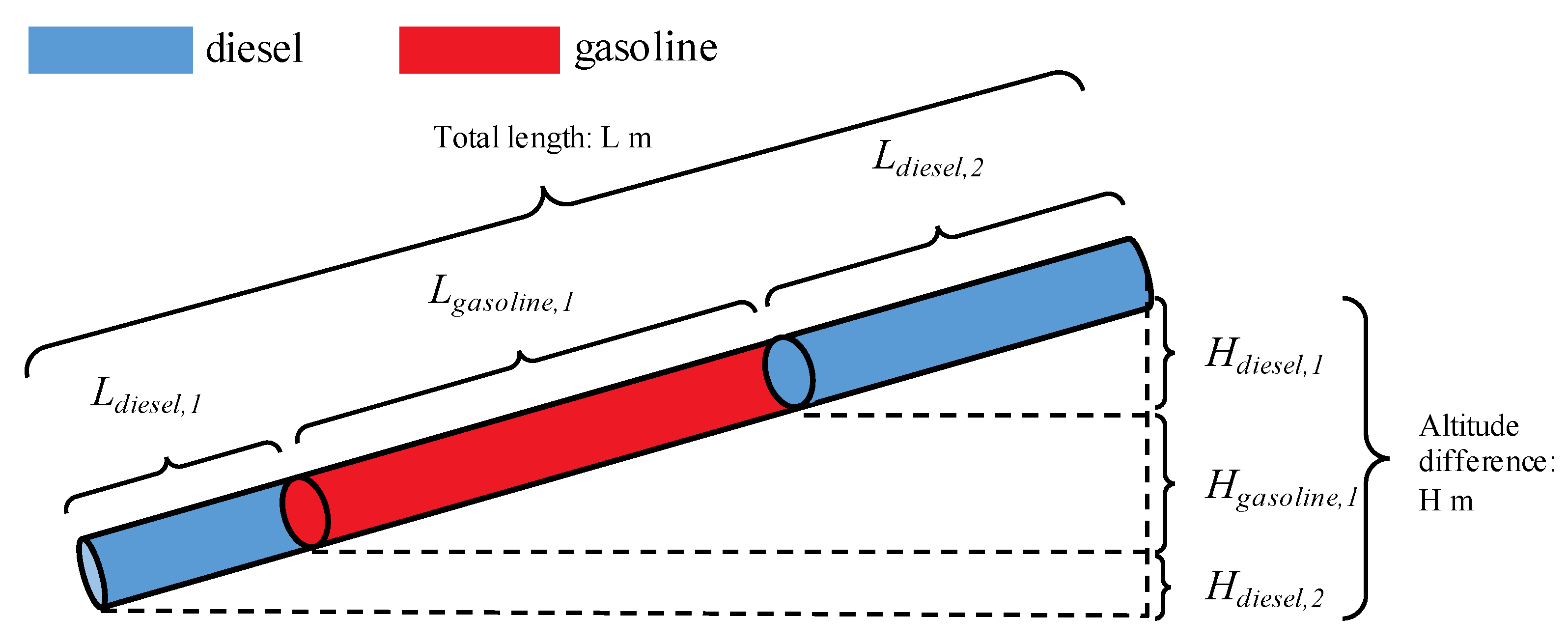
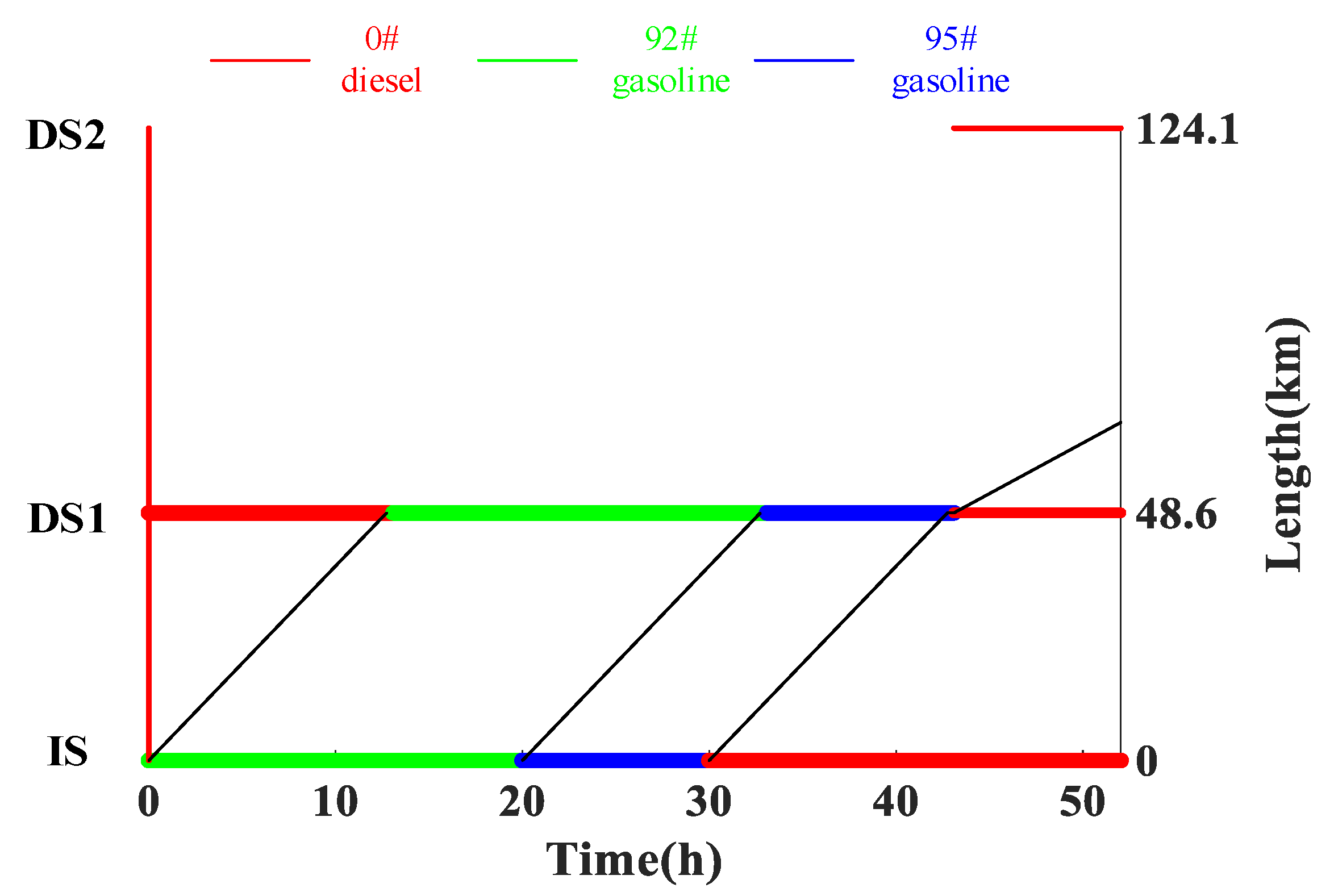
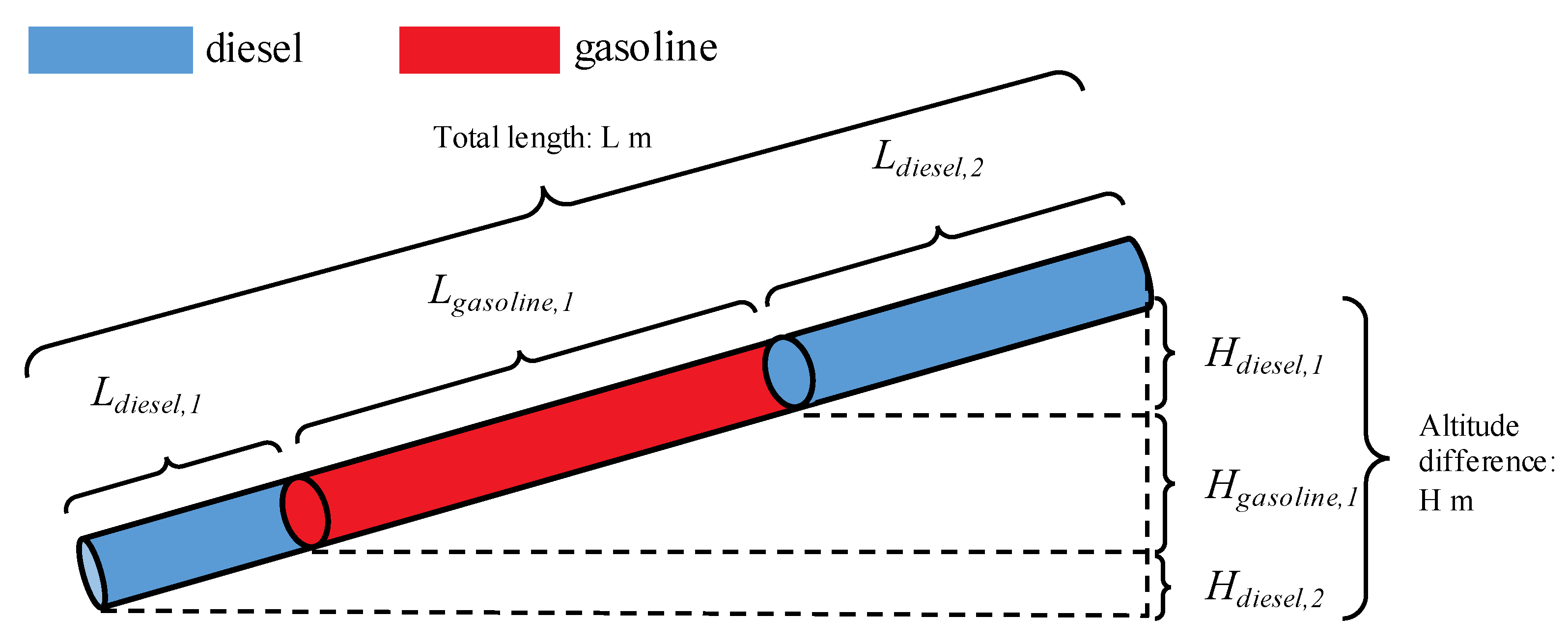
- Different from the studies in previous works which only considered a single kind of fluid in the pipeline, the multi-batch sequential transportation process and the differences in the physical properties between different kinds of refined oil in the pipelines are considered. The network input feature “the length ratio of gasoline and diesel” is chosen to describe the pressure loss change in refined oil pipelines during the multi-batch sequential transportation process;
- The sequential time effect of the drag reducer such as the dispersing effect that captures the sequential information of calculating the pressure loss is considered, which is paid scarce attention to in previous works. Different from the model of previous works that added an amendment to the formula, the time effect is captured and reflected by the LSTM module in the proposed model with high accuracy.
2. Methodology
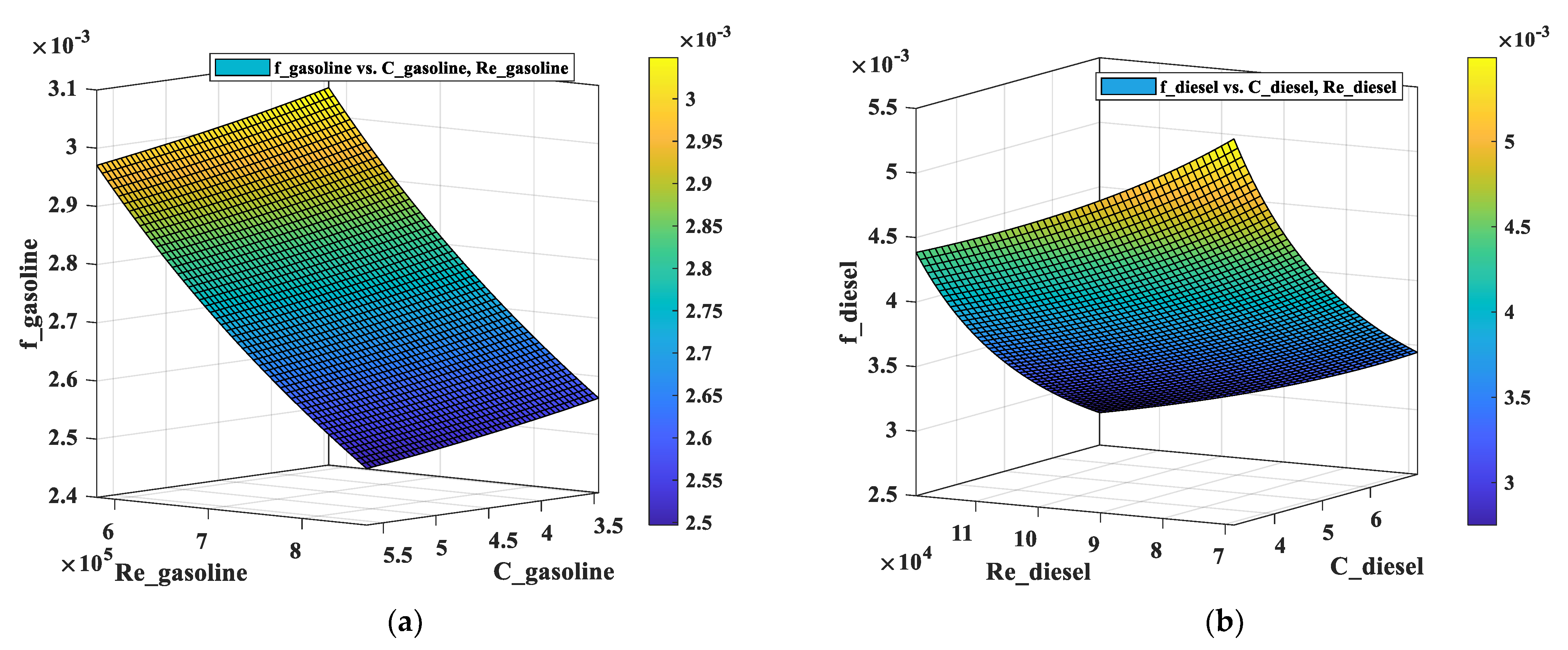
2.1. Modeling of Pressure Loss in Multi-Batch Refined Oil Pipelines Using Methods in Previous Literature
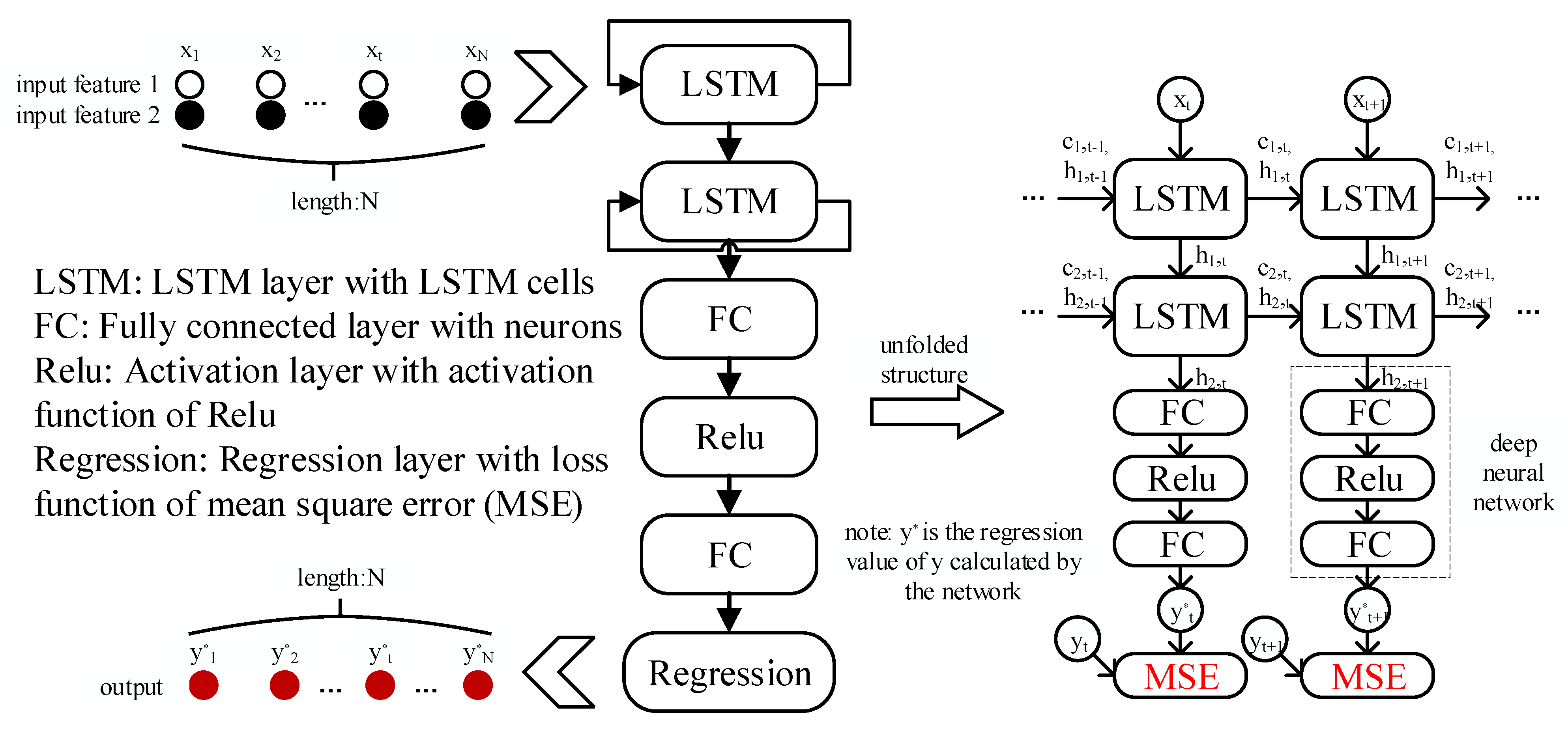
2.2. Modeling of Pressure Loss in Multi-Batch Refined Oil Pipelines with Drag Reducer Using the LSTM Network
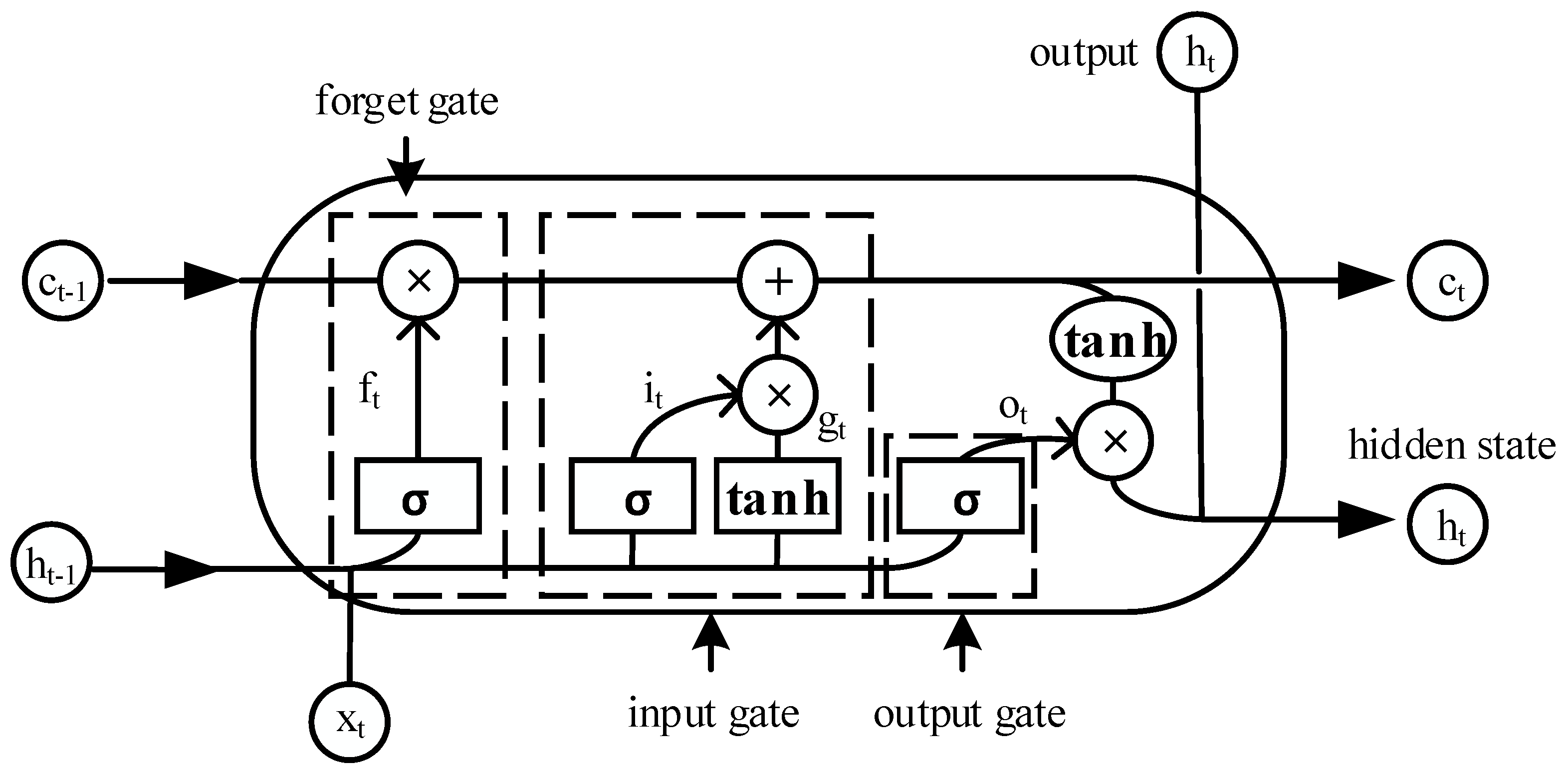
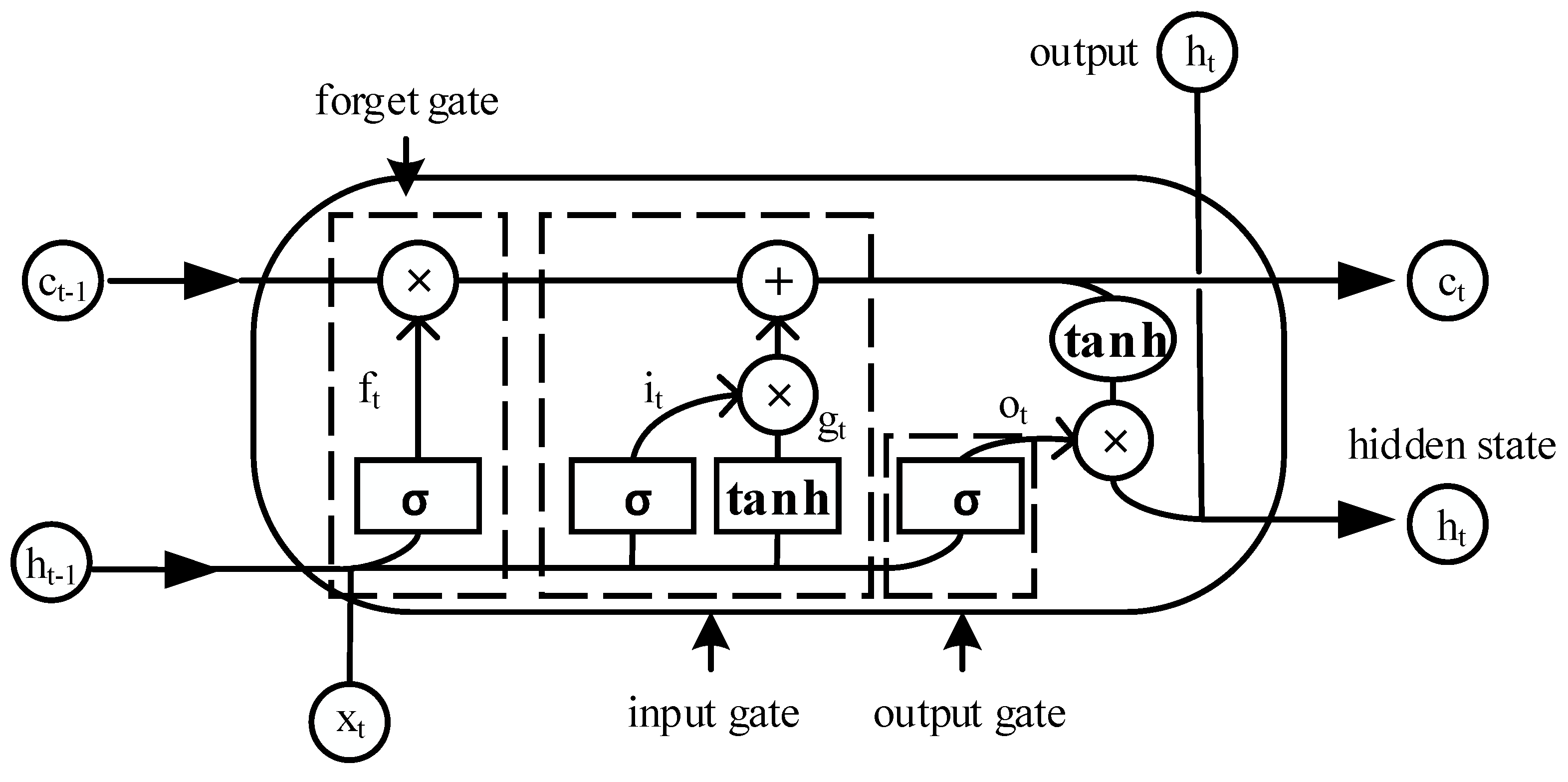
2.2.1. The Theory of LSTM Cells
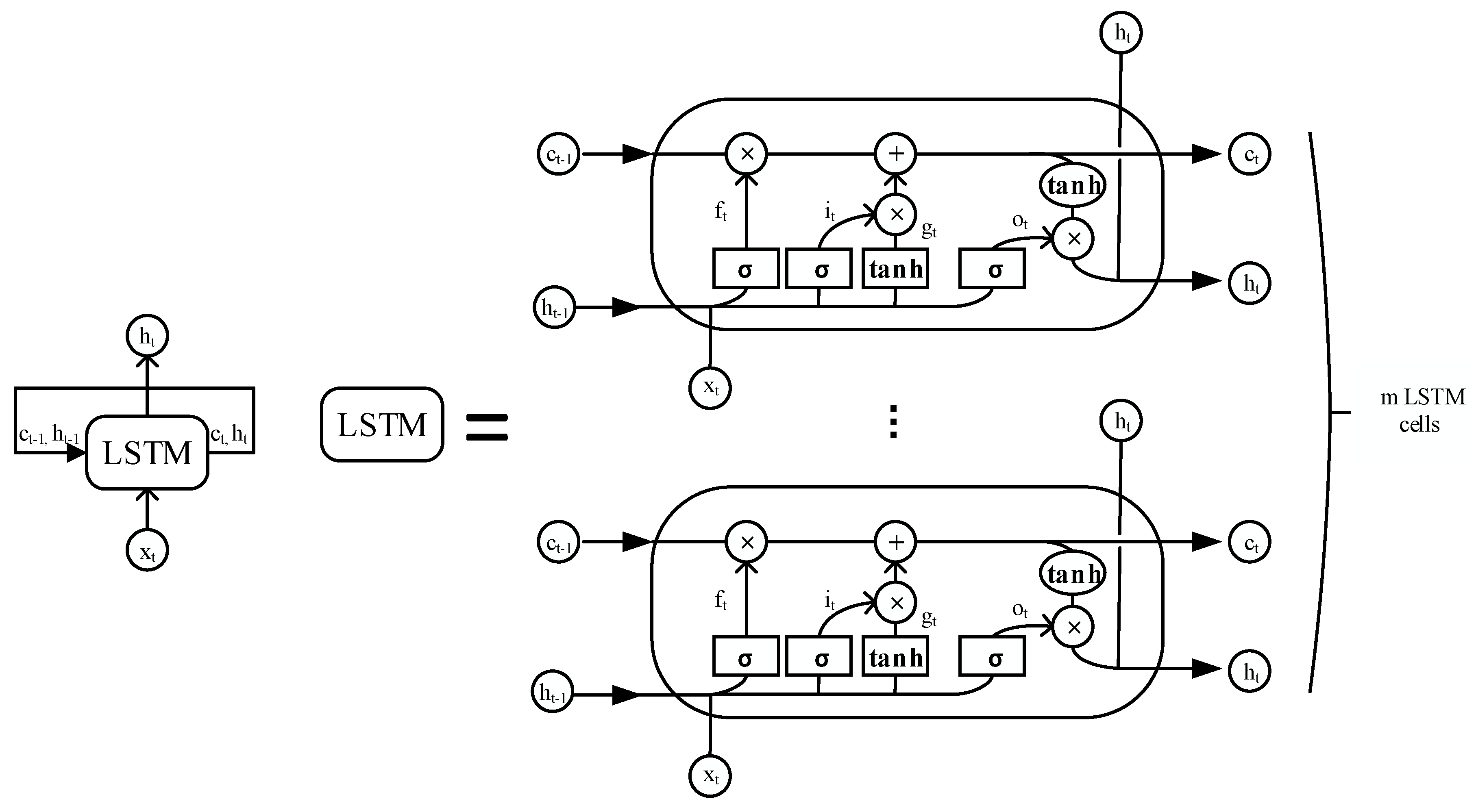
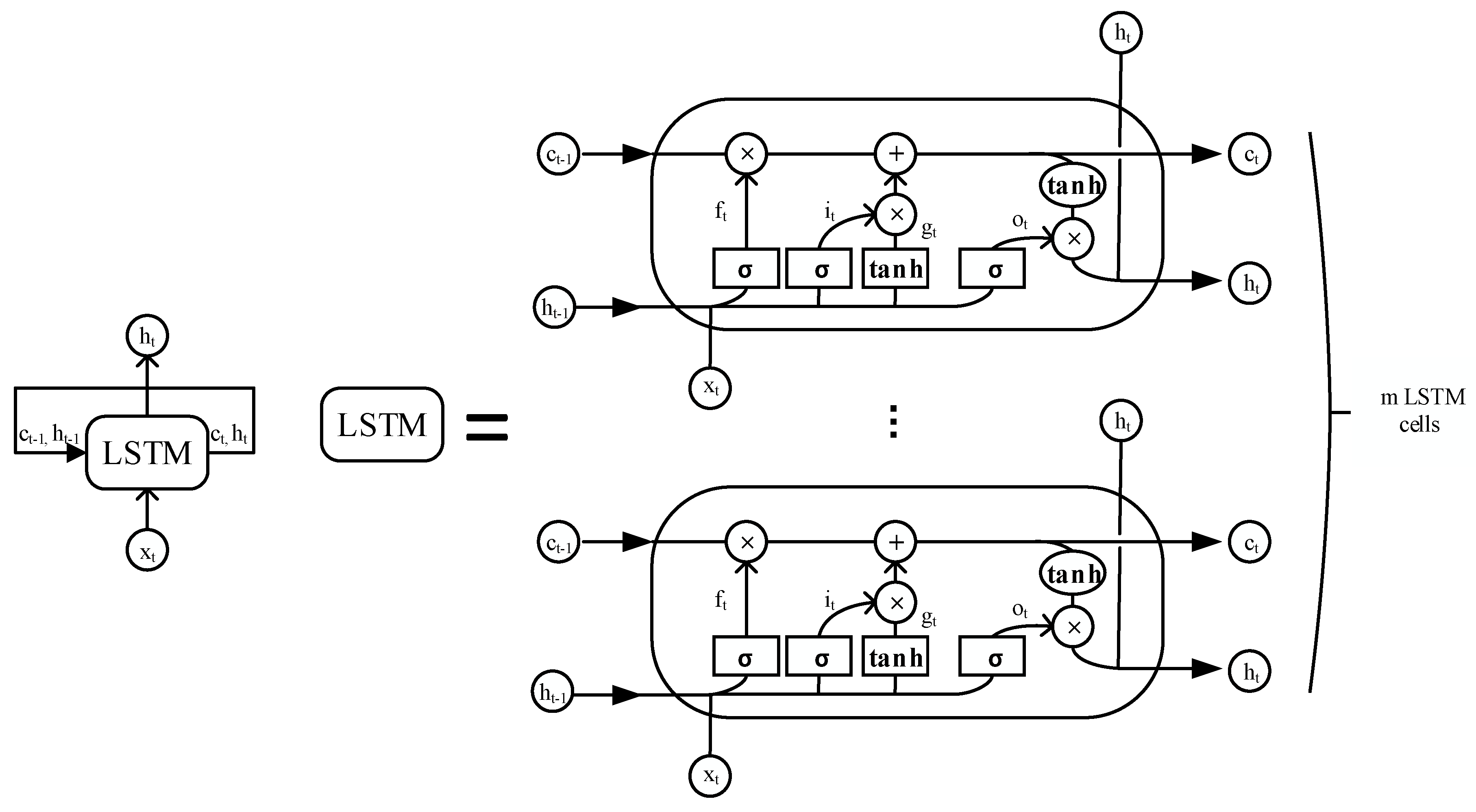
2.2.2. The Proposed Model Using the LSTM Network
2.2.3. Training the Proposed Model
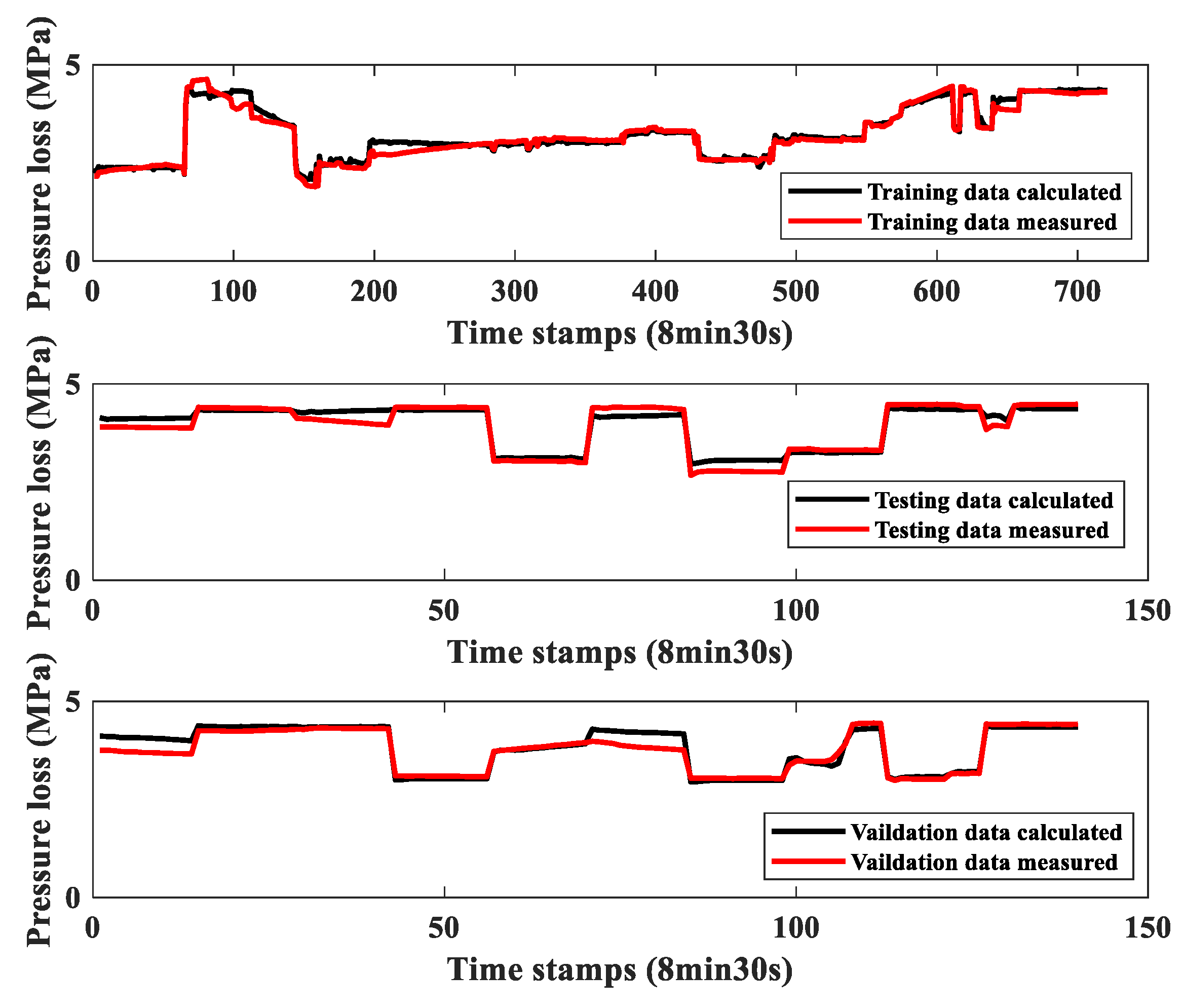
3. Results and Discussion
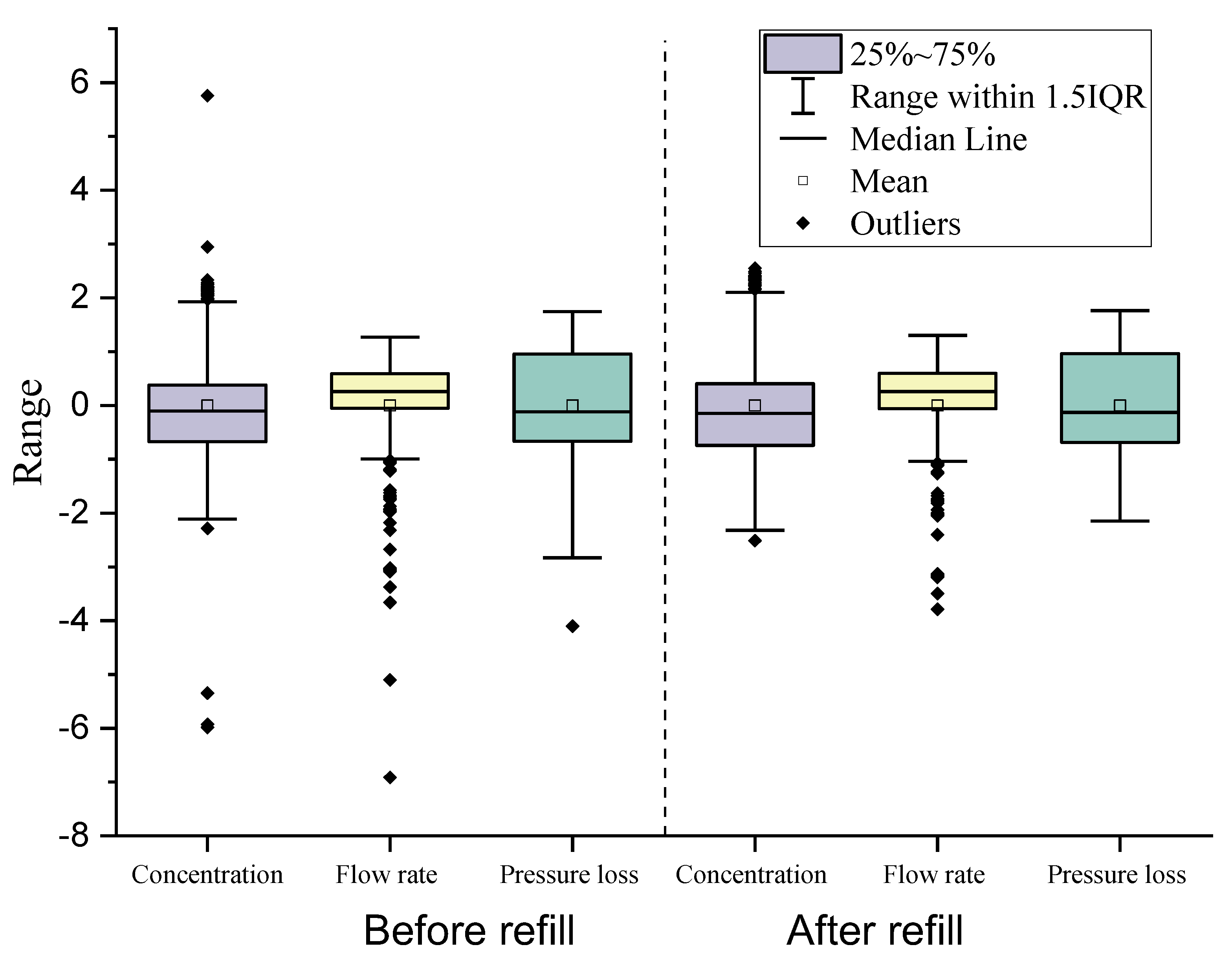
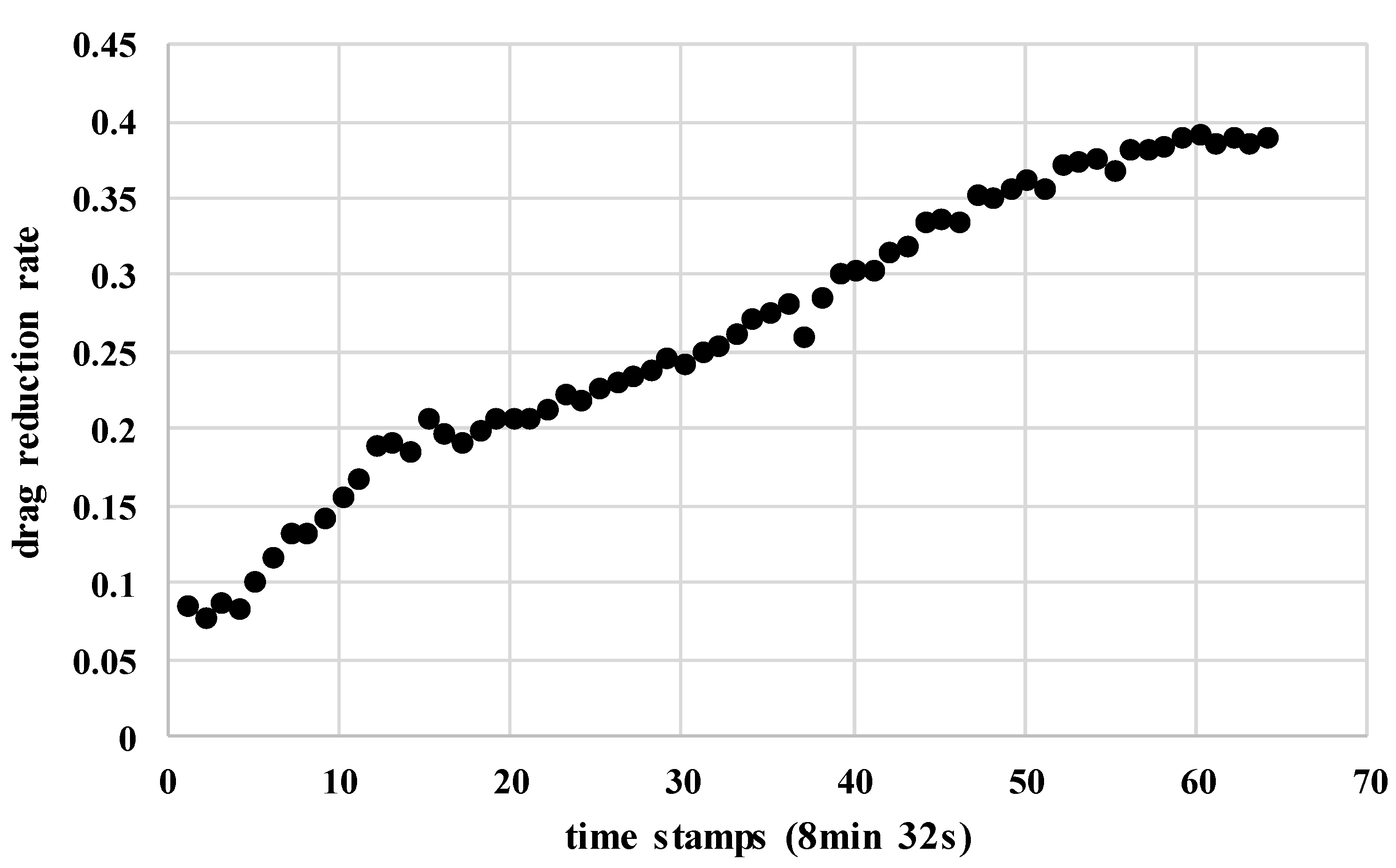
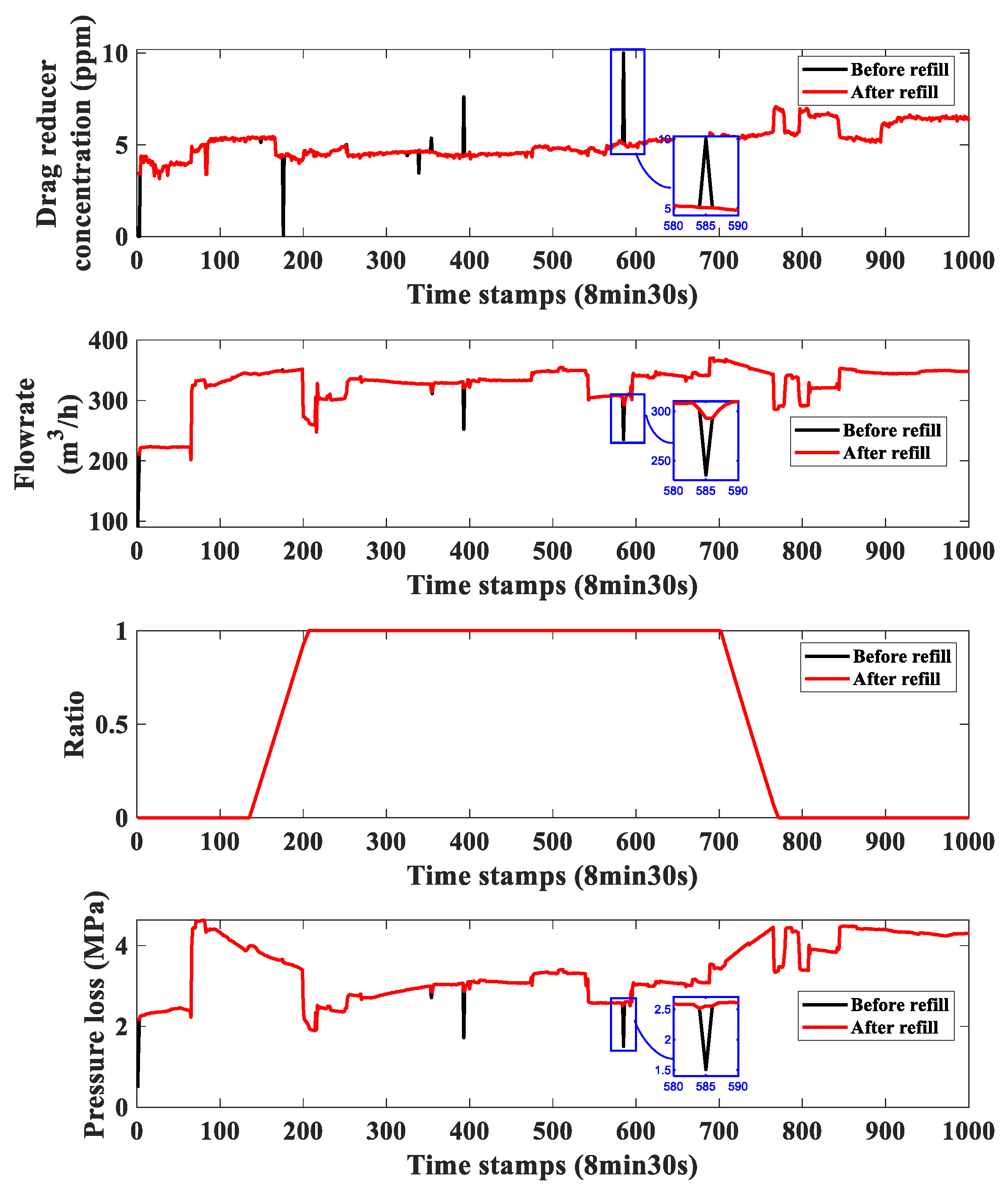
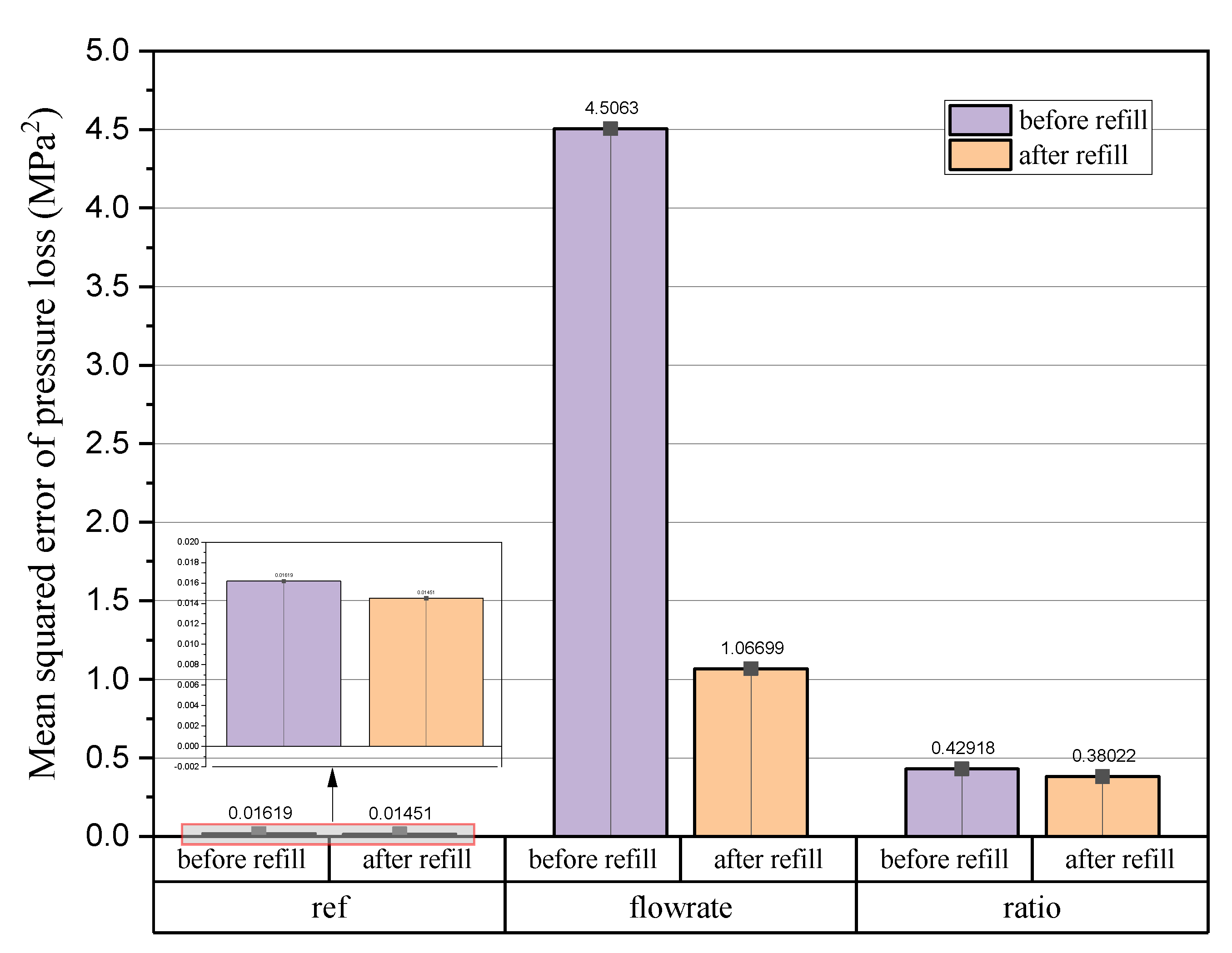
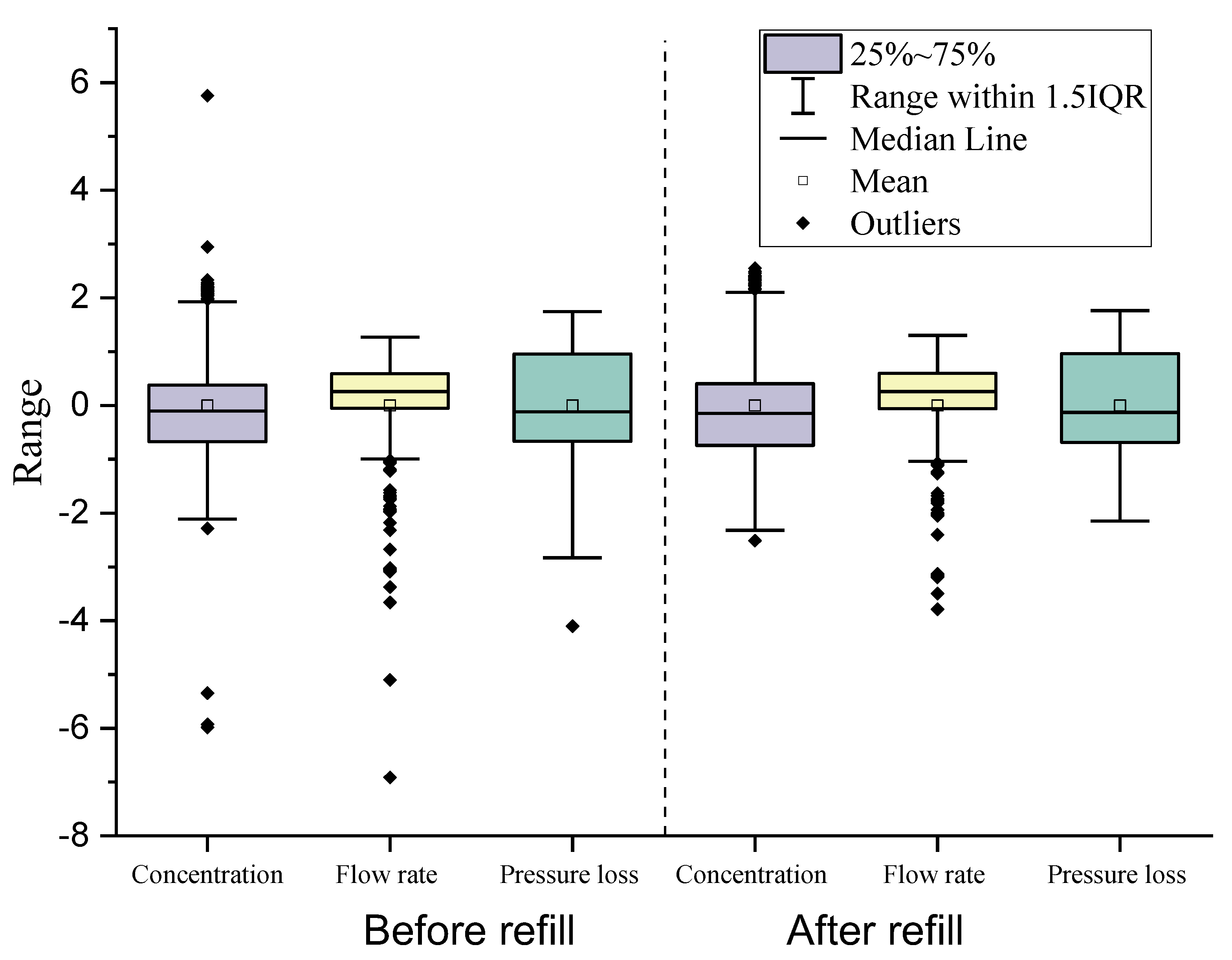
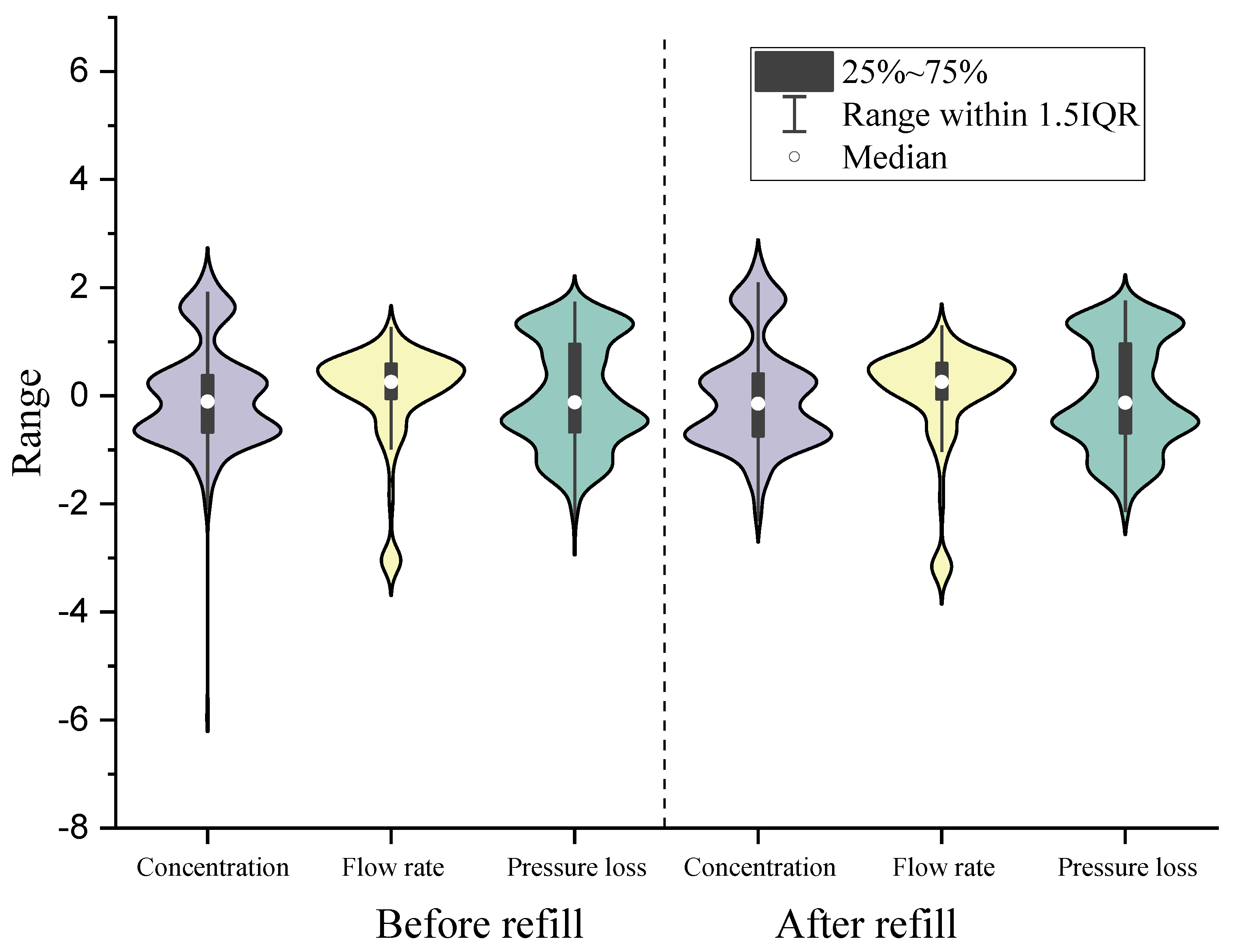
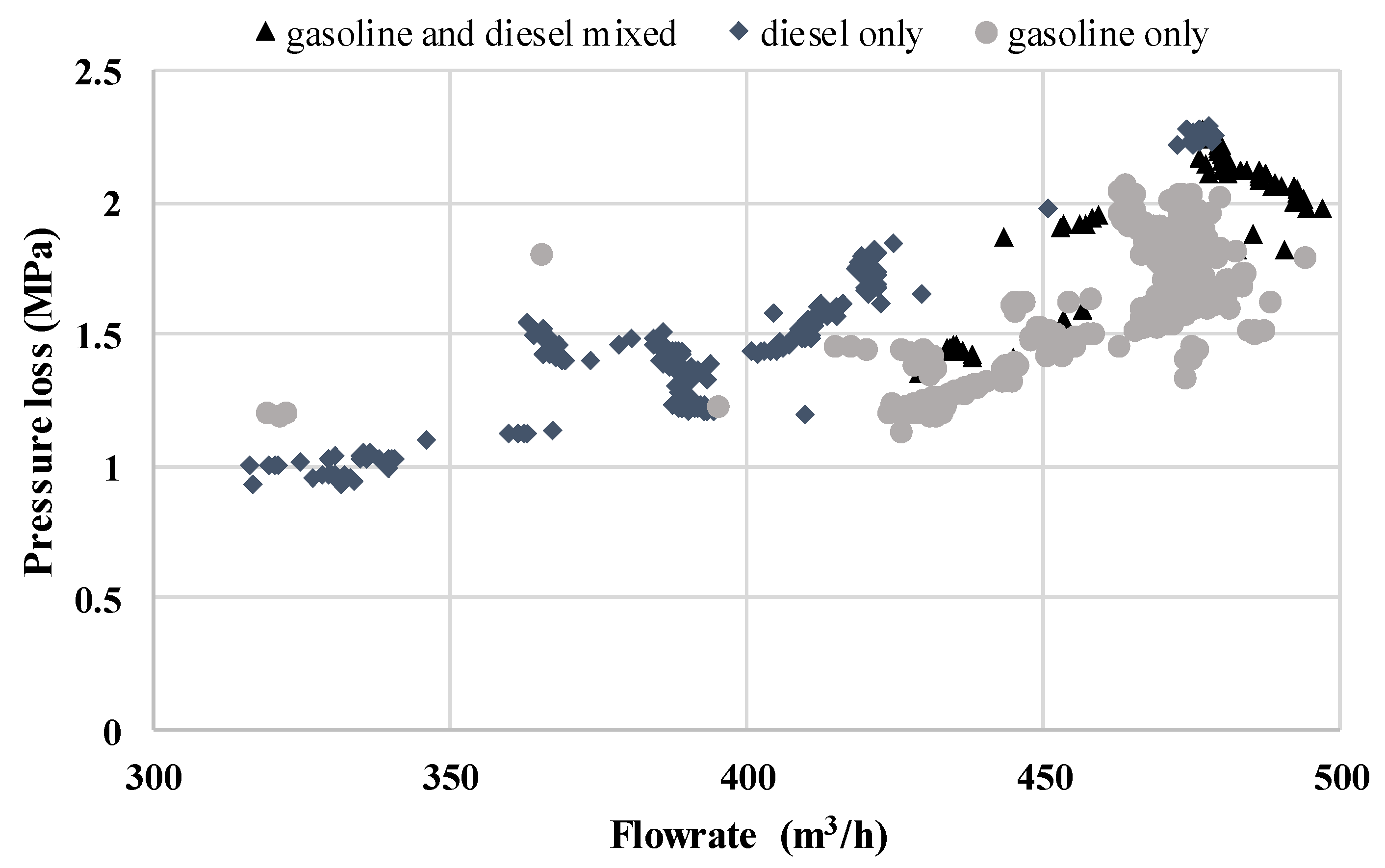
3.1. Data Analysis before the Case Studies
3.2. Case Studies
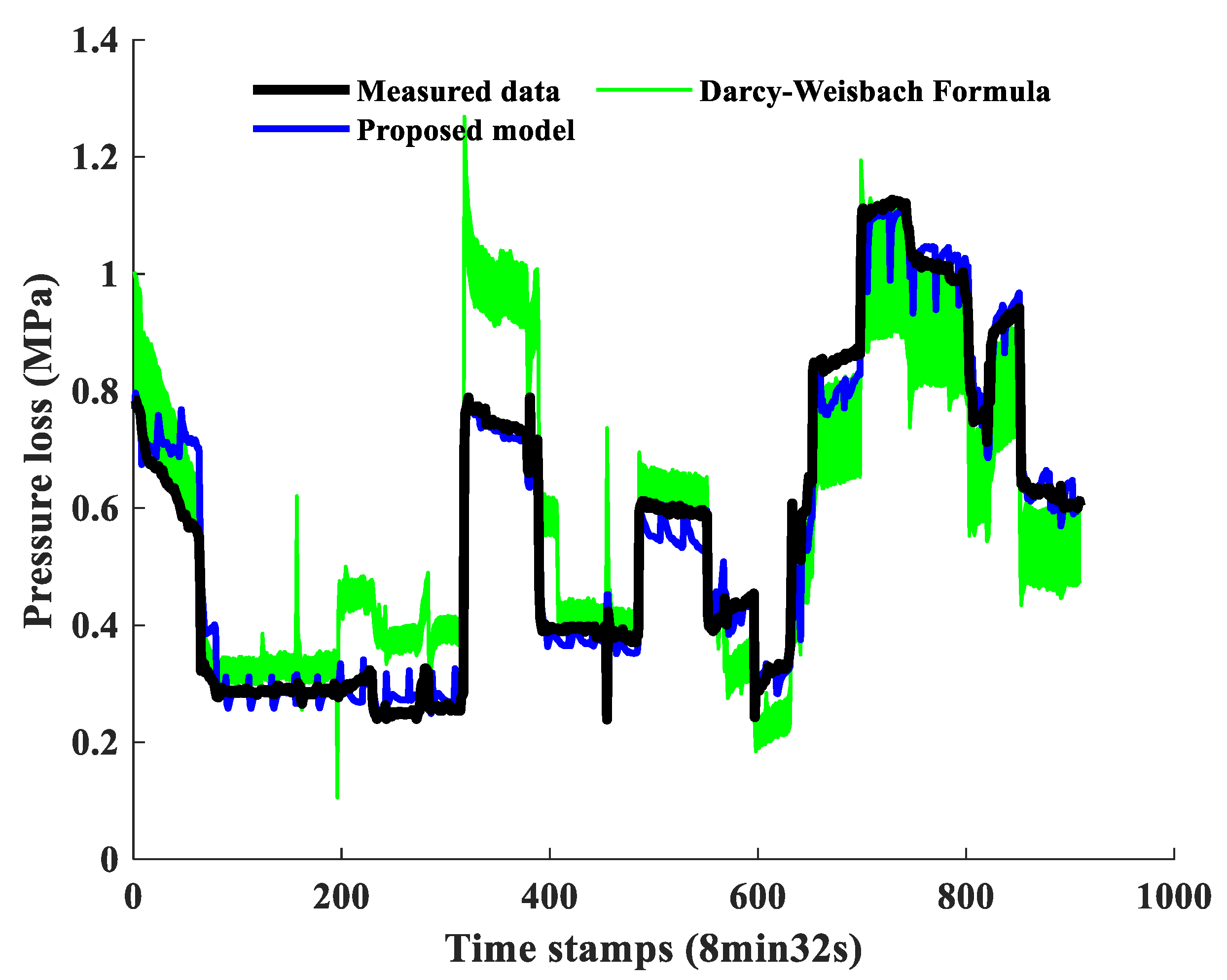
3.2.1. Case 1
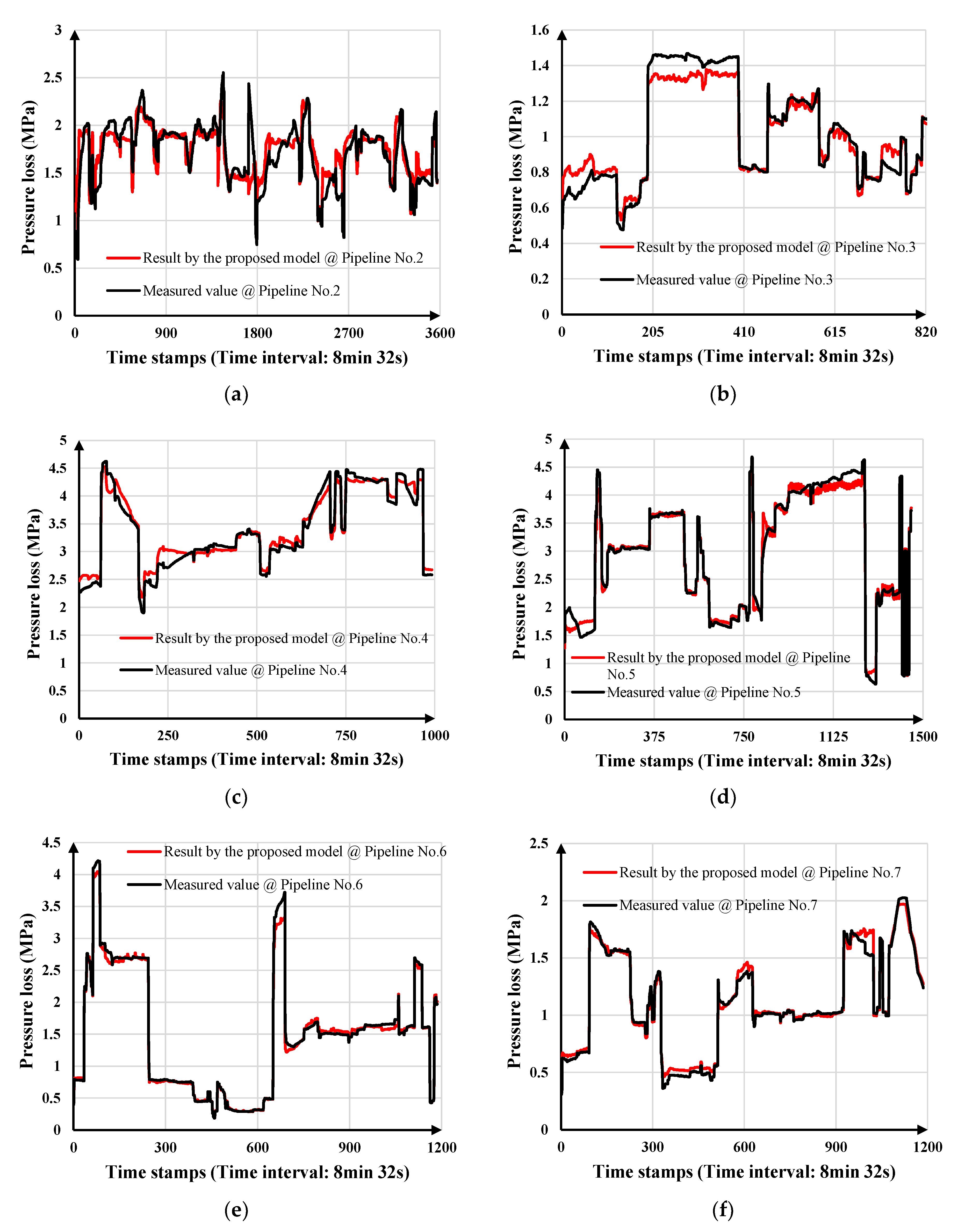
3.2.2. Case 2
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
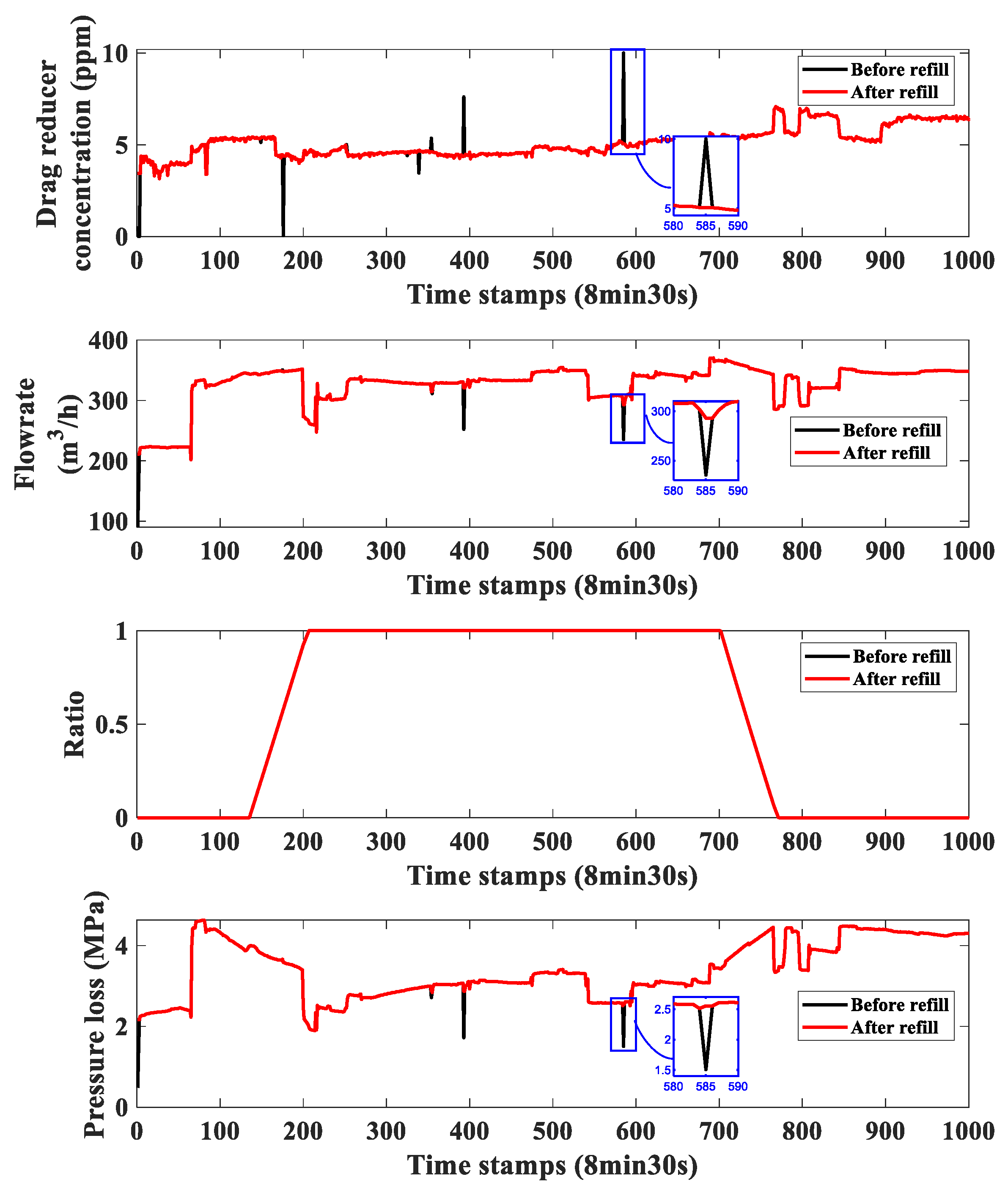
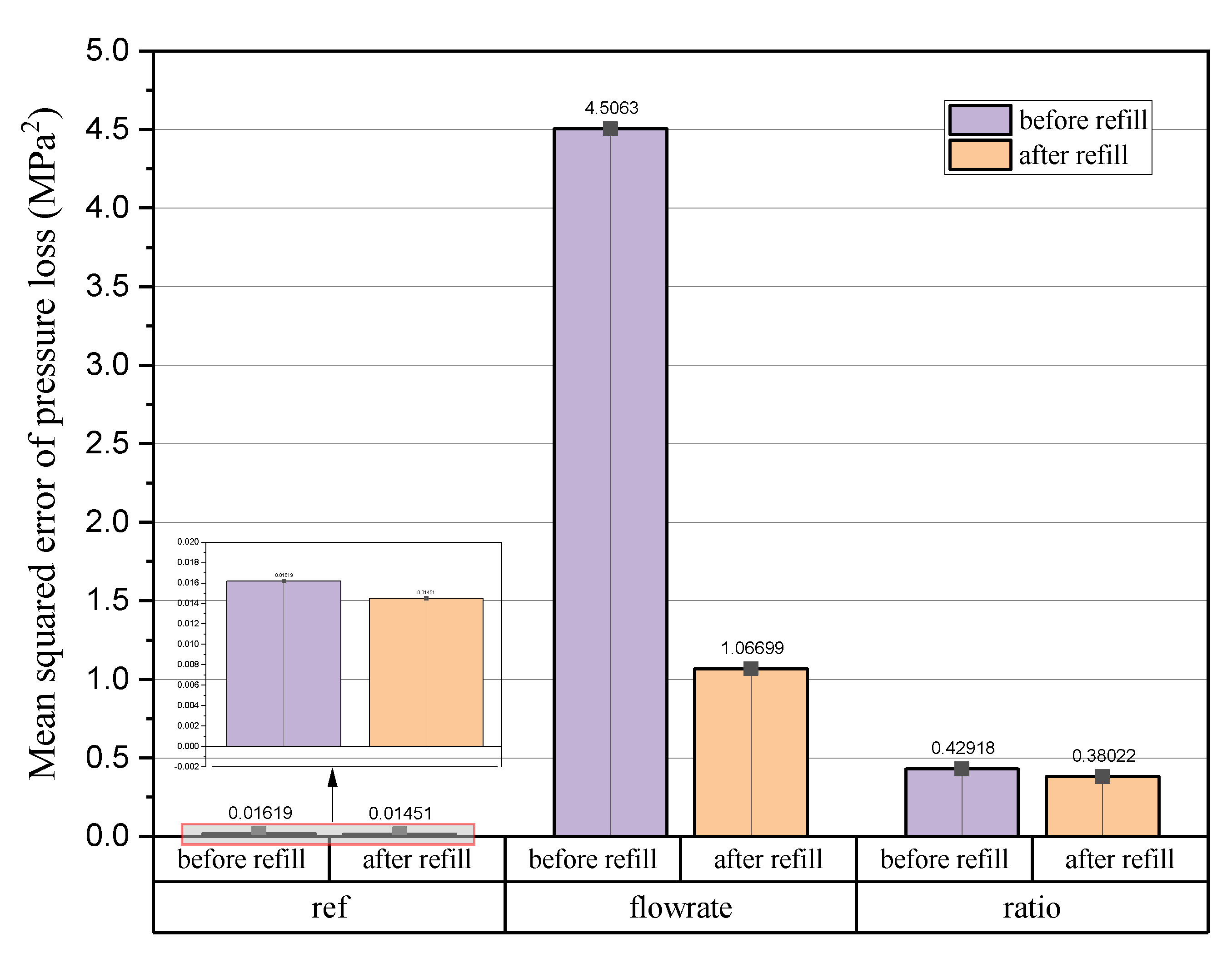
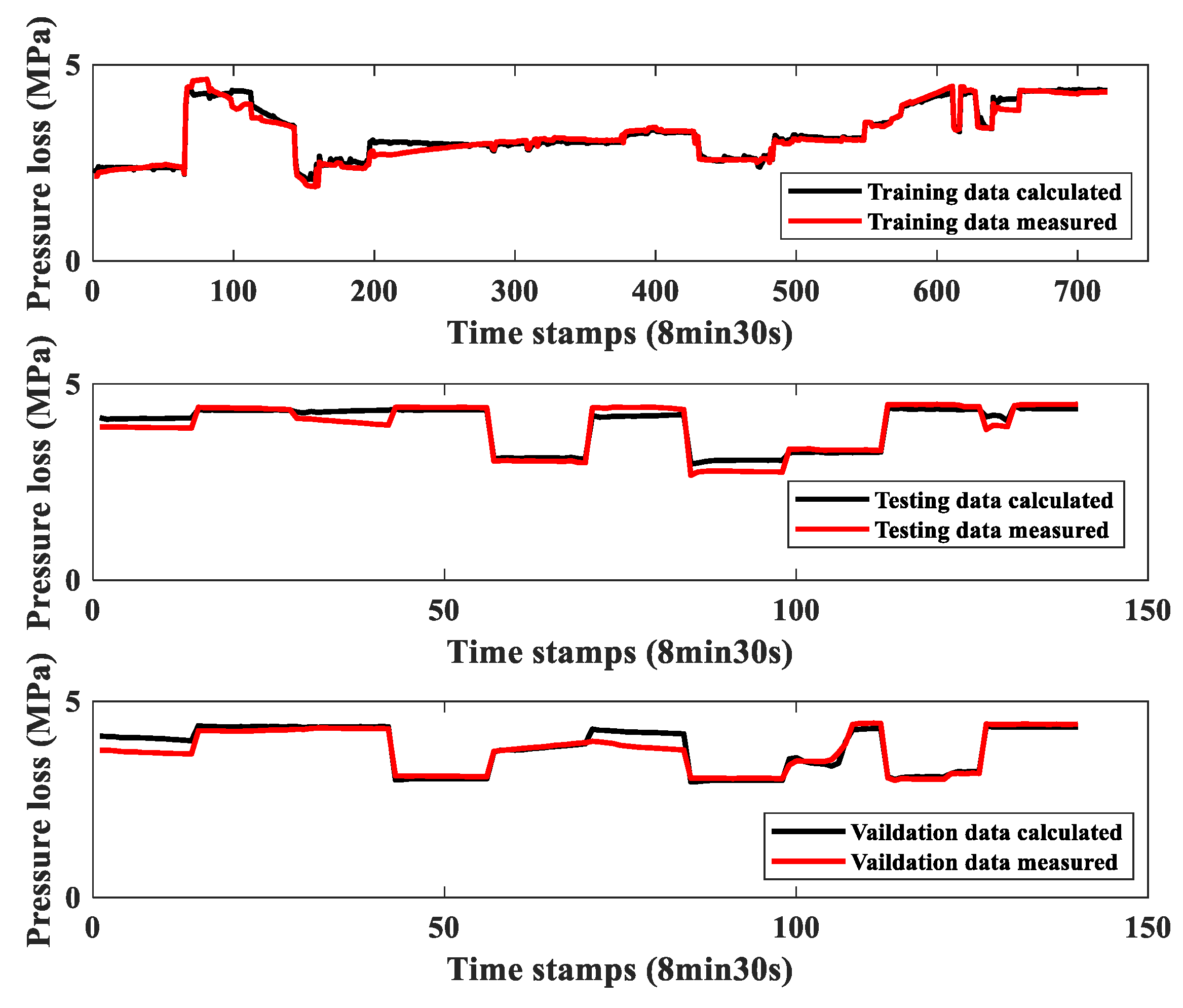
Appendix B
Appendix C
- MAE is the acronym of mean absolute error, which is defined as:
- RMSE is the acronym of root mean squared error, which is defined as:
- MAPE is the acronym of mean absolute percentage error, which is defined as:
- R2 is the R squared value, which is the coefficient of determination in statistics and is defined as:
Appendix D


References
- Ayegba, P.O.; Edomwonyi-Otu, L.C.; Abubakar, A.; Yusuf, N. Drag Reduction for Single-Phase Water Flow in and around 180o Bends. J. Non-Newton Fluid 2021, 295, 104596. [Google Scholar] [CrossRef]
- Abdel-Gawad, N.M.; El Dein, A.Z.; Magdy, M. Mitigation of induced voltages and AC corrosion effects on buried gas pipeline near to OHTL under normal and fault conditions. Electr. Pow. Syst. Res. 2015, 127, 297–306. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Q.; Wei, J. Experimental study on drag reduction performance of mixed polymer and surfactant solutions. Chem. Eng. Res. Des. 2018, 132, 460–469. [Google Scholar] [CrossRef]
- Quan, Q.; Wang, S.; Wang, L.; Shi, Y.; Xie, J.; Wang, X.; Wang, S. Experimental study on the effect of high-molecular polymer as drag reducer on drag reduction rate of pipe flow. J. Pet. Sci. Eng. 2019, 178, 852–856. [Google Scholar] [CrossRef]
- Karami, H.R.; Mowla, D. Investigation of the effects of various parameters on pressure drop reduction in crude oil pipelines by drag reducing agents. J. Non-Newton Fluid 2012, 177–178, 37–45. [Google Scholar] [CrossRef]
- Virk, P.S. Drag reduction fundamentals. AICHE J. 1975, 21, 625–656. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, H.; Qiu, R.; Liang, Y.; Wu, G.; Xiang, C.; Yan, X. A hybrid time MILP model for the pump scheduling of multi-product pipelines based on the rigorous description of the pipeline hydraulic loss changes. Comput. Chem. Eng. 2019, 121, 174–199. [Google Scholar] [CrossRef]
- Huang, L.; Liao, Q.; Yan, J.; Liang, Y.; Zhang, H. Carbon footprint of oil products pipeline transportation. Sci. Total Environ. 2021, 783, 146906. [Google Scholar] [CrossRef]
- Zhou, B.; Fang, J.; Ai, X.; Yang, C.; Yao, W.; Wen, J. Dynamic Var Reserve-Constrained Coordinated Scheduling of LCC-HVDC Receiving-End System Considering Contingencies and Wind Uncertainties. IEEE Trans. Sustain. Energy 2021, 12, 469–481. [Google Scholar] [CrossRef]
- Gómez Cuenca, F.; Gómez Marín, M.; Folgueras Díaz, M.B. Energy-Savings Modeling of Oil Pipelines That Use Drag-Reducing Additives. Energy Fuels 2008, 22, 3293–3298. [Google Scholar] [CrossRef]
- Virk, P. Drag reduction by collapsed and extended polyelectrolytes. Nature 1975, 253, 109–110. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, P.; Liu, Y.; Zhao, W.; Mao, J. Prediction of Field Drag Reduction by a Modified Practical Pipe Diameter Model. Chem. Eng. Technol. 2018, 41, 1417–1424. [Google Scholar] [CrossRef]
- Karami, H.R.; Mowla, D. A general model for predicting drag reduction in crude oil pipelines. J. Pet. Sci. Eng. 2013, 111, 78–86. [Google Scholar] [CrossRef]
- Dodge, D.; Metzner, A. Turbulent flow of non-Newtonian systems. AICHE J. 1959, 5, 189–204. [Google Scholar] [CrossRef]
- Karami, H.R.; Keyhani, M.; Mowla, D. Experimental analysis of drag reduction in the pipelines with response surface methodology. J. Pet. Sci. Eng. 2016, 138, 104–112. [Google Scholar] [CrossRef]
- Zhou, B.; Ai, X.; Fang, J.; Yao, W.; Zuo, W.; Chen, Z.; Wen, J. Data-adaptive robust unit commitment in the hybrid AC/DC power system. Appl. Energy 2019, 254, 113784. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Elsisi, M.; Mahmoud, K.; Lehtonen, M.; Darwish, M.M. Effective Nonlinear Model Predictive Control Scheme Tuned by Improved NN for Robotic Manipulators. IEEE Access 2021, 9, 64278–64290. [Google Scholar] [CrossRef]
- Ali, M.N.; Mahmoud, K.; Lehtonen, M.; Darwish, M.M. Promising MPPT Methods Combining Metaheuristic, Fuzzy-Logic and ANN Techniques for Grid-Connected Photovoltaic. Sensors 2021, 21, 1244. [Google Scholar] [CrossRef]
- Zabihi, R.; Mowla, D.; Karami, H.R. Artificial intelligence approach to predict drag reduction in crude oil pipelines. J. Pet. Sci. Eng. 2019, 178, 586–593. [Google Scholar] [CrossRef]
- Moayedi, H.; Aghel, B.; Vaferi, B.; Foong, L.K.; Bui, D.T. The feasibility of Levenberg–Marquardt algorithm combined with imperialist competitive computational method predicting drag reduction in crude oil pipelines. J. Pet. Sci. Eng. 2020, 185, 106634. [Google Scholar] [CrossRef]
- Cao, D.; Li, C.; Li, H.; Yang, F. Effect of dispersing time on the prediction equation of drag reduction rate and its application in the short distance oil pipeline. Pet. Sci. Technol. 2018, 36, 1312–1318. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Song, E.; Soong, F.K.; Kang, H. Effective Spectral and Excitation Modeling Techniques for LSTM-RNN-Based Speech Synthesis Systems. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2152–2161. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Salehinejad, H.; Sankar, S.; Barfett, J.; Colak, E.; Valaee, S. Recent Advances in Recurrent Neural Networks. arXiv 2018, arXiv:1801.01078. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Goodfellow, I.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Chu, X.; Ilyas, I.F.; Krishnan, S.; Wang, J. Data cleaning: Overview and emerging challenges. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 2201–2206. [Google Scholar]
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. preprint. [Google Scholar]
- Del Valle, Y.; Venayagamoorthy, G.K.; Mohagheghi, S.; Hernandez, J.C.; Harley, R.G. Particle Swarm Optimization: Basic Concepts, Variants and Applications in Power Systems. IEEE Trans. Evol. Comput. 2008, 12, 171–195. [Google Scholar] [CrossRef]
- Fang, S.; He, C. A new one parameter viscosity model for binary mixtures. AICHE J. 2011, 57, 517–524. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Tayman, J.; Swanson, D.A. On the validity of MAPE as a measure of population forecast accuracy. Popul. Res. Policy Rev. 1999, 18, 299–322. [Google Scholar] [CrossRef]
- Blomquist, N.S. A note on the use of the coefficient of determination. Scand. J. Econ. 1980, 82, 409–412. [Google Scholar] [CrossRef]
- Kemp, S.J.; Zaradic, P.; Hansen, F. An approach for determining relative input parameter importance and significance in artificial neural networks. Ecol. Model 2007, 204, 326–334. [Google Scholar] [CrossRef]
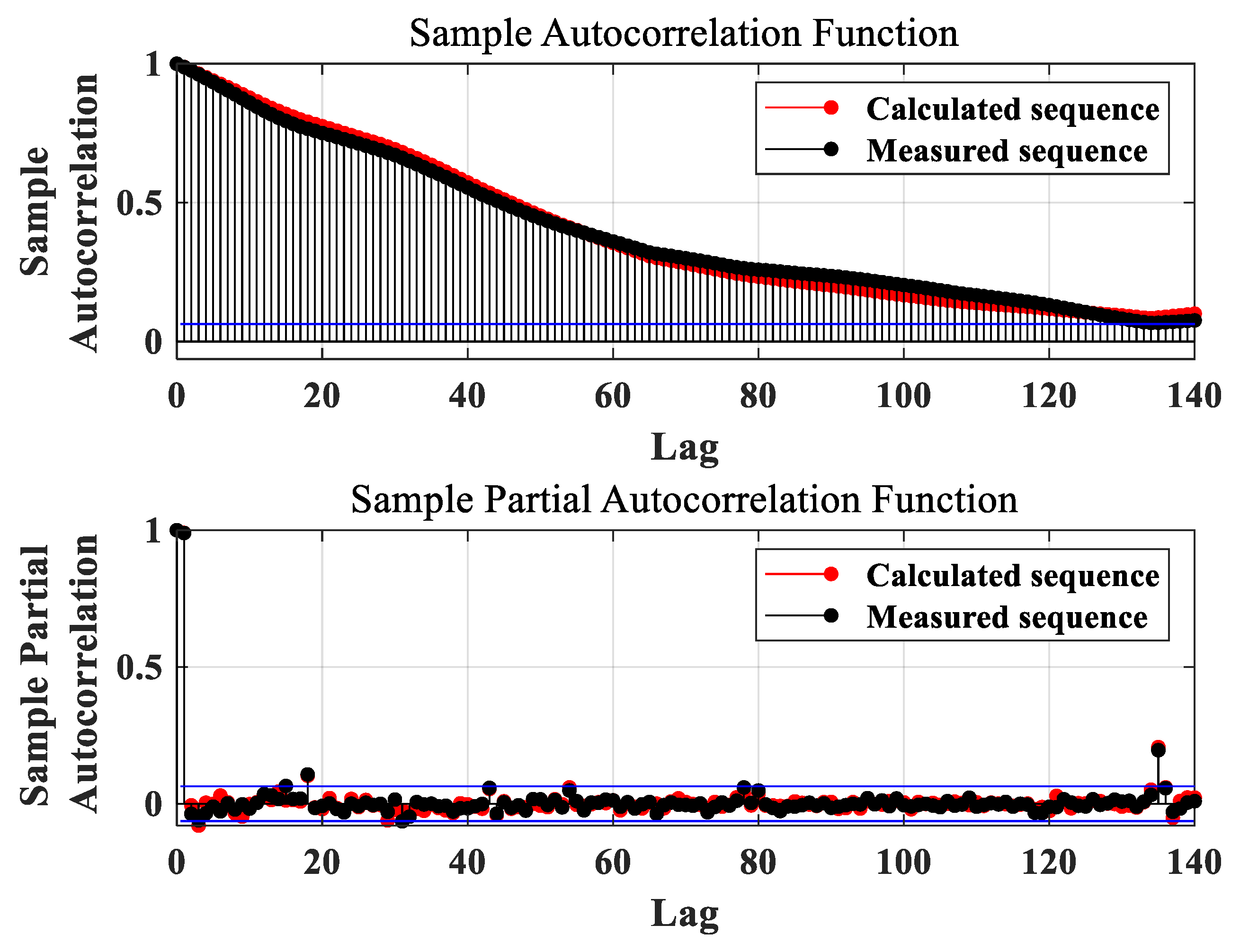
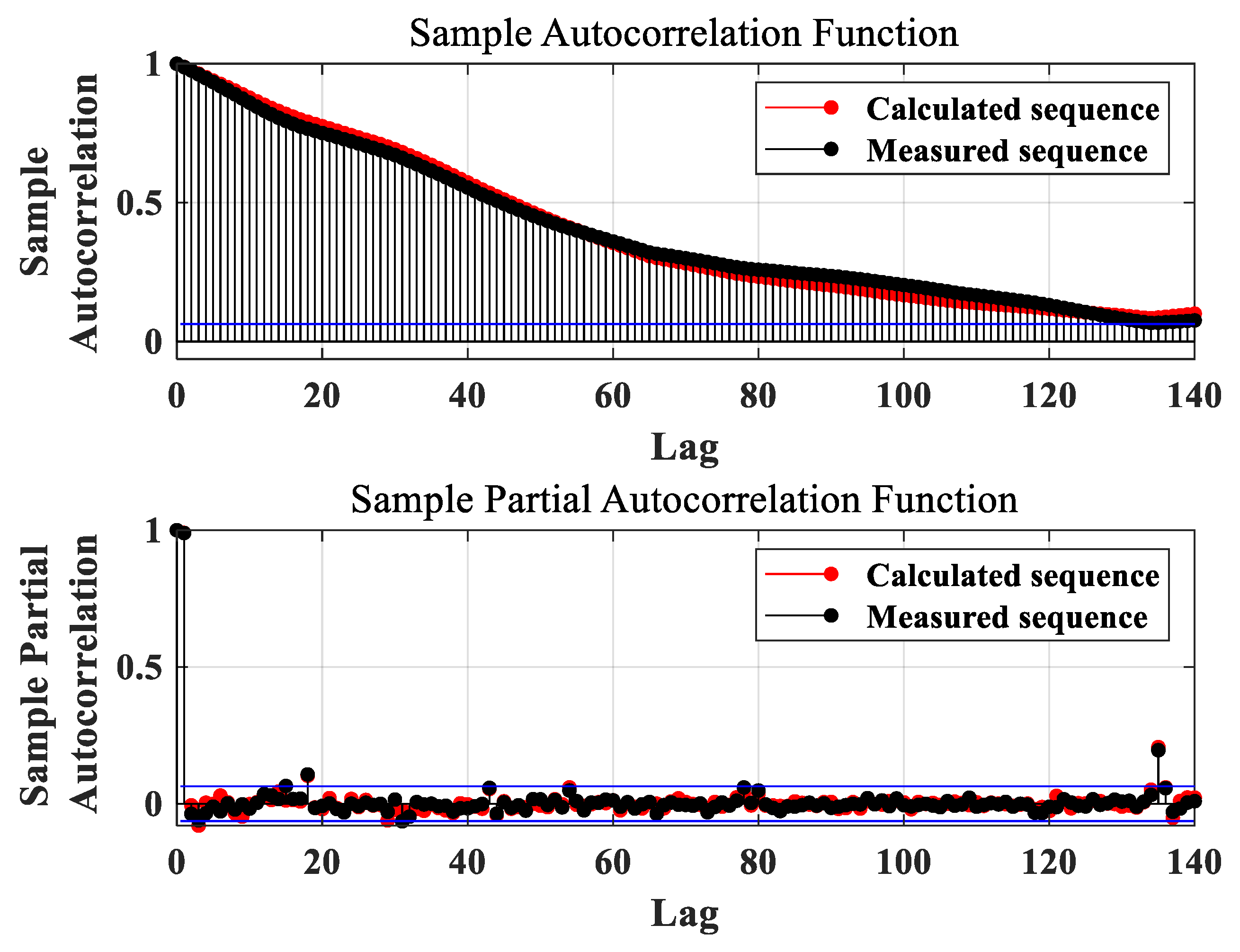
- Tinungki, G.M. The analysis of partial autocorrelation function in predicting maximum wind speed. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2019; Volume 235, p. 012097. [Google Scholar]

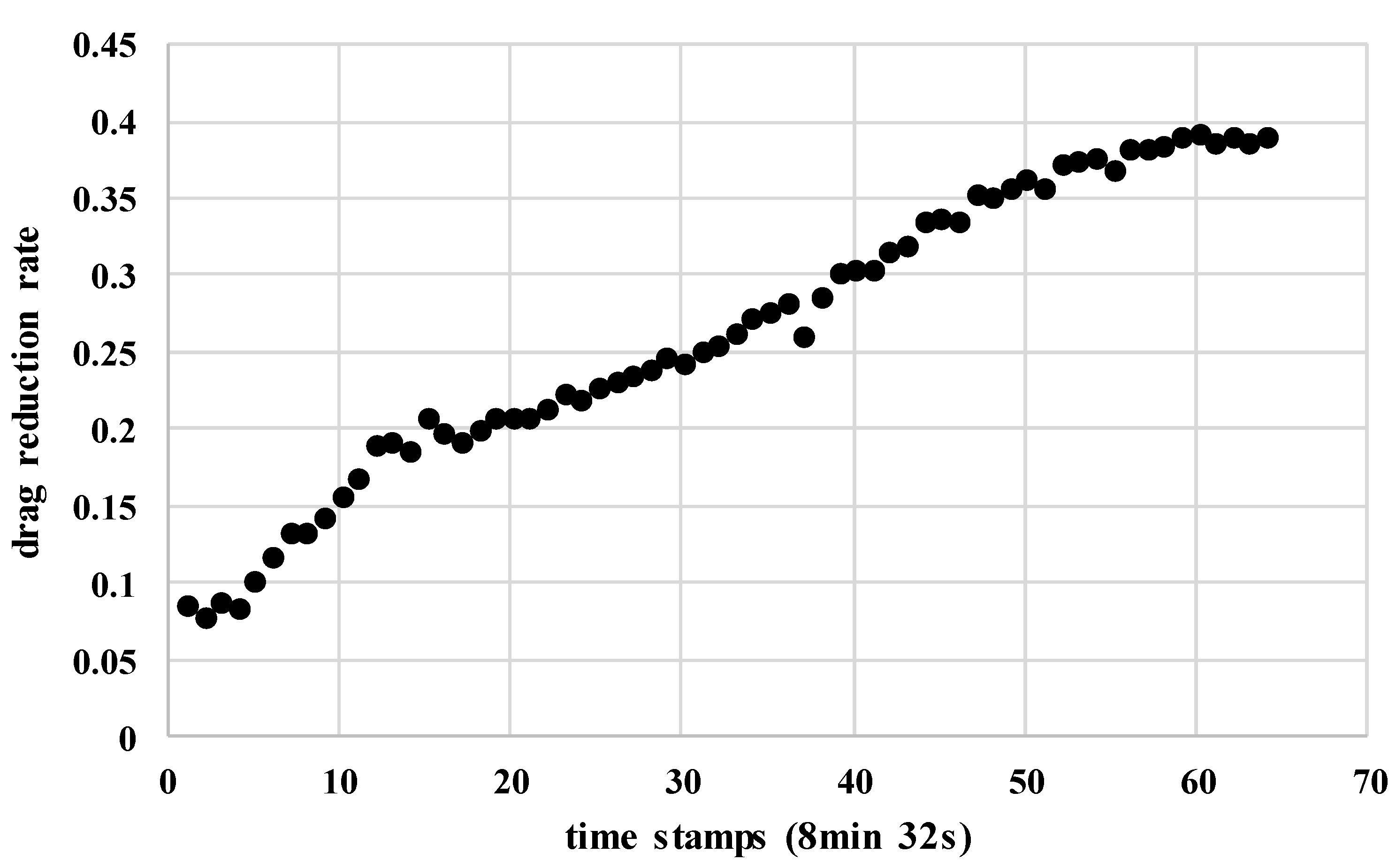
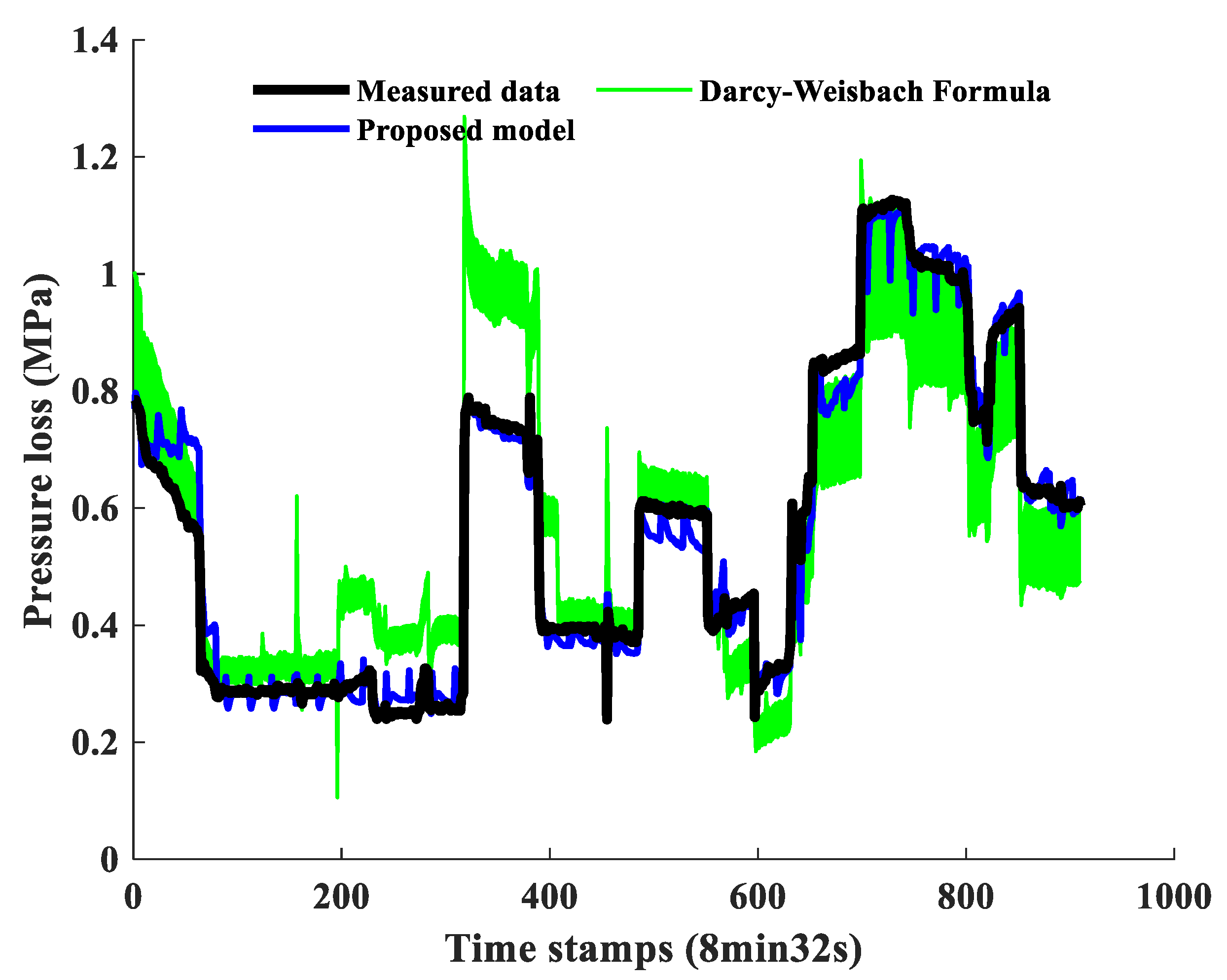
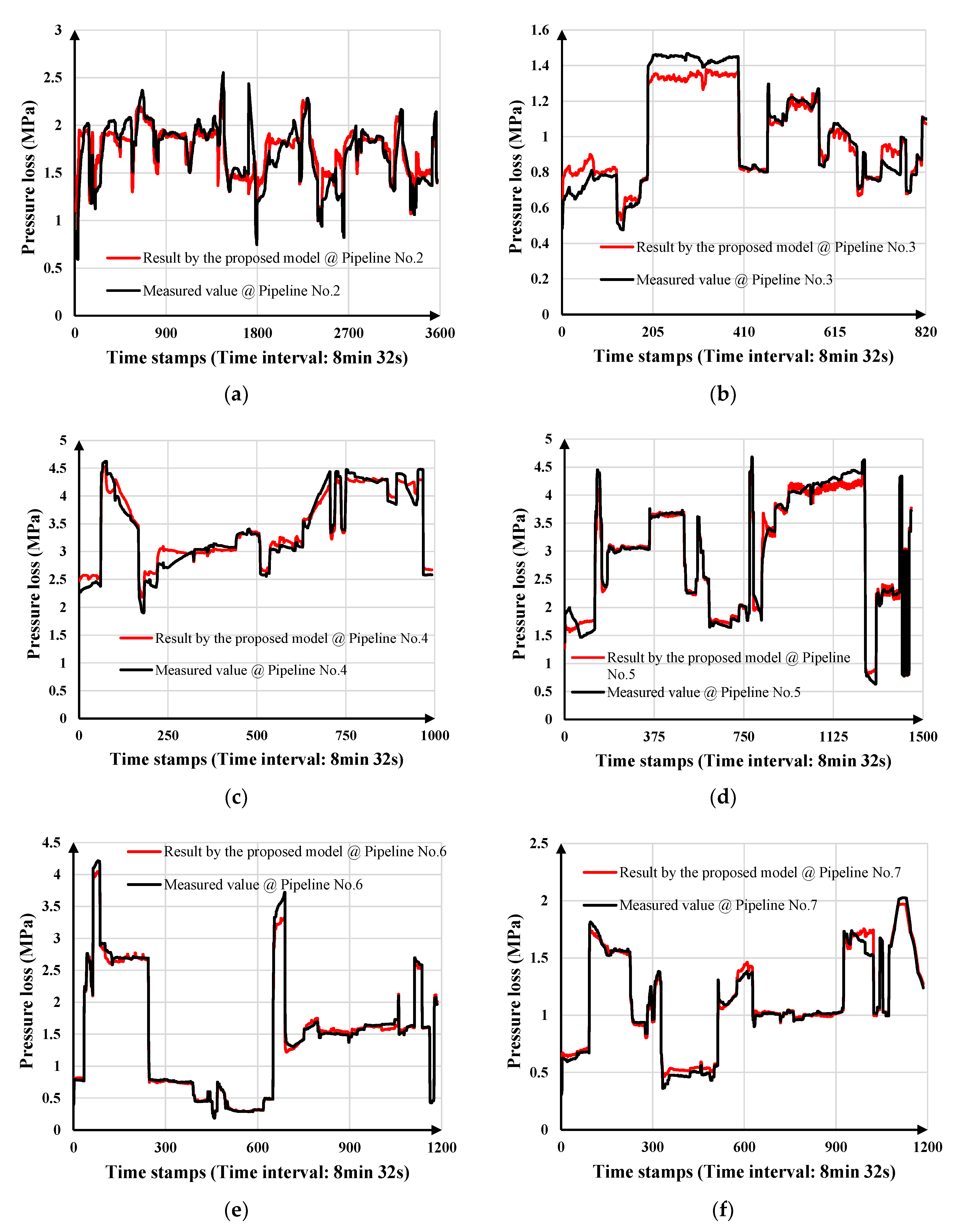
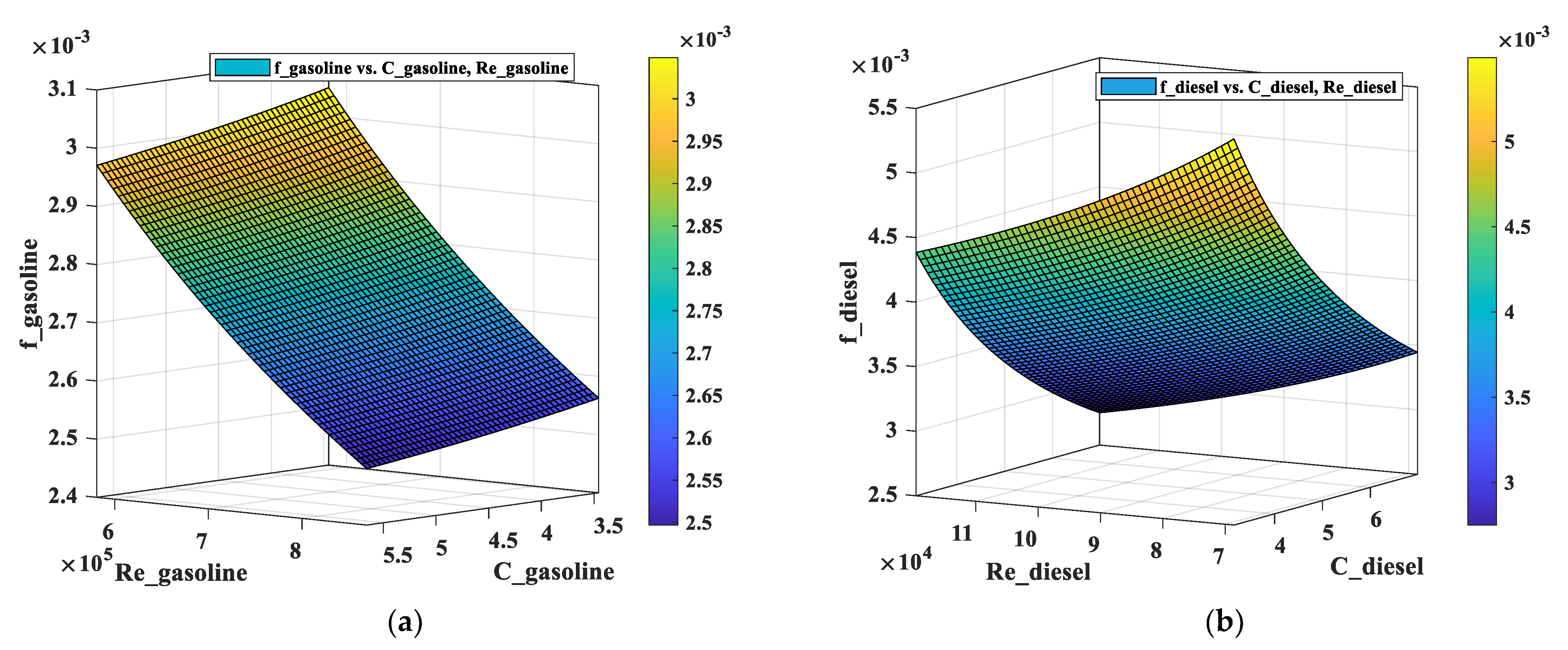
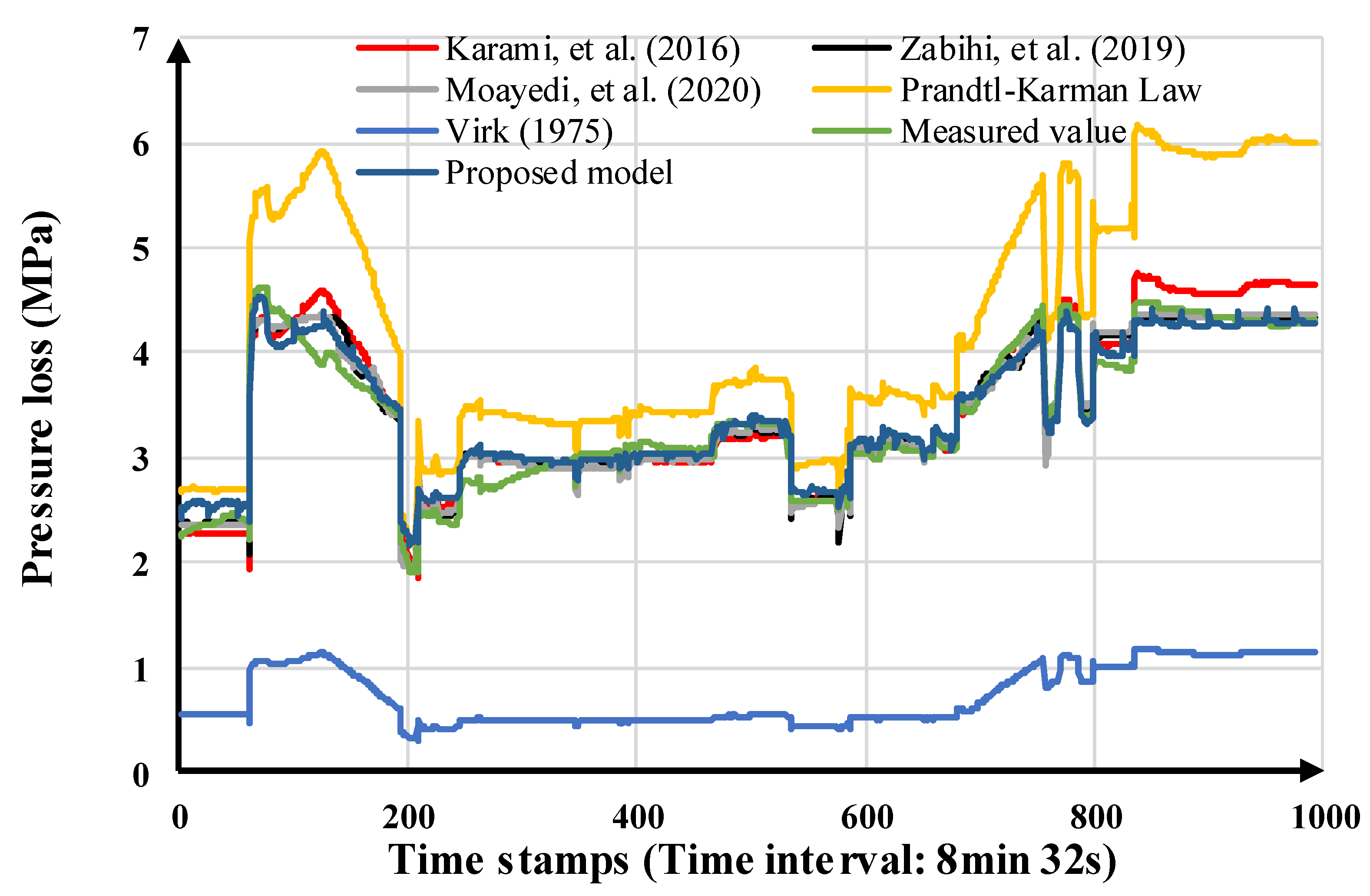
| Pipeline No. | Pipeline Length (km) | Inner Diameter (m) | Altitude Difference (m) |
|---|---|---|---|
| 1 | 38.71 | 0.392 | 1.08 |
| 2 | 55.31 | 0.311 | 3.49 |
| 3 | 35.83 | 0.311 | 0.08 |
| 4 | 65.14 | 0.26 | 1.91 |
| 5 | 32.34 | 0.208 | 2.32 |
| 6 | 45.48 | 0.208 | −2.73 |
| 7 | 51.75 | 0.208 | 0.47 |
| Type of Refined Oil | Density (kg/m3) | Kinematic Viscosity (m2/s) |
|---|---|---|
| gasoline | 760 | 5.8 × 10−7 |
| diesel | 840 | 4.0 × 10−6 |
| Pipeline No. | Model | MAE (MPa) 1 | RMSE (MPa) 2 | MAPE (%) 3 | R2 4 |
|---|---|---|---|---|---|
| 1 | Proposed model (full data set 5) | 0.0296 | 0.042 | 5.9 | 0.9741 |
| Darcy-Weisbach Formula (full data set) | 0.1166 | 0.095 | 18.1 | 0.8102 |
| Type of Refined Oil | Density (kg/m3) | Kinematic Viscosity (m2/s) |
|---|---|---|
| gasoline | 740 | 8 × 10−7 |
| diesel | 830 | 4.0 × 10−6 |
| Pipeline No. | Model 1,2 | Data Set | MAE (MPa) | RMSE (MPa) | MAPE | R2 |
|---|---|---|---|---|---|---|
| 2 | Proposed model | Testing data set | 0.039477 | 0.051727 | 2.0478% | 0.98138 |
| 3 | Proposed model | Testing data set | 0.020316 | 0.025194 | 2.2958% | 0.96926 |
| 4 | Proposed model | Training data set | 0.094731 | 0.12234 | 2.9234% | 0.96753 |
| Testing data set | 0.12842 | 0.15219 | 3.2601% | 0.9349 | ||
| Full data set | 0.098088 | 0.12551 | 2.9262% | 0.96732 | ||
| Karami et al. (2016) [15] | Training data set | 0.17198 | 0.21694 | 5.1497% | 0.90763 | |
| Testing data set | 0.22454 | 0.28593 | 5.7048% | 0.84177 | ||
| Full data set | 0.1786 | 0.2268 | 5.2196% | 0.90071 | ||
| Zabihi et al. (2019) [21] | Training data set | 0.097467 | 0.12681 | 2.9903% | 0.96512 | |
| Testing data set | 0.17736 | 0.22011 | 4.6056% | 0.86383 | ||
| Full data set | 0.10794 | 0.14255 | 3.2019% | 0.95794 | ||
| Moayedi et al. (2020) [22] | Training data set | 0.10032 | 0.12597 | 3.0615% | 0.96558 | |
| Testing data set | 0.17513 | 0.2269 | 4.5171% | 0.8553 | ||
| Full data set | 0.11012 | 0.14331 | 3.2523% | 0.9575 | ||
| 5 | Proposed model | Training data set | 0.097122 | 0.13888 | 4.0678% | 0.98226 |
| Testing data set | 0.051544 | 0.06589 | 2.6843% | 0.99792 | ||
| 6 | Proposed model | Training data set | 0.044789 | 0.077051 | 2.8387% | 0.99370 |
| Testing data set | 0.030634 | 0.039497 | 1.7549% | 0.99573 | ||
| 7 | Proposed model | Training data set | 0.037734 | 0.054331 | 4.6859% | 0.98183 |
| Testing data set | 0.014215 | 0.018376 | 1.3627% | 0.99483 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Zuo, L.; Li, M.; Wang, Q.; Xue, X.; Liu, Q.; Jiang, S.; Wang, J.; Duan, X. The Data-Driven Modeling of Pressure Loss in Multi-Batch Refined Oil Pipelines with Drag Reducer Using Long Short-Term Memory (LSTM) Network. Energies 2021, 14, 5871. https://doi.org/10.3390/en14185871
Wang S, Zuo L, Li M, Wang Q, Xue X, Liu Q, Jiang S, Wang J, Duan X. The Data-Driven Modeling of Pressure Loss in Multi-Batch Refined Oil Pipelines with Drag Reducer Using Long Short-Term Memory (LSTM) Network. Energies. 2021; 14(18):5871. https://doi.org/10.3390/en14185871
Chicago/Turabian StyleWang, Shengshi, Lianyong Zuo, Miao Li, Qiao Wang, Xizhen Xue, Qicong Liu, Shuai Jiang, Jian Wang, and Xitong Duan. 2021. "The Data-Driven Modeling of Pressure Loss in Multi-Batch Refined Oil Pipelines with Drag Reducer Using Long Short-Term Memory (LSTM) Network" Energies 14, no. 18: 5871. https://doi.org/10.3390/en14185871
APA StyleWang, S., Zuo, L., Li, M., Wang, Q., Xue, X., Liu, Q., Jiang, S., Wang, J., & Duan, X. (2021). The Data-Driven Modeling of Pressure Loss in Multi-Batch Refined Oil Pipelines with Drag Reducer Using Long Short-Term Memory (LSTM) Network. Energies, 14(18), 5871. https://doi.org/10.3390/en14185871