Abstract
Daily peak load forecasting is an important part of power load forecasting. The accuracy of its prediction has great influence on the formulation of power generation plan, power grid dispatching, power grid operation and power supply reliability of power system. Therefore, it is of great significance to construct a suitable model to realize the accurate prediction of the daily peak load. A novel daily peak load forecasting model, CEEMDAN-MGWO-SVM (Complete Ensemble Empirical Mode Decomposition with Adaptive Noise and Support Vector Machine Optimized by Modified Grey Wolf Optimization Algorithm), is proposed in this paper. Firstly, the model uses the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) algorithm to decompose the daily peak load sequence into multiple sub sequences. Then, the model of modified grey wolf optimization and support vector machine (MGWO-SVM) is adopted to forecast the sub sequences. Finally, the forecasting sequence is reconstructed and the forecasting result is obtained. Using CEEMDAN can realize noise reduction for non-stationary daily peak load sequence, which makes the daily peak load sequence more regular. The model adopts the grey wolf optimization algorithm improved by introducing the population dynamic evolution operator and the nonlinear convergence factor to enhance the global search ability and avoid falling into the local optimum, which can better optimize the parameters of the SVM algorithm for improving the forecasting accuracy of daily peak load. In this paper, three cases are used to test the forecasting accuracy of the CEEMDAN-MGWO-SVM model. We choose the models EEMD-MGWO-SVM (Ensemble Empirical Mode Decomposition and Support Vector Machine Optimized by Modified Grey Wolf Optimization Algorithm), MGWO-SVM (Support Vector Machine Optimized by Modified Grey Wolf Optimization Algorithm), GWO-SVM (Support Vector Machine Optimized by Grey Wolf Optimization Algorithm), SVM (Support Vector Machine) and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data. The experimental results fully demonstrate the reliability and effectiveness of the CEEMDAN-MGWO-SVM model proposed in this paper for daily peak load forecasting, which shows the strong generalization ability and robustness of the model.
1. Introduction
The development of modern society is inseparable from the supply of electricity. The power industry plays a crucial role in promoting social and economic development and improving people’s living standards. With the rapid development of the power industry, the precision of power system for power load forecasting is becoming more and more demanding. Daily peak load forecasting is an important part of power load forecasting. The accuracy of its prediction has great influence on the formulation of power generation plan, power grid dispatching, power grid operation and power supply reliability of power system. Therefore, it is of great significance to construct a suitable model to realize the accurate prediction of the daily peak load.
The core problem of load forecasting is the method and model of prediction. With the rapid development of science and technology, the technology of load forecasting is also being deepened. At present, load forecasting technology has gradually transferred from traditional prediction method to artificial intelligence prediction technology. Traditional load forecasting methods, such as time series method, regression analysis method and grey prediction method [1,2,3], have some shortcomings. The forecasting accuracy of traditional methods for complex load series with larger volatility needs to be improved. However, the artificial intelligence prediction method shows a strong superiority in the face of complex load sequence, and has achieved good prediction effect [4]. The artificial neural network (ANN) algorithm, originating in the 1940s, is an artificial intelligence technology, which simulates the biological process of human brain [5]. The BP (Back Propagation) algorithm, also known as the error back propagation algorithm, is a supervised learning algorithm in artificial neural networks, which is often used for load forecasting [6,7]. Wang et al. [8] put forward a new back-propagation neural network algorithm to apply it in the semi-distributed model. The improved hydrological model could update the flow forecasting error without losing the leading time. However, BP neural network algorithm has some disadvantages, such as slow convergence speed, long training time, easy to fall into local optimal solution and so on [9,10]. Support vector machine (SVM) is a small sample machine learning method based on the theory of VC (Vapnik-Chervonenkis) dimension of statistical learning theory and the principle of minimum structure risk. It seeks the best compromise between the complexity of the model and the learning ability based on the limited sample information to achieve the best promotion [11,12,13]. Wei et al. [14] used the seeker optimization algorithm to get the optimal parameters selection of SVM. Then the short-term load prediction of the next 24 h in one region was achieved by the SVM model based on the historical load data as input. Support vector machine algorithm has strong generalization ability, fast convergence speed, and can avoid falling into local optimal solution [15,16]. At present, many optimization algorithms, such as particle swarm optimization (PSO), simulated annealing (SA) and genetic algorithm (GA), are proposed for the optimization of SVM parameters. Huang and Dun [17] put forward a novel PSO–SVM model that hybridized the particle swarm optimization and support vector machines to improve the classification accuracy with a small and appropriate feature subset. Liu and Huang [18] used simulated annealing algorithm (SA) to optimize the parameters of SVM and proposed a model based on simulated annealing algorithm and support vector machine to forecast the power load that has proven to be of good prediction effect. Wang et al. [19] put forward a forecasting model based on environmental factors and support vector machine optimized by genetic algorithm to predict the short-term PV power using the gray correlation coefficient algorithm to find out a similar day of the predicted day. In this paper, the grey wolf optimization algorithm is used to optimize the parameters of support vector machine. GWO (Grey Wolf Optimization) algorithm is a new meta heuristic optimization algorithm proposed by Mirjalili et al. in 2014. It is a new swarm intelligence optimization algorithm, has superior performance in finding optimal solutions, and is simple and efficient [20,21,22]. Xu and Ding [23] put forward the model of Grey wolf optimization algorithm which is improved by extremal optimization and support vector machine for cloud computing resource load short-term forecasting and tested the performance of EGWO-SVM by simulation experiments. The experimental results showed that the proposed model could precisely characterize the complicated trends of cloud computing resource short-term load and efficiently promote the short-term resource load prediction accuracy.
The daily peak load forecasting is easily disturbed by external factors, and the load sequence contains some noise and strong volatility, which brings great difficulties to the prediction work. Wavelet decomposition and empirical mode decomposition are two effective time frequency analysis methods to deal with non-stationary signals. The wavelet decomposition gradually refines the signal through the telescopic translation operation, and finally realizes the time subdivision at high frequency and the frequency subdivision at low frequency [24,25,26]. Seo et al. [27] proposed two hybrid models for daily water level forecasting. They were wavelet-based artificial neural network and wavelet-based adaptive neuro-fuzzy inference system. It was proven that the combination of wavelet decomposition and artificial intelligence models can be a useful tool for accurate forecasting daily water level through empirical analysis. The essence of empirical mode decomposition is to smooth the signal, and decompose the complex signal into Intrinsic Mode Function (IMF) [28,29,30]. Premanode and Toumazou [31] put forward the differential Empirical Mode Decomposition (EMD) for improving prediction of exchange rates under support vector regression (SVR), which has the capability of smoothing and reducing the noise. Compared with the traditional forecasting methods, the hybrid EMD-SVM forecasting method could effectively improve the forecasting accuracy and track the change of wind power. Compared with the wavelet decomposition, empirical mode decomposition is not affected by the selection of wavelet base and the number of decomposition layers, but based on the adaptability of data itself, and the noise reduction performance of load sequence is better. Based on the traditional EMD, Ensemble Empirical Mode Decomposition (EEMD) adopted Gauss white noise to reduce the generation of modal aliasing in a certain range [32,33]. Jiang et al. [34] proposed a hybrid approach based on the ensemble empirical mode decomposition and grey support vector machine for short-term high-speed rail passenger flow forecasting. However, due to the addition of white noise sequences, the accuracy of the EEMD algorithm reconstruction sequence will be affected. Therefore, based on previous studies of EEMD, Colominas proposed the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN). The CEEMDAN method adds adaptive white noise smooth pulse interference in each decomposition to make the decomposition of the signal data more complete [35,36,37]. Jun and Qing [38] developed an effective combined model based on complete ensemble empirical mode decomposition with adaptive noise, permutation entropy and echo state network with leaky integrator neurons for medium-term power load forecasting. Therefore, in this paper, we choose the CEEMDAN method to do the noise reduction for the daily peak load sequence.
A novel daily peak load forecasting model of CEEMDAN-MGWO-SVM is proposed in this paper. Firstly, the model uses the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) algorithm to decompose the daily peak load sequence into multiple sub sequences. Then, the model of modified grey wolf optimization and support vector machine (MGWO-SVM) is adopted to forecast the sub sequences. Finally, the forecasting sequence is reconstructed and the forecasting result is obtained. The model provides a new idea for daily peak load forecasting. The main contents and structure of this paper are as follows: Section 2 introduces the algorithm of complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN), which is used to reduce the noise of non-stationary daily peak load sequence. Section 3 introduces the MGWO-SVM model, which is the core algorithm for daily peak load forecasting in this paper. The model adopts the grey wolf optimization algorithm improved by introducing the population dynamic evolution operator and the nonlinear convergence factor to enhance the global search ability and avoid falling into the local optimum, which can better optimize the parameters of the SVM algorithm for improving the forecasting accuracy of daily peak load. Section 4 introduces the forecasting process of the CEEMDAN-MGWO-SVM model. Section 5 carries out an empirical analysis. Three cases are taken to test the forecasting accuracy of the CEEMDAN-MGWO-SVM model. We choose the models of EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data, which proves the superiority of the CEEMDAN-MGWO-SVM model. Section 6 summarizes the full text.
2. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise
2.1. EMD
The Empirical Mode Decomposition (EMD), which is the core of Hilbert–Huang Transform (HHT), is a technique to stabilize signals and decompose the complex signal into a finite number of Intrinsic Mode Functions (IMFs) containing local characteristic signals at different time scales [28,29,30]. The EMD should meet the following two requirements:
- (1)
- either the number of extrema and the number of zero crossings are equal or differ at most by one; and
- (2)
- the mean value of the upper envelope and the lower envelope is zero.
For a given signal , the result after decomposition is given by
where is the component of IMF containing local characteristic signals at different time scales, and is the residual signal.
Detailed steps of the EMD are as follows:
- (1)
- Determine all the local extremum points of , and fit the upper envelope and the lower envelope respectively with the cubic spline function.
- (2)
- Compute the mean value of upper and lower envelopes.
- (3)
- Compute the difference of and , where .
- (4)
- Set as the original sequence, repeat Step (1) to Step (3), and then obtain the first IMF component when envelope mean tends to be zero.
- (5)
- Define and set as the original sequence; repeat above steps until the residual signal becomes a constant function or monotonic function; and then end the decomposition.
2.2. EEMD
The Ensemble Empirical Mode Decomposition (EEMD) adds the Gaussian white noise into traditional EMD to solve the problem of mode mixing [32,33]. Detailed steps are as follows:
- (1)
- Add the Gaussian white noise into given original signal to obtain the signal :
- (2)
- Carry out the EDM decomposition on signal to get the IMF component which is the th IMF component after EMD decomposition when adding the Gaussian white noise at the th time.
- (3)
- Repeat Step (1) and Step (2) for times, and add different Gaussian white noise each time.
- (4)
- Set the mean value of IMF components of N-time decomposition as the final IMF:
2.3. CEEMDAN
Although EEMD can reduce mode mixing to a certain degree, due to the newly added white noise sequence, the error cannot be completely eliminated after a finite number of averaging computation, affecting the accuracy of the reconstruction sequence. Therefore, based on previous studies of EEMD, Colominas proposed the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN), which adds adaptive white noise smoothing pulse interference in decomposition, and utilizes the characteristic of mean Gaussian white noises whose mean equals to zero to make the decomposition of signal data more complete, thus to effectively eliminate mode mixing [35,36,37].
Detailed steps of CEEMDAN are as follows:
- (1)
- Consistent with the EEMD, in N-times computation of CEEMDAN, decompose the signal , where the parameter controls the signal-to-noise ratio of the additional noise to the original signal. The first IMF component is:The residual signal is:
- (2)
- Define as the th IMF component by EMD, and then decompose the sequence to get the second IMF component asThe residual signal is:
- (3)
- Similar to what has been carried out above, the th residual signal can be expressed byThe th IMF component can be expressed by:
- (4)
- Repeat above steps until the residual signal meets the requirement of ending criterion. Supposing that there are IMF components, the original sequence can be expressed by:where is the final residual signal.
3. Support Vector Machine Optimized by Modified Grey Wolf Optimization Algorithm
3.1. SVM
Support Vector Machine (SVM) is a kind of machine learning method based on the principle of VC dimension of statistical learning theory and the principle of structural risk minimization. Based on limited sample information, SVM seeks the best compromise between model complexity and learning ability, and obtains the best promotion ability [11,12,13].
When SVM is used for forecasting, the input samples are mapped into high dimensional feature space through loss function , and linear regression is carried out. The regression function of SVM in high dimensional feature space is:
where is the weight vector of high dimensional feature space, ; and is the bias constant, .
According to the principle of structural risk minimization, Equation (11) can be converted into:
where controls the complexity of this model, is the regularization parameter, is the insensitive coefficient; and are relaxation factors.
Introducing the Lagrange multipliers into the model to convert the problem into convex quadratic optimization problem:
where are Lagrange multipliers, and they meet the requirement of .
To speed up computation, Equation (13) is converted into its dual form:
The kernel function is taken to replace of inner product of vectors in high-dimensional space to avoid dimensionality disaster, and the regression function of SVM is:
In this paper, the radial basis function is used as the kernel function which is given by:
where is the width of the radial basis function.
3.2. MGWO
3.2.1. GWO
The Grey Wolf Optimization Algorithm (GWO) is a biologically inspired optimization algorithm by simulating the social hierarchy and hunting nature of grey wolf family [20,21]. The grey wolves are gregarious animals, and there are usually a dozen wolves in each pack, which build a strict grey wolf pyramid hierarchy [22].
The alpha () wolves, who are at the top of the pyramid with the highest authority, are the leader of other wolves. The wolves are mainly responsible for predation and decision-making, and other wolves must obey theirs command.
The beta () wolves, who are at the second layer of the pyramid with the status second only to the wolves, are mainly responsible for assisting the wolves for decision-making. wolves have control over other individuals in the pack and can feed the information of other wolves back to the wolves.
The delta () wolves, who are at the third layer of the pyramid, are mainly responsible for decision implementation of wolves and wolves. The status of wolves is higher than that of wolves.
The omega () wolves, who are at the bottom of the pyramid, are mainly responsible for help prey.
In the GWO, the , and wolves are mainly responsible for attacking prey, and wolves are responsible for tracking and encircling until finally successfully capturing the prey.
For mathematical modeling of GWO algorithm which simulates hunting behavior of grey wolves, we need first generate a group of wolves randomly in the search space, then use and wolves to estimate the position of the prey. As for other wolves, they are ordered to calculate the distance between themselves and the , and wolves, then get close to the prey and encircle it, finally capture the prey successfully. Detailed steps are shown in Figure 1.
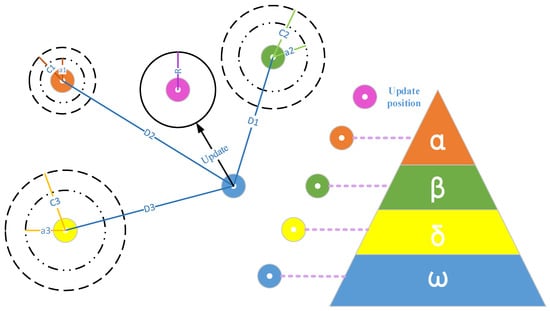
Figure 1.
The diagram of GWO (Grey Wolf Optimization) algorithm.
The modeling steps of GWO are as follows: supposing that there are wolves in a pack and the searching space has dimensions, the position of grey wolf can be expressed as , the behavior of grey wolves encircling the prey can be mathematically expressed using the following equations:
where is the current iteration, represents the position of wolves at the th iteration, is the position of the prey. The vector and can be obtained by Equations (19) and (20).
where and are random vectors ranging from 0 to 1. With the time of iteration increasing, decreases from 2 to 0.
Assuming that , and wolves are closest to the prey, and we can rely on the position of these three kinds of wolves to estimate the prey’s position, the way to update the position of other wolves is as shown in Equations (21)–(27).
3.2.2. MGWO
For complex optimization problems, the GWO is apt to fall into the local optimal solution. To solve this problem, in this paper, we improve the GWO algorithm by introducing the population dynamic evolution operator and nonlinear convergence factor to effectively avoid falling into the local optimum.
By introducing population dynamic evolution operator, the search range of wolves in GWO algorithm can be expanded to the entire solution space during each iteration of algorithm to increase the probability of obtaining the global optimal solution. Specific steps are as follows:
In the GWO, the wolves update their positions according to the position of wolves, wolves and wolves. We modify the equations as:
where and are the upper and lower bounds of search space, respectively; and is a random number ranging from 0 to 1.
The updated potential optimal solution vector is:
In GWO, though the convergence factor linearly decreasing from 2 to 0 over the course of iteration, the algorithm cannot be changed linearly in the process of convergence, making the convergence factor fails to fully reflect the actual optimization search process. Therefore, in this paper, we introduce nonlinear convergence factor to improve the GWO algorithm, as shown in Equation (32):
where is the convergence factor. is the base of natural logarithm, which approximates 2.718. is the current iteration. is the maximum of iterations.
The convergence trend of with the increase of iterations is shown in Figure 2.
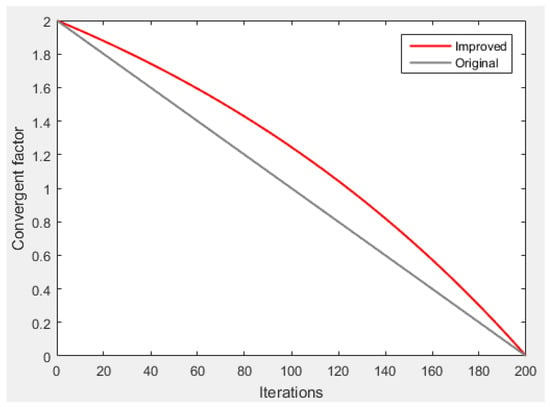
Figure 2.
The convergence trend of .
As can be seen in Figure 2, the improved convergence factor decreases nonlinearly with the increase of iterations. During that process, it decreases slowly in the initial period to facilitate global search, but decreases rapidly in the later period to enhance the local optimization.
3.3. MGWO-SVM
The values of regularization parameter and radial basis function parameter have a direct impact on the accuracy of the forecast model of SVM with RBF kernel. In this paper, the MGWO is used to optimize the two parameters of SVM. Based on GWO, the global search ability is improved by introducing the population dynamic evolution operator and nonlinear convergence factor to avoid falling into the local optimum, so as to improve the forecasting accuracy of SVM. Concrete steps of MGWO-SVM are as follows:
- Step 1:
- Set the ranges of parameters related to the MGWO, regularization parameter and radial basis function parameter in SVM.
- Step 2:
- Randomly initialize the wolf population, and make the position vector of each wolf consist of and .
- Step 3:
- Use the initialized SVM to learn the training set and calculate the fitness value of each grey wolf individual.
- Step 4:
- StepClassify the grey wolves according to the fitness value, and determine the positions of wolves, wolves, wolves and wolves.
- Step 5:
- Update positions of the wolves to generate a new population, calculate the corresponding fitness values, and compare them with that of the last iteration, so as to retain the preference.
- Step 6:
- Determine whether it reaches the maximum iteration, if reached, end the training and output the optimized and . Otherwise, jump to Step 4 to continue the parameter optimization.
- Step 7:
- Use the optimized parameters to establish the SVM forecast model and carry out forecast for the test set.
4. The Forecast Model Based on CEEMDAN-MGWO-SVM
The forecasting accuracy of daily peak load is influenced by many factors. To accurately forecast the daily peak load, in this paper, by taking meteorological factors and date types into account, we propose a forecasting model based on CEEMDAN-MGWO-SVM for daily peak load forecasting. Steps for this model are as follows:
(1) Data acquisition and preprocessing
We collect sample data including historical daily peak load, daily maximum temperature, daily minimum temperature, daily average temperature, daily average relative humidity, maximum daily wind speed, date type and other data. Then, data preprocessing is to be carried out, that is, the meteorological data are normalized, and we mark holidays and working days as 1 and 0, respectively.
(2) Sequence de-noising based on CEEMDAN
To obtain multiple IMF components, the CEEMDAN is to be performed on the original daily peak load sequence.
(3) Daily peak load forecast based on MGWO-SVM
Based on considering the meteorological factors and date types, the IMF components derived from CEEMDAN are used to carry out the forecast by MGWO-SVM model, and the forecasting results are reconstructed to obtain the final daily peak load forecast results.
The flow chart of CEEMDAN-MGWO-SVM is shown in Figure 3.
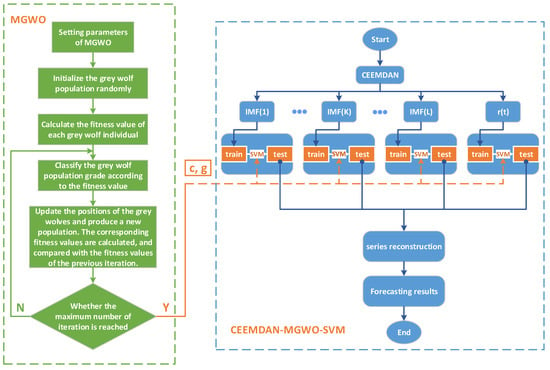
Figure 3.
The flow chart of CEEMDAN-MGWO-SVM.
5. Empirical Analysis
5.1. Case 1
5.1.1. Sample Selection
In this paper, the daily peak load of S power grid of 92 days from March to May 2017 is selected as the research object. The daily peak load, daily maximum temperature, daily minimum temperature, daily average temperature, daily average relative humidity, maximum daily wind speed, date type and other data are collected. (The source of the data is State grid Jibei electric power Co., LTD. in Hebei Province, China)
The collected data are shown in Figure 4.
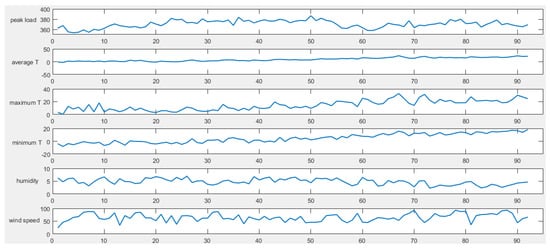
Figure 4.
The collected data.
Owing to too many influencing factors, we use the index of Mean Impact Value (MIV) to sift the influence factors for model input. Mean impact value (MIV) is one of the commonly used indexes to evaluate the influence of the independent variable on the dependent variable. The symbol represents the direction of the correlation, and the absolute value represents the relative importance of the influence. Through calculation, the rank of the absolute value of the mean impact value of each influence factor can be obtained, which is shown in Table 1.

Table 1.
The rank of the absolute value of the mean impact value of each influence factor.
According to Table 1, we select the six influence factors that the absolute value of MIV is more than 5‰ as the model input. They are the average daily peak load of one week before the forecasting day, daily average relative humidity, the daily peak load of first day before the forecasting day, the daily peak load of second day before the forecasting day, date type and daily average temperature. The model output is the daily peak load of the forecasting day. We use the data from March to April as the training set sample, and the data of May as the test set sample.
5.1.2. Daily Peak Load Forecasting Based on CEEMDAN-MGWO-SVM Model
Before entering into the proposed model, we have a unit root test for the original daily peak load sequence. The unit root test result is shown in Table 2.
Table 2.
The unit root test result.
According to Table 2, p is greater than 0.05, which shows that there is a unit root and the original daily peak load sequence is non-stationary.
Therefore, the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise is applied to the original daily peak load sequence. The daily peak load of S power grid from March to May 2017 is used as the signal sequence to input the CEEMDAN model, and six IMFs and one residual signal are obtained. The decomposition result is shown in Figure 5.
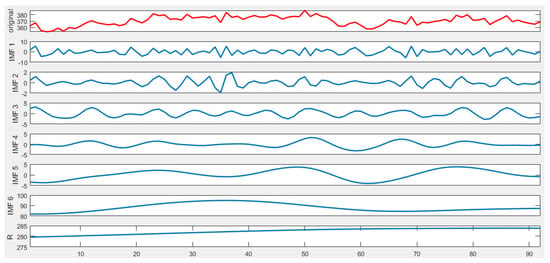
Figure 5.
The IMFs (intrinsic mode functions) of CEEMDAN.
The MGWO-SVM model is used to forecast the IMFs and the residual signal, respectively. The parameters of model are set as follows: the number of grey wolf population is 20, the search range of regularization parameter is [0.1, 200], and the search range of RBF kernel parameters is [0.01, 20], and the maximum iteration number is 200. The forecasting results are shown in Figure 6.
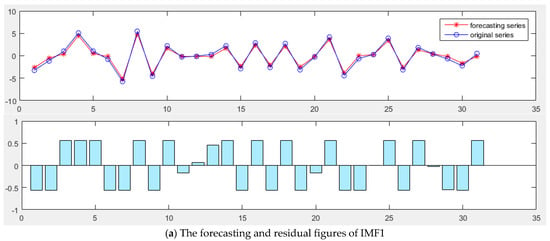
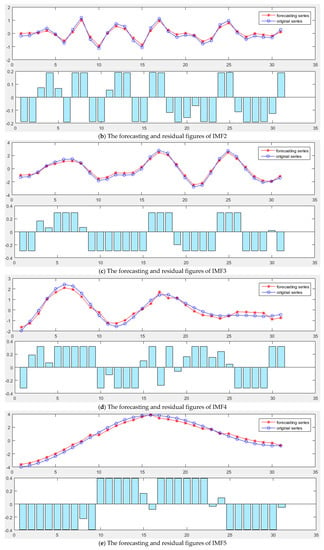
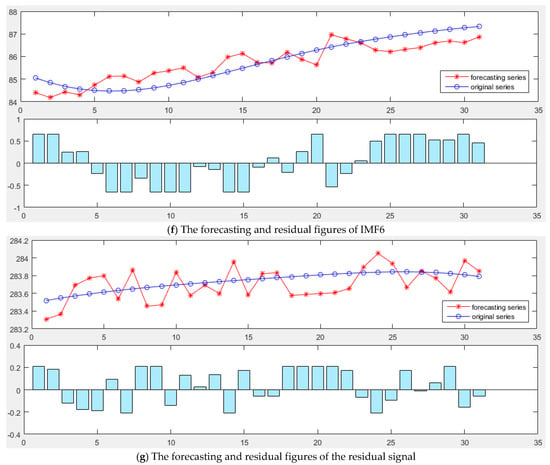
Figure 6.
The forecasting results of IMFs: (a) IMF1; (b) IMF2; (c) IMF3; (d) IMF4; (e) IMF5; (f) IMF6; and (g) Residual.
The forecasting results of the IMF components and the residual signal are reconstructed, and the daily peak load forecasting result of the S power grid in May 2017 is shown in Figure 7.
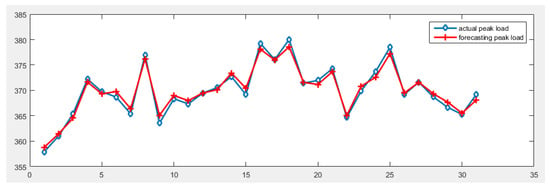
Figure 7.
Figure of the final forecasting result (Unit: 10 MW).
As shown in Figure 7, we can see that using the CEEMDAN-MGWO-SVM model to forecast the daily peak load of the S power grid in May can achieve good forecasting effect, and the forecasting curve fits the actual curve very well.
5.1.3. Error analysis
To evaluate the forecasting performance of the CEEMDAN-MGWO-SVM model more accurately, the relative error , the mean absolute percentage error , nonlinear function goodness of fit , Akaike Information Criterion and Bayesian information criterion are used in this paper. The calculation equations of the indexes are as shown in Equations (33)–(37).
where is the residual sum of squares; is the sample size; and is the number of independent variables.
Through calculation, we can obtain the , , and of the forecasting results of the CEEMDAN-MGWO-SVM model. They are 0.196%, 99.77%, −111.21 and −83.47 respectively. The relative errors of the CEEMDAN-MGWO-SVM model forecasting results are shown in Table 3 and Figure 8.
Table 3.
The relative errors of forecasting results.
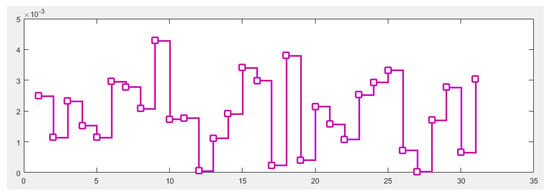
Figure 8.
Figure of the relative error.
According to the table and figure above, the forecasting accuracy of the CEEMDAN-MGWO-SVM model is very high, and the relative error of each prediction point is not more than 0.5%.
5.1.4. Comparison of Forecasting Models
To further verify the effectiveness and superiority of the CEEMDAN-MGWO-SVM model proposed in this paper for daily peak load forecasting, we choose the models EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data. The comparison of the forecasting results and the relative errors for different models are shown in Figure 9 and Figure 10, respectively.
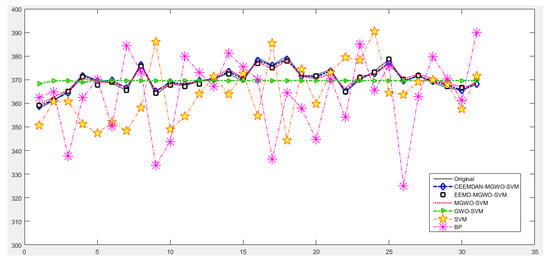
Figure 9.
Comparison of forecasting results.
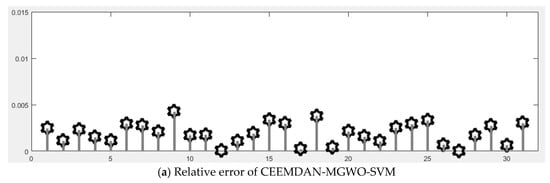
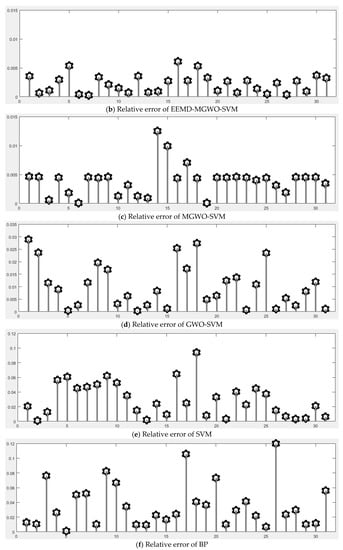
Figure 10.
The relative errors of different models: (a) CEEMDAN-MGWO-SVM; (b) EEMD-MGWO-SVM; (c) MGWO-SVM; (d) GWO-SVM; (e) SVM; and (f) BP.
Figure 9 shows the fitting situation of the daily peak load curve predicted by each model and the actual daily peak load curve. Figure 10 shows the relative errors of different models for daily peak load forecasting of S power grid in May 2017. It can be seen that the forecasting curve of the CEEMDAN-MGWO-SVM model in this paper fits best.
To show the forecasting accuracy of each model more intuitively, we use the boxplot to compare the relative errors of each forecasting model. The boxplot displays the following five statistics of the relative error for each forecasting model: the minimum, first quartile, the median, third quartile and the maximum. The boxplot of relative errors for different models are shown in Figure 11.
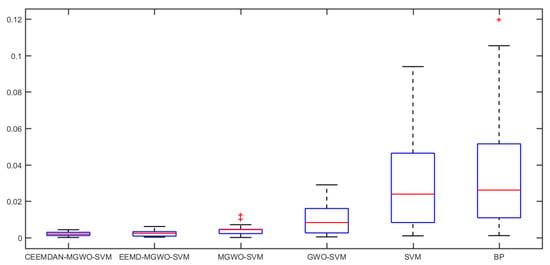
Figure 11.
The boxplot of relative errors for different models.
As shown in Figure 10, the relative error of the CEEMDAN-MGWO-SVM model forecasting result is the smallest, followed by EEMD-MGWO-SVM model, and the relative error of BP neural network forecasting result is the largest. The relative errors of the forecasting results for different models are shown in Table 4.
Table 4.
The relative errors of the forecasting results for different models.
The , , and of the forecasting results for the models of CEEMDAN-MGWO-SVM, EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network are calculated, respectively, as shown in Table 5.
Table 5.
Comparison of the forecasting accuracy for different models.
As shown in Table 5, the MAPE, and of the CEEMDAN-MGWO-SVM model is the smallest, and the goodness of fit is the best, reaching 99.7743%. Next is the EEMD-MGWO-SVM model, and the goodness of fit is 99.724%. The MAPE, and of BP model is the largest, and the goodness of fit is the worst, reaching 95.3255%. Besides, the prediction effect of MGWO-SVM model is better than that of GWO-SVM, SVM and BP model.
Overall, the evaluation results of the two indexes for different models tend to be consistent. The forecasting accuracy is ranked as follows: CEEMDAN-MGWO-SVM > EEMD-MGWO-SVM > MGWO-SVM > GWO-SVM > SVM > BP.
5.2. Case 2
To fully prove the reliability and universality of the above conclusions, and verify the validity of the CEEMDAN-MGWO-SVM model proposed in this paper for daily peak load forecasting, further experiments are carried out in this paper. In this paper, we select the daily peak load of S power grid from September to November in 2017 as the research object. The daily peak load, daily maximum temperature, daily minimum temperature, daily average temperature, daily average relative humidity, maximum daily wind speed, date type and other data are collected. We use the data from September to October as the training set sample, and the data of November as the test set sample. We choose the models of EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data. The boxplot of relative errors for different models is shown in Figure 12.
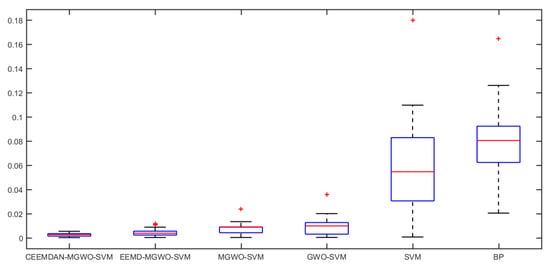
Figure 12.
The boxplot of relative errors for different models.
As shown in Figure 12, the relative error of the CEEMDAN-MGWO-SVM model forecasting result is the smallest, followed by EEMD-MGWO-SVM model, and the relative error of BP neural network forecasting result is the largest. The relative errors of the forecasting results for different models are shown in Table 6.
Table 6.
The relative errors of the forecasting results for different models.
The , and of the forecasting results for the models of CEEMDAN-MGWO-SVM, EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network are calculated, respectively, as shown in Table 7.
Table 7.
Comparison of the forecasting accuracy for different models.
As shown in Table 7, the MAPE, and of the CEEMDAN-MGWO-SVM model is the smallest in all models, and the goodness of fit is the best, reaching 99.7035%. Next is the EEMD-MGWO-SVM model, and the goodness of fit is 99.4445%. The MAPE, and of BP model is the largest, and the goodness of fit is the worst, reaching 91.6074%. Besides, the prediction effect of MGWO-SVM model is better than that of GWO-SVM, SVM and BP model. The evaluation results of the two indexes for different models tend to be consistent. The forecasting accuracy is ranked as follows: CEEMDAN-MGWO-SVM > EEMD-MGWO-SVM > MGWO-SVM > GWO-SVM > SVM > BP.
5.3. Case 3
Since the first two cases are both focused on the daily peak load of S power grid, to avoid the contingency of the experimental conclusions, we select the daily peak load of M power grid from March to May 2017 as the research object to do further research. The daily peak load, daily maximum temperature, daily minimum temperature, daily average temperature, daily average relative humidity, maximum daily wind speed, date type and other data are collected. We use the data from March to April as the training set sample, and the data of May as the test set sample. We choose the models of EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data. The boxplot of relative errors for different models is shown in Figure 13.
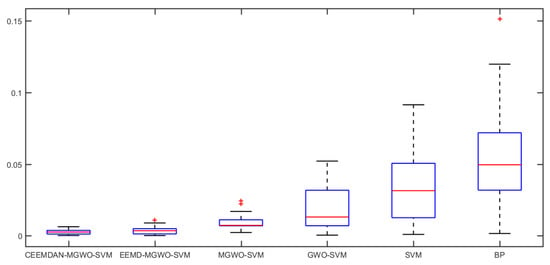
Figure 13.
The boxplot of relative errors for different models.
As shown in Figure 13, the relative error of the CEEMDAN-MGWO-SVM model forecasting result is the smallest, followed by EEMD-MGWO-SVM model, and the relative error of BP neural network forecasting result is the largest. The relative errors of the forecasting results for different models are shown in Table 8.
Table 8.
The relative errors of the forecasting results for different models.
The , and of the forecasting results for the models of CEEMDAN-MGWO-SVM, EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network are calculated, respectively, as shown in Table 9.
Table 9.
Comparison of the forecasting accuracy for different models.
As shown in Table 9, the MAPE, and of the CEEMDAN-MGWO-SVM model is the smallest, and the goodness of fit is the best, reaching 99.6915%. Next is the EEMD-MGWO-SVM model, and the goodness of fit is 99.5631%. The MAPE, and of BP model is the largest, and the goodness of fit is the worst, reaching 93.4167%. Besides, the prediction effect of MGWO-SVM model is better than that of GWO-SVM, SVM and BP model. The evaluation results of the two indexes for different models tend to be consistent. The forecasting accuracy is ranked as follows: CEEMDAN-MGWO-SVM > EEMD-MGWO-SVM > MGWO-SVM > GWO-SVM > SVM > BP.
5.4. Analysis of Empirical Results
According to the experimental results of the above three cases, the ranking of the forecasting accuracy for each model tends to be consistent and the forecasting accuracy of the CEEMDAN-MGWO-SVM model is significantly higher than other models, which proves that the CEEMDAN-MGWO-SVM model proposed in this paper is practical and effective for daily peak load forecasting.
Through the comparison and analysis of the experimental results, we found that:
- (1)
- Daily peak load is susceptible to festival factors and meteorological factors such as daily maximum temperature, daily minimum temperature, daily average temperature, daily average relative humidity and maximum daily wind speed, which present certain volatility. Doing the operation of signal decomposition-forecasting-reconstruction for the original daily peak load sequence can obtain the higher accuracy forecasting results compared with direct prediction.
- (2)
- Adding the adaptive white noise to improve the EEMD algorithm can effectively eliminate the chaos of the original data and reduce the noise of the daily peak load sequence.
- (3)
- Using the combined model for forecasting can achieve complementary advantages between different algorithms, which greatly improves the forecasting accuracy.
The CEEMDAN-MGWO-SVM model proposed in this paper realizes noise reduction for non-stationary daily peak load sequence by complete ensemble empirical mode decomposition with adaptive noise, which makes the daily peak load sequence more regular. The model adopts the grey wolf optimization algorithm, which is improved by introducing the population dynamic evolution operator and the nonlinear convergence factor to enhance the global search ability and avoid falling into the local optimum, thus can better optimize the parameters of the SVM algorithm. The CEEMDAN-MGWO-SVM model greatly improves the forecasting accuracy of daily peak load and shows the powerful generalization ability and robustness.
6. Conclusions
A novel daily peak load forecasting model, CEEMDAN-MGWO-SVM, is proposed in this paper. Firstly, the model uses the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) algorithm to decompose the daily peak load sequence into multiple sub-sequences. Then, the model of modified grey wolf optimization and support vector machine (MGWO-SVM) is adopted to forecast the sub-sequences. Finally, the forecasting sequence is reconstructed and the forecasting result is obtained. Using CEEMDAN can realize noise reduction for non-stationary daily peak load sequence, which makes the daily peak load sequence more regular. The model adopts the grey wolf optimization algorithm, which is improved by introducing the population dynamic evolution operator and the nonlinear convergence factor to enhance the global search ability and avoid falling into the local optimum, thus can better optimize the parameters of the SVM algorithm for improving the forecasting accuracy of daily peak load. In this paper, three cases are used to test the forecasting accuracy of the CEEMDAN-MGWO-SVM model. We choose the models EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data. The experimental results fully demonstrate the reliability and effectiveness of the CEEMDAN-MGWO-SVM model proposed in this paper for daily peak load forecasting, which shows the strong generalization ability and robustness of the model.
Acknowledgments
This work was supported by Natural Science Foundation of China (Project No. 71471059).
Author Contributions
In this research activity, all authors were involved in the data collection and preprocessing phase, model constructing, empirical research, results analysis and discussion, and manuscript preparation. All authors have approved the submitted manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lee, W.J.; Hong, J. A hybrid dynamic and fuzzy time series model for mid-term power load forecasting. Int. J. Electr. Power Energy Syst. 2015, 64, 1057–1062. [Google Scholar] [CrossRef]
- Chikobvu, D.; Sigauke, C. A frequentist and Bayesian regression analysis to daily peak electricity load forecasting in South Africa. Afr. J. Bus. Manag. 2012, 6, 10524–10533. [Google Scholar] [CrossRef]
- Guo, L.; Jiang, D.; Liu, Y.; Ren, L.; Yang, F.; Li, J.; Wang, B.; State Grid Sichuan Electric Power Company; State Grid Deyang Power Supply Company; State Grid Aba Power Supply Company; School of Electrical Engineering, Wuhan University. Medium and Long-term Load Forecasting Based on Adaptive Weight Buffer Gray Theory. Shaanxi Electr. Power 2016, 44, 33–37. [Google Scholar]
- Wang, W.C.; Kwokwing, C.; Cheng, C.T.; Qiu, L. A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J. Hydrol. 2009, 374, 294–306. [Google Scholar] [CrossRef]
- Jurasz, J. Day ahead electric power load forecasting by WT-ANN. Prz. Elektrotech. 2016, 1, 154–156. [Google Scholar] [CrossRef]
- Xiao, Z.; Ye, S.J.; Zhong, B.; Sun, C.X. BP neural network with rough set for short term load forecasting. Expert Syst. Appl. 2009, 36, 273–279. [Google Scholar] [CrossRef]
- Zhaoyu, P.; Li, S.; Zhang, H.; Zhang, N. The Application of the PSO Based BP Network in Short-Term Load Forecasting. Phys. Procedia 2012, 24, 626–632. [Google Scholar] [CrossRef]
- Wang, J.J.; Shi, P.; Jiang, P.; Hu, J.W.; Qu, S.; Chen, X.; Chen, Y.; Dai, Y.; Xiao, Z. Application of BP Neural Network Algorithm in Traditional Hydrological Model for Flood Forecasting. Water 2017, 9, 48. [Google Scholar] [CrossRef]
- Huang, D.Z.; Gong, R.X.; Gong, S. Prediction of Wind Power by Chaos and BP Artificial Neural Networks Approach Based on Genetic Algorithm. J. Electr. Eng. Technol. 2015, 10, 41–46. [Google Scholar] [CrossRef]
- Narayanakumar, S.; Raja, K. A BP Artificial Neural Network Model for Earthquake Magnitude Prediction in Himalayas, India. Circuits Syst. 2016, 7, 3456–3468. [Google Scholar] [CrossRef]
- Pai, P.F.; Hong, W.C. Support vector machines with simulated annealing algorithms in electricity load forecasting. Energy Convers. Manag. 2005, 46, 2669–2688. [Google Scholar] [CrossRef]
- Hong, W.C. Electric load forecasting by support vector model. Appl. Math. Model. 2009, 33, 2444–2454. [Google Scholar] [CrossRef]
- Nie, H.; Liu, G.; Liu, X.; Wang, Y. Hybrid of ARIMA and SVMs for Short-Term Load Forecasting. Energy Procedia 2012, 16, 1455–1460. [Google Scholar] [CrossRef]
- Wei, L.; Zhao, F.; Wang, S. Short-term power load forecasting of support vector machine based on parameters optimization of population search algorithm. Electr. Meas. Instrum. 2016, 53, 45–49. [Google Scholar]
- Sun, Y.; Leng, B.; Guan, W. A novel wavelet-SVM short-time passenger flow prediction in Beijing subway system. Neurocomputing 2015, 166, 109–121. [Google Scholar] [CrossRef]
- Shi, X.; Huang, J.; Chang, J.; Wang, J.; Zhao, J. Optimal parameters of the SVM for temperature prediction. Proc. Int. Assoc. Hydrol. Sci. 2015, 368, 162–167. [Google Scholar] [CrossRef]
- Huang, C.L.; Dun, J.F. A distributed PSO–SVM hybrid system with feature selection and parameter optimization. Appl. Soft Comput. 2008, 8, 1381–1391. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, Z. Research on power load forecasting models based on simulated annealing support vector machine (SA-SVM) algorithm mathematical. Metall. Min. Ind. 2015, 9, 924–929. [Google Scholar]
- Wang, J.; Ran, R.; Song, Z.; Sun, J. Short-Term Photovoltaic Power Generation Forecasting Based on Environmental Factors and GA-SVM. J. Electr. Eng. Technol. 2017, 12, 64–71. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Softw. Eng. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Mirjalili, S.; Saremi, S.; Mirjalili, S.M.; Coelhod, L.D.S. Multi-objective grey wolf optimizer: A novel algorithm for multi-criterion optimization. Expert Syst. Appl. 2016, 47, 106–119. [Google Scholar] [CrossRef]
- Turabieh, H. A Hybrid ANN-GWO Algorithm for Prediction of Heart Disease. Am. J. Oper. Res. 2016, 6, 136–146. [Google Scholar] [CrossRef]
- Xu, D.Y.; Ding, S. Research on improved GWO-optimized SVM-based short-term load prediction for cloud computing. Comput. Eng. Appl. 2017, 53, 68–73. [Google Scholar]
- Benaouda, D.; Murtagh, F.; Starck, J.L.; Renaudd, O. Wavelet-based nonlinear multiscale decomposition model for electricity load forecasting. Neurocomputing 2006, 70, 139–154. [Google Scholar] [CrossRef]
- Xiang, Z.R.; Wang, X.P. Forecasting Approach to Short-time Load Using Wavelet Decomposition and Artificial Neural Network. J. Syst. Simul. 2008, 20, 5018–5020. [Google Scholar]
- Fei, S.W.; He, Y. Wind speed prediction using the hybrid model of wavelet decomposition and artificial bee colony algorithm-based relevance vector machine. Int. J. Electr. Power Energy Syst. 2015, 73, 625–631. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S.; Kisi, O.; Singhd, V.P. Daily water level forecasting using wavelet decomposition and artificial intelligence techniques. J. Hydrol. 2015, 520, 224–243. [Google Scholar] [CrossRef]
- Huang, N.E. A Study of the Characteristics of White Noise Using the Empirical Mode Decomposition Method. Proc. R. Soc. A 2004, 460, 1597–1611. [Google Scholar] [CrossRef]
- Sha, F.; Zhu, F.; Guo, S.N.; Gao, J.T. Based on the EMD and PSO-BP Neural Network of Short-Term Load Forecasting. Adv. Mater. Res. 2013, 614–615, 1872–1875. [Google Scholar] [CrossRef]
- Zheng, H.; Yuan, J.; Chen, L. Short-Term Load Forecasting Using EMD-LSTM Neural Networks with a Xgboost Algorithm for Feature Importance Evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef]
- Premanode, B.; Toumazou, C. Improving prediction of exchange rates using Differential EMD. Expert Syst. Appl. 2013, 40, 377–384. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, M.; Yu, Q.; Zhang, H. Comparing the application of EMD and EEMD on time-frequency analysis of seimic signal. J. Appl. Geophys. 2012, 83, 29–34. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, W.; Zeng, J. A new short-term load forecasting method of power system based on EEMD and SS-PSO. Neural Comput. Appl. 2014, 24, 973–983. [Google Scholar] [CrossRef]
- Jiang, X.; Zhang, L.; Chen, X. Short-term forecasting of high-speed rail demand: A hybrid approach combining ensemble empirical mode decomposition and gray support vector machine with real-world applications in China. Transp. Res. Part C Emerg. Technol. 2014, 44, 110–127. [Google Scholar] [CrossRef]
- Colominas, M.A.; Schlotthauer, G.; Torres, M.E. Improved complete ensemble EMD: A suitable tool for biomedical signal processing. Biomed. Signal Process. Control 2014, 14, 19–29. [Google Scholar] [CrossRef]
- Helske, J.; Luukko, P. Ensemble Empirical Mode Decomposition (EEMD) and Its CompleteVariant (CEEMDAN). Int. J. Public Health 2015, 60, 1–9. [Google Scholar]
- Zhang, W.; Qu, Z.; Zhang, K.; Mao, W.; Ma, Y.; Fan, X. A combined model based on CEEMDAN and modified flower pollination algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 136, 439–451. [Google Scholar] [CrossRef]
- Jun, L.I.; Qing, L.I. Medium term electricity load forecasting based on CEEMDAN-permutation entropy and ESN with leaky integrator neurons. Electr. Mach. Control 2015, 19, 70–80. [Google Scholar] [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).