1. Introduction
The development of modern society is inseparable from the supply of electricity. The power industry plays a crucial role in promoting social and economic development and improving people’s living standards. With the rapid development of the power industry, the precision of power system for power load forecasting is becoming more and more demanding. Daily peak load forecasting is an important part of power load forecasting. The accuracy of its prediction has great influence on the formulation of power generation plan, power grid dispatching, power grid operation and power supply reliability of power system. Therefore, it is of great significance to construct a suitable model to realize the accurate prediction of the daily peak load.
The core problem of load forecasting is the method and model of prediction. With the rapid development of science and technology, the technology of load forecasting is also being deepened. At present, load forecasting technology has gradually transferred from traditional prediction method to artificial intelligence prediction technology. Traditional load forecasting methods, such as time series method, regression analysis method and grey prediction method [
1,
2,
3], have some shortcomings. The forecasting accuracy of traditional methods for complex load series with larger volatility needs to be improved. However, the artificial intelligence prediction method shows a strong superiority in the face of complex load sequence, and has achieved good prediction effect [
4]. The artificial neural network (ANN) algorithm, originating in the 1940s, is an artificial intelligence technology, which simulates the biological process of human brain [
5]. The BP (Back Propagation) algorithm, also known as the error back propagation algorithm, is a supervised learning algorithm in artificial neural networks, which is often used for load forecasting [
6,
7]. Wang et al. [
8] put forward a new back-propagation neural network algorithm to apply it in the semi-distributed model. The improved hydrological model could update the flow forecasting error without losing the leading time. However, BP neural network algorithm has some disadvantages, such as slow convergence speed, long training time, easy to fall into local optimal solution and so on [
9,
10]. Support vector machine (SVM) is a small sample machine learning method based on the theory of VC (Vapnik-Chervonenkis) dimension of statistical learning theory and the principle of minimum structure risk. It seeks the best compromise between the complexity of the model and the learning ability based on the limited sample information to achieve the best promotion [
11,
12,
13]. Wei et al. [
14] used the seeker optimization algorithm to get the optimal parameters selection of SVM. Then the short-term load prediction of the next 24 h in one region was achieved by the SVM model based on the historical load data as input. Support vector machine algorithm has strong generalization ability, fast convergence speed, and can avoid falling into local optimal solution [
15,
16]. At present, many optimization algorithms, such as particle swarm optimization (PSO), simulated annealing (SA) and genetic algorithm (GA), are proposed for the optimization of SVM parameters. Huang and Dun [
17] put forward a novel PSO–SVM model that hybridized the particle swarm optimization and support vector machines to improve the classification accuracy with a small and appropriate feature subset. Liu and Huang [
18] used simulated annealing algorithm (SA) to optimize the parameters of SVM and proposed a model based on simulated annealing algorithm and support vector machine to forecast the power load that has proven to be of good prediction effect. Wang et al. [
19] put forward a forecasting model based on environmental factors and support vector machine optimized by genetic algorithm to predict the short-term PV power using the gray correlation coefficient algorithm to find out a similar day of the predicted day. In this paper, the grey wolf optimization algorithm is used to optimize the parameters of support vector machine. GWO (Grey Wolf Optimization) algorithm is a new meta heuristic optimization algorithm proposed by Mirjalili et al. in 2014. It is a new swarm intelligence optimization algorithm, has superior performance in finding optimal solutions, and is simple and efficient [
20,
21,
22]. Xu and Ding [
23] put forward the model of Grey wolf optimization algorithm which is improved by extremal optimization and support vector machine for cloud computing resource load short-term forecasting and tested the performance of EGWO-SVM by simulation experiments. The experimental results showed that the proposed model could precisely characterize the complicated trends of cloud computing resource short-term load and efficiently promote the short-term resource load prediction accuracy.
The daily peak load forecasting is easily disturbed by external factors, and the load sequence contains some noise and strong volatility, which brings great difficulties to the prediction work. Wavelet decomposition and empirical mode decomposition are two effective time frequency analysis methods to deal with non-stationary signals. The wavelet decomposition gradually refines the signal through the telescopic translation operation, and finally realizes the time subdivision at high frequency and the frequency subdivision at low frequency [
24,
25,
26]. Seo et al. [
27] proposed two hybrid models for daily water level forecasting. They were wavelet-based artificial neural network and wavelet-based adaptive neuro-fuzzy inference system. It was proven that the combination of wavelet decomposition and artificial intelligence models can be a useful tool for accurate forecasting daily water level through empirical analysis. The essence of empirical mode decomposition is to smooth the signal, and decompose the complex signal into Intrinsic Mode Function (IMF) [
28,
29,
30]. Premanode and Toumazou [
31] put forward the differential Empirical Mode Decomposition (EMD) for improving prediction of exchange rates under support vector regression (SVR), which has the capability of smoothing and reducing the noise. Compared with the traditional forecasting methods, the hybrid EMD-SVM forecasting method could effectively improve the forecasting accuracy and track the change of wind power. Compared with the wavelet decomposition, empirical mode decomposition is not affected by the selection of wavelet base and the number of decomposition layers, but based on the adaptability of data itself, and the noise reduction performance of load sequence is better. Based on the traditional EMD, Ensemble Empirical Mode Decomposition (EEMD) adopted Gauss white noise to reduce the generation of modal aliasing in a certain range [
32,
33]. Jiang et al. [
34] proposed a hybrid approach based on the ensemble empirical mode decomposition and grey support vector machine for short-term high-speed rail passenger flow forecasting. However, due to the addition of white noise sequences, the accuracy of the EEMD algorithm reconstruction sequence will be affected. Therefore, based on previous studies of EEMD, Colominas proposed the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN). The CEEMDAN method adds adaptive white noise smooth pulse interference in each decomposition to make the decomposition of the signal data more complete [
35,
36,
37]. Jun and Qing [
38] developed an effective combined model based on complete ensemble empirical mode decomposition with adaptive noise, permutation entropy and echo state network with leaky integrator neurons for medium-term power load forecasting. Therefore, in this paper, we choose the CEEMDAN method to do the noise reduction for the daily peak load sequence.
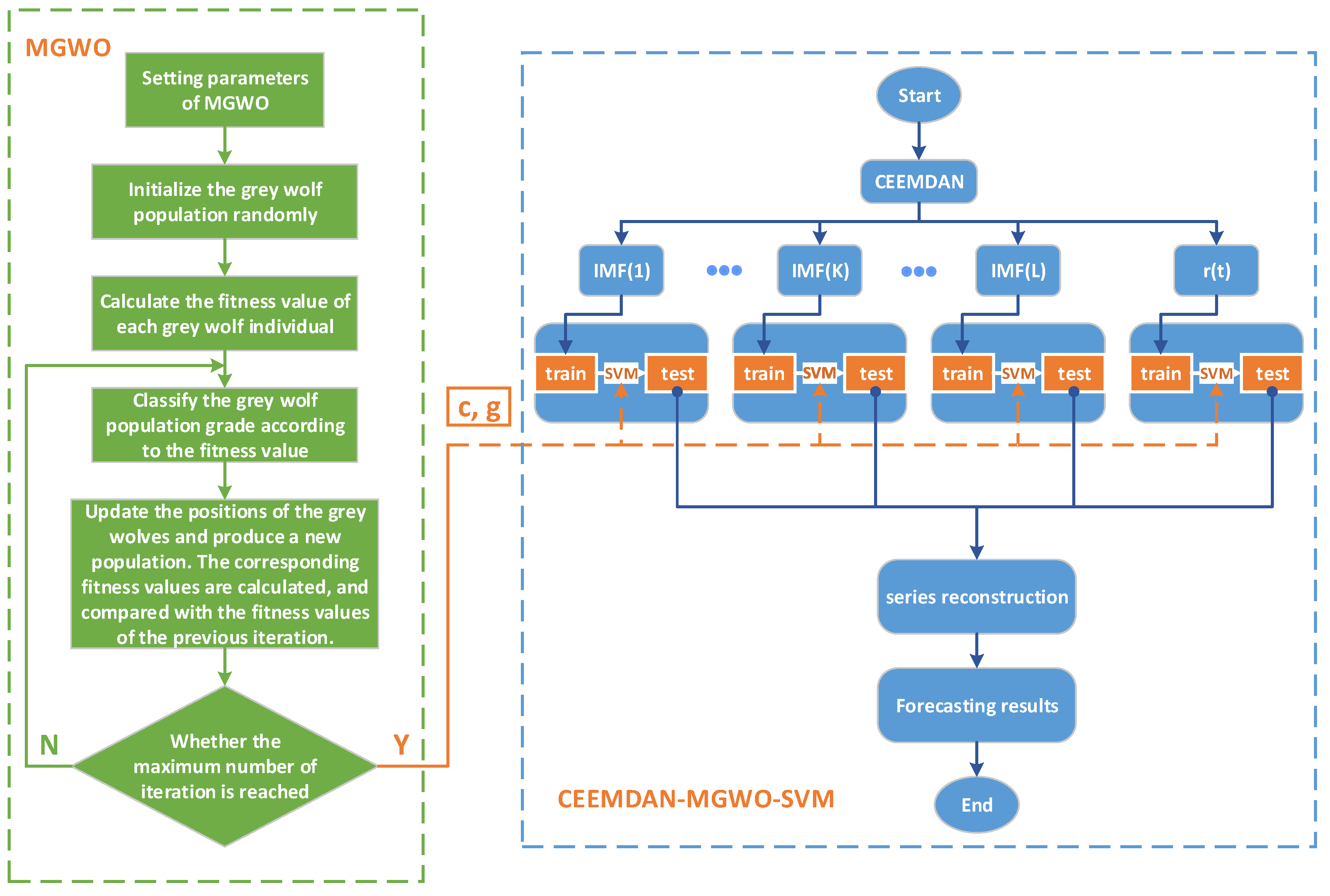
A novel daily peak load forecasting model of CEEMDAN-MGWO-SVM is proposed in this paper. Firstly, the model uses the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) algorithm to decompose the daily peak load sequence into multiple sub sequences. Then, the model of modified grey wolf optimization and support vector machine (MGWO-SVM) is adopted to forecast the sub sequences. Finally, the forecasting sequence is reconstructed and the forecasting result is obtained. The model provides a new idea for daily peak load forecasting. The main contents and structure of this paper are as follows:
Section 2 introduces the algorithm of complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN), which is used to reduce the noise of non-stationary daily peak load sequence.
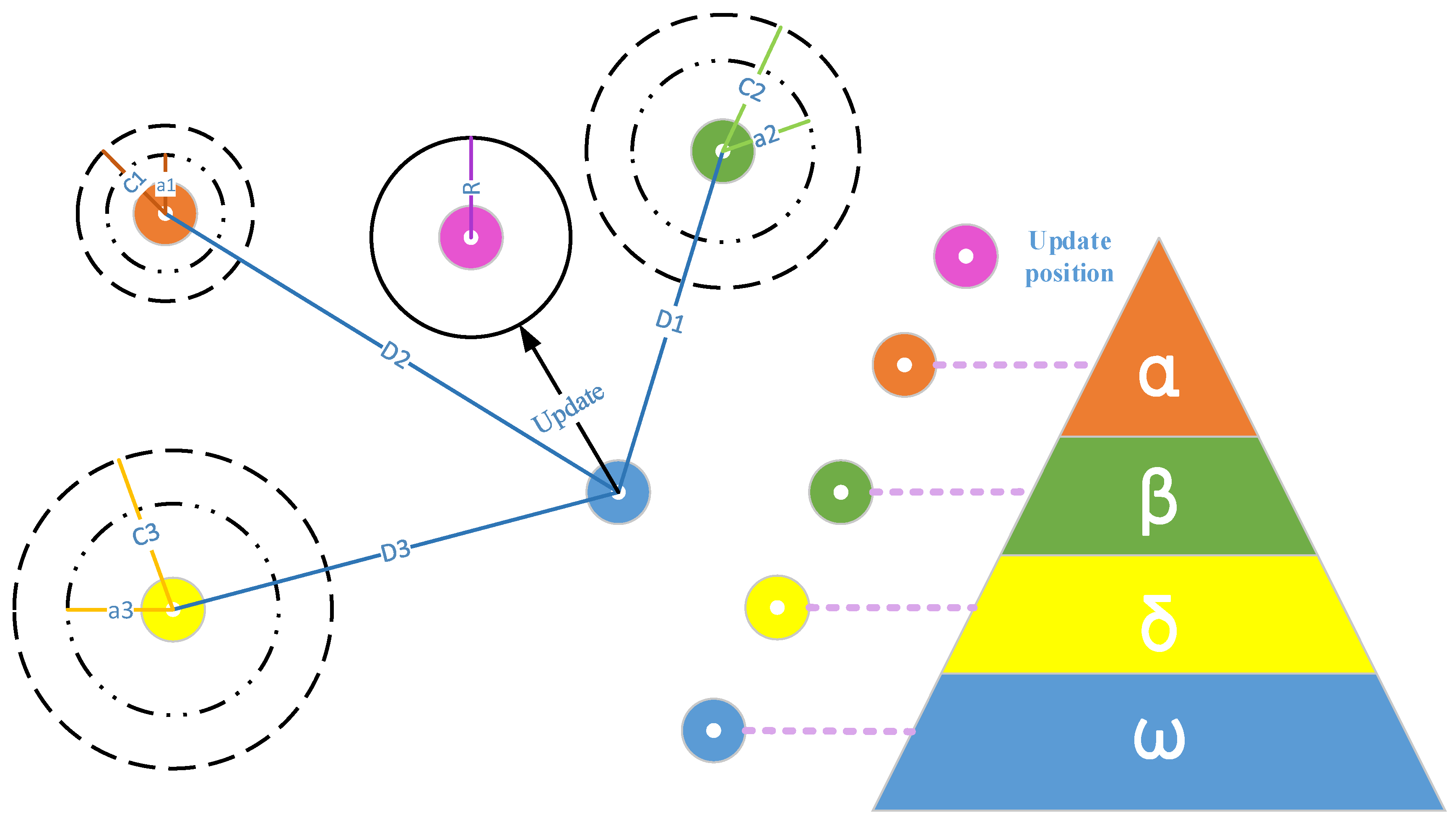
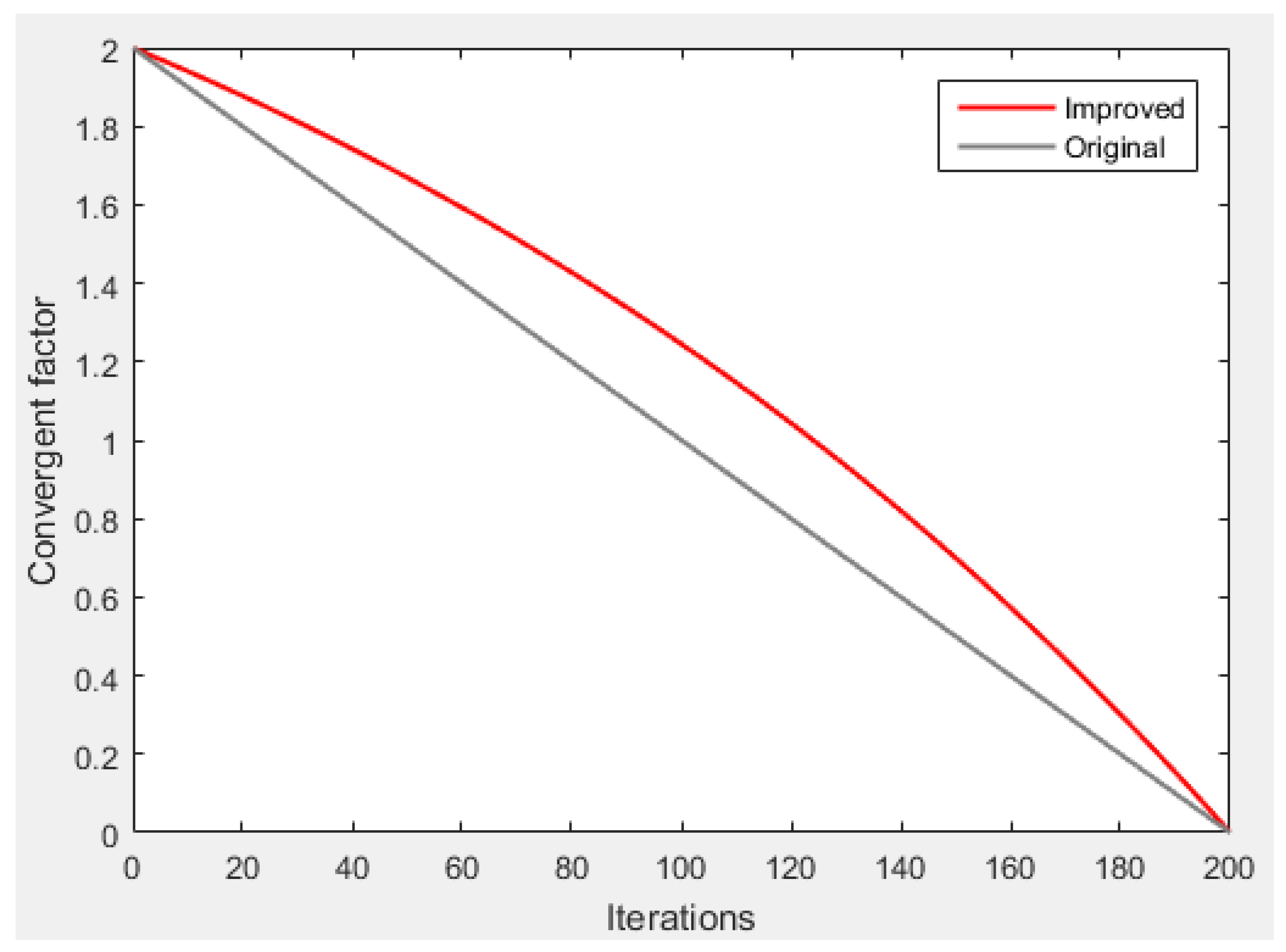
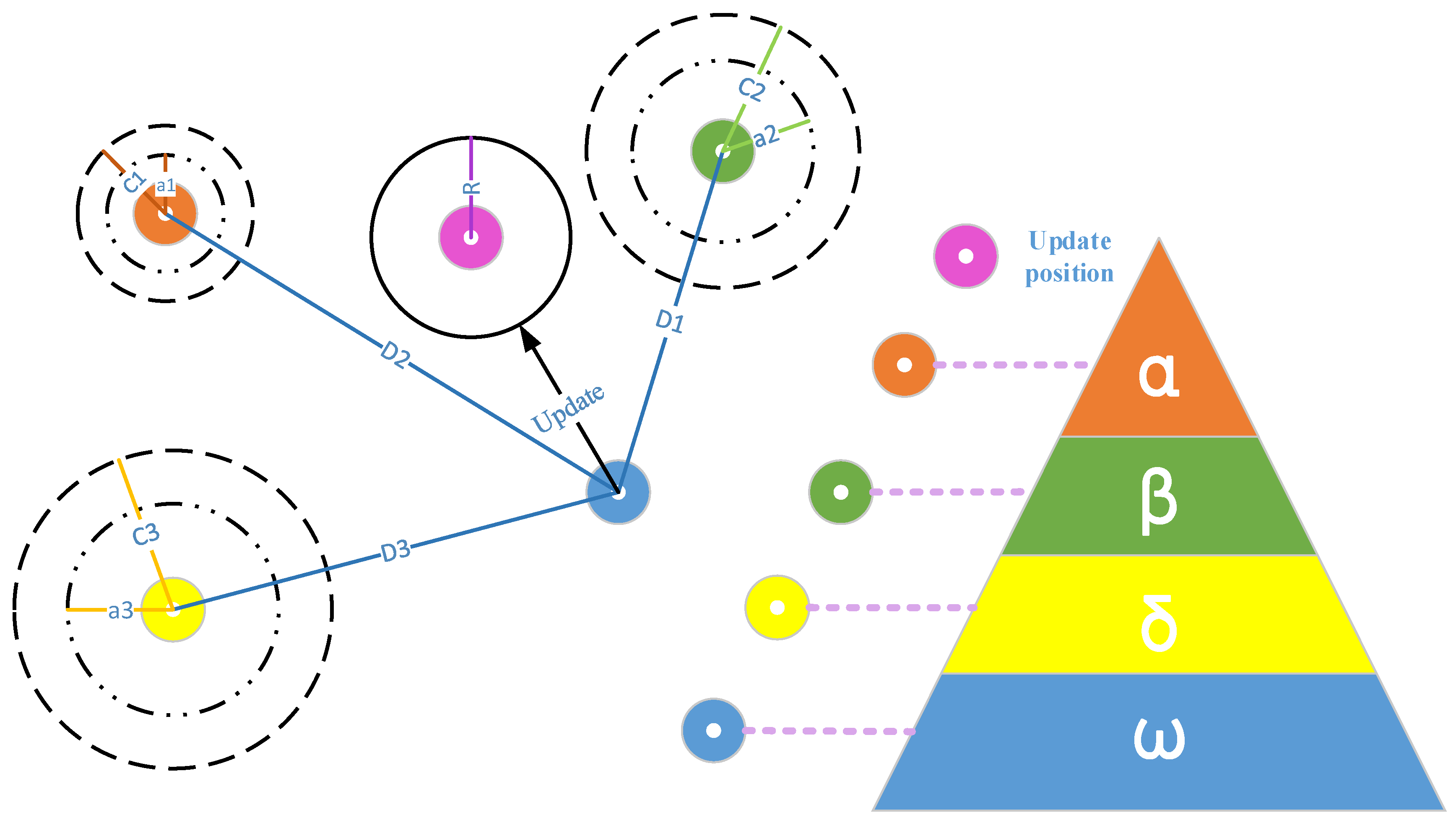
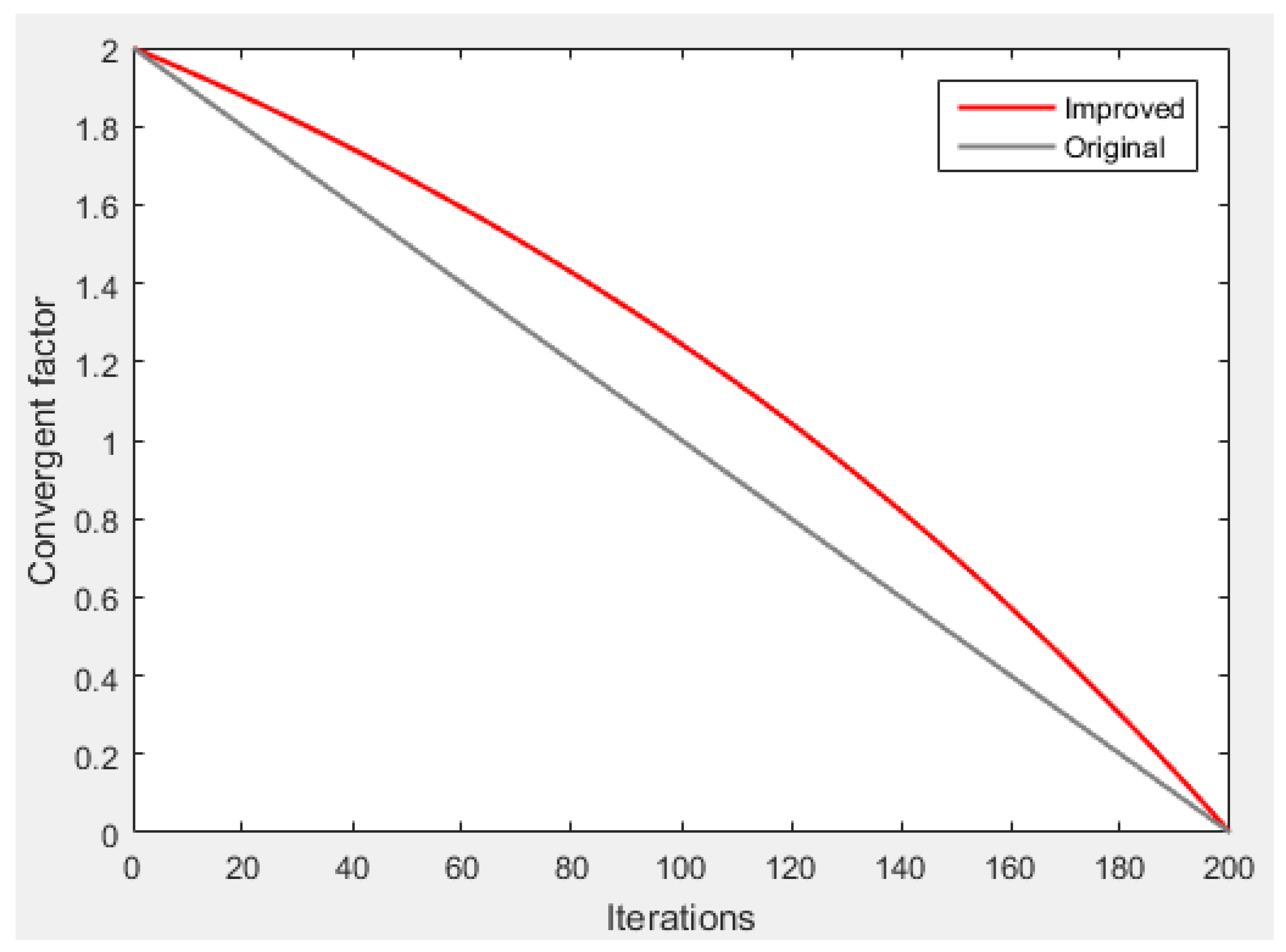
Section 3 introduces the MGWO-SVM model, which is the core algorithm for daily peak load forecasting in this paper. The model adopts the grey wolf optimization algorithm improved by introducing the population dynamic evolution operator and the nonlinear convergence factor to enhance the global search ability and avoid falling into the local optimum, which can better optimize the parameters of the SVM algorithm for improving the forecasting accuracy of daily peak load.
Section 4 introduces the forecasting process of the CEEMDAN-MGWO-SVM model.
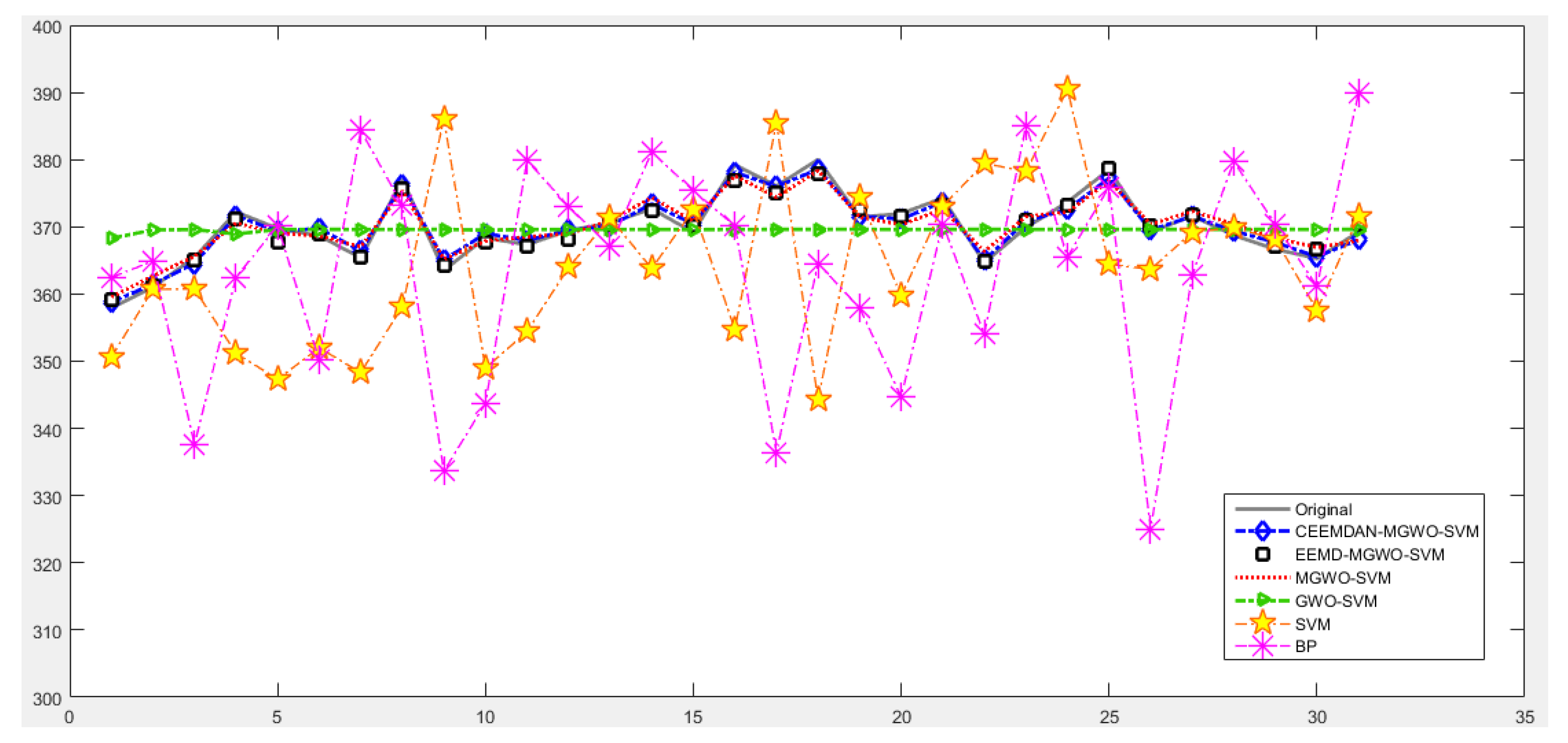
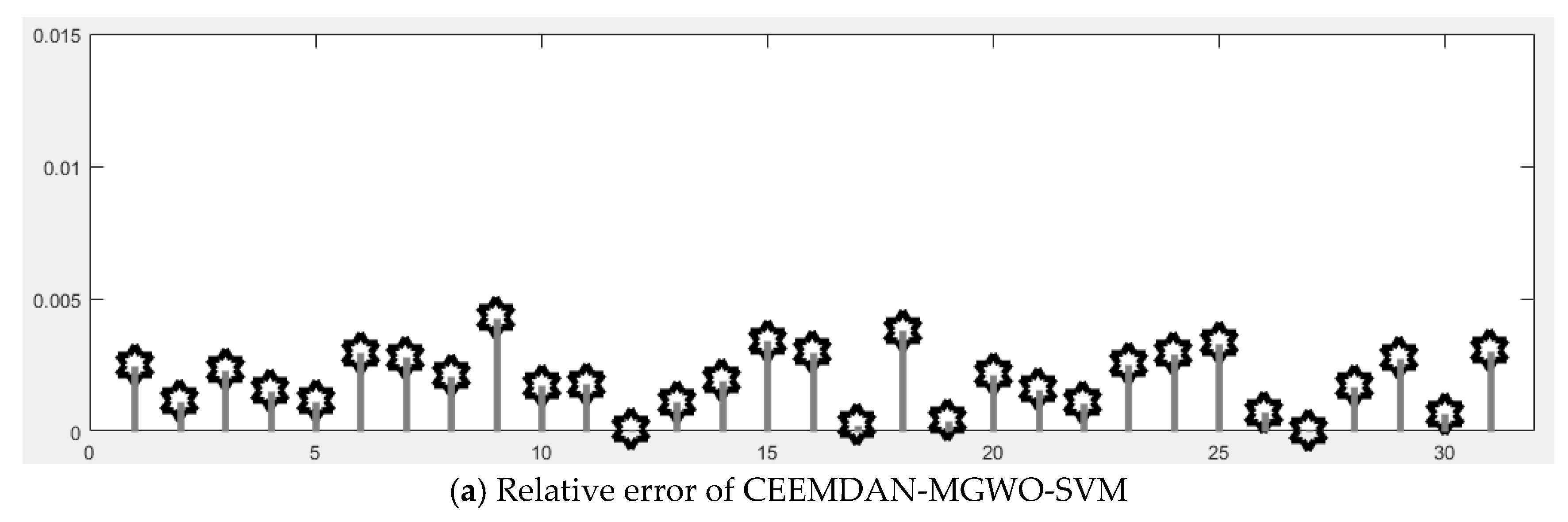
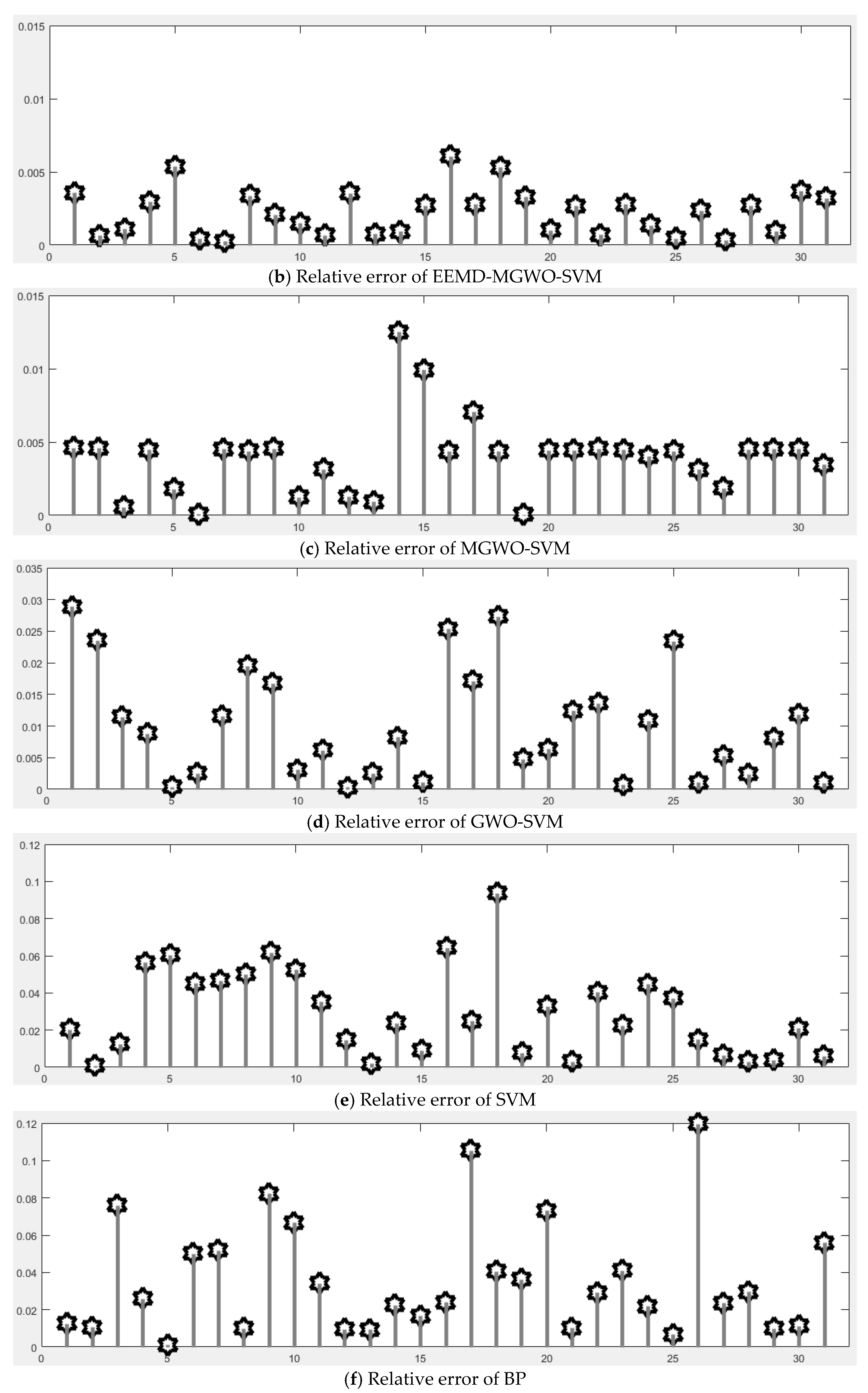
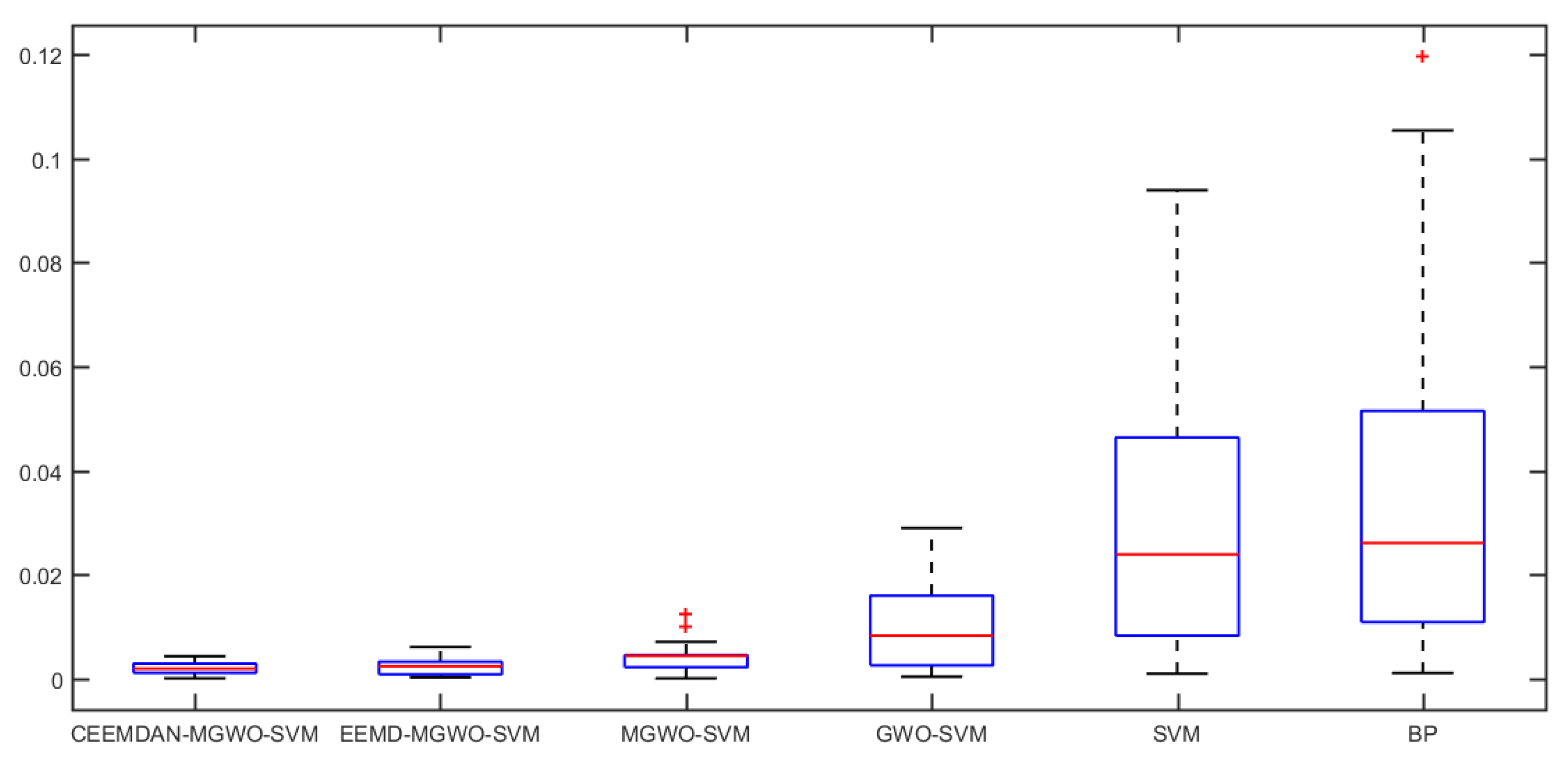
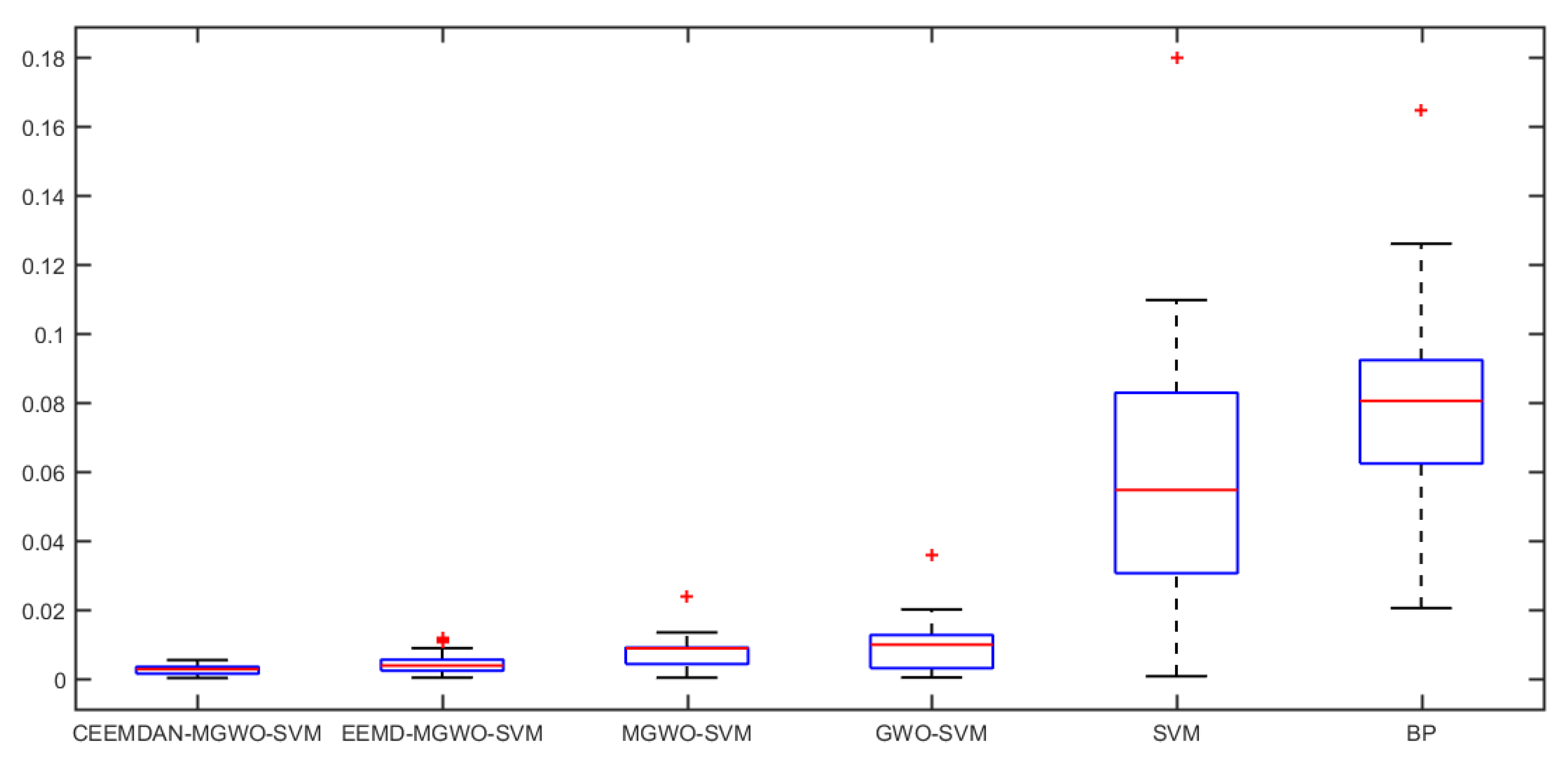
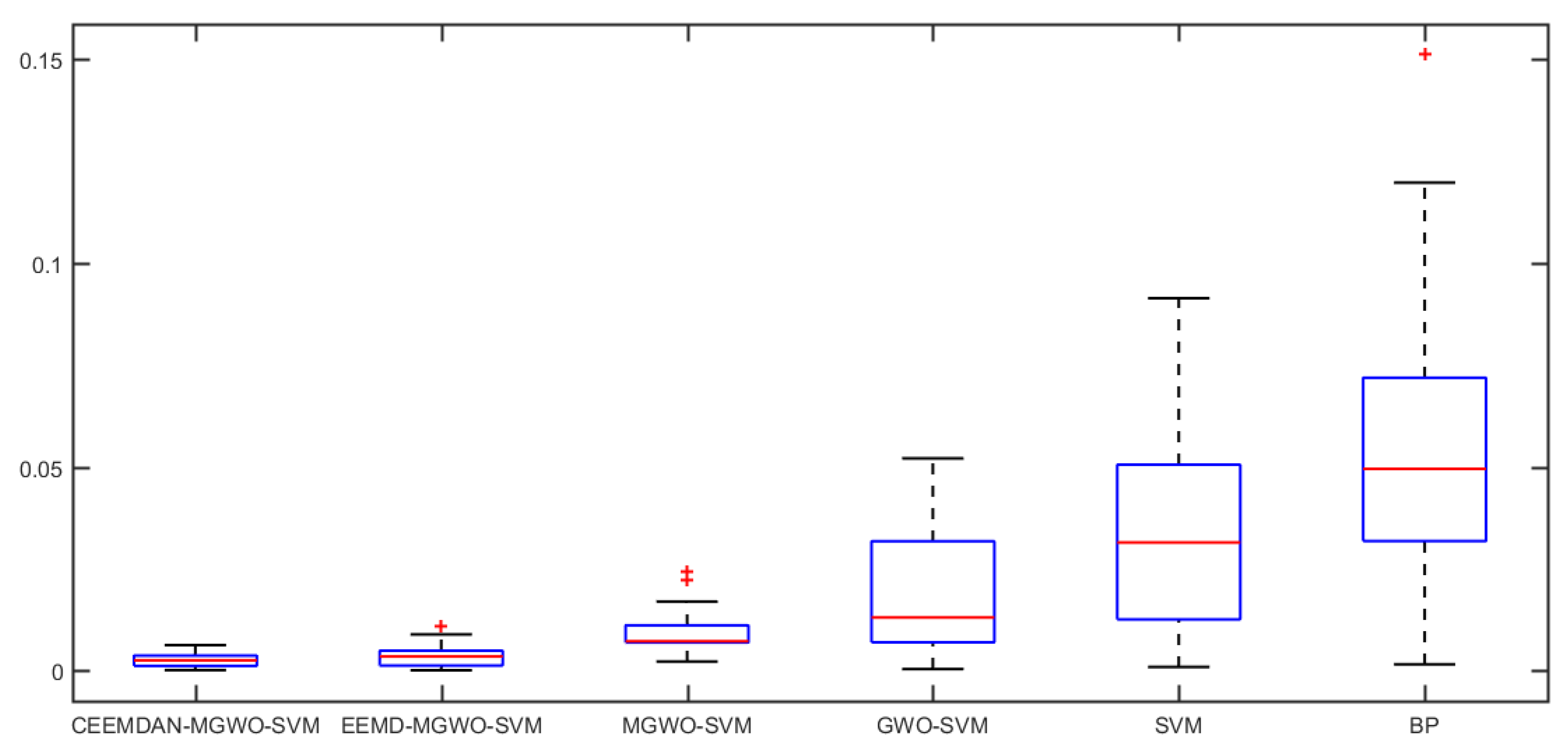
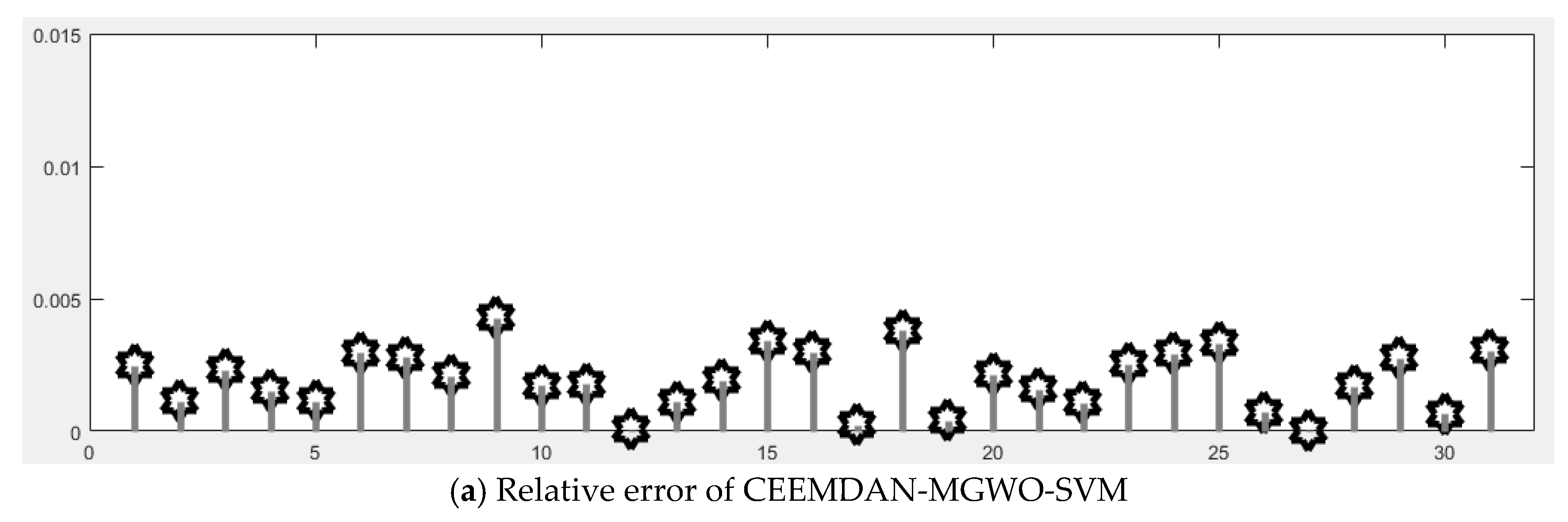
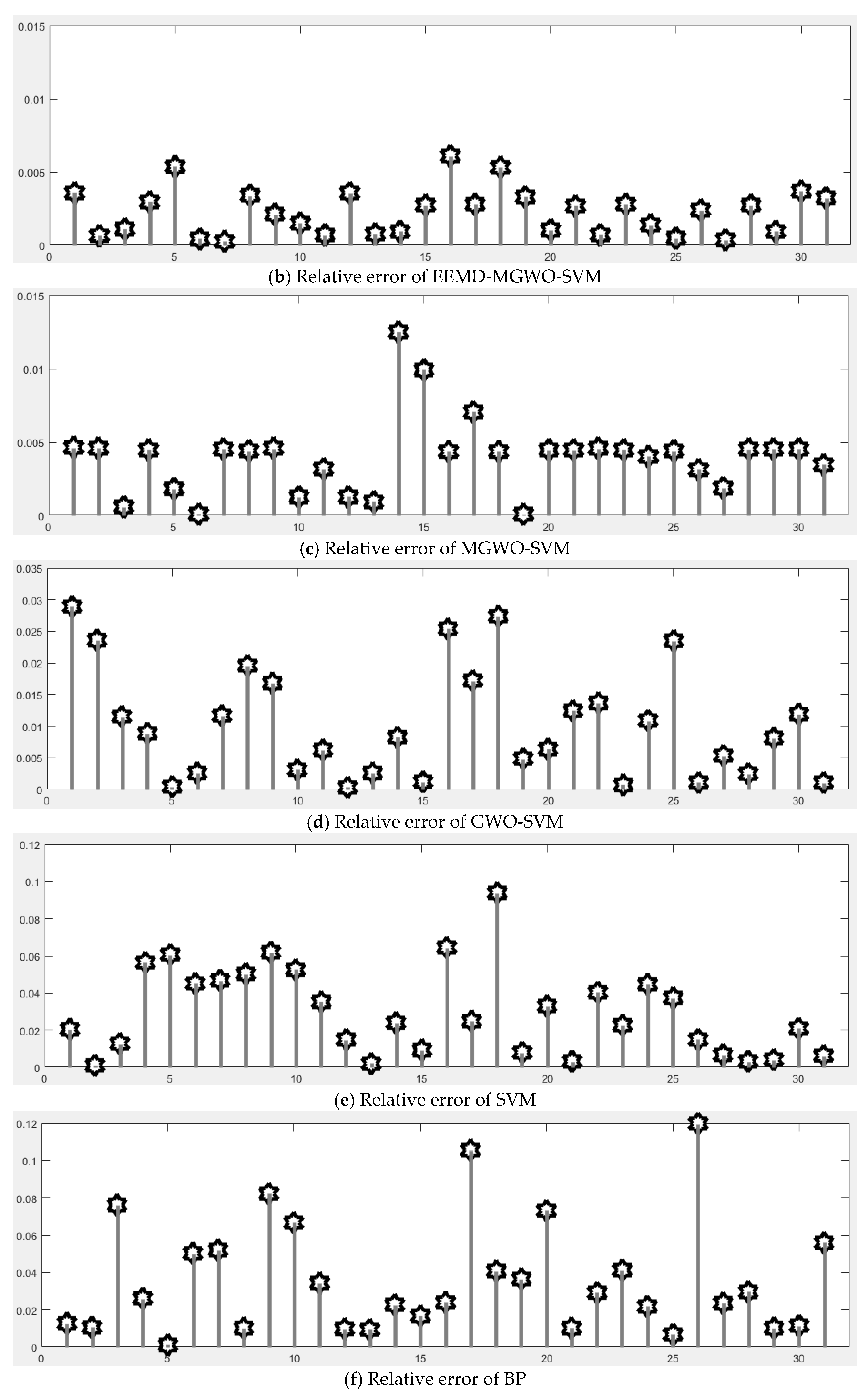
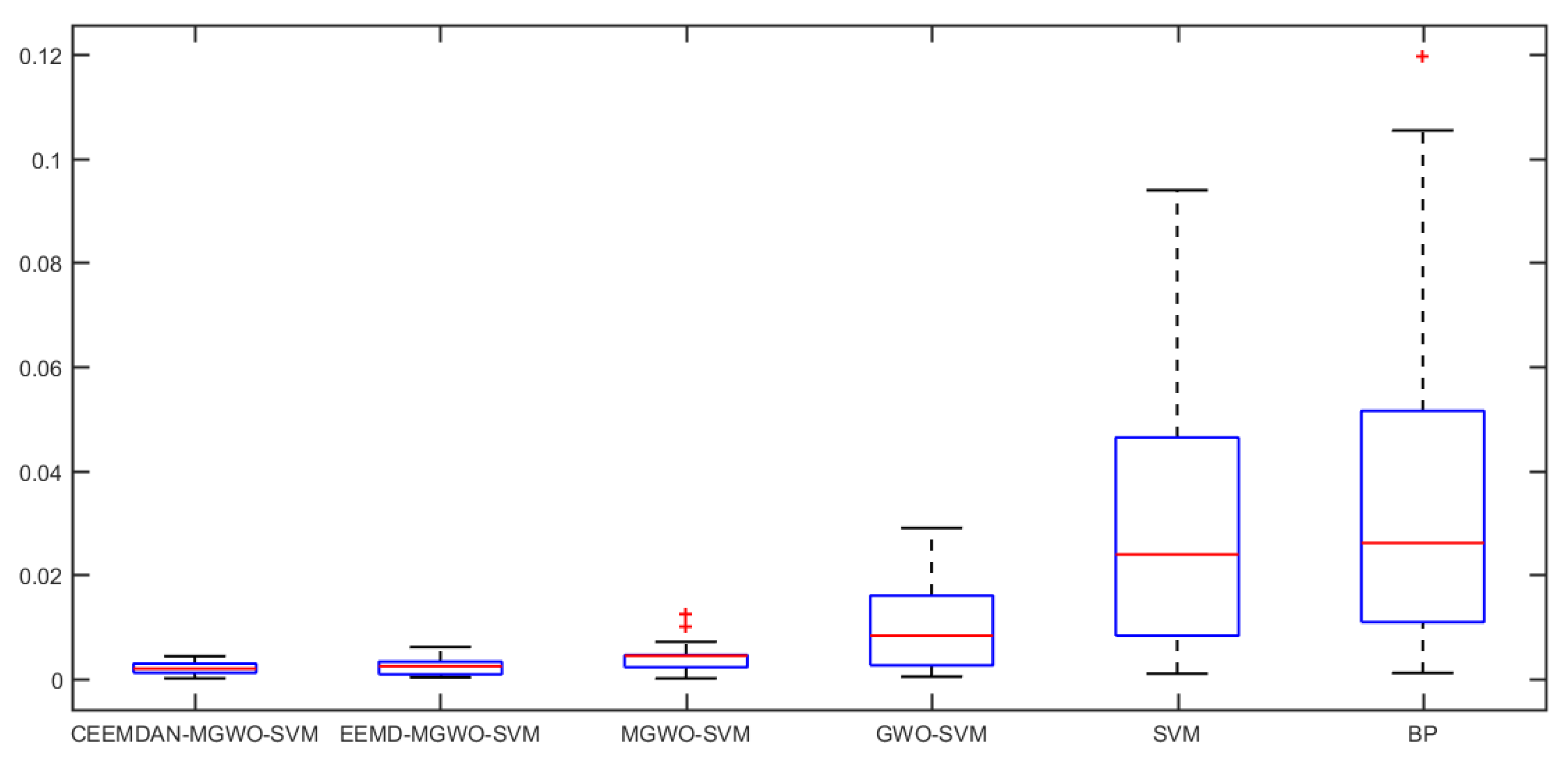
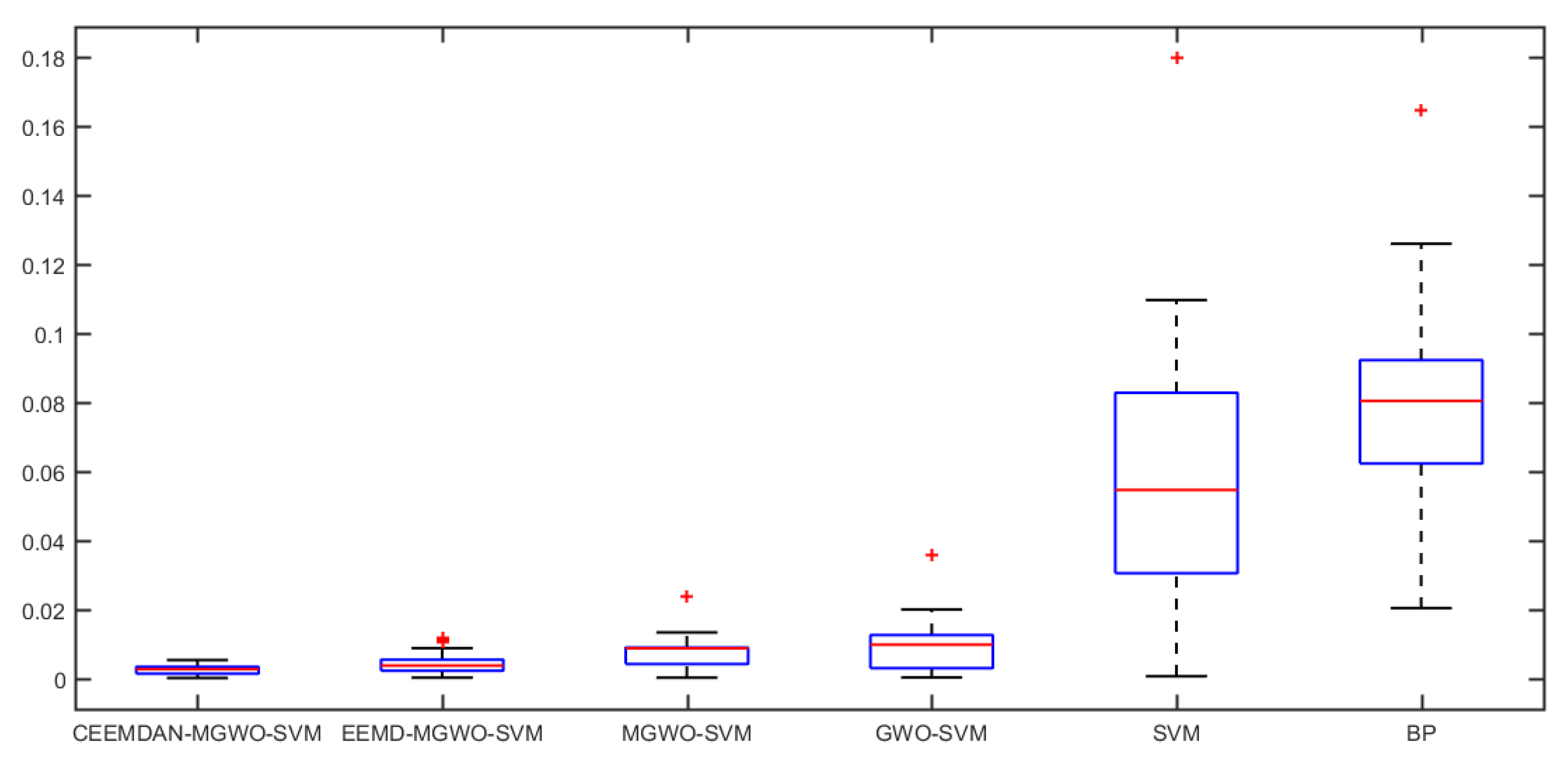
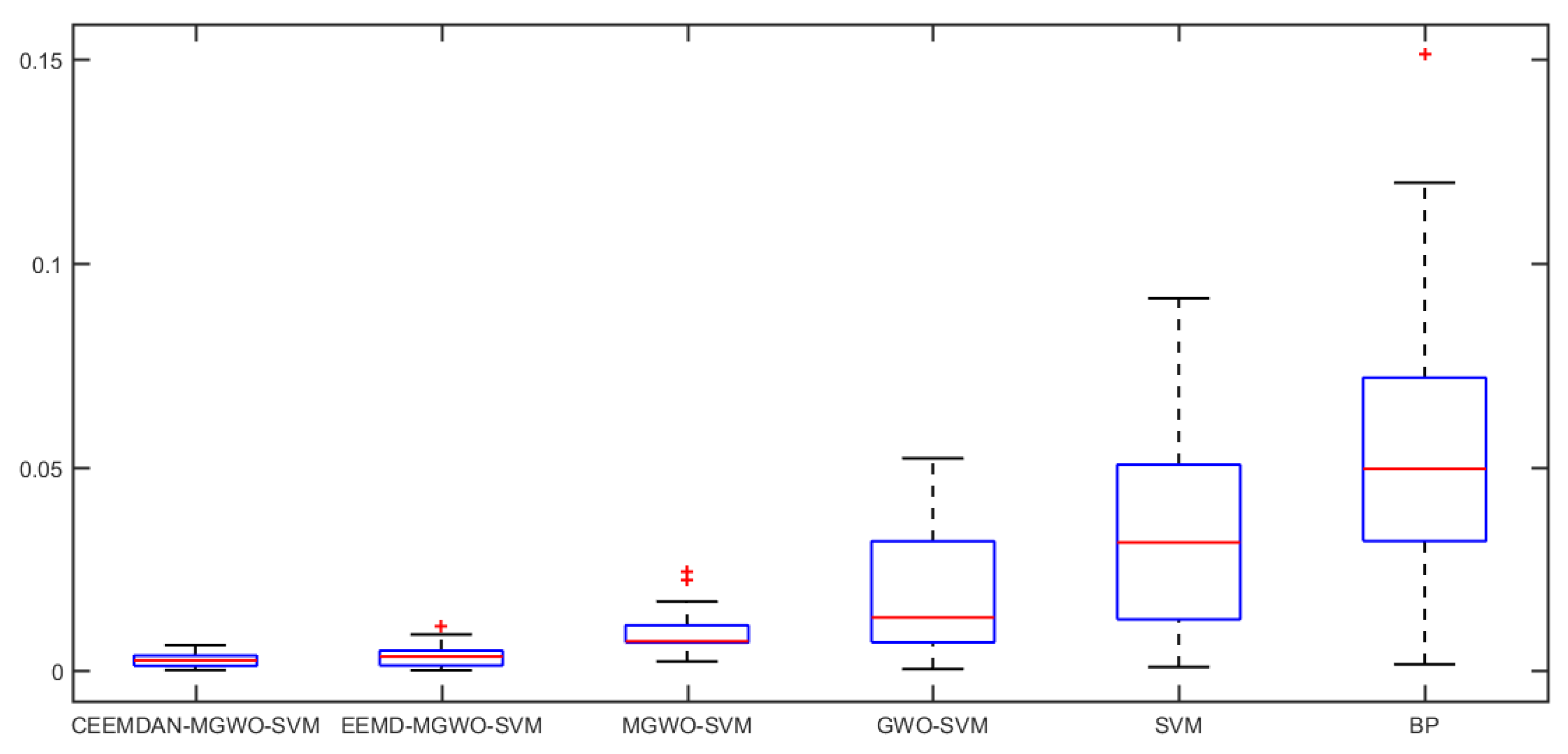
Section 5 carries out an empirical analysis. Three cases are taken to test the forecasting accuracy of the CEEMDAN-MGWO-SVM model. We choose the models of EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data, which proves the superiority of the CEEMDAN-MGWO-SVM model.
Section 6 summarizes the full text.
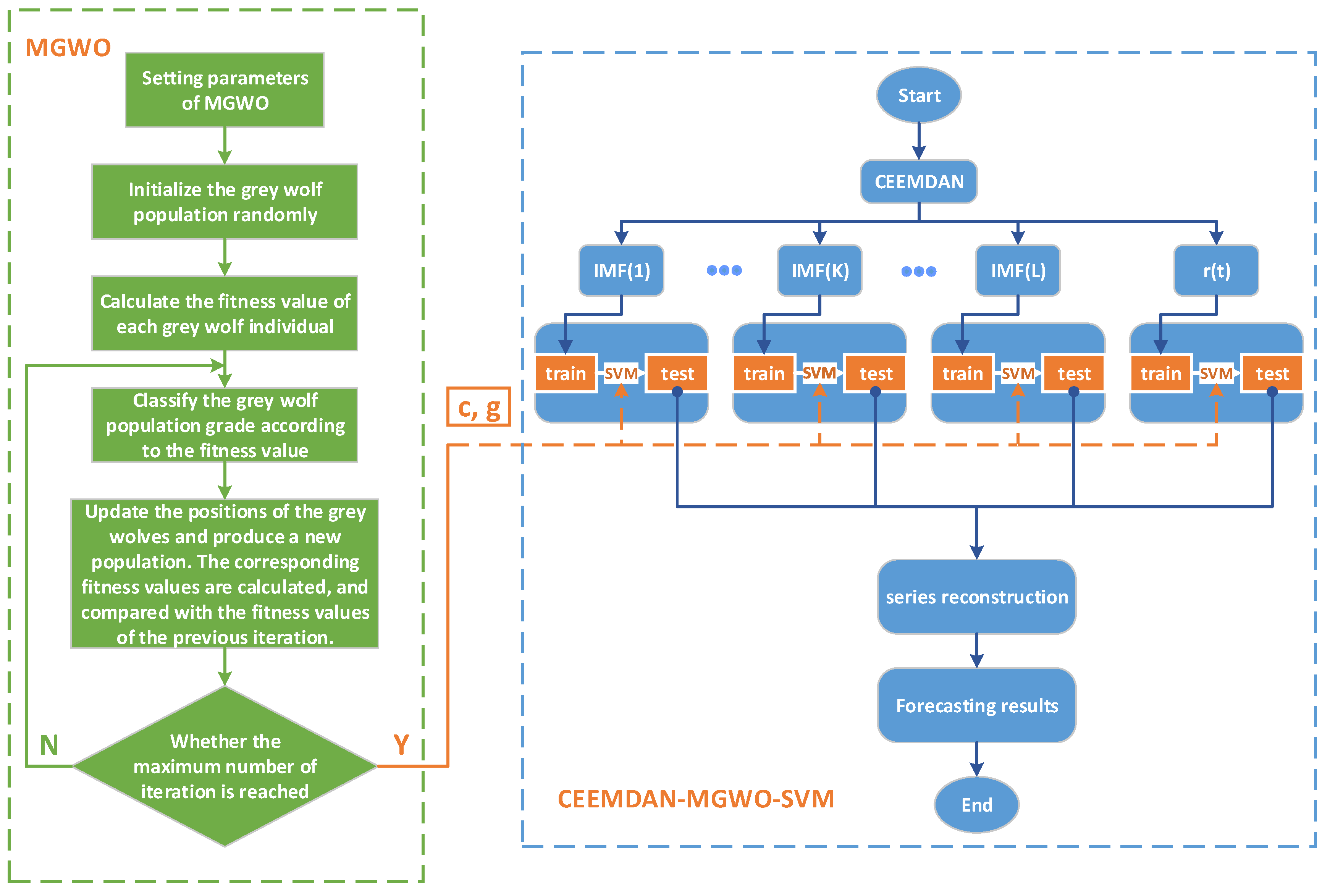
4. The Forecast Model Based on CEEMDAN-MGWO-SVM
The forecasting accuracy of daily peak load is influenced by many factors. To accurately forecast the daily peak load, in this paper, by taking meteorological factors and date types into account, we propose a forecasting model based on CEEMDAN-MGWO-SVM for daily peak load forecasting. Steps for this model are as follows:
(1) Data acquisition and preprocessing
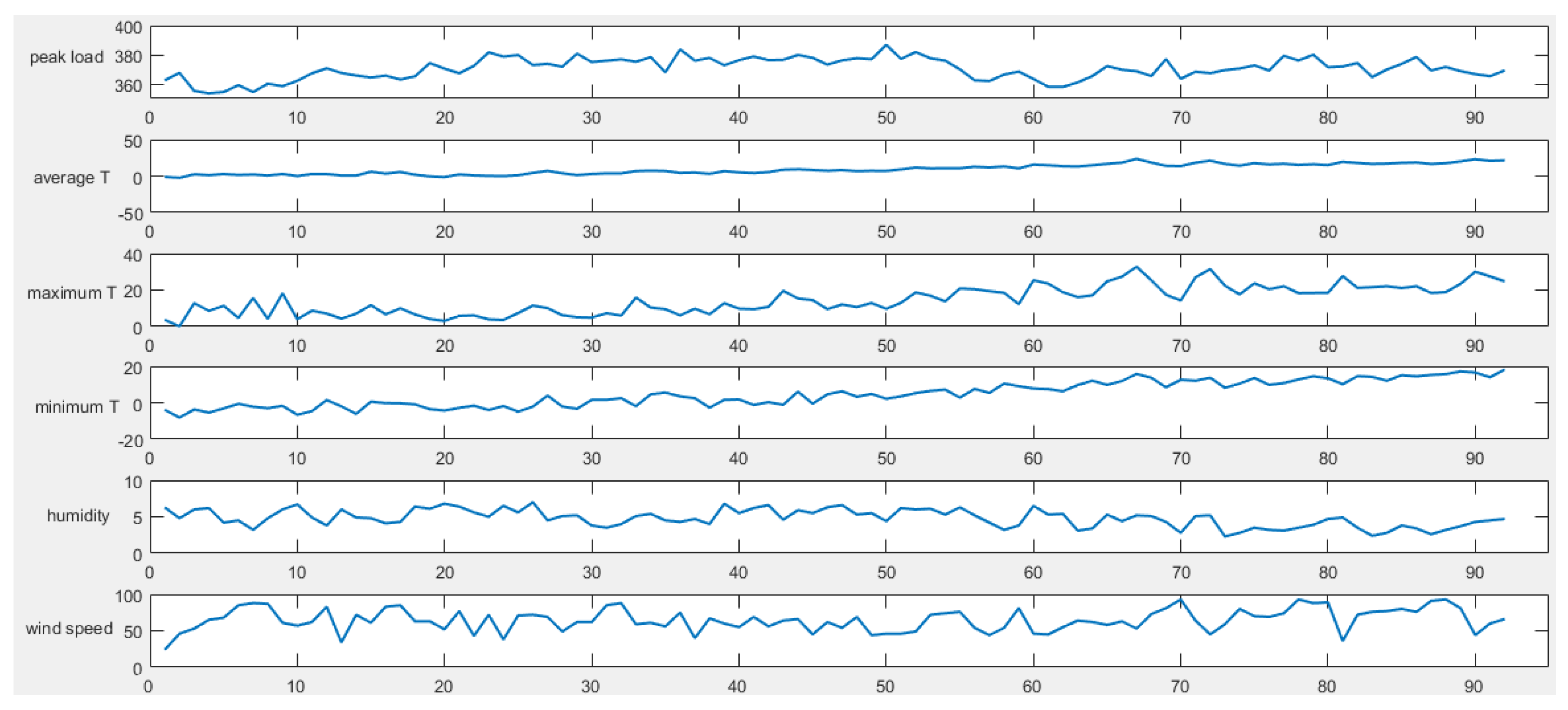
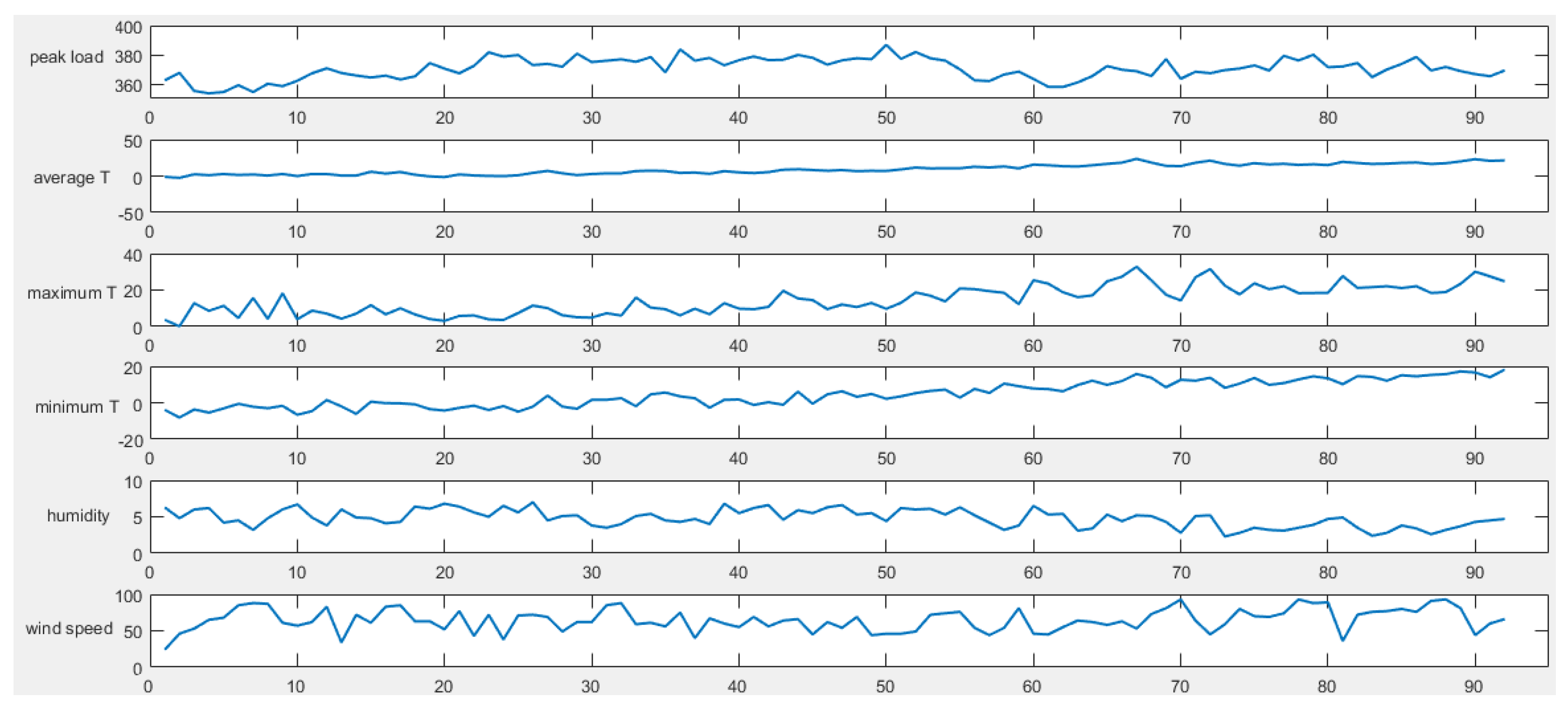
We collect sample data including historical daily peak load, daily maximum temperature, daily minimum temperature, daily average temperature, daily average relative humidity, maximum daily wind speed, date type and other data. Then, data preprocessing is to be carried out, that is, the meteorological data are normalized, and we mark holidays and working days as 1 and 0, respectively.
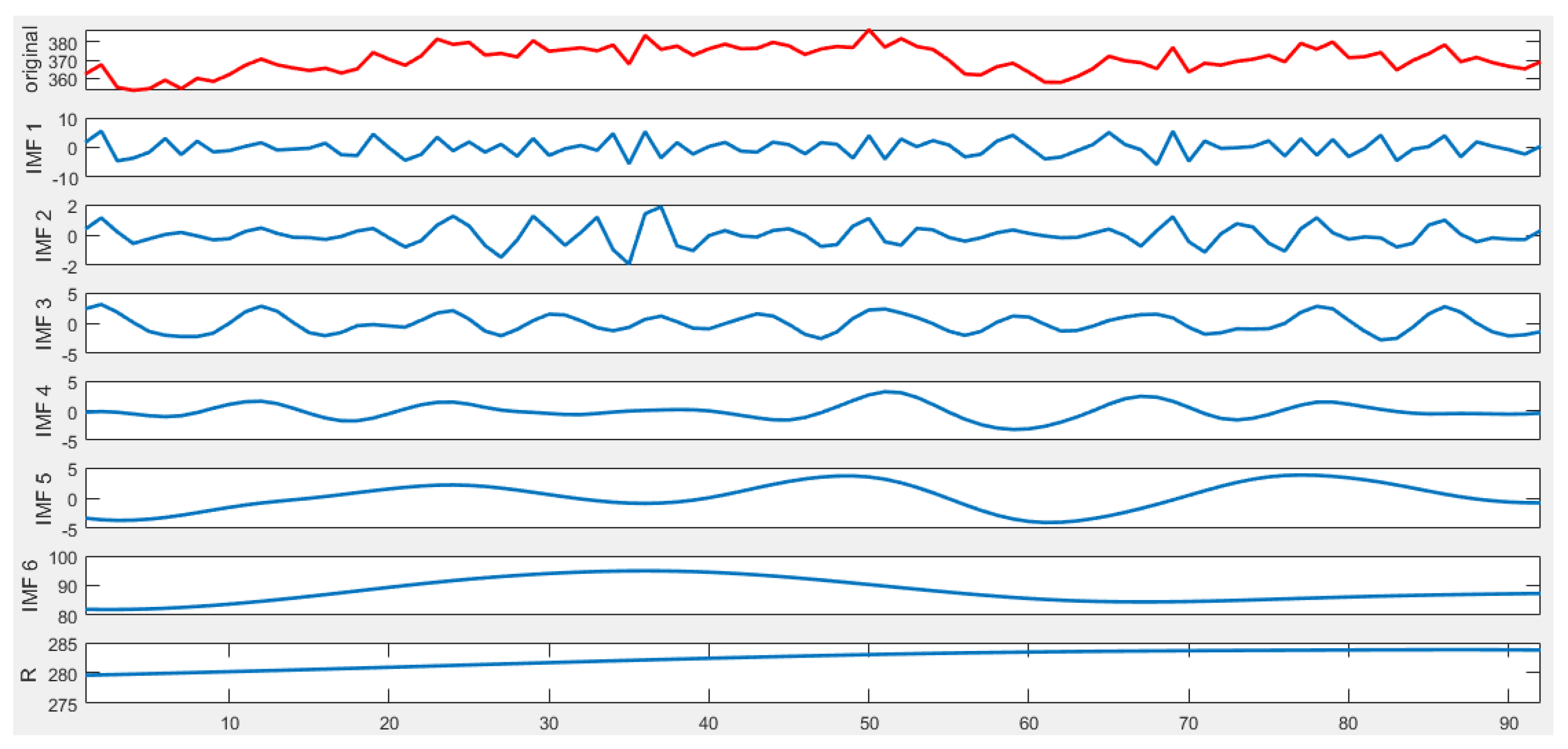
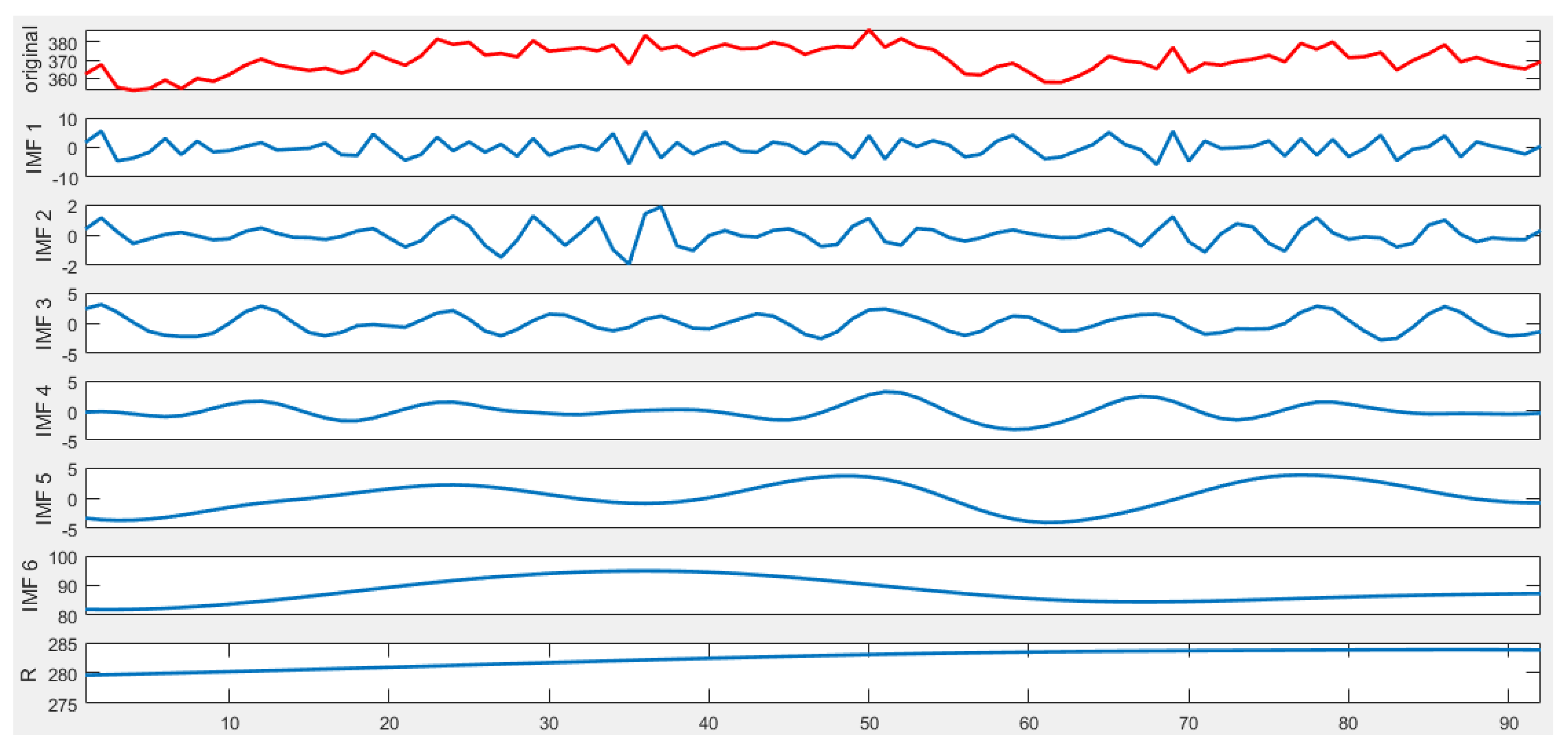
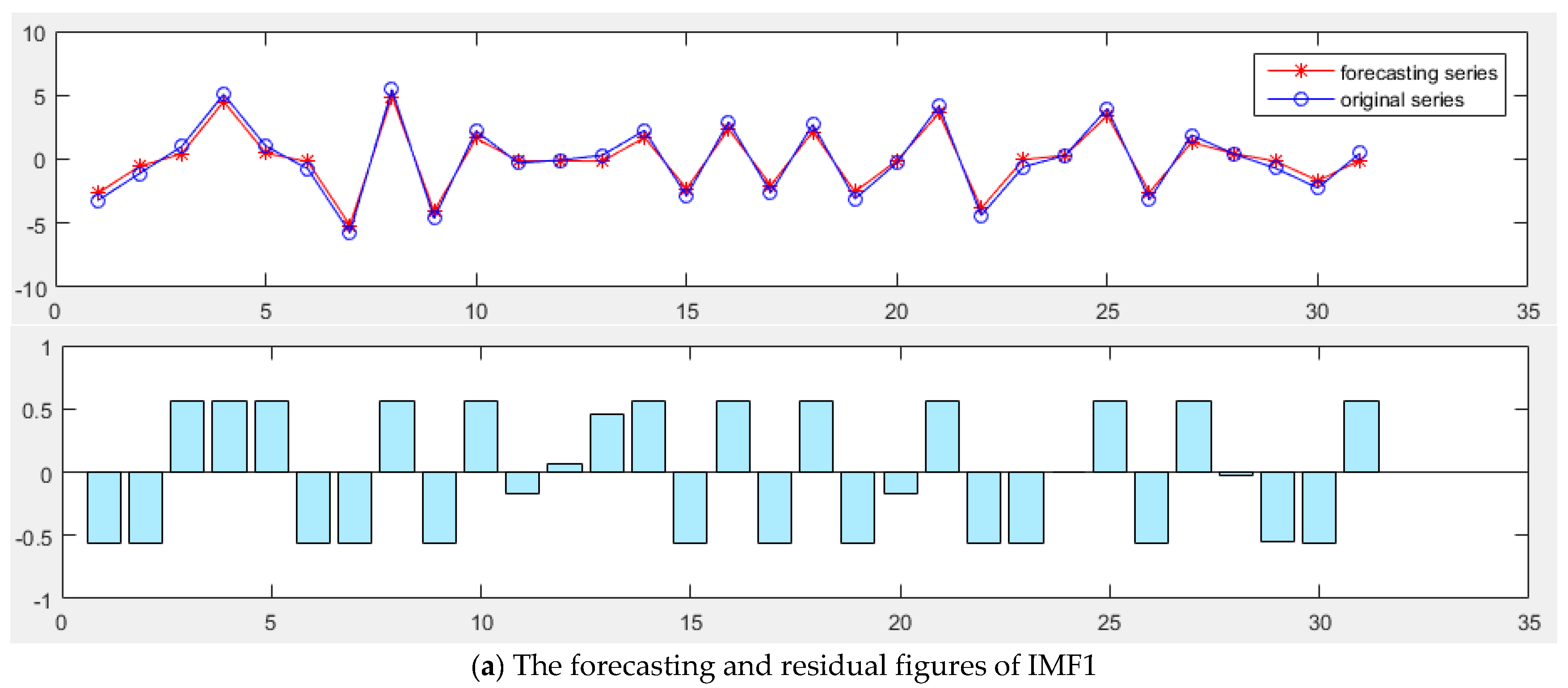
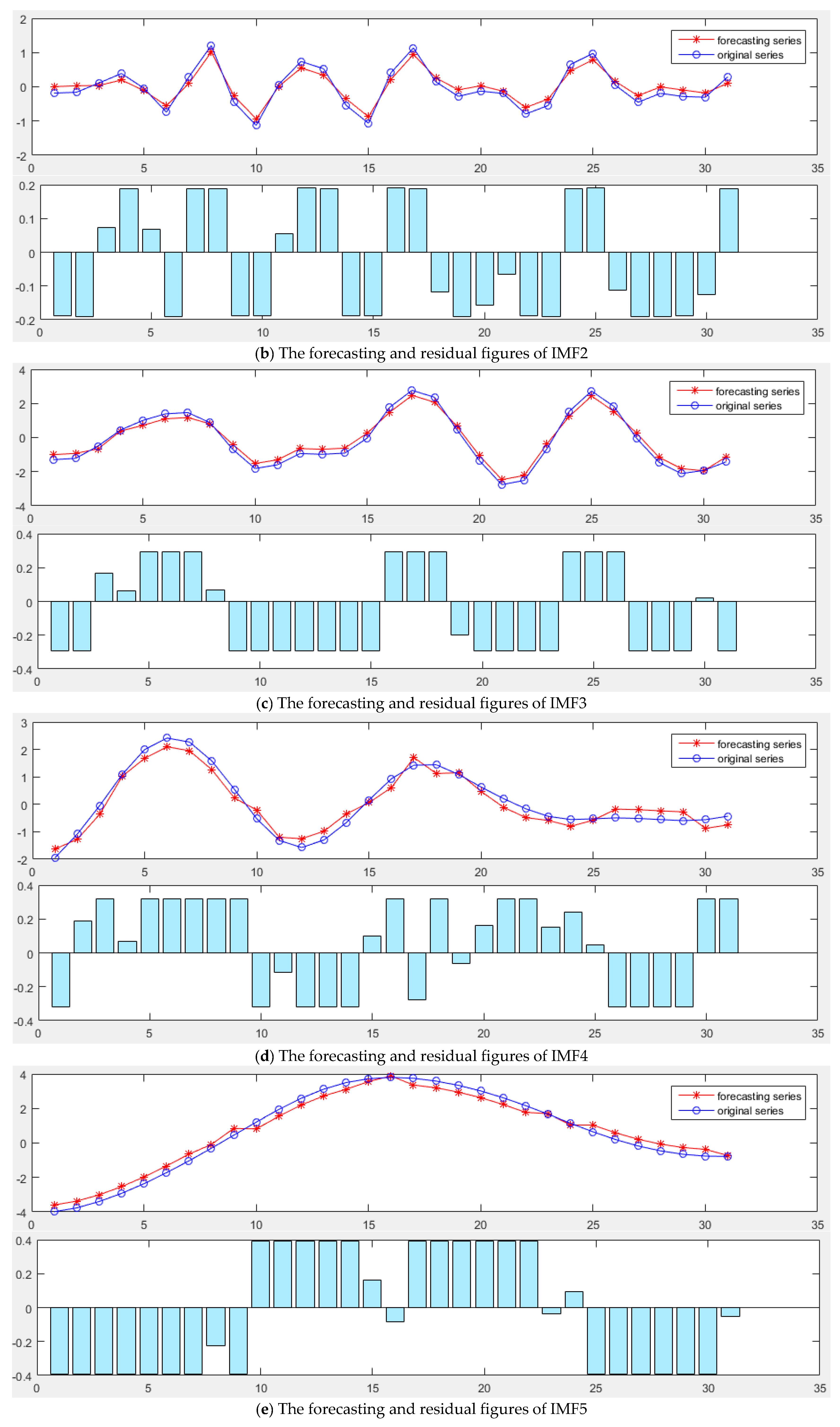
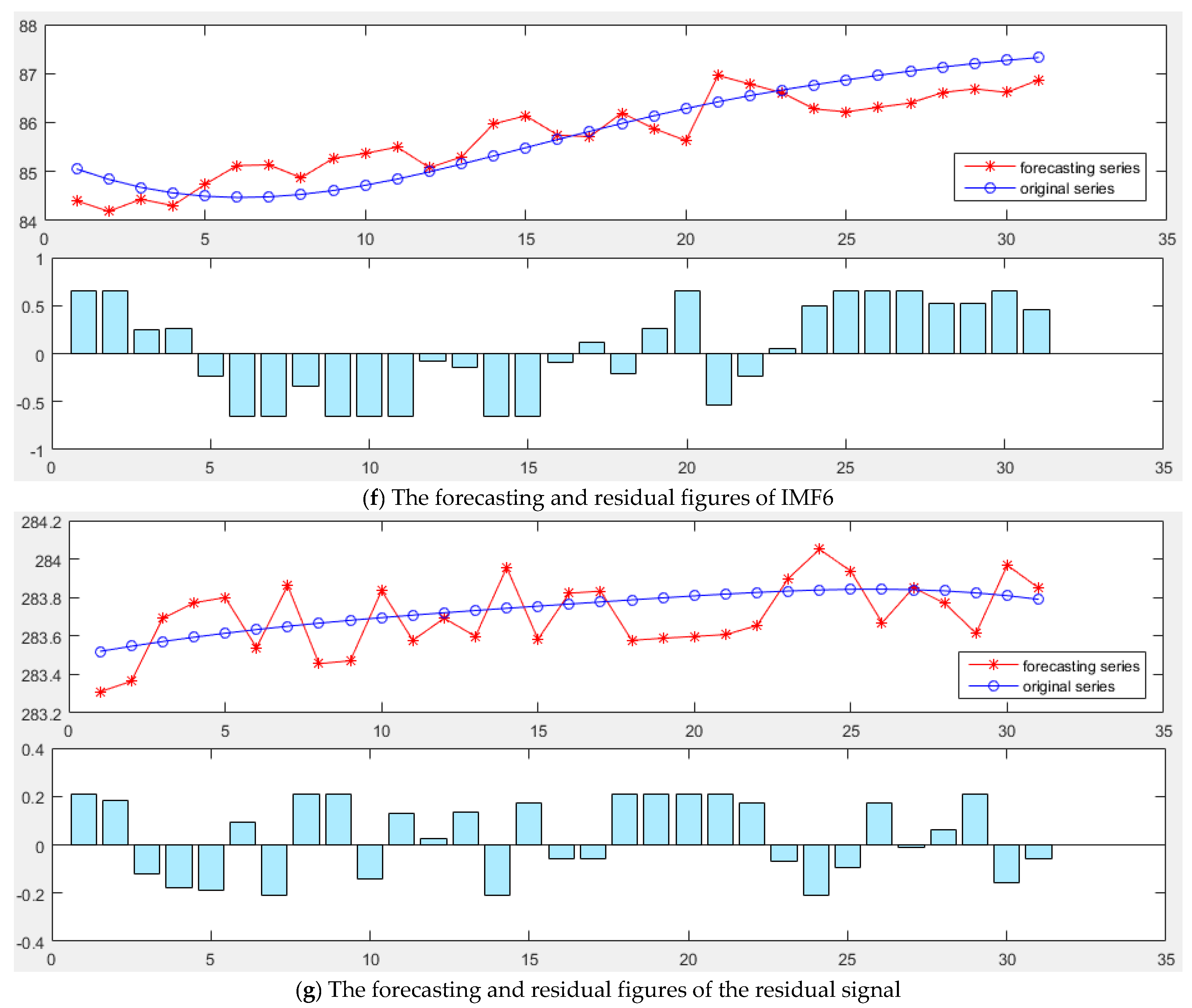
(2) Sequence de-noising based on CEEMDAN
To obtain multiple IMF components, the CEEMDAN is to be performed on the original daily peak load sequence.
(3) Daily peak load forecast based on MGWO-SVM
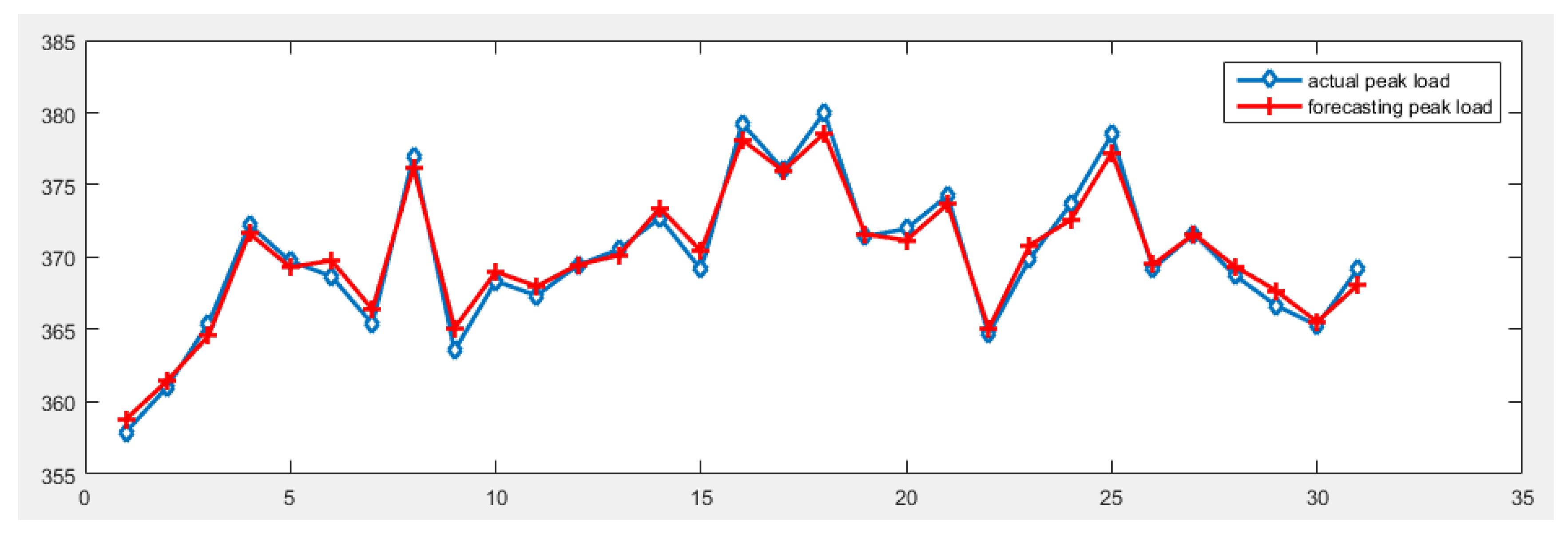
Based on considering the meteorological factors and date types, the IMF components derived from CEEMDAN are used to carry out the forecast by MGWO-SVM model, and the forecasting results are reconstructed to obtain the final daily peak load forecast results.
The flow chart of CEEMDAN-MGWO-SVM is shown in
Figure 3.
6. Conclusions
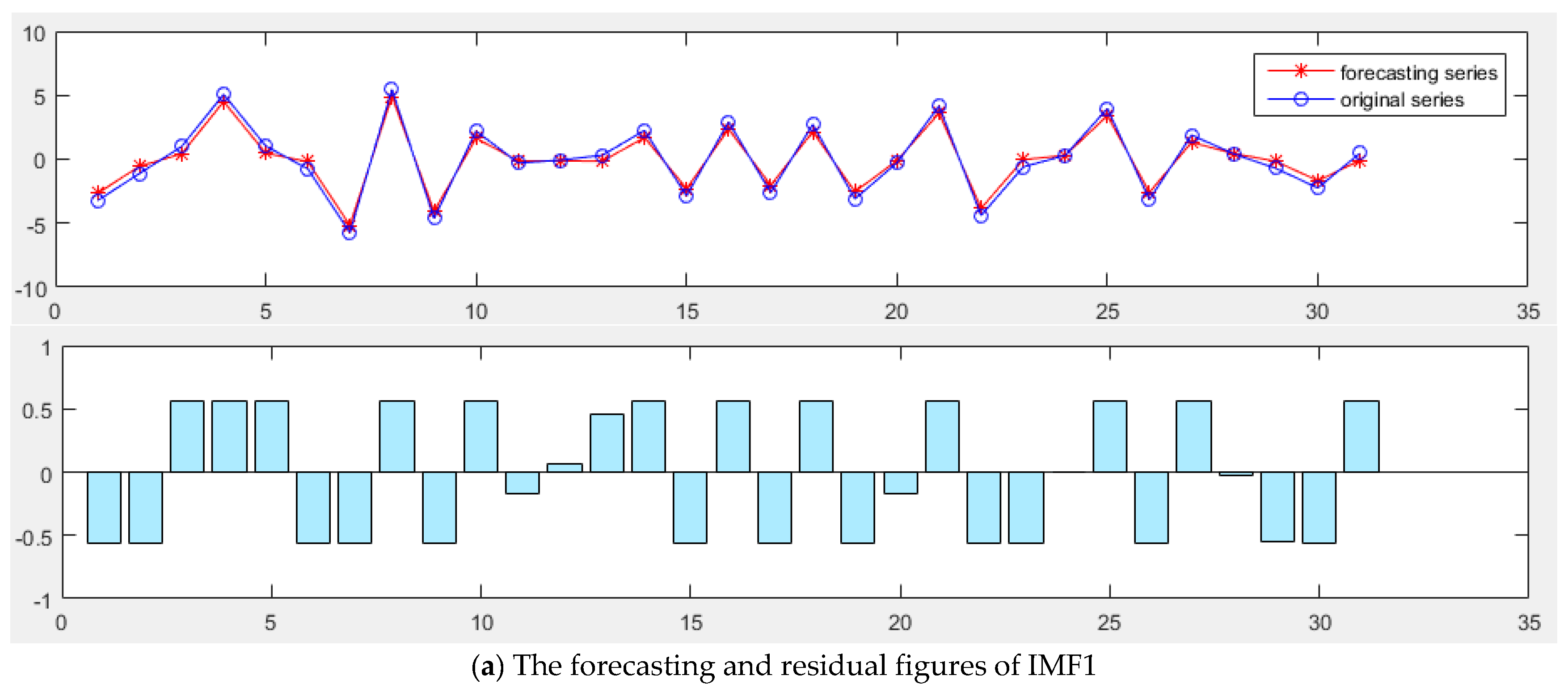
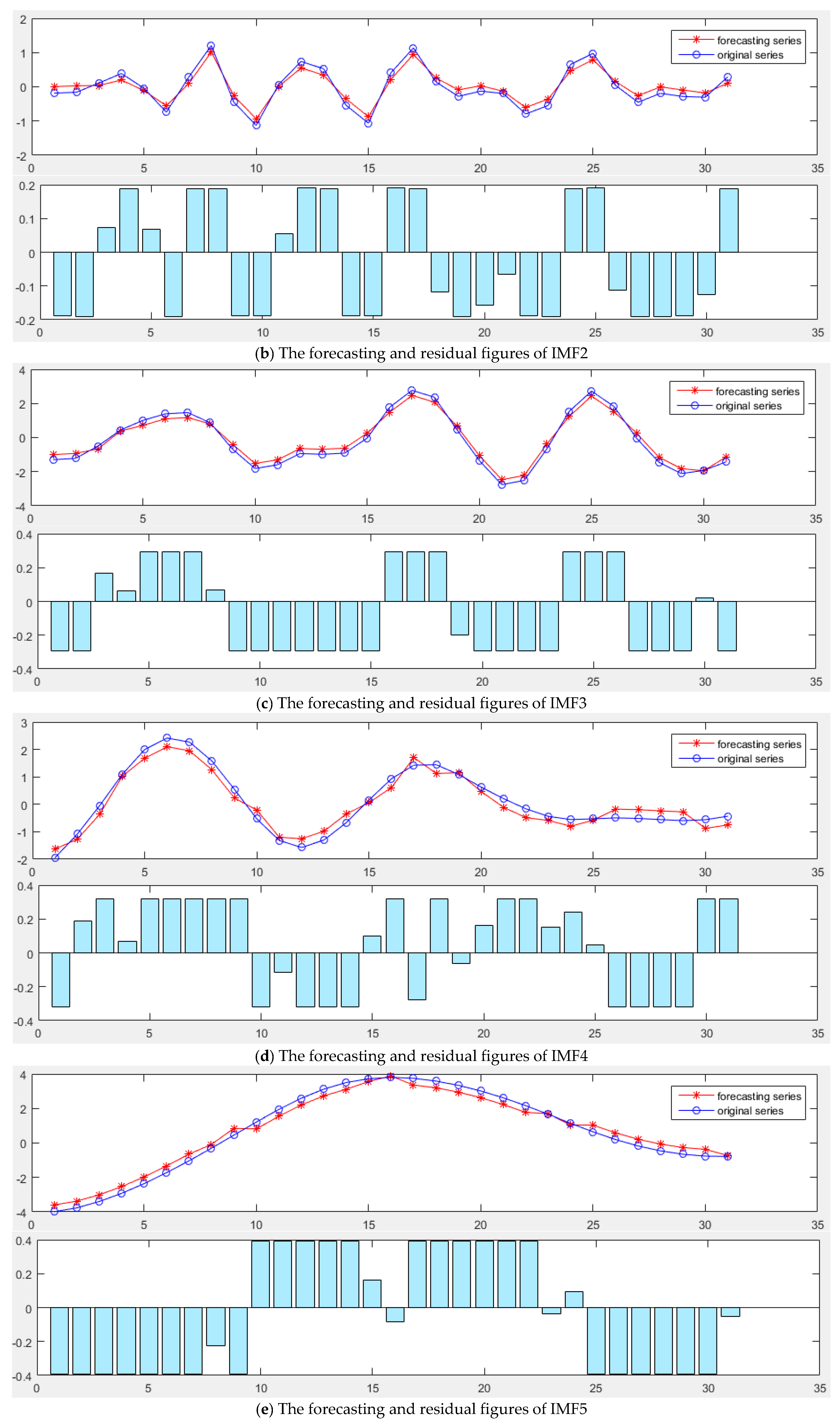
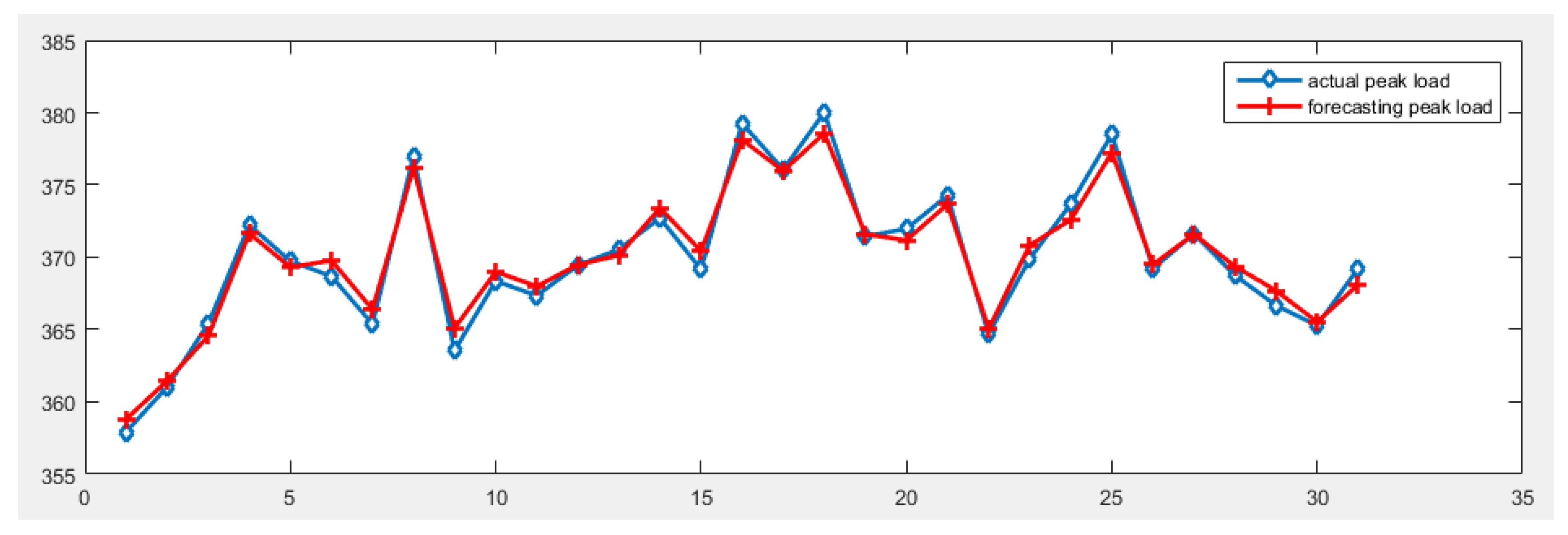
A novel daily peak load forecasting model, CEEMDAN-MGWO-SVM, is proposed in this paper. Firstly, the model uses the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) algorithm to decompose the daily peak load sequence into multiple sub-sequences. Then, the model of modified grey wolf optimization and support vector machine (MGWO-SVM) is adopted to forecast the sub-sequences. Finally, the forecasting sequence is reconstructed and the forecasting result is obtained. Using CEEMDAN can realize noise reduction for non-stationary daily peak load sequence, which makes the daily peak load sequence more regular. The model adopts the grey wolf optimization algorithm, which is improved by introducing the population dynamic evolution operator and the nonlinear convergence factor to enhance the global search ability and avoid falling into the local optimum, thus can better optimize the parameters of the SVM algorithm for improving the forecasting accuracy of daily peak load. In this paper, three cases are used to test the forecasting accuracy of the CEEMDAN-MGWO-SVM model. We choose the models EEMD-MGWO-SVM, MGWO-SVM, GWO-SVM, SVM and BP neural network to compare with the CEEMDAN-MGWO-SVM model and analyze the forecasting results of the same sample data. The experimental results fully demonstrate the reliability and effectiveness of the CEEMDAN-MGWO-SVM model proposed in this paper for daily peak load forecasting, which shows the strong generalization ability and robustness of the model.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}