
Best-Arm Identification Using Extreme Value Theory Estimates of the CVaR


Abstract
:1. Introduction
2. Preliminaries
2.1. Risk Measures
2.2. Extreme Value Theory and Heavy Tails
3. Estimating the CVaR through EVT
3.1. Maximum Likelihood Estimation of the GPD Parameters
3.2. Choosing the Threshold
| The distribution of the excesses above | |
| follows the GPD. |
| Algorithm 1: EVT CVaR estimation with automated threshold selection |
 |
4. Algorithm for Risk-Averse MABs
| Algorithm 2: EVT CVaR-SR algorithm |
 |
5. Numerical Experiments
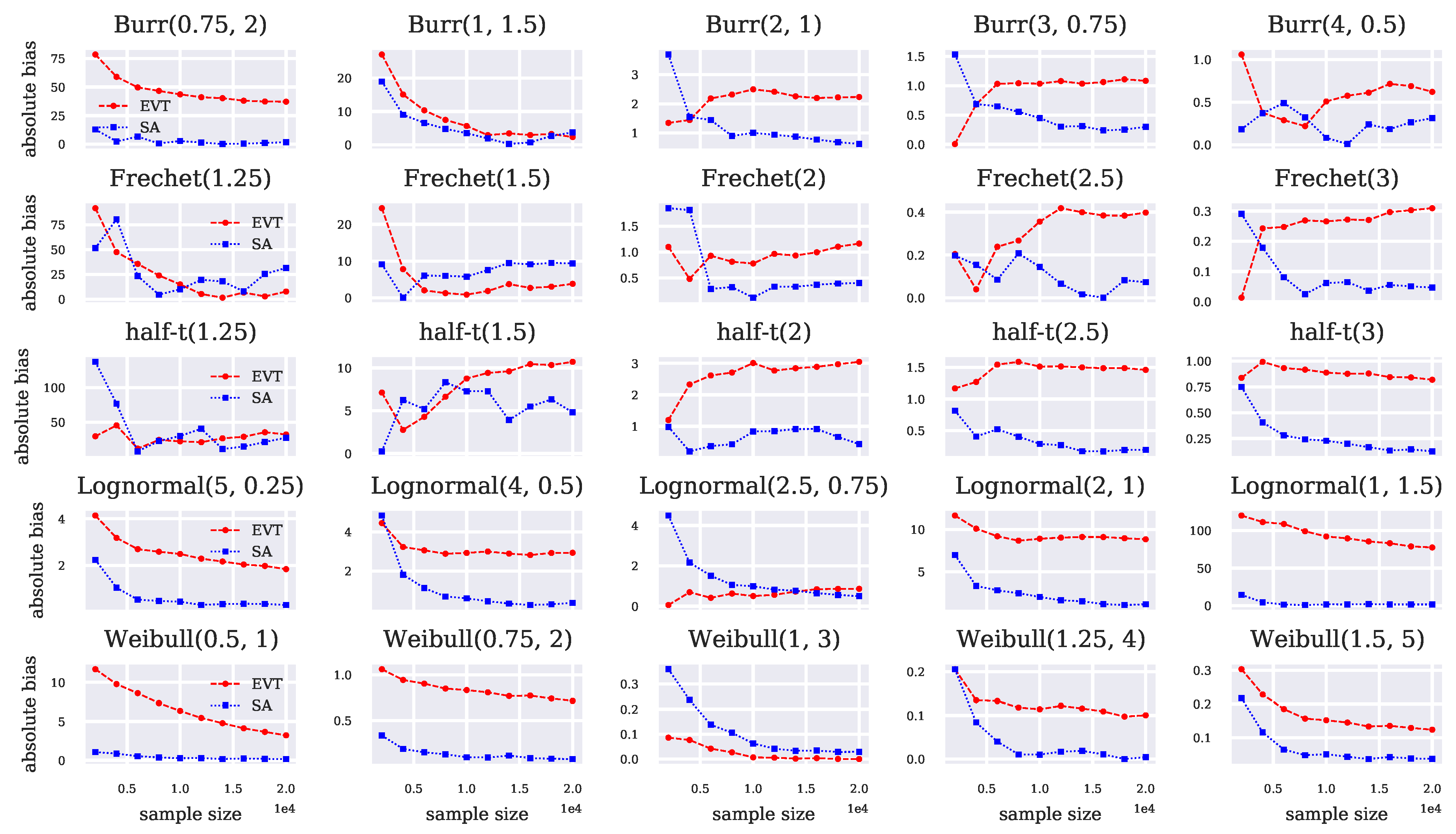
5.1. Single-Arm CVaR Estimation Experiment
5.2. Multi-Armed Bandit Experiment
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Probability Distributions and Their CVaRs
Appendix A.1. Burr
Appendix A.2. Fréchet
Appendix A.3. Half-t
Appendix A.4. Lognormal
Appendix A.5. Weibull
Appendix B. Numerical Results

{kind=link}
{kind=link}
{kind=link}
| CVaR | CVaR-SA | CVaR-EVT | Threshold Pct. | Rejection Rate | |
|---|---|---|---|---|---|
| Burr(0.75, 2) | 184.5 | 182.79 | 221.65 | 0.8 | 0.05 |
| Burr(1, 1.5) | 187.99 | 184.29 | 190.3 | 0.8 | 0.03 |
| Burr(2, 1) | 44.71 | 44.08 | 42.47 | 0.8 | 0.0 |
| Burr(3, 0.75) | 28.5 | 28.2 | 27.41 | 0.8 | 0.0 |
| Burr(4, 0.5) | 44.72 | 44.41 | 44.1 | 0.8 | 0.0 |
| Frechet(1.25) | 721.25 | 689.63 | 713.4 | 0.8 | 0.18 |
| Frechet(1.5) | 188.96 | 179.57 | 185.14 | 0.8 | 0.03 |
| Frechet(2) | 44.71 | 45.12 | 43.55 | 0.8 | 0.0 |
| Frechet(2.5) | 20.02 | 20.09 | 19.62 | 0.8 | 0.0 |
| Frechet(3) | 11.9 | 11.86 | 11.59 | 0.8 | 0.0 |
| half-t(1.25) | 530.66 | 503.19 | 498.46 | 0.8 | 0.17 |
| half-t(1.5) | 156.58 | 161.38 | 145.87 | 0.8 | 0.03 |
| half-t(2) | 44.7 | 45.13 | 41.65 | 0.81 | 0.0 |
| half-t(2.5) | 23.1 | 22.91 | 21.64 | 0.82 | 0.0 |
| half-t(3) | 15.41 | 15.28 | 14.59 | 0.82 | 0.0 |
| Lognormal(5, 0.25) | 328.63 | 328.32 | 326.79 | 0.84 | 0.0 |
| Lognormal(4, 0.5) | 269.11 | 268.73 | 266.18 | 0.8 | 0.0 |
| Lognormal(2.5, 0.75) | 134.45 | 133.96 | 135.32 | 0.8 | 0.0 |
| Lognormal(2, 1) | 183.83 | 182.69 | 192.67 | 0.8 | 0.0 |
| Lognormal(1, 1.5) | 351.98 | 350.52 | 429.49 | 0.84 | 0.0 |
| Weibull(0.5, 1) | 53.05 | 52.9 | 56.26 | 0.9 | 0.0 |
| Weibull(0.75, 2) | 27.99 | 27.92 | 28.71 | 0.82 | 0.0 |
| Weibull(1, 3) | 21.64 | 21.61 | 21.64 | 0.8 | 0.0 |
| Weibull(1.25, 4) | 19.41 | 19.41 | 19.31 | 0.81 | 0.0 |
| Weibull(1.5, 5) | 18.63 | 18.6 | 18.51 | 0.82 | 0.0 |
References
- Acerbi, Carlo, and Dirk Tasche. 2002. On the coherence of expected shortfall. Journal of Banking & Finance 26: 1487–503. [Google Scholar]
- Ariffin, Wan Nur Suryani Firuz Wan, Xinruo Zhang, and Mohammad Reza Nakhai. 2016. Combinatorial multi-armed bandit algorithms for real-time energy trading in green c-ran. Paper presented at the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, May 22–27; pp. 1–6. [Google Scholar]
- Artzner, Philippe, Freddy Delbaen, Jean-Marc Eber, and David Heath. 1999. Coherent measures of risk. Mathematical Finance 9: 203–28. [Google Scholar] [CrossRef]
- Audibert, Jean-Yves, and Sébastien Bubeck. 2010. Best Arm Identification in Multi-Armed Bandits. Paper presented at the COLT—23th Conference on Learning Theory, Haifa, Israel, June 27–29. [Google Scholar]
- Bader, Brian, Jun Yan, and Xuebin Zhang. 2018. Automated threshold selection for extreme value analysis via ordered goodness-of-fit tests with adjustment for false discovery rate. The Annals of Applied Statistics 12: 310–29. [Google Scholar] [CrossRef]
- Balkema, August A., and Laurens De Haan. 1974. Residual life time at great age. The Annals of Probability 2: 792–804. [Google Scholar] [CrossRef]
- Bhat, Sanjay P., and L. A. Prashanth. 2019. Concentration of risk measures: A Wasserstein distance approach. In Advances in Neural Information Processing Systems 32. Edited by Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Edward A. Fox and Roman Garnett. Red Hook: Curran Associates, pp. 11762–71. [Google Scholar]
- Bouneffouf, Djallel, Irina Rish, and Charu Aggarwal. 2020. Survey on applications of multi-armed and contextual bandits. Paper presented at the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, July 19–24; pp. 1–8. [Google Scholar]
- Bubeck, Sébastien, Nicolo Cesa-Bianchi, and Gábor Lugosi. 2013. Bandits with heavy tail. IEEE Transactions on Information Theory 59: 7711–17. [Google Scholar] [CrossRef]
- Cannelli, Loris, Giuseppe Nuti, Marzio Sala, and Oleg Szehr. 2020. Hedging using reinforcement learning: Contextual k-armed bandit versus q-learning. arXiv arXiv:2007.01623. [Google Scholar]
- Choulakian, Vartan, and Michael A. Stephens. 2001. Goodness-of-fit tests for the generalized Pareto distribution. Technometrics 43: 478–84. [Google Scholar] [CrossRef]
- Costa, Manuel L., and Fernando S. Oliveira. 2008. A reinforcement learning algorithm for agent-based modeling of investment in electricity markets. Researchgate Net, 1–30. [Google Scholar]
- Daouia, Abdelaati, Stéphane Girard, and Gilles Stupfler. 2018. Estimation of tail risk based on extreme expectiles. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 80: 263–92. [Google Scholar] [CrossRef] [Green Version]
- David, Yahel, Balázs Szörényi, Mohammad Ghavamzadeh, Shie Mannor, and Nahum Shimkin. 2018. PAC bandits with risk constraints. Ppper present at the ISAIM, Fort Lauderdale, FL, USA, January 3–5. [Google Scholar]
- De Haan, Laurens, and Ana Ferreira. 2006. Extreme Value Theory: An Introduction. New York: Springer. [Google Scholar] [CrossRef] [Green Version]
- Embrechts, Paul, Claudia Klüppelberg, and Thomas Mikosch. 2013. Modelling Extremal Events: For Insurance and Finance. Berlin and Heidelberg: Springer Science & Business Media, vol. 33. [Google Scholar]
- Embrechts, Paul, Sidney I. Resnick, and Gennady Samorodnitsky. 1999. Extreme value theory as a risk management tool. North American Actuarial Journal 3: 30–41. [Google Scholar] [CrossRef]
- Galichet, Nicolas, Michèle Sebag, and Olivier Teytaud. 2013. Exploration vs. exploitation vs. safety: Risk-aware multi-armed bandits. Paper presented at the fifth Asian Conference on Machine Learning, Canberra, Australia, November 13–15; pp. 245–60. [Google Scholar]
- G’Sell, Max Grazier, Stefan Wager, Alexandra Chouldechova, and Robert Tibshirani. 2016. Sequential selection procedures and false discovery rate control. Journal of the Royal Statistical Society Series B 78: 423–44. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, Matthew, Eric Brochu, and Nando de Freitas. 2011. Portfolio allocation for bayesian optimization. Paper presented at the UAI, Barcelona, Spain, July 14–17; pp. 327–36. [Google Scholar]
- Huo, Xiaoguang, and Feng Fu. 2017. Risk-aware multi-armed bandit problem with application to portfolio selection. Royal Society Open Science 4: 171377. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kagrecha, Anmol, Jayakrishnan Nair, and Krishna Jagannathan. 2019. Distribution oblivious, risk-aware algorithms for multi-armed bandits with unbounded rewards. In Advances in Neural Information Processing Systems 32. Edited by Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Edward A. Fox and Roman Garnett. Red Hook: Curran Associates, pp. 11272–81. [Google Scholar]
- Kumar, Devendra. 2017. The singh–maddala distribution: Properties and estimation. International Journal of System Assurance Engineering and Management 8: 1297–311. [Google Scholar] [CrossRef]
- Lattimore, Tor, and Csaba Szepesvári. 2020. Bandit Algorithms. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- McNeil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2005. Quantitative Risk Management: Concepts, Techniques and Tools. Princeton: Princeton University Press, vol. 3. [Google Scholar]
- Moeini, Mahdi, Oliver Wendt, and Linus Krumrey. 2016. Portfolio optimization by means of a chi-armed bandit algorithm. Paper presented at the Asian Conference on Intelligent Information and Database Systems, Da Nang, Vietnam, March 14–16; pp. 620–29. [Google Scholar]
- Norton, Matthew, Valentyn Khokhlov, and Stan Uryasev. 2019. Calculating CVaR and bPOE for Common Probability Distributions With Application to Portfolio Optimization and Density Estimation. Annals of Operations Research 299: 1287–315. [Google Scholar] [CrossRef] [Green Version]
- Pickands, James, II. 1975. Statistical inference using extreme order statistics. The Annals of Statistics 3: 119–31. [Google Scholar]
- Prashanth, L. A., Krishna Jagannathan, and Ravi Kolla. 2020. Concentration bounds for CVaR estimation: The cases of light-tailed and heavy-tailed distributions. Paper presented at International Conference on Machine Learning, Virtual. July 12–18; pp. 5577–86. [Google Scholar]
- Sani, Amir, Alessandro Lazaric, and Rémi Munos. 2012. Risk-aversion in multi-armed bandits. Advances in Neural Information Processing Systems 25: 3275–83. [Google Scholar]
- Scarrott, Carl, and Anna MacDonald. 2012. A review of extreme value threshold estimation and uncertainty quantification. REVSTAT–Statistical Journal 10: 33–60. [Google Scholar]
- Shen, Weiwei, Jun Wang, Yu-Gang Jiang, and Hongyuan Zha. 2015. Portfolio choices with orthogonal bandit learning. Paper presented at the Twenty-fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, July 25–31. [Google Scholar]
- Torossian, Léonard, Aurélien Garivier, and Victor Picheny. 2019. X-armed bandits: Optimizing quantiles, CVaR and other risks. Paper presented at the Asian Conference on Machine Learning, Nagoya, Japan, November 17–19. [Google Scholar]
- Troop, Dylan, Frédéric Godin, and Jia Yuan Yu. 2021. Bias-corrected peaks-over-threshold estimation of the cvar. Paper presented at the Uncertainty in Artificial Intelligence, online. July 27–29; pp. 1809–18. [Google Scholar]
- Yu, Jia Yuan, and Evdokia Nikolova. 2013. Sample complexity of risk-averse bandit-arm selection. Paper presented at the IJCAI, Beijing, China, August 3–9; pp. 2576–82. [Google Scholar]
- Yu, Xiaotian, Han Shao, Michael R. Lyu, and Irwin King. 2018. Pure exploration of multi-armed bandits with heavy-tailed payoffs. Paper presented at the UAI, Monterey, CA, USA, August 6–10. [Google Scholar]
- Zhao, Xu, Weihu Cheng, and Pengyue Zhang. 2018. Extreme tail risk estimation with the generalized Pareto distribution under the peaks-over-threshold framework. Communications in Statistics—Theory and Methods 49: 827–44. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Troop, D.; Godin, F.; Yu, J.Y. Best-Arm Identification Using Extreme Value Theory Estimates of the CVaR. J. Risk Financial Manag. 2022, 15, 172. https://doi.org/10.3390/jrfm15040172
Troop D, Godin F, Yu JY. Best-Arm Identification Using Extreme Value Theory Estimates of the CVaR. Journal of Risk and Financial Management. 2022; 15(4):172. https://doi.org/10.3390/jrfm15040172
Chicago/Turabian StyleTroop, Dylan, Frédéric Godin, and Jia Yuan Yu. 2022. "Best-Arm Identification Using Extreme Value Theory Estimates of the CVaR" Journal of Risk and Financial Management 15, no. 4: 172. https://doi.org/10.3390/jrfm15040172
APA StyleTroop, D., Godin, F., & Yu, J. Y. (2022). Best-Arm Identification Using Extreme Value Theory Estimates of the CVaR. Journal of Risk and Financial Management, 15(4), 172. https://doi.org/10.3390/jrfm15040172